Abstract
Software clustering is usually used for program comprehension. Since it is considered to be the most crucial NP-complete problem, several genetic algorithms have been proposed to solve this problem. In the literature, there exist some objective functions (i.e., fitness functions) which are used by genetic algorithms for clustering. These objective functions determine the quality of each clustering obtained in the evolutionary process of the genetic algorithm in terms of cohesion and coupling. The major drawbacks of these objective functions are the inability to (1) consider utility artifacts, and (2) to apply to another software graph such as artifact feature dependency graph. To overcome the existing objective functions’ limitations, this paper presents a new objective function. The new objective function is based on information theory, aiming to produce a clustering in which information loss is minimized. For applying the new proposed objective function, we have developed a genetic algorithm aiming to maximize the proposed objective function. The proposed genetic algorithm, named ILOF, has been compared to that of some other well-known genetic algorithms. The results obtained confirm the high performance of the proposed algorithm in solving nine software systems. The performance achieved is quite satisfactory and promising for the tested benchmarks.
1. Introduction
Comprehending the code of a large and complicated program is hard and sometimes impossible. Program understanding is an essential activity for application development and maintenance [1]. Software clustering is an effective method to improve the comprehensibility of the software architecture and to discover the software structure [1]. In [2,3], the impact of software clustering on software understanding and software evolution has been investigated. The software architecture extracting aims to use clustering algorithms to partition an application from the source code into meaningful and understandable segments [1]. In fact, this assists to understand the application in the software maintenance process.
Most search-based software clustering algorithms use the Artifact Dependency Graph (ADG) (or Module Dependency Graph) for modeling a software system [4,5,6,7,8,9,10,11]. It is used for modeling the relationship between artifacts (e.g., calling dependency between artifacts) and provides an abstract view of software structure. In these graphs, the software system’s artifacts (such as class, function, file, etc.) are presented as nodes and their connections as edges. The end of software clustering is to locate the artifacts within clusters, so that cohesion (i.e., connections between the artifacts of the same cluster) is maximized and coupling (i.e., connections between artifacts of two different clusters) is minimized [1,4,5]. Since the problem of finding the best clustering for a software system is an NP-hard problem [5], genetic-based algorithms are applied to obtain a good clustering [5]. Figure 1 depicts an ADG for an example software system that comprises six program files, namely a–f, and two utility files, namely g and h, and Figure 2 and Figure 3 show two different clusterings of it.
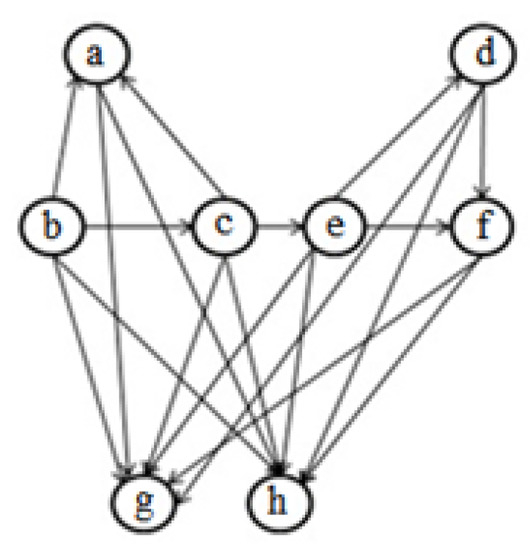
Figure 1.
A sample Artifact Dependency Graph (ADG).
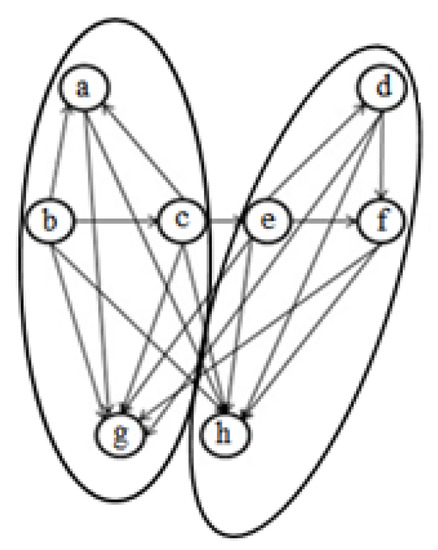
Figure 2.
An obtained clustering for Figure 1.
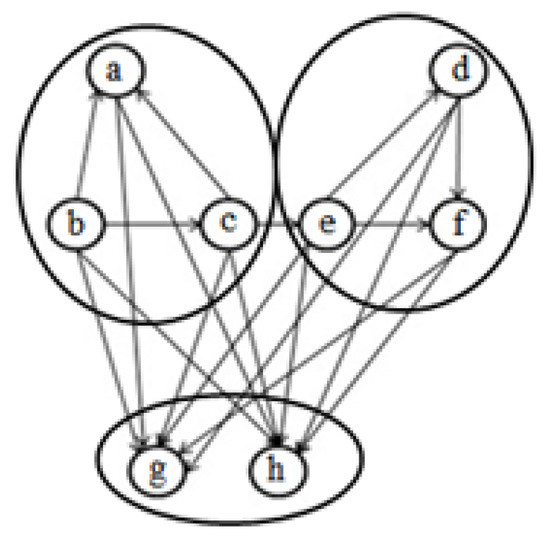
Figure 3.
Another clustering for Figure 1.
Libraries and drivers are examples of utility artifacts. Libraries provide services to many of the other artifacts, and drivers consume the services of many of the other artifacts. These files should be isolated in one cluster in the clustering process because they tend to obfuscate the software’s structure [11].
Several genetic algorithms have been developed to solve the software clustering problem. One of the operators that largely affect the performance of a genetic algorithm in finding the appropriate clustering is the objective function (other names are: fitness function or quality function). As the aim of the genetic algorithm is to optimize the objective function. Several objective functions have been developed in the literature for software clustering so that the existing evolutionary algorithms in this context use these objective functions for clustering. Maximizing cohesion and minimizing coupling is the overall goal of these functions. However, these objective functions have disadvantages in which clustering found are not so acceptable. These disadvantages are: (1) There is no reason for a software developer to use principles of maximum cohesion and minimum coupling in the development of a software application; (2) almost there are a number of utility in every system that are not necessarily dependent on each other; therefore, the existing objective functions in each different clustering locate them in different clusters and thus they obscure the system’s structure; (3) objective functions available are used only on graphs that have been created by relationship between artifacts, such as calling operations, and cannot perform the clustering on other graphs that can be extracted from a program, such as semantic graphs, or the graphs used in hierarchical clustering algorithms.
In this paper, using information theory and the concept of entropy, a new objective function is proposed, which can solve the problems mentioned in the existing objective functions and improves the quality of clustering. The aim is to propose a new objective function that an evolutionary algorithm (e.g., genetic algorithm) can use to put artifacts with the minimum information loss into the same cluster.
The rest of this paper is organized as follows. Section 2 addresses the existing objective functions. Section 3 describes the proposed objective function based on information theory. To validate the performance of the proposed objective function, a genetic algorithm is adopted to optimize it in this section. Section 4 compares the proposed algorithm. Finally, the conclusions and future work are presented in Section 5.
2. Related Work
Software clustering (or software modularization) algorithms can be categorized into hierarchical (e.g., see [12,13]) and non-hierarchical (including search-based methods and greedy algorithms) categories.
In search-based clustering methods, the problem of clustering is counted as a search problem. Since the software clustering problem is an NP-hard problem, evolutionary approaches such as genetic algorithms are utilized to find the more qualified clustering. Most search-based algorithms aims to find a modularization with maximum cohesion and minimum coupling. Objective functions in search-based software clustering algorithms guide optimization algorithms to find a good clustering for a software system. The two most popular objective functions are BasicMQ and TurboMQ [4]. If is an internal connection (internal edges) for a cluster and represents connection level between two clusters and , then having a program graph divided to clusters, BasicMQ is defined as follows:
The BasicMQ has five shortcomings, as follows:
- The execution time of BasicMQ is high, which restricts its application to small systems,
- unable to handle the ADGs with weighted edges,
- only considers cohesion and coupling in the calculation of the clustering quality,
- unable to handle the non-structural features,
- unable to detect utility artifacts.
Let the internal relationships of a cluster and relationships between two clusters are respectively denoted by and , TurboMQ is computed as follows:
The TurboMQ has three drawbacks, as follows:
- Only considers cohesion and coupling in the calculation of the clustering quality,
- unable to handle the non-structural features,
- unable to detect utility artifacts.
Most search-based software clustering algorithms use BasicMQ and TurboMQ as objective function such as E-CDGM [6], EDA [7], Bunch [4,8], DAGC [9], SAHC [8], NAHC [8], HC+Bunch [5], modified firefly algorithm [14], MAEA-SMCP [15] and GAKH [16]. The limitations of using these objective functions are mentioned before. In addition, there are a number of objective functions that we will discuss below.
In [17], two multi-objective functions, namely MCA and ECA, are proposed for clustering. The objectives used in MCA include “maximizing the sum of intra-edges of all clusters”, “minimizing the sum of inter-edges of all clusters”, “maximizing the number of clusters”, “maximizing TurboMQ”, “minimizing the number of isolated clusters”; and the objectives used in ECA are the same as the MCA, with the difference that instead of the last one, the “difference between the maximum and minimum number of modules in a cluster (minimizing)”, has been used. These two objective functions also suffer from the same TurboMQ drawbacks.
Huang and Liu in [18] stated that the BasicMQ does not take into account utility artifacts and edge directions between two obtained clusters. Therefore, they proposed an objective function, to overcome these limitations of BasicMQ. To evaluate the performance of the proposed objective function, they developed three algorithms named hill-climbing algorithm (HC-SMCP), genetic algorithm (GA-SMCP), and multi-agent evolutionary algorithm (MAEA-SMCP).
In [19], a PSO-based algorithm, named PSOMC, was proposed for software clustering. The objectives used in PSOMC for clustering are the “intracluster dependency”, “intercluster dependency”, “number of clusters”, and “number of module per cluster”.
In [20], a Harmony search-based algorithm, named HSBRA, was proposed for object-oriented software systems clustering. The objectives used in HSBRA for clustering are “cohesion”, “coupling”, “package count index”, and “package size index”.
3. Entropy-Based Objective Function
We use Figure 1 to illustrate how to calculate the new objective function. The corresponding data table matrix for this graph is shown in Table 1. Rows of this matrix indicate the artifacts that will be clustered and the columns indicate the number of features that characterize these artifacts. An entry, if equal to “1” indicates the dependency between two artifacts and if equal to “0” indicates no relation between them.

Table 1.
Data table for Figure 1.
To use the concepts of information theory [21] in the software clustering context, the data table matrix should be normalized so that the elements of each row sum up to one. Let A be a random variable that gains its values from the artifacts set and F represents a random variable that gets its values from feature set . Suppose M indicates a data table matrix, this matrix can be normalized using Equation (4).
The normalized matrix for Table 1 is shown in Table 2. Each row of a normalized matrix represents a feature vector for an artifact, which equals to the conditional probability: . In information theory, the mutual information (MI) of two random variables measures how much one random variable tells us about another. More specifically, it quantifies the “amount of information" obtained about one random variable, through the other random variable. MI between two random variables is computed as follow:
Table 2.
Normalized matrix for Table 1.
In information theory, higher entropy reflects more uncertainty; in contrast, lower entropy represents more certainty. In the clustering problem, lower entropy is preferred. In the clustering of software, it is ideal that the selection probability of each feature of an artifact is the same before and after clustering.
Assume and are two artifacts before clustering and represents merging them after clustering. Our aim will be to calculate the distance between and with (actually to know how much information is lost). Let , , so we define:
Using Equations (4)–(6), the information loss between and , , is computed as follows:
By substituting (i.e., ) in Equation (7), is calculated as follows:
means that after clustering of and , what is the possibility to identify their features. We used information theory to determine the distance between , with . In the following we define information loss respectively for two artifacts, a cluster and a clustering.
Definition 1.
Divergence for a cluster (denoted by DM)—for cluster k with nodes is computed as follows:
where n denotes the number of artifacts in a cluster.
Definition 2.
Divergence for a clustering (denoted by MQ)—for an obtained clustering, it is computed as follows:
The lower MQ indicates that less information is lost, so a proper clustering is obtained. We need to convert this minimization problem to maximization one (see Equation (11)).
Definition 3.
Objective Function (denoted by O.F.)—we define our new objective function as follows:
where n is the number of artifacts.
To illustrate, Figure 2 and Figure 3 represent the clusterings created by the Bunch algorithm and our algorithm, respectively. As it can be seen, our objective function identifies the utilities and isolate them while TurboMQ used in Bunch cannot identify them.
Genetic Algorithm
In the standard genetic algorithm, initially, a set of all solutions (known as the chromosomes) is produced and then the chromosomes are assessed utilizing an objective function (fitness function). Then until the end condition is satisfied, chromosomes are chosen and crossover and mutation operators are done on them respectively and the previous solutions are replaced by the new solutions. In our proposed genetic algorithm, the initial population (i.e., the set of all solutions) is generated randomly. We employ the encoding method used in the Bunch algorithm [4,8]. In this method, the number of gens in each chromosome is equal to the number of artifacts. The content of each gene represents the cluster number that the artifact has to allocate to it. This value ranges between one and the number of artifacts. For example, Figure 4 illustrates a sample encoding and Figure 5 shows obtained clustering for that.

Figure 4.
The chromosome structure for a sample ADG.
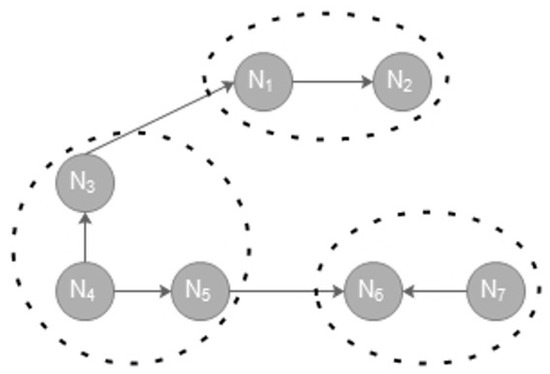
Figure 5.
Obtained clustering for a sample string S = 1122233.
The objective function. The objective function has a great impact on the performance of the genetic algorithm to find a suitable solution. The objective function measures the quality of each clustering achieved during the evolutionary process of the genetic algorithm. To calculate an obtained clustering quality, we use Equation (11). The designed genetic algorithm aims to maximize the proposed quality function.
4. Results
For evaluating and comparing the effect of the proposed objective function, we choose nine real-world applications. The descriptions concerning these applications are presented in Table 3.
Table 3.
The description of tested software systems.
For evaluating the achieved clustering by an algorithm, internal metrics are employed [1]. Internal metrics measure how well the clusters are separated. We use the silhouette coefficient, denoted by SC, and separation criteria for internal evaluation [1]. Let n denotes the number of artifacts, Table 4 gives the parameter tuning for the experiments. In a genetic algorithm, the number of generations is usually greater than the population size. Therefore, we have followed this principle in the proposed algorithm, and we also considered this value linearly and a coefficient of the number of artifacts.
Table 4.
The parameter setting for experiments.
In Table 5, the proposed algorithm, named ILOF, is compared on nine software systems with five algorithms in terms of SC and Separation. We chose the mean of results for each algorithm over 20 independent runs. The results demonstrate that the clustering achieved with ILOF are higher quality than those achieved with other algorithms for all the ADGs in terms of SC and separation. According to the definition of SC and Separation, their values should be as high as possible (close to one). In all of these cases, it appears that the proposed algorithm is better able to separate the clusters with the new objective function.
Table 5.
Comparing the proposed algorithm against five search-based algorithms.
5. Conclusions
This paper presents a new objective function based on information theory. Like other objective functions (such as TurboMQ), the proposed objective function can be used by evolutionary approaches for software clustering. To use the proposed objective function, we have developed a genetic algorithm that can maximize the proposed objective function. The results showed that the results of the proposed objective function are very promising.
The following suggestions are made for future work:
- Evaluating the presented objective function on other real-world applications with differing sizes from various fields.
- Use of other formulas of entropy as an objective function and addressing the obtained results.
References
- Isazadeh, A.; Izadkhah, H.; Elgedawy, I. Source Code Modularization: Theory and Techniques; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Mohammadi, S.; Izadkhah, H. A new algorithm for software clustering considering the knowledge of dependency between artifacts in the source code. Inform. Softw. Technol. 2019, 105, 252–256. [Google Scholar] [CrossRef]
- Beck, F.; Diehl, S. On the impact of software evolution on software clustering. Empir. Softw. Eng. 2013, 18, 970–1004. [Google Scholar] [CrossRef]
- Mitchell, B.S. A Heuristic Search Approach to Solving the Software Clustering Problem. Ph.D. Thesis, Drexel University, Philadelphia, PA, USA, 2002. [Google Scholar]
- Mahdavi, K. A Clustering Genetic Algorithm for Software Modularisation with a Multiple Hill Climbing Approach. Ph.D. Thesis, Brunel University, London, UK, 2005. [Google Scholar]
- Izadkhah, H.; Elgedawy, I.; Isazadeh, A. E-CDGM: An Evolutionary Call-Dependency Graph Modularization Approach for Software Systems. Cybern. Inf. Technol. 2016, 16, 70–90. [Google Scholar] [CrossRef][Green Version]
- Tajgardan, M.; Izadkhah, H.; Lotfi, S. Software Systems Clustering Using Estimation of Distribution Approach. J. Appl. Comput. Sci. Methods 2016, 8, 99–113. [Google Scholar] [CrossRef]
- Mitchell, B.S.; Mancoridis, S. On the automatic modularization of software systems using the bunch tool. IEEE Trans. Softw. Eng. 2006, 32, 193–208. [Google Scholar] [CrossRef]
- Parsa, S.; Bushehrian, O. A new encoding scheme and a framework to investigate genetic clustering algorithms. J. Res. Pract. Inf. Technol. 2005, 37, 127. [Google Scholar]
- Lutellier, T.; Chollak, D.; Garcia, J.; Tan, L.; Rayside, D.; Medvidović, N.; Kroeger, R. Measuring the impact of code dependencies on software architecture recovery techniques. IEEE Trans. Softw. Eng. 2018, 44, 159–181. [Google Scholar] [CrossRef]
- Jalali, N.S.; Izadkhah, H.; Lotfi, S. Multi-objective search-based software modularization: Structural and non-structural features. Soft Comput. 2019, 23, 11141–11165. [Google Scholar] [CrossRef]
- Maqbool, O.; Babri, H. Hierarchical clustering for software architecture recovery. IEEE Trans. Softw. Eng. 2007, 33, 759–780. [Google Scholar] [CrossRef]
- Andritsos, P.; Tzerpos, V. Information-theoretic software clustering. IEEE Trans. Softw. Eng. 2005, 2, 150–165. [Google Scholar] [CrossRef]
- Mamaghani, A.S.; Hajizadeh, M. Software modularization using the modified firefly algorithm. In Proceedings of the 2014 8th Malaysian Software Engineering Conference (MySEC), Langkawi, Malaysia, 23–24 September 2014; pp. 321–324. [Google Scholar]
- Huang, J.; Liu, J.; Yao, X. A multi-agent evolutionary algorithm for software module clustering problems. Soft Comput. 2017, 21, 3415–3428. [Google Scholar] [CrossRef]
- Akbari, M.; Izadkhah, H. Hybrid of genetic algorithm and krill herd for software clustering problem. In Proceedings of the 2019 5th Conference on Knowledge Based Engineering and Innovation (KBEI), Tehran, Iran, 28 February–1 March 2019. [Google Scholar]
- Praditwong, K.; Harman, M.; Yao, X. Software module clustering as a multi-objective search problem. IEEE Trans. Softw. Eng. 2011, 37, 264–282. [Google Scholar] [CrossRef]
- Huang, J.; Liu, J. A similarity-based modularization quality measure for software module clustering problems. Inf. Sci. 2016, 342, 96–110. [Google Scholar] [CrossRef]
- Prajapati, A.; Chhabra, J.K. A Particle Swarm Optimization-Based Heuristic for Software Module Clustering Problem. Arab. J. Sci. Eng. 2017, 2017, 1–12. [Google Scholar] [CrossRef]
- Chhabra, J.K. Harmony search based remodularization for object-oriented software systems. Comput. Lang. Syst. Struct. 2017, 47, 153–169. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).