Abstract
In this paper, we undertake the problem of evaluating interrelation among time series. Interrelation is measured using a similarity index. In this paper, we suggest a new one based on the known fuzzy transform (F-transform), which has been proven to remove higher frequencies than a given threshold and reduce the random noise significantly. The F-transform also provides an estimation of the slope of time series in a given imprecisely delineated time. We prove some of the suggested index properties and show its ability to measure similarity (and thus the interrelation) on a selection of several real financial time series. The method is well interpretable and easy to adjust.
1. Introduction
Time series form a topic of research that has been widely studied for many years (for some recent references, see [1,2,3,4,5]). In 2006, Yang and Wu [6] rated mining information from time series as one of the top ten challenging data mining problems due to its particular properties. One of its subareas is assessing similarity between time series, i.e., the degree to which a given time series resembles another one is the core of many tasks, such as retrieval and clustering, classification, and even forecasting [7].
Analysis of time series in theoretical and practical aspects is an crucial part of the study of stock markets. Empirical research started in 1933 [8] and was focused on the analysis of the stock market as a single independent time series, often referred to as a univariate time series analysis. The financial time series consists, in this case, of single observations recorded sequentially over equal time increments. However, in recent decades, worldwide economies have become increasingly related to each other. Various phenomena such as politics, social media platforms, and even pandemics can influence a set of financial time series similarly. Nowadays, there are likely to be groups of stocks that follow similar time-based patterns behavior simultaneously or with some time delay; Therefore, a crucial question is raised: “what are all the stocks that behave similarly to given stock A? ”. Nevertheless, devising a proper similarity measure to find a similar behavior among time series is a non-trivial task [3].
Besides Euclidean distance measures, many others can be found in the literature [9,10,11,12,13,14,15]. In 1999, Mantegna suggested a methodology known as the standard one adopted and followed by many researchers in different areas. As of 2020, his paper and his book, Ref. [16] have been cited several thousand times. To calculate the distance (similarity) among assets, Mantegna recommends the use of correlation among returns. Many researchers aim to improve his method concerning the clustering algorithm or the distance measure itself in continuation of his work. This can be briefly described as follows.
Let N be the number of assets, be the price at time t of asset i, 1 ≤ i ≤ N, then the log-return of an asset , is calculated as follows:
To determine the distance (similarity) between each pair of assets, he suggests to compute the correlation of returns and then correlation coefficients into distance using the following equation:
He employs a minimum spanning tree (MST) to cluster the most similar assets in the form of a tree. A distinctive indexed hierarchy is another product of the resulting MST, corresponding to the one given by the dendrogram obtained using the single linkage clustering algorithm. However, there are few concerns regarding this standard methodology. The biggest problem is instability, which can be partially caused by the MST algorithm or by the correlation coefficient. Note that the correlation is not applied to the financial time series but to their returns; therefore, the price values’ dependence might be lost. Moreover, it is known that Pearson linear correlation is sensitive towards outliers and generally not suitable for other probability distributions except for the Gaussian one. It is also challenging to interpret linkage changes during the time since there is a high level of statistical uncertainty associated with the correlation estimation [17]. Interestingly, as one might expect, the higher the correlation coefficient between an asset pair, the more reliable their link should be. However, in [18], the authors show that this hypothesis is not always satisfied in practice. Mantegna [19] concludes that a better approach is needed to use a distance measure other than the expected square deviation and one that is distribution-free. Thus, researchers have investigated different measures of distance from specific viewpoints.
The similarity between two-time series should not be computed based on their values only but also based on the corresponding slopes. This is important specifically in the stock market because relative variations in the price values affect the trading performance. A positive slope indicates an uptrend, and a negative slope indicates a downtrend. However, a question is raised, how we can include the slopes. A possible and very reasonable solution is provided by the fuzzy transform (F-transform). Recall that we distinguish degrees of the F-transform: the zero-degree F-transform provides components giving information about the given function’s average values in a specified area. The first-degree F-transform provides an estimation of the tangent of the given function in a specified area.
This paper aims to suggest a new similarity index between two time series that combines both values of time series and their slopes. We prove some of its properties of this index and demonstrate its behavior on a selection of several real financial time series.
2. Preliminaries
2.1. The Principle of F-Transform
The fuzzy (F-)transform is a universal approximation technique which was introduced by I. Perfilieva in [20,21]. Its fundamental idea consists in two steps:
- (i)
- Direct F-transform: Transform a bounded real continuous function to a finite vector of components. This is realized using a fuzzy partition which is a finite set of fuzzy sets distributed over the domain .
- (ii)
- Inverse F-transform: Transform the vector back into a function that approximates the original function f.
The F-transform has the following properties:
- it is a universal approximator,
- it has ability to filter out high frequencies and to reduce noise [22],
- it provides estimation of average values of derivatives over an imprecisely specified area [23],
- its computational complexity is polynomial.
The parameters of the F-transform can be set in such a way that the approximating function has the desired properties.
These properties make the F-transform suitable for applications in various tasks when processing time series. More about F-transform and its applications can be found in [24].
2.1.1. Fuzzy Partition
Recall that by a fuzzy set, we understand a function where U is a set (a universe) and is the interval of reals understood as a set of truth degrees. The element is called membership degree of in the fuzzy set A. In general, it is a support of a certain algebra (cf. Section 2.3) whose operations induce operations with fuzzy sets ( We refer the reader to the extensive literature on fuzzy set theory and fuzzy logic, for example [24] and the citations therein). The support of a fuzzy set A is the set .
The fundamental step of the F-transform procedure is forming a fuzzy partition of the domain , which is a finite set of fuzzy sets
defined over nodes such that
and for each , . Furthermore, each fuzzy set , , has the support , which implies that for all (We formally put and ). The fuzzy sets are often called basic functions. Note that cover the whole domain , i.e., (since ). For and , we consider only halves of the functions , i.e., has the support and the support . A typical h-uniform triangular fuzzy partition is depicted in Figure 1.
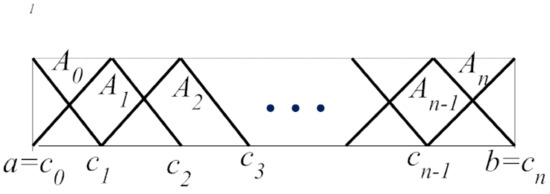
Figure 1.
A typical h-uniform triangular fuzzy partition.
Remark 1.
In general, the fuzzy sets from must fulfill five axioms, namely: normality, locality (bounded support), continuity, unimodality, and orthogonality, where the latter is formally defined as , . For precise formulation of these axioms see [20,24].
A fuzzy partition is called h-uniform if the nodes are h-equidistant, i.e., for all , , where and the fuzzy sets are shifted copies of a generating function such that for all
2.1.2. Zero Degree Fuzzy Transform
After determining the fuzzy partition , we construct a direct F-transform of a continuous function f as a vector , where each k-th component is equal to
One can see that each component is a weighted average of the functional values , where weights are the membership degrees . The inverse F-transform of f with respect to is a continuous function such that
Theorem 1.
The inverse F-transform has the following properties:
- (a)
- It coincides with f if the latter is a constant function.
- (b)
- The sequence of inverse F-transforms determined by a sequence of uniform fuzzy partitions based on uniformly distributed nodes with uniformly converges to f for .
- (c)
- The F-transform is linear, i.e., if then for all arguments x.
- (d)
- Let for all . Then, for any .
All the details and full proofs can be found in [20,21].
2.1.3. Higher Degree Fuzzy Transform
The components of the zero degree F-transform are real numbers (in the sequel, we will write F-transform). If we replace by polynomials of m-th degree, , we obtain a higher degree F-transform (F transform). A detailed description of this F-transform including full proofs of its properties can be found in [21]. It is important to note that the F transform enables us to also estimate derivatives of the given function f over a non-precisely specified area.
The direct -transform of f with respect to is a vector linear functions
with the coefficients given by
Note that , i.e., the coefficients are just the components given in (3). The F-transform enjoys the properties stated in Theorem 1 (see [21]). In comparison with the F transform, it is more precise. Let us remark that in general, we can define n-th degree F-transform. Of course, for higher n, it is more complex but also more precise. In practice, it is sufficient to consider only .
The following theorem is important for mining information from time series [24].
Theorem 2.
If f is four-times continuously differentiable on , then for each ,
Thus, each F-transform component provides a weighted average of values of the function f in the area around the node (7), and also a weighted average of slopes (22) of f in the same area.
Lemma 1.
If is an h-uniform fuzzy partition and each basic function has a triangular shape, then the following can be proved:
Lemma 2.
Let be an h-uniform fuzzy partition with triangular membership functions and let for all . Then,
- (a)
- .
- (b)
- If then .
2.2. Time Series and F-Transform
A time series is a stochastic process (see [25,26])
where is a set of elementary random events and is a finite set whose elements are interpreted as time moments. Statistical models assume that each , is a random variable having a specific distribution function.
Fuzzy techniques are based on the following decomposition model:
where is a trend-cycle that can be further decomposed into trend and cycle, i.e., . The is a seasonal component that is a mixture of r periodic functions
where are frequencies and , are constants. Without loss of generality, we can assume that the frequencies are ordered .
Note that and S are ordinary non-stochastic functions. Only R is a random noise, i.e., a stationary stochastic process such that the mean and variance , .
In practice, we always have only one realization of time series at disposal. Formally, this means that we fix . Then, we write
and understand that X is an ordinary real (or complex) valued function.
Let us now assume that inside (14), the real time series is hidden
where and . In other words, we assume that the time series X is “spoiled” by some frequencies that are too high (they may correspond, e.g., to a certain unwelcome volatility) that are removed in Z.
The following theorem demonstrates the power of the F-transform for time series analysis.
Theorem 3.
Let be realization of the stochastic process (4) and Z be its smoothed version (15). Let be a fuzzy partition over the set of equidistant nodes (2) with the distance h. Let the fuzzy sets be N-times differentiable and put .
- (a)
- The corresponding inverse F-transform of gives the following estimation of Z:for , where is a modulus of continuity of Z w.r.t. 2 h (The modulus of continuity of a function w.r.t. h is ).
- (b)
- and .
The details for the proof of this theorem can be found in [20,27,28,29]. The theorem holds both for the F- as well as for F-transform. It follows from this theorem that the F-transform filters out frequencies higher than a given threshold and reduces the noise R. In [27], it was even proved that if the correlation function of R has a quick decay, then .
Remark 2.
The fuzzy partition is not constructed over the discrete set of natural numbers but over the interval of real numbers .
It follows from Theorem 3 that ; we can estimate the real time series Z with high fidelity. First, we set a proper fuzzy partition and and compute the F-transform of :
Then, we compute the inverse , which approximates the real time series Z. According to [22], we should set
for some natural number q (in practice, it is sufficient to put ). The frequencies can be found using the well known periodogram—see [25,26].
Remark 3.
The edge components are distorted because only half of the corresponding basic functions are used. This problem can be solved in two ways: either we confine only to the complete components for , or we artificially prolong to the left and right by h and extrapolate the corresponding values for , and similarly in the right side of .
2.3. Fuzzy Equality
Let be an algebra of truth values where , , , , . This algebra is called Łukasiewicz standard algebra (Of course, there are also other algebras used as algebras of truth values for fuzzy set theory and fuzzy logic. However, the Łukasiewicz algebra, has a prominent position because of its good properties in many respects and, therefore, we confine our theory to it only). It serves us as the algebra of truth values. The operations with fuzzy sets are defined using the operations on it [30,31].
A binary fuzzy relation is a fuzzy set . If , then we often write the membership degree of the couple in R as .
Definition 1.
Let be a binary fuzzy relation.
- (i)
- It is reflexive if for all .
- (ii)
- It is symmetric if for all .
- (iii)
- It is transitive if for all .
- (iv)
- It is separated if for all(fuzzy equality in the degree 1 reduces to the classical equality).
Definition 2.
- (i)
- A binary fuzzy relation ≐ on U is a fuzzy symmetry if it is reflexive and transitive.
- (ii)
- A fuzzy symmetry is a fuzzy equality if it is also transitive.
3. Similarity of Time Series
As already mentioned, there are many kinds of similarity indexes introduced. Most of them are based on the distance between the values of time series (cf., e.g., [2,32,33,34]). The problem is that all such indexes are necessarily distorted by random noise. Consequently, the real shape of time series is hidden. Solution of these difficulties can be given by the fuzzy transform.
Let us consider two time series with the same time domain . Since the time series values can fall within very different ranges, we first normalize both time series to make their values comparable. The normalization will be done w.r.t. maximal values , . Then, we put
Let us choose two numbers , compute and and form two , -uniform fuzzy partitions , of the time domain .
Let us compute components of zero- and first-degree F-transforms of the time series (18) and (19):
where the zero-degree components are computed on the basis of the fuzzy partition , and the first-degree ones on the basis of . Note that in the direct F-transforms above, we omitted the first and the last components. For further processing, we need only the coefficients , , and , defined in (5) and (6).
Based on that, we form to each time series , two new reduced time series, namely a time series of values and that of tangents:
Hence, and are time series of average values of the respective time series over the imprecisely specified areas , , and and are time series of average values of tangents of the time series over the imprecisely specified areas , .
Definition 3.
Let be time series (14). Then the index of similarity of two time series is the number
where φ is a common normalization factor assuring that both for all and are sensitivity constants.
The suggested similarity index thus considers not only distances between average values of time series but also distances between average values of tangents in the same areas. The constants increase or decrease sensitivity of values and slopes of the compared time series. Clearly, if then is more sensitive to differences between the corresponding values of , while does the same for their slopes.
The normalization factor can be specified, e.g., as follows. Let be time series (14) and put
Then,
is a normalization factor common for and
is a normalization factor common for .
The following is immediate.
Lemma 3.
Theorem 4.
Let be time series (14).
- (a)
- The similarity index is a separated fuzzy symmetry.
- (b)
- If then, the transitivity property holds for any time series Z.
Proof.
(a) If then, obviously, . The symmetry follows immediately from the properties of absolute value.
(b) Let be a common normalization factor for . After rewriting, we obtain
If the left-hand side is equal to 0, then the inequality is trivially fulfilled. By the assumption, we have to verify that
which holds using the triangular inequality and the properties of ordered groups.
Finally, let . Then, it follows from (26) that for all , as well as for all . Since all the fuzzy sets as well as cover the whole time domain , we conclude that . □
Proposition 1.
Let and be two constant time series. Then,
Proof.
It follows from this proposition that if both time series are constant then they are fully similar.
4. Demonstration
In this section, we will apply the similarity index (26) to real data. In all cases, we used F-transform with and the sensitivity constant , and F-transform with and the sensitivity constant . These parameters were estimated according to the expert opinion based on practical experience. Setting is determined so as to not harm the real course of the time series too much, since longer h leads to greater smoothing. Similarly, is determined by the idea that the slope should be evaluated over a larger area since otherwise, it can be non-convincing. The parameters are estimated by testing the behavior of the index. The conditions for the setting of all four parameters are still a topic of further investigation.
For demonstration, we are inspired by a study [35]. In this paper, Junior et al. provide a view of which indices are the strongest influencers between 83 international market indices. Their results suggest that France and Germany were among the top index to send out the information to other markets. Based on the correlation dependency, the Czech Republic was among the top information receivers. Therefore, we chose these international stock exchange indices with the Russian market as a sample for demonstration. The data contain daily adjusting closing prices for 2016 ( Four international stock exchange indices, namely, Prague (PX), Paris (FCHI), Frankfurt (GDAXI), and Moscow (MOEX), were obtained from Yahoo finance). Several exciting events, such as the falling of oil prices and the Brexit announcement and voting, heavily affected the stock market in 2016 and its interrelations. Therefore, it is valuable to investigate the underlying relations. Figure 2 demonstrates the daily closing price of the above-mentioned four markets. Due to different national holidays, each market contains some missing values, which were omitted for similarity measurement.
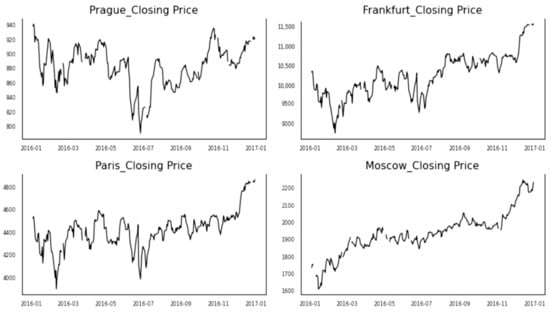
Figure 2.
Closing price of four stocks.
Using the suggested similarity index, we evaluate pairwise similarities between the stocks and compare them with the known correlation coefficients based on rank correlations, namely Spearman, Kendall and Hoeffing D. The results are summarized in Table 1.

Table 1.
Comparison of the similarity index with the known statistical correlation coefficients.
The results reveal several interesting relations. The most similar stock to Prague is the Paris market, while Moscow has the lowest similarity. Another exciting relation is with regard to the Frankfurt market. The pair (Paris–Frankfurt) has a higher similarity in comparison with (Prague–Frankfurt). These relations are also visible in Figure 2. In Figure 3, Figure 4, Figure 5 and Figure 6, we demonstrate the behavior of the normalized prices for the mentioned similarity indices.
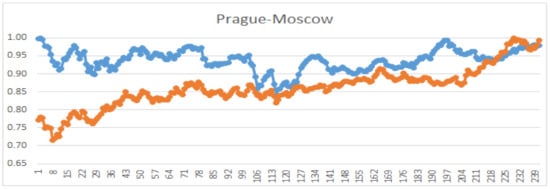
Figure 3.
Comparison of graphs of normalized prices for Prague and Moscow; .
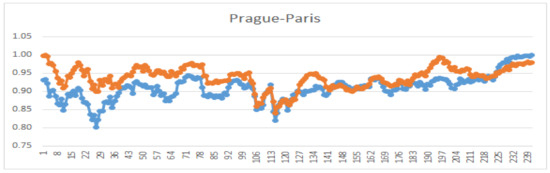
Figure 4.
Comparison of graphs of normalized prices for Prague and Paris; .
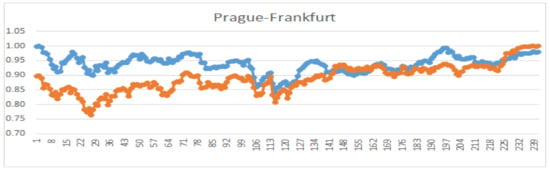
Figure 5.
Comparison of graphs of normalized prices for Frankfurt and Prague; .
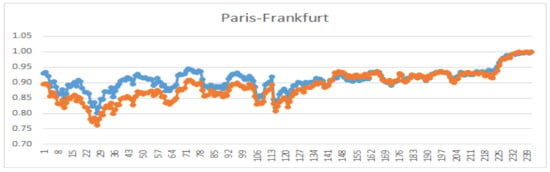
Figure 6.
Comparison of graphs of normalized prices for Frankfurt and Paris; .
To see whether the similarity index (26) reacts on very dissimilar time series, we artificially distorted the Moscow market and also artificially inverted the Prague market’s price values. The comparison (Prague–Moscow distorted) and (Prague–Prague inverted) is in Figure 7 and Figure 8. As one expects, there is zero similarity between Prague and distorted Moscow. However, the similarity between Prague and its inverted version remained non-zero, which is caused mainly by the found similarities between their corresponding slopes.
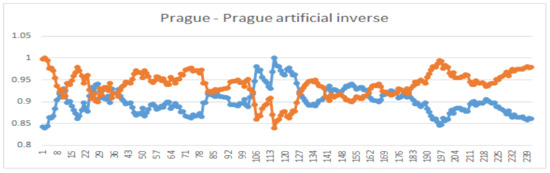
Figure 7.
Comparison of graphs of Prague and its artificial inverse stock prices; .
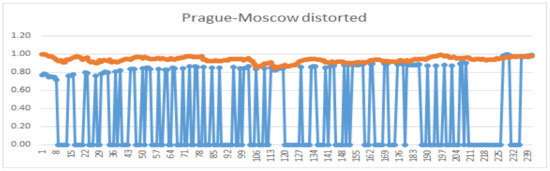
Figure 8.
Comparison of graphs of Prague and artificially distorted Moscow stock prices; (Prague,Moscow−distorted) = 0.
The rank correlation coefficients are a measure of a monotonic relationship. We chose them because they are less sensitive to outliers. Hoeffding’s D correlation is a measure of a non-linear and non-monotonous relationship. Note, that the sign of the Hoeffding’s D coefficient has no interpretation.
If the Spearman (and Kendall) coefficient is close to 0 and the Hoeffding coefficient is high, then the relationship is probably non-monotonic and non-linear. In our case, this did not happen. According to the statistical tests, all the correlation coefficients are non-zero (the p-values are practically zero) if the similarity index (26) is high. In the case (Prague,Moscow−distorted) = 0, the correlation coefficients are statistically zero. However, when comparing (Prague–Prague inverted), the statistical tests show negative dependence, while . This is correct because the correlation coefficients measure dependence, while (26) measures similarity. The slopes of both time series have opposite signs and so, they decrease the value of the similarity (26). However, when inspecting Figure 7, one can see similarity in values of both time series and, therefore, the index still has non-zero value.
5. Conclusions
In this paper, we developed a new method for measuring similarity between time series. The method is based on the application of the fuzzy transform. The index compares F-transform and F-transform components. While the former measures similarity between time series values after the highest frequencies were removed and noise reduced, the former measures similarity between slopes of time series in short local periods.
We demonstrated the application of our index to four real financial time series and two artificial ones. Experimental results confirm its ability to measure the similarity between time series.
Further work will focus on the extension of the method to time series of various lengths. Another direction is to judge the evolution of the similarity throughout the years. We also plan to extend this idea to measuring dependence between time series.
Author Contributions
Writing—original draft and writing—review and editing, V.N. and S.M. All authors have read and agreed to the published version of the manuscript.
Funding
The research was supported by from ERDF/ESF by the project “Centre for the development of Artificial Intelligence Methods for the Automotive Industry of the region” No. CZ.02.1.01/0.0/0.0/17-049/0008414.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mining, W.I.D. Data mining: Concepts and techniques. Morgan Kaufinann 2006, 10, 559–569. [Google Scholar]
- Keogh, E.; Kasetty, S. On the need for time series data mining benchmarks: A survey and empirical demonstration. Data Min. Knowl. Discov. 2003, 7, 349–371. [Google Scholar] [CrossRef]
- Fu, T.C. A review on time series data mining. Eng. Appl. Artif. Intell. 2011, 24, 164–181. [Google Scholar] [CrossRef]
- Liao, T.W. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Yang, Q.; Wu, X. 10 challenging problems in data mining research. Int. J. Inf. Technol. Decis. Mak. 2006, 5, 597–604. [Google Scholar] [CrossRef]
- Serra, J.; Arcos, J.L. An empirical evaluation of similarity measures for time series classification. Knowl.-Based Syst. 2014, 67, 305–314. [Google Scholar] [CrossRef]
- Mills, T.C.; Markellos, R.N. The Econometric Modelling of Financial Time Series; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Goldin, D.Q.; Kanellakis, P.C. On similarity queries for time-series data: Constraint specification and implementation. In Proceedings of the International Conference on Principles and Practice of Constraint Programming, Cassis, France, 19–22 September 1995; Springer: Berlin/Heidelberg, Germany, 1995; pp. 137–153. [Google Scholar]
- Agrawal, R.; Faloutsos, C.; Swami, A. Efficient similarity search in sequence databases. In Proceedings of the International Conference on Foundations of Data Organization and Algorithms, Chicago, IL, USA, 13–15 October 1995; Springer: Berlin/Heidelberg, Germany, 1993; pp. 69–84. [Google Scholar]
- Berndt, D.J.; Clifford, J. Using dynamic time warping to find patterns in time series. In Proceedings of the KDD Workshop, Seattle, WA, USA, 31 July–1 August 1994; Volume 10, pp. 359–370. [Google Scholar]
- Ozsoyoglu, T.B.N.Y.M. Matching and indexing sequences of different lengths. In Proceedings of the Sixth International Conference on Information and Knowledge Management: CIKM’97, Las Vegas, NV, USA, 10–14 November 1997; Volume 6, p. 128. [Google Scholar]
- Alcock, R.J.; Manolopoulos, Y. Time-series similarity queries employing a feature-based approach. In Proceedings of the 7th Hellenic Conference on Informatics, Ioannina, Greece, 26–29 August 1999; pp. 27–29. [Google Scholar]
- Ruspini, E.H.; Zwir, I.S. Automated qualitative description of measurements. In Proceedings of the 16th IEEE Instrumentation and Measurement Technology Conference (Cat. No. 99CH36309), IMTC/99, Venice, Italy, 24–26 May 1999; Volume 2, pp. 1086–1091. [Google Scholar]
- Morrill, J.P. Distributed recognition of patterns in time series data: From sensors to informed decisions. Commun. ACM 1998, 41, 45–52. [Google Scholar] [CrossRef]
- Mantegna, R.N.; Stanley, H.E. Introduction to Econophysics: Correlations and Complexity in Finance; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Marti, G.; Nielsen, F.; Bińkowski, M.; Donnat, P. A review of two decades of correlations, hierarchies, networks and clustering in financial markets. arXiv 2017, arXiv:1703.00485. [Google Scholar]
- Tumminello, M.; Coronnello, C.; Lillo, F.; Micciche, S.; Mantegna, R.N. Spanning trees and bootstrap reliability estimation in correlation-based networks. Int. J. Bifurc. Chaos 2007, 17, 2319–2329. [Google Scholar] [CrossRef]
- Mantegna, R.N. Hierarchical structure in financial markets. Eur. Phys. J. B-Condens. Matter Complex Syst. 1999, 11, 193–197. [Google Scholar] [CrossRef]
- Perfilieva, I. Fuzzy Transforms: Theory and applications. Fuzzy Sets Syst. 2006, 157, 993–1023. [Google Scholar] [CrossRef]
- Perfilieva, I.; Daňková, M.; Bede, B. Towards a Higher Degree F-transform. Fuzzy Sets Syst. 2011, 180, 3–19. [Google Scholar] [CrossRef]
- Novák, V.; Perfilieva, I.; Holčapek, M.; Kreinovich, V. Filtering out high frequencies in time series using F-transform. Inf. Sci. 2014, 274, 192–209. [Google Scholar] [CrossRef]
- Kreinovich, V.; Perfilieva, I. Fuzzy Transforms of Higher Order Approximate Derivatives: A Theorem. Fuzzy Sets Syst. 2011, 180, 55–68. [Google Scholar]
- Novák, V.; Perfilieva, I.; Dvořák, A. Insight into Fuzzy Modeling; Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Anděl, J. Statistical Analysis of Time Series; SNTL: Praha, Czech Republic, 1976. (In Czech) [Google Scholar]
- Hamilton, J. Time Series Analysis; Princeton University Press: Princeton, NJ, USA, 1994. [Google Scholar]
- Nguyen, L.; Holčapek, M. Higher Degree Fuzzy Transform: Application to Stationary Processes and Noise Reduction. In Advances in Fuzzy Logic and Technology 2017; Kacprzyk, J., Szmidt, E., Zadrożny, S., Atanassov, K., Krawczak, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 3, pp. 1–12. [Google Scholar]
- Nguyen, L.; Holčapek, M. Suppression of High Frequencies in Time Series Using Fuzzy Transform of Higher Degree. In Information Processing and Management of Uncertainty in Knowledge-Based Systems: 16th International Conference, IPMU 2016; Carvalho, J., Lesot, M.J., Kaymak, U., Vieira, S., Bouchon-Meunier, B., Yager, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 2, pp. 705–716. [Google Scholar]
- Nguyen, L.; Novák, V. Filtering out high frequencies in time series using F-transform with respect to raised cosine generalized uniform fuzzy partition. In Proceedings of the International Conference FUZZ-IEEE 2015, Istanbul, Turkey, 2–5 August 2015. [Google Scholar]
- Gottwald, S. Fuzzy Sets and Fuzzy Logic. The Foundations of Application—From a Mathematical Point of View; Vieweg: Braunschweig/Wiesbaden, Germany; Teknea: Toulouse, France, 1993. [Google Scholar]
- Novák, V.; Perfilieva, I.; Močkoř, J. Mathematical Principles of Fuzzy Logic; Kluwer: Boston, MA, USA, 1999. [Google Scholar]
- Keogh, E.; Wei, L.; Xi, X.; Lee, S.-H.; Vlachos, M. LB-Keogh Supports Exact Indexing of Shapes Under Rotation Invariance With Arbitrary Representations and Distance Measures. In Proceedings of the 32nd International Conference on Very Large Data Bases, Seoul, Korea, 12–15 September 2006. [Google Scholar]
- Wang, X.; Mueen, A.; Ding, H.; Trajcevski, G.; Scheuermann, P.; Keogh, E. Experimental comparison of representation methods and distance measures for time series data. Data Min. Knowl. Discov. 2013, 26, 275–309. [Google Scholar] [CrossRef]
- Yeh, C.M.; Zhu, Y.; Ulanova, L.; Begum, N.; Ding, Y.; Dau, H.A.; Silva, D.F.; Mueen, A.; Keogh, E. Matrix Profile I: All Pairs Similarity Joins for Time Series: A Unifying View That Includes Motifs, Discords and Shapelets. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016. [Google Scholar]
- Junior, L.S.; Mullokandov, A.; Kenett, D.Y. Dependency relations among international stock market indices. J. Risk Financ. Manag. 2015, 8, 227–265. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).