
Intelligent Ensemble Learning Approach for Phishing Website Detection Based on Weighted Soft Voting


Abstract
:1. Introduction
- -
- To improve the detection accuracy of phishing websites, a novel weighted soft voting method based on the k-statistic is suggested to evaluate the contributions of each classifier and assign higher influence weights to stronger classifiers and lower impact weights to weaker classifiers.
- -
- The proposed intelligent ensemble technique for phishing websites incorporates the results of individual learners in accordance with their significance in distinguishing phishing from legitimate websites.
- -
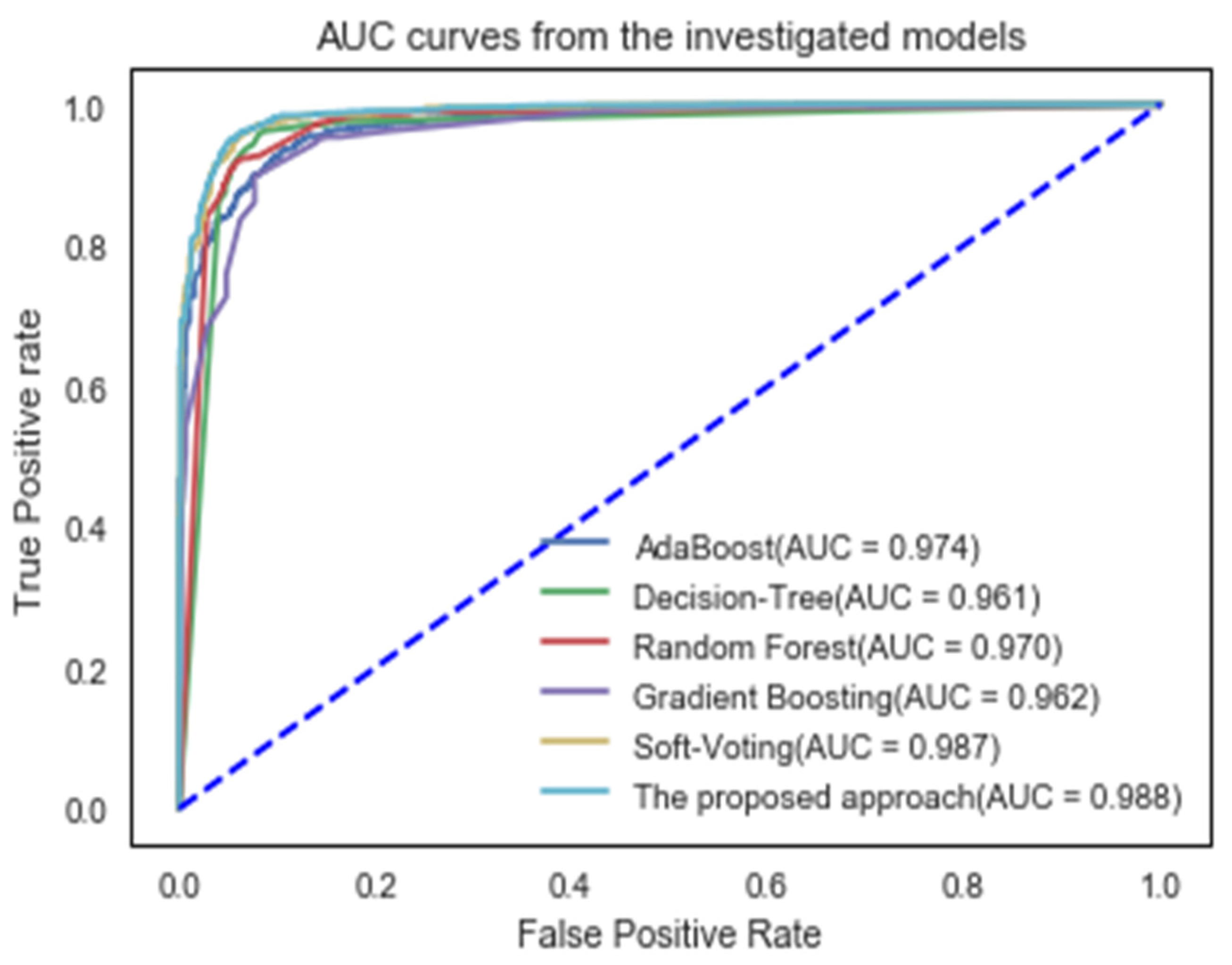
- Individual classifiers and soft voting ensembles were outperformed by the proposed approach, which achieved a detection accuracy of 95% for phishing websites using publicly available datasets. One of the issues is that single classifier approaches are unable to accurately detect evolving phishing websites. This was demonstrated by the fact that most single classifier models are usually outperformed by ensemble techniques or hybridization algorithms. As a result, this study focused on developing a more effective approach (Intelligent Ensemble Learning Approach) for detecting phishing websites.
2. Related Work
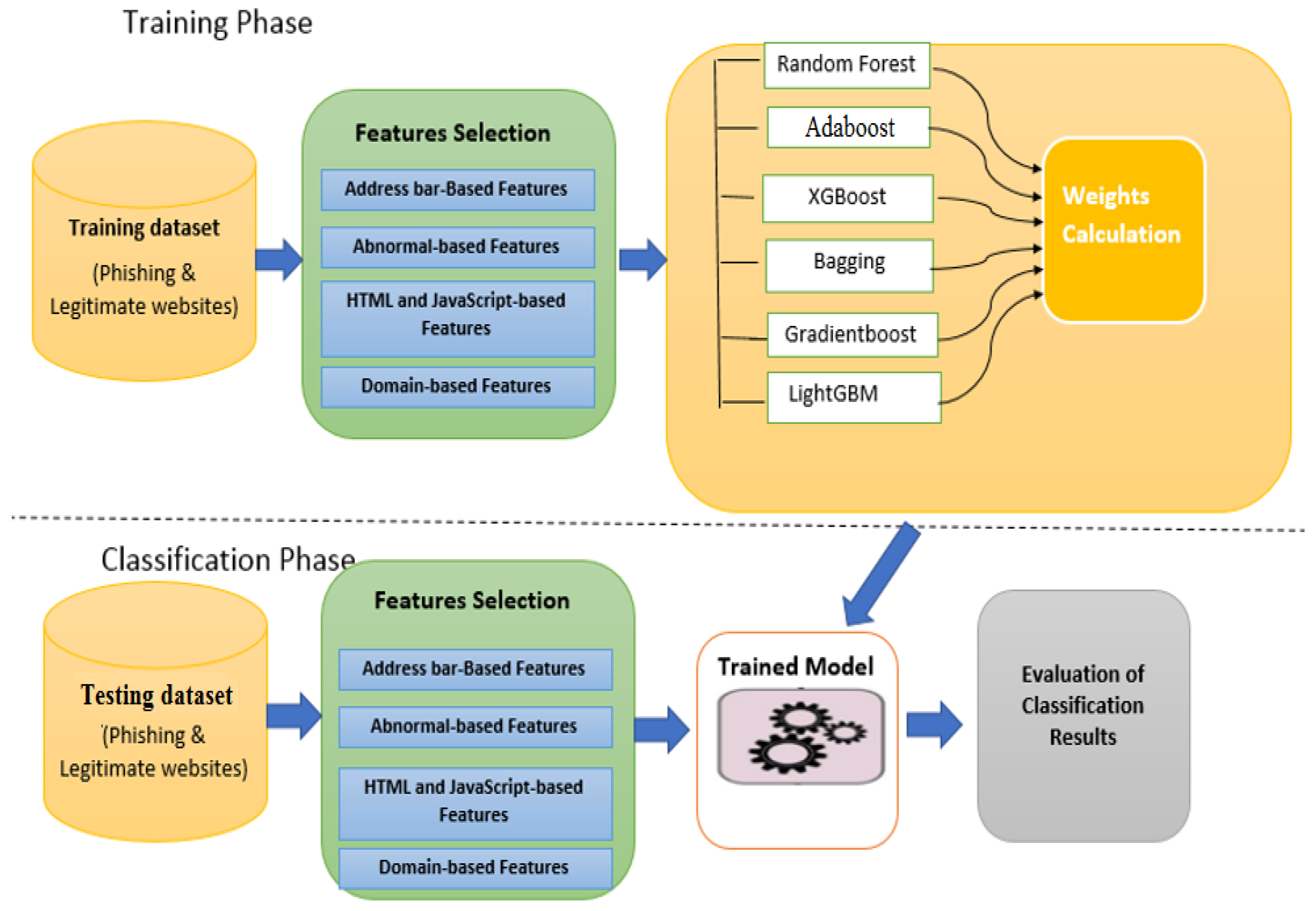
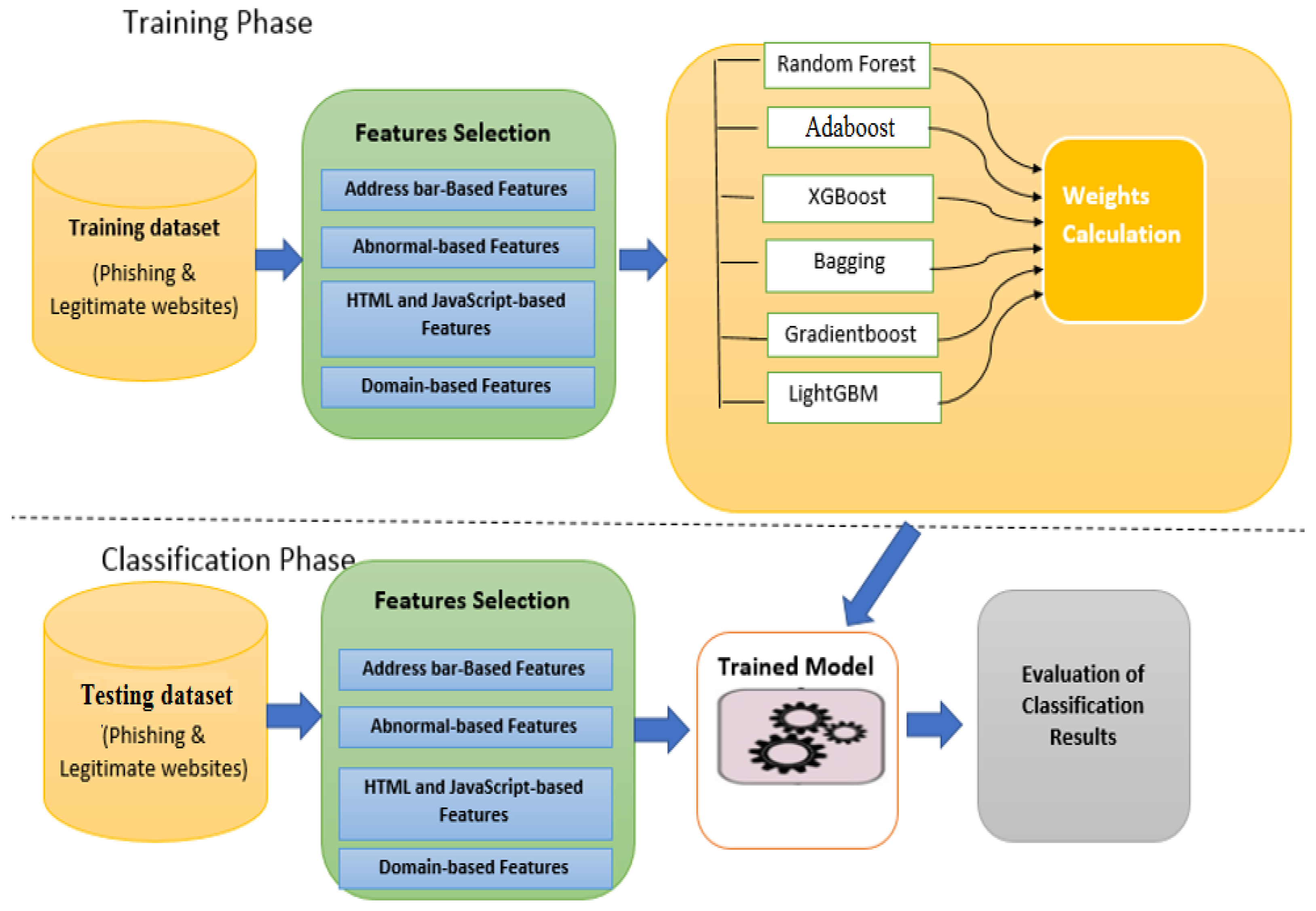
3. Proposed Intelligent Ensemble Learning Approach for Phishing Website Detection Based on Weighted Soft Voting
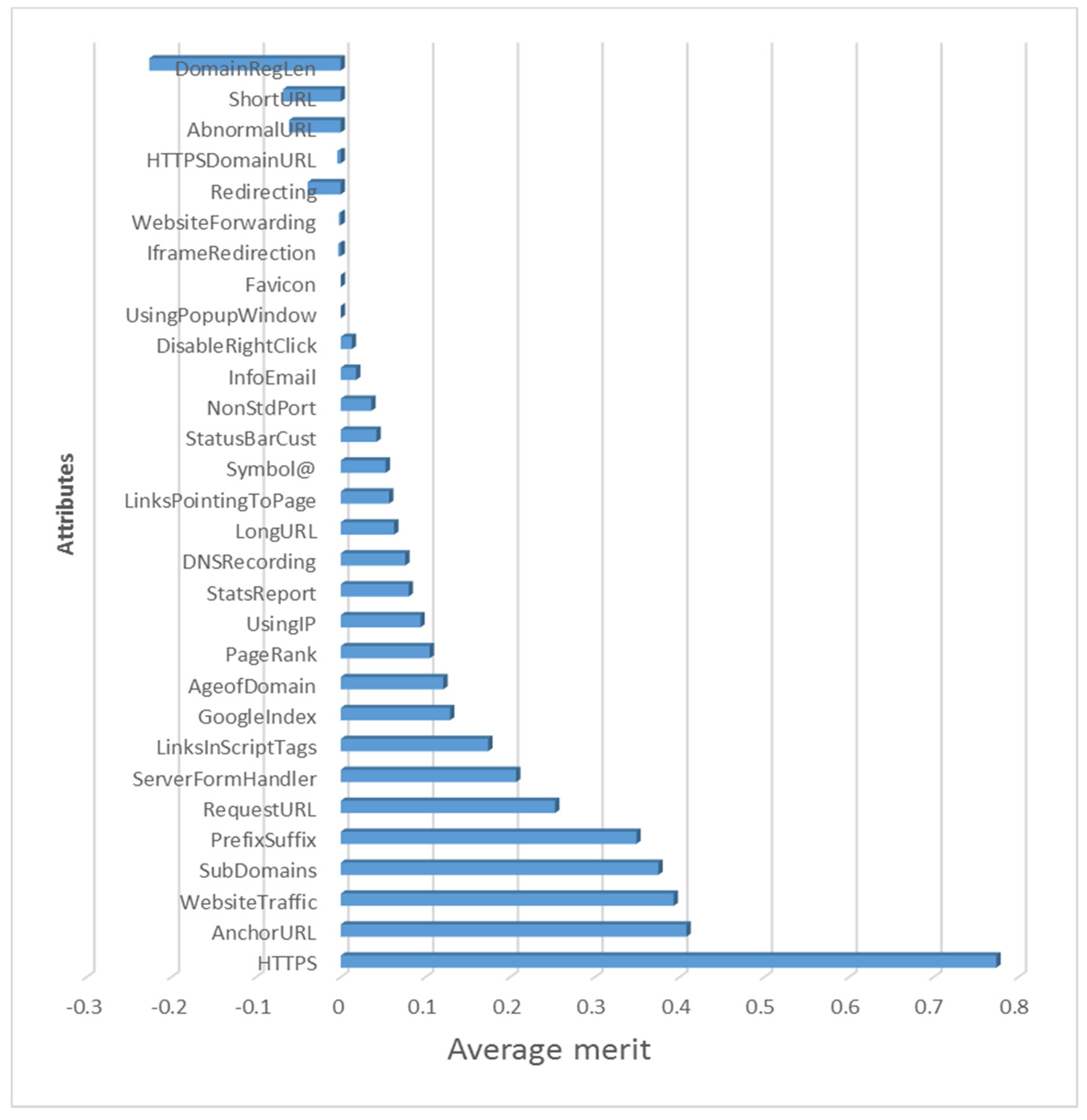
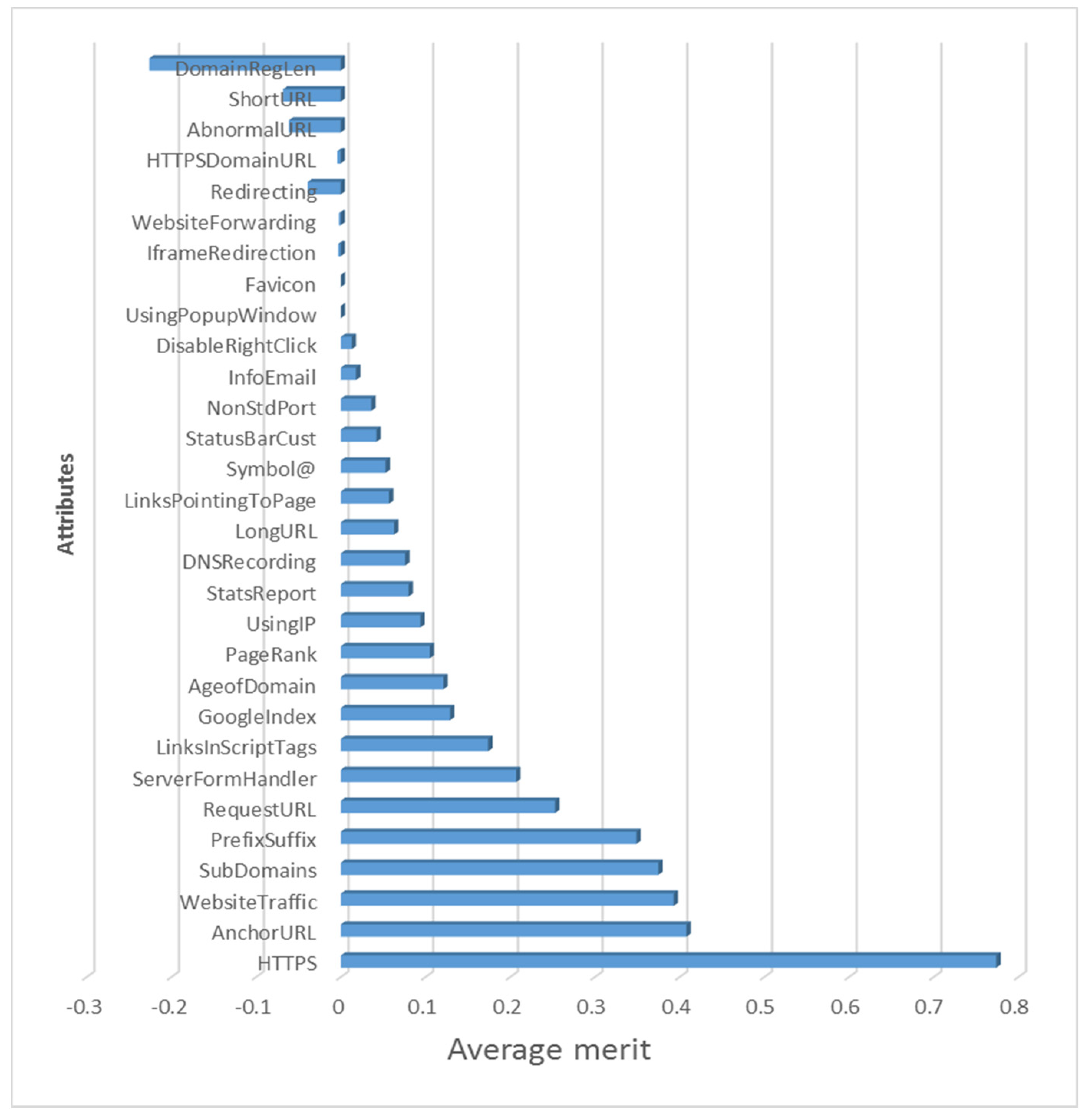
3.1. Dataset and Data Preprocessing
3.2. Weighted Soft Voting Based on k Statistics
3.3. Performance Evaluation Measures
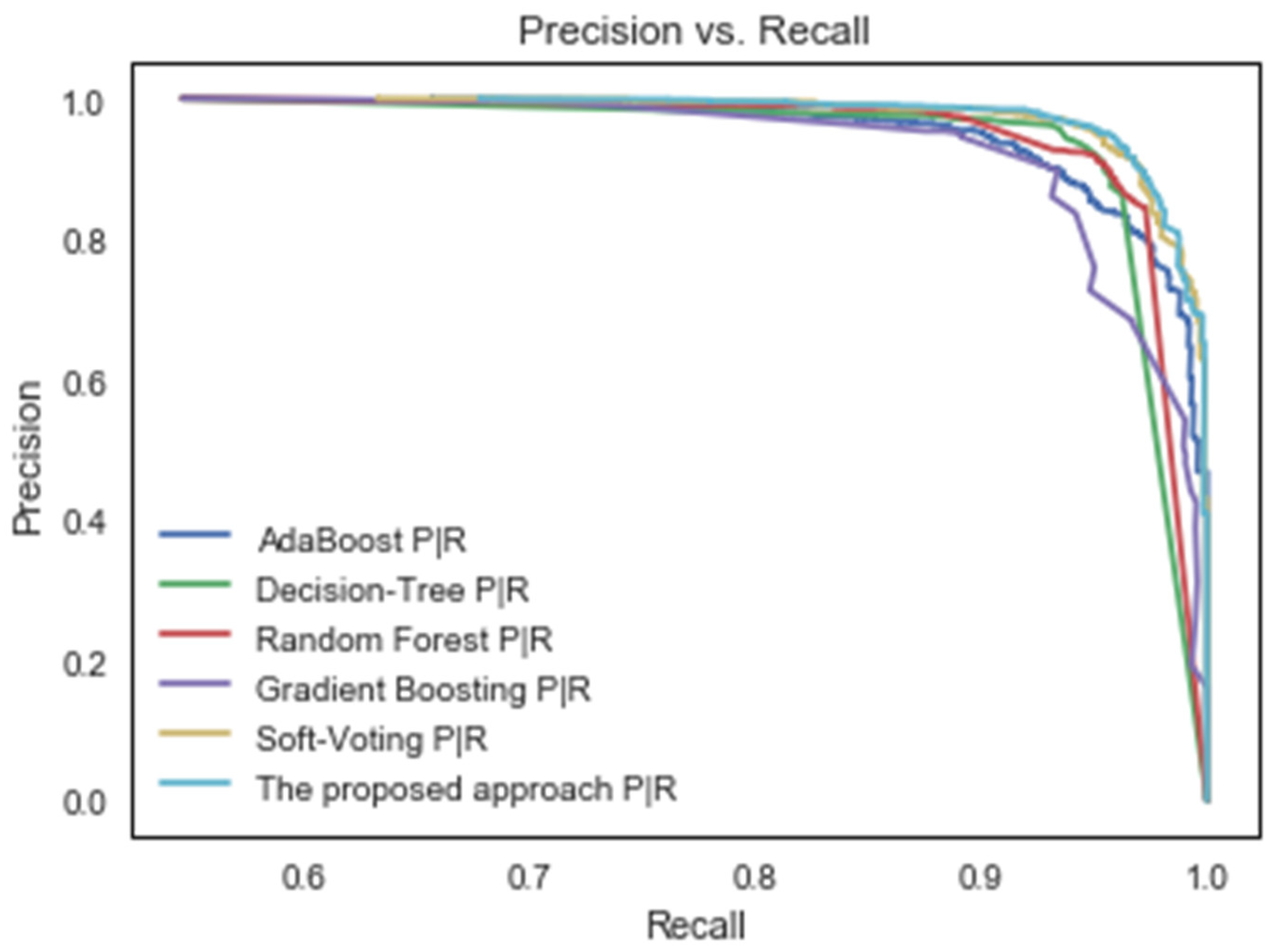
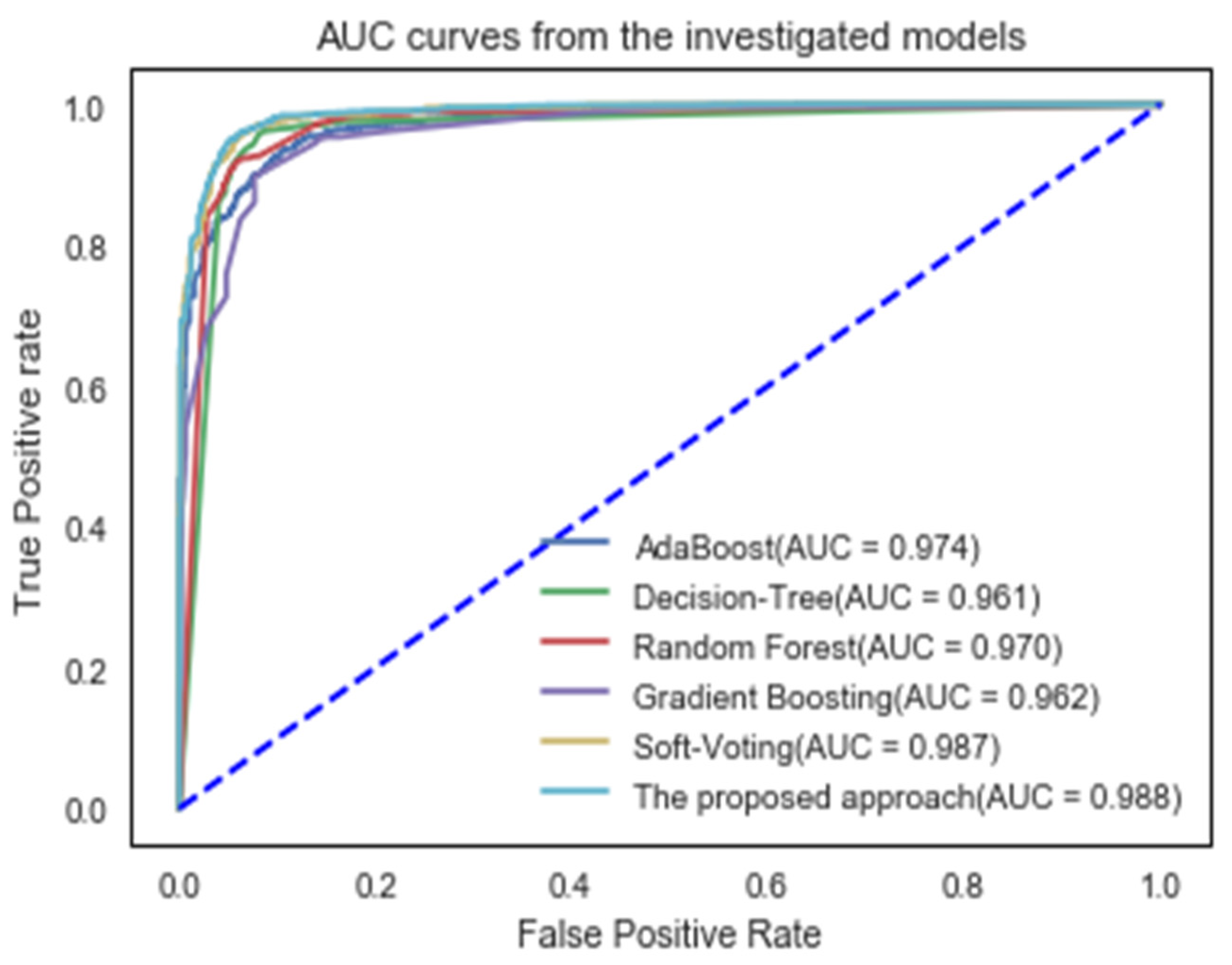
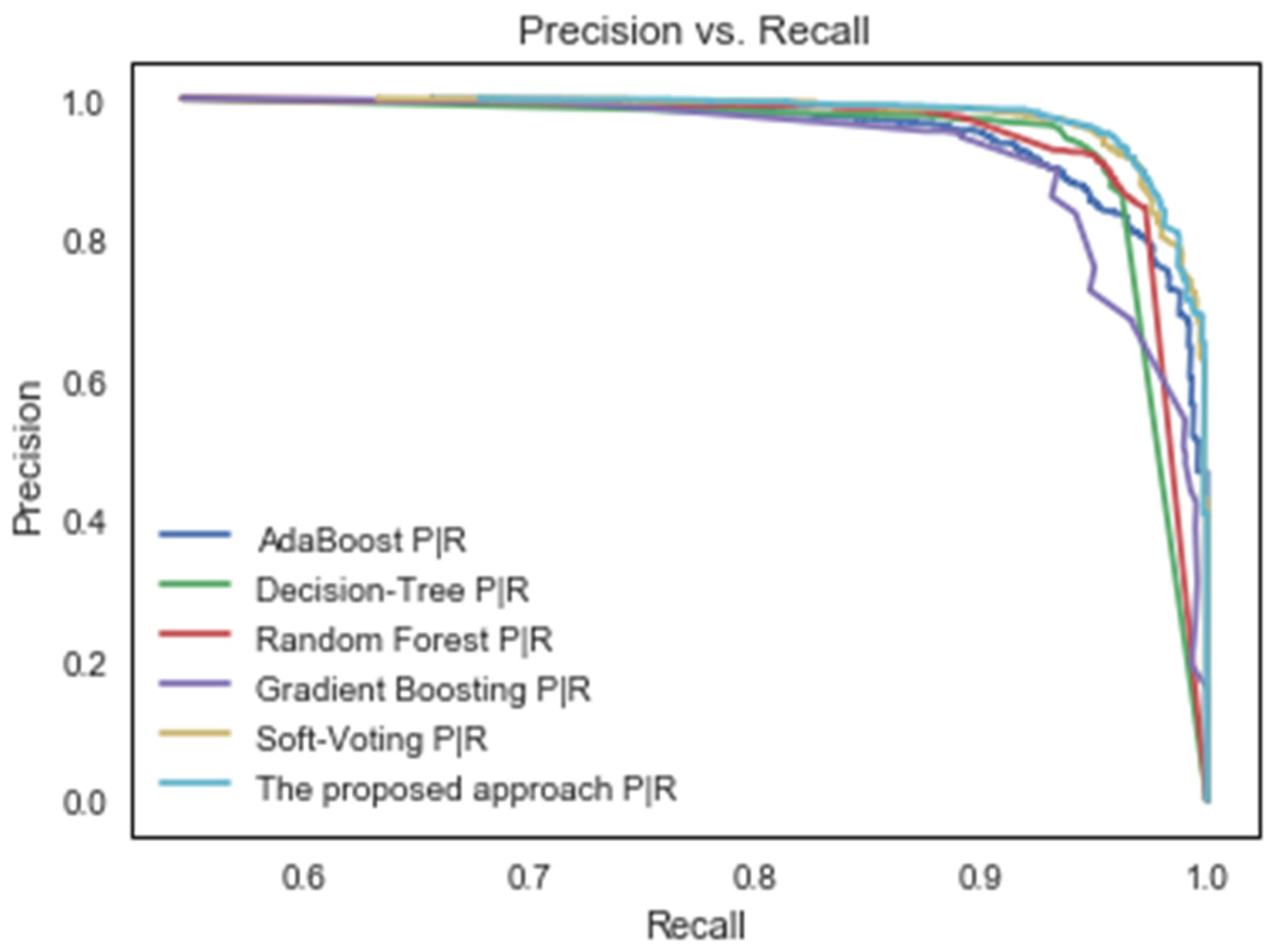
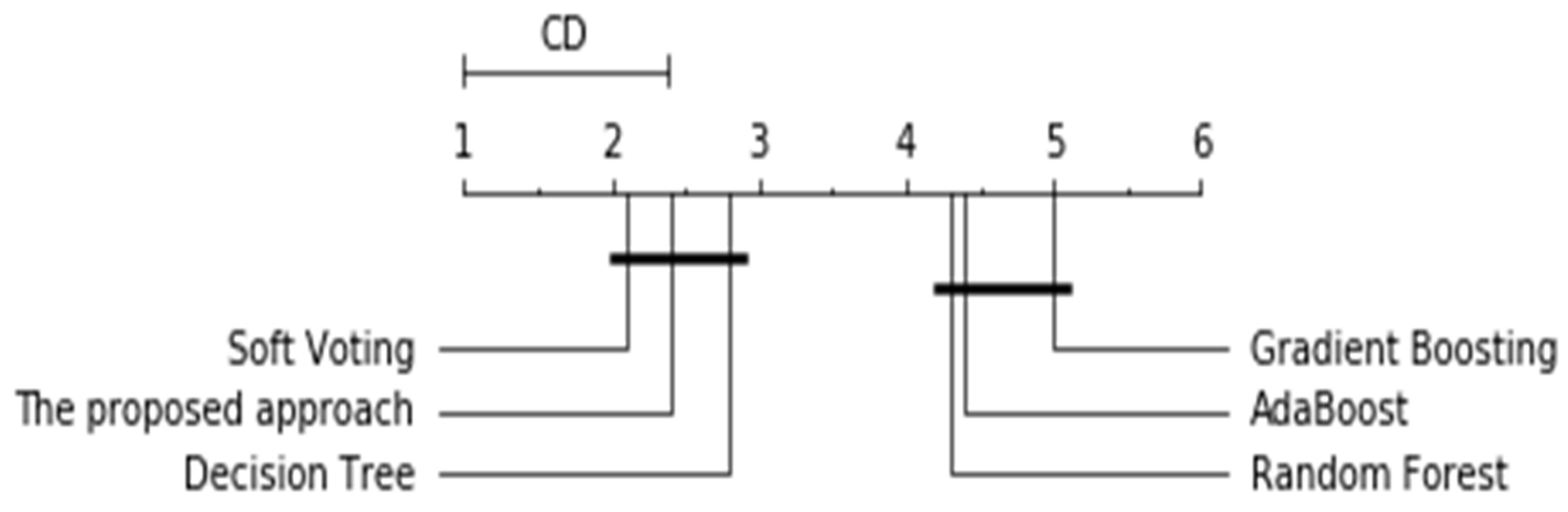
4. Results and Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chiew, K.L.; Tan, C.L.; Wong, K.K.; Yong, S.C.; Tiong, W.K. A new hybrid ensemble feature selection framework for machine learning-based phishing detection system. Inf. Sci. 2019, 484, 153–166. [Google Scholar] [CrossRef]
- Sahingoz, O.K.; Buber, E.; Demir, O.; Diri, B. Machine learning based phishing detection from URLs. Expert Syst. Appl. 2019, 117, 345–357. [Google Scholar] [CrossRef]
- Jain, A.K.; Gupta, B.B. A survey of phishing attack techniques, defence mechanisms and open research challenges. Enterp. Inf. Syst. 2021, 1–39. [Google Scholar] [CrossRef]
- Soon, G.K.; Chiang, L.C.; On, C.K.; Rusli, N.M.; Fun, T.S. Comparison of ensemble simple feedforward neural network and deep learning neural network on phishing detection. In Computational Science and Technology; Springer: Singapore, 2020; pp. 595–604. [Google Scholar]
- Wei, B.; Hamad, R.A.; Yang, L.; He, X.; Wang, H.; Gao, B.; Woo, W.L. A deep-learning-driven light-weight phishing detection sensor. Sensors 2019, 19, 4258. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Priya, S.; Selvakumar, S.; Velusamy, R.L. Evidential theoretic deep radial and probabilistic neural ensemble approach for detecting phishing attacks. J. Ambient. Intell. Hum. Comput. 2021, 1–25. [Google Scholar] [CrossRef]
- APWG. Anti Phishing Working Group Report. 2020. Available online: https://docs.apwg.org/reports/apwg_trends_report_q2_2020.pdf (accessed on 7 August 2021).
- Yang, P.; Zhao, G.; Zeng, P. Phishing website detection based on multidimensional features driven by deep learning. IEEE Access 2019, 7, 15196–15209. [Google Scholar] [CrossRef]
- Zamir, A.; Khan, H.U.; Iqbal, T.; Yousaf, N.; Aslam, F.; Anjum, A.; Hamdani, M. Phishing web site detection using diverse machine learning algorithms. Electron. Libr. 2020, 38, 65–80. [Google Scholar] [CrossRef]
- Zhu, E.; Ju, Y.; Chen, Z.; Liu, F.; Fang, X. DTOF-ANN: An artificial neural network phishing detection model based on decision tree and optimal features. Appl. Soft Comput. 2020, 95, 106505. [Google Scholar] [CrossRef]
- Gupta, B.B.; Arachchilage, N.A.; Psannis, K.E. Defending against phishing attacks: Taxonomy of methods, current issues and future directions. Telecommun. Syst. 2018, 67, 247–267. [Google Scholar] [CrossRef] [Green Version]
- Harinahalli Lokesh, G.; BoreGowda, G. Phishing website detection based on effective machine learning approach. J. Cyber Secur. Technol. 2021, 5, 1–14. [Google Scholar] [CrossRef]
- Altaher, A. Phishing websites classification using hybrid svm and knn approach. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 90–95. [Google Scholar] [CrossRef]
- He, Q.; Meng, X.; Qu, R.; Xi, R. Machine Learning-Based Detection for Cyber Security Attacks on Connected and Autonomous Vehicles. J. Math. 2020, 8, 1311. [Google Scholar] [CrossRef]
- Alsariera, Y.A.; Adeyemo, V.E.; Balogun, A.O.; Alazzawi, A.K. Ai meta-learners and extra-trees algorithm for the detection of phishing websites. IEEE Access 2020, 8, 142532–142542. [Google Scholar] [CrossRef]
- Chandra, Y.; Jana, A. Improvement in Phishing Websites Detection Using Meta Classifiers. In Proceedings of the 2019 6th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 13–15 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 637–641. [Google Scholar]
- Agarwal, A.; Dixit, A. Fake news detection: An ensemble learning approach. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1178–1183. [Google Scholar]
- Granik, M.; Mesyura, V.; Yarovyi, A. Determining fake statements made by public figures by means of artificial intelligence. In Proceedings of the 2018 IEEE 13th International Scientific and Technical Conference on Computer Sciences and Information Technologies (CSIT), Lviv, Ukraine, 11–14 September 2018; IEEE: Piscataway, NJ, USA, 2018; Volume 1, pp. 424–427. [Google Scholar]
- Wei, W.; Ke, Q.; Nowak, J.; Korytkowski, M.; Scherer, R.; Woźniak, M. Accurate and fast URL phishing detector: A convolutional neural network approach. Comput. Netw. 2020, 178, 107275. [Google Scholar] [CrossRef]
- Azeez, N.A.; Salaudeen, B.B.; Misra, S.; Damaševičius, R.; Maskeliūnas, R. Identifying phishing attacks in communication networks using URL consistency features. Int. J. Electron. Secur. Digit. Forensics 2020, 12, 200–213. [Google Scholar] [CrossRef]
- Mao, J.; Bian, J.; Tian, W.; Zhu, S.; Wei, T.; Li, A.; Liang, Z. Phishing page detection via learning classifiers from page layout feature. EURASIP J. Wirel. Commun. Netw. 2019, 1, 43. [Google Scholar] [CrossRef]
- Babagoli, M.; Aghababa, M.P.; Solouk, V. Heuristic nonlinear regression strategy for detecting phishing websites. Soft Comput. 2019, 23, 4315–4327. [Google Scholar] [CrossRef]
- Buber, E.; Dırı, B.; Sahingoz, O.K. Detecting phishing attacks from URL by using NLP techniques. In Proceedings of the 2017 International conference on computer science and Engineering (UBMK), Antalya, Turkey, 5–8 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 337–342. [Google Scholar]
- Machado, L.; Gadge, J. Phishing sites detection based on C4.5 decision tree algorithm. In Proceedings of the 2017 International Conference on Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 17–18 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. Predicting phishing websites based on self-structuring neural network. Neural. Comput. Appl. 2014, 25, 443–458. [Google Scholar] [CrossRef] [Green Version]
- Chiew, K.L.; Chang, E.H.; Tiong, W.K. Utilisation of website logo for phishing detection. Comput. Secur. 2015, 54, 16–26. [Google Scholar] [CrossRef]
- Aggarwal, A.; Rajadesingan, A.; Kumaraguru, P. PhishAri: Automatic realtime phishing detection on twitter. In Proceedings of the 2012 eCrime Researchers Summit, Las Croabas, PR, USA, 23–24 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1–12. [Google Scholar]
- Dedakia, M.; Mistry, K. Phishing detection using content based associative classification data mining. J. Eng. Comput. Appl. Sci. 2015, 4, 209–214. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository; School of Information and Computer Science, University of California: Irvine, CA, USA, 2015; Available online: https://archive.ics.uci.edu/ml/datasets/Phishing+Websites (accessed on 10 June 2021).
- Hall, M.A. Correlation-based feature selection for machine learning. Ph.D. Thesis, The University of Waikato, Hamilton, New Zealand, April 1999. [Google Scholar]
- Barandela, R.; Sánchez, J.S.; Garcıa, V.; Rangel, E. Strategies for learning in class imbalance problems. Pattern Recognit. 2003, 36, 849–851. [Google Scholar] [CrossRef]
- Shukla, S.; Yadav, R.N. Unweighted class specific soft voting based ensemble of extreme learning machine and its variant. Int. J. Comput. Sci. Inf. Secur. 2015, 13, 59. [Google Scholar]
- Ferri, C.; Hernández-Orallo, J.; Modroiu, R. An experimental comparison of performance measures for classification. Pattern Recognit. Lett. 2009, 30, 27–38. [Google Scholar] [CrossRef]
- Jeni, L.A.; Cohn, J.F.; De La Torre, F. Facing imbalanced data–recommendations for the use of performance metrics. In Proceedings of the Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 245–251. [Google Scholar]
- Brzeziński, D.; Stefanowski, J.; Susmaga, R.; Szczȩch, I. Visual-based analysis of classification measures and their properties for class imbalanced problems. Inf. Sci. 2018, 462, 242–261. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Ben-David, A.; Frank, E. Accuracy of machine learning models versus ‘hand crafted’ expert systems A credit scoring case study. Expert Syst. Appl. 2009, 36, 5264–5271. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; Chapman and Hall/CRC: Boca Raton, FL, USA, 2012. [Google Scholar]
- Dal Pozzolo, A.; Caelen, O.; Le Borgne, Y.A.; Waterschoot, S.; Bontempi, G. Learned lessons in credit card fraud detection from a practitioner perspective. Expert Syst. Appl. 2014, 41, 4915–4928. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The relationship between precision-recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 233–240. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | Description |
|---|---|
| Website Features | The address bar-based type has 12 features, the abnormality-based type has 6 features, the HTML and JavaScript types have 5 features, and the domain-based type has 7 features. |
| Number of features | 30 |
| Classes | Phishing or legitimate website |
| Number of classes | 2 |
| Number of websites | 11,055 |
| Number of phishing websites | 4898 |
| Percentage of phishing websites | 44% |
| Number of legitimate websites | 6157 |
| Percentage of legitimate websites | 56% |
| Predicted Class | |||
|---|---|---|---|
| Legitimate | Phishing | ||
| Actual Class | Legitimate | True Negative (TN) | False Positive (FP) |
| Phishing | False Negative (FN) | True Positive (TP) | |
| Classification Measure | Formula |
|---|---|
| Accuracy | |
| Precision | |
| Recall | |
| F1-score |
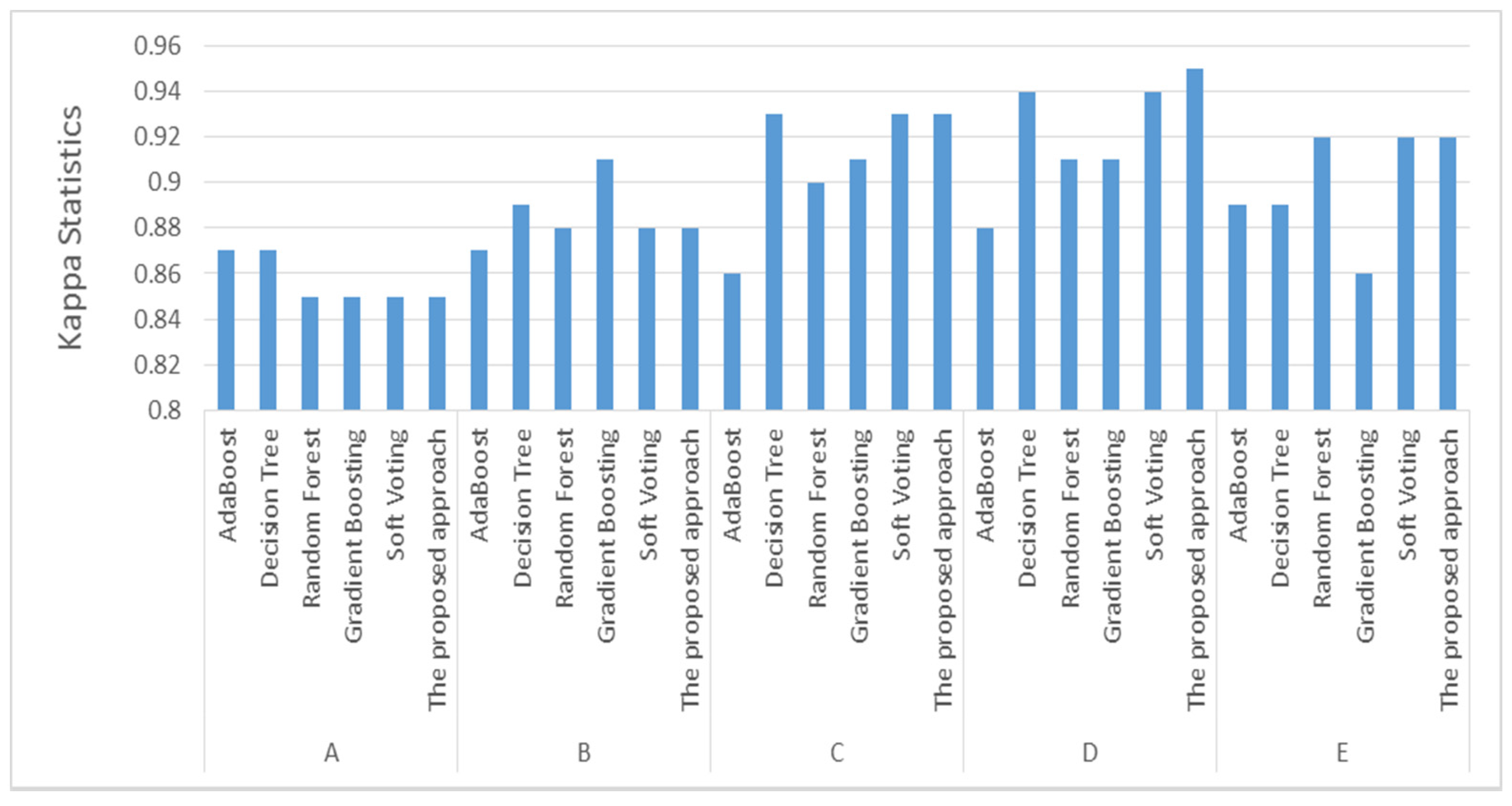
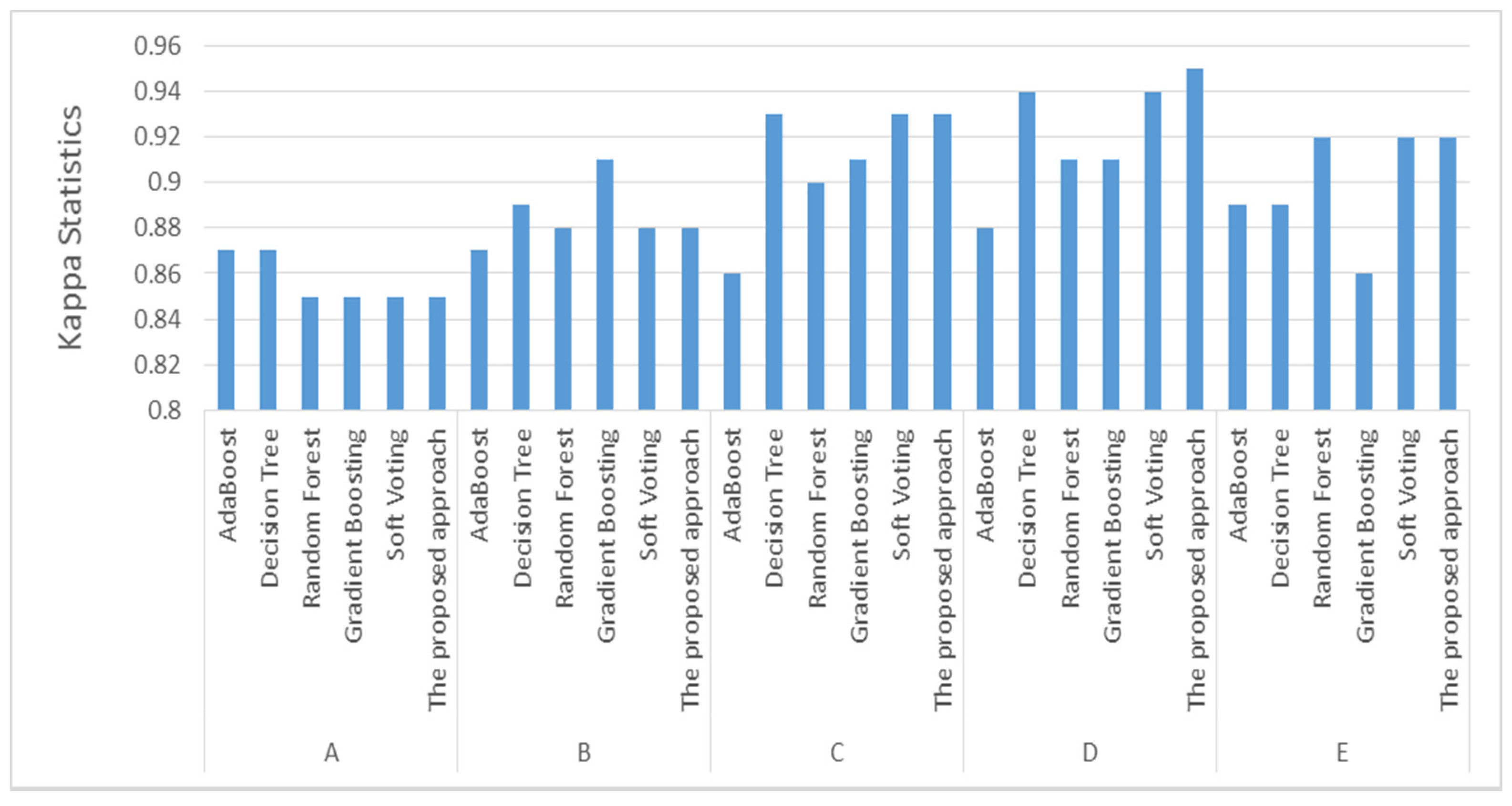
| Features Subset | Algorithm | Accuracy | Precision | Recall | F1-Score | Kappa Statistics |
|---|---|---|---|---|---|---|
| A | AdaBoost | 0.91 | 0.91 | 0.91 | 0.91 | 0.87 |
| Decision Tree | 0.91 | 0.91 | 0.91 | 0.91 | 0.87 | |
| Random Forest | 0.91 | 0.91 | 0.91 | 0.91 | 0.85 | |
| Gradient Boosting | 0.91 | 0.91 | 0.91 | 0.91 | 0.85 | |
| Soft Voting | 0.91 | 0.91 | 0.90 | 0.91 | 0.85 | |
| The proposed approach | 0.91 | 0.91 | 0.91 | 0.91 | 0.85 | |
| B | AdaBoost | 0.91 | 0.91 | 0.91 | 0.91 | 0.87 |
| Decision Tree | 0.92 | 0.92 | 0.92 | 0.92 | 0.89 | |
| Random Forest | 0.91 | 0.92 | 0.91 | 0.91 | 0.88 | |
| Gradient Boosting | 0.91 | 0.91 | 0.91 | 0.91 | 0.91 | |
| Soft Voting | 0.92 | 0.92 | 0.92 | 0.92 | 0.88 | |
| The proposed approach | 0.92 | 0.92 | 0.92 | 0.92 | 0.88 | |
| C | AdaBoost | 0.91 | 0.91 | 0.91 | 0.91 | 0.86 |
| Decision Tree | 0.93 | 0.93 | 0.93 | 0.93 | 0.93 | |
| Random Forest | 0.92 | 0.92 | 0.92 | 0.92 | 0.90 | |
| Gradient Boosting | 0.91 | 0.91 | 0.91 | 0.91 | 0.91 | |
| Soft Voting | 0.94 | 0.94 | 0.94 | 0.94 | 0.93 | |
| The proposed approach | 0.94 | 0.94 | 0.94 | 0.94 | 0.93 | |
| D | AdaBoost | 0.92 | 0.92 | 0.92 | 0.92 | 0.88 |
| Decision Tree | 0.94 | 0.94 | 0.94 | 0.94 | 0.94 | |
| Random Forest | 0.93 | 0.93 | 0.93 | 0.93 | 0.91 | |
| Gradient Boosting | 0.91 | 0.91 | 0.91 | 0.91 | 0.91 | |
| Soft Voting | 0.94 | 0.94 | 0.94 | 0.94 | 0.94 | |
| The proposed approach | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | |
| E | AdaBoost | 0.92 | 0.92 | 0.92 | 0.92 | 0.89 |
| Decision Tree | 0.92 | 0.92 | 0.92 | 0.92 | 0.89 | |
| Random Forest | 0.91 | 0.91 | 0.91 | 0.91 | 0.92 | |
| Gradient Boosting | 0.91 | 0.91 | 0.91 | 0.91 | 0.86 | |
| Soft Voting | 0.93 | 0.93 | 0.93 | 0.93 | 0.92 | |
| The proposed approach | 0.93 | 0.93 | 0.93 | 0.93 | 0.92 |
| Approach | Classification Accuracy |
|---|---|
| Chiew et al. [1] | 94.6%. |
| Babagoli et al. [22] | 92.80% |
| Buber et al. [23] | 89.9% |
| MacHado and Gadge [24] | 89.40% |
| Mohammad et al. [25] | 92.18% |
| Chiew et al. [26] | 93.4% |
| Aggarwal et al. [27] | 92.52% |
| Dedakia and Mistry [28] | 94.29% |
| Mao et al. [21] | 93% |
| The proposed approach | 95% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taha, A. Intelligent Ensemble Learning Approach for Phishing Website Detection Based on Weighted Soft Voting. Mathematics 2021, 9, 2799. https://doi.org/10.3390/math9212799
Taha A. Intelligent Ensemble Learning Approach for Phishing Website Detection Based on Weighted Soft Voting. Mathematics. 2021; 9(21):2799. https://doi.org/10.3390/math9212799
Chicago/Turabian StyleTaha, Altyeb. 2021. "Intelligent Ensemble Learning Approach for Phishing Website Detection Based on Weighted Soft Voting" Mathematics 9, no. 21: 2799. https://doi.org/10.3390/math9212799
APA StyleTaha, A. (2021). Intelligent Ensemble Learning Approach for Phishing Website Detection Based on Weighted Soft Voting. Mathematics, 9(21), 2799. https://doi.org/10.3390/math9212799