1. Introduction
As petroleum and gas pipelines age, their structural integrity deteriorates, which makes pipeline safety a critical concern. Given the flammable and explosive nature of oil and gas products, pipeline leakage incidents can have severe and often irreversible consequences for society. This highlights the importance of effective leakage detection as a fundamental component of pipeline safety management, ensuring the secure and reliable operation of pipeline systems.
Pipeline leakage detection technologies use various techniques to determine whether a leak has occurred by analyzing changes in key parameters. These methods include the negative pressure wave method [
1,
2], the acoustic method [
3,
4,
5], optical fiber sensing [
6], flow modeling [
7,
8], big data analytics, and machine learning algorithms [
9].
Among these, machine learning (ML) algorithms [
10,
11] have emerged as a highly effective approach for classification and prediction tasks in big data environments. In leakage detection studies, the issue is usually presented as a binary classification task. Several ML algorithms have been widely applied in this domain, including support vector machine (SVM) [
12,
13,
14], logistic regression (LR) [
10,
11,
15], decision tree (Classification and Regression Tree, CART) [
16,
17], random forest (RF) [
18,
19,
20,
21], and backpropagation neural network (BPNN) [
22,
23,
24,
25,
26]. These algorithms offer high accuracy, ease of implementation, and strong adaptability, making them widely adopted in leakage detection applications. Their continued development has significantly enhanced the precision and efficiency of pipeline leakage detection systems.
In pipeline leakage detection research, single-method approaches are often used to identify leaks, limiting the ability to leverage the advantages of various detection techniques. Moreover, while some systems integrate multiple detection methods, these methods typically operate independently and trigger alarms separately. This results in an excessive number of leakage alarms, creating challenges for operators in managing and verifying alerts. Therefore, there is an urgent need for a unified approach to evaluate leakage alarm information from multiple detection methods, which will enhance the reliability of alarms while reducing false or redundant notifications. In response to these challenges, this study proposes a multi-algorithm fusion framework based on ML and Dempster–Shafer evidence theory (DS) [
27,
28]. ML algorithms are employed to identify pipeline leakage status. A novel method for constructing basic probability assignment (BPA) functions based on a confusion matrix and a simple support function (SSF) is proposed and compared with the conventional triangular fuzzy number (TFN) method. Furthermore, a discount factor is computed based on the results of multiple algorithms to evaluate the reliability of each algorithm, and the BPA of each sample is adjusted accordingly. Finally, the refined probability assignments are processed using DS evidence fusion theory to generate a unified recognition result, enhancing the precision and reliability of leakage alarms. Therefore, the advantage of this method is that the constructed BPA can be dynamically modified according to the performance of the algorithm, allowing the DS evidence fusion theory to combine the advantages of various algorithms to produce a more reliable BPA and improve the accuracy of the algorithm.
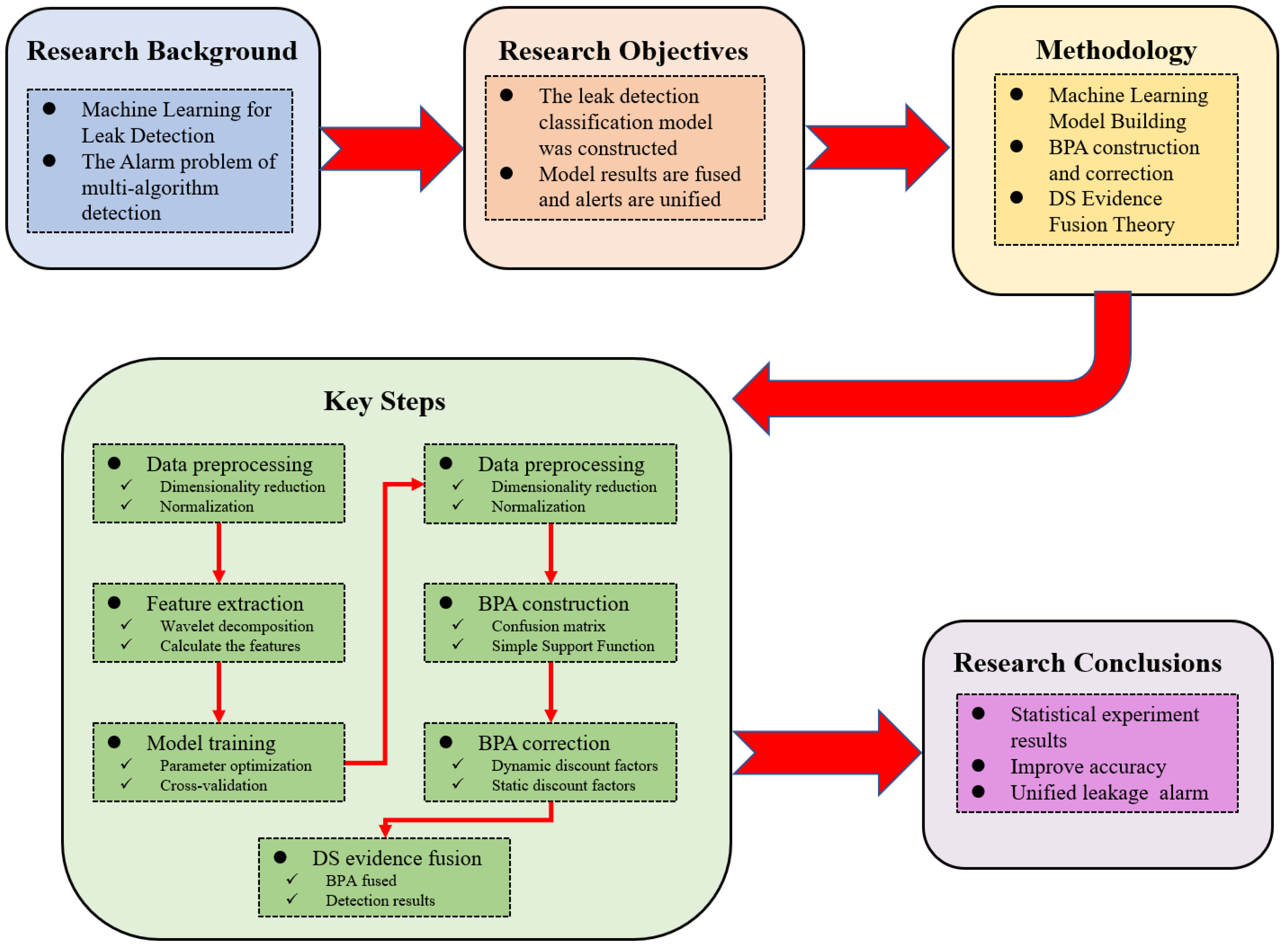
The arrangement of sections and the workflow of this paper are shown in
Figure 1.
Section 1 provides an overview of the causes of pipeline leakage incidents, their significance, classification, and the development of leakage detection technologies, with a focus on advancements driven by ML algorithms in recent years.
Section 2 presents the theoretical foundations and computational processes of ML models. It outlines the calculation process of TFN, the determination of discount factors, and the application of DS evidence fusion theory in pipeline leakage detection systems.
Section 3 presents and analyzes the target recognition results obtained using the methods outlined in
Section 2.
Section 4 presents the main conclusions of this study, summarizing the key innovations, findings, and contributions of the study while discussing future research directions and potential advancements in pipeline leakage detection.
2. Materials and Methods
2.1. Machine Learning Algorithms
2.1.1. Support Vector Machines
The core idea of SVM is to maximize the margin of classification. The basic model is a linear classifier with the maximum margin in the feature space. Using a kernel function transforms it into a nonlinear classifier. It has several advantages, including high efficiency for high dimensional data, strong generalization ability, a kernel function that can adapt to complex nonlinear decision boundaries, and robustness.
The regression function of a nonlinear SVM is expressed as:
where
represents the weight vector,
is the kernel function, and
denotes the bias term,
b* = 0.5640. A dataset
is considered, where
.
An appropriate kernel function
and a penalty factor
are selected, and initial
C = 1. Then, the problem is formulated as a convex quadratic programming optimization, as follows:
Solving this optimization problem yields the optimal solution , .
From this,
is selected, with
satisfying the condition
, with the bias term computed as follows:
For small datasets, the Lagrange operator is introduced to transform the problem into a least squares optimization, ultimately yielding the following function:
where
is a kernel function, which is calculated as follows:
where x and z represent the sample points,
is the square of the Euclidean distance between two points, and
σ is used to control the super parameter of the width of the Gaussian function, with a value of 1.8708.
2.1.2. Logistic Regression
When logistic regression (LR) is used for classification, the primary objective is to minimize the cost function, which quantifies the difference between the predicted results and the actual values. The optimization process yields the optimal model parameters. The advantages include strong interpretability of the model and output, high computational efficiency, suitability for big data, strong ability to model linear relationships, regularization to avoid overfitting, and good robustness to noise and missing data.
The sigmoid function, which maps any input to a probability value between 0 and 1, is depicted in
Figure 2.
where
x is the normalized input vector,
θ are the model coefficients to be solved,
, and
z is a linear combination of the input features. The hypothesis function for logistic regression is formulated as follows:
The cost function is expressed as follows:
where
m is the number of training samples,
represents the true label in the data set,
is the model predicted value, and
is the regularization term to mitigate overfitting. To minimize the cost function, the gradient descent update rule is applied as follows:
where
α is the learning rate, initial
α = 0.1,
λ is the regularization penalty factor, and initial
λ = 1.
2.1.3. Decision Tree and Random Forest
Decision trees (Classification and Regression Tree, CART) and random forests (RF) are both tree-based machine learning algorithms. CART starts at the root node, evaluates feature attributes, selects an output branch, and ultimately reaches a leaf node that contains the final decision result. In contrast, random forest is an ensemble learning method that combines multiple decision trees to enhance performance. The final classification result is calculated by averaging the results of multiple decision trees. The advantages of decision trees include high interpretability, low data preprocessing requirements, handling of nonlinear relationships and complex boundaries, high computational efficiency, fast training speed, and in-sensitivity to noise and outliers. The advantages of RF include high prediction accuracy and generalization ability, processing of high-dimensional data and complex nonlinear relationships, evaluation of global feature importance, and parallel calculation.
During the construction of each decision tree, the node-splitting process is guided by a measure of feature purity. Each feature split results in a reduction in information gain. In classification trees, the Gini coefficient is commonly used to evaluate the purity of a node. It is calculated as follows:
where
T represents the training set,
k is the number of categories,
k = 2, and
pi represents the probability that a sample in
T belongs to category
i. The Gini coefficient is calculated for sub-nodes
T1 and
T2 as follows:
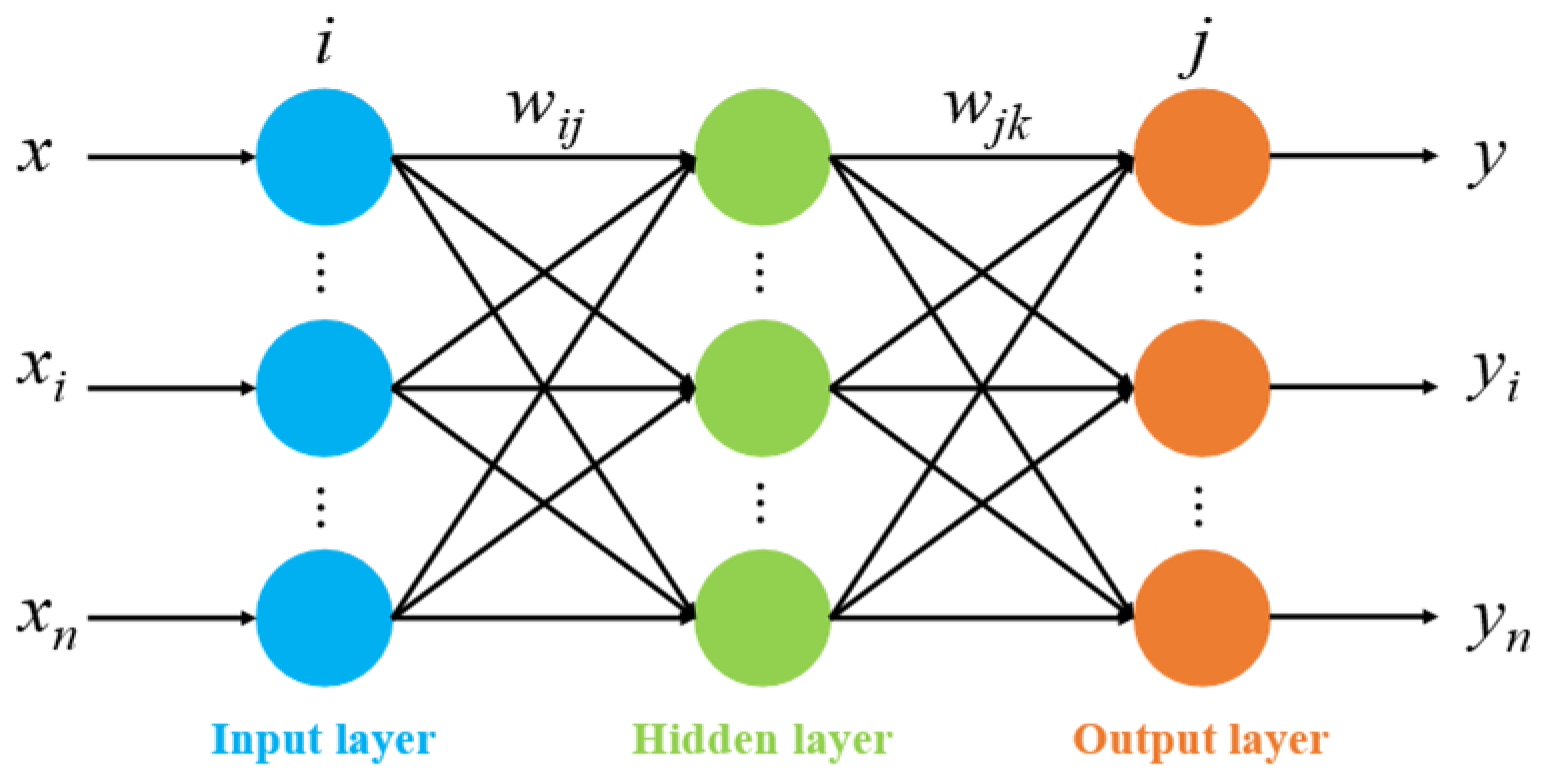
2.1.4. Back Propagation Neural Networks
Back Propagation Neural Networks (BPNN) are a type of feedforward network that utilizes error backpropagation for optimization. The overall structure and functioning of BPNN are illustrated in
Figure 3. Its self-learning process involves both information forward propagation and error backpropagation. During forward propagation, the data are passed from the input layer. If the actual output of the output layer does not meet the expectation, error backpropagation is performed, and the weights of each node layer are adjusted according to the error. Because of the ability to adjust for reverse errors, determining the relationship between input and output is easy. Its advantages include strong nonlinear modeling ability, self-learning feature representation, parallel computing ability, and good scalability, which can suppress overfitting and improve generalization performance, as well as suitability for high-dimensional and complex data. The self-learning process of BPNN consists of two main stages: forward propagation of information and backpropagation of errors [
26].
Let each sample be denoted as , where represensts the input features and denotes the target values.
The process begins by using the sample feature
to calculate the ai for each node in the hidden layer and the output
yi for the output layer. Then, we calculate error
for the output layer nodes as follows:
In addition, error
for the hidden layer nodes is calculated as follows:
where
wki represents the weight between node
i and its next layer node
k, and
denotes the error associated with the output node.
Finally, the weights are updated as follows:
where
wji is the weight from node
i to node
j,
η is the learning rate, and
η = 0.001. In the initial state, where
i = 7, the error
, and the weight matrix
wji is as shown in
Table 1:
2.2. Triangular Fuzzy Number
For target recognition, the minimum, maximum, and average values of a specific indicator from the sample data can be obtained [
28]. A TFN can be constructed based on these values. TFN is especially important in DS evidence fusion theory because it can deal with multi-source heterogeneous data better than other methods in the field of multi-sensor fusion. At the same time, it is an important method to construct BPA functions based on the membership degree of TFN. Its advantage is that the mathematical characteristics of TFN make the operation rules clear, the computational complexity is low, the calculation is efficient and simple to implement, the modeling is intuitive, and the interpretability is strong.
As shown in
Figure 4, two TFNs
and
are defined as:
The membership function
for TFN
is constructed as follows:
where
a,
b, and
c are the minimum, maximum, and mean, respectively,
w is the membership function value when
x =
b, initial
w = 1.0,
, and
.
Assume the recognition framework for target recognition is . For an observed target , the classifiers S1, …, Sk, …, SK correspond to the K indicators of the recognition category. For each category θi, the recognition result vector of each classifier SK for each training sample is defined as .
Where
represents the measure that classifier
SK assigns to the sample
belonging to the category
θi. Assuming
θi has
MK samples, for indicator
k, the following calculations are performed as follows:
The strategy for generating BPA using the TFN representation model can be described as follows:
(1) Case 1: If m = 0, this indicates that the measurement value for indicator k is outside the minimum and maximum range for all categories. The measurement value does not intersect with any TFN representation model, i.e., m(Θ) = 1 or m() = 1.
(2) Case 2: If m = 1, the measurement value V intersects with the TFN representation of a single-element proposition. In this case, the ordinate of the intersection point represents the support of the measurement value V for the single-element proposition.
(3) Case 3: If m > 1, the measurement value V intersects with the TFN representation of multiple propositions. The maximum ordinate of the intersection point is considered the support of the measurement value V for the single-element proposition.
(4) Generating BPA: After obtaining the support for each proposition, the BPA can be generated using the following two methods:
The maximum membership value is subtracted from 1 and is assigned to the whole set Θ. This represents the part of the information considered to be completely unknown, i.e., , and initial = 0.
The support values
of each proposition obtained from the above strategy to calculate the BPA for each proposition are normalized as follows:
Then, the calculation formula of W1 is used to normalize the new support and obtain the BPA for each proposition.
2.3. Machine Learning Algorithms in Pipeline Leak Detection
2.3.1. Training Machine Learning Algorithms
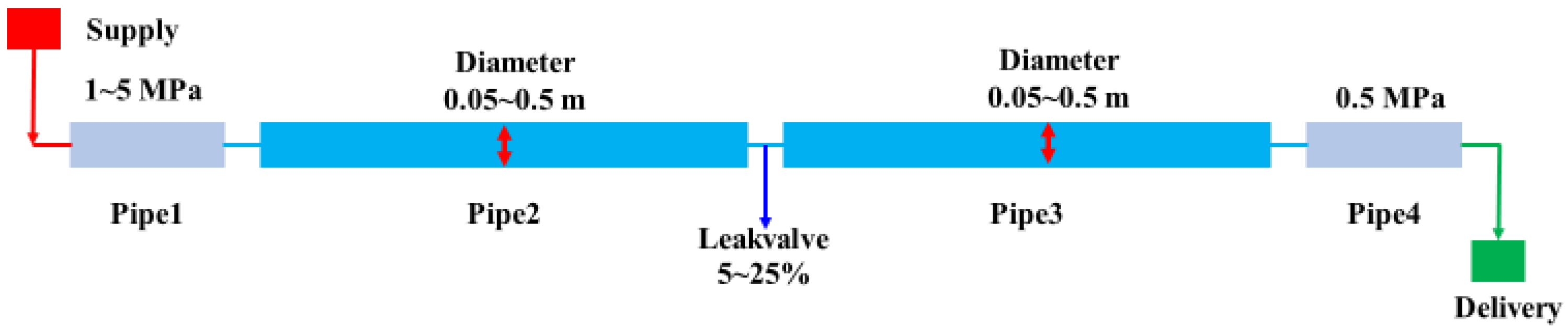
This study utilizes Pipeline Studio V4.0.1.0 software to simulate pipeline leakage detection, generating pipeline operation data as input data for ML algorithms. A total of 150 simulated leakage datasets were generated, with each simulation providing both normal operation and leakage data, resulting in a total of 300 datasets. The numerical simulation considers variations in starting pressure, pipeline diameter, and leakage. The simulation parameters are summarized in
Table 2.
The schematic diagram of the simulated pipeline model is shown in
Figure 5.
- 2.
Features
For the pipeline leakage detection problem, this study directly selects pressure and flow as the primary features. In many pipeline leakage detection methods, common features include energy and envelope spectrum entropy. In this paper, wavelet packet analysis is employed to construct energy features. The process involves performing wavelet packet analysis on the data using MATLAB R2016a V9.0 software, followed by calculating the energy of the decomposed signal [
14].
- 3.
Data dimensionality reduction
To reduce the dimensionality of the data, the principal component analysis (PCA) algorithm is applied.
- 4.
Data preprocessing
Data preprocessing refers to the transformation of raw data into a format suitable for model training, aiming to enhance the quality of the input data. In this study, both flow and pressure data are normalized to map them to the [0, 1] range. The normalization process is defined as follows:
- 5.
Algorithm training
The grid search method is used to train the model, and 5-fold cross-validation is employed to evaluate the model’s performance. This process aims to determine the optimal parameter combination to enhance the algorithm’s efficiency. According to the experience of a large number of experiments, the selection range for the initial values of the model parameters is presented in
Table 3.
- 6.
Result evaluation
To evaluate the classification ability of the model, a confusion matrix and overall precision are utilized.
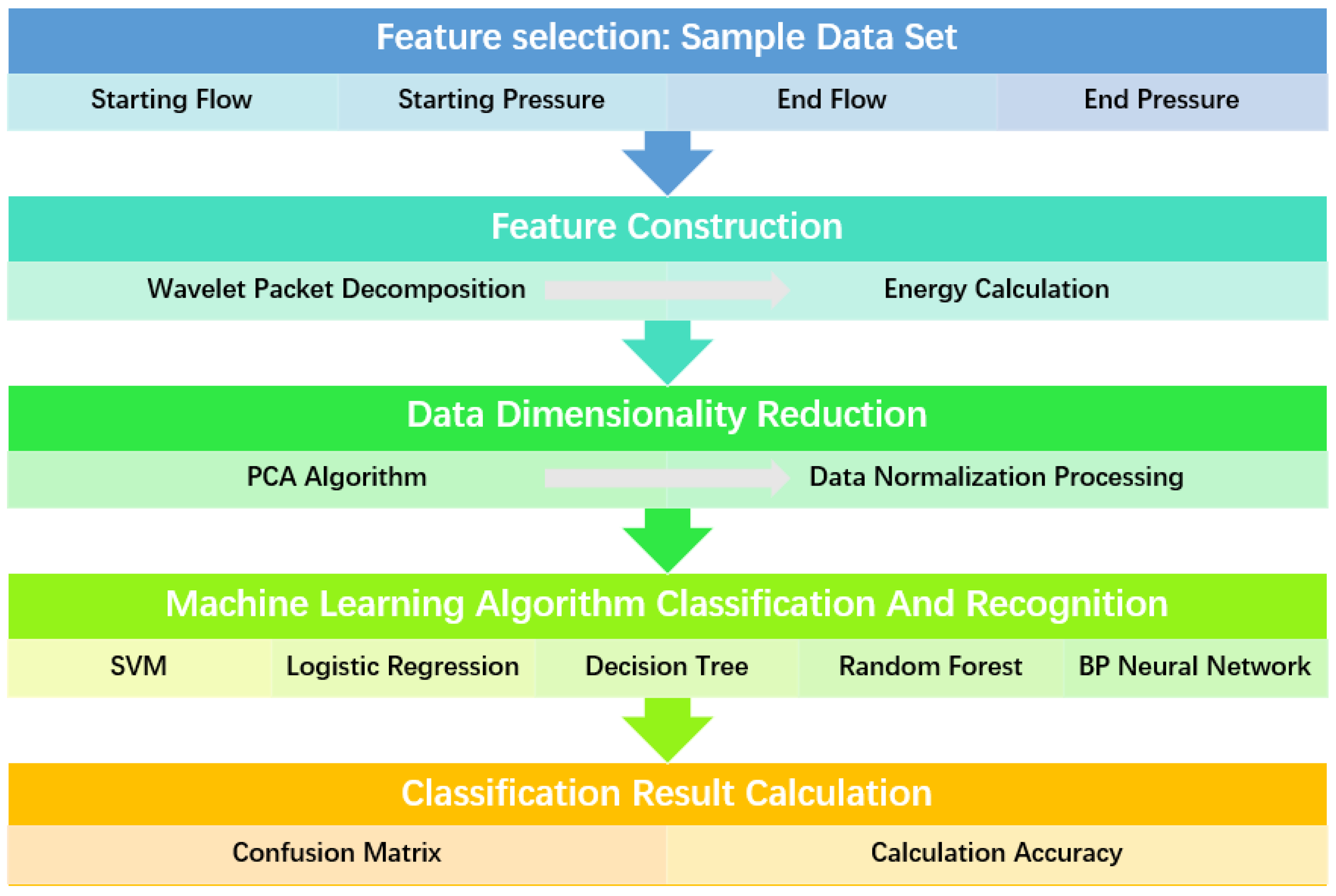
The target classifiers for pipeline leakage detection based on each algorithm were implemented in Python V3.8.5, with the Sklearn library handling all classifier functionalities. The calculation process is depicted in
Figure 6. The training process of the algorithm includes obtaining the data set through numerical simulation, constructing the features of the data, and calculating the energy features after the data are decomposed by a wavelet packet. The PCA algorithm is used to reduce the dimensions of the data, which are then normalized. Finally, the machine learning model is trained, and the target is recognized.
2.3.2. Construction of the Basic Probability Assignment (BPA) Function
In the multi-information fusion model proposed in this paper, four pieces of evidence (starting flow, ending flow, starting pressure, and ending pressure) are used, with five algorithm classifiers trained on these respective datasets. The recognition framework is Θ = (leakage, no leakage), where event A represents leakage and event B represents no leakage. The algorithm constructs the BPA, which consists of the following steps:
(1) Method 1: BPA calculation using Xu’s method: For a given classifier, the classification result is expressed by the confusion matrix
Ck, which is then normalized. This method was previously proposed in [
27].
where
, with
representing the sample size for a specific category, and
is the total sample size for the
i-th category, defined as
.
Specifically, for the classifier treating output category
ωj, the BPA is calculated as follows:
(2) Method 2: BPA calculation using SSF (simple support function). The BPA calculation process based on a SSF was proposed by Xie [
28]. The BPA is given as follows:
where
.
This paper uses both of the above strategies to calculate the BPA and compares them to explore a more accurate BPA construction method.
2.4. Calculation of Comprehensive Discount Factor
2.4.1. Static Discount Factors α and β
There are two types of static discount factors,
α and
β, each calculated differently and exhibiting distinct capabilities. This study compares both methods.
where
αi represents the static discount factor of the
i-th sample,
N is the total number of samples,
BPAi represents the BPA of the
i-th sample,
BPA0 denotes the BPA of the actual output for the sample, and
DBBA represents the Jousselme distance.
The calculation for the reliability of the classifier is expressed as follows:
The reliability actor is given as follows:
The static discount factor is calculated as follows:
2.4.2. Dynamic Discount Factor γ
To evaluate the mutual support reliability between classifiers, the dynamic discount factor
γ is introduced. Its calculation process is as follows:
where
mi and
mj are the BPA calculated by the
i-th and
j-th classifiers of the training sample
Oi, respectively.
ρ represents the correlation coefficient,
is the support degree,
is the relative support degree, and
is the absolute reliability.
2.4.3. Comprehensive Discount Factor
By combining both static discount factors, a comprehensive factor for the
k-th classifier is computed using the weighted average, with initial
= 0.5.
2.5. Dempster–Shafer Evidence Theory
In Dempster–Shafer (DS) evidence theory [
29], the identification framework
Θ is defined as a set of n mutually exclusive elements,
, where
θi (1 ≤
i ≤
n) represents a single subset of
Θ that contains all objects. The power set
represents the set of all subsets of
Θ.
2.5.1. DS Evidence Fusion Rules
Two credibility functions,
Bel1 and
Bel2 [
30], are defined in the same framework
Θ, with corresponding assignments
m1 and
m2. The focal elements of evidence are
and
. The basic probability assignments for these focal elements are
and
). Given that
, the basic credibility distribution of the two credibility functions,
Bel1 and
Bel2, is computed by the following function
, expressed as follows:
where
φ denotes the empty set, and
, considering
m1,
m2,…,
mn.
2.5.2. Application of Multi-Algorithm Fusion in Leak Detection
Discount operations based on the Shafer discount rule are used for identifying target . After obtaining the comprehensive discount factor from the confusion matrix of classifier Sk, the comprehensive reliability factor is calculated. Guided by this approach, the Basic Probability Assignment (BPA) output by classifier Sk for the identification target Oi is adjusted according to its corresponding comprehensive discount factor.
Once the discount factor is determined by evaluating the classifiers’ reliability, it is applied to the output evidence of the local classifier, thereby enabling the discount operation on the respective BPA [
31]. This paper employs the classical Shafer discount rule for this purpose. The rule is defined as follows:
where initial
= 0.5. By applying the Shafer discount rule, the modified BPA is obtained as
. Finally, after applying a betting transformation, the final
is derived and used as the input for the Dempster–Shafer (DS) decision algorithm.
The model progression procedure is depicted in
Figure 7. The calculation process of the model includes the following steps: first, the confusion matrix is obtained from the classification results of the machine learning algorithm, which is then normalized, and the BPA function is calculated using Methods 1 and 2. Then, the static, dynamic, and comprehensive discount factors (
α,
β,
γ) are calculated, and the BPA is corrected using various combinations of discount factors. Finally, the BPA is combined with DS evidence to produce a unified classification result.
4. Discussion
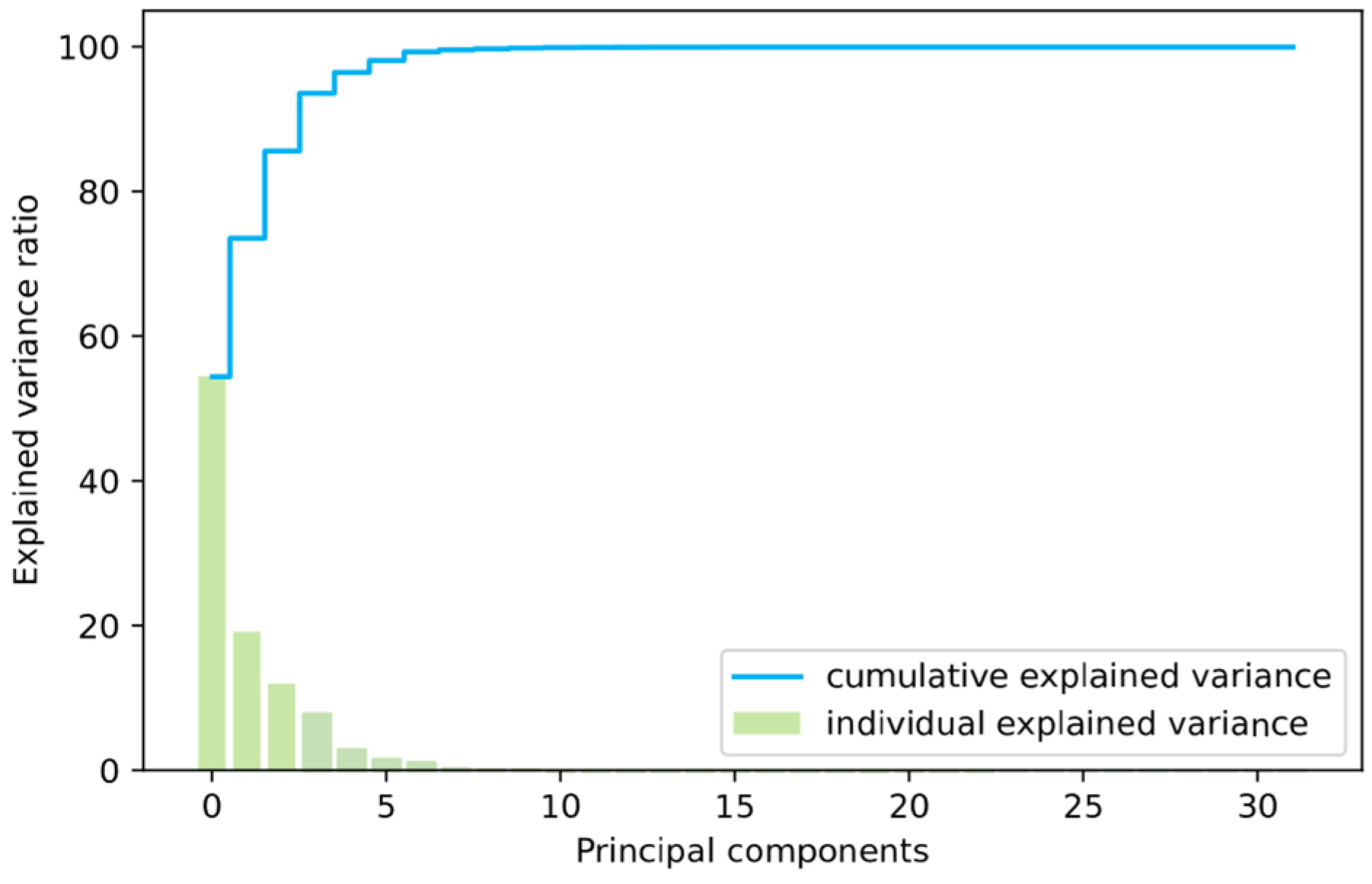
As shown in
Figure 8 and
Table 4, the cumulative variance of the first seven principal components exceeds 99%, which is sufficient to capture the main characteristics of the dataset. Consequently, the original dataset is reduced to a 7-dimensional form.
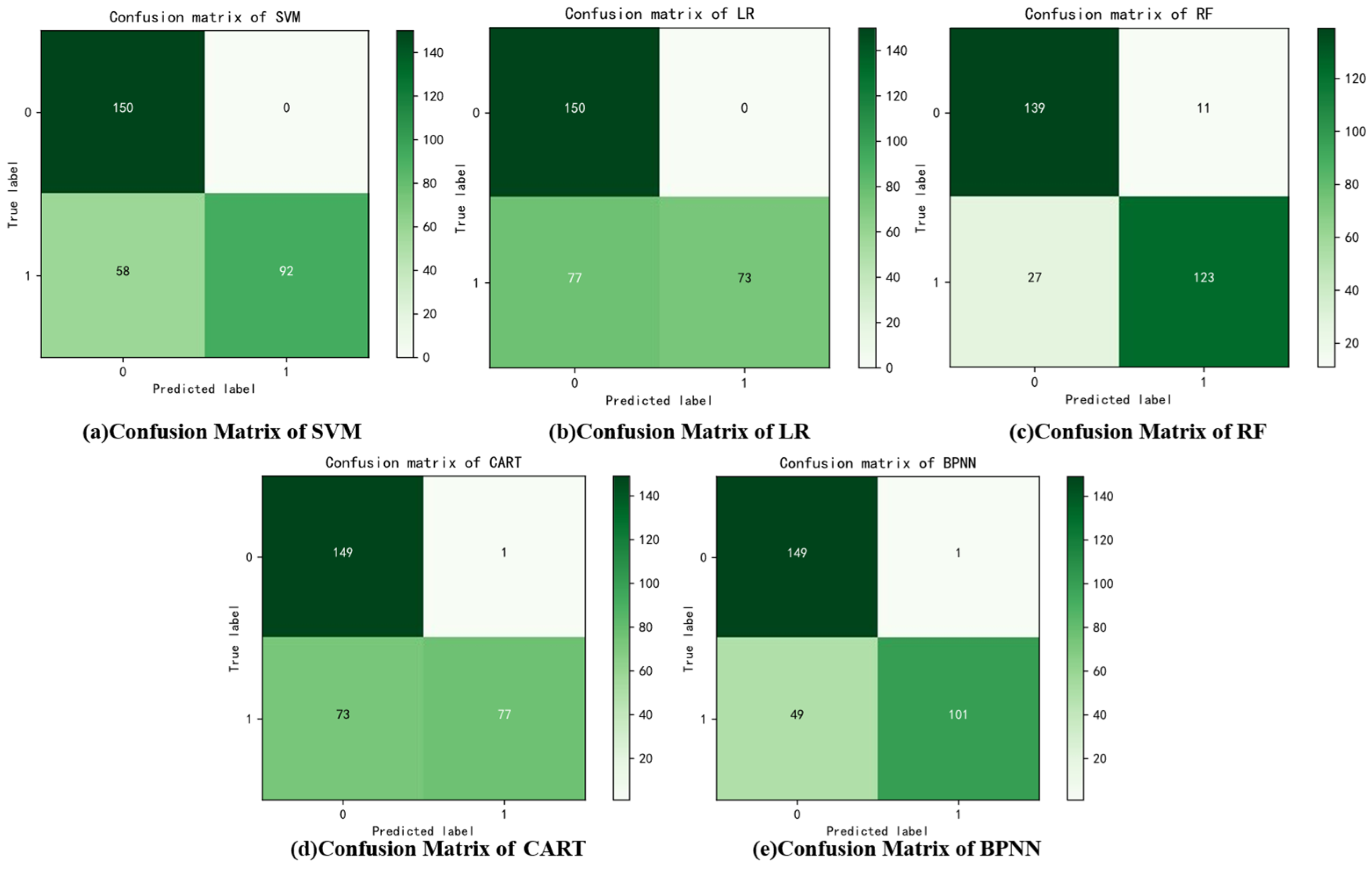
The classification and recognition results of each algorithm are displayed in
Figure 9 and
Table 5. The classification accuracies for each algorithm are as follows: SVM (0.807%), LR (0.743%), RF (0.873%), CART (0.753%), and BPNN (0.834%). The average accuracy across all algorithms is 0.802%. Among these, the RF algorithm achieves the highest accuracy due to its ensemble nature. The BPNN algorithm follows closely, as its neural network structure, with a large number of neurons, provides a more effective simulation of the data, yielding better classification performance.
Method 1 calculates the average discount factor based on Xu’s method, with the results for
α,
β, and
γ presented in
Table 6. It is evident that the LR and CART algorithms exhibit a larger discount for
α and
β, while the RF algorithm shows a higher discount for
γ. The results of the comprehensive discount factor are presented in
Table 7. It can be observed that the combination of
α +
γ yields a larger overall discount, whereas the combination of
β +
γ results in a smaller discount. Additionally, both combinations lead to greater discounts for the LR and CART algorithms. Furthermore, Method 2 calculates the average discount factor using the SSF method. The results for
α,
β, and
γ are presented in
Table 8. It is evident that the average static discount factors
α and
β exhibit a larger discount for the LR and CART algorithms, whereas the average dynamic discount factor
γ indicates a higher discount for the RF algorithm. The calculation results of the comprehensive discount factor are shown in
Table 9. It can be observed that the combination of
α +
γ yields a larger overall discount, while the combination of
β +
γ results in a smaller discount. Both combinations also lead to larger discounts for the LR and CART algorithms, a trend that is consistent with the results from Method 1.
The calculation results of the multi-algorithm fusion based on DS evidence theory for different methods are presented in
Table 10. It is evident that the classification accuracy for the BPA method based on Xu’s study’s findings is 0.983% and 0.947%. For the BPA method using SSF, the classification accuracy is 0.977% and 0.923%. Additionally, the classification accuracy using the comprehensive factor
α +
γ is higher than that of
β +
γ, with increases of 0.006% and 0.024%, respectively. Overall, the classification accuracy achieved by the DS evidence fusion algorithm surpasses that of single ML algorithms.
In addition, the accuracy comparison for the TFN method is presented in
Table 11. Before the DS evidence fusion, the classification accuracy is 0.814%, 0.785%, 0.823%, and 0.772%, with an average precision of 0.799%. After the DS evidence fusion, the classification accuracy improves to 0.903%, 0.873%, 0.903%, and 0.880%, with an average precision of 0.890%. The classification accuracy of the comprehensive factor-modified BPA method proposed in this paper is significantly higher than the traditional TFN-based BPA method. Moreover, the target recognition and BPA construction method using ML-based approaches outperform the traditional BPA construction method of TFN.
The multi-algorithm fusion method is effective because the DS evidence fusion theory can combine the detection results of each ML algorithm and calculate the comprehensive discount factor of the BPA of each algorithm for the sample, resulting in higher accuracy. Specifically, for samples with conflicting classification results in ML algorithms, considering the difference in recognition ability of each algorithm for different categories and the mutual support between algorithms, the correct classification results in the DS evidence fusion process are increased by the comprehensive discount factor to modify the BPA, and the classification accuracy of pipeline leak detection is improved. In addition, DS evidence fusion will provide a unified detection result, potentially reducing false and repeated alarms in the leak detection system.
On the other hand, the reliability of the performance indicators of the classification algorithm is tested, and the confidence interval of the accuracy quantifies the estimation uncertainty of the model accuracy.
Table 12 and
Figure 10 show the calculation results for each algorithm’s accuracy and 95% confidence interval. The analysis of the confidence interval reveals that the interval range of each algorithm is large, and its credibility and accuracy are low.
The accuracy and confidence intervals calculated using the DS fusion method are shown in
Table 13 and
Figure 11. The analysis of the confidence interval indicates that the interval range of the DS fusion method is smaller, and the calculation accuracy and reliability of the algorithm are greater.
The statistical test determines whether the difference in the performance of the classification algorithm is statistically significant. That is, it determines whether there is a significant difference in performance between two classifiers on the same dataset. The
t-test was conducted with the following null hypothesis
H0: there is no significant difference between the two models. The significance level is
α = 0.05. If the calculated
p-value is less than
α, the null hypothesis is rejected, indicating a significant difference in performance between the two models. Otherwise, the null hypothesis is accepted, and the model performance difference is insignificant. The significance levels of the machine learning algorithm and the algorithm fused in this paper were compared, and their
p-values were calculated as shown in
Table 14. We can see that all
p-values < 0.05, indicating that the null hypothesis is rejected and that the differences between the algorithms are significant.
The fused methods were compared for significance levels, and
p-values were calculated, as shown in
Table 15. It can be seen that in Xu +
α +
γ + DS of Method 1 and SSF +
α +
γ + DS of Method 2, the calculated
p-value is 0.23267 > 0.05; thus, the null hypothesis is accepted, and the difference between these two construction methods is not significant. The other
p-values < 0.05 reject the null hypothesis and indicate a significant difference between the various algorithms.
The robustness of the method proposed in this paper can be addressed through data preprocessing, which uses standardization and normalization methods to process the data. During the feature selection, a single feature is avoided, and flow and pressure data are used for feature extraction. In the model selection and training, the regularization of LR, the dropout parameter in BPNN, and cross-validation in the model training process are used to prevent overfitting and improve the robustness of the method. In addition, the robustness of the method can be further improved by including sensor noise or random disturbance in the data, as well as actual pipeline leakage data, to enrich the dataset.
The limitation of this paper is that only the flow and pressure are considered in the data, and no actual pipeline leakage data are included. In order to apply the algorithm to the detection of actual leakage events, the data sample size should be larger. Only the leakage results from the ML algorithm were fused, but the detection results from the traditional physical model were not. In subsequent research, real leakage data and multi-source sensor data, such as sound, will be considered to build more waveform, time, and frequency domain features, and other BPA construction methods will be investigated for decision fusion and other methods for improvement. At the same time, heuristic optimization methods can be considered to optimize the hyperparameters of the model, while deep learning algorithms, such as the Long Short Term Memory network (LSTM), convolutional neural network (CNN), and other models, can be used for classification and recognition.
5. Conclusions
This paper proposes a multi-algorithm fusion method based on the ML and DS evidence fusion theory. Various machine learning models, such as SVM, LR, CART, RF, and BPNN algorithms, are used to identify pipeline leakage targets. The energy calculation method of wavelet packet analysis is used for feature construction, and the PCA algorithm is used to reduce the dimension of the data, and then the data are normalized. Two BPA construction methods based on Xu and SSF methods are proposed, as well as the comprehensive discount factor that includes both static discount factors (α, β) and dynamic discount factors (γ). A BPA correction scheme based on these comprehensive discount factors is proposed. To achieve uniform recognition results and improve alarm accuracy, this paper proposed a BPA fusion method based on DS evidence fusion. After fusing the two ML algorithms, the average accuracy is increased by 0.1565%, and the average accuracy is increased by 0.091% after fusing the TFN method.
Future research can focus on developing a unified evaluation framework that integrates both prior knowledge-based methods with data-driven analysis. Specifically, for alarm results generated by traditional techniques, such as pressure analysis and leak detection models, it would be valuable to explore how to develop a comprehensive and unified evaluation method that combines multiple algorithms. This approach could then be enhanced with emerging ML algorithms to achieve more cohesive analysis results, ultimately improving the precision and effectiveness of the system.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}