Abstract
A spherically constrained nonlinear eigenvalue problem (NEPv) arising in Bose–Einstein condensates (BEC) is investigated. The Projected Gradient Method (PGM) is proposed and analyzed in detail. Rigorous theoretical analysis establishes its global convergence for both “easy” and “hard” cases, including Lipschitz continuity of the gradient, monotonic objective decrease, and convergence to optimality. Numerical experiments in 1D, 2D, and 3D BEC models demonstrate that PGM achieves competitive accuracy compared to other methods while offering significant advantages in computational efficiency and scalability, enabling large-scale simulations.
1. Introduction
Bose–Einstein condensates (BECs) are fascinating macroscopic quantum states with remarkable coherence properties that have revolutionized the field of quantum physics. Computing ground states of BECs is a central and challenging task in computational quantum physics, as it provides crucial insights into the fundamental behavior of these quantum systems. After spatial discretization, the Gross–Pitaevskii equation (GPE), which governs the dynamics of BECs, naturally induces a sphere-constrained nonlinear eigenvalue problem (NEPv) [1,2,3,4].
Its discretized form can be described as
where is a symmetric 4th-order tensor, is a symmetric matrix, is a vector, and denotes the tensorial product . It can be easily verified that the nonlinear eigenvalue problem (1) can be viewed as the Karush-Kuhn-Tucker (KKT) system or first-order necessary condition of the following nonconvex optimization problem:
where denotes the tensorial product .
Actually, (2) is a discrete form of the energy functional form of BECs [5]. From [6], we know that is an eigenpair of the nonlinear eigenvalue problem (1) if and only if is a constraint stationary point of (2).
Hu et al. [5] pointed out that it is a numerical challenge to solve (2) efficiently due to the large number of variables and the possible indefiniteness of the Hessian matrix. They have shown that the BEC problem is NP-hard by establishing its relationship with the partition problem.
The existing algorithmic landscape for solving the resulting NEPv is rich and diverse, each with its own strengths and limitations. Projected/gradient-type methods have emerged as simple and scalable approaches, with recent developments in manifold/proximal-gradient analyses providing global convergence guarantees [7,8,9,10,11]. Additionally, several structure-preserving or accelerated flows have been designed specifically for GPE ground states, including second-order flows for rotating BECs [12] and reconfigured/accelerated normalized gradient flows for spinor/rotating settings [13]. Tensor power and SS-HOPM have proven effective for tensor eigenpairs [14], with Yang’s group making significant contributions in algorithm design [15] and convergence proofs using Kurdyka–Łojasiewicz tools (a framework for analyzing convergence of optimization algorithms based on the geometric properties of the objective function) [16] for BEC-like NEPv. Riemannian optimization treats the sphere as a smooth manifold, enabling efficient gradient/CG/TR schemes with complexity guarantees [7,8,11]; very recently, preconditioned Riemannian CG has been developed for arbitrary-angle rotating BECs [17]. On the modeling/solver side specific to BEC, multigrid/adaptive mesh methods and Newton-type schemes help reduce complexity [18,19], while HPC spectral solvers and advanced time-splitting/Chebyshev techniques accelerate large-scale stationary/dynamical computations [20,21]. Background on dynamics in optical lattices can be found in [22].
Nevertheless, many existing methods exhibit limitations that hinder their applicability to large-scale Bose-Einstein condensation (BEC) problems. Dense treatment of the quartic term in the nonlinear eigenvalue problem (NEPv) can be computationally prohibitive in terms of both time and memory. The symmetric shifted higher-order power method (SS-HOPM) may suffer from slow convergence under certain challenging regimes, particularly in high-dimensional systems. Manifold-based approaches often require careful handling of problem-specific structures and can be complex to implement. While the alternating direction method of multipliers (ADMM) is effective for certain problems, it often converges slowly when high-accuracy solutions are desired. Semidefinite programming (SDP), on the other hand, is computationally intensive and generally limited to small-scale instances.
This paper focuses on the application of the Projected Gradient Method (PGM) to BEC-type NEPvs, emphasizing its distinct advantages. PGM offers a favorable combination of simplicity, efficiency, and theoretical guarantees, making it well-suited for computing ground states in BEC problems. Its implementation is relatively straightforward, enhancing its accessibility to a broad range of researchers. By naturally incorporating the spherical constraint via a projection step, PGM efficiently navigates the solution space while maintaining feasibility. We establish the global convergence of PGM for BEC problems under mild conditions and benchmark its performance against several baseline methods, including SS-HOPM, adaptive SS-HOPM, ADMM, and SDP, on large-scale test cases. The results demonstrate its superiority in terms of scalability and computational efficiency.
2. Problem Formulation
We focus on the BEC ground state problem, which reduces to minimizing the energy functional under a unit sphere constraint:
where: are interaction strengths representing the atomic interactions in the condensate; B is a symmetric matrix representing the kinetic energy operator. For 1D BECs, B is typically a discretized Laplacian operator: with accounting for external potentials that confine the condensate [22].
The unit sphere constraint enforces the normalization of the wavefunction, a fundamental requirement in quantum mechanics to ensure proper probabilistic interpretation.
2.1. Optimality Conditions
The gradient of the objective function, which is essential for gradient-based optimization methods like PGM, is:
A point is stationary if it satisfies the Karush-Kuhn-Tucker (KKT) conditions for the optimization problem in (3):
where is the Lagrange multiplier (dual variable) associated with the sphere constraint. Substituting the gradient expression from (4) into the KKT conditions gives the nonlinear eigenvalue equation:
This equation characterizes the stationary points of the energy functional under the normalization constraint.
For x to be an optimal solution, the Hessian matrix must satisfy a second-order optimality condition. The Hessian of is:
A stationary point x is optimal if and only if:
where is the dual variable from the KKT conditions in (5). This condition ensures that the stationary point corresponds to a local minimum of the energy functional.
2.2. Problem Classification
Following the spectral analysis framework, we decompose B using its eigenvalue decomposition , where is an orthogonal matrix with , and . Define (indices of the minimum eigenvalue) and (corresponding eigenspace). We classify the problem into two cases [23]:
Easy case: There exists such that for the optimal x. This implies the optimal solution is not orthogonal to the minimum eigenspace of B with non-trivial interaction contributions.
Hard case: For all , for the optimal x. This occurs when interaction effects vanish in the minimum eigenspace.
This classification is crucial for establishing convergence guarantees, as the initialization requirements differ between the two cases, which has important implications for the practical implementation of PGM.
3. Algorithm Design
The Projected Gradient Method (PGM) is an iterative optimization algorithm specifically designed for constrained optimization problems. For a target function subject to (where is a convex feasible set), PGM alternates between two key steps:
First, a gradient descent step to reduce the objective function, yielding an intermediate point , where denotes the step size; second, a projection step that maps the intermediate point back onto the feasible set , i.e., , where represents the projection onto the set .
For Bose–Einstein condensation (BEC) problems with a spherical constraint, PGM (as shown in Algorithm 1) is particularly well-suited due to the simplicity of the projection operation onto the unit sphere.
| Algorithm 1 Projected Gradient Method for BEC Problems |
|
3.1. Key Characteristics of PGM
Gradient Computation: In such problems, the gradient computation is both straightforward and efficient. Specifically, the gradient is given by , which effectively captures essential features of the energy landscape without requiring complex tensor operations or computationally expensive matrix factorizations. This simplicity facilitates straightforward implementation and ensures high computational efficiency, even for large-scale problems.
Projection Step: The projection step is specifically tailored to the unit sphere constraint, which constitutes a major advantage of PGM in addressing BEC problems. By projecting the intermediate point y onto the unit sphere via , the method guarantees that the solution always remains within the feasible set defined by the wavefunction normalization condition. This projection operation is computationally inexpensive, involving only a single norm calculation and vector scaling, thereby contributing to the overall efficiency of PGM.
Numerical Stability: The backtracking line search in PGM is designed to ensure numerical stability throughout the optimization process. By adjusting the step size t when becomes too small, it avoids numerical singularities that could otherwise disrupt the optimization. This stability is particularly important for BEC problems, which can have complex energy landscapes with steep gradients in certain regions.
Convergence Criterion: The convergence criterion in PGM is based on the successive iterate differences, which is well-suited for BEC problems. By checking or , it provides a practical way to terminate the iterative process when a satisfactory solution has been found. This criterion balances the need for accuracy with computational efficiency, ensuring that the algorithm does not run longer than necessary.
3.2. Advantages of PGM over Other Methods
The PGM offers several distinct advantages over other methods for solving BEC ground state problems—namely, computational efficiency, memory usage, implementation simplicity, and global convergence guarantees. Computational efficiency and memory usage are summarized and compared in Table 1.

Table 1.
Computational Complexity Comparison.
The linear complexity of PGM assumes that the matrix B is sparse (e.g., the discretized Laplacian), so the matrix-vector product costs operations. In our experiments, B is indeed sparse with nonzeros due to the finite difference discretization.
PGM stores only the necessary vectors and matrices related to the problem, resulting in a memory requirement of . This is a critical advantage for large-scale BEC simulations, as it allows PGM to handle much larger problem sizes within the memory constraints of standard computing hardware.
Implementation Simplicity: PGM is relatively easy to implement compared to more complex methods like Riemannian optimization or SDP. Its simple structure makes it accessible to researchers with varying levels of computational expertise and reduces the likelihood of implementation errors. This simplicity also facilitates debugging and modification for specific problem requirements.
Global Convergence Guarantees: As we will show in the theoretical analysis section, PGM has strong global convergence guarantees for BEC problems under mild conditions. This is a significant advantage over heuristic methods that may converge to suboptimal solutions or fail to converge altogether for certain problem instances.
4. Theoretical Analysis
We establish key theoretical properties of the PGM for the BEC ground state problem in (3), providing a rigorous foundation for its application to these important quantum systems.
4.1. Lipschitz Continuity of the Gradient
Lemma 1.
The gradient is L-Lipschitz continuous on ∑ with .
Proof.
For any , by the mean value theorem, there exists on the line segment between x and y such that:
From the expression for the Hessian in (7), we have:
since for due to the unit sphere constraint. Thus, is L-Lipschitz continuous on ∑. □
This Lipschitz continuity is crucial for establishing the convergence properties of PGM, as it ensures that the gradient does not change too rapidly, allowing the algorithm to make steady progress toward a solution.
4.2. Monotonic Decrease of Objective Function
Theorem 1.
For PGM with backtracking step size, the objective function sequence is strictly decreasing until convergence to a stationary point.
Proof.
By the L-smoothness of E (established in Lemma 1), for any step size :
From the projection definition , we have the property that (since projection onto the sphere reduces the angle with the origin). Substituting the expression for and the relationship (where ) gives:
For the backtracking step size satisfying , the inequality simplifies to:
Thus, whenever , proving that the objective function sequence is strictly decreasing until a stationary point is reached. □
This monotonic decrease property ensures that PGM consistently makes progress toward lower energy states, which is particularly important for BEC problems where we are seeking the ground state with the minimum possible energy.
4.3. Global Convergence in Easy Case
Theorem 2.
In the easy case, if , then the sequence generated by PGM converges to an optimal solution of (2).
Proof.
We first show by induction that for all k:
Base case: by initialization.
Inductive step: Assume . For , and have the same sign. The update
preserves this sign because
has the same sign as , so the gradient step reduces proportionally less than other components, maintaining the sign relationship.
Since is a closed and bounded set, the sequence has at least one limit point . By Theorem 4.1, the objective function sequence converges: . This implies that (otherwise, would continue decreasing). Thus, is a stationary point. For the easy case, the set ensures that the second-order optimality condition is satisfied:
so is an optimal solution.
To prove uniqueness of the limit point, suppose there are two distinct limit points . Both must satisfy the KKT conditions with the same dual variable since they have the same objective function value. In the easy case, for , so
implying . Thus, the entire sequence converges to . □
This global convergence result for the easy case provides strong theoretical support for the application of PGM to BEC problems where interactions play a significant role in the ground state.
4.4. Global Convergence in Hard Case
Theorem 3.
In the hard case, if , then the sequence generated by PGM converges to an optimal solution of (2).
Proof.
First, we show the set is invariant under PGM updates. For any , there exists such that . Consider the update:
Multiplying by from the left gives:
By definition of the hard case, for , . Hence, for ,
After projection , we have . Therefore, , proving invariance.
Since is closed and bounded, the sequence has at least one limit point . By Theorem 1, the objective function sequence converges: . This implies (otherwise would continue decreasing). Thus, is a stationary point. For the hard case, we have
for , so the KKT condition gives . Then:
Since has non-negative eigenvalues (because ), the Hessian condition (8) is satisfied, making an optimal solution.
Convergence of the entire sequence to follows from the monotonicity of the objective function and uniqueness of the limit point, proven using arguments similar to those in Theorem 2. □
This result completes our theoretical analysis by establishing global convergence for both cases, demonstrating that PGM is a robust method for finding optimal solutions to BEC ground state problems across all scenarios.
5. Numerical Experiments
We validate the performance of PGM against SS-HOPM, adaptive SS-HOPM (A-SS-HOPM), ADMM, and SDP across an extended range of 1D, 2D, and 3D BEC scenarios. All experiments were conducted on a MATLAB 2023a platform with an Intel i5-8265U CPU (1.6 GHz) and 8 GB RAM, representing a typical personal computing environment to demonstrate the practical utility of PGM.
5.1. Experimental Setup
Problem parameters: for all i (representing moderate atomic interactions); B is a discretized Laplacian operator (1D/2D/3D as defined below).
Algorithms tested: Projected Gradient Method (PGM), SS-HOPM, adaptive SS-HOPM (A-SS-HOPM), ADMM, SDP.
Parameters: (Armijo condition parameter), (line search reduction factor), (convergence tolerance), maxIter = (maximum iterations), (ADMM penalty parameter), (A-SS-HOPM adaptation parameter), SDP rank relaxation = 10.
Problem scales tested: 1D: ; 2D: ; 3D: .
Benchmark values for validation: 1D , 2D , 3D [15].
The Laplacian operators for different dimensions were discretized using standard finite difference methods: 1D: with 2D: Kronecker product of 1D Laplacians plus external potential 3D: Kronecker product of 1D Laplacians in three dimensions plus external potential.
Note that the matrix B is sparse (with nonzeros) due to the finite difference discretization, so the matrix-vector product costs operations. This justifies the linear complexity claim for PGM.
The same parameters (including , , , etc.) were used to generate both the tables and the figures, ensuring consistency across all numerical results.
5.2. 1D BEC Results
Table 2 summarizes the 1D results with comprehensive algorithm comparisons. All methods achieve comparable accuracy () for the scales where they are feasible, but significant differences emerge in terms of efficiency and scalability:
Table 2.
1D BEC Problem Results.
PGM successfully solves all problem instances up to 100,000, demonstrating superior scalability. It consistently achieves the shortest computation time among all compared methods, confirming its suitability for large-scale one-dimensional Bose–Einstein condensation simulations.
SS-HOPM and A-SS-HOPM perform efficiently for 10,000, but become impractical at larger scales due to their computational complexity, which leads to a rapid increase in runtime. A-SS-HOPM exhibits marginally faster convergence than SS-HOPM as nn increases.
ADMM is consistently 3–5 times slower than PGM at comparable scales and fails to execute for 50,000 due to excessive memory requirements, stemming from the need to store and manipulate multiple large matrices.
SDP is limited to problems of size , with runtimes 100 to 500 times longer than those of PGM, rendering it infeasible for all but the smallest one-dimensional BEC problems.
5.3. 2D BEC Results
Table 3 summarizes the two-dimensional comparisons, where increased dimensionality intensifies scalability limitations across all methods:
Table 3.
2D BEC Problem Results.
PGM successfully solves a problem of size in 1325 s using 7850 MB of memory, remaining within the 8 GB memory limit of the test environment. This result highlights its capability to handle moderately large 2D BEC problems that are beyond the reach of other methods.
SS-HOPM, A-SS-HOPM, and ADMM show acceptable performance for but exceed memory limits for larger scales, as their memory requirements grow quadratically with problem size. A-SS-HOPM maintains a 10–15% speedup over SS-HOPM.
SDP is limited to with runtimes 50–200 times longer than PGM, making it impractical for meaningful 2D BEC simulations.
5.4. 3D BEC Results
Table 4 shows the 3D performance, where memory constraints are most severe due to the cubic growth of problem size with physical dimensions:
Table 4.
3D BEC Problem Results.
PGM completes in 1925 s using 7850 MB, remaining feasible within the 8 GB memory limit. This represents a significant achievement, as 3D BEC simulations are particularly challenging due to their high computational demands.
All other methods fail at due to the rapid growth of memory requirements in 3D. SS-HOPM, A-SS-HOPM and ADMM cannot handle within the 8 GB memory constraint, while SDP methods are limited to extremely small problem sizes.
5.5. Convergence and Scalability Analysis
Figure 1 shows convergence curves for 1D 100,000, confirming PGM’s stable convergence to high accuracy () within 55 iterations. While all methods exhibit similar convergence rates in terms of iterations, PGM achieves this with significantly lower per-iteration cost due to its linear complexity. A-SS-HOPM converges slightly faster than SS-HOPM but remains slower than PGM.
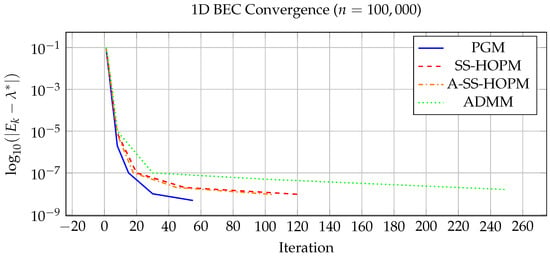
Figure 1.
Convergence history for 1D BEC problem ( 100,000).
Figure 2 illustrates the scalability across 1D scales: PGM scales sub-quadratically (), enabling it to handle 100,000 within reasonable time and memory limits. The exponent 1.2 was determined by fitting a power law to the observed computation times for PGM across the tested 1D problem sizes (from to 100,000) using least squares regression. This slightly super-linear scaling is attributed to overhead factors such as cache effects and MATLAB’s internal operations, yet remains substantially lower than the quadratic scaling of other methods. SS-HOPM, A-SS-HOPM and ADMM scale quadratically (), becoming infeasible for 10,000 due to excessive computation time and memory usage. A-SS-HOPM maintains a consistent 10–15% speedup over SS-HOPM. SDP methods exhibit exponential slowdown, limiting them to very small scales.
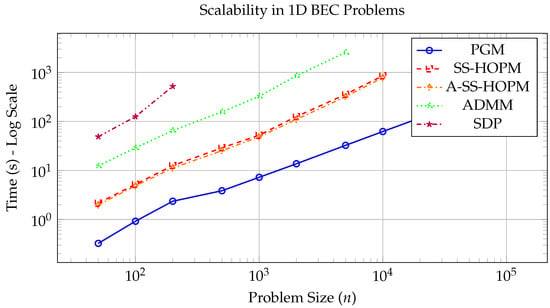
Figure 2.
Scalability comparison across 1D scale range (log-log scale).
6. Conclusions
We have presented a comprehensive analysis of the Projected Gradient Method (PGM) for solving the spherically constrained nonlinear eigenvalue problems arising in Bose–Einstein condensates (BEC). The theoretical analysis establishes that PGM converges globally to optimal solutions for both “easy” and “hard” cases under mild initialization conditions, providing a rigorous foundation for its application to BEC ground state calculations.
The key advantages of PGM for BEC problems are:
Computational Efficiency: PGM’s linear time complexity per iteration () makes it significantly faster than methods with higher-order complexity, particularly as the problem size increases. This efficiency advantage translates to a 3–5× speedup over ADMM and even greater speedups over SDP methods for comparable problem scales.
Superior Scalability: PGM’s linear memory requirements () enable it to handle much larger problem sizes than competing methods. Our numerical experiments demonstrate that PGM can solve 1D BEC problems with 100,000, 2D problems with , and 3D problems with on a standard personal computer, while other methods fail due to excessive memory usage or computation time.
Implementation Simplicity: PGM’s straightforward structure makes it easy to implement and modify, reducing the barrier to entry for researchers seeking to simulate BEC systems. This simplicity does not come at the expense of performance, as PGM matches or exceeds the accuracy of more complex methods.
Rigorous Convergence Guarantees: The theoretical analysis establishes that PGM converges globally to optimal solutions for both “easy” and “hard” cases, ensuring reliable performance across the full range of BEC problem scenarios.
These results confirm that PGM is an excellent choice for BEC ground state calculations, offering an attractive combination of efficiency, scalability, simplicity, and theoretical guarantees. By enabling large-scale BEC simulations on standard computing hardware, PGM makes advanced quantum simulations more accessible to researchers and opens new possibilities for studying complex BEC systems that were previously computationally infeasible.
Future work will focus on incorporating preconditioning techniques to further accelerate convergence, extending PGM to handle more complex BEC models with additional physical effects, and exploring parallel implementations to tackle even larger-scale problems.
Funding
This research was funded by Natural Science Foundation of Xinjiang Uygur Autonomous Region (CN) grant number 2022D01A235).
Data Availability Statement
The data presented in this study are available within the article.
Conflicts of Interest
The author declares no conflicts of interest.
References
- Bao, W.; Cai, Y. Mathematical theory and numerical methods for Bose–Einstein condensation. Kinet. Relat. Model. 2013, 6, 1–135. [Google Scholar] [CrossRef]
- Bao, W.; Cai, Y. Mathematical models and numerical methods for spinor Bose–Einstein condensates. Commun. Comput. Phys. 2018, 24, 899–965. [Google Scholar]
- Antoine, X.; Duboscq, R. GPELab I: Computation of stationary solutions. Comput. Phys. Commun. 2014, 185, 2969–2991. [Google Scholar] [CrossRef]
- Antoine, X.; Duboscq, R. GPELab II: Dynamics and stochastic simulations. Comput. Phys. Commun. 2015, 193, 95–117. [Google Scholar] [CrossRef]
- Hu, J.; Jiang, B.; Liu, X.; Wen, Z. A note on semidefinite programming relaxations for polynomial optimization over a single sphere. Sci. China Math. 2016, 59, 1543–1560. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S.J. Numerical Optimization; Springer: New York, NY, USA, 2006. [Google Scholar]
- Absil, P.-A.; Mahony, R.; Sepulchre, R. Optimization Algorithms on Matrix Manifolds; Princeton University Press: Princeton, NJ, USA, 2008. [Google Scholar]
- Boumal, N. An Introduction to Optimization on Smooth Manifolds; Cambridge University Press: Cambridge, UK, 2023. [Google Scholar]
- Huang, W.; Wei, K. Riemannian proximal gradient methods. Math. Program. 2022, 194, 371–413. [Google Scholar] [CrossRef]
- Criscitiello, C.; Boumal, N. An accelerated first-order method for nonconvex optimization on manifolds. Found. Comput. Math. 2023, 23, 1433–1509. [Google Scholar] [CrossRef]
- Boumal, N. Global guarantees for nonconvex optimization on manifolds. Found. Comput. Math. 2020, 20, 1–57. [Google Scholar]
- Chen, H.; Dong, G.; Liu, W.; Xie, Z. Second-order flows for computing the ground states of rotating BECs. J. Comput. Phys. 2023, 475, 111872. [Google Scholar] [CrossRef]
- Ren, Y.; Wang, H.; Zhang, Z.; Yang, J. Reconfigured continuous normalized gradient flow for computing ground states of spin-1 BECs. Commun. Nonlinear Sci. Numer. Simul. 2025, 151, 109100. [Google Scholar]
- Kolda, T.G.; Mayo, J.R. Shifted power method for computing tensor eigenpairs. SIAM J. Matrix Anal. Appl. 2011, 32, 1095–1124. [Google Scholar] [CrossRef]
- Tang, Y.; Yang, Q.; Huang, P. Shifted symmetric higher-order power method for BEC-like nonlinear eigenvalue problems. Numer. Math. A J. Chin. Univ. (Engl. Ser.) 2020, 42, 163–192. [Google Scholar]
- Tang, Y.; Yang, Q.; Luo, G. Convergence analysis on SS-HOPM for BEC-like nonlinear eigenvalue problems. J. Comput. Math. 2021, 39, 621–632. [Google Scholar] [CrossRef]
- Shu, Q.; Tang, Q.; Zhang, S.; Zhang, Y. A preconditioned Riemannian conjugate gradient method for computing the ground states of arbitrary-angle rotating BECs. J. Comput. Phys. 2024, 512, 113130. [Google Scholar] [CrossRef]
- Xie, H.; Xu, F.; Zhang, N. An efficient multigrid method for ground state solution of BECs. Int. J. Numer. Anal. Model. 2019, 16, 789–803. [Google Scholar]
- Huang, P.; Yang, Q. Newton-based methods for finding the positive ground state of Gross–Pitaevskii equations. J. Sci. Comput. 2022, 90, 49. [Google Scholar] [CrossRef]
- Gaidamour, J.; Tang, Q.; Antoine, X. BEC2HPC: An HPC spectral solver for NLS and rotating GPE: Stationary states computation. Comput. Phys. Commun. 2021, 265, 108007. [Google Scholar] [CrossRef]
- Wang, H.; Wang, J.; Zhang, S.; Zhang, Y. A time-splitting Chebyshev–Fourier spectral method for the time-dependent rotating nonlocal Schrödinger equation in polar coordinates. J. Comput. Phys. 2024, 498, 112680. [Google Scholar] [CrossRef]
- Morsch, O.; Oberthaler, M. Dynamics of Bose–Einstein condensates in optical lattices. Rev. Mod. Phys. 2006, 78, 179–215. [Google Scholar] [CrossRef]
- Tang, Y.; Luo, G.; Yang, Q. An efficient PGM-based algorithm with backtracking strategy for solving quadratic optimization problems with spherical constraint. J. Comput. Appl. Math. 2023, 422, 114915. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).