
Unsupervised Insurance Fraud Prediction Based on Anomaly Detector Ensembles

Abstract
:1. Introduction
- we present BHAD, a novel Bayesian histogram-based anomaly detection method, which directly estimates the unknown number of bins using an informative hierarchical prior
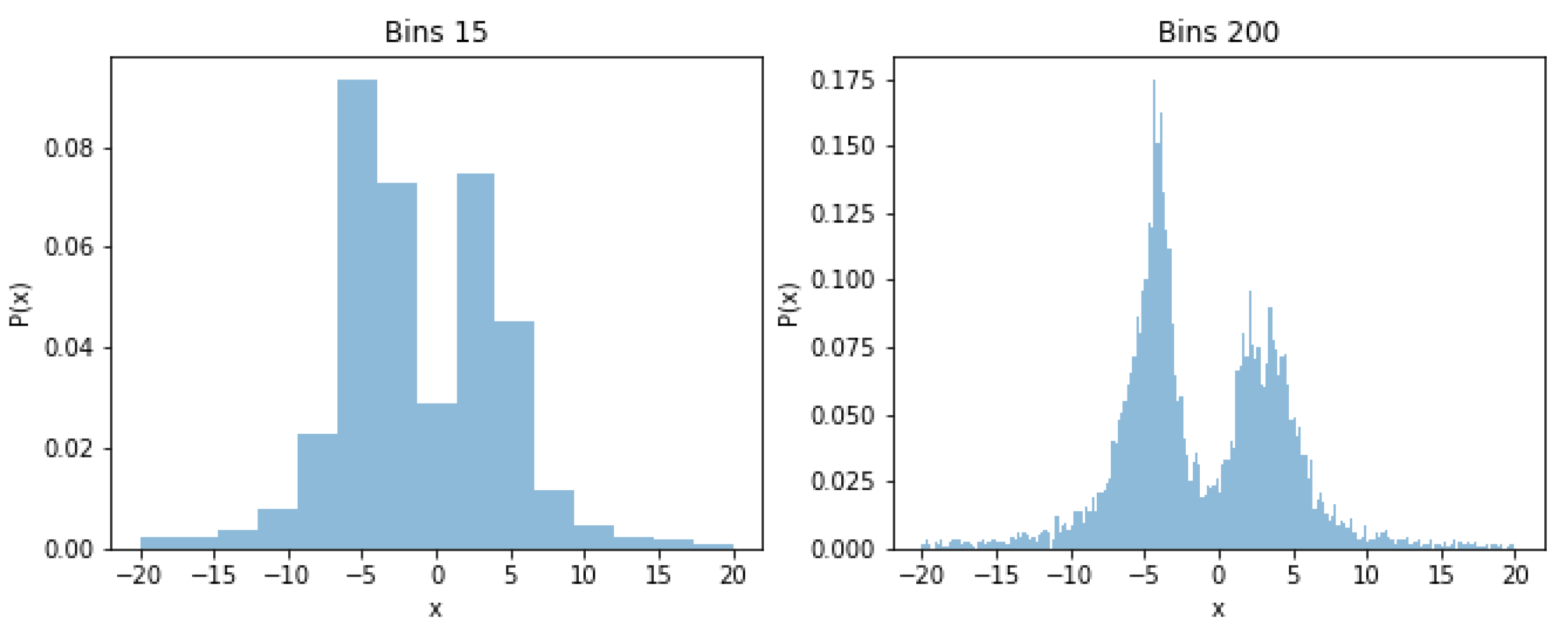
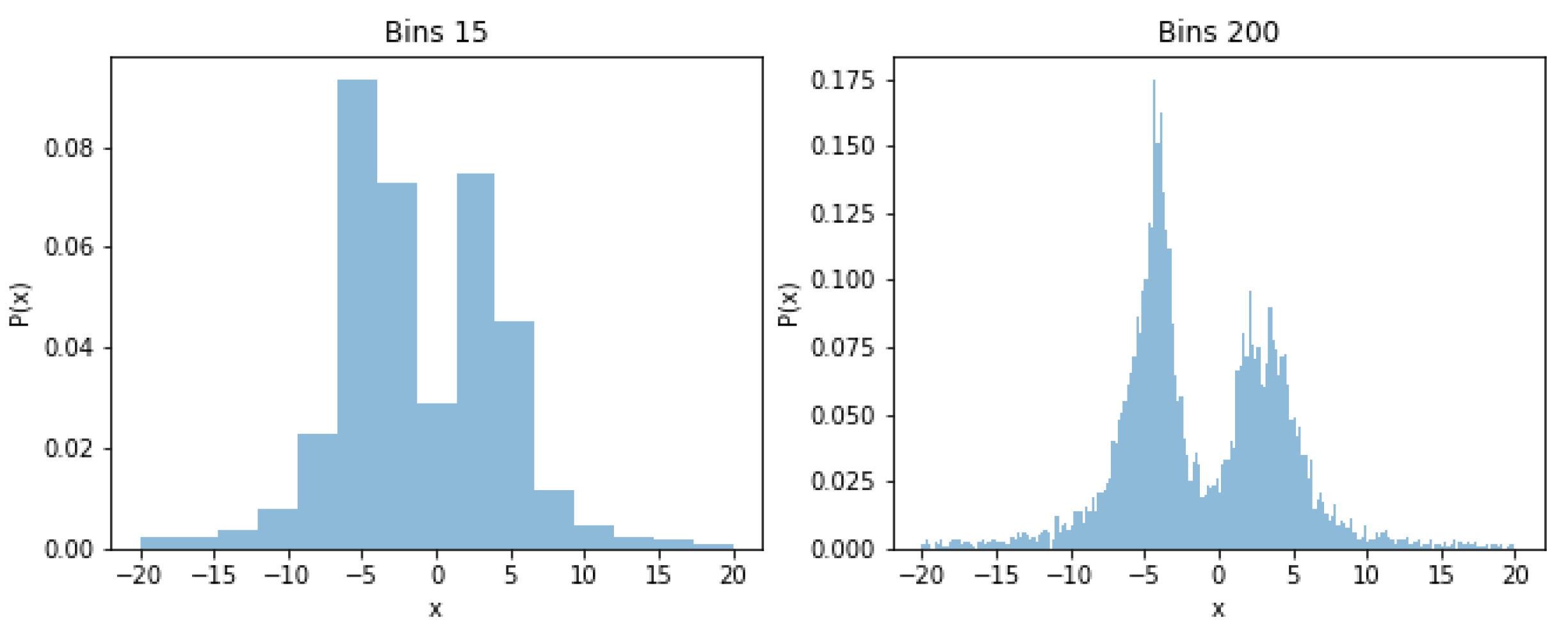
- we introduce a generic approach to enable local and global model explanations for outlier ensembles using a supervised surrogate model
- we propose a variation of the Greedy model selection algorithm of Schubert et al. (2012) using the mutual information of two score distributions as a similarity measure
- we give a detailed description of a real insurance claims fraud detection application and share various feature engineering ideas, e.g., utilizing natural language processing and clustering techniques
2. Bhad: Bayesian Histogram-Based Anomaly Detector
2.1. Likelihood Function
2.2. Prior Distributions
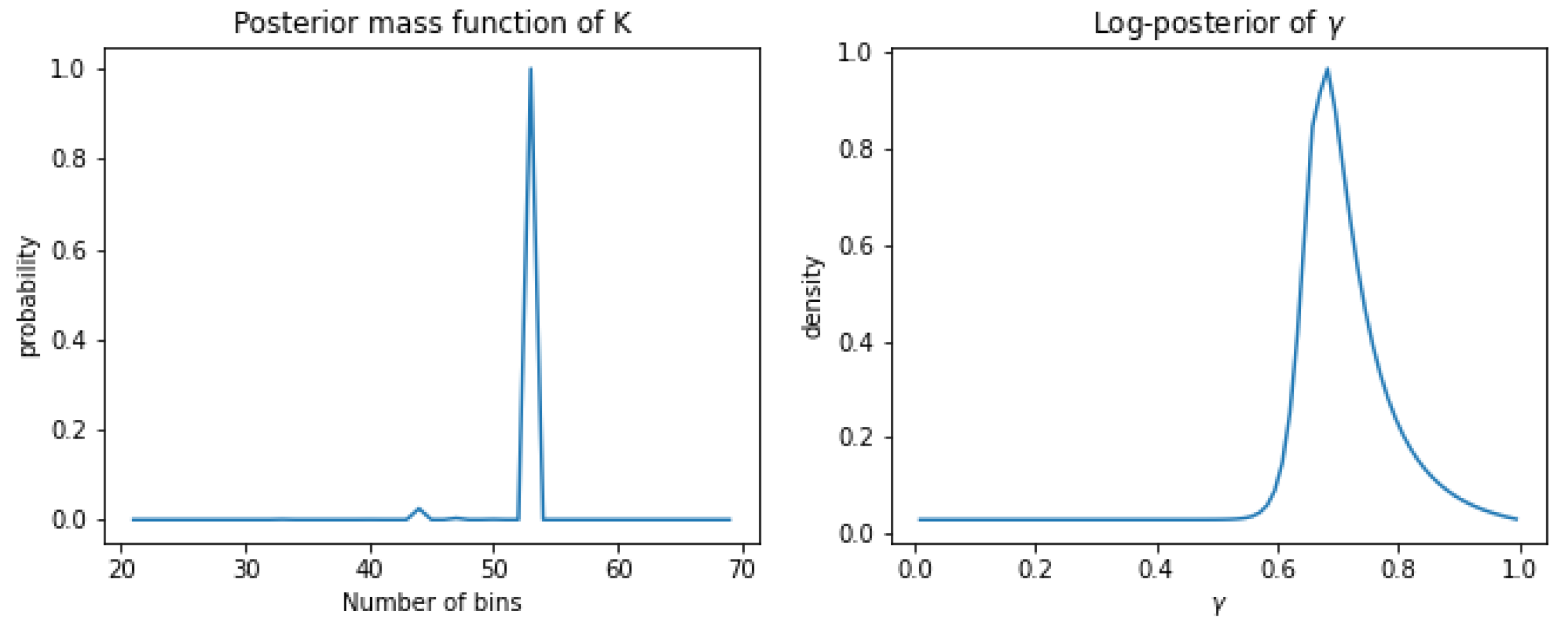
2.3. Posterior Distributions
2.4. Anomaly Prediction
| Algorithm 1: Bayesian Histogram-based Anomaly Detector |
 |
3. Model Combination
3.1. Static Ensemble Approach
3.2. Dynamic Ensemble Approach
| Algorithm 2: Greedy Model Selection |
 |
3.3. Model Explanation
4. Simulation Experimental Design
- Gaussian VAE: we choose 80 training epochs, learning rate of 0.001, latent space of dimension 10 and a single fully connected hidden layer with 200 nodes in the encoder and decoder network (see Kingma and Welling 2014 for details)
- SB-VAE: we choose as shape hyperparameters of the Beta prior p.d.f. used in the stickbreaking algorithm, a learning rate of 0.001 and the network architecture as for the VAE (see Nalisnick and Smyth 2017 for details).12
- Bayesian histogram-based anomaly detector (BHAD) using
- Isolation Forest with number of trees
- One-class SVM with radial basis function kernel
- Average k-Nearest Neighbors over
- Angle-based outlier detector (ABOD) using
- Local Outlier Factor (LOF) using
- Greedy algorithm with weight boosting using a drop rate (see Campos et al. 2018)
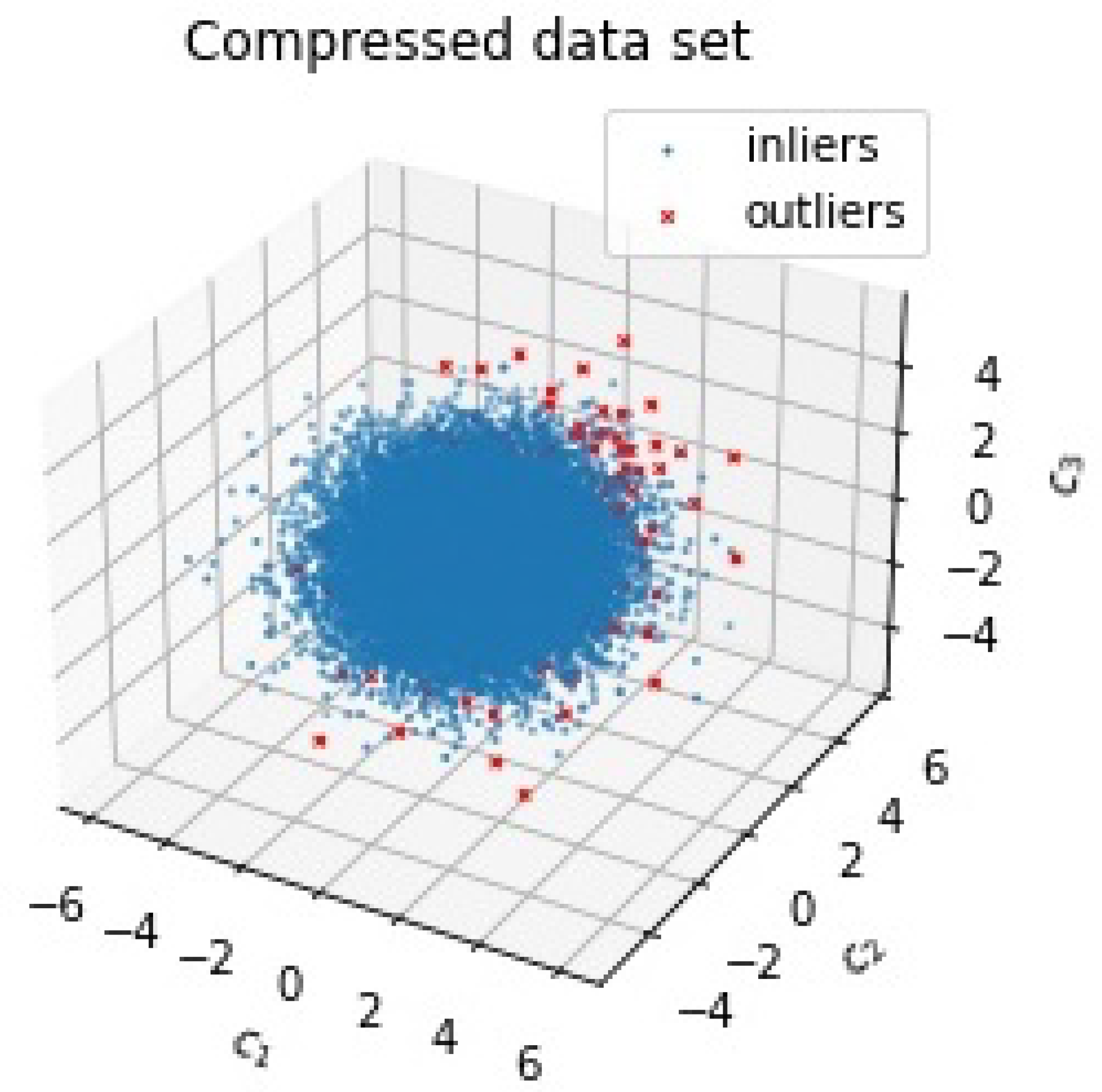
5. Application: Benchmarks Datasets
6. Application: Detection of Fraudulent Insurance Claims
6.1. Feature Engineering
6.2. Empirical Results
7. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Short Description | Type |
|---|---|
| Diff. in days—notification date and date of loss | numeric |
| Years of client relationship | numeric |
| Number of claims per policy | numeric |
| Rolling number of claims per policy | numeric |
| Number of claims per claimant | numeric |
| Rolling number of claims (insureds) per group of claimants | numeric |
| Number of claims per insured | numeric |
| Loss ratio per insured (in percentage) | numeric |
| Claim description contains keywords for accidents and natural causes | numeric |
| Claim description contains collision, impact, crash, sink, grounding and similar | numeric |
| Claim description contains fire, burn and similar | numeric |
| Claim description contains luggage, baggage, cash, money, item, belonging and similar | numeric |
| Claim description contains passenger, bodily injury, poisoning and similar | numeric |
| Claim description contains plane, aircraft, helicopter and similar | numeric |
| Claim description contains storm, wind, weather and similar | numeric |
| Claim description contains stolen, theft, disappear and similar | numeric |
| Claim description contains vessel, ship and similar | numeric |
| Claim description contains water, damage, broken, repair and similar | numeric |
| Claim description contains yacht and similar | numeric |
| Claim description contains similar fraud keywords | numeric |
| Diff. in days—date of policy expiration and date of notification | numeric |
| Various interaction variables of claim amount and combinations of above features | numeric |
| Date of loss is public holiday | categorical |
| Date of notification is public holiday | categorical |
| 1 | Note expression (1) constitutes a proper density function. |
| 2 | |
| 3 | We will omit conditioning on in the following to keep notation simple. |
| 4 | For comparison: frequentist estimates using Sturges rule are and using Freedman-Diaconis rule. |
| 5 | With scalar replaced by scalar in the following. |
| 6 | Obviously the AVF algorithm could easily extended to continuous data, by simply using a discretization, like binning. |
| 7 | This is equivalent to the non-parametric Spearman’s coefficient. |
| 8 | The only restriction on the selected density model is that we should know how to generate draws from it. |
| 9 | This is sometimes called the contamination rate in the literature. |
| 10 | This puts both groups of observations on the same footing since otherwise the mutual information would be driven by the vast majority of non-outlier cases. |
| 11 | Here all features are normalized to having zero mean and variance of one. |
| 12 | We used the publicly available Theano code of the authors and integrated it into a generic scikit-learn Python class API. |
| 13 | Both datasets are available online from http://odds.cs.stonybrook.edu/ (accessed on 1 May 2022). |
| 14 | This is the AGCS SE standard on Anti-Fraud issued by AGCS compliance. |
| 15 | Subsequently each claim description corresponds to a “document”. |
| 16 | These are easily accessible via Python libraries like spaCy. |
| 17 | Setting and in case needed. |
References
- Adadi, Amina, and Mohammed Berrada. 2018. Peeking inside the black-box: A survey on explainable artificial intelligence (xai). IEEE Access 6: 52138–60. [Google Scholar] [CrossRef]
- Aggarwal, Charu C. 2012. Outlier Analysis. Cham: Springer. [Google Scholar]
- An, Jinwon, and Sungzoon Cho. 2015. Variational autoencoder based anomaly detection using reconstruction probability. Special Lecture on IE 2: 1–18. [Google Scholar]
- Angiulli, Fabrizio, and Clara Pizzuti. 2002. Fast outlier detection in high dimensional spaces. Paper presented at the 6th European Conference on Principles of Data Mining and Knowledge Discovery (PKDD), Helsinki, Finland, August 19–23; pp. 15–26. [Google Scholar]
- Box, George E. P. 1979. Robustness in the Strategy of Scientific Model Building. Edited by Robert L. Launer and Graham N. Wilkinson. Robustness in Statistics. Cambridge: Academic Press. [Google Scholar]
- Breunig, Markus M., Hans-Peter Kriegel, Raymond T. Ng, and Jörg Sander. 2000. Lof: Identifying density-based local outliers. Paper presented at the ACM International Conference on Management of Data (SIGMOD), Dallas, TX, USA, May 15–18; pp. 93–104. [Google Scholar]
- Buonaguidi, Bruno, Antonietta Mira, Herbert Bucheli, and Viton Vitanis. 2022. Bayesian Quickest Detection of Credit Card Fraud. Bayesian Analysis 17: 261–90. [Google Scholar] [CrossRef]
- Campos, Guilherme O., Arthur Zimek, and Wagner Meira. 2018. An unsupervised boosting strategy for outlier detection ensembles. Paper presented at the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Melbourne, VIC, Australia, June 3–6; pp. 564–76. [Google Scholar]
- Chen, Zhaomin, Chai Kiat Yeo, Bu Sung Lee, and Chiew Tong Lau. 2018. Autoencoder-based network anomaly detection. Wireless Telecommunications Symposium (WTS) 2018: 1–5. [Google Scholar]
- Dietterich, Thomas. 1998. Approximate statistical tests for comparing supervised classification learning algorithms. Neural Computation 10: 1895–923. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dietterich, Thomas. 2000. Ensemble methods in machine learning. Proc. MCS 2000: 1–15. [Google Scholar]
- Ekin, Tahir, Greg Lakomski, and Rasim Muzaffer Musal. 2019. An unsupervised bayesian hierarchical method for medical fraud assessment. Statistical Analysis and Data Mining: The ASA Data Science Journal 12: 116–24. [Google Scholar] [CrossRef]
- Elkan, Charles, and Keith Noto. 2008. Learning classifiers from only positive and unlabeled data. Paper presented at the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, August 24–27; pp. 213–20. [Google Scholar]
- Ester, Martin, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. 1996. A density-based algorithm for discovering clusters in large spatial databases with noise. Paper presented at the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), Portland, OR, USA, August 2–4; pp. 226–31. [Google Scholar]
- Goldstein, Markus, and Andreas Dengel. 2012. Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm. Paper presented at the KI-2012: Poster and Demo Track, Saarbrucken, Germany, September 24–27; pp. 59–63. [Google Scholar]
- Gomes, Chamal, Zhuo Jin, and Hailiang Yang. 2021. Insurance fraud detection with unsupervised deep learning. Journal of Risk and Insurance 88: 591–624. [Google Scholar] [CrossRef]
- Ghosh, Joydeep, and Ayan Acharya. 2011. Cluster ensembles. WIREs DMKD 4: 305–15. [Google Scholar] [CrossRef]
- Hawkins, Douglas. 1980. Identification of Outliers. London and New York: Chapman and Hall, CRC Press. [Google Scholar]
- Jeffreys, Harold. 1961. Theory of Probability. Oxford: Oxford University Press. [Google Scholar]
- Kingma, Diederik P., and Max Welling. 2014. Auto-encoding variational bayes. CoRR, 226–31. Available online: https://arxiv.org/abs/1312.6114 (accessed on 8 May 2022).
- Knorr, Edwin M., and Raymond T. Ng. 1997. A unified notion of outliers: Properties and computation. Paper presented at the 3rd ACM International Conference on Knowledge Discovery and Data Mining (KDD), Newport Beach, CA, USA, August 14–17; pp. 219–22. [Google Scholar]
- Knuth, Kevin H. 2019. Optimal data-based binning for histograms and histogram-based probability density models. Digital Signal Processing 95: 102581. [Google Scholar] [CrossRef]
- Koufakou, Anna, Enrique G. Ortiz, Michael Georgiopoulos, Georgios C. Anagnostopoulos, and Kenneth M. Reynolds. 2007. A scalable and efficient outlier detection strategy for categorical data. Paper presented at the 19th IEEE International Conference on Tools with Artificial Intelligence (ICTAI 2007), Patras, Greece, October 29–31; pp. 210–17. [Google Scholar]
- Kriegel, Hans-Peter, Matthias Schubert, and Arthur Zimek. 2008. Angle-based outlier detection in high dimensional data. Paper presented at the 14th ACM International Conference on Knowledge Discovery and Data Mining (SIGKDD), Las Vegas, NV, USA, August 24–27; pp. 444–52. [Google Scholar]
- Liu, Fei T., Kai M. Ting, and Zhi-Hua Zhou. 2012. Isolation-based anomaly detection. ACM Transactions on Knowledge Discovery from Data (TKDD) 3: 1–39. [Google Scholar] [CrossRef]
- Lundberg, Scott M., and Su-In Lee. 2017. A unified approach to interpreting model predictions. Advances in Neural Information Processing Systems 30: 4765–74. [Google Scholar]
- Molnar, Christoph. 2022. Interpretable Machine Learning—A Guide for Making Black Box Models Explainable, 2nd ed. Munich: Mucbook Clubhouse. [Google Scholar]
- Murphy, Kevin P. 2012. Machine Learning: A Probabilistic Perspective. Cambridge: MIT Press. [Google Scholar]
- Müller, Peter, Fernando A. Quintana, Alejandro Jara, and Tim Hanson. 2015. Bayesian Nonparametric Data Analysis. Heidelberg: Springer. [Google Scholar]
- Nalisnick, Eric, and Padhraic Smyth. 2017. Stick-breaking variational autoencoders. Paper presented at the 5th International Conference on Learning Representations, ICLR, Toulon, France, April 24–26. [Google Scholar]
- Nelson, Kenric P. 2017. Assessing probabilistic inference by comparing the generalized mean of the model and source probabilities. Entropy 19: 286. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, David F. N., Lucio F. Vismari, Alexandre M. Nascimento, Jorge Rady De Almeida, Paulo S. Cugnasca, João B. Camargo, Leandro P. F. de Almeida, Rafael Gripp, and Marcelo M. Neves. 2021. A new interpretable unsupervised anomaly detection method based on residual explanation. arXiv arXiv:2103.07953. [Google Scholar] [CrossRef]
- Papadimitriou, Spiros, Hiroyuki Kitagawa, Phillip B. Gibbons, and Christos Faloutsos. 2003. Loci: Fast outlier detection using the local correlation integral. Paper presented at the 19th International Conference on Data Engineering (ICDE), Bangalore, India, May 5–8; pp. 315–26. [Google Scholar]
- Pennington, Jeffrey, Richard Socher, and Christopher Manning. 2014. Paper presented at the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, October 25–29; Doha: Association for Computational Linguistics.
- Phua, Clifton, Vincent C.-S. Lee, K. Smith-Miles, and R. Gayler. 2010. A comprehensive survey of data mining-based fraud detection research. arXiv arXiv:1009.6119. [Google Scholar]
- Scargle, Jeffrey D., Jay P. Norris, Brad Jackson, and James Chiang. 2013. Studies in astronomical time series analysis. vi. bayesian block representations. The Astrophysical Journal 764: 167. [Google Scholar] [CrossRef] [Green Version]
- Schubert, Erich, Wojdanowski Remigius, Arthur Zimek, and Hans-Peter Kriegel. 2012. On evaluation of outlier rankings and outlier scores. Paper presented at the 12th SIAM International Conference on Data Mining (SDM), Anaheim, CA, USA, April 29–May 1; pp. 210–17. [Google Scholar]
- Scott, David W. 2015. Multivariate Density Estimation: Theory, Practice, and Visualization. Wiley Series in Probability and Statistics; Hoboken: Wiley. [Google Scholar]
- Valentini, Giorgio, and Francesco Masulli. 2002. Ensemble of learning machines. Proc. Neural Nets WIRN 2486: 3–22. [Google Scholar]
- Vosseler, Alexander. 2016. Bayesian model selection for unit root testing with multiple structural breaks. Computational Statistics and Data Analysis 100: 616–30. [Google Scholar] [CrossRef]
- Vosseler, Alexander, and Enzo Weber. 2018. Forecasting seasonal time series data: A bayesian model averaging approach. Computational Statistics 33: 1733–65. [Google Scholar]
- Zafari, Babak, and Tahir Ekin. 2019. Topic modelling for medical prescription fraud and abuse detection. Journal of the Royal Statistical Society Series C Applied Statistics 68: 751–69. [Google Scholar] [CrossRef]
- Zhao, Yue, Xiyang Hu, Cheng Cheng, Cong Wang, Changling Wan, Wen Wang, Jianing Yang, Haoping Bai, Zheng Li, Cao Xiao, and et al. 2021. Suod: Accelerating large-scale unsupervised heterogeneous outlier detection. Paper presented at the Machine Learning and Systems, San Jose, CA, USA, April 4–7. [Google Scholar]
- Zhao, Yue, Zain Nasrullah, Maciej K. Hryniewicki, and Zheng Li. 2019. Lscp: Locally selective combination in parallel outlier ensembles. Paper presented at the 2019 SIAM International Conference on Data Mining (SDM), Calgary, AB, Canada, May 2–4; pp. 585–93. [Google Scholar]
- Zhou, Zhi-Hua. 2012. Ensemble Methods: Foundations and Algorithms. New York: Chapman and Hall, CRC Press. [Google Scholar]
- Zimek, Arthur, Ricardo J. G. B. Campello, and Jörg Sander. 2014. Ensembles for unsupervised outlier detection: Challenges and research questions. ACM SIGKDD Explorations 15: 11–22. [Google Scholar] [CrossRef]

| Model | F1 Score | Precision | Recall | AUC |
|---|---|---|---|---|
| SB-VAE | 0.9791 | 0.9996 | 0.9598 | 0.9998 |
| VAE | 0.9566 | 0.9991 | 0.9180 | 0.9977 |
| BHAD | 0.9715 | 0.9995 | 0.9455 | 0.9996 |
| IForest | 0.9437 | 0.9989 | 0.8947 | 0.9986 |
| OCSVM | 0.9390 | 0.9987 | 0.8865 | 0.9974 |
| kNN | 0.9828 | 0.9997 | 0.9671 | 0.9999 |
| ABOD | 0.9533 | 0.9924 | 0.9176 | 0.9966 |
| LOF | 0.9723 | 0.9999 | 0.9477 | 0.9999 |
| Full ensemble 1 | 0.9735 | 0.9995 | 0.9493 | 0.9997 |
| Minimum rank 2 | 0.9640 | 0.9993 | 0.9317 | 0.9997 |
| Greedy MInfo 3 | 0.9817 | 0.9997 | 0.9651 | 0.9998 |
| Greedy Pearson 4 | 0.9828 | 0.9997 | 0.9671 | 0.9999 |
| Model | F1 Score | Precision | Recall | AUC |
|---|---|---|---|---|
| SB-VAE | 0.6670 | 0.5030 | 0.9901 | 0.6691 |
| VAE | 0.6669 | 0.5027 | 0.9904 | 0.6452 |
| BHAD | 0.7767 | 0.6523 | 0.9600 | 0.9410 |
| IForest | 0.7900 | 0.6714 | 0.9609 | 0.9508 |
| OCSVM | 0.7004 | 0.5532 | 0.9542 | 0.8304 |
| kNN | 0.6838 | 0.5333 | 0.9525 | 0.7290 |
| ABOD | 0.6727 | 0.5237 | 0.9401 | 0.6714 |
| LOF | 0.6731 | 0.5143 | 0.9739 | 0.5125 |
| Full ensemble | 0.7022 | 0.5556 | 0.9543 | 0.8515 |
| Minimum rank | 0.7245 | 0.5832 | 0.9563 | 0.8635 |
| Greedy MInfo | 0.7759 | 0.6512 | 0.9601 | 0.9412 |
| Greedy Pearson | 0.7766 | 0.6520 | 0.9601 | 0.9409 |
| Model | F1 Score | Precision | Recall | AUC |
|---|---|---|---|---|
| SB-VAE | 0.6941 | 0.5329 | 0.9954 | 0.8924 |
| VAE | 0.6703 | 0.5071 | 0.9886 | 0.7556 |
| BHAD | 0.8152 | 0.6988 | 0.9793 | 0.9485 |
| IForest | 0.7967 | 0.6734 | 0.9763 | 0.9390 |
| OCSVM | 0.7225 | 0.5778 | 0.9642 | 0.6693 |
| kNN | 0.7797 | 0.6507 | 0.9734 | 0.9252 |
| ABOD | 0.7295 | 0.5912 | 0.9539 | 0.9027 |
| LOF | 0.6865 | 0.5278 | 0.9823 | 0.7903 |
| Full ensemble | 0.7183 | 0.5720 | 0.9660 | 0.9113 |
| Minimum rank | 0.7608 | 0.6242 | 0.9749 | 0.9091 |
| Greedy MInfo | 0.8089 | 0.6882 | 0.9821 | 0.9482 |
| Greedy Pearson | 0.8105 | 0.6902 | 0.9824 | 0.9485 |
| Country | Recall/Sensitivity | 95% HPD 1 interval |
|---|---|---|
| UK | 0.26 | [0.19, 0.36] |
| US | 0.14 | [0.13, 0.16] |
| Spain | 0.10 | [0.02, 0.41] |
| Germany | 0.55 | [0.37, 0.72] |
| South-Africa | 0.07 | [0.02, 0.32] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vosseler, A. Unsupervised Insurance Fraud Prediction Based on Anomaly Detector Ensembles. Risks 2022, 10, 132. https://doi.org/10.3390/risks10070132
Vosseler A. Unsupervised Insurance Fraud Prediction Based on Anomaly Detector Ensembles. Risks. 2022; 10(7):132. https://doi.org/10.3390/risks10070132
Chicago/Turabian StyleVosseler, Alexander. 2022. "Unsupervised Insurance Fraud Prediction Based on Anomaly Detector Ensembles" Risks 10, no. 7: 132. https://doi.org/10.3390/risks10070132
APA StyleVosseler, A. (2022). Unsupervised Insurance Fraud Prediction Based on Anomaly Detector Ensembles. Risks, 10(7), 132. https://doi.org/10.3390/risks10070132