
Direct Visual Editing of Node Attributes in Graphs


Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Related Work
2.1. Visualization
2.2. Interaction
3. Approach
3.1. Outline and Requirements
- The base visualization has to show the graph structure and graph attributes in a single view [13]. This enables users to spot relations between structural aspects and associated data (e.g., hubs exhibit high attribute value). Attribute values being potential candidates for editing (e.g., missing values, outliers) should be emphasized. A necessary condition in terms of interaction is that nodes are displayed as discrete, modifiable graphical objects. Moreover, the nodes have to be laid out in a fashion that goes hand in hand with the interaction for editing.
- Direct visual editing requires interaction mechanisms for selecting values to be edited and for specifying new values from the attributes’ value ranges. The interaction should be engaging [4] and the costs for interacting should be low [40]. To this end, the interactions are to be carried out with the visualization using a direct manipulation approach. Appropriate methods have to be included to assist users in the editing procedure. Interesting challenges are the precise adjustment of continuous data values and the interaction with information that is off-screen.
- Informative visual feedback must be provided constantly during edit operations. This requires immediate updates of the base visualization once a new value has been set. The visual feedback should convey not only the locally changed data values, but also the global effect on the value distribution. In addition to visual feedback, it makes sense to consider visual feedforward [41] as well. Feedforward is useful for giving users an idea of what they can expect from their interaction with the system.
3.2. Strategy for Quantitative Values
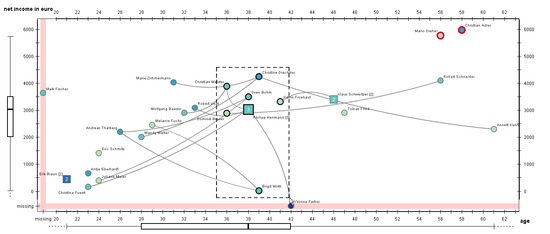
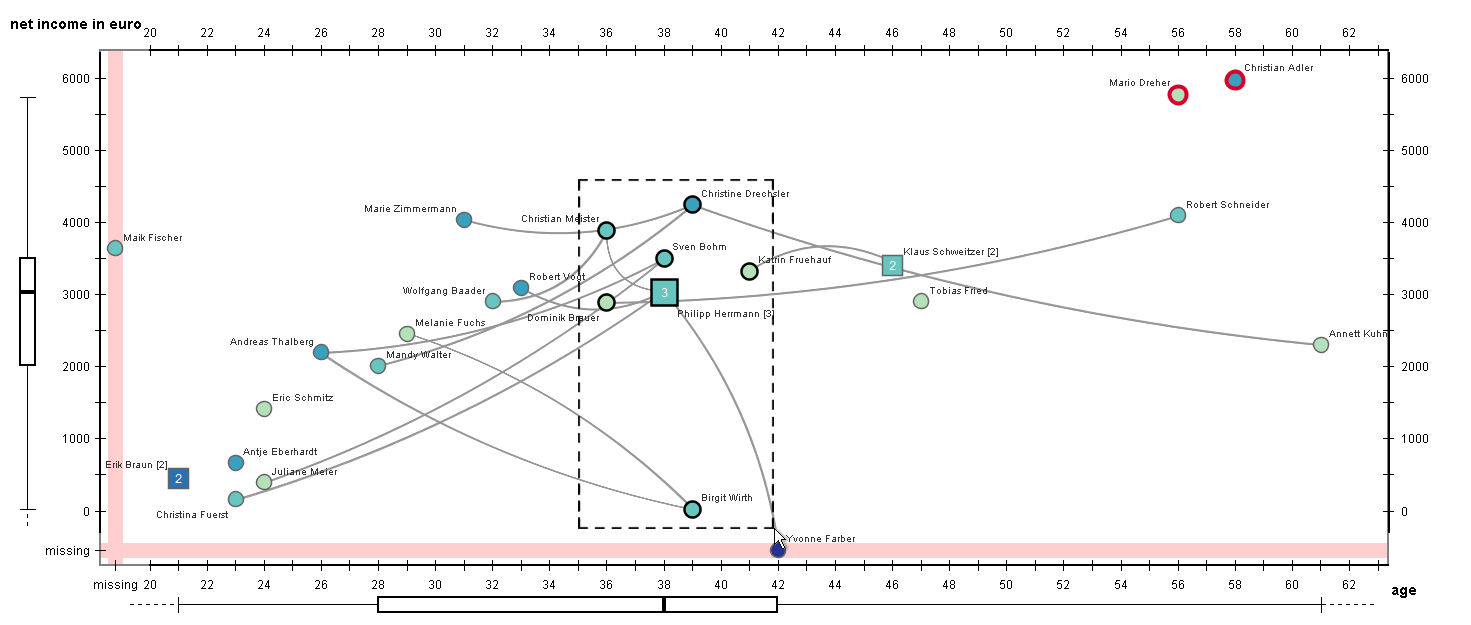
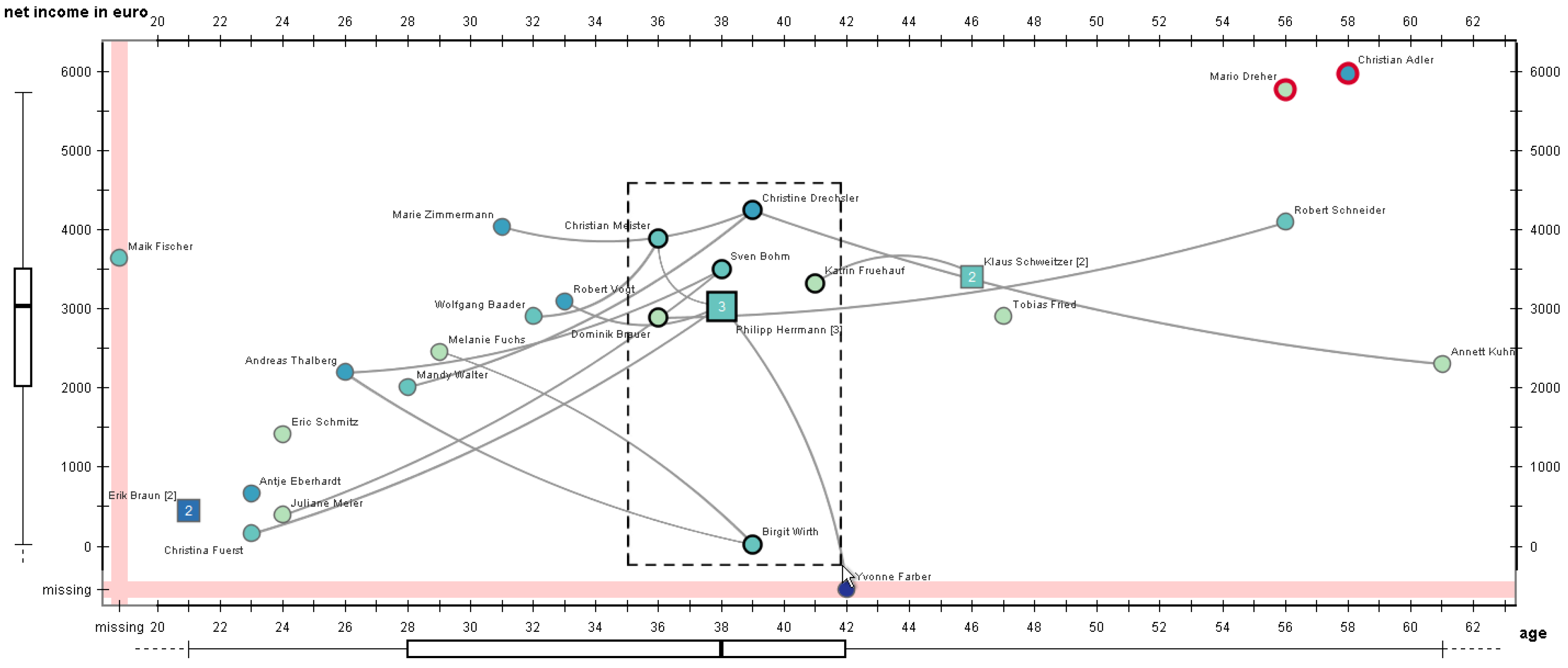
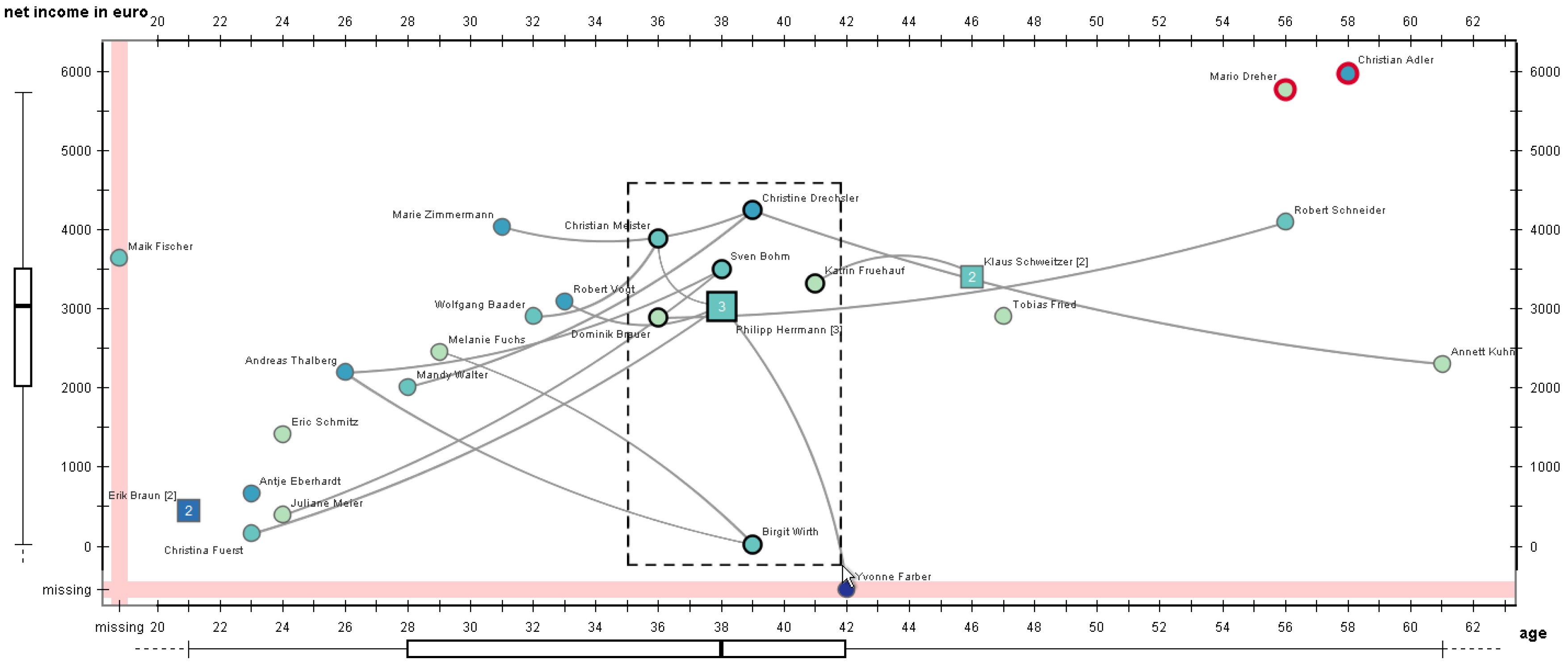
3.2.1. Visualizing Quantitative Node Attributes Using a Scatter Plot Layout
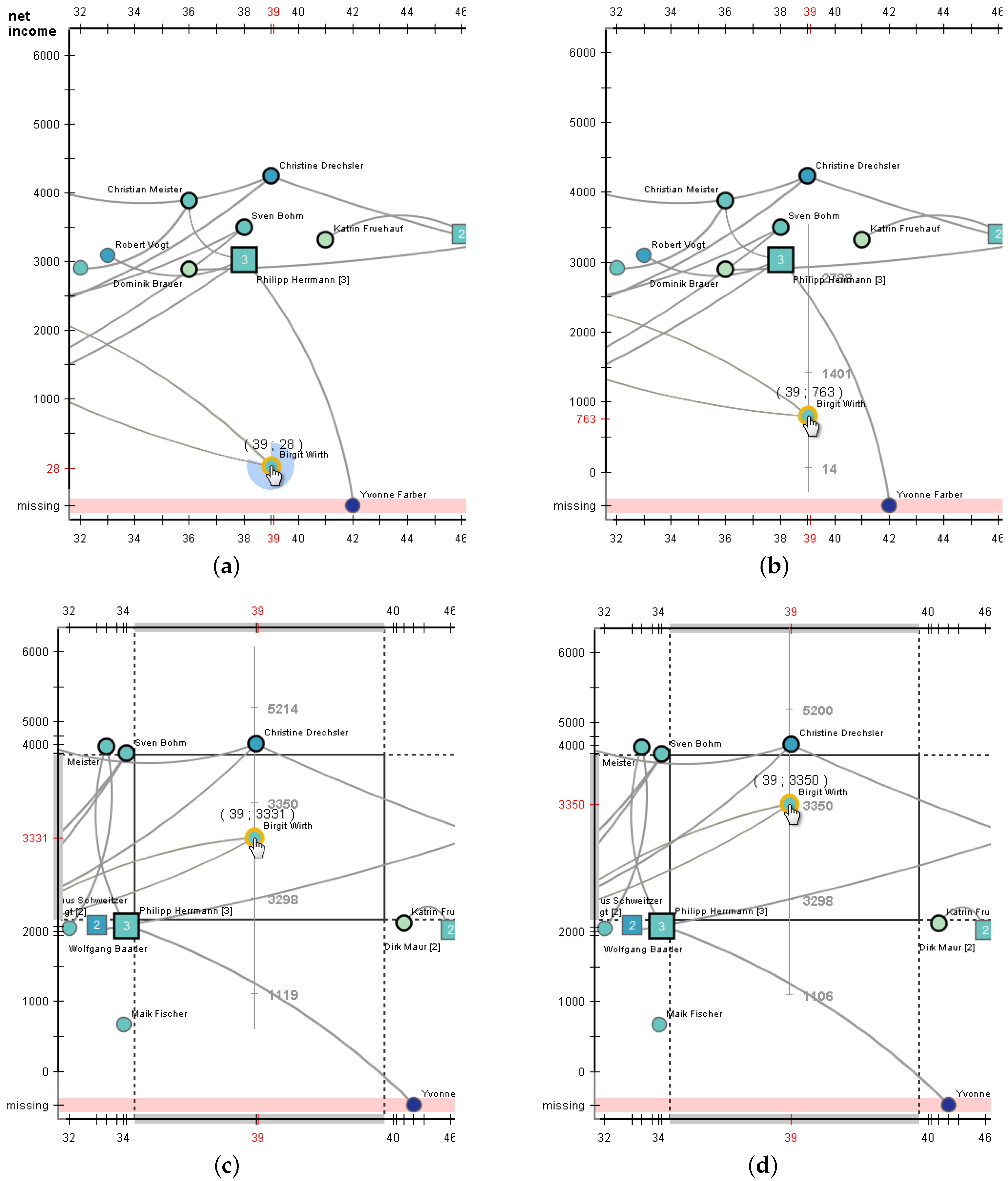
3.2.2. Direct Editing Interaction and Visual Feedback
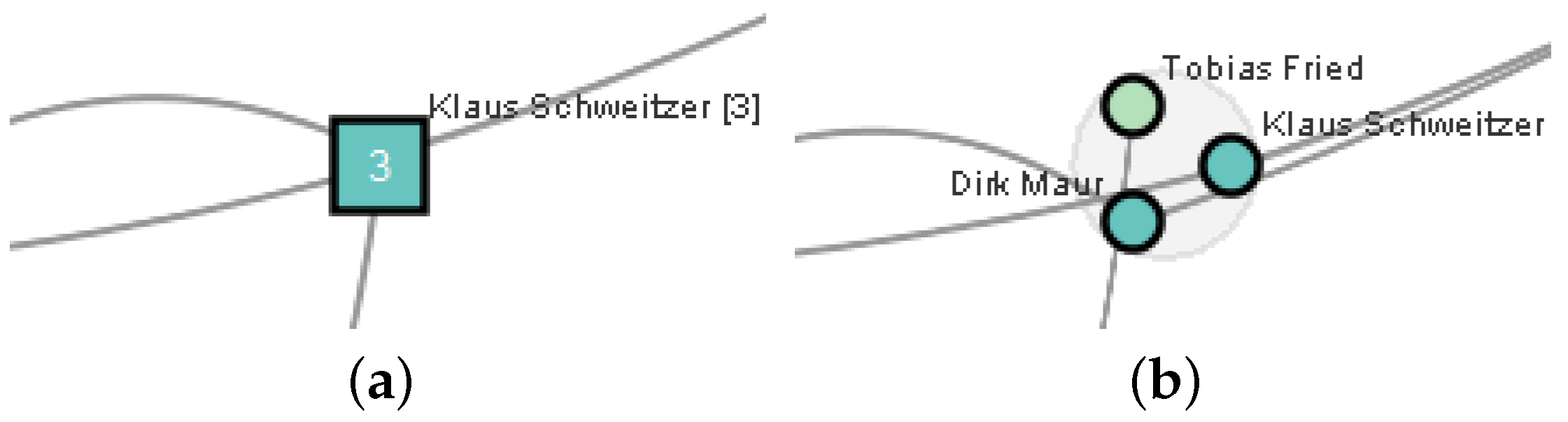
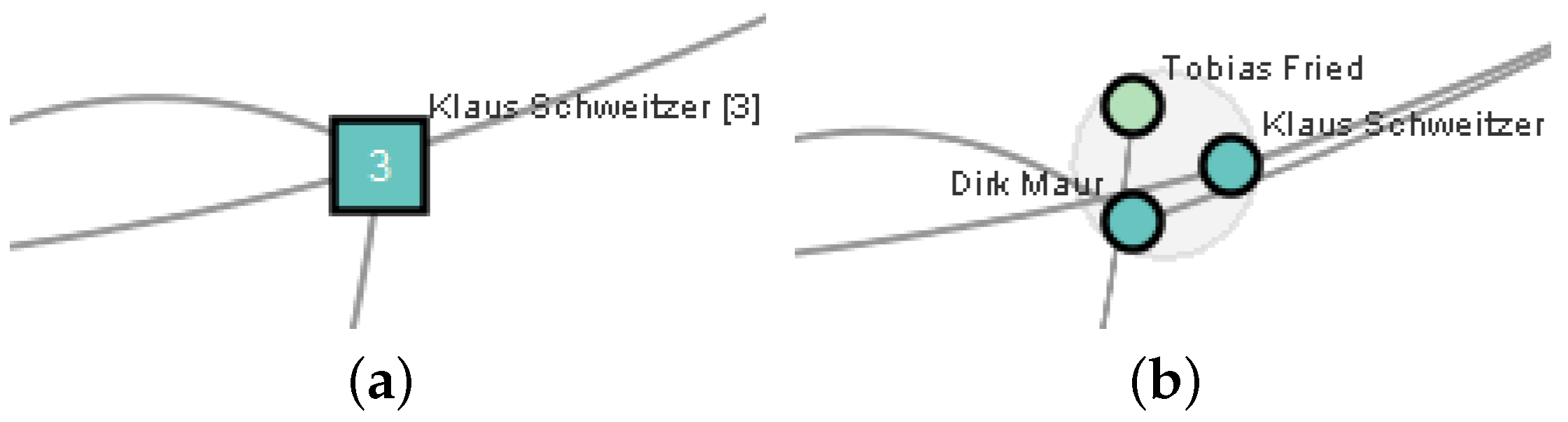
3.2.3. Editing Aids
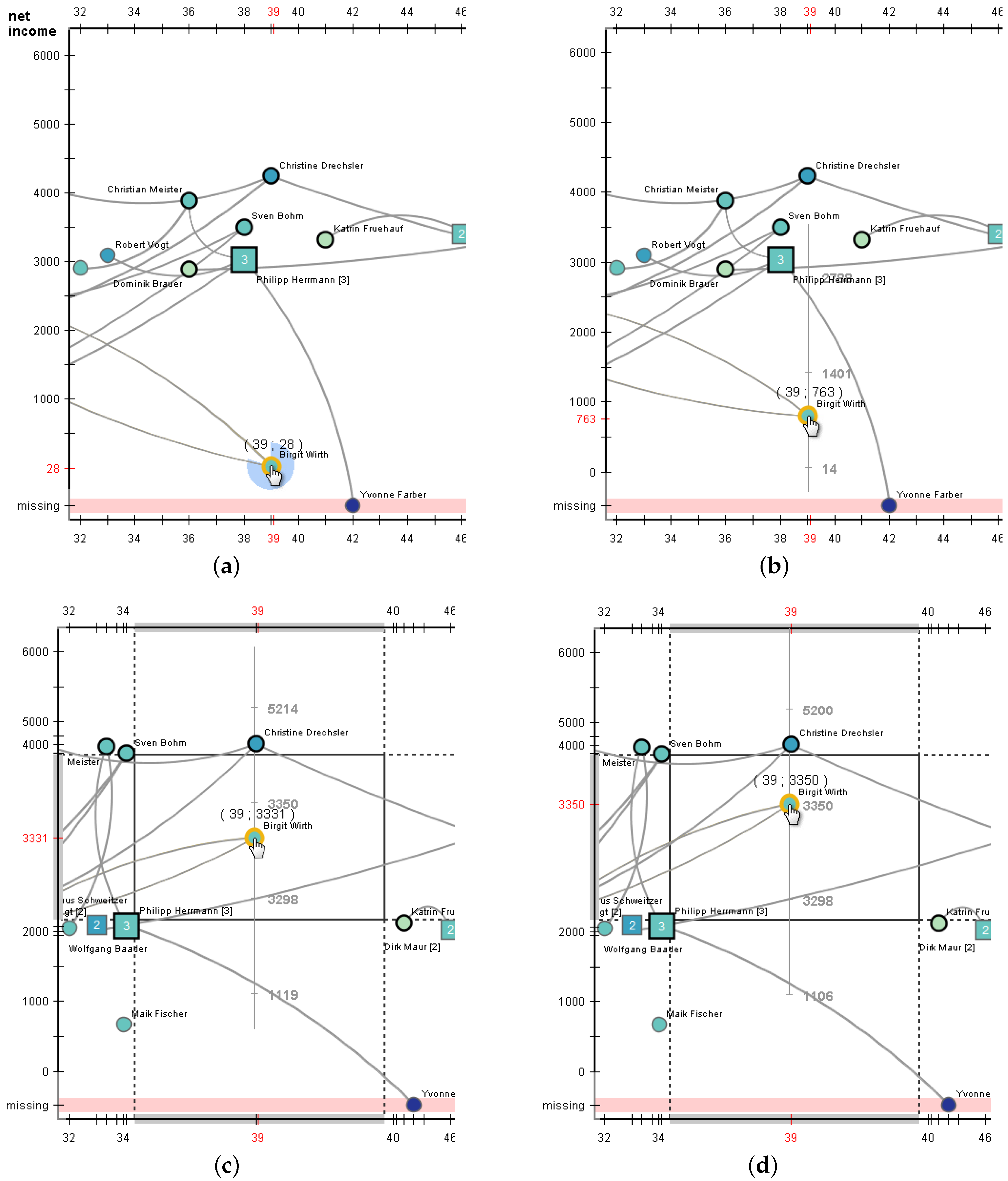
3.2.4. Increasing Editing Precision
- (a)
- Long press to unlock the node for editing.
- (b)
- Drag the node roughly toward the target position.
- (c)
- Activate the focus+context transformation and optionally adjust the magnification factor.
- (d)
- Exploit the increased interaction precision to set the node’s position exactly to the target value.
3.3. Strategy for Qualitative Values
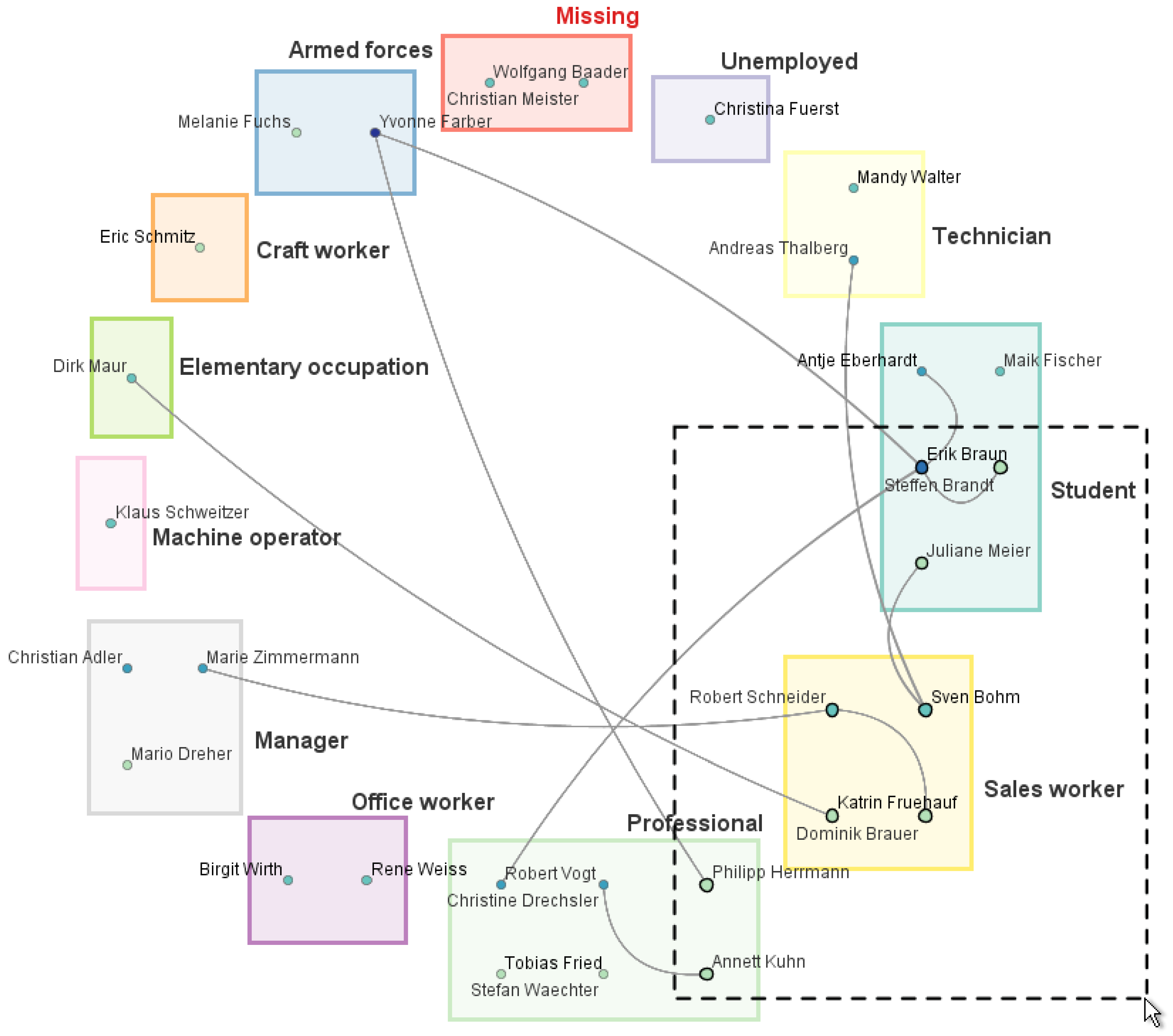
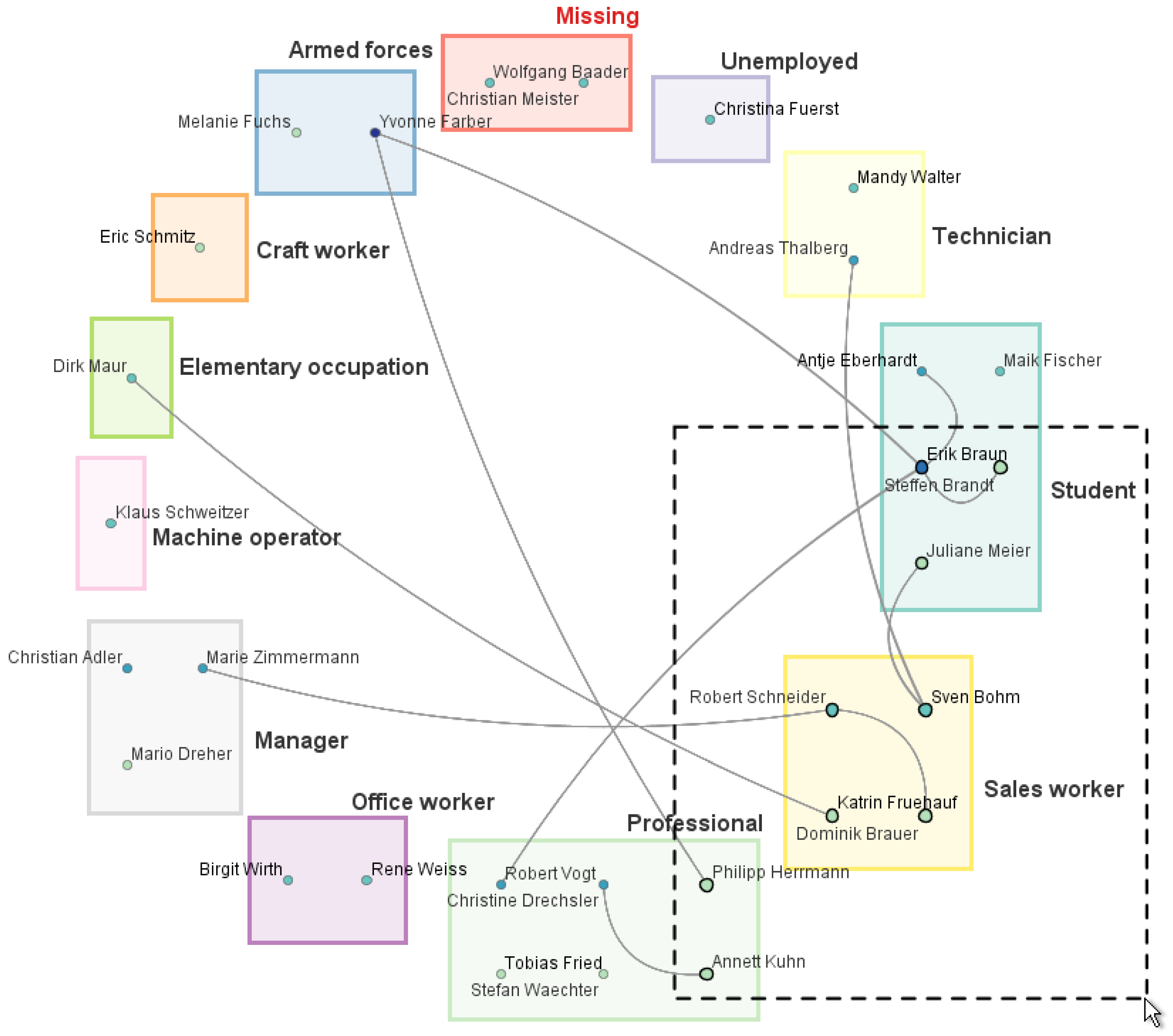
3.3.1. Visualizing Qualitative Node Attributes Using a Semantic Substrates Layout
3.3.2. Direct Editing Interaction and Visual Feedback
3.3.3. Editing Aids
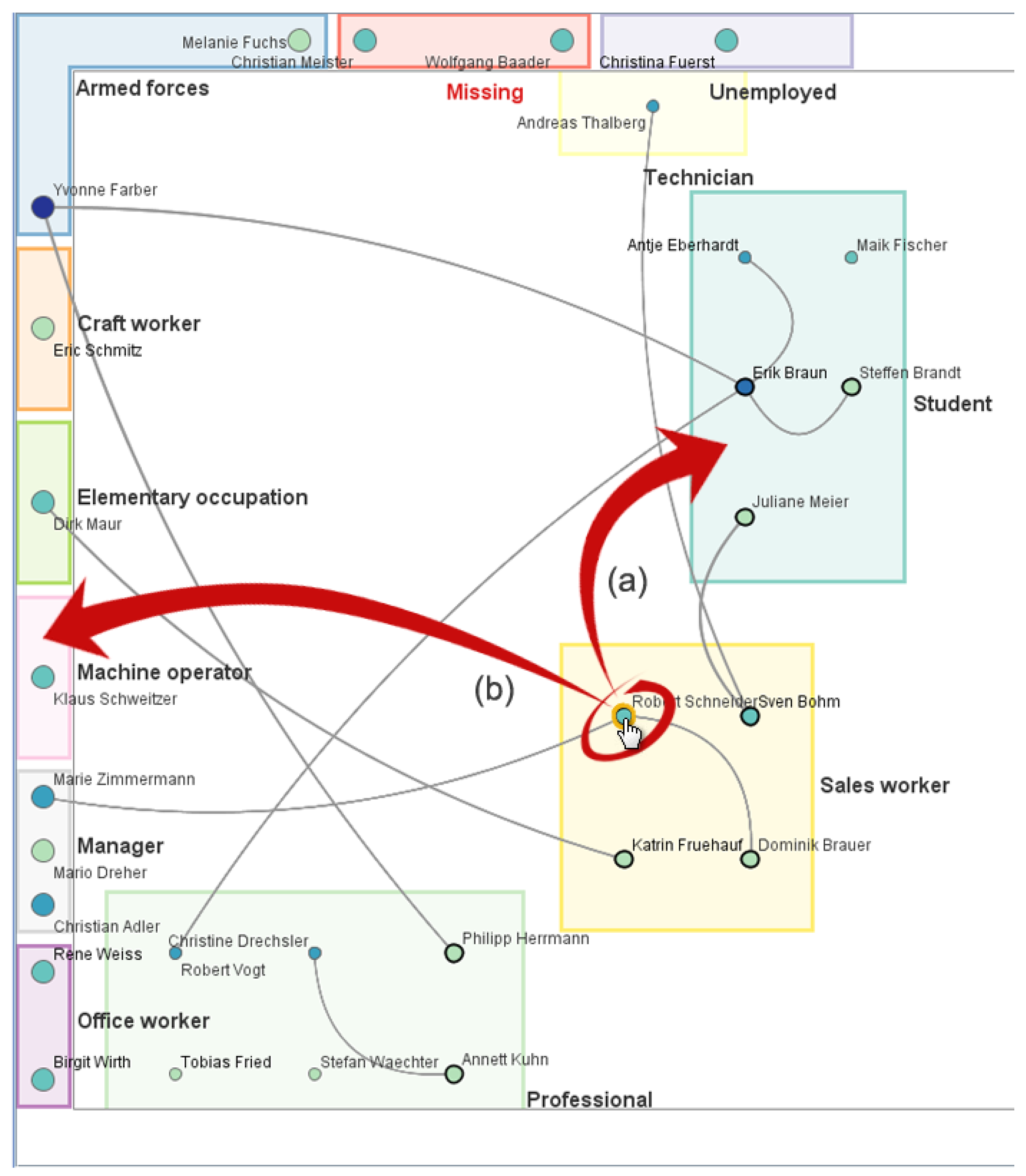
- Approximately determine the position and size of each proxy by projecting its off-screen region to the border.
- Detect overlaps among the projected proxies and resolve them by iteratively shifting and resizing them.
- Determine important nodes based on a degree-of-interest function [50].
- Optimize proxy size and position so that important nodes can be displayed within the proxies while still maintaining the proxies’ purpose of indicating direction and distance.
4. Preliminary User Feedback and Application Examples
4.1. Preliminary User Feedback
4.1.1. Participants, Data, and Setup
4.1.2. Procedure and Tasks
4.1.3. Results
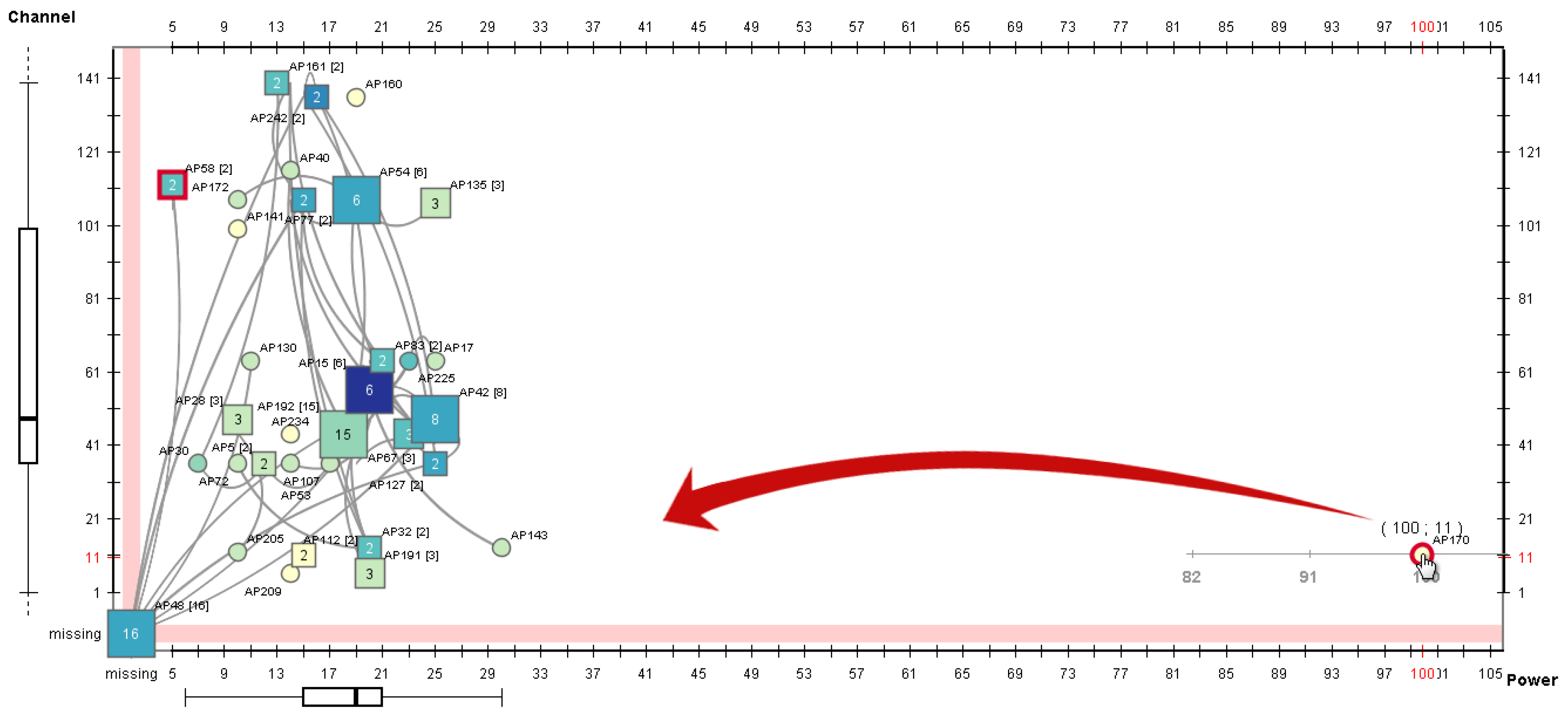
4.2. Application Examples
5. Discussion
6. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Heer, J.; Shneiderman, B. Interactive Dynamics for Visual Analysis. Commun. ACM 2012, 55, 45–54. [Google Scholar] [CrossRef]
- Kandel, S.; Heer, J.; Plaisant, C.; Kennedy, J.; van Ham, F.; Riche, N.H.; Weaver, C.; Lee, B.; Brodbeck, D.; Buono, P. Research Directions in Data Wrangling: Visualizations and Transformations for Usable and Credible Data. Inf. Vis. 2011, 10, 271–288. [Google Scholar] [CrossRef]
- Baudel, T. From Information Visualization to Direct Manipulation: Extending a Generic Visualization Framework for the Interactive Editing of Large Datasets. In Proceedings of the ACM Symposium on User Interface Software and Technology (UIST), Montreux, Switzerland, 15–18 October 2006; ACM Press: New York, NY, USA, 2006; pp. 67–76. [Google Scholar]
- Elmqvist, N.; Moere, A.V.; Jetter, H.C.; Cernea, D.; Reiterer, H.; Jankun-Kelly, T. Fluid Interaction for Information Visualization. Inf. Vis. 2011, 10, 327–340. [Google Scholar] [CrossRef]
- Shneiderman, B. Direct Manipulation: A Step Beyond Programming Languages. IEEE Comput. 1983, 16, 57–69. [Google Scholar] [CrossRef]
- Hadlak, S.; Schumann, H.; Schulz, H.J. A Survey of Multi-Faceted Graph Visualization. In Proceedings of the Eurographics Conference on Visualization (EuroVis)—STARs, Cagliari, Italy, 25–29 May 2015; Eurographics Association: Geneve, Switzerland, 2015; pp. 1–20. [Google Scholar]
- Battista, G.D.; Eades, P.; Tamassia, R.; Tollis, I.G. Graph Drawing: Algorithms for the Visualization of Graphs; Prentice Hall: Upper Saddle River, NJ, USA, 1998. [Google Scholar]
- Henry, N. Exploring Large Social Networks with Matrix-Based Representations. Ph.D. Thesis, Université Paris-Sud, Paris, France, University of Sydney, Sydney, Australia, 2008. [Google Scholar]
- Henry, N.; Fekete, J.D.; McGuffin, M.J. NodeTrix: A Hybrid Visualization of Social Networks. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1302–1309. [Google Scholar] [CrossRef] [PubMed]
- Rao, R.; Card, S.K. The Table Lens: Merging Graphical and Symbolic Representations in an Interactive Focus+Context Visualization for Tabular Information. In Proceedings of the SIGCHI Conference Human Factors in Computing Systems (CHI), Boston, MA, USA, 24–28 April 1994; ACM Press: New York, NY, USA, 1994; pp. 318–322. [Google Scholar]
- Cleveland, W.C.; McGill, M.E. Dynamic Graphics for Statistics; CRC Press: Boca Raton, FL, USA, 1988. [Google Scholar]
- Inselberg, A.; Dimsdale, B. Parallel Coordinates: A Tool for Visualizing Multi-dimensional Geometry. In Proceedings of the IEEE Visualization Conference (Vis), San Francisco, CA, USA, 23–26 October 1990; IEEE Computer Society Press: Los Alamitos, CA, USA, 1990; pp. 361–378. [Google Scholar]
- Kerren, A.; Purchase, H.C.; Ward, M.O. (Eds.) Multivariate Network Visualization. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2014; Volume 8380.
- Crnovrsanin, T.; Muelder, C.; Faris, R.; Felmlee, D.; Ma, K. Visualization Techniques for Categorical Analysis of Social Networks with Multiple Edge Sets. Soc. Netw. 2014, 37, 56–64. [Google Scholar] [CrossRef]
- Jusufi, I.; Dingjie, Y.; Kerren, A. The Network Lens: Interactive Exploration of Multivariate Networks Using Visual Filtering. In Proceedings of the International Conference Information Visualisation (IV), London, UK, 26–29 July 2010; IEEE Computer Society Press: Los Alamitos, CA, USA, 2010; pp. 35–42. [Google Scholar]
- Shneiderman, B.; Aris, A. Network Visualization by Semantic Substrates. IEEE Trans. Vis. Comput. Graph. 2006, 12, 733–740. [Google Scholar] [CrossRef] [PubMed]
- Bezerianos, A.; Chevalier, F.; Dragicevic, P.; Elmqvist, N.; Fekete, J. GraphDice: A System for Exploring Multivariate Social Networks. Comput. Graph. Forum 2010, 29, 863–872. [Google Scholar] [CrossRef]
- Rodrigues, E.M.; Milic-Frayling, N.; Smith, M.A.; Shneiderman, B.; Hansen, D.L. Group-in-a-Box Layout for Multi-Faceted Analysis of Communities. In Proceedings of the International Conference on Privacy, Security, Risk and Trust and Inernational Conference on Social Computing (PASSAT/SocialCom), Boston, MA, USA, 9–11 October 2011; IEEE Computer Society Press: Los Alamitos, CA, USA, 2011; pp. 354–361. [Google Scholar]
- Van den Elzen, S.; van Wijk, J.J. Multivariate Network Exploration and Presentation: From Detail to Overview via Selections and Aggregations. IEEE Trans. Vis. Comput. Graph. 2014, 20, 2310–2319. [Google Scholar] [CrossRef] [PubMed]
- Tominski, C.; Abello, J.; Schumann, H. CGV—An Interactive Graph Visualization System. Comput. Graph. 2009, 33, 660–678. [Google Scholar] [CrossRef]
- Wang Baldonado, M.Q.; Woodruff, A.; Kuchinsky, A. Guidelines for Using Multiple Views in Information Visualization. In Proceedings of the Conference on Advanced Visual Interfaces (AVI), Palermo, Italy, 24–26 May 2000; ACM Press: New York, NY, USA, 2000; pp. 110–119. [Google Scholar]
- Tominski, C. Interaction for Visualization. In Synthesis Lectures on Visualization; Morgan & Claypool: San Rafael, CA, USA, 2015; Volume 3. [Google Scholar]
- Sedig, K.; Parsons, P. Design of Visualizations for Human-Information Interaction: A Pattern-Based Framework. In Synthesis Lectures on Visualization; Morgan & Claypool: San Rafael, CA, USA, 2016; Volume 4. [Google Scholar]
- Spence, R. Information Visualization: Design for Interaction, 2nd ed.; Prentice-Hall: Harlow, Essex, UK, 2007. [Google Scholar]
- Bederson, B.B. The Promise of Zoomable User Interfaces. Behav. Inf. Technol. 2011, 30, 853–866. [Google Scholar] [CrossRef]
- Tominski, C.; Gladisch, S.; Kister, U.; Dachselt, R.; Schumann, H. Interactive Lenses for Visualization: An Extended Survey. Comput. Graph. Forum 2016, in press. [Google Scholar] [CrossRef]
- Raisamo, J.; Raisamo, R.; Karkkainnen, P. A Method for Interactive Graph Manipulation. In Proceedings of the International Conference Information Visualisation (IV), London, UK, 16 July 2004; IEEE Computer Society Press: Los Alamitos, CA, USA, 2004; pp. 581–587. [Google Scholar]
- Spritzer, A.S.; Freitas, C.M.D.S. A Physics-Based Approach for Interactive Manipulation of Graph Visualizations. In Proceedings of the Conference on Advanced Visual Interfaces (AVI), Naples, Italy, 28–30 May 2008; ACM Press: New York, NY, USA, 2008; pp. 271–278. [Google Scholar]
- McGuffin, M.J.; Jurisica, I. Interaction Techniques for Selecting and Manipulating Subgraphs in Network Visualizations. IEEE Trans. Vis. Comput. Graph. 2009, 15, 937–944. [Google Scholar] [CrossRef] [PubMed]
- Riche, N.H.; Dwyer, T.; Lee, B.; Carpendale, S. Exploring the Design Space of Interactive Link Curvature in Network Diagrams. In Proceedings of the Conference on Advanced Visual Interfaces (AVI), Capri Island (Naples), Italy, 22–25 May 2012; ACM Press: New York, NY, USA, 2012; pp. 506–513. [Google Scholar]
- Shannon, P.; Markiel, A.; Ozier, O.; Baliga, N.S.; Wang, J.T.; Ramage, D.; Amin, N.; Schwikowski, B.; Ideker, T. Cytoscape: A Software Environment for Integrated Models of Biomolecular Interaction Networks. Genome Res. 2003, 13, 2498–2504. [Google Scholar] [CrossRef] [PubMed]
- Adar, E. GUESS: A Language and Interface for Graph Exploration. In Proceedings of the SIGCHI Conference Human Factors in Computing Systems (CHI), Montreal, QC, Canada, 22–27 April 2006; ACM Press: New York, NY, USA, 2006; pp. 791–800. [Google Scholar]
- Mathieu, B.; Heymann, S.; Jacomy, M. Gephi: An Open Source Software for Exploring and Manipulating Networks. In Proceedings of the Third International Conference on Weblogs and Social Media (ICWSM), San Jose, CA, USA, 17–20 May 2009; AAAI Press: Menlo Park, CA, USA, 2009; pp. 361–362. [Google Scholar]
- Auber, D.; Archambault, D.; Bourqui, R.; Lambert, A.; Mathiaut, M.; Mary, P.; Delest, M.; Dubois, J.; Melançon, G. The Tulip 3 Framework: A Scalable Software Library for Information Visualization Applications Based on Relational Data; Research Report RR-7860; INRIA: Rocquencourt, France, 2012. [Google Scholar]
- Grundy, J.; Hosking, J. Supporting Generic Sketching-Based Input of Diagrams in a Domain-Specific Visual Language Meta-Tool. In Proceedings of the International Conference on Software Engineering (ICSE), Minneapolis, MN, USA, 20–26 May 2007; IEEE Computer Society Press: Los Alamitos, CA, USA, 2007; pp. 282–291. [Google Scholar]
- Frisch, M.; Heydekorn, J.; Dachselt, R. Diagram Editing on Interactive Displays Using Multi-touch and Pen Gestures. In Proceedings of the International Conference on Diagrammatic Representation and Inference (Diagrams), Portland, OR, USA, 9–11 August 2010; Springer: Berlin, Germany, 2010; pp. 182–196. [Google Scholar]
- Gladisch, S.; Schumann, H.; Ernst, M.; Füllen, G.; Tominski, C. Semi-Automatic Editing of Graphs with Customized Layouts. Comput. Graph. Forum 2014, 33, 381–390. [Google Scholar] [CrossRef]
- Gladisch, S.; Schumann, H.; Luboschik, M.; Tominski, C. Toward Using Matrix Visualizations for Graph Editing. In Poster at IEEE Conference on Information Visualization (InfoVis), Chicago, IL, USA, 25–30 October 2015; 2015. [Google Scholar]
- Gladisch, S.; Tominski, C. Toward Integrated Exploration and Manipulation of Data Attributes in Graphs. In Poster at IEEE Conference on Information Visualization (InfoVis), Paris, France, 9–14 November 2014.
- Lam, H. A Framework of Interaction Costs in Information Visualization. IEEE Trans. Vis. Comput. Graph. 2008, 14, 1149–1156. [Google Scholar] [CrossRef] [PubMed]
- Vermeulen, J.; Luyten, K.; van den Hoven, E.; Coninx, K. Crossing the Bridge over Norman’s Gulf of Execution: Revealing Feedforward’s True Identity. In Proceedings of the SIGCHI Conference Human Factors in Computing Systems (CHI), Paris, France, 27 April–2 May 2013; ACM Press: New York, NY, USA, 2013; pp. 1931–1940. [Google Scholar]
- Harrower, M.A.; Brewer, C.A. ColorBrewer.org: An Online Tool for Selecting Color Schemes for Maps. Cartogr. J. 2003, 40, 27–37. [Google Scholar] [CrossRef]
- Luboschik, M.; Schumann, H.; Cords, H. Particle-Based Labeling: Fast Point-Feature Labeling without Obscuring Other Visual Features. IEEE Trans. Vis. Comput. Graph. 2008, 14, 1237–1244. [Google Scholar] [CrossRef] [PubMed]
- Norman, D.A. The Design of Everyday Things; Basic Books: New York, NY, USA, 2013. [Google Scholar]
- Cockburn, A.; Karlson, A.; Bederson, B.B. A Review of Overview+Detail, Zooming, and Focus+Context Interfaces. ACM Comput. Surv. 2008, 41, 2:1–2:31. [Google Scholar] [CrossRef]
- Appert, C.; Fekete, J.D. OrthoZoom Scroller: 1D Multi-Scale Navigation. In Proceedings of the SIGCHI Conference Human Factors in Computing Systems (CHI), Montreal, QC, Canada, 22–27 April 2006; ACM Press: New York, NY, USA, 2006; pp. 21–30. [Google Scholar]
- Rosario, G.E.; Rundensteiner, E.A.; Brown, D.C.; Ward, M.O.; Huang, S. Mapping Nominal Values to Numbers for Effective Visualization. Inf. Vis. 2004, 3, 80–95. [Google Scholar] [CrossRef]
- Jusufi, I.; Klukas, C.; Kerren, A.; Schreiber, F. Guiding the Interactive Exploration of Metabolic Pathway Interconnections. Inf. Vis. 2012, 11, 136–150. [Google Scholar] [CrossRef]
- Frisch, M.; Dachselt, R. Visualizing Offscreen Elements of Node-Link Diagrams. Inf. Vis. 2013, 12, 133–162. [Google Scholar] [CrossRef]
- Abello, J.; Hadlak, S.; Schumann, H.; Schulz, H.J. A Modular Degree-of-Interest Specification for the Visual Analysis of Large Dynamic Networks. IEEE Trans. Vis. Comput. Graph. 2014, 20, 337–350. [Google Scholar] [CrossRef] [PubMed]
- Eichner, C.; Nocke, T.; Schulz, H.J.; Schumann, H. Interactive Presentation of Geo-Spatial Climate Data in Multi-Display Environments. ISPRS Int. J. Geo-Inf. 2015, 4, 493–514. [Google Scholar] [CrossRef]
- Wilkinson, L.; Anand, A.; Grossman, R.L. High-Dimensional Visual Analytics: Interactive Exploration Guided by Pairwise Views of Point Distributions. IEEE Trans. Vis. Comput. Graph. 2006, 12, 1363–1372. [Google Scholar] [CrossRef] [PubMed]
- Sips, M.; Neubert, B.; Lewis, J.P.; Hanrahan, P. Selecting Good Views of High-Dimensional Data Using Class Consistency. Comput. Graph. Forum 2009, 28, 831–838. [Google Scholar] [CrossRef]
- Chevalier, F.; Vuillemot, R.; Gali, G. Using Concrete Scales: A Practical Framework for Effective Visual Depiction of Complex Measures. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2426–2435. [Google Scholar] [CrossRef] [PubMed]



© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eichner, C.; Gladisch, S.; Schumann, H.; Tominski, C. Direct Visual Editing of Node Attributes in Graphs. Informatics 2016, 3, 17. https://doi.org/10.3390/informatics3040017
Eichner C, Gladisch S, Schumann H, Tominski C. Direct Visual Editing of Node Attributes in Graphs. Informatics. 2016; 3(4):17. https://doi.org/10.3390/informatics3040017
Chicago/Turabian StyleEichner, Christian, Stefan Gladisch, Heidrun Schumann, and Christian Tominski. 2016. "Direct Visual Editing of Node Attributes in Graphs" Informatics 3, no. 4: 17. https://doi.org/10.3390/informatics3040017
APA StyleEichner, C., Gladisch, S., Schumann, H., & Tominski, C. (2016). Direct Visual Editing of Node Attributes in Graphs. Informatics, 3(4), 17. https://doi.org/10.3390/informatics3040017