Abstract
In the intelligent tomato-picking scenario, challenges such as insufficient accuracy in recognizing the growth pose of target tomatoes and inaccurate positioning of picking and grasping points have led to low efficiency in automated picking. To address these issues, this paper introduces an object detection optimization model based on Yolov8s, termed YOLOv8S-ECC. The model focuses on “Judging tomato pose by the spatial vector of the relative position between the calyx and the center point of the fruit,” aiming to enhance high-precision positioning of both the tomato calyx and fruit, thereby laying the groundwork for subsequent pose judgment and picking point positioning. We have integrated the ECA (Efficient Channel Attention) and Coordinate attention mechanisms into the Backbone network and introduced the CBAM (Convolutional Block Attention Module) attention mechanism into the Neck network. The combined effect of these attention mechanisms effectively overcomes the recognition challenges posed by the calyx’s color texture, which closely resembles the environment. This integration has also enhanced the model’s robustness in complex field environments. Test results indicate significant improvements: the accuracy rate, recall rate, and mAP@50 for detecting tomato fruits and calyces are 81.7% and 87.5%, 92.7% and 85.9%, and 89.7% and 91.3%, respectively, compared to the original model. By encapsulating the algorithm and integrating it with the picking robot, tests in a simulated environment (different lighting conditions and foliage occlusion situations) show picking success rates of 93.02%, with an average picking operation time of 14.2 ± 0.855 s, including an image recognition and processing time of 0.035 s. This research offers an effective technical solution for high-precision visual perception and pose judgment in fruit and vegetable picking robots, contributing to improved quality in tomato industry picking operations.
1. Introduction
Tomatoes, a high-value crop cultivated globally, depend heavily on manual labor for traditional harvesting, necessitating significant labor annually. However, with accelerated urbanization and an aging population, agricultural labor shortages have become increasingly pronounced, complicating large-scale harvesting demands. Consequently, automating tomato harvesting has become an essential trend and a critical strategy to address labor challenges [1,2]. Robot-based fruit harvesting systems not only enhance agricultural production efficiency and reduce costs but also ensure operator safety and improve fruit quality [3,4]. For robots to achieve efficient and precise harvesting, accurately identifying and locating target fruits is crucial [5,6]. This task is fundamental for subsequent motion planning, obstacle avoidance, and precise manipulator grasping, ultimately determining the overall efficiency and success of the automated picking system [7,8].
Tomato harvesting is primarily categorized into two methods: cluster harvesting, suitable for small tomatoes like cherry tomatoes, and single-fruit harvesting, typically used for larger tomato varieties. This study concentrates on single-fruit harvesting techniques. Unlike cluster harvesting, single-fruit harvesting is necessary for larger tomatoes because their maturity often varies significantly within the same cluster [9]. Consequently, cluster harvesting becomes impractical, requiring individual attention for each ripe tomato. Additionally, large tomatoes usually grow in unstructured environments. The presence of branches and leaves, along with the overlapping and varied orientations of fruits in the same cluster, complicates the accurate identification of geometric information. Thus, developing high-precision target detection and positioning technology is a core challenge and a primary research focus in advancing tomato-picking robots.
To acquire geometric information about fruit, depth maps combined with color images are typically employed to deliver three-dimensional (3D) coordinates and visual pixel representation. For instance, Song et al. [10] developed an enhanced YOLOv8 model integrated with a depth camera, achieving a 91.3% success rate in identifying and locating picking points on string tomato fruit stalks. Similarly, Yin et al. [11] introduced a method for detecting grape clusters and accurately recognizing their postures using mask R-CNN with binocular images. Suguru Uramoto et al. [12] calculated the center coordinates and diameters of tomato fruits using depth data from a depth camera, achieving a recognition accuracy rate of 96.3% in facility horticulture. While deep learning-based fruit detection has been applied to various target fruits, most studies have concentrated on providing geometric information for fruit capture [13,14,15]. The methods above effectively support fruit localization but remain fundamentally “fruit-centered” detection strategies. This fruit-centric approach to geometric information acquisition has a critical limitation: it neglects the calyx region, which is directly related to the picking point. As the structural hub that links the fruit and the pedicel, the calyx’s spatial position and morphology are essential for assessing the fruit’s growth posture and for identifying the optimal grasping site. Using only the fruit center coordinates cannot fully capture the fruit’s orientation in three-dimensional space, and this shortcoming is a primary cause of the limited positioning accuracy observed in current methods under complex grasping conditions.
Current research has demonstrated that the disturbance and separation effects between fruits like tomatoes and plants during picking, as well as the grasping posture, are linked to the separation mode [16]. Therefore, acquiring comprehensive information about fruit pose is crucial for enhancing the success rate of robotic automated picking operations. To address fruit growth pose identification, Kang et al. [17] developed a DNN-based modeling method for apple segmentation and harvesting environments, which identifies the fruit center and determines the grasping direction. Kim et al. [18] introduced an attitude estimation method for tomato fruit-bearing systems. By employing a bottom-up detection method to identify and pair four key points (fruit-center, calyx, abscission zone, and branch point) of multiple tomato stems, they reduced the computational load associated with detecting numerous tomatoes simultaneously. Kim et al. [19] proposed the tomatoes deep learning network, which identifies the maturity of each tomato and estimates the 6D postures of the fruits and lateral stems, achieving average recognition accuracies of 96.90% and 96.83%, respectively [20]. This network uses depth information to guide robotic arms in picking point identification, with real-world experiments showing a 65% success rate in recognition and 92.6% accuracy in vision processing for picking point localization. Although recent studies have shifted attention to detecting fruit stalk posture and key points, two limitations remain. First, these methods target the stalk rather than the calyx. Because the abscission layer lies near the calyx, the calyx’s position relative to the fruit more directly indicates the fruit’s growth posture. Second, although multi-key-point detection yields rich information, such models are relatively complex, which makes it difficult to balance accuracy and efficiency for multi-target real-time detection. In 2023, Sun et al. [21] introduced a method for fruit recognition, location, and picking using deep learning and active perception in environments with occlusion and varying illumination. Their method achieved a picking success rate of 90% and an average occlusion estimation error of 16%. Despite some researchers emphasizing the importance of fruit stalk posture and key point detection for picking, particularly related to the calyx region, there is still a lack of detection models specifically targeting calyx morphology [22,23]. Although significant progress has been made in detecting fruit growth poses in real environments, practical application in picking robots remains limited. High-precision models often have complex structures and heavy computational demands, hindering their ability to ensure both recognition accuracy and real-time performance in complex field environments. In scenarios with dense areas, occlusions, and overlaps, traditional or simplified models struggle, significantly reducing positioning accuracy and failing to meet actual picking requirements [24,25].
Despite significant advancements in target detection and pose estimation technology, challenges persist when applying these techniques to automated tomato harvesting. Existing research primarily focuses on detecting and localizing tomato fruits, overlooking the crucial calyx region essential for precise fruit identification and determining optimal picking positions. The calyx, linking the fruit to the stalk, plays a vital role in assessing fruit growth posture. However, current research lacks emphasis on this aspect. In complex field settings with overlapping fruits and obstructing foliage, deep convolutional networks often lose critical spatial information during down sampling, reducing the model’s accuracy in locating dense small targets like calyxes. Moreover, high-precision detection models suffer from high computational complexity and slow inference rates, failing to strike a balance between accuracy and real-time performance on resource-constrained robotic platforms. These limitations hinder the efficiency and stability required for practical field applications. Hence, developing an effective visual perception model capable of jointly detecting tomato fruits and calyxes in intricate settings and enabling posture differentiation is crucial for enhancing the automation proficiency of tomato-harvesting robots.
Although the YOLO series has undergone rapid iteration with releases such as YOLOv9 and YOLOv10, YOLOv8s offers a favorable trade-off between detection accuracy and inference speed and is therefore better suited for deployment on picking robots. To address the shortcomings of prior work, this study proposes YOLOv8s-ecc, a tomato growth posture detection model based on an optimized version of YOLOv8s. Additionally, a tomato-picking robot is designed to validate the model experimentally. To overcome the challenge of missing calyx detection at the target level, a synchronous detection model for tomato fruits and calyxes is developed. The growth posture of tomatoes is determined by identifying the spatial vectors of the center points of calyxes and fruits. To improve spatial positioning accuracy in complex environmental scenarios, module design is conducted. Given the high similarity in color and texture between the calyx of a tomato and the background of branches and leaves, traditional convolution struggles to distinguish them effectively. Therefore, enhancing feature expression in both the channel and spatial dimensions simultaneously becomes necessary. Specifically, we integrate the ECA (Efficient Channel Attention) module into the backbone network to facilitate lightweight local cross-channel interaction via one-dimensional convolution, thereby enhancing the channel response sensitive to the fine texture of the calyx. Simultaneously, we introduce the Coordinate Attention module, which decomposes spatial attention into horizontal and vertical directions for encoding. This approach retains precise spatial position information within the deep network and improves the positioning capability of occluded targets. Building on this foundation, we incorporate the CBAM (Convolutional Block Attention Module) into the neck network. Through a sequential mechanism of “channel screening first, then spatial focusing,” we recalibrate the channel and spatial dimensions of the fused features, effectively mitigating noise interference from the branch and leaf background. To tackle the challenge of balancing accuracy and efficiency at the model level, we employ the aforementioned lightweight attention module, which enhances detection accuracy with only a slight increase in the number of parameters. Furthermore, by identifying the centers of tomato fruits and calyxes, we propose a multi-feature fusion algorithm to determine the picking and grasping points, as well as to estimate the grasping posture of the picking manipulator. Finally, we map the camera coordinate system to the robotic arm coordinate system using the hand-eye calibration algorithm, enabling the end effector of the picking robot to accurately position and adjust its posture for autonomous picking operations.
2. Materials and Methods
This study develops a tomato pose–detection method tailored to complex natural environments and integrates it into the computing platform of a harvesting robot. Here we describe the methodology used to evaluate tomato fruit and calyx detection under challenging conditions. The protocol covers image acquisition, data preprocessing, model enhancement, model training, and validation.
2.1. System Design and Operation
We designed a tomato-picking robot that uses machine vision and deep learning to operate in greenhouse growth environments (see Figure 1). The system comprises three main components: a six-axis grasping arm, an Ackermann-steered intelligent mobile chassis, and a depth camera. Because tomato clusters create a complex, cluttered workspace, the picker must perform real-time obstacle avoidance to minimize disturbances and damage to surrounding foliage. For this reason, we selected a six-axis robotic arm (FR3MT, FAIRINO, Suzhou, China) with a 3 kg effective payload and a 622 mm working radius. A soft end-effector mounted on the arm can grasp fruits up to 150 mm in diameter. The mobile base is the MK-mini chassis (Shenzhen Yuhesen Technology Co., Ltd., Shenzhen, China). To detect and localize target fruits at both short and long ranges, we selected a RealSense D435i depth camera (RealSense D435i, Intel Corporation, Santa Clara, CA, USA) with a 0.3–3 m detection range. A six-axis robotic arm is mounted on the base of an Ackermann intelligent mobile chassis to ensure stability and sufficient reach during picking (the tomato fruits in the greenhouse used for the experiment are below 600 mm in height). The depth camera is mounted on the arm’s end effector in an “eye-in-hand” configuration so its viewing angle adjusts in real time as the arm moves. A soft picking manipulator attaches to the arm’s terminus, and silicone fingertips protect the fruits from damage. An industrial computer (MIX 8745H48 high-performance industrial computer, Thunderobot Technology Co., Ltd., Qingdao, China) and the battery management system are integrated inside the chassis to provide dust and splash protection.

Figure 1.
Machine Organization.
The tomato-picking robot’s operational process (see Figure 2) begins with field route planning and autonomous navigation through the fusion of LiDAR and depth camera data. Simultaneously, the onboard depth camera captures real-time images of potential ripe fruits. Upon detecting a ripe fruit, the harvester halts and transitions into a stationary picking mode. Subsequently, to enhance grip precision, the control shifts to a high-accuracy visual-servo routine guided by the manipulator’s end-effector depth camera. By utilizing the collaborative recognition and localization model for calyx-fruit interaction detailed in this study, along with detailed fruit images from the depth camera, the system calculates the spatial positions and orientations of the fruit and its calyx. It then devises the optimal picking trajectory and grasp pose for the manipulator. The computed 3D coordinates are converted into the manipulator frame via a pre-calibrated hand-eye transformation matrix, which guides the arm to the target and refines the grasp posture. The robot detaches the fruit with a combined twisting-and-pulling motion and then moves the manipulator to the next pre-grasp position for the following target.
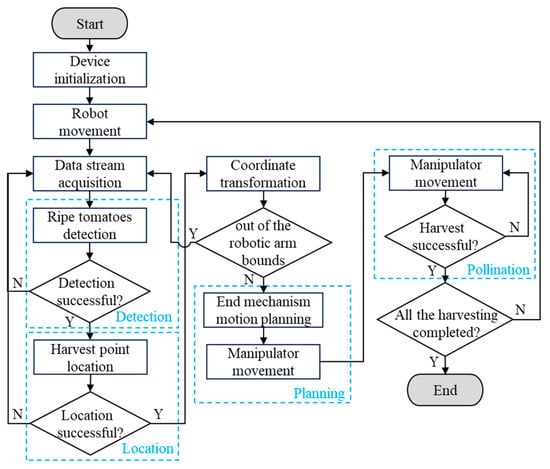
Figure 2.
Operation Flowchart.
2.2. Object Detection
To develop a tomato fruit dataset that accurately reflects the complex conditions found in real agricultural fields, RGB images of tomatoes were collected at the Xinyuan Vegetable Planting Professional Cooperative in Qinggang County, Suihua City, Heilongjiang Province (126°9′17″ E, 46°42′36″ N). This cooperative employs a solar greenhouse cultivation model. Data collection occurred during the peak fruiting period of the plants, specifically from June to July 2025. Daily collection times were scheduled from 08:00 to 11:30 and from 14:00 to 16:30. These timeframes correspond to morning side light irradiation and afternoon frontal light irradiation, effectively covering the typical lighting angles encountered during the operation of a picking robot. Images were captured using a smartphone (Huawei Mate40pro, equipped with a rear main camera) at a resolution of 3072 × 4096 pixels. The shooting distance was maintained between 0.2 and 0.8 m, simulating the actual working distance of the camera at the end of the robotic arm as it approaches the target. The collection environment was intentionally designed to replicate the visual conditions experienced during the operation of the picking robot. Various shooting perspectives were utilized, including front view, top view, and oblique view. The lighting conditions encompassed strong direct light, weak light, and scattered light on cloudy days (see Figure 3), with a maximum occlusion area of 50% for the target.

Figure 3.
Photos from different perspectives and lighting datasets: (a) overhead view, (b) elevated view, (c) strong light, (d) dim light and (e) diffused light.
After the initial collection, we screened images according to the morphological characteristics and visibility of tomato fruits and calyces under practical cultivation conditions. We removed images in which a fruit or calyx was occluded by leaves, stems, or other fruits by more than 50% or captured from extreme angles that do not reflect the observation geometry of routine robotic operations. Images with severe blur, defocus, or overexposure that obscured key features were also excluded. After this screening, 700 images with clear, distinguishable features remained.
During data preprocessing, all images were resized to 640 × 640 pixels to comply with the input specifications of the YOLOv8s model, ensuring preservation of crucial fruit and calyx texture details. Subsequently, manual bounding box labeling for the targets was conducted on the Roboflow online labeling platform. Tomatoes were categorized into ripe (red/pink) and unripe (green) groups during labeling, with a distribution ratio of 11:12. Additionally, the calyx was individually labeled, with its boundary adjusted to snugly enclose the target region. To enhance the model’s resilience in challenging field conditions and mitigate sensor discrepancies between smartphone cameras and Intel RealSense D435i depth cameras on harvesting robots, data augmentation techniques were applied to the training images. These techniques included random rotation (±15°), salt-and-pepper noise, and Gaussian blur to replicate image variations such as jitter, lighting changes, and slight defocusing (see Figure 4a).
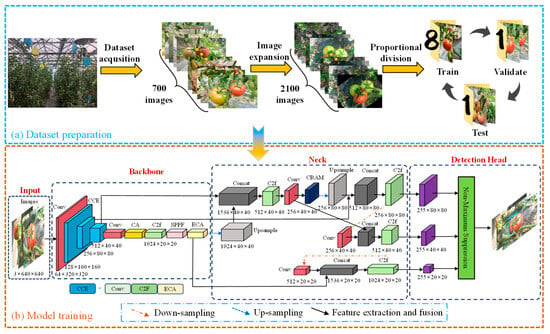
Figure 4.
Model structure diagram: (a) Dataset preparation and (b) Model training.
In complex, unstructured natural environments, tomato fruits often overlap and occlude one another, and ripe fruits share similar colors and shapes. Calyces have texture features that resemble nearby stems and leaves. Frequent mutual occlusion between fruits and foliage blurs object boundaries and creates feature ambiguity, which severely impairs recognition and localization. As neural networks deepen, spatial information in deep features diminishes and the spatial cues needed for precise localization are progressively lost. This loss makes it difficult for models to separate individual fruits and their calyces from dense foliage. These environmental challenges therefore increase false negatives and false positives and degrade localization accuracy in baseline models.
Considering the need for real-time performance, high detection accuracy, and lightweight deployment in agricultural settings, we adopted YOLOv8s as the baseline and enhanced it with a triple-attention mechanism (see Figure 4b). By integrating three lightweight modules—ECA channel attention, CA coordinate attention, and CBAM hybrid attention—we build a multi-level feature enhancement network that improves detection performance in complex agricultural environments.
To improve detection of tomato fruits and their calyces, we augment the YOLOv8s model with a three-part attention framework. An ECA channel-attention module is inserted after key backbone layers; using adaptive one-dimensional convolution, it amplifies channel responses tied to fine-grained features and thus improves recognition under occlusion. A CA coordinate attention mechanism is added at the trunk network’s terminus; by means of decomposed global pooling, it encodes direction-aware spatial coordinates and complements the downstream SPPF module, thereby improving localization of dense targets. During feature fusion, a CBAM module is applied; its sequential channel and spatial branches jointly emphasize salient feature channels and spatial regions to optimize multi-scale fusion. Together, the three attention modules form a cohesive pipeline that spans channel to spatial and local to global scales, enhancing robustness and accuracy in complex agricultural settings while imposing minimal additional computational overhead.
- (1)
- ECA (Efficient Channel Attention mechanism)
The Efficient Channel Attention (ECA) mechanism implements lightweight local cross-channel interactions using a one-dimensional convolution [26]. Its main advantage is that it avoids conventional dimensionality reduction, which enhances channel dependency modeling while adding a few parameters. The module has three steps-global average pooling, adaptive determination of the convolution kernel, and a one-dimensional convolution-incurring negligible inference overhead and making it suitable for real-time detection (see Figure 5).
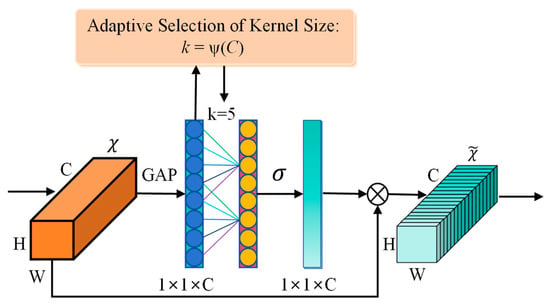
Figure 5.
ECA attention mechanism structure diagram.
In this study, we inserted the ECA module after each scale-changing layer of the backbone network. The module generates a weight for every feature map channel, enhancing key channel responses and suppressing irrelevant information with minimal computational overhead. As a result, the network gains adaptive feature selection capability and concentrates computation on the most discriminative features, improving detection robustness for occluded tomatoes and for objects with diverse calyx morphology.
After integrating the ECA module into the C2f module, channel-level refinement is applied to rich multi-scale features to select informative channels and suppress noise. This refinement amplifies responses in channels that register subtle textures, such as calyces, and improves discrimination among similar features. Concurrently, ECA dynamically down weights redundant channels in deep layers and highlights discriminative ones, which increases robustness to occlusion and scale variation while balancing detection accuracy and inference efficiency.
- (2)
- CA (Coordinate Attention mechanism)
A major challenge in deep learning visual detection of tomatoes and calyces is precise localization of targets that share similar shapes, vary in size, and often occlude one another. Conventional convolutional neural networks lose crucial spatial positional information as they extract high-level semantic features. To mitigate this loss, we integrated a CA coordinate attention mechanism into the model (see Figure 6) [27].
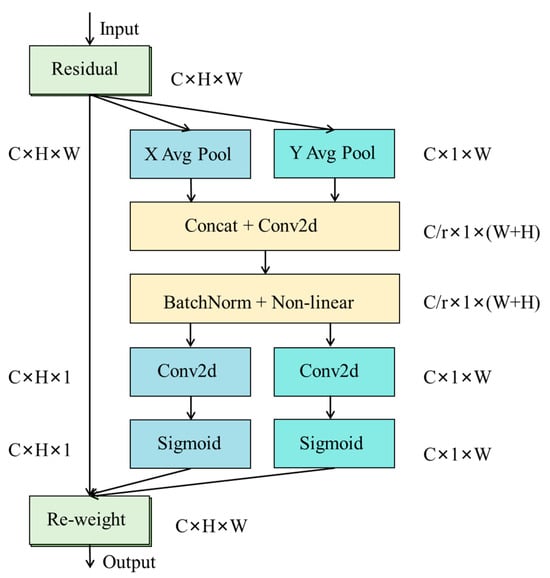
Figure 6.
CA attention mechanism structure diagram.
The Coordinate Attention (CA) mechanism is a lightweight module that decomposes global spatial awareness into two independent directions, width and height, for processing. By performing parallel one-dimensional global pooling along the horizontal and vertical axes, it generates direction-aware feature encodings that capture long-range spatial dependencies. These encodings align feature responses precisely with specific image rows and columns, reconstructing spatial awareness within deep semantic features. In this study, the CA module is appended to the backbone network to restore spatial information attenuated by down sampling in semantically rich, deep layers, thus allowing subsequent predictions to combine semantic context with positional cues. The CA-enhanced feature maps are then passed to an SPPF module for multi-scale context fusion, forming a complementary pair: CA supplies precise positional encoding while SPPF aggregates multi-scale semantic information. Together, they establish a foundation for the detection head to achieve precise localization in scenes with dense targets and complex backgrounds. The addition of CA therefore improves the model’s spatial localization capacity and multi-scale perception.
- (3)
- CBAM (Convolutional Block Attention Module)
As a lightweight, general-purpose module with a sequential architecture, CBAM sequentially infers attention weights along two independent dimensions channel and spatial and multiplies these weights with the input feature map to achieve adaptive feature refinement (see Figure 7) [28].
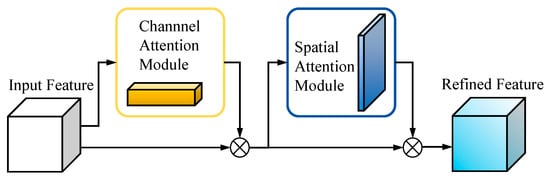
Figure 7.
CBAM attention mechanism structure diagram.
The CBAM module is inserted at key fusion nodes of the feature pyramid, immediately after up sampling deep features and concatenating them with mid-level features. It progressively recalibrates the fused features through sequential channel and spatial attention submodules. The channel attention submodule applies global average pooling and global max pooling in parallel, then passes the pooled descriptors through a shared MLP to produce channel-wise weights that amplify discriminative channels. The spatial attention submodule performs analogous pooling on the reweighted features and uses a convolutional layer to generate a spatial weight map that highlights salient regions and suppresses background interference.
In tomato fruit and calyx detection, CBAM’s bidirectional refinement is especially valuable. Faced with occlusion, morphologically similar calyces, and small targets, the module increases the discriminative power of the feature pyramid. By adding contextual awareness, it converts simple multiscale concatenations into feature representations that are more relevant to the task. This change improves the model’s ability to separate easily confused targets and to localize small calyces, while mitigating channel redundancy and spatial entanglement during feature fusion. CBAM suppresses distracting information and highlights critical fruit and calyx features, supplying the detection head with inputs that have a higher signal-to-noise ratio for more reliable detection in complex natural environments.
2.3. Positioning of the Harvesting and Grabbing Points for Tomato Fruits
Before harvesting, the robot captures RGB images and depth maps of the tomato plants with a D435i depth camera to detect and localize fruits and calyces. Once targets are identified, we perform hand-eye calibration between the manipulator and the depth camera to map image coordinates into the robot arm’s workspace precisely. Ignoring lens distortion, the mapping converts pixel coordinates of the target frame center and its depth, using the camera intrinsic matrix and the extrinsic matrix that specifies the pose between the camera and the robot base. The coordinate transformation is illustrated in Figure 8a.
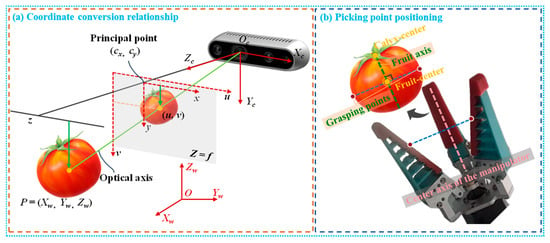
Figure 8.
Schematic diagram of picking point positioning and twisting.
First, image coordinates are converted to camera coordinates using Equation (1). Next, rotation and translation are applied via Equation (2). Finally, the camera coordinates are converted to world coordinates (the robot arm base coordinates) using Equation (3).
In the equation, (, , ) denotes the camera coordinate system, (, , ) denotes the world coordinate system, and (, ) denotes a point in the pixel coordinate system. and are the transformation matrices, with the rotation matrix and the translation matrix. and are the rotation matrix and translation vector of the camera relative to the robot end-effector. Reb and teb are the rotation matrix and translation vector of the robot end-effector relative to the robot base. is the depth of the target center pixel. and are the camera’s horizontal and vertical focal lengths, respectively, and and are the pixel centers in the horizontal and vertical image directions, respectively.
The Intel RealSense D435i is factory-calibrated and can directly provide three-dimensional coordinates. We determine the transformation from the camera coordinate frame to the robot base frame via hand–eye calibration. The rotation matrix is:
The translation vector is:
The transformation from the robot base to its end effector is obtained using the Denavit–Hartenberg (DH) parameters. Together, the above transformation matrices provide a complete mapping from the camera coordinate system to the end-effector coordinate system of the robotic arm.
The pedicel spatial vector is obtained from the line connecting the tomato calyx center to the fruit center (see Figure 8b). The grasping position is defined as the intersection of the fruit contour and the line through the fruit center that is perpendicular to the pedicel. After computing the pedicel vector, the end effector is commanded to align its central axis with that vector by rotating and translating the manipulator so the central axis coincides with the pedicel direction. Once the end-effector pose is adjusted, real-time depth data from the depth camera are fused with two-dimensional pixel coordinates via the calibrated hand-eye transformation to yield the three-dimensional position in the robot base frame; this position is the final picking-point coordinate. The system then plans and controls the manipulator to move to the picking point and actuates the gripper to grasp, thereby achieving precise tomato harvesting.
2.4. Experimental Configuration and Evaluation Metrics
Experiments were performed on a Windows 11 Pro 64-bit workstation configured for YOLOv8 training. The hardware included an NVIDIA RTX 4060 GPU (8 GB GDDR6, CUDA 11.8 support), an Intel Core i7-14650HX CPU, and high-speed storage to ensure adequate computation and data I/O performance. We used PyTorch 2.0.0 as the primary deep-learning framework and CUDA 11.8 for GPU acceleration. During training, the batch size was set to Batch_size = 8, and the input image resolution was fixed at 640 × 640 pixels to perform target detection in agricultural scenarios.
To assess the model’s detection performance on tomatoes and calyxes and its engineering practicality, we used precision (P), recall (R), mean average precision at IoU 0.5 (mAP@0.5), weight, and parameters as the primary evaluation metrics.
Precision is the fraction of predicted positive samples (tomato/calyces) that are correctly identified, and it primarily assesses the model’s ability to reduce false positives.
Here, TP denotes true positives, the number of positive samples the model correctly predicts. FP denotes false positives, the number of negative samples the model incorrectly labels as positive. TP + FP is the total number of instances the model predicts as positive.
Recall denotes the proportion of ground-truth target instances correctly identified by the model. It primarily reflects the model’s rate of missed detections (False Negatives) across challenging sample types, such as occlusion, small object size, and complex backgrounds.
Mean Average Precision (mAP@0.5) is a principal composite metric for object detection. For this evaluation, we compute the average precision for the two classes, tomato and calyx, at a fixed IoU threshold and then average those values. This yields a single measure that reflects the model’s detection performance across confidence thresholds and gauges its overall robustness.
P denotes precision, R denotes recall, and N denotes the total number of classes; mAP@0.5 denotes the mean Average Precision calculated at an IOU threshold of 0.5.
To assess deployment feasibility and computational efficiency, we also report Weights and parameter count as auxiliary metrics. Weight determines storage requirements and loading speed on embedded or mobile platforms. Parameter count indicates model complexity and computational demand, and it serves as a key indicator of expected real-time performance and hardware compatibility.
In summary, precision, recall, and mAP@0.5 together quantify the model’s detection accuracy, while weight and parameter count indicate its engineering practicality and deployment efficiency. The accuracy metrics exhibit an intrinsic trade-off, whereas the size and parameter measures more directly determine operational performance in real-world systems.
3. Results and Discussion
3.1. Comparison of Indicators Between the Baseline Model and the Optimized Model
To assess the overall performance of the proposed YOLOv8s-ECC model, we performed a systematic comparison with the original YOLOv8s baseline. We examined visualization results for key metrics, including training and validation losses (see Figure 9) and detection accuracy (see Figure 10). This analysis clarifies how the ECC optimization strategy affects model performance and provides an intuitive, reliable basis for evaluating the effectiveness of the optimization.
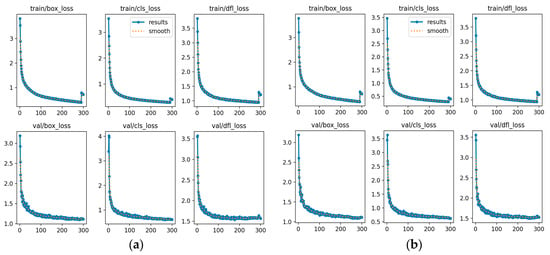
Figure 9.
Comparison chart of losses between the baseline model and the optimized model: (a) Loss curve of the original model; (b) Loss curve of the YOLOv8s-ECC model.
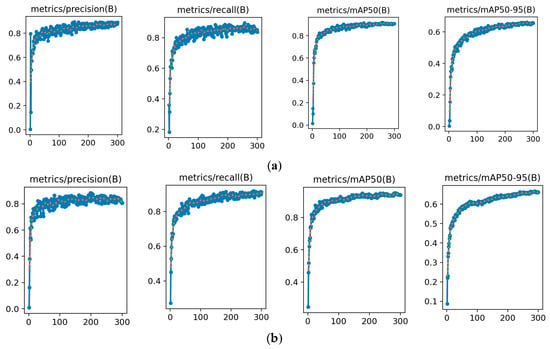
Figure 10.
Comparison chart of the accuracy between the baseline model and the optimized model: (a) Accuracy curve of the original model; (b) Accuracy curve of the YOLOv8s-ECC model.
Compared with the baseline YOLOv8s model, YOLOv8s-ECC exhibits a faster decline and a steeper slope in the early training stage, indicating that the optimized model captures data features more rapidly and its gradients converge more quickly. In the middle and late stages, the YOLOv8s-ECC training loss shows smaller fluctuations and greater smoothness, demonstrating that the optimization strategy enhances training stability and reduces gradient noise during parameter updates.
The validation–loss curve for YOLOv8s-ECC consistently lies below that of the baseline model, and the gap between training loss and validation loss is reduced. These observations indicate that YOLOv8s-ECC improves fit to the training set and, in turn, enhances the model’s generalization and robustness.
Across the six loss curves, YOLOv8s-ECC clearly outperforms the baseline YOLOv8s in three main aspects: convergence speed, training stability, and final accuracy. The optimization strategy reduces the baseline model’s late-stage overfitting by modifying the model architecture and training mechanisms. At the same time, it speeds loss convergence, providing a foundation for improved object detection accuracy.
For the final stable values, both precision and recall of YOLOv8s-ECC exceed those of the baseline YOLOv8s. Higher precision indicates the model more effectively reduces false detections and thus improves the reliability of predicted bounding boxes. Higher recall indicates enhanced detection of small targets, occluded targets, and targets in complex backgrounds, substantially lowering the missed-detection rate.
Across comprehensive evaluation metrics, YOLOv8s-ECC surpasses the baseline. Its final stable mAP@50 is higher, indicating improved overall detection accuracy under looser localization requirements. The two models show similar values on the more demanding mAP@50-95, indicating that the proposed improvements preserve precise localization ability and maintain strong performance at stricter IoU thresholds, which supports deployment in applications with high positioning accuracy demands.
In summary, YOLOv8s-ECC surpasses the baseline YOLOv8s across all key detection metrics, validating the effectiveness and superiority of the improvement strategy proposed in this paper and offering a more competitive solution for object detection tasks.
3.2. Ablation Test
To evaluate the contribution of each improved module, we conducted ablation experiments and compared performance across different module combinations. We assessed the effects of these combinations on the model’s ability to detect tomato fruit and calyx (see Table 1).

Table 1.
Comparison of ablation experimental data.
Ablation results show that the YOLOv8s-ECC model, which integrates ECA, CA, and CBAM attention modules, yields the best overall performance for tomato and calyx detection. The model offers especially strong improvements in tomato recall and calyx precision, confirming that the proposed combination of modules enhances detection robustness and accuracy.
When the model includes only the CBAM module and lacks the CA module, calyx detection shows a pattern of high precision but low recall. Precision reaches 86.1%, while recall is only 74.8%. This outcome stems from the strong similarity in color (both green) and texture between calyces and the surrounding branches and leaves, which limits the ability of conventional convolutions to discriminate them. The CBAM first applies channel-wise weighting to the feature map, amplifying channels that respond to the calyx’s fine texture. It then uses spatial attention to emphasize the spatial regions containing the target and suppress responses from background branches and leaves. This serial strategy of “channel selection followed by spatial focusing” directly matches the visual task of “identifying calyx features before locating the calyx,” and it therefore improves the model’s accuracy on positive samples. Nevertheless, when CBAM is used alone, it does not explicitly encode spatial location information, so its ability to increase detection coverage remains limited. After adding the CA module (Group 8), the calyx recall rose from 74.8% to 85.9% while precision remained stable. The CA module separates spatial attention into horizontal and vertical components, preserving precise location information in deep layers. Consequently, the model locates occluded or densely clustered calyx targets more effectively and reduces missed detections.
The ECA module’s primary function is optimized selection of feature channels. Introduced alone, the ECA module markedly improves precision in calyx detection, showing that it increases attention to channels that separate the calyx from background and enhances discrimination of subtle texture cues. Comparing Groups 5 and 8, adding ECA raises calyx recall from 79.4% to 85.9% while precision remains high. Thus, ECA complements the CA and CBAM modules, together providing a coherent optimization pipeline for channel selection, spatial localization, and feature calibration. Notably, all improved models retain parameter counts comparable to the baseline model, indicating that the introduced attention mechanisms substantially enhance performance without adding significant computational burden and thus offer practical feasibility for engineering and deployment. The multi-attention fusion strategy described here aligns with the recent detection results reported for the YOLO-TMPPD model proposed by Wang et al. [29]. In their ablation study, they added three modules—DWConv, CARAFE, and CBAM, and showed that CBAM increases the model’s focus on key tomato-picking regions along both channel and spatial dimensions. This finding agrees with our conclusion that CBAM improves calyx-detection accuracy. In addition, the ECA and CA modules introduced in this work complement CBAM by enhancing channel-wise selection and positional encoding, respectively.
In summary, the ablation studies confirm both the individual contributions of each attention module and, more importantly, their complementary interaction. The ECA module increases feature discriminability through a lightweight channel-attention mechanism. The CA module concentrates on spatial information extraction to improve recall. The CBAM module refines feature-weight allocation by applying attention across both channel and spatial dimensions. This multi-level, multi-dimensional attention scheme allows the YOLOv8s-ECC model to deliver more accurate and robust detection in complex agricultural settings, thereby laying a technical foundation for subsequent harvesting-point localization tasks.
3.3. Comparative Tests of Different Models
To evaluate model performance on tomato and calyx identification comprehensively, we compared SSD, Faster R-CNN, YOLOv5n, YOLOv5s, YOLOv6n, YOLOv10s, YOLOv11n, YOLOv11s, and the improved YOLOv8s-ECC proposed. The comparison covered two aspects: detection accuracy (precision P, recall R, and mean average precision mAP@0.5) and model complexity (weight file size and number of parameters) (Table 2).
Table 2.
Comparison of different model data.
The proposed YOLOv8s-ECC model achieved recalls of 92.7% for tomatoes and 85.9% for calyxes, and a calyx mAP@0.5 of 91.3%, outperforming the other models. These results indicate strong detection performance and robust recognition accuracy in complex natural environments. Although YOLOv6n attained a slightly higher tomato mAP@0.5 of 92.0% compared with YOLOv8s-ECC’s 89.7%, YOLOv8s-ECC surpassed YOLOv6n on all calyx metrics. Together, these findings show that the improved model better balances tomato and calyx detection and provides a distinct advantage for multi-object cooperative detection tasks.
YOLOv8s-ECC has 11.16 M parameters and a weight file size of 21.56 MB, which is substantially smaller than the two-stage detector Faster R-CNN. Although it is marginally larger than lightweight models such as YOLOv5s and YOLOv6, it offers a favorable trade-off between accuracy and efficiency, making it better suited for practical deployment.
Through comprehensive evaluation, the YOLOv8s-ECC model sustained high accuracy for calyx detection. Relative to YOLOv5n, it increased calyx recall by 12% and calyx mAP@0.5 by 7.8%, indicating that the introduced attention mechanism effectively reduces missed detections arising from the visual similarity between calyces and the plant background. The model also achieved 81.7% precision and 92.7% recall for tomato detection, yielding the highest recall among the compared models and demonstrating strong coverage of tomato targets in practical harvesting scenarios. Compared with traditional threshold segmentation and shape-factor image-processing methods for detecting tomatoes and calyxes, which achieve accuracies of 84–87.5% [30], the YOLOv8s-ECC proposed here automatically extracts features via deep learning and integrates multiple attention mechanisms, yielding higher detection accuracy in complex backgrounds.
In summary, the strategies introduced in this study significantly improved the feature extraction and discrimination capabilities of the YOLOv8s model. These modifications enabled more comprehensive and accurate detection of tomatoes and calyxes, substantially increasing recall while also improving precision, thereby demonstrating the effectiveness and superiority of the proposed approach.
3.4. Visual Analysis Under Different Improved Models
In complex field environments, a model’s capacity to extract salient features determines its final detection accuracy for tomato fruits. Based on the model quantification comparisons in Table 1, Faster R-CNN and SSD were excluded as viable baselines. Table 1 shows that Faster R-CNN and SSD reach mAP@0.5 values of only 66.5% and 54.8%, respectively, while their parameter counts are 41.3 M and 24.0 M, producing large weights and inference speeds unsuitable for real-time harvesting deployment. Consequently, this study adopts lightweight YOLO-family networks recently shown to offer a better balance of accuracy and efficiency as the basis for comparison and subsequent improvement, thereby preserving both detection performance and system real-time capability. To probe the internal effects of the proposed enhancements, we generated feature activation visualizations for YOLOv5, YOLOv6, YOLOv8s, YOLOv10, and YOLOv11, as well as for variants incorporating ECA, CBAM, and CA attention mechanisms; the resulting activation heatmaps are shown in Figure 11.
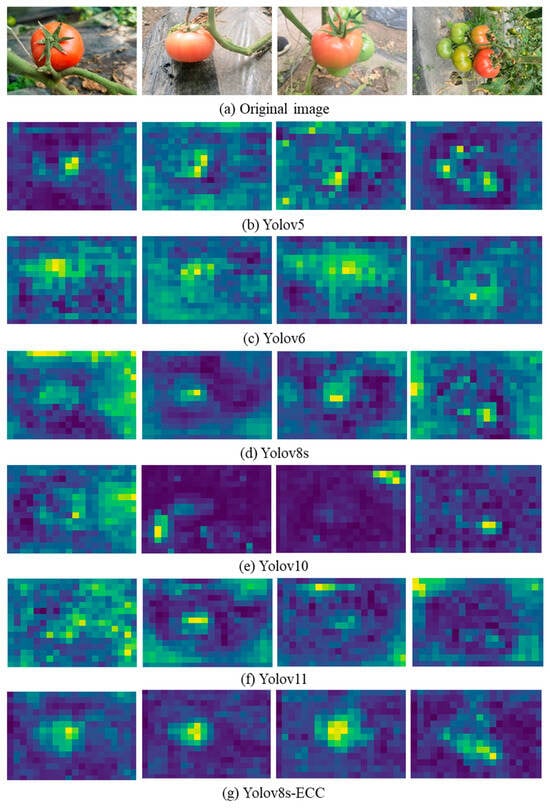
Figure 11.
Comparison of thermal maps for each model.
First, regarding localization precision, the original YOLO series models (see Figure 11b–f) produce heatmaps whose high-activation regions are often diffuse or offset from the tomato center. This pattern indicates that conventional convolutional networks, without attention guidance, distribute weights across object edges or noncritical regions. In contrast, the heatmap energy of the proposed YOLOv8s-ECC model is tightly concentrated on the fruit core, and the shape of the high-activation region closely matches the tomato’s biological morphology. This concentrated activation shows that integrating the three attention mechanisms enables the model to focus more precisely on discriminative target features and thus increases localization confidence.
Second, the improved model shows a clear advantage in selectively suppressing complex background noise in agricultural scenes. In YOLOv8s and YOLOv10, reflections from mulching film, dense foliage, and illumination changes produce numerous bluish-green, fragmented “pseudo-activation” points in non-target regions on model heatmaps; these noise activations largely drive false positives. By adding ECA to capture cross-channel interactions and combining it with CBAM for spatial attention weighting, the proposed model suppresses irrelevant background responses at the feature level. Experimental results indicate the enhanced model produces uniformly deep-colored background regions with virtually no misleading activations, which accounts for its very low false-positive rate in complex environments.
A detailed analysis of the multi-mechanism fusion shows that adding CA substantially improves localization. In scenes with clustered tomatoes and occluded fruits, heatmaps from competing models often merge multiple targets into a single contiguous region, obscuring individual boundaries. In contrast, our model preserves strong activation at each fruit’s center while encoding targets’ spatial positions. This benefit stems from the CA mechanism, which aggregates features along horizontal and vertical axes and thus enables the network to capture long-range spatial dependencies. When CA is combined with CBAM’s fine-grained highlighting of salient regions, the model reliably recovers independent feature contours for closely spaced or overlapping fruits, substantially improving discrimination of occluded targets.
In summary, the heatmap comparisons visually confirm the improved algorithm’s effectiveness. By integrating ECA, CBAM, and CA, the model refines features along spatial, channel, and positional dimensions, increasing the perceptual salience of tomato targets and suppressing environmental noise. This finding aligns with the gains in detection accuracy reported by the quantitative metrics and supports the practical value of combining multiple attention mechanisms for tomato detection.
3.5. Model Comparison Test in Complex Environment
To further validate the practical detection performance of the proposed YOLOv8s-ECC model, we selected representative tomato growth scenarios, single targets, environmental interference, occlusions from overlap, and dense multi-target distributions for visual comparative testing. We compared the recognition performance of YOLOv5, YOLOv6, YOLOv8, YOLOv10, YOLOv11, and YOLOv8s-ECC (see Figure 12).

Figure 12.
Comparison of model recognition performance.
In the single-target scenario, all models showed strong detection performance. In the second-row scenario, where peduncles occluded the fruits, YOLOv5 and YOLOv6 produced bounding boxes with noticeable localization errors, while the predicted boxes from YOLOv8s-ECC most closely matched the fruit boundaries, indicating its superior ability to suppress environmental noise.
In common overlap scenarios during tomato growth (third row), the baseline YOLO models often produce localization ambiguity at fruit boundaries and sometimes fail to detect fruits. In contrast, YOLOv8s-ECC, with optimized modules that strengthen local feature extraction, more reliably captures the partial contours of occluded targets and, through spatial-dimension feature augmentation, lowers the false-positive rate. In the most challenging case of densely clustered targets (fourth row), the complex background includes green leaves whose color and texture resemble the calyx [31]. Compared with YOLOv8s-ECC, YOLOv10 and YOLOv11 show larger confidence fluctuations for small peripheral tomatoes, display weaker calyx recognition, and are more prone to background texture interference that causes bounding-box drift.
In contrast, YOLOv8s-ECC achieved complete coverage of all tomatoes in the field of view and produced substantially more robust bounding boxes than the benchmark models while maintaining high confidence scores. Overall, YOLOv8s-ECC mitigates the native model’s weaknesses in inaccurate localization under complex backgrounds and missed detections of dense targets, striking an effective balance between detection accuracy and environmental adaptability and thus providing reliable technical support for subsequent autonomous harvesting robot operations.
3.6. Analysis of Harvesting Experiment Results
To validate the proposed tomato pose recognition method under realistic harvesting conditions, we constructed a simulated growth environment in the Northeast Agricultural University greenhouse and performed an automated picking test (see Figure 13a). Tomatoes were grown on a vertical trellis with crop heights ranging from 100 to 600 mm. Vines were intentionally arranged around some fruits to mimic the complexity of field harvesting. Experiments ran from 14:00 to 16:00, with indoor temperature maintained at 22–24 °C.

Figure 13.
(a) Tomato harvesting experimental verification; (b) Clustered mature fruit harvesting strategy; and (c) Strategies for harvesting clusters of immature fruits.
To determine the appropriate grasping force, we conducted preliminary experiments on a batch of tomato samples (fruit width-to-height ratio 1.17–1.32; mass 135 g–147 g). We actuated the soft end-effector with a motor and incrementally increased the applied force while observing grasp stability and pericarp damage at each deformation level. We selected the deformation that provided both stable grasping and successful detachment of the fruit as the operating parameter for subsequent picking trials.
During picking, the robot uses a depth camera to locate the target fruit and its calyx. The manipulator then adjusts its pose to align the end effector with the fruit, rotates to detach the fruit, and places it in the collection basket. A pick is scored as successful only if the fruit is detached intact and deposited in the basket. Picks are scored as failures if the manipulator cannot grasp the fruit, the fruit falls during the operation, or separation fails owing to vine interference.
We conducted 43 picking attempts, of which 40 were successful and 3 failed, yielding a success rate of 93.02% (see Table 3). Because the greenhouse floor exhibited large irregularities, we limited the robot chassis speed to approximately 0.2 m/s to allow the depth camera to reliably detect target fruits; the chassis transit time was therefore excluded from the picking time. The mean picking time was 14.2 ± 0.855 s. Image recognition and processing required 0.035 s in total, comprising 1.4 ms for image pre-processing, 25.6 ms for inference, and 8 ms for post-processing. This total is effectively unchanged from the baseline model’s 0.034 s, indicating that the model’s computational efficiency is adequate for real-time picking operations. Analysis of the three failed cases reveals two primary causes: recognition bias arising from environmental complexity, and motion-planning conflict due to the limited field of view of the camera mounted on the robotic-arm end effector. First, some target fruits were occluded by vines, branches, or leaves, producing offsets in the localized calyx key points and yielding inaccurate end-effector grasp positions. Second, even when fruits were isolated, nearby branches and leaves interfered with approach; as the arm adjusted its end pose, the manipulator collided with surrounding vegetation, displacing the fruit from its planned location and preventing completion of the intended rotation-and-separation maneuver. Together, these failure modes indicate that in highly unstructured environments, continuous visual perception and real-time integration with motion planning still require further optimization.
Table 3.
The results of the experiments for automatic harvesting.
Although the number of picking attempts was limited, the experiments preliminarily confirmed that the YOLOv8s–ECC model proposed here can recognize tomato fruits and calyces in complex environments and that the fruit-axis-vector method effectively locates grasping points. Future work will improve recognition robustness under occlusion, optimize robotic-arm path planning and automatic obstacle-avoidance algorithms for complex settings, and develop dynamic recognition and tracking methods for tomatoes to increase the efficiency and success rate of single-fruit picking.
4. Discussion
This study presents a synchronous detection model for tomato fruits and calyxes, based on YOLOv8s-ECC, and integrates it into a robotic harvesting system. For detection performance, the paper’s proposed fusion strategy of a triple-attention mechanism substantially improves the model’s ability to recognize calyxes, which are fine-grained targets. Ablation experiments demonstrate that the three modules interact synergistically rather than by simple superposition, yielding optimal recall and mAP@0.5 for calyx detection. Heatmap visualizations confirm that the improved model concentrates activation on the fruit’s core region while suppressing noise from complex backgrounds (such as branches, leaves, and plastic-film reflections), indicating that the multi-dimensional attention mechanism offers pronounced advantages for target detection in agricultural settings.
The pose-estimation method based on the “calyx–fruit center point” spatial vector provides an effective basis for locating grasp points. In 43 picking attempts, the system rotated and detached fruits successfully 40 times, placing them intact in the collection basket for a success rate of 93.02%. This outcome demonstrates the method’s feasibility in practical operation. Analysis of the failures indicates two principal causes. First, recognition errors caused by environmental complexity: some target fruits were occluded by vines, branches, or leaves, which shifted the detected calyx key points and produced inaccurate end-effector grasp positions. Second, motion-planning conflicts arising from the camera’s limited field of view at the arm tip: surrounding foliage forced the arm to alter its end pose during approach, which led to collisions that displaced the fruit from its planned location and prevented the intended rotational separation. These failure modes indicate that, in highly unstructured environments, continuous visual perception and real-time coordination with motion planning require further optimization.
Although this study achieved preliminary validation in a simulated environment, several limitations remain. First, we excluded fruit images with occlusion exceeding 50%, severe blurring, or overexposure when constructing the dataset to preserve annotation quality and prevent noisy samples from corrupting the model’s learning of fruit and calyx features. This screening strategy, however, may introduce a bias: by training primarily on “ideal” samples, the model risks overfitting and thus may lose generalizability when confronted with real-field challenges such as occlusion and motion blur.
Second, the pose-detection method presented here depends on the spatial vector from the calyx to the fruit’s centroid. If the calyx is entirely occluded by branches, leaves, or other fruits, the method fails. Future work could explore pose-estimation algorithms that leverage fruit geometric features or temporal information as complementary approaches.
The system also lacks sufficient adaptability to dynamic conditions during harvesting, preventing real-time motion planning for changes such as fruit shaking and plant movement. Its robustness in truly unstructured environments therefore remains inadequate. Although experiments have introduced vine occlusion and controlled lighting variations, real greenhouses present additional challenges such as fluctuating light and shadow and heterogeneous plant density. Future work should incorporate these factors into training to improve recognition robustness in natural settings. In addition, dynamic motion-planning algorithms should be adopted so the robotic arm can update its trajectory based on real-time environmental perception.
5. Conclusions
This paper introduces an optimization model for the co-recognition and pose judgment of tomato calyx and fruit, utilizing a YOLOv8s fusion multi-attention mechanism (YOLOv8S-ECC). Additionally, it outlines the design of a tomato-picking robot, detailing its hardware components, workflow, visual system, and picking strategy, which encompasses picking sequence planning and grasping pose estimation. The study specifically addresses the following aspects:
In response to the need for automated tomato picking, a robot was developed utilizing machine vision technology. A dataset of tomatoes in their natural setting was compiled. The YOLOv8s-ECC algorithm was introduced to accurately identify the tomatoes and their calyxes for harvesting. Additionally, a method was devised to estimate the tomatoes’ poses and determine the precise picking and grasping points.
The YOLOv8s-ECC algorithm improves the channel-level perception of local features in calyx and fruit by integrating the ECA attention mechanism into its backbone network. By incorporating the CA coordinate attention mechanism, the algorithm effectively preserves spatial position information within the deep network, thereby enhancing target positioning accuracy in complex scenarios. Additionally, the CBAM module combines dual-dimensional feature information from channels and spaces. Together, these components create a multi-level attention system that spans from local to global and from channel to space, thereby enhancing the algorithm’s robustness and generalization. In complex natural environments, the YOLOv8s-ECC model achieved an mAP@0.5 of 89.7% for tomato fruit detection and 91.3% for calyx detection, with a model weight of 21.56 MB. This demonstrates its strong detection performance and recognition accuracy.
The automated tomato picking experiment reveals that the average time for recognizing and processing the fruit pose of tomatoes is efficient. The success rate for picking tomatoes is 93.02%. The average time spent on picking actions is 14.2 ± 0.855 s. The system effectively enables the robot to recognize and position the tomato’s posture in the simulated environment, guiding the mechanical hand to successfully execute picking and grasping actions.
Author Contributions
Conceptualization, J.D. and L.Z.; writing—original draft preparation, Y.Z. and Y.W.; writing—review and editing, Y.W. and Z.C.; visualization, H.L. and J.Z.; project administration, Y.Z.; funding acquisition, Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Heilongjiang Province Doctoral Support Project, grant number LBH-Z22078.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Lytridis, C.; Kaburlasos, V.G.; Pachidis, T.; Manios, M.; Vrochidou, E.; Kalampokas, T.; Chatzistamatis, S. An overview of cooperative robotics in agriculture. Agronomy 2021, 11, 1818. [Google Scholar] [CrossRef]
- Rose, D.C.; Lyon, J.; de Boon, A.; Hanheide, M.; Pearson, S. Responsible development of autonomous robotics in agriculture. Nat. Food 2021, 2, 306–309. [Google Scholar] [CrossRef] [PubMed]
- Marinoudi, V.; Sørensen, C.G.; Pearson, S.; Bochtis, D. Robotics and labour in agriculture. A context consideration. Biosyst. Eng. 2019, 184, 111–121. [Google Scholar] [CrossRef]
- Jiao, Z.; Huang, K.; Wang, Q.; Zhong, Z.; Cai, Y. Real-time litchi detection in complex orchard environments: A portable, low-energy edge computing approach for enhanced automated harvesting. Artif. Intell. Agric. 2024, 11, 13–22. [Google Scholar] [CrossRef]
- Chen, J.; Ma, W.; Liao, H.; Lu, J.; Yang, Y.; Qian, J.; Xu, L. Balancing Accuracy and Efficiency: The Status and Challenges of Agricultural Multi-Arm Harvesting Robot Research. Agronomy 2024, 14, 2209. [Google Scholar] [CrossRef]
- Gao, G.H.; Zhang, L.Y.; Ding, T.; Wang, H.L. Optimizing census stereo matching algorithm for accurate tomato localization in complex agricultural scenes. Signal Image Video Process. 2025, 19, 1289. [Google Scholar] [CrossRef]
- Wang, W.; Zhu, L.; Zhao, B.; Gao, J.; Cui, X.; Han, Z.; Zhao, S. LPNet: A lightweight progressive network for calyx-aware apple pose estimation in orchard environments. Artif. Intell. Agric. 2026, 16, 672–694. [Google Scholar] [CrossRef]
- Hou, G.Y.; Chen, H.H.; Niu, R.X.; Li, T.B.; Ma, Y.K.; Zhang, Y.C. Research on multi-layer model attitude recognition and picking strategy of small tomato picking robot. Comput. Electron. Agric. 2025, 232, 110125. [Google Scholar] [CrossRef]
- Fang, J.M.; Dai, N.Z.; Xin, Z.B.; Yuan, J.; Liu, X.M. Design and interaction dynamics analysis of novel hybrid bending-twisting-pulling end-effector for robotic tomato picking. Comput. Electron. Agric. 2025, 231, 110011. [Google Scholar] [CrossRef]
- Song, G.; Wang, J.; Ma, R.; Shi, Y.; Wang, Y. Study on the fusion of improved YOLOv8 and depth camera for bunch tomato stem picking point recognition and localization. Front Plant Sci. 2024, 15, 1447855. [Google Scholar] [CrossRef]
- Yin, W.; Wen, H.; Ning, Z.; Ye, J.; Dong, Z.; Luo, L. Fruit detection and pose estimation for grape cluster–harvesting robot using binocular imagery based on deep neural networks. Front. Robot. AI 2021, 8, 626989. [Google Scholar] [CrossRef] [PubMed]
- Uramoto, S.; Suzuki, H.; Kuwahara, A.; Kitajima, T.; Yasuno, T. Tomato recognition algorithm and grasping mechanism for automation of tomato harvesting in facility cultivation. J. Signal Process. 2021, 25, 151–154. [Google Scholar] [CrossRef]
- Zhuang, Y.; Xu, K.; Liu, Z.; Li, J.; Shen, L.; Wang, J. Design and experimental investigation of the grasping system of an agricultural soft manipulator based on FMDS-YOLOv8. Front. Plant Sci. 2025, 16, 1683380. [Google Scholar] [CrossRef]
- Magalhães, S.A.; Castro, L.; Moreira, G.; dos Santos, F.N.; Cunha, M.; Dias, J.; Moreira, A.P. Evaluating the Single-Shot MultiBox Detector and YOLO Deep Learning Models for the Detection of Tomatoes in a Greenhouse. Sensors 2021, 21, 3569. [Google Scholar] [CrossRef]
- Onishi, Y.; Yoshida, T.; Kurita, H.; Fukao, T.; Arihara, H.; Iwai, A. An automated fruit harvesting robot by using deep learning. ROBOMECH J. 2019, 6, 13. [Google Scholar] [CrossRef]
- Weng, W.; He, M.; Zheng, Z.; Lin, T.; Lai, Z.; Zheng, S.; Wu, X. Tomato Pedicel Physical Characterization for Fruit-Pedicel Separation Tomato Harvesting Robot. Agronomy 2024, 14, 2274. [Google Scholar] [CrossRef]
- Kang, H.; Zhou, H.; Chen, C. Visual perception and modeling for autonomous apple harvesting. IEEE Access. 2020, 8, 62151–62163. [Google Scholar] [CrossRef]
- Kim, T.; Lee, D.H.; Kim, K.-C.; Kim, Y.J. 2D pose estimation of multiple tomato fruit-bearing systems for robotic harvesting. Comput. Electron. Agric. 2023, 211, 108004. [Google Scholar] [CrossRef]
- Kim, J.Y.; Pyo, H.R.; Jang, I.; Kang, J.; Ju, B.K.; Ko, K.E. Tomato harvesting robotic system based on Deep-ToMaToS: Deep learning network using transformation loss for 6D pose estimation of maturity classified tomatoes with side-stem. Comput. Electron. Agric. 2022, 201, 107300. [Google Scholar] [CrossRef]
- Kounalakis, N.; Kalykakis, E.; Pettas, M.; Makris, A.; Kavoussanos, M.M.; Sfakiotakis, M.; Fasoulas, J. Development of a tomato harvesting robot: Peduncle recognition and approaching. In 2021 3rd International Congress on Human Computer Interaction, Optimization and Robotic Applications (HORA); IEEE: New York, NY, USA, 2021; pp. 495–500. [Google Scholar]
- Sun, T.; Zhang, W.; Miao, Z.; Zhang, Z.; Li, N. Object localization methodology in occluded agricultural environments through deep learning and active sensing. Comput. Electron. Agric. 2023, 212, 108141. [Google Scholar] [CrossRef]
- Rong, J.C.; Wang, P.B.; Wang, T.J.; Hu, L.; Yuan, T. Fruit pose recognition and directional orderly grasping strategies for tomato harvesting robots. Comput. Electron. Agric. 2022, 202, 107430. [Google Scholar] [CrossRef]
- Zhang, F.; Gao, J.; Zhou, H.; Zhang, J.X.; Zou, K.L.; Yuan, T. Three-dimensional pose detection method based on keypoints detection network for tomato bunch. Comput. Electron. Agric. 2022, 195, 106824. [Google Scholar] [CrossRef]
- Li, P.; Wen, M.; Zeng, Z.; Tian, Y. Cherry tomato bunch and picking point detection for robotic harvesting using an RGB-D sensor and a StarBL-YOLO network. Horticulturae 2025, 11, 949. [Google Scholar] [CrossRef]
- Du, X.; Meng, Z.; Ma, Z.; Zhao, L.; Lu, W.; Cheng, H.; Wang, Y. Comprehensive visual information acquisition for tomato picking robot based on multitask convolutional neural network. Biosyst. Eng. 2024, 238, 51–61. [Google Scholar] [CrossRef]
- Wang, Q.L.; Wu, B.G.; Zhu, P.F.; Li, P.H.; Zuo, W.M.; Hu, Q.H. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hou, Q.B.; Zhou, D.Q.; Feng, J.S. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 13708–13717. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, X.F.; Wen, X.; Li, Y.; Du, C.F.; Zhang, D.K.; Sun, C.X.; Chen, B.H. A precise detection method for tomato fruit ripeness and picking points in complex environments. Horticulturae 2025, 11, 585. [Google Scholar] [CrossRef]
- Rokunuzzaman, M.; Jayasuriya, H.P.W. Development of a low cost machine vision system for sorting of tomatoes. Agric. Eng. Int. CIGR J. 2013, 15, 173–180. [Google Scholar]
- Long, C.F.; Yang, Y.J.; Liu, H.M.; Su, F.; Deng, Y.J. An approach for detecting tomato under a complicated environment. Agronomy 2025, 15, 667. [Google Scholar] [CrossRef]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.