Abstract
Cross-modality person re-identification faces challenges such as illumination discrepancies, local occlusions, and inconsistent modality structures, leading to misalignment and sensitivity issues. We propose GLCN, a framework that addresses these problems by enhancing representation learning through locality enhancement, cross-modality structural alignment, and intra-modality compactness. Key components include the Locality-Preserved Cross-branch Fusion (LPCF) module, which combines Local–Positional–Channel Gating (LPCG) for local region and positional sensitivity; Cross-branch Context Interpolated Attention (CCIA) for stable cross-branch consistency; and Graph-Enhanced Center Geometry Alignment (GE-CGA), which aligns class-center similarity structures across modalities to preserve category-level relationships. We also introduce Intra-Modal Prototype Discrepancy Mining Loss (IPDM-Loss) to reduce intra-class variance and improve inter-class separation, thereby creating more compact identity structures in both RGB and IR spaces. Extensive experiments on SYSU-MM01, RegDB, and other benchmarks demonstrate the effectiveness of our approach.
1. Introduction
Visible–Infrared Person Re-Identification (VI-ReID) [1,2,3] aims to match pedestrian images across modalities under varying illumination conditions, serving as a key component for all-weather intelligent surveillance. Modern camera systems can automatically switch to infrared mode during nighttime, providing abundant cross-modality data for ReID models. However, the feature distributions of the two modalities differ drastically due to inherent differences between visible and infrared images such as spectral responses, texture structures, and background noise, posing significant challenges to effective cross-modality feature alignment.
In recent years, extensive studies have aimed to mitigate the modality discrepancy in VI-ReID. Existing methods can generally be grouped into two directions: ne line of work attempts to reduce the distribution gap between visible and infrared features by learning a shared feature space or constructing a unified cross-modality mapping [4,5,6,7,8], while the other improves the separability of cross-modality features by incorporating additional information or auxiliary constraints to refine the structure of the learned feature space [9,10,11,12].
Despite the progress brought by these methods, several limitations remain. First, cross-modality feature interaction is insufficient and the complementary semantic information between visible and infrared modalities is not fully exploited. This results in suboptimal cross-modality correlation learning, as illustrated in Figure 1. Second, the modeling of identity–structure relationships is often overlooked. Existing approaches typically lack explicit constraints on stripe-level local features and the geometric relations among identity centers, leading to limited inter-class discriminability. Finally, the issue of intra-modality feature dispersion persists; features belonging to the same identity within a single modality are loosely clustered, which weakens representation stability and degrades retrieval robustness.
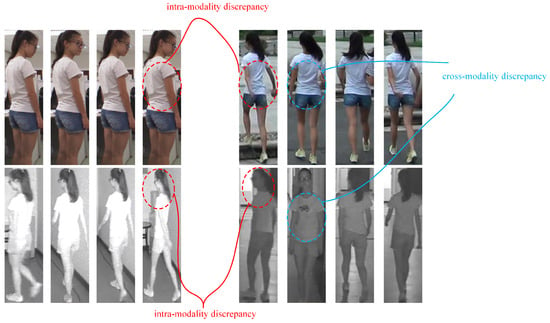
Figure 1.
Even within a single modality, images of the same identity can vary significantly due to changes in pose and illumination. When matching across modalities, the discrepancy is further amplified because visible and infrared images are produced by fundamentally different imaging mechanisms, making cross-modality matching considerably more challenging.
To address the issues discussed above, this paper proposes GLCN, a graph-aware locality-enhanced cross-modality network that jointly optimizes cross-modality interaction, structural alignment, and intra-modality compactness. First, at the level of local enhancement and cross-branch interaction, we construct the LPCF module, where LPCG strengthens fine-grained structural cues through local region awareness, positional encoding, and channel selectivity while CCIA introduces a tunable interpolation gate between self-attention and cross-modality contextual attention, enabling stable and controllable semantic interaction across branches. Second, we propose the GE-CGA module, which builds a class-center graph and explicitly aligns the geometric relationship structure at the identity-center level, thereby preserving topology consistency across modalities and enhancing global discriminability. Finally, we introduce the IPDM-Loss, which imposes prototype-guided intra-class compactness and inter-class separation constraints to reduce feature dispersion within each modality and improve identity aggregation. Experiments conducted on the SYSU-MM01, RegDB, and LLCM benchmarks demonstrate that GLCN significantly outperforms state-of-the-art methods across multiple metrics, validating the effectiveness and generality of our cross-modality alignment and locality-enhancement strategies. The main contributions of this work are as follows:
- We propose a unified cross-modality re-identification framework called GLCN which jointly optimizes feature learning through locality enhancement, cross-branch interaction, and structural alignment.
- We design the LPCF module, consisting of LPCG and CCIA, to enhance local structural sensitivity and enable controllable cross-branch semantic interaction.
- We introduce GE-CGA, a graph-enhanced center geometry alignment module that preserves cross-modality topological structures at the class-center level and improves global discriminability.
- We develop the IPDM-Loss, which enhances intra-modality representation compactness and separability through prototype-guided intra-class contraction and inter-class dispersion.
2. Related Work
2.1. Visible–Infrared Person Re-Identification
VI-ReID aims to match visible and infrared images of the same pedestrian, yet direct feature alignment remains challenging due to the inherent differences between the two modalities in imaging principles, texture distributions, and illumination dependencies. Earlier methods mainly relied on shared feature space mapping, in which metric learning or distribution-level constraints are applied to reduce modality discrepancies. However, these approaches often rely heavily on global representations and struggle to preserve fine-grained discriminative details while enforcing cross-modality consistency. To overcome this limitation, recent studies have introduced local region modeling and multi-level feature fusion strategies. For example, Zhang et al. [6] performed modality compensation at the feature level to achieve cross-modality alignment; Sun et al. [13] enhanced pixel-level local consistency through dense contrastive learning; and Fang et al. [10] explicitly combined local and global features in semantic-level alignment and affinity reasoning. Hua et al. [14] also leveraged vision transformers to model modality-invariant features, focusing on global dependency capture. While this approach excels at learning global representations, it tends to lose finer local details as the network depth increases, making it less effective at capturing and preserving the detailed local information that is crucial for stable cross-modality alignment. Although these methods considerably improve cross-modality alignment, achieving stable and controllable modeling of cross-modality local dependencies without introducing modality specific noise remains an unresolved challenge.
To address this issue, we first construct the LPCF module, which performs structured regional decomposition of features and maintains local spatial constraints, enabling the network to more effectively capture discriminative cues from key body parts during encoding. Meanwhile, LPCF preserves local consistency during cross-branch information interaction, thereby preventing noise interference that may arise from modality discrepancies.
2.2. Graph-Based Relational Modeling
Graph structures have been widely adopted in Re-ID to model relationships among samples, body parts, or prototypes, which can effectively enhance identity-level structural representation. Existing graph-based approaches typically perform alignment by constructing explicit node relations; however, most of them treat center features as static nodes and implicitly assume geometric consistency between modalities. In VI-ReID, the substantial modality discrepancy leads to asymmetric geometric distributions of identity centers, while directly aligning these structures often introduces deformation errors. Moreover, graph relations are usually defined within the same semantic level or scale, making it difficult to maintain consistency of cross-modality prototypes in deeper representation spaces. For example, Wu et al. [15] treated visible and infrared modalities as two separate graphs and performed progressive graph matching to explore cross-modality identity correspondence. Similarly, Qiu et al. [16] introduce higher-order structural graphs to model mid-level feature relations and enhance multi-scale structural consistency. Although these approaches extend the role of graph modeling in VI-ReID, they primarily focus on discovering correspondences or modeling mid-level feature graphs while lacking the ability to perform cross-modality geometric and topological alignment at the identity-center graph level.
The proposed GE-CGA module does not align features directly; instead, it aligns the pairwise similarity structures between class centers, constraining the geometric relationship patterns of the two modalities on the identity-level relation graph. This enables the construction of a stable and consistent high-level identity structure across modalities.
2.3. Auxiliary Learning in VI-ReID
Another line of research attempts to improve the cross-modality discriminability of VI-ReID through auxiliary learning. The central idea is to introduce additional modality forms, auxiliary image styles, or extra feature branches to provide richer intra-modality variation during training. For instance, Huang et al. [11] enhanced the robustness of cross-modality features using modality-adaptive and invariant decomposition strategies; Miao et al. [12] employed human keypoint estimation as an auxiliary task to strengthen local structural cues; and Zhang et al. [17] integrated multi-modal augmentation branches within a multi-stage auxiliary learning framework to improve representation capability. Hu et al. [18] also followed a similar strategy by introducing an auxiliary modality to enhance its feature extraction capabilities. DJANet employs a dual-branch structure in which one branch processes visible images and the other handles infrared images. This approach aims to reduce modality discrepancies and improve cross-modality matching; however, it often requires additional network branches, image-generation pipelines, or extra modality inputs, which can lead to substantially increased model complexity and even unstable training. Moreover, such methods primarily focus on leveraging complementary information across modalities, yet pay limited attention to whether the intra-modality feature distributions themselves are compact and structurally separable.
In contrast, our approach does not introduce additional modalities or construct extra feature pathways. Instead, we propose IPDM-Loss, which enhances the separability and geometric clarity of the intra-modality feature space by directly acting on the feature structures themselves through multi-level constraints, including intra-class aggregation, inter-class separation, and local–prototype relational consistency. This design provides a more robust representational foundation for subsequent cross-modality alignment. Our strategy represents a lightweight form of auxiliary learning that requires no extra branches, no generative modules, and no expanded input modalities, leading to significantly improved cross-modality matching performance while keeping the inference cost unchanged.
3. Methods
3.1. Overview
Our proposed GLCN is built upon a ViT-B/16 [19] backbone, in which visible and infrared images of the same identity are fed into the network to obtain paired features. The overall pipeline of our framework is illustrated in Algorithm 1. On this foundation, we design the LPCF module, in which LPCG first enhances structural and positional sensitivity within local regions and CCIA then performs controllable interpolation between self-attention and cross-branch contextual attention to stably incorporate complementary cross-modality and cross-view information. The interaction between LPCG and CCIA is crucial to the stability and effectiveness of the model. Specifically, LPCG enhances the model’s sensitivity to local structural details, improving its ability to capture fine-grained information within each modality; on the other hand, CCIA addresses the challenge of balancing shallow and deep information by facilitating the interaction between cross-modality self-attention and contextual cross-branch attention, ensuring that both high-level and low-level information are effectively incorporated in the final representation. Meanwhile, the graph-enhanced center geometry alignment module (GE-CGA) constructs a class-center relation graph and aligns its geometric structure across modalities, effectively mitigating semantic structural shifts caused by modality discrepancies. Furthermore, we introduce the Intra-Modal Prototype Discrepancy Mining Loss (IPDM-Loss) to reduce intra-class variance and enlarge inter-class separation, thereby improving the discriminability of features within each modality. Overall, through the coordinated design of local structural modeling, cross-branch information fusion, cross-modality structural alignment, and intra-modality discrepancy regularization, GLCN achieves more robust and discriminative cross-modality representations, as illustrated in Figure 2.
| Algorithm 1: Overall Training Pipeline of the Proposed GLCN Framework |
 |
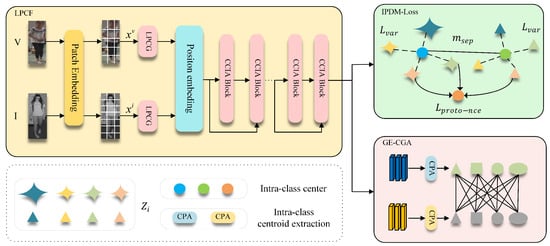
Figure 2.
Overall graph-aware locality-enhanced cross-modality Re-ID network architecture.
3.2. LPCF
In cross-modality Re-ID, the multi-layer global self-attention in ViT tends to weaken shallow-layer local discriminative semantics, causing deep features to become less sensitive to clothing textures, fine-grained regions, and occlusion details. Recent studies have attempted to enhance locality preservation and local sensitivity; for example, Ni et al. [20] exploited part-aware attention to mine local similarity and improve generalization, Zhang et al. [21] introduced a global–local dual-branch structure to handle occlusions, and Zhou et al. [22] performed local pairwise graph modeling under cross-modality conditions. However, these methods either rely heavily on predefined regions or fixed-granularity partitions or enhance locality only within a single branch, making it difficult to preserve and fuse local details in a stable and progressive manner across different views and modalities. To address this, we propose LPCF, illustrated in Figure 3. LPCG first adaptively preserves local and positional cues at the token level; CCIA then performs controllable interpolation between self-attention and cross-branch contextual attention, enabling effective retention of local information while ensuring stability and consistency during cross-branch feature fusion.
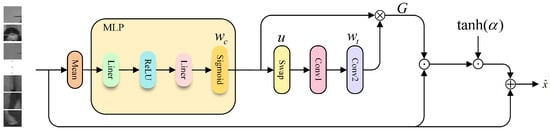
Figure 3.
LPCF overall flowchart.
Specifically, given infrared and visible images , we obtain feature maps through patch embedding and flatten them into token sequences . Prior to feeding the concatenated sequence (stacked from visible and infrared tokens) into the transformer backbone, we introduce the LPCG module to perform joint recalibration across local, positional, and channel dimensions. This strengthens and preserves local discriminative semantics at an early stage, providing a more stable feature foundation for deeper modeling and subsequent cross-branch fusion. We first apply mean pooling along the token dimension and feed the result into a two-layer MLP to generate the channel weights :
where denotes averaging along the token dimension, is the sigmoid activation function, represents the ReLU activation, and , together with are learnable linear projection matrices and their associated bias terms. To further model local positional dependencies among tokens, we first aggregate the input feature map along the channel dimension to obtain a single-channel descriptor and subsequently apply a 1D convolution along the token sequence to capture local neighborhood context. The resulting output is passed through a sigmoid activation to generate the token attention weights , where the 1D convolution extracts local dependencies across token positions and the sigmoid function ensures normalized attention responses:
where exchanges the two groups of sub-channels along the channel dimension, Conv1 is a 1D convolution with a kernel size of 1 for channel compression, and Conv2 is a 1D convolution with a kernel size of 3 for capturing local dependencies along the token sequence. The two attention weights are then fused via an outer product to form the joint weighting matrix , which enables fine-grained local modulation across both positional and channel dimensions. Finally, the recalibrated feature x is obtained through residual-style modulation:
where ⊗ denotes the outer product, ⊙ implemented as element-wise multiplication, is the hyperbolic tangent activation, and randomly deactivates a portion of features during training with a fixed probability. The coefficient is a learnable scalar parameter. After the LPCF module performs joint token–channel recalibration and local positional enhancement, the resulting feature sequence becomes more locally discriminative and cross-modality stable. We then feed the enhanced sequence into the transformer backbone for cross-layer semantic integration and global modeling. However, as the transformer becomes deeper, shallow-layer semantics tend to be gradually forgotten. To address this issue, we design the CCIA module to enable each block’s self-attention to leverage both the current features and the preserved shallow semantic cues, allowing the attention computation to no longer rely solely on the representation of a single layer. Inspired by the Regional Division (RD) strategy in LAReViT [14], we partition the patch tokens into three non-overlapping regions corresponding to head, trunk, and leg along the vertical spatial dimension. Notably, LAReViT systematically evaluated different numbers of partitions and demonstrated that a three-part division achieves the best performance, striking a favorable balance between local discrimination and global semantic consistency.
After obtaining the global sequence , we divide it into three local regions according to the human body structure: the head , trunk , and legs , denoted as . We then construct a global branch and three local branches , , , where the shared class token in the transformer used for aggregating global semantics. The global branch adopts the full positional encoding , while the local branches extract their corresponding sub-positional encodings from according to the patch indices associated with , , and , respectively.
After constructing the four input branches, we feed the global branch and the three local branches sequentially into the CCIA blocks, which incorporate cross-layer semantic injection, as illustrated in Figure 4.
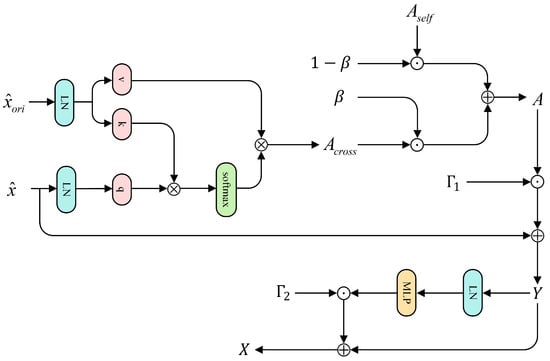
Figure 4.
CCIA flowchart.
Specifically, for any branch, let the current-layer input be denoted as and the previous-layer feature as . Note that in the 0-th block, all branches operate purely with self-attention; thus, we set . Starting from the block 1 onward, the global branch continues to use while each of the three local branches sets to the output of its corresponding branch from the previous layer, thereby injecting cross-layer semantic context. Prior to computing attention, both the current sequence and its reference feature are individually normalized using layer normalization.
We then compute the self-attention and cross-branch attention separately:
where the attention operator denotes the standard multi-head scaled dot-product attention. For any input X and its reference feature , we have
When , the operation corresponds to self-attention, whereas setting yields cross-branch attention. We then introduce a learnable scalar gate to control the proportion of cross-branch contextual injection:
To prevent cross-branch injection from disrupting local semantic consistency, we incorporate LayerScale into the residual path:
where X denotes the output feature after the CCIA module and are learnable scaling parameters that ensure a smooth transition from local self-attention to cross-branch fusion without requiring additional stabilization strategies. After completing attention mixing and inter-layer residual updating, the global branch and the three local branches are normalized using LayerNorm and BatchNorm1d, respectively, yielding the final cross-layer semantic–enhanced features denoted as , collectively referred to as the cross-layer semantic–enhanced representations.
Then, to ensure that the extracted person features are identity-discriminative, we apply the cross-entropy loss () [23] and the triplet loss () [24] to supervise the enhanced representations:
In summary, LPCF is designed to enhance the model’s ability to capture local details while performing cross-branch information fusion. It achieves this by using the LPCG module, which focuses on enhancing the model’s sensitivity to local structural and positional information, ensuring that fine-grained details are maintained. The CCIA module then facilitates the controlled interpolation of cross-branch contextual information, allowing for stable interaction between the branches. LPCF improves the model’s understanding of local structures and helps mitigate the loss of shallow features during deep-layer processing. This design ensures both global and local features are integrated effectively, enhancing cross-modality alignment.
3.3. GE-CGA
In cross-modality Re-ID, the substantial differences between visible and infrared imaging mechanisms often lead to class-center shifts and inconsistent geometric structures for the same identity across the two modalities. In feature space, RGB and IR representations may differ not only in absolute position but also in their inter-class distances and decision boundaries, which become distorted across modalities. Recent approaches attempt to achieve cross-modality alignment by constructing shared or intermediate modalities. For example, Yu et al. [4] introduced a unified modality hub to mitigate distribution discrepancies, while Cheng et al. [25] employed a cross-modality contrastive memory bank to pull positive pairs closer and push negative pairs apart for improved modality consistency. However, these methods generally focus on bringing the two modalities closer at a global distribution level, aligning center positions or overall shapes without ensuring that the relative distances among different identity classes are preserved. To address this limitation, we propose the GE-CGA module, which explicitly constructs a class-center graph and aligns the pairwise geometric structure of class centers across modalities, thereby preserving inter-class topological relationships. This ensures that the resulting feature space still maintains clear identity boundaries and strong discriminative capability when achieving cross-modality alignment.
We first compute the class centers for the visible and infrared modalities within each batch. Let the global features be split into visible features and infrared features , where and their corresponding identity labels are denoted by y. The class centers for the two modalities are then defined as
where and denote the sets of visible and infrared samples belonging to identity y, respectively. To ensure numerical stability, we apply -normalization to all centers, and the centers of the same identity from the two modalities are encouraged to be close to each other:
Subsequently, to further construct a class-center contrastive learning objective, the visible and infrared centers of the same identity are treated as mutual positive pairs in the similarity space, while the centers of different identities are regarded as negative samples. This encourages stronger cross-modality identity discrimination:
where is the temperature coefficient. In addition, to preserve the relative topological structure among classes across modalities, we align the similarity matrices of the two modality-specific class centers:
where and denote the similarity matrices constructed from all class centers in the RGB and IR modalities, respectively. Because the diagonal elements represent self-similarity and are always equal to 1, they do not convey geometric structure information among different classes. Therefore, we constrain only the non-diagonal entries, denoted as and . The matrices and are formed by stacking all l2-normalized class centers from the two modalities. Finally, the overall GE-CGA loss is defined as
Overall, GE-CGA focuses on the alignment of identity centers across modalities. Rather than directly aligning features, it aligns the pairwise similarity structures between class centers by constraining their geometric relationships on the identity-level relation graph. This approach stabilizes the cross-modality alignment by addressing geometric discrepancies between visible and infrared modalities. GE-CGA allows for the construction of a consistent high-level identity structure across modalities, enhancing the robustness of the model without introducing complex architectures or additional memory requirements. This offers a more efficient and effective way of managing cross-modality differences compared to traditional alignment methods.
3.4. Intra-Modal Prototype Discrepancy Mining Loss (IPDM-Loss)
Although cross-modality alignment can mitigate the distribution discrepancy between visible and infrared features, intra-modality variations caused by illumination changes, pose differences, and occlusions may still lead to intra-class dispersion and blurred inter-class boundaries within a single modality. To address this issue, we propose the IPDM-Loss, which constructs identity prototypes separately for each modality and explicitly enforces samples of the same identity to move closer to their corresponding modality-specific prototype while introducing inter-class separation among prototypes. This yields more compact intra-class structures and clearer inter-class distinctions. Unlike approaches that rely solely on global contrastive learning or center-based constraints, the IPDM-Loss operates independently within each modality, avoiding the risk of cross-modality alignment adversely affecting the internal structure of a single modality. As a result, it promotes tightly clustered intra-class distributions and preserves well-separated identity boundaries within each modality.
To avoid forming positive pairs between a sample and itself during contrastive learning, we construct a self-excluded prototype representation based on the modality-specific identity centers :
To enhance the compactness of identity representations within each modality, we unify the prototype-level contrastive constraint and the variance reduction constraint into an intra-modality compactness term. We first construct the prototype-level loss as follows:
This term constrains each sample based on relative similarity, encouraging it to be closer to the prototype of its own identity than to other prototypes. This helps to improve discriminative consistency within the modality. In addition, to further compress intra-class distributions and reduce local feature variance, we explicitly minimize the smooth L1 distance [26] between each sample and its self-excluded class center:
This term provides an absolute geometric contraction constraint, encouraging samples of the same identity to form a more compact distribution within the modality. By increasing the matching score between a sample and its corresponding identity prototype in the prototype-level similarity space, the relative discriminative consistency within each class is enhanced. Meanwhile, further contracts intra-class distributions in the absolute feature space by directly minimizing the distance between each sample and its self-excluded class center. The combination of these two terms simultaneously improves both the discriminability and compactness of intra-modality representations.
In addition, to prevent excessive intra-class compression from blurring inter-class boundaries, we impose a margin-based separation constraint between the centers of different identities:
where K denotes the number of identities within the batch, controls the minimum separable margin to preserve clear decision boundaries between identities, and and represent the mean features of the k-th and j-th identities within the modality, respectively. Finally, the overall formulation of IPDM-Loss is provided by
3.5. Total Loss
Finally, by integrating all components of the model, the total loss is formulated as
4. Experiments
4.1. Dataset Introduction
The SYSU-MM01 [27] dataset contains a total of 491 identities. The training set includes 395 identities with 22,258 visible images and 11,909 infrared images, while the test set includes 96 identities with 301 visible images and 3803 infrared images. The RegDB [28] dataset consists of 412 identities, each captured by two overlapping cameras, providing 10 visible (VIS) images and 10 infrared (IR) images per identity. The LLCM [29] dataset contains 713 identities in the training set and 351 identities in the test set.
4.2. Evaluation Metrics
During evaluation, we measure the performance of the model by adopting three commonly used metrics in cross-modality ReID: the Cumulative Matching Characteristic (CMC) [30], Mean Average Precision (mAP) [31], and Mean Inverse Negative Penalty(mINP) [1].
4.3. Experimental Settings
This study is implemented in PyTorch 2.8.0 and all training and testing are conducted on a single vGPU with 48 GB memory. We adopt ViT-B/16 as the backbone network. All images are resized to 288 × 144; visible images undergo random horizontal flipping, random erasing, and random grayscale augmentation, while infrared images are augmented using independent geometric transformations to maintain modality consistency. During training, each iteration samples four VIS images and four IR images from eight randomly selected identities. We use the AdamW optimizer with a base learning rate of , cosine learning rate decay, and a weight decay of . The model is trained for 40 epochs on all three VI-ReID datasets, with the loss hyperparameters set to = 0.3 and = 0.5.
For SYSU-MM01, we strictly follow the official single-shot evaluation protocol. Results are reported under both the ALL-search and Indoor-search settings, where ALL-search uses all cameras for query and gallery construction, while Indoor-search restricts both query and gallery samples to indoor cameras only. For RegDB, we adopt the standard evaluation protocol provided by the dataset, conducting experiments under both VIS-to-IR and IR-to-VIS settings, where visible images are used as queries and infrared images as the gallery, and vice versa. For LLCM, we follow the original training and testing splits released with the dataset and report results under both IR-to-VIS and VIS-to-IR retrieval settings. No deviation from the official dataset splits or evaluation protocols is introduced in our experiments.
4.4. Comparison with State-of-the-Art Methods
To comprehensively evaluate the effectiveness of the proposed method, we compare our model with a series of state-of-the-art cross-modality person re-identification (VI-ReID) approaches, including PMT [32], CAL [33], DEEN [29], CSMSF [34], CAJ [35], EIFJLF [36], CSC-Net [37], DCPLNet [38], DMPF [39], AGPI2 [40], CSCL [41], MDANet [42], MSCMNet [43], CSDN [44], DDAG [45], AGW [1], DART [46], MIAM [47], HOS-Net [16], LAReViT [14], and DJANet [18]. The comparison is conducted on three challenging image-level VI-ReID benchmarks: SYSU-MM01, RegDB, and LLCM. For SYSU-MM01, we report results under both the ALL-search and Indoor-search settings; for RegDB, evaluations follow the VIS-to-IR and IR-to-VIS testing protocols; and for LLCM, we include both IR-VIS and VIS-IR retrieval tasks.
As shown in Table 1 and Table 2, our method achieves leading performance across all three image-level VI-ReID benchmarks. On SYSU-MM01, our approach is compared with PMT [32], which relies on global transformer-based feature modeling; CAL [33], which focuses on cross-modality alignment enhancement; and DEEN [29], which employs multi-branch fine-grained fusion, achieving Rank-1/mAP scores of 78.0%/74.9% under the ALL-search setting and 86.6%/87.3% under the Indoor-search setting. On RegDB, our approach is compared with MDANet [42], which leverages local detail modeling, and MSCMNet [43], which captures multi-scale semantic correlations; our method reaches 94.2%/91.8% in the VIS→IR setting and 92.6%/90.8% in the IR→VIS setting, demonstrating superior modality alignment and feature consistency. On the more challenging LLCM dataset, which involves low-light conditions and cross-device domain shifts, our method surpasses graph-alignment-based DDAG [45], discriminative-loss-enhanced AGW [1], and the multi-scale local-enhanced transformer architecture LAReViT [14], achieving 56.9%/64.1% for IR→VIS and 66.2%/68.8% for VIS→IR. Overall, while many existing approaches focus on global attention mechanisms, structural labels, or unimodal alignment, our proposed locality enhancement and prototype alignment strategies provide more robust cross-modality representations, particularly in scenarios with significant modality discrepancies.

Table 1.
Performance comparison on SYSU-MM01 and RegDB.
Table 2.
Performance comparison on LLCM.
4.5. Ablation Study
We also conduct a systematic ablation study on SYSU-MM01 to evaluate the contribution of each component, as shown in Table 3. Introducing the inter-class structural constraint improves performance from the baseline to 75.1%/71.5%, indicating that preserving relative class relationships helps to alleviate modality discrepancies. Incorporating the CCIA block brings a further improvement to 75.5%/72.0%, while adding local modeling yields a moderate gain of 75.4%/71.6%, demonstrating the robustness of local regions against occlusion and pose variations. Introducing the graph-based structural constraint significantly enhances global alignment capability, resulting in 75.8%/73.2%. Combining CCIA-based interaction with graph modeling further improves the performance to 76.3%/73.2%, and adding the intra-modal compactness constraint boosts the mAP to 73.9%. Finally, when cross-layer local enhancement, graph-based structural alignment, and intra-modal compactness are jointly applied, the model achieves its best performance of 78.0% Rank-1 and 74.9% mAP, demonstrating the effectiveness and complementarity of all components in cross-modality representation learning.
Table 3.
Ablation study of the GLCN framework. The symbol # denotes different module configurations, and - indicates that the corresponding module is not included in that setting.
To further investigate the generalization of the proposed components, we additionally report compact ablation results on the RegDB and LLCM datasets in Table 3. RegDB is a relatively small-scale dataset with limited training samples per identity, making it highly sensitive to model capacity and hyperparameter settings. Insufficient model complexity may lead to underfitting, while excessive parameters can easily cause overfitting. Consequently, the performance gains introduced by the proposed modules on RegDB are relatively limited and not always pronounced. In contrast, LLCM provides a larger-scale and more diverse evaluation setting with increased identities and samples, where the proposed model can better accommodate the introduced components. The ablation results on LLCM demonstrate that our method effectively adapts to larger-scale datasets and maintains stable performance improvements, further validating its robustness and generalization capability across datasets of different scales.
Since the class centers in GE-CGA are computed on-the-fly within each mini-batch, we further investigate the sensitivity of GE-CGA to different batch compositions by varying the number of identities per batch while keeping the total batch size fixed. Specifically, we evaluate four configurations with 2, 3, 4, 6 identities per batch, where the corresponding numbers of samples per identity are set to 12, 8, 6, 4, respectively, resulting in a constant batch size of 24. The results are summarized in Table 4, where both the single-run performance and the mean ± standard deviation over multiple trials are reported. Among all settings, the configuration with four identities and six samples per identity achieves the best overall performance, reaching 78.0% Rank-1 accuracy and 74.9% mAP, as well as the highest averaged results (77.07 ± 1.28 Rank-1 and 74.31 ± 1.00 mAP). Notably, although the batch composition varies significantly across different settings, the performance differences remain moderate and do not exhibit noticeable oscillations or instability. This observation indicates that GE-CGA is robust to changes in batch composition and does not overly rely on a specific identity-to-sample ratio. Therefore, the current batch-wise center computation strategy is sufficiently stable in practice, and introducing additional memory banks or momentum-updated centers is unnecessary under our experimental setting.
Table 4.
Results of the ablation study for GE-CGA module.
For a fair and reliable evaluation, we report the performance statistics following dataset-specific evaluation protocols. For SYSU-MM01 and LLCM, all reported results are obtained by averaging over ten independent runs with different random seeds (from 0 to 9), and both the mean and standard deviation are provided to explicitly reflect the stability of the model under different random initializations and data sampling orders. The results are summarized in Table 5. For RegDB, the benchmark itself defines ten fixed testing splits, and the final performance is conventionally reported as the average over these splits. Therefore, the reported results on RegDB already correspond to an averaged performance across multiple trials, and the mean values naturally coincide with the reported numbers.Overall, the consistent performance across multiple random seeds and predefined testing splits demonstrates the robustness and stability of the proposed method under different evaluation settings.
Table 5.
Mean (±std) R-1/mAP results with statistical analysis for different ablation modules. Modules 1 to 8 correspond to the modules listed in Table 3.
4.6. Visualization Analysis
4.6.1. t-SNE Feature Distribution Visualization Analysis
Figure 5 presents the t-SNE visualization of high-dimensional feature distributions for the baseline and our method. In the baseline, some identities exhibit loose clusters and severe inter-class mixing, as highlighted by the dashed regions, indicating that cross-modality features are still affected by illumination variations and modality discrepancies. In contrast, our method produces more compact clusters for each identity and significantly reduces overlaps between different classes, resulting in clearer and more separable category boundaries. This demonstrates that the proposed locality enhancement, intra-modality compactness, and graph-structured consistency modules effectively improve the global topological structure of cross-modality features, leading to more natural and discriminative identity clustering.
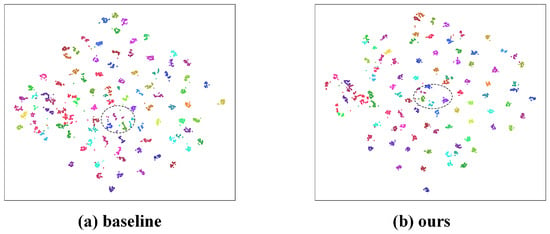
Figure 5.
Visualizes the t-SNE results on the SYSU-MM01 test set by randomly sampling about 5000 VIS/IR feature points, covering approximately 90 identities.
4.6.2. Retrieval Visualization
Figure 6 illustrates the top-10 retrieval results of the baseline and our method in the cross-modality retrieval task. As shown, the baseline frequently retrieves distractor samples with similar poses but incorrect identities (red boxes), indicating that its cross-modality features still suffer from modality shifts. In contrast, our method consistently retrieves more correct matches, as evidenced by the increased number of green-box results, and maintains high consistency under variations in clothing, pose, and background. It also demonstrates notably stronger robustness when matching between low-light thermal images and visible images. These observations further verify the effectiveness of our approach in modeling cross-modality consistency and identity discrimination.

Figure 6.
Top-10 cross-modality retrieval visualization. Green boxes indicate correct matches, and red boxes indicate incorrect matches. Compared with the baseline, GLCN retrieves significantly more correct samples and demonstrates markedly improved cross-modality consistency.
4.6.3. Visualization of Intra-Class and Inter-Class Distance Distributions
As shown in Figure 7, we compare the intra-class and inter-class distance distributions of the baseline and our method in the feature space. The baseline exhibits a large overlap between intra-class and inter-class distributions, with a margin of only 0.235, indicating limited feature discriminability. In contrast, after introducing prototype compression and graph-structure alignment, our method significantly enlarges the separability between the two distributions: the intra-class distances shift leftward overall, while the inter-class distances shift rightward, increasing the margin to 0.342. A larger margin indicates more compact samples within the same class and greater separation between different classes, demonstrating the clear advantage of our approach in enhancing cross-modality discriminability.
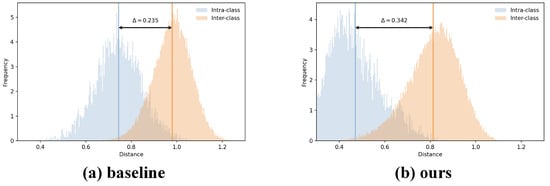
Figure 7.
Visualization of intra-class and inter-class distance distributions, where blue indicates intra-class distances and orange indicates inter-class distances. GLCN significantly enlarges the margin , improving feature separability.
4.6.4. Hyperparameter Analysis Figure
Figure 8 presents the visualization results of the two hyperparameters and in our loss function. When fixing = 1.0 and increasing from 0.1 to 1.9 with a step size of 0.2, both Rank-1 and mAP exhibit a rise-then-fall trend, indicating that a moderate value of provides a better balance between constraint strength and feature stability. Similarly, when fixing = 0.3 and sweeping over the same range, the model shows the most stable performance in the mid-range, with the best results obtained around = 0.5. Based on these observations, we adopt = 0.3 and = 0.5 as the final hyperparameter settings in subsequent experiments to achieve optimal and stable performance.
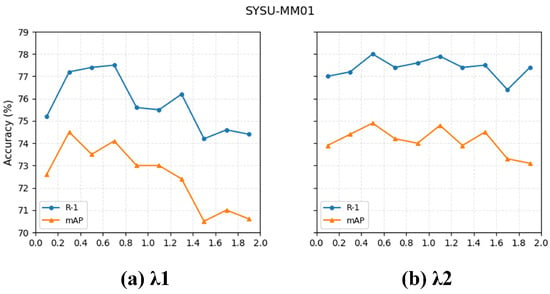
Figure 8.
Trends of Rank-1 and mAP under different combinations of and . The best performance is achieved with = 0.3 and = 0.5.
4.7. Efficiency and Computational Cost Analysis
In this section, we present a detailed analysis of the computational efficiency and cost of ours compared to strong baseline methods. Table 6 summarizes the Params, GPU latency (ms/img), and peak GPU memory for ours and several state-of-the-art methods.
Table 6.
Comparison of model performance, parameters, and computational overhead on SYSU-MM01.
As shown in Table 6, ours has a parameter count similar to LAReViT, indicating that the model size is comparable. However, ours outperforms LAReViT on the SYSU-MM01 dataset, demonstrating its superior performance with efficient use of computational resources.
Furthermore, while ours has a smaller parameter count compared to models such as MIP [48] and DEEN, it achieves better results on the SYSU-MM01 dataset. This result highlights that our approach effectively balances model size and accuracy, making it more efficient for Visible-Infrared Person Re-Identification tasks.
5. Conclusions
In this work, we address the key challenges of visible–infrared person re-identification, including the loss of local details, significant modality discrepancies, and unstable intra-modality feature distributions. We propose a unified and efficient cross-modality feature learning framework called GLCN. In the proposed framework, the LPCF module is designed to enhance local detail preservation and contextual modeling, the GE-CGA module maintains structural relationships across modality-specific identity classes, and the IPDM-Loss compresses intra-modality variations to improve feature compactness. Ablation studies and visualization analyses further demonstrate the effectiveness of each component in enhancing feature discriminability and cross-modality consistency. Overall, this study provides a concise yet robust solution for cross-modality person re-identification, delivering stable and superior performance under challenging lighting conditions, modality transitions, and real-world environmental disturbances.
Author Contributions
Conceptualization, J.C. and X.X.; methodology, J.C. and Y.Y.; software, J.C.; validation, J.C. and Y.Y.; formal analysis, J.C.; investigation, J.C. and Y.Y.; resources, R.R. and X.X.; data curation, Y.Y.; writing—original draft preparation, J.C.; writing—review and editing, X.X.; visualization, Y.Y.; supervision, X.X.; project administration, X.X.; funding acquisition, X.X. All authors have read and agreed to the published version of the manuscript.
Funding
Thiswork was supported by the Nantong Basic Science Research Program (JC2023021), the Doctoral Research Startup Fund of Nantong University (25B03), and partially by the Qing Lan Project of Jiangsu Province.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable. This study does not involve humans.
Data Availability Statement
The datasets used in this study (SYSU-MM01, RegDB, and LLCM) are publicly available. No new data were created or analyzed in this study.
Acknowledgments
The authors would like to thank the anonymous reviewers for their valuable comments.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| VI-ReID | Visible–Infrared Person Re-Identification |
| LPCF | Locality-Preserved Cross-branch Fusion |
| LPCG | Local–Positional–Channel Gating |
| CCIA | Cross-Branch Context Interpolation Attention |
| GE-CGA | Graph-Enhanced Center Geometry Alignment |
| IPDM | Intra-Modal Prototype Discrepancy Mining |
| ViT | Vision Transformer |
| CNN | Convolutional Neural Network |
| MLP | Multi-Layer Perceptron |
| GAP | Global Average Pooling |
| mAP | Mean Average Precision |
| Rank-1 | Rank-1 Accuracy |
| SYSU-MM01 | SYSU Multi-Modal ReID Dataset |
| RegDB | Visible–Thermal Person ReID Dataset |
| LLCM | Large-Scale Light-Cloud Modality Dataset |
References
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Ye, M.; Chen, S.; Li, C.; Zheng, W.S.; Crandall, D.; Du, B. Transformer for object re-identification: A survey. Int. J. Comput. Vis. 2025, 133, 2410–2440. [Google Scholar] [CrossRef]
- Zhang, G.; Yang, Y.; Zheng, Y.; Martin, G.; Wang, R. Mask-Aware Hierarchical Aggregation Transformer for Occluded Person Re-identification. IEEE Trans. Circuits Syst. Video Technol. 2025, 35, 5821–5832. [Google Scholar] [CrossRef]
- Yu, H.; Cheng, X.; Peng, W.; Liu, W.; Zhao, G. Modality unifying network for visible-infrared person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October2023; pp. 11185–11195. [Google Scholar]
- Zheng, A.; Liu, J.; Wang, Z.; Huang, L.; Li, C.; Yin, B. Visible-infrared person re-identification via specific and shared representations learning. Vis. Intell. 2023, 1, 29. [Google Scholar] [CrossRef]
- Zhang, Q.; Lai, C.; Liu, J.; Huang, N.; Han, J. Fmcnet: Feature-level modality compensation for visible-infrared person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7349–7358. [Google Scholar]
- Yang, B.; Chen, J.; Ye, M. Towards grand unified representation learning for unsupervised visible-infrared person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 11069–11079. [Google Scholar]
- Li, S.; Leng, J.; Gan, J.; Mo, M.; Gao, X. Shape-centered representation learning for visible-infrared person re-identification. Pattern Recognit. 2025, 167, 111756. [Google Scholar] [CrossRef]
- Kim, M.; Kim, S.; Park, J.; Park, S.; Sohn, K. Partmix: Regularization strategy to learn part discovery for visible-infrared person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18621–18632. [Google Scholar]
- Fang, X.; Yang, Y.; Fu, Y. Visible-infrared person re-identification via semantic alignment and affinity inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 11270–11279. [Google Scholar]
- Huang, Z.; Liu, J.; Li, L.; Zheng, K.; Zha, Z.J. Modality-adaptive mixup and invariant decomposition for RGB-infrared person re-identification. Proc. AAAI Conf. Artif. Intell. 2022, 36, 1034–1042. [Google Scholar] [CrossRef]
- Miao, Y.; Huang, N.; Ma, X.; Zhang, Q.; Han, J. On exploring pose estimation as an auxiliary learning task for visible–infrared person re-identification. Neurocomputing 2023, 556, 126652. [Google Scholar] [CrossRef]
- Sun, H.; Liu, J.; Zhang, Z.; Wang, C.; Qu, Y.; Xie, Y.; Ma, L. Not all pixels are matched: Dense contrastive learning for cross-modality person re-identification. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 5333–5341. [Google Scholar]
- Hua, X.; Cheng, K.; Zhu, G.; Lu, H.; Wang, Y.; Wang, S. Local-Aware Residual Attention Vision Transformer for Visible-Infrared Person Re-Identification. ACM Trans. Multimed. Comput. Commun. Appl. 2025, 146, 1–24. [Google Scholar] [CrossRef]
- Wu, Z.; Ye, M. Unsupervised visible-infrared person re-identification via progressive graph matching and alternate learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9548–9558. [Google Scholar]
- Qiu, L.; Chen, S.; Yan, Y.; Xue, J.H.; Wang, D.H.; Zhu, S. High-order structure based middle-feature learning for visible-infrared person re-identification. Proc. AAAI Conf. Artif. Intell. 2024, 38, 4596–4604. [Google Scholar] [CrossRef]
- Zhang, H.; Cheng, S.; Du, A. Multi-stage auxiliary learning for visible-infrared person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 12032–12047. [Google Scholar] [CrossRef]
- Hu, M.; Zhou, Q.; Wang, R. Bridging visible and infrared modalities: A dual-level joint align network for person re-identification. Vis. Comput. 2025, 41, 7063–7078. [Google Scholar] [CrossRef]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Ni, H.; Li, Y.; Gao, L.; Shen, H.T.; Song, J. Part-aware transformer for generalizable person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 11280–11289. [Google Scholar]
- Zhang, G.; Chen, C.; Chen, Y.; Zhang, H.; Zheng, Y. Transformer-based global–local feature learning model for occluded person re-identification. J. Vis. Commun. Image Represent. 2023, 95, 103898. [Google Scholar] [CrossRef]
- Zhou, J.; Dong, Q.; Zhang, Z.; Liu, S.; Durrani, T.S. Cross-modality person re-identification via local paired graph attention network. Sensors 2023, 23, 4011. [Google Scholar] [CrossRef]
- Rubinstein, R. The cross-entropy method for combinatorial and continuous optimization. Methodol. Comput. Appl. Probab. 1999, 1, 127–190. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Cheng, D.; Wang, X.; Wang, N.; Wang, Z.; Wang, X.; Gao, X. Cross-modality person re-identification with memory-based contrastive embedding. Proc. AAAI Conf. Artif. Intell. 2023, 37, 425–432. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Wu, A.; Zheng, W.S.; Yu, H.X.; Gong, S.; Lai, J. RGB-infrared cross-modality person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5380–5389. [Google Scholar]
- Nguyen, D.T.; Hong, H.G.; Kim, K.W.; Park, K.R. Person recognition system based on a combination of body images from visible light and thermal cameras. Sensors 2017, 17, 605. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, H. Diverse embedding expansion network and low-light cross-modality benchmark for visible-infrared person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2153–2162. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Xiao, T.; Li, H.; Ouyang, W.; Wang, X. Learning deep feature representations with domain guided dropout for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1249–1258. [Google Scholar]
- Lu, H.; Zou, X.; Zhang, P. Learning progressive modality-shared transformers for effective visible-infrared person re-identification. Proc. AAAI Conf. Artif. Intell. 2023, 37, 1835–1843. [Google Scholar] [CrossRef]
- Wu, J.; Liu, H.; Su, Y.; Shi, W.; Tang, H. Learning concordant attention via target-aware alignment for visible-infrared person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 11122–11131. [Google Scholar]
- Yang, X.; Dong, W.; Li, M.; Wei, Z.; Wang, N.; Gao, X. Cooperative separation of modality shared-specific features for visible-infrared person re-identification. IEEE Trans. Multimed. 2024, 26, 8172–8183. [Google Scholar] [CrossRef]
- Ye, M.; Wu, Z.; Chen, C.; Du, B. Channel augmentation for visible-infrared re-identification. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 2299–2315. [Google Scholar] [CrossRef]
- Du, G.; Zhang, L. Enhanced invariant feature joint learning via modality-invariant neighbor relations for cross-modality person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 2361–2373. [Google Scholar] [CrossRef]
- Li, H.; Li, M.; Peng, Q.; Wang, S.; Yu, H.; Wang, Z. Correlation-guided semantic consistency network for visible-infrared person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 4503–4515. [Google Scholar] [CrossRef]
- Chan, S.; Meng, W.; Bai, C.; Hu, J.; Chen, S. Diverse-feature collaborative progressive learning for visible-infrared person re-identification. IEEE Trans. Ind. Inform. 2024, 20, 7754–7763. [Google Scholar] [CrossRef]
- Lu, Z.; Lin, R.; Hu, H. Disentangling modality and posture factors: Memory-attention and orthogonal decomposition for visible-infrared person re-identification. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 5494–5508. [Google Scholar] [CrossRef]
- Alehdaghi, M.; Josi, A.; Cruz, R.M.; Shamsolameli, P.; Granger, E. Adaptive generation of privileged intermediate information for visible-infrared person re-identification. IEEE Trans. Inf. Forensics Secur. 2025, 20, 3400–3413. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, Z.; Bian, Y.; Wang, X.; Sun, Y.; Zhang, B.; Wang, Y. Cross-Modality Semantic Consistency Learning for Visible-Infrared Person Re-Identification. IEEE Trans. Multimed. 2024, 27, 568–580. [Google Scholar] [CrossRef]
- Cheng, X.; Yu, H.; Cheng, K.H.M.; Yu, Z.; Zhao, G. MDANet: Modality-Aware Domain Alignment Network for Visible-Infrared Person Re-Identification. IEEE Trans. Multimed. 2024, 27, 2015–2027. [Google Scholar] [CrossRef]
- Hua, X.; Cheng, K.; Lu, H.; Tu, J.; Wang, Y.; Wang, S. Mscmnet: Multi-scale semantic correlation mining for visible-infrared person re-identification. Pattern Recognit. 2025, 159, 111090. [Google Scholar] [CrossRef]
- Yu, X.; Dong, N.; Zhu, L.; Peng, H.; Tao, D. Clip-driven semantic discovery network for visible-infrared person re-identification. IEEE Trans. Multimed. 2025, 27, 4137–4150. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; J. Crandall, D.; Shao, L.; Luo, J. Dynamic dual-attentive aggregation learning for visible-infrared person re-identification. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 229–247. [Google Scholar]
- Yang, M.; Huang, Z.; Hu, P.; Li, T.; Lv, J.; Peng, X. Learning with twin noisy labels for visible-infrared person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14308–14317. [Google Scholar]
- Chongrui, S.; Baohua, Z.; Yu, G.; Jianjun, L.; Ming, Z.; Jingyu, W. A visible-infrared person re-identification method based on meta-graph isomerization aggregation module. J. Vis. Commun. Image Represent. 2024, 104, 104265. [Google Scholar] [CrossRef]
- Wu, R.; Jiao, B.; Liu, M.; Wang, S.; Wang, W.; Wang, P. Enhancing Visible-Infrared Person Re-identification with Modality- and Instance-aware Adaptation Learning. IEEE Trans. Circuits Syst. Video Technol. 2025, 35, 8086–8103. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.