1. Introduction
Cluster analysis is one of the most popular techniques in statistical data analysis and machine learning. It aims to uncover group structures within a dataset by grouping objects (e.g., insurance policies) into distinct clusters (groups). These clusters are formed so that they are as heterogeneous as possible, while objects within them are as homogeneous as possible. In actuarial applications, clustering can help identify dominant groups of policies. The resulting clusters can further be used to create maps of insured risks and unsupervised pricing grids.
Although clustering techniques have been extensively studied in fields such as image processing, interest in their application to actuarial research was slower to emerge. Early notable contributions include
Williams and Huang (
1997), who applied K-means to identify policyholders with high claims ratio in a motor vehicle insurance portfolio, and
Hsu et al. (
1999), who introduced self-organizing maps (SOMs) in knowledge discovery tasks involving insurance policy data. More recently,
Hainaut (
2019) compared the effectiveness of K-means and SOMs in discriminating motorcycle insurance policies, based on the analysis of joint frequencies of categorical variables.
Originally designed to be used in numerical settings, conventional clustering methods are not well suited for handling the mixed-type nature of insurance data. Specifically, K-means relies on Euclidean distance, a dissimilarity measure for vectors in
. In the statistical literature,
Huang (
1997) introduced the K-modes algorithm to address this limitation. It substitutes Euclidean distance in K-means with Hamming, a dissimilarity measure for binary coded categorical variables.
Huang (
1998) later extended their approach to mixed-type data with the K-prototypes algorithm, a hybrid method that combines K-means and K-modes using a weighted sum of Euclidean and Hamming distances. In the actuarial literature,
Abdul-Rahman et al. (
2021) used K-modes as a benchmark method for their decision tree classifier in customer segmentation and profiling for life insurance. Similarly,
Gan (
2013) benchmarked K-prototypes against their Kriging method for the valuation of variable annuity guarantees.
Yin et al. (
2021) introduced an extension of K-prototypes to spatial data in life insurance, while
Zhuang et al. (
2018) extended K-prototypes to account for missing data and reduce the method’s sensitivity to prototype initialization. More recent adaptations have incorporated
Gower (
1971) distance, an alternative to Hamming, into K-medoids (
Kaufman and Rousseeuw 2009) to handle mixed data types. For applications in insurance, we refer to
Campo and Antonio (
2024);
Debener et al. (
2023);
Gan and Valdez (
2020).
Clustering techniques are not limited to the well-studied centroid-based methods such as K-means. In
Weiss (
1999), Weiss had already stressed the appeal of methods based on the eigenvectors of the affinity matrix for segmentation. The simplicity and stability of eigendecomposition algorithms are often cited as advantages for spectral decomposition. For further details, readers may refer to works by
Belkin and Niyogi (
2001);
Ng et al. (
2001);
Shi and Malik (
2000).
Von Luxburg (
2007) also provides a concise step-by-step tutorial on the graph theory underlying spectral clustering. Recently,
Mbuga and Tortora (
2021) extended spectral clustering to heterogeneous datasets, by defining a global dissimilarity measure using a weighted sum.
In their article on feature transformation,
Wei et al. (
2015) discuss the challenges associated with developing a linear combination of distances to effectively handle mixed-type datasets. Instead of adapting the dissimilarity measure in K-means to accommodate categorical data,
Shi and Shi (
2023) proposed to project categorical data into Euclidean space using categorical embedding and then applying standard K-means clustering.
Xiong et al. (
2012) adopted a different approach with their divisive hierarchical clustering algorithm specifically designed for categorical objects. Their method starts with an initialization based on Multiple Correspondence Analysis (MCA), and employs the Chi-square
distance between individual objects and sets of objects to define the objective function of their clustering algorithm.
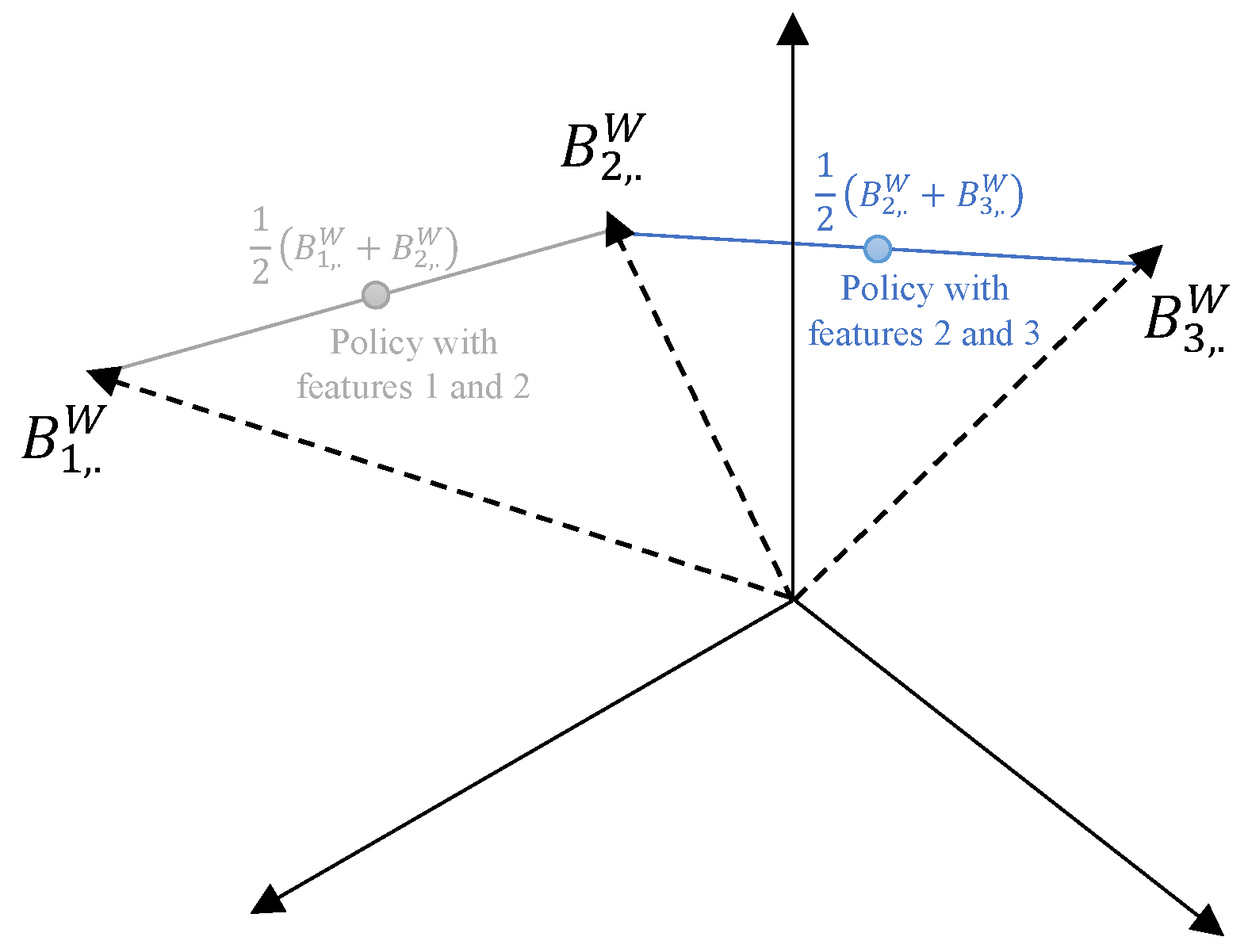
The aim of this article is to adapt well-established clustering methods (such as K-means, its variants, and spectral clustering) to complex insurance datasets containing both categorical and numerical variables. The primary challenge lies in defining an appropriate distance measure between insurance policies characterized by mixed data types. To achieve this, we propose a novel approach based on Burt distance.
This study contributes to the literature by introducing Burt distance as a novel dissimilarity measure for clustering heterogeneous data. We evaluate our approach through benchmarking against standard clustering methods, including K-means, K-modes, K-prototypes, and K-medoids, using a motor insurance portfolio. Unlike Hamming distance, our Burt distance-based framework accounts for potential dependencies between categorical classes (modalities). Moreover, our approach offers a more scalable alternative to the computationally expensive Gower distance, particularly when handling insurance portfolios that typically involve thousands of policies described by multiple attributes. Additionally, we empirically validate the applicability of our Burt approach to K-means variants (mini-batch and fuzzy) and spectral clustering. Lastly, we contribute to the literature by introducing a data reduction method, based on our Burt-adapted K-means, to mitigate the computational complexity associated with spectral clustering runtime.
The outline of the article is as follows. In
Section 2, we provide a holistic overview of the unsupervised K-means algorithm and its K-means++ heuristic to establish the foundational concepts and notations for our Burt distance-based framework. We empirically assess the performance of our proposed Burt distance-based K-means, comparing it with K-modes (Hamming distance) for categorical data, K-means (Euclidean distance) for numeric data, K-prototypes (Euclidean and Hamming distances), and K-medoids (Gower distance) for mixed-type data, using a motor insurance portfolio. In
Section 3.1 and
Section 3.2, we adapt the mini-batch and fuzzy K-means variants to our Burt approach. The mini-batch extension is particularly suited to address computational challenges associated with large-scale data, a common issue with insurance datasets, whereas fuzzy K-means is a soft form of clustering (each object can belong to multiple clusters), which is more aligned with the actuarial perspective on policy “classification”. Finally, in
Section 4, we adapt spectral clustering to our Burt approach. We propose a prior data reduction method using our Burt-adapted K-means to mitigate the computational complexity associated with spectral clustering’s eigendecomposition for large-scale datasets.
4. Burt-Adapted Spectral Clustering
Since K-means relies on Euclidean distance, each iteration partitions the space into (hyper)spherical clusters. This makes K-means unsuitable for detecting clusters with non-convex shapes. For example, in
Figure 7, K-means fails to distinguish the inner and outer rings or the upper and lower moons of the circular and moon-shaped data. This poor clustering performance stems from the fact that the natural clusters do not form convex regions.
By exploiting a deeper data geometry, spectral clustering (
Belkin and Niyogi 2001;
Ng et al. 2001;
Shi and Malik 2000) addresses the lack of flexibility of K-means in cluster boundaries. While K-means attempts to associate each cluster with a hard-edged sphere, spectral clustering embeds the data into a new space derived from a graphical representation of the dataset. Applying the K-means algorithm to this representation bypasses the spherical limitation, and results in the intended non-convex cluster shapes.
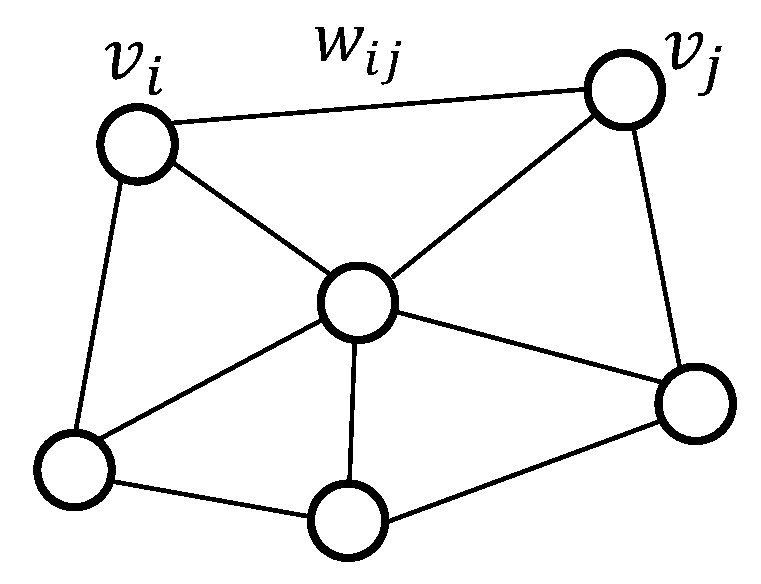
The graph theory is the core component in the graph representation of the dataset. As illustrated in
Figure 8, an undirected graph
is defined by three elements:
a set of vertices where each vertex represents one of the n data points in the dataset;
a set of edges whose entries are equal to 1 if two vertices and are connected by an undirected edge , and 0 otherwise;
a set of weights that contains the similarity between two vertices linked by an edge.
E and W can both be represented as matrices. The matrix W is often referred to as the weighted adjacency matrix A.
The dataset
, where
can thence be represented as a graph
by first associating each data point
with a vertex
. A measure of similarity is then defined between two data points
i and
j. A common choice is the Gaussian kernel:
where
is a tuning parameter. Two highly similar data points are connected by an edge
with a weight
equal to their similarity measure, while data points with low similarity are considered disconnected. Various methods exist for constructing a pairwise similarity graph, including (
Hainaut and Thomas 2022):
The -neighborhood graph: Points are connected if the pairwise distance between them is smaller than a threshold . In practice, we keep all similarities smaller than , while setting others to zero.
The (mutual) k-nearest neighbor graph: The vertex is connected to vertex if is among the k-nearest neighbors of . Since the neighborhood relationship is not symmetric, and the graph must be symmetric, we need to enforce the symmetry. The graph is made symmetric by ignoring the directions of the edges, i.e., by connecting and if either is among the k-nearest neighbors of or is among the k-nearest neighbors of , resulting in the k-nearest neighbor graph. Alternatively, the connection is made if and are mutual k-nearest neighbors, resulting in the mutual k-nearest neighbor graph.
The fully connected graph: All points in the dataset are connected.
Note that the choice of rule for constructing the graph influences the edge matrix and and may affect the resulting clusters.
To work with the graph representation, we apply the graph Fourier transform, which is based on the graph’s Laplacian representation. The Laplacian of a graph
G is given by the difference between its degree matrix
D and adjacency matrix
A:
But why is matrix
L called a graph Laplacian? We can understand this by defining a function on the vertices of the graph,
such that each vertex is mapped to a value,
. Consider a discrete periodic function that takes
N values at times
. This periodic structure can be represented by a ring graph, as depicted in
Figure 9, where the function wraps around to reflect the periodicity.
In order to find the Laplacian representation, we subtract the adjacency matrix
A from the diagonal degree matrix
D. The matrix
D contains on its diagonal the degree of each vertex
=
. The degree of a vertex
represents the weighted number of edges connected to it and is equal to the sum of the row
i in the adjacency matrix. The entries of the matrix
A indicate the absence or presence of a (weighted) edge between the vertices. In this particular case, none of the vertices have edges to themselves, so its diagonal elements are 0. Because our graph is undirected,
. Both the adjacency and degree matrices are encased in the resulting Laplacian matrix; the diagonal entries are the degrees of the vertices, and the off-diagonal elements are the negative edge weights:
Let represent the vector of function values evaluated at the vertices of a graph G. The product , where L is the graph Laplacian, corresponds precisely to the second-order finite difference derivative of the function . This operation plays a key role in analyzing the graph’s structure, as the partitioning of the graph (including determining the number of clusters) can be inferred from the eigenvalues and eigenvectors of the graph Laplacian matrix, a process known as spectral analysis.
Since L is a symmetric matrix, it can be decomposed using eigenvalue decomposition as , where U is the matrix of eigenvectors, and is a diagonal matrix containing the eigenvalues. As the Laplacian is positive semi-definite, it can be easily shown that the smallest eigenvalue of L is always zero.
The analysis of the eigenvalues provides useful insights into the graph’s structure. Specifically, the multiplicity of the zero eigenvalue reflects the number of disconnected components in the graph, giving a way to partition the graph. For instance, if all vertices are disconnected, all eigenvalues will be zero. As edges are added, some eigenvalues become non-zero, and the number of zero eigenvalues corresponds to the number of connected components in the graph. To illustrate this, consider the graph in
Figure 10, composed of
K disconnected sub-graphs. In this case, the Laplacian matrix will have
K zero eigenvalues, indicating that the graph consists of
K independent components.
Beyond identifying the number of connected components, the eigenvalues of the graph Laplacian provide information about the density of the connections. The smallest non-zero eigenvalue, known as the spectral gap, indicates the overall connectivity density of the graph. A large spectral gap suggests a densely connected graph, while a small spectral gap implies that the graph is close to being disconnected. Thus, the first positive eigenvalue offers a continuous measure of the graph’s connectedness.
The second smallest non-zero eigenvalue, often referred to as the Fiedler value or the algebraic connectivity, is particularly useful for partitioning the graph. This value approximates the minimum graph cut required to divide the graph into two connected components. For example, if the graph consists of two groups of vertices,
and
, connected by an additional edge (as shown in
Figure 11), vertices
and
on either side of the cut can be assigned to
or
by analyzing the values in the Fiedler vector.
If a graph consists of
K disconnected sub-graphs, it can be shown that the elements of the
K eigenvectors with null eigenvalues are approximately constant over each cluster. In other words, the eigenvectors’ coordinates of points belonging to the same cluster are identical. Intuitively, since the eigenvectors of zero tell us how to partition the graph, the first
K columns of
U (the eigenvectors’ coordinates) consist of the cluster indicator vectors. Let us assume two well-separated sub-graphs. The eigenvectors’ coordinates
with a null eigenvalue are constant for all vertices
belonging to the same sub-graph
. Formally, for
, we have
. The proof is detailed in
Appendix A. If the
K clusters are not identified, K-means can be applied to the rows of the first
K eigenvectors, as these rows can serve as representations of the vertices. The complete procedure is outlined in Algorithm 5 (
Von Luxburg 2007) from
Hainaut and Thomas (
2022).
| Algorithm 5: Spectral clustering. |
Input: Dataset X Init: Represent the dataset X as a graph (1) Calculation of the Laplacian matrix (2) Extract the eigenvector matrix U and diagonal matrix of eigenvalues from (3) Fix k and build the matrix of eigenvectors with the k eigenvalues closest to zero (4) Run the K-means (Algorithm 1) with the dataset of for (5) The data point is associated to the cluster of |
As demonstrated by
Von Luxburg (
2007), spectral clustering’s performance is superior to other widely used clustering algorithms, particularly due to its ability to accommodate for non-convex cluster shapes. To illustrate this, we apply spectral clustering to the circular dataset introduced earlier in this section, which consists of 1200 data points—800 in the outer ring, and 400 in the inner circle.
For this analysis, we construct a graph using the mutual k-nearest neighbors with
and set the similarity parameter to
. The left plot of
Figure 12 clearly shows that spectral clustering effectively identifies the distinct inner and outer rings of the dataset. In the right plot, we present the coordinates of all pairs of eigenvectors,
. Consistent with the above property, we observe in the right plot of
Figure 12 that the eigenvector coordinates for points within the same cluster are identical (they are superimposed).
In real-world applications, performing spectral clustering on large datasets presents significant challenges, primarily due to the rapid growth in the size of the edge and weight matrices
. When only few vertices are connected, it is possible to represent
as a sparse matrix, where most elements are zero, thus saving memory and computational resources. An alternative approach to manage this complexity involves first reducing the size of the initial dataset using the K-means algorithm. By applying K-means, we can reduce the number of data points to a manageable number of centroids, and then perform spectral clustering on these centroids. This method not only reduces the dimensionality but also mitigates the high computational cost associated with the graph representation.
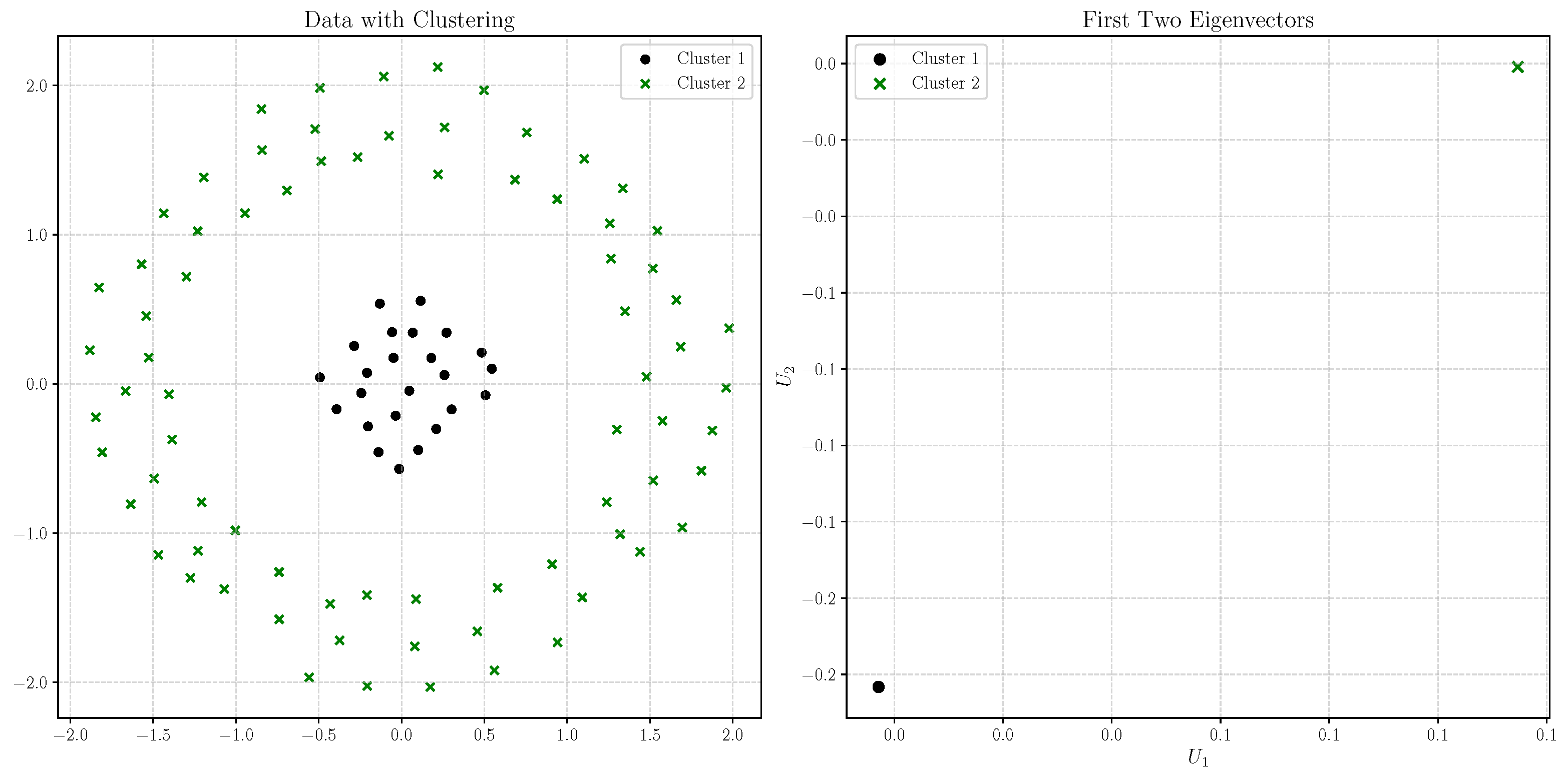
Figure 13 demonstrates the effectiveness of this approach. The figure shows the 100 centroids obtained from applying K-means to the original dataset of 1200 points, along with their corresponding cluster. The right plot illustrates the coordinates of the pairs of eigenvectors,
, for
i ranging from 1 to 100, reflecting the results of the spectral clustering applied to these centroids.
To conclude this section, we apply the spectral clustering algorithm to the Wasa insurance dataset. We first convert the variables “driver’s age” and “vehicle age” into categorical variables, as described in
Section 2.3.
We then compute the disjunctive table
and the weighted Burt matrix
using Burt distance. Following the procedure outlined in
Section 2.2, each insurance policy
i = 1, …, N characterized by multiple modalities is represented by its center of gravity in Burt space:
.
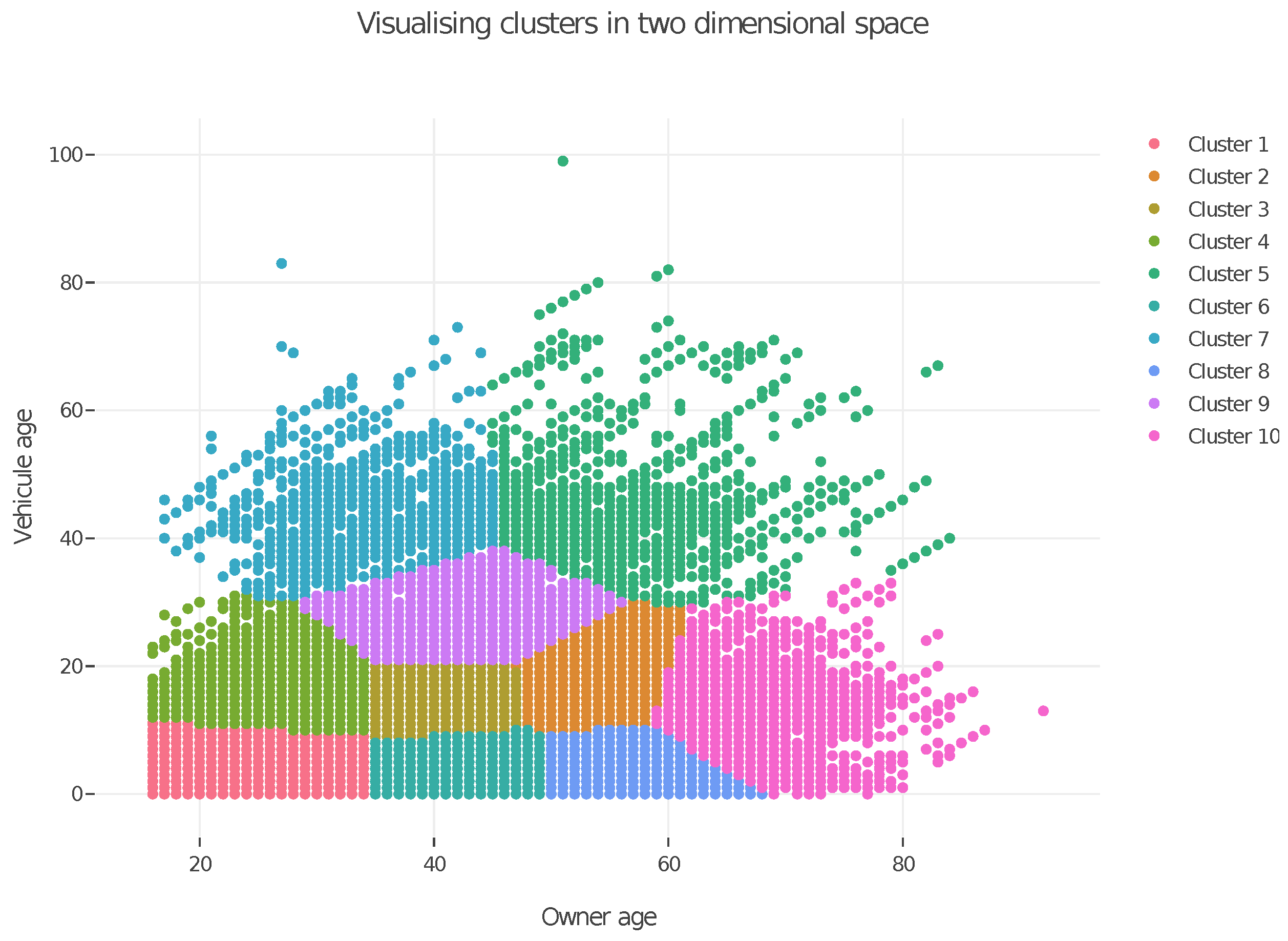
The dataset contains 62,436 contracts. We reduce its dimension by applying our Burt distance-based K-means algorithm with 1500 centroids. We then construct a graph based on these centroids using the mutual k-nearest neighbors (with ) and a similarity parameter . We run the spectral clustering algorithm on this reduced dataset with clusters.
Table 21 summarizes the results, including the policy allocation, the dominant features for each cluster, and the average claim frequency. The application of spectral clustering to the reduced dataset, processed through our Burt distance-based K-means, demonstrates its effectiveness in discriminating between drivers with different risk profiles.
Notably, unlike K-means (and its mini-batch and fuzzy variants), spectral clustering can identify a greater number of clusters predominantly consisting of female drivers, who are underrepresented in the insurance portfolio. Additionally, the allocation of policies differs significantly from previous results, with the cluster exhibiting the lowest claim frequency containing the majority of policies (approximately 40%). This indicates that spectral clustering effectively identifies the rarety of claim events.
Table 22 further supports our method’s efficacy, achieving reasonable goodness of fit in terms of deviance.











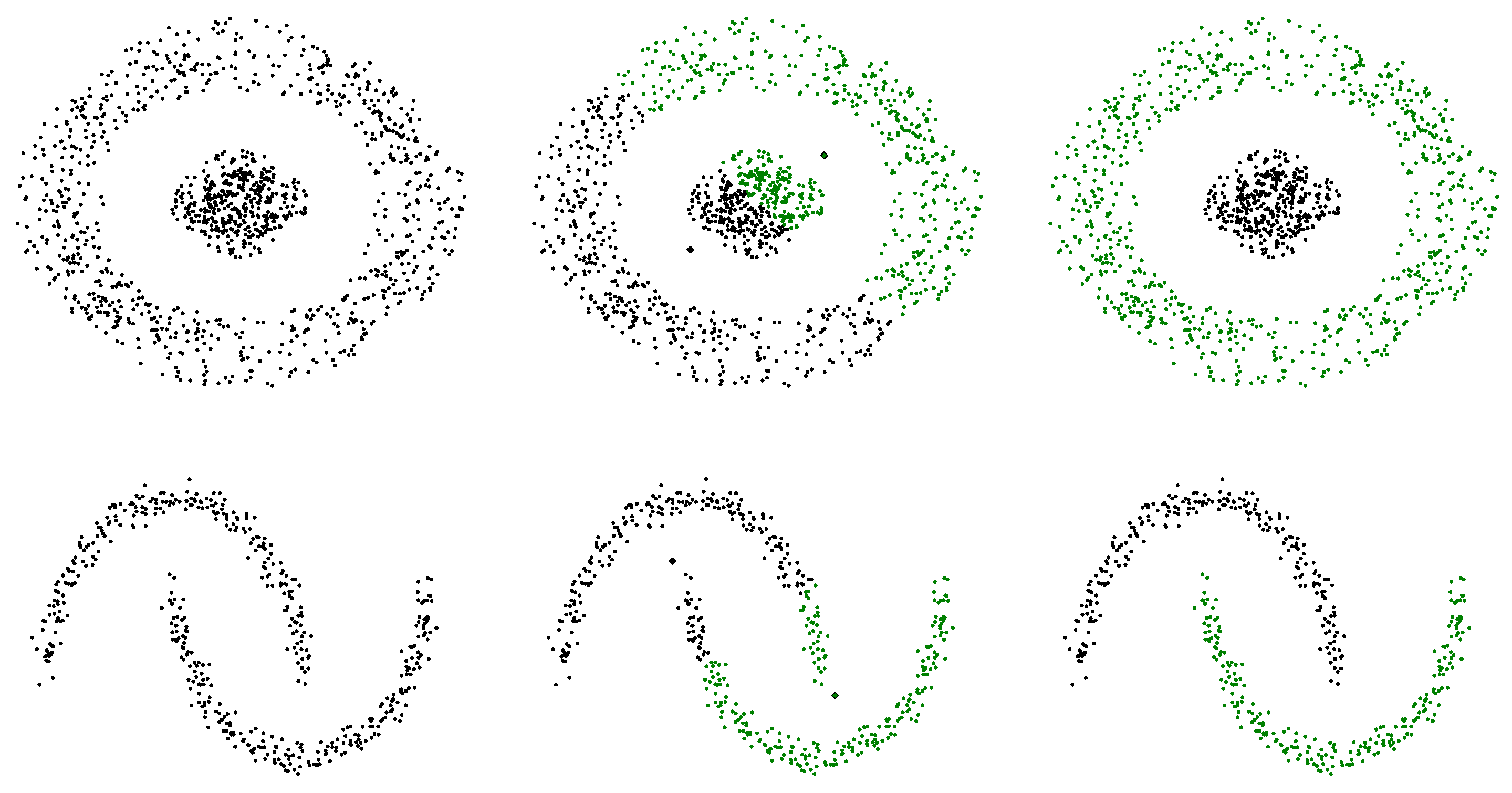





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}