
Colony Binary Classification Based on Persistent Homology Feature Extraction and Improved EfficientNet

 , , and
, , and 
Abstract

1. Introduction
- 1.
- The experimental dataset selects colonies that have grown in a Petri dish for 18 h for identification, eliminating the need to wait for significant colony features to appear or to use sequencing instruments. This approach establishes a foundation for improving the overall identification speed of colonies, reducing the cost of manual judgment, and decreasing the dependence on medical expertise in the identification process.
- 2.
- This study fully leverages the ease of integration and the advantage of processing deep features of the PH algorithm, successfully extracting the topological features of CA and SE. It effectively addresses the challenge of vague and difficult-to-distinguish features in the early stage of colony culture, significantly enhancing the classification accuracy of the model when dealing with medical images with indistinct characteristics. Furthermore, this research offers robust support for the in-depth exploration of the structure and characteristics of colony growth.
- 3.
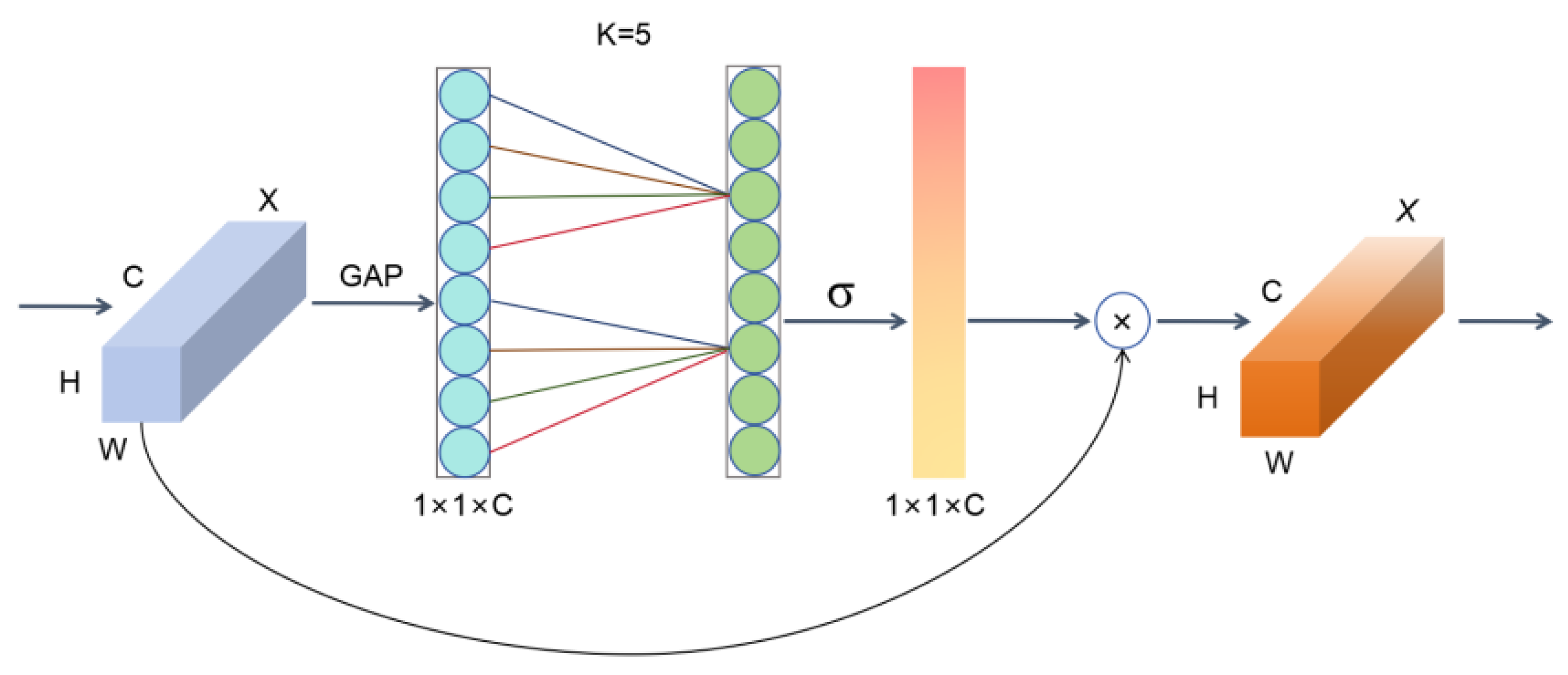
- This study utilizes the efficiency, computational lightweightness, and advantages in sensitivity and specificity of the EfficientNet model. It optimizes the MBConv module within EfficientNet by integrating the Efficient Channel Attention (ECA) mechanism, constructing the EMBConv architecture. This approach mitigates the negative effects caused by dimensionality reduction in the original module, reduces computational complexity, and enhances its performance in handling small local targets.
- 4.
- Prior to the tail convolution of the model, this study incorporates the SCoT self-attention mechanism, which comprehensively considers the contextual relationships and spatial channel information of the image. Through multi-scale processing, it enhances information integration, thereby improving the resolution of input image data in orthogonal directions and the aggregation capability of the feature map.
- 5.
- In this study, five evaluation metrics—accuracy, precision, recall, F-score, and Matthews Correlation Coefficient (MCC)—are introduced to comprehensively assess the model’s performance, significantly enhancing the generalization capability of the results.
2. Related Work
2.1. Feature Extraction Algorithms
2.2. Classification Algorithms
2.2.1. Traditional Classification Algorithm
2.2.2. Deep Learning Algorithm
3. Materials and Methods
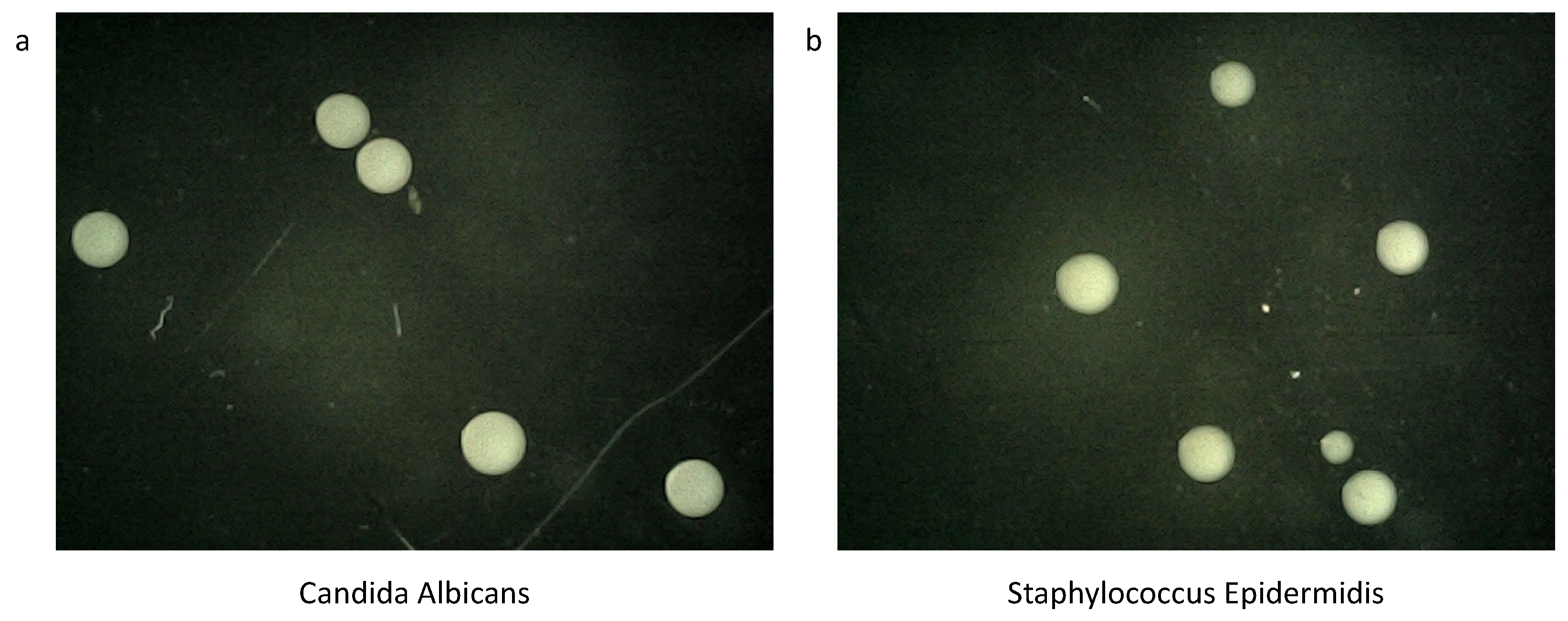
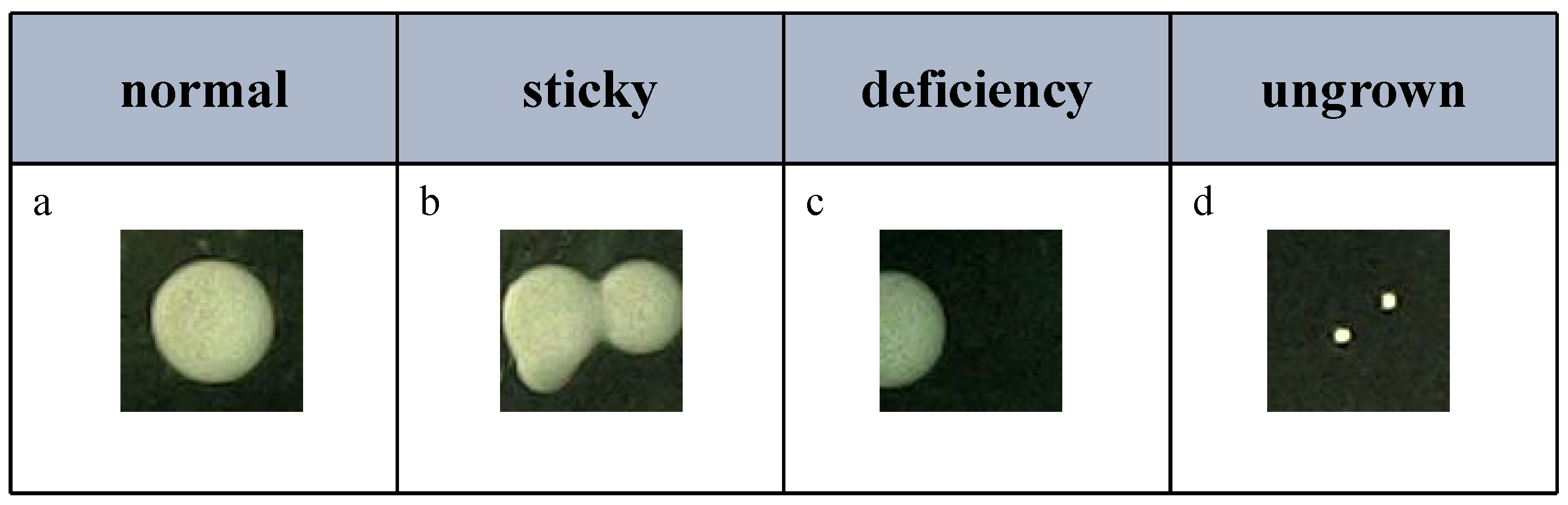
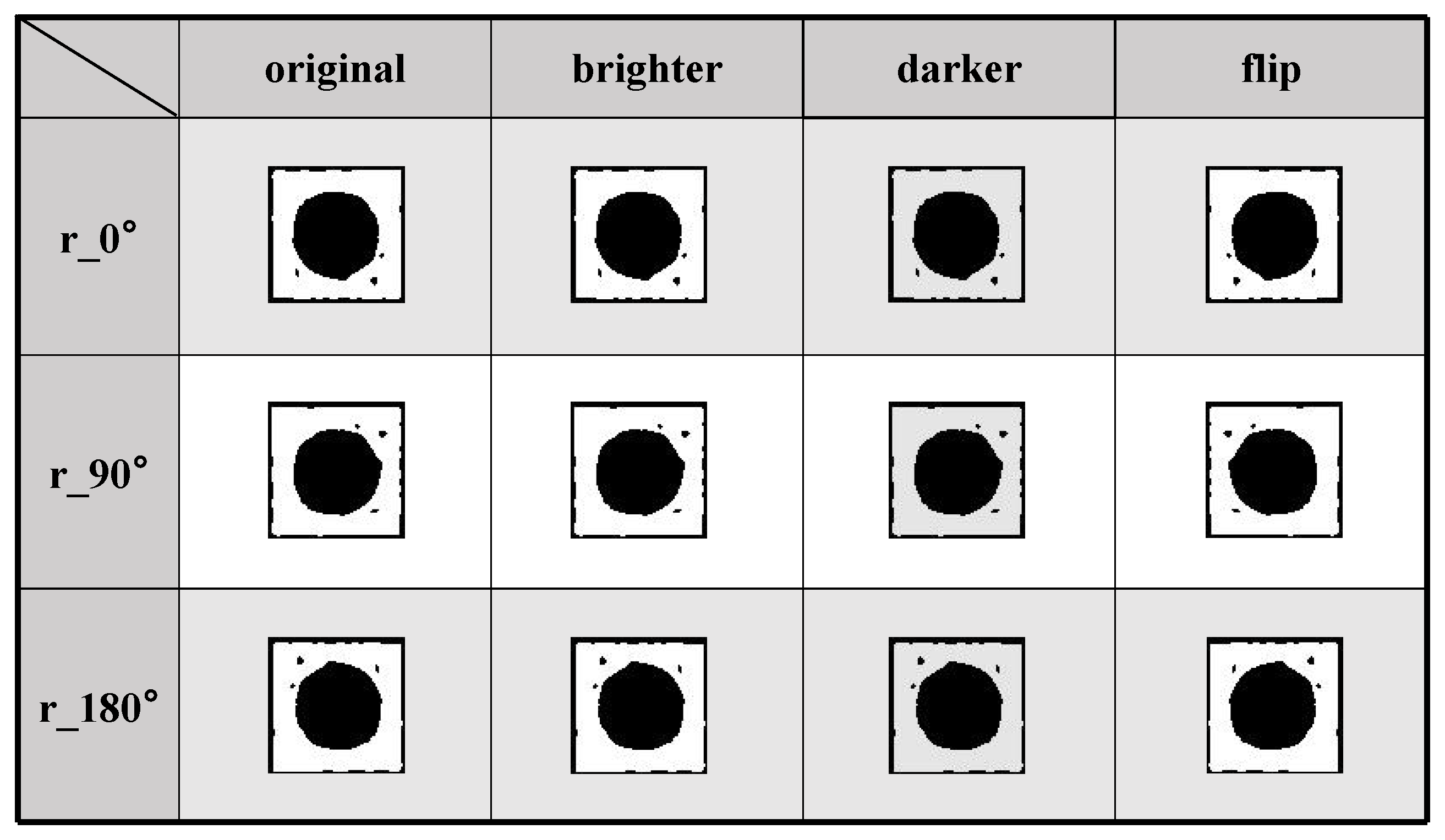
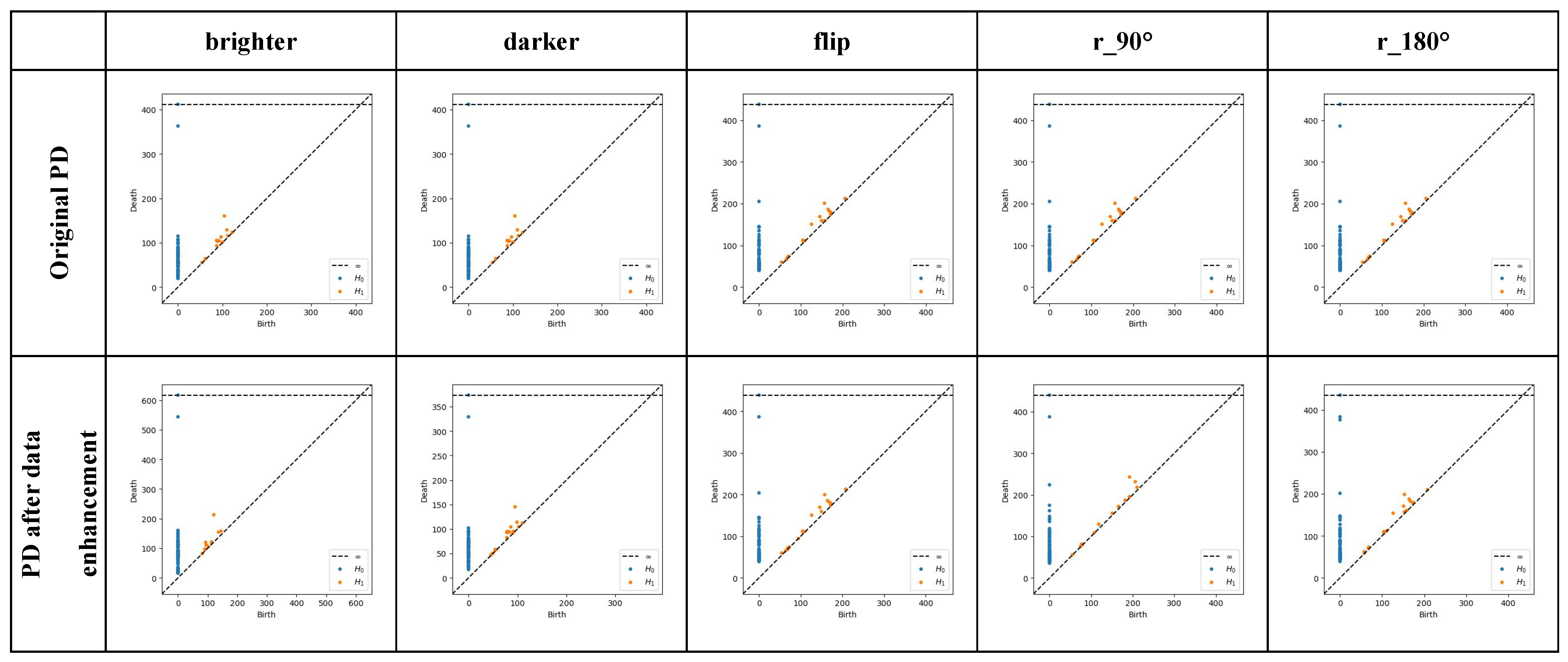
3.1. Data Collection and Processing
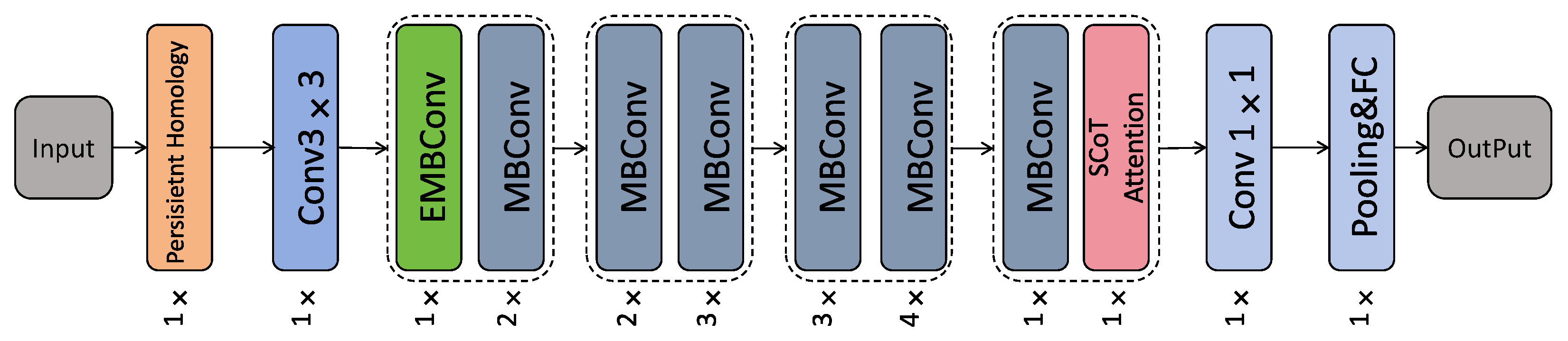
3.2. Framework
3.3. Persistent Homology
3.3.1. Vietoris–Rips (VR) Complex
- Build a point cloud. A set P containing data points is generated from the colony data, which is the point cloud.
- Determine the parameters. Select a parameter that represents the radius of the build shape. determines the maximum distance between two points in P that can form a connection. As shown in Figure 5, topological feature extraction graphs formed by different parameters are different.
- Construct complex [33]. A dotted ball of radius is drawn around each point in P, and lines are drawn between this point and all other points in its circle, thus constructing a topological complex that best matches the characteristics of the colony.
- This part of the algorithm has two main steps:
- 1.
- Construct a neighborhood plot of point set data. A domain graph is an undirected weighted graph , where , V is the set of vertices, E is the set of edges, and weight is the mapping of each edge to the real numbers. Edges are obtained by linking examples defined by . Just like Formula (1):where is the distance function between two points. The weight function simply sets the weight of each edge to equal the distance between two points on the edge. Just like Formula (2):Thus, the colony image is generated to form an undirected weighted neighborhood graph composed of a feature points set, which is used for the next calculation.
- 2.
- In the first step, the generated field map forms the expansion. Combined with the results of the previous step, the given domain figure is obtained. The weight filtering of complex is given by Formula (3):
- For :In general, a ball around a point in d-dimensional space is a generalization of the ball around that point in dimensional space (the ball refers to the set of all points in space that are the same distance from a point). So, the ball in R is a line segment around a point, the ball in is a circle, the ball in is a sphere, and so on, forming the complex. As shown in Formula (5), the complex structure is contained in proportion , and for all subsets of P in set , the distance between all its different points is not greater than the parameter :
- Analyze the topology. By analyzing the topology of the constructed complex, topological information about the colony dataset, such as connectivity and the presence of holes, can be obtained. First, the homology group of a simple complex is calculated. Considering simplex complex as a linear combination of integer bit coefficients , , one can define group addition to form a group:Its identity element is 0, forming the Abelian group, that is, the chain group, and then the d-dimensional homology group of K of the simple complex is defined as:where represents the d-chain group on the simplicial complex K, and its boundary homomorphism is mapped to , and the homomorphism kernel of the identity element obtained through the submapping is a subgroup of the d-dimensional chain group , and is also a d-dimensional closed chain group, denoated as . All edges in , that is, the homomorphic image obtained by homomorphic mapping , are subgroups of the d-dimensional chain group , and also subgroups of the D-dimensional closed group chain , referred to as the d-dimensional edge group , where . The connectivity number of the simple complex is obtained from this calculation. The columns of the matrix are regarded as a set of basis vectors: , then the dimension of the space composed of these column vectors is the rank of the matrix, and the connected number is defined to obtain the topology information of the complex.
3.3.2. Filtration
- 1.
- A 0-dimensional simplex must precede a 1-dimensional simplex, a 1-dimensional simplex must have fewer than 2-dimensional simplices, and so on. This means that any face of a simplex (i.e., ) is automatically ordered before the simplex itself. That is:
- 2.
- If the dimensions of , are equal, then the value of each simplex is determined by its longest 1-dimensional simplex, that is, its highest gravity. So if , then
- 3.
- If , have the same dimension and their longest sides are equal, then the value of each simplex is determined by its largest node. So if and at the same time, then
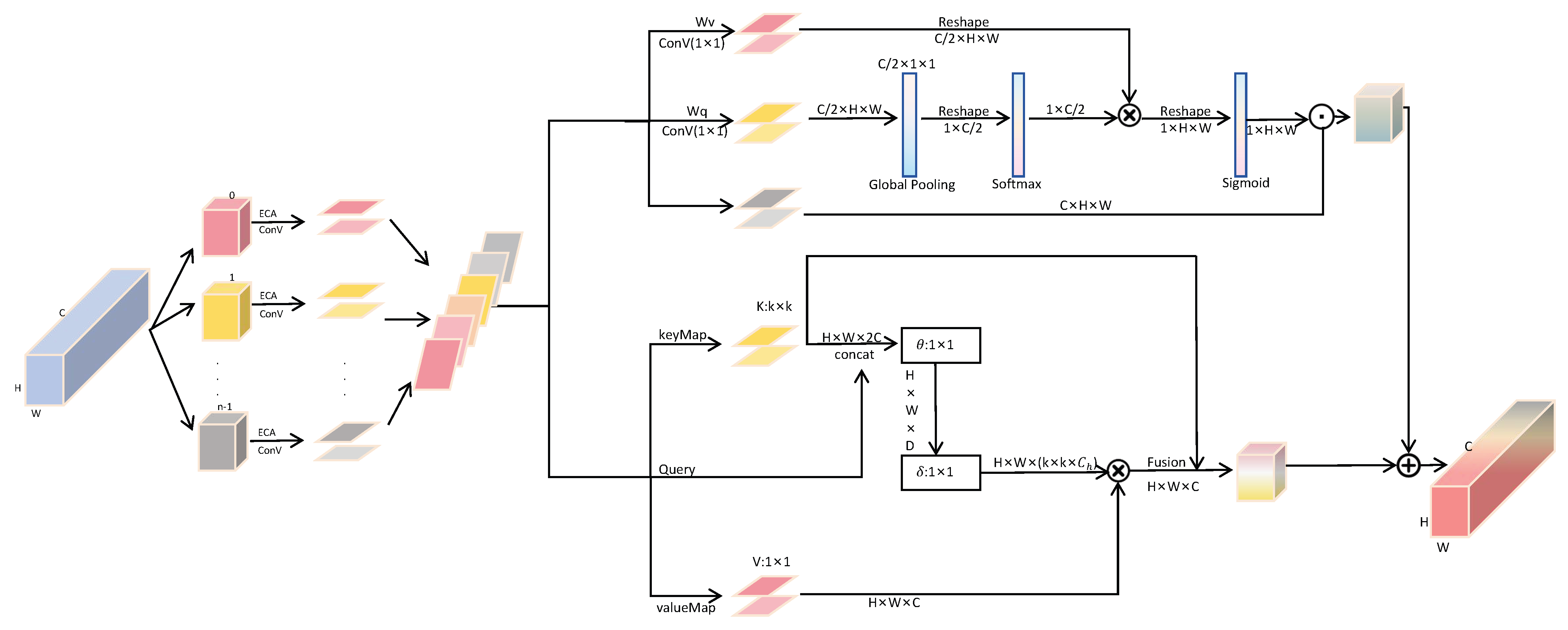
3.4. SCoT_EfficientNet
3.4.1. EfficientNet
3.4.2. SCoT
3.4.3. EMBCouv
4. Experiment and Results
4.1. Experimentation
4.1.1. Experimental Environment and Evaluation Metrics
4.1.2. Persistent Homology
4.1.3. SCoT_EfficientNet
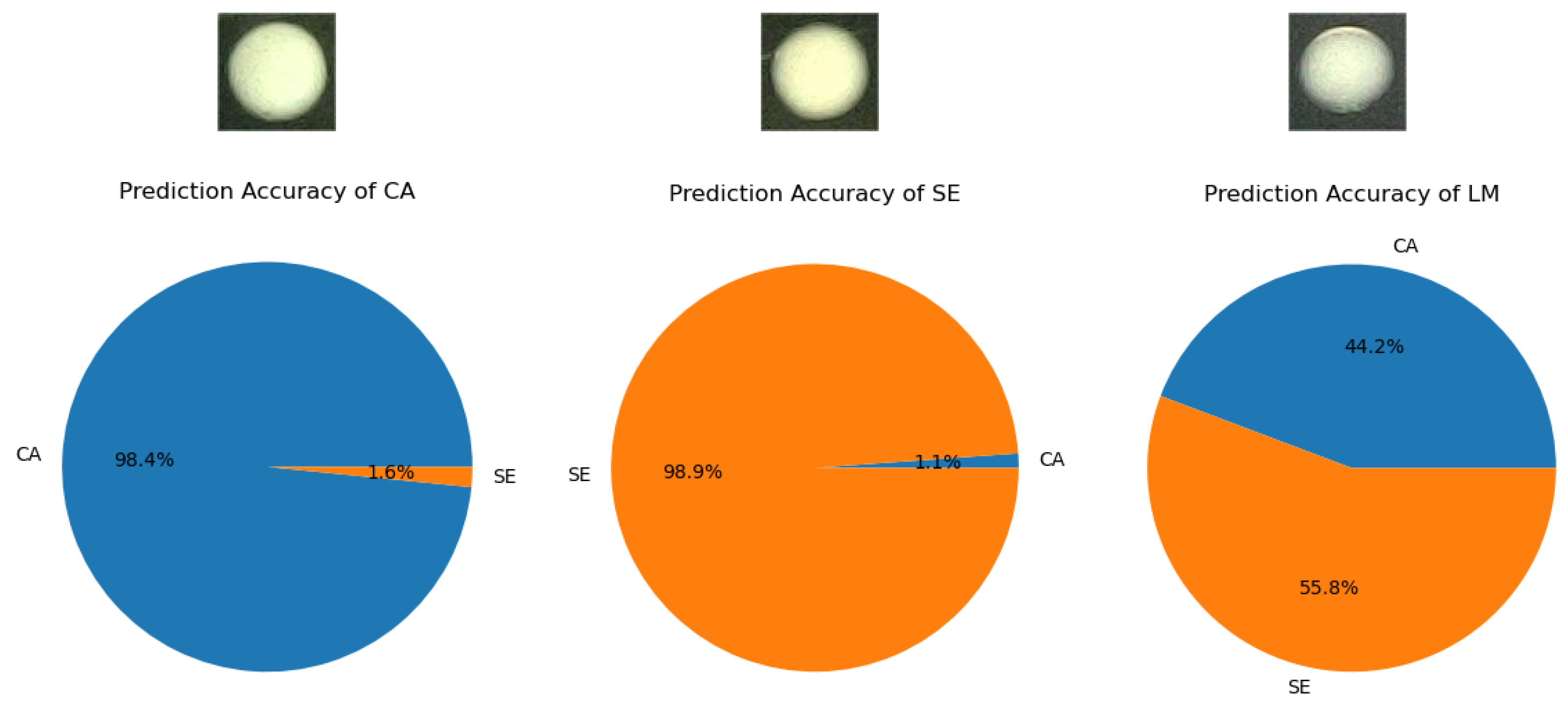
4.2. Experimental Outcomes
5. Discussion
- 1.
- Expanding the scope of application. The current experimental model can only classify CA and SE colonies with normal morphology. In the future, we plan to extend its application to colonies with overlapping structures, greater noise interference, and other colony types, thereby completing classification tasks involving multiple colony categories, diverse morphologies, and various colony forms. Furthermore, we will explore the robustness of our methods under varying environmental conditions and colony densities, thereby improving the generalizability and reliability of the classification model.
- 2.
- Incorporation of object detection algorithms [46]. Current experiments have been conducted exclusively on isolated bacterial colonies. To better meet practical application requirements, future studies will incorporate object detection algorithms to reduce the preprocessing complexity. This will facilitate the accurate identification and enumeration of bacterial colonies in scenarios where multiple bacterial species coexist. Specifically, we aim to evaluate state-of-the-art deep-learning-based object detection frameworks to determine the most suitable approach for our application. Additionally, we will investigate the integration of object detection and classification tasks into a unified pipeline, potentially enhancing the efficiency and accuracy of colony analysis.
- 3.
- Workflow integration. To ensure the practical implementation of the proposed methods, future work will aim to integrate these approaches into clinical workflows. Specifically, we plan to develop a user-friendly visualization interface and establish a comprehensive, streamlined operational protocol. By deploying these tools within commonly used clinical systems, we seek to effectively address the challenge of early-stage classification between CA and SE colonies. Furthermore, we will collaborate closely with clinical microbiologists and laboratory technicians to ensure the developed system aligns with actual clinical needs and laboratory practices. User feedback will be systematically collected and analyzed to iteratively refine the interface design and workflow integration, ultimately facilitating the acceptance and widespread adoption of our proposed methodology in clinical settings.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, J.; Li, C.; Han, Y.; Yang, J.; Hu, Y.; Xu, H.; Zhou, Y.; Zuo, J.; Tang, Y.; Lei, C.; et al. Bacterial membrane vesicles from swine farm microbial communities harboring and safeguarding diverse functional genes promoting horizontal gene transfer. Sci. Total Environ. 2024, 951, 175639. [Google Scholar] [CrossRef] [PubMed]
- Carolus, H.; Van Dyck, K.; Van Dijck, P. Candida albicans and Staphylococcus species: A threatening twosome. Front. Microbiol. 2019, 10, 2162. [Google Scholar] [CrossRef] [PubMed]
- Gallo, R.L.; Nakatsuji, T. Microbial symbiosis with the innate immune defense system of the skin. J. Investig. Dermatol. 2011, 131, 1974–1980. [Google Scholar] [CrossRef] [PubMed]
- Calderone, R.A.; Clancy, C.J. Candida and candidiasis. American Society for Microbiology Press. Emerg. Infect. Dis. 2011, 8, 872–880. [Google Scholar]
- Lagudas, M.F.G.; Bureros, K.J.C. Inhibition of Candida albicans and Staphylococcus epidermidis mixed biofilm formation in a catheter disk model system treated with EtOH–EDTA solution. Lett. Appl. Microbiol. 2023, 76, ovac074. [Google Scholar] [CrossRef]
- Adam, B.; Baillie, G.S.; Douglas, L.J. Mixed species biofilms of Candida albicans and Staphylococcus epidermidis. J. Med. Microbiol. 2002, 51, 344–349. [Google Scholar] [CrossRef]
- Bedore, T.; Kumar, G.; McIntyre, C.; Alvarez, A.; Leslie, A.; Snead, A.; Hudson, A.O. Genomic analysis of five antibiotic-resistant bacteria isolated from the environment. Microbiol. Resour. Announc. 2024, 13, e0075124. [Google Scholar] [CrossRef]
- Hong, B.Y.; Driscoll, M.; Gratalo, D.; Jarvie, T.; Weinstock, G.M. Improved DNA extraction and amplification strategy for 16S rRNA gene amplicon-based microbiome studies. Int. J. Mol. Sci. 2024, 25, 2966. [Google Scholar] [CrossRef]
- Zhou, X.; Liu, X.; Liu, M.; Liu, W.; Xu, J.; Li, Y. Comparative evaluation of 16S rRNA primer pairs in identifying nitrifying guilds in soils under long-term organic fertilization and water management. Front. Microbiol. 2024, 15, 1424795. [Google Scholar] [CrossRef]
- Hopkins, L.; Yim, K.; Rumora, A.; Baykus, M.F.; Martinez, L.; Jimenez, L. Genotypic Identification of Trees Using DNA Barcodes and Microbiome Analysis of Rhizosphere Microbial Communities. Genes 2024, 15, 865. [Google Scholar] [CrossRef]
- Xie, Q.; Wang, W.; Huang, Y.; Zheng, M.; Shang, S.; Jiang, L.; Khan, S.; Wu, K. LiteCrypt: Enhancing IoMT Security with Optimized HE and Lightweight Dual-Authorization. In Proceedings of the 2024 IEEE 30th International Conference on Parallel and Distributed Systems (ICPADS), Belgrade, Serbia, 10–14 October 2024; pp. 166–175. [Google Scholar]
- Zieliński, B.; Plichta, A.; Misztal, K.; Spurek, P.; Brzychczy-Włoch, M.; Ochońska, D. Deep learning approach to bacterial colony classification. PLoS ONE 2017, 12, e0184554. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. Proc. Int. Conf. Mach. Learn. PMLR 2019, 94, 6105–6114. [Google Scholar]
- Samee, N.A.; Alhussan, A.A.; Ghoneim, V.F.; Atteia, G.; Alkanhel, R.; Al-Antari, M.A.; Kadah, Y.M. A hybrid deep transfer learning of CNN-based LR-PCA for breast lesion diagnosis via medical breast mammograms. Sensors 2022, 22, 4938. [Google Scholar] [CrossRef]
- Arhin, J.R.; Zhang, X.; Coker, K.; Agyemang, I.O.; Attipoe, W.K.; Sam, F.; Adjei-Mensah, I.; Agyei, E. ADCGNet: Attention-based dual channel Gabor network towards efficient detection and classification of electrocardiogram images. J. King Saud-Univ.-Comput. Inf. Sci. 2023, 35, 101763. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, H.; Sonka, M.; Chen, D.Z. PHG-Net: Persistent Homology Guided Medical Image Classification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 7583–7592. [Google Scholar]
- Li, Y.; Liu, T.; Koydemir, H.C.; Wang, H.; O’Riordan, K.; Bai, B.; Haga, Y.; Kobashi, J.; Tanaka, H.; Tamaru, T.; et al. Deep learning-enabled detection and classification of bacterial colonies using a thin-film transistor (TFT) image sensor. ACS Photonics 2022, 9, 2455–2466. [Google Scholar] [CrossRef]
- Balmages, I.; Liepins, J.; Zolins, S.; Bliznuks, D.; Broks, R.; Lihacova, I.; Lihachev, A. Tools for classification of growing/non-growing bacterial colonies using laser speckle imaging. Front. Microbiol. 2023, 14, 1279667. [Google Scholar] [CrossRef]
- Babenko, V.; Nastenko, I.; Pavlov, V.; Horodetska, O.; Dykan, I.; Tarasiuk, B.; Lazoryshinets, V. Classification of Pathologies on Medical Images Using the Algorithm of Random Forest of Optimal-Complexity Trees. Cybern. Syst. Anal. 2023, 59, 346–358. [Google Scholar] [CrossRef]
- Periyasamy, S.; Prakasarao, A.; Menaka, M.; Venkatraman, B.; Jayashree, M. Support vector machine based methodology for classification of thermal images pertaining to breast cancer. J. Therm. Biol. 2022, 110, 103337. [Google Scholar] [CrossRef]
- Huang, H.; Wang, C.; Zhao, L.; Wang, W.; Ding, S.; Vasilakos, A. Wi-Fi Sensing Based on Deep Supervised Dictionary Learning for Robust Device-Free Localization. IEEE Trans. Veh. Technol. 2025, 1–11. [Google Scholar] [CrossRef]
- Taruno, P.E.N.; Nugraha, G.S.; Dwiyansaputra, R.; Bimantoro, F. Monkeypox Classification based on Skin Images using CNN: EfficientNet-B0. In Proceedings of the E3S Web of Conferences; EDP Sciences: Jules, France, 2023; Volume 465, p. 02031. [Google Scholar]
- Chen, Y.; Lin, Y.; Xu, X.; Ding, J.; Li, C.; Zeng, Y.; Liu, W.; Xie, W.; Huang, J. Classification of lungs infected COVID-19 images based on inception-ResNet. Comput. Methods Programs Biomed. 2022, 225, 107053. [Google Scholar] [CrossRef]
- Sun, J.; Wu, B.; Zhao, T.; Gao, L.; Xie, K.; Lin, T.; Sui, J.; Li, X.; Wu, X.; Ni, X. Classification for thyroid nodule using ViT with contrastive learning in ultrasound images. Comput. Biol. Med. 2023, 152, 106444. [Google Scholar] [CrossRef] [PubMed]
- Mahesh, A.; Banerjee, D.; Saha, A.; Prusty, M.R.; Balasundaram, A. CE-EEN-B0: Contour Extraction Based Extended EfficientNet-B0 for Brain Tumor Classification Using MRI Images. Comput. Mater. Contin. 2023, 74, 5967–5982. [Google Scholar] [CrossRef]
- Arévalo-Jaimes, B.V.; Admella, J.; Blanco-Cabra, N.; Torrents, E. Culture media influences Candida parapsilosis growth, susceptibility, and virulence. Front. Cell. Infect. Microbiol. 2023, 13, 1323619. [Google Scholar] [CrossRef] [PubMed]
- Ni, H.; Shi, Z.; Karungaru, S.; Lv, S.; Li, X.; Wang, X.; Zhang, J. Classification of typical pests and diseases of Rice based on the ECA attention mechanism. Agriculture 2023, 13, 1066. [Google Scholar] [CrossRef]
- Leykam, D.; Angelakis, D.G. Topological data analysis and machine learning. Adv. Phys. X 2023, 8, 2202331. [Google Scholar] [CrossRef]
- Corcoran, P.; Jones, C.B. Topological data analysis for geographical information science using persistent homology. Int. J. Geogr. Inf. Sci. 2023, 37, 712–745. [Google Scholar] [CrossRef]
- Jazayeri, N.; Jazayeri, F.; Sajedi, H. Medical Image Segmentation for Skin Lesion Detection via Topological Data Analysis. In Proceedings of the IEEE: 2022 16th International Conference on Ubiquitous Information Management and Communication (IMCOM), Seoul, Republic of Korea, 3–5 January 2022; pp. 1–8. [Google Scholar]
- Hu, C.S.; Lawson, A.; Chen, J.S.; Chung, Y.M.; Smyth, C.; Yang, S.M. Toporesnet: A hybrid deep learning architecture and its application to skin lesion classification. Mathematics 2021, 9, 2924. [Google Scholar] [CrossRef]
- Adams, H.; Virk, Ž. Lower bounds on the homology of Vietoris–Rips complexes of hypercube graphs. Bull. Malays. Math. Sci. Soc. 2024, 47, 72. [Google Scholar] [CrossRef]
- Baccini, F.; Geraci, F.; Bianconi, G. Weighted simplicial complexes and their representation power of higher-order network data and topology. Phys. Rev. E 2022, 106, 034319. [Google Scholar] [CrossRef]
- Chen, X.; Cai, Y.; Wu, Y.; Xiong, B.; Park, T. Multi-Scale Semantic Segmentation with Modified MBConv Blocks. arXiv 2024, arXiv:2402.04618. [Google Scholar]
- Winnarto, M.N.; Mailasari, M.; Purnamawati, A. Klasifikasi Jenis Tumor Otak Menggunakan Arsitekture Mobilenet V2. J. Simetris 2022, 13, 1–12. [Google Scholar]
- de Santana Correia, A.; Colombini, E.L. Attention, please! A survey of neural attention models in deep learning. Artif. Intell. Rev. 2022, 55, 6037–6124. [Google Scholar] [CrossRef]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized self-attention: Towards high-quality pixel-wise regression. arXiv 2021, arXiv:2107.00782. [Google Scholar]
- Guang, J.; Xi, Z. ECAENet: EfficientNet with efficient channel attention for plant species recognition. J. Intell. Fuzzy Syst. 2022, 43, 4023–4035. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The Matthews correlation coefficient (MCC) should replace the ROC AUC as the standard metric for assessing binary classification. Biodata Min. 2023, 16, 4. [Google Scholar] [CrossRef]
- Mumuni, A.; Mumuni, F.; Gerrar, N.K. A survey of synthetic data augmentation methods in machine vision. Mach. Intell. Res. 2024, 21, 1–39. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, G.; Zhang, W.; Wang, H. Finger Vein Recognition Based on ResNet With Self-Attention. IEEE Access 2024, 12, 1943–1951. [Google Scholar] [CrossRef]
- He, Y.; Kang, X.; Yan, Q.; Li, E. ResNeXt+: Attention mechanisms based on ResNeXt for malware detection and classification. IEEE Trans. Inf. Forensics Secur. 2023, 19, 1142–1155. [Google Scholar] [CrossRef]
- Scholz, C.; Santoso, L.; Kuhn, C.; Kunze, S.; Friese, K.; Jeschke, U. TLR2 ligation by Listeria moncytogenes and its effects on the cytokine profile of trophoblast cells. J. Reprod. Immunol. 2009, 2, 139. [Google Scholar] [CrossRef]
- Chen, S.H.; Wu, Y.L.; Pan, C.Y.; Lian, L.Y.; Su, Q.C. Breast ultrasound image classification and physiological assessment based on GoogLeNet. J. Radiat. Res. Appl. Sci. 2023, 16, 100628. [Google Scholar] [CrossRef]
- Taye, G.D.; Sisay, Z.H.; Gebeyhu, G.W.; Kidus, F.H. Thoracic computed tomography (CT) image-based identification and severity classification of COVID-19 cases using vision transformer (ViT). Discov. Appl. Sci. 2024, 6, 384. [Google Scholar] [CrossRef]
- Sneha; Kaul, A. Hyperspectral imaging and target detection algorithms: A review. Multimed. Tools Appl. 2022, 81, 44141–44206. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Specification |
|---|---|
| Operating System | Ubuntu 22.04.5 LTS (GNU/Linux 6.8.0-57-generic x86_64) |
| CPU | Intel(R) Xeon(R) W-2295 CPU @ 3.00 GHz |
| RAM | 128 GB |
| GPU | NVIDIA RTX A6000 (48 GB) |
| GPU Driver Version | 575.51.03 |
| CUDA Version | 12.9 |
| Storage | SSD: 1 TB; HDD: 4 TB |
| Networks | Accuracy | Precision | Recall | F-Score | MCC |
|---|---|---|---|---|---|
| PH + EfficientNet | 0.9505 | 0.9468 | 0.9558 | 0.9513 | 0.9010 |
| PH + MobileNet | 0.8778 | 0.8158 | 0.9795 | 0.8902 | 0.7711 |
| PH + ResNet | 0.9535 | 0.9286 | 0.9447 | 0.9366 | 0.8707 |
| PH + ResNeXt | 0.9353 | 0.9272 | 0.9463 | 0.9367 | 0.8707 |
| PH + SCoT_EfficientNet | 0.9864 | 0.9889 | 0.9842 | 0.9865 | 0.9729 |
| PH_Networks | Accuracy | Precision | Recall | F-Score | MCC |
|---|---|---|---|---|---|
| EfficientNet | 0.9505 | 0.9468 | 0.9558 | 0.9513 | 0.9010 |
| ECA + EfficientNet | 0.9784 | 0.9840 | 0.9731 | 0.9786 | 0.9869 |
| SCoT + EfficientNet | 0.9760 | 0.9748 | 0.9779 | 0.9763 | 0.9521 |
| ECA + SCoT + EfficientNet | 0.9864 | 0.9889 | 0.9842 | 0.9865 | 0.9729 |
| Networks | Accuracy | Precision | Recall | F-Score | MCC |
|---|---|---|---|---|---|
| EfficientNet | 0.8835 | 0.9762 | 0.7885 | 0.8723 | 0.7822 |
| PH + EfficientNet | 0.9505 | 0.9468 | 0.9558 | 0.9513 | 0.9010 |
| SCoT_EfficientNet | 0.9515 | 0.9796 | 0.9231 | 0.9505 | 0.9045 |
| Our Method | 0.9864 | 0.9889 | 0.9842 | 0.9865 | 0.9729 |
| Networks | Accuracy | Precision | Recall | F-Score | MCC |
|---|---|---|---|---|---|
| GoogleNet | 0.835 | 0.8889 | 0.7692 | 0.8247 | 0.6766 |
| MobileNet | 0.8641 | 0.9130 | 0.8077 | 0.8571 | 0.7334 |
| ResNet | 0.835 | 0.7612 | 0.9808 | 0.8571 | 0.6994 |
| ResNeXt | 0.8349 | 0.7869 | 0.9231 | 0.8496 | 0.6798 |
| EfficientNet | 0.8835 | 0.9762 | 0.7885 | 0.8723 | 0.7822 |
| ViT | 0.8058 | 0.82 | 0.7885 | 0.8039 | 0.6122 |
| Our method | 0.9864 | 0.9889 | 0.9842 | 0.9865 | 0.9729 |
| Networks | Params (M) | FLOPs (G) | Inference Time (s) |
|---|---|---|---|
| GoogleNet | 6.8 | 1.5 | 0.019 |
| ResNet | 25.5 | 4.1 | 0.009 |
| ResNeXt | 25 | 4.3 | 0.025 |
| ViT | 86 | 17.6 | 0.041 |
| EfficientNet | 5.3 | 0.39 | 0.028 |
| Our Method | 5.8 | 0.52 | 0.022 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Yang, K.; Tang, J.; Gao, J.; Zhang, Y.; Xu, W.; Huang, C.-M. Colony Binary Classification Based on Persistent Homology Feature Extraction and Improved EfficientNet. Bioengineering 2025, 12, 625. https://doi.org/10.3390/bioengineering12060625
Wang Z, Yang K, Tang J, Gao J, Zhang Y, Xu W, Huang C-M. Colony Binary Classification Based on Persistent Homology Feature Extraction and Improved EfficientNet. Bioengineering. 2025; 12(6):625. https://doi.org/10.3390/bioengineering12060625
Chicago/Turabian StyleWang, Zumin, Ke Yang, Jie Tang, Jun Gao, Yuhao Zhang, Wei Xu, and Chun-Ming Huang. 2025. "Colony Binary Classification Based on Persistent Homology Feature Extraction and Improved EfficientNet" Bioengineering 12, no. 6: 625. https://doi.org/10.3390/bioengineering12060625
APA StyleWang, Z., Yang, K., Tang, J., Gao, J., Zhang, Y., Xu, W., & Huang, C.-M. (2025). Colony Binary Classification Based on Persistent Homology Feature Extraction and Improved EfficientNet. Bioengineering, 12(6), 625. https://doi.org/10.3390/bioengineering12060625