Abstract
Due to increasing energy consumption, green scheduling in the manufacturing industry has attracted great attention. In distributed manufacturing involving heterogeneous plants, accounting for complex work sequences and energy consumption poses a major challenge. To address distributed heterogeneous green hybrid flowshop scheduling (DHGHFSP) while optimising total weighted delay (TWD) and total energy consumption (TEC), a deep reinforcement learning-based evolutionary algorithm (DRLBEA) is proposed in this article. In the DRLBEA, a problem-based hybrid heuristic initialization with random-sized population is designed to generate a desirable initial solution. A bi-population evolutionary algorithm with global search and local search is used to obtain the elite archive. Moreover, a distributional Deep Q-Network (DQN) is trained to select the best local search strategy. Experimental results on 20 instances show a 9.8% increase in HV mean value and a 35.6% increase in IGD mean value over the state-of-the-art method. The results show the effectiveness and efficiency of the DRLBEA in solving DHGHFSP.
1. Introduction
The advancement of automation technology has led to a significant expansion in the the modern industrial sector‘s production potential. The scheduling of production processes represents a pivotal decision-making challenge in manufacturing systems [1] and is a subject of extensive study. The flowshop scheduling problems (FSPs), such as the no-wait flowshop [2], hybrid flowshop [3,4], distributed flowshop [5] problems, etc., are classic problems in scheduling problems. To quickly adapt to market demands and shorten production lead times, components for large-scale equipment are often allocated to multiple factories for simultaneous manufacturing. Distributed manufacturing enables the production of high-quality products at lower costs and reduced risks, which is more relevant to the actual production.
The distributed hybrid flowshop scheduling problem (DHFSP) is a complex production scheduling problem that combines the characteristics of the hybrid flowshop scheduling problem (HFSP) and distributed production systems [6]. A significant challenge arises from the necessity of coordinating the production schedule of each shop in a distributed environment. This entails the consideration of factory allocation, which can be represented by the addition of a vector. This design is more aligned with the complexities of real-world production. However, due to the inherent variability of actual production processes and the differences in production methods across machines, each factory is characterised by a unique set of circumstances. This results in a distributed heterogeneous hybrid flowshop scheduling problem (DHHFSP) [7]. The expanded decision space renders it more complex to resolve than the standard DHFSP. The DHHFSP necessitates the concurrent optimisation of job processing sequences, machine assignments, and plant allocations.
In light of the advancements made in the field of sustainable development, environmental protection has emerged as a critical consideration in industrial production [8]. It is inevitable that a considerable amount of energy will be consumed during the manufacturing process, with the inevitable consequence that non-renewable resources will be depleted. The distribution of machinery in a factory setting is not uniform and may be subject to different processing techniques. Consequently, it is vital for the manufacturing industry as a whole to develop effective scheduling strategies and to improve existing technologies in order to reduce total energy consumption [9]. The distributed heterogeneous hybrid flowshop scheduling problem (DHGHFSP) is a DHHFSP that considers energy saving.
The DHGHFSP can be elaborated as follows: Multiple jobs need to be processed within factories that are geographically dispersed. Each factory boasts a certain number of stages, each stage has some parallel machines capable of handling the tasks that can process one job at a time. Each job has a due date and priority. The scheduling objective, subject to various constraints such as operation sequence, machine capacity, and processing time constraints, is to optimise one or more performance metrics. These metrics typically include makespan, total energy consumption, and total weight delay. The DHHFSP is an NP-hard problem as a expansion of the HFSP [10], and it is difficult to solve this problem through simple analytical methods. Researchers have proposed a variety of approaches to solve these problems include tabu search [11], NSGA-II [12], iterative local search [7], and iterative greedy search, among others.
The DHGHFSP is a problem which has a heterogeneous factory environment and a complex scheduling environment that require a more effective approach. Reinforcement Learning (RL) is an effective method for learning and controlling complex and uncertain environments. The goal of RL is to maximize the cumulative rewards gained by an intelligent body during interaction with its environment [13]. RL comprises five principles: (1) input and output systems; (2) rewards; (3) artificial intelligence environment; (4) Markov Decision Process (MDP); (5) training and inference. Value-based reinforcement learning focuses on estimating the value of each state or state–action pair to select the action that yields the highest reward in each state, thus indirectly determining the optimal policy. In this study, a deep reinforcement learning is used to choose the best local search strategies, and a distributional DQN is used to estimate the Q-value distribution of the current state–action.
In this study, a deep reinforcement learning-based evolutionary algorithm (DRLBEA) is proposed to solve the DHGHFSP. To solve the large-scale scheduling problem, this article introduces a distributional DQN-based evolutionary algorithm. Our contributions are as follows:
(1) Considering real-world production scheduling, this study addresses the problem of plant heterogeneity in the DHFSP. It addresses the constraints in time production by recognising that each plant may have different processing times and each job has a deadline completion date and priority
(2) A genetic algorithm was chosen, combined with local search based on problem features to form the overall framework. A multi-population initialization is designed which has different equal-sized subpopulations (Section 4.5) which enhance the initial solution.
(3) This research utilizes a distributional DQN-based algorithm to choose the best operator for the local search by interacting with the environment and updating weights to estimate the Q-value distribution of the current state–action. Unlike traditional DQN, which calculates the Q-value for each action separately, distributional DQN splits the Q-value into two parts: the state-value function , representing the overall value of a state; and the advantage function , which quantifies the advantage of each action relative to the state.
2. Literature Review
For solving scheduling problem, heuristic algorithms are mostly currently employed [14]. The FSP, as the basic issue, has a different expansion. In [15], a Q-learning algorithm is designed to adaptively adjust the selection probabilities of four key population update strategies in the classic Aquila optimiser which do well in improving the performance of the Aquila optimiser but do not consider the exploration and exploitation period in the Aquila optimiser. In [2], a two-stage cooperative evolutionary algorithm with problem-specific knowledge called TS-CEA is proposed to address the energy-efficient scheduling of the no-wait flowshop problem (EENWFSP) with the criteria of minimizing both makespan and total energy consumption which is effective at designing the initialization method but is limited by application scenarios.
As for the HFSP, Janis et al. provided a detailed review of the multiobjective HFSP [4], presenting a systematisation of performance criteria for evaluating the Pareto front. In [3], an energy-aware multiobjective optimisation algorithm (EA-MOA) was proposed, which designed various neighbourhood structures and adaptive neighbourhood selection and had good robustness and effectiveness but lacked local search capabilities. Fan et al. applied a hybrid evolutionary algorithm (HEA) using two solution representations; using a tabu search (TS) process based on a disjunctive graph representation to expand the search space, that method better balanced the optimality and efficiency but tended to be time-consuming in solving large-scale instances [11]. Considering an uncertain situation in the energy-efficient HFSP, Wang extended the Existing Nondominated Sorting Genetic Algorithm-II (ENSGA-II) to address the energy-efficient fuzzy HFSP with variable machine speeds; ENSGA-II had powerful parameter adjustment strategy and a novel historical information utilization method but lacked in interruption and pre-emption [12].
Regarding the DHFSP, Wang considered a bi-population cooperative memetic algorithm (BCMA) and designed two knowledge-based heuristics to overcome; the BCMA could balance global exploration and local exploitation but was weak in solving other types of distributed scheduling problems [16]. Zheng addressed a multiobjective fuzzy DHFSP with fuzzy processing times and fuzzy due dates, and a co-evolutionary algorithm with problem-specific strategies was proposed by rationally combining the Estimation of Distribution Algorithm (EDA) and Iterative Greedy Search (IG). The model balanced exploration and exploitation of the algorithm, but it was difficult to solve scheduling problems with uncertainties [17]. Zhang et al. dealt with a distributed hybrid differentiation flowshop problem (DHDFSP), proposing a distributed co-evolutionary memetic algorithm (DCMA); DCMA had a superior architecture as well as well-designed modules but was weak in multiobjective and heterogeneous scenarios [18]. In [19], Zhang presented an archive-assisted adaptive memetic algorithm (EAMA) to solve the DHDFSP which had an excellent architecture and components, but it was hard to cope with more realistic DHFSPs. Wang proposed a cooperative memetic algorithm (CMA) with a reinforcement learning (RL)-based policy agent; that method’s enhanced search combining multi-problem operators had a high search capability; however, the disadvantage of the CMA was solving other types of energy-aware distributed scheduling problems [20].
Concerning the DHHFSP, Chen et al. investigated a distributed heterogeneous hybrid flowshop scheduling problem with lot-streaming (DHHFSPLS) and established a knowledge-driven many-objective optimisation evolutionary algorithm (KDMaOEA), which was strong in exploitation abilities and helped the algorithm optimise each objective sufficiently but lacked any consideration of costs and uncertainties [7]. Qin et al. studied a mathematical model of the DHHFSP with blocking constraints and designed a collaborative iterative greedy (CIG) algorithm; the local intensification strategy was developed to optimise the scheduling sequence of each factory, but CIG did not consider the adjustment of the number of jobs in the factory after the factory was allocated to the jobs [21]. Under nonidentical time-of-use electricity tariffs, Shao et al. proposed an ant colony optimisation behaviour-based multiobjective evolutionary algorithm based on decomposition, using a problem-specific ant colony behaviour to construct offspring individuals; the method performed well in energy saving, but the contribution of the global search was not enough [22].
Nowadays, reinforcement learning is widely used and can be applied to a variety of problems. In [20], a reinforcement learning-based policy agent was used to select solutions with appropriate improvement operator. In [23], a deep reinforcement learning was used for solving the re-entrant hybrid flowshop scheduling problem with stockers (RHFS2). In this study, the states, actions, and rewards of the Markov decision process for this problem are designed, and two deep Q-network (DQN) approaches based on the actions for determining machines and jobs, respectively, are proposed. Li et al. proposed a deep Q-network-based co-evolution algorithm which were applied to learn and select the best operator for each solution [24]. Table 1 shows the methods of these literature and their advantages and disadvantages.

Table 1.
Methods in the literature review.
3. Problem Description and Mathematical Model
3.1. Problem Description
The DHGHFSP is similar to the DHFSP, however, in the DHGHFSP, the composition varies from plant to plant. There are n jobs that need to be assigned to factories, and each factory possesses t stages and parallel machines. Specifically, each job has a due date and a priority Each job should be completed before . The lower the , the more important and urgent the job. There are three issues to consider in this model: (1) Job allocation to a specific factory, (2) parallel machine selection at every stage for each job, (3) processing order across all heterogeneous factories. In addition, the conditions of the DHGHFSP are shown bellow:
(1) Each concurrent unit is capable of handling only a single task simultaneously.
(2) A job should be allocated to one factory only.
(3) These heterogeneous factories have different processing times at each stage for different jobs.
(4) All machines are available at time 0.
(5) The setup time and dynamic events are disregarded.
3.2. MILP Model for DHGHFSP
The notation is described in Table 2.
Table 2.
Notation of DHGHFSP.
The DHGHFSP is considered to minimize two conflicting objectives, including total weighted delay (TWD) [25] and total energy consumption (TEC), elaborated as follows:
(1) Total energy consumption: include the energy consumption of processing time and idle time.
(2) Total weighted delay: this reflect the income of the factory; a smaller means all orders are better fulfilled and priority and expiry data limits are better balanced.
The MILP model can be defined as:
subject to:
Equations (1) and (2) are two optimisation objectives’ definition. Equation (3) aims to minimize the total energy consumption and total weighted delay. Equation (4) means a single job can only be executed within a single manufacturing factory. Equation (5) makes sure that a single job can only be processed on one machine at a time. Equation (6) implies that at each stage of one factory, each job should occur. Equation (7) ensures the positional relationship of the job on the machine. Equation (8) defines the processing time. Equations (9) and (10) describe the relationship between two stages and between two positions. Equation (11) introduces the energy consumption. Equation (12) guarantees that a job is completed by the due date, job. Equations (13) and (14) are the decision variables.
3.3. A Small Example of DHGHFSP
An example is presented as follows to illustrate the DHGHFSP. The data are shown in Table 3. There are six jobs , two factories , and three priorities , and the for each is , each manufacturing facility comprises two stages, and within each stage, there are two concurrent machines. The processing time and the deadline of each job are also given. In this example, the job sequence and factory assignment , which means the job sets are assigned to factory , and job sets are assigned to factory . The scheduling result is shown in Figure 1; the figure implies that the job in has exceeded the due date, so . (The corresponding to is 1.5). Meanwhile, in , , and . Assuming that the idle power rate and work power rate are 1 kW/h and 3 kW/h, then, for , the energy consumption kW. For , the energy consumption kW. The energy consumption of idle power is 0 as the machines operate continuously from start to the end. Thus, The total energy consumption kW.
Table 3.
An example of DHGHFSP with six jobs, two factories, and three priorities.
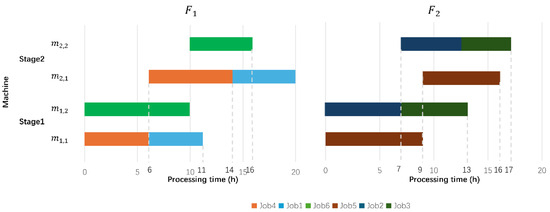
Figure 1.
Gantt chat of example in Table 3.
4. Description of DRLBEA
4.1. Motivation
The DHGHFSP considers the collaboration and heterogeneity among multiple factories, which are commonly encountered in real-life production environments. In previous research on the DHGHFSP, a local search was used to enhance the convergence performance, but it usually fell into local optimisation due to a lack of effective elite individual selection. In this study, to improve the success rate of the local search, distributional deep Q-learning (DQN) is applied [26] to the DHGHFSP, a system capable of discerning the distribution of potential solutions and forecasting the selection of operators. Inspired by [17,23,24,27], a new evolutionary algorithm based on the combination of a heuristic algorithm and deep reinforcement learning is designed.
4.2. Framework of DRLBEA
The overall framework is described in Algorithm 1, including the initialization strategy, local search strategy, evolutionary strategy, and elite archive.
4.3. Encoding and Decoding
In this study, two one-dimensional vectors are used to convey a solution. shows the processing sequence of different jobs. shows the factory allocation of different jobs. Figure 2 shows a sample example of encoding schema. The number in the first line represents the job sequence of these six jobs, the second line implies the factory to which each job is assigned (assuming that there are two factories in total).
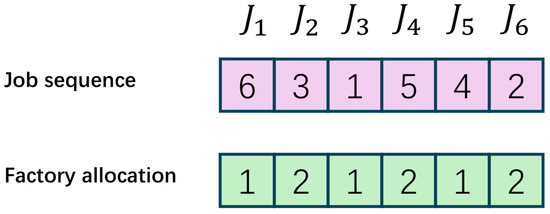
Figure 2.
Encoding representation.
The decoding method converts the encoding values of and into appropriate scheduling schemes. Each job is allocated to the factory according to , and the job sequence of each factory is obtained by the job sequence. Then, jobs are assigned to each parallel machine under constraints.
| Algorithm 1 The framework of the DRLBEA |
|
4.4. Energy-Saving Strategy
To achieve the goal of energy saving, one should consider idle power. This study adopts a right-shift strategy to achieve the purpose of reducing energy consumption. For a set of decoded solutions, the process of reverse decoding advances from the last job to the first job forward. First, determine whether it meets the conditions for rightward movement, that is, if (1) there is idle time behind the job, (2) the completion time of a job cannot exceed the deadline of that job, (3) the completion time of a job on a machine cannot exceed the start time of the next job, (4) the end time of that job cannot exceed the start time of the next phase; if these conditions are fulfilled, then rightward movement can be performed. The right-shift is performed within each phase and does not affect the completion time of the previous phase when the job is transferred to another phase. Then, the final impact results in a reduction in idle time, i.e., the energy consumption of the idle time machine is reduced, and the overall duration does not change. Assuming that there is idle time between two jobs at the same stage, in Figure 3, assuming that the idle power is 1 kW/h and the processing power is 3 kW/h, the due date of Job1 is 8, the due date of Job2 is 10, and a right-shift strategy can obviously be used; we know that the original kW, and after the right shift, kW.
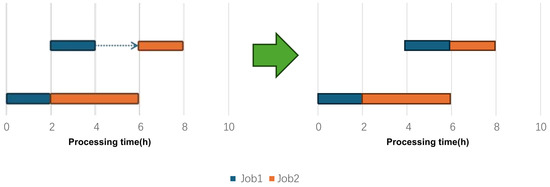
Figure 3.
Right-shift strategy.
4.5. Initialization of DRLBEA
This section introduces the initialization of the DRLBEA. A high-quality initial solution is very important for solving the whole optimisation problem and can be the start of the whole solution process from a better solution set space. Many previous studies used multiple initialization methods to obtain a better initial solution [2,28]. In this study, several initialization methods were used:
(1) Problem features-based initialization, shown in Algorithm 2, where each job is sorted by priority in ascending order to generate a index array, and another sorting is based on the due date of each job in ascending order to generate another index array. The final array is the combination of two sets’ selection probabilities calculated through the algorithm in [23].
(2) Load balance initialization, where jobs are always assigned to the factory which has the minimum load.
(3) Random initialization, which randomly assigns a job sequence to each factory.
The original population was divided into equal-sized subpopulations; in this study, the numbers of subpopulations were , The first and the second initialization had the same minimum subpopulation, and the remaining job sequences were generated randomly. Every time the initialization started, we selected one of them randomly as the result of the initialization.
| Algorithm 2 Rank based on the priority and the due date |
|
4.6. Global Search and Local Search
The proposed evolutionary algorithm is a hybrid framework. In this section, the global search and local search are introduced.
Global search: The population was first evolved through a global search. We chose a genetic algorithm [29] as the algorithmic framework, since genetic algorithms are applicable to various types of optimisation problems, do not depend on the specific mathematical form of the problem, and have strong adaptive ability to deal with more complex large-scale scheduling problems such as the DHGHFSP. Furthermore, genetic algorithms are simple to operate and easy to implement and extend. First, a tournament selection strategy [30] was applied to the individual selection. Then, we generated a new sequence via crossover. After that, mutation occurred to change some points in a sequence. Last, the outcome was combined with the population, the Pareto solutions were calculated by fast nondominated sorting and a crowding distance diversity strategy. The Algorithm 3 shows the whole course of events. All Pareto solutions were maintained within the elite archive.
| Algorithm 3 Global search |
|
Local search: There were four neighbourhood structures in this study. These four strategies focused on the critical job, that is, the job that had the biggest TWD.
(1) : Iterate backwards from the critical work; if the found job’s priority is smaller or the due date is earlier while the priority is the same, change these two jobs.
(2) : Iterate backwards from the critical work; if the found job’s priority is smaller or the due date is earlier while the priority is the same, insert the critical job before the found job.
(3) : Iterate backwards from the critical work; if the found job’s due date is smaller or the priority is earlier while the due date is the same, change these two jobs.
(4) : Iterate backwards from the critical work; if the found job’s due date is smaller or the priority is earlier while the due date is the same, insert the critical job before the found job.
4.7. Distributional DQN for Operator Selection
In this section, a distributional DQN is trained for the operator selection of the local search; Figure 4 shows the structure. Two neural networks are utilized in the distributional DQN, an evaluation network (or online network) and a target network [33]. The distributional Q-function is a model of the distribution of Q-values. The evaluation network learns by interacting with the environment (Section 4.6, global search) directly and updating weights to estimate the Q-value distribution of the current state–action. The target network is used to calculate Q-values as follows:
where is the value distribution for the state s and atom z, and is the advantage distribution for state s and action a at atom z. Compared to Q-learning, the distributional DQN has better learning performance and a more stable training process.
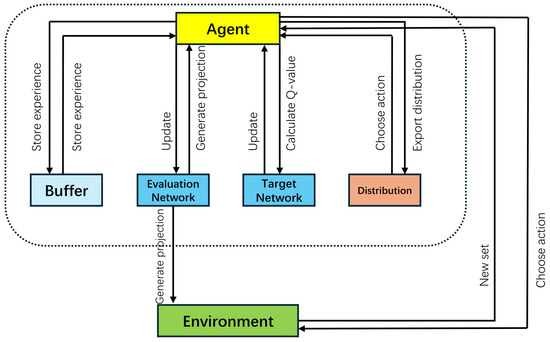
Figure 4.
The structure of the distributional DQN.
Neural network architecture: To facilitate feature extraction and generate value distributions, we designed a composite network comprising three layers: a feature layer, a value stream, and an advantage stream. Each part had two full connection layers and “ReLU” as the activation function. After that, softmax normalization was utilized to generate the action distribution.
Experience replay strategy: In order to improve the training efficiency and stability of the agent, the interactions between the agent and the environment needed to be stored to generate empirical data for subsequent updates. Pushing an experience included the state, action, reward, next state, and done flag where is a vector formed by combining the JS and FA, and is the local search action in Section 4.6. The value of was given by the following definition: If the objectives and were smaller after executing the selected action, the reward was 20; if only was smaller, the reward was 15; if only is lower, the reward was 10; else the reward was 0. is a flag indicating whether the episode ends into the buffer. A new element was appended into the pool if the buffer was not full; otherwise, the earliest stored one was changed.
Training process: The agent chose an action according to the current state and epsilon-greedy policy [34]. Then, executing the corresponding action to obtain a set to build a transition which was stored in the buffer. (1) For each sample in the batch, the agent computed the next state distribution (next state’s Q-atoms) using the target network. The target value for each atom was calculated by using the Bellman equation:
where r is the reward received in the current state–action pair, is a discount factor, which was set 0.9 in this study, is the next state value atom (bounded between and ). (2) The target value was mapped to the closest atoms in the value distribution using linear interpolation. The indices of the nearest atoms were determined using the floor and ceil functions to approximate the target distribution over atoms. (3) The loss function used for training was the Categorical Cross-Entropy Loss between the predicted and target distributions over the value atoms. The predicted distribution was the one generated by the current policy (evaluation network), while the target distribution was derived from the target network; the loss function was as follows:
where is the target probability mass for the ith atom, and is the predicted probability mass for the ith atom in the distribution. (4) The loss was minimized using backpropagation with the Adam optimiser. This updated the weights of the evaluation network to better approximate the true Q-distribution. At every iteration, the target network was updated with the weights of the evaluation network to ensure more stable training. The process is summarized in Algorithm 4.
| Algorithm 4 Training process of Distributional DQN |
|
5. Experimental Results and Discussion
The proposed DRLBEA was implemented using pycharm with python 3.10 and cuda 12.3 on Win 11 and run on an AMD core Ryzen7 6500H 3.2 GHz processor and 16.0 GB of RAM and NVIDIA GeForce RTX 3060 GPU. There are few existing DHGHFSP benchmarks, so we used the instances proposed by Li et al. [35]. In the 20 instances, n = 20, 40, 60, 80, 100, = 3, 5, and f = 2, 3. In terms of energy consumption, the processing energy consumption was kW/h, and the idle energy consumption was = 1.0 kW/h. The instances were named aJbScF, where a, b, and c represent the total number of jobs, stages in each factory, and factories.
5.1. Evaluation Metrics
The hypervolume (HV) and Inverted Generational Distance (IGD) were used to represent the performance of the proposed DRLBEA. Before calculating the HV and IGD, solutions in nondominated should be normalized as follows:
where and is the minimum and maximum of the ith objective in the Pareto front.
- (1)
- HV metric:
The HV is the volume of the region in the target space enclosed by the set of nondominated solutions and the reference point. P is the nondominated solution set, and is the hypercube formed between P and the reference point (the maximum value). In this study, we normalized the solution set; thus, the reference point was 1, 1. A higher HV has better algorithm synthesis performance.
- (2)
- IGD metric:
The IGD measures the average distance from the points in the reference Pareto front to the generated solution set. P is the obtained nondominated solution set, is the Pareto front set, and refers to the Euclidean distance between the reference point z and the point x in the solution set. A lower IGD means a better solution set.
5.2. Parameter Setting
Different parameters affect the performance of the DRLBEA. In this study, six key parameters needed to be adjusted: the population size , the crossover rate , the mutation rate , the learning rate , the greedy factor , the the batch size , and a design-of-experiment (DOE) Taguchi method [36] was applied to make sure the parameters were properly sampled. An orthogonal array was used for the experiments, and we ran these 18 combinations ten times on a randomly generated pattern. Table 4 shows the mean HV of each parameter combination.
Table 4.
Levels of parameters.
Figure 5 shows the result of the parameter setting experiments; the average HV was calculated six times. From the result, the best parameter configuration was , , , , , and .
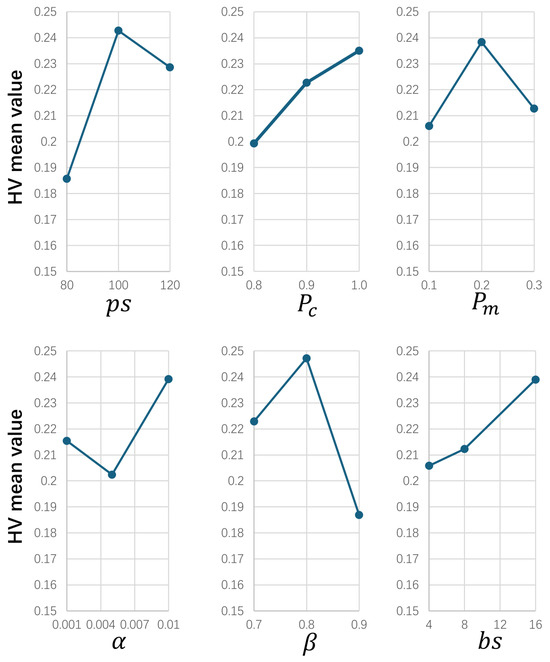
Figure 5.
Parameter levels.
5.3. Evaluation of Each Strategy of DRLBEA
In this section, we used different conditions to verify the efficiency of each strategy. According to different improvements, we designed three experiments named , , to prove the effectiveness of the proposed DRLBEA. Table 5 shows the HV and Table 6 shows the IGD obtained by these five algorithms over 20 instances. First, represented the DRLBEA without the initialization strategy, where all individuals were randomly generated. The HV of was higher than that of the DRLBEA on 3 instances and lower in the other 17 instances. As for IGD, DRLBEA had lower values than on 18 instances; this indicated that our initialization strategy was efficient.
Table 5.
Derived HV mean value of DRLBEA and its variants across all instances.
Table 6.
Derived IGD mean value of DRLBEA and its variants across all instances.
represented the DRLBEA without deep reinforcement learning, where the local search strategy (Section 4.5) was randomly selected from four strategies to generate the new elite archive. The HV of DRLBEA was higher than that of except for “80J5S3F”, the IGD of DRLBEA was lower than that of except for “20J3S3F”. This means the deep reinforcement learning plays a vital role in the DRLBEA.
represented the DRLBEA without the local search; the HV of performed better than that of DRLBEA on 3 instances and worse than DRLBEA on 17 instances. The IGD of DRLBEA was lower than that of on all instances. This result indicates that the local search strategy expands the search space and improve the performance of the DRLBEA.
represented the DRLBEA without the energy-saving strategy, where we removed right-shift strategy from the DRLBEA to verify its efficiency. DRLBEA performed better than on 16 instances; in other 4 instances, performed slightly better than DRLBEA. These results show that the energy-saving strategy is efficient in reducing the energy consumption.
Table 7 shows the results of the Friedman’s rank-sum test, with a confidence level of = 0.05. From the experimental results, we can conclude that a p-value of less than 0.05 demonstrates that the DRLBEA outperforms all variants, and the effectiveness of all strategies used in the DRLBEA.
Table 7.
Statistical value and Friedman’s test of all variant algorithms (significant level = 0.05).
5.4. Comparison with Other Algorithms
Next, we compared the proposed DRLBEA with the state-of-the-art algorithms, including NSGA-II [37], MOEA/D [38], two-stage NSGA-II(TSNSGA-II) [39], IMPGA [24], D2QCE [35]. To further test the performance, all tested algorithms used the same encoding and decoding methods including the energy-saving strategy and ran on these 20 instances 20 times using the same stopping criterion. These algorithms adopted the same initialization and local search strategy. The parameter setting of each algorithm was as follows: (1) was 100, was 1.0, was 0.8; (2) the neighbourhood size T was 10; (3) the inertial weight w, personal best weight , global best weight of IMPGA were 0.5, 1.5, and 1.5, respectively; (4) for D2QCE, all parameters were set according to [36].
Table 8 and Table 9 show the results of all algorithms on each instance. Compared to other algorithms, the DRLBEA performed best for both HV and IGD metrics overall except in one instance of D2QCE, and IMPGA had the worst performance, which means we could achieve a better solution set when using the DRLBEA.
Table 8.
Comparison of HV mean value on 20 instances.
Table 9.
Comparison of IGD mean value on 20 instances.
Moreover, Friedman’s test was performed to prove the superiority of the DRLBEA. We conducted 20 Friedman tests since all algorithms were run on each instance 20 times. The average statistical value, the average rank, and the average p-value are shown in Table 10, the significant level was 0.05, where a p-value lower than 0.05 meant significant differences between the algorithms. DRLBEA performed better than other algorithms on most instances since the DRLBEA achieved the highest HV and IGD ranks.
Table 10.
Statistical value and Friedman’s test of all compared algorithms (significant level = 0.05).
Figure 6 is the visualization of different algorithms’ generated Pareto front on 20J2S3F. The figure shows that the DRLBEA was the closest to the coordinate origin, indicating a better solution set could be obtained through the DRLBEA.
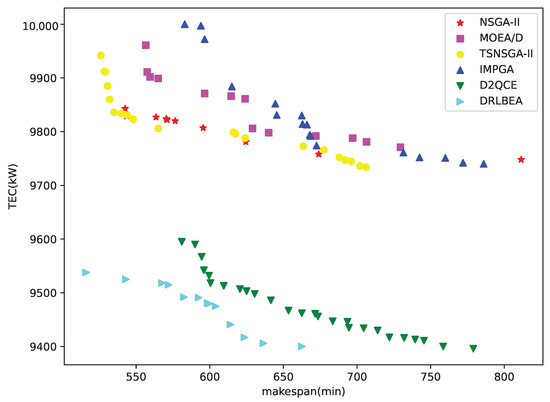
Figure 6.
Pareto front of different algorithms on 20J3S2F.
5.5. Experiment on Real-World Case
To better assess the effectiveness of the DRLBEA, the compared algorithms were tested on a real-world case [35]. The algorithms in Section 5.4 were compared with the DRLBEA using the same settings. Table 11 shows the results; the DRLBEA clearly outperformed all compared algorithms in terms of HV and IGD metrics. The p-value < 0.05 implies that the DRLBEA performed better than the compared algorithms.
Table 11.
Statistical value and Friedman’s test of all compared algorithms (significant level = 0.05).
6. Conclusions
This article presented a deep reinforcement learning-based evolutionary algorithm to solve the distributed heterogeneous green hybrid flowshop scheduling problem. A multi-population initialization with hybrid initialization rules was used to improve the convergence and diversity. Then, an energy-saving strategy was devised to better reduce the energy consumption. Finally, a deep reinforcement learning-based local search selection was employed to achieve a better elite archive and obtain a more diversified solution set.
Many experiments designed to demonstrate the efficiency of the DRLBEA were conducted. We compared the DRLBEA with different combinations of improved strategies to verify the efficient of the DRLBEA. The DRLBEA was compared with other well-known algorithms on 20 instances of varying sizes, and it achieved better performance, obtaining a better Pareto front.
In the future, additional problems can be addressed, such as a more complex shop environment including dynamic events, the speed of machines, and heterogeneous parallel machines, using a wide application of deep reinforcement learning in scheduling problems.
Author Contributions
Conceptualization, H.X., L.H., J.Z. and J.T.; methodology, H.X., L.H. and C.Z.; software, H.X., L.H. and C.Z.; validation, H.X., L.H. and J.Z.; formal analysis, L.H. and J.T.; writing—original draft preparation, H.X. and L.H.; writing—review and editing, J.T., J.Z. and C.Z.; visualization, H.X. and L.H.; supervision, J.T., J.Z. and C.Z.; project administration, H.X. All authors have read and agreed to the published version of the manuscript.
Funding
The authors did not receive support from any organization for the submitted work.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The code in this article cannot be published due to privacy but can be obtained from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare that they have no conflicts of interest or competing interests.
References
- Adel, A. Future of industry 5.0 in society: Human-centric solutions, challenges and prospective research areas. J. Cloud Comput.-Adv. Syst. Appl. 2022, 11, 40. [Google Scholar] [CrossRef] [PubMed]
- Zhao, F.; He, X.; Wang, L. A Two-Stage Cooperative Evolutionary Algorithm with Problem-Specific Knowledge for Energy-Efficient Scheduling of No-Wait Flow-Shop Problem. IEEE Trans. Cybern. 2021, 51, 5291–5303. [Google Scholar] [CrossRef] [PubMed]
- Li, J.Q.; Sang, H.Y.; Han, Y.Y.; Wang, C.G.; Gao, K.Z. Efficient multi-objective optimization algorithm for hybrid flow shop scheduling problems with setup energy consumptions. J. Clean. Prod. 2018, 181, 584–598. [Google Scholar] [CrossRef]
- Neufeld, J.S.; Schulz, S.; Buscher, U. A systematic review of multi-objective hybrid flow shop scheduling. Eur. J. Oper. Res. 2023, 309, 1–23. [Google Scholar] [CrossRef]
- Li, Y.Z.; Pan, Q.K.; Gao, K.Z.; Tasgetiren, M.F.; Zhang, B.; Li, J.Q. A green scheduling algorithm for the distributed flowshop problem. Appl. Soft Comput. 2021, 109. [Google Scholar] [CrossRef]
- Ying, K.C.; Lin, S.W. Minimizing makespan for the distributed hybrid flowshop scheduling problem with multiprocessor tasks. Expert Syst. Appl. 2018, 92, 132–141. [Google Scholar] [CrossRef]
- Chen, S.; Wang, X.; Wang, Y.; Gu, X. A knowledge-driven many-objective algorithm for energy-efficient distributed heterogeneous hybrid flowshop scheduling with lot-streaming. Swarm Evol. Comput. 2024, 91, 107526. [Google Scholar] [CrossRef]
- Fernandes, J.M.R.C.; Homayouni, S.M.; Fontes, D.B.M.M. Energy-Efficient Scheduling in Job Shop Manufacturing Systems: A Literature Review. Sustainability 2022, 14, 6264. [Google Scholar] [CrossRef]
- Lu, C.; Gao, L.; Yi, J.; Li, X. Energy-Efficient Scheduling of Distributed Flow Shop With Heterogeneous Factories: A Real-World Case From Automobile Industry in China. IEEE Trans. Ind. Inform. 2021, 17, 6687–6696. [Google Scholar] [CrossRef]
- He, L.; Sun, S.; Luo, R. A hybrid two-stage flowshop scheduling problem. Asia-Pacific J. Oper. Res. 2007, 24, 45–56. [Google Scholar] [CrossRef]
- Fan, J.; Li, Y.; Xie, J.; Zhang, C.; Shen, W.; Gao, L. A Hybrid Evolutionary Algorithm Using Two Solution Representations for Hybrid Flow-Shop Scheduling Problem. IEEE Trans. Cybern. 2023, 53, 1752–1764. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.J.; Wang, G.G.; Tian, F.M.; Gong, D.W.; Pedrycz, W. Solving energy-efficient fuzzy hybrid flow-shop scheduling problem at a variable machine speed using an extended NSGA-II. Eng. Appl. Artif. Intell. 2023, 121, 105977. [Google Scholar] [CrossRef]
- Chen, R.; Yang, B.; Li, S.; Wang, S. A self-learning genetic algorithm based on reinforcement learning for flexible job-shop scheduling problem. Comput. Ind. Eng. 2020, 149, 106778. [Google Scholar] [CrossRef]
- Qiao, J.; He, M.; Sun, N.; Sun, P.; Fan, Y. Factors affecting the final solution of the bike-sharing rebalancing problem under heuristic algorithms. Comput. Oper. Res. 2023, 159, 106368. [Google Scholar] [CrossRef]
- Ge, Z.; Wang, H. Integrated Optimization of Blocking Flowshop Scheduling and Preventive Maintenance Using a Q-Learning-Based Aquila Optimizer. Symmetry 2023, 15, 1600. [Google Scholar] [CrossRef]
- Wang, J.J.; Wang, L. A Bi-Population Cooperative Memetic Algorithm for Distributed Hybrid Flow-Shop Scheduling. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 947–961. [Google Scholar] [CrossRef]
- Zheng, J.; Wang, L.; Wang, J. A cooperative coevolution algorithm for multi-objective fuzzy distributed hybrid flow shop. Knowl.-Based Syst. 2020, 194, 105536. [Google Scholar] [CrossRef]
- Zhang, G.; Liu, B.; Wang, L.; Yu, D.; Xing, K. Distributed Co-Evolutionary Memetic Algorithm for Distributed Hybrid Differentiation Flowshop Scheduling Problem. IEEE Trans. Evol. Comput. 2022, 26, 1043–1057. [Google Scholar] [CrossRef]
- Zhang, G.; Ma, X.; Wang, L.; Xing, K. Elite Archive-Assisted Adaptive Memetic Algorithm for a Realistic Hybrid Differentiation Flowshop Scheduling Problem. IEEE Trans. Evol. Comput. 2022, 26, 100–114. [Google Scholar] [CrossRef]
- Wang, J.J.; Wang, L. A Cooperative Memetic Algorithm with Learning-Based Agent for Energy-Aware Distributed Hybrid Flow-Shop Scheduling. IEEE Trans. Evol. Comput. 2022, 26, 461–475. [Google Scholar] [CrossRef]
- Qin, H.X.; Han, Y.Y. A collaborative iterative greedy algorithm for the scheduling of distributed heterogeneous hybrid flow shop with blocking constraints. Expert Syst. Appl. 2022, 201, 117256. [Google Scholar] [CrossRef]
- Shao, W.; Shao, Z.; Pi, D. An Ant Colony Optimization Behavior-Based MOEA/D for Distributed Heterogeneous Hybrid Flow Shop Scheduling Problem Under Nonidentical Time-of-Use Electricity Tariffs. IEEE Trans. Autom. Sci. Eng. 2022, 19, 3379–3394. [Google Scholar] [CrossRef]
- Lin, C.C.; Peng, Y.C.; Chang, Y.S.; Chang, C.H. Reentrant hybrid flow shop scheduling with stockers in automated material handling systems using deep reinforcement learning. Comput. Ind. Eng. 2024, 189, 109995. [Google Scholar] [CrossRef]
- Li, R.; Gong, W.; Wang, L.; Lu, C.; Dong, C. Co-Evolution With Deep Reinforcement Learning for Energy-Aware Distributed Heterogeneous Flexible Job Shop Scheduling. IEEE Trans. Syst. Man Cybern.-Syst. 2024, 54, 201–211. [Google Scholar] [CrossRef]
- Vasquez, O.C. On the complexity of the single machine scheduling problem minimizing total weighted delay penalty. Oper. Res. Lett. 2014, 42, 343–347. [Google Scholar] [CrossRef]
- Lim, B.; Vu, M. Distributed Multi-Agent Deep Q-Learning for Load Balancing User Association in Dense Networks. IEEE Wirel. Commun. Lett. 2023, 12, 1120–1124. [Google Scholar] [CrossRef]
- Cui, H.; Li, X.; Gao, L. An improved multi-population genetic algorithm with a greedy job insertion inter-factory neighborhood structure for distributed heterogeneous hybrid flow shop scheduling problem. Expert Syst. Appl. 2023, 222, 119805. [Google Scholar] [CrossRef]
- Yang, J.; Xu, H.; Cheng, J.; Li, R.; Gu, Y. A decomposition-based memetic algorithm to solve the biobjective green flexible job shop scheduling problem with interval type-2 fuzzy processing time. Comput. Ind. Eng. 2023, 183, 109513. [Google Scholar] [CrossRef]
- Liu, S.C.; Chen, Z.G.; Zhan, Z.H.; Jeon, S.W.; Kwong, S.; Zhang, J. Many-Objective Job-Shop Scheduling: A Multiple Populations for Multiple Objectives-Based Genetic Algorithm Approach. IEEE Trans. Cybern. 2023, 53, 1460–1474. [Google Scholar] [CrossRef]
- Yang, J.; Soh, C. Structural optimization by genetic algorithms with tournament selection. J. Comput. Civ. Eng. 1997, 11, 195–200. [Google Scholar] [CrossRef]
- Zhang, C.; Li, P.; Rao, Y.; Li, S. A new hybrid GA/SA algorithm for the job shop scheduling problem. In Lecture Notes in Computer Science, Proceedings of the 5th European Conference on Evolutionary Computation in Combinatorial Optimization (EvoCOP 2005), Lausanne, Switzerland, 30 March–1 April 2005; Raidl, G., Gottlieb, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3448, pp. 246–259. [Google Scholar]
- Yang, W.; Wang, B.; Quan, H.; Hu, C. Strategy uniform crossover adaptation evolution in a minority game. Chin. Phys. Lett. 2003, 20, 1659–1661. [Google Scholar]
- Huang, L.; Fu, M.; Rao, A.; Irissappane, A.A.; Zhang, J.; Xu, C. A Distributional Perspective on Multiagent Cooperation with Deep Reinforcement Learning. IEEE Trans. Neural Networks Learn. Syst. 2024, 35, 4246–4259. [Google Scholar] [CrossRef] [PubMed]
- Hao, J.; Yang, T.; Tang, H.; Bai, C.; Liu, J.; Meng, Z.; Liu, P.; Wang, Z. Exploration in Deep Reinforcement Learning: From Single-Agent to Multiagent Domain. IEEE Trans. Neural Networks Learn. Syst. 2024, 35, 8762–8782. [Google Scholar] [CrossRef]
- Li, R.; Gong, W.; Wang, L.; Lu, C.; Pan, Z.; Zhuang, X. Double DQN-Based Coevolution for Green Distributed Heterogeneous Hybrid Flowshop Scheduling With Multiple Priorities of Jobs. IEEE Trans. Autom. Sci. Eng. 2024, 21, 6550–6562. [Google Scholar] [CrossRef]
- Reynolds, P.S. Between two stools: Preclinical research, reproducibility, and statistical design of experiments. BMC Res. Notes 2022, 15, 73. [Google Scholar] [CrossRef] [PubMed]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Ming, F.; Gong, W.; Wang, L. A Two-Stage Evolutionary Algorithm with Balanced Convergence and Diversity for Many-Objective Optimization. IEEE Trans. Syst. Man Cybern.-Syst. 2022, 52, 6222–6234. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).