Abstract
Multi-objective derivative-free optimization has broad applications in engineering fields, with its main challenge being how to solve problems efficiently without gradient information. This article proposes a novel multi-objective derivative-free optimization algorithm that integrates sparse modeling techniques with a new non-dominated comparison function within a direct multisearch framework. To fully leverage information from historically evaluated points, the algorithm employs quadratic surrogate models constructed from these points to enhance the search step, with model coefficients determined through either linear programming or least-squares methods. Simultaneously, a Pareto dominance-based comparison function is introduced to improve the selection capability of candidate solutions. Experimental results on ZDT and WFG benchmark problems demonstrate that, through comparisons of hypervolume values and performance profiles, the proposed algorithm exhibits competitiveness and robustness under limited function evaluation budgets compared to existing state-of-the-art methods.
1. Introduction
As computational simulations and data-driven modeling have become critical research tools, practical optimization increasingly involves derivative-free objectives from these sources while balancing competing goals. This defines multi-objective derivative-free optimization (DFO) problems, which are prevalent in engineering domains like chemical engineering and steel metallurgy. A general multi-objective DFO problem can be formulated as follows:
where is an n-dimensional decision vector within the feasible decision set . The corresponding feasible objective set is then defined as the mapping of under the objective function . Moreover, the objective function for satisfies the following: (i) At least one is a black-box (derivative-free) function. (ii) For any , there exists such that and conflict, meaning that no point in can simultaneously minimize all objectives. This article focuses specifically on the bound-constrained case, i.e.,
where and denote element-wise lower- and upper-bound vectors for the decision variable .
The optimization methods for solving such problems can be broadly classified into three categories: direct search methods, model-based methods, and population-based heuristic methods. Direct search methods generate candidate solutions through systematic geometric sampling patterns, as exemplified in [1,2,3,4]. Model-based methods, also referred to as surrogate-based methods, construct approximation models from evaluated points and generate new candidates by optimizing these surrogates, often embedded within trust-region frameworks [5,6,7,8]. Population-based heuristic algorithms, which simulate evolutionary processes or collective behaviors within solution sets to generate candidate solutions, have long been commonly used for solving multi-objective DFO problems [9,10,11].
However, such heuristic algorithms typically require a large number of function evaluations and lack mathematical convergence guarantees, making them unsuitable for expensive black-box functions. To mitigate this limitation, surrogate-assisted population-based algorithms have been developed. For instance, ref. [12] proposed a surrogate-assisted multi-objective evolutionary algorithm with a two-level model management strategy to balance convergence and diversity under a limited evaluation budget. Similarly, ref. [13] introduced a linear subspace surrogate modeling approach for large-scale expensive optimization, which constructs effective models in high-dimensional spaces using minimal historical data. Additionally, decision variable clustering has been applied to enhance multi-objective optimization (MOO) algorithms in addressing large-scale problems [14].
Meanwhile, multi-objective DFO methods derived from model-based trust-region frameworks are also attracting growing research attention. For example, building on the scalarization approach in [15], a DFO method was developed under the trust-region framework for bi-objective optimization problems [16]. Subsequently, ref. [17] proposed a direct multi-objective trust-region algorithm for problems where at least one objective is an expensive black-box function. More recently, ref. [7] presented a modified trust-region approach for approximating the complete Pareto front in multi-objective DFO problems.
Furthermore, directional direct search methods, whose global convergence and computational complexity have been thoroughly characterized [18,19], have also been extended to multi-objective DFO. For instance, mesh adaptive search was extended to bi-objective optimization problems, though the uniformity of solution distribution was limited by the design of aggregation functions in pre-decision techniques [15]. Later, ref. [20] developed the multi-objective MADS algorithm using the normal boundary intersection (NBI) method and established necessary convergence conditions. However, the construction of convex hulls for individual objective minimization in NBI led to significant sensitivity of MADS performance to convex hull parameters. To address this, ref. [1] proposed the direct multisearch (DMS) framework, integrating pattern search with mesh adaptive strategies. The original DMS framework did not incorporate a search step. To overcome this limitation, ref. [21] developed the BoostDMS algorithm, which enhances performance through the integration of a model-based search step. Building upon this, ref. [22] further extended the framework to a parallel multi-objective DFO algorithm that unifies both search and poll steps. To tackle challenges from local optima in multi-modal problems, ref. [2] introduced multi-start strategies into algorithm design. Inspired by [2,23], ref. [3] proposed a novel mesh adaptive search-based optimizer to improve convergence properties. For better handling of nonlinear constraints in multi-objective DFO, ref. [24] replaced the extreme barrier constraints in DMS with a filter strategy incorporating inexact feasibility restoration. Additionally, to improve computational efficiency in practical applications, ref. [4] established an adaptive search direction selection mechanism, validated through numerical experiments on benchmark functions and automotive suspension design.
This article presents a multi-objective DFO algorithm designed to approximate the complete Pareto front within a limited function evaluation budget. The proposed algorithm, developed within the DMS framework and denoted as DMSCFSM, incorporates sparse modeling and a novel non-dominated comparison function technique. It integrates several strategies from previous works, including the use of previously evaluated points for surrogate model construction [21], the building of both incomplete and complete models [25], the generation of positively spanning search directions [1], and a Pareto dominance-based comparison mechanism [26].
Inspired by [25], a sparse modeling approach is adopted in the search step to formulate surrogate models. This method plays a crucial role in mitigating the curse of dimensionality and differs from the modeling strategy employed in [21]. Moreover, it has been observed that conventional non-dominated set updates, which rely solely on Pareto dominance, often overlook differences in dominance strength, which is defined as the number of solutions a point dominates within the mutually non-dominated set. This oversight can result in retaining solutions with weak dominance strength, making them vulnerable to replacement by new non-dominated points in subsequent iterations. To address this issue, a new comparison function is introduced in the proposed algorithm. A detailed description of DMSCFSM is provided in Section 3.
The structure of this article is organized as follows: Section 2 presents the preliminaries. The modified algorithm is elaborated in Section 3. Section 4 delves into numerical results and the experimental implementation of the method, which includes a comparison of the algorithm’s numerical performance with state-of-the-art algorithms. Finally, conclusions are provided in Section 5.
2. Preliminaries
In this section, relevant preliminaries are given, such as preliminaries on MOO and the DMS framework.
2.1. Preliminaries on MOO
In MOO, no solution exists that simultaneously minimizes all m objectives due to inherent conflicts between at least two objective functions. Consequently, unlike single-objective optimization, which seeks a single optimal solution, MOO aims to obtain a set of Pareto-optimal solutions that capture the trade-offs between competing objectives. For a minimization MOO, a solution dominates a solution if and only if
where . The solutions that are not dominated by any other solutions are known as Pareto-optimal solutions. The points in the Pareto-optimal set correspond to the Pareto front of the MOO problem in the objective space. Figure 1 illustrates the relationship between Pareto-optimal solutions and the Pareto front.
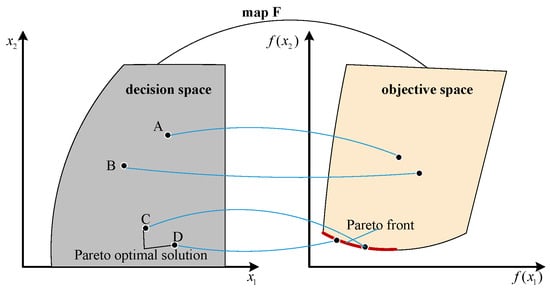
Figure 1.
Graphical depiction of multi-objective optimization.
2.2. Extreme Barrier Approach
Constraints are handled using the extreme barrier approach [1]. The original objective function is extended to a barrier function , defined as
This definition ensures that infeasible points are automatically dominated in any optimization comparison, thereby guiding the search toward the feasible region .
2.3. DMS Framework Overview
Since its introduction in [1], the DMS method has demonstrated superior performance in benchmarking new solvers and industrial implementations [21]. Figure 2 illustrates the key algorithmic steps of the DMS method, with a complete description provided in [1].
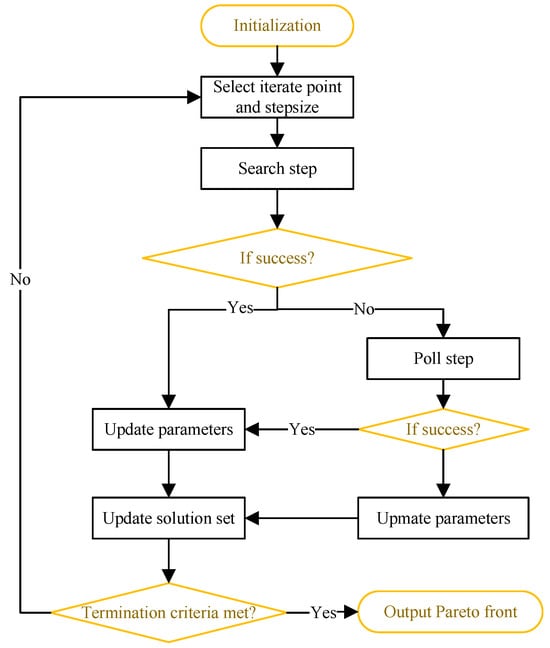
Figure 2.
Major algorithmic steps of DMS.
At each iteration, the algorithm begins by selecting an iterate point and a corresponding step-size parameter from the current list of feasible non-dominated points. Different ordering strategies for this list produce various algorithmic variants. In the numerical experiments, a spread metric is used to order points in a way that minimizes gaps between consecutive solutions along the current approximation of the Pareto front.
Following the selection of an iterate point, the algorithm executes a search step. If this step fails to improve the non-dominated set, a poll step is initiated around the current iterate. Notably, the search step is executed only after a poll step has been completed and when the current step size exceeds a predefined stopping threshold.
During the poll step, DMS employs a positive spanning set [27] as direction vectors to generate new points from the poll center. It evaluates the objective function at displacements scaled by a step-size parameter along these vectors, implementing a complete polling strategy.
At the end of each iteration, all relevant parameters are updated. Specifically, the step-size parameter is increased (or maintained) upon a successful iteration and decreased otherwise. Other parameters are then adjusted accordingly.
3. Proposed Algorithm Description
In this section, the proposed model-search DFO algorithm is presented, along with a detailed description of the surrogate modeling method for the search step, a definition of the Pareto dominance-based comparison function, and a comprehensive outline of the complete algorithmic framework.
3.1. Surrogate Modeling Method for Search Step
In this article, the model construction approach is consistent with that employed in trust-region model-based algorithms. Without loss of generality, one objective function (denoted as ) is considered to illustrate the surrogate modeling approach. In trust-region model-based algorithms, obtaining each iteration step requires finding a solution to the following subproblem:
where , and denotes the trust-region radius at the k-th iteration. Here, and are the gradient and the approximate Hessian of , respectively, which are obtained from the surrogate model .
The quadratic polynomial surrogate models are formulated using selected historical points from the evaluation cache to compute and . The model may be either an incomplete or a complete quadratic approximation, depending on the number of available evaluated points. Let represent the sample set filtered from the cache, where the objective functions have been evaluated. Each point in this set is defined as . Define as a basis for the polynomial space (degree polynomials in ), where is the space dimension. The model can be formulated as
The interpolation conditions lead to the following linear system (7):
where is the coefficient vector, contains observed values, and is the interpolation matrix with elements .
For exact interpolation (if ), the matrix must be invertible. However, when , the system becomes either underdetermined (if ) or overdetermined (if ), and a direct solution is not feasible.
When , the parameter coefficients can be determined by solving the following least-squares problem (8):
By taking the partial derivatives with respect to and setting them to zero, the following system of Equation (9) is obtained:
If has full column rank, then is non-singular.
When , a Dantzig selector approach is employed to construct the surrogate model, which possesses the oracle properties [28]. This method differs from the surrogate modeling technique presented in [21], while offering variable selection capabilities for handling sparse optimization problems. The resulting parameter estimation problem leads to the non-smooth convex optimization problem (10).
where is a tolerance parameter whose selection affects the accuracy of the predictive model [28] and influences the algorithm’s performance. Adaptive selection is required when solving different problems. In this article, it was uniformly set to eps during the numerical experiments. Problem (10) is an NP-hard optimization problem. Motivated by the well-established theoretical guarantees of linear programming, this issue is addressed by reformulating the problem (10) in the form of (11) by introducing non-negative variables and . Alternatively, problem (10) can also be solved directly by other methods, such as the alternating direction method of multipliers (ADMM) [29] and basis-pursuit denoising [30].
where with and . And , denotes the all-ones vector of dimension . Moreover, and .
Algorithm 1 outlines the pseudocode for constructing quadratic surrogate models, from which (gradient) and (approximate Hessian) are derived. The trial points are then obtained by solving the trust-region subproblem (5), which minimizes the surrogate model within the current-iteration trust region.
| Algorithm 1 Surrogate model construction |
|
3.2. Pareto Dominance-Based Comparison Function
Let and denote the initial point and the corresponding step-size parameter, respectively. Let be the list of non-dominated points along with their corresponding step-size parameters, where . Define as the set of new candidate points and their step-size parameters generated during the k-th iteration. Now suppose and are two points in that are mutually non-dominated with respect to the points in , but dominates more points in than does. According to the principle of Pareto dominance, both and would typically be added to the updated non-dominated list . However, in practice, is more likely to be dominated by other points in subsequent iterations. This information is overlooked when selecting non-dominated points solely based on Pareto dominance.
To address this issue, a Pareto dominance-based comparison function is proposed, defined as follows:
where and are two feasible candidate points that are non-dominated with respect to points in . The function is defined as Equation (13).
where is the set of solutions in dominated by , and denotes set cardinality.
Based on Equation (12), the comparison function determines which candidate point are incorporated into the current non-dominated set to form : when and , the set is updated as ; if, instead, , then , whereas when , the update becomes .
3.3. The General Framework of the DMSCFSM Algorithm
DMSCFSM operates within the DMS framework. The algorithm begins with an initialization phase, and then enters an iterative cycle of search and poll steps. This iteration continues until a stopping or convergence criterion is met. At the k-th iteration, the algorithm aims to refine the approximate Pareto front . The complete procedure is formalized in Algorithm 2.
| Algorithm 2 DMSCFSM Algorithm Framework |
|
It is important to note that the search step is executed only after the poll step has been performed. During the initialization phase, Latin hypercube sampling (LHS) is conducted to generate the initial non-dominated set and a cache set . Additionally, the non-dominated set is defined as
Within the main loop, the algorithm iterates until either the stopping condition or the convergence condition is satisfied, where denotes the vector of step sizes corresponding to all non-dominated points in during the k-th iteration. In the search step, for the MOO problem (1), surrogate models are constructed for each objective function at the k-th iteration using the method described in Section 3.1. Pareto non-dominated solutions are then obtained by optimizing a subset of these objective functions, formulated as the single-objective optimization problem (14):
where is a selected subset of objective function indices. Let ; then, the trust-region radius threshold is given by . In the numerical experiments, the parameters are set as and . The number of objective functions to be minimized simultaneously depends on the cardinality of the selected subset I. For a fixed cardinality , the number of possible combinations is given by . For a detailed description of the combination strategy, readers are referred to Algorithm 2 in [21]. The main framework of the search step is presented in Lines 9–24 of Algorithm 2.
The poll step is activated when the search step fails to yield non-dominated solutions. It performs structured exploration around the current poll center using a positive spanning set to discover candidate points that may lead to improvement. First, a positive spanning set is selected from a predefined collection . For each direction , a candidate point is generated via . Following the extreme barrier approach, only points lying within the feasible region are retained for evaluation. Each feasible candidate is then evaluated using the objective function . All evaluated points are added to a cache set . From these, points dominated by the current non-dominated solution set are filtered out, resulting in a set of non-dominated candidates . If is non-empty, define . To facilitate implementation, the first element of is selected as the new poll center . Points in that are dominated by are then removed to obtain , and the non-dominated set is updated as .
For updating the step-size parameter, the adjustment follows the strategy outlined in references [1,21]. While this method ensures numerical stability and has proven effective across various problems, adaptive step-size adjustment remains a promising area for further research.
4. Numerical Experiments
This section presents an evaluation of the effectiveness of DMSCFSM by comparing it with several state-of-the-art multi-objective DFO algorithms, including DMS [1], BoostDMS [21], MultiGlods [2], MOIF [31], NSGA-II [9], and MOEA/D [10]. Among these, DMS, BoostDMS, and MultiGlods represent directional direct search methods. Notably, BoostDMS incorporates surrogate models based on DMS. DMSCFSM applies a new surrogate modeling method and Pareto dominance comparison function compared with BoostDMS. MOIF is included as a representative of implicit filtering techniques, while NSGA-II and MOEA/D are well-established population-based heuristic algorithms.
The experimental analysis is organized as follows: The first part outlines the experimental configuration. The second part describes the benchmark problems under investigation. The third part introduces the performance indicators, including the hypervolume (HV) metric and an extended version of performance profiles based on HV. Finally, the fourth part provides a comprehensive comparison of DMSCFSM with the state-of-the-art algorithms and a detailed discussion of the results.
4.1. Experimental Configuration
4.1.1. Experimental Environment
All computations were conducted on a computer with a 64-bit Windows 10 operating system, equipped with a 13th Gen Intel(R) Core(TM) i9-13900 processor (2.00 GHz) and 32 GB of RAM. The NSGA-II and MOEA/D algorithms in jMetal 5.7 [32] were implemented using JDK 15, and the HV metric was also computed in this environment, while the other algorithms were run in MATLAB R2021b.
4.1.2. Parameter Setting
To ensure a fair comparison, all algorithmic parameters were configured in accordance with their original publications, with the complete specifications provided in Table 1. Common parameters across all algorithms were set as follows: The maximum number of function evaluations was 10,000, and each benchmark problem was solved over 30 independent runs. Unless otherwise stated, the average result of these runs was reported as the final outcome. In the experiments, n denotes the number of decision variables. Moreover, to ensure the reproducibility of the algorithmic results, the same random seeds and initial Latin hypercube samples were employed across all compared algorithms during testing. Furthermore, all algorithms were treated as black-box optimizers, meaning that they operated solely on the input–output relationships of the objective functions without utilizing any internal derivative information.

Table 1.
The specific parameters of the comparison algorithms.
4.2. Benchmark Problems
The comparative experiments utilized standard benchmark function sets from the ZDT [9] and WFG [33] series. The WFG benchmark set is specifically designed to assess algorithm robustness under challenging conditions, including non-separable objectives and diverse Pareto front geometries. These benchmark problems exhibit considerable diversity. The number of objectives ranges from 2 to 3, and decision variables vary between 8 and 30. Moreover, Pareto front shapes include concave, convex, mixed, and other complex geometries. Table 2 summarizes the parameter settings for each benchmark problem, including the number of decision variables, objectives, and variable bounds. Here, denotes a column vector of zeros of length , and represents a column vector of ones of length .
Table 2.
Parameters of test benchmark problems.
4.3. Performance Indicators
4.3.1. Hypervolume
The HV indicator, first proposed by Zitzler and Thiele [34], simultaneously evaluates both the convergence and diversity of a solution set. This indicator evaluates the performance of an algorithm by calculating the HV value of the space enclosed by non-dominated solutions and a reference point. The mathematical expression for calculating the HV indicator is shown in Equation (15):
where is the Lebesgue measure, S is the non-dominated set obtained by the algorithm, i.e., the approximate Pareto front, and represents the HV formed by the non-dominated individual () and the reference point . Figure 3 shows a schematic diagram of the calculation of the HV indicator in two-dimensional space. The “solid ∘” represents the non-dominated solutions obtained by the algorithm, the “solid □” represents the selected reference point, and the area of the shaded part represents the value of . Formally, for two solution sets S and , if solution set S is superior to solution set , then the HV indicator value of S is greater than that of . It is not difficult to find from (15) that the calculation of the HV indicator does not require prior knowledge of the real Pareto front information. Therefore, when measuring the quality of the Pareto front solved by an algorithm, the HV indicator has extensive practicality. Its disadvantages are large computational complexity and, to a certain extent, dependence on the selection of the reference point. In the numerical experiments, Equation (16) is employed to calculate the HV reference point based on the reference Pareto front.
where represents an offset parameter capable of dynamic determination.
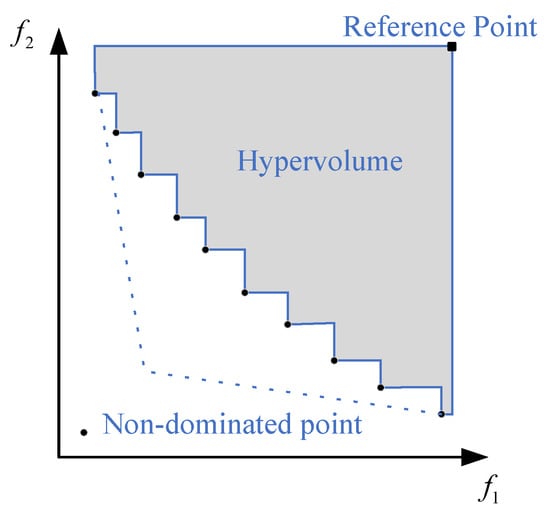
Figure 3.
Schematic diagram of HV indicators in two-dimensional space.
4.3.2. Performance Profile Based on Hypervolume
To evaluate and compare the performance of different algorithms, a performance profile [9] based on the HV metric over the entire set of benchmark problems is employed. For a given test problem and an algorithm , let be the reciprocal of the HV value, since a larger HV value indicates better algorithm performance. The performance profile of algorithm is then defined as the fraction of problems whose performance ratio is within a given threshold , as expressed in Equation (17):
where . Note that if and only if algorithm fails to solve problem satisfactorily, where .
4.4. Results and Discussion
4.4.1. Performance Analysis Based on HV
Table 3, Figure 4 and Figure 5 collectively demonstrate distinct performance differences among the compared algorithms on both the ZDT and WFG benchmark sets. In Table 3, the best algorithm is labeled with a darker gray background and the second best algorithm with a lighter gray background. Additionally, to determine whether there are statistically significant differences among all tested algorithms when solving different benchmark problems, Table 4 presents the results of the two-sided Wilcoxon rank-sum test [35] on the HV metric across all algorithms. A significance level of 0.05 is adopted. In the table, “+” indicates that the algorithm in the corresponding row is statistically significantly better than the algorithm in the corresponding column for a given problem; “-” means that the algorithm in the corresponding column is statistically significantly better than the one in the row; and “=” denotes no statistically significant difference between the two compared algorithms.
Table 3.
Statistical results of HV obtained by the compared algorithms.
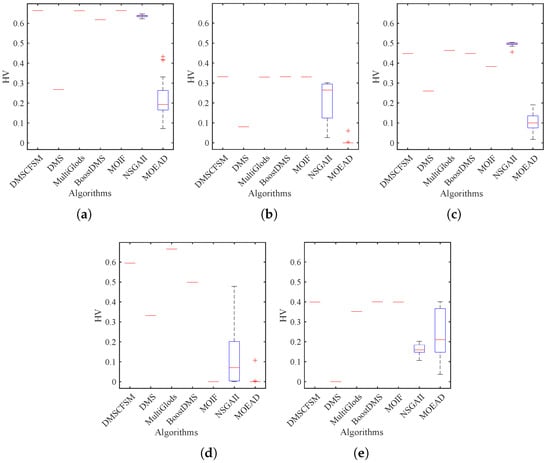
Figure 4.
HV boxplots for ZDT benchmark set. (a) ZDT1; (b) ZDT2; (c) ZDT3; (d) ZDT4; (e) ZDT6.
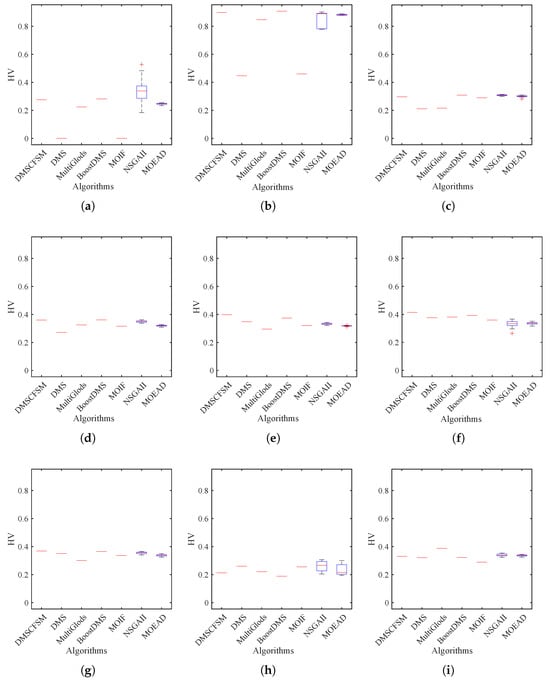
Figure 5.
HV boxplots for WFG benchmark set. (a) WFG1; (b) WFG2; (c) WFG3; (d) WFG4; (e) WFG5; (f) WFG6; (g) WFG7; (h) WFG8; (i) WFG9.
Table 4.
Results of Wilcoxon rank-sum test of .
Table 3 and Table 4 and Figure 4 demonstrate that the proposed DMSCFSM method exhibits a clear advantage in solving ZDT problems (with the exception of ZDT3), which may be attributed to the discontinuous nature of ZDT3’s Pareto front. In contrast, both NSGA-II and MultiGlods show superior performance in solving ZDT3, which can be linked to their enhanced global search capabilities. When examining solution stability across DMSCFSM, DMS, MultiGlods, BoostDMS, MOIF, and the population-based algorithms NSGA-II and MOEA/D, the former group shows significantly lower variability. Specifically, their standard deviations remain at throughout all the benchmark problems, indicating superior stability compared to NSGA-II and MOEA/D.
Through comparative analysis of DMSCFSM, BoostDMS, and DMS, it can be observed that BoostDMS demonstrates clear superiority over DMS. This indicates that incorporating the search step design into the DMS framework significantly enhances the algorithm’s performance. Although DMSCFSM substantially outperforms DMS, it surpasses BoostDMS only on ZDT1 and ZDT4 problems. These findings collectively indicate that integrating search steps improves algorithmic performance. Furthermore, DMS-based methods with search steps require fewer function evaluations to achieve high-quality Pareto fronts. However, the incorporation of the search step increases the algorithm’s computational time in some cases. As a result, both DMSCFSM and BoostDMS show particular advantages for expensive MOO problems where function evaluations are computationally costly. In contrast, for problems with inexpensive objective functions, the additional computational cost introduced by search steps may not be justified by the performance gains.
On the WFG benchmark set, Table 3 and Table 4 and Figure 5 collectively demonstrate that DMSCFSM achieves the best performance among all compared algorithms. Except WFG8, DMSCFSM outperforms both DMS and MOIF across the WFG benchmark set. Specifically, it surpasses MultiGlods on seven out of nine problems, exceeds MOEA/D on six problems, and outperforms both BoostDMS and NSGA-II on five problems. The stability analysis of DMSCFSM, DMS, MultiGlods, BoostDMS, MOIF, and the population-based algorithms NSGA-II and MOEA/D yields results consistent with those from the ZDT benchmark problems, demonstrating that algorithms derived from single-objective mathematical optimization methods exhibit significantly better stability than population-based approaches.
The comparison among DMS, BoostDMS, and DMSCFSM similarly demonstrates that BoostDMS, enhanced with surrogate models, exhibits improved robustness and effectiveness over the basic DMS framework. Furthermore, DMSCFSM significantly outperforms BoostDMS on a larger number of benchmark problems, highlighting the efficacy of the proposed improvements.
Based on the Wilcoxon test results in Table 4, DMSCFSM shows no statistically significant difference from MOEA/D only on the WFG8 problem, while exhibiting significant differences in all other benchmark problems. Specifically, DMSCFSM significantly outperforms other algorithms in 64 out of 84 comparisons and surpasses BoostDMS in 62 scenarios, implying the superiority of the proposed method.
However, compared to BoostDMS, DMSCFSM incurs additional computational costs due to the incorporation of a Pareto dominance-based comparison function. Nonetheless, this function enables the algorithm to systematically leverage the dominance strength of solutions to efficiently filter out non-dominated solutions that are likely to be dominated later. This approach reduces the number of Pareto dominance comparisons (as implemented in Lines 9–24 of Algorithm 2) required in subsequent iterations. Moreover, the introduced sparse modeling technique helps mitigate the curse of dimensionality and enhances the generalization ability of the surrogate models. Consequently, DMSCFSM achieves superior performance compared to other algorithms under the same function evaluation budget. In particular, for expensive MOO problems, such as those involving simulation-based objectives, the computational time required for the comparison function becomes negligible compared to the cost of each objective function evaluation. This makes DMSCFSM especially advantageous for problems with computationally intensive objectives. Therefore, it is essential to balance the computational overhead of the comparison process against the cost of objective function evaluations when selecting an approach.
4.4.2. Performance Analysis Based on Performance Profile
To effectively visualize and compare algorithm performance across a diverse set of problems, performance profiles are employed. Figure 6 presents the performance profiles plotted on a log scale for the performance ratio. The height of each curve at represents the proportion of problems where the corresponding algorithm achieves the best performance among all compared algorithms. These profiles are constructed based on the HV metric, evaluating seven algorithms (DMSCFSM, DMS, BoostDMS, MultiGlods, MOIF, NSGA-II, and MOEA/D) across the comprehensive benchmark set.
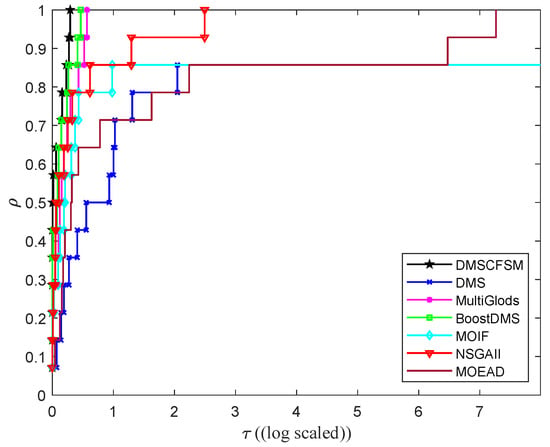
Figure 6.
Comparing algorithms based on performance profiles.
As observed in Figure 6, the DMSCFSM algorithm achieves the highest efficiency, demonstrating the best performance at on the log scale, while maintaining robustness comparable to that of BoostDMS. Its performance profile shows the fastest initial convergence at small values and eventually reaches the maximum height, indicating DMSCFSM’s effectiveness in solving most benchmark problems under the given experimental setup. BoostDMS ranks second in performance, while MultiGlods also displays a rapidly ascending curve and high final attainment level, demonstrating considerable problem-solving capability. In contrast, NSGA-II, MOIF, MOEA/D, and DMS exhibit relatively weaker performance, requiring substantially larger thresholds to reach comparable solution proportions.
5. Conclusions
Multi-objective DFO plays a significant role in real-world applications, as the accurate resolution of such problems provides crucial support for decision-making processes. However, in many practical optimization scenarios, particularly those involving computationally expensive simulations, objective function evaluations tend to be extremely time-consuming. This underscores the importance of obtaining high-quality Pareto fronts with limited function evaluations.
This article presents a novel multi-objective DFO method developed within the DMS framework. The proposed algorithm incorporates two key improvements. The first is the application of a sparse modeling technique for surrogate model construction. The second is the implementation of a Pareto dominance-based comparison function to fully utilize non-dominated solution information. To assess algorithmic performance, comprehensive comparisons were conducted with six state-of-the-art algorithms using ZDT and WFG benchmark problems. Numerical experiments demonstrate that the proposed method achieves high-quality Pareto fronts with competitive performance and efficiency. However, the incorporation of comparison functions introduces additional computational costs, which may limit the algorithm’s applicability in certain scenarios. To assess the practical impact of this limitation, future work is required to evaluate its performance on more complex, high-dimensional problems and real-world engineering problems that are computationally expensive. Additionally, the algorithm’s performance is influenced by several parameters, such as the step-size update parameters ( and ) and the tolerance (). Therefore, future research will also focus on enhancing the algorithm’s adaptive capabilities to reduce this dependency on manual parameter tuning.
Author Contributions
Conceptualization Y.L., Formal analysis Y.L., Funding acquisition Y.L., Investigation Y.L., Resources Y.L., Software Y.L., Visualization Y.L., Validation Y.L., Writing—original draft Y.L. and D.S., Writing—review & editing Y.L. and D.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by the National Natural Science Foundation of China under Grant No. 62373204, 61977043, and the Talent Research Project Qilu University of Technology (Shandong Academy of Sciences) under Grant No. 2023RCKY159.
Data Availability Statement
The original contributions presented in the study are included in the article Further inquiries can be directed to the corresponding author.
Acknowledgments
Grateful acknowledgment is given to the editor and reviewers for their valuable insights and constructive feedback on our manuscript. Their expertise greatly contributed to enhancing the quality of our work.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Custódio, A.L.; Madeira, J.F.A.; Vaz, A.I.F.; Vicente, L.N. Direct multisearch for multiobjective optimization. SIAM J. Optim. 2011, 21, 1109–1140. [Google Scholar] [CrossRef]
- Custodio, A.L.; Madeira, J.F.A. MultiGLODS: Global and local multiobjective optimization using direct search. J. Glob. Optim. 2018, 72, 323–345. [Google Scholar] [CrossRef]
- Jean Bigeon, S.L.D.; Salomon, L. DMulti-MADS: Mesh adaptive direct multisearch for bound-constrained blackbox multiobjective optimization. Comput. Optim. Appl. 2021, 79, 301–338. [Google Scholar] [CrossRef]
- Sander Dedoncker, W.D.; Naets, F. An adaptive direct multisearch method for black-box multi-objective optimization. Optim. Eng. 2022, 23, 1411–1437. [Google Scholar] [CrossRef]
- Berkemeier, M.; Peitz, S. Derivative-free multiobjective trust region descent method using radial basis function surrogate models. Math. Comput. Appl. 2021, 26, 31. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, C.; Liu, F.; Duan, Z.; Zhao, H. A trust-region-like algorithm for expensive multi-objective optimization. Appl. Soft Comput. 2023, 148, 110892. [Google Scholar] [CrossRef]
- Mohammadi, A.; Hajinezhad, D.; Garcia, A. A trust-region approach for computing Pareto fronts in multiobjective derivative-free optimization. Optim. Lett. 2024, 19, 233–266. [Google Scholar] [CrossRef]
- Bisui, N.K.; Panda, G. A trust-region scheme for constrained multi-objective optimization problems with superlinear convergence property. Optim. Methods Softw. 2025, 40, 24–64. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Stewart, R.H.; Palmer, T.S.; DuPont, B. A survey of multi-objective optimization methods and their applications for nuclear scientists and engineers. IEEE Trans. Syst. Man Cybern. Syst. 2021, 138, 103830. [Google Scholar] [CrossRef]
- Liu, Y.; Ding, J.; Li, Q.; Li, F.; Liu, J. A two-level model management-based surrogate-assisted evolutionary algorithm for medium-scale expensive multiobjective optimization. IEEE Trans. Syst. Man Cybern. Syst. 2025, 55, 8166–8180. [Google Scholar] [CrossRef]
- Si, L.; Zhang, X.; Tian, Y.; Yang, S.; Zhang, L.; Jin, Y. Linear subspace surrogate modeling for large-scale expensive single/multiobjective optimization. IEEE Trans. Evol. Comput. 2025, 29, 697–710. [Google Scholar] [CrossRef]
- Liu, J.; Liu, T. A two-stage multi-objective optimization algorithm for solving large-scale optimization problems. Algorithms 2025, 18, 164. [Google Scholar] [CrossRef]
- Audet, C.; Savard, G.; Zghal, W. Multiobjective optimization through a series of single-objective formulations. SIAM J. Optim. 2008, 19, 188–210. [Google Scholar] [CrossRef]
- Ryu, J.h.; Kim, S. A derivative-free trust-region method for biobjective optimization. SIAM J. Optim. 2014, 24, 334–362. [Google Scholar] [CrossRef]
- Thomann, J.; Eichfelder, G. A trust-region algorithm for heterogeneous multiobjective optimization. SIAM J. Optim. 2019, 29, 1017–1047. [Google Scholar] [CrossRef]
- Torczon, V. On the convergence of pattern search algorithms. SIAM J. Optim. 1997, 7, 1–25. [Google Scholar] [CrossRef]
- Audet, C.; Dennis, J.E. Mesh adaptive direct search algorithms for constrained optimization. SIAM J. Optim. 2006, 17, 188–217. [Google Scholar] [CrossRef]
- Audet, C.; Savard, G.; Zghal, W. A mesh adaptive direct search algorithm for multiobjective optimization. Eur. J. Oper. Res. 2010, 204, 545–556. [Google Scholar] [CrossRef]
- Brás, C.P.; Custódio, A.L. On the use of polynomial models in multiobjective directional direct search. Comput. Optim. Appl. 2020, 77, 897–918. [Google Scholar] [CrossRef]
- Tavares, S.; Brás, C.P.; Custódio, A.L.; Duarte, V.; Medeiros, P. Parallel strategies for direct multisearch. Numer. Algorithms 2023, 92, 1757–1788. [Google Scholar] [CrossRef]
- Liuzzi, G.; Lucidi, S.; Rinaldi, F. A derivative-free approach to constrained multiobjective nonsmooth optimization. SIAM J. Optim. 2016, 26, 2744–2774. [Google Scholar] [CrossRef]
- Silva, E.J.; Custódio, A.L. An inexact restoration direct multisearch filter approach to multiobjective constrained derivative-free optimization. Optim. Methods Softw. 2025, 40, 406–432. [Google Scholar] [CrossRef]
- Powell, M.J.D. Developments of NEWUOA for minimization without derivatives. IMA J. Numer. Anal. 2008, 28, 649–664. [Google Scholar] [CrossRef]
- Dejemeppe, C.; Schaus, P.; Deville, Y. Derivative-free optimization: Lifting single-objective to multi-objective algorithm. In Proceedings of the Integration of AI and OR Techniques in Constraint Programming, Barcelona, Spain, 18–22 May 2015; Michel, L., Ed.; Springer: Cham, Switzerland, 2015; pp. 124–140. [Google Scholar] [CrossRef]
- Davis, C. Theory of positive linear dependence. Am. J. Math. 1954, 76, 733–746. [Google Scholar] [CrossRef]
- Candes, E.; Tao, T. The Dantzig selector: Statistical estimation when p is much larger than n. Ann. Stat. 2007, 35, 2313–2351. [Google Scholar] [CrossRef]
- Mazumder, R.; Choudhury, A.; Iyengar, G.; Sen, B. A computational framework for multivariate convex regression and its variants. J. Am. Stat. Assoc. 2019, 114, 318–331. [Google Scholar] [CrossRef]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic decomposition by basis pursuit. SIAM J. Sci. Comput. 1998, 20, 33–61. [Google Scholar] [CrossRef]
- Cocchi, G.; Liuzzi, G.; Papini, A.; Sciandrone, M. An implicit filtering algorithm for derivative-free multiobjective optimization with box constraints. Comput. Optim. Appl. 2018, 69, 267–296. [Google Scholar] [CrossRef]
- Durillo, J.J.; Nebro, A.J. jMetal: A Java framework for multi-objective optimization. Adv. Eng. Softw. 2011, 42, 760–771. [Google Scholar] [CrossRef]
- Huband, S.; Barone, L.; While, L.; Hingston, P. A scalable multi-objective test problem toolkit. In Proceedings of the Evolutionary Multi-Criterion Optimization, Guanajuato, Mexico, 9–11 March 2005; Coello Coello, C.A., Hernández Aguirre, A., Zitzler, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 280–295. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Haynes, W. Wilcoxon rank sum test. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013; pp. 2354–2355. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).