
A First Approach to Closeness Distributions


Abstract
:1. Introduction
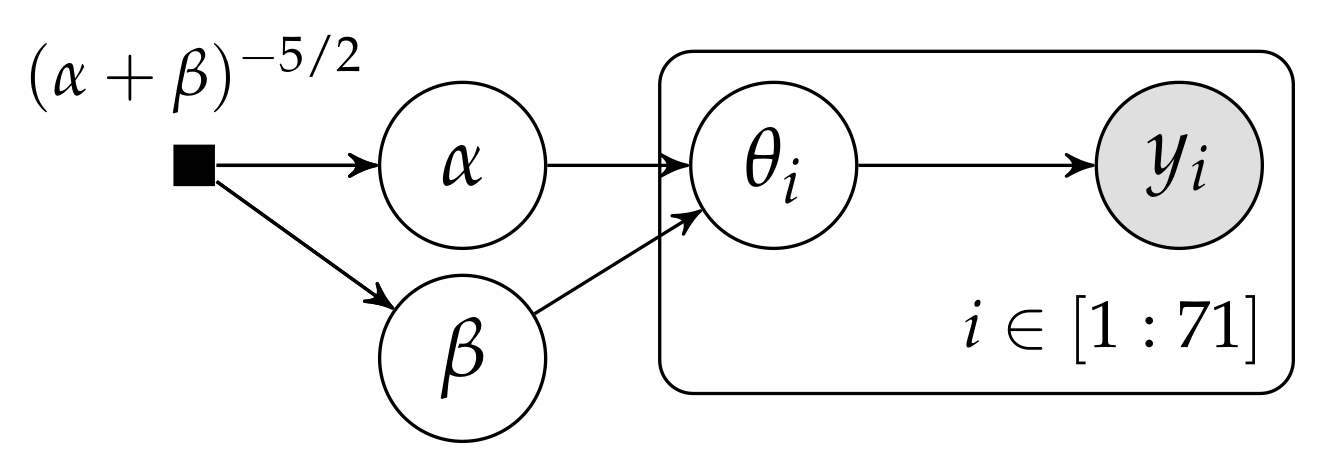
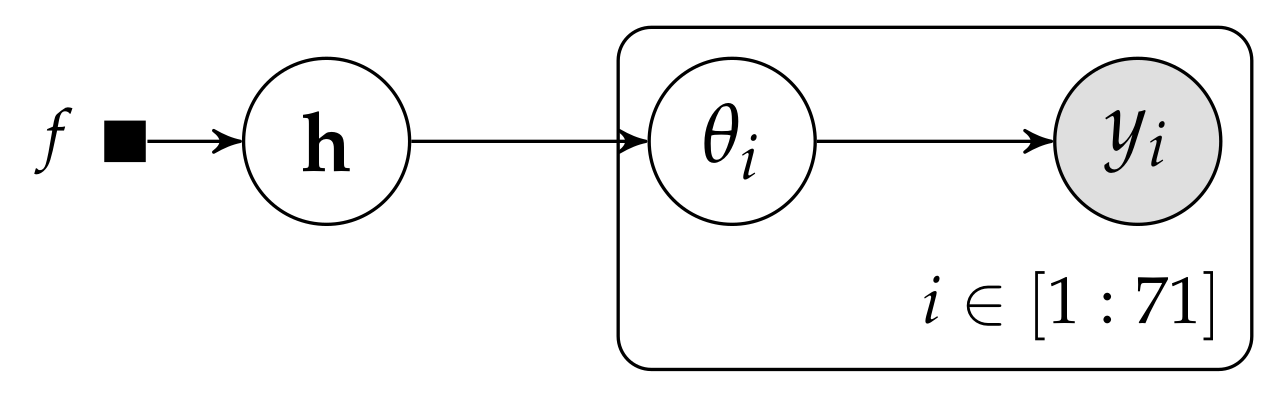
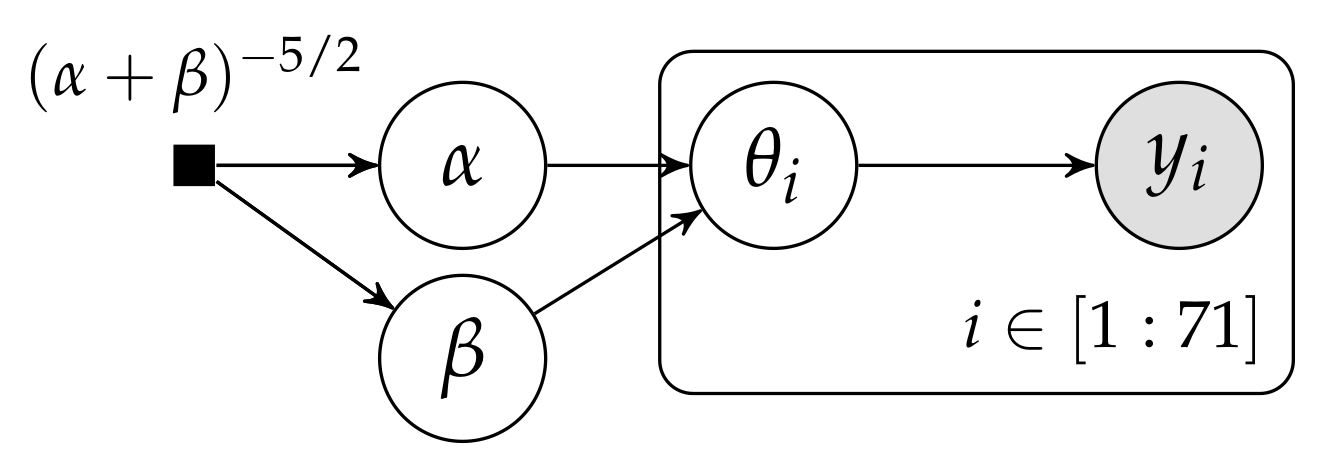
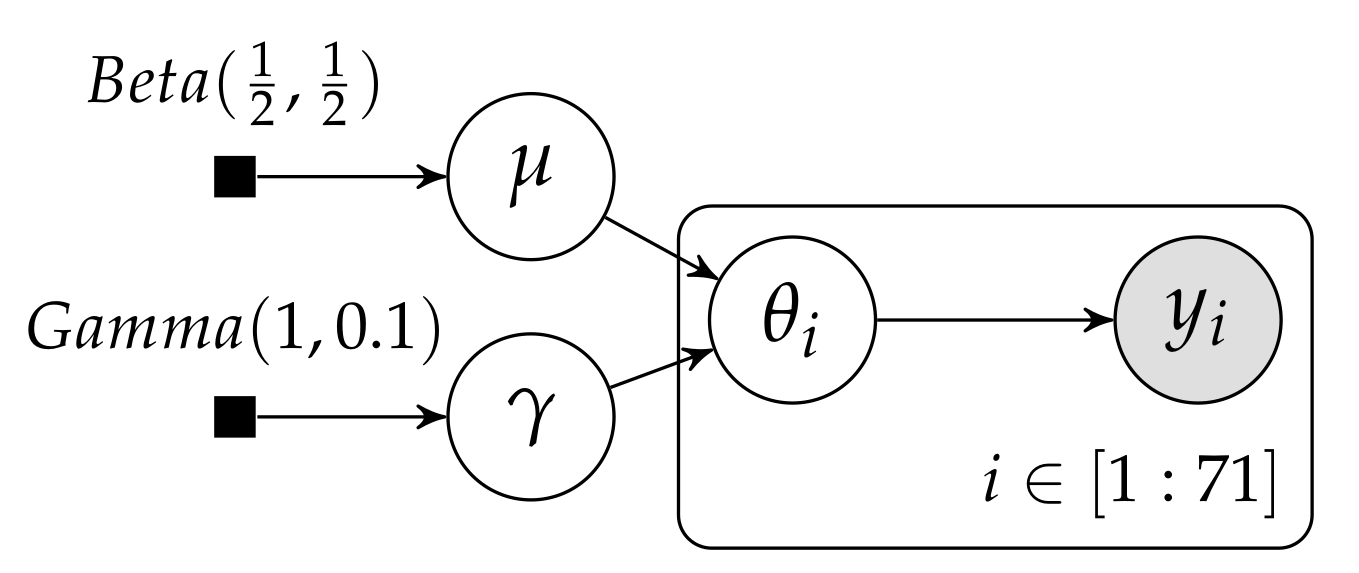
In the evaluation of drugs for possible clinical application, studies are routinely performed on rodents. For a particular study drawn from the statistical literature, suppose the immediate aim is to estimate θ, the probability of a tumor in a population of female laboratory rats of type ‘F344’ that receive a zero dose of the drug (a control group). The data show that 4 out of 14 rats developed endometrial stromal polyps (a kind of tumor). (...) Typically, the mean and standard deviation of underlying tumor risks are not available. Rather, historical data are available on previous experiments on similar groups of rats. In the rat tumor example, the historical data were in fact a set of observations of tumor incidence in 70 groups of rats (Table 1). In the ith historical experiment, let the number of rats with tumors be and the total number of rats be . We model the ’s as independent binomial data, given sample sizes and study-specific means .
2. Closeness Distributions
2.1. Probabilities over Probabilities
2.2. Formalizing Remoteness and Closeness
3. KL-Closeness Distributions for Multinomials
3.1. Closeness Distributions for KL as Remoteness Function
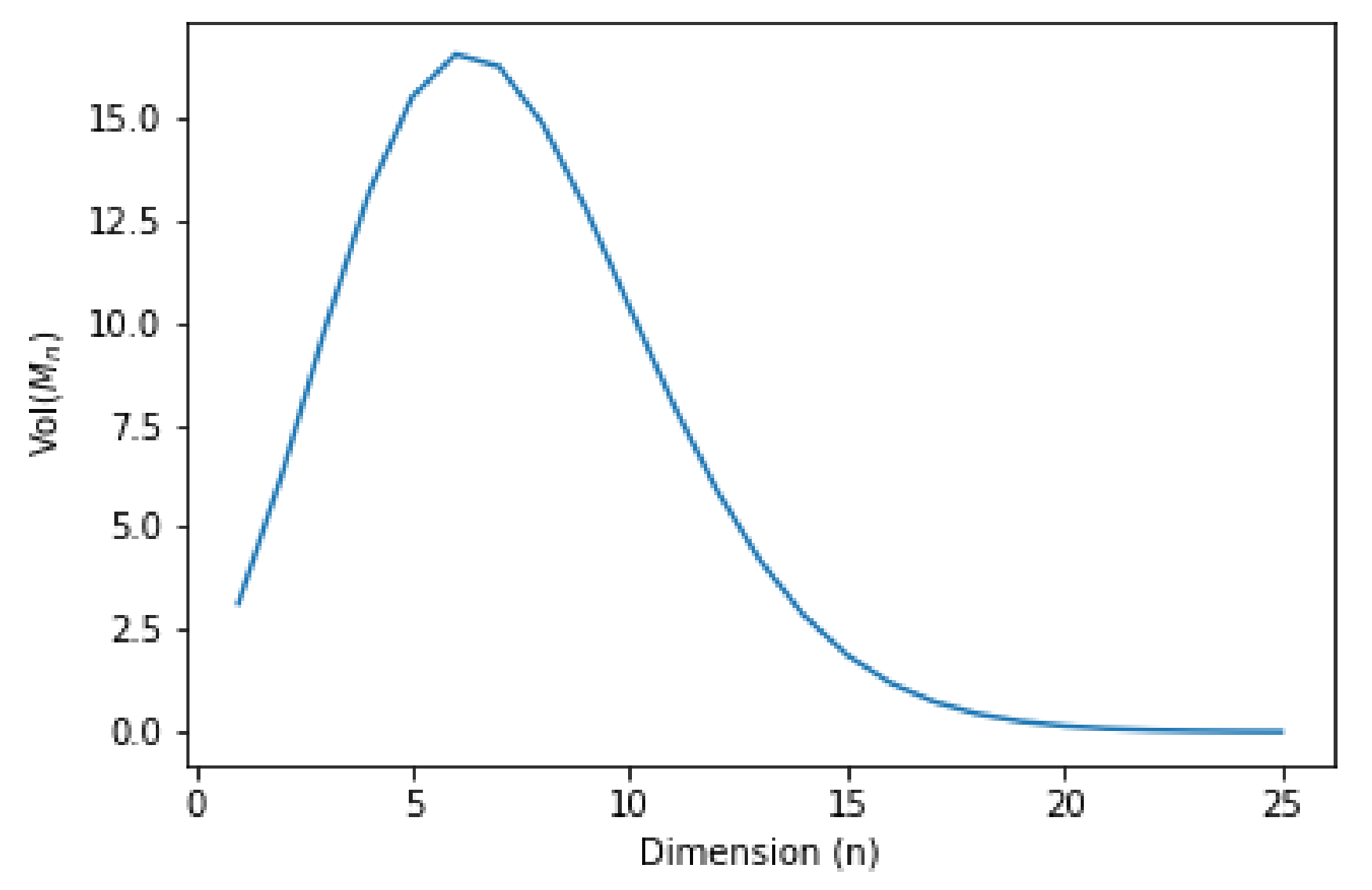
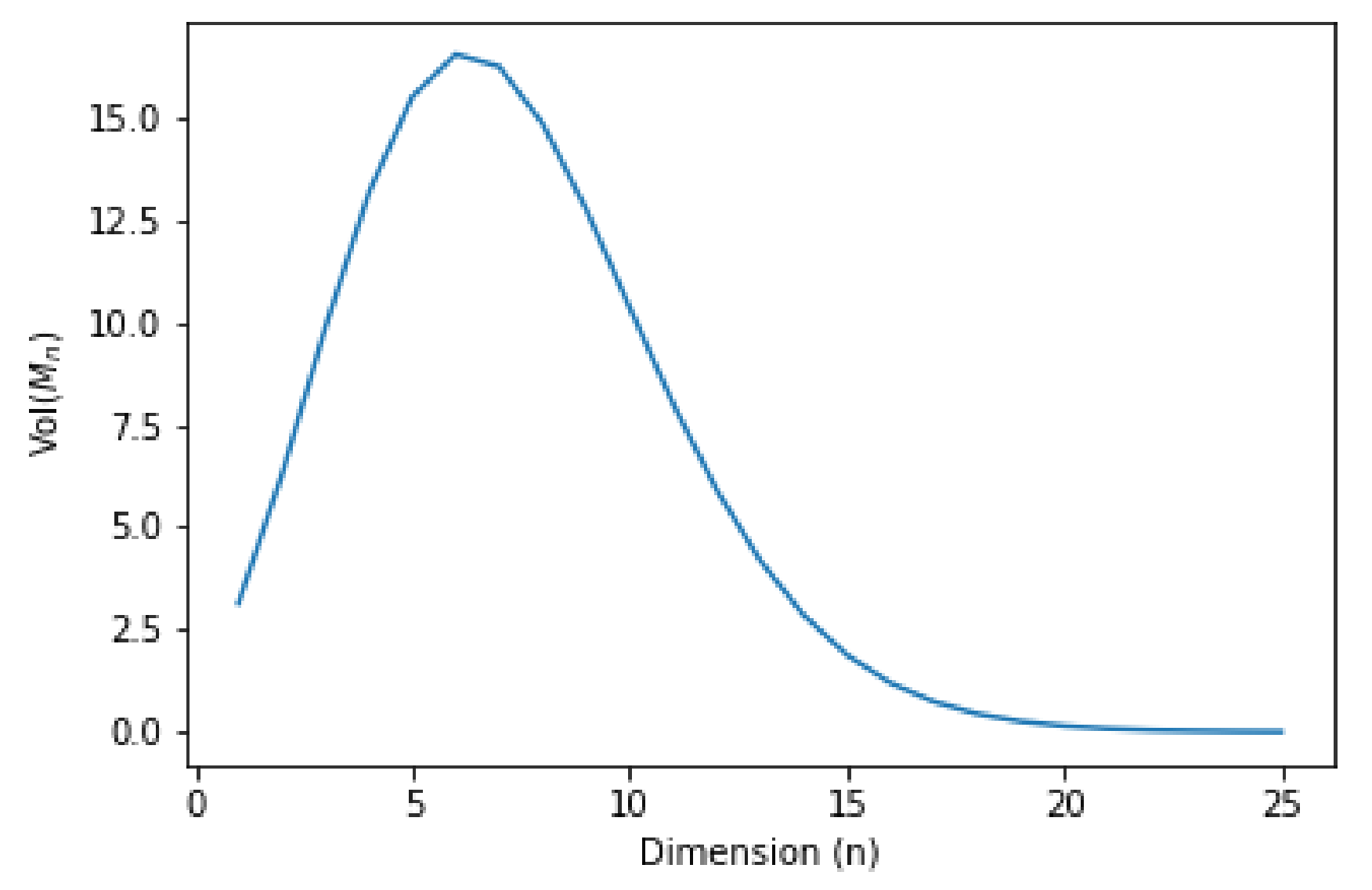
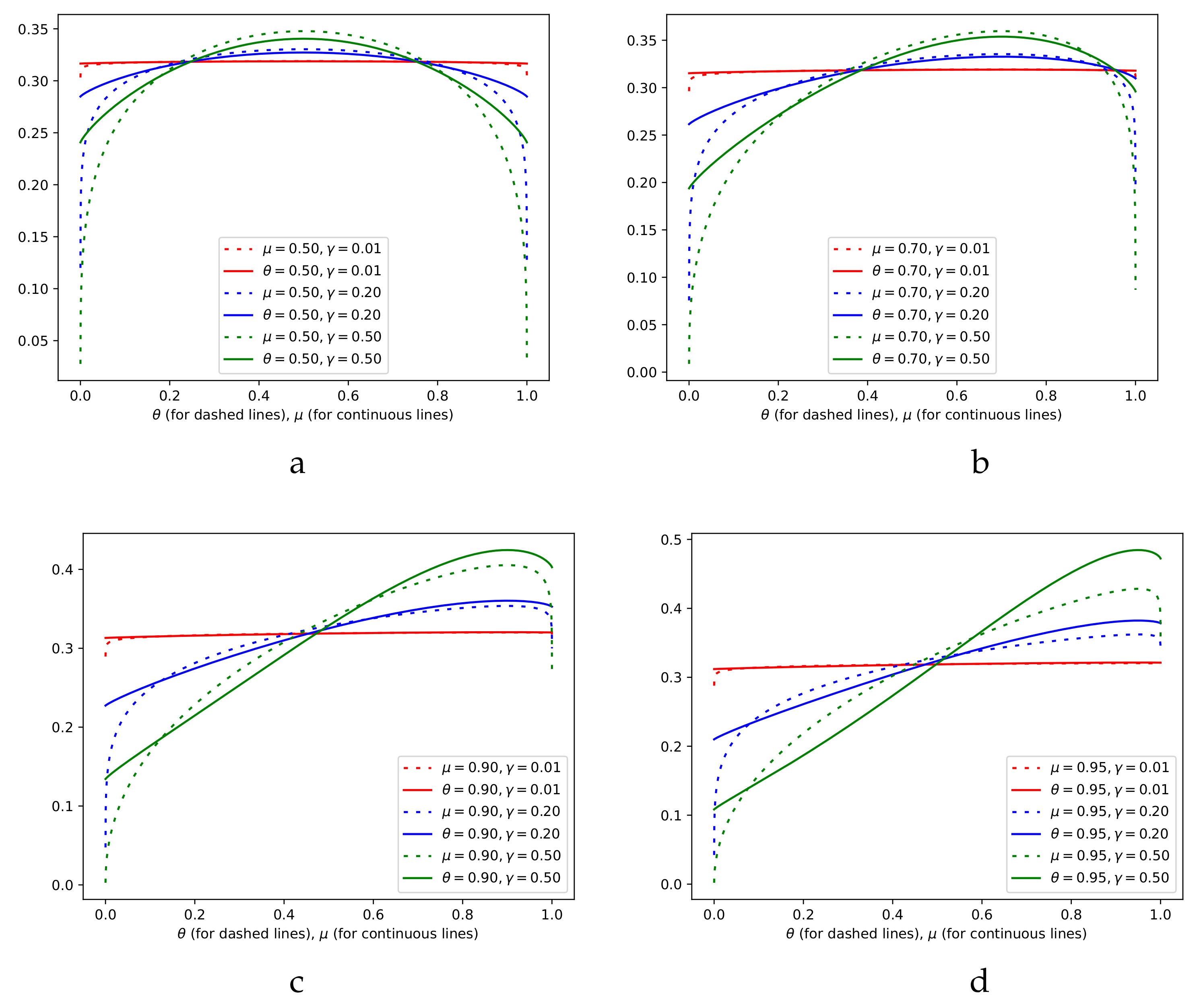
3.2. Visualizing the Distributions
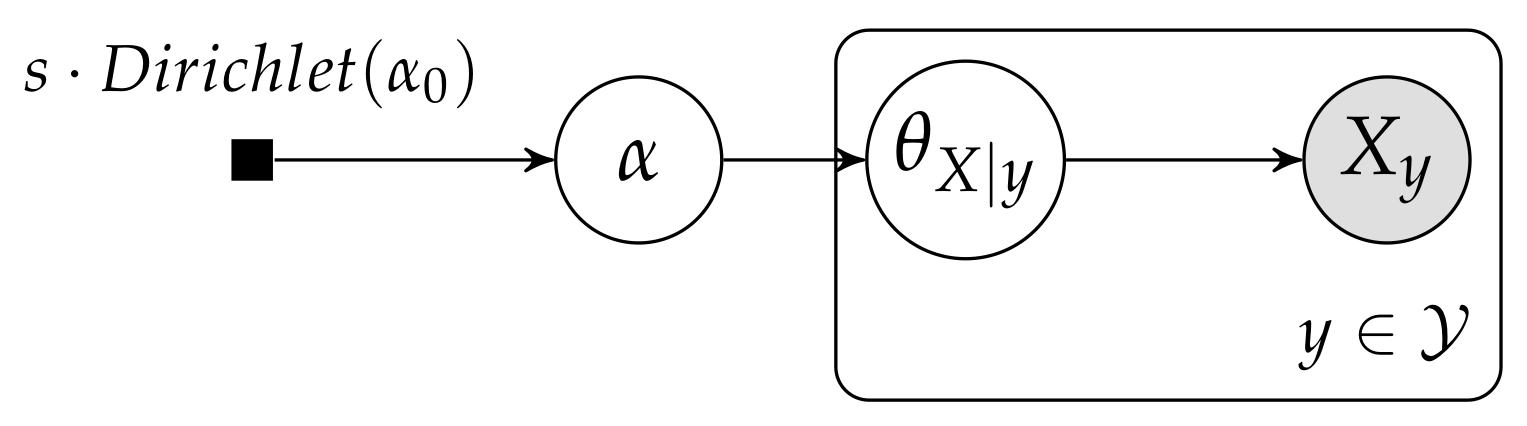
4. Reinterpreting the Beta-Binomial Model
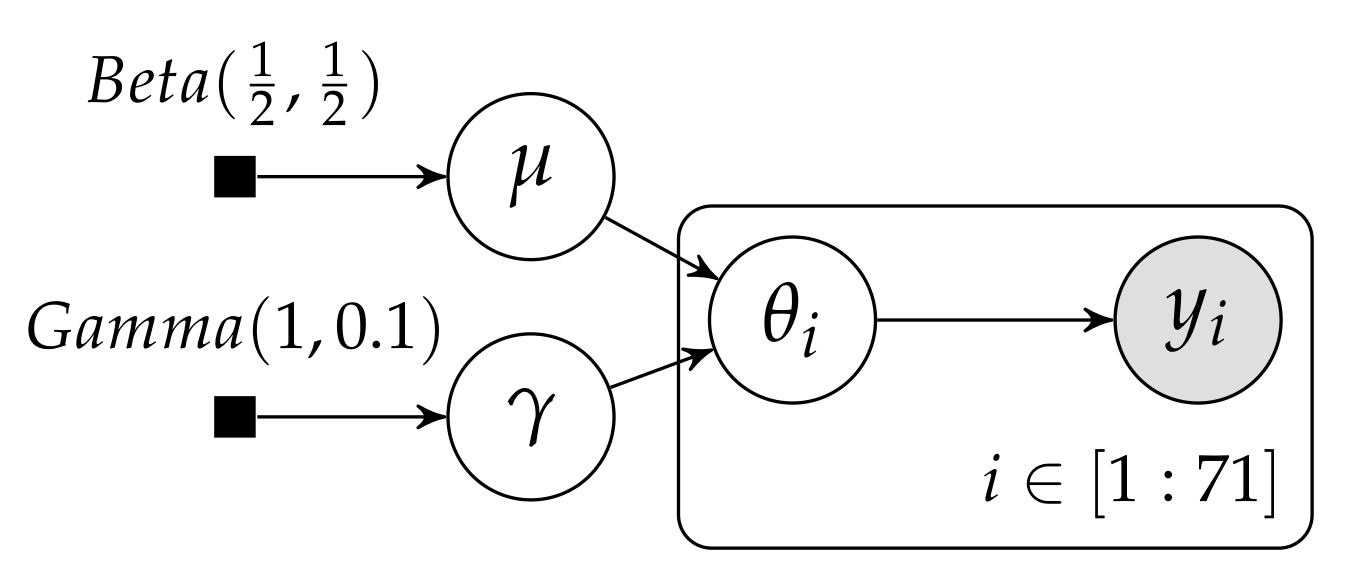
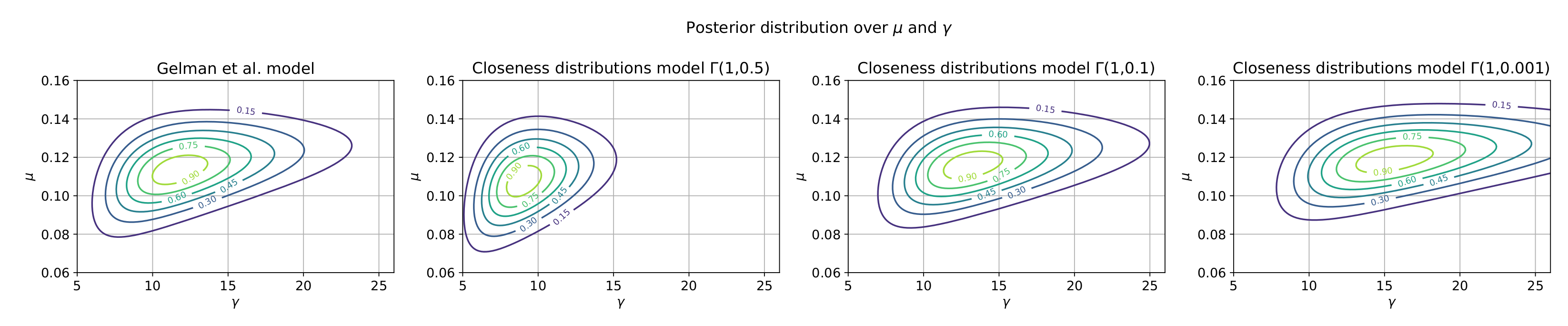
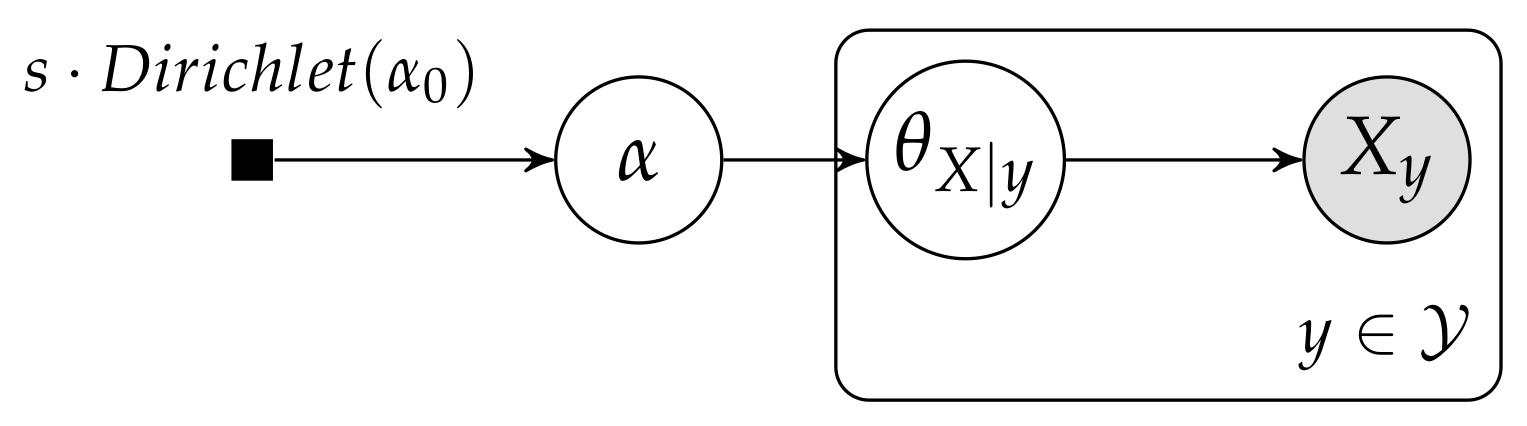
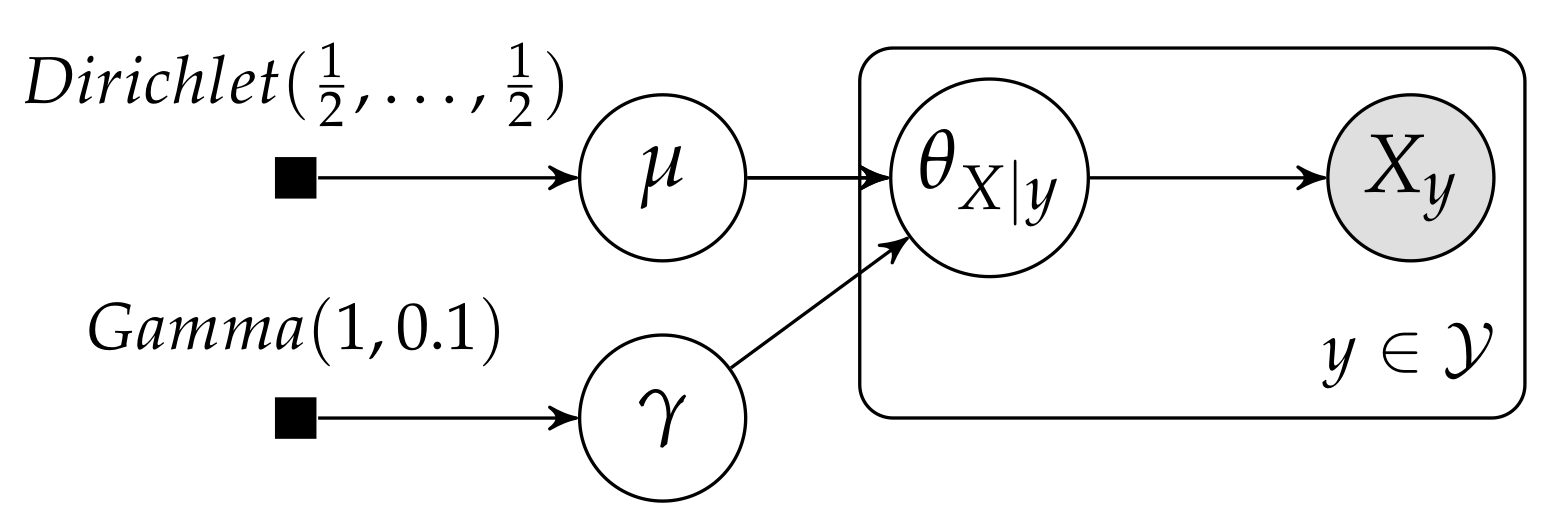
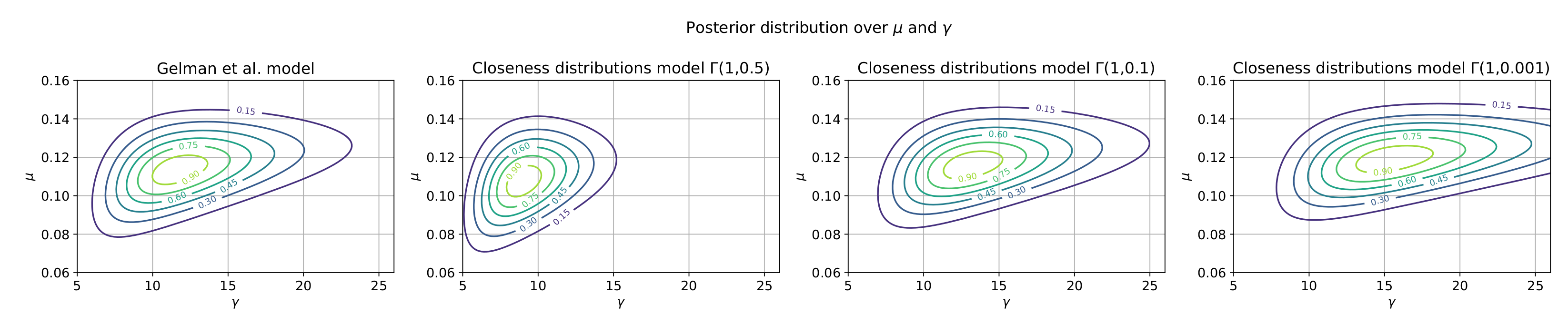
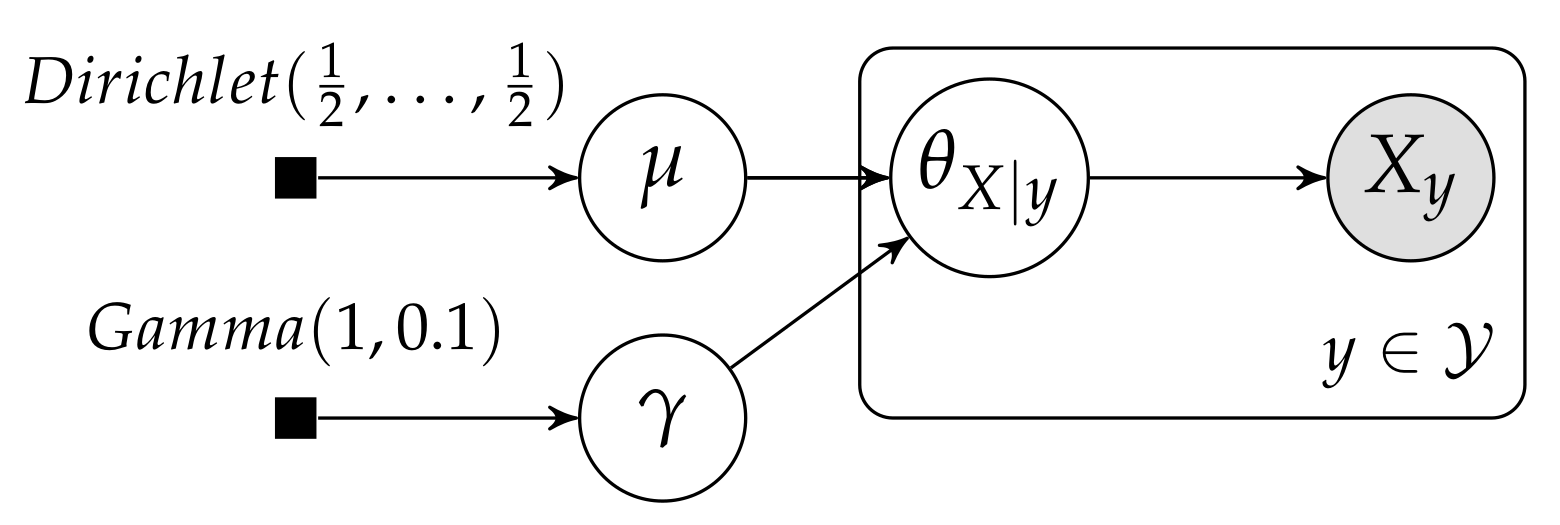
5. Hierarchical Dirichlet Multinomial Model
6. Conclusions and Future Work
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Total Order Induced by a Function
Appendix B. Detailed Derivation of the KL Based Closeness Distributions for Multinomials
Closeness Distributions for KL as Remoteness Function
References
- Van de Schoot, R.; Depaoli, S.; King, R.; Kramer, B.; Märtens, K.; Tadesse, M.G.; Vannucci, M.; Gelman, A.; Veen, D.; Willemsen, J.; et al. Bayesian statistics and modelling. Nat. Rev. Methods Prim. 2021, 1, 1. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis; Chapman and Hall/CRC: London, UK, 2013. [Google Scholar]
- Allenby, G.M.; Rossi, P.E.; McCulloch, R. Hierarchical Bayes Models: A Practitioners Guide. SSRN Electron. J. 2005. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.Y.; Lei, B.; Mallick, B. Estimation of COVID-19 spread curves integrating global data and borrowing information. PLoS ONE 2020, 15, e0236860. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.Y.; Mallick, B.K. Bayesian Hierarchical Modeling: Application Towards Production Results in the Eagle Ford Shale of South Texas. Sankhya B 2021. [Google Scholar] [CrossRef]
- Tarone, R.E. The Use of Historical Control Information in Testing for a Trend in Proportions. Biometrics 1982, 38, 215–220. [Google Scholar] [CrossRef]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Obermeyer, F.; Bingham, E.; Jankowiak, M.; Pradhan, N.; Chiu, J.; Rush, A.; Goodman, N. Tensor variable elimination for plated factor graphs. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 4871–4880. [Google Scholar]
- Azzimonti, L.; Corani, G.; Zaffalon, M. Hierarchical Multinomial-Dirichlet Model for the Estimation of Conditional Probability Tables. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; pp. 739–744. [Google Scholar] [CrossRef] [Green Version]
- Azzimonti, L.; Corani, G.; Zaffalon, M. Hierarchical estimation of parameters in Bayesian networks. Comput. Stat. Data Anal. 2019, 137, 67–91. [Google Scholar] [CrossRef]
- Azzimonti, L.; Corani, G.; Scutari, M. Structure Learning from Related Data Sets with a Hierarchical Bayesian Score. In Proceedings of the International Conference on Probabilistic Graphical Models, PMLR, Aalborg, Denmark, 23–25 September 2020; pp. 5–16. [Google Scholar]
- Amari, S.I. Information Geometry and Its Applications; Springer: Berlin/Heidelberg, Germany, 2016; Volume 194. [Google Scholar]
- Dudley, R.M. Real Analysis and Probability, 2nd ed.; Cambridge Studies in Advanced Mathematics; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar] [CrossRef]
- Jost, J. Riemannian Geometry and Geometric Analysis; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar] [CrossRef]
- Pennec, X. Probabilities and Statistics on Riemannian Manifolds: A Geometric Approach; Technical Report RR-5093; INRIA: Rocquencourt, France, 2004. [Google Scholar]
- Amann, H.; Escher, J. Analysis III; Birkhäuser: Basel, Switzerland, 2009. [Google Scholar] [CrossRef]
- Kass, R.E.; Vos, P.W. Geometrical Foundations of Assimptotic Inference; Wiley-Interscience: Hoboken, NJ, USA, 1997. [Google Scholar]
- Jeffreys, H. An invariant form for the prior probability in estimation problems. Proc. R. Soc. Lond. Ser. A Math. Phys. Sci. 1946, 186, 453–461. [Google Scholar] [CrossRef] [Green Version]
- Jeffreys, H. The Theory of Probability; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Cerquides, J. Parametrization invariant interpretation of priors and posteriors. arXiv 2021, arXiv:2105.08304. [Google Scholar]
- Laplace, P.S.m.d. Essai Philosophique sur les Probabilités; Courcier: Le Mesnil-Saint-Denis, France, 1814. [Google Scholar]
- Haldane, J.B.S. A note on inverse probability. Math. Proc. Camb. Philos. Soc. 1932, 28, 55–61. [Google Scholar] [CrossRef]
- Cerquides, J.; Mülâyim, M.O.; Hernández-González, J.; Ravi Shankar, A.; Fernandez-Marquez, J.L. A Conceptual Probabilistic Framework for Annotation Aggregation of Citizen Science Data. Mathematics 2021, 9, 875. [Google Scholar] [CrossRef]
- Jeffreys, H.; Swirles Jeffreys, B. Methods of Mathematical Physics; Cambridge University Press: Cambridge, UK, 1950. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Previous experiments: | |||||||||
| 0/20 | 0/20 | 0/20 | 0/20 | 0/20 | 0/20 | 0/20 | 0/19 | 0/19 | 0/19 |
| 0/19 | 0/18 | 0/18 | 0/17 | 1/20 | 1/20 | 1/20 | 1/20 | 1/19 | 1/19 |
| 1/18 | 1/18 | 2/25 | 2/24 | 2/23 | 2/20 | 2/20 | 2/20 | 2/20 | 2/20 |
| 2/20 | 1/10 | 5/49 | 2/19 | 5/46 | 3/27 | 2/17 | 7/49 | 7/47 | 3/20 |
| 3/20 | 2/13 | 9/48 | 10/50 | 4/20 | 4/20 | 4/20 | 4/20 | 4/20 | 4/20 |
| 4/20 | 10/48 | 4/19 | 4/19 | 4/19 | 5/22 | 11/46 | 12/49 | 5/20 | 5/20 |
| 6/23 | 5/19 | 6/22 | 6/20 | 6/20 | 6/20 | 16/52 | 15/47 | 15/46 | 9/24 |
| Current experiment: 4/14 | |||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cerquides, J. A First Approach to Closeness Distributions. Mathematics 2021, 9, 3112. https://doi.org/10.3390/math9233112
Cerquides J. A First Approach to Closeness Distributions. Mathematics. 2021; 9(23):3112. https://doi.org/10.3390/math9233112
Chicago/Turabian StyleCerquides, Jesus. 2021. "A First Approach to Closeness Distributions" Mathematics 9, no. 23: 3112. https://doi.org/10.3390/math9233112
APA StyleCerquides, J. (2021). A First Approach to Closeness Distributions. Mathematics, 9(23), 3112. https://doi.org/10.3390/math9233112