1. Introduction
Optimization theory and its practical applications are undergoing unprecedented transformation in contemporary industrial practice, with their core value lying in the targeted enhancement of key system performance indicators. Driven by the continuous expansion of engineering frontiers and the rapid advancements in computational science, classical optimization paradigms—such as Newton’s method and gradient descent—have increasingly revealed their limitations [
1,
2,
3]. Applied to modern engineering problems with high dimensionality and strong nonlinearity, these methods often face exponential time complexity, making exact solutions practically infeasible. This practical challenge has catalyzed the vigorous development of metaheuristic optimization techniques. These algorithms, inspired by natural phenomena or social behavior [
4,
5], offer promising alternatives by delivering global or high-accuracy approximate solutions under acceptable computational costs. The balance between solution quality and computational efficiency makes modern metaheuristic algorithms—such as genetic algorithms (GA) [
6], particle swarm optimization (PSO) [
7], and ant colony optimization (ACO) [
8]—powerful tools with wide-ranging applicability. These methods have demonstrated exceptional performance in solving complex optimization problems across various interdisciplinary domains, including intelligent manufacturing, logistics scheduling, and financial modeling [
9,
10,
11].
As a vital branch of metaheuristic algorithms, swarm intelligence optimization techniques have attracted increasing attention in the academic community in recent years. These algorithms emulate the cooperative behavior of biological populations—such as the flock migration model in particle swarm optimization (PSO), the mating behavior pattern in butterfly optimization algorithm (BOA) [
12], and the deep-sea migration strategy in the salp swarm algorithm (SALP) [
13]—demonstrating distinctive computational advantages. Their simple and intuitive structural design, rapid convergence, and multimodal optimization capabilities enable excellent adaptability in solving complex, nonlinear, and high-dimensional engineering optimization problems. Notably, bio-inspired optimization paradigms are undergoing continuous innovation. Modern engineering design methodologies have accelerated the iterative process through parallel search mechanisms and have adopted dynamic balance strategies to coordinate exploration and exploitation. These approaches have delivered significant application value in improving mechanical system performance, reducing operational costs, and optimizing resource allocation efficiency. For instance, Houssein et al. [
14] proposed a dimension learning-enhanced equilibrium optimizer that constructs multi-level feature interaction mechanisms, significantly improving the lesion segmentation accuracy of COVID-19 lung CT images, particularly in low-contrast regions. Alkayem et al. [
15] developed an adaptive pseudo-inverse stochastic fractal search algorithm that employs intelligent dimensionality reduction strategies within the solution space, enabling robust detection of subtle defects in complex steel structure damage assessments and greatly enhancing diagnostic reliability. Abdollahzadeh et al. [
16] introduced the puma optimization (PO) algorithm, which simulates jaguar-inspired intelligent behavior for designing exploration–exploitation mechanisms. By integrating a hyper-heuristic phase transition strategy, the algorithm adaptively balances optimization stages according to problem characteristics, thereby substantially improving the capability to solve complex optimization problems. Liu et al. [
17] integrated the Q-learning mechanism from reinforcement learning to dynamically hybridize the Aquila optimizer (AO) with the improved arithmetic optimization algorithm (IAOA). By reconstructing the mathematical acceleration function, they achieved a better balance between global search and local exploitation while optimizing the reward model to enhance decision-making efficiency. Wang et al. [
18] proposed an underwater image enhancement method based on reinforcement learning. The reward was constructed by a human visual perception index, the features were extracted by residual network, and the image was gradually optimized by combining various enhancement algorithms. The visual effect could be improved without reference to the image. Li et al. [
19] proposed a joint detection and tracking (IDT) method based on reinforcement learning, which guided the detector to dynamically optimize the threshold through the feedback prediction information of the tracker, and established an adaptive detection gate in the range-Doppler diagram, thus effectively improving the detection probability and tracking continuity of high-frequency ground wave radar for weak targets. Zhu et al. [
20] combined the global exploration capability of the black-winged kite algorithm (KA), the local optimization strength of particle swarm optimization (PSO), and the mutation strategy of differential evolution (DE) to balance search abilities, effectively preventing premature convergence and significantly improving both the convergence speed and solution accuracy in high-dimensional optimization problems. However, with the increasing complexity of engineering optimization tasks—characterized by multi-constraint coupling and high-dimensional nonlinearity—current swarm intelligence algorithms have begun to exhibit theoretical limitations when handling non-convex solution spaces and adapting to dynamic environments. In particular, for complex system designs involving strong time-varying properties and multi-objective conflicts, challenges arise in ensuring convergence stability and maintaining well-distributed solution sets.
The differential creative search (DCS) algorithm [
21] represents a cutting-edge advancement in the field of metaheuristic optimization. This algorithm introduces an innovative multi-stage co-evolution framework in which a heterogeneous knowledge transfer mechanism dynamically integrates population experience, while a dynamic solution space reconstruction strategy enhances adaptability to complex optimization problems. DCS demonstrates strong global convergence performance in tackling high-dimensional, non-convex, and multimodal engineering optimization tasks. Liu et al. [
22] proposed a hybrid approach incorporating an opposition-based learning strategy along with an adaptive reset mechanism that balances fitness and distance. This design encourages low-performance individuals to migrate toward the vicinity of the optimal solution, thereby facilitating the exploration of promising regions in the search space. Cai et al. [
23] improved the shortcomings of DCS algorithm through collaborative development mechanism and population evaluation strategy. However, DCS still suffers from limitations in terms of solution distribution bias and insufficient local convergence precision during iterations, which restrict its ability to effectively explore the boundary regions of the search space and identify the global optimum. To address these challenges, we propose an improved initialization strategy that integrates a refined set with a clustering process to enhance the diversity of the initial population. Furthermore, we incorporate a double Q-learning strategy using dual Q-tables, enabling a more effective balance between exploration and exploitation. This balance empowers the algorithm to explore unknown regions in complex environments more effectively, thereby reducing the risk of premature convergence to local optima.
The main contributions of the proposed algorithm in this study are summarized as follows.
- (1)
A novel algorithm is developed by integrating a refined set, a clustering process, and a double Q-learning strategy into the differential creative search (DCS) framework. Ablation studies are conducted to verify that each of these strategies contributes positively to the performance enhancement of the DCS algorithm.
- (2)
The proposed DQDCS algorithm is benchmarked against ten state-of-the-art algorithms on the CEC2019 and CEC2022 test suites. Extensive simulations demonstrate the superior performance of DQDCS. Its improvements are visualized through convergence curves and boxplots, and further validated by the Wilcoxon rank-sum test to confirm its overall effectiveness.
- (3)
The DQDCS algorithm is applied to two real-world constrained engineering design problems: the design of hydrostatic thrust bearings and the synchronous optimal pulse width modulation (SOPWM) problem in three-level inverters. In both cases, the goal is to minimize the objective function under complex constraints. The results show that DQDCS is particularly suitable for solving practical engineering optimization problems.
The remainder of this study is organized as follows.
Section 2 introduces the fundamentals of the differential creative search (DCS) algorithm.
Section 3 elaborates on the three enhancement strategies incorporated into DQDCS.
Section 4 reports the experimental comparisons between DQDCS and other algorithms on the CEC2019 and CEC2022 benchmarks.
Section 5 presents the application of DQDCS to practical engineering problems and offers a comprehensive analysis of the results. Finally,
Section 6 concludes the study.
2. Differentiated Creative Search Algorithm Thoughts and Process
The differentiated creative search (DCS) algorithm is a swarm intelligence-based optimization method whose core framework integrates differentiated knowledge acquisition (DKA) and creative realism (CR). A dual-strategy mechanism is employed to balance divergent and convergent thinking. In this framework, high-performing individuals adopt a divergent thinking strategy, utilizing existing knowledge and creative reasoning to conduct global exploration guided by the Linnik distribution. In contrast, the remaining individuals adopt a convergent thinking strategy, integrating feedback from both the team leader and peer members to perform local exploitation. This process involves local optimization informed by both elite and randomly selected individuals. The overall procedure of the DCS algorithm is summarized as follows.
2.1. Initialization
The initial population X is randomly generated, with each individual represented as a random solution:
satisfying Equation (1):
where
and
represent the lower and upper bounds of the
d-th dimension, respectively, and
follows a uniform distribution on the interval
.
2.2. Differentiated Knowledge Acquisition
Differentiated knowledge acquisition (DKA) emphasizes the rate at which new knowledge is acquired, exerting differential effects on individual agents. These effects are primarily manifested through the modification of the individual’s existing knowledge attributes or dimensional components. The parameter
denotes the quantified knowledge acquisition rate of the
i-th individual at iteration
t, as defined in Equation (2).
In Equation (2),
represents the coefficient associated with variable
for the individual at the t-th iteration, and is calculated using Equation (3). Here,
NP denotes the population size, and
indicates the rank of the
i-th individual at the beginning of iteration t. The influence of the DKA process on each component of
is described in Equation (4), where
denotes an integer uniformly selected from the set
and D represents the dimensionality of the problem.
2.3. Convergent Thinking
The strategy for low-performing individuals leverages the knowledge base of high performers and incorporates the stochastic contributions of two randomly selected team members into the solution proposed by the current individual. The inertia weight
F is generated randomly, and this process is described by Equation (5), where
F the inertia weight and
represents the best global solution in the current population.
draws upon convergent thinking by integrating the information provided by team members
and
, thereby refining the knowledge of the team leader,
, as described by Equation (6). Here, the coefficient
governs the extent to which peer influence shapes an individual’s social cognition within the team environment. It reflects the degree to which team dynamics affect individual perspectives. The value of
decreases over time, as defined in Equation (7), where
NFET and
NFEmax denote the number of function evaluations in the current iteration and the maximum allowable number of function evaluations, respectively.
Two random individuals,
and
, are selected, and a new candidate solution is generated by incorporating the best individual with stochastic components, as defined in Equation (8).
2.4. Divergent Thinking
A random individual
is selected, and a new candidate solution is generated using the Linnik distribution, as defined in Equation (9), where
denotes a random variable drawn from the Linnik distribution with parameters
and
.
2.5. Team Diversification
As the team continues to evolve, it generates increasingly diverse ideas. To maintain diversity and adaptability, the DCS algorithm replaces underperforming members with newly generated individuals. The equation used to generate new individuals is provided in Equation (10).
2.6. Offspring Population
For each individual
, a trial solution
is generated. The decision to retain or replace the original solution is based on a comparison of their fitness values. If the trial solution
exhibits superior fitness, it replaces the original solution
; otherwise, the original solution is retained. This process is formulated in Equation (11).
In each iteration, all individuals
in the newly generated population are evaluated, and the best global solution
is subsequently updated. This process is formally defined in Equation (12).
Algorithm 1 outlines the detailed steps of the DCS algorithm described above.
| Algorithm 1: Particle swarm optimization |
Step 1: Random Initialization of the Population
The initial population is generated randomly to ensure diversity in the solution space.
Step 2: Fitness Evaluation
The fitness of each individual is evaluated by computing its objective function value, which reflects the individual’s performance on the optimization problem.
Step 3: Determination of the Number of High-Performance Individuals
The number of top-performing individuals is determined based on a predefined proportion of the population.
Step 4: Initialization of Iteration Counter and Parameters
Set the iteration counter t = 1, the number of function evaluations NFE = 0, and the probability of population migration to 0.5.
Step 5: Main Optimization Loop
Continue the optimization process while NFE < NFEmax, repeating the position updating and fitness evaluation steps. |
3. Hybrid Multi-Strategy Differentiated Creative Search Algorithm
Firstly, the DCS algorithm initializes the population using pseudo-random numbers, which results in limited population diversity and a lack of target-oriented search in the early stages, thereby reducing optimization efficiency. Secondly, the algorithm relies heavily on the best-performing individual during position updates, making it susceptible to premature convergence and hindering its ability to escape local optima. These issues ultimately lead to reduced optimization accuracy and a slower convergence rate.
To address these limitations, targeted strategies are introduced to enhance the algorithm’s overall performance. Previous studies have shown that the diversity of the initial population significantly influences the algorithm’s ability to converge rapidly and accurately. A higher degree of initial diversity allows the algorithm to explore a broader solution space during the search process, thereby increasing the likelihood of identifying the global optimum.
To improve population diversity, generate higher-quality initial solutions, and effectively overcome the limitations of the basic DCS algorithm, a refined set strategy and clustering strategy are incorporated during the population initialization phase. Although the DCS algorithm enhances global exploration through its “creativity” mechanism, it lacks sufficient flexibility in dynamic environments, such as path planning with moving obstacles for UAVs (unmanned aerial vehicles) or real-time demand changes in industrial scheduling.
The incorporation of double Q-learning allows the algorithm to interact continuously with the environment, facilitating real-time perception and autonomous decision-making. This enables the DCS algorithm to adapt its search strategy more precisely under dynamic conditions, thereby maintaining high operational efficiency. Furthermore, the learning capability of double Q-learning enhances the algorithm’s generalization ability, enabling robust performance in unseen scenarios and increasing the practical value of intelligent optimization techniques.
3.1. Refined Set Initialization
Compared to traditional pseudo-random initialization, the refined set strategy achieves a more uniform distribution of the population across the search space through a carefully designed sampling method. This uniformity reduces the likelihood of the algorithm becoming trapped in local optima during the early stages of optimization. By promoting a broader distribution of individuals, the algorithm gains increased opportunities to explore diverse regions and identify superior solutions.
The mathematical formulation of the refined set strategy is presented in Equations (13) and (14), where
L and
U represent the lower and upper bounds of the
d-th dimension, respectively, and
indicates the index of the
i-th individual. The parameter p denotes the smallest prime number that satisfies specific conditions, and
refers to the result of the modulo operation applied to
with respect to
p. Specifically, it involves calculating the remainder of
divided by
p. The value of
p directly influences the initial distribution of the population. A larger
p value enhances global exploration capability by promoting a more uniform distribution, while a smaller
p value may cause the algorithm to prematurely enter the local exploitation phase. The parameter
p is calculated using Equation (15), where
N represents the set of natural numbers and
denotes the smallest prime number greater than
.
3.2. Clustering Process
After the population is generated using the refined set strategy, a clustering algorithm is applied for further enhancement. In this study, the k-means clustering method is adopted to allow the DCS algorithm to focus on salient features during the learning phase while minimizing the impact of low-quality data. This process improves the algorithm’s generalization ability on unseen data, thereby increasing its robustness and stability in practical applications. The detailed implementation steps are presented as follows.
- (1)
Select the Cluster Centers
Randomly select
k points as the initial cluster centers
where
. In this experiment, the value of
k is determined by Equation (16), where NP denotes the population size. The value of
k linearly varies with the population size, ensuring that each cluster contains a sufficient number of individuals. When the population is large, increasing the value of
k allows for capturing more intricate details. Conversely, when the population is small, reducing the value of
k helps prevent excessive subdivision.
- (2)
Calculate the distance and assign individuals
For each individual
in the population, the Euclidean distance between
and each cluster center
is calculated. The individual
is then assigned to the cluster corresponding to the nearest cluster center. This is specifically expressed by Equation (17).
- (3)
Update the cluster centers
For each cluster, the cluster center is recalculated. Let the set of individuals in the j-th cluster be denoted . The new cluster center is computed as the mean of the individuals in , where denotes the number of individuals in the set .
- (4)
Iterative process
Repeat steps 2 and 3 until the cluster centers no longer undergo significant changes.
- (5)
Density-based uniform selection
Calculate the local density of each individual
, denoted
, where
is the truncation distance used in the density calculation. Individuals with moderate density are selected, and the final initialized population is given by Equation (18).
3.3. Double Q-Table Reinforcement Learning Model (Double Q-Learning Model)
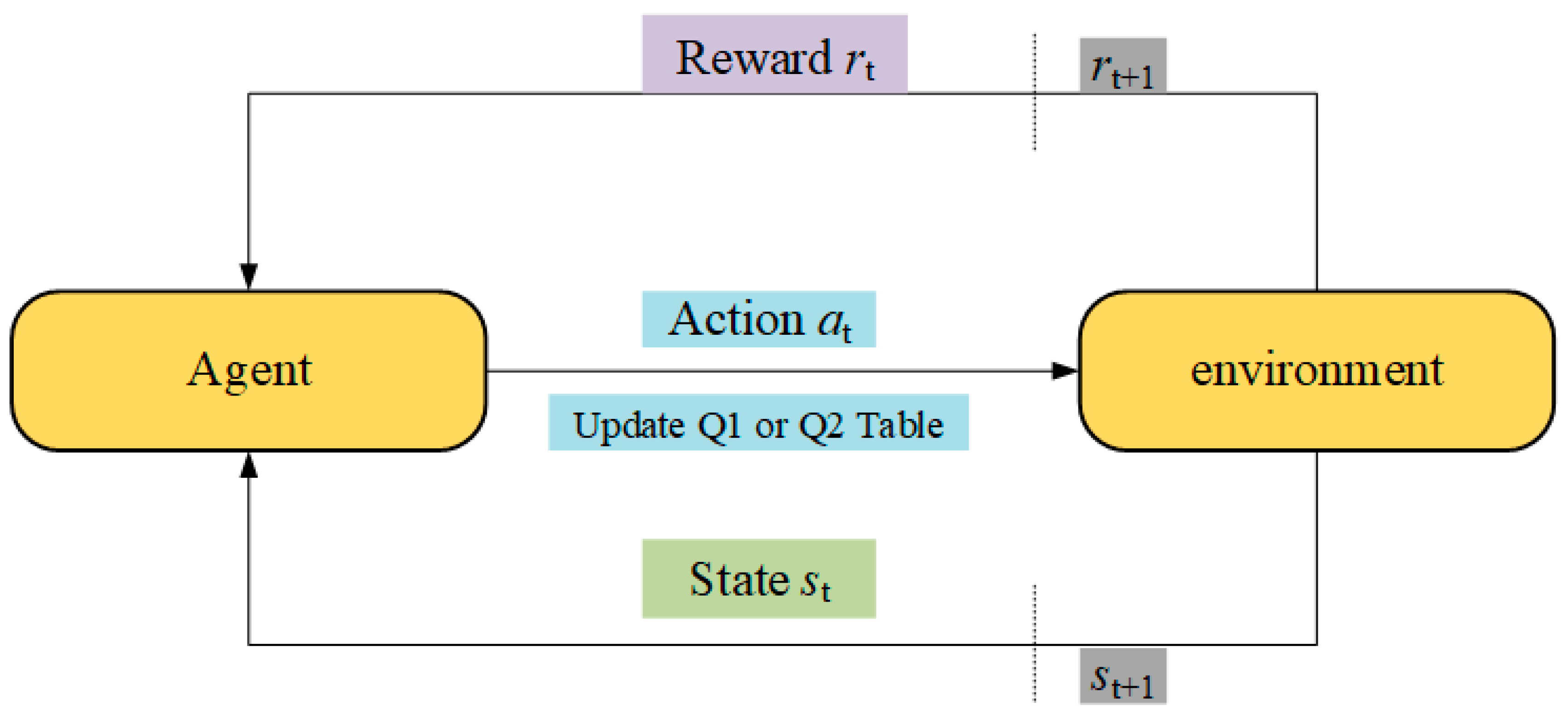
The Q-learning model consists of five fundamental components: the agent, environment, action, state, and reward. Its operational procedure can be succinctly described as a cyclical interaction of state transition, action selection mechanism, and reward feedback. In traditional Q-learning, a single Q-table is employed to store the estimated values of state–action pairs. However, this approach often suffers from issues such as overestimation bias and limited exploration capacity. To mitigate these limitations, double Q-learning introduces two independent Q-tables, each of which is updated independently. This dual-table framework significantly reduces the estimation bias inherent in the single-table approach and enables a more balanced, robust evaluation of the learned policy.
Let denote the set of environment states and represent the set of actions that the agent can execute. In each iteration, the agent occupies a certain state and selects an action to perform. After executing the action, the environment provides a reward and a new state . The reward is computed according to Equation (19), where denotes the solution at the new position and represents the solution at the current position. Upon receiving this information, the agent evaluates the expected value for each possible action.
In double Q-learning, either
or
is selected for updating with equal probability. The update equations are provided in Equations (20) and (21). In the equations,
represents the state of the agent,
denotes the action executed by the agent,
is the immediate reward obtained by the agent after executing the action, and
is the discount factor, which penalizes future rewards. When
, double Q-learning considers only the current reward; when
, it prioritizes long-term rewards,
is the learning rate, typically within the interval
. Double Q-learning maintains two Q-tables, traditional Q-learning, but with distinct update logic.
Figure 1 simplified illustration example of the operational process of double Q-learning, the arrows in the figure indicate the flow direction of the data, while the dotted line represents the dividing line of time, the transition from time t to t+1. The agent alternates between updating the two Q-tables and combines information from both when selecting actions, thereby reducing estimation bias and enhancing policy robustness.
In the DCS algorithm, the last individual is considered inefficient and updated using random initialization, which often results in low-quality solutions. To address this issue, double Q-learning introduces two independent Q-tables and employs a dual Q-table mechanism to improve solution quality. This separation makes the calculation of target Q-values more reliable, helping to reduce estimation bias.
3.4. Ablation Experiment
To evaluate the effectiveness of the proposed strategies, four representative test functions from the CEC2019 benchmark suite were selected. The performance of the refined set strategy, the clustering process strategy, their combination, and the double Q-learning strategy was systematically compared. Each algorithm was executed for 500 iterations across 30 independent runs. Specifically, D1 adopts the refined set strategy, D2 employs the clustering process strategy, D3 integrates both the refined set and clustering process strategies, and D4 incorporates the double Q-learning mechanism. The corresponding results are summarized in
Table 1. Experimental results demonstrate that population initialization using the combined refined set and clustering process significantly enhances the algorithm’s capability to approach the global optimum. Moreover, the D4 variant, augmented with the double Q-learning strategy, achieves the best overall fitness across all test functions.
3.5. Hybrid Multi-Strategy DQDCS Algorithm
The DQDCS algorithm integrates both the refined-point set strategy and a clustering-based approach, and further incorporates a double Q-learning model to construct a multi-strategy hybrid optimization framework. The refined-point set is generated through mathematically guided sampling techniques to ensure a more uniform distribution of individuals across the search space, thereby replacing conventional pseudo-random initialization methods. Such a distribution promotes broader coverage of the solution space and mitigates early-stage search blind spots. A high-quality initial population enhances the algorithm’s ability to converge more reliably toward optimal solutions and reduces performance fluctuations caused by poor initial positioning.
In contrast to purely random initialization, the refined-point set strategy employs structured sampling to diminish the randomness-induced variability in the initial population, thereby improving the algorithm’s robustness. Moreover, this strategy can be tailored to the specific characteristics of the optimization problem; for example, in constrained optimization scenarios, it helps ensure that the initial population satisfies constraint conditions, thus avoiding infeasible solutions and enhancing overall algorithmic stability.
The clustering strategy divides the population into multiple subgroups, with each subgroup representing distinct regions or features of the search space. This structural partitioning aids in preserving diverse solution patterns throughout the optimization process, thereby reducing the risk of premature convergence to local optima. By maintaining diversity and promoting exploration, the algorithm is better positioned to locate the global optimum efficiently.
By integrating the probability distributions and maximum values derived from two independent Q-tables, the double Q-learning mechanism enables more balanced action selection between exploration and exploitation. Within the DQDCS algorithm, this dual-Q-table framework effectively mitigates the estimation bias commonly associated with single-Q-table implementations and facilitates more comprehensive policy evaluation, thereby enhancing the algorithm’s global search capability. Specifically, double Q-learning selects the optimal action based on the current state, which subsequently guides population updates. This approach allows for broader exploration during the early stages of optimization while gradually shifting toward refined exploitation of promising regions in the later stages. As such, the algorithm achieves accelerated convergence without compromising solution quality. A flowchart of the DQDCS algorithm is illustrated in
Figure 2.
Algorithm 2 presents the pseudocode of the proposed DQDCS algorithm.
| Algorithm 2: DQDCS algorithm. |
Initialize the population using Equation (1);
Evaluate fitness for all individuals;
Determine the refined set via the clustering process;
Initialize Q-tables to zero;
Set key parameters: exploration threshold pc, golden ratio, η and φ values;
while the number of function evaluations (nfe) < max_nfe do
Sort the population by fitness;
Identify the best solution x_best;
Compute λt using Equation (7);
for each individual i do
Compute ηi and φi using Equations (2) and (3);
Determine behavior category (high-, average-, or low-performing);
if i is low-performing and rand < pc then
Generate a new solution randomly;
else if i is high-performing then
Select r1 ≠ i;
Update selected dimensions using Equation (8);
else//average-performing
Select r1, r2 ≠ i;
Compute ωi;
Update selected dimensions using Equation (8);
end if
Apply reflection-based boundary handling;
Evaluate fitness of the new solution;
If improved, update position and fitness;
Compute reward from fitness change;
Update Q1 using Q2 for value estimation (Equation (20));
Update Q2 using Q1 similarly (Equation (21));
end for
Update the best solution and record convergence data;
end while
Return best solution, best fitness; |
3.6. Complexity Analysis of the Algorithm
The implementation of the DQDCS algorithm involves certain design challenges, yet it maintains relatively low computational complexity. The overall complexity is stage-dependent, as each phase—initialization, fitness evaluation, and solution generation—contributes differently to the total computational cost.
In general, the DQDCS algorithm comprises three fundamental procedures: population initialization, fitness evaluation, and generation of new solutions. The main loop iterates for a maximum of Max_iter iterations, and in each iteration, operations are performed for each of the N search agents.
The computational complexity of the initialization phase is O(N), owing to the refined set-based initialization method and clustering process. Additionally, the time complexity for fitness evaluation depends on the complexity of the objective function, denoted O(F). Therefore, the overall computational complexity of the algorithm can be expressed as O(Max_iter × N × F).
4. Simulation Environment and Result Analysis
In the field of optimization, particularly in the study of evolutionary algorithms and metaheuristic methods, validating the effectiveness of proposed algorithms is of paramount importance, as these approaches are expected to address complex challenges encountered in real-world applications. To assess their performance, standardized test cases or well-established benchmark problems are commonly employed. These benchmark evaluations offer a unified platform for objective comparison, enabling fair and consistent performance assessment across different algorithms and facilitating a rigorous analysis of their strengths and limitations.
This experiment was conducted using MATLAB 2023 and a Windows 11 operating system with Intel Core i5-13400 CPU and 8 GB RAM (Intel Corporation, Santa Clara, CA, USA). The CEC2019 [
24] and CEC2022 [
25] benchmark functions were employed to evaluate the performance of the DQDCS algorithm. These benchmark functions enable a systematic comparison between DQDCS and other state-of-the-art metaheuristic algorithms, thereby verifying the competitiveness and applicability of the proposed method in solving complex optimization problems. This evaluation framework ensures scientific rigor and provides clear directions for further algorithmic enhancements.
Considering the inherent stochastic nature of metaheuristic algorithms, relying on a single run for each benchmark function may lead to unreliable conclusions. Therefore, multiple simulations were conducted for each algorithm, including puma algorithm [
16], the original differentiated creative search algorithm (DCS) [
21], the multi-strategy hybrid DQDCS algorithm, a differentiated creative search algorithm with multi-strategy improvement (MSDCS) [
22], Chernobyl disaster optimizer (CDO) [
26], adaptive spiral flying sparrow search algorithm (ASFSSA) [
27], waterwheel plant algorithm (WWAP) [
28], subpopulation improved grey wolf optimizer with Gaussian mutation and Lévy flight (SPGWO) [
29], dung beetle optimizer (DBO) [
30] and nonlinear randomly reuse-based mutated whale optimization algorithm (NRRMWOA) [
31]. The detailed experimental results are presented as follows.
4.1. The CEC2019 Benchmark Functions Are Employed for Performance Evaluation
The CEC2019 benchmark functions are specifically designed to evaluate and compare the performance of optimization algorithms. They encompass a diverse set of challenging optimization problems, including multimodal, high-dimensional, and dynamic characteristics, thereby closely simulating real-world complexities. Given the inherent stochastic nature of metaheuristic algorithms, a single run per benchmark function is insufficient to reliably demonstrate an algorithm’s effectiveness. To enhance the reliability and fairness of performance evaluation, each algorithm was independently tested 100 times on each benchmark function, with a maximum of 500 iterations per run. The population size was consistently established at 200 individuals.
4.1.1. CEC2019 Optimization Accuracy Analysis
To accurately evaluate and compare the performance on the CEC2019 benchmark functions, the experimental results are summarized in terms of the best, mean, and standard deviation (Std) values. In the result tables, the best mean values, which serve as key performance indicators, are highlighted with underlining. The detailed outcomes are presented in
Table 2.
As shown in the statistical results in
Table 2, the proposed DQDCS algorithm consistently achieves the best values on all functions from F1 to F10. Moreover, it obtains the best mean performance on F3–F10 compared to other competing algorithms. In addition, the DQDCS achieves the smallest standard deviation on functions F3, F5, F6, F8, and F9, demonstrating superior robustness. These findings indicate that DQDCS not only offers stable performance but also exhibits highly competitive exploration capability among the compared algorithms.
4.1.2. CEC2019 Convergence Curve Analysis
To facilitate a more intuitive comparison of the convergence behavior across different functions in the CEC2019 benchmark functions, convergence curves for the DQDCS algorithm and ten other competing algorithms were plotted. As shown in
Figure 3, the horizontal axis represents the number of iterations, while the vertical axis denotes the fitness value. It can be observed that the DQDCS algorithm demonstrates superior convergence accuracy on functions F1–F7, F9, and F10. Notably, it is capable of approaching the optimal value at the early stages of the search process, particularly on functions F1 and F10, where the curves converge almost linearly to the optimum. These results indicate that the DQDCS algorithm exhibits relatively strong performance and that the incorporation of multi-strategy enhancements is both feasible and effective in improving optimization precision.
4.1.3. CEC2019 Boxplot Analysis
To compare the performance of different algorithms across multiple runs—particularly in terms of stability and robustness—boxplots are employed as an evaluation tool. As shown in
Figure 4, for the DQDCS algorithm, the median values for functions F3, F4, F6, F7, and F9 are located near the lower boundaries of the boxes, indicating a right-skewed (positively skewed) distribution. This suggests that the majority of runs yielded relatively favorable results. Moreover, no outliers are observed in functions F1, F4, F5, F7, or F9 and only a few outliers appear in F2, F3, F6, F8, and F10, demonstrating that DQDCS exhibits stronger robustness compared to the other algorithms.
4.1.4. CEC2019 Wilcoxon Rank-Sum Test
The Wilcoxon rank-sum test [
32], a non-parametric statistical test, was employed to evaluate the significant differences between two algorithms. The objective was to verify whether there exists a significant difference between the DQDCS algorithm and the other ten comparison algorithms, thereby assessing the optimization performance of DQDCS. A
p-value below 0.05 indicates the rejection of the null hypothesis, signifying a significant difference between the two algorithms.
Table 3 presents the
p-values obtained from the Wilcoxon rank-sum test conducted between DQDCS and the other ten representative comparison algorithms when solving the CEC2019 benchmark. As shown in
Table 3, DQDCS outperforms the other comparison algorithms in solving the CEC2019 functions, with
p-values between DQDCS and each of the comparison algorithms being lower than 0.05. The results unequivocally emphasize that DQDCS exhibits significant differences compared to the other algorithms in the majority of the functions, highlighting its distinct advantage in solution performance.
4.2. The CEC2022 Benchmark Functions Are Employed for Performance Evaluation
The CEC2022 benchmark functions are a standardized set of problems used to assess the performance of optimization algorithms in research and development. These test functions simulate various aspects of real-world optimization problems, including local minima, maxima, global optima, and a range of complexities such as nonlinearity and discontinuities. By validating algorithms on these diverse test sets, it ensures that the algorithms exhibit high robustness and stability when confronted with different challenging scenarios. This approach helps avoid the issue of algorithms performing exceptionally well in specific environments while failing in others, thereby enhancing the generality and reliability of the algorithm. For a comprehensive evaluation, the complex functions described in the CEC2022 test suite are used to assess the effectiveness of the DQDCS algorithm. The number of iterations is set to 500, and 100 independent tests are conducted for each benchmark function. The population size is consistently established at 200 individuals.
4.2.1. CEC2022 Optimization Accuracy Analysis
To visually observe and compare the results of the CEC2022 benchmark functions, the following table presents the optimal values (best), mean values (mean), and standard deviations (Std) for each test function. In these tables, the mean value is used as the performance indicator, and the best mean values are underlined. These results are provided in
Table 4 below.
From the statistical results in
Table 4, it can be observed that for test functions F1 to F3, DQDCS achieved the best mean values and found the optimal solutions when compared to the other algorithms. Moreover, when searching for the optimal values of functions F1 to F3, DQDCS exhibited the lowest standard deviation among all algorithms.
For test functions F4 to F8, DQDCS found the optimal solutions for functions F5 to F8. It achieved the best mean values across all algorithms for functions F6, F7, and F8. Additionally, for function F4, DQDCS outperformed DCS in terms of the mean value, and DQDCS also achieved lower standard deviations than the other algorithms in functions F4, F5, and F7.
In the case of test functions F9 to F12, DQDCS found the optimal solutions for functions F11 and F12. For functions F9, F10, and F12, DQDCS achieved the best mean values across all algorithms. For function F11, DQDCS outperformed DCS in terms of the mean value. Furthermore, DQDCS exhibited the lowest standard deviation in functions F10 and F12, and its standard deviation was lower than that of DCS in functions F9 and F11.
4.2.2. CEC2022 Convergence Curve Analysis
To more intuitively compare the optimization accuracy and convergence speed of various algorithms, the convergence curves for each algorithm based on the CEC2022 benchmark functions are presented in
Figure 5, which shows a comparison of the convergence curves for eleven algorithms, with the horizontal axis representing the number of iterations and the vertical axis representing fitness values. The DQDCS algorithm exhibits the highest convergence speed on functions F1, F4, F7, F8, F10, F11, and F12, achieving the highest convergence accuracy on functions F1 to F3 and F5 to F12. Furthermore, it almost finds the optimal value at the beginning, especially for functions F2, F8, F9, F10, and F12, where it converges to the optimal value in an almost linear manner. This further confirms that the DQDCS algorithm performs relatively well, and the multi-strategy improvements are effective and feasible in enhancing both the convergence speed and accuracy of the algorithm.
4.2.3. CEC2022 Boxplot Analysis
In order to compare the performance of different algorithms, a boxplot evaluation based on the CEC2022 benchmark functions was drawn to assess and compare the algorithms. As shown in
Figure 6, the DQDCS algorithm exhibits no outliers across functions F1 to F12, indicating superior robustness compared to the other algorithms. Furthermore, the boxplots for functions F1 to F3 and F5 to F12 are relatively flat, suggesting that the DQDCS algorithm demonstrates stable data behavior.
4.2.4. CEC2022 Wilcoxon Rank-Sum Test
To further evaluate the effectiveness of the DQDCS algorithm, the Wilcoxon rank-sum test was utilized. This test is ideal for comparing the performance of original and improved algorithms, as it can assess significant differences between two independent samples, particularly when the data do not follow a normal distribution. A key advantage of the Wilcoxon rank-sum test is its non-parametric nature, which makes it particularly effective for comparing two independent sets of samples without assuming a specific distribution, regardless of sample size.
By conducting the Wilcoxon rank-sum test on the DQDCS algorithm and other algorithms based on the CEC2022 test set, the superiority and reliability of the DQDCS algorithm were further evaluated. The specific results are shown in
Table 5. The
p-value indicates the degree of significance between the two algorithms. When the
p-value is less than 5%, the difference is considered significant; otherwise, it is not. The results presented in
Table 5 indicate that the
p-values are all less than 5%, which demonstrates a significant difference between DQDCS and the other comparison algorithms, further validating the superiority and effectiveness of the DQDCS algorithm.
In conclusion, the DQDCS algorithm significantly enhances the overall performance of the DCS algorithm. When compared with other algorithms, it exhibits outstanding performance and strong overall capability. However, there are still some limitations to the DQDCS algorithm. For instance, the increased diversity in the initialization stage sacrifices some of the algorithm’s convergence speed. Additionally, when solving certain functions, the increased computational load leads to slight performance degradation. Therefore, there remains room for improvement. These results suggest that the hybrid multi-strategy approach is effective for most of the test functions, which aligns with the “no free lunch” theorem.
5. Engineering Case Studies and Results Analysis
In the research and development of metaheuristic optimization algorithms, the construction and refinement of algorithm performance evaluation systems have always been a central focus in the academic community. Traditional evaluation paradigms are often based on benchmark test function sets. While these functions provide a standardized testing environment and clear theoretical optimal solutions, they significantly differ from the complexities of real-world engineering problems, making it difficult to fully reflect the practical applicability of algorithms in real-world scenarios. In contrast, real-world engineering problems typically exhibit highly complex characteristics. First, the optimal global solution is difficult to determine in advance using analytical methods, and its existence and uniqueness often lack rigorous mathematical proof. Second, the problem space generally contains various complex constraints, such as nonlinear constraints, inequality constraints, and boundary conditions, which are interwoven and greatly increase the difficulty of solving the problem. These features make real-world engineering problems an ideal benchmark for testing the robustness, adaptability, and engineering practicality of optimization algorithms.
From both the algorithm validation and engineering application perspectives, employing real-world problems with actual engineering constraints as test cases holds irreplaceable significance for thoroughly evaluating the practical performance of optimization algorithms. This testing approach not only more accurately simulates the algorithm’s performance in real operational environments, but also effectively addresses the limitations of benchmark function tests in reflecting the generalization capability of algorithms. Based on this, this study carefully selected the design of static pressure thrust bearings [
33] and the application of synchronous optimal pulse width modulation (SOPWM) in three-level inverters [
34] as typical test cases. This study aimed to conduct a systematic empirical analysis to evaluate the effectiveness and superiority of the proposed algorithm in solving complex engineering optimization problems.
The design of static pressure thrust bearings is a typical multidisciplinary optimization problem involving fields such as fluid mechanics, materials science, and thermodynamics. The optimization of its design parameters requires balancing multiple performance metrics, including load-bearing capacity, stability, and energy consumption. On the other hand, the application of synchronous optimal pulse width modulation (SOPWM) in three-level inverters focuses on the field of power electronics, aiming to find the optimal solution among several objectives, such as ensuring output voltage waveform quality, reducing switching losses, and suppressing harmonics. These two engineering cases are highly representative and complementary: on one hand, they encompass various constraints from different engineering fields, such as mechanical and power electronics, which allows for a comprehensive assessment of the algorithm’s capability in handling complex constrained optimization problems; on the other hand, through in-depth analysis of real engineering data, the performance of the algorithm in terms of solution quality, efficiency, and convergence speed can be directly evaluated. The research results not only provide essential empirical evidence for further optimization of the algorithm but also lay a solid theoretical and practical foundation for its broader application in various engineering domains.
5.1. Static Pressure Thrust Bearing
The primary objective of this design problem is to optimize the bearing power loss using four design variables, with the goal of minimizing the power loss. These design variables include the bearing radius , groove radius , oil viscosity , and flow rate . The problem involves seven nonlinear constraints, labeled , which are defined in Equations (23)–(29). These constraints pertain to the load-carrying capacity W, the inlet oil pressure , and the oil film thickness h, as specified in Equations (30), (31), and (32), respectively.
The objective function
primarily includes the flow rate of the lubricant, inlet oil pressure, and the power loss function resulting from friction under specific constraints. The detailed formulation is provided in Equation (22). Additionally, the power loss caused by friction is closely related to the temperature rise of the lubricant and the oil film thickness. The axial load constraint
W ensures that the bearing can withstand the specified axial load, which is a fundamental requirement for its proper operation. This constraint is directly related to the bearing’s load-carrying capacity and stability. The inlet oil pressure constraint
guarantees a reasonable inlet pressure, which is crucial for effective lubrication and normal operation of the bearing. Insufficient oil pressure may result in inadequate lubrication, while excessive pressure could lead to leakage or other failures. The oil film thickness constraint
h ensures an appropriate film thickness, which is essential for reducing friction, minimizing power loss, and preventing surface wear. This constraint plays a critical role in maintaining the bearing’s performance and extending its service life.
Figure 7 illustrates the structure of the static pressure thrust bearing, the blue background indicates regional visualization.
In the objective function
:
represents the flow rate of the lubricant oil;
denotes the inlet oil pressure; and
represents the power loss caused by friction. The constraints associated with the objective function are mainly composed of the following seven inequality constraints.
The temperature rise expression can be calculated using Equations (32) and (33).
The frictional power loss,
, is given by Equation (34).
The film thickness, h, is defined as shown in Equation (35).
The remaining parameters are defined as shown in Equations (36)–(39).
To compare the performance of DQDCS with several classical algorithms, the population size was set to 30, the number of iterations to 200, and each algorithm was executed 30 times. The results of the static pressure thrust bearing design problem are presented in
Table 6, where the best values are underlined for clarity. It can be observed that DQDCS ranks first in terms of best solution, variance, mean, and worst-case performance. Additionally, the median value of DQDCS ties for first place with DBO. In summary, DQDCS demonstrates superior overall performance in solving this engineering problem.
5.2. Application of SOPWM (Synchronous Optimal Pulse Width Modulation) in Three-Level Inverter
Synchronous optimal pulse width modulation (SOPWM) is an advanced technique used for controlling medium-voltage (MV) drives. It significantly reduces the switching frequency without introducing additional distortion, thereby decreasing switching losses and improving the performance of inverters. Within one fundamental period, the switching angles are computed to minimize current distortion simultaneously. SOPWM can be transformed into a scalable constrained optimization problem. For inverters with different voltage levels, the application of SOPWM in three-level inverters can be described as follows. The primary objective of this problem is to minimize the current distortion
f, subject to the constraints g and
h, as described by Equations (40)–(43).
Figure 8 illustrates the structure of the SOPWM application in a three-level inverter.
The constraint on the relationship between adjacent switching angles is defined by Equation (44). Specifically, it requires that the difference between two consecutive switching angles must exceed a threshold . This is intended to ensure a certain degree of regularity and stability in the variation of switching angles, thereby preventing potential control issues caused by excessively close switching angles. The constraint condition involves a modulation-related parameter m, and is expressed by Equation (45). This condition states that under specific circumstances, the sum of cosine terms involving and must be equal to . It serves to constrain the switching angles and other related parameters to ensure compliance with the operational requirements of the system. Equation (46) defines the constraint on the switching angle , restricting its values to a range between 0 and . This limitation is established based on the physical characteristics and operational requirements of the inverter, ensuring that the switching angle varies within a reasonable range. Such a constraint is essential for maintaining proper inverter functionality and achieving optimal performance.
The proposed improved algorithm is compared against several classical algorithms using a population size of 30 and 200 iterations, with each algorithm executed 30 times. The experimental results for the application of synchronous optimal pulse width modulation (SOPWM) in a three-level inverter are presented in
Table 7, where the best values are underlined for clarity. As observed, DQDCS achieves the best rank in terms of the optimal value and standard deviation, ranks second in both mean and median values, and ranks fourth in the worst-case performance. Taken together, these results demonstrate that DQDCS exhibits the best overall performance in solving this problem.
5.3. Analysis of CPU Running Time for Each Algorithm
The CPU running time of an algorithm is a critical performance metric, directly affecting both the efficiency and responsiveness of a program. By analyzing time complexity, we can quantify the algorithm’s running time under various input sizes. Time complexity represents the number of CPU cycles required for the algorithm’s execution, assisting in predicting performance in large-data environments. The CPU running time is influenced not only by the algorithm itself but also by factors such as hardware architecture, compiler optimizations, and the operating environment. Practical testing and performance benchmarking enable the validation of theoretical analysis and provide a foundation for algorithm optimization.
Therefore, a comprehensive analysis of CPU running time serves as an essential tool for algorithm selection and system design. By comparing the CPU running times of different algorithms under identical conditions, the most efficient solution can be identified. As shown in
Figure 9, the DQDCS algorithm ranks third in CPU running time when applied to the static pressure bearing problem. It significantly outperforms the original DCS algorithm, with shorter running times reducing hardware load, extending equipment lifespan, and lowering operational costs.
Moreover, the DQDCS algorithm also ranks third in CPU running time for solving the SOPWM (synchronous optimal pulse width modulation) problem in a three-level inverter, as depicted in
Figure 10. The reduced CPU running time contributes to lower energy consumption, particularly in large-scale computations, resulting in savings in both electricity and hardware resources.
In summary, the DQDCS algorithm demonstrates excellent performance when addressing specific engineering problems, with its shorter CPU running time bringing significant economic and environmental benefits to real-world applications. These results further validate the importance of algorithm optimization and provide valuable insights for future algorithm design and enhancement. Through an in-depth analysis and comparison of CPU running times, we can select the most suitable algorithm for various computationally intensive tasks, thereby ensuring optimal resource utilization while maintaining computational efficiency.
6. Conclusions
A novel variant of the differential creative search (DCS) algorithm, termed DQDCS, is proposed to address the issue of uneven optimization performance in engineering applications. This improved version integrates a refined set-based clustering process and a double Q-learning mechanism. By leveraging a uniformly distributed initial population derived from the refined set and clustering process, the algorithm significantly reduces the risk of premature convergence to local optima in the early search phase, introducing a diverse set of individuals characterized by high randomness and non-determinism. The double Q-learning strategy is employed to effectively balance exploration and exploitation, enhancing the algorithm’s ability to escape local optima and substantially improving search efficiency and convergence accuracy.
Comparative simulation experiments were conducted between DQDCS, the original DCS, and several other state-of-the-art algorithms using both standard benchmark functions and constrained engineering optimization problems. The results demonstrate that DQDCS offers superior optimization speed and accuracy, maintaining its ability to avoid local optima even in later stages of the search. Specifically, DQDCS achieved 19 first-place rankings across the CEC2019 and CEC2022 benchmark functions, indicating robust and consistent performance. Furthermore, in the static thrust bearing design problem and the SOPWM (synchronous optimal pulse width modulation) application in three-level inverters, DQDCS consistently ranked first in overall performance, validating its effectiveness for solving real-world engineering optimization tasks.
The DQDCS algorithm involves substantial computational processes during each iteration, including population initialization, fitness evaluation, and position updating. These procedures can lead to extended computational times and increased demands on hardware resources, particularly when addressing large-scale or complex optimization problems. To enhance the efficiency of the algorithm, parallel computing strategies can be adopted. In this approach, individuals within the population are distributed across multiple processors or computational nodes, enabling concurrent execution and significantly accelerating the algorithm’s performance. While the DQDCS algorithm is primarily designed for continuous optimization problems, its application to discrete or combinatorial optimization tasks requires specific modifications. For discrete optimization problems, a feasible solution is to encode discrete variables into a continuous representation, execute the optimization within the continuous domain, and subsequently decode the solutions back to their original discrete forms. Furthermore, it is crucial to investigate and develop mutation, crossover, and other evolutionary operators explicitly adapted for discrete search spaces. Such enhancements are expected to improve the algorithm’s capability and efficiency in addressing discrete optimization challenges.
Future research will prioritize extending the application of the DQDCS algorithm to electro-hydraulic servo control and autonomous robotic arm control. Particular emphasis will be placed on the deep integration of reinforcement learning with DQDCS to further enhance its optimization capabilities. Additionally, future studies will explore the development of hybrid metaheuristic algorithms that incorporate multiple strategies or novel mathematical concepts. These improvements aim to enhance population diversity, maintain a balanced exploration-exploitation trade-off, and mitigate premature convergence, thereby improving optimization accuracy and accelerating convergence speed.
The DQDCS algorithm exhibits substantial potential in various engineering design and manufacturing fields. It can be effectively applied to mechanical structure optimization, enhancing strength, stiffness, and fatigue life while simultaneously reducing weight and minimizing costs. In the energy and power sectors, DQDCS can be employed to optimize power system generation scheduling and energy storage configurations, thereby improving overall efficiency and cost-effectiveness. Beyond these applications, DQDCS demonstrates promise in autonomous driving and robotics, where it can facilitate real-time path planning and trajectory optimization, ultimately enhancing safety and operational efficiency.
Despite its promising applications, DQDCS still faces certain limitations, such as computational inefficiencies in high-dimensional problems and local convergence challenges in complex constrained optimization tasks. To address these issues, future work will focus on refining the algorithm’s structure and parameter settings to enhance its solution efficiency and accuracy in high-dimensional, complex scenarios. Additionally, research will investigate more effective constraint-handling mechanisms to improve DQDCS’s global convergence ability and robustness in solving complex constrained optimization problems. These advancements aim to elevate the algorithm’s performance, making it more adaptable and resilient in real-world engineering applications.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}