AVIST: A GPU-Centric Design for Visual Exploration of Large Multidimensional Datasets

Abstract
:1. Introduction
- (1)
- We propose a GPU-centric design to support interactive visual exploration of large datasets, which emphasizes the use of GPU for data management and computation.
- (2)
- We design a data dependency graph to characterize GPU based data transformations, which supports data aggregation and visualization on demand.
- (3)
- We implement AVIST following our GPU-centric design as a proof-of-concept. AVIST features animation and cross-filtering interactions to slice big data into small data and GPU parallel computing to transform raw data into visual primitives.
- (4)
- We present two usage scenarios to demonstrate that AVIST can help analysts identify abnormal behaviors and infer new hypotheses by visual exploration of big datasets.
- (5)
- We discuss lessons learned about the application of GPU methods to address performance challenges in interactive, visual exploration of big data.
2. Related Work
2.1. Exploration of Multidimensional Datasets
2.2. Big Data Management
2.3. GPU Acceleration
- (1)
- More cores and fine levels of parallelism: The GPU has a many-core architecture, which may include thousands of cores. This feature makes the GPU specialized at compute-intensive, highly parallel computation.
- (2)
- Higher memory bandwidth: The GPU can access data at a higher speed (usually more than 100 GB/s) or more data in a fixed time period than the CPU does.
2.4. Big Data Exploration
3. The GPU-Centric Design
3.1. Design Principles
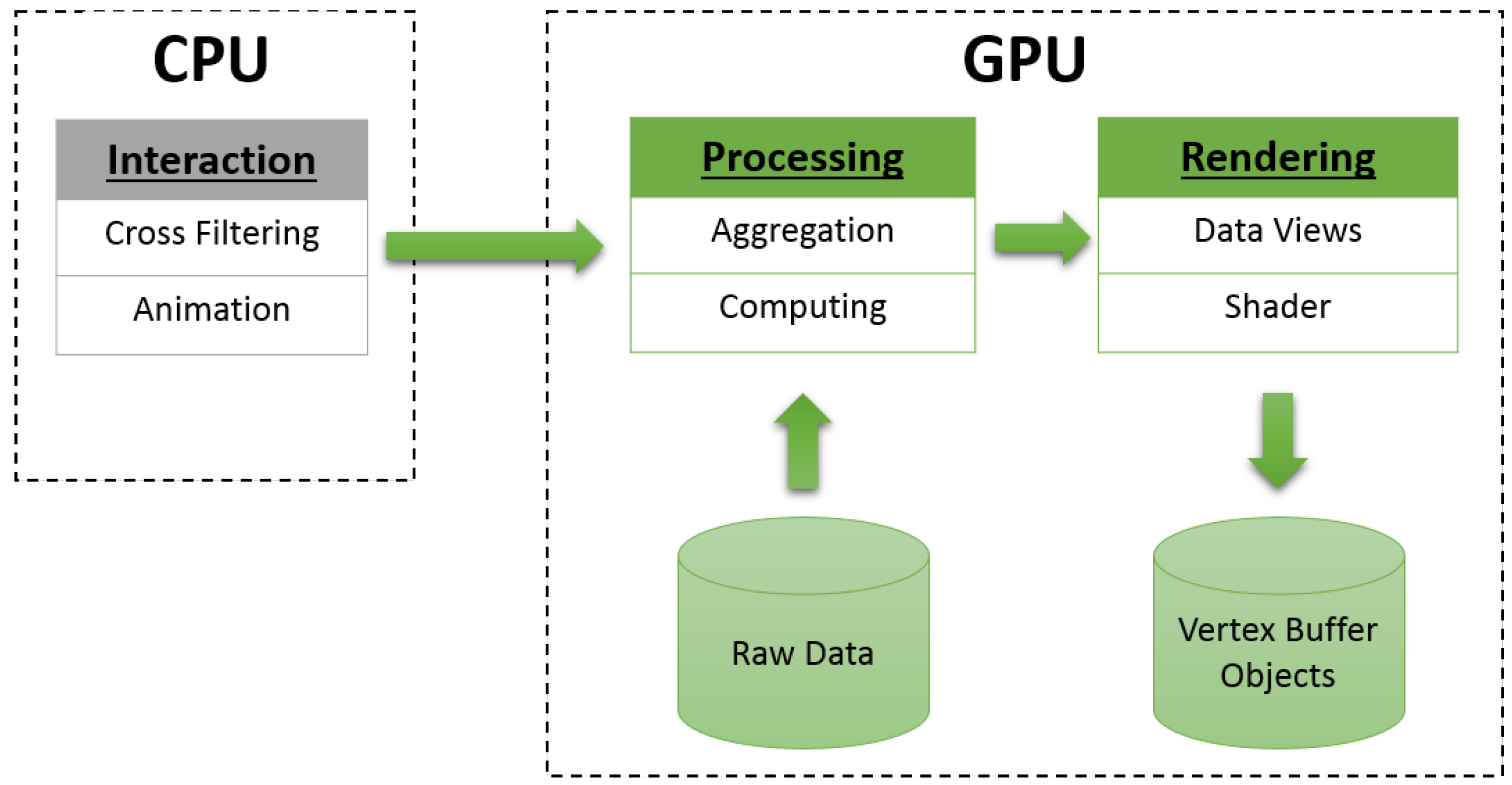
- Data management: We store raw data in the GPU memory. In addition, all derived data are stored in the GPU memory to take advantage of its high memory bandwidth.
- Data computation: We highlight cross-filtering for slicing data from different attributes (e.g., animation for the time domain). To support such data aggregation and visualization on demand, a data dependency graph is proposed to characterize data transformations on the GPU.
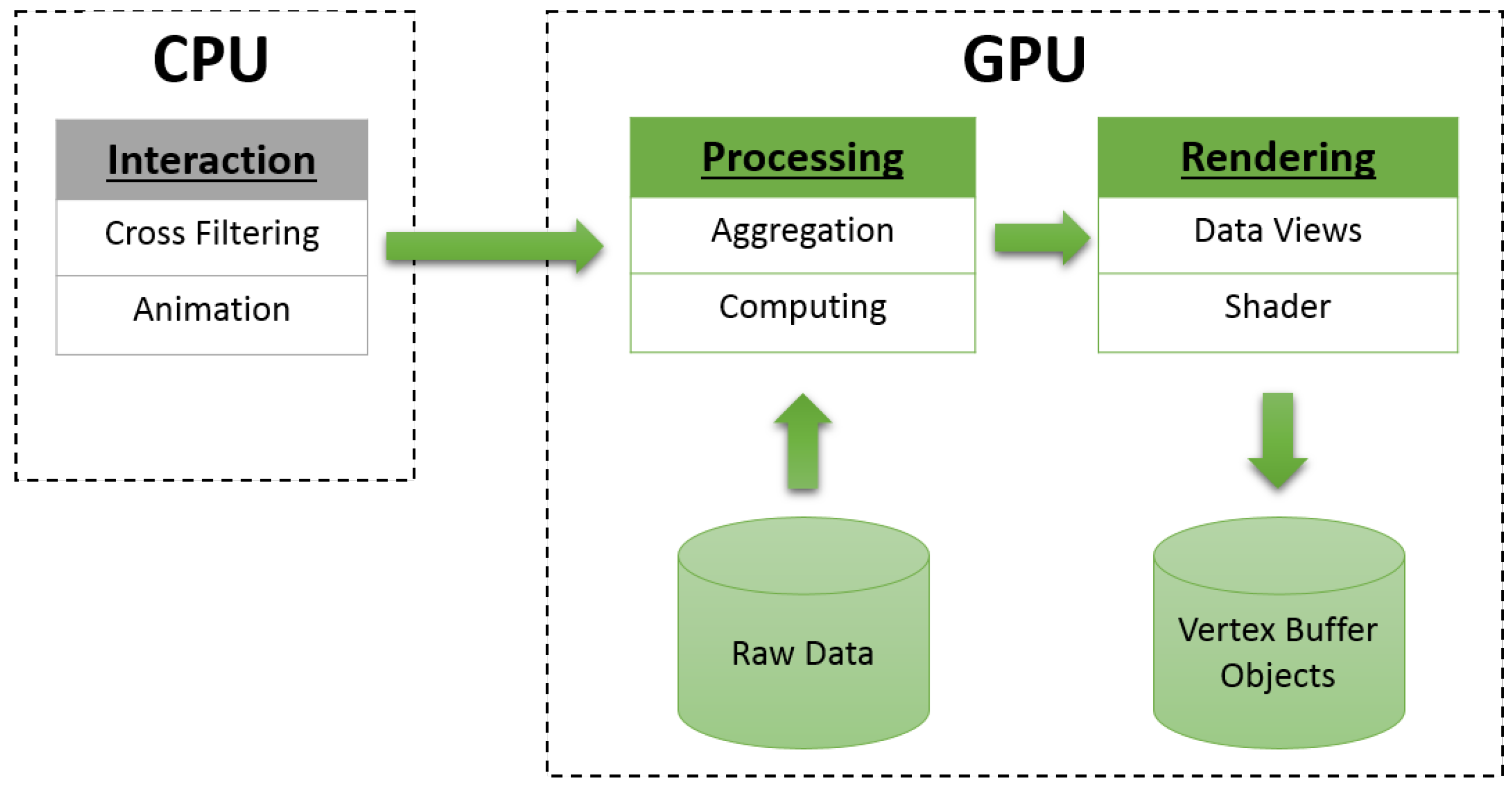
3.2. Design
3.3. Data Management
3.4. Data Computation
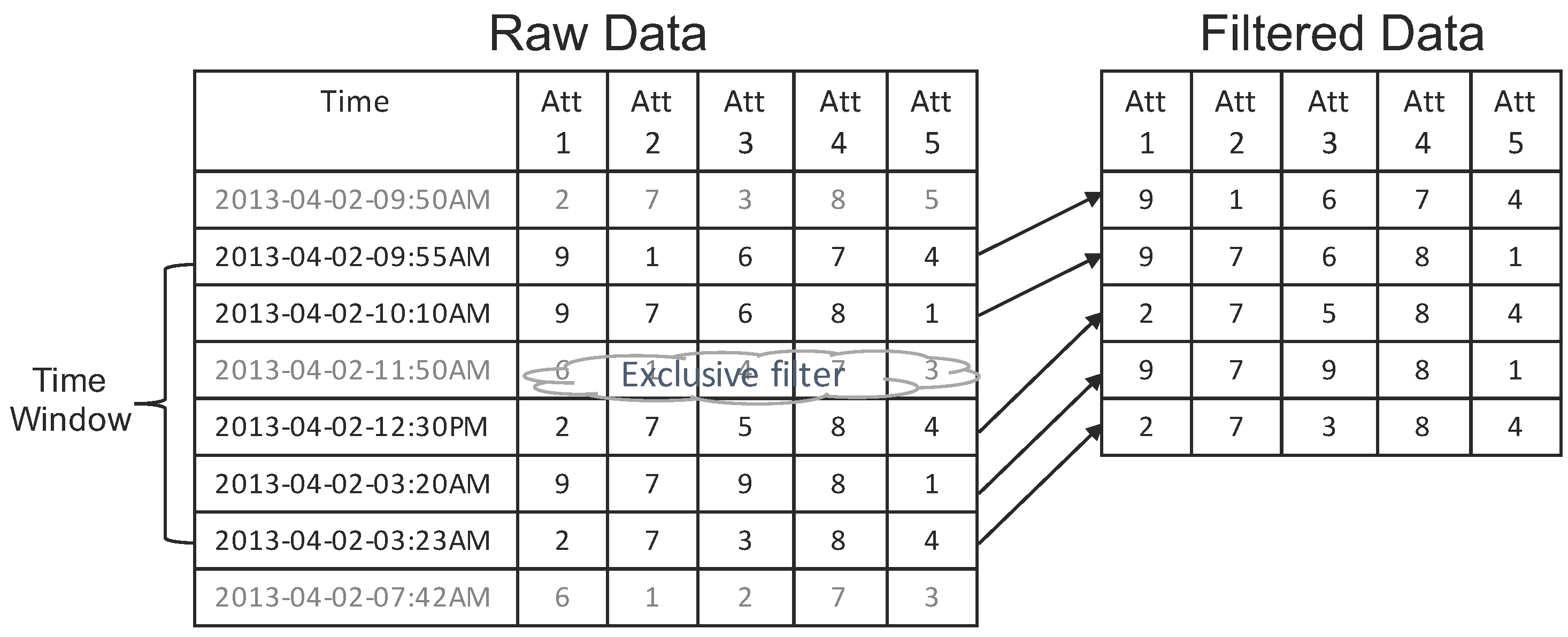
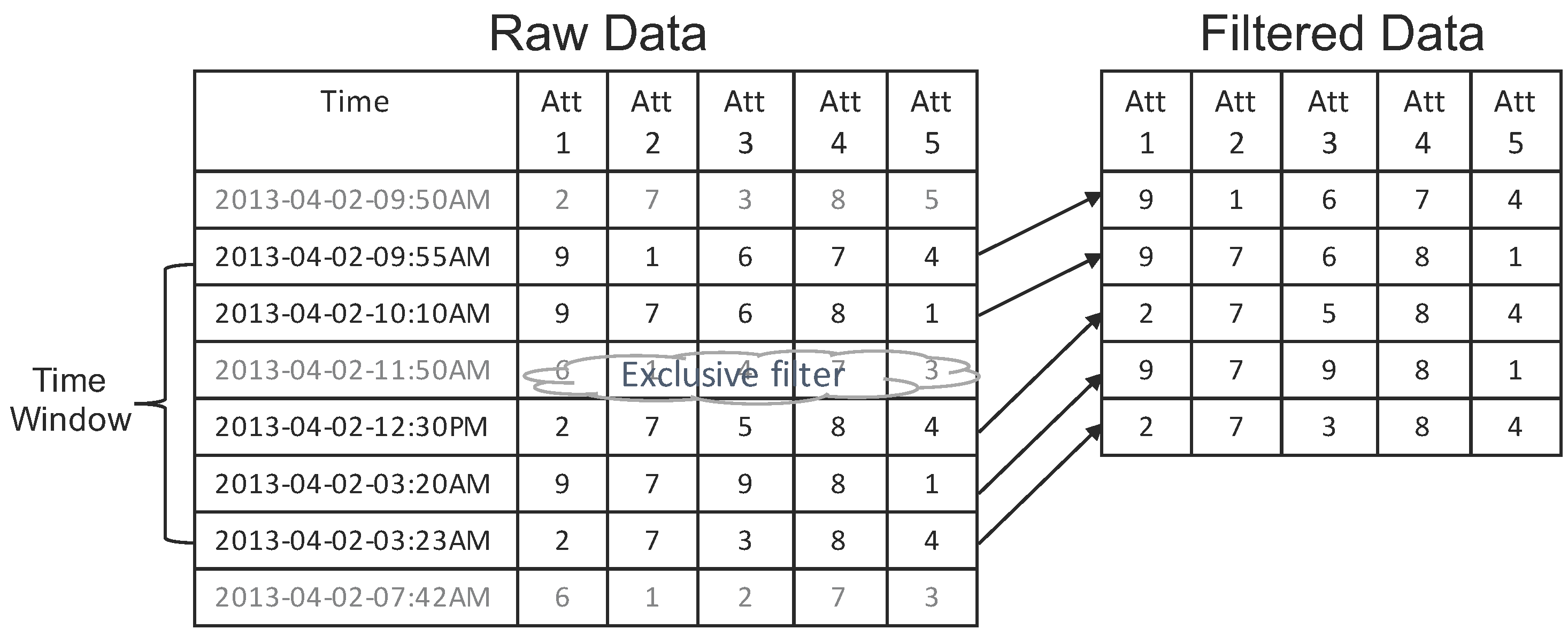
- Data filtering: Data filters (e.g., time window, filters and highlights) are generated by user interactions on the CPU side, then they are passed to the GPU side. The data flow is described as follows: (1) the time window is applied to slice raw data into data snapshots; (2) filters are applied to data snapshots by removing data records for which the user is uninterested; (3) highlighted filters emphasize important data items from the filtered data list.
- Data processing: This step transforms filtered data into visual primitives. Additionally, data transformation methods depend on each data view. We summarize data processing into two stages in each data view: (1) data aggregation, which generates geometry data (e.g., binning data for a histogram view) from filtered dataset; and (2) data computation, which transforms geometry data into visual primitives (e.g., the bar height for a histogram view).
- Data rendering: All generated visual primitives are stored in the GPU vertex buffer objects. We use GLSL (the OpenGL Shading Language) to generate the ultimate visual results, then render the visual primitives on the screen (e.g., splitting one vertex into four for rendering rectangles using the geometry shader, filling colors in triangles using the fragment shader).
4. AVIST
4.1. MVC Architecture
4.2. Data Transformation
4.2.1. Data Filtering
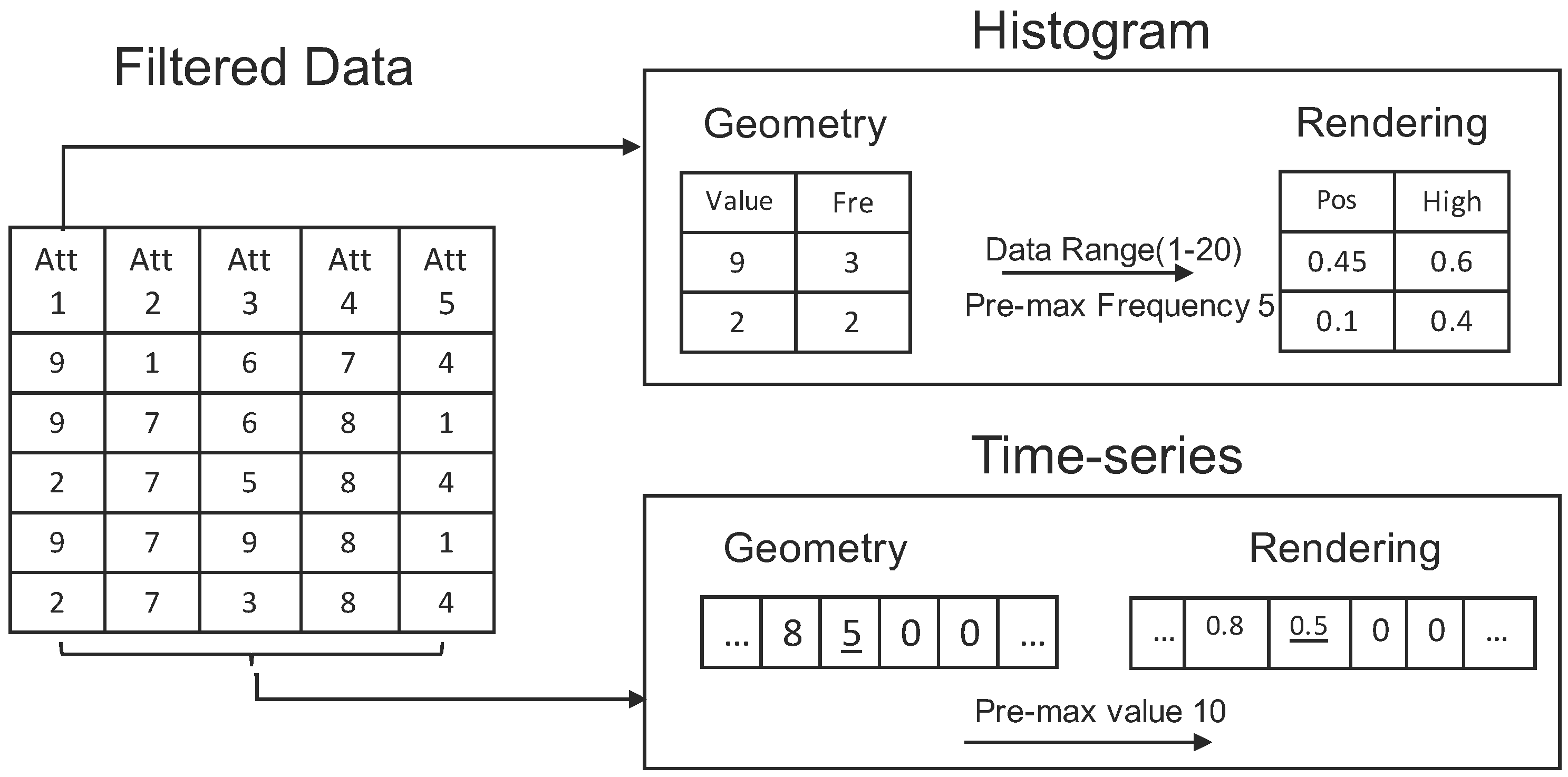
4.2.2. Data Processing
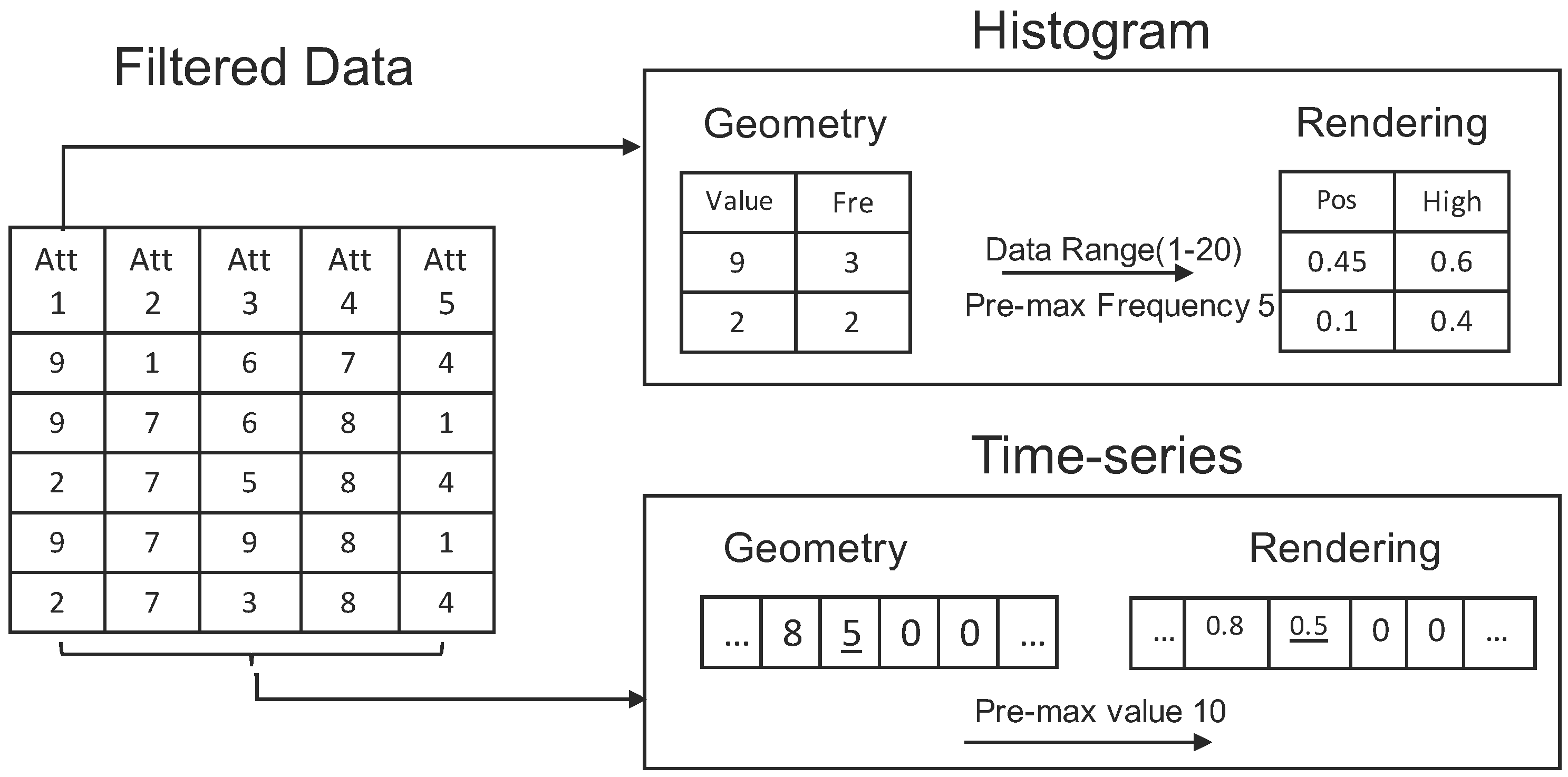
- Sort one data column to get unique values and their frequency.
- Get the X position of each unique value based on the data range ( is the position column of the rendering table in the histogram box in Figure 5). This value is calculated as:
- Get the Y position of each unique value based on previous maximum frequency, and then, update this value for the next computation ( is the height column of the rendering table in the histogram box in Figure 5). They are calculated as:
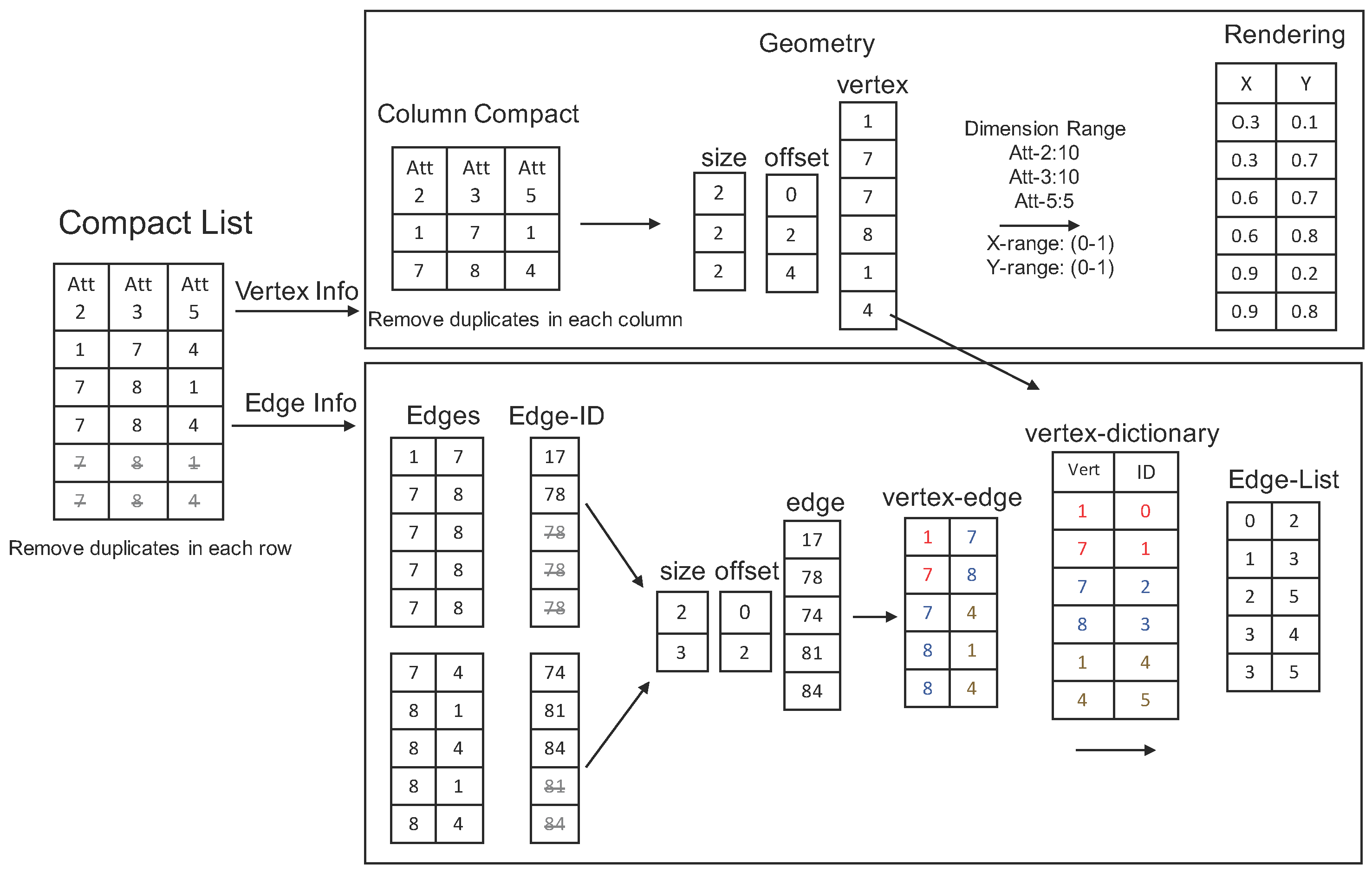
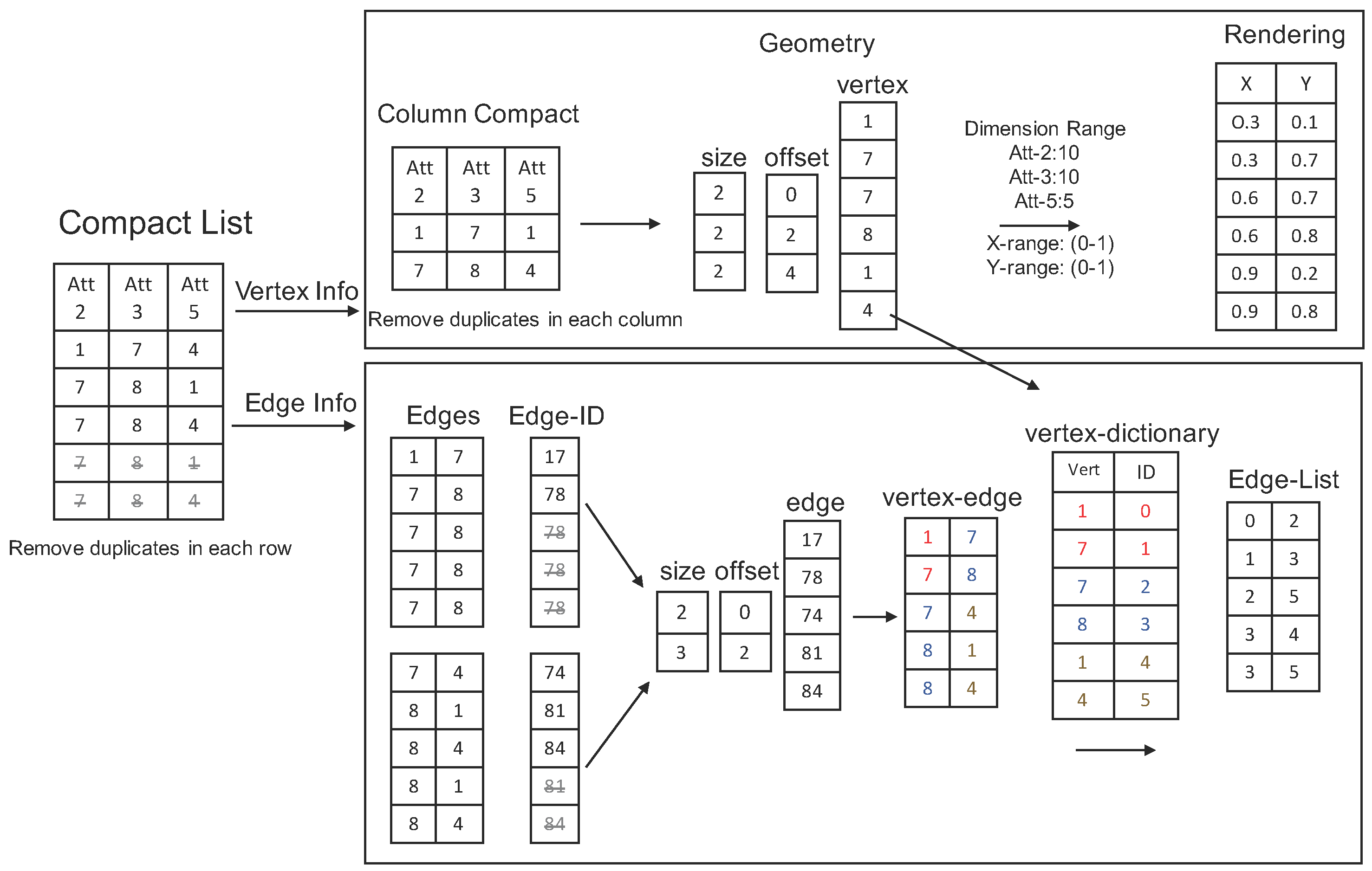
- Sort each column individually to remove duplicated values.
- Assemble the compact columns into three arrays: vertex array, size array and offset array.
- Generate each node position: the X-axis is based on the selected order of each column, and the Y-axis is based on the item value and its dimension range.
- Two neighboring columns are grouped into one array (Edge-ID array) as edges. The value in this array is calculated as: -
- Sort the Edge-ID array and remove duplicates.
- Compact multiple Edge-ID arrays into three data arrays: edge array, size array and offset array.
- Convert the edge array into the vertex-edge array.
- Replace each vertex value in the vertex-edge array with its order based on the vertex-dictionary to generate Edge-List array.
4.2.3. Data Rendering
4.3. Coordinated Multiple Views
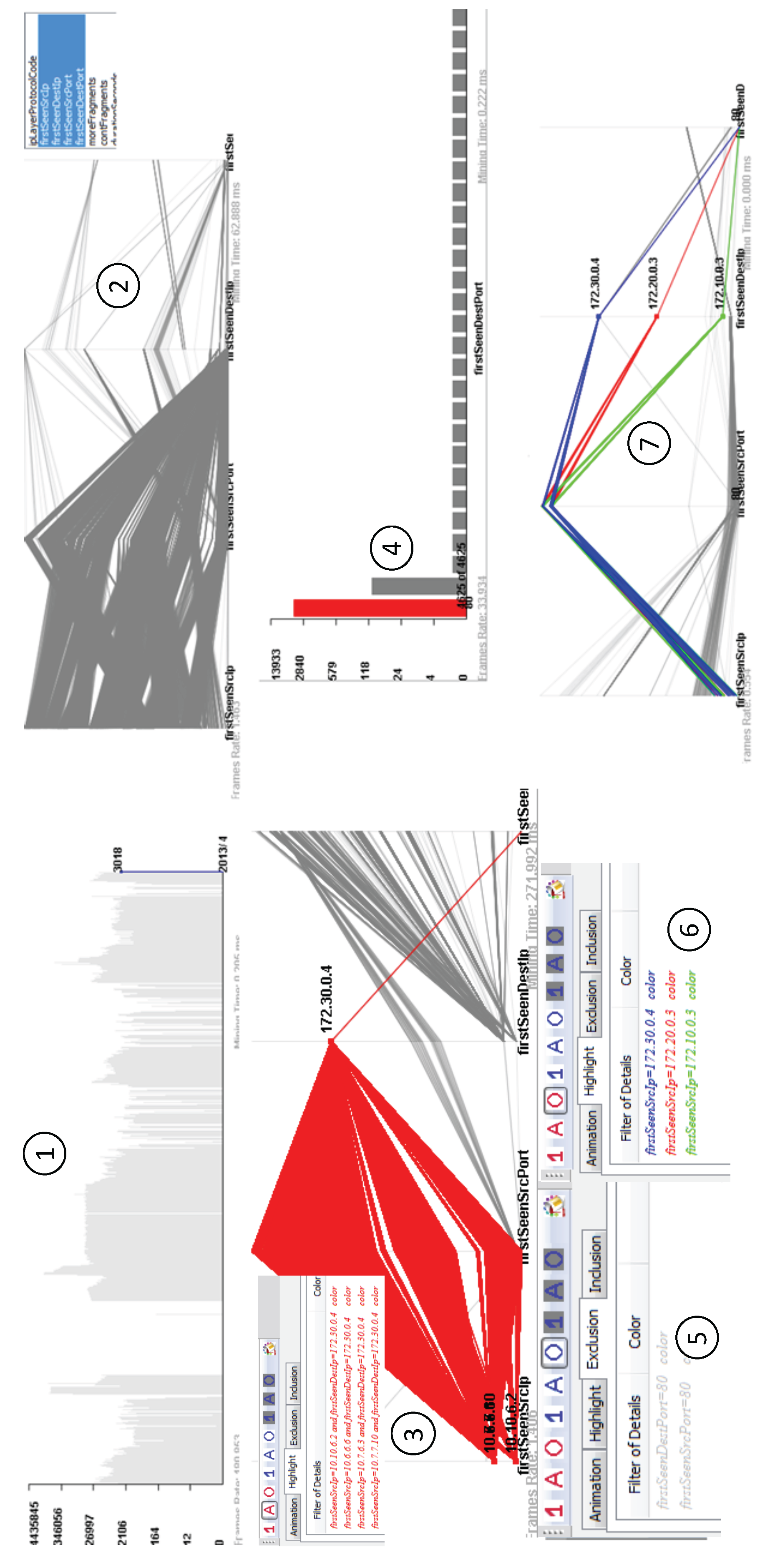
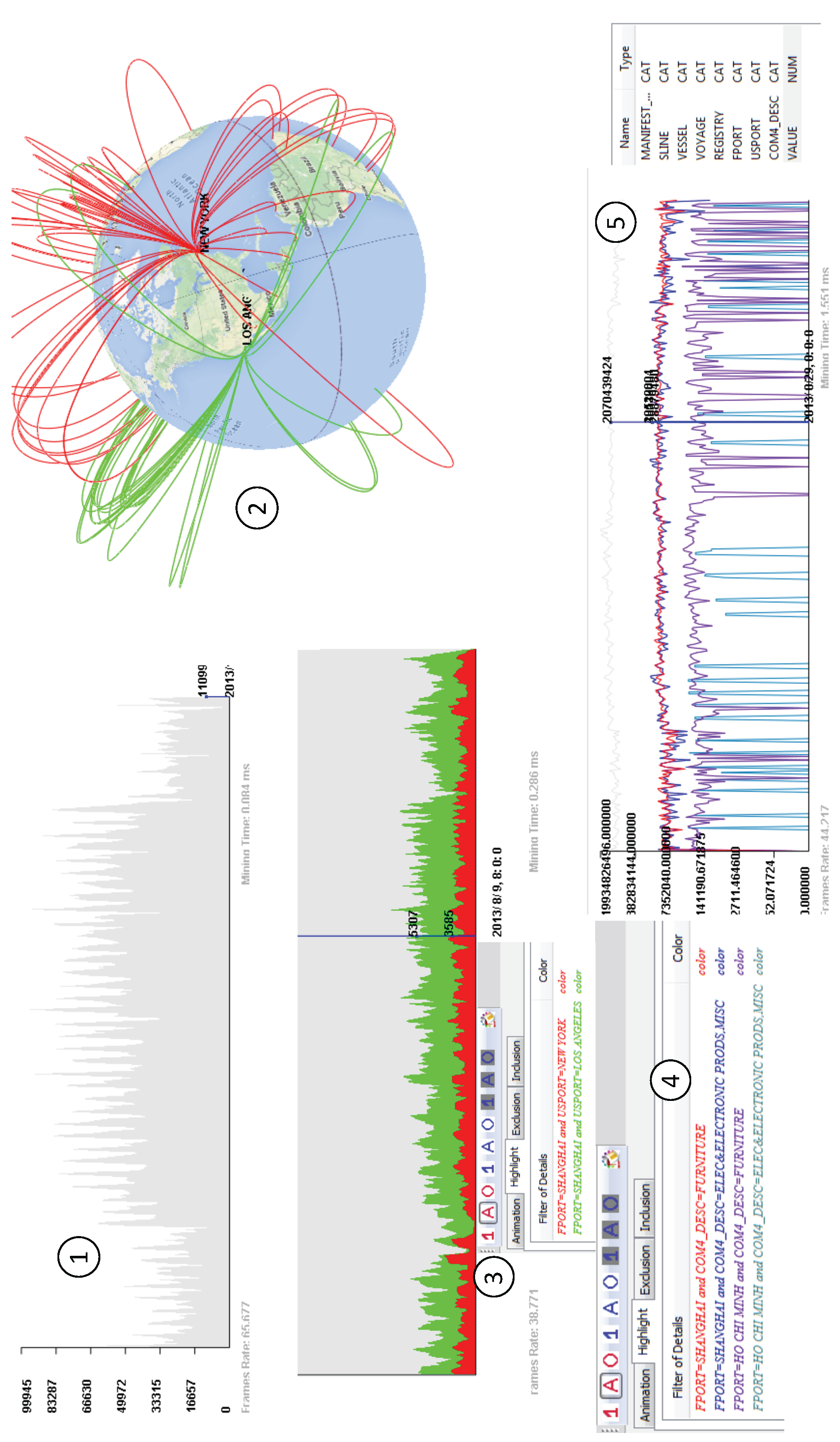
- A histogram view shows the data distribution of a sliced data snapshot. Analysts can choose different dimensions to explore aggregated information.
- A time series view shows data aggregation about certain filtered events over a period of time. When an analyst changes data filters, the time series view clears previous visualization and redraws everything.
- Parallel coordinate plots show data details. Analysts can select multiple data dimensions to generate their customized parallel coordinate plots. The axes are organized based on their selected order.
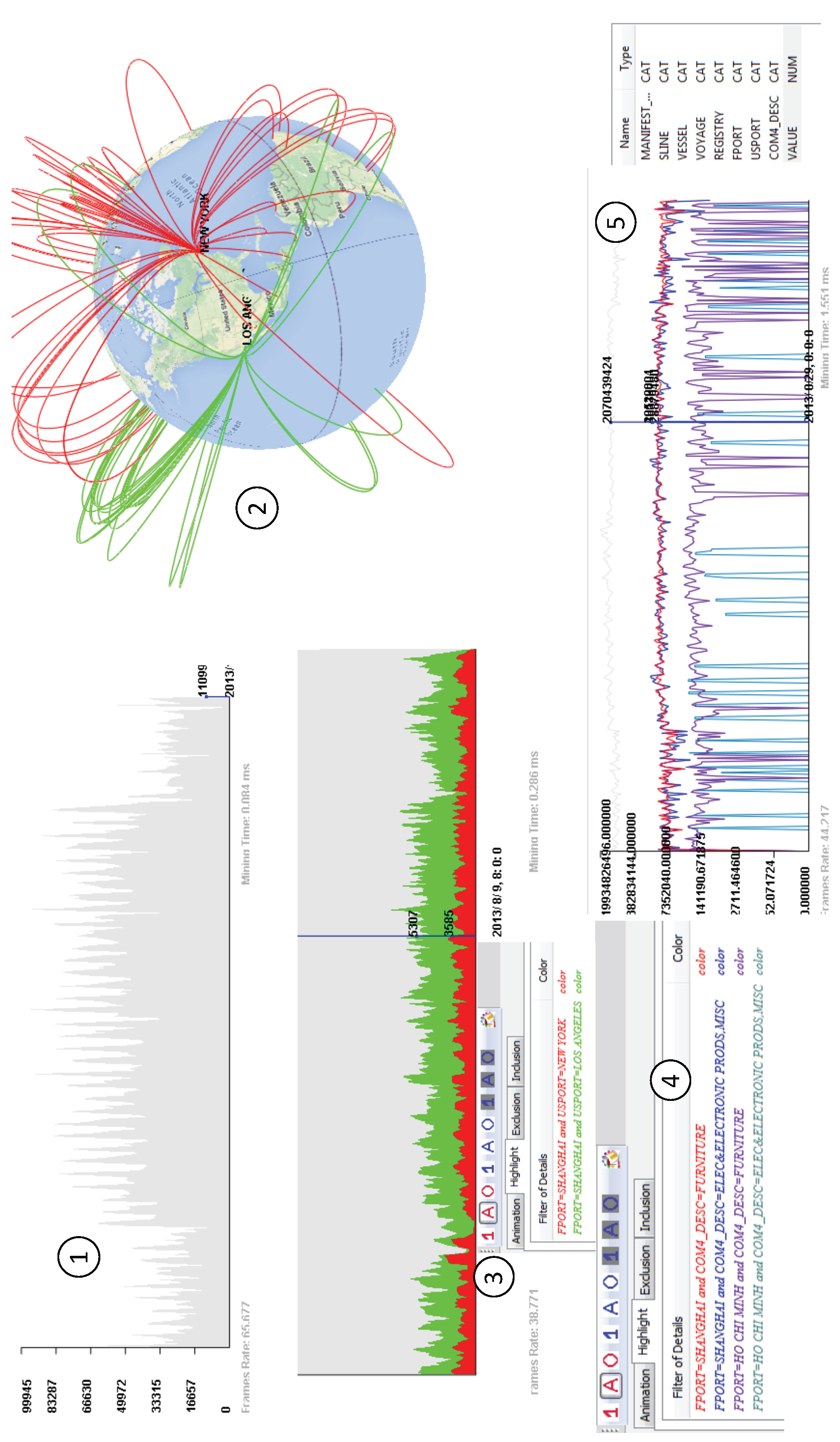
- A virtual global view shows geographical information. The Bezier curves are used to link locations on the virtual globe for representing data relationship.
4.4. User Interactions
4.4.1. Animation
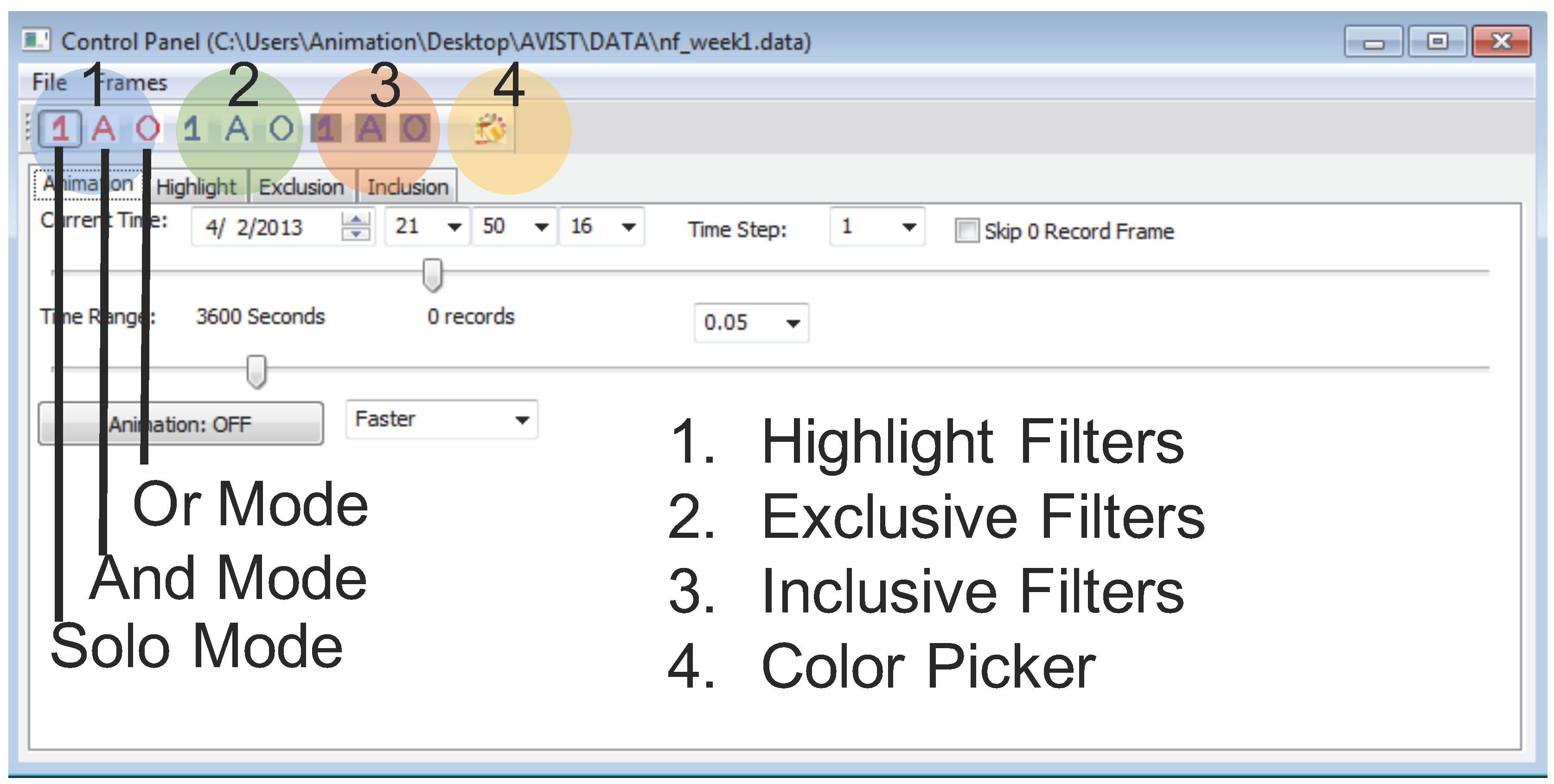
4.4.2. Filtering
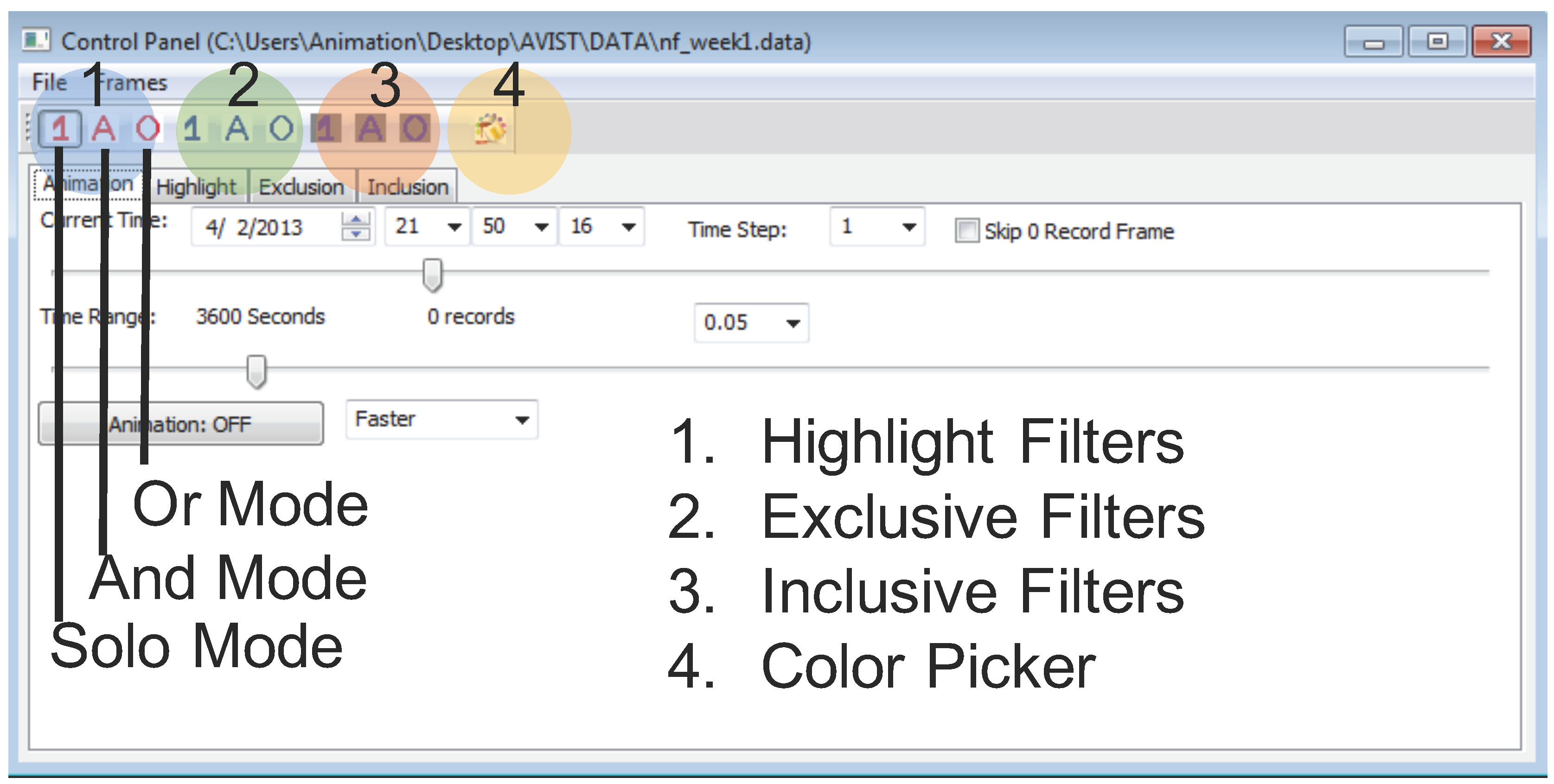
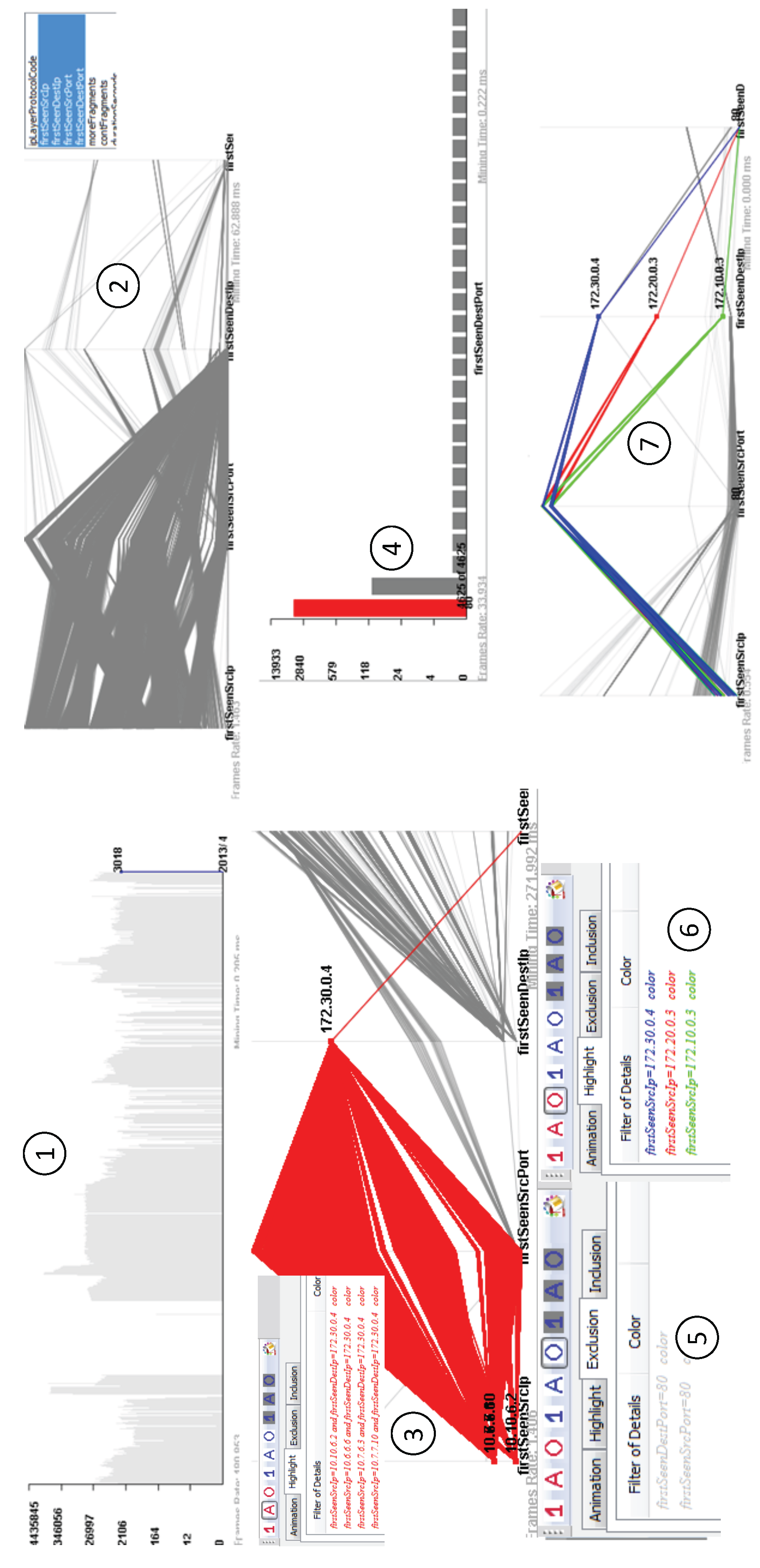
- Highlight filters: making selected data items stand out from the rest with different colors.
- Exclusive filters: removing uninteresting data items.
- Inclusive filters: the exact opposite of exclusive filters, removing all data items except those marked by an analyst.
- Solo mode: allowing only one filtered item in the current filter set.
- And mode: combing several filters together as a whole and selecting data records to satisfy all conditions.
- Or mode: selecting data records to meet at least one of all of the filter conditions.
4.4.3. Capacities
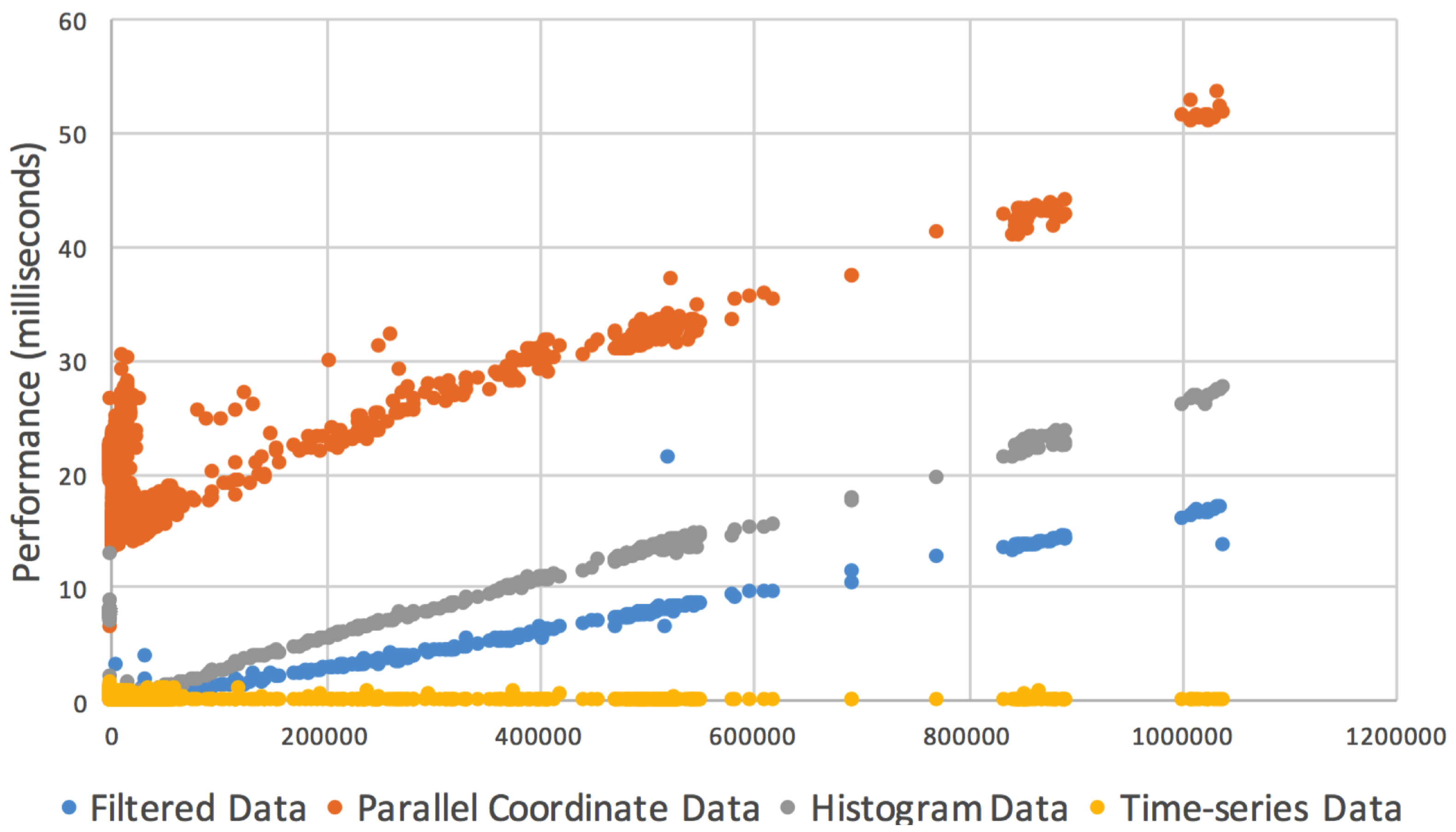
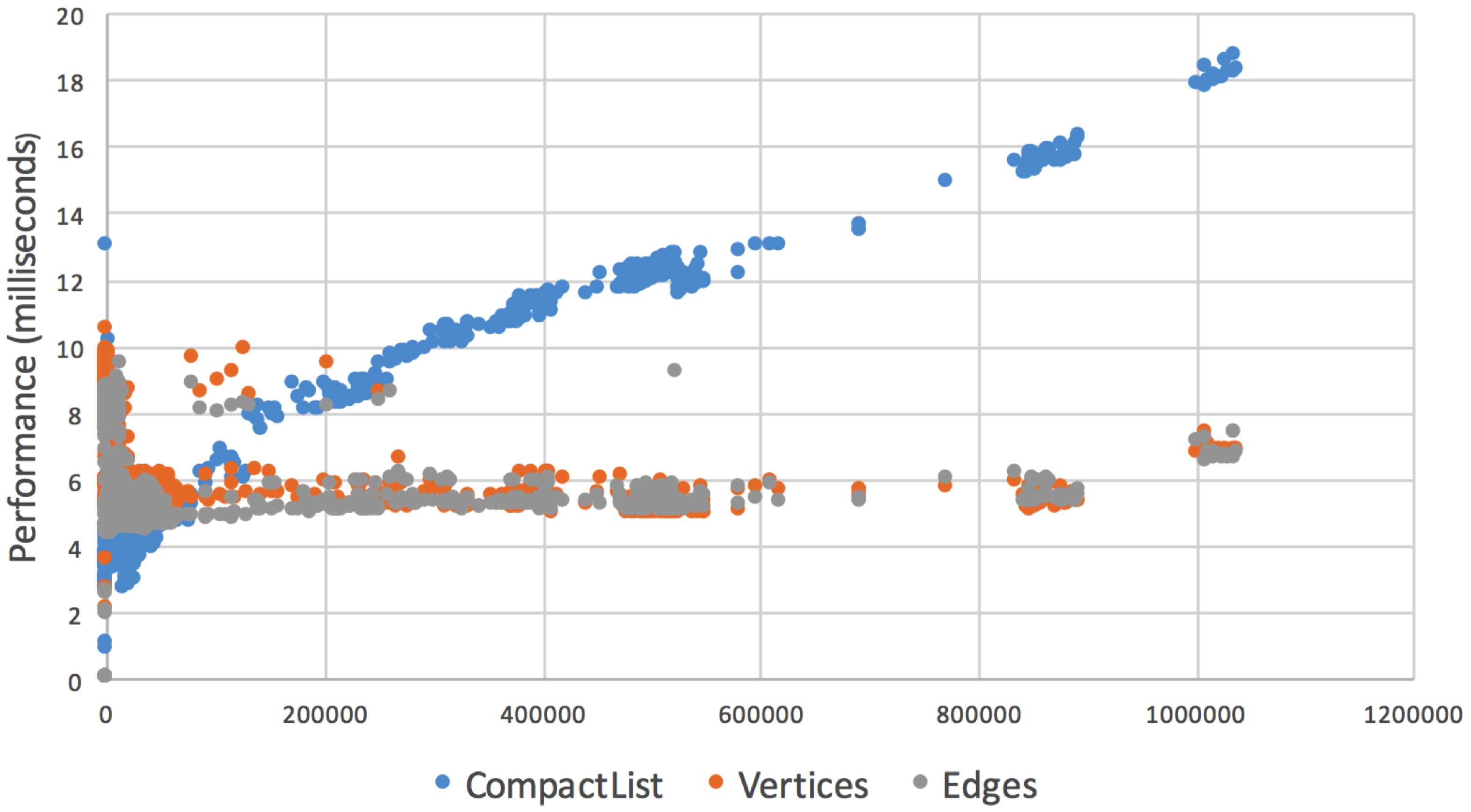
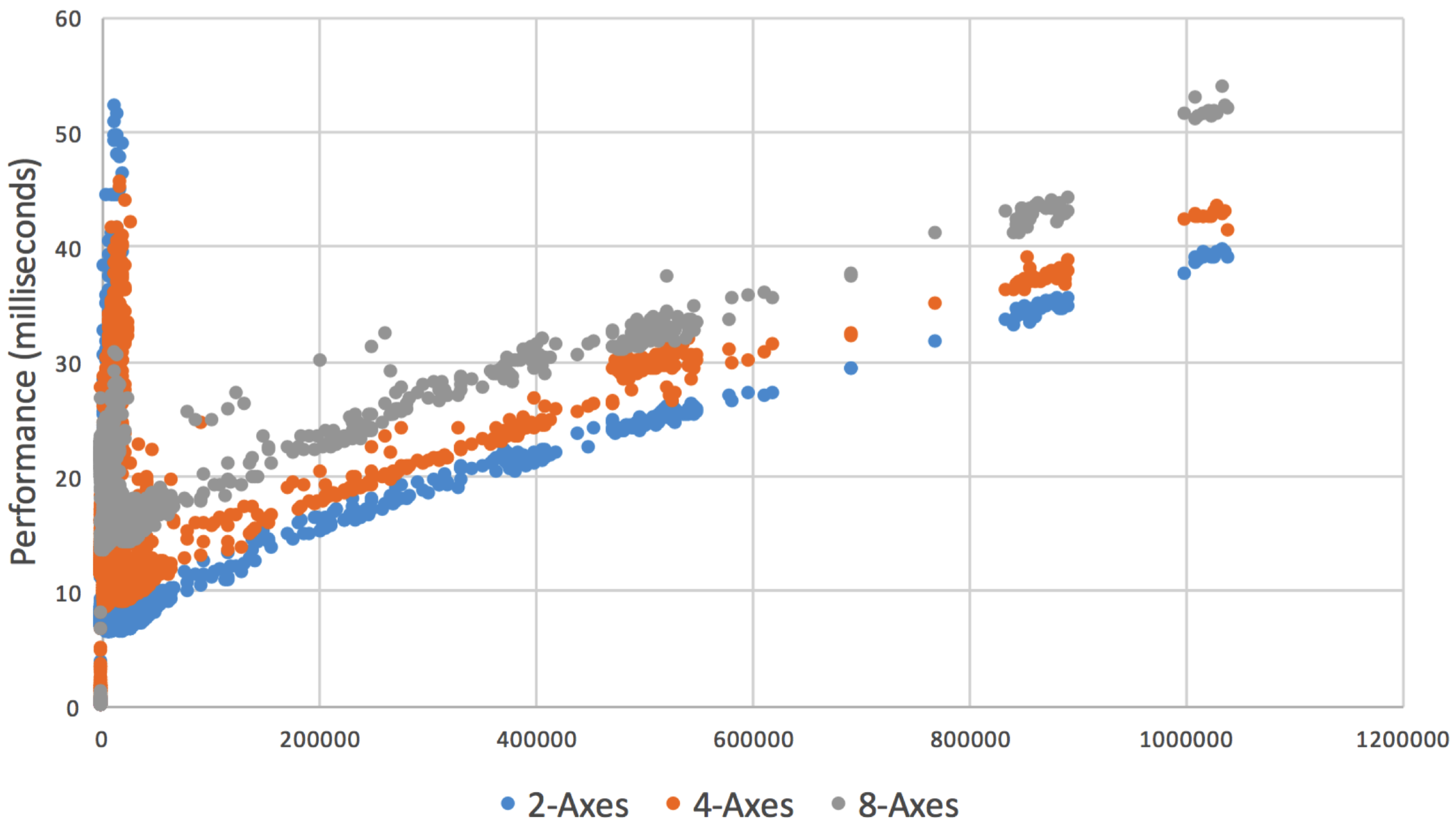
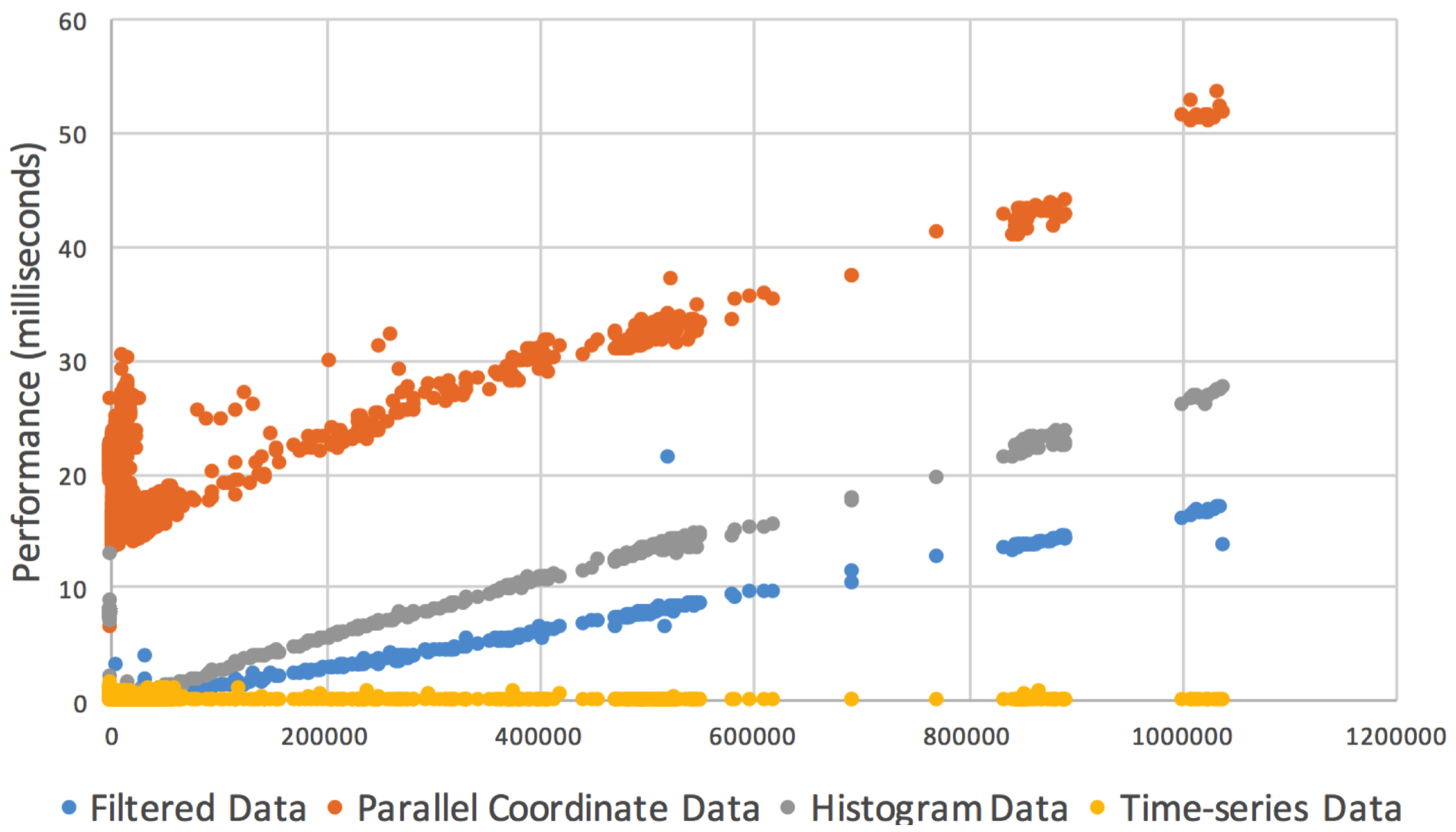
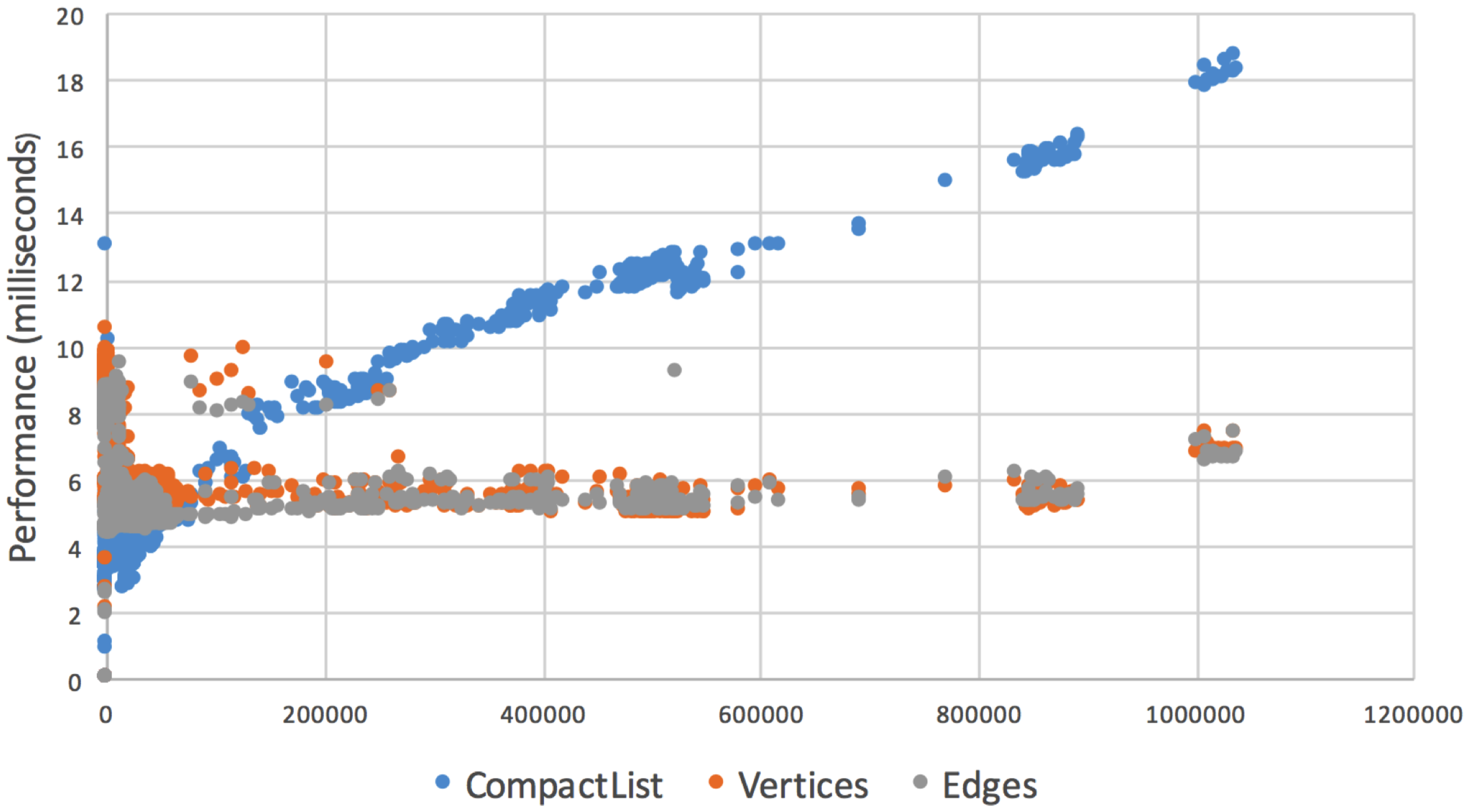
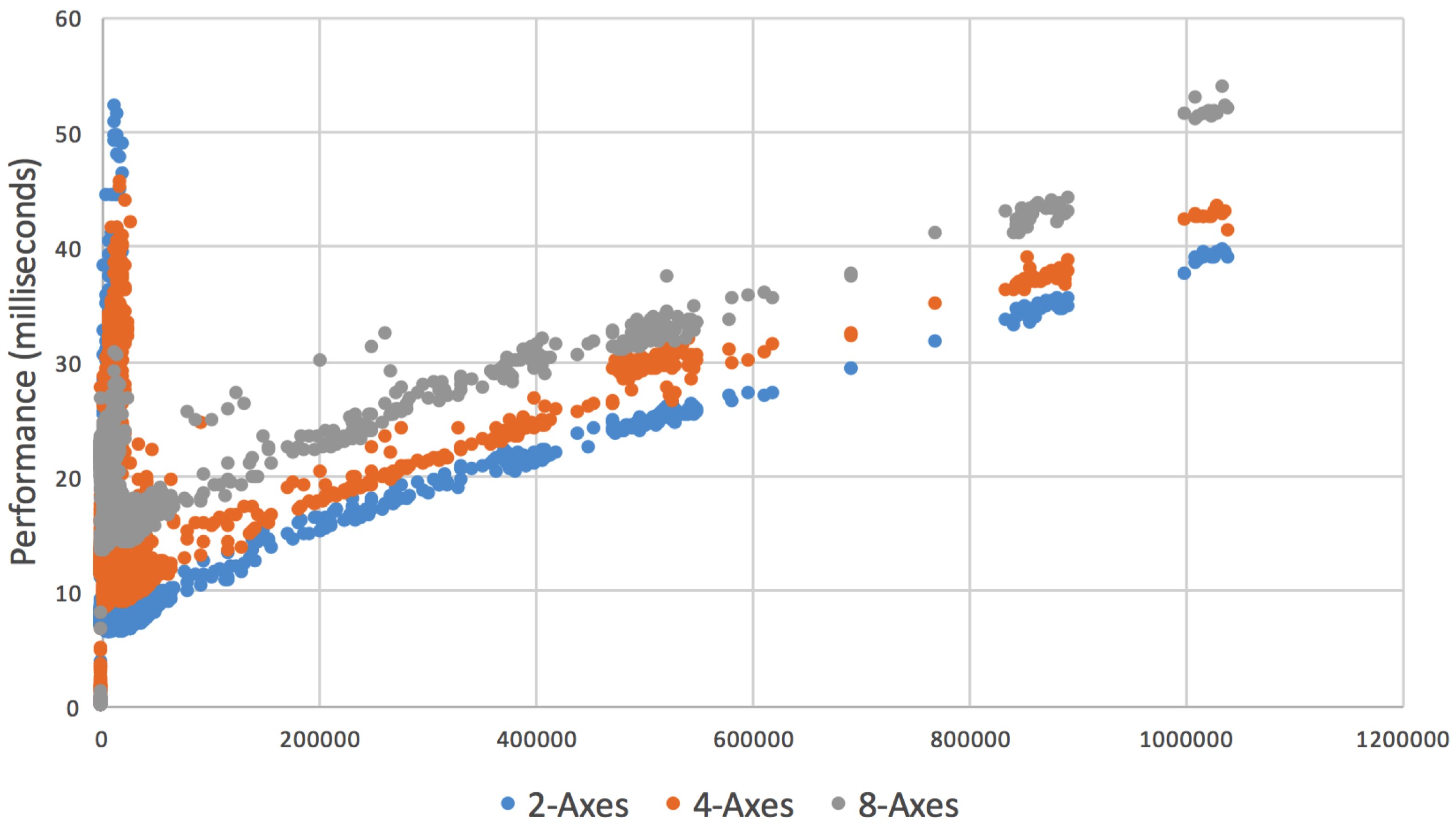
5. Performance
6. Usage Scenario
6.1. Network Flow Analysis
6.2. International Trade Analysis
7. Lessons Learned
- Aggregated visualization vs. atomic visualization: These are two strategies to present big data visually. Atomic visualization uses one visual element for each data record [29]. Pixel-oriented visualization is an extreme case, where each data record is mapped to a single pixel, its color indicating some attribute of this record [30]. However, this technique is constrained by display resolution, which sometimes leads to the over-plotting problem [5]. Different from atomic visualization, aggregated visualization highlights one visual primitive for multiple data records. It allows users to see a subset of data as coarse views with interactions (e.g., zooming and animation). In the case of limited screen pixels, aggregated visualization is more useful than atomic visualization because it can avoid the over-plotting problem. For instance, in AVIST, after a user clicks on a bar in the histogram view, the parallel coordinate plots highlight thousands of lines to reveal corresponding details. Thus, in a setting of limited screen pixels, aggregated visualization is more scalable than atomic visualization. Moreover, aggregated visualization can help reduce the performance overhead since it does not plot all data at once.
- Pre-aggregation vs. aggregation on demand: Pre-aggregation is a strategy to achieve high level data exploration by reducing big data into small data. imMens [5] is a pre-aggregation big data visual querying system. It aggregates data using the data cube technique, then it allows users to explore the aggregated data. This method is constrained by: (1) preprocessing methods; (2) huge memory requirements (derived data may be larger than original data); and (3) lacking flexible filtering and querying. In contrast, aggregation on demand has no such constraints, and it emphasizes aggregated data generated on the fly. Thus, it supports flexible data filtering. AVIST aggregates data based on users’ demands, and features the GPU-centric design to enable online data aggregation.
- Column-oriented vs. row-oriented: These are two basic data management methods, and both of them have pros and cons. In the “big data” era, column-based methods gain more attentions, since a columnar database has two features. First, it has a better compression ratio by storing similar things together, and it reduces IO (Input/Output) cost during data transferring from disk to memory. Second, it supports high level analytical workloads well. On the other hand, row-based databases are better for On-Line Transaction Processing (OLTP) applications, which support frequently reading and writing small transactions. The key advantage of the row-oriented data format is efficiently retrieving small data to find a “needle in a haystack”. Thus, we use the row-oriented format for querying fine data details.
- Analytically-driven vs. exploration-driven: These are two approaches for sensemaking of big data. Analytically-driven systems focus on “known-unknowns” insight synthesis, and they care about integrating statistics and machine learning techniques with human interactions and visualizations. However, exploration-driven applications emphasize “unknown-unknowns” discovery and highlight data exploration and interaction techniques. Thus, if users do not know what they want to know from big data, exploration-oriented applications are better choices. Users can identify some unexpected knowledge by exploring the data.
- Scaling out vs. scaling up: These are two ways to improve performance. The scaling out techniques are general approaches to handle big data, where more computers are added based on demand. Distributed computing technology is the key to manage many computers. However, distributed computing is designed for long batch jobs. Nowadays, researchers in this area concentrate on interactive analysis tasks and propose new frameworks (e.g., Spark [31]). Even though, most of them are analytically driven, which emphasize scaling data mining and machine learning from small data into big data, rather than exploring large datasets. As an alternative, the scaling up techniques add more resources on a single machine to boost performance. In this paper, we emphasize performance improvement by fully exploiting GPU resources. Thus, we achieve visual analysis of big data in real-time performance on an off-the-shelf computer.
- Data management on the GPU: The GPUs are compute-intensive processors. They are designed to perform data-parallel computation, in which a single instruction works over a large block of data. Working in blocks of data is more efficient than working with a single cell at a time. A large block of parallel working units means high throughput computation. This kind of throughput-oriented computation needs high memory bandwidth. Thus, the GPU favors array-based data structures.When programming on the CPU, designers can write to any location in memory at any point in their program. However, when programming on the GPU, designers access the GPU memory in a much more structured manner. The GPU is a SIMD (Single-Instruction Multiple-Data) architecture, which ensures that the computation on one data element cannot affect another. The only values that can be used in a GPU kernel are kernel input parameters and the GPU global memory reads. In addition, the output of a GPU kernel should be independent. GPU kernels cannot have random writes into the GPU global memory; each thread of a GPU kernel may perform writes to a single element in the output memory.Considering GPU memory organization, designers need to pay special attention to the data memory layout. Compared to the CPU, the GPU has different cache optimization. Designers need to explicitly cache heavily-used variables in GPU shared memory to improve performance. GPU shared memory is limited in terms of size, and inappropriate usage of GPU shared memory may hamper the performance. The reason is that the GPU shared memory is divided into memory banks. If two memory addresses occur in the same bank, then a bank conflict occurs [32] during which the memory access is done serially, losing the advantages of parallel access.Additionally, designers should take care of how to access GPU global memory efficiently. GPU global memory features combining multiple memory accesses into as few transactions as possible to minimize its bandwidth, which is referred to as memory coalescing. Thus, designers should be aware of improper GPU memory access patterns (e.g, sparse memory access, misaligned memory access, etc.).In AVIST, we carefully consider the GPU programming pitfalls listed above. Our data structures are based on data arrays, and we have removed duplicated data items in those data arrays to reduce computation overhead. We have compacted multiple small data arrays into one array to have a better GPU memory access pattern.Designing an efficient GPU kernel is nontrivial, especially when considering GPU memory organization. Instead of designing complex GPU kernels, we implement data transformations based on existing GPU libraries (e.g, Thrust). In AVIST, we use the sort operation to eliminate duplicates and obtain unique values; we also use the reduction operation to organize data arrays.
- Data visualization on the GPU: We highlight the usage of the GPU VBOs to improve the performance of big data visualizations. The basic visual primitives for GPU rendering are vertices or triangles. To generate complex visual primitives (e.g., bars and areas) or obtain advanced visual features, we use the GLSL, which transforms GPU geometric primitives into a raster image. The GPU features its rendering pipeline with three programmable shader stages: vertex shader, geometry shader and fragment shader. Marroquim et al. [33] provide a detailed description of each stage. In fact, the graphics pipeline is independent across stages, which makes rendering performance significantly improved. Thus, the GPU is a powerful weapon for rendering big data.
- Data interaction on the GPU: The data interaction in AVIST emphasizes highlighting, brushing and filtering. The implementation of these interactions includes two stages.(1) Keyboard and mouse events are collected on the CPU side, and they are transformed from the windows 2D space into the image space based on the view port setting of the GPU. After that, these events are assembled and transferred to the GPU side.(2) The GPU parses these data and links the current visual primitives back to raw data. To achieve this, the GPU VBOs map visual primitives back to the GPU global memory. Then, the GPU filters each visual primitive in parallel to get the filtered ones. After that, the GPU traces back to raw data based on the filtered ones and continues data transformations for the next frame.
8. Limitations
- GPU memory: The GPU memory capacity is limited, while the volume of big data can be far beyond its capability. We have applied a lossless compression technique in AVIST to shrink the data size. However, this technique cannot scale to some bigger datasets.
- GPU computation: The computational capability of GPUs has reached tera-FLOPS (Floating-point Operations Per Second), which may be ten-times faster than state-of-the-art CPUs. However, GPUs perform well for arithmetic intense computation with regular memory access patterns. Thus, they are incapable of some problems with unpredicted memory accesses and highly sequential solutions (e.g., graph traversal). GPUs are specialized for certain problems and are incapable of achieving significant performance gains for all problems.
9. Conclusions
Acknowledgments
Conflicts of Interest
References
- Weaver, C. Cross-Filtered views for multidimensional visual analysis. IEEE Trans. Vis. Comput. Graph. 2010, 16, 192–204. [Google Scholar] [CrossRef] [PubMed]
- Weaver, C. Multidimensional visual analysis using cross-filtered views. In Proceedings of the IEEE Symposium on Visual Analytics Science and Technology, Columbus, OH, USA, 21–23 October 2008; pp. 163–170.
- Tableau Software. Available online: http://www.tableau.com/ (accessed on 27 September 2016).
- Wesley, R.; Eldridge, M.; Terlecki, P.T. An analytic data engine for visualization in tableau. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; pp. 1185–1194.
- Liu, Z.; Jiang, B.; Heer, J. imMens: Real-time Visual Querying of Big Data. In Proceedings of the 15th Eurographics Conference on Visualization, Leipzig, Germany, 17–21 June 2013; pp. 421–430.
- Gray, J.; Chaudhuri, S.; Bosworth, A.; Layman, A.; Reichart, D.; Venkatrao, M.; Pellow, F.; Pirahesh, H. Data cube: A relational aggregation operator generalizing group-by, cross-tab, and sub-totals. Data Min. Knowl. Discov. 1997, 1, 22–53. [Google Scholar] [CrossRef]
- Canny, J.; Zhao, H. Big data analytics with small footprint: Squaring the cloud. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 95–103.
- Zikopoulos, P.; Eaton, C. Understanding Big Data: Analytics for Enterprise Class Hadoop and Streaming Data. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; McGraw-Hill Osborne Media: New York, NY, USA, 2011. [Google Scholar]
- Idreos, S.; Papaemmanouil, O.; Chaudhuri, S. Overview of Data Exploration Techniques. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Melbourne, Australia, 31 May–4 June 2015; pp. 277–281.
- Battle, L.; Chang, R.; Stonebraker, M. Dynamic Prefetching of Data Tiles for Interactive Visualization. In Proceedings of the International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 1363–1375.
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The hadoop distributed file system. In Proceedings of the IEEE Symposium on Mass Storage Systems and Technologies, Incline Villiage, NV, USA, 3–7 May 2010; pp. 1–10.
- Abadi, D.J.; Madden, S.R.; Hachem, N. Column-stores vs. row-stores: How different are they really? In Proceedings of the ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 967–980.
- Lins, L.; Klosowski, J.T.; Scheidegger, C. Nanocubes for real-time exploration of spatiotemporal datasets. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2456–2465. [Google Scholar] [CrossRef] [PubMed]
- Balsa, R.M.; Gobbetti, E.; Iglesias, G.J.; Makhinya, M.; Marton, F.; Pajarola, R.; Suter, S.K. State-of-the-Art in Compressed GPU-Based Direct Volume Rendering. Comput. Graph. Forum 2014, 33, 77–100. [Google Scholar] [CrossRef]
- Thrust - Parallel Algorithm Library. Available online: http://docs.nvidia.com/cuda/thrust/ (accessed on 27 September 2016).
- cuBLAS - Basic Linear Algebra Subprograms on CUDA. Available online: http://docs.nvidia.com/cuda/cublas/ (accessed on 27 September 2016).
- Pawliczek, P.; Dzwinel, W.; Yuen, D.A. Visual exploration of data by using multidimensional scaling on multicore CPU, GPU, and MPI cluster. Concurr. Comput. Pract. Exp. 2014, 26, 662–682. [Google Scholar] [CrossRef]
- McDonnel, B.; Elmqvist, N. Towards Utilizing GPUs in Information Visualization: A Model and Implementation of Image-Space Operations. IEEE Trans. Vis. Comput. Graph. 2009, 15, 1105–1112. [Google Scholar] [CrossRef] [PubMed]
- MapD Technology. Available online: https://www.mapd.com/ (accessed on 27 September 2016).
- LLVM Complier Infrastructure. Available online: http://llvm.org/ (accessed on 27 September 2016).
- Stolte, C.; Tang, D.; Hanrahan, P. Polaris: A system for query, analysis, and visualization of multidimensional databases. Commun. ACM 2008, 51, 75–84. [Google Scholar] [CrossRef]
- Fekete, J.D.; Plaisant, C. Interactive information visualization of a million items. In Proceedings of the IEEE Symposium on Information Visualization, Boston, MA, USA, 28–29 October 2002; pp. 117–124.
- Heer, J.; Robertson, G. Animated transitions in statistical data graphics. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1240–1247. [Google Scholar] [CrossRef] [PubMed]
- Hatanaka, I.; Hughes, S.C. Providing Multiple Views in a Model-View-Controller Architecture. U.S. Patent 5,926,177, 20 July 1999. [Google Scholar]
- Musser, D.R.; Derge, G.J.; Saini, A. STL Tutorial and Reference Guide: C++ Programming with the Standard Template Library; Hendrickson, M., Ed.; Addison-Wesley Professional: Boston, MA, USA, 2009. [Google Scholar]
- Merrill, D.; Grimshaw, A. High Performance and Scalable Radix Sorting: A Case Study of Implementing Dynamic Parallelism for GPU Computing. Parallel Process. Lett. 2011, 21, 245–272. [Google Scholar] [CrossRef]
- The Visual Analytics Science and Technology (VAST) Challenge 2013. Available online: http://vacommunity.org/VAST+Challenge+2013 (accessed on 27 September 2016).
- PIERS Global Intelligence Solutions. Available online: https://www.ihs.com/products/piers.html (accessed on 27 September 2016).
- Shneiderman, B. Extreme visualization: Squeezing a billion records into a million pixels. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 3–12.
- Keim, D.A. Pixel-Oriented visualization techniques for exploring very large data bases. J. Comput. Graph. Stat. 1996, 5, 58–77. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. In Proceedings of the USENIX Conference on Hot Topics in Cloud Computing, Boston, MA, USA, 22–25 June 2010; pp. 1–10.
- Mark, H.; Shubhabrata, S.; John, D. Parallel prefix sum (scan) with CUDA. GPU Gems 2007, 3, 851–876. [Google Scholar]
- Marroquim, R.; Maximo, A. Introduction to GPU Programming with GLSL. In Proceedings of the 2009 Tutorials of the XXII Brazilian Symposium on Computer Graphics and Image Processing, Rio de Janeiro, Brazil, 11–14 October 2009; pp. 3–16.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | GPU Memory Binary Format | Main Memory Metadata |
|---|---|---|
| Time | time_t 8 bytes | minimum value maximum value |
| Quantitative | Int or Float 4 bytes | minimum value maximum value |
| Categorical-Ordinal | 1∼4 bytes | Dictionary (IDs and data values) |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mi, P.; Sun, M.; Masiane, M.; Cao, Y.; North, C. AVIST: A GPU-Centric Design for Visual Exploration of Large Multidimensional Datasets. Informatics 2016, 3, 18. https://doi.org/10.3390/informatics3040018
Mi P, Sun M, Masiane M, Cao Y, North C. AVIST: A GPU-Centric Design for Visual Exploration of Large Multidimensional Datasets. Informatics. 2016; 3(4):18. https://doi.org/10.3390/informatics3040018
Chicago/Turabian StyleMi, Peng, Maoyuan Sun, Moeti Masiane, Yong Cao, and Chris North. 2016. "AVIST: A GPU-Centric Design for Visual Exploration of Large Multidimensional Datasets" Informatics 3, no. 4: 18. https://doi.org/10.3390/informatics3040018
APA StyleMi, P., Sun, M., Masiane, M., Cao, Y., & North, C. (2016). AVIST: A GPU-Centric Design for Visual Exploration of Large Multidimensional Datasets. Informatics, 3(4), 18. https://doi.org/10.3390/informatics3040018