Abstract
Theoretical and applied researchers have been frequently interested in proposing alternative skewed and symmetric lifetime parametric models that provide greater flexibility in modeling real-life data in several applied sciences. To fill this gap, we introduce a three-parameter bounded lifetime model called the exponentiated new power function (E-NPF) distribution. Some of its mathematical and reliability features are discussed. Furthermore, many possible shapes over certain choices of the model parameters are presented to understand the behavior of the density and hazard rate functions. For the estimation of the model parameters, we utilize eight classical approaches of estimation and provide a simulation study to assess and explore the asymptotic behaviors of these estimators. The maximum likelihood approach is used to estimate the E-NPF parameters under the type II censored samples. The efficiency of the E-NPF distribution is evaluated by modeling three lifetime datasets, showing that the E-NPF distribution gives a better fit over its competing models such as the Kumaraswamy-PF, Weibull-PF, generalized-PF, Kumaraswamy, and beta distributions.
Keywords:
power function distribution; exponentiated distribution; Rényi entropy; hazard rate function; moments; simulations; type II censoring scheme; maximum likelihood estimation MSC:
60E05; 62P12; 62P30
1. Introduction
Over the past three decades, the promising attention of researchers towards the development of new generalized models has increased to explore the hidden characters of baseline models. New generalized models open new horizons to address real-world problems and to provide an adequate fit to the complex and asymmetric random phenomena. Hence, various models have been constructed and studied in the literature. One of the simplest and most handy lifetime models induced in the statistical literature is the Lehmann Type I (L-I) and Type II models [1]. In the literature, the L-I model is most often discussed in favor of the power function (PF) distribution. The L-I model is simply the exponentiation of any baseline model, and it can be specified by the following cumulative distribution function (CDF):
Gupta et al. [2] utilized the L-I approach to define a generalized form of the exponential distribution. On the other hand, Cordeiro et al. [3] proposed a dual transformation to the L-I approach and defined the Lehmann Type II (L-II) G class of distributions, which is specified by the CDF:
where is the CDF of the arbitrary baseline model with a parametric vector and shape parameter .
The L-I and L-II approaches have been extensively utilized to propose more flexible and modified forms of classical models, due to their simple closed-form CDFs. The PF distribution is a simple form of the L-I distribution. The simplicity and usefulness of the PF distribution have attracted many researchers to study and explore its further extensions and applications in different applied areas. For example, Dallas [4] developed a relationship between the PF and Pareto distributions, Meniconi and Barry [5] adopted the PF distribution to model electronic components data, Chang [6] discussed the independence of record values based on the characterization of the PF distribution, Tavangar [7] characterized the PF distribution by dual generalized order statistics, Ahsanullah et al. [8] adopted the lower record values to characterize the PF distribution, Zaka et al. [9] discussed the estimation of the PF parameters via various estimation methods, and Shahzad et al. [10] discussed the estimation of the PF parameters via the trimmed L moments. Furthermore, some notable extensions of the PF distribution include, for example, the beta-PF [11], Weibull-PF [12,13], transmuted-PF [14], weighted-PF [15], Marshall–Olkin PF [16], transmuted generalized-PF [17], exponentiated transmuted-PF [18], and odd generalized exponential PF [19], and recently, Arshad et al. [20,21] developed a bounded bathtub-shaped failure rate PF model via L-II class, called the exponentiated-PF distribution.
The basic aim to carry out the present study is to develop a flexible bathtub-shaped failure rate model called the exponentiated new power function (E-NPF) distribution, which has some useful properties such as (i) its CDF, probability density function (PDF), and likelihood function are simple and easy to interpret; (ii) from the application perspective, this model is quite uncomplicated; (iii) its density and failure rate shapes follow the skewed and bathtub shapes; and (iv) this model provides a consistently better fit over its competitors.
Moreover, the E-NPF parameters are estimated using several classical methods of estimation. The comparisons and performance of these estimators have been explored via simulation results. Moreover, the maximum likelihood is adopted under type II censored samples to estimate the E-NPF parameters. Several articles have addressed the estimation of the model parameters using different estimators and compared them to determine the best estimation approach. For example, see [22,23,24,25] and the references therein.
This paper is arranged in the following sections. The proposed E-NPF model is developed in Section 2. Comprehensive studies on its mathematical and reliability characteristics are presented in Section 3. Estimations of the E-NPF parameters by eight estimation methods are presented in Section 4. Section 5 illustrates the simulation results by using eight estimation methods. Applications of the E-NPF model to three real datasets are discussed in Section 6 to illustrate its importance and flexibility. Some final conclusions are discussed in Section 7.
2. Materials and Methods
Iqbal et al. [26] studied a two-parameter model called the new power function (NPF) distribution which is specified by the following CDF:
and its associated PDF reduces to
where are the scale and shape parameters, respectively.
To this end, we define the E-NPF distribution that can model asymmetric and bathtub-shaped failure rate phenomena. For this, following Gupta et al. [2], we add up a shape parameter to the baseline NPF model. The newly added parameter advances the tail weight of the E-NPF density and starts providing a consistently better fit over its competitors.
A random variable is said to follow the E-NPF distribution, say E-NPF(), if its CDF takes the form
and its corresponding PDF reduces to
where is a scale and are the two shape parameters, respectively. The two special models of the E-NPF distribution are listed in Table 1.

Table 1.
Sub-models for different parameters.
3. Mathematical Properties
3.1. Shape
Several shapes for the E-NPF density and failure rate functions are displayed in Figure 1 and Figure 2 for various choices of the parameters. Note that the possible shapes of the PDF corresponding to the parameter , which controls the scale of the distribution, along with the two shape parameters and , which control the shapes of the distribution, including increasing, symmetric, upside-down bathtub, decreasing, and J shapes. These shapes are presented in Figure 1a,b. Furthermore, Figure 2a,b presents the hazard rate function (HRF) shapes, including increasing, U, and bathtub shapes. These flexible HRF shapes are suitable for both the monotonic and non-monotonic hazard rate behaviors, which are most likely to appear in real-time situations (see Pu et al. [27] and Oluyede et al. [28]). Such kinds of shapes are often observed in non-stationary lifetime phenomena.
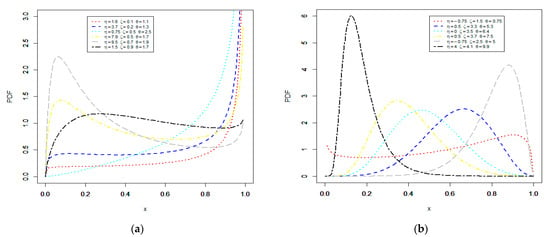
Figure 1.
Plots of the probability density function (PDF) of the E-NPF model for different values of its parameters (a,b).
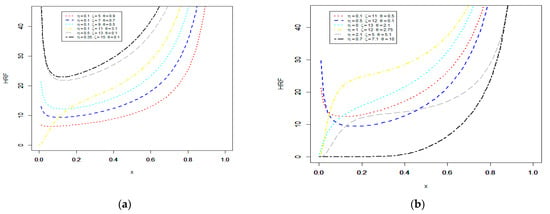
Figure 2.
Plots of the hazard rate function (HRF) of the E-NPF model for different values of its parameters (a,b).
3.2. Linear Representation
Linear combination provides a simple way to explore the mathematical properties of the model. For this reason, binomial expansion is utilized. It is given as
Infinite linear combinations of CDF and PDF in Equations (1) and (2) are given, respectively, by
and
where
The expression in Equation (4) will be adopted in the forthcoming calculations of several mathematical properties of the E-NPF distribution.
3.3. Reliability Characteristics of the E-NPF Model
Analyzing and predicting the lifetime of a component are important roles in reliability engineering. Hence, some useful and well-established reliability measures are accessible in the literature.
The survival function of , which represents the probability that a component will survive till time x, takes the form
In reliability theory, the function that measures the failure rate of a component in a particular period t is also referred to as the force of mortality or HRF. The HRF of the E-NPF distribution has the form
It is well known that most mechanical parts/components of some systems follow a bathtub-shaped hazard rate phenomenon. The cumulative hazard rate (CHR) function is expressed by The CHR function of X is given by
The reverse HRF (RHRF) is expressed by The RHRF of the E-NPF model takes the form
The Mills ratio (MR) is expressed by The MR of reduces to
The odd function is expressed by and it is defined, for the E-NPF model, by
3.4. Limiting Behavior
The limiting behaviors of cumulative distribution, density, reliability, and hazard rate functions of the E-NPF distribution, which are defined, respectively, in Equations (1), (2), (6), and (7) at x and x, are discussed in Propositions 1 and 2.
Proposition 1.
The limiting behaviors of functions (1), (2), (6), and (7) at xare, respectively, presented by
F_(E-NPF) (x)~0,
f_(E-NPF) (x)~θζ(1+η),
S_(E-NPF) (x)~1,
h_(E-NPF) (x)~0.
f_(E-NPF) (x)~θζ(1+η),
S_(E-NPF) (x)~1,
h_(E-NPF) (x)~0.
Proposition 2.
The limiting behaviors of functions (1), (2), (6), and (7) at xare, respectively, determined by
F_(E-NPF) (x)~1,
f_(E-NPF) (x)~0,
S_(E-NPF) (x)~0,
h_(E-NPF) (x)~Indeterminate.
f_(E-NPF) (x)~0,
S_(E-NPF) (x)~0,
h_(E-NPF) (x)~Indeterminate.
3.5. Quantile Function, Skewness, and Kurtosis
Hyndman and Fan [29] introduced the concept of quantile function (QF). The q-th QF of the E-NPF distribution can be adapted to generate random numbers and is obtained by inverting its CDF (1). The QF is defined by Then, the QF of X follows as
To derive the 1st quartile, median, and 3rd quartile of , one may place q = 0.25, 0.5, and 0.75, respectively, in Equation (14).
The Bowley [30] skewness, say , and Moors [31] kurtosis, say , of the E-NPF distribution can be calculated using Equation (14) with the following two formulas:
and
These descriptive measures depend on quartiles and octiles and can provide more robust estimates than the traditional measures of skewness and kurtosis. Additionally, and are less sensitive to the outliers and work more effectively for the deficient moment distributions. Some possible shapes of the skewness and kurtosis for various choices of and are presented in Figure 3.
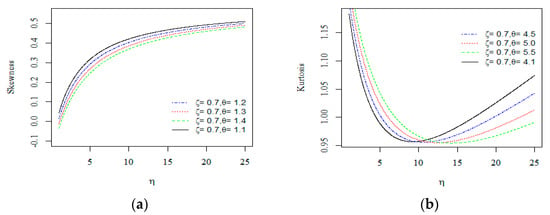
Figure 3.
Plots of the skewness (a) and kurtosis (b) of the E-NPF distribution.
3.6. Moments and Associated Measures
Moments have a useful role in distribution theory, to address the significant characteristics of a probability distribution such as mean, variance, skewness, and kurtosis.
Theorem 1.
IfE-NPF(), with, then the r-th ordinary moment () ofis given by
where B() = is the beta function (BF).
Proof.
Using Equation (2), can be written as
After some algebra, we get
Simple computations on the last expression lead to the final form of as follows:
where B() = is the BF and □
The moment formula (15) is supportive in the development of some useful statistical measures. For instance, the mean of follows with in Equation (15). The 2nd, 3rd, 4th, and higher-order moments of are formulated by replacing r = 2, 3, and 4 in Equation (15), respectively. Additionally, the Fisher index (F.I. = ()) plays a significant role in discussing the variability in . The negative moment of is simply derived through substituting r by –w in (15). Moreover, one can calculate the skewness () and kurtosis () of by integrating Equation (15). Well-established relationships between the central moments and cumulants () of may easily be defined through . The moment generating (MG) function of , , is defined by
The MG function of follows as
Table 2 displays some numerical results of the first four moments , variance , , and for some choices of and . The results are presented for S-I(), S-II(), S-III(), S-IV(), and S-V(). The results indicate that the moments and variance decrease gradually, though skewness falls between 0 and 1, and kurtosis might be negative as per the different combinations of the parameters.
Table 2.
Some numerical results of moments, variance (), skewness (), and kurtosis ().
3.7. Incomplete Moments
Incomplete moments (IM) are categorized into the lower IM (LIM) and the upper IM (UIM).
The r-th LIM is defined as
The LIM of has the form
where B() = is the BF and
The conditional survivor/residual life function is the probability that the life of a component, say x, will survive in an additional interval at t.
It is given by
The residual life function of X has the form
Furthermore, the reverse residual life is obtained by It is derived for by the formula
3.8. Entropy
In general, entropy is defined as the system’s disorderedness, uncertainty, or a measure of entanglement.
The Rényi [32] entropy is given as follows:
First, using Equation (2), we get
By applying the binomial expansion to the last expression, Equation (19) takes the form
Hence, the simplified form of follows as
where
3.9. Stress–Strength Reliability
Let X1 and X2 be defined to discuss the strength and stress of a component, respectively. The reliability, say R, of is defined (for ) by
Theorem 2.
LetE-NPF() andE-NPF() be independent random variables, then the reliability R reduces to
Proof.
The reliability R is given by
Hence, R reduces to
On simplification, Equation (21) takes the form
After simple computations, R can be expressed in terms of and as
The last expression illustrates that the reliability R of the E-NPF distribution is an increasing function of and a decreasing function of . □
3.10. Stochastic Ordering
Over the past 40 years, the concept of stochastic ordering has engaged scientists and practitioners and is quite useful in economics, reliability theory, queuing theory, insurance, and ecology, among other fields of science.
Let X1 and X2 be the two continuous, nonnegative, and univariate random variables, with Q1(X) and Q2(X) being the CDFs with corresponding PDFs q1(x) and q2(x), respectively. The random variable X1 is smaller than X2 under the following constraints:
- (i)
- stochastic order (st) (denoted by X1 X2) if Q1(X) Q2(X) x;
- (ii)
- reversed hazard rate (rhr) order (denoted by X1 X2) if Q1(X)/Q2(X) is decreasing for x 0;
- (iii)
- likelihood ratio (lkr) order (denoted by X1 X2) if Q1(x)/Q2(x) is decreasing for x 0;
- (iv)
- hazard rate (hr) order (denoted by X1 X2) if Q1(X)/Q2(X) is decreasing for x 0.
The four stochastic orders are connected to each other based on the following implications [33].
Theorem 3.
Let X1E-NPF() and X2E-NPF(), if , then X1 X2 and hence X1 X2 X1 X2 and X1 X2.
Proof.
Using Equation (2), we have
and
Hence, we can write
By taking derivative w.r.t x on both sides, we get
Then,
is a decreasing function for all .
Hence, X1 X2 for . □
3.11. Order Statistics
Order statistics (OS) and their moments are considered noteworthy measures in quality control, reliability analysis, and life testing. Let be a random sample of size n that follows the E-NPF distribution and be the corresponding OS.
The PDF of is
By replacing (1) and (2) in the above equation, the PDF of takes the form
The above equation is adopted to compute the w-th moment OS of the E-NPF distribution. Furthermore, the minimum and maximum OS of follow directly from the above equation with , respectively. The w-th moment OS, , of follows as
The CDF of is defined (for ) by
For the E-NPF model, the CDF of reduces to
4. Estimation of the E-NPF Distribution
4.1. Estimation under Complete Samples
In this section, we estimate the E-NPF parameters , and using eight frequentist approaches under complete samples.
4.1.1. Maximum Likelihood Estimation under Complete Samples
In this section, we estimate the parameters of the E-NPF distribution using the maximum likelihood (ML) method. Let be a random sample of size n from the E-NPF distribution, then the likelihood function of , , takes the form
The log-likelihood function, , of is
By taking partial derivatives of Equation (24), we get
and
The ML estimators (MLE) , and of the E-NPF distribution can be obtained by maximizing Equation (24) or by solving the above equations simultaneously. These equations cannot provide analytical solutions for the MLEs and the optimum values of and . Consequently, the Newton–Raphson-type algorithm is an appropriate way in the support of the MLE. This can be done by using different programs, namely (optim function), Mathematica, or SAS (PROC NLMIXED), or by solving the nonlinear likelihood equations determined by differentiating .
4.1.2. Ordinary and Weighted Least-Squares Estimators
Let be the OS of the random sample of size from in (1). The ordinary least-squares estimators (OLSE), , and , can be obtained by minimizing
with respect to , , and . Or equivalently, the OLSE follow by solving the nonlinear equations
where
Note that the solution of for can be obtained numerically.
The weighted least-squares estimators (WLSE), , , and , can be obtained by minimizing the following equation:
Furthermore, the WLSE can also be derived by solving the nonlinear equations
where , and are provided in (25).
4.1.3. Maximum Product of Spacing
The maximum product of spacing (MPS) method, as an approximation to the Kullback–Leibler information measure, is a good alternative to the MLE method.
Let , for be the uniform spacing of a random sample from the E-NPF distribution, where , , and The MPS estimators (MPSE) for , , and can be obtained by maximizing the geometric mean of the spacing
with respect to , and , or, equivalently, by maximizing the logarithm of the geometric mean of sample spacings.
The MPSE of the E-NPF parameters can be obtained by solving the nonlinear equations defined by
where , and are provided in (25).
4.1.4. The Cramér–von Mises Estimators
The Cramér–von Mises estimators (CVME) as a type of minimum distance (MD) estimator have less bias than the other MD estimators. The CVME are obtained based on the difference between the estimates of the CDF and the empirical distribution function. The CVME of the E-NPF parameters, , , and , can be obtained by minimizing
with respect to , and . Furthermore, the CVME follow by solving the nonlinear equations
where , , and are provided in (25).
4.1.5. The Anderson–Darling and Right-Tail Anderson–Darling Estimators
The Anderson–Darling (AD) statistic or AD estimator is another type of minimum distance estimator. The AD estimators (ADE) of the E-NPF parameters, , , and , can be obtained by minimizing
with respect to , , and . These ADE can also be obtained by solving the nonlinear equations
The right-tail AD estimators (RADE) of the E-NPF parameters, , , and , can be obtained by minimizing
with respect to , and . The RADE can also be obtained by solving the nonlinear equations
where , and are provided in (25).
4.1.6. Method of Percentile Estimation
Let be an unbiased estimator of . Then, the percentile estimators (PCE) of the parameters of the E-NPF distribution are obtained by minimizing the following function:
with respect to , and , where is the QF of the E-NPF distribution defined in (14).
4.2. Estimation under Type II Censored Samples
In this section, we estimate the E-NPF parameters , and under complete samples using the MLE method.
Let be a random sample of size n from the E-NPF distribution; if in the type II censoring scheme we observe only the first order statistics, then the likelihood function of , takes the form
where is a constant that does not depend on the parameters and , , , are the censored data. The log-likelihood function without the constant term can be written as follows:
The log-likelihood function, , of is
By taking partial derivatives of Equation (26), we get
The type II censored ML estimators (CMLE) , , and of the E-NPF distribution can be obtained by maximizing Equation (26) or by solving the above equations simultaneously by any numerical method as in Section 4.1.1.
5. Simulation Study
In this section, we perform the simulation study of the E-NPF distribution for complete samples using eight estimation methods and under the type II censored samples for the MLE method.
5.1. Simulation Results under Complete Samples
In this section, the performance of the estimates is discussed by the following algorithm.
- Step 1:
- A random sample of sizes , and are generated from the QF in Equation (14).
- Step 2:
- The required results are obtained based on 36 combinations of the parameters and
- Step 3:
- Each sample is replicated times.
- Step 4:
- Results of the average of absolute value of biases (), the average of mean square errors (MSE), , and the average of mean relative errors (MRE), , where are computed for the 36 combinations; to save more space, we present just the result of 4 combinations in Table 3, Table 4, Table 5 and Table 6.
Table 3. Simulated results of the E-NPF distribution for .
Table 4. Simulated results of the E-NPF distribution for .
Table 5. Simulated results of the E-NPF distribution for .
Table 6. Simulated results of the E-NPF distribution for .
We used software (version 4.1.0) [34]. Furthermore, Table 3, Table 4, Table 5 and Table 6 show the rank of each of the estimators among all the estimators in each row, which is the superscript indicators, and the , which is the partial sum of the ranks for each column in a certain sample size. From the results of the 36 combinations, we observe that all the estimation methods show the property of consistency for all parameter combinations, except the Cramér–von Mises method at the combinations: and for the parameter .
Table S1 (in Supplementary Materials) shows the partial and overall rank of the estimators. From Table S1, and for the parametric values, we can conclude that the AD method outperforms all the other methods (its overall score of 236). Therefore, we confirm the superiority of ADE for the E-NPF distribution.
For visual illustration, we display the MSE of and graphically to show that the MSE decrease with an increase in as expected. Figure 4 and Figure 5 show the MSE of the three parameters based on the values in Table 5 and Table 6, respectively. The plots illustrate that the MSE of the parameters decrease gradually with the increase in .
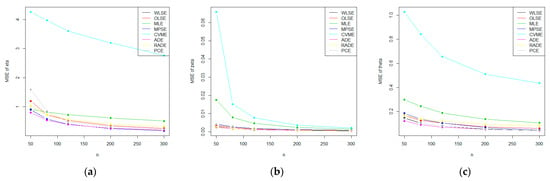
Figure 4.
Plots of the mean square errors (MSE) of the E-NPF parameters for the eight methods of estimation using the values in Table 5 (a–c).

Figure 5.
Plots of the mean square errors (MSE) of the E-NPF parameters for the eight methods of estimation using the values in Table 6 (a–c).
5.2. Simulation Results under Type II Censored Samples
In this section, the performance of the estimates is explored. We consider that the random sample of sizes , and were generated from the QF in Equation (14), and the values of are chosen to be of . We choose different values for the parameters and and replicate the process times.
In each setting, we obtain the mean of the estimates (ME), and the corresponding and MRE. These results are displayed in Table 7.
Table 7.
Simulated results of the E-NPF distribution under complete and type II censored samples for various combinations of Θ.
From Table 7, it is observed that the MSEs decrease as the sample size increases in all the cases under the complete sample, as we discussed in Section 5.1. In the case of type II censored sample, as the number of failures increases, the MSE decrease in all the cases. Furthermore, the MEs tend to the true parameter values as the sample size increases. Thus, we can say that the MLEs of the parameters and under the two schemes are asymptotically unbiased and consistent.
6. Results and Discussion
In this section, we report the application of the E-NPF distribution in applied sciences by analyzing three suitable lifetime datasets. The first dataset relates to oceanography, and it represents the synthetic aperture radar (SAR) image for modeling oil slick visibility in the ocean [35]. The second dataset from the reliability engineering field consists of 20 observations about failure times of mechanical components [36]. The third dataset is discussed by Ahsanullah et al. [8], and it contains measurements on petroleum rock samples. It is worth mentioning that the observations of the three datasets are bounded in the interval (0, 1). The E-NPF distribution is compared with its competing models, which are present in Table 8, based on some criteria such as the Akaike information criterion (AIC), Cramér–von Mises (CM), Anderson–Darling (AD), and Kolmogorov–Smirnov (KS) test with its p-value (KS p-value) statistics. However, using the statistical software under the package Adequacy Model [37] is considered. In addition, Some choices of descriptive statistics are presented in Table 9.
Table 8.
List of some competitive models along with their CDFs.
Table 9.
Descriptive statistics of the three datasets.
Table 10, Table 11 and Table 12 illustrate the estimates of the parameters, standard errors (S.E.), and goodness-of-fit statistics. For the three datasets, the E-NPF distribution has the lowest values of AIC, CM, DA, and KS measures and the largest KS p-value among all models studied. That is, the E-NPF distribution provides a superior fit than other models for the three datasets.
Table 10.
Parameter estimates, S.E., and information criterion for SAR image modeling data.
Table 11.
Parameter estimates, S.E., and information criterion for failure times of 20 mechanical components data.
Table 12.
Parameter estimates, S.E., and information criterion for rock samples from petroleum reservoir data.
Furthermore, the empirically fitted plots of the PDF, CDF, Kaplan–Meier survival, and probability–probability for the three datasets are presented in Figure 6, Figure 7 and Figure 8, respectively. These plots confirm the close fit of the E-NPF distribution to the three datasets. The numerical results in this section are calculated using the statistical software under the package Adequacy Model [37].
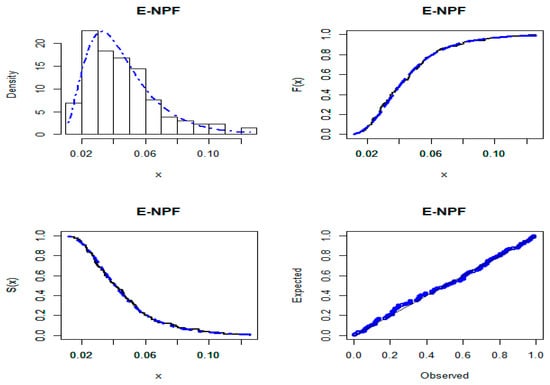
Figure 6.
Curves of the E-NPF distribution for SAR image modeling data.
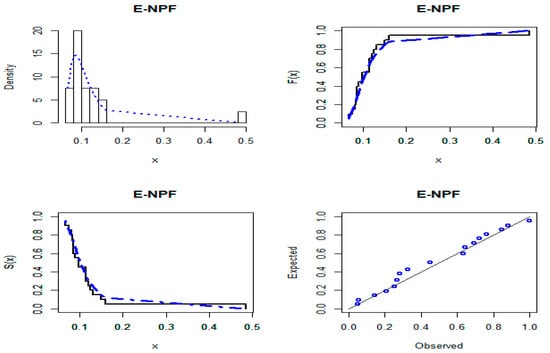
Figure 7.
Curves of the E-NPF distribution for mechanical component data.
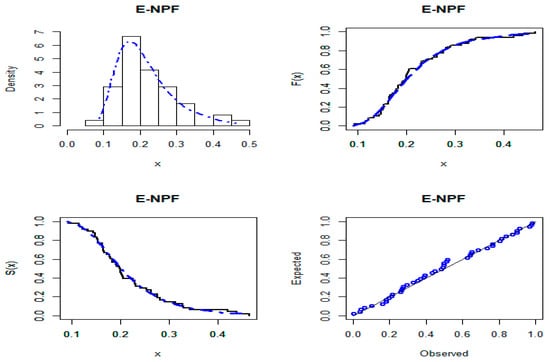
Figure 8.
Curves of the E-NPF distribution for petroleum reservoir data.
7. Conclusions
In this article, we develop a bounded lifetime model that exhibits a bathtub-shaped failure rate. The proposed distribution is called the exponentiated new power function (E-NPF) distribution. Numerous mathematical and reliability measures are derived in explicit expressions. Some classical methods of estimation are adopted to estimate the E-NPF parameters. Moreover, the maximum likelihood is utilized to estimate the E-NPF parameters under the type II censored samples. Two Monte Carlo simulation studies are carried out to investigate the asymptotic performances of the estimates under complete and type II censored samples. The most efficient and consistent results of the E-NPF distribution are explored by modeling three real-life datasets related to the fields of oceanography, reliability engineering, and petroleum engineering. It is hoped that in the future the E-NPF distribution will be quite helpful for researchers and will be considered a better choice against the baseline model.
Supplementary Materials
The following is available online at https://www.mdpi.com/article/10.3390/math9172024/s1: Table S1: Partial and overall ranks of all estimation methods for various combinations of .
Author Contributions
A.A.M.: data analysis, interpretations, resources, supervision, writing—review and editing; M.Z.I., M.Z.A. and A.Z.A.: conceptualization; M.Z.I., M.Z.A. and H.A.-M.: writing—original draft preparation, supervision; M.Z.I., B.A., H.A.-M. and A.Z.A.: methodology; M.Z.I., B.A., H.A.-M. and A.Z.A.: writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
The authors would like to thank the Editorial Board and the referees for their valuable comments and suggestions, which improved the final version of the manuscript.
Conflicts of Interest
There are no conflict of interest for any of the authors.
References
- Lehmann, E.L. The power of rank tests. Ann. Math. Stat. 1953, 24, 23–43. [Google Scholar] [CrossRef]
- Gupta, R.C.; Gupta, P.; Gupta, R.D. Modeling failure time data by Lehmann alternatives. Commun. Stat.-Theory Methods 1998, 27, 887–904. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; De Castro, M. A new family of generalized distributions. J. Stat. Comput. Simul. 2011, 81, 883–893. [Google Scholar] [CrossRef]
- Dallas, A.C. Characterization of Pareto and power function distribution. Ann. Math. Stat. 1976, 28, 491–497. [Google Scholar] [CrossRef]
- Meniconi, M.; Barry, D. The power function distribution: A useful and simple distribution to assess electrical component reliability. Microelectron Reliab. 1996, 36, 1207–1212. [Google Scholar] [CrossRef]
- Chang, S.K. Characterizations of the power function distribution by the independence of record values. J. Chungcheong Math. Soc. 2007, 20, 139–146. [Google Scholar]
- Tavangar, M. Power function distribution characterized by dual generalized order statistics. J. Iran. Stat. Soc. 2011, 10, 13–27. [Google Scholar]
- Ahsanullah, M.; Shakil, M.; Golam-Kibria, B.M.G. A characterization of the power function distribution based on lower records. ProbStat Forum. 2013, 6, 68–72. [Google Scholar]
- Zaka, A.; Akhter, A.S.; Farooqi, N. Methods for estimating the parameters of the power function distribution. J. Stat. 2014, 21, 90–102. [Google Scholar] [CrossRef]
- Shahzad, M.N.; Asghar, Z.; Shehzad, F.; Shahzadi, M. Parameter estimation of power function distribution with TL-moments. Rev. Colomb. Estad. 2015, 38, 321–334. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Brito, R.D.S. The beta power distribution. Braz. J. Probab. 2012, 26, 88–112. [Google Scholar]
- Tahir, M.H.; Alizadeh, M.; Mansoor, M.; Cordeiro, G.M.; Zubair, M. The Weibull power function distribution with applications. Hacettepe J. Math. Stat. 2014, 45, 245–265. [Google Scholar] [CrossRef]
- Tahir, M.H.; Cordeiro, G.M.; Alizadeh, M.; Mansoor, M.; Zubair, M.; Hamedani, G.G. The odd generalized exponential family of distributions with applications. J. Stat. Distrib. Appl. 2015, 2, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Ahsan-ul-Haq, M.; Butt, N.S.; Usman, R.M.; Fattah, A.A. Transmuted power function distribution. Gazi Univ. J. Sci. 2016, 29, 177–185. [Google Scholar]
- Al-Mutairi, A.O. Transmuted weighted power function distribution. Pak. J. Statist. 2017, 33, 491–498. [Google Scholar]
- Okorie, I.E.; Akpanta, A.C.; Ohakwe, J. Marshall-Olkin extended power function distribution. Eur. J. Stat. Probab. 2017, 5, 16–29. [Google Scholar]
- Abdul-Moniem, I.B.; Diab, L.S. Generalized transmuted power function distribution. J. Stat. Appl. Probab. 2018, 7, 401–411. [Google Scholar] [CrossRef]
- Usman, R.M.; Ahsan-ul-Haq, M.; Bursa, N.; Özel, G. Exponentiated transmuted power function distribution: Theory & applications. Gazi Univ. J. Sci. 2018, 31, 660–675. [Google Scholar]
- Hassan, A.; Elshrpieny, E.; Mohamed, R. Odd generalized exponential power function distribution. Gazi Univ. J. Sci. 2019, 32, 351–370. [Google Scholar]
- Arshad, M.Z.; Iqbal, M.Z.; Ahmad, M. Exponentiated power function distribution: Properties and applications. JSTA 2020, 19, 297–313. [Google Scholar] [CrossRef]
- Arshad, M.Z.; Iqbal, M.Z.; Anees, A.; Ahmad, Z.; Balogun, O.S. A new bathtub shaped failure rate model: Properties, and applications to engineering sector. Pak. J. Statist. 2021, 37, 57–80. [Google Scholar]
- Sen, S.; Afify, A.Z.; Al-Mofleh, H.; Ahsanullah, M. The quasi xgamma-geometric distribution with application in medicine. Filomat 2019, 33, 5291–5330. [Google Scholar] [CrossRef] [Green Version]
- Ramos, P.L.; Louzada, F.; Ramos, E.; Dey, S. The Fréchet distribution: Estimation and application-An overview. J. Stat. Manag. Syst. 2020, 23, 549–578. [Google Scholar] [CrossRef] [Green Version]
- Afify, A.Z.; Mohamed, O.A. A new three-parameter exponential distribution with variable shapes for the hazard rate: Estimation and applications. Mathematics 2020, 8, 135. [Google Scholar] [CrossRef] [Green Version]
- Alsubie, A.; Akhter, Z.; Athar, H.; Alam, M.; Ahmad, A.E.B.A.; Cordeiro, G.M.; Afify, A.Z. On the omega distribution: Some properties and estimation. Mathematics 2021, 9, 656. [Google Scholar] [CrossRef]
- Iqbal, M.Z.; Arshad, M.Z.; Özel, G.; Balogun, O.S. A better approach to discuss medical science and engineering data with a modified Lehmann Type–II model. F1000Research 2021, 10, 823. [Google Scholar] [CrossRef]
- Pu, S.; Oluyede, B.O.; Qiu, Y.; Linder, D. A generalized class of exponentiated modified Weibull distribution with applications. Data Sci. J. 2016, 14, 585–614. [Google Scholar] [CrossRef]
- Oluyede, B.O.; Pu, S.; Makubate, B.; Qiu, Y. The gamma-Weibull-G family of distributions with applications. Austrian J. Stat. 2018, 47, 45–76. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, R.J.; Fan, Y. Sample quantile in statistical packages. Am. Stat. 1996, 50, 361–365. [Google Scholar]
- Bowley, A.L. Elements of Statistics, 4th ed.; Charles Scribner: New York, NY, USA, 1920. [Google Scholar]
- Moors, J.J.A. A quantile alternative for kurtosis. J. R. Stat. Soc. Ser. D Stat. 1998, 37, 25–32. [Google Scholar] [CrossRef] [Green Version]
- Rényi, A. On measures of entropy and information. In Proceedings of the 4th Fourth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 20–30 July 1960; University of California Press: Berkeley, CA, USA, 1961; pp. 547–561. [Google Scholar]
- Shaked, M.; Shanthikumar, J.G. Stochastic Orders and Their Applications; Academic Press: New York, NY, USA, 1994. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 18 May 2021).
- Frery, A.C.; Muller, H.J.; Yanasse, C.C.F.; Sant’Anna, S.J.S. A model for extremely heterogeneous clutter. IEEE Trans. Geosci. Remote Sens. 1997, 35, 648–659. [Google Scholar] [CrossRef]
- Murthy, D.N.P.; Xie, M.; Jiang, R. Weibull Models; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Rafael, P.; Bourguignon, M.; Rafael, C. Adequacy Model: Adequacy of Probabilistic Models and General Purpose Optimization. R Package Version 2.0.0. 2016. Available online: https://CRAN.R-project.org/package=AdequacyModel (accessed on 20 June 2021).
- Mood, A.M.; Graybill, F.A.; Boes, D.C. Introduction to the Theory of Statistics; McGraw-Hill: New York, NY, USA, 1974. [Google Scholar]
- Topp, C.W.; Leone, F.C. A family of J-shaped frequency functions. J. Am. Stat. 1955, 50, 209–219. [Google Scholar] [CrossRef]
- Kumaraswamy, P. Generalized probability density-function for double-bounded random-processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Saran, J.; Pandey, A. Estimation of parameters of power function distribution and its characterization by the kth record values. Statistica 2004, 14, 523–536. [Google Scholar]
- Abdul-Moniem, I.B. The Kumaraswamy power function distribution. J. Stat. Appl. Probab. 2017, 6, 81–90. [Google Scholar] [CrossRef]
- Muhammad, M. A new lifetime model with a bounded support. Asian J. Math. 2017, 7, 1–11. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).