Abstract
The problem of randomized maximum entropy estimation for the probability density function of random model parameters with real data and measurement noises was formulated. This estimation procedure maximizes an information entropy functional on a set of integral equalities depending on the real data set. The technique of the Gâteaux derivatives is developed to solve this problem in analytical form. The probability density function estimates depend on Lagrange multipliers, which are obtained by balancing the model’s output with real data. A global theorem for the implicit dependence of these Lagrange multipliers on the data sample’s length is established using the rotation of homotopic vector fields. A theorem for the asymptotic efficiency of randomized maximum entropy estimate in terms of stationary Lagrange multipliers is formulated and proved. The proposed method is illustrated on the problem of forecasting of the evolution of the thermokarst lake area in Western Siberia.
1. Introduction
Estimating the characteristics of models is a very popular and, at the same time, important problem of science. This problem arises in applications with unknown parameters, which have to be estimated somehow using real data sets. In particular, such problems have turned out to be fundamental in machine learning procedures [1,2,3,4,5]. The core of these procedures is a parametrized model trained by statistically estimating the unknown parameters based on real data. Most of the econometric problems associated with reconstructing functional relations and forecasting also reduce to estimating the model parameters; for example, see [6,7].
The problems described above are solved using traditional mathematical statistics methods, such as the maximum likelihood method and its derivatives, the method of moments, Bayesian methods, and their numerous modifications [8,9].
Among the mathematical tools for parametric estimation mentioned, a special place is occupied by entropy maximization methods for finite-dimensional probability distributions [10,11].
Consider a random variable x taking discrete values with probabilities respectively, and r functions of this variable with discrete values. The discrete probability distribution function is defined as the solution of the problem
where are given constants.
If then the system of equalities specifies constraints on the kth moments of the discrete random variable In the case of equality constraints, some modifications of this problem adapted to different applications were studied in [10,11,12,13]. Since this problem is conditionally extremal, it can be solved using the Lagrange method, which leads to a system of equations for Lagrange multipliers. The latter often turn out to be substantially nonlinear functions, and hence, rather sophisticated techniques are needed for their numerical calculation [14,15].
In the case of inequality constraints, this problem belongs to the class of mathematical programming problems [16].
The entropy maximization principle is adopted to estimate the parameters of a priori distributions when constructing Bayesian estimates [17,18] or maximum likelihood estimates.
The parameters of probability distributions (continuous or discrete) can be estimated using various mathematical statistics methods, including the method of entropy maximization. Their efficiency in hydrological problems was compared in [19]. Apparently, the method of entropy maximization yields the best results in such problems due to the structure of hydrological data.
The problem of estimating some model characteristics on real data was further developed in connection with the appearance of new machine learning methods, called randomized machine learning (RML) [20]. They are based on models with random parameters, and it is necessary to estimate the probability density functions of these parameters. The estimation algorithm (RML algorithm) is formulated in terms of functional entropy-linear programming [21].
The original statement of this problem was to estimate probability density functions (PDFs) in RML procedures. However, in recent times, a more general context has been assumed—the method of maximizing entropy functionals for constructing estimates of continuous probability density functions using real data (randomized maximum entropy (RME) estimation).
In this paper, the general RME estimation problem is formulated; its solutions, numerical algorithms, and the asymptotic properties of the solutions are studied. The theoretical results are illustrated by an important application—estimating the evolution of the thermokarst lake area in Western Siberia.
2. Statement of the RME Estimation Problem
Consider a scalar continuous function with parameters Assume that this function is a characteristic of an object’s model with an input x and an output . Let and be given measurements at time . Note that the latter measurements are obtained with random vector errors which are generally different for different time points.
Thus, after r measurements, the model and observations are described by the equations
where the vector function has the components , where are the time points; denotes the observed output of the model containing measurement noises of the object’s output.
Let us introduce a series of assumptions necessary for further considerations.
- The random parameters are , where is a vectorial segment in the space [22].
- The PDF of the parameters is continuously differentiable on its support
- The random noise is where
- The PDF of the measurement noises is continuously differentiable on the support and also has the multiplicative structure
The estimation problem is stated as follows: Find the estimates of the PDFs and that maximize the generalized information entropy functional
subject to
—the normalization conditions of the PDFs given by
and
3. Optimality Conditions
The optimality conditions in optimization problems of the Lyapunov type are formulated in terms of Lagrange multipliers. In addition, the Gâteaux derivatives of the problem’s functionals are used [25].
The Lagrange functional is defined by
Let us recall the technique for obtaining optimality conditions in terms of the Gâteaux derivatives [26].
The PDFs and , are continuously differentiable, i.e., belong to the class Choosing arbitrary functions and , from this class, we represent the PDFs as
where the PDFs and are the solutions of problems (4)–(6), and and are parameters.
Next, we substitute the above representations of the PDFs into (7). If all functions from are assumed to be fixed, the Lagrange functional depends on the parameters and . Then, the first-order optimality conditions for the functional (7) in terms of the Gâteaux derivative take the form
These conditions lead to the following system of integral equations:
which are satisfied for any functions and from if and only if
Hence, the entropy-optimal PDFs of the model parameters and measurement noises have the form
where
Due to equalities (10) and (11), the entropy-optimal PDFs are parametrized by the Lagrange multipliers which represent the solutions of the empirical balance equations
where
The solution of these equations depends on the sample used for constructing the RME estimates of the PDFs.
4. Existence of an Implicit Function
The second term in the balance Equations (12) and (13) is the mean value of the noise in each measurement t. The noises and their characteristics are often assumed to be equal over the measurements:
Therefore, the mean value of the noise is given by
The balance equations can be written as
where
In the vector form, Equation (16) is described by
Equation (21) defines an implicit function . The existence and properties of this implicit function depend on the properties of the Jacobian matrix
which has the elements
Theorem 1.
Let the next conditions be valid (assume that):
- The function is continuous in all variables.
- For any
Then, there exists a unique implicit function defined on .
Proof of Theorem 1.
Due to the first assumption, the continuous function induces the vector field in the space
We choose an arbitrary vector in and define the vector field
By condition (22), the field with a fixed vector has no zeros on the spheres of a sufficiently large radius
Hence, a rotation is well defined on the spheres of a sufficiently large radius For details, see [27].
Consider the two vector fields
These vector fields are homotopic on the spheres of a sufficiently large radius, i.e., the field
has no zeros on the spheres of a sufficiently large radius for any Homotopic fields have identical rotations [27]:
The vector fields and are nondegenerate on the spheres of a sufficiently large radius; in the ball however, each of them may have a number of singular points. We denote by and the numbers of singular points of the vector fields and respectively. As the vector fields are homotopic,
In view of (21), these singular points are isolated.
Now, let us utilize the index of a singular point introduced in [27]:
where is the number of eigenvalues of the matrix with the negative real part. By definition, the value of this index depends not on the magnitude of , but on its parity. Due to condition (21), all singular points have the same parity. Really, , and hence, for any , the eigenvalues of the matrix may move from the left half-plane to the right one in pairs only: Real eigenvalues are transformed into pairs of complex–conjugate ones, passing through the imaginary axis.
In view of this fact, the rotation of the homotopic fields (20) is given by
where is the number of eigenvalues of the matrix for some singular point.
It remains to demonstrate that the vector field has a unique singular point in the ball Consider the equation
Assume that for each fixed pair this equation has singular points, i.e., the functions Therefore, it defines a multivalued function , whose branches are isolated (the latter property follows from the isolation of the singular points). Due to condition (21), each of the branches defines an open set in the space and
This is possible if and only if Hence, for each pair from there exists a unique function for which the function will vanish. □
Theorem 2.
Under the assumptions of Theorem 1, the function is real analytical in all variables.
Proof of Theorem 2.
From (15), it follows that the function is analytical in all variables. Therefore, the left-hand side of Equation (15) can be expanded into the generalized Taylor series [26], and the solution can be constructed in the form of the generalized Taylor series as well. The power elements of this series are determined using a recursive procedure. □
5. Asymptotic Efficiency of RME Estimates
The RME estimate yields the entropy-optimal PDFs (10) for the arrays of input and output data, each of size For the sake of convenience, consider the PDFs parametrized by the exponential Lagrange multipliers Then, equalities (10) take the form
Consequently, the structure of the PDF significantly depends on the values of the exponential Lagrange multipliers which, in turn, depend on the data arrays and
Definition 1.
The estimates and are said to be asymptotically efficient if
where
Consider the empirical balance Equation (21), written in terms of the exponential Lagrange multipliers:
As has been demonstrated above, Equation (26) defines an implicit analytical function for
Differentiating the left- and right-hand sides of these equations with respect to and yields
Then, passing to the norms and using the inequality for the norm of the product of matrices [28], we obtain the equalities
Both of the inequalities incorporate the norm of the inverse matrix
Lemma 1.
Let a square matrix A be nonsingular, i.e., Then, there exists a constant such that
Proof of Lemma 1.
Since the matrix A is nondegenerate, the elements of the inverse matrix can be expressed in terms of the algebraic complement (adjunct) of the element in the determinant of the matrix A [28]:
and they are bounded:
Hence, there exists a constant for which inequality (29) is satisfied. □
Lemma 1 can be applied to the norm of the inverse matrix. As a result,
where
Lemma 2.
Let
Then,
6. Thermokarst Lake Area Evolution in Western Siberia: RME Estimation and Testing
Permafrost zones, which occupy a significant part of the Earth’s surface, are the locales of thermokarst lakes, which accumulate greenhouse gases (methane and carbon dioxide). These gases make a considerable contribution to global climate change.
The source data in studies of the evolution of thermokarst lake areas are acquired through remote sensing of the Earth’s surface and ground measurements of meteorological parameters [29,30].
The state of thermokarst lakes is characterized by their total area in a given region, measured in hectares (ha), and the factors influencing thermokarst formations—the average annual temperatures measured in Celsius (C), and the annual precipitation measured in millimeters (mm), where t denotes the calendar year.
We used the remote sensing data and ground measurements of the meteorological parameters for a region of Western Siberia between N– N and E– E that were presented in [31]. We divided the available time series into two groups, which formed the training collection ( and the testing collection (.
6.1. RME Estimation of Model Parameters and Measurement Noises
The temporal evolution of the lake area is described by the following dynamic regression equation with two influencing factors, the average annual temperature and the annual precipitation :
The model parameters and measurement noises are assumed to be random and of the interval type:
The probabilistic properties of the parameters are characterized by a PDF
The variable is the observed output of the model, and the values of the random measurement noise at different time instants t may belong to different ranges:
with a PDF , , where N denotes the length of the observation interval. The order and the parameter ranges for the dynamic randomized regression model (34) (see Table 1 below) were calculated based on real data using the empirical correlation functions and the least-square estimates of the residual variances.

Table 1.
Parameter ranges for the model.
For the training collection the model can be written in the vector–matrix form
with the matrix
and the vectors and .
The RME estimation procedure yielded the following entropy-optimal PDFs of the model parameters (36) and measurement noises:
Note that and are the data from the collection . The two-dimensional sections of the function and the function are shown in Figure 1.
Figure 1.
Two-dimensional section of the function P* and the function Q*.
6.2. Testing
Testing was performed using the data from the collection , which included the lake area , the average annual temperature , and the annual precipitation , . An ensemble of trajectories of the model’s observed output was generated using Monte Carlo simulations and sampling of the entropy-optimal PDFs , on the testing interval. In addition, the trajectory of the empirical means and the dimensions of the empirical standard deviation area were calculated.
The quality of RME estimation was characterized by the absolute and relative errors:
The generated ensemble of the trajectories is shown in Figure 2.
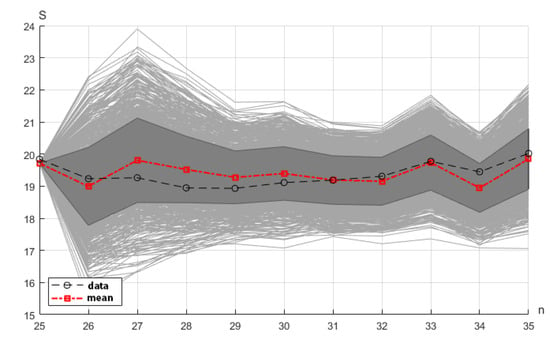
Figure 2.
Ensemble of the trajectories (gray domain), the standard deviation area (dark gray domain), the empirical mean trajectory, and the lake area data.
7. Discussion
Given an available data collection, the RME procedure allows estimation of the PDFs of a model’s random parameters under measurement noises corresponding to the maximum uncertainty (maximum entropy). In addition, this procedure needs no assumptions about the structure of the estimated PDFs or the statistical properties of the data and measurement noises.
An entropy-optimal model can be simulated by sampling the PDFs to generate an empirical ensemble of a model’s output trajectories and to calculate its empirical characteristics (the mean and median trajectories, the standard deviation area, interquartile sets, and others).
The RME procedure was illustrated with an example of the estimation of the parameters of a linear regression model for the evolution of the thermokarst lake area in Western Siberia. In this example, the procedure demonstrated a good estimation accuracy.
However, these positive features of the procedure were achieved with computational costs. Despite their analytical structure, the RME estimates of the PDFs depend on Lagrange multipliers, which are determined by solving the balance equations with the so-called integral components (the mathematical expectations of random parameters and measurement noises). Calculating the values of multidimensional integrals may require appropriate computing resources.
8. Conclusions
The problem of randomized maximum entropy estimation of a probability density function based on real available data has been formulated and solved. The developed estimation algorithm (the RME algorithm) finds the conditional maximum of an information entropy functional on a set of admissible probability density functions characterized by the empirical balance equations for Lagrange multipliers. These equations define an implicit dependence of the Lagrange multipliers on the data collection. The existence of such an implicit function for any values in a data collection has been established. The function’s behavior for a data collection of a greater size has been studied, and the asymptotic efficiency of the RME estimates has been proved.
The positive features of RME estimates have been illustrated with an example of estimation and testing a linear dynamic regression model of the evolution of the thermokarst lake area in Western Siberia with real data.
Funding
This research was funded by the Ministry of Science and Higher Education of the Russian Federation, project no. 075-15-2020-799.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The author declares no conflict of interest.
References
- Vapnik, V.N. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Witten, I.H.; Eibe, F. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Heidelberg, Germany, 2005. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning. Series: Information Theory and Statistics; Springer: New York, NY, USA, 2006. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2001. [Google Scholar]
- Vorontsov, K.V. Mathematical Methods of Learning by Precedents: A Course of Lectures; Moscow Institute of Physics and Technology: Moscow, Russia, 2013. [Google Scholar]
- Goldberger, A.S. A Course in Econometrics; Harvard University Press: Cambridge, UK, 1991. [Google Scholar]
- Aivazyan, S.A.; Enyukov, I.S.; Meshalkin, L.D. Prikladnaya Statistika: Issledovanie Zavisimostei (Applied Statistics: Study of Dependencies); Finansy i Statistika: Moscow, Russia, 1985. [Google Scholar]
- Lagutin, M.B. Naglyadnaya Matematicheskaya Statistika (Visual Mathematical Statistics); BINOM, Laboratoriya Znanii: Moscow, Russia, 2013. [Google Scholar]
- Roussas, G. A Course of the Mathematical Statistics; Academic Press: San Diego, CA, USA, 2015. [Google Scholar]
- Malouf, R. A comparison of algorithms for maximum entropy parameters estimation. In Proceedings of the 6th Conference on Natural Language Learning 2002 (CoNLL-2002), Taipei, Taiwan, 31 August–1 September 2002; Volume 20, pp. 1–7. [Google Scholar]
- Borwein, J.; Choksi, R.; Marechal, P. Probability distribution of assets inferred from option prices via principle of maximum entropy. SIAM J. Optim. 2003, 14, 464–478. [Google Scholar] [CrossRef]
- Golan, A.; Judge, G.; Miller, D. Maximum Entropy Econometrics: Robust Estimation with Limited Data; John Wiley & Sons: New York, NY, USA, 1997. [Google Scholar]
- Golan, A. Information and Entropy econometrics—A review and synthesis. Found. Trends Econom. 2008, 2, 1–145. [Google Scholar] [CrossRef]
- Csiszar, I.; Matus, F. On minimization of entropy functionals under moment constraints. In Proceedings of the IEEE International Symposium on Information Theory, Toronto, ON, Canada, 6–11 July 2008. [Google Scholar]
- Loubes, J.-M. Approximate maximum entropy on the mean for instrumental variable regression. Stat. Probab. Lett. 2012, 82, 972–978. [Google Scholar] [CrossRef]
- Borwein, J.M.; Lewis, A.S. Partially-finite programming in L1 and existence of maximum entropy estimates. SIAM J. Optim. 1993, 3, 248–267. [Google Scholar] [CrossRef]
- Burg, J.P. The relationship between maximum entropy spectra and maximum likelihood spectra. Geophysics 1972, 37, 375–376. [Google Scholar] [CrossRef]
- Christakos, G. A Bayesian/maximum entropy view to the spatial estimation problem. Math. Geol. 1990, 22, 763–777. [Google Scholar] [CrossRef]
- Singh, V.P.; Guo, H. Parameter estimation for 3-parameter generalized Pareto distribution by the principle of maximum entropy. Hydrol. Sci. J. 1994, 40, 165–181. [Google Scholar] [CrossRef]
- Popkov, Y.S.; Dubnov, Y.A.; Popkov, A.Y. Randomized machine learning: Statement, solution, applications. In Proceedings of the 2016 IEEE 8th International Conference on Intelligent Systems (IS), Sofia, Bulgaria, 4–6 September 2016. [Google Scholar] [CrossRef]
- Popkov, A.Y.; Popkov, Y.S. New methods of entropy-robust estimation for randomized models under limited data. Entropy 2014, 16, 675–698. [Google Scholar] [CrossRef]
- Krasnosel’skii, M.A.; Vainikko, G.M.; Zabreyko, R.P.; Ruticki, Y.B.; Stet’senko, V.V. Approximate Solutions of Operator Equations; Wolters-Noordhoff Publishing: Groningen, The Netherlands, 1972. [Google Scholar] [CrossRef]
- Ioffe, A.D.; Tikhomirov, V.M. Theory of Extremal Problems; Elsevier: New York, NY, USA, 1974. [Google Scholar]
- Alekseev, V.M.; Tikhomirov, V.M.; Fomin, S.V. Optimal Control; Springer: Boston, MA, USA, 1987. [Google Scholar]
- Kaashoek, M.A.; van der Mee, C. Recent Advances in Operator Theory and Its Applications; Birkhäuser Basel: Basel, Switzerland, 2006. [Google Scholar]
- Kolmogorov, A.N.; Fomin, S.V. Elements of the Theory of Functions and Functional Analysis; Dover Publication: New York, NY, USA, 1999. [Google Scholar]
- Krasnoselskii, M.A.; Zabreiko, P.P. Geometrical Methods of Nonlinear Analysis; Springer: Berlin, Germany; New York, NY, USA, 1984. [Google Scholar]
- Gantmacher, F.R.; Brenner, J.L. Applications of the Theory of Matrices; Dover: New York, NY, USA, 2005. [Google Scholar]
- Riordan, B.; Verbula, D.; McGruire, A.D. Shrinking ponds in subarctic Alaska based on 1950–2002 remotely sensed images. J. Geophys. Res. 2006, 111, G04002. [Google Scholar] [CrossRef]
- Kirpotin, S.; Polishchuk, Y.; Bruksina, N. Abrupt changes of thermokarst lakes in Western Siberia: Impacts of climatic warming on permafrost melting. Int. J. Environ. Stud. 2009, 66, 423–431. [Google Scholar] [CrossRef]
- Western Siberia Thermokarsk Lakes Dataset. Available online: https://cloud.uriit.ru/index.php/s/0DOrxL9RmGqXsV0 (accessed on 20 February 2021).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).