Abstract
In the present paper, a novel approach is introduced for the study, estimation and exact tracking of the finite precision error generated and accumulated during any number of multiplications. It is shown that, as a rule, this operation is very “toxic”, in the sense that it may force the finite precision error accumulation to grow arbitrarily large, under specific conditions that are fully described here. First, an ensemble of definitions of general applicability is given for the rigorous determination of the number of erroneous digits accumulated in any quantity of an arbitrary algorithm. Next, the exact number of erroneous digits produced in a single multiplication is given as a function of the involved operands, together with formulae offering the corresponding probabilities. In case the statistical properties of these operands are known, exact evaluation of the aforementioned probabilities takes place. Subsequently, the statistical properties of the accumulated finite precision error during any number of successive multiplications are explicitly analyzed. A method for exact tracking of this accumulated error is presented, together with associated theorems. Moreover, numerous dedicated experiments are developed and the corresponding results that fully support the theoretical analysis are given. Eventually, a number of important, probable and possible applications is proposed, where all of them are based on the methodology and the results introduced in the present work. The proposed methodology is expandable, so as to tackle the round-off error analysis in all arithmetic operations.
Keywords:
finite precision error in a single multiplication; finite precision error in successive multiplications; exact tracking of round-off error; finite precision error; multiplication with finite word length; statistical properties of finite precision error; loss of significance during multiplication 1. Introduction
All contemporary computing machines store both integer and floating-point numbers with a finite number of digits. This piece of fixed-sized data that is handled as a unity by the instruction set or the processor’s hardware is called finite word; the number of bits that form this piece of data, is frequently called “finite word length” or “employed precision”. In addition, on the hardware level, a computer performs fundamental operations, using a finite word length. Nowadays, dedicated software programs have been developed, which perform operations with a finite number of digits, the value of which is chosen by the programmer and/or the user, the only limitation being the memory and time constraints. We shall also use for this number of digits the term “finite word length” or “employed precision”.
Due to the fact that the precision with which all arithmetic operations are made is always limited, a numerical error is, as a rule, accumulated during the execution of most algorithms. In particular, in various algorithms and corresponding applications, the obtained results may be totally erroneous and/or unreliable due to the aforementioned reasons, which are inherent to all computing machines. We stress that this problem exists even when an arbitrarily large finite word length is employed for the execution of the algorithm, as it will become evident from the analysis introduced in the present paper. For this reason, we will use the term “finite precision error” for this numerical error; various authors and researchers also use the term “quantization error”, “round-off error” or other equivalent terms.
Consequently, a number of articles address the associated issues and the problems they generate. Thus, for example, authors in [1] study the finite precision error in the least mean square (LMS) adaptive algorithm and they show that the error’s mean squared value is inversely proportional to the adaptation step size μ. Reference [2] introduces a fast algorithm for exponentially weighted least squares Kalman filtering, which suffers less from finite precision error drawbacks, intrinsic to this class of algorithms. Reference [3] presents algorithms for accurately converting floating-point numbers to decimal representation. Article [4] studies the finite precision effects on the execution of the Lanczos algorithm for solving the standard non-symmetric eigenvalue problem. The authors of [5] study round-off error propagation in an algorithm which computes the orthonormal basis of a Krylov subspace with Householder orthonormal matrices. Authors in [6] study the propagation of round-off error near the periodic orbits of a discretized linear area-preserving map. The round-off error probability distribution, considered as a function of time, is shown to be a calculable algebraic number. In [7] it is shown that there are theoretically convergent schemes that solve non-linear partial differential equations, which can produce numerical steady state solutions that do not correspond to steady state solutions of the boundary value problem. In [8], it is pointed out that the convergence of Gegenbauer polynomials at the endpoints is affected by round-off error; the article proposes both parameter optimization and reduction of the round-off error for the Gegenbauer reconstruction method. In [9], a set of specific semantics is introduced which describes the propagation of round-off error during a calculation. The authors of [10] give an estimation of the round-off error generated in long-time integration in a number of standard, nonlinear systems. Authors in [11] introduce an algorithm for the computation of the orthogonal Fourier–Mellin moments which is of linear complexity and is resistant to finite precision error effects. Reference [12] proposes a method for dealing with the instability of the digital frequency synthesis (DFS), caused by the round-off error. Article [13] presents bounds for round-off error, generated in various algorithms. Moreover, another approach is presented in [14], according to which, the evolution of round-off error in chaotic maps is treated as an additive noise to the expected exact solutions; the introduced method spots a threshold below which global errors may be ignored. Article [15] studies the round-off error generated during computation of Hardy’s multiquadric and its related interpolators and proposes the use of arbitrary precision arithmetics to circumvent the associated finite precision error problems. Authors of [16] propose a fast, resistant to finite precision error method for evaluation of high order Zernike moments. Article [17] proposes a method for an improved scaling of finite precision error analysis. Finally, in [18,19], a preliminary form of the approach introduced here is presented.
In the present paper, we introduce a novel approach for studying and evaluating the finite precision error generated during the operation of multiplication. It is shown that, as a rule, this operation is very “toxic”, in the sense that it may force the finite precision error accumulation to grow arbitrarily large. The exact amount of the generated number of erroneous digits added or subtracted to the result (product) of this operation is given. Consequently, the probabilities the number of erroneous digits of the product differ by k from the maximum number of erroneous digits of the operands are explicitly computed. In the process of doing so, a set of general definitions is given, applicable to all operations performed with finite word length by a computing machine. Then, the accumulation of erroneous digits after an arbitrary number of successive multiplications is extensively analyzed. Statistical properties of this accumulated error are stated that allow for exact error prediction when the distribution of the associated operands are given. In addition, a number of theoretical results are introduced, which allow for the exact tracking of the generated and accumulated finite precision error during any number of multiplications in general. Numerous experimental results are presented, which fully support the presented theoretical analysis. We stress that the introduced methodology is expandable, so as to tackle all arithmetic operations.
2. A Set of Basic Definitions, Notations and Abbreviations
The entire analysis will be mainly made in the decimal arithmetic system, only because this system is far more familiar to most users. However, all results referred to in the present work hold perfectly well for the binary system too, or any other radix; the corresponding analysis and deductions may be obtained by means of a quite straightforward and slight modification of the approach introduced here.
In any arithmetic system, we assume that all numbers are expressed in scientific/canonical form. Thus, any number is written as , in the decimal arithmetic system, where ; in the binary system, the same number is expressed as , where . Independently of the employed radix, we will use the symbols and for the mantissa and the exponent of any quantity respectively. We shall demonstrate in the following that the analysis introduced here based on the decimal radix offers accurate results and prediction for the multiplication(s) performed by computing machines.
Abbreviations 1.
We will use the acronym e. d. d. in place of “erroneous decimal digits” and c. d. d. for “correct decimal digits”. In general, abbreviation “d. d.” stands for “decimal digits”. The abbreviation f. p. e. stands for “finite precision error”. The symbolsandstand for the number of e. d. d. accumulated in quantity, due to f. p. e., and its number of c. d. d. respectively.
Notation 1.
The expressions the algorithm “has failed” or it “has been destroyed due to f. p. e.” mean that the algorithm in hand offers completely unreliable results, at a certain iteration.
Suppose that any two numbers and are given, both written in canonical form. In order to unambiguously verify if these two numbers share a common number of initial digits (i.e., stem of digits), starting from the most significant one, we shall employ the following:
Definition 1.
Consider two numbers,of the same sign, written in scientific form, with the same number,, of decimal digits in the mantissa:
whereand. Let us assume, without any loss of generality, thatholds. Then, these two numbers share the firstdigits (they have the firstdigits in common) if and only if:
Consequently,anddiffer in the lastdigits if and only if:
Evidently, in the binary system, the two numbers share the firstbits if and only if
whereis the finite word length, while they differ in the lastdigits if and only if
If the aforementioned relation offers a negative, then, by definition,, namelyandare identical as far as all theirdigits are concerned.
Now, we shall give a couple of examples in order to clarify the content of Definition 1.
Example 1.
A simple inspection might lead someone to deduce that these two numbers differ by six (6) decimal digits. Actually and according to Definition 1, the following holds:
where the absolute difference is
Hence,
Therefore, the two aforementioned numbers differ in four (4) decimal digits, contrary to a probable initial expectation.
Example 2.
According to Definition 1, the two numbers with 32 decimal digits in the mantissa,
differ by 14 decimal digits, shown in bold, since, while their absolute difference is; hence,.
Additionally, the two numbersanddiffer by 4 decimal digits in the mantissa, sinceand; therefore,.
Similarly, the two numbersanddo not differ at all, since; hence
Suppose, moreover, that all operations were made with infinite precision; then, let an arbitrary quantity have the value , where superscript indicates the ideally correct value of . Next, suppose that the very same quantity is calculated in a computing machine which performs the same operations as in the infinite case, using digits in the mantissa; suppose that this machine generates the representation for the specific quantity . Then, a rigorous relation between and is obtained via the following:
Definition 2.
Let us assume that we restrict the infinite precision quantityto its firstdigits, obtaining quantity. Let us also assume that comparison ofandby means of Definition 1, manifests that these two quantities differ bydigits. Then, we deduce that quantityhas the firstdigits correct and all its other digits erroneous. The aforementioned statement holds for both the binary system, which is the base of contemporary computing machines, as well as for the decimal radix.
A number of practical examples associated with the above Definition, will be given in Section 6.
It is known that a mantissa represented by a number of bits, say , in a computing machine is approximated in the decimal radix by a number of d. d., pretty close to the nearest integer of . Since is, as a rule, not an integer, then the number of correct digits of a quantity’s decimal representation may fluctuate by one digit at most.
3. Generation of Finite Precision Error in a Single Multiplication and Corresponding Probabilities
This Section presents a solution to the following problem: consider two arbitrary numbers, say , found in a computing machine that uses a finite word length of decimal digits in the mantissa. Moreover, suppose due to an ensemble of previous calculations has been computed with erroneous decimal digits (e. d. d.) in its mantissa, while with e. d. d. in the mantissa. In addition, consider that multiplication is executed in this computing machine. Then, so far, it has been an open question to determine the exact number of e. d. d. with which is evaluated; moreover, the corresponding probabilities that is computed with a specific number of e. d. d. must be evaluated.
3.1. Bounds and Evaluation of the Finite Precision Error Produced in a Single Multiplication
Consider any two quantities having ideally correct digits, should all operations and representations be made with infinite precision. Next, suppose that quantities and have been evaluated in a computing machine using d. d. in the mantissa; we let the representations of these two numbers in this computing machine be and , respectively. In addition, following Definition 2, we let the restriction of in this machine be respectively. We would like to emphasize that the difference between and is the following: quantity may have been evaluated with finite precision error, due to previous calculations. On the contrary, is free of finite precision error since it is always considered to be a restriction of the ideally correct value of in decimal digits.
Consider, moreover, the product , executed both with infinite precision yielding product , as well as in a computing machine using digits in the mantissa, generating . In addition, suppose that, due to previous calculations, has been computed with erroneous decimal digits (e. d. d.), ( correct decimal digits), while with e. d. d. ( c. d. d.) due to the fact that all operations have been made with a finite word length. We note, as it will become evident in the following analysis, that the finite precision error generated in the multiplication process is located only in the mantissae of the involved terms. Hence, we may assume that , , and are plain mantissae, namely that . In order to study the finite precision error generated in the computation of the product , we distinguish a number of cases, which are analytically presented below; in addition, a concise presentation of all these cases takes place in Table 1 and Table 2, positioned in the end of the present sub-section. Thus:

Table 1.
This refers to Case 1, with . The first column under the title “sub-cases”, the eventual values of are shown. In Line 3, in the right of the same title, the possible values of the product are presented. The obtained number of correct decimal digits (c. d. d.) of product is shown in bold in each corresponding square.
Table 2.
It refers to Case 2, where and in particular , without any loss of generality. The first column under the title “sub-cases”, the eventual values of are shown. In Line 3, in the right of the same title, the possible values of the product are presented. The obtained number of correct decimal digits (c. d. d.) of product is shown in bold in each corresponding square.
Case 1. Quantities and share the same number of correct decimal digits .
Therefore, according to Definition 2, it holds that
from which we deduce that we can express quantities and as follows:
where and are the signed mantissae of the finite precision error. Taking (3.1) into consideration, we may write:
Since, by hypothesis, , the above expression becomes
Thus, according to Definition 2, the finite precision error (f. p. e.) with which product has been evaluated is
We point out that the subsequent analysis may use (3.3) with slight, straightforward modifications; in fact, in practice, it is sufficient to keep the first-order terms when , since term is practically negligible. Should the algorithm tend to fail, i.e., if , then, of (3.3) can be used in the subsequent analysis, in a very straightforward manner. To compute the number of erroneous decimal digits (e. d. d.) of , it is absolutely necessary to distinguish the cases and , for reasons that will become evident in the following. In fact:
Case 1.i. It refers to inequality
Immediately below we will show that, in this case, the maximum number of additional erroneous decimal digits generated in the multiplication is 2. Indeed, here, since we have assumed that all involved quantities have zero exponents, the product , is given by ; now, (3.2) becomes
using the aforementioned first-order approximation. Hence, given that , it is rather straightforward to show that the supremum of quantity may acquire is , since all terms, , are mantissae. Therefore, we distinguish the following sub-cases:
Case 1.i.a:
Then, , which implies that
The above relation (3.7) implies that
Which according to Definition 2 shows that quantity has been computed with two less correct decimal digits, namely with correct decimal digits (c. d. d.) or equivalently with two additional erroneous decimal digits than those of the operands and .
Case 1.i.b:
In this sub-case, , which implies that
Consequently, Definition 2, implies that has been computed with one less c. d. d. than and .
Case 1.i.c:
Now, , implying that
Together with Definition 2, this means that has the same number of c. d. d. with and , namely .
Case 1.i.d:
Here it holds that , implying that
Consequently, one may deduce that the number of ’s erroneous decimal digits (e. d. d.) has been reduced by one.
Case 1.i.e. This constitutes a generalization of Case 1.i.d.; in fact, now, we assume that the following inequality holds:
In this, more general case, it holds that , therefore,
Hence, the number of correct decimal digits (c. d. d.) of has been increased by . The same approach may be applied for ; however, we will show that the corresponding probabilities are negligible in practice.
Case 1.ii, which concerns inequality
Since are mantissae, holds. Therefore, we distinguish the following cases:
Case 1.ii.a:
In this case, , which implies that
However, , if the algorithm has not failed, which means that . Thus, (3.18) now reads:
The above equality (3.19), together with Definition 2 dictates that has been evaluated with correct decimal digits (c. d. d.). Even though (3.6) and (3.17) are quite similar, now, the number of erroneous decimal digits (e. d. d.) of has been reduced by one, due to the right shift the computing machine has performed, to represent in its canonical form.
Case 1.ii.b:
In this case, holds. However, now, once more, provided that the algorithm has not failed, one obtains and Hence,
Definition 2 indicates that has been evaluated with c. d. d. (i.e., with no additional finite precision error (f. p. e.)).
Case 1.ii.c:
Now it holds that . Supposing that the algorithm has not failed, one deduces
The later implies that quantity has been computed with an additional correct decimal digit, i.e., that the multiplication operation has relaxed the finite precision error (f. p. e.) by one decimal digit.
Case 1.ii.d:
In this case, it holds that , hence,
Consequently, the number of correct decimal digits (c. d. d.) of product has been increased by in this case.
Case 2. and have been calculated with different number of correct decimal digits Without any loss of generality, we may assume that . Consequently, once more it holds that:
As in Case 1, we will use a first-order approximation in (3.26).
Again, the introduced analysis may be extended in a straightforward manner to incorporate the higher order term, too; however, as it will become clear from the subsequent sections, the accuracy improvement is negligible, given also the dramatic increase in complexity. Thus, we may safely assume that . After setting , we obtain:
We must now repeat the analysis previously made in connection with Case 1, by letting play the role of and play the role of . Hence, we again distinguish the cases and , thus getting:
Case 2.i:
Case 2.i.a:
In this case, .
Namely, product is computed with two additional erroneous decimal digits (e. d. d.) than .
Case 2.i.b:
Now which means that product is calculated with one additional erroneous decimal digits (e. d. d.) than .
Case 2.i.c:
Here, it holds that .
Hence, product is calculated with no additional e. d. d. when compared to , namely .
Case 2.i.d:
In this case, .
Then, is computed with less e. d. d. than . The same approach may be applied for , however, the probability that such a case holds, is negligible in practice.
Case 2.ii:
For this case, we distinguish the following sub-cases:
Case 2.ii.a:
In this case we obtain .
The above equation dictates that product has been evaluated with correct decimal digits (c. d. d.).
Case 2.ii.b:
Then, . Consequently, Definition 2 implies that has exactly the same number of erroneous decimal digits (e. d. d.) as .
Case 2.ii.c:
Now . Therefore, quantity has been computed with an additional c. d. d., as compared to .
Case 2.ii.d:
Here, it holds that . Hence, the number of c. d. d. of is greater by than .
3.2. Probabilities for Obtaining a Specific Number of Erroneous Digits in the Execution of a Single Multiplication
We once more adopt the distinction in cases made in Section 3.1, which are presented in Table 1 and Table 2 below, in a very concise manner. In fact,
Case 1: .
Moreover, in connection with Case 2 (), we cite the following Table 2:
Consider any multiplication of two numbers and sharing the same number of e. d. d. Thus, quantity is computed with e. d. d. If , is computed with additional e. d. d., while if , is computed with less e. d. d. Then, following Section 3.1, is a random variable, independent of . Therefore, the probabilities for obtaining a specific value of are independent of ; this suggests the use of the following notation:
Notation 2.
Let; then, quantityis computed withe. d. d.,. We denote the corresponding probabilities by.
As before, and are mantissae and are the mantissae of the f. p. e. stochastic part. Hence, for the evaluation of , it is necessary to know the joint probability density function (pdf) of the random variables , which express the f. p. e. of the mantissae respectively; we shall symbolize this joint pdf as . We shall give the general formulae of the sought-for probabilities for a generic pdf. Later on, we shall specify a class of pdfs encountered in practice, we shall calculate the corresponding probabilities and present the associated numeric results. At this point, since , we form the square shown in Figure 1, where every mantissae couple corresponds to a certain point of the sub-domain
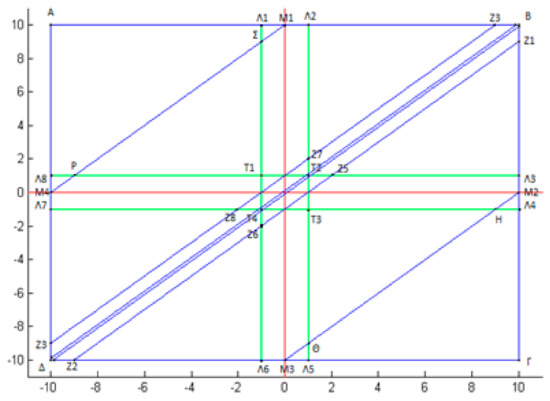
Figure 1.
Geometric representation of all pairs of finite precision error mantissae . Since these pairs do not belong to the cross , the corresponding joint probability function is restricted within .
We point out that the joint probability is a conditional pdf, where , in the sense that it satisfies relation . If the initial pdf is defined in a superset of , then, we restrict it to by means of the conditional probability rule. Notice that the points of the “cross” do not belong to , since and are mantissae. We again distinguish the sub-cases introduced in Section 3.1.
Case 1.i: , namely relation (3.4).
Case 1.i.a: , which is (3.6).
In order to determine the sub-domain of , where inequality (3.6) holds, we assume, first, that both are positive mantissae and we draw the straight lines:
Let be the set of points of that lie between and , where superscript and subscript express the last two letters of the Case in hand. Further, consider the straight lines:
Let be the set of points of lying between and and ; includes all points of satisfying (3.6). Then, probability . However, in this case only, according to the analysis of Section 3.1, is computed with additional e. d. d. than . Hence,
Case 1.i.b: , namely inequality (3.8).
For an arbitrary pair of multiplication operands , consider, now, the straight lines:
Let be the set of points lying between and and be the set of points lying between and . is the entire ensemble of points in satisfying (3.8), depicted in magenta in Figure 2. Then, probability
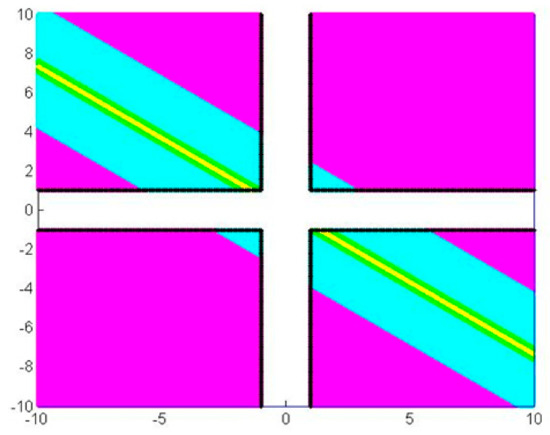
Figure 2.
Depiction of the various sub-domains of , which give rise to different numbers of erroneous decimal digits of , where . In this example, we have selected and ; consequently: (a) the sub-region generating one additional e. d. d. is depicted in magenta, (b) the sub-domain that does not increase the f. p. error is shown in cyan (c) the sub-region relaxing the e. d. d. number by one is depicted in green and (d) the one relaxing the number of e. d. d. by two is shown in yellow. Sub-domains that represent an even greater relaxation of the f. p. e. are too small to appear.
Case 1.i.c: , that is (3.10).
Next, in accordance with the previous analysis, we draw the straight lines:
Then, is the sub-domain of bounded by and , while is the sub-region bounded by and . Setting (cyan area in Figure 2), the probability that a pair of error mantissae satisfies (3.10) is:
Finally, concerning the remaining Case 1.i.d, it holds that:
Case 1.i.d: , namely the condition (3.14).
With a similar reasoning, we define the lines which in turn give rise to the sub-domains , and . Sub-domains and are depicted in green and yellow respectively in Figure 2. Eventually, the corresponding probabilities are
Case 1.ii: , specifically inequality (3.16).
This case may be treated as Case 1.i; however, here, as stated in Section 3.1, the computing machine performs a right shift in order to restore the product in its canonical form. Therefore, product is computed with a number of e.d.d. reduced by one with respect to the previous Case 1.i. Thus, briefly, we note the following:
Case 1.ii.a: , which is (3.17).
Once again, lines and , confine , and lines and , confine . Let, again, (shown in magenta in Figure 3, for a specific pair of multiplication operands ). When , product is computed with exactly one additional e. d. d. with probability
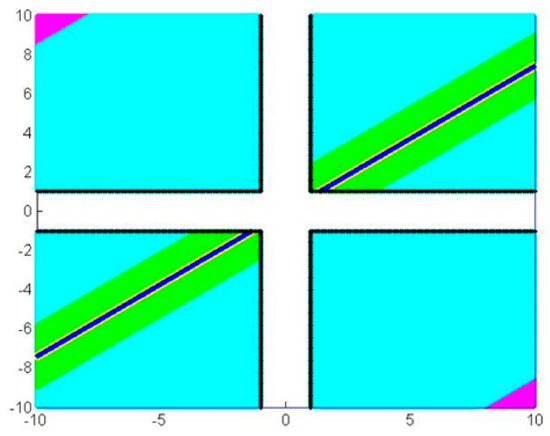
Figure 3.
Depiction of the various sub-domains of , which give rise to different numbers of erroneous decimal digits of , where . In this example, we have selected and : therefore (a) the sub-domain generating one additional e. d. d. is depicted in magenta, (b) the sub-region that does not increase the f. p. error is shown in cyan, (c) the sub-domain relaxing the e. d. d. number by one is depicted in green, (d) the one relaxing the number of e. d. d. by two is shown in yellow, while (e) the one relaxing the number of e. d. d. by three is depicted in blue. The sub-domains that represent an even greater relaxation of the f. p. e. are too small to appear.
Case 1.ii.b: , i.e., (3.20).
We draw the straight lines to obtain , lines to confine and we let (shown in cyan in Figure 3). The probability is
Case 1.ii.c: , that is condition (3.22).
We select points lying between and , forming and points lying between and , forming ; again, we let (green area in Figure 3). Now, the probability that f. p. e. is relaxed by one digit is
Case 1.ii.d: , namely the condition (3.24).
Along very similar lines we define sub-domains of , and (shown in yellow and blue respectively in Figure 3 for a specific pair of operands and ). We eventually evaluate
Case 2: .
Suppose that without any loss of generality and that is the number of erroneous d. d. with which product ; let, moreover, .
Notation 3.
In this case, the f. p. error also depends on(see Section 3.1). Hence, for the corresponding probability, we use the notation, where as always, without any loss of generality, we assume thatandare mantissae and that. If the opposite inequalityholds, then we use the notation.
We once more consider straight lines , which confine the corresponding sub-domains of : . The probabilities that a pair of mantissae lies in one of the aforementioned domains are:
Case 2.i: , namely condition (3.4).
Case 2.i.a: , i.e., (3.28).
Case 2.i.b: , that corresponds to (3.29)
Case 2.i.c: , which is the one of (3.30)
Case 2.i.d:, i.e. (3.31)
Case 2.ii:
Case 2.ii.a: , i.e., the inequality of (3.32).
Case 2.ii.b:, that corresponds to (3.33)
Case 2.ii.c:, namely inequality (3.34)
Case 2.ii.d:, i.e. the case of (3.35)
3.3. Experimental Confirmation of the Previous Theoretical Results
In order to test the validity of the analysis and the results of previous Section 3.1 and Section 3.2, we have performed the following experiment:
First, we have chosen a set consisting of 100,000 couples of randomly chosen mantissae , having d. d. in the mantissa. We assume that these numbers are all correct, concerning the first 16 d. d.
We have “contaminated” all , each one with a different error obtained from a normal population, with various values of the std. In fact, for each , we have produced 25,000 normally distributed error values that will play the role of f. p. e. of and , should all operations had been made with d. d. precision and the set of contaminated pairs . In addition, we have extended and into a representation of d. d., by simply zeroing all decimal digits from the seventeenth one up to 64-th digit.
We have performed all multiplications , evidently in 16 d. d. precision, as well as multiplications , in 64 d. d. precision. Then, using Definition 2 and Theorem 5, we have obtained the number of e. d. d. of quantity , with respect to the e. d. d. of and and the set of f. p. e. differences . Using this set, we have compared the corresponding experimental frequencies with the theoretical probabilities predicted in the present section, for various standard deviations of f. p. e. Representative results are shown in Table 3, Table 4, Table 5 and Table 6; Table 4 refers to the case where , for four arbitrarily chosen pairs , shown in Table 3. On the contrary, Table 5 and Table 6 refer to the case where . Table 5 corresponds to the case in which , while Table 6 corresponds to the one in which . From both tables, the excellent agreement between theory and experiment is pretty evident.
Table 3.
Four arbitrarily chosen pairs of .
Table 4.
The theoretical probabilities numerically evaluated, as compared to the actually observed corresponding experimental frequencies of .
Table 5.
The theoretical probabilities , namely for the case where , numerically evaluated, as compared to the actually observed corresponding experimental frequencies of .
Table 6.
The theoretical probabilities , namely for the case where , numerically evaluated, as compared to the actually observed corresponding experimental frequencies of .
We have repeated the previous step, using uniformly distributed “contamination numbers” , in the interval [, producing numbers .
By repeating all actions of previous Step 3 for the case of uniform contamination, the obtained results have confirmed an excellent agreement between theory and practice.
A set of concrete experiments and associated tables.
We have randomly chosen couples of mantissae terms , covering all cases referred to in Section 3.1 and Section 3.2. We have embedded both and in d. d. precision, as described previously in the present sub-section, thus forming corresponding couples . We have contaminated each such pair with 25,000 normally distributed error values for various distinct values of standard deviation . In this way, we have generated corresponding contaminated pairs .
We have performed all multiplications , as well as the associated products and, finally, we have evaluated the number of erroneous decimal digits of by comparing it with .
The results of this experiment for a specific value of are shown in Table 3, Table 4, Table 5 and Table 6. In Table 3, four arbitrarily chosen different pairs are presented. Table 4 refers to the case where ), for the corresponding contaminated pairs , while Table 5 and Table 6 refer to the cases in which and respectively, where .
For all arbitrarily chosen contaminated pairs , we have evaluated the theoretical probabilities introduced in Section 3.1, numerically. From all tables, the excellent agreement between theory and experiment is pretty evident. We would like to point out that this excellent agreement appears in all performed experiments, concerning of different values of standard deviation .
4. Analysis of the Case of Many Successive Multiplications
In this section, we will compute the probability that successive multiplications generate erroneous d. d. in the final product.
In fact, suppose that any two numbers, and , are multiplied in a computing machine using decimal digits (d. d.) in the mantissa; let . Next, is multiplied by an arbitrary number, say , giving rise to and so on. The analysis of Section 3 indicates that a different number of erroneous d. d. emerges as it is analytically presented in Table 1 and Table 2. Therefore, in order to estimate the number of erroneous decimal digits (e. d. d.) accumulated in a result of many successive multiplications, one may employ the following:
- The mantissa of the finite precision error (f. p. e.) accumulated at an arbitrary quantity, say , is a random variable, already symbolized as . Therefore, when two quantities and are multiplied with f. p. e. mantissae and , then the f. p. error of the product is itself a random variable.
- As before, without any loss of generality, suppose that is the maximum number of e. d. d. between and . Then, reminding that the symbol “” stands for cardinal number, differ from by e. d. d. Evidently, is a random variable itself, having integer values .
- In Section 3, we have given a method for evaluating the probabilities , namely the probability that product is computed with a number of erroneous decimal digits (e. d. d.) differing by ξ decimal digits from the common e. d. d. of . In the same section, we have also proposed a method for evaluating the probabilities , i.e., the probability that product is computed with a number of e. d. d. differing by ξ decimal digits from the maximum number of e. d. d. between . For brevity, in the present section, we will assume that in all successive multiplications the worst case always takes place, namely that the two multiplication operands share the same number of correct decimal digits (c. d. d.). Moreover, we will momentarily simplify notation by letting , , .
- We have performed an extensive number of multiplications , where, initially, and are chosen uniformly from the interval and with d. d. precision in the mantissa. Then, the f. p. e. mantissa of the product follows a normal distribution with zero (0) mean value and standard deviation . Hence, probabilities are immediately obtained via the analysis of Section 3. However, the present analysis is valid for any distribution of error mantissae that gives rise to a set of probabilities .
- For brevity and simplicity reasons, we shall assume that the ensemble of probabilities remains unaltered throughout the entire successive multiplications process. Should any concern on that arise, as we will explicitly state below, a proper source code may be used in order to compute dynamically, while the essence of the following analysis remains intact.
Subsequently, we will compute the probability that successive multiplications generate erroneous d. d. in the final product . In fact, suppose that one performs successive multiplications and that of them produce two additional e. d. d. (), of them produce one additional e. d. d. (), of them produce no additional e. d. d. () and products “enjoyed” relaxation of the number of e. d. d. by digits (). Then, the number of e. d. d. with which the final product of successive multiplications is obtained, is given by . We are interested in the mean value and variation of quantity . To achieve that, we shall present a set of quite general lemmas and theorems; for this reason, for the present section only, we shall introduce an alternative, equivalent notation described below:
Notation 4.
Letbe defined as in the previous analysis above. Then, one may define events as follows:,,,, where eventsrefer to error correction bydigits.
Intimately associated with Notation 4 is the following:
Hypothesis 1.
In order to obtain proper bounds of the number of e. d. d. accumulated in the final product of successive multiplications, it is sufficient to assume that at each one of these successive multiplications, the corresponding probabilities remain constant.
Under this assumption, we let:
In order to obtain the aforementioned bounds for , we shall employ the subsequent quite general results.
Lemma 1.
Consider a multinomial distribution with possible outcomes , with corresponding probability of appearance . Suppose that one performs an experiment times, whose outcome is modeled by this distribution. Let the first event with outcome be observed times, the second event with outcome times and so on. Then, quantity has a mean value and a variance :
Proof of Lemma 1.
The probability that ω occurs is given by
For the mean value : By definition:
We treat each multiple sum separately. Therefore,
-sum is a version of the identity
Hence,
By employing the same approach, we obtain the previous relation (4.1)
For the variance : By definition:
By employing the previously given expression for , we obtain:
Expanding , we obtain the partial sums:
Following an analogous process for the other similar terms of quantity , we obtain
We now calculate the cross-product
Similarly, for the remaining cross-products, we obtain
Summing up and , we eventually obtain
□
This Lemma along with the central limit theorem, offer the following:
Lemma 2.
Suppose that one executes successive multiplications. Then, the number of erroneous d. d. generated in the product obtained after these multiplications, , follows a normal distribution with mean value and variance given by (4.1) and (4.2).
We will apply all the previous results to the three more important cases, described below.
Case 1. The worst case, where in all multiplications holds.
Case 2. The most favorable case, where always holds.
Case 3. The general case, where the distribution of is arbitrary.
Case 1. If at each multiplication, inequality (3.4) holds, namely
then we choose the following values around which the corresponding probabilities are more frequently encountered:
- : (i.e., almost negligible). We repeat that we use probabilities only, since we consider the worst case as far as f. p. error generation and accumulation is concerned, namely that .
- : .
- : .
- : .
- : .
- −3: . (i.e., almost negligible).
Therefore, if such successive multiplications take place, then, the overall number of generated e. d. d. follows a multinomial distribution, which may be very well approximated by a normal distribution with and , . Hence, quantity follows a standard Gauss distribution, i.e., .
However, now, inequality (3.4) holds, thus, is positive and inequality holds with confidence 99.999%; coefficient corresponds to the aforementioned confidence level. With this level of significance, the accumulated number of erroneous d. d. in the final product, after successive multiplications, obeying inequality (3.4), satisfies relation
However, in this case, the right-hand side of inequality (4.6) is always positive and, moreover, is a monotonically increasing function of . Consequently, the accumulated number of erroneous decimal digits of every product , tends to rapidly increase even for a particularly small number of successive multiplications . This is fully supported by the contents of Table 7 and Table 8, below.
Table 7.
is a percentage of multiplications in which inequality (3.16) holds. Thus, when holds, then becomes completely erroneous after a relatively small number of multiplications, in full accordance with the theoretical predictions. These predictions are based on the results of Theorems 1, 3 and 5, refer to the lower bound of the expected e. d. d. for each and they are presented in the last column for confidence level . For each the experimental and theoretical results manifest an excellent agreement.
Table 8.
Demonstration of the results of experiment associated with Case 3, described in the Section 4: 3 × 105 successive multiplications have been performed for various percentages of them satisfying . The obtained maximum and average numbers of e. d. d. are in full accordance with Theorems 1, 3 and 5. In fact, when holds, then the evaluated products manifest a considerable resistance to finite precision error. The closest to 1 is, the smaller the number of erroneous digits with which all are computed, exactly as predicted by the theoretical analysis.
Theorem 1.
Let us assume that a number ofsuccessive multiplicationsis performed and that for every multiplication, inequalityholds. In this case, the productis prone to serious finite precision error accumulation. We also assume that Hypothesis 1 now holds. Let, in the-th iteration the number, , be the number of erroneous d. d. with which quantityhas been evaluated. Then, it holds that
whereis the desired level of significance andis the lower bound of the corresponding confidence interval.
The theorem holds for any desired level of significance. Due to the fact that quantityis always positive in this case and it is a monotonically increasing function of, quantitytends to increase rapidly, even for particularly small numbers of.
Hypothesis 2 and Associated Notation 5.
Suppose that probabilities do not remain constant throughout the successive multiplications, but on the contrary, they depend on the current multiplication. In this case, we consider the following events and the corresponding probabilities for an arbitrary multiplication, say the one:
;
; ,
;
; etc.
If one adopts the above Hypothesis 2, the following result holds:
Theorem 2.
Under the conditions imposed by Hypothesis 2, one may dynamically compute the exact (up to d. d.) number of erroneous decimal digits, which are accumulated at the , arbitrary, product , by applying the method introduced in Section 3. This dynamic computation of can be made by a rather straightforward code based on the results of Section 3.
Case 2. Now, we assume that at each one of the successive multiplications, inequality (3.16) holds, i.e., that
Then, consider the following associated, quite representative probabilities, in accordance with the analysis of Section 3.2, Case 1.ii:
- Probability that occurs is , since in this case equality can never occur.
- Probability that occurs is .
- Probability that occurs is .
- Probability that occurs is .
- Probability that occurs is .
- Probability that occurs is .
As a rule, the probabilities of events are pretty small, practically zero; however, the entire analysis is absolutely valid if one incorporates the (very small) corresponding probabilities in it. Hence, according to Lemma 1, and .
We would like to emphasize that in this case, the mean value of generated e. d. d. is negative.
Now, quantity follows a standard Gauss distribution, i.e., . Hence, inequality holds with confidence 99.999%. With this confidence level, the accumulated number of e. d. d. after successive multiplications obeying (3.16), satisfies
Here, is a monotonically decreasing function of . Thus, the accumulated number of e. d. d. remains very close to zero, even for a very large number of multiplications. This has been fully experimentally verified as described in Section 4. Hence, the following holds:
Theorem 3.
Suppose that a number of successive multiplications is performed. For every such multiplication, let inequality (3.16) holds. Then, for all practical purposes, these multiplications accumulate a negligible amount of f. p. error on the product for all
Moreover, the number of erroneous decimal digits (e. d. d.) accumulated in the arbitrary product, is, as a rule, a decreasing function of .
If, in addition, Hypothesis 1 is adopted, then the numberof e. d. d. accumulated in the-th multiplication satisfies inequality (4.8).
The theorem holds for any desired level of significance, the only difference being the coefficient of.
By a complete analogy with Theorem 2, one may adopt Hypothesis 2, in which case the following result holds:
Theorem 4.
Under the conditions imposed by Hypothesis 2, one may dynamically compute the exact (up to d. d.) number of erroneous decimal digits, which are accumulated at the , arbitrary, product , by applying the method introduced in Section 3. This dynamic computation of can be made by a rather straightforward code based on the results of Section 3.
Case 3. In the general case, either inequality (3.16) or inequality (3.4) arbitrarily holds. Then, in order to obtain a rigorous estimation of the number of e. d. d. in each multiplication, together with the corresponding probability, one must know the statistical distribution of , as compared to ten (10). In general, these distributions may highly depend on the algorithm in hand. However, in order to obtain an estimation of the corresponding generated f. p. error, we will state the very interesting example where both and follow a uniform distribution in the interval . In fact, in this case, the set of in the -plain satisfying (3.4), is the 2D domain bounded by the straight lines and and the hyperbola . Dually, the 2D domain for which the alternative inequality (3.16) holds, is the one limited by the straight lines , and the same hyperbola. Then, we follow the results of Section 3 and we use the graphical representation associated with the square of Figure 1 for the probability density function , defined on this square except the cross. Consequently, in a rather straightforward manner, we obtain .
In case that there is no discernible distribution of within the course of the algorithm, we may dynamically calculate the finite precision error accumulation for every product in order to estimate the accumulation of the finite precision error in the algorithm in general, as described in Theorems 2 and 4; we remind that Theorem 2 refers to the worst case in which always holds, while Theorem 4 is connected to the dual inequality (3.16), which is most favorable from the point of view of generation of finite precision error during multiplication. In any case, the following holds:
Theorem 5.
Suppose again that during successive multiplications and that for a fraction, say , of these multiplications, inequality (3.16) holds, while for the other fraction of them inequality (3.4) holds. Then, concerning the f. p. error accumulation in the products , the following two cases hold:
- (i)
- if , product tends to behave as described in Case 2, i.e., the overall number of e. d. d. of is restrained. The closer to 1 fraction is, the greater the restriction of the number of e. d. d. accumulated in products (see Table 8).
- (ii)
- If , the accumulated f. p. error in the products is amplified. The closer to 0 is, the more rapidly the f. p. e. accumulated in products grows (Table 7).
5. Comparing the Finite Precision Error Generation and Accumulation during Execution of the Same Algorithm Including Successive Multiplications, with Different Finite Word Length/Precision
We shall begin by giving a brief description of the goal of the present section: consider an algorithm , involving multiplications at each iteration. We execute first with decimal digits in the mantissa (say ) and simultaneously with decimal digits (d. d.) in the mantissa, where we assume that , using exactly the same input in both cases. Consider any quantity of and let be the value of this quantity at the iteration of , where all calculations are made with precision of d. d. in the mantissa. Similarly, let be the value of this quantity at the same iteration of , when all operations are made with precision of d. d. In the present section, we will compare the number of erroneous d. d. with which any such two quantities are calculated and, in particular, for the difference .
In Section 4 we have concluded that, independently of the finite word length, the number of e. d. d. of any product follows a normal distribution if the number of successive multiplications which generated , is greater than or equal to 30. Thus, the difference in the number of e. d. d. between and also follows a normal distribution with mean value zero and a variance that can be immediately estimated from the results of Section 4. Hence, one may deduce:
Theorem 6.
Suppose that an algorithm including an arbitrary number of successive multiplications, is executed in parallel with two different finite word lengths corresponding to and decimal digits (d. d.). Let the two representations of an arbitrary quantity of be and respectively, in these two finite word lengths. Consider the random variable
follows a normal distribution with mean value zero and variance, whereis given in (4.2). Letbe the cumulative distribution function of’s normal distribution. Then, the probability thatis greater thand. d. (where, clearly,) is given by
Corollary 1.
Theorem 7.
As in Theorem 6, we let be executed in parallel with the two different finite word lengths and , where . Then, for an arbitrary quantity of , the following hold:
- 1.
- We project to d. d. in the mantissa, obtaining a restricted representation of We compare and by means of Definitions 1 and 2. If the obtained result is e. d. d. , then we deduce that precisely the last digits of are erroneous.
- 2.
- We also deduce that has at most e. d. d. or, equivalently, that the first d. d. of are correct.
- 3.
- As long as holds, then, is a fully correct representation of with d. d.
6. Experiments That Fully Support the Theoretical Analysis
In this section, we shall introduce a number of experiments that have been specifically designed by the authors, in order to test the validity and the reliability of the theoretical analysis and results presented in the previous sections.
6.1. Description of a First Class of Experiments That Confirm the Theoretical Approach
Aiming at testing methodology and the associated theoretical results introduced in Section 3 and Section 4, we have proceeded as follows: first, we have selected a set of randomly chosen floating point numbers having 16 decimal digits (d. d.) in the mantissa (subscript stands for 16); the elements of this set come from a uniform distribution. All numbers were expressed in scientific form.
Next, we have extended each number of into a 40 d. d. representation, in scientific form, setting the last 24 d. d. of each number’s mantissa to zero. Thus, we have obtained floating point numbers forming set ().
Subsequently, we have chosen an arbitrary, momentarily fixed value of in the interval . We have performed multiplications with d. d., for which the multiplication operands satisfied (3.16). Next, we have performed multiplications with 16 d. d. word length, where the opposite inequality, (3.4), namely that the mantissa of the product terms have absolute value smaller than 10, holds. We have ensured that no repetition of any multiplication occurred.
The very same multiplications have been repeated with 40 d. d. precision, among the corresponding numbers . Suppose that two numbers , , when multiplied, generate with finite precision error (f. p. e.) , while is generated with f. p. e. . These errors have been computed via Definition 2 and Theorems 5 and 6 introduced in Section 5. More specifically:
- (i)
- We have restricted into d. d., thus obtaining the number .
- (ii)
- According to Theorem 6, is a correct representation of product having decimal digits in its mantissa.
- (iii)
- We have compared and using Definitions 1 and 2, i.e., by forming their difference . In this way, we have obtained the exact number of erroneous decimal digits (e. d. d.) with which quantity has been evaluated.
By merging the obtained products in two distinct ensembles, we have formed two new sets, , being in a natural biunivocal relation ().
Moreover, for the same value , we have performed multiplications between , satisfying (3.16), as well as multiplications where (3.4) holds, obtaining products . Again, during the aforementioned process, no repetition of any multiplication occurred. The very same multiplications have been performed with 40 decimal digits precision, between corresponding elements of set , obtaining products . The erroneous d. d. of have been computed using , as described above based on the results of Section 2 and Section 5. We let products and form sets and respectively, maintaining the natural biunivocal relation ().
We continued in this way, forming sets (,, etc. with the same factor . In all these cases we evaluated the number of e. d. d. with which products , are computed as it has been previously described in connection with and . In addition, whenever an exponent exceeded a large absolute value (e.g., 50) during the previous process, it was set to zero, since the exponent of the scientific form plays no role in the f. p. e. generation and accumulation in the multiplication process in general. We have taken this action, in order to avoid possible effects of overflow or underflow in consecutive multiplications, since these easily spotted problems have nothing to do with the present study. However, we have kept the overall exponent of each product by simple recursive additions.
We have repeated the aforementioned experiment for various values of , where always . At this point, we have distinguished two additional sub-cases: (a) and (b) .
Sub-case (a) is quite analogous to Case 1, for which inequality (3.4) holds permanently. Specifically, the obtained products , have been calculated with all digits erroneous after a relatively small number of iterations, as shown in Table 7. The smaller fraction , the more serious the f. p. error is.
On the contrary, Sub-case (b) is quite similar to Case 2, in the sense that products manifested substantially smaller f. p. e. accumulation, as Table 8 manifests. In full accordance with the theoretical analysis, the smaller , the smaller the accumulated f. p. e. in is.
6.2. A Second Class of Experiments for Testing the Theoretical Analysis Concerning Successive Multiplications
Case 1. All Successive Multiplications Satisfy Inequality (3.4), .
In connection to it, we have performed the following experiment: we have implemented an artificial algorithm, which forces all successive multiplications to satisfy (3.4). The flow chart of this algorithm is the following:
Starting from an arbitrary number , we express it with a certain number of decimal digits (d. d.), as well as with d. d. We then multiply by itself in both precisions. In case exceeds ten, then we subtract a properly selected positive integer , from in both precisions; we do so, in order that now holds. We stress that is adequately selected to be an integer in order that its subtraction from the initial does not add any e. d. d. to ; in all performed experiments, we ensured this by checking the number of e. d. d. of the difference , via Definition 2. By comparing product in both precisions, we calculate the erroneous decimal digits (e. d. d.) of in the digits precision. Next, we set the exponent of equal to zero, in order to avoid overflow or underflow and we let the obtained mantissa of be a new number, , expressed in both precisions. Then, we repeat the previous actions by letting play the role of and we evaluate and store the number of e. d. d. with which is computed, after ensuring that , via a proper subtraction , as before. We continue this process until the obtained is calculated in the digits precision with all its digits erroneous, while we have ensured that .
We have executed this algorithm for 1000 different initial values of , always belonging to the interval . The obtained maximum number of iterations for which was totally erroneous is shown in Table 9 for various values of precision . Thus, we obtain the particularly important result that is totally erroneous after an impressively small number of iterations, in comparison to the employed precision, in full accordance with the theory and in particular with Theorem 1 of Section 4.
Table 9.
Table demonstrating the number of iterations after which the output of the algorithm described in Case 1 of the present Section, offered totally erroneous results, for various employed finite word lengths . The results are in full accordance with the theoretical analysis presented in the previous sub-sections. The experimentally observed results are in excellent agreement with the content of Theorem 1 of Section 4.
Case 2. All Successive Multiplications Satisfied .
We have, again, performed an additional experiment, in which we have written an artificial algorithm, that forces all successive multiplications to satisfy . Indeed, this algorithm is quite similar to the one described in connection with Case 1 above and it has the following flow chart:
Starting, again, from an arbitrary number , we express it in both and d. d. precision. We then execute in both precisions. In case is smaller than ten, then we add a properly selected positive integer to in both precisions, so as . We stress that never manifests any e. d. d. By comparing product in both precisions, we calculate and store the -precision number’s e. d. d., again by means of Definition 2 and Theorem 5. Next, we set the exponent of to zero, once more to avoid overflow or underflow and we let the obtained mantissa of be a new number expressed in both precisions. Next, we repeat the previous actions by letting play the role of and we store and evaluate the number of e. d. d. with which number is computed, after ensuring that by adding a proper to , if necessary. We repeated this process for an arbitrarily large number of iterations, while monitoring the f. p. error of .
We have executed this algorithm times in 16 and 42 d. d. precision for 1000 initial values of , always belonging to the interval . The experiment has shown that the number of erroneous decimal digits with which has been calculated never exceeded two (2), while the mean value of these e. d. d. remained always pretty close to zero, even for the larger numbers of iterations of the algorithm, in full accordance with Theorem 3.
6.3. Description of a Third Experiment That Fully Supports the Theoretical Results regarding the Case of Successive Multiplications with a Varying Word Length
We have experimentally tested the correctness of Theorem 7 of Section 5, by performing successive multiplications as described in Section 4. However, now, each multiplication has been executed three times with 16, 40 and 128 d. d. in the mantissa. In this way for each product we have obtained three representations, and in parallel. Next, we have restricted to 16 d. d., obtaining representation as described before. Similarly, we have projected to both 16 and 40 d. d., obtaining the corresponding representations and . Eventually, we have compared with and by means of Definitions 1 and 2; we have also compared with and with via the same method. The obtained results are shown in Table 10 and fully justify the aforementioned Theorems of Section 5, but also of Section 4.
Table 10.
Comparison of the number of erroneous decimal digits (e. d. d.) accumulated in all the intermediate results of 108 successive multiplications. All these multiplications have been executed in parallel, with 16, 40 and 128 d. d. in the mantissa. All obtained experimental results fully support the theoretical analysis introduced in Section 5 and in particular the content of Theorems 6 and 7.
7. Eventual Applications Associated with the Present Work
In the section in hand, we shall present and highlight an ensemble of possible and probable applications, which will be based in the analysis and methodology introduced here. Thus:
- In certain applications, like the ones that will be described below, it is preferable and/or necessary to use finite elements methods, which employ polynomials of high order to approximate the considered function on each element, usually called “higher order basis functions”. In this approach, if the higher order basis functions are of order , then one must use elements consisting of nodes; moreover, one frequently uses the following basis functions ([20]):where (a) is the cardinal number of the node in hand, , (b) represents the cardinal number of the other nodes of the specific element, hence , (c) is the independent variable of the polynomial basis function and (d) evidently , is the value that this variable acquires on the element of the node in hand.
It is rather clear that both the nominator and the denominator in relation (7.1) are results of successive multiplications.
However, even in the case of second order basis functions, one employs the basis functions:
which includes multiplications. Consequently, the entire previous analysis may be applied immediately, so that together with computation, the user may know the exact number of erroneous decimal digits with which this quantity has been evaluated, each time. Clearly, in case that the numerical value of such a basis function for a certain is highly or even totally “contaminated”, then the user may immediately receive a corresponding signal.
Therefore, more specifically, this method can be applied to the subsequent applications:
- In research associated with the modelling of the fatigue of materials employed in the rail-wheel system ([21,22]).
- In the study of rail corrugation ([23,24]).
- In the study of the influence of bending on the value of friction coefficient ([25]).
- In tackling important classes of contact problems in elatostatics ([26,27]).
- In the investigation and analysis of the spatial stress-strain states of a pipe with respect to its corrosion damage, taking into account various types of complex loading ([28]).
- In real time analysis of local damage in wear-and-fatigue tests, whenever finite elements methods are required/applied ([29]).
It is worthwhile noticing that in many of the aforementioned studies the involved models frequently include multiplications; consequently the approach introduced in the present manuscript may also be proved helpful in associated numerical experiments.
- B.
- The sequence of powers of a real number.
Consider a single real number, say . Moreover, consider the sequence of powers of , usually computed recursively by means of the following succession of multiplications:
Suppose that the numerical value of is such that, statistically, multiplication , , satisfies inequality (3.4)
more frequently than the opposite one (3.16), namely
Then, according to the previous analysis, one expects that will continually be evaluated with a larger number of erroneous decimal digits (e. d. d.), as grows. To verify/demonstrate that, we have employed , we have generated sequence of the powers of by means of the aforementioned sequence of successive multiplications and we have evaluated the exact number of e. d. d. with which is calculated each time; the determination of the exact number of erroneous d. d. has been made as described in Section 5 and Section 6, using decimal digits word length and decimal digits precision. The associated results are depicted in Figure 4, from which it is evident that after the impressively small number of 55 iterations, the power is computed with all its digits erroneous.
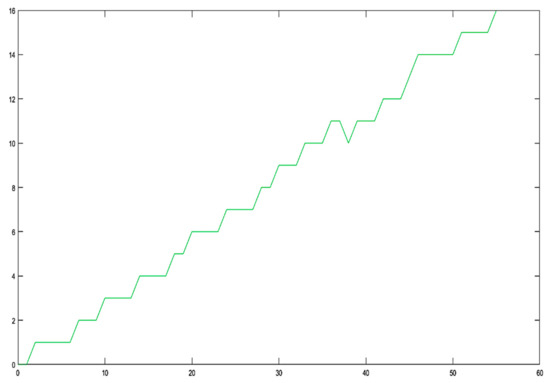
Figure 4.
The evolution of the number of the erroneous decimal digits (e. d. d.) accumulated in the power , due to finite precision error. The abscissa represents the recursions’ cardinal number, while axis represents the number of e. d. d. Number has been chosen in such a way, so as inequality holds more frequently than the dual one (3.16). As a consequence, the number of e. d. d. grows rapidly, in full accordance with the analysis and the results of Section 4 and Section 6.
We must emphasize that, in order to circumvent the effects of overflow, each time we have multiplied the mantissae of only and not the entire number . Equivalently, whenever the exponent of exceeded a rather large number, say , then we have divided with . However, we have registered the power’s exponent each time by simple recursive additions. It is important to stress that, in both these approaches the number of erroneous decimal digits accumulated in were identical.
- C.
- Continual multiplication of contaminated numbers.
Exactly the same analysis holds true, in the case that instead of multiplying with itself to produce , we instead perform the sequence of multiplications:
where is an arbitrary sequence of contaminated numbers, to which erroneous digits are accumulated probably due to another procedure. The application (D) that follows, we believe that it will clarify the content of these statements.
- D.
- Finite Precision Error Accumulated in Various Fast Kalman Algorithms.
One of the most widely used filtering procedures is the Kalman one [30]. In many of these algorithmic schemes a certain scalar quantity, say , is updated at the time instant by means of a formula of the type
where (i) is the so-called “forgetting factor” almost always belonging to the interval and (ii) is another quantity of the algorithm, which is also computed recursively. In many applications [30], quantities have values such that inequality (3.4)
holds very frequently, statistically. Hence, every formula of the type (7.3), tends to generate one additional erroneous decimal digit in a relatively small number of recursions; this erroneous digit is added to the value of . Subsequently, since enters directly or indirectly, in all other formulae of the corresponding Kalman algorithms, including , it follows that these schemes are very frequently destroyed due to this successive-multiplication-based finite precision error, in an impressively small number of iterations [30].
Thus, for example, the faster existing Kalman algorithm (the FAEST [31]) can never converge in practice due to this type of f. p. e.
In general, the methodology introduced here allows for both the evaluation of the number of erroneous decimal digits with which all quantities in any fast Kalman algorithm are computed, as well as for finding methods of stabilizing various algorithms of this class ([32]).
8. Conclusions
In this paper, we have presented a new approach to the study of the finite precision error generation and accumulation in the multiplication process. We have initially given a strict mathematical definition of the number of correct digits of a real quantity expressed in any finite word length. We emphasize that although the analysis introduced here is made in the decimal radix, it offers accurate results and prediction of the f. p. e. generated and accumulated in any computing machine that performs an arbitrary number of multiplications, successively.
Along this new approach, we have shown the following fundamental result: suppose that one executes an arbitrary multiplication in a computing environment employing the equivalent of decimal digits in the mantissa. Moreover, let operands and have erroneous decimal digits at most in their mantissae. Then, the number of e. d. d. with which product is calculated depends on the value of . In fact, if inequality holds, then product is calculated with at most erroneous d. d. or with e. d. d. In case the complementary inequality holds, then product may be calculated with up to , or with e. d. d.
We have also shown that the chance of encountering one of the aforementioned cases heavily depends on the exponent of quantity , where and are the multiplication operands’ f. p. e. mantissae and .
In order to calculate the probabilities that each one of the aforementioned cases holds, we have introduced the rectangular shaped set of points of Figure 1 and we have defined the sub-domains in which the values of the random variables and correspond, in order that product is computed with a specific number of e. d. d. Then, by integration on the corresponding sub-domains, we have calculated the associated probabilities.
We have also given exact formulae for the mean value and standard deviation of the number of e. d. d. accumulated in the results of successive multiplications.
Moreover, we have established that if we perform the exact same set of successive multiplications using and d. d., then we may easily track the number of e. d. d. accumulated in the precision results.
Finally, in order to test the validity of the introduced theoretical analysis, we have performed a number of specially developed experiments. The results of these experiments fully supported the theoretical analysis introduced here.
We emphasize that the developed novel methodology is expandable, so as to tackle the finite precision error generation and accumulation in any arithmetic operation; this will be the subject of forthcoming manuscripts.
Author Contributions
Conceptualization, C.P., D.A., F.G., C.C. and A.R.M.; Funding acquisition; Investigation, A.R.M. and C.C.; Project administration, C.P.; Resources, F.G. and C.C.; Software, C.P., C.C., A.R.M., F.G. and D.A.; Supervision, C.P. and D.A.; Validation, C.P., D.A., F.G., A.R.M. and C.C.; Writing—original draft, C.P. and F.G.; Writing—review & editing, A.R.M., C.P., D.A. and C.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The study did not employ any data sets.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Caraiscos, C.; Liu, B. A roundoff error analysis of the LMS adaptive algorithm. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 34–41. [Google Scholar] [CrossRef]
- Moustakides, G.V. Correcting the instability due to finite precision of the fast Kalman identification algorithms. Signal Process. 1989, 18, 33–42. [Google Scholar] [CrossRef]
- Steele, G.L.; White, J.L. How to Print Floating-Point Numbers Accurately. In Proceedings of the ACM SIGPLAN 1990 Conference on Programming Language Design and Implementation, New York, NY, USA, 20–22 June 1990; pp. 112–126. [Google Scholar] [CrossRef]
- Bai, Z. Error Analysis of the Lanczos Algorithm for the Nonsymmetric Eigenvalue Problem. Math. Comput. 1994, 62, 209–226. [Google Scholar] [CrossRef]
- Arioli, M.; Fassino, C. Roundoff error analysis of algorithms based on Krylov subspace methods. Bit Numer. Math. 1996, 36, 189–205. [Google Scholar] [CrossRef]
- Lowenstein, J.H.; Vivaldi, F. Anomalous transport in a model of Hamiltonian round-off. Nonlinearity 1998, 11, 1321–1350. [Google Scholar] [CrossRef]
- Allen, E.; Burns, J.; Gilliam, D.; Hill, J.; Shubov, V. The impact of finite precision arithmetic and sensitivity on the numerical solution of partial differential equations. Math. Comput. Model. 2002, 35, 1165–1195. [Google Scholar] [CrossRef]
- Gelb, A. Parameter Optimization and Reduction of Round Off Error for the Gegenbauer Reconstruction Method. J. Sci. Comput. 2004, 20, 433–459. [Google Scholar] [CrossRef]
- Martel, M. Semantics of roundoff error propagation in finite precision calculations. High. Order Symb. Comput. 2006, 19, 7–30. [Google Scholar] [CrossRef]
- Wang, P.; Huang, G.; Wang, Z. Analysis and application of multiple-precision computation and round-off error for nonlinear dynamical systems. Adv. Atmos. Sci. 2006, 23, 758–766. [Google Scholar] [CrossRef][Green Version]
- Papakostas, G.; Karras, D.; Boutalis, Y.; Mertzios, B. Fast numerically stable computation of orthogonal Fourier–Mellin moments. IET Comput. Vis. 2007, 1, 11–16. [Google Scholar] [CrossRef]
- Kountouris, A. A randomized algorithm for controlling the round-off error accumulation in recursive digital frequency synthesis (DFS). Digit. Signal Process. 2009, 19, 534–544. [Google Scholar] [CrossRef]
- Linderman, M.D.; Ho, M.; Dill, D.L.; Meng, T.H.; Nolan, G.P. Towards program optimization through automated analysis of numerical precision. In Proceedings of the 8th annual IEEE/ACM International Symposium on Code Generation and Optimization, Toronto, ON, Canada, 24–28 April 2010; pp. 230–237. [Google Scholar] [CrossRef]
- Turchetti, G.; Vaienti, S.; Zanlungo, F. Relaxation to the asymptotic distribution of global errors due to round off. EPL Europhys. Lett. 2010, 89, 40006. [Google Scholar] [CrossRef][Green Version]
- Cheng, A.-D. Multiquadric and its shape parameter—A numerical investigation of error estimate, condition number, and round-off error by arbitrary precision computation. Eng. Anal. Bound. Elem. 2012, 36, 220–239. [Google Scholar] [CrossRef]
- Deng, A.-W.; Wei, C.-H.; Gwo, C.-Y. Stable, fast computation of high-order Zernike moments using a recursive method. Pattern Recognit. 2016, 56, 16–25. [Google Scholar] [CrossRef]
- Das, A.; Briggs, I.; Gopalakrishnan, G.; Krishnamoorthy, S.; Panchekha, P. Scalable yet Rigorous Floating-Point Error Analysis. In Proceedings of the SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 9–19 November 2020; pp. 1–14. [Google Scholar] [CrossRef]
- Papaodysseus, C.; Koukoutsis, E.; Vassilatos, C. Error propagation and methods of error correction in LS FIR filtering and l-step ahead linear prediction. IEEE Trans. Signal Process. 1994, 42, 1097–1108. [Google Scholar] [CrossRef]
- Papaodysseus, C.; Koukoutsis, E.; Triantafyllou, C. Error sources and error propagation in the Levinson-Durbin algorithm. IEEE Trans. Signal Process. 1993, 41, 1635–1651. [Google Scholar] [CrossRef]
- Becker, E.B.; Carey, G.F.; Oden, J.T.; Belytschko, T. Finite Elements, An Introduction. J. Appl. Mech. 1982, 49, 682. [Google Scholar] [CrossRef]
- Bendikiene, R.; Bahdanovich, A.; Cesnavicius, R.; Ciuplys, A.; Grigas, V.; Jutas, A.; Marmysh, D.; Nasan, A.; Shemet, L.; Sherbakov, S.; et al. Tribo-fatigue Behavior of Austempered Ductile Iron MoNiCa as New Structural Material for Rail-wheel System. Mater. Sci. 2020, 26, 432–437. [Google Scholar] [CrossRef]
- Iannitti, G.; Ruggiero, A.; Bonora, N.; Masaggia, S.; Veneri, F. Micromechanical modelling of constitutive behavior of austempered ductile iron (ADI) at high strain rate. Appl. Fract. Mech. 2017, 92, 351–359. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, B.; Zhou, Z. An experimental study of rail corrugation. Wear 2003, 255, 1121–1126. [Google Scholar] [CrossRef]
- Ahlbeck, D.R.; Daniels, L.E. Investigation of rail corrugations on the Baltimore Metro. Wear 1991, 144, 197–210. [Google Scholar] [CrossRef]
- Trzepiecinski, T.; Lemu, H.G. Effect of Lubrication on Friction in Bending under Tension Test-Experimental and Numerical Approach. Metals 2020, 10, 544. [Google Scholar] [CrossRef]
- Campos, L.; Oden, J.; Kikuchi, N. A numerical analysis of a class of contact problems with friction in elastostatics. Comput. Methods Appl. Mech. Eng. 1982, 34, 821–845. [Google Scholar] [CrossRef]
- Migórski, S.; Gamorski, P. A new class of quasistatic frictional contact problems governed by a variational–hemivariational inequality. Nonlinear Anal. Real World Appl. 2019, 50, 583–602. [Google Scholar] [CrossRef]
- Sherbakov, S. Three-Dimensional Stress-Strain State of a Pipe with Corrosion Damage Under Complex Loading. Tribol. lubr. Lubr. 2011. [Google Scholar] [CrossRef]
- Sosnovskiy, L.; Bogdanovich, A.; Yelovoy, O.; Tyurin, S.; Komissarov, V.; Sherbakov, S. Methods and main results of Tribo-Fatigue tests. Int. J. Fatigue 2014, 66, 207–219. [Google Scholar] [CrossRef]
- Papaodysseus, C.; Koukoutsis, E.; Stavrakakis, G.; Halkias, C. Exact analysis of the finite precision error generation and propagation in the FAEST and the fast transversal algorithms: A general methodology for developing robust RLS schemes. Math. Comput. Simul. 1997, 44, 29–41. [Google Scholar] [CrossRef]
- Carayannis, G.; Manolakis, D.; Kalouptsidis, N. A fast sequential algorithm for least-squares filtering and prediction. IEEE Trans. Acoust. SpeechSignal Process. 1983, 31, 1394–1402. [Google Scholar] [CrossRef]
- Boutalis, Y.; Papaodysseus, C.; Koukoutsis, E. A New Multichannel Recursive Least Squares Algorithm for Very Robust and Efficient Adaptive Filtering. J. Algorithms 2000, 37, 283–308. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).