
Mixture of Species Sampling Models

{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- is an mSSS;
- with probability one , where is a sequence of integer-valued random variables independent of the Zs such that, conditionally on , the are independent and .
- with probability one , where is an exchangeable sequence with the same law of , Π is an exchangeable partition, independent of , obtained by sampling from , and is the index of the block in Π containing n.
2. Background Materials
2.1. Exchangeable Random Partitions
2.2. Species Sampling Models
- (PS1) ;
3. Mixture of Species Sampling Models
3.1. Definitions and Relation to Other Models
- is a random variable taking values in U with law Q;
- ;
- are exchangeable random variables with directing random measure ;
- is sequence of random weight in ∇ such that and the conditional distribution of given depends only on . In particular, the (conditional) EPPF associated with the law of given has the form
3.2. Representation Theorems for mSSS
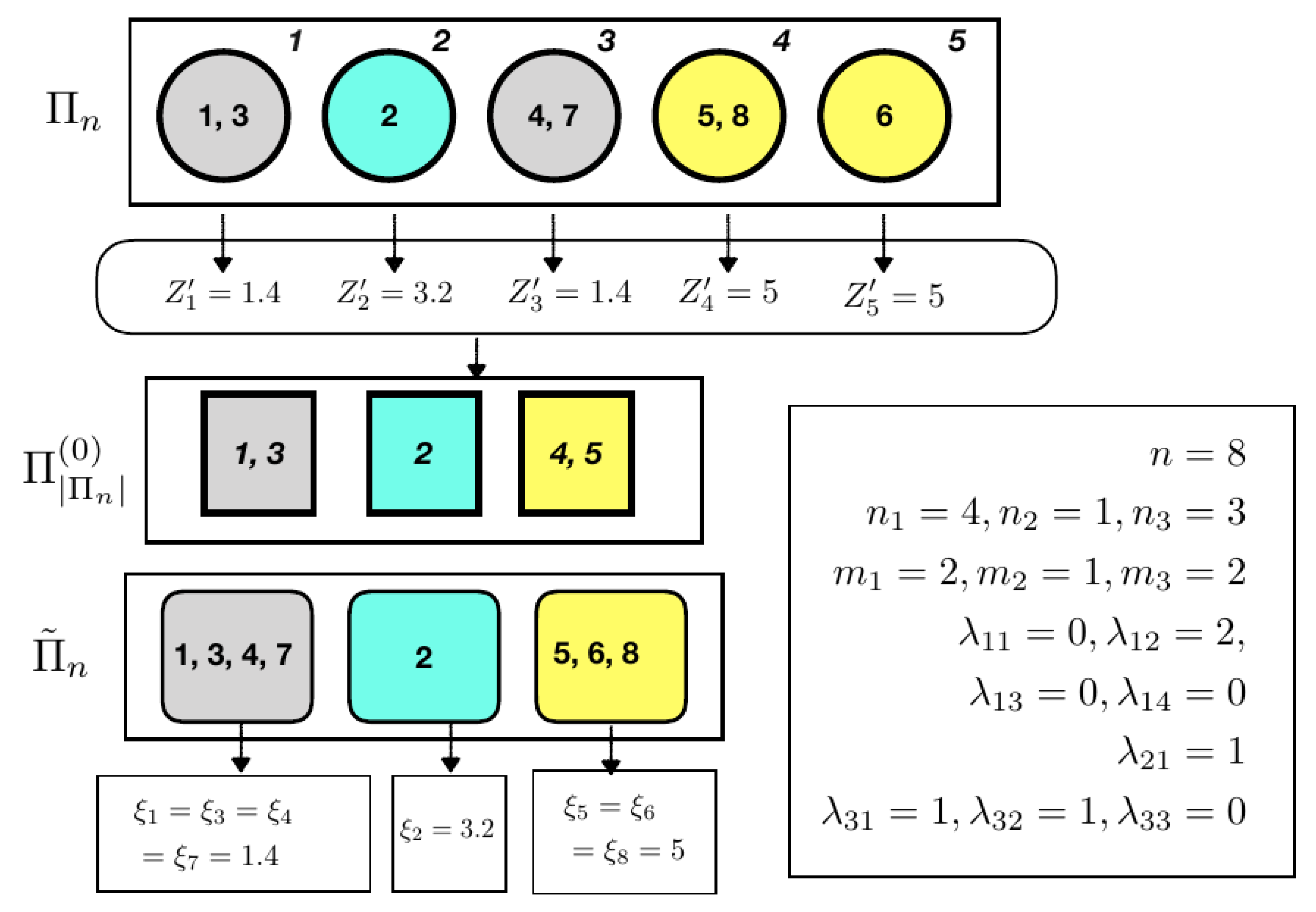
4. Random Partitions Induced by mSSS
4.1. Explicit Expression of the EPPF
- it is possible to determine k subset containing of these blocks;
- the union of the blocks in the i-th subset coincides with the i-th block of for ;
- in the i-th block, there are blocks with j elements, for .
4.2. EPPF When Is of Gibbs Type
4.3. The EPPF of a
4.4. EPPF for with Spike-and-Slab Base Measure
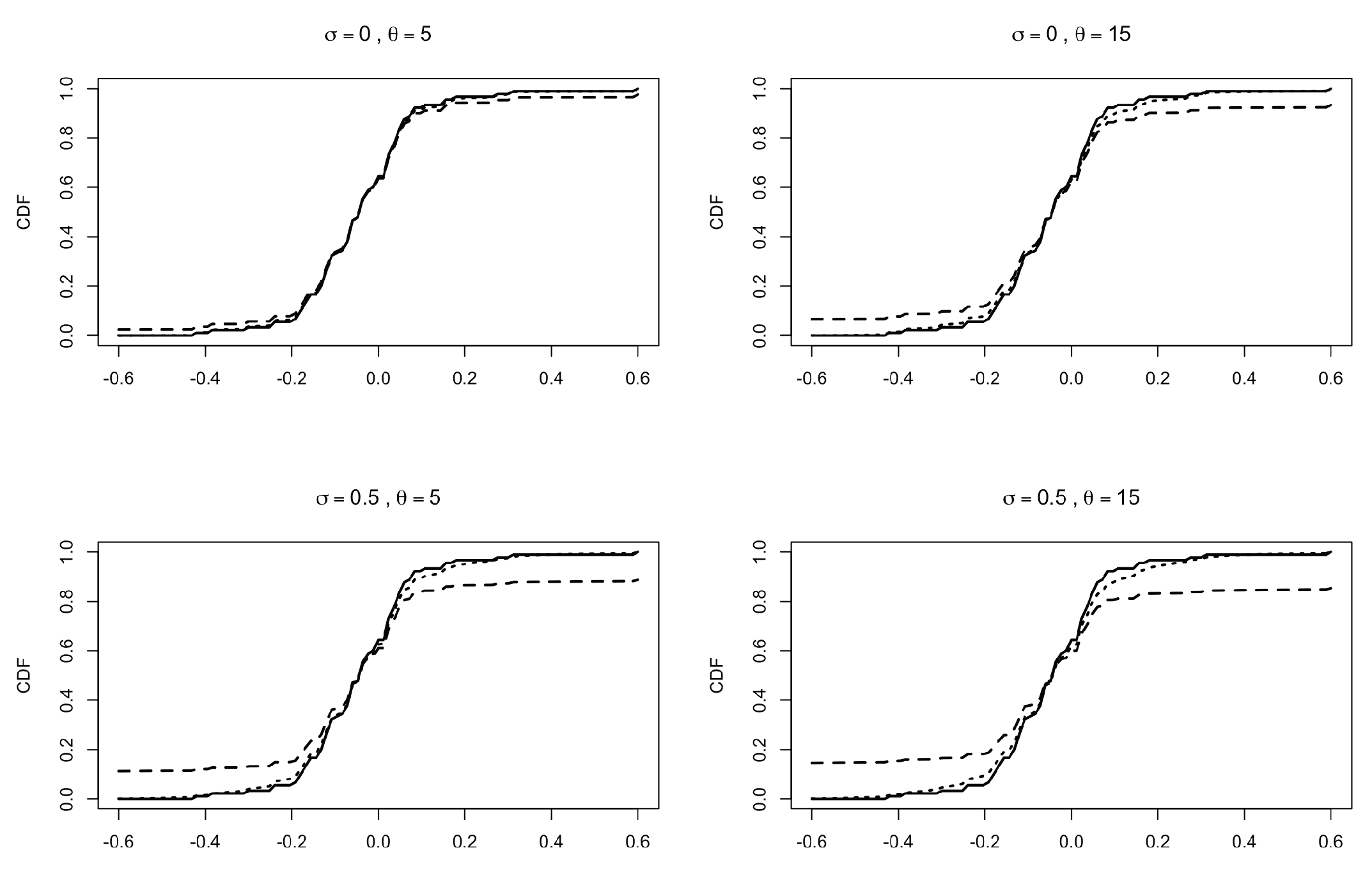
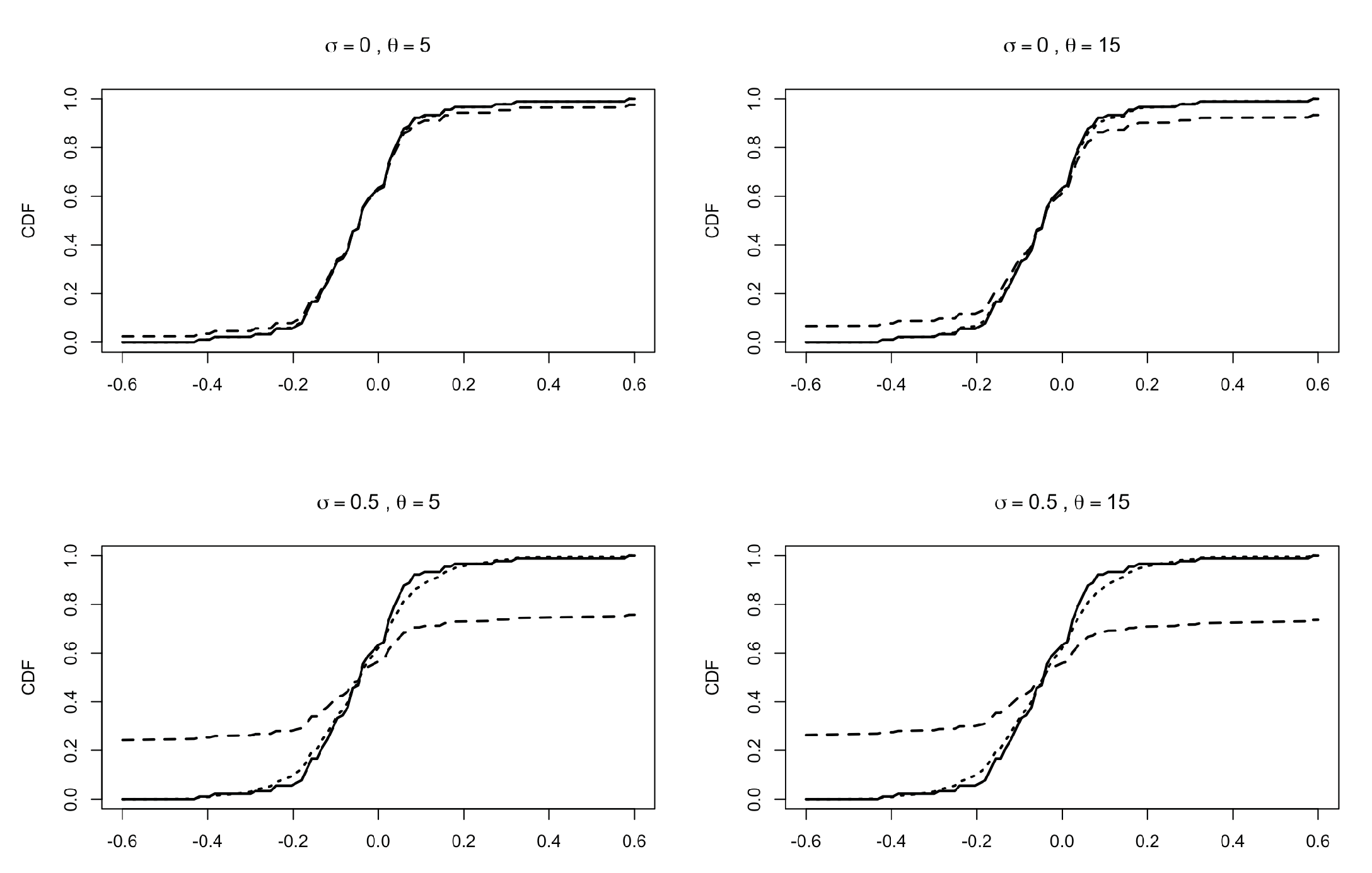
5. Predictive Distributions
5.1. Some General Results
5.2. Predictive Distributions for
6. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- a.s.
- .
References
- Ferguson, T.S. A Bayesian analysis of some nonparametric problems. Ann. Stat. 1973, 1, 209–230. [Google Scholar] [CrossRef]
- Pitman, J.; Yor, M. The two-parameter Poisson-Dirichlet distribution derived from a stable subordinator. Ann. Probab. 1997, 25, 855–900. [Google Scholar] [CrossRef]
- Perman, M.; Pitman, J.; Yor, M. Size-biased sampling of Poisson point processes and excursions. Probab. Theory Relat. Fields 1992, 92, 21–39. [Google Scholar] [CrossRef]
- Regazzini, E.; Lijoi, A.; Prünster, I. Distributional results for means of normalized random measures with independent increments. Ann. Stat. 2003, 31, 560–585. [Google Scholar] [CrossRef]
- James, L.F.; Lijoi, A.; Prünster, I. Posterior analysis for normalized random measures with independent increments. Scand. J. Stat. 2009, 36, 76–97. [Google Scholar] [CrossRef]
- Lijoi, A.; Prünster, I. Models beyond the Dirichlet process. In Bayesian Nonparametrics; Hjort, N.L., Holmes, C., Müller, P., Walker, S., Eds.; Cambridge University Press: New York, NY, USA, 2010. [Google Scholar]
- De Blasi, P.; Favaro, S.; Lijoi, A.; Mena, R.H.; Prunster, I.; Ruggiero, M. Are Gibbs-Type Priors the Most Natural Generalization of the Dirichlet Process? IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 212–229. [Google Scholar] [CrossRef]
- Pitman, J. Poisson-Kingman partitions. In Statistics and Science: A Festschrift for Terry Speed; IMS Lecture Notes Monograph Series; Institute of Mathematical Statistics: Beachwood, OH, USA, 2003; Volume 40, pp. 1–34. [Google Scholar]
- Ishwaran, H.; James, L.F. Gibbs sampling methods for stick-breaking priors. J. Am. Stat. Assoc. 2001, 96, 161–173. [Google Scholar] [CrossRef]
- Antoniak, C.E. Mixtures of Dirichlet processes with applications to Bayesian nonparametric problems. Ann. Stat. 1974, 2, 1152–1174. [Google Scholar] [CrossRef]
- Cifarelli, D.M.; Regazzini, E. Distribution functions of means of a Dirichlet process. Ann. Stat. 1990, 18, 429–442. [Google Scholar] [CrossRef]
- Sangalli, L.M. Some developments of the normalized random measures with independent increments. Sankhyā 2006, 68, 461–487. [Google Scholar]
- Broderick, T.; Wilson, A.C.; Jordan, M.I. Posteriors, conjugacy, and exponential families for completely random measures. Bernoulli 2018, 24, 3181–3221. [Google Scholar] [CrossRef]
- Bassetti, F.; Ladelli, L. Asymptotic number of clusters for species sampling sequences with non-diffuse base measure. Stat. Probab. Lett. 2020, 162, 108749. [Google Scholar] [CrossRef]
- Pitman, J. Some developments of the Blackwell-MacQueen urn scheme. In Statistics, Probability and Game Theory; IMS Lecture Notes Monograph Series; Institute of Mathematical Statistics: Hayward, CA, USA, 1996; Volume 30, pp. 245–267. [Google Scholar] [CrossRef]
- Dunson, D.B.; Herring, A.H.; Engel, S.M. Bayesian selection and clustering of polymorphisms in functionally related genes. J. Am. Stat. Assoc. 2008, 103, 534–546. [Google Scholar] [CrossRef]
- Kim, S.; Dahl, D.B.; Vannucci, M. Spiked Dirichlet process prior for Bayesian multiple hypothesis testing in random effects models. Bayesian Anal. 2009, 4, 707–732. [Google Scholar] [CrossRef] [PubMed]
- Suarez, A.J.; Ghosal, S. Bayesian Clustering of Functional Data Using Local Features. Bayesian Anal. 2016, 11, 71–98. [Google Scholar] [CrossRef]
- Cui, K.; Cui, W. Spike-and-Slab Dirichlet Process Mixture Models. Spike Slab Dirichlet Process. Mix. Model. 2012, 2, 512–518. [Google Scholar] [CrossRef][Green Version]
- Barcella, W.; De Iorio, M.; Baioa, G.; Malone-Leeb, J. Variable selection in covariate dependent random partition models: An application to urinary tract infection. Stat. Med. 2016, 35, 1373–13892. [Google Scholar] [CrossRef]
- Canale, A.; Lijoi, A.; Nipoti, B.; Prünster, I. On the Pitman–Yor process with spike and slab base measure. Biometrika 2017, 104, 681–697. [Google Scholar] [CrossRef]
- Teh, Y.; Jordan, M.I. Hierarchical Bayesian nonparametric models with applications. In Bayesian Nonparametrics; Hjort, N.L., Holmes, C., Müller, P., Walker, S., Eds.; Cambridge University Press: New York, NY, USA, 2010. [Google Scholar]
- Teh, Y.W.; Jordan, M.I.; Beal, M.J.; Blei, D.M. Hierarchical Dirichlet processes. J. Am. Stat. Assoc. 2006, 101, 1566–1581. [Google Scholar] [CrossRef]
- Camerlenghi, F.; Lijoi, A.; Orbanz, P.; Pruenster, I. Distribution theory for hierarchical processes. Ann. Stat. 2019, 1, 67–92. [Google Scholar] [CrossRef]
- Bassetti, F.; Casarin, R.; Rossini, L. Hierarchical Species Sampling Models. Bayesian Anal. 2020, 15, 809–838. [Google Scholar] [CrossRef]
- Pitman, J. Combinatorial Stochastic Processes; Lectures from the 32nd Summer School on Probability Theory Held in Saint-Flour, 7–24 July 2002, with a Foreword by Jean Picard; Lecture Notes in Mathematics; Springer: Berlin, Germany, 2006; Volume 1875. [Google Scholar]
- Crane, H. The ubiquitous Ewens sampling formula. Stat. Sci. 2016, 31, 1–19. [Google Scholar] [CrossRef]
- Kingman, J.F.C. The representation of partition structures. J. Lond. Math. Soc. 1978, 18, 374–380. [Google Scholar] [CrossRef]
- Aldous, D.J. Exchangeability and related topics. In École d’été de Probabilités de Saint-Flour, XIII—1983; Lecture Notes in Mathematics; Springer: Berlin, Germany, 1985; Volume 1117, pp. 1–198. [Google Scholar] [CrossRef]
- Kallenberg, O. Canonical representations and convergence criteria for processes with interchangeable increments. Z. Wahrscheinlichkeitstheorie Und Verw. Geb. 1973, 27, 23–36. [Google Scholar] [CrossRef]
- Pitman, J. Exchangeable and partially exchangeable random partitions. Probab. Theory Relat. Fields 1995, 102, 145–158. [Google Scholar] [CrossRef]
- Gnedin, A.; Pitman, J. Exchangeable Gibbs partitions and Stirling triangles. Zap. Nauchn. Sem. S.-Peterburg. Otdel. Mat. Inst. Steklov. (POMI) 2005, 325, 83–102, 244–245. [Google Scholar] [CrossRef]
- Schervish, M.J. Theory of Statistics; Springer Series in Statistics; Springer: New York, NY, USA, 1995. [Google Scholar] [CrossRef]
- Marin, J.M.; Robert, C.P. Bayesian Core: A Practical Approach to Computational Bayesian Statistics; Springer Texts in Statistics; Springer: New York, NY, USA, 2007; pp. xiv+255. [Google Scholar]
- Kallenberg, O. Foundations of Modern Probability, 3rd ed.; Probability Theory and Stochastic Modelling; Springer: New York, NY, USA, 2021; Volume 99. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bassetti, F.; Ladelli, L. Mixture of Species Sampling Models. Mathematics 2021, 9, 3127. https://doi.org/10.3390/math9233127
Bassetti F, Ladelli L. Mixture of Species Sampling Models. Mathematics. 2021; 9(23):3127. https://doi.org/10.3390/math9233127
Chicago/Turabian StyleBassetti, Federico, and Lucia Ladelli. 2021. "Mixture of Species Sampling Models" Mathematics 9, no. 23: 3127. https://doi.org/10.3390/math9233127
APA StyleBassetti, F., & Ladelli, L. (2021). Mixture of Species Sampling Models. Mathematics, 9(23), 3127. https://doi.org/10.3390/math9233127