Abstract
Researchers in the fields of machine learning and artificial intelligence have recently begun to focus their attention on object recognition. One of the biggest obstacles in image recognition through computer vision is the detection and identification of similar items. Identifying similar musical instruments can be approached as a classification problem, where the goal is to train a machine learning model to classify instruments based on their features and shape. Cellos, clarinets, erhus, guitars, saxophones, trumpets, French horns, harps, recorders, bassoons, and violins were all classified in this investigation. There are many different musical instruments that have the same size, shape, and sound. In addition, we were amazed by the simplicity with which humans can identify items that are very similar to one another, but this is a challenging task for computers. For this study, we used YOLOv7 to identify pairs of musical instruments that are most like one another. Next, we compared and evaluated the results from YOLOv7 with those from YOLOv5. Furthermore, the results of our tests allowed us to enhance the performance in terms of detecting similar musical instruments. Moreover, with an average accuracy of 86.7%, YOLOv7 outperformed previous approaches and other research results.
1. Introduction
Object detection is an example of computer technology which is related to computer vision. This method is used to find specific examples of semantic items that belong to a particular class, such as people [1,2], musical instruments [3,4], buildings [5], traffic signs [6], or cars [7,8], in video and digital images.
Despite the widespread application of object detection, its performance is likely to vary, depending on the possibilities. A suitable illustration of this phenomenon is provided by the condition where two object classes share the same appearance, as seen in Figure 1. Due to this, the detector is distracted from the class of object being examined. Imagine for a moment that different things that have similar external characteristics are grouped together as pairs of related objects.

Figure 1.
Similar musical instruments: (a) guitar, (b) cello, and (c) violin.
Both the flute and the clarinet have several complementary characteristics. The clarinet is a woodwind device consisting of a mouthpiece with a single reed, a cylindrical tube with a flared end, and a key that conceals a hole in the tube. Both the flute and the clarinet are important members of the woodwind family of musical instruments, and they are often played concurrently. The presence or absence of reeds is one of the most important differences between the flute and the clarinet. The flute has no reed, while the clarinet has only one reed.
Moreover, although the cello and violin belong to the family of stringed instruments, they cannot be confused with each other in any way. The distinction in size between the cello and the violin is the main differentiator between the two instruments. When one plays the cello, it is customary to take a sitting position and hold the instrument between the knees while doing so. The violinist, on the other hand, holds the instrument so that it is supported between the shoulder and the chin. The cello can play lower notes than the violin. The cello and violin are both played with a bow, which is one thing they have in common. The right hand is used to play the cello using a bow that crosses all four strings, similar to how the violin is played. Overall, while these instruments have some similarities, they also have unique features that make them distinct from each other.
However, as can be seen in Figure 1, the designs of the guitar, violin, and cello are fundamentally very similar to one another. Computers have a far harder time differentiating among similar musical instruments than people do. The simplicity with which humans can recognize visual identification cues, such as detecting highly similar musical instrument objects, was impressive in our research study because it was one of the challenges that we investigated. In addition, even though people have no difficulty understanding the task, computers experience greater difficulty.
Recognizing similar musical instruments is important for several reasons. Firstly, in the field of musical education, by recognizing musical instruments through image detection, we can help students to learn and understand different types of instruments. This can aid in their musical education and development, especially if they do not have access to physical instruments to practice with. In the field of music production, recognizing musical instruments through image detection can help producers to create better and more engaging music. They can use this technology to identify the instruments being used in a recording or performance and make decisions on how to enhance or balance the sound. In the area of classifying instruments, image detection can be used to classify musical instruments on the basis of their physical characteristics. This can be useful in identifying and cataloguing different types of instruments and can aid in research into and preservation of musical history. In the field of performance analysis, image detection can also be used to analyze and evaluate musical performances. Through recognition of the instruments being played, it is possible to assess the quality and accuracy of a performance and provide feedback for improvement. Lastly, recognizing musical instruments through image detection can make music more accessible to those with disabilities or limitations. For example, individuals who are visually impaired can benefit from this technology, as it can provide them with a visual representation of the instruments being used in a piece of music.
Overall, recognizing musical instruments through image detection can improve musical education, production, classification, performance analysis, and accessibility. It is a valuable tool for musicians, music educators, producers, researchers, and anyone else involved in the creation and performance of music.
The most effective use of You Only Look Once (YOLO) is found in circumstances that call for faster detection. It offers a high degree of precision and a high detection rate at the same time. YOLOv7’s trainable bag of freebies represents the new state-of-the-art for real-time object detectors and is the latest version of YOLO, which was announced in 2022 [9]. In terms of both speed and accuracy, YOLOv7 is superior to any other object detector that has been developed. In this study, convolutional neural network (CNN) models and feature extractors, including YOLOv7 for object recognition, as well as other approaches to feature extraction were investigated in detail.
Our research fine-tuned the models to the People Playing Musical Instruments (PPMI) dataset [10]. The PPMI dataset contains photographs of individuals interacting with a variety of musical instruments, with 12 distinct types of instruments represented. It can be challenging to locate many object detectors in published research that have been built on deep learning and tailored specifically to the domain of detecting similar musical instruments, and thus it was difficult to locate a prior study that assessed a variety of crucial factors, such as the mAP, precision, and recall.
The following is a summary of the contributions made by this study. Firstly, we aimed to distinguish objects that appear to the human eye as very similar to each other. In the second step of our process, we applied YOLOv7 to determine which musical instruments were similar to one another. After that, we analyzed and evaluated the YOLOv7 model. Performance metrics were used to track crucial data, including the mean average precision (mAP), precision (P), and recall (R).
During this investigation, we became familiar with a wide variety of musical instruments that are similar to each other.
This article is organized as follows. Relevant prior work is presented in Section 2. Our recommended methodology is described in Section 3. In Section 4, we discuss the experimental results, and present a comprehensive analysis and interpretation of our results. At the end of the article, in Section 5, our conclusions are presented, along with recommendations for additional research.
2. Related Works
2.1. Identifing Similar Musical Instruments with CNN
Over the past few years, significant advances have been made possible by the application of deep learning to most object recognition and identification algorithms. The act of recognizing objects is simple for people, but it is quite difficult for computers to distinguish between two things that are almost identical in both their appearance and their function [11]. Two-stage detection consists of two processes that cooperate with each other to achieve the desired result. Utilizing a technique known as region-based CNN (RCNN), the detector first generates hypotheses about the possible locations of the objects in the image. This location is just a suggestion. After that, each region of interest (RoI) is classified independently, and then the classifications are combined [12].
However, two-stage detection, despite its excellent performance, has some significant drawbacks. Since there are two different processes involved, it takes a long time to train the model, and even more time to test it. To reduce the amount of time spent predicting the results, it is recommended to use a single-stage detector. YOLO [13] and the Single-Shot Detector (SSD) [14] are the most representative single-stage detectors. Compared with their two-stage equivalents, single-stage detectors are superior in terms of their overall performance, efficiency, and the number of model parameters that they require.
Ju et al. [15] described a method of object recognition that makes use of entropy loss in order to improve the ability to correctly recognize items that have a similar outward appearance. When entropy loss is applied, the detector can generate more accurate predictions regarding the bounding box class that has been observed, which ultimately leads to a higher probability of receiving a satisfactory score. In addition to this, it has the effect of reducing the deterioration of reliability. As a direct consequence, the performance in terms of detecting similar things is improved. A more effective architecture for a CNN network was created by Shijin Song and colleagues [16]. This design made it possible for small objects to be identified with greater precision, while also needing less processing and enabling simpler deployment. They eliminated the CNN network, which significantly reduced the model’s size and the amount of time the model was operational, while preserving its accuracy. To improve the effectiveness of computation, the fully convoluted layers were simultaneously replaced with fully connected layers.
Dewi et al. [17] used the YOLO approach in conjunction with the Generative Adversarial Network (GAN) in order to identify musical instruments that were comparable to one another. YOLO is a strong region-based convolutional neural network (CNN) that is extremely fast. When Deep Convolution YOLO-GAN is utilized, the capacity of the YOLO detection process will rise, even beyond what was previously possible with YOLO. In this experiment, we used the most recent version of YOLOv7 in conjunction with the PPMI dataset, which included 12 unique musical instruments in total.
2.2. YOLOv5 and YOLOv7
Here, we describe the timeline of the YOLO versions. The first version of YOLO, YOLOv1, was introduced in 2015. It was designed to detect objects in real time using a single neural network. YOLO9000v2 was introduced in 2016. It used a more powerful neural network architecture called Darknet-19 and introduced anchor boxes and batch normalization to improve the accuracy of object detection. Next, YOLOv3 was introduced in 2018. It introduced several new features, including a feature pyramid network, improved anchor box clustering, and multi-scale predictions. YOLOv3 achieved state-of-the-art performance on several object detection benchmarks [18]. It divided the input images into N × N grid cells [19] of the same size, and forecasted the bounding boxes and probabilities for each grid cell. YOLOv3 made use of multi-scale integration for producing predictions, and a single neural network was utilized to construct a general overview of the input. Both processes can be carried out by YOLOv3. YOLOv3 can generate a one-of-a-kind bounding box anchor for each ground truth item [20].
YOLOv4 was introduced in 2020. It introduced several advanced techniques, including CSPDarknet53, scaled-YOLOv4, PP-YOLO, YOLOv5, YOLOv6, and Mish activation. YOLOv4 achieved state-of-the-art performance on several object detection benchmarks [21]. The structure of YOLOv4 is as follows: (1) backbone: CSPDarknet53 [22], (2) neck: SPP [23] and PAN [24], and (3) head: YOLOv3 [18]. In the backbone, YOLOv4 utilizes a Mish [25] activation function. YOLOv5 was also introduced in 2020. It used a different neural network architecture called CSPNet and was designed to be faster and more accurate than previous versions of YOLO. YOLOv5 achieved state-of-the-art performance on several object detection benchmarks.
There are five unique designs for the architecture of YOLOv5, namely YOLOv5s, YOLOv5m, YOLOv5n, YOLOv5l, and YOLOv5x. The major component that distinguishes them is the number of feature extraction modules and convolution kernels that are scattered over the network at various preset points. YOLOv5 has four main components: the input, the backbone, the neck, and the output [26]. The major task of the backbone model is to identify significant segments for analysis from inside the input image.
Automatic learning bounding box anchoring, mosaic data enhancement, and cross-stage partial networking are just a few of the technologies that have been incorporated into the architecture of YOLOv5. The design makes use of the state-of-the-art algorithm optimization techniques for convolutional neural networks that have emerged in the last few years. YOLO’s detection architecture is the foundation on which it was constructed. YOLOv5 uses cross-stage partial networks (CSP) and spatial pyramid pooling (pSPP) as its fundamental building blocks to extract rich, significant attributes from the input pictures. To correctly generalize a model in terms of scaling the objects, SPP is useful for detecting the same item in different sizes and scales. The feature pyramid architectures of the feature pyramid network (FPN) [27] and the path aggregation network (PANet) [28,29] were utilized in the construction of the neck network.
YOLOv6 and YOLOv7 were released in 2022 along with other methods such as DAMO YOLO and PP-YOLOE. Some researchers have created their own versions of YOLO by modifying the existing architectures or using different backbones. YOLOv6 focused on making the system more efficient and reducing its memory footprint. It made use of a new CNN architecture called SPP-Net (spatial pyramid pooling network). This architecture is designed to handle objects with different sizes and aspect ratios, making it ideal for object detection tasks. YOLOv7 was then introduced. One of the key improvements in YOLOv7 is the use of a new CNN architecture called ResNeXt.
The YOLOv7 method has caused a sensation in the fields of computer vision and machine learning. When compared with other object detection models and older YOLO versions, the newest YOLO algorithm is much faster and more accurate. Moreover, YOLOv7 is a variant of the YOLO (You Only Look Once) object detection algorithm, which was first introduced by Joseph Redmon et al. in 2016 [18]. YOLOv7 is based on a deep neural network and is capable of detecting and localizing objects within an image in real time. Compared with earlier versions of YOLO, YOLOv7 has several improvements, including the use of skip connections and the introduction of residual blocks in the network architecture. These changes allow YOLOv7 to detect objects with greater accuracy and speed. In order for the YOLOv7 method to function properly, the input image must first be segmented into a grid of cells. Next, the algorithm must predict the bounding boxes and class probabilities of the objects contained within each cell. Each bounding box’s prediction includes a confidence score, indicating the probability that the predicted box contains an object. The algorithm also predicts the class probabilities for each object, which are used to label the objects within the bounding boxes. Furthermore, YOLOv7 is a popular algorithm for object detection tasks due to its high speed and accuracy. It has many applications, including in autonomous vehicles, surveillance systems, and robotics. YOLOv8 is the latest version of YOLO and was released in 2023. However, Ultralytics YOLOv8 provides the most advanced capabilities and has outperformed previous versions. Ultralytics YOLOv8 provides a unified framework for training models for the tasks of object detection, instance segmentation, and image classification. This means that users can use a single model for all three tasks, simplifying the training process.
In addition to being able to be trained significantly more quickly on tiny datasets without any pre-learned weights, it also requires technology that is several times cheaper than other neural networks. YOLOv7’s architecture is a combination of YOLOv4, scaled YOLOv4, and YOLO-Rs, among others. To produce a new and enhanced version of YOLOv7, more tests were carried out using these models as a foundation. The extended efficient layer aggregation network (E-ELAN) serves as the computing node of YOLOv7′s backbone [30,31]. It was based on earlier studies on how effective networks are. It was developed by considering the following elements that affect speed and accuracy, such as the memory access cost, the ratio of the input to the output channel, element-wise operation, activations, and the gradient path. Expansion, shuffling, and merging the cardinality are the three techniques that the proposed E-ELAN uses in order to keep the initial gradient path intact, while continuously enhancing the network’s capacity for learning. In order to make YOLOv7 better, a compound model scaling technique was utilized. Within this framework, the width and depth of models based on concatenation can be scaled in a consistent manner.
Bag of freebies (BoF) techniques improve a model’s output without adding to its training budget. The following are some of the new BoF techniques included in YOLOv7. First, planned re-parameterized convolution, which improves a model by applying re-parameterization, is a common practice following training [32]. The model takes longer to train but yields better inference results [33]. Model-level and module-level ensemble re-parametrization were used to construct the models. Second, with the “coarse for auxiliary and fine for lead loss” technique, the YOLO architecture comprises of a backbone, a neck, and a head. The outputs that were anticipated are stored in the head. YOLOv7 is not restricted to utilizing a single head at a time [34]. It can accomplish everything it wants since it possesses several heads. Moreover, the lead head-guided label assigner encapsulates the concepts of the lead head, the auxiliary head, and the soft label assigner. The YOLOv7 network’s lead head is the part responsible for making the final predictions. These results serve as the basis for the generation of soft labels. The loss is calculated for both the lead head and the auxiliary head on the basis of the same soft labels being created, which is crucial to take into consideration. Ultimately, both heads will be trained using the soft labels. Further, the coarse-to-fine labels include a fine label to train the lead head and a set of coarse labels to train the auxiliary head.
YOLO is a popular object detection algorithm that is widely used in computer vision applications. YOLO has several versions, with YOLOv5 and YOLOv7 being the latest ones. YOLOv5 is a later version of the algorithm and has several improvements over its predecessor, YOLOv4. Some of the key features of YOLOv5 include its improved speed and improved accuracy, and that it is a smaller model. In terms of speed, YOLOv5 is faster than YOLOv4, allowing real-time object detection in video streams. In terms of accuracy, YOLOv5 has better accuracy compared with previous versions, with a better ability to detect small objects and objects at a distance. As a lighter model, YOLOv5 has a smaller model compared with previous versions, making it easier to deploy on embedded devices and systems with limited resources. On the other hand, YOLOv7 is a more recent development. The main difference between YOLOv5 and YOLOv7 is that YOLOv7 uses a different architecture from YOLOv5. YOLOv7 uses an anchor-free architecture, which eliminates the need for anchor boxes, which can improve the accuracy of object detection. YOLOv7 also uses a different backbone network, which can improve the speed and efficiency of the algorithm. Overall, both YOLOv5 and YOLOv7 are powerful object detection algorithms that can be used for a wide range of applications. The choice between the two depends on the specific requirements of the application, such as the need for speed and/or accuracy, or the model’s size.
In our experiment, we implemented YOLOv5n, YOLOv5s, YOLOv5m, YOLOv7, and YOLOv7x, as described in Table 1.

Table 1.
An overview of the YOLOv5 and YOLOv7 models used with the COCO dataset.
3. Methodology
3.1. Dataset
Pictures of individuals posing with a wide variety of musical instruments can be found within the People Playing Musical Instruments (PPMI) dataset. Bassoons, cellos, clarinets, French horns, erhus, flutes, guitars, harps, saxophones, trumpets, recorders, and violins are among the instruments in the dataset. Yao gathered images of musical instruments and published them in [10]. In September 2010, Aditya Khosla published a collection of photos of various musical instruments that he had taken. These photos include cellos, clarinets, harps, recorders, and trumpets. Initially, the dataset contained 100 examples from each category to be used for training, as well as 100 images to use for testing. The first table provides an overview of the entire dataset. During this study, we used the PPMI dataset to train and validate our model. Figure 2 shows the PPMI dataset we used in these experiments.

Figure 2.
Sample images in the PPMI dataset.
The labels of the PPMI dataset are depicted in Figure 3. The PPMI dataset includes 12 classes, and the vast majority of those classes have more than 300 photos. The values for x and y can vary anywhere from 0.0 to 1.0, while the width can be any number between 0.0 and 0.1, and the height can be any value between 0.0 and 0.1. We used 70% of it for training purposes and 30% for testing. Table 2 presents the distribution of the PPMI dataset in its entirety.
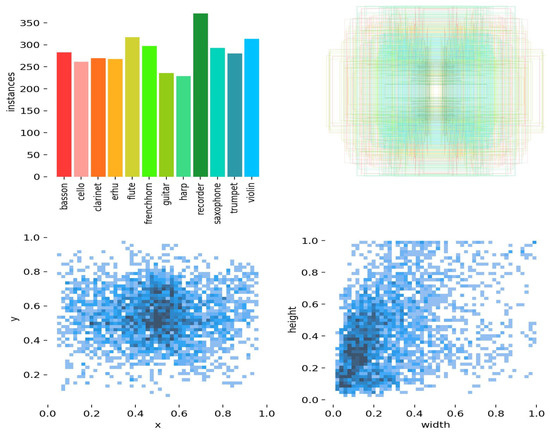
Figure 3.
Instances in the PPMI dataset.
Table 2.
Distribution of the PPMI dataset.
3.2. YOLOv7
In these sections, we explain our proposed YOLOv7 architecture, as shown in Figure 4. The PPMI dataset was used as the input in our systems, and then we trained the model with YOLOv7. YOLOv7’s E-ELAN architecture uses “expand, shuffle, and merge cardinality” to acquire the ability to continuously increase the network’s learning capability without losing the original gradient path, allowing the model to learn better. Compound model scaling, which is based on concatenation, is new in YOLOv7. The compound scaling approach preserves the model’s characteristics from the time of its inception, allowing for the most efficient architecture to be kept. Re-parameterization of the model is scheduled to take place in the architecture of YOLOv7. The RepConv of a layer that has concatenation or residual connections should not have an identity connection. Due to this, the RepConv of that layer is replaced by RepConvN, which does not have any identity connections. The next step is to generate the final model by averaging their relative weights. The model’s weights from different times should be averaged out. In our research, we examined both the training procedure and the testing procedure in depth for object recognition.
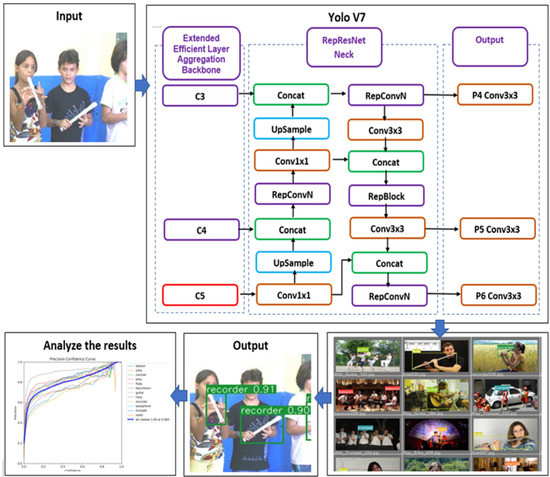
Figure 4.
Architecture of YOLOv7.
RepConvN, which has no identification ties, can be used in its place under certain conditions. RepConv is a convolutional layer that includes 3 × 3 convolutions, 1 × 1 convolution, and identity connections. The authors used RepConv without an identity connection (RepConvN) to create the architecture of the planned re-parameterized convolution after examining the combination and corresponding performance of RepConv and other architectures. In this study, when a convolutional layer including residuals or concatenations is swapped for re-parameterized convolution, there should be no identity connections [35,36].
The following is a list of the key differences between the various basic versions of YOLOv7. YOLOv7 is the foundational model, and it was designed to be as efficient as possible for general GPU computing. YOLOv7x was developed through the implementation of the suggested compound scaling method. YOLOv7-tiny is a fundamental model that has been tailored specifically for edge GPU. YOLOv7-W6 is a basic model optimized for cloud GPU computing. In our work, we only focused on YOLOv7 and YOLOv7x, and tuned them with the PPMI datasets. During the training of YOLOv7, we set the following parameters: image size = 640 × 640, conf-thres = 0.25, iou_thres = 0.45, learning_rate = 0.0001, number of classes = 12, depth_multiple = 1.0, momentum = 0.999, optimizer = Adam with lr0, epoch = 100, and width_multiple = 1.0. As a comparison, we also trained and tested our model with YOLOv5. Throughout the training of YOLOv5, we specified the following parameters: picture size = 640 × 640, conf-thres = 0.25, iou_thres = 0.45, learning rate = 0.0001, max_det = 1000, number of classes = 12, depth_multiple = 0.33, momentum = (0.3, 0.6, 0.98), batch size = 16, epoch = 100, and width_multiple = 0.50.
3.3. Training Results
During every stage of the training process, this study made use of several data augmentation techniques, including padding, cropping, and horizontal flipping, among others. These methods are often used in the creation of large neural networks because of their benefits. Diagrams of the training process and the validation process for Batch 0 are shown in Figure 5 and Figure 6, respectively. The YOLOv7 network augments its training material with random splicing of four images using mosaic data augmentation. This greatly increases the detection dataset, strengthens the network, and releases more video processing power on the GPU. In addition, a Nvidia RTX3060Ti GPU accelerator with 11 GB of RAM, an i7 central processing unit (CPU), and 16 GBDDR2 memory comprised the environment of the training model. YOLOv7’s primary goal was real-time detection, and it was trained using only a single graphics processing unit (GPU).

Figure 5.
Training process: Example of Batch 0.

Figure 6.
Validation process for Batch 0. (a) Labels and (b) predictions.
The BBox marking tool [37] was implemented to create a bounding box for all musical instruments. YOLO labeling is the standard output format for most annotation programs, and it creates a single text file that contains all the annotations for all images. Each text file has one bounding box, abbreviated as “BBox”, and the annotation for each of the objects displayed in the image. The image-appropriate scaling of the annotations yields a value ranging from 0 to 1 for all of the labels [38]. Equations (1)–(6) were the basis for the procedure of adjustment for calculating the YOLO format:
where H is used to denote the height of the image, dh refers to the absolute height of the image, W is used to denote the width of the image, and dw represents the absolute width of the image. The results of training for all classes are shown in Table 3 and Table 4, which includes the mAP, precision, and recall for each class. According to Table 3, YOLOv7x achieved a mAP of 88.2%, followed by YOLOv7, with a mAP of 86.6%. In addition, the cello, erhu, guitar, harp, and saxophone classes all earned a maximum mAP score of over 90% when YOLOv7x was used. The precision and recall curve for YOLOv7x is displayed in Figure 7a, and the training and validation curve can be seen in Figure 7b. In addition, the harp, erhu, and saxophone classes had the highest mAP (91.1%, 97.6%, and 91.6%, respectively) with YOLOv7. As a comparison, we also trained YOLOv5, and the results are depicted in Table 4. YOLOv5m achieved the highest mAP of 82.5%, followed by YOLOv5s with 81.3% and YOLOv5n with 75%.
Table 3.
Evaluation of the performance of training on the PPMI dataset with YOLOv7.
Table 4.
Evaluation of the performance of training on the PPMI dataset with YOLOv5.
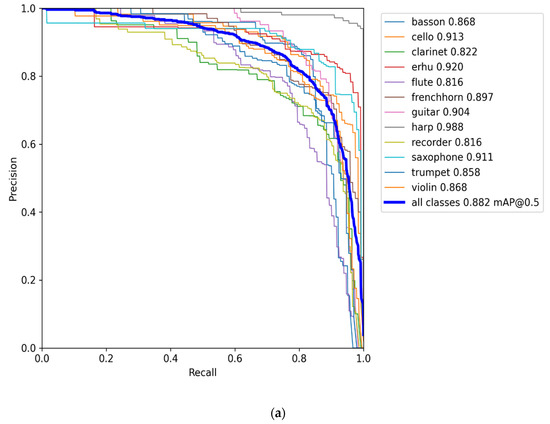
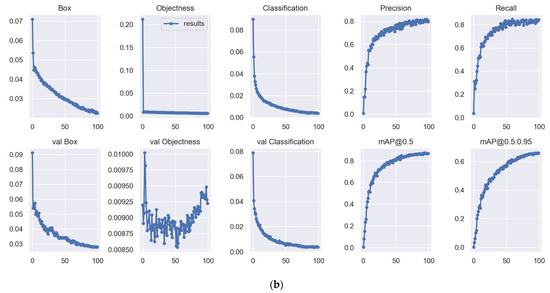
Figure 7.
The YOLOv7x curves. (a) Precision and recall curves for YOLOv7x, and (b) training and validation curves for YOLOv7x.
The loss function of YOLO was based on Equation (7) [13]:
where indicates that the object appears in cell i, and indicates that the jth bounding box predictor in cell i is responsible for the prediction. Next, were used to express the anticipated bounding box’s center coordinates, width, height, confidence, and category probability. Moreover, our experiment defined the as 0.5, indicating that the errors in width and height were less useful in the computation. In order to lessen the effect of multiple grids, a loss value that is empty of objects, = 0.5, was utilized.
Equation (8) describes the average mean average precision (mAP) as the integral over the precision p(o):
where p(o) is the precision of object detection. IoU calculates the overlap ratio between the boundary box of the prediction (pred) and the ground truth (gt) and is shown in Equation (9). Precision and recall were calculated by Equations (10) and (11) [39].
where N is the number of objects found, TP is the true positives, FP is the false positives, and FN is the false negatives (including true positives and false positives). Another evaluation index, F1 [40], is shown in Equation (12). Figure 8 describes the confusion matrix of YOLOv7x.
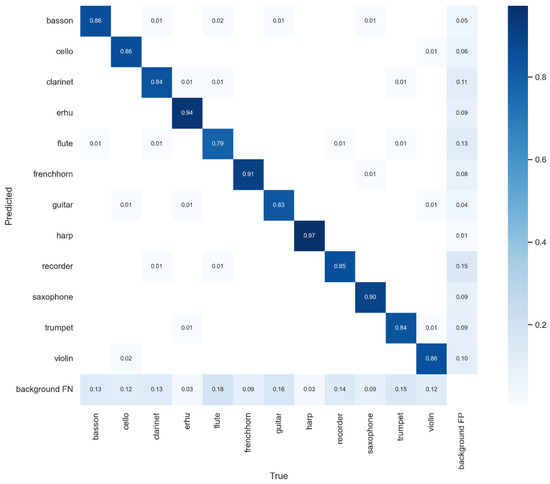
Figure 8.
Confusion matrix for YOLOv7x.
4. Results and Discussion
The test results of YOLOv7’s performance are detailed in Table 5, whereas the results for YOLOv5 are shown in Table 6. Our results showed that YOLOv7 achieved the highest average mAP (86.7%), followed by YOLOv7x (86.1%), YOLOv5m (80.5%), YOLOv5s (72.6%), and YOLOv5n (64%.) The harp class had the optimum mAP of 97.3% using YOLOv7 during the testing process.
Table 5.
The performance of YOLOv7.
Table 6.
The performance of YOLOv5.
Figure 9 shows the results of recognition for all models in the experiment. According to these results, all models could detect all objects in the images very well, except that YOLOv7x and YOLOv5m failed to detect all the cellos in Figure 9b,c. In addition, in Figure 9a, YOLOv7 could detect the erhu class with mAP values of 75%, 71%, and 76%. The flute class had a mAP of 92% and 76%, and of 57% and 81%.


Figure 9.
Results of recognition. (a) YOLOv7, (b) YOLOv7x, (c) YOLOv5n, (d) YOLOv5s, and (e) YOLOv5m.
A comparison with previous studies is presented in Table 7. In general, YOLOv7 was more accurate than the version that came before it. Majority of the classes had an improvement in their accuracy with YOLOv7 compared with previous methods. Moreover, the erhu, harp, and saxophone classes had the highest accuracy of over 90% for YOLOv7. The optimal total average accuracy was achieved by YOLOv7, with an accuracy of 86.70%, followed by YOLOv7x with a mAP of 86.10%. Next, Grouplet [10] achieved 85.10% accuracy, and Resnet 50 SPP [41] exhibited an accuracy of 84.66%. Moreover, the clarinet class had the maximum accuracy of 95.70% with Grouplet [10]. The harp class achieved the highest mAP of 98% with Resnet 50 SPP [41]. In terms of size, shape, and appearance, the clarinet and flute are two wind instruments that are very similar to each other. The guitar, violin, and cello are very similar stringed instruments. The sizes of these three musical instruments are different, despite that they are visually similar to one another. The violin is the smallest, the guitar is the second smallest, and the cello is the largest.
Table 7.
Comparison with previous studies.
Table 8 shows the results for testing with Dataset 2. Dataset 2 includes images of 30 musical instrument classes for image classification, created by Kaggle (https://www.kaggle.com/datasets/gpiosenka/musical-instruments-image-classification, accessed on 12 April 2023), with 4793 training, 150 testing, and 150 validation images. The images have a size of 224 × 224 × 3 and are in jpg format. Our experiment used seven classes: clarinet, flute, guitar, harp, trumpet, saxophone, and violin. YOLOv7 had the highest average accuracy of 71.9%, with a detection time of 0.014 s. This model was the most accurate and the fastest compared with other models in the experiment. The results of YOLOv7 for recognition in Dataset 2 can be seen in Figure 10.
Table 8.
Performance with Dataset 2.

Figure 10.
Results of YOLOv7 for recognition in Dataset 2.
5. Conclusions
In this study, the focus was on distinguishing objects that appear very similar to the human eye. In the process of our investigations, we made use of YOLOv7 and YOLOv5 to determine the identities of various musical instruments. During this investigation, we found several musical instruments that were very similar to one another. YOLOv7 and YOLOv5 are just two of the many backbone architectures and extractor features that our research investigated in conjunction with CNN models for the purpose of object recognition.
According to the findings of our experiment, we were also successful in improving the performance of the system in detecting musical instruments that are similar to one another. YOLOv7 showed a maximum average accuracy of 86.70% compared with previous results: YOLOv7 exhibited a mAP of 86.10%, whereas Grouplet [10] only achieved an accuracy of 85.10%, and Resnet 50 SPP achieved 84.64% [41]. As part of our future research, we hope to find a way to determine whether an image of a musical instrument has the wrong shape. We also plan to use Explainable Artificial Intelligence (XAI) in our future research to help us better understand the images.
Author Contributions
Conceptualization, C.D. and A.P.S.C.; data curation, H.J.C.; formal analysis, C.D. and A.P.S.C.; investigation, C.D. and H.J.C.; methodology, C.D.; project administration, C.D.; resources, H.J.C.; software, C.D. and H.J.C.; supervision, A.P.S.C.; validation, C.D., A.P.S.C. and H.J.C.; visualization, H.J.C.; writing—original draft, C.D. and A.P.S.C.; writing—review and editing, C.D. and A.P.S.C. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by the National Science and Technology Council, Taiwan (Grant number: MOST-111-2637-H-324-001-).
Institutional Review Board Statement
Ethical review and approval were waived for this study because we used the public free PPMI dataset. The human faces in the figures are all from the public datasets.
Informed Consent Statement
Written informed consent was waived for this study because we used the public free PPMI dataset. The human faces in the figures are all from the public datasets.
Data Availability Statement
The PPMI dataset can be found at (http://ai.stanford.edu/~bangpeng/ppmi.html, accessed on 8 January 2023). Dataset 2 was from Kaggle (https://www.kaggle.com/datasets/gpiosenka/musical-instruments-image-classification, accessed on 1 May 2023).
Acknowledgments
The authors would like to thank all their colleagues from Chaoyang Technology University, Atma Jaya Catholic University of Indonesia, Satya Wacana Christian University, Indonesia, and all others involved in this research.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wetzel, J.; Laubenheimer, A.; Heizmann, M. Joint Probabilistic People Detection in Overlapping Depth Images. IEEE Access 2020, 8, 28349–28359. [Google Scholar] [CrossRef]
- Saponara, S.; Elhanashi, A.; Gagliardi, A. Implementing a Real-Time, AI-Based, People Detection and Social Distancing Measuring System for COVID-19. J. Real Time Image Process. 2021, 18, 1937–1947. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, A.C.M.; Scharlach, R.C.; Pinheiro, M.M.C. Assessment of Temporal Aspects in Popular Singers. CODAS 2015, 27, 520–525. [Google Scholar] [CrossRef] [PubMed]
- Lavinia, Y.; Vo, H.; Verma, A. New Colour Fusion Deep Learning Model for Large-Scale Action Recognition. Int. J. Comput. Vis. Robot. 2020, 10, 41–60. [Google Scholar] [CrossRef]
- Bai, T.; Pang, Y.; Wang, J.; Han, K.; Luo, J.; Wang, H.; Lin, J.; Wu, J.; Zhang, H. An Optimized Faster R-CNN Method Based on DRNet and RoI Align for Building Detection in Remote Sensing Images. Remote Sens. 2020, 12, 762. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.C.; Yu, H. Weight Analysis for Various Prohibitory Sign Detection and Recognition Using Deep Learning. Multimed. Tools Appl. 2020, 79, 32897–32915. [Google Scholar] [CrossRef]
- Xi, X.; Yu, Z.; Zhan, Z.; Yin, Y.; Tian, C. Multi-Task Cost-Sensitive-Convolutional Neural Network for Car Detection. IEEE Access 2019, 7, 98061–98068. [Google Scholar] [CrossRef]
- Qin, S.; Liu, S. Towards End-to-End Car License Plate Location and Recognition in Unconstrained Scenarios. Neural Comput. Appl. 2021, 34, 21551–21566. [Google Scholar] [CrossRef]
- Chien-Yao, W.; Bochkovskiy, A.; Hong-Yuan, L.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Yao, B.; Li, F. Grouplet: A Structured Image Representation for Recognizing Human and Object Interactions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Zhang, X.; Wan, F.; Liu, C.; Ji, X.; Ye, Q. Learning to Match Anchors for Visual Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3096–3109. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Kuala Lumpur, Malaysia, 10 June 2016; pp. 21–37. [Google Scholar]
- Ju, M.; Moon, S.; Yoo, C.D. Object Detection for Similar Appearance Objects Based on Entropy. In Proceedings of the 2019 7th International Conference on Robot Intelligence Technology and Applications, RiTA 2019, Daejeon, Republic of Korea, 1–3 November 2019. [Google Scholar]
- Song, S.; Que, Z.; Hou, J.; Du, S.; Song, Y. An Efficient Convolutional Neural Network for Small Traffic Sign Detection. J. Syst. Archit. 2019, 97, 269–277. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.C.; Hendry; Liu, Y.T. Similar Music Instrument Detection via Deep Convolution YOLO-Generative Adversarial Network. In Proceedings of the 2019 IEEE 10th International Conference on Awareness Science and Technology, iCAST 2019-Proceedings, Morioka, Japan, 23–25 October 2019. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Chen, H.; He, Z.; Shi, B.; Zhong, T. Research on Recognition Method of Electrical Components Based on YOLO V3. IEEE Access 2019, 7, 157818–157829. [Google Scholar] [CrossRef]
- Zhao, L.; Li, S. Object Detection Algorithm Based on Improved YOLOv3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Mark Liao, H.-Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.; Liao, H.M.; Wu, Y.; Chen, P. CSPNet: A New Backbone That Can Enhance Learning Capability of Cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR Workshop), Seattle, WA, USA, 14–19 June 2020; p. 2. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Misra, D. Mish: A Self Regularized Non-Monotonic Neural Activation Function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Li, Z.; Tian, X.; Liu, X.; Liu, Y.; Shi, X. A Two-Stage Industrial Defect Detection Framework Based on Improved-YOLOv5 and Optimized-Inception-ResnetV2 Models. Appl. Sci. 2022, 12, 834. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2124. [Google Scholar]
- Li, Y.; Pei, X.; Huang, Q.; Jiao, L.; Shang, R.; Marturi, N. Anchor-Free Single Stage Detector in Remote Sensing Images Based on Multiscale Dense Path Aggregation Feature Pyramid Network. IEEE Access 2020, 8, 63121–63133. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, A.P.S.; Christanto, H.J. Deep Learning for Highly Accurate Hand Recognition Based on Yolov7 Model. Big Data Cogn. Comput. 2023, 7, 53. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef] [PubMed]
- Hu, M.; Li, Y.; Fang, L.; Wang, S. A2-FPN: Attention Aggregation Based Feature Pyramid Network for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Huang, G.; Li, Y.; Pleiss, G.; Liu, Z.; Hopcroft, J.E.; Weinberger, K.Q. Snapshot Ensembles: Train 1, Get M for Free. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017—Conference Track Proceedings, Toulon, France, 24–26 April 2017. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; Volume 2016. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 10–15 June 2019; Volume 2019. [Google Scholar]
- Ultralytics Yolo V5. Available online: https://github.com/ultralytics/yolov5 (accessed on 13 January 2021).
- Chen, J.; Jia, K.; Chen, W.; Lv, Z.; Zhang, R. A Real-Time and High-Precision Method for Small Traffic-Signs Recognition. Neural Comput. Appl. 2022, 34, 2233–2245. [Google Scholar] [CrossRef]
- Bbox Label Tool. Available online: https://github.com/puzzledqs/BBox-Label-Tool (accessed on 13 January 2022).
- Long, J.W.; Yan, Z.R.; Peng, L.; Li, T. The Geometric Attention-Aware Network for Lane Detection in Complex Road Scenes. PLoS ONE 2021, 16, e0254521. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.; Xiong, Z.; Wang, Q. An Incremental Framework for Video-Based Traffic Sign Detection, Tracking, and Recognition. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1918–1929. [Google Scholar] [CrossRef]
- Kang, H.; Chen, C. Fast Implementation of Real-Time Fruit Detection in Apple Orchards Using Deep Learning. Comput. Electron. Agric. 2020, 168, 105–108. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C. Combination of Resnet and Spatial Pyramid Pooling for Musical Instrument Identification. Cybern. Inf. Technol. 2022, 22, 104. [Google Scholar] [CrossRef]












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).