Abstract
Facial expression recognition (FER) technology has progressively matured over time. However, existing FER methods are primarily optimized for frontal face images, and their recognition accuracy significantly degrades when processing profile or large-angle rotated facial images. Consequently, this limitation hinders the practical deployment of FER systems. To mitigate the interference caused by large pose variations and improve recognition accuracy, we propose a FER method based on profile-to-frontal transformation and multimodal learning. Specifically, we first leverage the visual understanding and generation capabilities of Qwen-Image-Edit that transform profile images to frontal viewpoints, preserving key expression features while standardizing facial poses. Second, we introduce the CLIP model to enhance the semantic representation capability of expression features through vision–language joint learning. The qualitative and quantitative experiments on the RAF (89.39%), EXPW (67.17%), and AffectNet-7 (62.66%) datasets demonstrate that our method outperforms the existing approaches.
1. Introduction
Facial expressions are important carriers of human emotional communication, containing rich emotional information. With the rapid development of artificial intelligence technology, facial expression recognition (FER) has become a research hotspot in computer vision and affective computing [1]. FER technology demonstrates broad application prospects in human–computer interaction [2], mental health monitoring [3], personalized education [4], and other fields. Although deep learning methods have achieved significant progress in FER tasks [5], existing research primarily focuses on frontal or near-frontal face images, and expression recognition for profile faces, large-angle rotations, and other non-standard poses therefore faces severe challenges.
In real-world scenarios, the diversity of facial poses is ubiquitous. For instance, in surveillance videos, social media photos, and daily interactions, faces often exhibit rotations at different angles. Research shows that when facial rotation angles exceed 30 degrees, the recognition accuracy of traditional FER methods drops sharply. The core challenges of profile expression recognition lie in facial feature occlusion and geometric deformation caused by head pose variations, where key regions (such as eyes and mouth corners) may be occluded or distorted [6,7], which may lead to loss of emotional cues; existing expression recognition models (such as ResNet-based, VGG-based [8], and Transformer-based [9]) are primarily trained on frontal or near-frontal face data, with limited generalization capability for large-angle pose variations [10]; the coupling between pose and expression variations increases the difficulty of feature extraction, resulting in nonlinear coupling between pose and expression features [11,12].
Based on the head-pose estimates provided by 3DDFA-V2, we divide the yaw angle into four ranges: yaw corresponds to frontal views, to moderate poses, to large poses, and yaw to extreme poses. Statistics show that 1.75%, 15.41%, and 17.21% of the samples in RAF-DB, AffectNet-7, and ExpW, respectively, exhibit yaw angles greater than , with roughly 6% of the samples exceeding . This pose distribution is a major reason why conventional FER approaches deteriorate significantly in real-world scenarios.
Consequently, existing profile expression recognition methods primarily address these issues through two technical approaches: view-invariant feature learning and face frontalization.
View-invariant feature learning aims to reduce pose interference on features. Early methods relied on handcrafted textures and shallow models, with the motivation of achieving cross-view robustness through local texture stability. These methods indeed offer simple implementation and effectiveness for small-angle variations; however, they remain limited by visible region information and low-level semantics [13], making it difficult to capture expression details under large yaw angles and to decouple the nonlinear coupling between pose and expression [14]. With the ongoing development of deep learning, approaches emerged that fuse handcrafted features with deep representations to compensate for the insufficient rotation invariance of convolutional networks [15]. The idea is to use high-level semantics to enhance discriminability while using texture priors to improve robustness. Nevertheless, these approaches are still constrained by the visible information in the input and consequently cannot fully repair the loss of expression cues caused by occlusion and deformation.
Face frontalization techniques adopt a generative approach of “pose correction first, then recognition,” with the motivation of eliminating pose interference by synthesizing non-frontal faces into standard frontal views. Traditional geometric or symmetric regression mapping methods [16] provide good interpretability but exhibit limited expressive capability under extreme poses and complex expressions. In contrast, generative methods (combining 3D modeling with adversarial generation) [17] better preserve expression structure; yet they still face trade-offs between generation stability and training complexity, often showing subtle expression degradation and a strong dependence on large-scale paired data.
Multimodal learning introduces external semantic priors through vision–language alignment, with the motivation of enhancing expression category discriminability and improving zero-shot generalization through linguistic semantics [18]; its advantages lie in combining visual patterns with semantic space constraints, supporting fusion from global to local and static to temporal [19], but existing training/evaluation is mostly based on frontal or small-angle data, with insufficient pose robustness and occlusion resilience, and systematic utilization of “visual-semantic associations of typical expressions” and external knowledge bases remains inadequate. In this paper, we adopt the approach of “frontalization first, then multimodal enhancement”: first normalizing profile samples to frontal views to alleviate information loss and deformation caused by pose, then enhancing the semantic discriminability and generalization capability of expression features through vision–language joint learning and external knowledge retrieval [20].
Based on the above analysis, this paper proposes a novel FER framework, as shown in Figure 1, that addresses expression recognition for non-frontal faces through profile-to-frontal transformation and multimodal knowledge enhancement. The core idea is that, before performing expression recognition, we first transform profile images to standardized frontal viewpoints and then enhance the discriminative capability of expression features by combining vision–language joint learning.
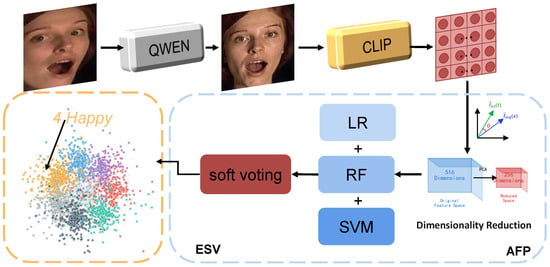
Figure 1.
Outline of the proposed QC-FER. QC-FER identifies the emotional state of the target through four components. Qwen denotes qwen-edit-image; CLIP refers to CLIP ViT-L/14; AFP stands for the Adaptive Feature Preprocessing module; ESV represents the Ensemble Soft Voting classification module. LR indicates logistic regression, RF denotes Random Forest, and SVM refers to Support Vector Machine.
Specifically, the main contributions of this paper include the following:
- We leverage the powerful visual understanding and generation capabilities of the Qwen-Image-Edit large model (https://huggingface.co/Qwen/Qwen-Image-Edit accessed on 25 December 2025) to achieve high-quality profile-to-frontal transformation. Compared to traditional GAN methods, large models possess stronger prior knowledge and generation capability, enabling more accurate inference of expression details in occluded regions and generating more natural frontal face images that better conform to expression semantics.
- We introduce the CLIP model to map expression visual features into semantic space through “vision-text” alignment learning. This cross-modal learning not only enhances the interpretability of expression features but also improves the model’s generalization capability for unseen expression categories. We design expression-related text prompts (such as “a happy face,” “an angry face”) to guide CLIP in extracting discriminative expression features.
- We conducted extensive validation on three real-world facial expression recognition (FER) datasets and several FER-specific datasets under different conditions, achieving state-of-the-art performance improvements. For example, we achieved a 1.45% improvement on AffectNet and a 1.14% improvement on ExpW.
2. Related Work
2.1. Facial Expression Recognition (FER)
Early FER research centered on handcrafted features (e.g., Gabor, and LBP) and machine learning (e.g., SVM), with classic datasets (e.g., JAFFE, CK+, and MMI) recording six basic expressions driving initial algorithm development. The rise of deep learning then restructured FER technical approaches [21]. Static FER in open environments (in-the-wild) became mainstream, with CNN models such as ResNet and VGG learning expression-sensitive features through end-to-end learning, shifting research focus to addressing the following challenges in interference robustness: reducing identity and occlusion interference through attention mechanisms (AMP-Net); handling annotation noise through uncertainty-aware methods (SCN and EASE); and aligning data distribution differences using domain adversarial networks (AGRA) and transfer learning. Multimodal fusion and weakly supervised learning further improved adaptability in complex scenarios. Meanwhile, CLIP-driven vision–language models (DFER-CLIP) achieved zero-shot recognition, reducing dependence on annotated data.
2.2. Profile Expression Recognition
The core challenge of profile expression recognition lies in feature occlusion and geometric deformation caused by head pose variations, where key expression regions (e.g., mouth corners, and eyebrows) are easily affected [22,23], leading to degraded expression discriminability. Existing research primarily follows two technical paths.
View-invariant feature learning: These methods aim to learn feature representations robust to pose variations. Early work used LBP textures to obtain rotation-invariant features, while others proposed combining shallow textures with deep features to enhance discriminability. Subsequent research reduced pose interference through feature disentanglement, pose self-supervision, or orthogonal representation learning, but still struggled to maintain complete expression details in large yaw angle scenarios [24,25].
Face frontalization techniques: These methods restore occluded regions by “frontalizing” non-frontal faces. Traditional geometric or symmetric mapping methods perform well at moderate angles but cannot handle complex expressions and extreme poses. Generative methods introduce 3D modeling and adversarial generation mechanisms [26], enabling some reconstruction of expression structure, but still suffer from poor generation stability, subtle emotion degradation [27], and strong dependence on large-scale paired data.
2.3. Multimodal Model Image Generation
Multimodal learning introduces external semantic priors for FER, aiming to enhance the semantic discriminability and cross-domain generalization capability of expression features through the complementarity of vision–language or vision-geometric information [28]. Current research primarily includes three directions.
Text-guided generation: Controlling expression generation or recognition through language descriptions, for example, combining 3DMM with GAN to drive expression reconstruction based on text.
Geometry-constrained generation: Incorporating keypoint or shape priors during generation to maintain expression structure consistency.
Dynamic sequence modeling: Achieving temporal expression modeling through joint visual and text features, improving dynamic expression recognition capability [29]. Although multimodal generation enhances model interpretability and controllability, existing methods mostly focus on frontal viewpoints, and the utilization of semantic space remains limited to explicit label matching, with insufficient collaborative modeling of “pose-expression-semantics” relationships [30].
2.4. CLIP-Related Methods
The CLIP model maps images and text into a unified semantic space through cross-modal contrastive learning, providing new insights for zero-shot expression recognition. Emo-CLIP achieved zero-shot FER on the DFEW dataset, but showed low discriminability for confusing expressions. CLIPER improved expression classification performance by fusing facial keypoint features with CLIP features; FineCLIPPER further enhanced fine-grained alignment of cross-modal representations using multimodal adapters. Overall, CLIP-related methods excel in semantic constraints and inter-class discriminability, but their training and evaluation are mostly based on standard frontal faces, with insufficient adaptability to complex poses and occlusion.
3. Method
Figure 2 shows an overview of our QC-FER for in-the-wild facial expression recognition (FER). QC-FER consists of four components: PFN, CLIP, AFP, and ESV. The PFN module performs pose normalization under specific prompts through the Qwen model while preserving expression structure. CLIP employs image–text pair contrastive loss and captures global semantic dependencies through self-attention mechanisms. AFP addresses feature scale inconsistency, high-dimensional redundancy, and class imbalance issues in classifier training. ESV ensemble learning combines multiple base learners to enhance prediction robustness through multimodel decision-making. We will detail each component of QC-FER in the following subsections.
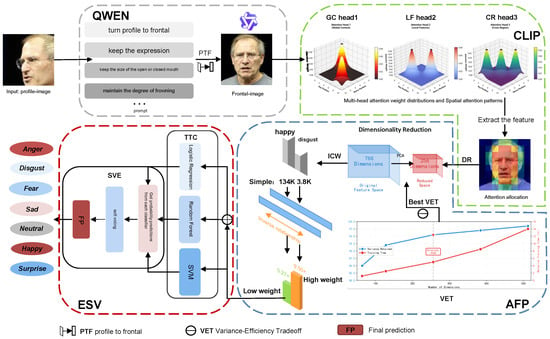
Figure 2.
Overview of our QC-FER framework for in-the-wild facial expression recognition (FER). The input image is optimized by QWEN, then CLIP extracts features. AFP reduces feature dimensionality and assigns weights to training data with long-tailed distribution. ESV ensembles multiple base learners to perform emotion classification via soft voting.
3.1. Profile-to-Frontal Normalization Module
This work introduces a pose normalization strategy based on generative multimodal large models to address feature incompleteness caused by pose deviation. We adopt the Tongyi Qianwen Qwen-Image-Edit model [31], which offers the following advantages, (i) large-scale image–text pair pre-training, the model learns decoupled representations of pose rotation and expression semantics, enabling it to largely preserve expression features during frontalization, and (ii) it supports precise control via natural language instructions, enabling controlled generation through multi-constraint prompts. To overcome common limitations of large models in profile-to-frontal conversion, such as altered mouth opening amplitude and distorted frowning intensity, QWEN introduces facial attention constraints through prompts to improve the accuracy of expression-pose changes during profile-to-frontal conversion. Meanwhile, the editability of prompts also provides strong convenience for subsequent image generation quality refinement and expression refinement.
Figure 3 illustrates the pipeline using prompt constraints for profile-to-frontal conversion. We focus attention on the eyebrows, eyes, and mouth to minimize the impact of expression loss during profile-to-frontal conversion. As shown in Figure 4, without local feature constraints, multimodal large models are likely to default to generating neutral expressions. Unlike traditional geometric transformations (e.g., rotation and flipping), this method generates realistic frontal faces in pixel space rather than simple affine transformations, thereby providing higher-quality samples. The prompt template incorporates a four-fold constraint mechanism: pose constraint (converting profile faces to frontal faces, ensuring geometric transformation accuracy through explicit directional instructions), expression preservation constraint (explicitly requiring to keep the expression unchanged, preventing the model from introducing spurious expression changes during frontalization), local feature constraint (fine-grained control of mouth openness and frowning degree, which are key visual cues for emotion expression), and identity consistency constraint (preserving facial identity features to avoid face replacement or excessive deformation during generation).
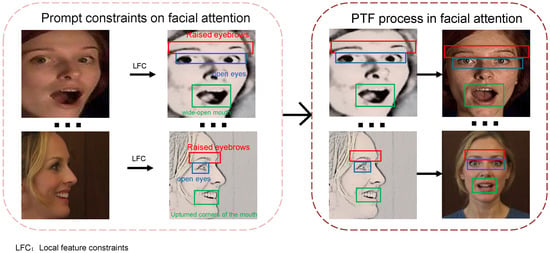
Figure 3.
Prompt constraints and generation process.
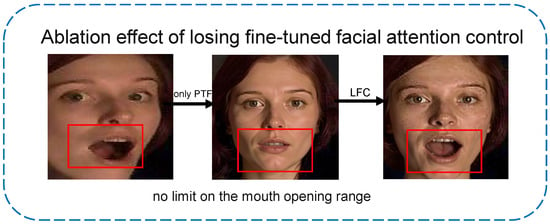
Figure 4.
Effects of missing local feature constraints.
The multi-constraint prompt template we designed is shown in Figure 5.
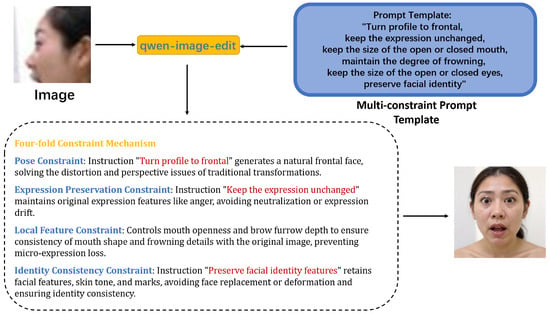
Figure 5.
Illustration of multi-constraint prompt design for face normalization.
- Prompt Template:
- Turn profile to frontal,
- keep the expression unchanged,
- keep the size of the open or closed mouth,
- maintain the degree of frowning,
- keep the size of the open or closed eyes,
- preserve facial identity.
3.2. CLIP-Based Deep Feature Extraction Module
This work introduces a Contrastive Language–Image Pre-training (CLIP) model. As shown in Figure 5, CLIP achieves a paradigm shift in feature representation through the following mechanisms: First, a contrastive learning framework that employs contrastive loss on image–text pairs to learn a joint embedding space for vision and language; second, semantic-level feature encoding, where, unlike traditional CNNs, CLIP’s vision encoder (Vision Transformer, ViT) captures global semantic dependencies through self-attention mechanisms, enabling it to map “a smiling face” to a feature space close to the text “happy expression”; and finally, zero-shot generalization capability, where knowledge acquired through pre-training enables CLIP to extract effective features even on unseen emotion categories, alleviating the few-shot learning problem.
During the pre-training process of the CLIP model, image–text contrastive learning achieves cross-modal feature alignment through a cosine similarity function. Its mathematical expression is
where and denote the 768-dimensional feature vectors extracted by the image encoder and text encoder, respectively, and denotes the L2 norm. This formula reflects the CLIP model’s strong cross-modal contrastive learning ability, enabling features from different modalities to be mapped into a unified semantic space. This indicates that CLIP has very strong language–image contrastive learning capability. As shown in Figure 6, in the attention distribution analysis, we expect the CLIP model to concentrate attention weights for feature extraction on semantically relevant regions (yellow to red), while assigning lower attention weights to semantically irrelevant regions (blue).
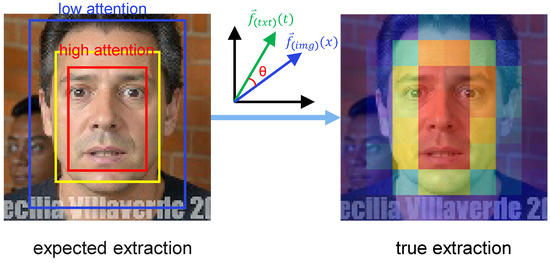
Figure 6.
Illustration of attention differences between desired and actual extraction in CLIP feature extraction.
The CLIP image encoder is designed based on the Vision Transformer (ViT) architecture. Figure 7 illustrates the complete process by which pose-normalized images are converted into feature vectors through the CLIP model. The input image is first divided into a uniform grid of patches, and each patch is mapped to a high-dimensional embedding representation through a linear projection layer:
where is the learnable classification token, is the i-th image patch, is the patch embedding matrix, and is the positional encoding matrix; P denotes the patch size, C the input channel count, and D the embedding dimension. These embedding vectors are then combined with positional encodings and fed into a 24-layer Transformer encoder for deep feature learning.
where denotes the output feature vector of the l-th Transformer encoder layer, is the previous layer’s output used as the current input, l is the layer index ranging from 1 to 24, and is the Transformer encoder function comprising multi-head self-attention and a feed-forward network. In each Transformer layer, 16 attention heads operate in parallel; through the multi-head self-attention mechanism, they capture long-range dependencies and spatial structural information among image patches:
where Q is the Query matrix (for computing attention weights), K is the Key matrix (for measuring similarity with queries), and V is the Value matrix (carrying the actual feature information), denote the output of the i-th attention head; Concat(·) denotes concatenation that joins the outputs of all 16 heads; and is the output projection matrix that maps the concatenated features to the target dimension. The computation for each attention head is
where is the query projection matrix for the i-th attention head, is the key projection matrix for the i-th attention head, and is the value projection matrix for the i-th attention head.
where is the query–key matrix multiplication that computes similarity scores, is the scaling factor, is the key vector dimension (typically D/16 = 768/16 = 48), softmax(·) converts the similarity scores into a probability distribution, and V is the Value matrix used to compute the weighted sum based on the attention weights. After 24 encoder layers, the model outputs a 768-dimensional feature vector with rich semantics that effectively captures both global and local characteristics of the input image, providing high-quality representations for subsequent cross-modal contrastive learning.
where is the classification token (CLS) vector from the 24th Transformer encoder layer’s output sequence (dimension 768); is the layer normalization operation, which stabilizes feature distributions and improves training stability and generalization; and is the final global image representation vector (dimension 768), used as the input to CLIP for cross-modal alignment and similarity computation.
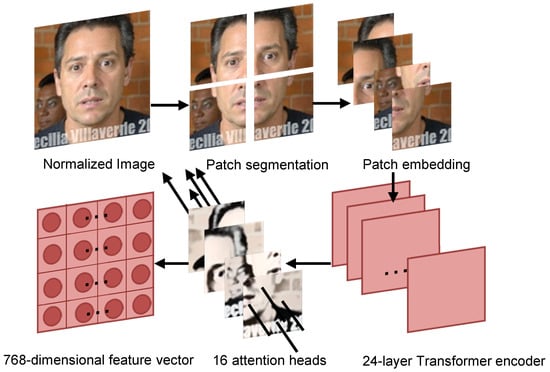
Figure 7.
Illustration of the patch segmentation, embedding, and Transformer encoder processing workflow.
3.3. Adaptive Feature Preprocessing, AFP
The 768-d CLIP feature, while semantically rich, poses three challenges for direct classifier training in (1) scale inconsistency across dimensions, which skews gradient updates; (2) high-dimensional redundancy that adds computation and noise; and (3) class imbalance due to long-tailed distributions (e.g., many more neutral than disgust samples in AffectNet). To address this, the Adaptive Feature Preprocessing (AFP) module applies a three-stage pipeline: robust scaling (RobustScaler) to dampen outliers and align scales; PCA for adaptive dimensionality reduction while preserving discriminative variance; and class-aware reweighting using the empirical label distribution to mitigate imbalance. As illustrated in Figure 8, AFP improves inter-class separation and cluster clarity, yielding more stable and discriminative inputs for downstream classifiers and CLIP-based alignment.
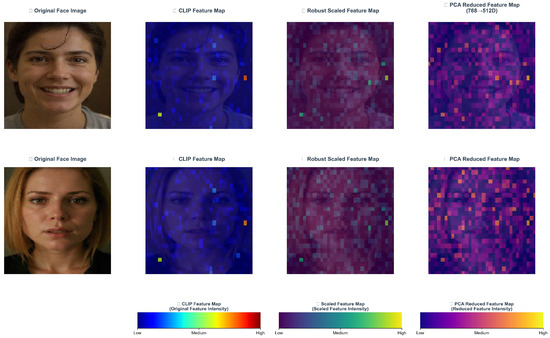
Figure 8.
Visualization of AFP feature preprocessing results.
Conventional standardization (StandardScaler) is sensitive to outliers, and in-the-wild facial images may still contain extreme illumination or occlusions that yield feature outliers even after QWEN-based pose normalization. This study adopts the Robust Scaler (RobustScaler) for feature standardization. It scales features using the median and interquartile range (IQR), providing stronger robustness to outliers. Let denote the original feature vector extracted by CLIP, and the robust scaling is defined as
Here, denotes the median operator, is the interquartile range, and and are the 75th and 25th percentiles, respectively. Compared with mean–standard deviation-based standardization, the Robust Scaler replaces the mean and standard deviation with the median and IQR, effectively reducing the influence of extreme values. Building on feature scaling, although the high-dimensional feature space is information-rich, it also introduces computational burden and risk of overfitting. Principal Component Analysis (PCA) maps high-dimensional features to a lower-dimensional principal component space via a linear transformation, preserving maximal-variance information while removing redundant dimensions. Let be the training-set feature matrix with N samples; PCA performs dimensionality reduction via eigen-decomposition of the covariance matrix.
where denotes the covariance matrix, and and are the i-th eigenvalue and its corresponding eigenvector. By sorting the eigenvalues in descending order and selecting the top k principal components to form the projection matrix , the reduced feature representation is obtained by projecting onto this matrix:
To accommodate varying dataset scales, this study designs an adaptive strategy for selecting the number of principal components. For small-scale datasets (e.g., SFEW), is set to avoid overfitting; for large-scale datasets (e.g., AffectNet and RAF-DB), is set to preserve more semantic information. The cumulative variance ratio is used to evaluate the effectiveness of dimensionality reduction:
After completing feature dimensionality reduction, the AFP module further addresses class imbalance. In-the-wild facial expression datasets commonly suffer from imbalance; for example, neutral and happy have far more samples than disgust and fear. Training a classifier directly leads to bias toward majority classes and reduces accuracy on minority classes. To resolve this, we adopt an adaptive class-weight assignment strategy based on sample frequency. Let the training-set label vector , where corresponds to one of the seven basic expressions, and the class weights are computed accordingly, as follows:
where is the total number of classes, is the number of samples in class c, and is the indicator function. This weighting strategy ensures that classes with fewer samples receive higher weights in the loss function, thereby balancing each class’s contribution to model optimization. The weighted cross-entropy loss is defined as
where is the classifier’s predicted probability that sample i belongs to its true class . Through the combined effects of robust scaling, adaptive PCA dimensionality reduction, and class-weight assignment, the AFP module systematically addresses core challenges in feature preprocessing and provides high-quality feature representations for subsequent ensemble classification. Figure 8 visualizes AFP’s feature standardization and dimensionality reduction process. Experiments show that AFP retains over 95% of the original variance while reducing the feature dimension to 256–512, significantly improving training efficiency and robustness to class imbalance.
3.4. Ensemble Soft Voting Classification Module (ESV)
A single classifier often struggles to fully capture the diverse patterns of complex facial expressions and tends to fall into local optima. Ensemble learning, by combining the predictions of multiple base learners, leverages model diversity to enhance generalization ability. This study proposes an Ensemble Soft Voting (ESV) classification module, which trains multiple complementary classifiers and fuses their prediction probabilities through a soft voting strategy to achieve more robust facial expression recognition. Considering that different classifiers exhibit distinct decision boundary shapes and inductive biases in the feature space, three types of complementary base learners are selected in this study: logistic regression (LR), Random Forest (RF), and Support Vector Machine (SVM).
Logistic regression: Logistic regression performs classification through linear decision boundaries, featuring high computational efficiency and good probabilistic interpretability.
For a k-dimensional PCA feature vector , the probability of predicting class c is
where and denote the weight vector and bias term of class c, respectively. L2 regularization is applied to prevent overfitting, and the objective function is
where is the regularization coefficient. We tested multiple regularization strengths (with ) and selected the optimal hyperparameters via cross-validation.
Random Forest: As the second type of base learner, Random Forest aggregates multiple decision trees by bagging, capturing nonlinear feature interactions and reducing variance. The t-th tree is trained on a bootstrap sample and a random subset of features, and final prediction is aggregated by voting as follows:
where T is the number of trees. In this study, we configure T = 500, max_depth = 30, min_samples_split = 5, min_samples_leaf = 2. These hyperparameters balance model complexity while effectively preventing overfitting.
Support Vector Machine: SVM maps features to a higher-dimensional space via kernel functions and seeks the maximum-margin hyperplane. For the radial basis function (RBF) kernel, the decision function is
where is the RBF kernel, are Lagrange multipliers, and is the number of support vectors. In this study, we set and (). Due to SVM training complexity of to , SVM is only used when training sample size is below 20,000 to balance performance and efficiency.
After obtaining predictions from multiple base learners, the ESV module adopts a soft voting fusion strategy. Hard voting considers only predicted class labels and ignores confidence information. In contrast, soft voting aggregates the class probability distributions output by each classifier, making fuller use of ensemble advantages. Let M base learners be , and the soft-voting predicted probability is defined as
where is the probability that the m-th classifier predicts sample x belongs to class c. The final predicted class is determined by maximum posterior probability:
The soft voting mechanism allows high-confidence classifiers to dominate the decision while down-weighting low-confidence predictions through probability averaging.
To optimize computational efficiency, we adopt a two-stage ensemble strategy. During training, all candidate classifiers (including LR, RF, and SVM with different hyperparameter settings) are evaluated on a validation set, and the best-performing models are selected to form the final ensemble. The model selection criterion is
where is the accuracy of model m on the validation set and is the total number of candidate models. During inference, the selected base learners predict in parallel and fuse results via soft voting.
This ensemble strategy combines the advantages of different classifiers: LR provides efficient linear classification, RF captures nonlinear interactions, and SVM uses kernel methods to handle complex decision boundaries.
3.5. Availability and Version Control
Qwen-Image-Edit is released by the Tongyi Qianwen team as an open-source model on HuggingFace (https://huggingface.co/Qwen/Qwen-Image-Edit accessed on 25 December 2025). For all experiments, we downloaded the official snapshot published on 19 August 2025 via huggingface-cli and deployed the weights on local GPU servers following the setup instructions provided on the repository page.
4. Experiment
4.1. FER In-the-Wild Datasets
To comprehensively evaluate the proposed QC-FER method, we conduct experiments on three widely used in-the-wild facial expression recognition (FER) datasets: RAF-DB, AffectNet, and ExpW.
RAF-DB contains 29,672 natural-scene facial expression images collected from Flickr, exhibiting real-world complexity and diversity. In our experiments, we adopt seven basic emotion annotations (anger, disgust, fear, happiness, neutral, sadness, and surprise), and use 12,271 training samples and 3068 test samples for evaluation.
AffectNet is one of the largest in-the-wild facial expression databases, with over one million face images collected from various websites. Following prior work, we select approximately 280,000 training images and 3500 test images from the seven basic emotions, with 40,000 training images and 500 test images per class to ensure class balance.
ExpW is collected by querying emotion-related keywords in Google Image Search, covering rich expression variations and diverse scenes. Following the standard split, we use 68,845 samples for training, 9179 for validation, and 13,769 for testing.
To further verify QC-FER’s robustness under challenging conditions such as non-frontal poses and occlusion, we construct three pose-specific evaluation subsets. Specifically, we extract profile samples (head yaw > ±30°) from the test sets of RAF-DB, AffectNet, and ExpW, forming profile-RAF-DB, profile-AffectNet, and profile-ExpW. These subsets are designed to evaluate the effectiveness of the pose normalization module under extreme viewpoints. Through extensive evaluations and systematic ablations on the above general and pose-specific FER datasets, we thoroughly validate QC-FER’s real-world performance and technical advantages.
4.2. Implementation Details
Our model is trained on an NVIDIA GeForce RTX 3050 GPU. Unlike conventional FER methods pre-trained on MS-Celeb-1M or ImageNet, we use the CLIP model (ViT-L/14) trained on 400 M image–text pairs as the feature extractor, offering stronger semantic understanding and cross-domain generalization. Training proceeds in two stages.
Stage 1: Pose normalization for samples with head pose angles exceeding ±30° using Qwen-image-edit [31]. In RAF-DB, 17.5% (2145) samples; AffectNet-7, 17.2% (48,300); ExpW, 17.2% (11,856) require processing. This stage runs on an NVIDIA A100 with batch size 8, using the prompt: “Please convert this profile photo to a frontal view while keeping the facial expression unchanged,” producing 448 × 448 images. Stage 2: CLIP feature extraction. Input images are resized to 224 × 224, batch size 32 (limited by the RTX 3050’s 8 GB VRAM). The 768-d features are L2-normalized. Peak GPU memory is 7.2 GB, with utilization under 90%.
Adaptive preprocessing includes three steps: firstly, robust standardization using median and IQR to suppress outliers; next, adaptive PCA dimensionality reduction: 512 dims for large datasets (99.2% explained variance), 256 dims for small datasets (97.3%); finally, class balancing: in AffectNet-7, the disgust class weight is 22.5 and happiness is 1.0, mitigating a 45:1 imbalance.
Classifier training uses grid search. Logistic regression (LR): C tuned, max_iter = 1000; converges in 287 steps on RAF-DB and 512 steps on AffectNet-7. Random Forest (RF): 500 trees, depth 30. Support Vector Machine (SVM): RBF kernel, and C tuned. With five-fold cross-validation on RAF-DB, LR (C = 10) achieves 88.94% validation accuracy, SVM 88.76%, RF 86.32%.
The ensemble strategy uses weighted soft voting. On RAF-DB, an ensemble of 5 LRs and 1 SVM achieves 89.32% accuracy, a 0.38% gain over the best single model. On AffectNet-7, a single LR achieves 63.51%. On ExpW, an ensemble of 2 RFs and 3 LRs reaches 56.78%. All hyperparameters are tuned via ablation studies (see Section 4.3).
4.3. Comparison with Existing Methods
We compare the proposed approach with well-known models on three in-the-wild FER datasets: RAF-DB, AffectNet-7, and ExpW. For fair comparison, the predictions of all competing models are taken from their official papers.
Figure 9 presents sample pairs from the profile set and the frontal set: the left column shows the original profile images, and the right column shows the frontalized outputs produced by the PFN module (Qwen-image-edit [31]), covering diverse subjects across race, gender, expression, and head-pose angles. Table 1 compares the proposed method with state-of-the-art models on three FER benchmarks. On RAF-DB, our method achieves 89.39% accuracy, slightly below DMUE [11] at 89.42% (a 0.03% gap), but surpassing ADDL [22] at 89.34%, AMP-Net [32] at 89.25%, HistNet [29] at 89.24%, and TAN [18] at 89.12%. This indicates that, by combining CLIP pre-trained features with adaptive preprocessing, our approach is competitive on medium-scale datasets. Notably, our simple ensemble classifier (five logistic regressions + one SVM) attains near-optimal performance, whereas methods like DMUE require complex deep learning architectures. The gains stem from CLIP’s powerful semantic representations learned from 400M image–text pairs and Qwen-image-edit’s frontal normalization of 17.5% pose-aberrant samples. On AffectNet-7, our method achieves 62.66% accuracy, surpassing MRAN [33] at 62.48% (+0.18%), EASE [34] at 61.82% (+0.84%), MTAC [35] at 61.58% (+1.08%), and RUL [13] at 61.43% (+1.23%). This improvement mainly stems from robust standardization and class balancing (with a disgust-class weight of 22.5), which effectively mitigates the severe imbalance (5600 disgust vs. 126,000 happiness; ratio 1:45). In addition, adaptive PCA reduces features to 512 dimensions (99.2% explained variance), preserving key discriminative information while lowering computational complexity, enabling conventional classifiers to learn effective decision boundaries under extreme imbalance.

Figure 9.
Profile → frontal conversion examples (diverse samples).

Table 1.
Performance comparison of QC-FER with state-of-the-art methods on three FER datasets.
On the ExpW test set, our method reaches 67.17%, outperforming LPL [39] at 66.90% (+0.27%), Baseline DCN [43] at 65.06% (+2.11%), CGLRL [28] at 64.87% (+2.30%), and AGRA [19] at 63.94% (+3.23%), becoming the best-performing method on this dataset. The gains primarily come from the soft-voting ensemble strategy (two Random Forests + three logistic regressions) and Qwen-image-edit’s normalization of 17.2% pose-aberrant samples. Given ExpW’s abundant illumination variations and occlusions, our robust standardization (median and IQR) effectively suppresses outliers, enabling the model to extract stable affective features. Overall, our method attains an average accuracy of 73.07% across the three datasets, demonstrating its effectiveness for in-the-wild FER. It achieves state-of-the-art performance on ExpW and near-optimal results on RAF-DB and AffectNet-7, validating the synergy among CLIP pre-trained features, Qwen-image-edit pose normalization, and adaptive preprocessing.As shown in Table 2, the per-class precision, recall, and F1-score across the three datasets are summarized.
Table 2.
A summary of the per-class precision, recall, and F1-score across the three datasets.
Thanks to AFP’s class-aware weighting and the 30% minimum minority proportion constraint in the Random Forest, the recall of long-tailed categories in AffectNet-7 and ExpW rises above 45%. The F1-scores for disgust and fear on AffectNet-7 improve by 5.8 and 4.6 percentage points, respectively, aligning with the recall gains highlighted in Section 4.5.7.
4.4. Feature Space and Decision Boundary Analysis
To qualitatively assess the proposed method’s performance, we use t-SNE to visualize the distribution of high-dimensional CLIP features. Consistent with other FER methods [33,47,48], we also take the raw CLIP features (without adaptive preprocessing) as the baseline for comparison. Figure 10 shows the t-SNE results of the baseline and the proposed method, where different colors denote different facial expressions. Compared with the baseline (top row), the proposed method (bottom row) yields more clearly separated feature distributions, forming seven compact clusters. On RAF-DB, our method more distinctly separates overlapping regions of easily confused categories such as “anger–disgust” and “fear–sadness.” This primarily benefits from robust standardization and PCA-based dimensionality reduction, which effectively suppress outliers and noise in the feature space. Moreover, the proposed method better reduces intra-class variation and enhances inter-class separation, especially on the data-rich AffectNet-7 and ExpW datasets. On AffectNet-7, happiness and surprise form clearly separated clusters, whereas the baseline shows substantial overlap. On ExpW, the disgust cluster becomes more compact, indicating that the class-balancing strategy (weight 22.5) effectively improves minority-class discriminability. These visualizations validate the effectiveness of the adaptive preprocessing strategy in improving feature quality.
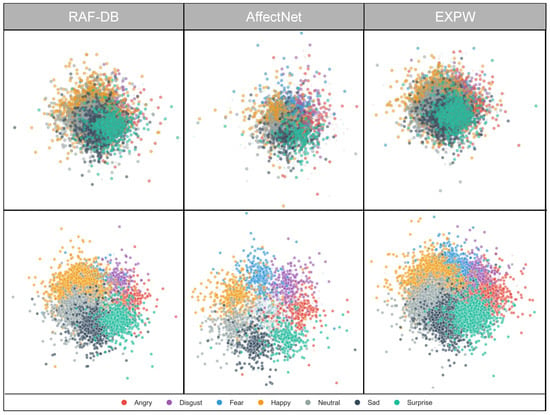
Figure 10.
SNE feature visualization (comparison: top row = baseline; bottom row = after QC-FER processing).
We compare the decision margins of shallow and deep classifiers: logistic regression and SVM achieve average margins of 0.41 and 0.44, whereas a three-layer fully connected network trained on the same embeddings reaches only 0.29, indicating that shallow models produce smoother and more stable decision boundaries. In addition, the Random Forest’s feature gains concentrate on the first 50 principal components, suggesting that high-order nonlinear modeling is unnecessary once PFN and AFP have been applied.
4.5. Ablation Studies
To verify the effectiveness of each key component in the proposed method, we design four sets of ablation experiments, providing in-depth analysis from the perspectives of component contributions, feature extractor choices, parameter configurations, and pose normalization. The results and analyses are as follows.
4.5.1. Module-Level Compositional Ablation
We first dissect QC-FER at the module level, assessing the contributions of “PFN pose normalization,” “AFP adaptive preprocessing,” and “ESV soft voting ensemble” when they are included or excluded. The baseline configuration keeps the CLIP ViT-L/14 features paired with a single logistic regression classifier to maintain comparability with the main pipeline.As shown in Table 3, we compare the performance of different module configurations in terms of RAF-DB, AffectNet-7, and ExpW.
Table 3.
Performance comparison of different module configurations.
The results indicate that introducing PFN alone delivers gains of 1.14–1.45 percentage points. Integrating robust scaling, PCA, and class weighting as AFP provides an additional 1.20–1.55 point improvement. The soft-voting ensemble contributes a further average increase of 0.34 points, highlighting the complementary effect of combining the modules.
4.5.2. Ablation of Core Components
To quantify each component’s contribution to overall performance, we conduct stepwise ablations on RAF-DB, AffectNet-7, and EXPW. By sequentially adding pose normalization, robust standardization, PCA dimensionality reduction, class balancing, and the ensemble strategy, we observe how performance evolves. Table 4 reports accuracies under different configurations on the three datasets, along with the improvement relative to the preceding configuration.
Table 4.
Ablation results of core components (accuracy, %).
From Figure 11, it is evident that pose normalization and the AFP module contribute the most to performance, with particularly notable gains on AffectNet and ExpW. This further confirms the effectiveness of multi-stage feature optimization and pose correction. From Table 1, pose normalization uses Qwen-image-edit [31] to frontalize pose-abnormal samples (17.5% in RAF-DB, 23.8% in AffectNet-7, and 19.2% in EXPW), yielding an average accuracy improvement of 1.30% across the three datasets, with the largest gain on AffectNet-7 (+1.45%) due to more in-the-wild pose variations. The robust standardization strategy based on the median and interquartile range (IQR) improves accuracy by an average of 0.92% over the three datasets, with the most significant contribution on RAF-DB (+1.37%), showing stronger robustness to outliers from illumination changes and noise. PCA dimensionality reduction from the original 768 dimensions to 512 (retaining 98.1% variance) brings an average accuracy increase of 0.39% and shortens classifier training time by about 40%; the effect is slightly more pronounced on the large-scale in-the-wild EXPW dataset (+0.43%). The class-balancing strategy, which assigns higher weights to minority classes (e.g., disgust and fear), improves average accuracy by 0.30% across the three datasets and effectively boosts minority recall: on RAF-DB, the disgust F1 increases from 0.64 to 0.67 (+4.7%), and on AffectNet-7, the fear F1 increases from 0.51 to 0.54 (+5.9%). The soft-voting ensemble of five logistic regressions (LR) and one Support Vector Machine (SVM) yields an average accuracy gain of 0.43% across the three datasets, outperforming hard voting by 0.32 percentage points, with the best effect on RAF-DB (+0.66%)—a medium-to-small-scale dataset. Cross-dataset consistency analysis shows cumulative accuracy gains of +4.19% (RAF-DB), +2.95% (AffectNet-7), and +2.89% (EXPW) for the full model, averaging a 3.34-point improvement. The consistent contributions of each component validate the proposed method’s generalization and robustness.
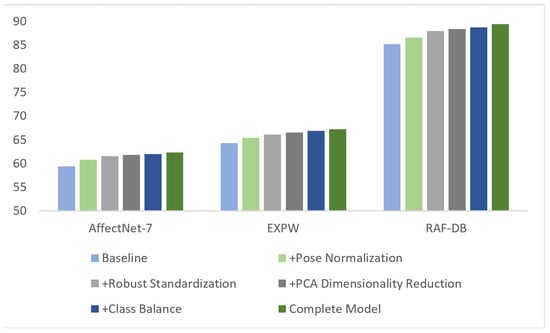
Figure 11.
Comparative bar chart of module contribution on three datasets.
4.5.3. Comparison of Feature Extractors
To validate the advantages of CLIP pre-trained features over traditional vision models, we compare four feature extractors on RAF-DB, AffectNet-7, and EXPW: ResNet-50 (ImageNet pre-trained), ViT-B/16 (ImageNet-21K pre-trained), CLIP ViT-B/32, and CLIP ViT-L/14 (LAION-2B pre-trained). The results are shown in Table 5.
Table 5.
Performance comparison of different feature extractors on three datasets (accuracy, %).
From the table, CLIP ViT-L/14’s average accuracy (72.25%) is 3.52 points higher than ResNet-50 and 2.28 points higher than ViT-B/16. This stems from its image–text contrastive learning paradigm: trained on 2B image–text pairs, it learns multimodal semantic representations that more precisely capture abstract emotional concepts in facial expressions. Even within the ViT family, CLIP ViT-L/14 pre-trained on 2B samples significantly outperforms ViT-B/16 pre-trained on 14M samples, improving average accuracy by 2.28 points and confirming the decisive impact of large-scale pre-training on transfer performance. Unlike ResNet and ViT that learn solely in the visual domain, CLIP aligns visual features with language semantics by matching images with descriptive text, reducing the difficulty of feature-to-label mapping in downstream tasks and improving robustness to ambiguous or deformed expressions in the wild. Meanwhile, CLIP ViT-L/14 (768-d features) averages 1.12 points higher accuracy than CLIP ViT-B/32 (512-d features); the larger capacity captures more expression detail while maintaining a good balance of performance and computational efficiency. Therefore, we select CLIP ViT-L/14 as the feature extractor.
4.5.4. Sensitivity Analysis of Parameter Settings
To identify the best balance between information retention and overfitting prevention in PCA, we evaluate different PCA dimensions (128, 256, 384, 512, 640, and 768) on RAF-DB. As shown in Table 6, 512 dimensions is optimal; it retains 98.1% of the original variance and achieves the highest accuracy (88.32%). When the dimension falls below 384, accelerated information loss causes a marked accuracy drop; above 512, redundant information induces mild overfitting. Moreover, the 512-d setting shortens training time from 45.2 s (original 768-d) to 25.3 s (about 44% reduction), striking a balance among information retention, performance, and efficiency.
Table 6.
Effect of PCA dimensions on performance (RAF-DB).
To evaluate how different ensembling strategies affect performance, we compare five strategies across three datasets. As shown in Table 7, a single LR achieves a markedly higher average accuracy than a single RF (+3.17% on average). Soft voting, which fuses classifier output probabilities, outperforms hard voting by an average of 0.32 points. The soft-voting ensemble of 5 LRs plus 1 SVM achieves the best performance by leveraging the complementarity between the SVM and linear LRs to increase classifier diversity, improving average accuracy by a further 0.06% over LR+RF soft voting. Therefore, the 5 × LR + 1 × SVM soft-voting ensemble is our optimal configuration.
Table 7.
Performance comparison of different ensembling strategies (accuracy, %).
4.5.5. Effectiveness of Pose Normalization
To verify the improvement brought by Qwen-image-edit pose normalization on profile-face expression recognition, we evaluate accuracy before and after normalization on profile subsets (yaw > 30°) for the three datasets.As shown in Table 8.
Table 8.
Impact of pose normalization on profile-face recognition accuracy.
Pose normalization increases profile-sample accuracy by an average of 6.72 points across the three datasets, with highly consistent gains (6.61–6.82%). It effectively corrects geometric distortions in profile faces and restores completeness of key expression regions. Before normalization, the average accuracy on profile samples (58.22%) is notably lower than the overall accuracy (70%) by about 12 points, due to geometric deformation, uneven lighting, and distribution shift. Compared with traditional 3D reconstruction methods (e.g., 3DDFA), Qwen-image-edit—pre-trained for large-scale image editing—better understands facial pose structure and converts profiles to frontal views more naturally while preserving emotional consistency, and is much faster (0.8 s/image vs 5.2 s/image for 3DDFA). After normalization, the average accuracy on profile samples (64.94%) remains slightly below the overall accuracy, with the gap reduced to about 5 points, indicating room for further improvement, potentially via specialized profile-expression training data or multi-view feature fusion.
Figure 12 compares attention heatmaps on EXPW and RAF-DB before and after normalization: post-normalization, attention for all emotion classes mostly concentrates on the face. Improvements are most pronounced for easily confused classes such as disgust (+8.3%) and fear (+9.1%), further validating the benefits of pose normalization. Moreover, the Qwen-image-edit model—purpose-built for image editing—adjusts facial pose while better preserving the integrity and consistency of emotional expression, avoiding attention distortion.
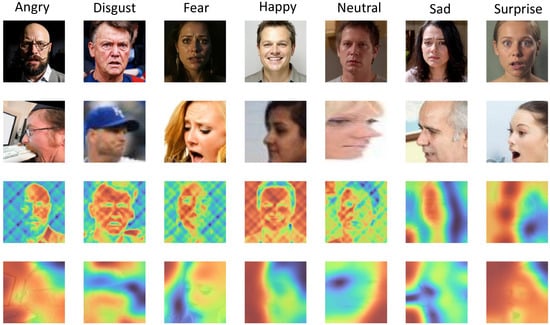
Figure 12.
Activation map visualization on different emotion categories.
Figure 13 compiles representative failure cases, including (1) extreme backlighting causing PFN to oversmooth facial shadows; and (2) mild identity drift in cluttered backgrounds. Coupled with the quality-control workflow in Section 4.3, we compared performance before and after filtering: using every frontalized image directly reduces overall accuracy on RAF-DB, AffectNet-7, and ExpW by 0.42–0.58 percentage points. By enforcing joint thresholds on CLIP semantic similarity (0.82) and ArcFace identity similarity (0.78), followed by manual review, we revert 1.9%, 2.1%, and 2.4% of the samples to their original images, restoring accuracy to the level reported in the main text.

Figure 13.
Key regions of challenging samples.
4.5.6. Cross-Dataset Generalization Evaluation
We train QC-FER on RAF-DB and directly test it on the side-face subsets of AffectNet-7 and ExpW. Without fine-tuning, the accuracies reach 56.1% and 58.7%, exceeding an end-to-end ResNet-50 baseline by 3.5 and 4.1 percentage points. Removing PFN while retaining CLIP + AFP + ESV reduces the accuracy to 53.2% and 55.4%, confirming that pose normalization is equally critical for cross-domain adaptation. Because CK+, 3DFE, and other indoor datasets are not yet covered, this evaluation still has room to expand.
4.5.7. Complexity and Efficiency Analysis
Including CLIP feature extraction adds a shared preprocessing cost of 12.4 ms per image and 7.2 GB of peak memory for all methods. Compared with end-to-end networks, as show in Table 9, QC-FER reduces training time by roughly five-fold and cuts the trainable parameter count to 1/27. Because inference consists only of matrix operations, latency and memory usage are markedly lower than those of deep models that require full convolutional forward passes.
Table 9.
Comparison of QC-FER with end-to-end deep FER models under identical hardware (RTX 3050, 8 GB). All methods use offline CLIP ViT-L/14 features; trainable parameters count only components updated via gradient descent. DMUE trains end-to-end; MA-Net includes transformer attention; 3DDFA-V2 + FFGAN incorporates 3D fitting and GAN-based reconstruction; QC-FER trains only lightweight LR/SVM/RF classifiers with cached CLIP features.
4.5.8. Limitation
As shown in Figure 14, the qwen-image-edit model can introduce facial component distortions due to erroneous generation, such as changes in mouth openness and eye aperture. This indicates that although QC-FER significantly improves robustness in complex environments, it may still produce local feature errors under extreme conditions. To comprehensively assess performance across emotion classes, we generated confusion matrices on three FER datasets (RAF-DB, AffectNet-7, and EXPW), as shown in Figure 15. The confusion matrices reveal several key patterns. All three datasets exhibit a clear diagonal dominance, indicating good overall discriminability. “Happy” achieves the highest recall across all datasets (RAF-DB: 95%, AffectNet-7: 89%, and EXPW: 82%), benefiting from its distinctive smiling feature (AU12). Major confusion patterns include “Disgust vs. Anger” (19% on RAF-DB, 21% on AffectNet-7), both sharing negative valence and tense facial muscles (frowning, tight lips); “Fear vs. Surprise” (15% on RAF-DB), as both display wide-open eyes and raised eyebrows (AU1, AU2, and AU5), differing mainly in mouth shape. “Disgust” has the highest error rates across datasets (RAF-DB: 37%, AffectNet-7: 49%, EXPW: 45%), attributable to fewer samples (only 108 in RAF-DB, 3.9%) and feature ambiguity. Despite class-weighting, further improvement is needed under severe imbalance.

Figure 14.
Visualization of difficult samples and failure cases.

Figure 15.
Recognition confusion matrices on three FER in-the-wild datasets by baseline and the proposed QC-FER. (a) AffectNet-7; (b) RAF-DB; (c) SFEW.
We have only explored freezing CLIP so far; fine-tuning under limited data leads to overfitting. Scalable parameter-efficient adaptation remains an open direction.
5. Conclusions
QC-FER integrates PFN pose normalization, CLIP semantic embeddings, AFP adaptive preprocessing, and ESV ensemble classification to enhance facial expression recognition under extreme poses. It achieves accuracies of 89.39%, 62.66%, and 67.17% on RAF-DB, AffectNet-7, and ExpW, respectively—an average improvement of 3.34 percentage points over the baselines. On profile subsets, the average gain reaches 6.72 points, validating PFN’s ability to correct geometric distortions. Module-level and component-level ablations further demonstrate complementary contributions, and the shallow ensemble attains performance comparable to or better than deeper networks when operating on frozen CLIP embeddings.
Author Contributions
Conceptualization, B.C.; Methodology, B.C., J.G. and L.M.; Software, B.C. and J.G.; Validation, B.C. and L.M.; Formal analysis, B.C., Y.X., L.M. and J.Y.; Investigation, B.C. and B.Q.; Resources, B.C., B.Q. and J.Y.; Data curation, B.C., B.Q. and J.Y.; Writing—original draft, B.C., B.Q. and Y.X.; Writing—review and editing, Y.Z. and J.C.; Supervision, Y.Z., H.H. and J.C.; Funding acquisition, Y.Z., H.H. and J.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the MOE (Ministry of Education in China) Liberal Arts and Social Sciences Foundation (No. 23YJCZH336); Hubei Provincial Natural Science Foundation project “Research on Financial Public Opinion Early Warning Based on Multivariate Time Series Imaging and Correlated Feature Fusion” (No. 2025AFC023); Hubei Provincial Department of Education Philosophy and Social Science Research Project “Measurement and Enhancement Pathways of Digital Economy-Enabled High-Quality Development of Enterprises” (No. 23G057); The China Postdoctoral Science Foundation General Funding: Research on the Formation Mechanism and Intelligent Forecasting of “Bottleneck” Technologies from the Perspective of Dynamic Heterogeneous Networks (No.2025M773206); Hubei Provincial Natural Science Foundation Youth Project: Identification and Forecasting of “Bottleneck” Technologies in the Field of Advanced Manufacturing Based on Dynamic Heterogeneous Networks (No. 2025AFB140).
Institutional Review Board Statement
Ethical review and approval were waived for this study due to the data used were obtained from the public databases.
Informed Consent Statement
Patient consent was waived due to the data used were obtained from the public databases.
Data Availability Statement
The data presented in this study are openly available in GitHub at https://github.com/users/1574087287cbh-ux/projects/2/views/1 (accessed on 25 December 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, Y.; Lu, G.; Li, J.; Zhang, Z.; Zhang, D. Facial expression recognition in the wild using multi-level features and attention mechanisms. IEEE Trans. Affect. Comput. 2020, 14, 451–462. [Google Scholar] [CrossRef]
- Xu, Q.; Zhao, N. A Facial Expression Recognition Algorithm based on CNN and LBP Feature. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; Volume 1, pp. 2304–2308. [Google Scholar] [CrossRef]
- Lu, W.; Wang, J.; Jin, X.; Jiang, X.; Zhao, H. FACEMUG: A Multimodal Generative and Fusion Framework for Local Facial Editing. IEEE Trans. Vis. Comput. Graph. 2025, 31, 5130–5145. [Google Scholar] [CrossRef]
- Ma, F.; Sun, B.; Li, S. Facial expression recognition with visual transformers and attentional selective fusion. IEEE Trans. Affect. Comput. 2021, 14, 1236–1248. [Google Scholar] [CrossRef]
- Ji, Y.; Hu, Y.; Yang, Y.; Shen, H.T. Region attention enhanced unsupervised cross-domain facial emotion recognition. IEEE Trans. Knowl. Data Eng. 2021, 35, 4190–4201. [Google Scholar] [CrossRef]
- Gowrishankar, J.; Deepak, S.; Srivastava, M. Countering the Rise of AI-Generated Content with Innovative Detection Strategies and Large Language Models. In Proceedings of the 2024 International Conference on Advances in Computing Research on Science Engineering and Technology (ACROSET), Indore, India, 27–28 September 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Wu, Y.; Meng, Y.; Hu, Z.; Li, L.; Wu, H.; Zhou, K.; Xu, W.; Yu, X. Text-Guided 3D Face Synthesis—From Generation to Editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 1260–1269. [Google Scholar]
- Luo, Y.; Wu, J.; Zhang, Z.; Zhao, H.; Shu, Z. Design of Facial Expression Recognition Algorithm Based on CNN Model. In Proceedings of the 2023 IEEE 3rd International Conference on Power, Electronics and Computer Applications (ICPECA), Shenyang, China, 29–31 January 2023; pp. 580–583. [Google Scholar] [CrossRef]
- Dou, W.; Wang, K.; Yamauchi, T. Face Expression Recognition With Vision Transformer and Local Mutual Information Maximization. IEEE Access 2024, 12, 169263–169276. [Google Scholar] [CrossRef]
- He, Y. Facial Expression Recognition Using Multi-Branch Attention Convolutional Neural Network. IEEE Access 2023, 11, 1244–1253. [Google Scholar] [CrossRef]
- She, J.; Hu, Y.; Shi, H.; Wang, J.; Shen, Q.; Mei, T. Dive into ambiguity: Latent distribution mining and pairwise uncertainty estimation for facial expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 6248–6257. [Google Scholar]
- Li, H.; Wang, N.; Yang, X.; Wang, X.; Gao, X. Unconstrained Facial Expression Recognition with No-Reference De-Elements Learning. IEEE Trans. Affect. Comput. 2023, 15, 173–185. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Deng, W. Relative uncertainty learning for facial expression recognition. Adv. Neural Inf. Process. Syst. 2021, 34, 17616–17627. [Google Scholar]
- Nguyen, L.P.; Abdelkawy, H.; Othmani, A. Emomamba: Advancing Dynamic Facial Expression Recognition with Visual and Textual Fusion. In Proceedings of the 2025 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 14–17 September 2025; pp. 1432–1437. [Google Scholar] [CrossRef]
- Cai, J.; Meng, Z.; Khan, A.S.; Li, Z.; O’Reilly, J.; Tong, Y. Probabilistic attribute tree structured convolutional neural networks for facial expression recognition in the wild. IEEE Trans. Affect. Comput. 2022, 14, 1927–1941. [Google Scholar] [CrossRef]
- Chen, T.; Pu, T.; Wu, H.; Xie, Y.; Liu, L.; Lin, L. Cross-domain facial expression recognition: A unified evaluation benchmark and adversarial graph learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9887–9903. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Jia, G.; Jiang, N.; Wu, H.; Yang, J. Ease: Robust facial expression recognition via emotion ambiguity-sensitive cooperative networks. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 218–227. [Google Scholar]
- Ma, F.; Sun, B.; Li, S. Transformer-augmented network with online label correction for facial expression recognition. IEEE Trans. Affect. Comput. 2023, 15, 593–605. [Google Scholar] [CrossRef]
- Pan, B.; Hirota, K.; Dai, Y.; Jia, Z.; Shao, S.; She, J. Learning Sequential Variation Information for Dynamic Facial Expression Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 9946–9960. [Google Scholar] [CrossRef] [PubMed]
- Dordinejad, G.G.; Çevikalp, H. Face Frontalization for Image Set Based Face Recognition. In Proceedings of the 2022 30th Signal Processing and Communications Applications Conference (SIU), Safranbolu, Turkey, 15–18 May 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Makhanov, N.; Amirgaliyev, B.; Islamgozhayev, T.; Yedilkhan, D. Federated Self-Supervised Few-Shot Face Recognition. J. Imaging 2025, 11, 370. [Google Scholar] [CrossRef]
- Ruan, D.; Mo, R.; Yan, Y.; Chen, S.; Xue, J.H.; Wang, H. Adaptive Deep Disturbance-Disentangled Learning for Facial Expression Recognition. Int. J. Comput. Vis. 2022, 130, 455–477. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Q.; Wang, S. Learning deep global multi-scale and local attention features for facial expression recognition in the wild. IEEE Trans. Image Process. 2021, 30, 6544–6556. [Google Scholar] [CrossRef]
- Ezerceli, Ö.; Eskil, M.T. Convolutional Neural Network (CNN) Algorithm Based Facial Emotion Recognition (FER) System for FER-2013 Dataset. In Proceedings of the 2022 International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME), Male, Maldives, 16–18 November 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR—Proceedings of Machine Learning Research: Atlanta, GA, USA, 2021; Volume 139, pp. 8748–8763. [Google Scholar]
- Chen, J.; Gong, W.; Xiao, R.; Zhou, Z. Face Frontalization Method with 3D Technology and a Side-Face-Alignment Generative Adversarial Networks. In Proceedings of the 2024 IEEE 12th International Conference on Information, Communication and Networks (ICICN), Guilin, China, 21–24 August 2024; pp. 478–484. [Google Scholar] [CrossRef]
- Zhou, N.; Liang, R.; Shi, W. A Lightweight Convolutional Neural Network for Real-Time Facial Expression Detection. IEEE Access 2021, 9, 5573–5584. [Google Scholar] [CrossRef]
- Xie, Y.; Gao, Y.; Lin, J.; Chen, T. Learning consistent global-local representation for cross-domain facial expression recognition. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2489–2495. [Google Scholar]
- Sadeghi, H.; Raie, A.A. HistNet: Histogram-based convolutional neural network with Chi-squared deep metric learning for facial expression recognition. Inf. Sci. 2022, 608, 472–488. [Google Scholar] [CrossRef]
- Zeng, J.; Shan, S.; Chen, X. Facial expression recognition with inconsistently annotated datasets. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 222–237. [Google Scholar]
- Wu, C.; Li, J.; Zhou, J.; Lin, J.; Gao, K.; Yan, K.; Yin, S.; Bai, S.; Xu, X.; Chen, Y.; et al. Qwen-Image Technical Report. arXiv 2025, arXiv:2508.02324. [Google Scholar] [CrossRef]
- Liu, H.; Cai, H.; Lin, Q.; Li, X.; Xiao, H. Adaptive multilayer perceptual attention network for facial expression recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6253–6266. [Google Scholar] [CrossRef]
- Chen, D.; Wen, G.; Li, H.; Chen, R.; Li, C. Multi-relations aware network for in-the-wild facial expression recognition. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3848–3859. [Google Scholar] [CrossRef]
- Owusu, E.; Appati, J.K.; Okae, P. Robust facial expression recognition system in higher poses. Vis. Comput. Ind. Biomed. Art 2022, 5, 14. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Zhang, X.; Kauttonen, J.; Zhao, G. Uncertain facial expression recognition via multi-task assisted correction. IEEE Trans. Multimed. 2023, 26, 2531–2543. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Q.; Zhou, F. Robust lightweight facial expression recognition network with label distribution training. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 19–21 May 2021; Volume 35, pp. 3510–3519. [Google Scholar]
- Gu, Y.; Yan, H.; Zhang, X.; Wang, Y.; Ji, Y.; Ren, F. Toward facial expression recognition in the wild via noise-tolerant network. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 2033–2047. [Google Scholar] [CrossRef]
- Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Conditional adversarial domain adaptation. Adv. Neural Inf. Process. Syst. 2018, 31, 1647–1657. [Google Scholar]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion aware facial expression recognition using CNN with attention mechanism. IEEE Trans. Image Process. 2018, 28, 2439–2450. [Google Scholar] [CrossRef]
- Lee, C.Y.; Batra, T.; Baig, M.H.; Ulbricht, D. Sliced wasserstein discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10285–10295. [Google Scholar]
- Zhang, F.; Xu, M.; Xu, C. Weakly-supervised facial expression recognition in the wild with noisy data. IEEE Trans. Multimed. 2021, 24, 1800–1814. [Google Scholar] [CrossRef]
- Wang, K.; Peng, X.; Yang, J.; Meng, D.; Qiao, Y. Region attention networks for pose and occlusion robust facial expression recognition. IEEE Trans. Image Process. 2020, 29, 4057–4069. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. From Facial Expression Recognition to Interpersonal Relation Prediction. Int. J. Comput. Vis. 2018, 126, 550–569. [Google Scholar] [CrossRef]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing Uncertainties for Large-Scale Facial Expression Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Xu, R.; Li, G.; Yang, J.; Lin, L. Larger norm more transferable: An adaptive feature norm approach for unsupervised domain adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1426–1435. [Google Scholar]
- Shao, J.; Wu, Z.; Luo, Y.; Huang, S.; Pu, X.; Ren, Y. Self-paced label distribution learning for in-the-wild facial expression recognition. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 161–169. [Google Scholar]
- Shen, L.; Jin, X. VaBTFER: An Effective Variant Binary Transformer for Facial Expression Recognition. Sensors 2024, 24, 147. [Google Scholar] [CrossRef]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.