

Fish Recognition in the Underwater Environment Using an Improved ArcFace Loss for Precision Aquaculture

Abstract
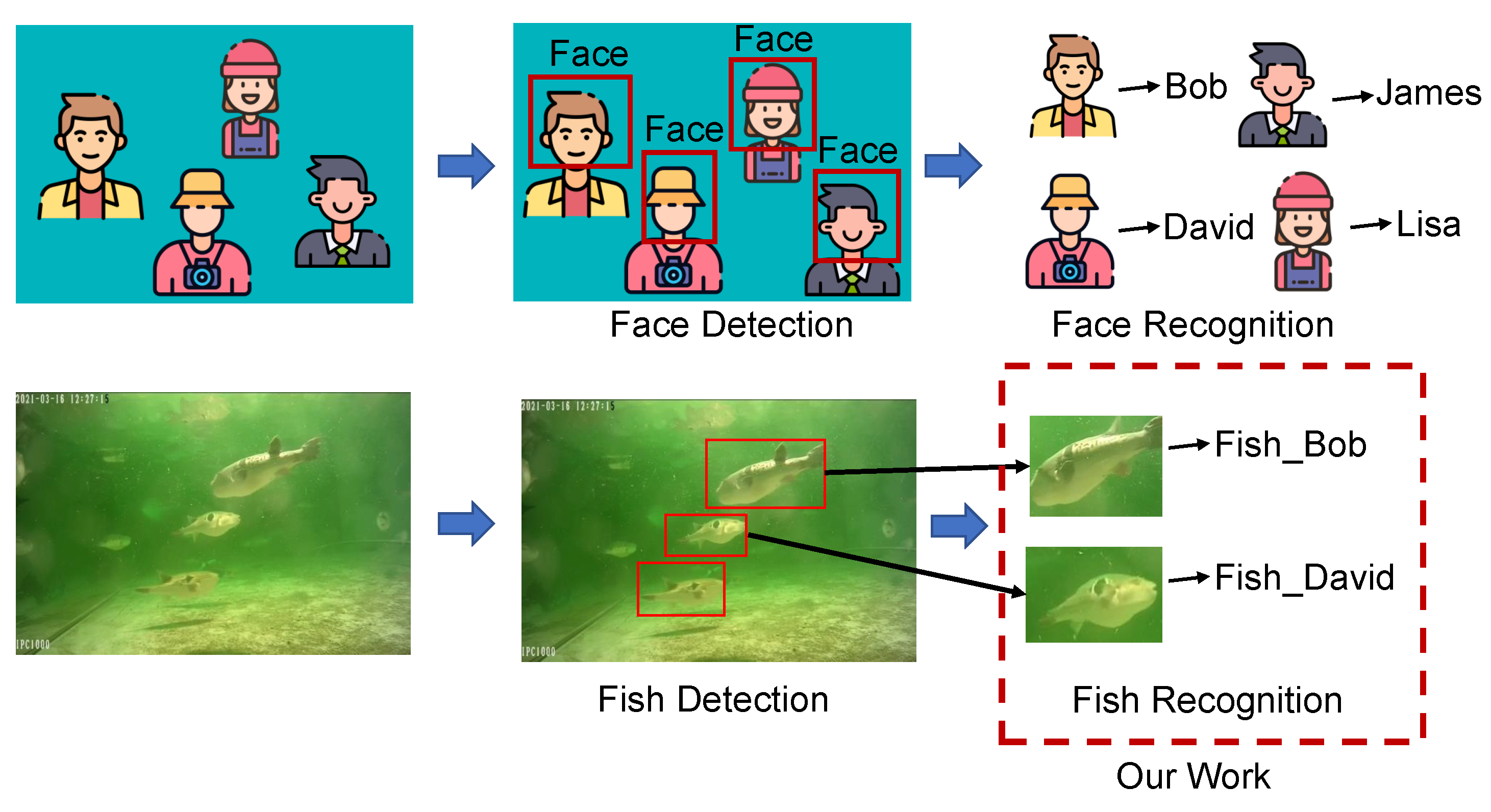
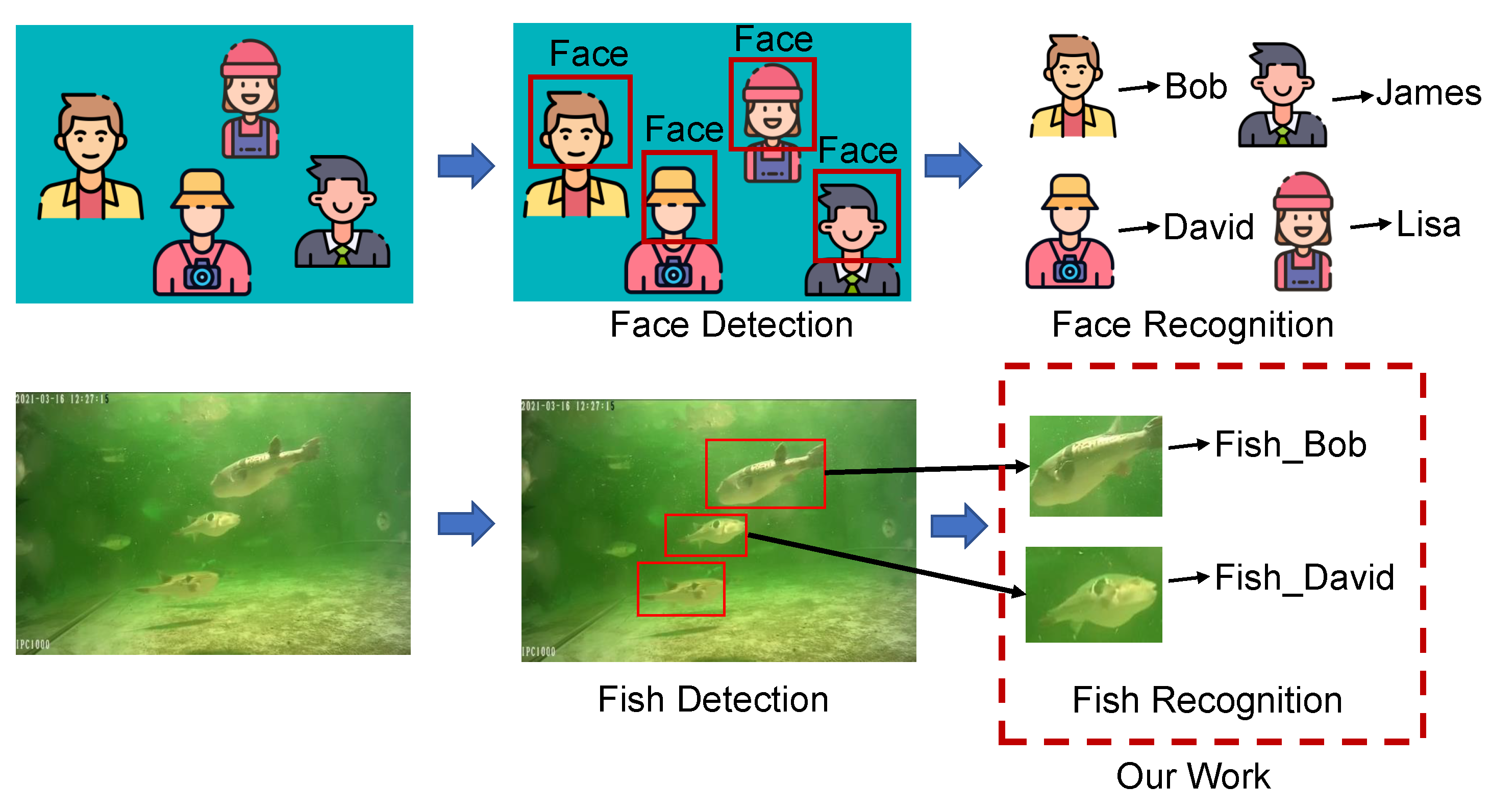
:1. Introduction
- We designed a fish individual recognition network with a quality assessment module, which can evaluate the quality of fish images well and does not require additional labeling.
- We propose a new loss function named FishFace Loss, which will weigh the loss according to the quality of the image so that the model focuses more on recognizable fish images and less on ideas that are difficult to recognize.
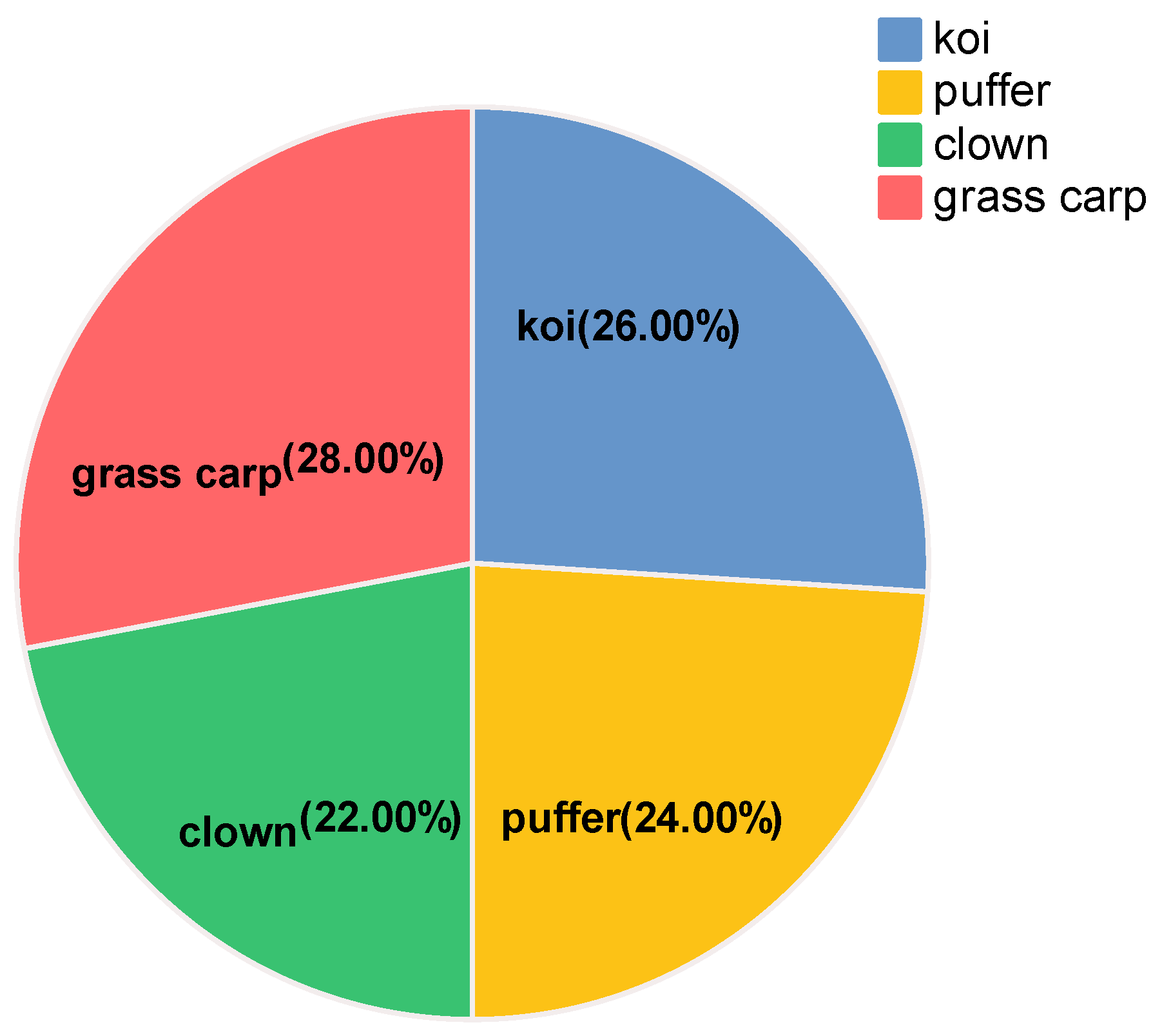
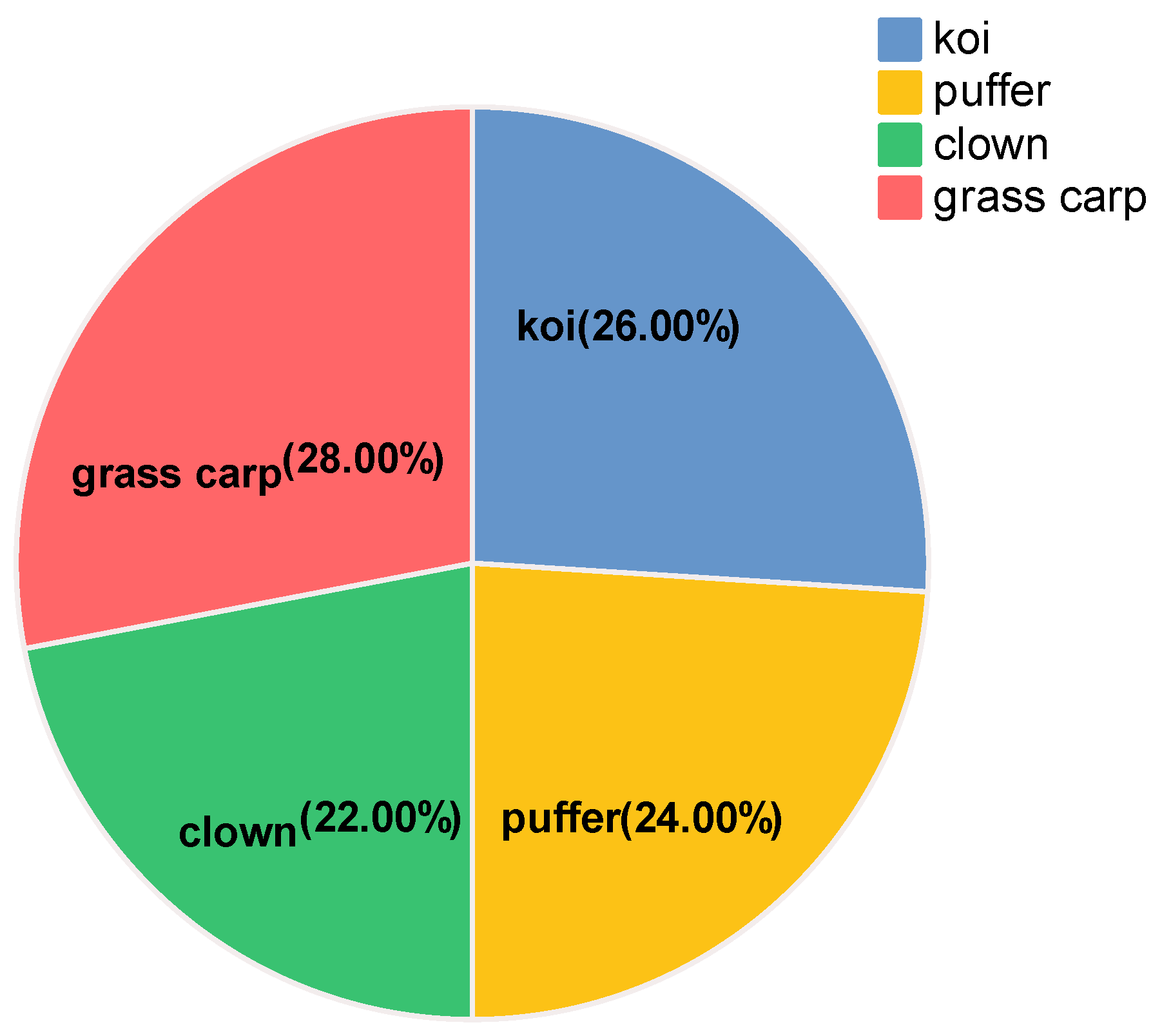
- We collected a dataset for fish individual recognition (WideFish), which contains and annotates 5000 images of 300 fish. This dataset was created to help train and test the fish individual recognition method.
2. Material and Methods
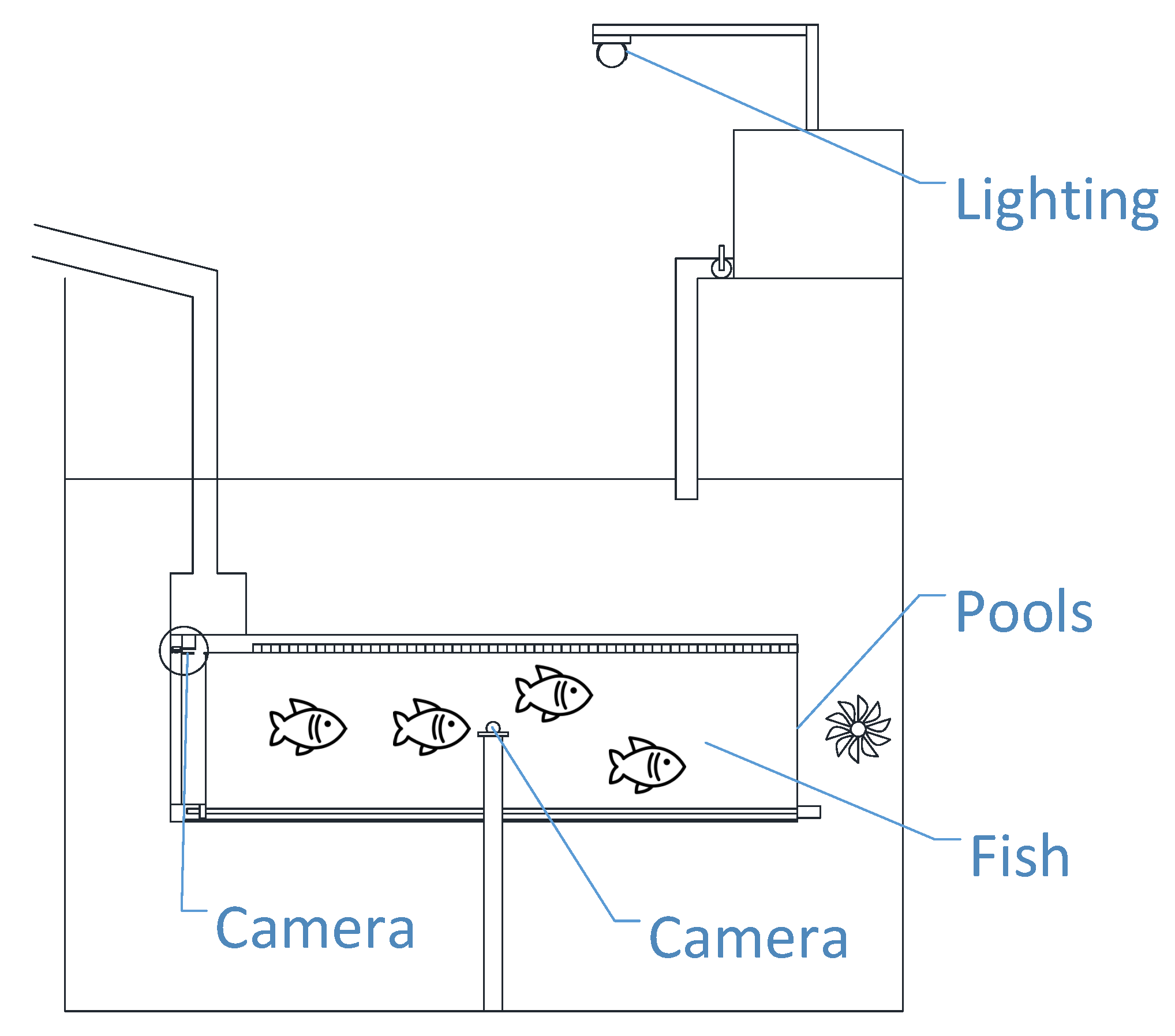
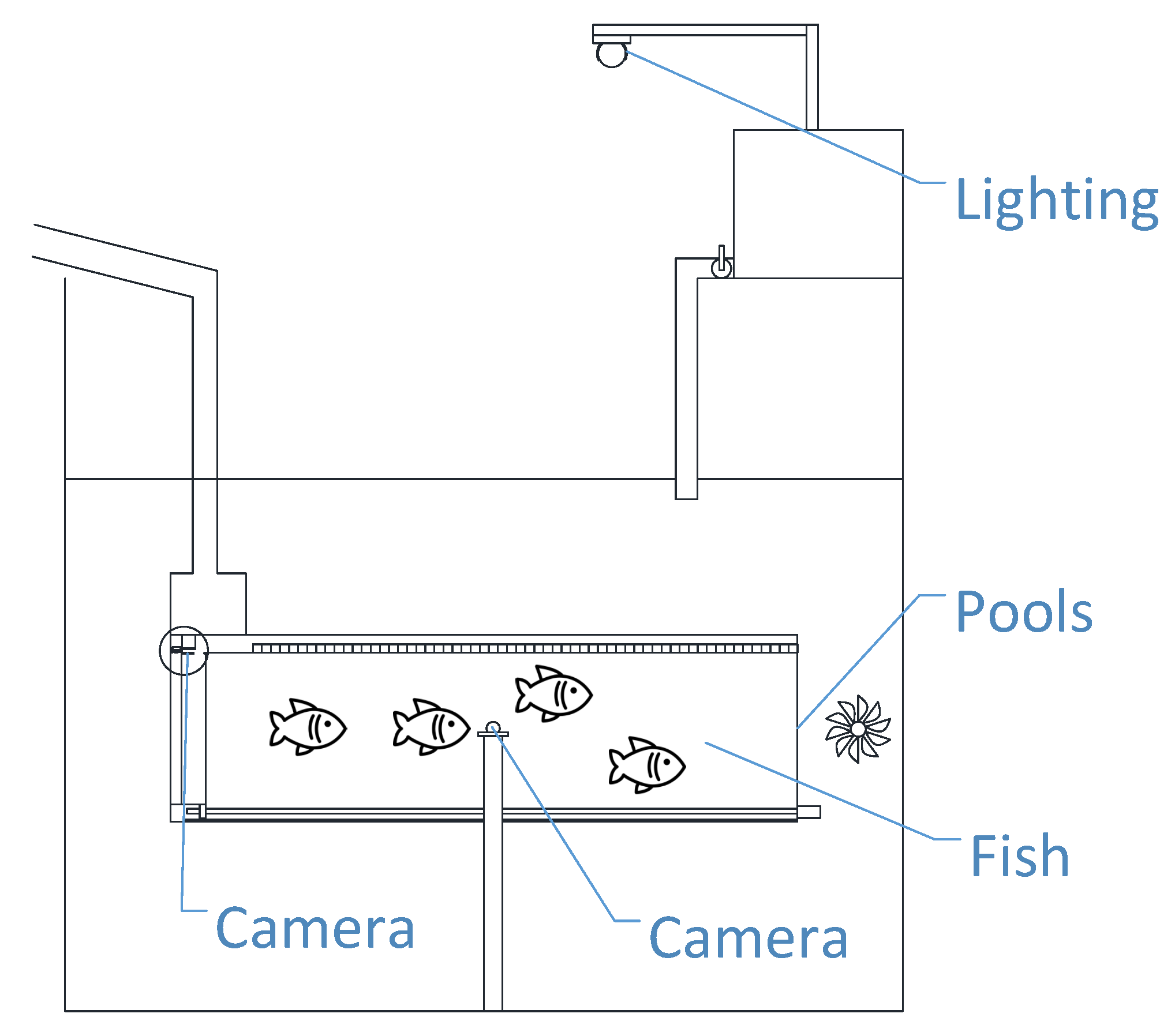
2.1. Data Preparation
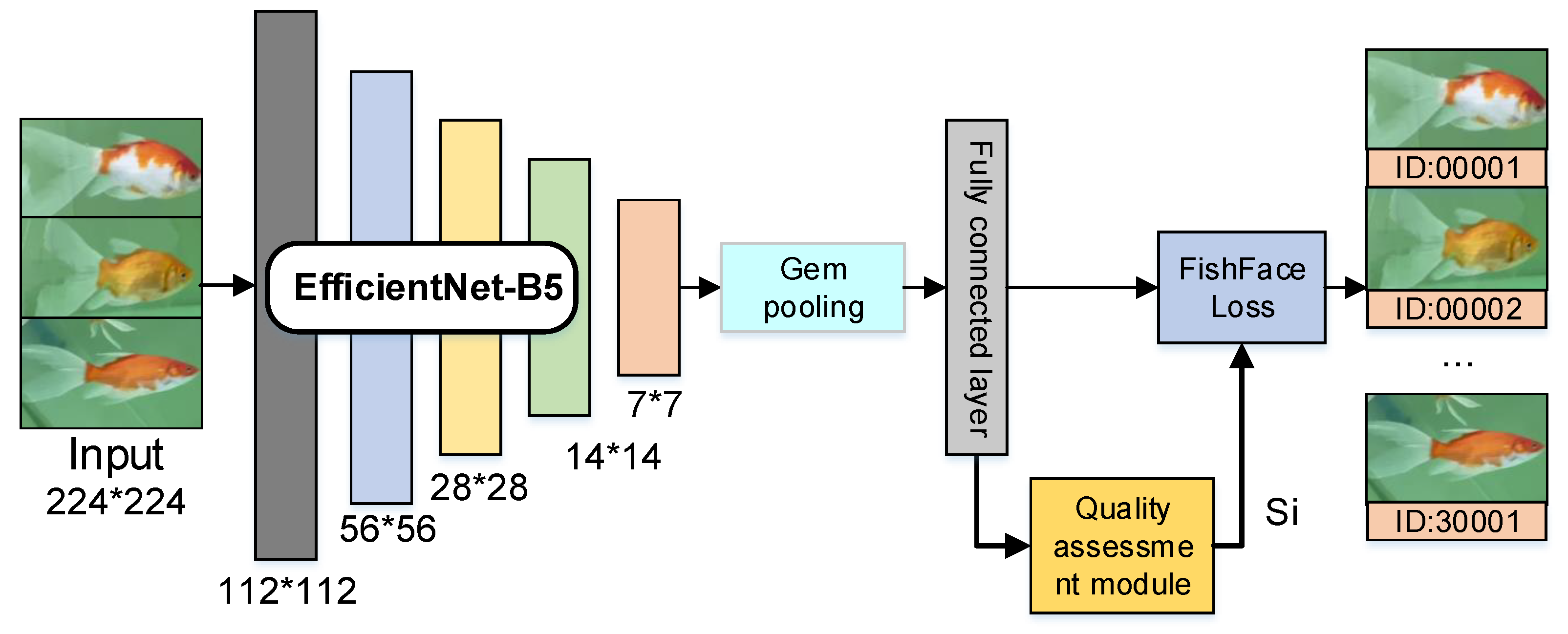
2.2. The Proposed Method
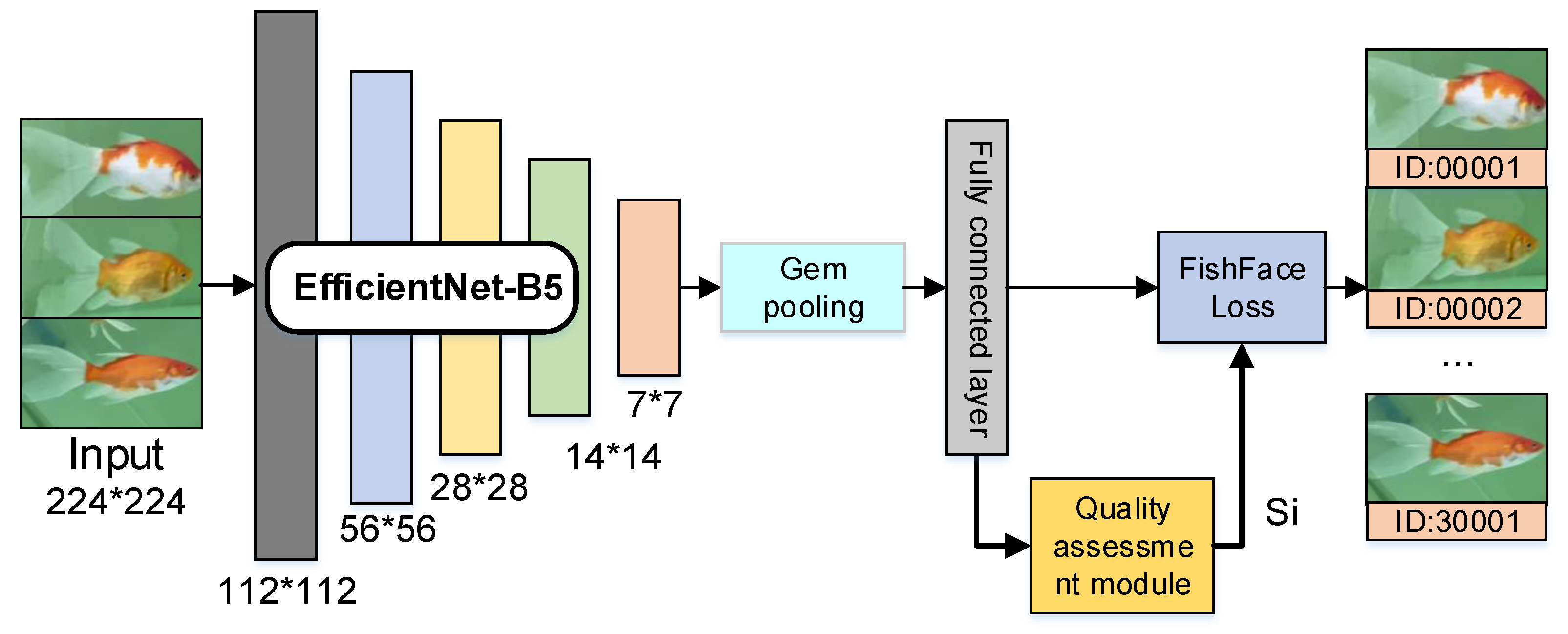
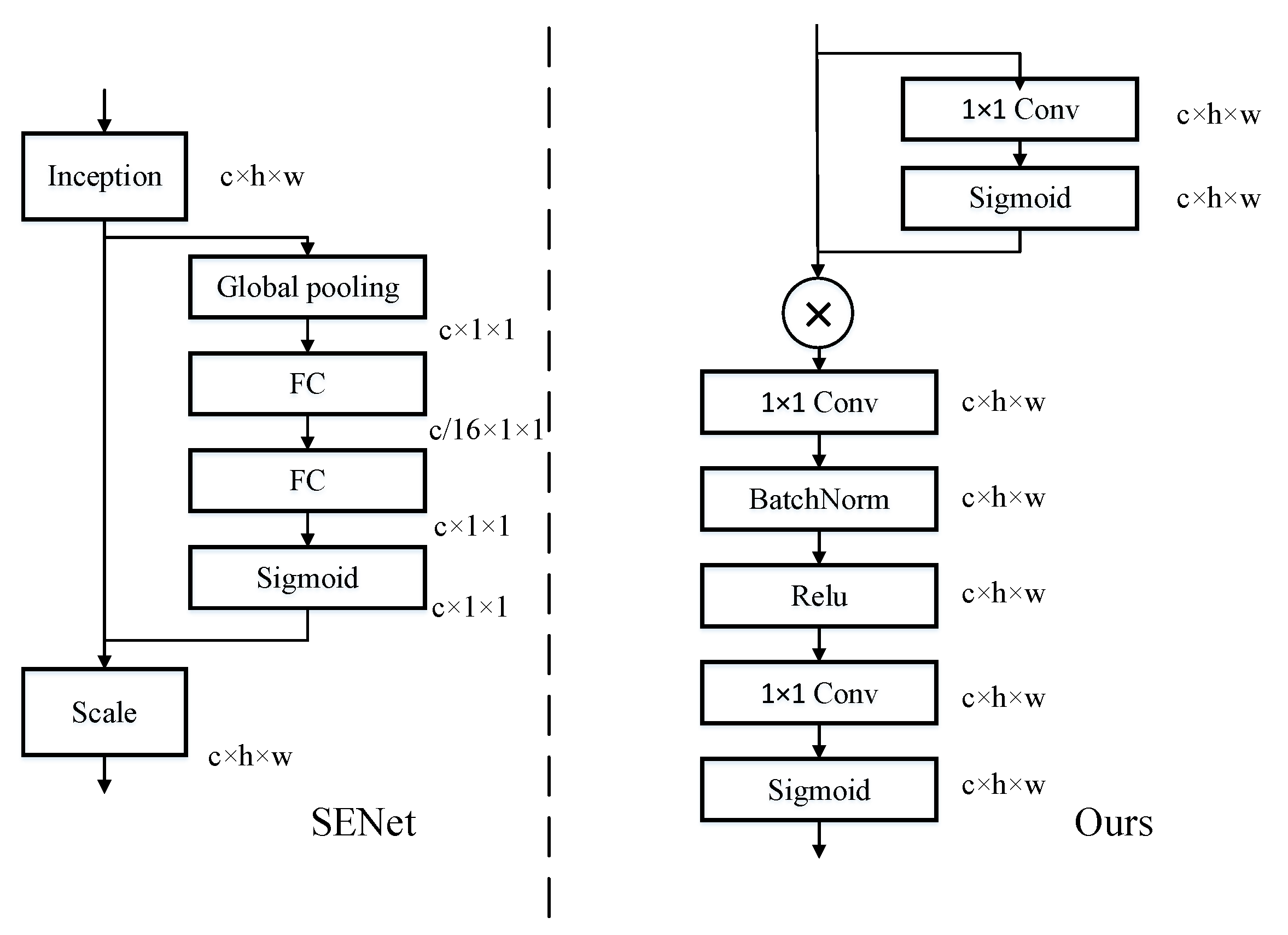
2.3. Improved Feature Extraction Module
2.4. Quality Assessment Module
2.5. FishFace Loss
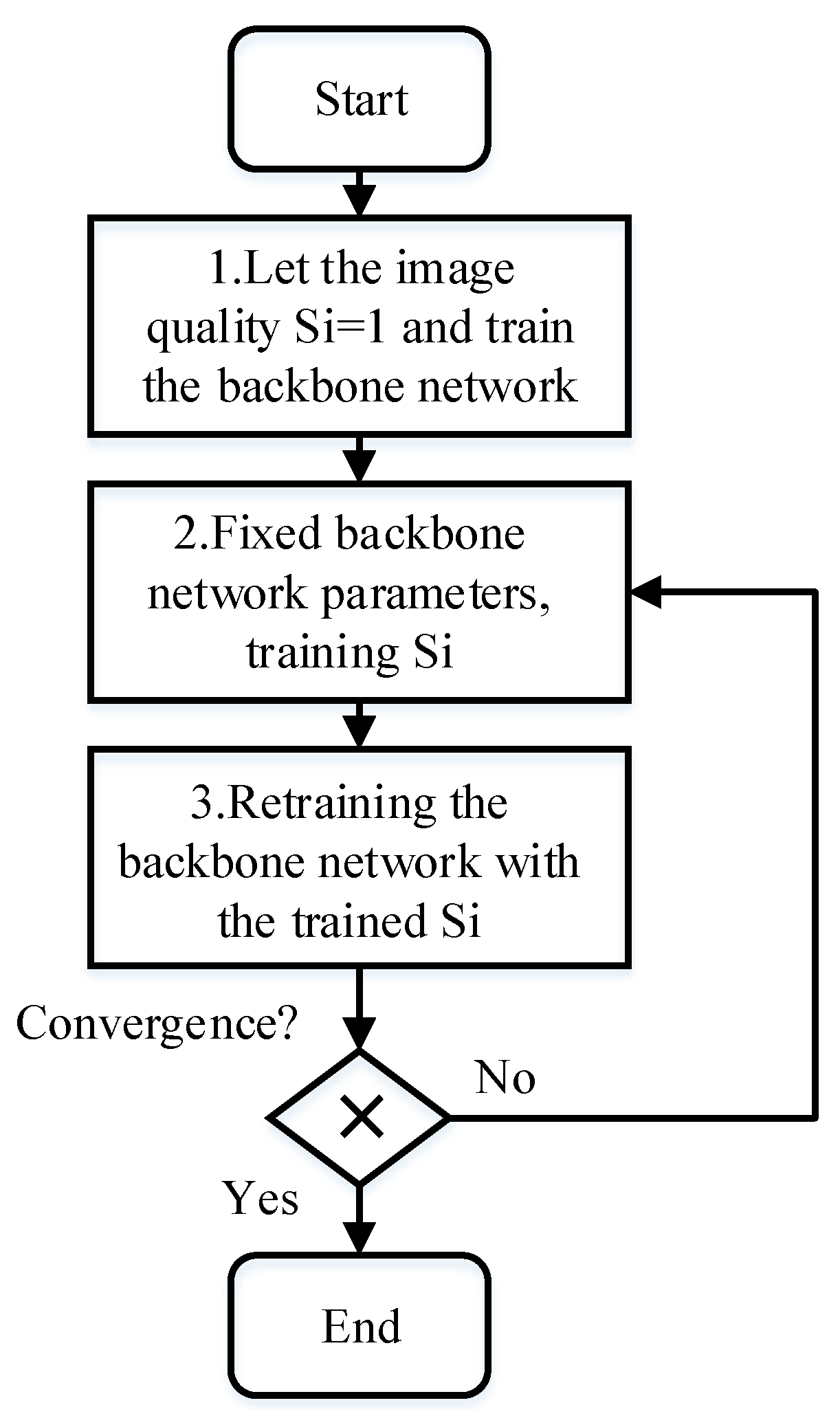
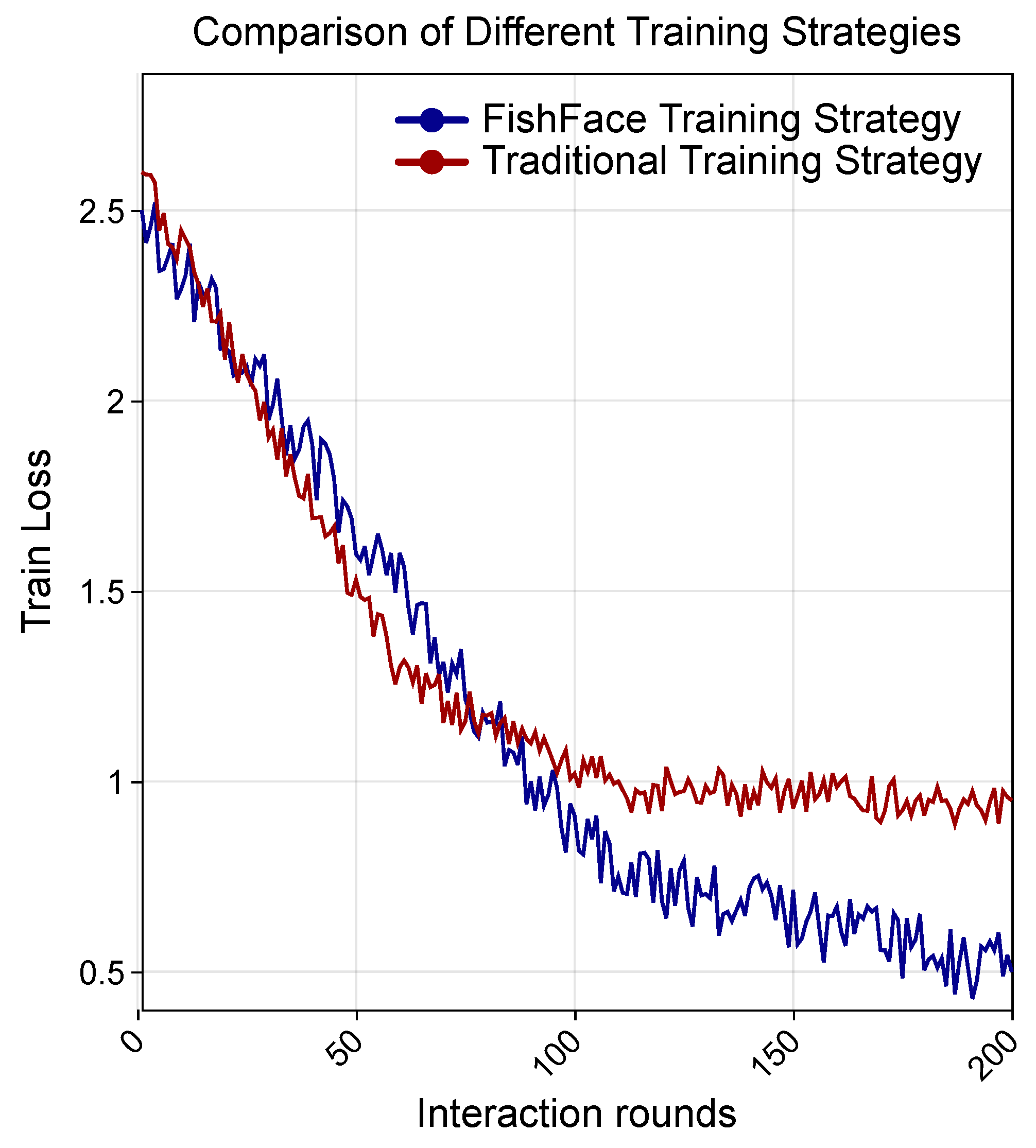
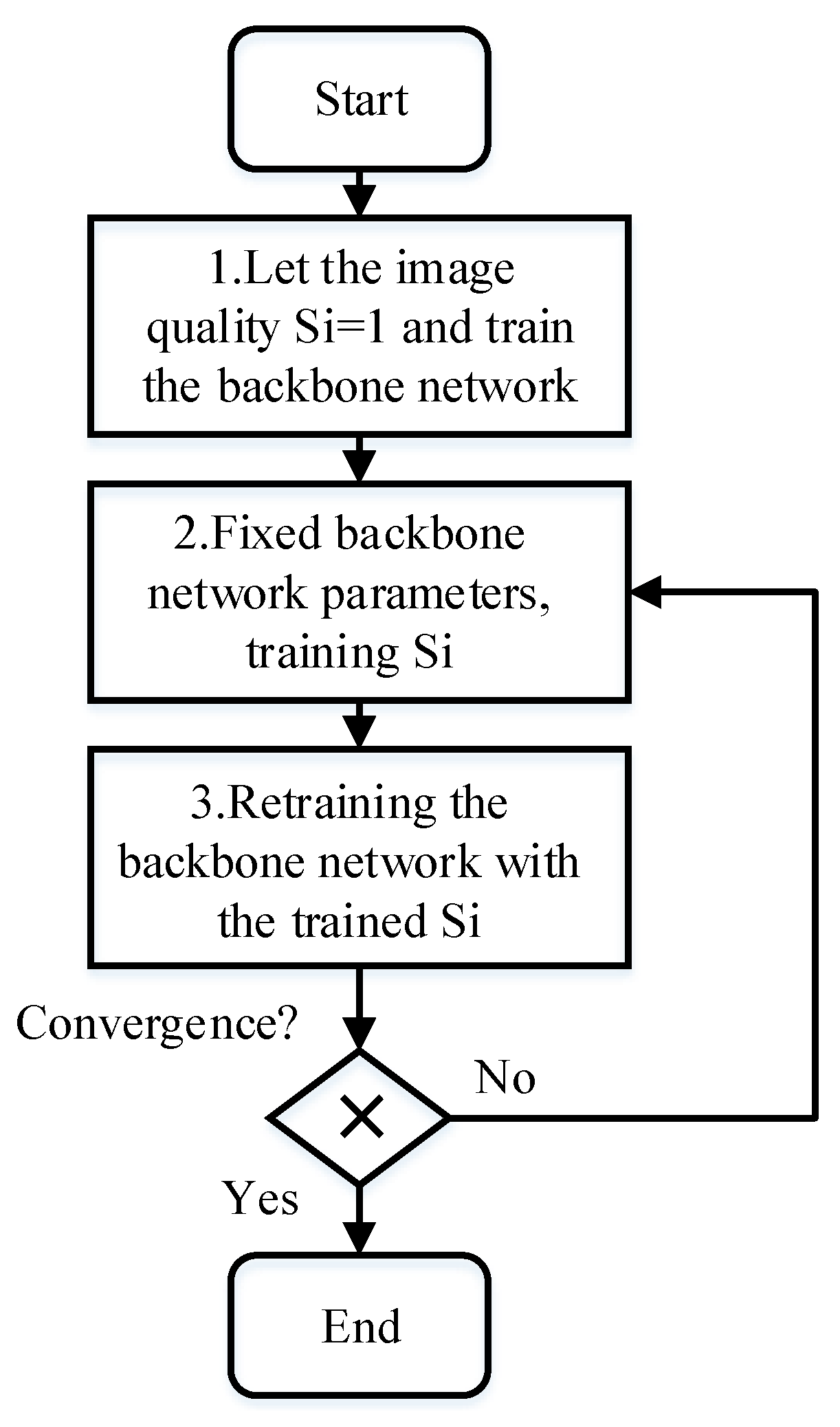
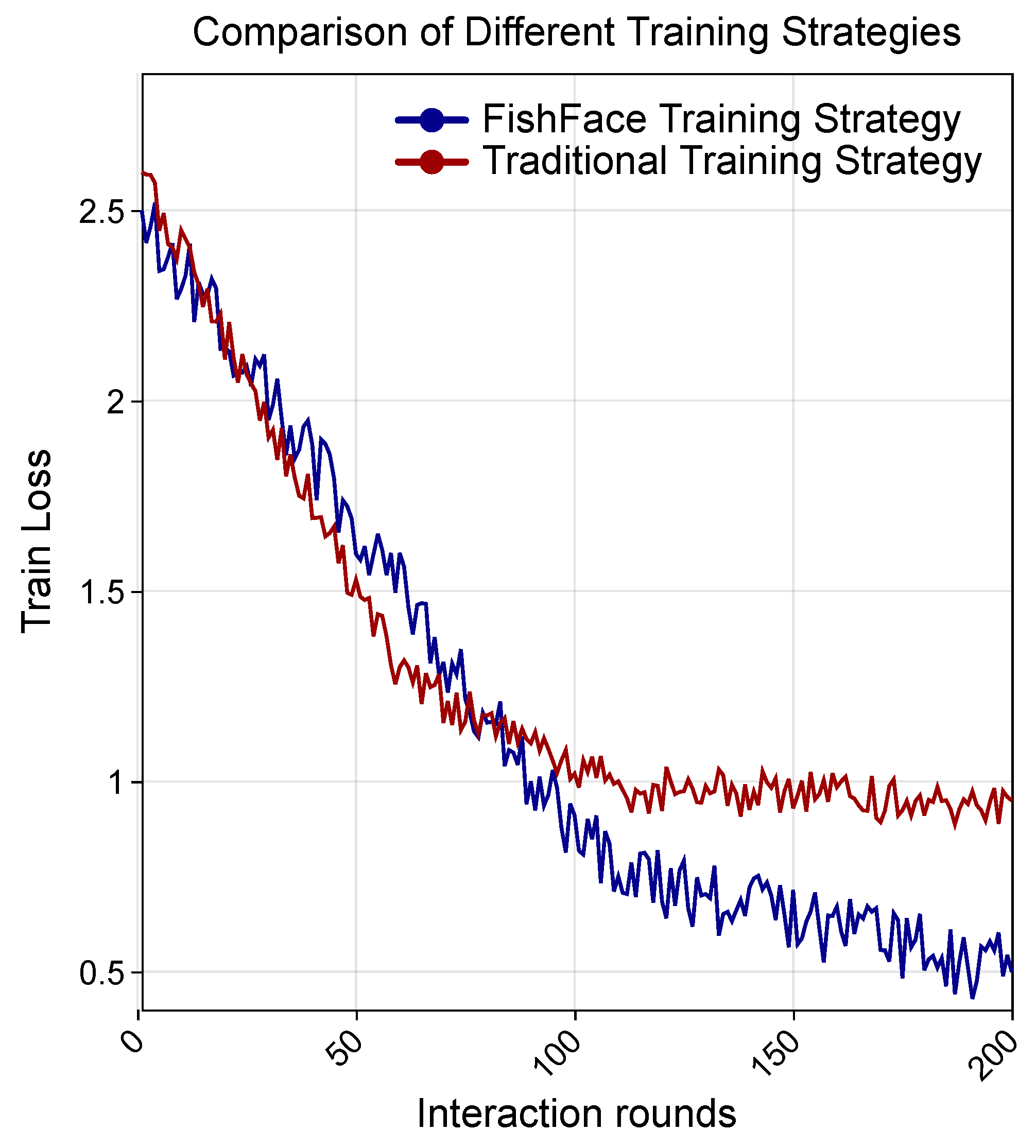
2.6. FishFace Training Strategy
2.7. Experimental Setup
3. Results
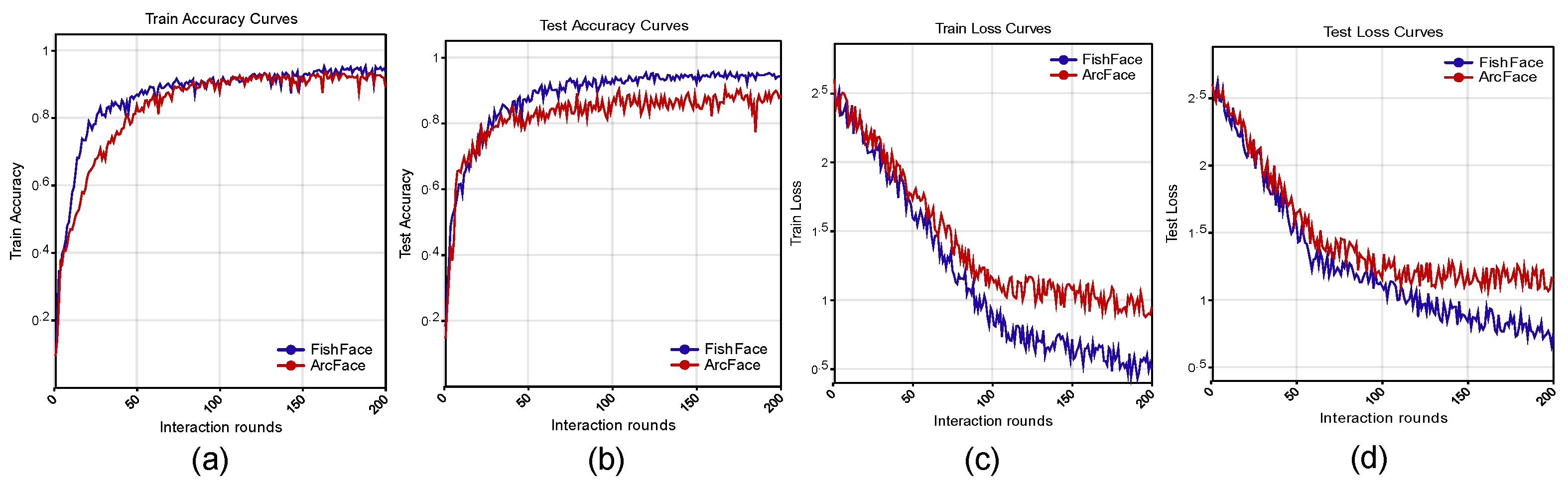
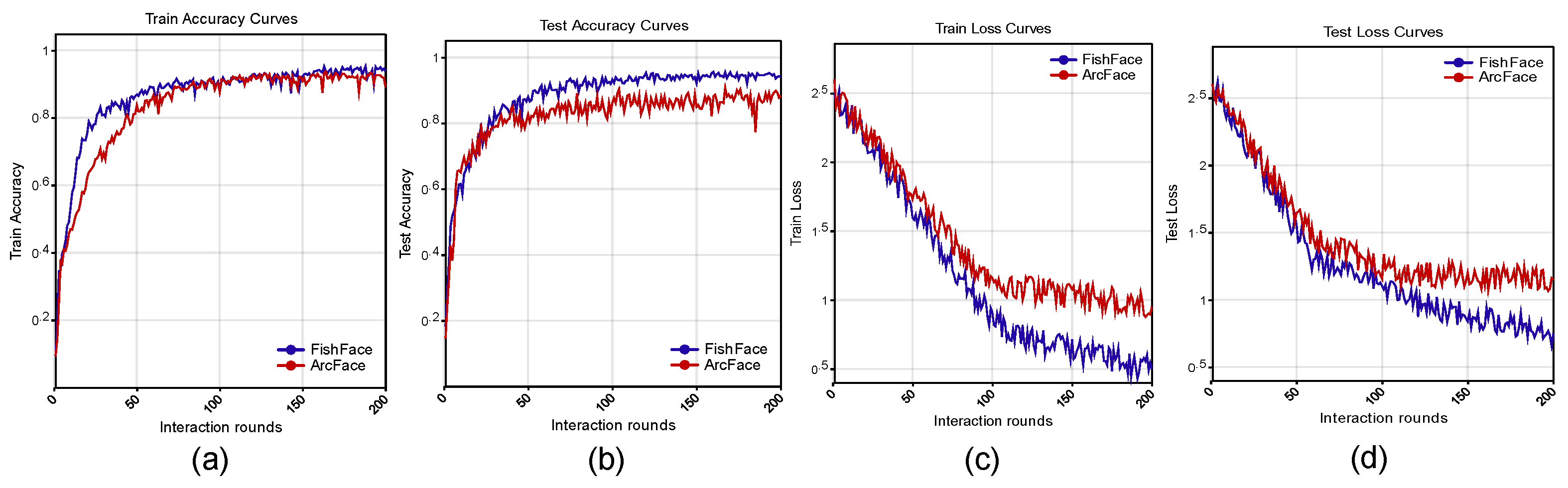
3.1. Performance Comparison between External Models
3.2. Validation of Internal Modules
4. Discussion
4.1. Analysis of the Experimental Results under Different Backbone Networks
4.2. Analysis of the Experimental Results of Different Background Environments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, X.; Zhang, S.; Liu, J.; Gao, Q.; Dong, S.; Zhou, C. Deep learning for smart fish farming: Applications, opportunities and challenges. Rev. Aquac. 2021, 13, 66–90. [Google Scholar] [CrossRef]
- Soom, J.; Pattanaik, V.; Leier, M.; Tuhtan, J.A. Environmentally adaptive fish or no-fish classification for river video fish counters using high-performance desktop and embedded hardware. Ecol. Inform. 2022, 72, 101817. [Google Scholar]
- Wu, D.; Zhang, M.; Chen, H.; Bhandari, B. Freshness monitoring technology of fish products in intelligent packaging. Crit. Rev. Food Sci. Nutr. 2021, 61, 1279–1292. [Google Scholar] [CrossRef]
- Li, D.; Wang, Z.; Wu, S.; Miao, Z.; Du, L.; Duan, Y. Automatic recognition methods of fish feeding behavior in aquaculture: A review. Aquaculture 2020, 528, 735508. [Google Scholar] [CrossRef]
- Meng, Q.; Zhao, S.; Huang, Z.; Zhou, F. Magface: A universal representation for face recognition and quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14225–14234. [Google Scholar]
- Sokolova, A.; Savchenko, A.V. Effective face recognition based on anomaly image detection and sequential analysis of neural descriptors. In Proceedings of the 2023 IX International Conference on Information Technology and Nanotechnology (ITNT), Samara, Russia, 17–21 April 2023; pp. 1–5. [Google Scholar]
- Wang, Q.; Du, Z.; Jiang, G.; Cui, M.; Li, D.; Liu, C.; Li, W. A Real-Time Individual Identification Method for Swimming Fish Based on Improved Yolov5. 2022. Available online: https://ssrn.com/abstract=4044575 (accessed on 15 October 2023).
- Petrellis, N.; Keramidas, G.; Antonopoulos, C.P.; Voros, N. Fish Monitoring from Low-Contrast Underwater Images. Electronics 2023, 12, 3338. [Google Scholar] [CrossRef]
- Khan, F.F.; Li, X.; Temple, A.J. FishNet: A Large-scale Dataset and Benchmark for Fish Recognition, Detection, and Functional Trait Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 20496–20506. [Google Scholar]
- Yin, J.; Wu, J.; Gao, C.; Jiang, Z. LIFRNet: A novel lightweight individual fish recognition method based on deformable convolution and edge feature learning. Agriculture 2022, 12, 1972. [Google Scholar] [CrossRef]
- Gao, C.; Wu, J.; Yu, H.; Yin, J.; Guo, S. FIRN: A Novel Fish Individual Recognition Method with Accurate Detection and Attention Mechanism. Electronics 2022, 11, 3459. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Aboah, A.; Wang, B.; Bagci, U.; Adu-Gyamfi, Y. Real-time multi-class helmet violation detection using few-shot data sampling technique and yolov8. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 5349–5357. [Google Scholar]
- Maswood, M.M.S.; Hussain, T.; Khan, M.B.; Islam, M.T.; Alharbi, A.G. CNN based detection of the severity of diabetic retinopathy from the fundus photography using efficientnet-b5. In Proceedings of the 2020 11th IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 4–7 November 2020; pp. 147–150. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Huang, G.; Liu, S.; Van der Maaten, L.; Weinberger, K.Q. Condensenet: An efficient densenet using learned group convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2752–2761. [Google Scholar]
- Lahuerta, J.J.; Paiva, B.; Vidriales. Depth of response in multiple myeloma: A pooled analysis of three PETHEMA/GEM clinical trials. J. Clin. Oncol. 2017, 35, 2900. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-margin softmax loss for convolutional neural networks. arXiv 2016, arXiv:1612.02295. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5265–5274. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 212–220. [Google Scholar]
- He, X.; Zhou, Y.; Zhou, Z.; Bai, S.; Bai, X. Triplet-center loss for multi-view 3d object retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1945–1954. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. Vggface2: A dataset for recognising faces across pose and age. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar]
- Shi, Y.; Yu, X.; Sohn, K.; Chandraker, M.; Jain, A.K. Towards universal representation learning for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6817–6826. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Proceedings of the Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, 17–20 October 2008. [Google Scholar]
- He, R.; Wu, X.; Sun, Z.; Tan, T. Learning invariant deep representation for nir-vis face recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Zheng, T.; Deng, W. Cross-Pose LFW: A Database for Studying Cross-Pose Face Recognition in Unconstrained Environments; Technical Report; Beijing University of Posts and Telecommunications: Beijing, China, 2018; Volume 5. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Gholami, A.; Kwon, K.; Wu, B.; Tai, Z.; Yue, X.; Jin, P.; Zhao, S.; Keutzer, K. Squeezenext: Hardware-aware neural network design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1638–1647. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modules | Resolution | Number of Channels | Number of Layers | |
|---|---|---|---|---|
| 1 | Conv 3 × 3 | 224 × 224 | 32 | 1 |
| 2 | MBConv1, 3 × 3 | 112 × 112 | 24 | 3 |
| 3 | MBConv6, 3 × 3 | 56 × 56 | 40 | 5 |
| 4 | MBConv6, 5 × 5 | 28 × 28 | 64 | 5 |
| 5 | MBConv6, 3 × 3 | 14 × 14 | 128 | 7 |
| 6 | MBConv6, 5 × 5 | 14 × 14 | 176 | 7 |
| 7 | MBConv6, 5 × 5 | 7 × 7 | 304 | 9 |
| 8 | MBConv6, 3 × 3 | 7 × 7 | 512 | 3 |
| 9 | Conv 1 × 1 and Gempooling and FC | 7 × 7 | 1280 | 1 |
| Family | Method | WideFish Dataset | DlouFish Dataset | Fps | ||
|---|---|---|---|---|---|---|
| Rank1 | Rank5 | Rank1 | Rank5 | |||
| Face Recognition Method | Center Loss | 87.17 | 89.72 | 89.38 | 91.54 | 18.5 |
| SphereFace | 89.21 | 90.24 | 91.01 | 92.12 | 19.3 | |
| ArcFace | 90.43 | 92.38 | 93.21 | 93.49 | 20.1 | |
| VGGFace2 | 91.72 | 90.83 | 92.09 | 92.11 | 16.2 | |
| Confidence Loss | 91.44 | 94.94 | 92.27 | 94.50 | 18.5 | |
| Fish Recognition Method | LIFRNet | 91.34 | 93.13 | 90.04 | 91.10 | 19.1 |
| FIRN | 90.10 | 91.17 | 91.32 | 92.06 | 17.6 | |
| Proposed method | Ours | 94.83 | 97.64 | 95.81 | 96.61 | 19.4 |
| Method | LFW | CALFW | CPLFW |
|---|---|---|---|
| Center Loss | 98.75 | 85.48 | 77.48 |
| ArcFace | 99.83 | 95.45 | 92.08 |
| VGGFace2 | 99.43 | 90.57 | 84.01 |
| Ours | 99.71 | 95.91 | 93.02 |
| Method | WideFish Dataset | DlouFish Dataset | ||
|---|---|---|---|---|
| Rank1 | Rank5 | Rank1 | Rank5 | |
| W/O Quality Assessment Module | 91.34 | 92.18 | 92.35 | 93.49 |
| W/ Quality Assessment Module | 94.83 | 97.64 | 95.81 | 96.61 |
| Backbone | Parameter Quantity | FLOPs | WideFish Dataset | DlouFish Dataset | ||
|---|---|---|---|---|---|---|
| Rank1 | Rank5 | Rank1 | Rank5 | |||
| VGG16 ResNet50 MobileNet v3 SqueezeNet v2 Efficient-B5 | 138.1 M 25.6 M 2.15 M 1.24 M 5.3 M | 15.5 G 3.8 G 0.22 G 0.15 G 0.39 G | 90.51 93.56 91.11 92.33 94.83 | 92.69 95.35 93.18 93.66 97.64 | 88.41 92.33 90.97 91.23 95.81 | 90.24 94.32 92.17 91.68 96.61 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Wu, J.; Zheng, T.; Zhao, H.; Kong, H.; Qu, B.; Yu, H. Fish Recognition in the Underwater Environment Using an Improved ArcFace Loss for Precision Aquaculture. Fishes 2023, 8, 591. https://doi.org/10.3390/fishes8120591
Liu L, Wu J, Zheng T, Zhao H, Kong H, Qu B, Yu H. Fish Recognition in the Underwater Environment Using an Improved ArcFace Loss for Precision Aquaculture. Fishes. 2023; 8(12):591. https://doi.org/10.3390/fishes8120591
Chicago/Turabian StyleLiu, Liang, Junfeng Wu, Tao Zheng, Haiyan Zhao, Han Kong, Boyu Qu, and Hong Yu. 2023. "Fish Recognition in the Underwater Environment Using an Improved ArcFace Loss for Precision Aquaculture" Fishes 8, no. 12: 591. https://doi.org/10.3390/fishes8120591
APA StyleLiu, L., Wu, J., Zheng, T., Zhao, H., Kong, H., Qu, B., & Yu, H. (2023). Fish Recognition in the Underwater Environment Using an Improved ArcFace Loss for Precision Aquaculture. Fishes, 8(12), 591. https://doi.org/10.3390/fishes8120591