Now, given a rule set and a particular pattern of afterimage intensities to be produced, we can determine the contents for corresponding bias and trigger images by applying the rule set to the pattern. In the following subsections, we will define various types of rule sets (accompanied by concrete examples), with properties in favor of shape display exclusive to the afterimage. For this, it is important to mention first that rule sets will be used non-deterministically: If more than one (b, t) pair may produce a given a = fr (b, t), one of them will be chosen at random.
2.4.1. Ambiguous Rule Sets
First, we will focus on the subgoal that a pattern of afterimage intensities should not be recognizable in the trigger image used to produce it. A certain way to achieve this would be to use a rule set in which any trigger intensity can lead to any afterimage intensity: We could then freely choose our pattern of trigger intensities, regardless of the afterimage that is to be produced. We say a rule set
fr is
trigger-ambiguous if:
The simplest examples of such rule sets would use a single trigger intensity to produce the minimum two afterimage intensities. Consider for example the rule set
f1, shown in the diagram of
Figure 4. (In the diagram,
B and
T indicate the subsets of
I containing
f1′s bias and trigger intensities, respectively. These subsets are formally defined below.) Rule set
f1 is based on a dark grey trigger intensity, which is either darkened by a preceding white intensity, giving
a1 =
f1 (1, 0.25), or lit up by a preceding black intensity, giving
a2 =
f1 (0, 0.25). This will not allow a choice in trigger intensity, but the ambiguity requirement still guarantees that shapes in the afterimage will not be recognizable in the always evenly grey trigger images.
This is illustrated by the image sequence depicted in
Figure 4, and demonstrated in Video Example II, which is the result of applying
f1 to an example afterimage pattern consisting of a symbol and a simple regular pattern. This sequence also shows how, by generating negative bias images and neutral trigger images, rule set
f1 implements the classic afterimage effect.
Since we would like shapes in the afterimage to go unrecognized in the bias image also, we introduce a second concept, analogous to trigger ambiguity. We say a rule set
fr is
bias-ambiguous if:
Our example for this type of rule set will introduce the simultaneous use of different bias-trigger intensity pairs to produce the same afterimage intensity. The starting point here will be the fact that black and white bias intensities can lead to two distinct afterimage intensities by simply remaining constant. This corresponds to a rule set
f2, shown in the diagram of
Figure 5, of which the first half is given by
a1 =
f2 (0, 0) and
a2 =
f2 (1, 1). To satisfy the ambiguity requirement, the second half will then have to allow each bias intensity to lead to both of the afterimage intensities.
In the case of black, for example, we have to find a t for which a2 = f2 (0, t). This can be done by varying t and judging how well the combination of f2 (0, t) and f2 (1, 1), applied to an all-a2 afterimage pattern, succeeds in creating an even impression in the afterimage. Three ranges will then be distinguishable for t: a high range where f2 (0, t) will seem lighter than f2 (1, 1); a low range where the opposite is true; and a range inbetween, where the afterimage intensities will seem similar, but still may flicker or otherwise remain visually separate. The most stable results in this middle range seemed to be around t = 0.87, so that we will use a2 ≈ f2 (0, 0.87).
Analogous steps taken for the white case, while testing with an all-a1 pattern, then yielded a1 ≈ f2 (1, 0.15), finishing rule set f2.
The next step, of using
f2 on a concrete target pattern, will mean that for each afterimage intensity within that pattern, a random choice will be made out of those bias-trigger intensity pairs that could produce it. Overall, the resulting bias image will therefore also be a random black-and-white pattern. This pattern will then by the same process also be present in the trigger image, distorting it in a limited way. This is demonstrated in
Figure 5 and Video Example III, which use the same example afterimage pattern as before.
The two examples above have concretely demonstrated how viewers will not be able to recognize the target afterimage pattern where an ambiguity requirement applies—be this in the trigger or bias image, respectively. However, it is also true for each example that in the image where ambiguity did not apply, the afterimage shape could easily be recognized. This leads us to wish for a rule set fr that has both bias and trigger ambiguity simultaneously. However, regrettably, such a fully ambiguous rule set cannot exist, and we can prove this within our framework.
Proof. Suppose a rule set fr is bias-ambiguous.
Define the sets B and T of fr’s bias and trigger intensities:
B = { b | b ∈ I ∧ (∃ t ∈ I, a ∈ A : fr (b, t) = a) }
T = { t | t ∈ I ∧ (∃ b ∈ I, a ∈ A : fr (b, t) = a) }
Then choose
bmax ∈ B so that ∀b ∈ B : b ≤ bmax
amax ∈ A so that ∀a ∈ A : a ≤ amax
amin ∈ A so that ∀a ∈ A : a ≥ amin .
Due to bias ambiguity, there must exist a t′∈ T with
fr (bmax, t′) = amax.
However, for this t′, trigger ambiguity will not hold, because
¬ ∃ b′ ∈ B : fr (b′, t′) = amin .
Proof. Suppose ∃ b′ ∈ B: fr (b′, t′) = amin .
Then fa (b′, t′) < fa (bmax, t′) by Prop. (2),
since n > 1 guarantees amin < amax .
It then follows by Prop. (1) that b′ > bmax ,
which is impossible by definition.
Therefore fr cannot be both bias- and trigger-ambiguous. □
This does not have to mean that ambiguity is completely useless to our purposes however: we may still realize a decrease in recognizability in both the bias and the trigger image by informally relaxing requirements to the level of a partial ambiguity, where it suffices that each bias or trigger intensity can lead to more than one of the afterimage intensities.
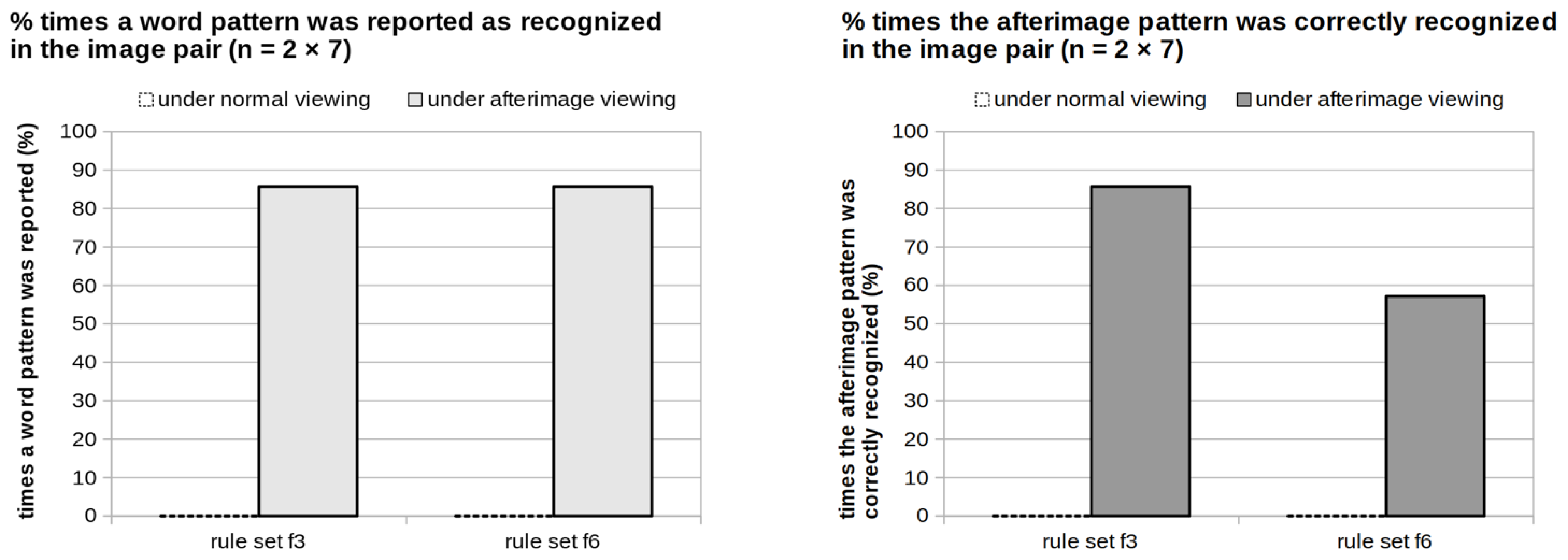
This idea is implemented in rule set
f3 which, while using the same two bias intensities as rule set
f2, will target three instead of two afterimage intensities (see
Figure 6). We begin its construction by attempting to find a
t1 and
t2 with
fa (0,
t1) =
fa (1,
t2). Trying to identify such a match can be done using the same procedure as was followed when constructing
f2—now, while varying an additional parameter
d:
t1 = 0.5 –
d and
t2 = 0.5 +
d, with
d being raised from zero, thereby moving the trigger intensities away from a middle grey. While doing this, the results produced near
d = 0.13 appeared to have the greatest stability, yielding
a2 ≈
f3 (0, 0.37) and
a2 ≈
f3 (1, 0.63).
Although the above has, so far, only provided us with the medium afterimage intensity a2, we can now quickly finalize f3 into a partially ambiguous rule set by having a3 = f3 (0, 0.63) and a1 = f3 (1, 0.37).
Now completed, rule set
f3 does seem to create a risk regarding recognizability when considering its afterimage intensities
a1 and
a3: Tracing these back within the diagram of
Figure 6, we can see how sections of the afterimage pattern that use these intensities will reoccur, in unambiguously differing greyscale levels, in both the trigger and bias images. However, given that the other areas of these images, leading to
a2, will use the same greyscale values randomly, recognition will still be hampered. In
Figure 6 and Video Example IV, this is demonstrated using a three-tone variant of the previously used example afterimage pattern.
2.4.2. Scrambling Rule Sets
A basic property of human visual perception is that adjacent areas of a similar shade tend to be grouped together and perceived as a shape. We will now introduce another approach to defining rule sets, using this tendency in a subversive manner. As before, the goal is to have shapes recognized in the afterimage not be recognized by normal viewing of the image sequence producing the afterimage.
First, we will need a tool to look at how rule sets reorder intensities, when comparing the bias images they generate to the target afterimage patterns. Given a rule set
fr, we can enumerate the set
B of its bias intensities (defined in
Section 2.4.1) according to
b1 < … <
b|B|—just as we have done for the set
A of afterimage intensities from the outset. We then define
fr’s
mapping scheme as a tuple of |
B| subsets from the set {1, … , |
A|}, where the
i-th subset consists of all
j for which ∃
t ∈
I :
fr (
bi,
t) =
aj.
This means that, reading a mapping scheme from left to right, we find for each bias intensity, from dark to light, the ranks of the afterimage intensities to which it is linked. For example, the mapping scheme for rule set
f1 is given by ({2}, {1}), meaning that firstly, its darkest bias intensity is mapped to its lightest afterimage intensity; and that secondly, its lightest bias intensity is mapped to its darkest afterimage intensity (see the diagram of
Figure 4). As another example, the mapping scheme for rule set
f2 is ({1, 2}, {1, 2}); just as it will be for any other bias-ambiguous rule set which uses two bias and two afterimage intensities (see the diagram of
Figure 5).
Now, suppose we have a target afterimage pattern displaying a shape on a background, with each in one intensity. Both will be repeated in the bias image, in bias intensities according to the rule set used. Arbitrarily choosing one of the bias intensities present for the shape, suppose that it is nearer in brightness to one of the bias intensities present for the background than to all other intensities also present for the shape. Where adjacent, these two bias intensities will tend to visually group together, distorting the perception of the original shape. A rule set
fr will have this property for all possible combinations of uniformly tinted shapes if:
However, given a rule set
fr, it may be more intuitive to look at its mapping scheme: if in it, multiple occurrences of the same afterimage intensity are always separated by occurrences of all other afterimage intensities lying strictly inbetween, the above property will hold. Consider for example the mapping schemes ({1}, {2}, {1}) and ({1}, {2}, {1}, {2}). (For an example illustrating the use of ({1}, {2}, {1}, {2}), please preview how the rule set shown in the diagram of Figure 8 links its trigger intensities to its afterimage intensities.) Both of the above mapping schemes correspond to rule sets satisfying the property, and both have a scrambling effect on the shapes of the afterimage, as is illustrated in
Figure 7. However, the effect of the first mapping scheme is crippled by the fact that it has afterimage intensity
a2 preceded by bias intensity
b2 only, which greatly aids shape recognition. We still need to make explicit that a rule set
fr should produce each afterimage intensity using multiple bias intensities:
Having Props. (3) and (4) now at our disposal, we consider a rule set fr that satisfies both of them to be bias-scrambling. We can then arrive at a very similar definition of trigger-scrambling rule sets (and trigger intensity mapping schemes) simply by reiterating the above discussion while replacing bias images with trigger images.
The next example rule set will then satisfy the scrambling requirement for both the bias and trigger images that it generates. These will each be constructed in four different intensities, starting with black and white bias intensities that are combined in such a way with two trigger intensities near middle grey as to produce two afterimage intensities that are ordered the other way around:
a1 =
f4 (1, 0.52) and
a2 =
f4 (0, 0.48), and see
Figure 8. To this we then add two inner bias intensities and two outer trigger intensities, by searching for two pairs of identical intensities that will also yield
a1 and
a2 in the afterimage. Here, iteratively testing with all-
a1 and all-
a2 patterns (like before in
Section 2.4.1) seemed to give the most stable results when choosing
a1 ≈
f4 (0.39, 0.39) and
a2 ≈
f4 (0.62, 0.62).
This means that both 0.39 and 0.62 will play double roles in f4: on the one hand, as the inner bias intensities, resulting in the bias intensity mapping scheme ({2}, {1}, {2}, {1}); and on the other hand, as the outer trigger intensities, resulting in the trigger intensity mapping scheme ({1}, {2}, {1}, {2}).
Visual outcomes of this are demonstrated by the image sequence of Video Example V, also presented in
Figure 8. When trying to assess how well the afterimage pattern is being scrambled, we can see that this is impaired in the trigger image by something documented in the rule set diagram: Each of the outer trigger intensities will visually group together with both of the inner trigger intensities almost equally well, due to their relative closeness. Placing the inner trigger intensities further apart involves a trade-off, however, because this in turn will place the afterimage intensities closer together, and thereby reduce afterimage contrast.
2.4.3. Hybrid Rule Sets
Reflecting on ambiguity versus scrambling, it is now clear that both have inherent strengths and weaknesses: Ambiguity is better for really guaranteeing that the afterimage pattern will not be recognizable—but it restricts this guarantee to either the bias or the trigger image. Scrambling, as we have seen, does allow simultanous use in the bias and trigger images—but it cannot provide a hard guarantee of unrecognizability. Given these characteristics, it becomes worthwhile to explore whether the two approaches could be combined within a single rule set.
The construction of our first example of this can start from the middle two trigger intensities of rule set
f4 (see
Figure 8), but with each intensity placed somewhat further away from medium grey. This for a rule set
f5 initially defined by
a1 =
f5 (1, 0.57) and
a2 =
f5 (0, 0.43). Searching for pairs of same-value bias and trigger intensities that would also produce these afterimage intensities yielded
a1 ≈
f5 (0.43, 0.43) and
a2 ≈
f5 (0.57, 0.57). This then completes a rule set which, like rule set
f4, on the one hand is bias-scrambling, using four bias intensities with a bias intensity mapping scheme of ({2}, {1}, {2}, {1}); but which, on the other hand, also is trigger-ambiguous for its two trigger intensities. This is illustrated in
Figure 9, along with an image sequence generated using
f5 that is demonstrated in Video Example VI.
It appears, however, that in rule set f5, a1 and a2 are too near eachother to obtain a good contrast in the afterimage: With the resulting greys seeming quite similar, shape is hard to separate from background. To improve on this, construction of our next rule set will ensure from the start that an afterimage contrast comparable to that of f4 will again be obtained—while switching the scrambling and ambiguity requirements.
Constructing rule set
f6 starts by copying from
f4, and initially defining its afterimage intensities as
a1 =
f6 (1, 0.52) and
a2 =
f6 (0, 0.48). Then, while testing iteratively using all-
a1 and all-
a2 afterimage patterns, we look for a
t1 that yields
a1 ≈
f6 (0,
t1) and a
t4 that yields
a2 ≈
f6 (1,
t4). The most stable impression here seemed to result when choosing
a1 ≈
f6 (0, 0.25) and
a2 ≈
f6 (1, 0.74). This then completes a rule set that is trigger-scrambling, based on four trigger intensities with a corresponding mapping scheme of ({1}, {2}, {1}, {2}). At the same time, the two bias intensities satisfy bias ambiguity. This is illustrated in
Figure 10, along with an image sequence generated using
f6 that is demonstrated in Video Example VII.
Comparing the current rule set to its predecessor, even though f6 does improve on the contrast between afterimage intensities, f5 will probably produce the more effective scrambling: Its middle bias intensities are relatively wider apart than the middle trigger intensities of f6, which suffers even more from the same weakening effect on scrambling that has already been discussed for rule set f4.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}