

Efficient Trajectory Prediction Using Check-In Patterns in Location-Based Social Network


Abstract
1. Introduction
- Machine Learning for LBSN Data Analysis: Machine learning techniques are utilized to categorize LBSN data into popular location categories and predict user and resident mobility patterns.
- Hidden Location Prediction: A method is developed for predicting hidden or privately visited locations that are not explicitly disclosed in a user’s publicly available trajectory, thereby reconstructing a more complete movement history.
- Association Rule Mining for Hidden Locations: Consecutive check-in pairings are identified and leveraged to infer hidden locations, hence enhancing trajectory prediction accuracy.
- Semantic Context Analysis: Implicit attributes are considered for evaluation, such as the semantic aspects of locations (e.g., location types), to improve the understanding of user mobility behavior.
- Comprehensive Real-World Evaluation: Extensive experiments on real-world LBSN datasets are conducted, demonstrating that the proposed model outperforms state-of-the-art techniques in trajectory prediction.
2. Related Work
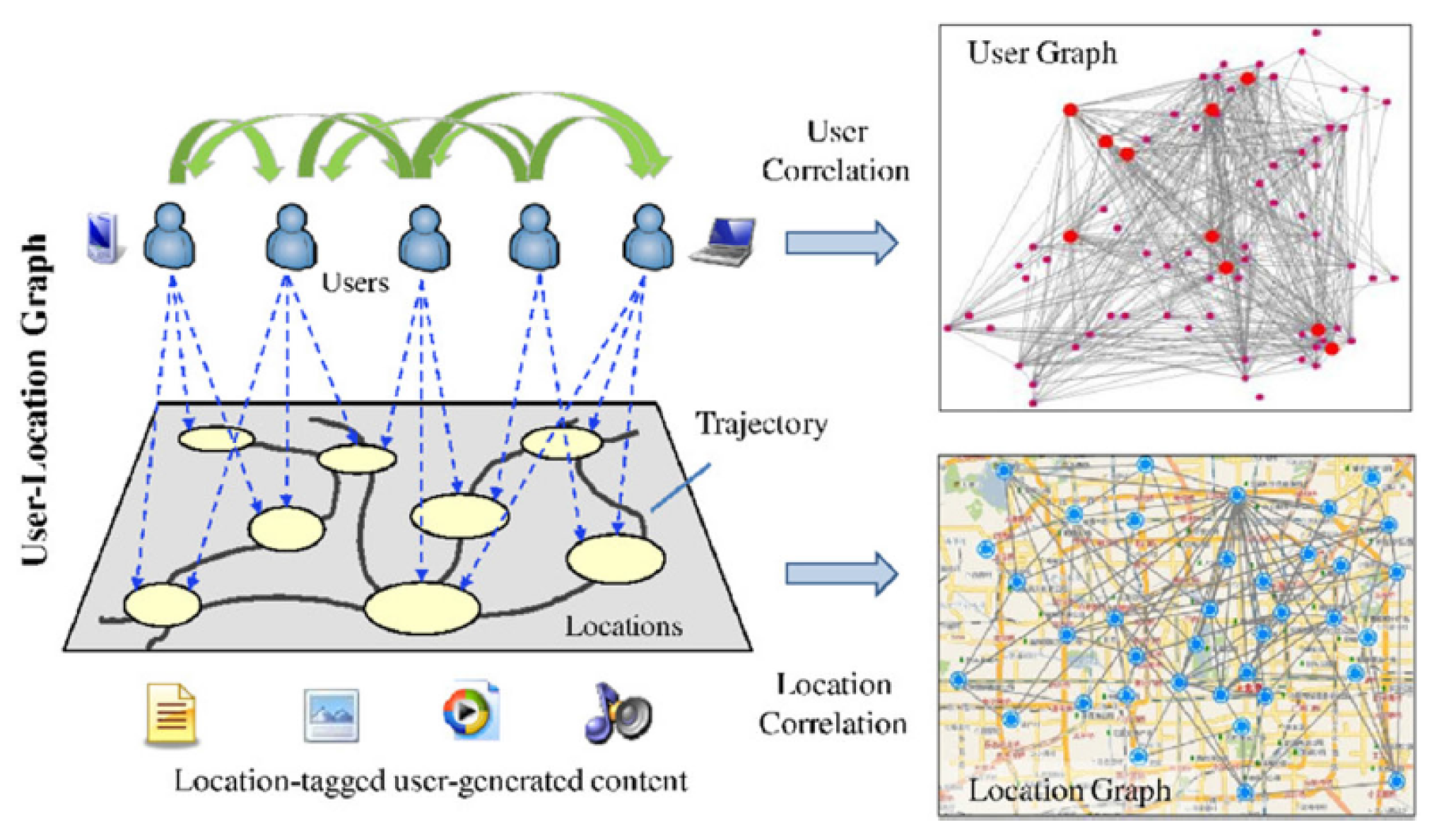
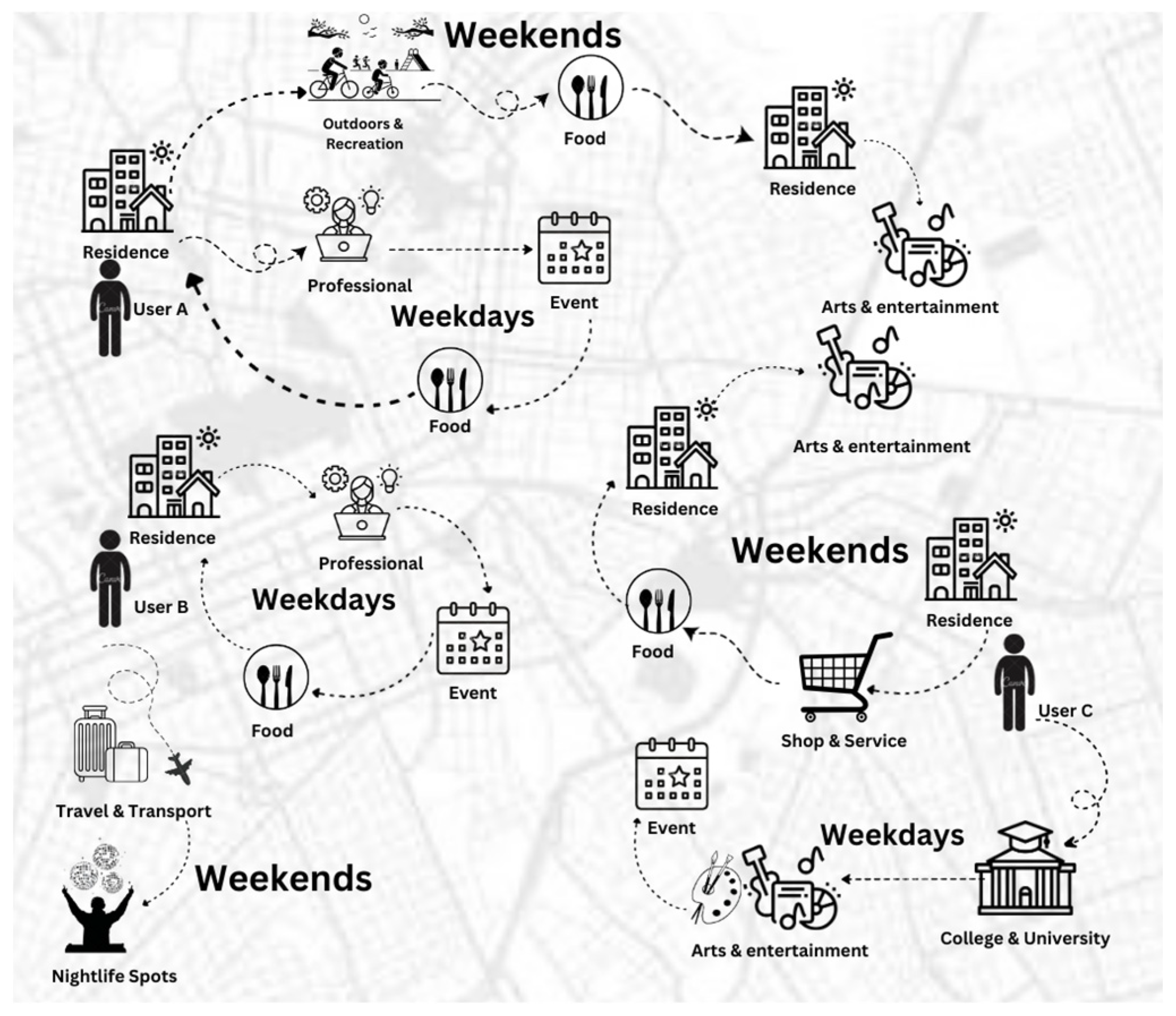
3. Problem Definition
Problem of Hidden Relationships
- Build the user trajectory Ti, which can be represented as a set of nodes {c1 → c2 → c3 → … cn}, each of which stands for a location at a specific point in time.
- Choose a series of check-ins as possible candidates for predicting a hidden location.
- Predict a collection of unchecked or hidden locations for every pair of successive check-ins that are chosen.
- Sort the anticipated locations according to the chance of occurrence.
- The trajectory prediction indicates the prediction of the whole check-in trajectory whether it includes explicit locations or hidden locations. In other words, the hidden location prediction is a part of trajectory prediction.
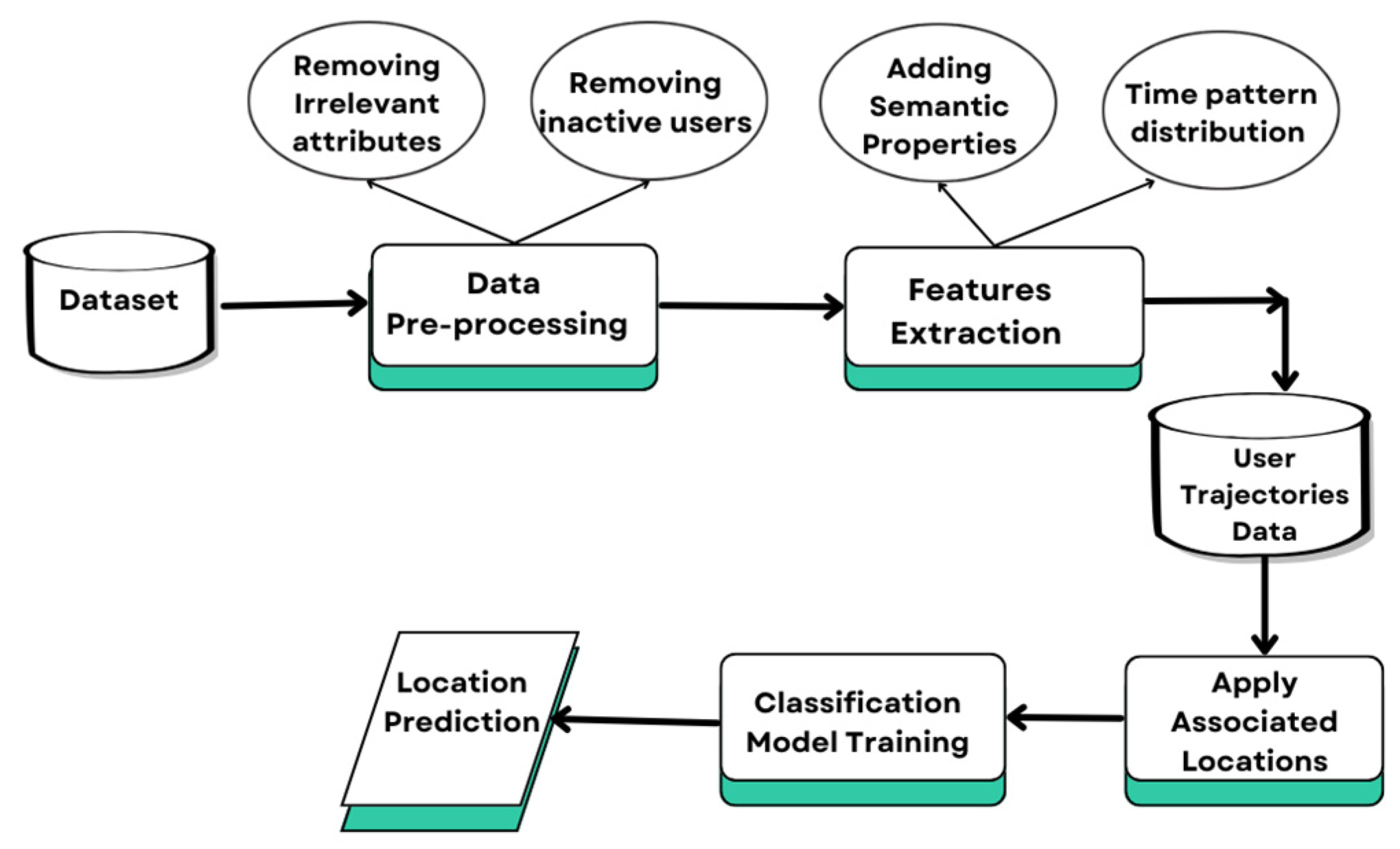
4. Proposed AHLTP Model and Methodology
4.1. Data Pre-Processing
4.2. Feature Extraction
4.3. Inferring Associated Locations
4.4. Classification into Several Types of Venues
4.4.1. K-Nearest Neighbor
4.4.2. Deep Learning
4.4.3. Gradient Boosted Trees
- Learning Rate (eta)—Controls the contribution of each tree to the final model. Default: 0.1, but in LBSN, a lower value (e.g., 0.05) can prevent overfitting, improving generalization.
- Number of Trees (n_estimators)—Defines how many trees are built. A higher number (50–300 trees) can improve accuracy, but too many may lead to overfitting.
- Maximum Depth (max_depth)—Determines how deep each tree can grow. Shallow trees (depth = 4–6) prevent overfitting while still capturing complex relationships.
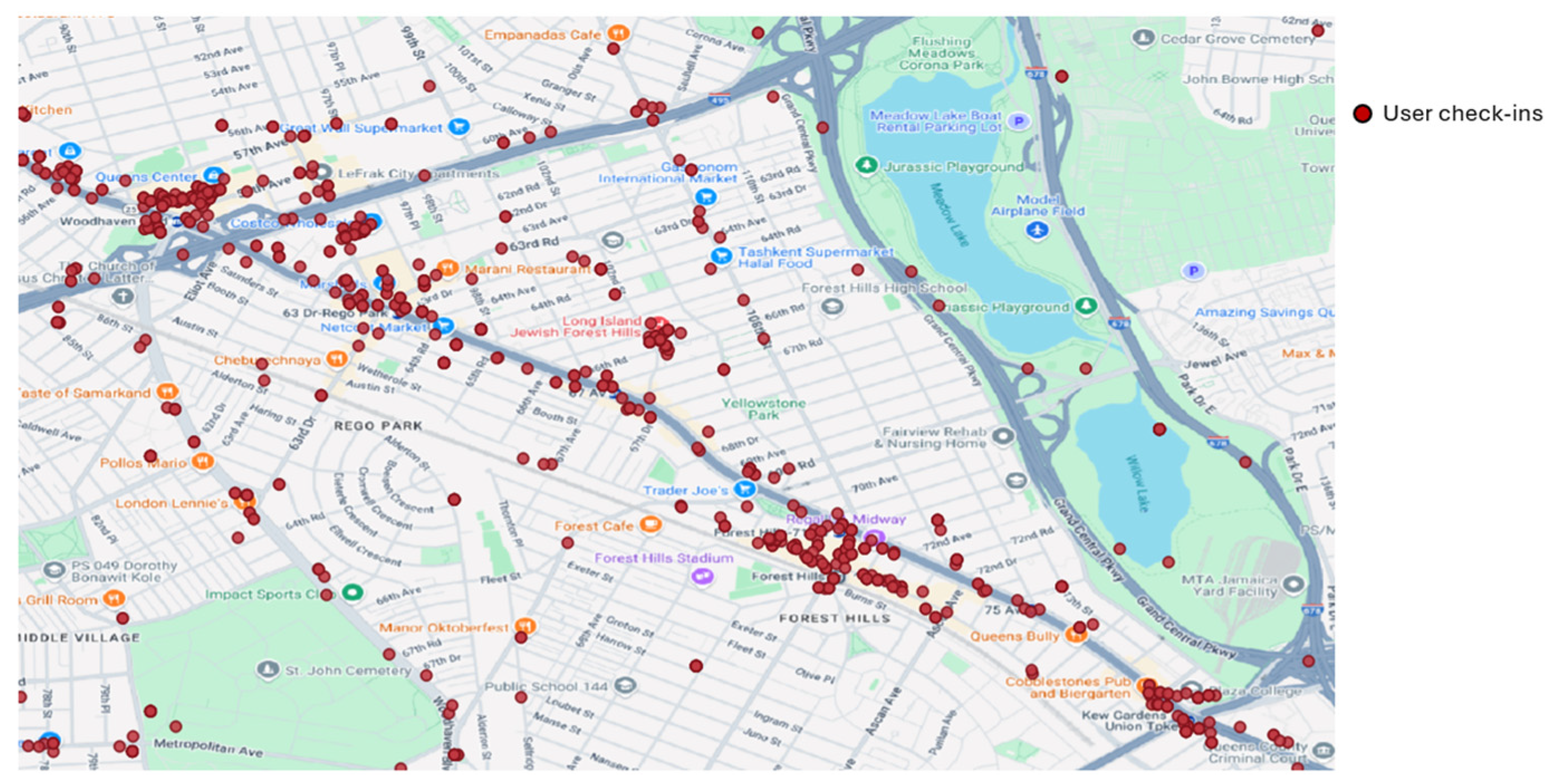
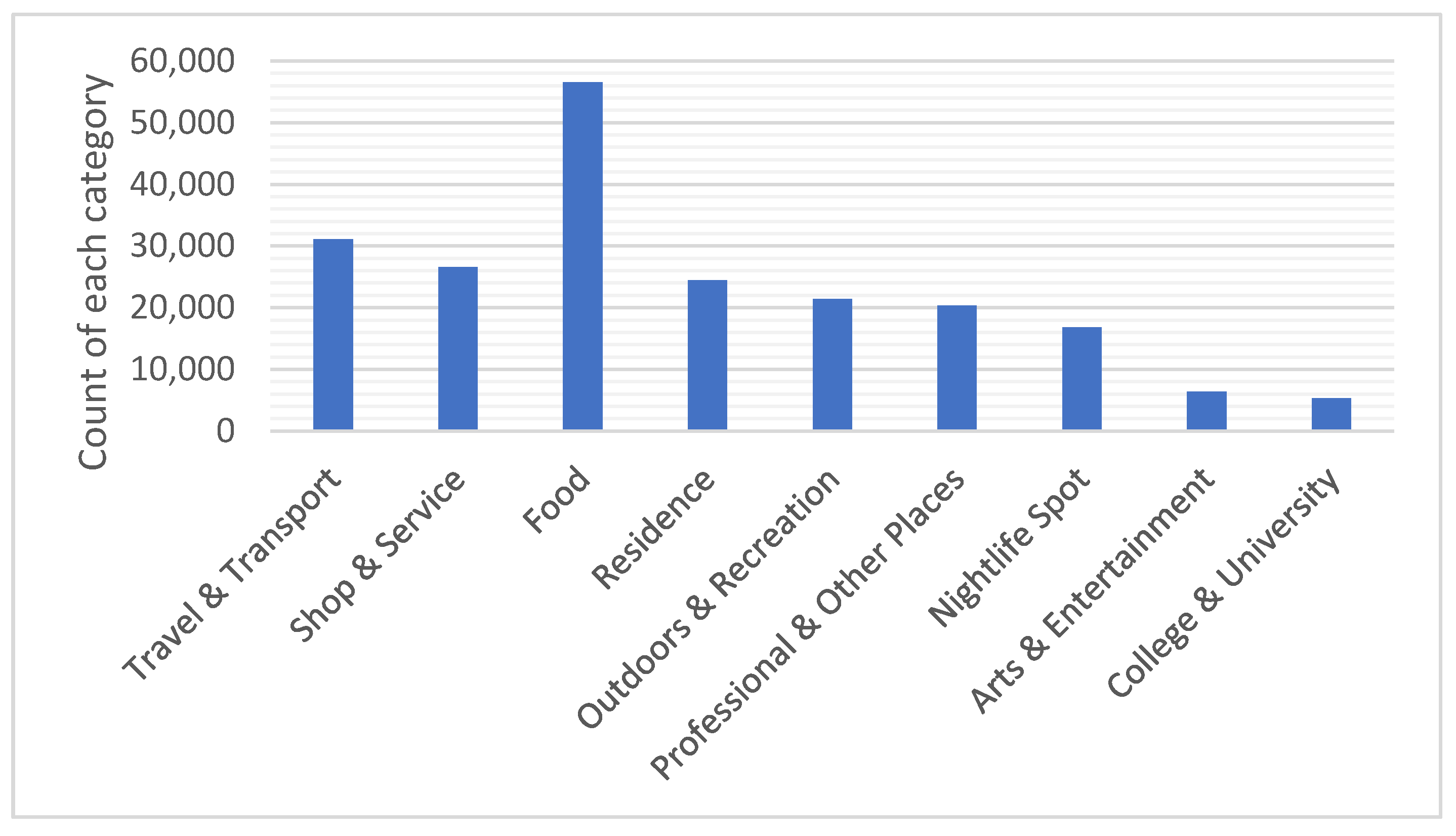
5. Empirical Data Analysis
- User ID (anonymized)
- Venue ID (Foursquare)
- Venue Category ID (Foursquare)
- Latitude
- Longitude
- UTC time
6. Experimental Evaluation and Results
- To compute the accuracy measure, the confusion matrix is calculated. The accuracy is calculated by dividing the number of correct predictions by the total number of predictions made by the model.
- Cohen’s kappa () is a statistical measure used to assess the agreement between two raters (or classifiers) who each classify items into mutually exclusive categories. It accounts for the possibility of an agreement occurring by chance.
- (Observed Agreement) is the proportion of times the two raters agree.
- (Expected Agreement by Chance) is the proportion of agreement that is expected if both raters are classifying randomly.
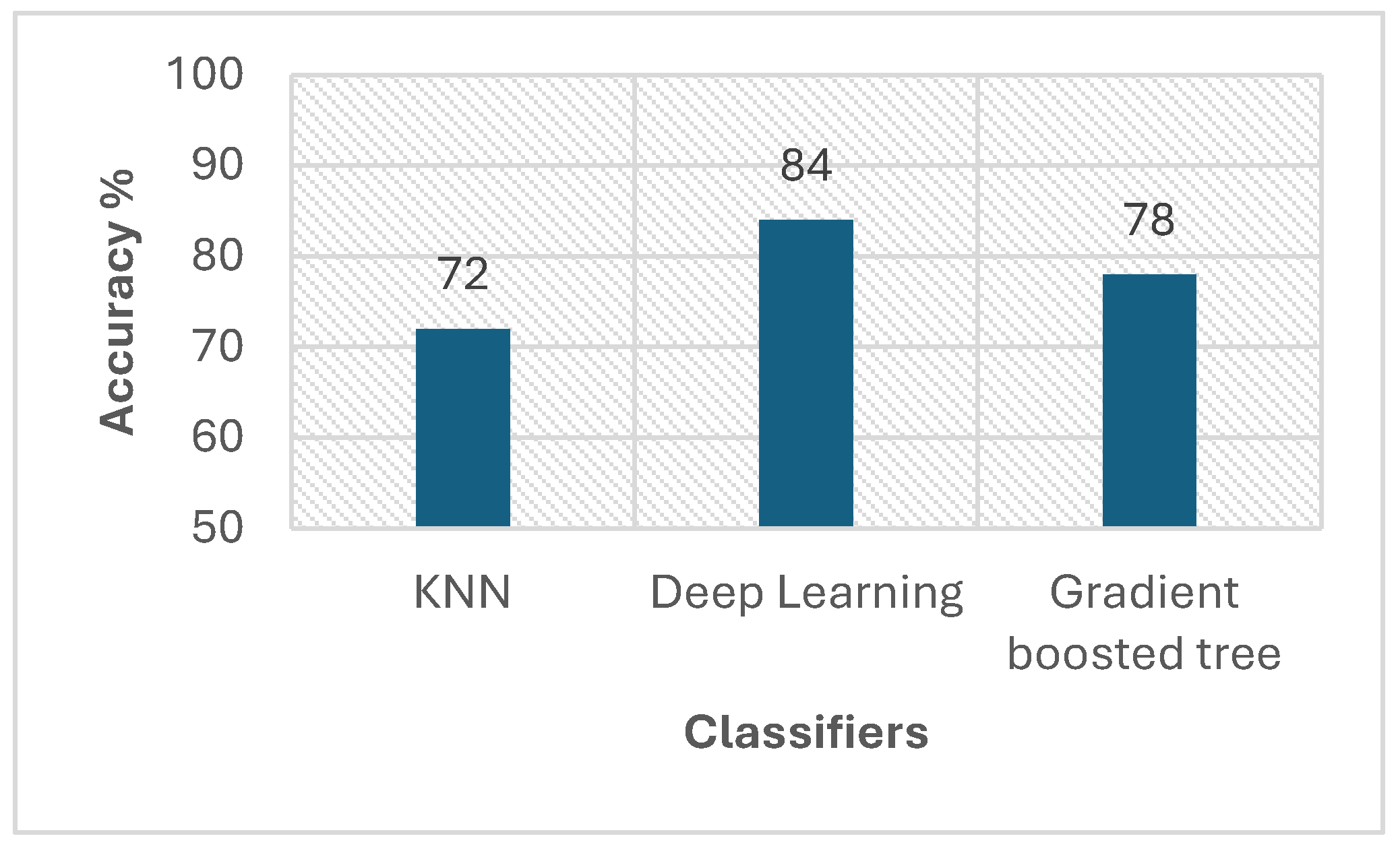
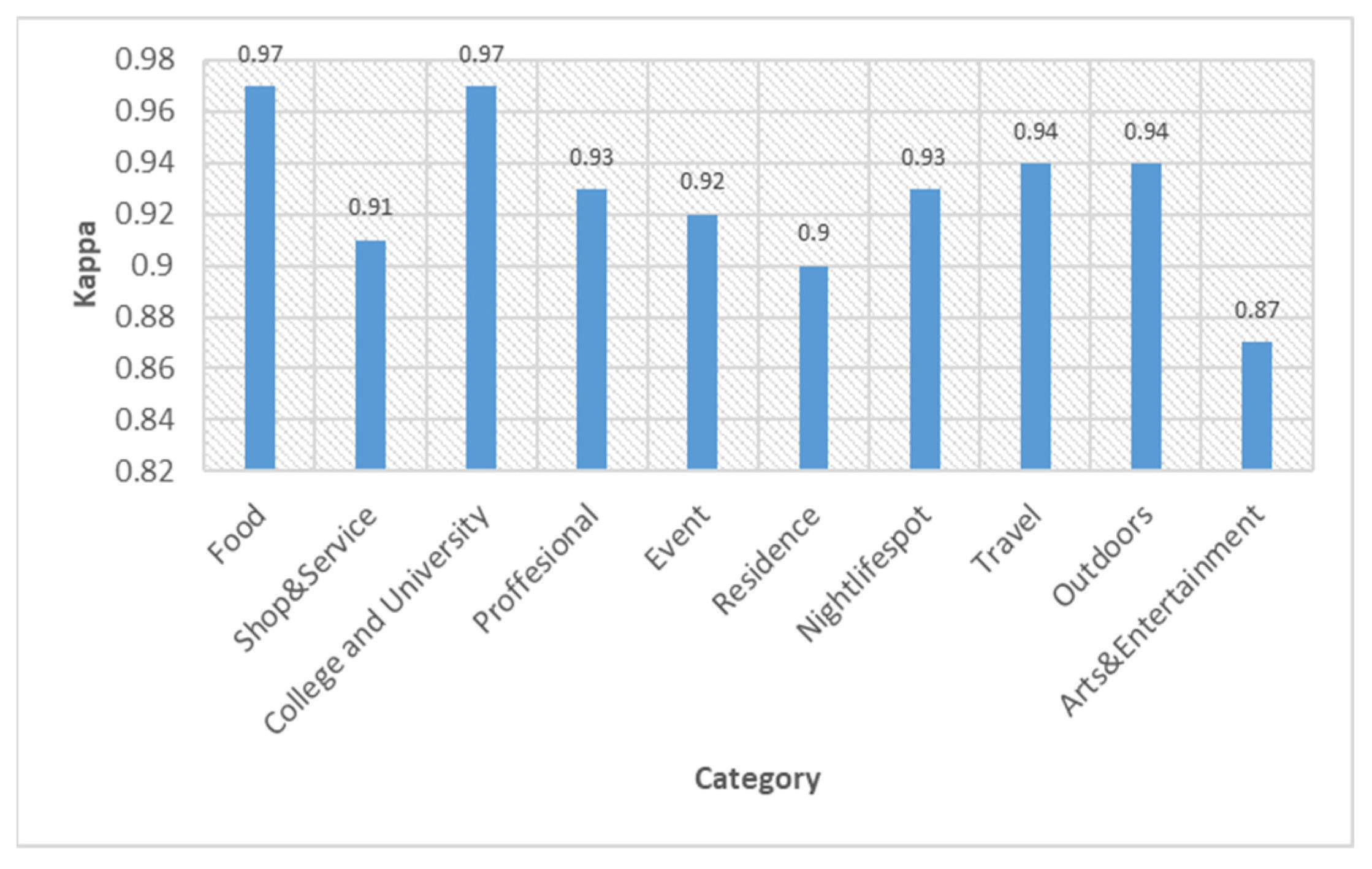
6.1. Machine Learning-Based Venue Classification
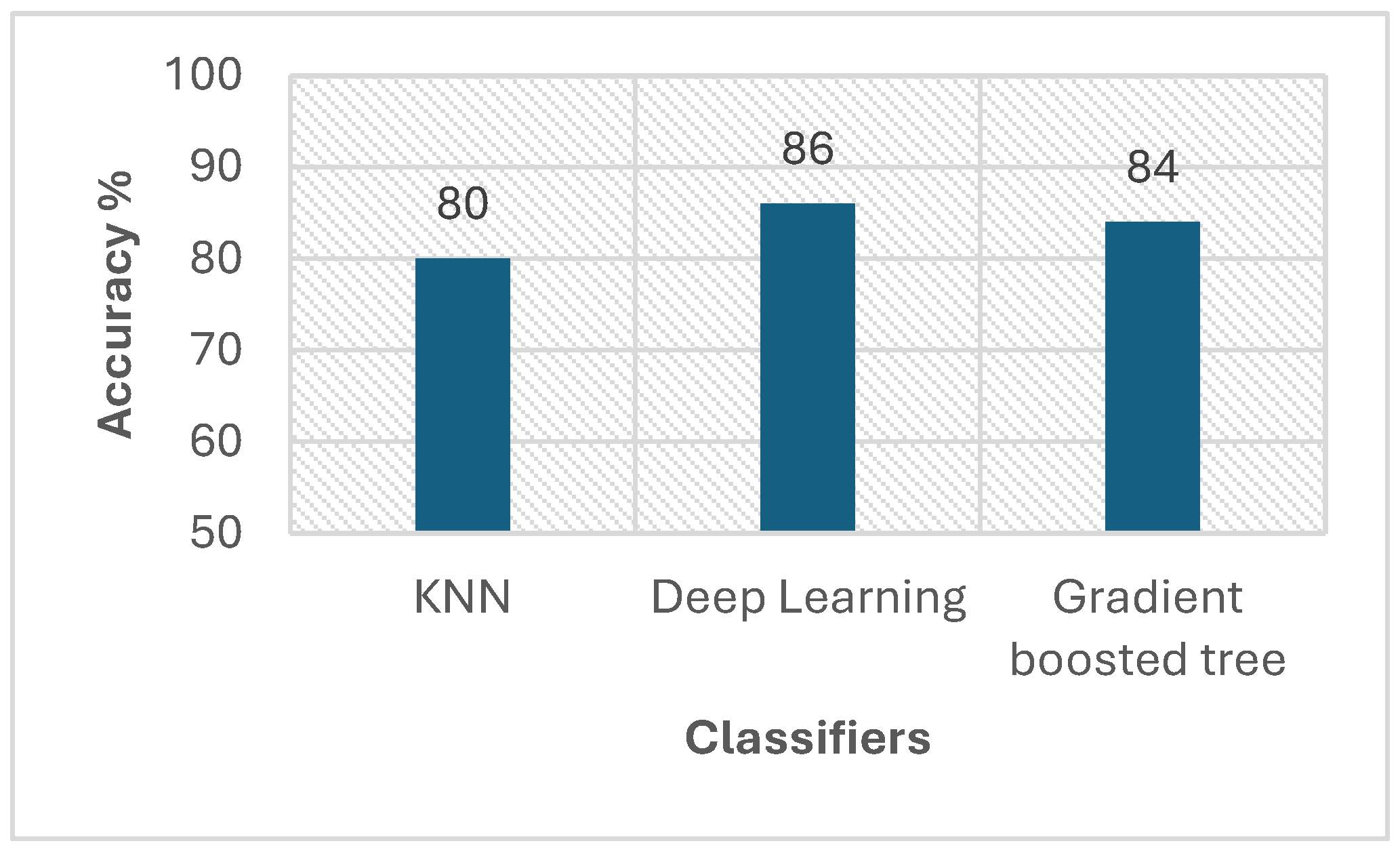
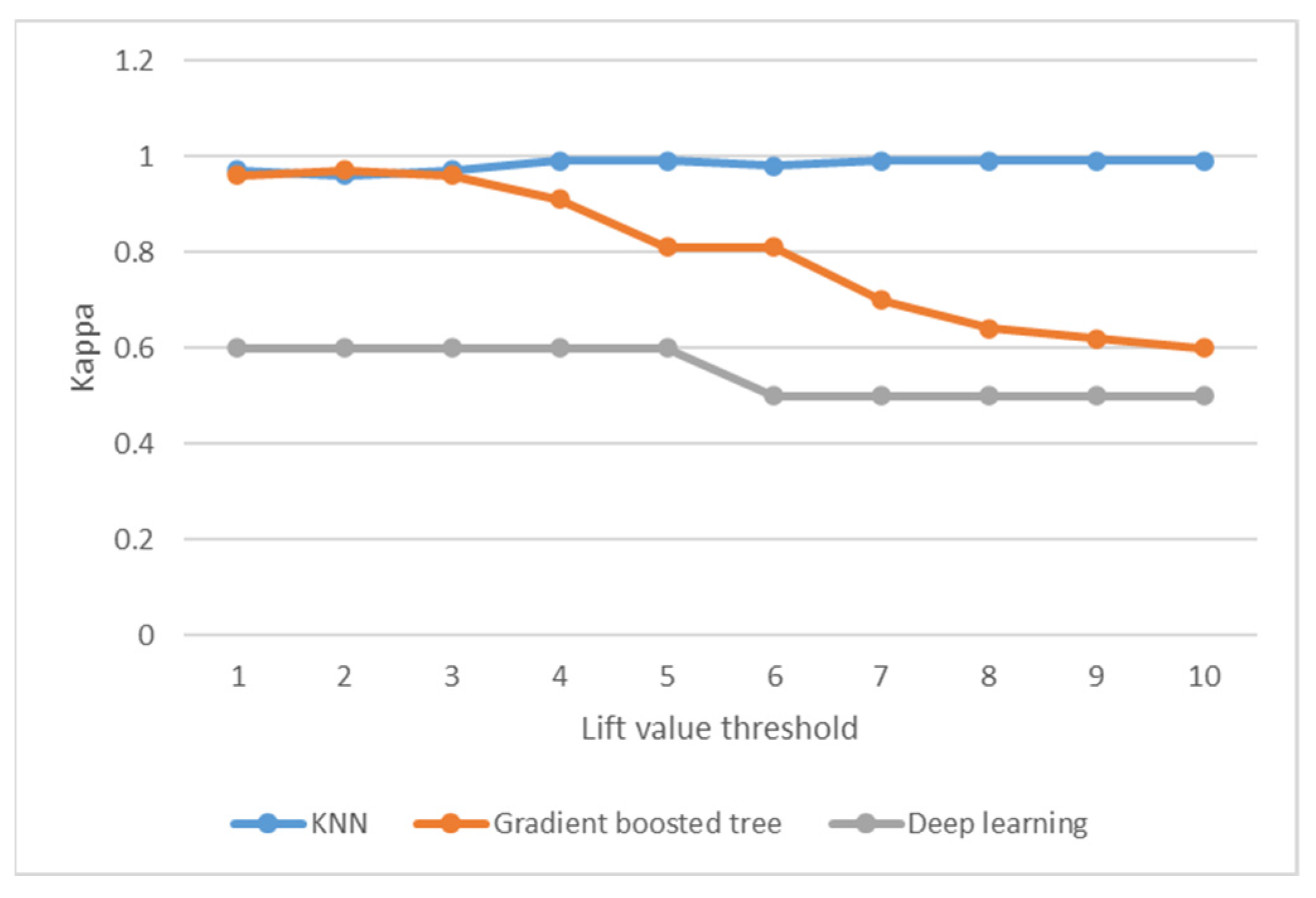
6.2. Enhanced ML by Integrating Sequential Trajectory Pattern for Check-Ins
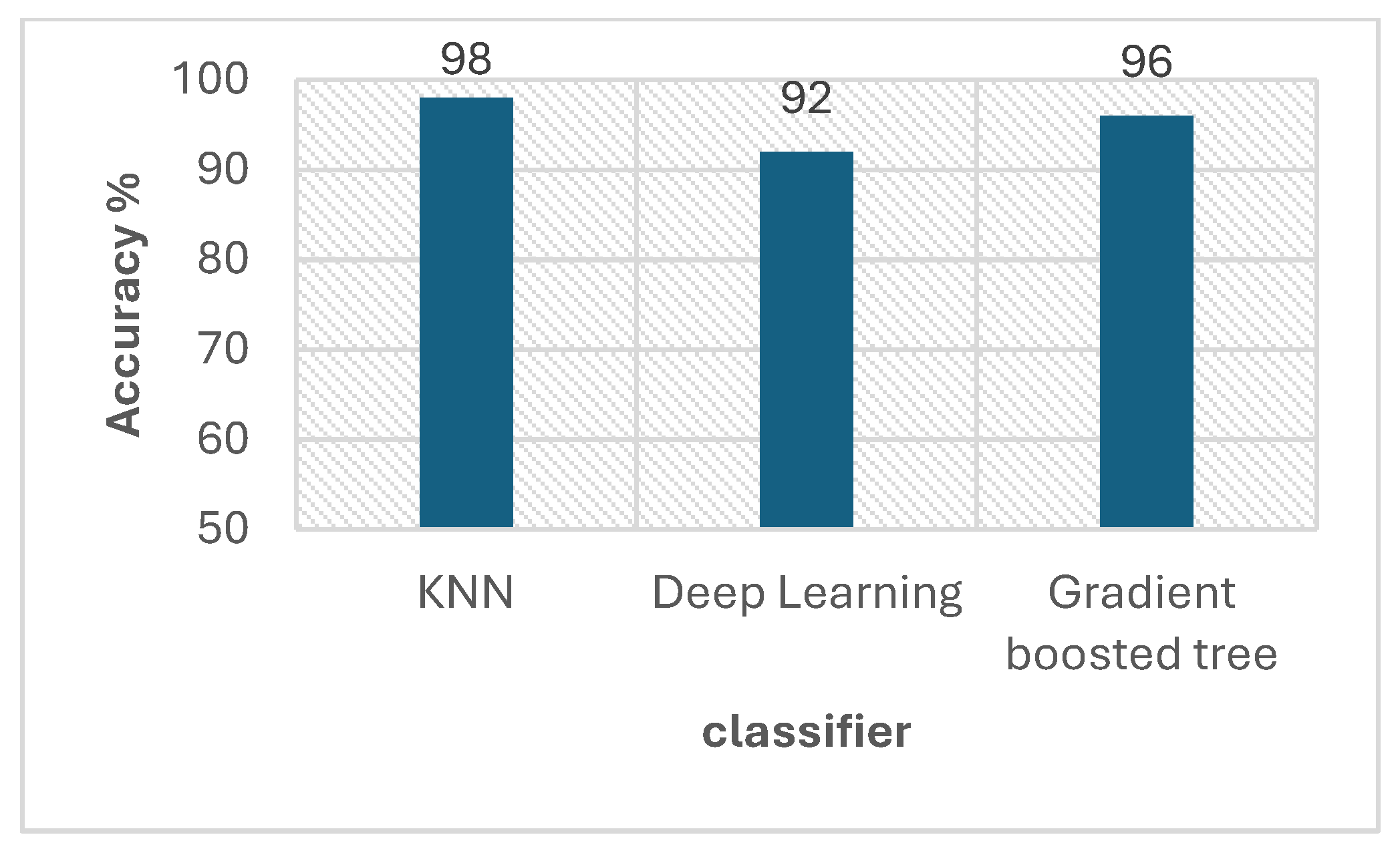
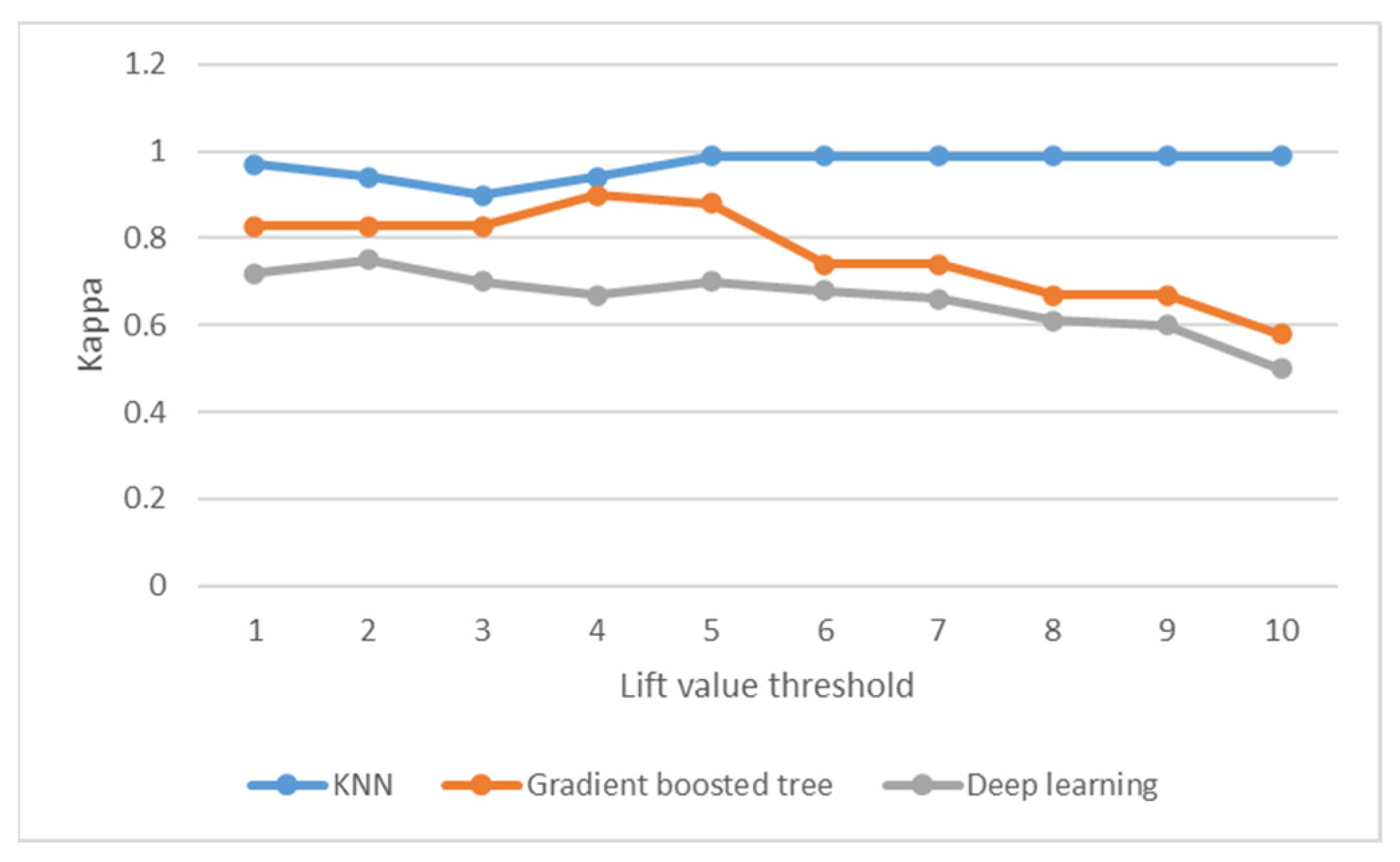
6.3. Enhanced Inference by AHLTP Model
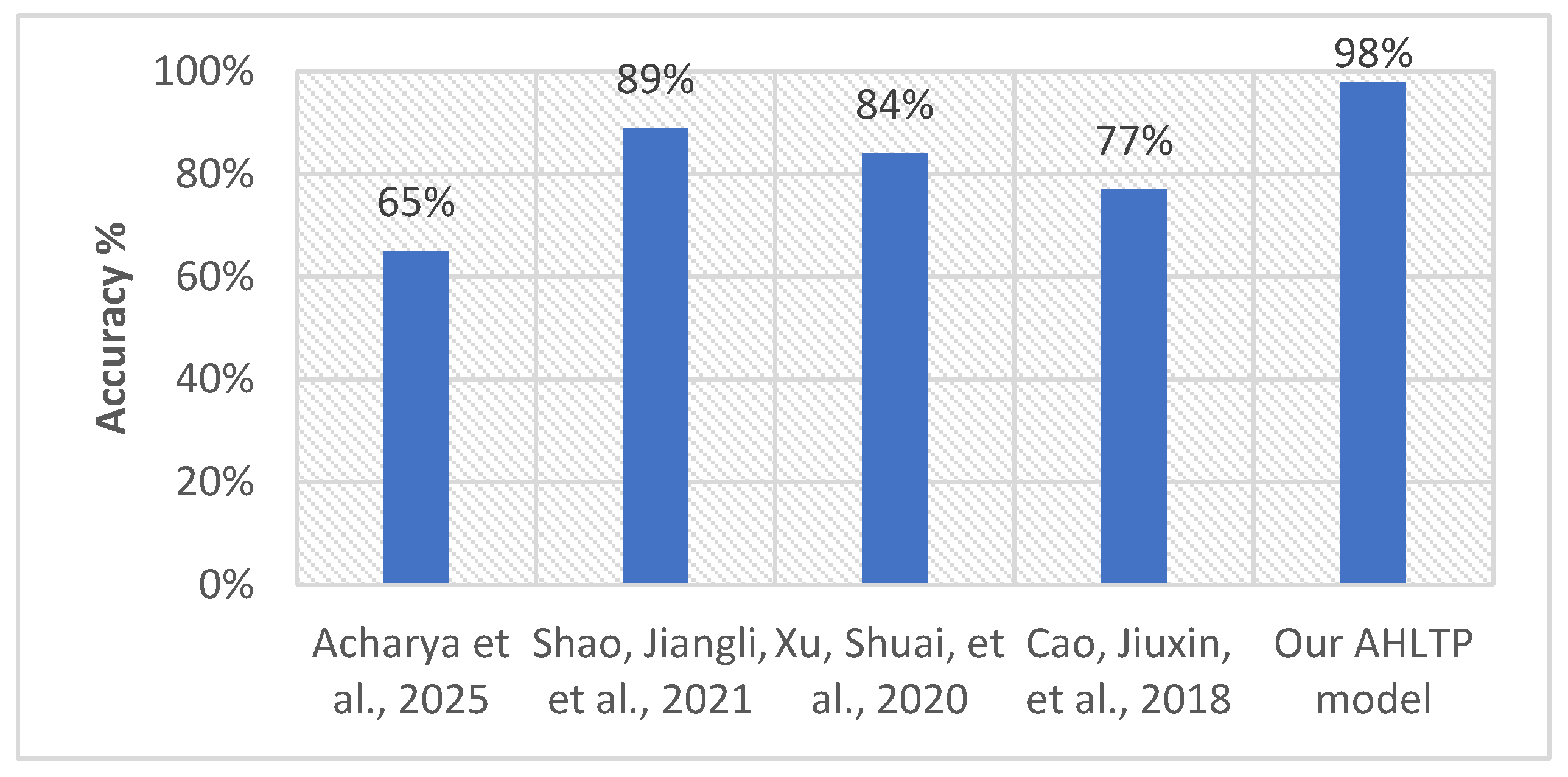
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Koolwal, V.; Mohbey, K.K. A Comprehensive Survey on Trajectory-Based Location Prediction. Iran J. Comput. Sci. 2020, 3, 65–91. [Google Scholar] [CrossRef]
- Khan, N.U.; Wan, W.; Yu, S. Location-Based Social Network’s Data Analysis and Spatio-Temporal Modeling for the Mega City of Shanghai, China. ISPRS Int. J. Geo-Inf. 2020, 9, 76. [Google Scholar] [CrossRef]
- Muhammad, R.; Zhao, Y.; Liu, F. Spatiotemporal Analysis to Observe Gender Based Check-In Behavior by Using Social Media Big Data: A Case Study of Guangzhou, China. Sustainability 2019, 11, 2822. [Google Scholar] [CrossRef]
- Bahgat, E.M.; Rady, S.; Abo-Alian, A.; Gharib, T.F. A Comparative Study on Point-of-Interest Recommendation Techniques in Location-Based Social Network. In Proceedings of the Eleventh International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 21–23 November 2023; IEEE: New York, NY, USA, 2024; pp. 360–365. [Google Scholar]
- Kim, J.S.; Jin, H.; Kavak, H.; Rouly, O.C.; Crooks, A.; Pfoser, D.; Wenk, C.; Züfle, A. Location-based social network data generation based on patterns of life. In Proceedings of the 2020 21st IEEE International Conference on Mobile Data Management (MDM), Versailles, France, 30 June–3 July 2020; IEEE: New York, NY, USA, 2020; pp. 158–167. [Google Scholar]
- Bao, J.; Zheng, Y.; Wilkie, D.; Mokbel, M.F. Recommendations in Location-Based Social Networks: A Survey. Geoinformatica 2015, 19, 525–565. [Google Scholar] [CrossRef]
- Abideen, Z.U.; Sun, X.; Sun, C. The Multi-Module Joint Modeling Approach: Predicting Urban Crowd Flow by Integrating Spatial–Temporal Patterns and Dynamic Periodic Relationship. Eng. Appl. Artif. Intell. 2024, 141, 109721. [Google Scholar] [CrossRef]
- Gad, W.; Mostafa, T.; Badr, N. A Location Prediction Methods: State of art. Int. J. Intell. Comput. Inf. Sci. 2021, 21, 119–133. [Google Scholar]
- Nezhadettehad, A.; Zaslavsky, A.; Abdur, R.; Shaikh, S.A.; Loke, S.W.; Huang, G.-L.; Hassani, A. Predicting Next Useful Location With Context-Awareness: The State-Of-The-Art. arXiv 2024, arXiv:2401.08081. [Google Scholar] [CrossRef]
- Yan, Z.; Chakraborty, D.; Parent, C.; Spaccapietra, S.; Aberer, K. Semantic Trajectories: Mobility Data Computation and Annotation. ACM Trans. Intell. Syst. Technol. 2013, 4, 49. [Google Scholar] [CrossRef]
- Yang, Y.; Fang, Z.; Xie, X.; Zhang, F.; Liu, Y.; Zhang, D. Extending Coverage of Stationary Sensing Systems with Mobile Sensing Systems for Human Mobility Modeling. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 100. [Google Scholar] [CrossRef]
- Chen, W.; Liang, Y.; Zhu, Y.; Chang, Y.; Luo, K.; Wen, H.; Li, L.; Yu, Y.; Wen, Q.; Chen, C.; et al. Deep Learning for Trajectory Data Management and Mining: A Survey and Beyond. arXiv 2024, arXiv:2403.14151. [Google Scholar] [CrossRef]
- Scellato, S.; Noulas, A.; Mascolo, C. Exploiting place features in link prediction on location-based social networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 1046–1054. [Google Scholar]
- Zhao, P.; Luo, A.; Liu, Y.; Xu, J.; Li, Z.; Zhuang, F.; Sheng, V.S.; Zhou, X. Where to Go Next: A Spatio-Temporal Gated Network for Next POI Recommendation. IEEE Trans. Knowl. Data Eng. 2022, 34, 2512–2524. [Google Scholar] [CrossRef]
- Si, Y.; Zhang, F.; Liu, W. An Adaptive Point-of-Interest Recommendation Method for Location-Based Social Networks Based on User Activity and Spatial Features. Knowl. Based Syst. 2019, 163, 267–282. [Google Scholar] [CrossRef]
- Zhao, G.; Lou, P.; Qian, X.; Qian, X.; Hou, X. Personalized Location Recommendation by Fusing Sentimental and Spatial Context. Knowl. Based Syst. 2020, 196, 105849. [Google Scholar] [CrossRef]
- Canturk, D.; Senkul, P.; Kim, S.-W.; Toroslu, I.H. Trust-Aware Location Recommendation in Location-Based Social Networks: A Graph-Based Approach. Expert Syst. Appl. 2022, 213, 119048. [Google Scholar] [CrossRef]
- Liu, J.; Yi, H.; Gao, Y.; Jing, R. Personalized Point-of-Interest Recommendation Using Improved Graph Convolutional Network in Location-Based Social Network. Electronics 2023, 12, 3495. [Google Scholar] [CrossRef]
- Seo, Y.-D.; Cho, Y.-S. Point of Interest Recommendations Based on the Anchoring Effect in Location-Based Social Network Services. Expert Syst. Appl. 2021, 164, 114018. [Google Scholar] [CrossRef]
- Yang, H.; Yao, X.; Whalen, C.C.; Kiwanuka, N. Exploring Human Mobility: A Time-Informed Approach to Pattern Mining and Sequence Similarity. Int. J. Geogr. Inf. Sci. 2025, 39, 627–651. [Google Scholar] [CrossRef]
- Khan, N.U.; Wan, W.; Yu, S.; Muzahid, A.A.M.; Khan, S.; Hou, L. A Study of User Activity Patterns and the Effect of Venue Types on City Dynamics Using Location-Based Social Network Data. ISPRS Int. J. Geo-Inf. 2020, 9, 733. [Google Scholar] [CrossRef]
- Yan, H.; Yu, Y. Large-Scale Trajectory Prediction via Relationship-Aware Adaptive Hierarchical Graph Learning. CCF Trans. Pervasive Comput. Interact. 2023, 5, 351–366. [Google Scholar] [CrossRef]
- Yang, D.; Fankhauser, B.; Rosso, P.; Cudr’e-Mauroux, P. Location Prediction over Sparse User Mobility Traces Using RNNs: Flashback in Hidden States! In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence Main track, Yokohama, Japan, 11–17 July 2020; pp. 2184–2190. [Google Scholar] [CrossRef]
- Khan, N.U.; Wan, W.; Riaz, R.; Jiang, S.; Wang, X. Prediction and Classification of User Activities Using Machine Learning Models from Location-Based Social Network Data. Appl. Sci. 2023, 13, 3517. [Google Scholar] [CrossRef]
- Xu, S.; Cao, J.; Legg, P.A.; Liu, B.; Li, S. Venue2Vec: An Efficient Embedding Model for Fine-Grained User Location Prediction in Geo-Social Networks. IEEE Syst. J. 2020, 14, 1740–1751. [Google Scholar] [CrossRef]
- Shao, J.; Wang, Y.; Gao, H.; Shen, H.; Li, Y.; Cheng, X. Locate who you are: Matching geo-location to text for user identity linkage. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual Event, 1–5 November 2021; pp. 3413–3417. [Google Scholar]
- Acharya, M.; Mohbey, K.K. Time-Aware Cross-Domain Point-of-Interest Recommendation in Social Networks. Eng. Appl. Artif. Intell. 2025, 139, 109630. [Google Scholar] [CrossRef]
- Mazumdar, P.; Patra, B.K.; Babu, K.S.; Lock, R. Hidden Location Prediction Using Check-in Patterns in Location-Based Social Networks. Knowl. Inf. Syst. 2018, 57, 571–601. [Google Scholar] [CrossRef]
- Cao, J.; Xu, S.; Zhu, X.; Lv, R.; Liu, B. Effective Fine-Grained Location Prediction Based on User Check-in Pattern in LBSNs. J. Netw. Comput. Appl. 2018, 108, 64–75. [Google Scholar] [CrossRef]
- Ghanaati, F.; Ekbatanifard, G.; Khoshhal, K. Using a Flexible Model to Compare the Efficacy of Geographical and Temporal Contextual Information of Location-Based Social Network Data for Location Prediction. ISPRS Int. J. Geo-Inf. 2023, 12, 137. [Google Scholar] [CrossRef]
- Kamal, R.; Hussein, W.; Ismail, R.M. A Novel Approach for Hiding Sensitive Association Rules Using DPQR Strategy in Recommendation Systems. Int. J. Intell. Comput. Inf. Sci. 2020, 20, 44–58. [Google Scholar] [CrossRef]
- Galal, M.; Rady, S.; Aref, M. Enhancing Machine Learning Engineering for Predicting Youth Loyalty in Digital Banking Using a Hybrid Meta-Learners. Int. J. Intell. Comput. Inf. Sci. 2024, 24, 28–40. [Google Scholar] [CrossRef]
- Zhang, S.; Menon, S.P. Challenges in KNN Classification. IEEE Trans. Knowl. Data Eng. 2021, 34, 4663–4675. [Google Scholar] [CrossRef]
- Forsquare Dataset. Available online: https://foursquare.com (accessed on 12 December 2024).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Methodology Used | Model | Implicit (Hidden)/Explicit | Challenges | Association Rule Mining | |
|---|---|---|---|---|---|---|
| Liu, J.; Yi et al., 2023 [18] | Yelp Foursquare | collaborative embedding vector between user and POI | graph convolutional network (PPR_IGCN) | Explicit data | Extract the potential features of users and POIs Data sparsity | Not applied |
| Yan, Hua, et al., 2023 [22] | Taxis in San Francisco Taxis in Beijing Foursquare | hierarchical graph pooling mechanism using spatial-temporal sequence representation | Relationship-aware Adaptive Hierarchical Graph Learning, or REAHG | Hidden data | Most of the graph convolutional networks rely only on local information, such as nearby neighbors | Not applied |
| Khan, Naimat Ullah, et al., 2023 [24] | Chinese dataset “Weibo” | machine learning classification and deep learning | Prediction of User Activities Using Machine Learning Models | Explicit data | Analyzing user activities and behavior | Not applied |
| Shao, Jiangli, et al., 2021 [26] | Foursquare Chinese dataset “Dianping3” | Multi-Layer Perception (MLP) | User Identity Linkage model | Explicit data | Utilizing asymmetric information for user identity linkage | Not applied |
| Acharya et al., 2025 [27] | Gowalla Foursquare | self-ensembled domain adaptation (SEDA) technique, which is a combination of transfer learning and reinforcement learning, | self-ensembled contextual Thompson sampling SECTS | Explicit data | Identifying cold-start users Data sparsity in the target domain | Not applied |
| Ghanaati, F., et al., 2023 [30] | Gowalla Foursquare | matrix factorization method (MF) in collaborative filtering CF-based approaches | extended attention gated recurrent unit (EAGRU) | Hidden data | Considering the efficacy of contextual information similarly | Not applied |
| UserID | VenueID | VenueCatID | Latitude | Longitude | UTC Time | |
|---|---|---|---|---|---|---|
| 470 | 49bbd6c0f964a520f4531fe3 | 4bf58dd8d48988d127951735 | 40.71981 | −74.0026 | Tue Apr 03 18:00:09 +0000 2012 | |
| 979 | 4a43c0aef964a520c6a61fe3 | 4bf58dd8d48988d1df941735 | 40.60679958 | −74.04416981 | Tue Apr 03 18:00:25 +0000 2012 | |
| 69 | 4c5cc7b485a1e21e00d35711 | 4bf58dd8d48988d103941735 | 40.71616168 | −73.88307006 | Tue Apr 03 18:02:24 +0000 2012 | |
| 395 | 4bc7086715a7ef3bef9878da | 4bf58dd8d48988d104941735 | 40.7451638 | −73.98251878 | Tue Apr 03 18:02:41 +0000 2012 | |
| Dataset | #Users | #Locations | #Checkins | #Links | Period |
|---|---|---|---|---|---|
| Gowalla | 319 K | 2.8 M | 36 M | 4.4 M | 20 mo |
| BrightKite | 58 K | 917 K | 4.49 M | 214 K | 30 mo |
| Foursquare | 2.7 M | 11.1 M | 90 M | 0 | 5 mo |
| Yelp | 1.00 M | 144 K | 4.10 M | 0 | 36 mo |
| True | Food | Arts & Entertainment | Nightlife Spot | Travel & Transport | Outdoors & Recreation | Shop & Service | Professional & Other Places | Event | Residence | College & University | Class Precision | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Predicted | ||||||||||||
| Food | 9006 | 172 | 509 | 303 | 330 | 677 | 233 | 312 | 121 | 45 | 76.92% | |
| Arts & Entertainment | 96 | 730 | 38 | 32 | 39 | 45 | 32 | 49 | 8 | 3 | 68.10% | |
| Nightlife Spot | 354 | 71 | 2376 | 85 | 69 | 101 | 44 | 87 | 34 | 10 | 73.54% | |
| Travel & Transport | 286 | 46 | 75 | 5245 | 129 | 151 | 83 | 166 | 72 | 8 | 83.77% | |
| Outdoors & Recreation | 238 | 64 | 79 | 140 | 3302 | 136 | 65 | 133 | 52 | 15 | 78.17% | |
| Shop & Service | 553 | 54 | 115 | 132 | 136 | 3902 | 81 | 152 | 58 | 22 | 74.97% | |
| Professional &Other Places | 255 | 48 | 52 | 79 | 66 | 94 | 3375 | 67 | 19 | 11 | 83.01% | |
| Event | 328 | 63 | 82 | 109 | 107 | 120 | 99 | 2637 | 34 | 21 | 73.25% | |
| Residence | 144 | 20 | 36 | 84 | 78 | 82 | 47 | 57 | 4475 | 7 | 88.97% | |
| College & University | 45 | 11 | 8 | 12 | 21 | 13 | 9 | 28 | 11 | 930 | 85.48% | |
| class recall | 79.66% | 57.08% | 70.50% | 84.31% | 77.20% | 73.33% | 82.96% | 71.50% | 91.63% | 86.75% | ||
| True | Food | Arts & Entertainment | Nightlife Spot | Travel & Transport | Outdoors & Recreation | Shop & Service | Professional & Other Places | Event | Residence | College & University | Class Precision | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Predicted | ||||||||||||
| Food | 9425 | 130 | 409 | 248 | 243 | 533 | 177 | 250 | 83 | 31 | 81.75% | |
| Arts & Entertainment | 98 | 808 | 44 | 24 | 47 | 39 | 33 | 45 | 6 | 6 | 70.26% | |
| Nightlife Spot | 337 | 63 | 2550 | 65 | 57 | 87 | 45 | 76 | 22 | 12 | 76.95% | |
| Travel & Transport | 211 | 46 | 61 | 5452 | 91 | 112 | 62 | 119 | 40 | 9 | 87.89% | |
| Outdoors & Recreation | 207 | 54 | 60 | 109 | 3502 | 108 | 51 | 132 | 52 | 7 | 81.78% | |
| Shop & Service | 486 | 48 | 110 | 102 | 117 | 4183 | 62 | 140 | 43 | 14 | 78.85% | |
| Professional & Other Places | 161 | 43 | 42 | 62 | 47 | 76 | 3519 | 54 | 15 | 6 | 87.43% | |
| Event | 265 | 60 | 74 | 93 | 100 | 119 | 77 | 2823 | 34 | 21 | 77.00% | |
| Residence | 80 | 16 | 16 | 52 | 56 | 53 | 34 | 38 | 4582 | 3 | 92.94% | |
| College & University | 35 | 11 | 4 | 14 | 17 | 11 | 8 | 11 | 7 | 963 | 89.08% | |
| class recall | 83.37% | 63.17% | 75.67% | 87.64% | 81.88% | 78.61% | 86.50% | 76.55% | 93.82% | 89.83% | ||
| True | Food | Arts & Entertainment | Nightlife Spot | Travel & Transport | Outdoors & Recreation | Shop & Service | Professional & Other Places | Event | Residence | College & University | Class Precision | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Predicted | ||||||||||||
| Food | 10,313 | 211 | 554 | 514 | 437 | 981 | 504 | 752 | 206 | 132 | 70.62% | |
| Arts & Entertainment | 14 | 914 | 7 | 3 | 2 | 6 | 7 | 9 | 1 | 0 | 94.91% | |
| Nightlife Spot | 93 | 11 | 2694 | 23 | 18 | 15 | 8 | 19 | 12 | 1 | 93.09% | |
| Travel & Transport | 187 | 39 | 24 | 5451 | 83 | 126 | 72 | 98 | 44 | 7 | 88.91% | |
| Outdoors & Recreation | 110 | 26 | 12 | 56 | 3559 | 50 | 28 | 51 | 25 | 11 | 90.61% | |
| Shop & Service | 283 | 25 | 27 | 65 | 59 | 3954 | 75 | 104 | 27 | 14 | 85.36% | |
| Professional & Other Places | 172 | 29 | 35 | 58 | 46 | 99 | 3299 | 70 | 15 | 5 | 86.18% | |
| Event | 55 | 11 | 5 | 15 | 33 | 23 | 33 | 2538 | 7 | 6 | 93.10% | |
| Residence | 64 | 5 | 11 | 34 | 31 | 62 | 29 | 28 | 4540 | 5 | 94.41% | |
| College & University | 14 | 8 | 1 | 2 | 9 | 1 | 13 | 19 | 7 | 891 | 92.33% | |
| class recall | 91.23% | 71.46% | 79.94% | 87.62% | 83.21% | 74.38% | 81.10% | 68.82% | 92.96% | 83.12% | ||
| Classifiers | p-Value |
|---|---|
| KNN vs. DL | 0.977 |
| KNN vs. GBT | 0.758 |
| DL vs. GBT | 0.959 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bahgat, E.M.; Abo-alian, A.; Rady, S.; Gharib, T.F. Efficient Trajectory Prediction Using Check-In Patterns in Location-Based Social Network. Big Data Cogn. Comput. 2025, 9, 102. https://doi.org/10.3390/bdcc9040102
Bahgat EM, Abo-alian A, Rady S, Gharib TF. Efficient Trajectory Prediction Using Check-In Patterns in Location-Based Social Network. Big Data and Cognitive Computing. 2025; 9(4):102. https://doi.org/10.3390/bdcc9040102
Chicago/Turabian StyleBahgat, Eman M., Alshaimaa Abo-alian, Sherine Rady, and Tarek F. Gharib. 2025. "Efficient Trajectory Prediction Using Check-In Patterns in Location-Based Social Network" Big Data and Cognitive Computing 9, no. 4: 102. https://doi.org/10.3390/bdcc9040102
APA StyleBahgat, E. M., Abo-alian, A., Rady, S., & Gharib, T. F. (2025). Efficient Trajectory Prediction Using Check-In Patterns in Location-Based Social Network. Big Data and Cognitive Computing, 9(4), 102. https://doi.org/10.3390/bdcc9040102