Abstract
(1) Background: Various machine learning techniques were used to predict hypertension in Korean adults aged 20 and above, using a range of body composition indicators. Muscle and fat components of body composition are closely related to hypertension. The aim was to identify which body composition indicators are significant predictors of hypertension for each gender; (2) Methods: A model was developed to classify hypertension using six different machine learning techniques, utilizing age, BMI, and body composition indicators such as body fat mass, lean mass, and body water of 2906 Korean men and women; (3) Results: The elastic-net technique demonstrated the highest classification accuracy. In the hypertension prediction model, the most important variables for men were age, skeletal muscle mass (SMM), and body fat mass (BFM), in that order. For women, the significant variables were age and BFM. However, there was no difference between soft lean mass and SMM; (4) Conclusions: Hypertension affects not only BFM but also SMM in men, whereas in women, BFM has a stronger effect than SMM.
1. Introduction
South Korea is currently facing serious issues of low birth rates and an aging population. As the population of newborns decreases, the average age of society members rises, emphasizing the importance of health management for those actively participating in economic activities [1]. Consequently, there is a need for managing various chronic adult diseases. However, access to clinical assistance has limitations in terms of accessibility and cost, highlighting the need for methods that can be easily managed at home [2]. Common methods that can be relatively easily monitored and controlled in daily life include weight and blood pressure. More specifically, body composition measurement devices have been released, allowing for more detailed analysis of the composition of different parts of the body, thus facilitating easier health management.
Body composition refers to the components that make up the human body, serving as an indicator of individual health characteristics through an expanded interpretation at the molecular level [3]. The molecular components of body composition include body fat, body water, protein, and minerals. Various body composition analyzers are used to measure these components. For body composition analysis, a small constant current of microamperes is sent through the body, and the voltage is measured to calculate the impedance, which is then analyzed [4]. Compared to the body mass index (BMI), which is the ratio of weight to height, body composition analysis is known to have higher reliability and validity as it provides a more detailed breakdown of body components [5]. There are various indicators for body composition analysis, including skeletal muscle mass, fat mass, muscle mass by body part, and body water, which are known to be indicators that can identify the presence of various diseases [6]. In particular, fat mass and muscle mass have been shown in various prior studies to be potential predictors of metabolic syndrome diseases such as hypertension, as well as cardiovascular diseases like arteriosclerosis [7,8]. Among these metabolic and cardiovascular diseases, a key clinical risk factor is hypertension. Hypertension is a straightforward indicator that can be checked using a simple blood pressure monitor; however, its measurement is limited to the systolic and diastolic values and it does not provide insights into the internal causes and conditions of the body that reflect these blood pressure values [9]. Understanding how the conditions of fat or muscle at specific body locations influence these values requires additional statistical methods and clinical interpretations to prove causality. Therefore, to manage such cardiovascular diseases, it is necessary to design or plan clinical approaches and personal health management methods based on the correlation and connectivity of more detailed elements and hypertension. Various prior studies have been conducted to develop predictive models based on the correlation between body composition indicators and hypertension for this purpose. In a study that examined the associations of body composition with blood pressure and hypertension using indicators from dual-energy X-ray absorptiometry of body composition and total skeletal muscle, body fat percentage and fat distribution were suggested as effective features for the model in predicting hypertension [10]. Another prior study examined the correlation between body size and composition and elevated blood pressure in adolescent girls, confirming the association between fat-free mass and blood pressure [11]. Another study developed a machine learning-based model to predict hypertension using body composition features without distinguishing between genders. In this study, body fat mass was included as a feature in the model, which achieved up to 90% prediction accuracy [12]. These prior studies commonly identified fat mass among body composition elements as a common indicator for classifying or predicting hypertension.
In addition to common indicators, various variables are presented as factors of hypertension but the results of most hypertension prediction models vary depending on the gender and demographic characteristics of the subjects. In addition, it is necessary to develop a prediction model using indicators that affect the occurrence of hypertension. Therefore, in order to identify hypertension indicators that take into account the characteristics of Koreans, priority should be given to identifying variables that differ in each gender.
This study aims to develop prediction models that can classify the presence of hypertension in Korean adults aged twenty and above, using various machine learning techniques and distinguishing between the models for men and women. This study also aims to verify the importance of the features included in the models.
2. Materials and Methods
2.1. Data Sources and Participant Selection
In this study, data collected through cross-sectional research were used from April 2022 to December 2022 at five hospitals in the Republic of Korea, including Dongguk University Ilsan Oriental Hospital, Pusan National University Korean Medicine Hospital, Gachon University Gill Hospital, Dongshin University Korean Medicine Hospital, and Semyung University Korean Medicine Hospital. This study was approved by the Institutional Review Boards of each hospital and was conducted according to the Declaration of Helsinki (IRB No., Dongguk University Ilsan Oriental Hospital, DUIOH-2022-01-005; Pusan National University Korean Medicine Hospital, PNUKHIRB-2022-02-001; Gachon University Gill Hospital, GIRB-22-101; Dongshin University Korean Medicine Hospital, NJ-IRB-013; Semyung University Korean Medicine Hospital, SMJOH-2022-06). All participants signed an informed consent form prior to enrollment.
A total of 3000 participants were assessed for eligibility for inclusion in the study. Of the 3000 participants, 2986 completed the clinical study after excluding individuals who did not meet inclusion/exclusion criteria. The inclusion criteria were as follows: (1) adults aged 19 years or older; (2) those without cognitive disorder; (3) those who voluntarily decided to participate after fully understanding the study, and agreed to participate in the study via written consent. The exclusion criteria were as follows: (1) those who were unable to measure their health status with a device due to mobility difficulties; (2) those who were diagnosed by a doctor with diseases such as cardiovascular diseases, cerebrovascular diseases, malignant neoplasms, mental diseases, arthritis, or thyroid disease, and have been suffering from them since diagnosis; (3) women who were pregnant, might be pregnant, or were menstruating; (4) those without a mobile phone in their name; (5) persons judged by the principal investigator to be unsuitable for participation. Among 2986 participants who completed the study, 80 participants with errors in the measurements of body composition were excluded. Finally, 820 men and 2086 women were included in the analysis (Figure 1).
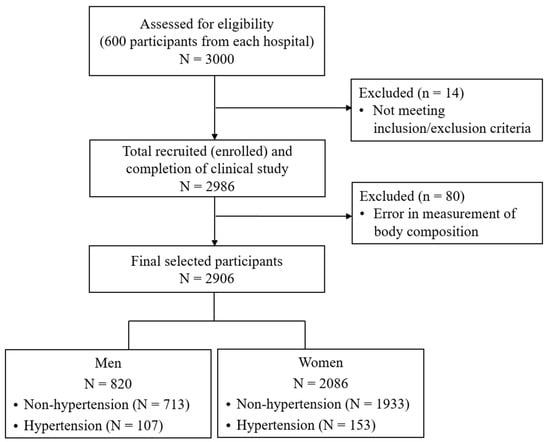
Figure 1.
Flow chart of study sample selection.
The hypertension group was defined by two questions: “Have you ever been diagnosed with hypertension by a physician?” and “Have you been suffering from hypertension since diagnosis”. Participants who answered “Yes” to both questions were classified into the hypertension group, and those who did not answer “Yes” to both questions were classified into the non-hypertension group.
2.2. Body Composition Measurement
Body composition indicators were calculated after measurement by a well-trained clinical research coordinator according to standardized protocols using a multifrequency bioelectric impedance analyzer (BWA 2.0; In-Body Co., Seoul, Republic of Korea). Subjects were asked to wear light clothes and to have a minimum fasting period of four hours for the measurement. The measurement was conducted after waiting for five minutes with the subject lying on the bed and wearing clamp-type sensors on both wrists and ankles. Individual variables for body fat mass, lean mass, and body water were obtained (Table 1).

Table 1.
Description of body composition indicators.
2.3. Model Development and Assessment
All statistical analyses were implemented using R version 4.2.1 (R Foundation for Statistical Computing, Vienna, Austria) [13]. In all statistical tests, two-tailed tests were applied and a significance level of 0.05 was used. To take sex-specific differences in body composition indicators into account, all statistical analyses were performed by sex. Data were randomly split into training and test sets in a 7:3 ratio. The training set was used for training and validation of model development and the test set was used for final model evaluation. To compare general characteristics and body composition indicators between the training set and test set, independent two-sample t-tests and chi-square tests were used for continuous and categorical variables in each sex, respectively. To compare general characteristics and body composition indicators between hypertension and non-hypertension groups, independent two-sample t-tests were used in the training set by sex. In each sex, simple logistic regression analyses were used in the training set to identify the association of individual body composition indices with hypertension.
To build the models, previously developed machine learning algorithms were applied using the Caret R package [14,15,16]. The Caret package has several functions, including data splitting, data preprocessing, feature selection, automatic hyperparameter tuning, training, variable importance estimation, and model assessment, which can streamline the processes of model development and evaluation.
The hypertension classification models using the combined body composition indicators were developed in the training set through six machine learning algorithms: elastic-net-regularized logistic regressions (E-net), k-nearest neighbor (K-NN), random forest (RF), support vector machine (SVM), extreme gradient boosting (XGBoost), and neural network (NN). E-net is a penalized linear or logistic regression method that combines ridge and lasso regressions, and has functions of efficient shrinkage regularization and feature selection [17]. Additionally, E-net is an effective regression method that secures the stability and generality of the model by reducing the impact of multicollinearity when multiple highly correlated explanatory variables are included. K-NN is a non-parametric method for classification and regression that works based on the similarity of data points in a given dataset [18]. K-NN is a simple and easy-to-implement method. RF is an ensemble machine learning method for classification, regression, and unsupervised learning based on a set of multiple trees [19]. RF is known to be robust to data with missing values, handles large and complex data, and reduces overfitting. SVN is a machine learning algorithm for linear or non-linear classification and regression that solves classification problems by constructing hyperplanes with optimal separation and maximum margin between individual classes [20]. SVM is known to be effective for high-dimensional data and can handle complex or non-linear relationships using kernel functions. XGBoost is a decision-tree-based ensemble machine learning method for classification and regression [21]. XGBoost can control model complexity and overfitting by adding a regular term in the loss function. NN is a machine learning algorithm that works similarly to the neural pathways in the human brain [22]. NN is composed of three connected layers of input, hidden and output, and is known to be powerful in capturing complex patterns and relationships in complex data. The hyperparameters were tuned to obtain the maximum area under the receiver operating characteristic curve (AUROC) using 5-fold stratified cross-validation in the training set to be randomly divided into the training and validation subsets in a 4:1 ratio. To investigate the contribution of body composition variables selected in the models, the relative importance of the variables was calculated.
The performance of each model was evaluated by constructing a receiver operating characteristic (ROC) curve and a confusion matrix for binary classification in the test set [23,24,25]; AUROC was obtained from the ROC curve, and kappa, F1 score, precision, accuracy, sensitivity, and specificity were obtained from the confusion matrix. The confusion matrix depends on the chosen threshold value. To obtain the optimal threshold value for each model, Youden’s index was used. AUROC is obtained by calculating the area under the ROC curve. The ROC curve is a curve drawn according to different threshold settings from 0 to 1, with the vertical axis representing sensitivity and the horizontal axis representing 1-specificity. To compare the AUROC of the model with the best AUROC value to the AUROC of each of the other models, p values were derived using the z score [26,27]. The accuracy is calculated as the proportion of accurately predicted samples to the total number of samples. Sensitivity and specificity refer to the proportion of predicted positive samples to the total number of observed positive samples and the proportion of predicted negative samples to the total number of observed negative samples, respectively. Precision presents the proportion of observed positive samples to the total number of predicted positive samples. F1 score is a combined measure of precision and sensitivity, calculated as the harmonic mean of precision and sensitivity. Kappa indicates the degree of agreement between the predicted and observed outcomes, and is calculated taking into account coincidence. The measures of performance evaluation were presented along with the 95% confidence interval (CI) obtained from 2000 bootstrap repetitions.
3. Results
3.1. General Characteristics and Body Composition
The data were randomly divided into the training and test sets in a 7:3 ratio by sex. Of a total of 820 men, 575 were included in the training set and 245 were included in the test set. Among a total of 2086 women, 1462 were included in the training set and 624 were included in the test set. In both men and women, there were no significant differences between the training and test sets in the percentage of participants in the hypertension group, or general characteristics such as age, temperature, blood pressure, pulse rate, height, weight, BMI, and other body composition variables (Table 2).
Table 2.
General characteristics and body composition indicators between the training set and test set.
Of a total of 575 men in the training set, 75 were included in the hypertension group and 500 were included in the non-hypertension group. Among the 1462 women in the training set, 108 were included in the hypertension group and 1354 were included in the non-hypertension group. For men, there were significant differences between the hypertension and non-hypertension groups in age, blood pressure, height, and BMI in the training set. For women, there were significant differences between the hypertension and non-hypertension groups in age, blood pressure, height, weight, and BMI in the training set. For both men and women, significant differences were found between the hypertension and non-hypertension groups in several variables related to body fat mass, lean mass, and body water as well as additional variables such as visceral fat level, visceral fat area, proportion of weight to ideal weight, proportion of total body water to fat-free mass, and the 50 kHz phase angle of the trunk in the training set (Table 3).
Table 3.
Comparison of general characteristics and body composition indicators between hypertension and non-hypertension groups.
3.2. Association of Individual Body Composition Variables with Hypertension
To investigate the association between individual body composition variables and hypertension, crude analyses were conducted in the training set (Table 4). Older men and women were more likely to be classified into the hypertension group (odds ratio [95% CI]; men, 4.32 [3.09, 6.06]; women, 3.36 [2.57, 4.4]). Men and women with higher BMI were also more likely to be in the hypertension group (men, 1.5 [1.2, 1.89]; women, 1.82 [1.55, 2.14]). For both men and women, hypertension was positively associated with most body fat mass variables. Men and women with higher percentages of body fat mass to weight were more likely to be in the hypertension group (men, 2.7 [2.02, 3.61]; women, 2.2 [1.79, 2.71]). In men, hypertension was negatively associated with lean mass variables of soft lean mass and skeletal muscle mass, whereas in women, hypertension had no association with these variables. Men and women with higher percentages of skeletal muscle mass to weight were less likely to be in the hypertension group (men, 0.33 [0.24, 0.44]; women, 0.44 [0.35, 0.54]). In men, hypertension was negatively associated with total body water, intracellular water, and extracellular water, whereas in women, hypertension was not associated with any of those variables. Men and women with higher percentages of total body water to weight were less likely to belong to the hypertension group (men, 0.38 [0.29, 0.51]; women, 0.46 [0.37, 0.57]). Men and women with higher proportions of extracellular water to total body water were more likely to belong to the hypertension group (men, 2.08 [1.61, 2.69]; women, 1.62 [1.33, 1.99]). In both men and women, hypertension was positively associated with visceral fat level, visceral fat area, proportion of weight to ideal weight, and proportion of total body water to fat-free mass. Men and women with a higher 50 kHz phase angle of the trunk were less likely to be in the hypertension group (men, 0.36 [0.27, 0.49]; women, 0.69 [0.56, 0.84]).
Table 4.
Association of individual body composition indices with hypertension.
3.3. Comparison of Performance of the Models
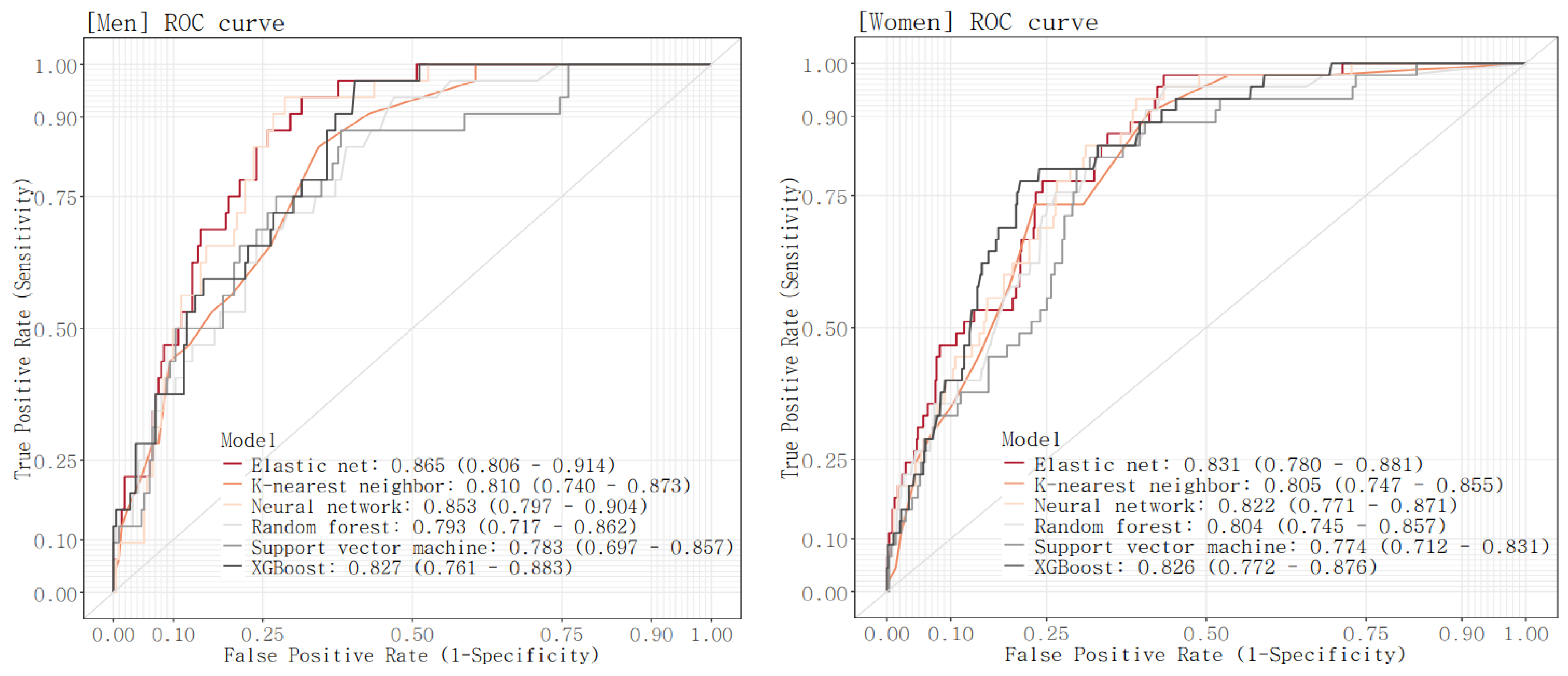
The ROC curve was drawn and the AUROC value was calculated for each model in the test set (Figure 2, Table 5). AUROC values of the six models ranged from 0.783 to 0.865 for men and 0.774 to 0.831 for women. For both men and women, the E-net model reported the highest AUROC (AUROC [95% CI]; men, 0.865 [0.806, 0.914]; women, 0.831 [0.78, 0.881]). This was followed by the NN model with an AUC of 0.853 [0.797, 0.904] and the XGBoost model with an AUC of 0.827 [0.761, 0.883] for men, and was followed by the XGBoost model with an AUC of 0.826 [0.772, 0.876] and the NN model with an AUC of 0.822 [0.771, 0.871] for women. For both men and women, the SVM model has the lowest AUROC (men, 0.783 [0.697, 0.857]; women, 0.774 [0.712, 0.831]). Comparing the AUROC of the model with the best AUROC value to the AUROC of each of the other models, there were significant differences in AUROC between the E-net model and the RF model and between the E-net model and the SVM model in men, while there were no significant differences in AUROC between the E-net model and each of the other models in women.
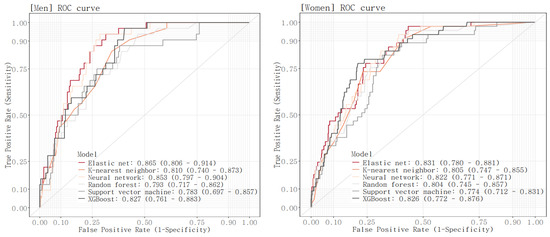
Figure 2.
ROC curves of the six models.
Table 5.
Performance of the six models.
Kappa, F1 score, precision, accuracy, sensitivity, and specificity were calculated using the classification confusion matrix obtained based on the optimal threshold for each model (Table 5). In men, the NN model exhibited the best kappa, F1 score, precision, and accuracy and achieved a well-balanced sensitivity and specificity (kappa, 0.365 [0.257, 0.469]; F1 score, 0.489 [0.37, 0.586]; precision, 0.33 [0.232, 0.424]; accuracy 0.743 [0.69, 0.796], sensitivity 0.941 [0.833, 1], specificity 0.714 [0.653, 0.771]). This was followed by the E-net model and then the XGBoost model. In women, the XGBoost model had the highest kappa, F1 score, precision, and accuracy and a good balance between sensitivity and specificity (kappa, 0.265 [0.186, 0.345]; F1 score, 0.347 [0.262, 0.43]; precision, 0.223 [0.162, 0.291]; accuracy 0.79 [0.758, 0.821], sensitivity 0.78 [0.653, 0.896], specificity 0.791 [0.758, 0.824]). The XGBoost model was followed by the NN model and then the E-net model.
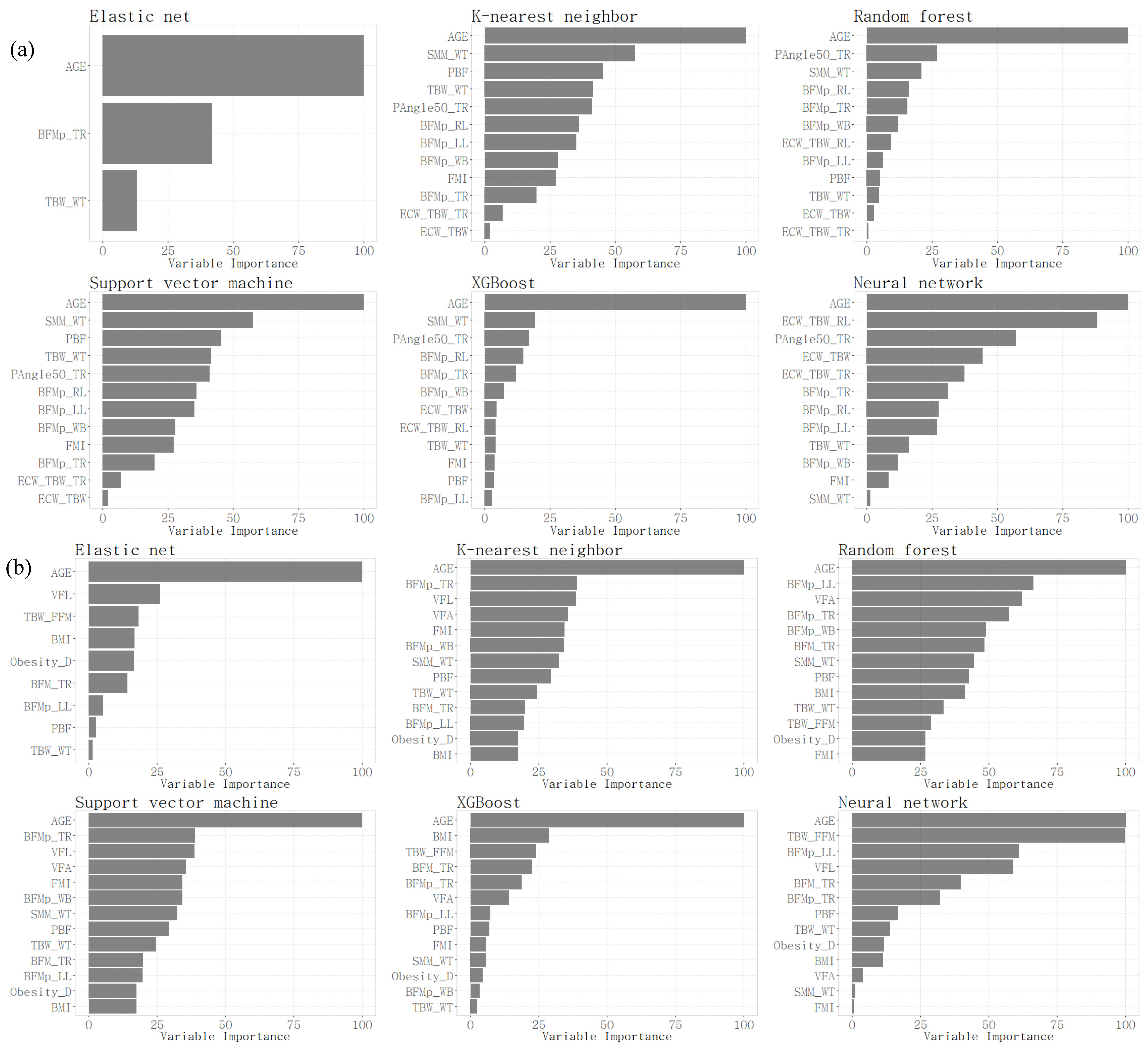
As a result of the model evaluation, the E-net model showed the best performance on most evaluation metrics for both men and women, followed by the XGBoost model and the NN model. For each final model, a selected subset of variables and their importance were obtained (Figure 3). In the E-net model, three variables were selected for men: age; body fat mass percentage of trunk; and percentage of total body water to weight. In the E-net model, nine variables were selected for women: age; visceral fat level; proportion of total body water to fat-free mass; BMI; proportion of weight to ideal weight; body fat mass of trunk; body fat mass percentage of the left leg; percentage of body fat mass to weight; and percentage of total body water to weight. In the XGBoost model and the NN model, age and the 50 kHz phase angle of the trunk were selected with relatively high importance for men, and age and proportion of total body water to fat-free mass were selected with relatively high importance for women.
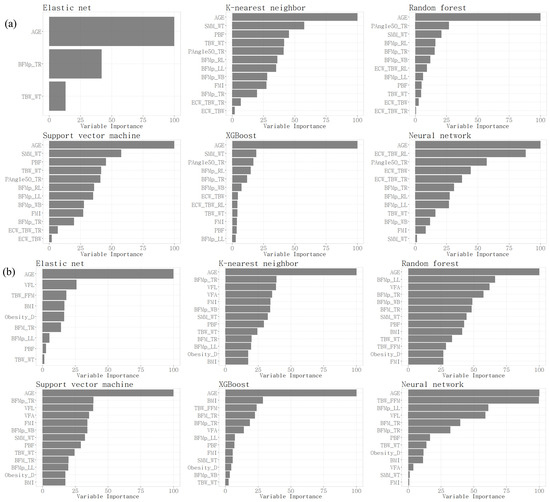
Figure 3.
Relative importance of selected variables in men (a) and women (b).
4. Discussion
In this study, we examined the correlations and differences in various body composition elements measured in Korean adult men and women based on the presence or absence of hypertension in each group. We then assessed the hypertension prediction accuracy when variables selected for their importance were used as features in a hypertension prediction model.
Before developing the model using machine learning techniques, we identified the variable importance factors, finding differences not only between men and women but also among the machine learning techniques themselves. Age was the common importance variable selected across six different machine learning techniques. The correlation between blood pressure and age has already been confirmed in various studies. In the study “On the interpretability of machine learning-based model for predicting hypertension”, age was presented as the highest importance feature for predicting the high risk of hypertension [28]. As age increases, blood vessels thicken and lose elasticity, and the decrease in heart pump function tends to increase systolic blood pressure [29]. This correlation is similarly mentioned in epidemiological studies like the Framingham Heart Study and other prior research that examined age-related changes in the risk of high blood pressure [30,31].
In Figure 3, to classify hypertension and non-hypertension, we identified the characteristics of the selected variables in both male and female groups. The common important variables for predicting hypertension in men were age, followed by SMM_WT, and then BFMp. In women, it was the opposite, with BFMp first, followed by SMM_WT. Prior research indicates that blood pressure is inversely associated with muscle mass and positively with fat mass [32]. Generally, men have a higher proportion of skeletal muscle mass and less fat mass compared to women. Besides this influence, the SLM and SMM of the recruited women in this study showed no statistical difference between the hypertension and non-hypertension groups; only the percentage divided by weight, SMM_WT, showed a difference, which seems to reflect the characteristics of these groups.
In Table 3, we identified the body composition variables with significant differences between the hypertension and non-hypertension groups for both men and women. In both groups, there was a statistically significant difference in the overall variable of body fat mass. However, for lean mass and muscle mass, the difference was observed only in the male group, with the hypertension group’s SLM, SMM, and SMM_WT being relatively lower than in the non-hypertension group. Overall, hypertension affects not only body fat mass but also muscle mass in men, whereas in women, body fat mass has a more significant impact than muscle mass.
In Table 4, examining the odds ratio results from the logistic regression analysis, it is evident that for both men and women, the hypertension group has approximately double the body fat mass variables compared to the non-hypertension group. Looking at the muscle variables, in men, the muscle mass in the hypertension group is about 0.33 to 0.67 times that of the non-hypertension group. This indicates that, for men, muscle mass is a more critical factor, suggesting that efforts to increase muscle mass, in addition to reducing body fat, are necessary for preventing hypertension. According to prior research, when the percentage of body fat exceeds 35%, it has a significant impact compared to when it is below 35%, with this impact being relatively higher in women than in men [33].
In Table 5, the performance metrics for the test set, commonly used as a classification performance indicator, are shown in both the men’s and women’s groups, where the E-net model demonstrated the best performance.
Elastic-net regression is one of the regression methods developed to overcome the drawbacks of Ridge and Lasso regressions [34]. Elastic-net regression applies a combination of penalties and offers the advantage of performing both variable selection and model shrinkage simultaneously [35]. Additionally, the results of logistic regression can be quantitatively explained by using the odds ratio to interpret the weight of the variables between the two groups.
Among the men’s group, the AUROC values for the five models, excluding E-net, were relatively high, ranging from 0.7 to 0.8. In the validation results based on the test set, NN, XGBoost, and K-NN showed the highest performance in that order. All three machine learning techniques, except for RF and SVM, showed no significant difference in the AUROC test values compared to E-net. When examining other metrics besides the AUROC, such as F1 score, precision, accuracy, sensitivity, and specificity, NN demonstrated the highest performance and exhibited a similar performance to E-net. The NN method has advantages in classifying complex patterns in data that cannot be explained by simple linear models. It also has advantages in handling high-dimensional data. However, its shortcomings include the potential for overfitting and the need for complex computations. The most significant disadvantage is the lack of explainability, as it is limited in providing reasons for its classifications.
In the women’s group, the AUROC for E-net was the highest, similar to the models in the men’s group. E-net also showed the best performance in sensitivity, while other metrics favored XGBoost. This is likely due to the influence of the selected variables. In the men’s group, three variables were selected by E-net, whereas in the women’s group, nine variables were selected. Having fewer selected variables offers advantages such as reduced curse of dimensionality, prevention of overfitting, increased computational efficiency, and reduced noise. Therefore, E-net’s best performance can be attributed to the smaller number of selected variables. Unlike the models in the men’s group, the women’s group models showed no statistically significant difference in AUROC compared to E-net. This suggests that when evaluating model performance based on AUROC, using various models can achieve similar classification performance. While model performance can be assessed using various criteria such as AUROC and other metrics, using classification techniques like E-net, which offer better explainability, may be advantageous for evaluating the weights or influence of each variable.
Previous studies using body composition features to classify hypertension and non-hypertension groups have demonstrated the feasibility of logistic regression for this purpose. For instance, classification models using variables obtained from Bioelectrical Impedance Analysis (BIA) achieved classification accuracies between 83% and 90% [12]. Another study developed classification models incorporating general characteristics such as age, height, weight, and BMI alongside body composition variables, achieving over 70% classification accuracy [36]. When classification accuracy is ensured, logistic regression models can identify the weights of each variable, contributing to the classification and prediction of hypertension.
The limitation of this study is the imbalance in the number of subjects between the hypertension and non-hypertension groups. Additionally, there is a need for more detailed investigations considering age-specific group characteristics to better understand the occurrence of hypertension across different age groups. Future research aims to address these limitations by including a larger sample of hypertension subjects, allowing for more detailed analysis and model development. In follow-up studies, we plan to compensate for limitations through more detailed analysis and model development by comparing more hypertension groups.
5. Conclusions
This study aims to develop a prediction model that can classify the presence or absence of hypertension in Korean adults aged 20 or older using various machine learning techniques. A common variable of interest across various machine learning techniques to investigate the association between individual body composition variables and hypertension was “age”. For men, the most important variables were skeletal muscle mass and body fat mass, and for women, they were BFM and SMM, in that order. Therefore, it can be concluded that for men, SMM is a more important factor, and efforts to increase muscle mass while reducing fat mass are important to prevent hypertension. Additionally, among the various classification techniques, E-net demonstrated the best performance when evaluating models based on the AUROC in both the men’s and women’s groups. It is important to choose and use a classification technique that aligns with the characteristics of the data in the group being classified, considering factors such as model explainability, the potential for overfitting, and the selected variables.
Author Contributions
Conceptualization, M.H.Y.; methodology, J.-W.S.; validation, S.L.; formal analysis, M.H.Y.; investigation, S.L.; resources, S.L.; data curation, M.H.Y.; writing—original draft preparation, J.-W.S.; writing—review and editing, M.H.Y.; visualization, M.H.Y.; supervision, M.H.Y.; project administration, S.L.; funding acquisition, S.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by a grant (“KSN1923111” & “KSN1824130”) from the Korea Institute of Oriental Medicine.
Institutional Review Board Statement
This study was conducted in accordance with the Declaration of Helsinki and approved by the Institutional Review Board (IRB No., Dongguk University Ilsan Oriental Hospital, DUIOH-2022-01-005; Pusan National University Korean Medicine Hospital, PNUKHIRB-2022-02-001; Gachon University Gill Hospital, GIRB-22-101; Dongshin University Korean Medicine Hospital, NJ-IRB-013; Semyung University Korean Medicine Hospital, SMJOH-2022-06).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data presented in this study are available upon request from the corresponding author. These data are not publicly available because of privacy concerns.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kim, E.H.; Lee, J.; Lee, S.A.; Jung, Y.W. Impact of Maternal Age on Singleton Pregnancy Outcomes in Primiparous Women in South Korea. J. Clin. Med. 2022, 11, 969. [Google Scholar] [CrossRef] [PubMed]
- Genaro, L.E.; Marconato, J.V.; Tagliaferro, E.P.d.S.; Pinotti, F.E.; Valsecki Júnior, A.; Adas Saliba, T.; Rosell, F.L. Home Care for the Elderly: An Integrated Approach to Perception, Quality of Life, and Cognition. Int. J. Environ. Res. Public Health 2024, 21, 539. [Google Scholar] [CrossRef]
- Heymsfield, S.B.; Ebbeling, C.B.; Zheng, J.; Pietrobelli, A.; Strauss, B.J.; Silva, A.M.; Ludwig, D.S. Multi-Component Molecular-Level Body Composition Reference Methods: Evolving Concepts and Future Directions. Obes. Rev. 2015, 15, 282–294. [Google Scholar] [CrossRef] [PubMed]
- Kyle, U.G.; Bosaeus, I.; De Lorenzo, A.D.; Deurenberg, P.; Elia, M.; Gómez, J.M.; Heitmann, B.L.; Kent-Smith, L.; Melchior, J.C.; Pirlich, M.; et al. Bioelectrical impedance analysis--part I: Review of principles and methods. Clin. Nutr. 2004, 23, 1226–1243. [Google Scholar] [CrossRef] [PubMed]
- Borga, M.; West, J.; Bell, J.D.; Harvey, N.C.; Romu, T.; Heymsfield, S.B.; Leinhard, O.D. Advanced body composition assessment: From body mass index to body composition profiling. J. Investig. Med. 2018, 66, 5. [Google Scholar] [CrossRef]
- Pi-Sunyer, X. Changes in body composition and metabolic disease risk. Eur. J. Clin. Nutr. 2019, 73, 231–235. [Google Scholar] [CrossRef]
- Li, Z.; Tong, X.; Ma, Y.; Bao, T.; Yue, J. Relationship between Low Skeletal Muscle Mass and Arteriosclerosis in Western China: A Cross-Sectional Study. Front. Cardiovasc. Med. 2021, 8, 735262. [Google Scholar] [CrossRef]
- Cleymaet, R.; D’Hondt, M.; Scheinok, T.; Malbrain, L.; De Laet, I.; Schoonheydt, K.; Dits, H.; Van Regenmortel, N.; Mekeirele, M.; Cordemans, C.; et al. Comparison of Bioelectrical Impedance Analysis (BIA)-Derived Parameters in Healthy Volunteers and Critically Ill Patients. Life 2024, 14, 27. [Google Scholar] [CrossRef]
- Ceniccola, G.D.; Castro, M.G.; Piovacari, S.M.F.; Horie, L.M.; Corrêa, F.G.; Barrere, A.P.N.; Toledo, D.O. Current technologies in body composition assessment: Advantages and disadvantages. Nutrition 2019, 62, 25–31. [Google Scholar] [CrossRef]
- Ye, S.; Zhu, C.; Wei, C.; Yang, M.; Zheng, W.; Gan, D.; Zhu, S. Associations of Body Composition with Blood Pressure and Hypertension. Obesity 2018, 26, 1644–1650. [Google Scholar] [CrossRef]
- Kim, S.T.; Song, Y.-H. Nutrition, Body Composition, and Blood Pressure in Children and Adolescents from the Korea National Health and Nutrition Examination Survey. Int. J. Environ. Res. Public Health 2022, 19, 13272. [Google Scholar] [CrossRef] [PubMed]
- Nematollahi, M.A.; Jahangiri, S.; Asadollahi, A.; Salimi, M.; Dehghan, A.; Mashayekh, M.; Roshanzamir, M.; Gholamabbas, G.; Alizadehsani, R.; Bazrafshan, M.; et al. Body composition predicts hypertension using machine learning methods: A cohort study. Sci. Rep. 2023, 13, 6885. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. 2022. Available online: https://www.R-project.org/ (accessed on 1 April 2024).
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B.; Team, C. Package ‘caret’. R J. 2020, 223, 7. [Google Scholar]
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B.; Benesty, M.; Lescarbeau, R.; Ziem, A.; et al. (The R Core Team) Caret: Classification and Regression Training; R Package Version 6.0-80. Available online: https://cran.r-project.org/web/packages/caret/caret.pdf (accessed on 11 September 2024).
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inform. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Yao, X. Evolving artificial neural networks. Proc. IEEE 1999, 87, 1423–1447. [Google Scholar]
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Provost, F.; Kohavi, R. Guest editors’ introduction: On applied research in machine learning. Mach. Learn. 1998, 30, 127–132. [Google Scholar] [CrossRef]
- Huang, J.; Ling, C.X. Using AUC and accuracy in evaluating learning algorithms. IEEE Trans. Knowl. Data Eng. 2005, 17, 299–310. [Google Scholar] [CrossRef]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed]
- Hanley, J.A.; McNeil, B.J. A method of comparing the areas under receiver operating characteristic curves derived from the same cases. Radiology 1983, 148, 839–843. [Google Scholar] [CrossRef]
- Elshawi, R.; Al-Mallah, M.H.; Sakr, S. On the interpretability of machine learning-based model for predicting hypertension. BMC Med. Inform. Decis. Mak. 2019, 19, 146. [Google Scholar] [CrossRef]
- Oh, Y.S. Arterial stiffness and hypertension. Clin. Hypertens. 2018, 24, 17. [Google Scholar] [CrossRef]
- Mahmood, S.S.; Levy, D.; Vasan, R.S.; Wang, T.J. The Framingham Heart Study and the epidemiology of cardiovascular disease: A historical perspective. Lancet 2014, 383, 999–1008. [Google Scholar] [CrossRef]
- Cheng, W.; Du, Y.; Zhang, Q.; Wang, X.; He, C.; He, J.; Jing, F.; Ren, H.; Guo, M.; Tian, J.; et al. Age-related changes in the risk of high blood pressure. Front. Cardiovasc. Med. 2022, 9, 939103. [Google Scholar] [CrossRef]
- Han, T.S.; Al-Gindan, Y.Y.; Govan, L.; Hankey, C.R.; Lean, M.E.J. Associations of body fat and skeletal muscle with hypertension. J. Clin. Hypertens. 2019, 21, 230–238. [Google Scholar] [CrossRef]
- Al-Sendi, A.M.; Shetty, P.; Musaiger, A.O.; Myatt, M. Relationship between body composition and blood pressure in Bahraini adolescents. Br. J. Nutr. 2003, 90, 837–844. [Google Scholar] [CrossRef]
- Gana, R. Ridge Regression and the Elastic Net: How Do They Do as Finders of True Regressors and Their Coefficients? Mathematics 2022, 10, 3057. [Google Scholar] [CrossRef]
- De Mol, C.; De Vito, E.; Rosasco, L. Elastic-net regularization in learning theory. J. Complex. 2009, 25, 201–230. [Google Scholar] [CrossRef]
- George, C.; Goedecke, J.H.; Crowther, N.J.; Jaff, N.G.; Kengne, A.P.; Norris, S.A.; Micklesfield, L.K. The Role of Body Fat and Fat Distribution in Hypertension Risk in Urban Black South African Women. PLoS ONE 2016, 11, e0154894. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).