Information Theoretic Objective Function for Genetic Software Clustering †


Abstract
1. Introduction
2. Related Work
- The execution time of BasicMQ is high, which restricts its application to small systems,
- unable to handle the ADGs with weighted edges,
- only considers cohesion and coupling in the calculation of the clustering quality,
- unable to handle the non-structural features,
- unable to detect utility artifacts.
- Only considers cohesion and coupling in the calculation of the clustering quality,
- unable to handle the non-structural features,
- unable to detect utility artifacts.
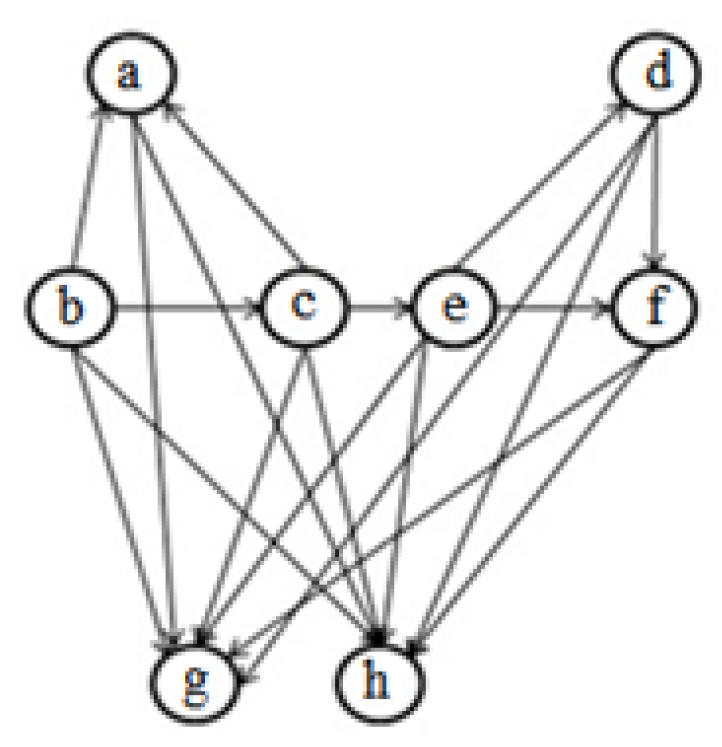
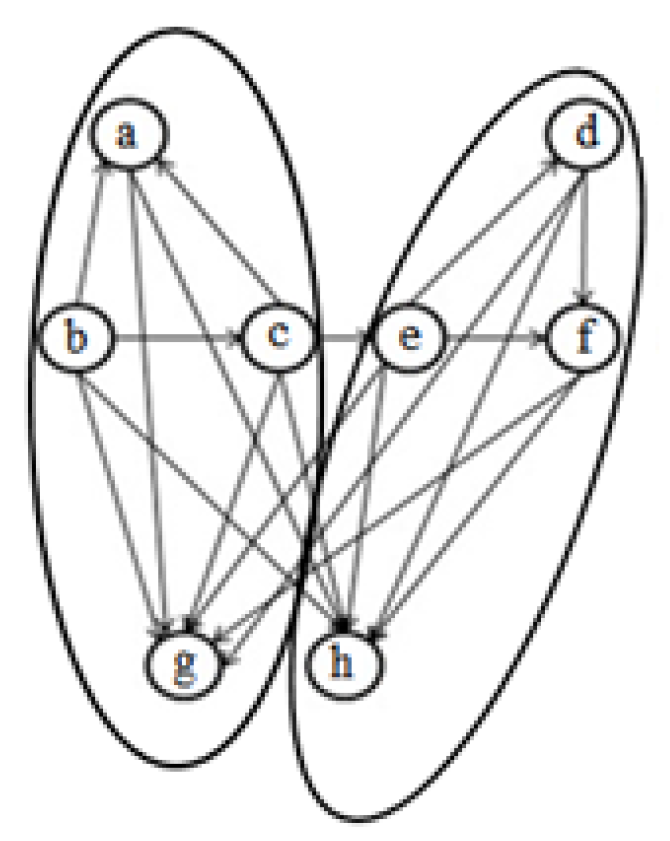
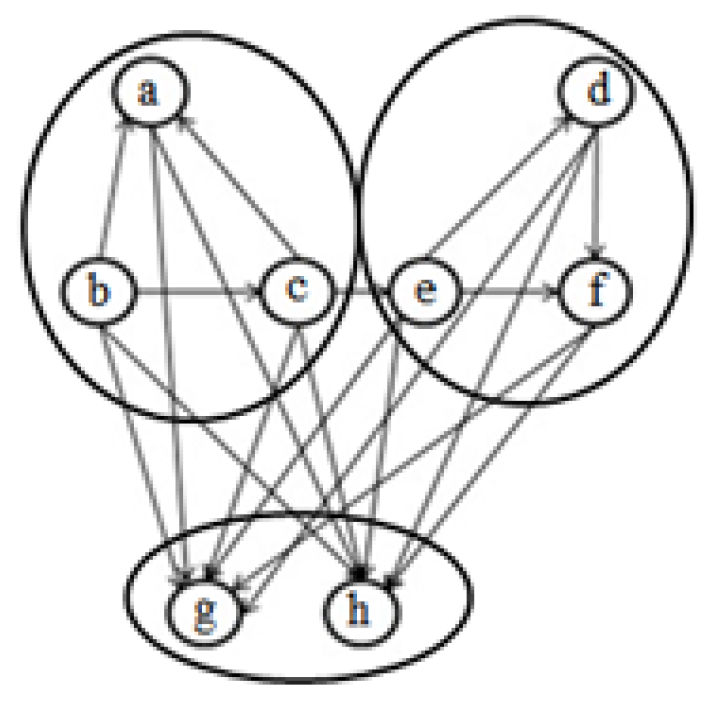
3. Entropy-Based Objective Function
Genetic Algorithm
4. Results
5. Conclusions
- Evaluating the presented objective function on other real-world applications with differing sizes from various fields.
- Use of other formulas of entropy as an objective function and addressing the obtained results.
References
- Isazadeh, A.; Izadkhah, H.; Elgedawy, I. Source Code Modularization: Theory and Techniques; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Mohammadi, S.; Izadkhah, H. A new algorithm for software clustering considering the knowledge of dependency between artifacts in the source code. Inform. Softw. Technol. 2019, 105, 252–256. [Google Scholar] [CrossRef]
- Beck, F.; Diehl, S. On the impact of software evolution on software clustering. Empir. Softw. Eng. 2013, 18, 970–1004. [Google Scholar] [CrossRef]
- Mitchell, B.S. A Heuristic Search Approach to Solving the Software Clustering Problem. Ph.D. Thesis, Drexel University, Philadelphia, PA, USA, 2002. [Google Scholar]
- Mahdavi, K. A Clustering Genetic Algorithm for Software Modularisation with a Multiple Hill Climbing Approach. Ph.D. Thesis, Brunel University, London, UK, 2005. [Google Scholar]
- Izadkhah, H.; Elgedawy, I.; Isazadeh, A. E-CDGM: An Evolutionary Call-Dependency Graph Modularization Approach for Software Systems. Cybern. Inf. Technol. 2016, 16, 70–90. [Google Scholar] [CrossRef][Green Version]
- Tajgardan, M.; Izadkhah, H.; Lotfi, S. Software Systems Clustering Using Estimation of Distribution Approach. J. Appl. Comput. Sci. Methods 2016, 8, 99–113. [Google Scholar] [CrossRef]
- Mitchell, B.S.; Mancoridis, S. On the automatic modularization of software systems using the bunch tool. IEEE Trans. Softw. Eng. 2006, 32, 193–208. [Google Scholar] [CrossRef]
- Parsa, S.; Bushehrian, O. A new encoding scheme and a framework to investigate genetic clustering algorithms. J. Res. Pract. Inf. Technol. 2005, 37, 127. [Google Scholar]
- Lutellier, T.; Chollak, D.; Garcia, J.; Tan, L.; Rayside, D.; Medvidović, N.; Kroeger, R. Measuring the impact of code dependencies on software architecture recovery techniques. IEEE Trans. Softw. Eng. 2018, 44, 159–181. [Google Scholar] [CrossRef]
- Jalali, N.S.; Izadkhah, H.; Lotfi, S. Multi-objective search-based software modularization: Structural and non-structural features. Soft Comput. 2019, 23, 11141–11165. [Google Scholar] [CrossRef]
- Maqbool, O.; Babri, H. Hierarchical clustering for software architecture recovery. IEEE Trans. Softw. Eng. 2007, 33, 759–780. [Google Scholar] [CrossRef]
- Andritsos, P.; Tzerpos, V. Information-theoretic software clustering. IEEE Trans. Softw. Eng. 2005, 2, 150–165. [Google Scholar] [CrossRef]
- Mamaghani, A.S.; Hajizadeh, M. Software modularization using the modified firefly algorithm. In Proceedings of the 2014 8th Malaysian Software Engineering Conference (MySEC), Langkawi, Malaysia, 23–24 September 2014; pp. 321–324. [Google Scholar]
- Huang, J.; Liu, J.; Yao, X. A multi-agent evolutionary algorithm for software module clustering problems. Soft Comput. 2017, 21, 3415–3428. [Google Scholar] [CrossRef]
- Akbari, M.; Izadkhah, H. Hybrid of genetic algorithm and krill herd for software clustering problem. In Proceedings of the 2019 5th Conference on Knowledge Based Engineering and Innovation (KBEI), Tehran, Iran, 28 February–1 March 2019. [Google Scholar]
- Praditwong, K.; Harman, M.; Yao, X. Software module clustering as a multi-objective search problem. IEEE Trans. Softw. Eng. 2011, 37, 264–282. [Google Scholar] [CrossRef]
- Huang, J.; Liu, J. A similarity-based modularization quality measure for software module clustering problems. Inf. Sci. 2016, 342, 96–110. [Google Scholar] [CrossRef]
- Prajapati, A.; Chhabra, J.K. A Particle Swarm Optimization-Based Heuristic for Software Module Clustering Problem. Arab. J. Sci. Eng. 2017, 2017, 1–12. [Google Scholar] [CrossRef]
- Chhabra, J.K. Harmony search based remodularization for object-oriented software systems. Comput. Lang. Syst. Struct. 2017, 47, 153–169. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| a | b | c | d | e | f | g | h | |
|---|---|---|---|---|---|---|---|---|
| a | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 |
| b | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
| c | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 |
| d | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
| e | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 |
| f | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 |
| g | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| h | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| a | b | c | d | e | f | g | h | |
|---|---|---|---|---|---|---|---|---|
| a | 0 | 1/4 | 1/4 | 0 | 0 | 0 | 1/4 | 1/4 |
| b | 1/4 | 0 | 1/4 | 0 | 0 | 0 | 1/4 | 1/4 |
| c | 1/5 | 1/5 | 0 | 0 | 1/5 | 0 | 1/5 | 1/5 |
| d | 0 | 0 | 0 | 0 | 1/4 | 1/4 | 1/4 | 1/4 |
| e | 0 | 0 | 1/5 | 1/5 | 0 | 1/5 | 1/5 | 1/5 |
| f | 0 | 0 | 0 | 1/4 | 1/4 | 0 | 1/4 | 1/4 |
| g | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 | 0 | 0 |
| h | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 | 0 | 0 |
| Software System | Description | #Artifacts | #Links |
|---|---|---|---|
| compiler | A small compiler developed at the University of Toronto | 13 | 32 |
| nos | A file system | 16 | 52 |
| boxer | Graph drawing tool | 18 | 29 |
| ispell | Spelling and typographical error correction software | 24 | 103 |
| ciald | Program dependency analysis tool | 26 | 64 |
| cia | Program dependency graph generator for C programs | 38 | 87 |
| grappa | Genome Rearrangements Analyzer | 86 | 295 |
| acqCIGNA | An industrial software | 114 | 188 |
| cia++ | Dependency graph generator for C++ programs | 124 | 369 |
| Parameters | Value |
|---|---|
| Population size | 10n |
| Generation | 200n |
| P (crossover rate) | 0.8 |
| P (mutation rate) | 0.05 |
| Selection operator | Roulette wheel selection |
| Crossover operation | One-point |
| Mutation operation | randomly changed a gene |
| Algorithms | Bunch | DAGC | EDA | ECA | GA-SMCP | ILOF | ||||||
| Software Systems | SC | Separation | SC | Separation | SC | Separation | SC | Separation | SC | Separation | SC | Separation |
| Compiler | 0.204 | 0.487 | 0.204 | 0.487 | 0.204 | 0.487 | 0.204 | 0.487 | 0.201 | 0.406 | 0.405 | 0.821 |
| nos | 0.14 | 0.574 | 0.069 | 0.459 | 0.14 | 0510 | 0.291 | 0.628 | 0.13 | 0.566 | 0.433 | 0.690 |
| boxer | 0.205 | 0.550 | 0.095 | 0.431 | 0.205 | 0.550 | 0.205 | 0.550 | 0.221 | 0.558 | 0.358 | 0.610 |
| ispell | 0.051 | 0.441 | 0.063 | 0.487 | 0.161 | 0.491 | 0.91 | 0.610 | 0.050 | 0.398 | 0.333 | 0.872 |
| ciald | 0.217 | 0.545 | 0.087 | 0.434 | 0.217 | 0.512 | 0.321 | 0.573 | 0.217 | 0.521 | 0.364 | 0.750 |
| cia | −0.004 | 0.577 | −0.194 | 0.460 | 0.003 | 0.464 | 0.005 | 0.600 | 0.008 | 0.581 | 0.28 | 0.831 |
| grappa | 0.082 | 0.554 | 0.245 | 0.786 | 0.082 | 0.563 | 0.422 | 0.536 | 0.082 | 0.494 | 0.249 | 0.590 |
| acqCIGNA | −0.167 | 0.525 | −0.329 | 0.435 | 0.001 | 0.510 | 0.031 | 0.530 | −0.209 | 0.369 | 0.049 | 0.590 |
| cia++ | −0.012 | 0.544 | −0.323 | 0.450 | 0.002 | 0.610 | 0.012 | 0.534 | 0.002 | 0.508 | 0.049 | 0.621 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Izadkhah, H.; Tajgardan, M. Information Theoretic Objective Function for Genetic Software Clustering. Proceedings 2020, 46, 18. https://doi.org/10.3390/ecea-5-06681
Izadkhah H, Tajgardan M. Information Theoretic Objective Function for Genetic Software Clustering. Proceedings. 2020; 46(1):18. https://doi.org/10.3390/ecea-5-06681
Chicago/Turabian StyleIzadkhah, Habib, and Mahjoubeh Tajgardan. 2020. "Information Theoretic Objective Function for Genetic Software Clustering" Proceedings 46, no. 1: 18. https://doi.org/10.3390/ecea-5-06681
APA StyleIzadkhah, H., & Tajgardan, M. (2020). Information Theoretic Objective Function for Genetic Software Clustering. Proceedings, 46(1), 18. https://doi.org/10.3390/ecea-5-06681