

Optimizing MRI Scheduling in High-Complexity Hospitals: A Digital Twin and Reinforcement Learning Approach



Abstract
1. Introduction
2. Literature Review
Comparative Analysis of Related Approaches
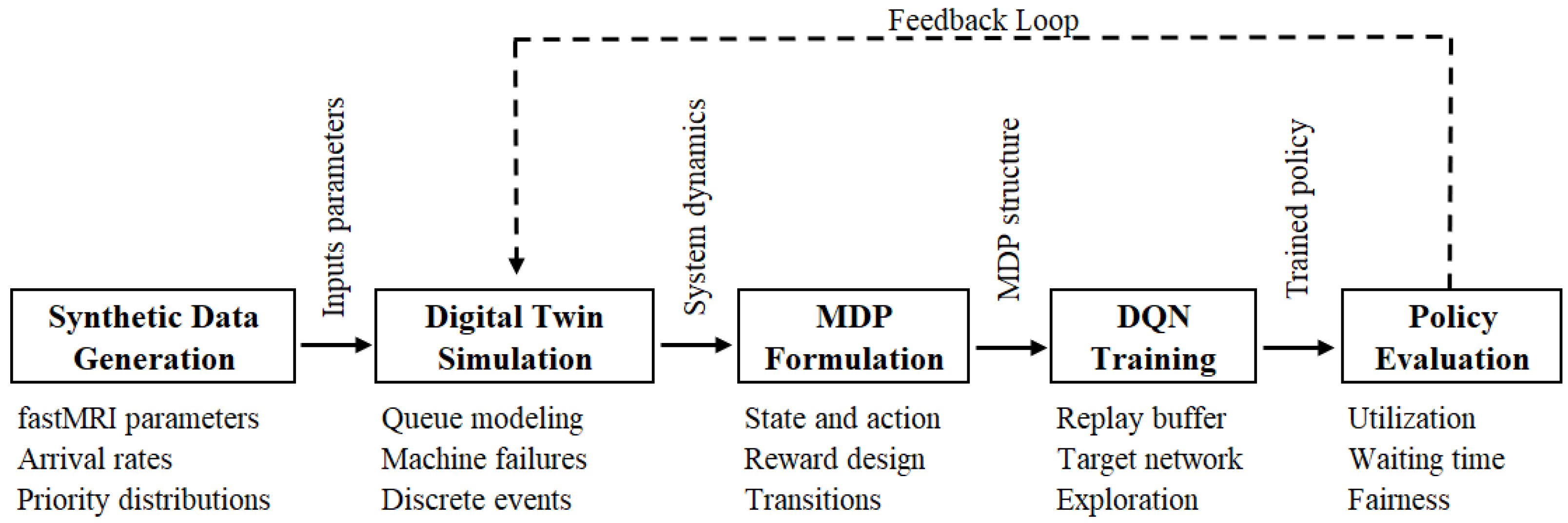
3. Methodology
3.1. Data Modeling and Environment Synthesis
- The number of patients waiting,
- The arrival times and elapsed waiting times,
- The priority levels, encoded numerically or via one-hot encoding,
- The status of each MRI machine (idle, busy, or failed).
3.2. Digital Twin Construction
- represents the queue of patients waiting,
- describes MRI machine statuses,
- records patient arrival times,
- stores patient clinical priorities.
3.3. Markov Decision Process Formulation
- State space : As defined in Section 3.2, we represent the state at time t as , recording the queue of waiting patients, the operational statuses of the MRI machines, the arrival times of patients, and the corresponding levels of clinical priority.
- Action space : We define the action space as the assignment of a patient i to an MRI machine m, or the decision to delay the assignment. If multiple patients and MRI machines are idle, the number of available actions scales combinatorially.
- Transition probability : We model the transitions as primarily deterministic, governed by the simulator logic, while incorporating stochastic elements arising from exogenous events such as patient arrivals and MRI machine failures.
- Reward function : We define the immediate reward obtained after taking action a in state s as:
3.4. Reinforcement Learning Agent Training
- Experience replay: We store up to transitions in a replay buffer, randomly sampling to stabilize learning and break the correlation between sequential experiences.
- Target network: We update a separate target network every 1000 steps to stabilize the estimation of target Q-values.
- -Greedy exploration: We apply a -greedy policy during training, where decays linearly from 1.0 to 0.01, balancing exploration and exploitation.
3.5. Evaluation via Scenario Simulation
- Different patient arrival patterns,
- Variable MRI machine reliability levels,
- Altered clinical priority mixes.
- MRI Machine Utilization Rate:
- Average Patient Waiting Time:
- Priority-weighted Fairness Index:
4. Results
4.1. Experimental Setup
- DQN Scheduling Policy: Our reinforcement learning-based scheduling agent.
- First-Come-First-Served (FCFS): Traditional queue-based policy.
- Static Priority Heuristic: Patients are scheduled strictly according to clinical urgency, disregarding the load balance of the MRI machine.
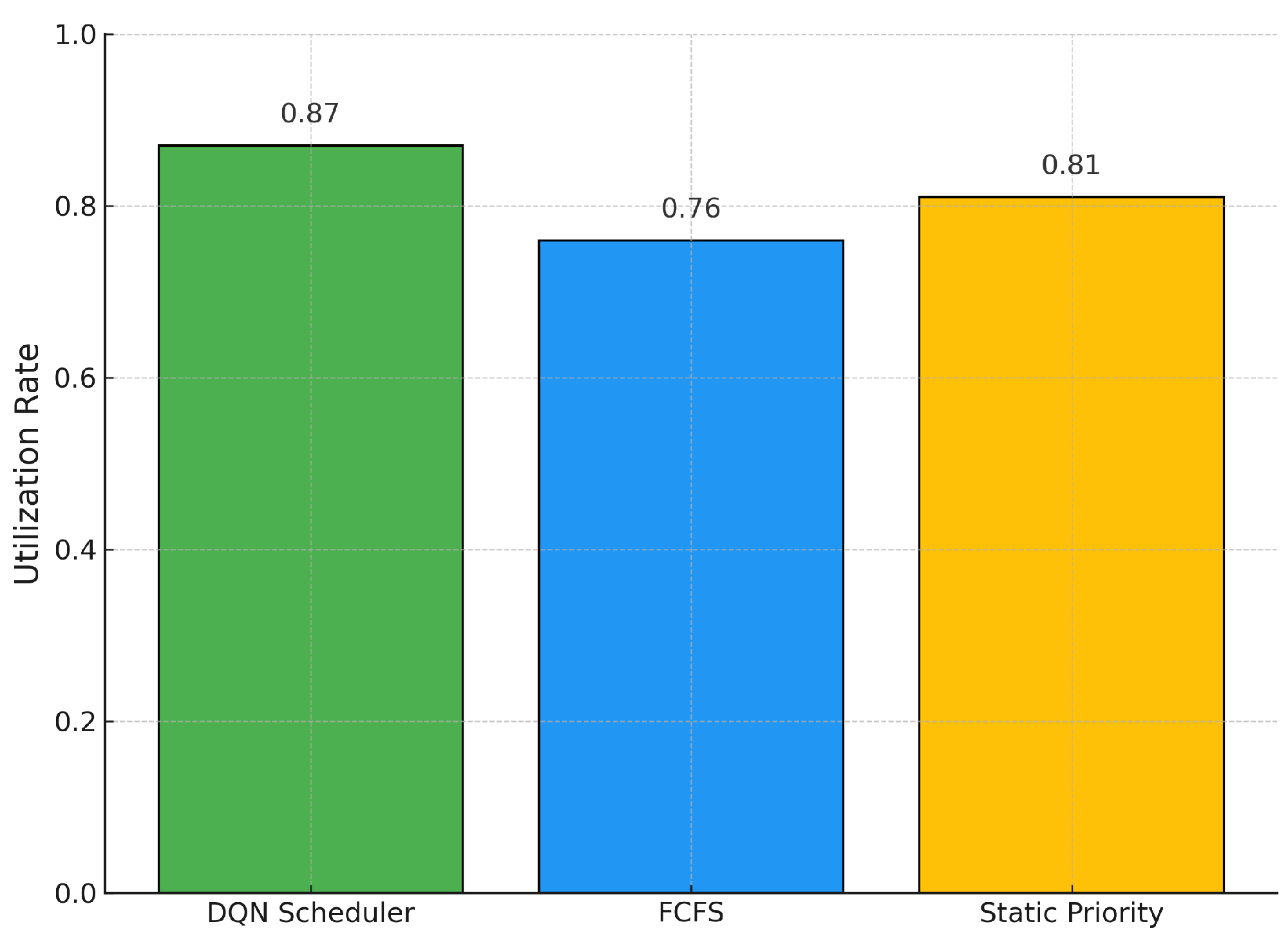
4.2. Comparison of Scheduling Strategies
4.3. Visual Comparison of Scheduling Performance
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Pseudocode of Reinforcement Learning Framework
| Algorithm A1: Reinforcement Learning Framework for MRI Scheduling using a Digital Twin |
 |
References
- de Freitas Almeida, J.F.; Conceição, S.V.; Magalhães, V.S. An optimization model for equitable accessibility to magnetic resonance imaging technology in developing countries. Decis. Anal. J. 2022, 4, 100105. [Google Scholar] [CrossRef]
- Hayatghaibi, S.E.; Cazaban, C.G.; Chan, S.S.; Dillman, J.R.; Du, X.L.; Huang, Y.T.; Iyer, R.S.; Mikhail, O.I.; Swint, J.M. Turnaround time and efficiency of pediatric outpatient brain magnetic resonance imaging: A multi-institutional cross-sectional study. Pediatr. Radiol. 2023, 53, 1144–1152. [Google Scholar] [CrossRef] [PubMed]
- Biloglav, Z.; Medaković, P.; Buljević, J.; Žuvela, F.; Padjen, I.; Vrkić, D.; Ćurić, J. The analysis of waiting time and utilization of computed tomography and magnetic resonance imaging in Croatia: A nationwide survey. Croat. Med. J. 2020, 61, 538. [Google Scholar] [CrossRef]
- Jiang, Y.; Abouee-Mehrizi, H.; Diao, Y. Data-driven analytics to support scheduling of multi-priority multi-class patients with wait time targets. Eur. J. Oper. Res. 2020, 281, 597–611. [Google Scholar] [CrossRef]
- Shehan, M. Investigations of External Resources and the Impact of Imaging on Patient Flow in the Emergency Department. Master’s Thesis, Clemson University, Clemson, SC, USA, 2022. [Google Scholar]
- Garlock, A.L. The Use of CT Contrast in the Emergency Department and Its Impact on Patients’ Length of Stay: A Quality Improvement Initiative. Ph.D. Thesis, National University, San Diego, CA, USA, 2024. [Google Scholar]
- Adenova, G.; Kausova, G.; Saliev, T.; Zhukov, Y.; Ospanova, D.; Dushimova, Z.; Ibrayeva, A.; Fakhradiyev, I. Optimization of Radiology Diagnostic Services for Patients with Stroke in Multidisciplinary Hospitals. Mater. Socio-medica 2024, 36, 160. [Google Scholar] [CrossRef]
- Gupta, D.; Denton, B. Appointment scheduling in health care: Challenges and opportunities. IIE Trans. 2008, 40, 800–819. [Google Scholar] [CrossRef]
- Masroor, F.; Gopalakrishnan, A.; Goveas, N. Machine learning-driven patient scheduling in healthcare: A fairness-centric approach for optimized resource allocation. In Proceedings of the 2024 IEEE Wireless Communications and Networking Conference (WCNC), Dubai, United Arab Emirates, 21–24 April 2024; pp. 1–6. [Google Scholar]
- Hulshof, P.J.; Kortbeek, N.; Boucherie, R.J.; Hans, E.W.; Bakker, P.J. Taxonomic classification of planning decisions in health care: A structured review of the state of the art in OR/MS. Health Syst. 2012, 1, 129–175. [Google Scholar] [CrossRef]
- Yu, C.; Liu, J.; Nemati, S.; Yin, G. Reinforcement learning in healthcare: A survey. Acm Comput. Surv. 2021, 55, 1–36. [Google Scholar] [CrossRef]
- Choudhary, V.; Shastri, A.; Silswal, S.; Kulkarni, A.J. A comprehensive review of patient scheduling techniques with uncertainty. In Handbook of Formal Optimization; Springer: Berlin/Heidelberg, Germany, 2024; pp. 933–953. [Google Scholar]
- Tay, Y.X.; Kothan, S.; Kada, S.; Cai, S.; Lai, C.W.K. Challenges and optimization strategies in medical imaging service delivery during COVID-19. World J. Radiol. 2021, 13, 102. [Google Scholar] [CrossRef]
- Zhou, L.; Geng, N.; Jiang, Z.; Wang, X. Dynamic multi-type patient advance scheduling for a diagnostic facility considering heterogeneous waiting time targets and equity. IISE Trans. 2022, 54, 521–536. [Google Scholar]
- Niu, T.; Lei, B.; Guo, L.; Fang, S.; Li, Q.; Gao, B.; Yang, L.; Gao, K. A review of optimization studies for system appointment scheduling. Axioms 2023, 13, 16. [Google Scholar] [CrossRef]
- Visintin, F.; Cappanera, P. Scheduling Magnetic Resonance Imaging Examinations: An Empirical Analysis. In Proceedings of the Health Care Systems Engineering for Scientists and Practitioners: HCSE, Lyon, France, 27 May 2015; pp. 65–77. [Google Scholar]
- Pang, B.; Xie, X.; Ju, F.; Pipe, J. A dynamic sequential decision-making model on MRI real-time scheduling with simulation-based optimization. Health Care Manag. Sci. 2022, 25, 426–440. [Google Scholar] [CrossRef]
- Cappanera, P.; Visintin, F.; Banditori, C.; Di Feo, D. Evaluating the long-term effects of appointment scheduling policies in a magnetic resonance imaging setting. Flex. Serv. Manuf. J. 2019, 31, 212–254. [Google Scholar] [CrossRef]
- Wu, X.; Li, J.; Khasawneh, M.T. Rule-based task assignment and scheduling of medical examinations for heterogeneous MRI machines. J. Simul. 2020, 14, 189–203. [Google Scholar] [CrossRef]
- Dijkstra, S. A Markov decision process with an ADP-based solution for MRI appointment scheduling in Rijnstate. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2020. [Google Scholar]
- Qiu, H.; Wang, D.; Wang, Y.; Yin, Y. MRI appointment scheduling with uncertain examination time. J. Comb. Optim. 2019, 37, 62–82. [Google Scholar] [CrossRef]
- Bhullar, H.; County, B.; Barnard, S.; Anderson, A.; Seddon, M.E. Reducing the MRI outpatient waiting list through a capacity and demand time series improvement programme. New Zealand Med. J. 2021, 134, 27–35. [Google Scholar]
- Sun, T.; He, X.; Li, Z. Digital twin in healthcare: Recent updates and challenges. Digit. Health 2023, 9, 20552076221149651. [Google Scholar] [CrossRef]
- Haleem, A.; Javaid, M.; Singh, R.P.; Suman, R. Exploring the revolution in healthcare systems through the applications of digital twin technology. Biomed. Technol. 2023, 4, 28–38. [Google Scholar] [CrossRef]
- Schwartz, S.M.; Wildenhaus, K.; Bucher, A.; Byrd, B. Digital twins and the emerging science of self: Implications for digital health experience design and “small” data. Front. Comput. Sci. 2020, 2, 31. [Google Scholar] [CrossRef]
- Ali, H. Reinforcement learning in healthcare: Optimizing treatment strategies, dynamic resource allocation, and adaptive clinical decision-making. Int. J. Comput. Appl. Technol. Res. 2022, 11, 88–104. [Google Scholar]
- Mehmood, Y. Reinforcement learning in intelligent applications: Algorithms and case studies. J. Spectr. 2025, 2, 12–22. [Google Scholar]
- Abdellatif, A.A.; Mhaisen, N.; Chkirbene, Z.; Mohamed, A.; Erbad, A.; Guizani, M. Reinforcement learning for intelligent healthcare systems: A comprehensive survey. arXiv 2021, arXiv:2108.04087. [Google Scholar]
- Abdellatif, A.A.; Mhaisen, N.; Mohamed, A.; Erbad, A.; Guizani, M. Reinforcement learning for intelligent healthcare systems: A review of challenges, applications, and open research issues. IEEE Internet Things J. 2023, 10, 21982–22007. [Google Scholar] [CrossRef]
- Ala, A.; Simic, V.; Pamucar, D.; Tirkolaee, E.B. Appointment scheduling problem under fairness policy in healthcare services: Fuzzy ant lion optimizer. Expert Syst. Appl. 2022, 207, 117949. [Google Scholar] [CrossRef]
- Seastedt, K.P.; Schwab, P.; O’Brien, Z.; Wakida, E.; Herrera, K.; Marcelo, P.G.F.; Agha-Mir-Salim, L.; Frigola, X.B.; Ndulue, E.B.; Marcelo, A.; et al. Global healthcare fairness: We should be sharing more, not less, data. PLoS Digit. Health 2022, 1, e0000102. [Google Scholar] [CrossRef]
- Fossati, F.; Rovedakis, S.; Secci, S. Distributed algorithms for multi-resource allocation. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 2524–2539. [Google Scholar] [CrossRef]
- Liu, X.; Lv, J.; Kim, B.G.; Li, K.; Jin, H.; Gao, W.; Bai, J. Cooperative Digital Healthcare Task Scheduling and Resource Management in Edge Intelligence Systems. Tsinghua Sci. Technol. 2024, 30, 926–945. [Google Scholar] [CrossRef]
- Keerthika, K.; Kannan, M.; Saravanan, T. Clinical Intelligence: Deep Reinforcement Learning for Healthcare and Biomedical Advancements. In Deep Reinforcement Learning and Its Industrial Use Cases: AI for Real-World Applications; John Wiley & Sons: Hoboken, NJ, USA, 2024; pp. 137–150. [Google Scholar]
- Lakhan, A.; Nedoma, J.; Mohammed, M.A.; Deveci, M.; Fajkus, M.; Marhoon, H.A.; Memon, S.; Martinek, R. Fiber-optics IoT healthcare system based on deep reinforcement learning combinatorial constraint scheduling for hybrid telemedicine applications. Comput. Biol. Med. 2024, 178, 108694. [Google Scholar] [CrossRef]
- Zbontar, J.; Knoll, F.; Sriram, A.; Murrell, T.; Huang, Z.; Muckley, M.J.; Defazio, A.; Stern, R.; Johnson, P.; Bruno, M.; et al. fastMRI: An Open Dataset for Accelerated MRI. arXiv 2018, arXiv:1811.08839. [Google Scholar]
- Knoll, F.; Knoll, F.; Sriram, A.; Murrell, T.; Huang, Z.; Muckley, M.J.; Defazio, A.; Stern, R.; Johnson, P.; Bruno, M.; et al. fastMRI: An Open Dataset and Benchmarks for Accelerated MRI. Radiol. Artif. Intell. 2020, 2, e190007. [Google Scholar] [CrossRef]
- Baas, S.; Dijkstra, S.; Braaksma, A.; van Rooij, P.; Snijders, F.J.; Tiemessen, L.; Boucherie, R.J. Real-time forecasting of COVID-19 bed occupancy in wards and Intensive Care Units. Health Care Manag. Sci. 2021, 24, 402–419. [Google Scholar] [CrossRef]
- Rea, D. Surviving the Surge: Real-time Analytics in the Emergency Department. Ph.D. Thesis, University of Cincinnati, Cincinnati, OH, USA, 2021. [Google Scholar]
- Dexter, F.; Epstein, R.H. Implications of the log-normal distribution for updating estimates of the time remaining until ready for phase I post-anesthesia care unit discharge. Perioper. Care Oper. Room Manag. 2021, 23, 100165. [Google Scholar] [CrossRef]
- Irshad, M.R.; Chesneau, C.; Nitin, S.L.; Shibu, D.S.; Maya, R. The generalized DUS transformed log-normal distribution and its applications to cancer and heart transplant datasets. Mathematics 2021, 9, 3113. [Google Scholar] [CrossRef]
- Bruynseels, K.; Santoni de Sio, F.; Van den Hoven, J. Digital twins in health care: Ethical implications of an emerging engineering paradigm. Front. Genet. 2018, 9, 31. [Google Scholar] [CrossRef]
- Karakra, A.; Fontanili, F.; Lamine, E.; Lamothe, J. A discrete event simulation-based methodology for building a digital twin of patient pathways in the hospital for near real-time monitoring and predictive simulation. Digit. Twin 2022, 2, 1. [Google Scholar] [CrossRef]
- Gorelova, A.; Meliá, S.; Gadzhimusieva, D. A Discrete Event Simulation of patient flow in an Assisted Reproduction Clinic with the integration of a smart health monitoring system. IEEE Access 2024, 12, 46304–46318. [Google Scholar] [CrossRef]
- Ng, K.; Ghalwash, M.; Chakraborty, P.; Sow, D.M.; Koseki, A.; Yanagisawa, H.; Kudo, M. Data-Driven Disease Progression Modeling. In Healthcare Information Management Systems: Cases, Strategies, and Solutions; Springer: Berlin/Heidelberg, Germany, 2022; pp. 247–276. [Google Scholar]
- Kumar, K.; Jain, M.; Shekhar, C. Machine repair system with threshold recovery policy, unreliable servers and phase repairs. Qual. Technol. Quant. Manag. 2024, 21, 587–610. [Google Scholar] [CrossRef]
- McCullum, L.B.; Karagoz, A.; Dede, C.; Garcia, R.; Nosrat, F.; Hemmati, M.; Hosseinian, S.; Schaefer, A.J.; Fuller, C.D.; Rice/MD Anderson Center for Operations Research in Cancer (CORC); et al. Markov models for clinical decision-making in radiation oncology: A systematic review. J. Med. Imaging Radiat. Oncol. 2024, 68, 610–623. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef]
- Zhang, K.; Yang, Z.; Başar, T. Multi-agent reinforcement learning: A selective overview of theories and algorithms. In Handbook of Reinforcement Learning and Control; Springer: Berlin/Heidelberg, Germany, 2021; pp. 321–384. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press Cambridge: Cambridge, MA, USA, 1998; Volume 1. [Google Scholar]
- Andrew, B.; Richard S, S. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Barto, A.G. Reinforcement learning: An introduction. by richard’s sutton. SIAM Rev. 2021, 6, 423. [Google Scholar]
- Stember, J.N.; Shalu, H. Reinforcement learning using Deep Q Networks and Q learning accurately localizes brain tumors on MRI with very small training sets. Bmc Med. Imaging 2022, 22, 224. [Google Scholar] [CrossRef] [PubMed]
- Ulaganathan, S.; Ramkumar, M.; Emil Selvan, G.; Priya, C. Spinalnet-deep Q network with hybrid optimization for detecting autism spectrum disorder. Signal Image Video Process. 2023, 17, 4305–4317. [Google Scholar] [CrossRef]
- Rajkomar, A.; Oren, E.; Chen, K.; Dai, A.M.; Hajaj, N.; Hardt, M.; Liu, P.J.; Liu, X.; Marcus, J.; Sun, M.; et al. Scalable and accurate deep learning with electronic health records. NPJ Digit. Med. 2018, 1, 18. [Google Scholar] [CrossRef] [PubMed]
- Harutyunyan, H.; Khachatrian, H.; Kale, D.C.; Ver Steeg, G.; Galstyan, A. Multitask learning and benchmarking with clinical time series data. Sci. Data 2019, 6, 96. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Methodology | Data Source | Real-Time Adaptivity | Patient Prioritization |
|---|---|---|---|---|
| Hayatghaibi et al. (2023) [2] | Optimization + Simulation | Simulated | No | No |
| Choudhary et al. (2024) [12] | Heuristic rules | Real data | No | Yes |
| Keerthika et al. (2024) [34] | Deep RL (DQN, A3C) | General healthcare data | No | Partial |
| Lakhan et al. (2024) [35] | Deep RL + Constraint Scheduling | IoT + Hybrid Telemedicine Data | Partial | Yes |
| Our work | Digital Twin + DQN (RL) | fastMRI-derived synthetic | Yes | Yes |
| Policy | Utilization Rate (U) | Avg. Waiting Time () [min] | Fairness Index (F) |
|---|---|---|---|
| DQN Scheduler | |||
| FCFS | |||
| Static Priority |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silva-Aravena, F.; Morales, J.; Jayabalan, M.; Sáez, P. Optimizing MRI Scheduling in High-Complexity Hospitals: A Digital Twin and Reinforcement Learning Approach. Bioengineering 2025, 12, 626. https://doi.org/10.3390/bioengineering12060626
Silva-Aravena F, Morales J, Jayabalan M, Sáez P. Optimizing MRI Scheduling in High-Complexity Hospitals: A Digital Twin and Reinforcement Learning Approach. Bioengineering. 2025; 12(6):626. https://doi.org/10.3390/bioengineering12060626
Chicago/Turabian StyleSilva-Aravena, Fabián, Jenny Morales, Manoj Jayabalan, and Paula Sáez. 2025. "Optimizing MRI Scheduling in High-Complexity Hospitals: A Digital Twin and Reinforcement Learning Approach" Bioengineering 12, no. 6: 626. https://doi.org/10.3390/bioengineering12060626
APA StyleSilva-Aravena, F., Morales, J., Jayabalan, M., & Sáez, P. (2025). Optimizing MRI Scheduling in High-Complexity Hospitals: A Digital Twin and Reinforcement Learning Approach. Bioengineering, 12(6), 626. https://doi.org/10.3390/bioengineering12060626