Abstract
This article addresses the non-trivial problem of classifying thoracic diseases in chest X-ray (CXR) images. A single CXR image may exhibit multiple diseases, making this a multi-label classification problem. Additionally, the inherent class imbalance makes the task even more challenging as some diseases occur more frequently than others. Our methodology is based on transfer learning aiming to fine-tune a pretrained DenseNet121 model using CXR images from the NIH Chest X-ray14 dataset. Training from scratch would require a large-scale dataset containing millions of images, which is not available in the public domain for this multi-label classification task. To address class imbalance problem, we propose a rank-based loss derived from the Zero-bounded Log-sum-exp and Pairwise Rank-based (ZLPR) loss, which we refer to as focal ZLPR (FZLPR). In designing FZLPR, we draw inspiration from the focal loss where the objective is to emphasize hard-to-classify examples (instances of rare diseases) during training compared to well-classified ones. We achieve this by incorporating a “temperature” parameter to scale the label scores predicted by the model during training in the original ZLPR loss function. Experimental results on the NIH Chest X-ray14 dataset demonstrate that FZLPR loss outperforms other loss functions including binary cross entropy (BCE) and focal loss. Moreover, by using test-time augmentations, our model trained using FZLPR loss achieves an average AUC of 80.96% which is competitive with existing approaches.
1. Introduction
Chest radiography is extensively utilized for identifying and diagnosing thoracic diseases. In healthcare facilities, radiologists rely on their expertise to visually examine these radiographs and report their findings. Recently, automated medical image analysis has emerged as a promising field, offering significant support to healthcare institutions in managing high patient volumes [1,2,3]. This progress has been made possible by remarkable advancements in areas such as computer vision, pattern recognition, and machine learning.
We have addressed the challenging task of the classification of thoracic diseases on chest X-rays (CXR) in this article. It is regarded as a multi-label classification (MLC) problem as multiple diseases can be found in a patient’s CXR. The task is challenging primarily due to the widely recognized long-tail distribution of disease occurrences as all diseases are not occurring with the same frequency in the dataset. Moreover, some diseases are also rare resulting in a class imbalance. In recent years, the problem has been a focus among computer vision and biomedical communities to build efficient deep learning-based models and associated training schemes to handle class imbalance [4,5,6,7,8]. Although the localization of diseases in CXR images is another related task alongside disease classification, this article focuses solely on the latter with emphasis on handling class imbalance.
Deep learning-based models have demonstrated outstanding performance in image recognition tasks within large-scale benchmark datasets such as ImageNet-1K [9] and ImageNet-21K [10]. The transfer learning technique is commonly employed to adapt models trained on these datasets to new tasks, including object detection [11], face recognition [12], image retrieval [13], image matching [14], medical image analysis [15,16,17], etc. These research works have shown that models using transfer learning outperform traditional machine learning methods in tasks they were not specifically trained for. It is important to note that the large-scale image recognition benchmark datasets like ImageNet-1K and ImageNet-21K associate a single label with each image, resulting in single-label prediction problems. Furthermore, these datasets typically feature balanced label distribution. Thus, the overall training scheme must be carefully designed to handle image classification tasks in the medical sector such as classifying thoracic diseases using CXR, which is a multi-label problem and also demonstrates class imbalance.
Over the past decade, significant efforts have been made to create benchmark datasets for detecting thoracic diseases in CXR images. In this regard, the NIH Chest X-ray8 dataset [4] was introduced in 2017, initially featuring labels for eight distinct thoracic diseases. This dataset was later expanded by the same authors to include 14 disease labels. It comprises 112,120 CXR images and is known as the NIH Chest X-ray14 benchmark dataset. Similarly, the CheXpert dataset [18], introduced in 2019, also includes 14 disease labels but contains a total of 224,316 CXR images. In the same year, the MIMIC-CXR dataset [7] was proposed, encompassing 377,110 images and 26 disease labels. Among these datasets, the NIH Chest X-ray14 is widely recognized for its usage, yet it remains particularly challenging due to its relatively smaller number of CXR images compared to the other two datasets. It is evident that these benchmark datasets are significantly smaller in scale than ImageNet-1K (1.2 million images) and ImageNet-21K (14 million images), which are commonly utilized to train deep networks. Consequently, transfer learning is the predominant approach for classifying thoracic diseases in CXR images [4,5,6,18,19,20]. For this very reason, it is common in the literature to find various well-established convolutional neural network architectures, such as ResNet [21], DenseNet [22], EfficientNet [23], MobileNet [24], Inception [25], and Xception [26], etc., being fine-tuned for this task. To address MLC, the sigmoid is commonly utilized in the final layer as the activation function, and the neural network is trained using binary cross-entropy (BCE) loss or its variants.
In this article, we also adopt transfer learning to fine-tune a pretrained densely connected convolutional network, specifically, DenseNet121. Contrary to the BCE loss, we have employed a rank-based loss to fine-tune the network. Specifically, we have modified the Zero-bounded Log-sum-exp and Pairwise Rank-based (ZLPR) loss function, proposed by Su et al. [27] for MLC tasks, to focus on hard examples during training, which are mainly instances of rare classes or labels. This is achieved by incorporating a temperature parameter in the loss function. As a result, the loss function is suited to addressing class imbalance effectively. We have drawn inspiration from the focal loss [11] in our methodology to modify the ZLPR loss. For this very reason, we call it the focal ZLPR (FZLPR) loss function. Experimental results on the NIH Chest X-ray14 dataset demonstrate that the proposed loss function surpasses both BCE loss and focal loss, and addresses class imbalance effectively. Similar to [6], we also employ test time augmentations as they are known to improve the classification accuracy. The following summarizes the main contributions of our work.
- The focal ZLPR (FZLPR) loss function is proposed by modifying the ZLPR loss function and incorporates a temperature parameter to effectively handle hard examples during training.
- Our experimental results demonstrate that the FZLPR loss function is effective in classifying thoracic diseases in CXR images. It outperforms the BCE loss and focal loss in terms of average AUC.
- By utilizing test-time augmentations, our model trained with the FZLPR loss achieves an average AUC of 80.96%, which is comparable to that of state-of-the-art methods.
The rest of article is organized as follows: Section 2 provides a review of existing techniques and methods proposed for disease classification in CXR images and loss functions for MLC tasks. Section 3 details the proposed methodology. The experimental results along with the implementation details are presented in Section 4. Finally, conclusions and future works are discussed in Section 5.
2. Literature Review
MLC is a focus of interest of researchers in the domains of natural language processing, computer vision, and medical image analysis. Numerous deep learning-based techniques, focusing on network architectures, loss functions, and training schemes, have been proposed in the literature. Below, we present a concise review of the literature on disease classification in CXR images, along with an overview of various loss functions proposed to handle class imbalance.
2.1. Multi-Label Classification for CXR Images
In a foundational work [4], pretrained models such as AlexNet, VGG-16, GoogLeNet, and ResNet50 are employed as feature extractors. The extracted features are fed into a transition layer (a convolutional layer) and a dense final classification layer, both of which are trained using weighted BCE loss for disease classification in chest X-ray (CXR) images. For disease localization, weighted spatial activation maps—acting as disease likelihood maps for each class—are generated by combining the outputs of the transition layer and the final classification layer. This approach achieved promising results on the NIH Chest X-ray8 dataset. In a related work [18], Irvin et al. investigated various convolutional neural network (CNN) architectures, including Inception-V4, ResNeXt101, ResNet152, and DenseNet121, using their proposed CheXpert dataset containing 14 distinct disease labels. The models were trained using a masked BCE loss function. Among the architectures evaluated, DenseNet121 demonstrated superior performance. Similarly, transfer learning is employed in [28] to fine-tune a pretrained EfficientNet on the NIH Chest X-ray14 dataset using BCE loss. The researchers utilized a non-official split of the dataset and achieved state-of-the-art results. In [29], a fine-grained framework trained using a combination of loss functions including multi-label Softmax loss, BCE loss, and label correlation loss, is proposed. ResNet101 and DenseNet121 are employed as backbones in the experiments using the NIH Chest X-ray14 dataset. They demonstrate that ResNet101 and DenseNet121 models trained with their proposed combined loss function achieve better performance compared to those trained with BCE loss alone. Baltruschat et al. [30] employed non-image data in addition to CXR images for disease classification. In addition to ImageNet-1K pretrained ResNet models, they developed custom ResNet models by varying the model depth. These models were trained from scratch using BCE loss on the NIH Chest X-ray14 dataset. Their findings indicate that while ImageNet-1K pretrained models perform adequately, a custom 38-layer ResNet model trained on CXR images and non-image data outperforms the others. Katona et al. [31] studied the impact of hyperparameters on fine-tuning the pretrained VGG16, ResNet50, and DenseNet121. A top network in the form of dense layers is added for the classification purpose. Experiments were conducted by varying batch sizes between 16 and 64, as well as exploring different optimizers during training using the NIH Chest X-ray14 dataset. Both BCE loss and focal loss were studied in their experiments. The results demonstrated consistent performance across all network architectures regardless of batch size, with the stochastic gradient descent (SGD) optimizer outperforming Adam and RMSprop. Moreover, BCE resulted in superior performance compared to the focal loss.
A category-wise residual attention learning (CRAL) framework is proposed in [20] for prediction of diseases in CXR images. In the first stage, a pretrained CNN backbone (ResNet50 or DenseNet121) is employed to extract features. The feature maps thus extracted are passed to an attention module composed of convolutional layers and residual connections. The purpose of attention module is to learn attention scores to weight different spatial positions of the feature maps. The CRAL is trained using BCE loss function in an end-to-end manner. Promising results are obtained on the NIH Chest X-ray14 benchmark dataset. In a complementary work, Han et al. [32] propose a knowledge-augmented contrastive learning framework for classification and localization of diseases in CXR images. Knowledge in the form of radiomic features is extracted with the help of Gradient-weighted class activation mapping (Grad-CAM) images and is combined with the image features extracted from a CNN-based image encoder—a pretrained ResNet18 model—in the proposed contrastive learning framework. Experimental results on the NIH Chest X-ray8 benchmark dataset show the efficacy of the proposed framework. In a similar work [19], an EfficientNet-B0-based detection and classification model is proposed for classification and localization of chest diseases in CXR images. In the proposed model, EfficientNet-B0 is utilized for feature extraction, followed by a feature network that performs feature blending in both top-down and bottom-up manners. A final detector then outputs the localization results with class labels. The results are presented on the NIH Chest X-ray8 benchmark dataset containing eight chest diseases only. An ensemble approach is proposed in [5] where features extracted from multiple CNNs are concatenated and passed through a dense layer for final prediction. The ensemble is trained with the BCE loss function using the MIMIC-CXR benchmark dataset. The experimental results on the NIH Chest X-ray14 benchmark dataset are presented using two distinct ensembles employing different CNN architectures like InceptionV3, MobileNet, DenseNet121, Xception, RegNet-X, and ResNet50. It is shown that the ensemble composed of InceptionV3, ResNet50, and DenseNet121 outperforms other state-of-the-art methods.
In general, ImageNet-1K pretrained models handle images of size 224 × 224 pixels. In the aforementioned works, this resolution is used to fine-tune models. However, high-resolution CXR images are also employed for disease classification in the literature. Guendel et al. [33] used 1024 × 1024 pixel images (more than four times the size of ImageNet-1K images) as inputs to train a DenseNet121 model. To accommodate the larger input size, two convolutional layers are added before DenseNet121, as the pretrained model can handle an input size of 224 × 224 pixels. This results in a highly compute-intensive model. Their experimental results showed that high-resolution CXR images were beneficial for disease classification on the NIH Chest X-ray14 dataset. In [6], EfficientNetV2 and ConvNeXt models, which can process large image sizes, were employed. Their model uses 768 × 768 pixel image as inputs. During training, several image augmentation techniques are employed to handle the class imbalance. Additionally, focal loss [11] is employed to handle the long-tail distribution of classes. The proposed method achieves a top-five ranking in the CXR-LT competition [8] on the MIMIC-CXR dataset.
2.2. Loss Functions for Class Imbalance
In non-trivial classification tasks like MLC, handling class imbalance effectively is highly desired but is challenging. The issue is not confined to the medical image classification tasks but extends to other research areas such as natural language processing and computer vision. The weighted BCE loss is frequently employed for MLC due to its simplicity. However, the class frequency based re-weighting scheme performs poorly [34,35]. Focal loss [11] was introduced in the context of objection detection tasks and aims to focus on hard examples through a dynamic re-weighting scheme during training. It has demonstrated superior performance compared to BCE loss. Asymmetric loss [36], inspired by focal loss, was proposed for MLC that uses different re-weighting scheme for positive and negative examples. The results on various computer vision tasks including object detection demonstrate that the asymmetric loss performs better than the focal loss. Bénédict et al. [37] propose SigmoidF1 loss that approximates the macro-F1 score for MLC. This differentiable loss function enables end-to-end model training using stochastic gradient descent. Experimental results on both text and image datasets demonstrate its superior performance compared to BCE, focal, and asymmetric loss functions. Huang et al. [38] applied Taylor series expansion to BCE loss and proposed a generalized asymmetric loss called asymmetric polynomial loss (APL). To address class imbalance, APL controls the gradients of positive and negative examples on a term-by-term basis within the loss function. While it has shown to outperform BCE and asymmetric loss on multi-label text and image classification tasks, it requires tuning a large number of hyperparameters. In a follow-up work [39], the authors proposed controlling the contribution of negative label gradients by adding a regularization term in APL loss. Experimental results on multi-label classification tasks demonstrate the effectiveness of this regularization compared to BCE, focal, and asymmetric loss functions. A similar approach is employed in [40], where balanced asymmetric loss (BAL) is proposed. BAL prioritizes hard positive examples during training and, when combined with the contrastive loss from contrastive language-image pre-Ttraining (CLIP), has been shown to outperform various loss functions, including focal and asymmetric losses, in long-tail multi-label classification tasks.
Ranking-based losses have also been discussed extensively in the literature for MLC. Among them, LSEP [41] is a pairwise ranking-based loss function that serves as a smooth approximation to the widely known hinge loss. The smoothness is achieved by utilizing the log-sum-exp function. It is shown that the LSEP delivers superior ranking performance compared to the standard pairwise ranking loss. However, unlike BCE and focal loss functions, LSEP lacks a built-in label decision mechanism. To address this, a separate method for determining the threshold for each class is introduced in [41]. In a follow-up work [27], Su et al. proposed a fixed threshold for LSEP and formulated a novel loss function called Zero-bounded Log-sum-exp and Pairwise Rank-based (ZLPR). The empirical results show that the proposed ZLPR loss handles label dependencies and ranking between positives and negatives effectively and performs better than LSEP, BCE and focal losses on text and image benchmark datasets. Recently, Ref. [42] proposed the hierarchy-aware biased bound margin (HBM) loss, conceived to modify ZLPR by incorporating learnable bounds, biases, and margins to address the limitations of fixed thresholds. Experimental results on text classification tasks reveal that HBM performs marginally better than ZLPR. Distributionally robust (DR) loss, proposed in [43], is based on class-wise LSEP loss. It incorporates a gradient constraint for negative labels to regulate their influence during training, as they constitute the majority and can disproportionately affect the LSEP loss, favoring negative labels. Experimental results on long-tail multi-label classification tasks show the effectiveness of DR loss compared to various loss functions, including LSEP and focal loss.
Based on the reviewed literature, it can be concluded that networks trained on ImageNet benchmark datasets are well-suited for thoracic disease classification in CXR images by employing transfer learning. Moreover, DenseNet121 has emerged as a promising architecture, frequently adopted in numerous research works, and has achieved superior performance compared to its counterparts. Furthermore, recent advancements in ranking-based loss functions demonstrate their potential in handling non-trivial classification tasks such as MLC. The methodology described in the following section is inspired by these insights from the literature.
3. Materials and Methods
Let be a multi-label dataset consisting of N image-label pairs where represents the image in the dataset and denotes its corresponding set of possible labels. Let be the set of all labels, totaling M. Then, and each image is associated to a different number of labels. The objective is to train a multi-label classifier with as learnable parameters that predicts all possible labels for a given input image . In this work, the is modeled as a CNN model that learns labels predictions from input images in an end-to-end manner using an appropriate loss function. The specifics of the loss function and CNN architecture are detailed in the following sections. In general, the function outputs a vector of unbounded real numbers called logits or label scores, which can be transformed into a probability using the sigmoid function. Let be the predicted score corresponding to mth label ; we can write
3.1. Focal ZLPR Loss
For accurate classification, it is desired for to yield higher values for labels that are associated with the image compared to those that are not. Consequently, each image is accompanied by both positive labels, , and negative labels, . The LSEP loss function [41] employs pairwise comparisons to achieve higher label scores for positive labels compared to negative labels. Mathematically, we can write the LSEP function as
The LSEP loss function can be seen as a smooth approximation of hinge loss. However, it is unable to handle scenarios where the number of output labels is unknown, as it lacks an associated threshold. To address this limitation, Su et al. proposed ZLPR loss function in [27], and introduced a fixed threshold T on the model’s output scores for positive and negative labels. Specifically, the predicted label score for positive labels, , where , must be greater than T, while the predicted label score for negative labels, , where , must be less than T. The ZLPR loss can be written as
Su et al. suggested and, thus, the above equations takes the following form:
It is evident from the ZLRP loss function, as represented by Equation (4), that all labels are treated uniformly. As a result, it lacks an effective mechanism for handling rare labels, which are challenging to classify in the presence of majority labels. Inspired by the focal loss [11], we propose a label score scaling strategy for the ZLPR loss function. This strategy enhances the model’s ability to focus on hard examples by increasing their contribution to the loss function while reducing the contribution of well-classified examples. To achieve this, a temperature parameter is introduced in the ZLPR function with the purpose to scales the label scores. As a result, the loss function focuses on rare labels and addresses the class imbalance effectively. We refer to the modified ZLPR function as Focal ZLPR, abbreviated as FZLPR. Mathematically, we can write it as
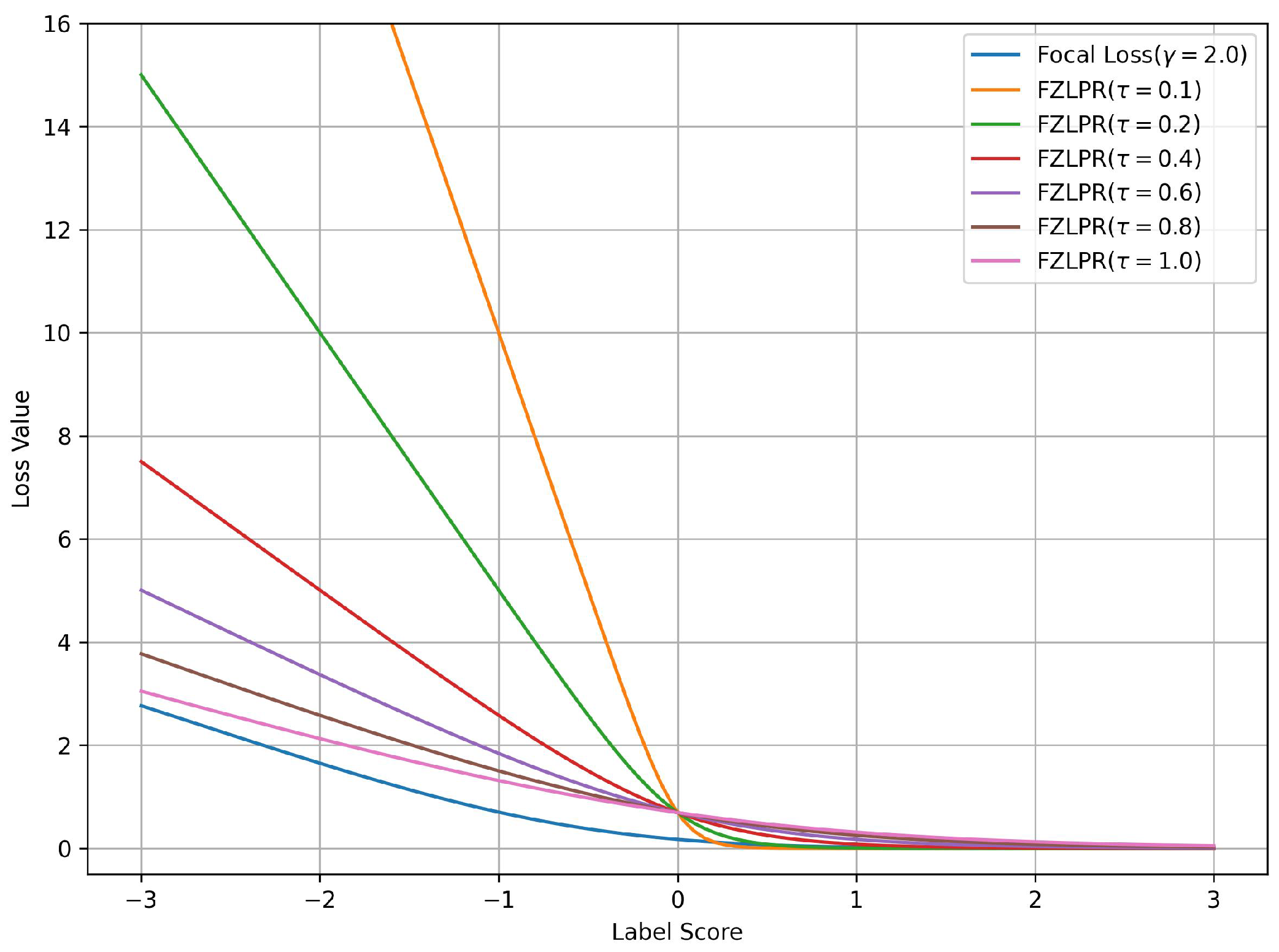
It is important to note that the Equation (5) is a generalization of the ZLPR function. To demonstrate the effectiveness of the label score scaling strategy in the FZLPR function, we analyze the impact of varying the temperature parameter on a single positive label and plot the corresponding loss values against the label scores in Figure 1. Since FZLPR treats both positive and negative labels similarly, this analysis applies to negative labels as well. Additionally, for reference, we include the focal loss with the recommended parameter setting () in the same plot. Now, we consider the following cases corresponding to different regions in Figure 1:
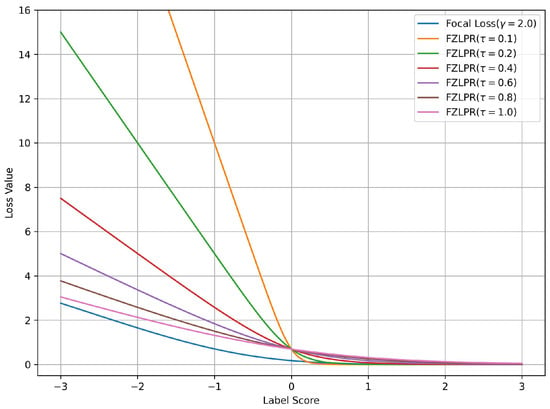
Figure 1.
Loss values for the focal and ZLPR loss functions for a positive label score. The label score is greater than 0 for a well-classified example and is less than 0 for a misclassified example. Best viewed on a color display.
- When the positive instance is correctly classified with high probability i.e., the label score , the weighting by causes its contribution to the loss function to become zero. This means the model does not focus on such instances, as their gradient is zero.
- When the positive instance is correctly classified but with low probability i.e., the label score , the weighting by ensures that its contribution is included in the loss function and its gradient flows during training.
- When the positive instance is incorrectly classified i.e., the label score , , the weighting by significantly increases its contribution to the loss function, ensuring that the model focuses on such instances and allowing a substantial gradient flow during training.
The results indicate that, in general, FZLPR behaves similarly to focal loss, reducing focus on well-classified examples while increasing the contribution of misclassified examples, which, in our case, are typically rare labels. Furthermore, misclassified examples incur a higher penalty compared to focal loss. The temperature parameter plays a critical role in scaling the label scores. In this work, is empirically determined as discussed in Section 4.
3.2. Transfer Learning
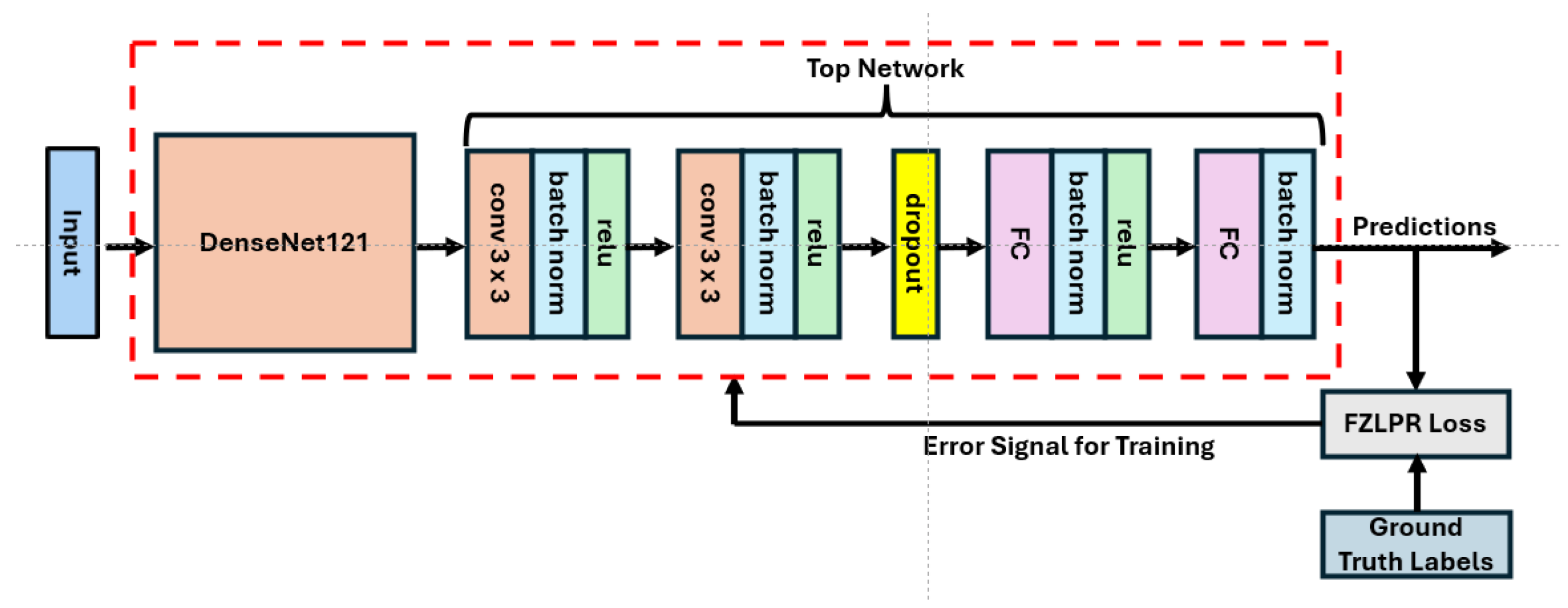
As stated in the introduction, transfer learning is a widely used technique for classifying thoracic diseases in CXR images. However, various sophisticated CNN architectures have been proposed in the literature for image classification. Among them, densely connected convolutional networks (DenseNets) are quite promising as they have shown remarkable performance on various vision tasks including image classification, object detection, semantic segmentation, etc. [22,44]. In this work, we have adopted DenseNet121 (pretrained on ImageNet-1K), which is a 121-layer DenseNet model, and have employed the standard transfer learning technique to tune it on the NIH Chest X-ray14 benchmark dataset. The architecture of our model, which includes DenseNet121 and a custom top network, is shown in Figure 2. The loss function computes the error signal that is used for training. The details of DenseNet121 and the custom network are presented below. Moreover, the implementation details are presented in Section 4.2.

Figure 2.
Architecture of our proposed model. The error signal generated by the loss function is used for training the model.
The input block of DenseNet121 consists of a single convolutional layer with a kernel size of 7 × 7, a stride of 2, and 64 filters, followed by batch normalization and the ReLU activation function. This block processes a 224 × 224 × 3 image as input. Its output is then passed to a max-pooling layer with a size of 2 × 2 and a stride of 2. The remainder of the model consists of four dense blocks and three transition blocks, arranged in an alternating sequence. Each dense block contains a specific number of convolutional blocks, with each convolutional block incorporating two convolutional layers. The first layer employs a 1 × 1 kernel, while the second uses a 3 × 3 kernel. The output of the second convolutional layer within a dense block is concatenated with its inputs. This enables the architecture to reuse feature maps from previous layers to construct rich feature representations and facilitate efficient gradient flow. Each transition block is composed of a single convolutional layer with a 1 × 1 kernel, designed with the objective to reduce the number of feature maps from the preceding dense block. Batch normalization and the ReLU activation function are also used in both dense and transition blocks along with the convolutional layers. The final dense block yields 1024 feature maps, each one of size of 7 × 7 pixels, which are then passed to a custom top network rather than the default one.
It is important to note that images from the ImageNet-1K dataset and CXR datasets have fundamental differences as they belong to different domains. As a result, we believe that the default top network (a global pooling layer and a final classification layer) is not optimal for generating a rich representation of CXR images. To overcome this limitation, our custom top network is designed by stacking two convolutional layers, a dropout layer with dropout rate of 0.1 for regularization, and two dense layers. Both convolutional layers use 3 × 3 kernels with a stride of 1, followed by batch normalization layers and ReLU activations. The number of filters in the convolutional layers is set to 256 and 128, respectively. This configuration yields a 1152-dimensional feature vector for each input image, which is then fed to the two dense layers composed of 64 and 14 hidden units, respectively. The output of the first dense layer is passed through a batch normalization layer and a ReLU activation function before feeding it to the second dense layer that acts as the final classification layer. Additionally, batch normalization is applied to the output of the final classification layer to ensure stable training. The number of parameters in DenseNet121 and the custom top network is approximately 7.03 million and 2.73 million, respectively.
4. Experimental Results
This section presents the experimental results of our proposed methodology on the NIH Chest X-ray14 benchmark dataset. We also provide details on the training methodology and implementation, along with a comprehensive analysis of the results. Finally, a comparison with existing methods is presented.
4.1. Chest X-Ray Dataset and Evaluation Metric
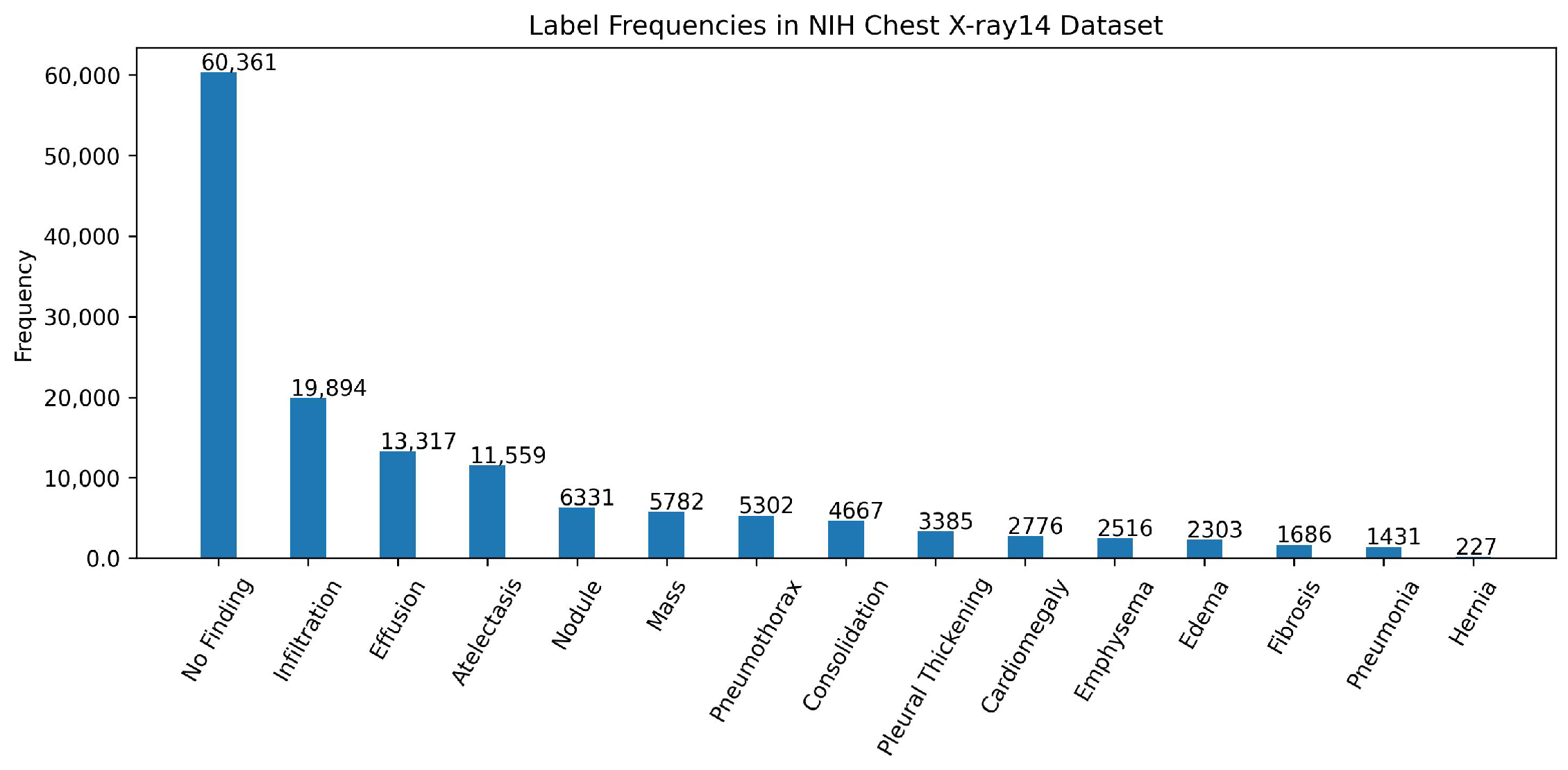
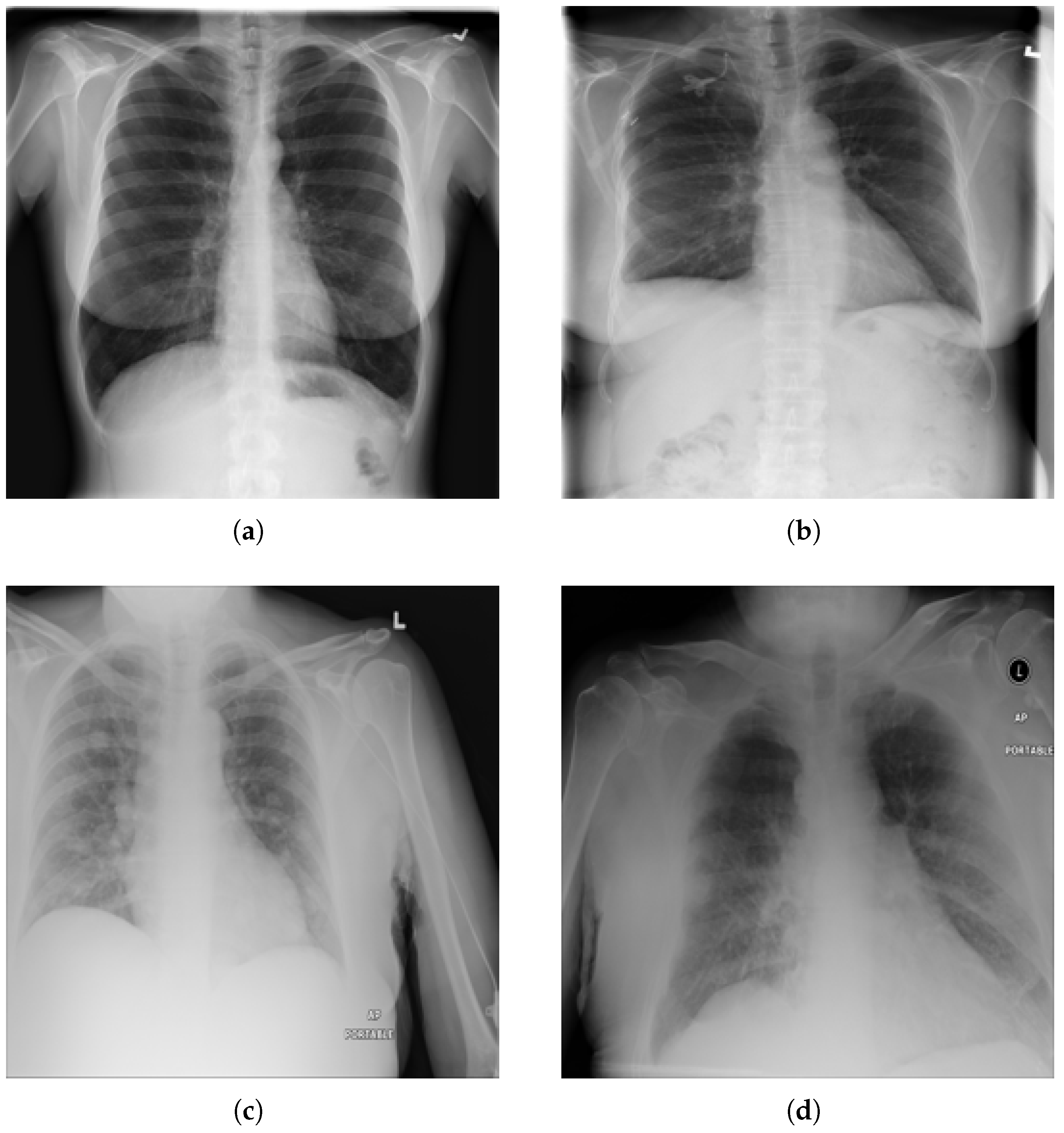
We have used the NIH Chest X-ray14 benchmark dataset [4], which is a well-known and widely used benchmark dataset. It contains a total of 112,120 frontal CXR images from 30,805 patients in Digital Imaging and Communications in Medicine (DICOM) format. For research purposes, the dataset is also made available in PNG format where each image has a resolution of 1024 × 1024 pixels. Out of the total, 86,524 images are allocated for training, and the remaining 25,596 are used for evaluation. There is no overlap in patients between the training and test datasets. The dataset includes 51,759 CXR images with 14 different disease labels in a multi-label format, meaning a single CXR image can exhibit more than one disease. Additionally, there are 60,361 CXR images of normal patients. The label frequencies are shown in Figure 3, which also indicates the class imbalance problem associated with the dataset and making it a challenging task. Moreover, some examples from the dataset along with the findings are shown Figure 4. For training purposes, all images were downscaled from their original resolution to 256 × 256 pixels using bicubic interpolation. Moreover, we split the training set randomly to create a validation set of 8652 images using a 90:10 ratio. Labels are coded using a multi-hot encoding scheme. For evaluation, we employ the standard performance metric proposed by Wang et al. [4], which is widely adopted by researchers for the NIH Chest X-ray14 dataset. Specifically, the area under the receiver operating characteristic curve (AUC) is computed for each class in the MLC.
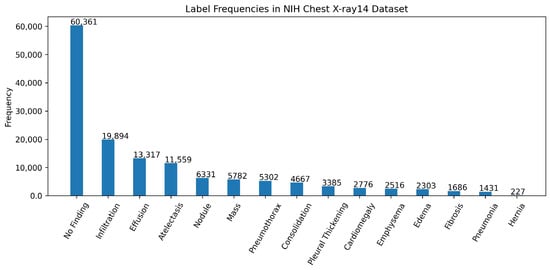
Figure 3.
Label frequencies in the NIH chest x-ray14 benchmarks dataset. Note that the labels are sorted according to their frequencies.
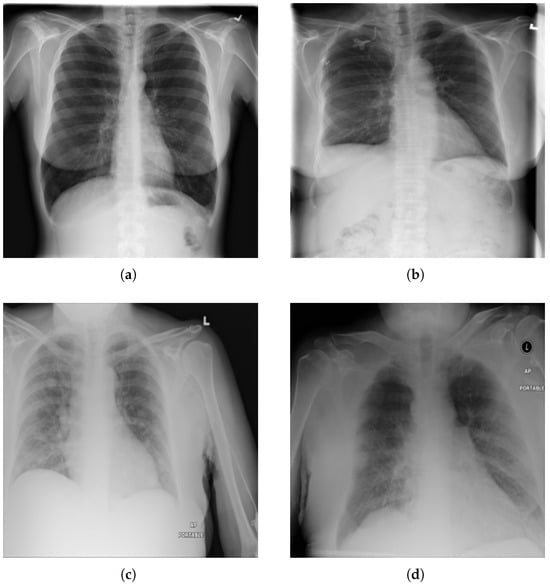
Figure 4.
Examples from NIH chest X-ray14 datasets with labels: (a) No Finding, (b) Fibrosis. (c) Mass, and (d) Edema, Pleural Thickening, and Pneumonia.
4.2. Training Methodology and Implementation Details
As mentioned in Section 3, we employ transfer learning using a pretrained DenseNet121 model. The training process consists of two stages. In the first stage, the DenseNet121 model, serving as the base model, remains frozen while the top network, composed of convolutional and dense layers, is trained. In the second stage, both the base model and the top network are trained together. In both stages, we use the AdamW optimizer (Adam with decoupled weight decay) [45]. Training is conducted using the mini-batch stochastic gradient descent algorithm with backpropagation, where the mini-batch size is set to 64. The learning rates are set to and for the first and second stages, respectively. The higher learning rate in the first stage facilitates adaptation of the top network using the generic features of the pretrained base model, while the lower learning rate in the second stage refines the complete model for the disease classification task at hand. Additionally, cosine annealing [46] is applied in the second stage to decay the learning rate to a minimum value of , starting from an initial value of . The weight decay is set to . The top network is trained for a total of five epochs in the first stage and 20 epochs in the second stage. These values were determined through early stopping in our initial experiments and subsequently fixed for all future experiments. Mini-batch preprocessing involves normalization using the mean and standard deviation of the ImageNet dataset. Furthermore, as described in [5], random augmentations are applied during batch formation, including random horizontal flipping, random rotations ( radians), and random cropping to 224 × 224 pixels from an original image size of 256 × 256 pixels.
Our computing platform consists of a desktop PC running Ubuntu 20.04, equipped with a single Nvidia GeForce RTX 1080Ti GPU with 11 GB of memory, an Intel® Core™ i7-4470 processor, and 24 GB of RAM. We use Google TensorFlow [47] for the implementation of DenseNet121, the proposed top network, and the loss function. The total training time for our model is 186 min when using BCE and focal loss, whereas it increases to 189 min with ZLPR and FZLPR.
4.3. Results and Discussion
In this section, we present various experimental results of our trained DenseNet121 model on the NIH Chest X-ray14 dataset. Firstly, we analyze and compare the performance of the model using different loss functions. Four DenseNet121 models were trained using different loss functions, BCE, focal loss, ZLPR, and our proposed FZLPR with , following the training methodology detailed in the previous section. An ablation study on the impact of the hyperparameter is included in the next section. We compare the performance of these four models based on their average AUC scores on the validation set, as listed in Table 1. It is observed that the model trained with FZLPR () outperforms all others, achieving an average AUC score of 83.44% on the validation set. The model trained with focal loss ranks second, while the model trained with BCE loss records the lowest average AUC score of 80.82%. To comprehensively compare the performance of these four models on the official test split of the NIH Chest X-ray14 dataset, we summarize the individual and average AUC scores obtained across 14 disease labels in Table 2. This follows established practices for reporting test set results in the field, as presented in previous research works [4,5,6]. The best and runner-up for each label is shown in bold and underlined text, respectively. It can be observed that both FZLPR and focal losses emphasize the correct prediction of rare labels including Hernia, Pneumonia, Fibrosis, Emphysema, Cardiomegaly, etc., while maintaining comparable AUC scores on the majority classes. FZLPR attained the best or runner-up positions for eight disease labels, while focal loss achieved the best or runner-up position for 12 disease labels. However, on average, the FZLPR loss outperforms focal, ZLPR, and BCE losses and achieves an average AUC of 80.45%.

Table 1.
Evaluation of models trained with different loss functions based on average AUC scores across different disease labels in the validation set.
Table 2.
Evaluation of models trained with different loss functions based on AUC scores across different disease labels in the test set. The best AUC scores are shown in bold text while the runner-up is shown in underlined text.
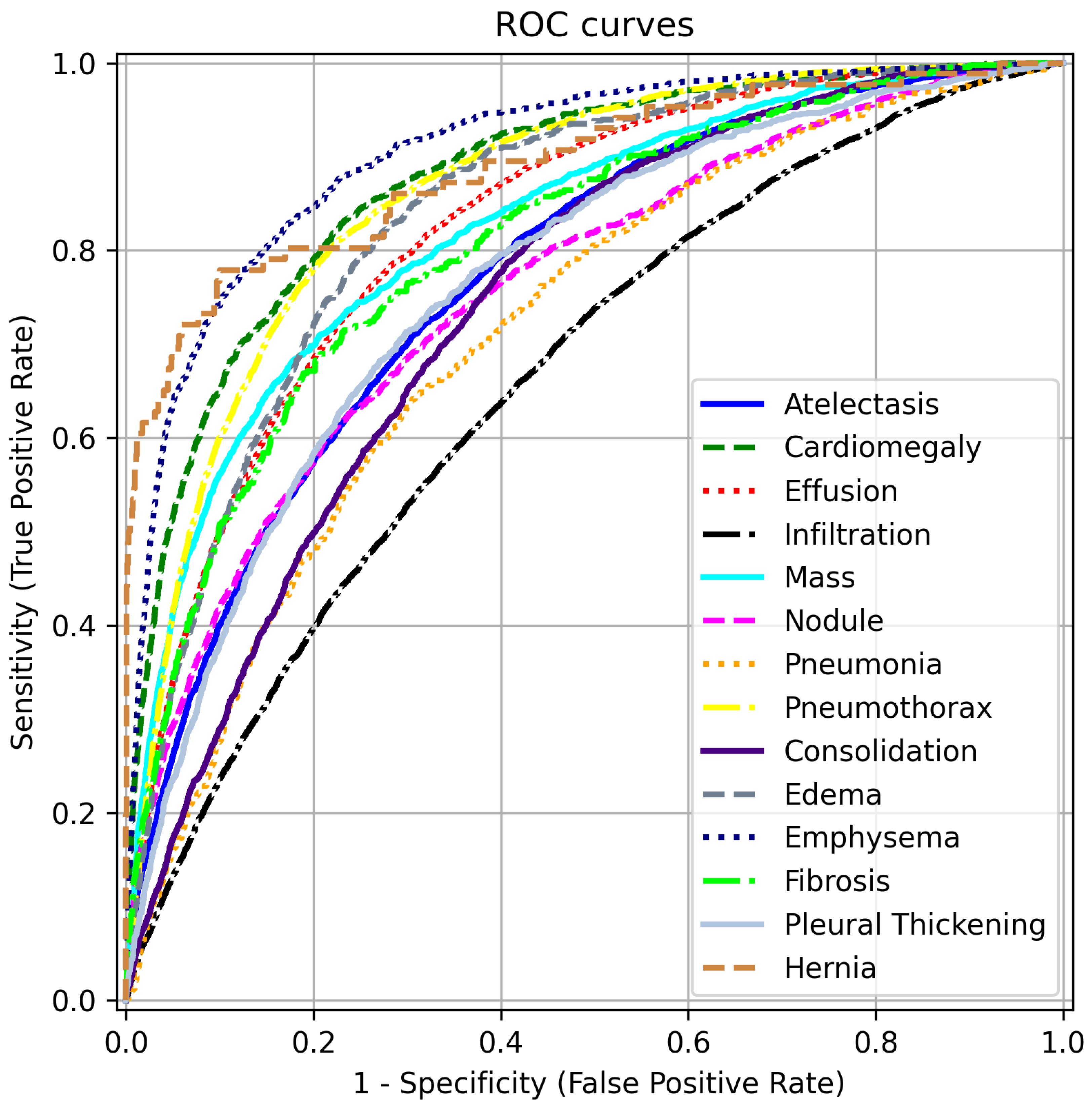
To complement the AUC scores in Table 2, we present ROC curves for each disease label in Figure 5. These curves are generated by varying the threshold applied to the label scores of our model, trained with FZLPR (), and computing sensitivity and specificity metrics. It can be observed that the model has good discrimination ability for all disease labels. In particular, the model achieves an AUC score of 80% or more for labels Including Emphysema, Hernia, Cardiomegaly, Pneumothorax, Edema, Effusion, Mass, And Fibrosis. This indicates that the model has significant clinical utility in distinguishing these pathologies from their absence. However, lower AUC scores are obtained for Infiltration and Pleural Thickening, which indicates that the model predictions must be accompanied by additional diagnostic information to be used in clinical settings.
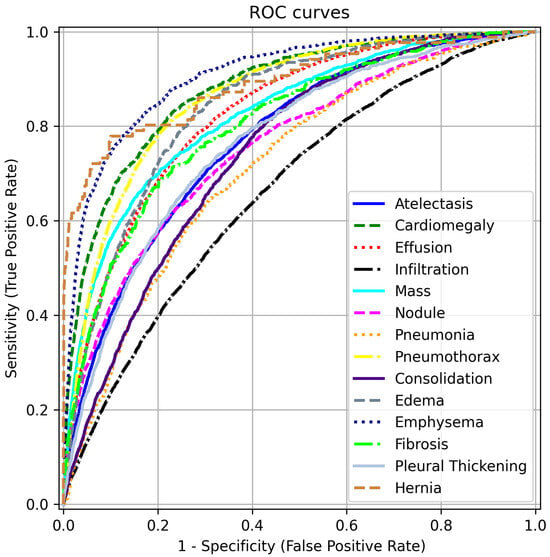
Figure 5.
ROC curves for different disease labels using FZLPR (). Best viewed on a color display.
Secondly, inspired by [6], we apply test-time augmentations (TTA) to the CXR images in the test set, as they are known to improve the generalization of the model. Specifically, we use horizontal flipping and a ±10% zoom transformation. Both the original and augmented images are fed into the model (DenseNet121+ FZLPR ()). The model’s outputs are then averaged to generate enhanced predictions. The impact of these transformations is summarized in Table 3. Notably, both augmentations contribute to improved model predictions. The average AUC increases by 0.25% when using only horizontal flipping, while employing both augmentations leads to a 0.51% increase.
Table 3.
AUC scores across different disease labels in the test set using the test time augmentations. HF: horizontal flip. Z: zoom (±10%).
4.4. Ablation Study
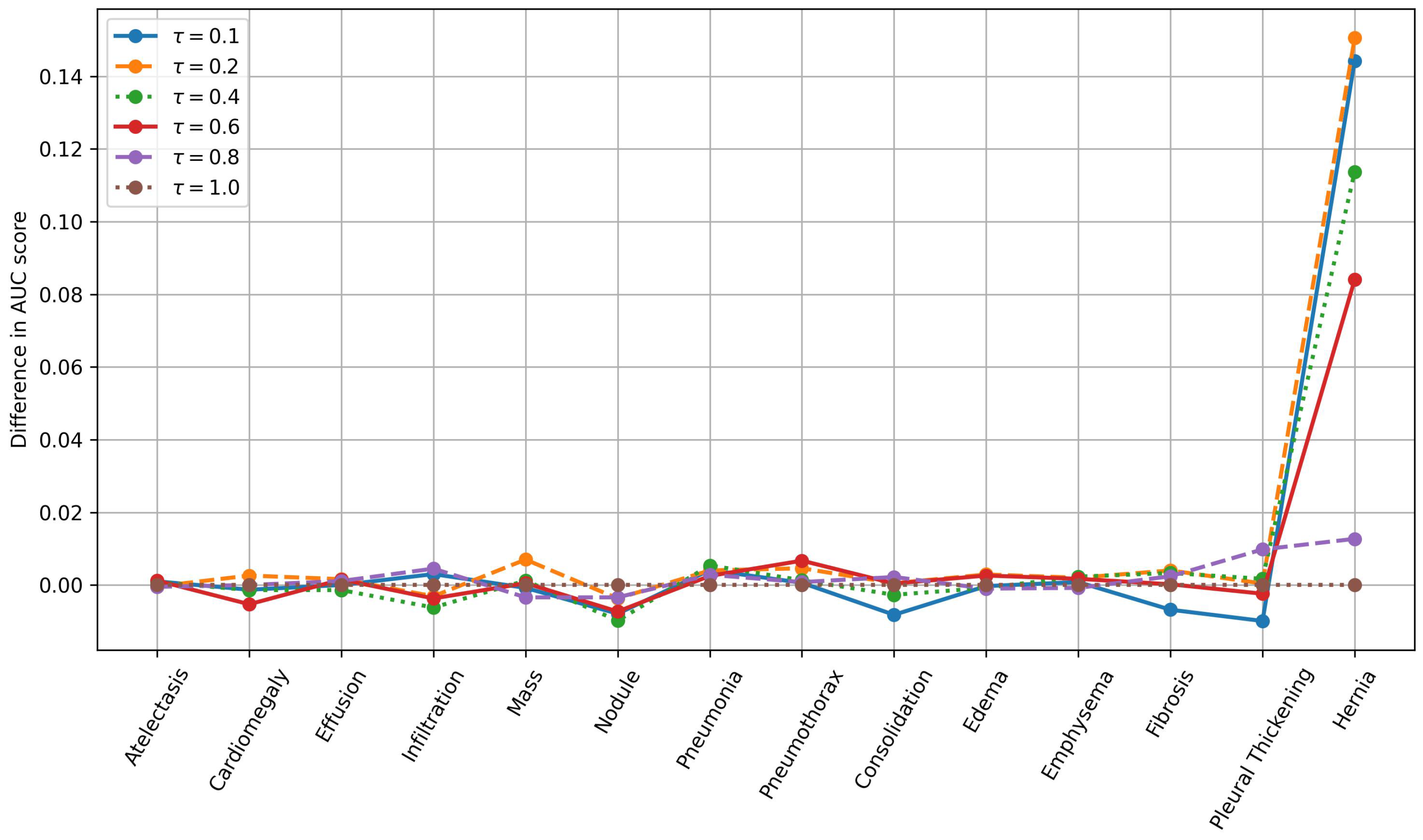
We conduct an ablation study to analyze the impact of the hyperparameter in the FZLPR loss function. The value of is varied between 0.1 and 1.0, using the discrete set . The individual AUC scores for different disease labels in the Chest X-ray14 dataset, along with the average AUC score, are presented in Table 4. The best and runner-up for each label is shown in bold and underlined text, respectively. Moreover, we present the variation in AUC scores across different disease labels for various values of , while fixing the baseline at , as shown in Figure 6. It is to be noted that the difference in AUC scores is plotted in the figure. The results indicate that achieves the highest AUC scores across six labels, outperforming all other choices. This is followed by , which attains the best AUC scores on three labels. If both the best and runner-up positions are considered, performs well across nine labels, followed by and , with each performing across five labels. Overall, as decreases from 1.0 to 0.2, the average AUC score improves from 79.21% to 80.45%, with the highest average AUC achieved at . However, at , the average AUC score decreases by 0.39% compared to . In terms of AUC scores across diseases labels, significant gains are achieved using compared to baseline (), particularly for the ‘Hernia’ label, as shown in Figure 6. In summary, these results indicate that when is small or large enough, the performance decreases, as it leads to extreme scaling of the label scores, which hinders the model’s effectiveness.
Table 4.
Ablation study on the impact of in the FZLPR loss function. The AUC scores across different disease labels in the Chest X-ray14 dataset are listed. The best AUC scores are shown in bold text while the runner-up is shown in underlined text.

Figure 6.
Variation in AUC scores across diseases labels for different values of . The baseline is chosen as and differences in AUC scores are plotted. Best viewed on a color display.
4.5. Comparison with Existing Methods
We now compare the experimental results of our proposed approach with existing methods. Six techniques from the literature are considered for comparison, including the foundational work of Wang et al. [4], which introduced the NIH Chest X-ray14 dataset. These methods were selected based on the diversity of their methodologies. The AUC scores across different disease labels are summarized in Table 5. To facilitate comparison, we have also included the difference () between the AUC of our approach and the best-performing method. Moreover, the best AUC is highlighted in bold. It is important to note that Kufel et al. [28], like many other researchers in the field, do not use the official split of the dataset and achieve the highest average AUC score among all methods by fine-tuning an EfficientNet model. Therefore, such comparisons must be interpreted with caution. All other methods, including ours, in Table 5 use the official split. It is to be noted that our method employs a ranking loss, in contrast to all other methods, which use either BCE or its variants for model training or fine-tuning. Our approach outperforms the foundational work of Wang et al. [4], which employs transfer learning to fine-tune a ResNet50 model. Their fine-tuned ResNet50 achieved an average AUC of 74.51%. Moreover, our method slightly outperforms those of Guendel et al. [33] and Baltruschat et al. [30]. It is noteworthy that Gundel et al. use high-resolution images (1024 × 1024 pixels) to fine-tune a DenseNet121 model and Baltruschat et al. integrate non-image data alongside high resolution CXR images (448 × 448 pixels) to train a custom ResNet model. The inclusion of additional information in these two approaches helped them achieve better AUC scores. However, in contrast, our method using 224 × 224 pixels image as input with no additional (non-image) data outperforms these two approaches. Gaun et al. [20] employ an attention module to assign weights to different spatial positions of the DenseNet121 feature maps, in addition to fine-tuning, and achieve a slightly higher average AUC score—just 0.63% above that of our approach. The ensemble model proposed by Kotana et al. [5], composed of InceptionV3, ResNet50, and DenseNet121, outperforms all other methods including ours, with an average AUC of 83.07%. It must be noted that their ensemble was pretrained on additional data from MIMIC-CXR dataset before fine-tuning on the NIH Chest X-ray14 dataset. Moreover, their ensemble model comprises 57.3 million parameters, which is significantly higher compared to our DenseNet121 model, which contains just 9.76 million parameters. When analyzing the AUC scores of individual disease labels, our method exhibits a maximum of 6.78% for the Consolidation label, while the minimum of 2.53% is observed for the Cardiomegaly label. However, in terms of average AUC, our approach falls short of the best-performing method [28] by just 3.31%. Based on this comparison with existing methods, we conclude that our proposed approach achieves competitive experimental results.
Table 5.
Comparison with existing methods using AUC score across different disease labels. The best AUC score is shown in bold text. is the difference between the AUC of our approach and the best-performing method.
4.6. Qualitative Results
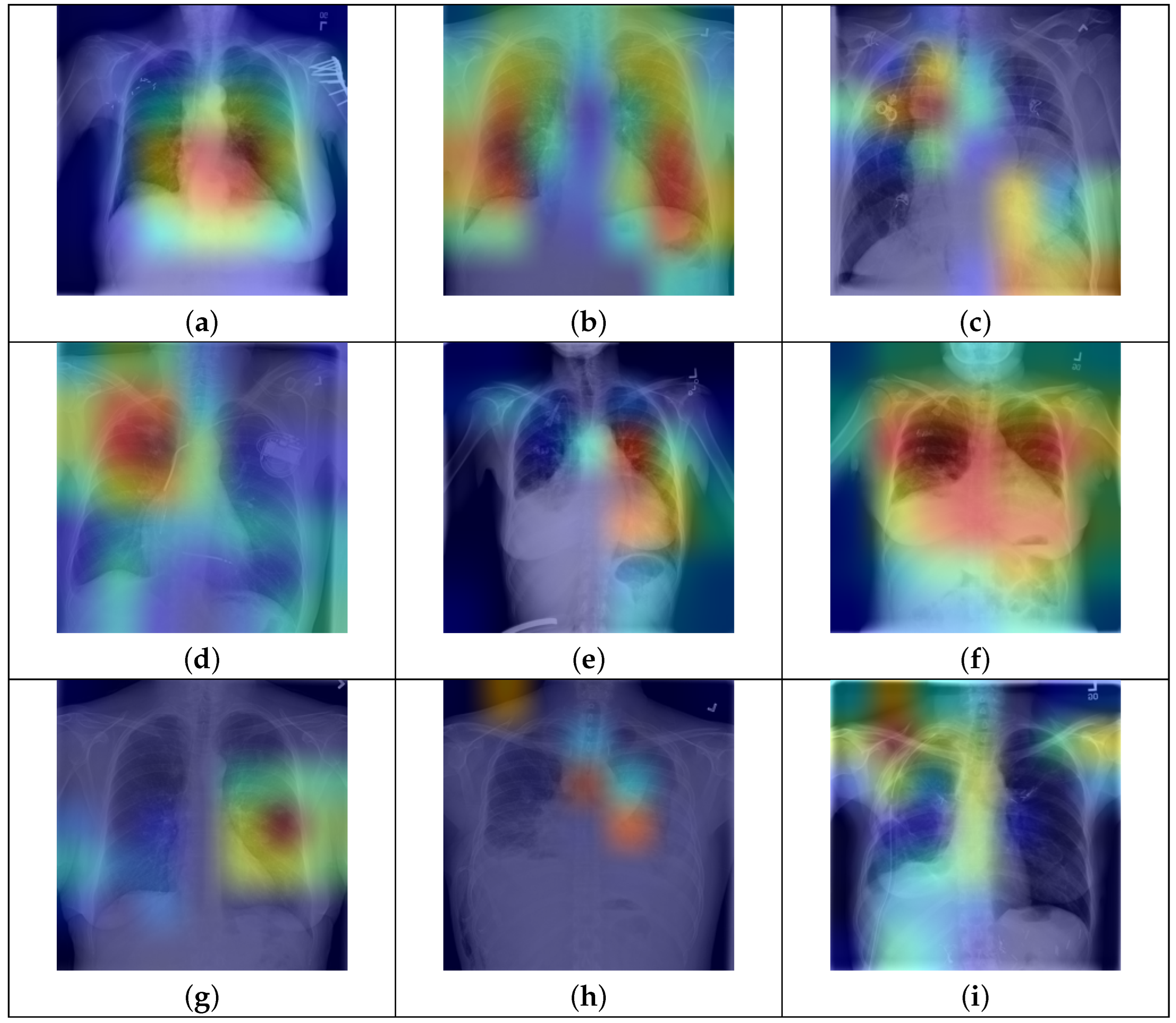
Finally, we present qualitative results of thoracic disease classification. To determine predictions for test CXR images, we set the label score threshold to 0. Ground truth and predicted labels for nine test CXR images are shown in Figure 7. Additionally, we employ the Grad-CAM technique to highlight the active regions of feature maps that significantly contribute to predictions. The feature maps from the “conv5” block of our model are used to generate Grad-CAMs. CXR images are then blended with the respective Grad-CAMs to visualize these regions, with high-activity areas displayed in red. Our model’s predictions align with the ground truth labels for both single and multiple disease cases, as seen in Figure 7a–f. It can be observed that the model highlights regions likely associated with disease, as indicated by high-activity areas in the Grad-CAM images. In the case labeled as “No Finding”, the model primarily focuses on regions of the lung that appear healthy. The third row highlights instances where the model fails to predict accurately. Specifically, in Figure 7g,h, the model could not predict one more disease label. In Figure 7i, we can observe that the model fails to accurately identify the disease-affected areas and, therefore, the prediction is incorrect.

Figure 7.
Qualitative results on the test set of NIH Chest X-ray14 dataset. Each CXR image is blended with its respective Grad-CAM and shows the high activity regions in red. Ground truth and predicted labels are mentioned for each test CXR image. (a) Ground Truth: Hernia Predicted: Hernia; (b) Ground Truth: Nodule Predicted: Nodule; (c) Ground Truth: Mass Predicted: Mass; (d) Ground Truth: No Finding Predicted: No Finding; (e) Ground Truth: Cardiomegaly, Effusion Predicted: Cardiomegaly, Effusion; (f) Ground Truth: Atelectasis, Effusion, Infiltration Predicted: Atelectasis, Effusion, Infiltration. (g) Ground Truth: Nodule, Fibrosis Predicted: Nodule; (h) Ground Truth: Effusion, Mass, Emphysema Predicted: Effusion, Mass; (i) Ground Truth: Pleural Thickening Predicted: Pneumothorax.
5. Conclusions and Future Works
In this article, we address the challenging task of automatic thoracic disease classification in CXR images, while also handling the inherent class imbalance. Our methodology is based on transfer learning, utilizing a pretrained DenseNet121 model, which we fine-tune on a CXR image dataset. To effectively handle class imbalance, we propose FZLPR loss—a modification of ZLPR loss—that scales model output scores to focus on hard examples during training. The results are presented on the NIH Chest X-ray14 benchmark dataset, a widely recognized and challenging dataset. A comparison of FZLPR loss with other loss functions, such as BCE and focal losses, demonstrates its effectiveness in addressing class imbalance. Furthermore, we find that test-time augmentations enhance model performance. A comparison with existing methods reveals that our model, trained using FZLPR loss, achieves a performance comparable to that of state-of-the-art approaches.
For future work, we plan to expand our experimentation on a dataset with a broader range of disease labels, as the current evaluation is conducted on the NIH Chest X-ray14 dataset containing 14 disease labels only. To achieve this, the MIMIC-CXR-JPG v2.1.0 dataset can be used, which includes 40 disease labels and also exhibits a long-tail distribution of labels. Additionally, we aim to assess the performance of FZLPR on multi-label classification tasks in fields other than medical image analysis. To achieve this, we plan to utilize datasets such as MS-COCO [48], a benchmark dataset for object detection, and AAPD [49], a benchmark dataset for text classification.
Author Contributions
Conceptualization, M.S.H., M.B., A.H.A. and U.M.A.-S.; Data curation, M.S.H. and M.B.; Formal analysis, M.S.H. and M.B.; Funding acquisition, A.H.A. and U.M.A.-S.; Investigation, M.S.H.; Methodology, M.S.H. and M.B.; Project administration, A.H.A. and U.M.A.-S.; Resources, A.H.A. and U.M.A.-S.; Software, M.S.H. and M.B.; Supervision, A.H.A. and U.M.A.-S.; Validation, M.S.H., M.B. and A.H.A.; Visualization, M.B., A.H.A. and U.M.A.-S.; Writing—original draft, M.S.H. and M.B.; Writing—review and editing, M.B., A.H.A. and U.M.A.-S. All authors have read and agreed to the published version of the manuscript.
Funding
This project was funded by the Deanship of Scientific Research (DSR) at King Abdulaziz University, Jeddah, under the grant no. (GPIP: 1698-140-2024). The authors, therefore, acknowledge with thanks DSR for technical and financial support.
Data Availability Statement
NIH Chest X-ray14 dataset is a publicly available benchmark dataset. It can be found here: https://nihcc.app.box.com/v/ChestXray-NIHCC (accessed on 15 June 2024).
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Li, J.; Jiang, P.; An, Q.; Wang, G.G.; Kong, H.F. Medical image identification methods: A review. Comput. Biol. Med. 2024, 169, 107777. [Google Scholar] [CrossRef]
- Wang, J.; Wang, S.; Zhang, Y. Deep learning on medical image analysis. CAAI Trans. Intell. Technol. 2025, 10, 1–35. [Google Scholar] [CrossRef]
- Zhang, S.; Metaxas, D. On the challenges and perspectives of foundation models for medical image analysis. Med. Image Anal. 2024, 91, 102996. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. Chest X-ray8: Hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar]
- Katona, T.; Tóth, G.; Petró, M.; Harangi, B. Advanced Multi-Label Image Classification Techniques Using Ensemble Methods. Mach. Learn. Knowl. Extr. 2024, 6, 1281–1297. [Google Scholar] [CrossRef]
- Nguyen-Mau, T.H.; Huynh, T.L.; Le, T.D.; Nguyen, H.D.; Tran, M.T. Advanced augmentation and ensemble approaches for classifying long-tailed multi-label chest x-rays. In Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 2729–2738. [Google Scholar]
- Johnson, A.E.; Pollard, T.J.; Berkowitz, S.J.; Greenbaum, N.R.; Lungren, M.P.; Deng, C.Y.; Mark, R.G.; Horng, S. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports. Sci. Data 2019, 6, 317. [Google Scholar] [CrossRef] [PubMed]
- CXR-LT: Multi-Label Long-Tailed Classification on Chest X-Rays. Available online: https://physionet.org/content/cxr-lt-iccv-workshop-cvamd/1.0.0/ (accessed on 1 March 2025).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Ridnik, T.; Ben-Baruch, E.; Noy, A.; Zelnik-Manor, L. ImageNet-21K Pretraining for the Masses. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), Virtual Conference, 6–14 December 2021. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Chai, J.C.L.; Ng, T.S.; Low, C.Y.; Park, J.; Teoh, A.B.J. Recognizability embedding enhancement for very low-resolution face recognition and quality estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 9957–9967. [Google Scholar]
- Liu, G.H.; Li, Z.Y.; Yang, J.Y.; Zhang, D. Exploiting sublimated deep features for image retrieval. Pattern Recognit. 2024, 147, 110076. [Google Scholar] [CrossRef]
- Revaud, J.; De Souza, C.; Humenberger, M.; Weinzaepfel, P. R2d2: Reliable and repeatable detector and descriptor. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 12414–12424. [Google Scholar]
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef] [PubMed]
- Shoeibi, A.; Khodatars, M.; Jafari, M.; Ghassemi, N.; Sadeghi, D.; Moridian, P.; Khadem, A.; Alizadehsani, R.; Hussain, S.; Zare, A.; et al. Automated detection and forecasting of COVID-19 using deep learning techniques: A review. Neurocomputing 2024, 577, 127317. [Google Scholar] [CrossRef]
- Kumar, R.; Kumbharkar, P.; Vanam, S.; Sharma, S. Medical images classification using deep learning: A survey. Multimed. Tools Appl. 2024, 83, 19683–19728. [Google Scholar] [CrossRef]
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K.; et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 590–597. [Google Scholar]
- Nawaz, M.; Nazir, T.; Baili, J.; Khan, M.A.; Kim, Y.J.; Cha, J.H. CXray-EffDet: Chest disease detection and classification from X-ray images using the EfficientDet model. Diagnostics 2023, 13, 248. [Google Scholar] [CrossRef] [PubMed]
- Guan, Q.; Huang, Y. Multi-label Chest X-ray Image Classification via Category-wise Residual Attention Learning. Pattern Recognit. Lett. 2020, 130, 259–266. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Su, J.; Zhu, M.; Murtadha, A.; Pan, S.; Wen, B.; Liu, Y. Zlpr: A novel loss for multi-label classification. arXiv 2022, arXiv:2208.02955. [Google Scholar]
- Kufel, J.; Bielówka, M.; Rojek, M.; Mitręga, A.; Lewandowski, P.; Cebula, M.; Krawczyk, D.; Bielówka, M.; Kondoł, D.; Bargieł-Łączek, K.; et al. Multi-label classification of chest X-ray abnormalities using transfer learning techniques. J. Pers. Med. 2023, 13, 1426. [Google Scholar] [CrossRef] [PubMed]
- Ge, Z.; Mahapatra, D.; Chang, X.; Chen, Z.; Chi, L.; Lu, H. Improving multi-label chest X-ray disease diagnosis by exploiting disease and health labels dependencies. Multimed. Tools Appl. 2020, 79, 14889–14902. [Google Scholar] [CrossRef]
- Baltruschat, I.M.; Nickisch, H.; Grass, M.; Knopp, T.; Saalbach, A. Comparison of deep learning approaches for multi-label chest X-ray classification. Sci. Rep. 2019, 9, 6381. [Google Scholar] [CrossRef] [PubMed]
- Katona, T.; Tóth, G.; Petró, M.; Harangi, B. Developing New Fully Connected Layers for Convolutional Neural Networks with Hyperparameter Optimization for Improved Multi-Label Image Classification. Mathematics 2024, 12, 806. [Google Scholar] [CrossRef]
- Han, Y.; Chen, C.; Tewfik, A.; Glicksberg, B.; Ding, Y.; Peng, Y.; Wang, Z. Knowledge-augmented contrastive learning for abnormality classification and localization in chest X-rays with radiomics using a feedback loop. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 2465–2474. [Google Scholar]
- Guendel, S.; Grbic, S.; Georgescu, B.; Liu, S.; Maier, A.; Comaniciu, D. Learning to recognize abnormalities in chest X-rays with location-aware dense networks. In Proceedings of the 23rd Iberoamerican Congress on Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications (CIARP), Madrid, Spain, 19–22 November 2019; pp. 757–765. [Google Scholar]
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Learning deep representation for imbalanced classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5375–5384. [Google Scholar]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar]
- Ridnik, T.; Ben-Baruch, E.; Zamir, N.; Noy, A.; Friedman, I.; Protter, M.; Zelnik-Manor, L. Asymmetric loss for multi-label classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Conference, 11–17 October 2021; pp. 82–91. [Google Scholar]
- Bénédict, G.; Koops, H.V.; Odijk, D.; de Rijke, M. sigmoidF1: A Smooth F1 Score Surrogate Loss for Multilabel Classification. arXiv 2022, arXiv:2108.10566. [Google Scholar]
- Huang, Y.; Qi, J.; Wang, X.; Lin, Z. Asymmetric polynomial loss for multi-label classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Park, W.; Park, I.; Kim, S.; Ryu, J. Robust asymmetric loss for multi-label long-tailed learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 2711–2720. [Google Scholar]
- Timmermann, C.; Jung, S.; Kim, M.; Lee, W. LM-CLIP: Adapting Positive Asymmetric Loss for Long-Tailed Multi-Label Classification. IEEE Access 2025, 13, 71053–71065. [Google Scholar] [CrossRef]
- Li, Y.; Song, Y.; Luo, J. Improving pairwise ranking for multi-label image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3617–3625. [Google Scholar]
- Kim, G.; Im, S.; Oh, H.S. Hierarchy-aware Biased Bound Margin Loss Function for Hierarchical Text Classification. In Proceedings of the Findings of the Association for Computational Linguistics ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 7672–7682. [Google Scholar]
- Lin, D.; Peng, T.; Chen, R.; Xie, X.; Qin, X.; Cui, Z. Distributionally Robust Loss for Long-Tailed Multi-label Image Classification. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 417–433. [Google Scholar]
- Kim, D.; Heo, B.; Han, D. DenseNets reloaded: Paradigm shift beyond ResNets and ViTs. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 395–415. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Loshchilov, I.; Hutter, R. SGDR: Stochastic Gradient Descent with Warm Restarts. In Proceedings of the International Conference on Learning Representations ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. Available online: https://www.tensorflow.org/ (accessed on 20 July 2024).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Yang, P.; Sun, X.; Li, W.; Ma, S.; Wu, W.; Wang, H. SGM: Sequence Generation Model for Multi-label Classification. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 3915–3926. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).