From Grammar Inference to Semantic Inference—An Evolutionary Approach




Abstract
1. Introduction
- Grammar Inference is able to infer only the syntactic structure, whilst, in many problems, there are additional restrictions on allowed structures [11,12] which can’t be described by Context-Free Grammars (CFGs). Hence, we also need to know the static semantics, or even the meaning of the structure (e.g., in the area of programming languages a program might be syntactically correct, but contains semantic errors such as undeclared identifiers). How can we extend Grammar Inference beyond discovering only the syntactic structure?
- The search space is enormous, even in the case for inferring regular and context-free languages [13], and it becomes substantially bigger for the context-sensitive languages (context-free languages with static semantics). How can we assure sufficient exploration and exploitation of the search space [14] for Semantic Inference? Note that the search space is too large for the exhaustive (brute-force) approach.
2. Related Work on Grammar Inference and Semantic Inference
2.1. Grammar Inference

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
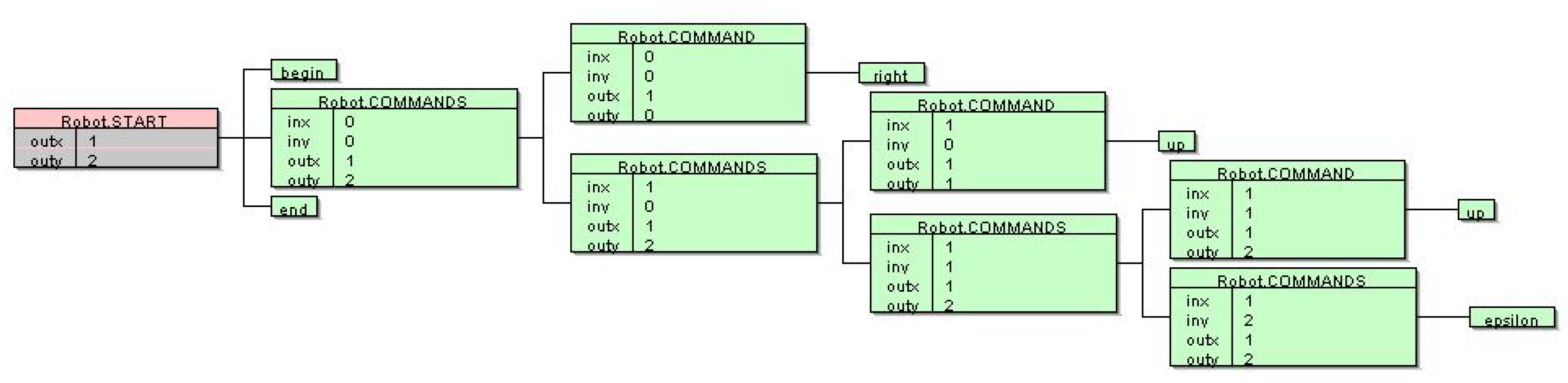{kind=link}
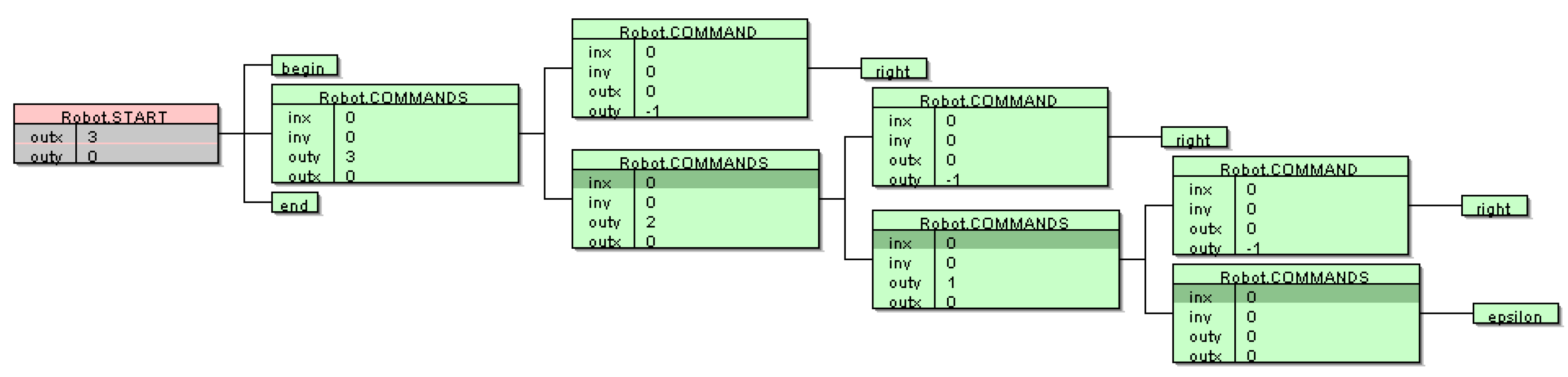{kind=link}
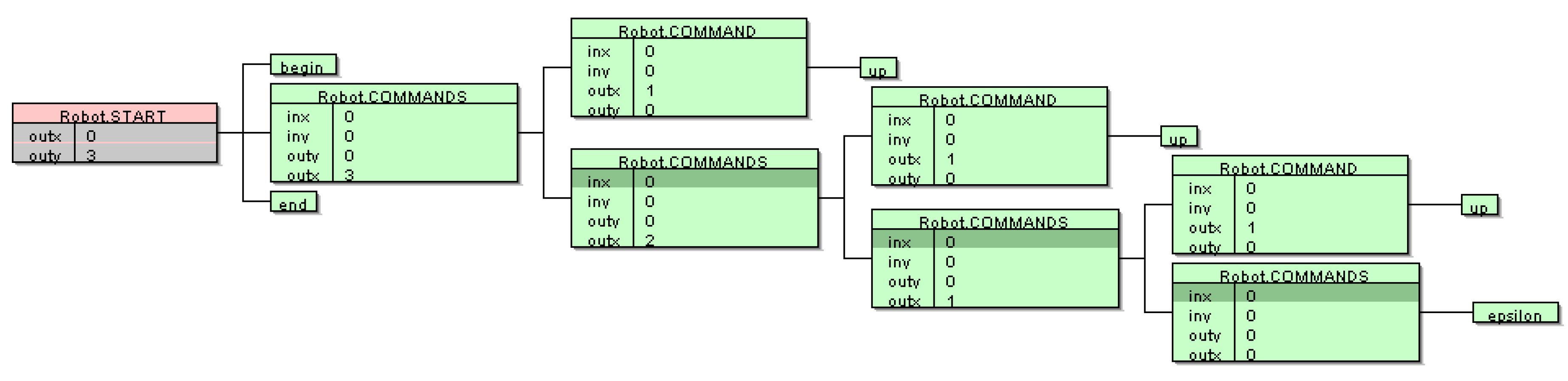{kind=link}
| 2. print 23 |
| 3. print a + 23 |
| 4. print a + b + c |
| 5. print a where a = 23 |
| 6. print 23 where b = 11 |
| 7. print 23 + c where c = 28 |
| 8. print 23 + 11 where c = 28 |
| 9. print a where a = 23; a = 28 |
| 10. print 28 where a = 23; b = 11 |
| 11. print 1 + 2 where b = 23; a = 5 |
| N2 → + N3 | ε |
| N3 → num N2 | id N2 |
| N4 → ; id = num N4 | ε |
2.2. Semantic Inference
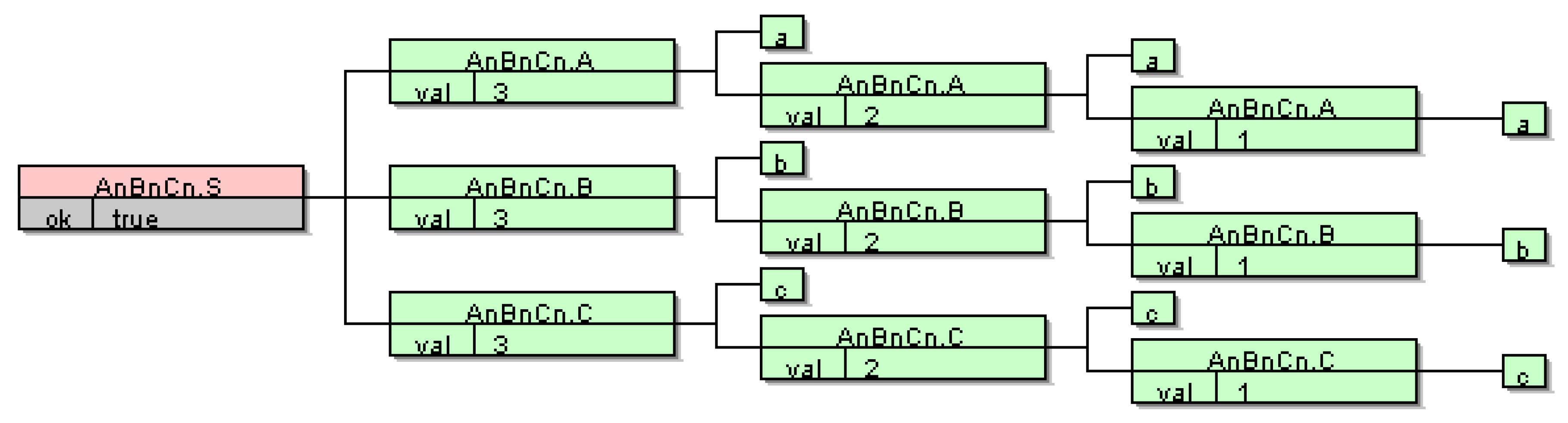
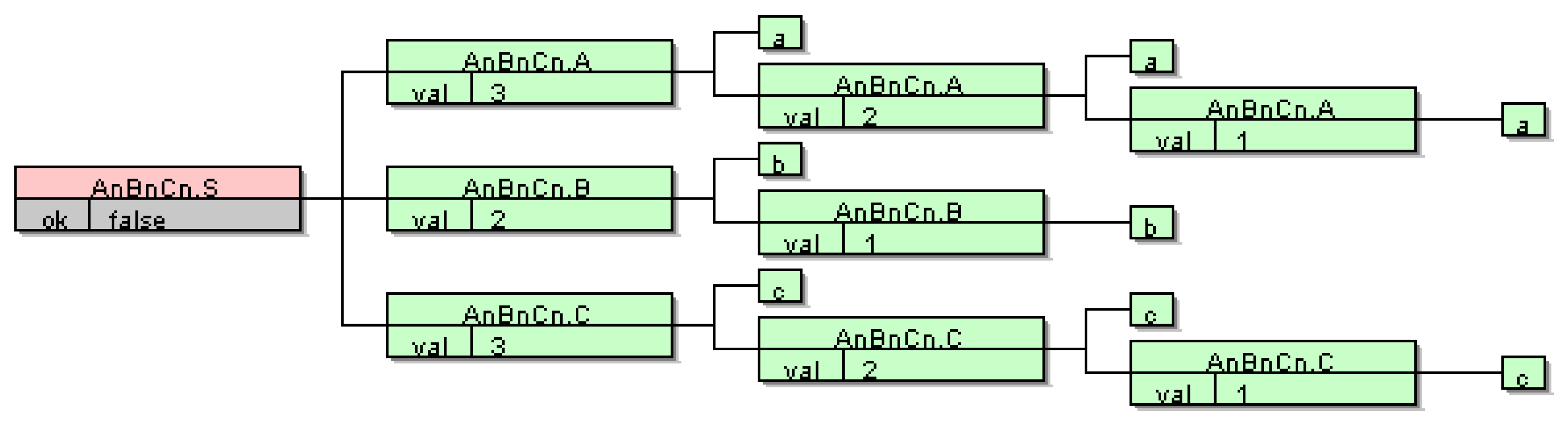
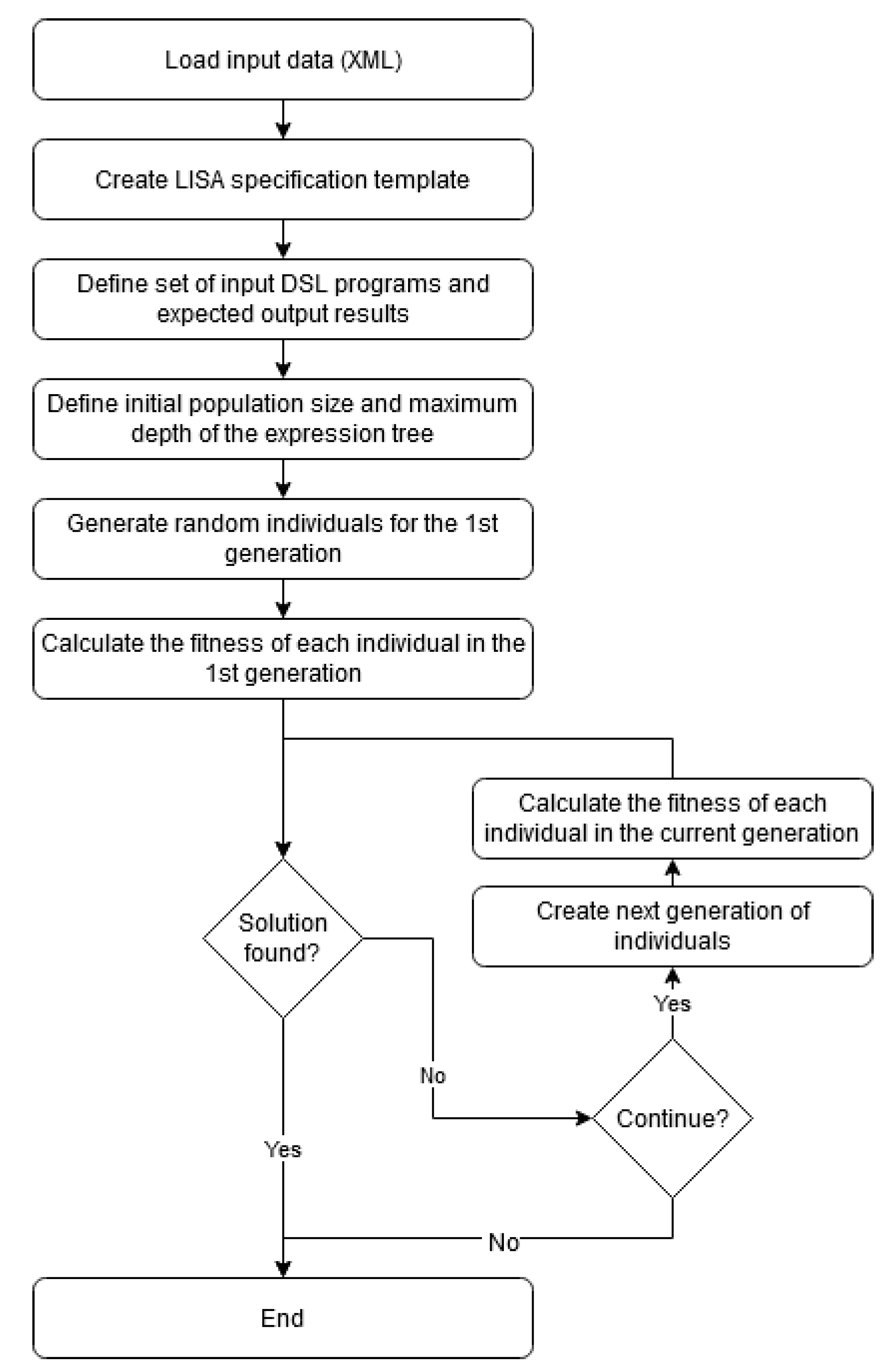
3. Semantic Inference with LISA
| parent1Probability = (parent1FitnessRatio ∗ (100 - mutationProbability)) / (parent1FitnessRatio + parent2FitnessRatio); |
| parent2Probability = (parent2FitnessRatio ∗ (100 - mutationProbability)) / (parent1FitnessRatio + parent2FitnessRatio); |
4. Experiments
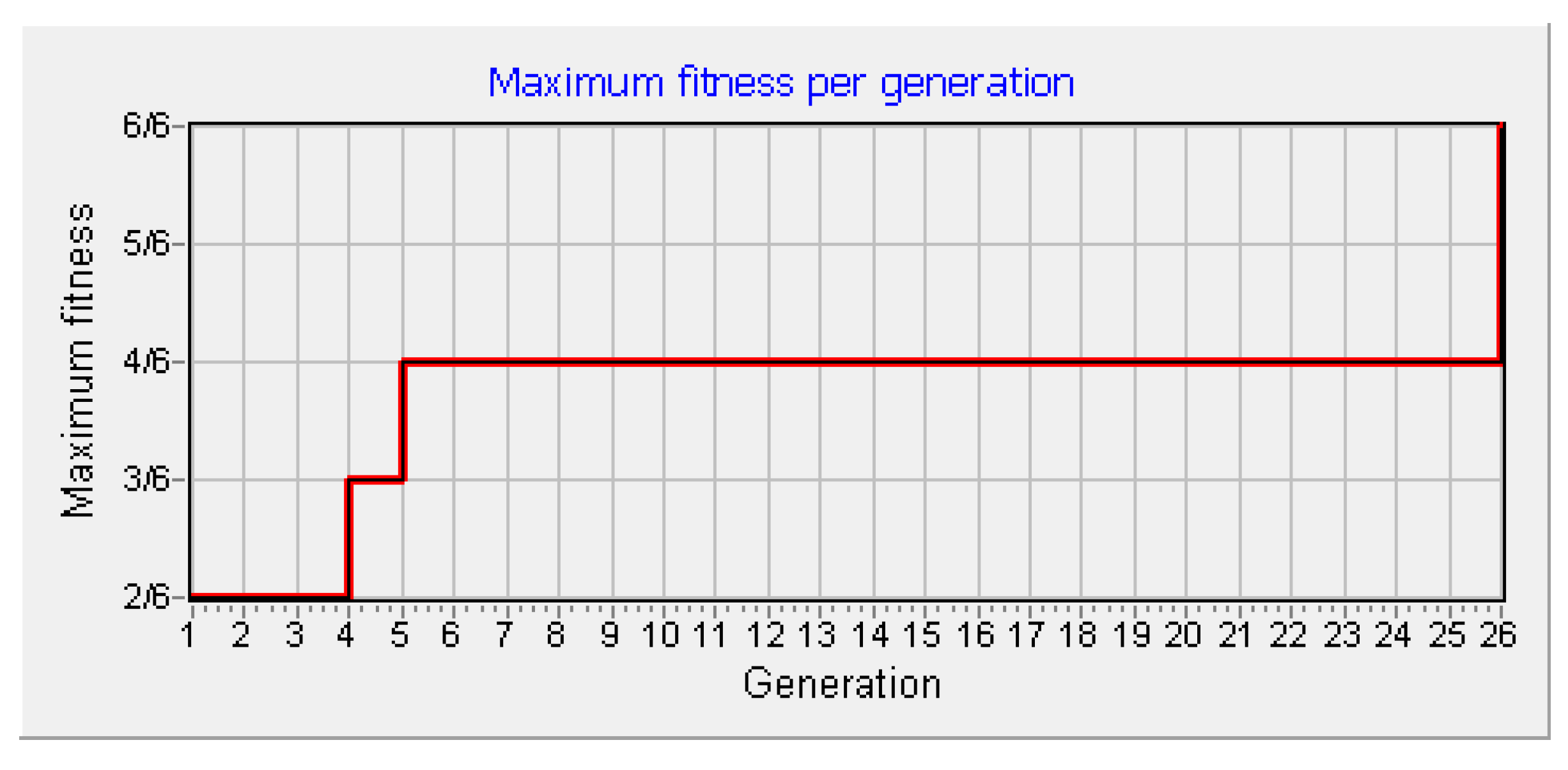
4.1. Example 1
4.2. Example 2
4.3. Example 3
| T = {START.outx, START.outy, COMMANDS.outx, COMMANDS.outy, COMMANDS.inx, COMMANDS.iny, COMMAND.outx, COMMAND.outy, COMMAND.inx, COMMAND.iny,COMMANDS[1].outx, COMMANDS[1].outy, COMMANDS[1].inx, COMMANDS[1].iny, 0, 1} |
5. Conclusions
- Few previous approaches were able to learn Attribute Grammars with synthesised attributes only. This limitation has been overcome in this paper, and we were able to learn Attribute Grammars with synthesised and inherited attributes. Consequently, few previous approaches inferred only S-attributed Attribute Grammars, whilst our approach inferred also L-attributed Attribute Grammars.
- The search space of all possible semantic equations is enormous and quantified in Section 3.
- We have shown that Genetic Programming can be used effectively to explore and exploit the search space solving the problem of Semantic Inference successfully.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- De la Higuera, C. A bibliographical study of grammatical inference. Pattern Recognit. 2005, 38, 1332–1348. [Google Scholar] [CrossRef]
- De la Higuera, C. Grammatical Inference: Learning Automata and Grammars; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Vidal, E.; Casacuberta, F.; García, P. Grammatical Inference and Automatic Speech Recognition. In Speech Recognition and Coding; Ayuso, A.J.R., Soler, J.M.L., Eds.; Springer: Berlin/Heidelberg, Germany, 1995; pp. 174–191. [Google Scholar]
- Sakakibara, Y. Grammatical Inference in Bioinformatics. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1051–1062. [Google Scholar] [CrossRef] [PubMed]
- López, V.F.; Aguilar, R.; Alonso, L.; Moreno, M.N.; Corchado, J.M. Grammatical inference with bioinformatics criteria. Neurocomputing 2012, 75, 88–97. [Google Scholar] [CrossRef]
- Stevenson, A.; Cordy, J.R. A survey of grammatical inference in software engineering. Sci. Comput. Program. 2014, 96, 444–459. [Google Scholar] [CrossRef]
- Moscato, P.; Cotta, C. A Gentle Introduction to Memetic Algorithms. In Handbook of Metaheuristics; Springer US: Boston, MA, USA, 2003; pp. 105–144. [Google Scholar]
- Hrnčič, D.; Mernik, M.; Bryant, B.R. Embedding DSLs into GPLs: A Grammatical Inference Approach. Inf. Technol. Control 2011, 40, 307–315. [Google Scholar] [CrossRef]
- Hrnčič, D.; Mernik, M.; Bryant, B.R.; Javed, F. A memetic grammar inference algorithm for language learning. Appl. Soft Comput. 2012, 12, 1006–1020. [Google Scholar] [CrossRef]
- Hrnčič, D.; Mernik, M.; Bryant, B.R. Improving Grammar Inference by a Memetic Algorithm. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2012, 42, 692–703. [Google Scholar] [CrossRef]
- Menendez, D.; Nagarakatte, S. Alive-Infer: Data-Driven Precondition Inference for Peephole Optimizations in LLVM. SIGPLAN Not. 2017, 52, 49–63. [Google Scholar] [CrossRef]
- Melo, L.T.C.; Ribeiro, R.G.; de Araújo, M.R.; Pereira, F.M.Q. Inference of Static Semantics for Incomplete C Programs. Proc. ACM Program. Lang. 2017, 2, 29. [Google Scholar] [CrossRef]
- Črepinšek, M.; Mernik, M.; Žumer, V. Extracting Grammar from Programs: Brute Force Approach. SIGPLAN Not. 2005, 40, 29–38. [Google Scholar] [CrossRef]
- Črepinšek, M.; Liu, S.H.; Mernik, M. Exploration and Exploitation in Evolutionary Algorithms: A Survey. ACM Comput. Surv. 2013, 45, 35:1–35:33. [Google Scholar] [CrossRef]
- Henriques, P.R.; Pereira, M.J.V.; Mernik, M.; Lenič, M.; Gray, J.; Wu, H. Automatic generation of language-based tools using the LISA system. IEE Proc. Softw. 2005, 152, 54–69. [Google Scholar] [CrossRef][Green Version]
- Wexler, K.; Culicover, P. Formal Principles of Language Acquisition; MIT Press: Cambridge, MA, USA, 1980. [Google Scholar]
- Fu, K. Syntactic Pattern Recognition and Applications; Prentice-Hall: Upper Saddle River, NJ, USA, 1982. [Google Scholar]
- Mernik, M.; Črepinšek, M.; Kosar, T.; Rebernak, D.; Žumer, V. Grammar-based systems: Definition and examples. Informatica 2004, 28, 245–255. [Google Scholar]
- Crespi-Reghizzi, S.; Melkanoff, M.A.; Lichten, L. The use of grammatical inference for designing programming languages. Commun. ACM 1973, 16, 83–90. [Google Scholar] [CrossRef]
- Oncina, J.; García, P. Inferring regular languages in polynomial update time. Pattern Recognit. Image Anal. 1992, 1, 49–61. [Google Scholar]
- Sakakibara, Y. Efficient learning of context-free grammars from positive structural examples. Inf. Comput. 1992, 97, 23–60. [Google Scholar] [CrossRef]
- Sakakibara, Y.; Muramatsu, H. Learning Context-Free Grammars from Partially Structured Examples. In Grammatical Inference: Algorithms and Applications, 5th International Colloquium, ICGI 2000, Lisbon, Portugal, 11–13 September 2000; Lecture Notes in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2000; Volume 1891, pp. 229–240. [Google Scholar]
- Mernik, M.; Heering, J.; Sloane, A.M. When and how to develop domain-specific languages. ACM Comput. Surv. 2005, 37, 316–344. [Google Scholar] [CrossRef]
- Kosar, T.; Bohra, S.; Mernik, M. Domain-Specific Languages: A Systematic Mapping Study. Inf. Softw. Technol. 2016, 71, 77–91. [Google Scholar] [CrossRef]
- Mernik, M.; Gerlič, G.; Žumer, V.; Bryant, B.R. Can a Parser Be Generated from Examples? In Proceedings of the 2003 ACM Symposium on Applied Computing, SAC’03, Melbourne, FL, USA, 9–12 March 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 1063–1067. [Google Scholar]
- Paakki, J. Attribute Grammar Paradigms—A High-Level Methodology in Language Implementation. ACM Comput. Surv. 1995, 27, 196–255. [Google Scholar] [CrossRef]
- Kelly, S.; Tolvanen, J.P. Domain-Specific Modeling: Enabling Full Code Generation; Wiley-IEEE Press: New York, NY, USA, 2007. [Google Scholar]
- Fuerst, L.; Mernik, M.; Mahnič, V. Graph Grammar Induction. Adv. Comput. 2020, 116, 133–181. [Google Scholar]
- Javed, F.; Mernik, M.; Gray, J.; Bryant, B.R. MARS: A metamodel recovery system using grammar inference. Inf. Softw. Technol. 2008, 50, 948–968. [Google Scholar] [CrossRef]
- Liu, Q.; Gray, J.G.; Mernik, M.; Bryant, B.R. Application of metamodel inference with large-scale metamodels. Int. J. Softw. Inform. 2012. [Google Scholar]
- Eiben, A.G.; Smith, J.E. Introduction to Evolutionary Computing; Springer: Heidelberg, Germany, 2015. [Google Scholar]
- O’Neill, M.; Ryan, C. Grammatical evolution. IEEE Trans. Evol. Comput. 2001, 5, 349–358. [Google Scholar] [CrossRef]
- Koza, J.R. Genetic Programming: On the Programming of Computers by Means of Natural Selection; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- De la Cruz Echeandía, M.; de la Puente, A.O.; Alfonseca, M. Attribute Grammar Evolution. In Artificial Intelligence and Knowledge Engineering Applications: A Bioinspired Approach; Mira, J., Álvarez, J.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 182–191. [Google Scholar]
- Ortega, A.; de la Cruz, M.; Alfonseca, M. Christiansen Grammar Evolution: Grammatical Evolution with Semantics. IEEE Trans. Evol. Comput. 2007, 11, 77–90. [Google Scholar] [CrossRef]
- Dulz, W.; Hofmann, S. Grammar-based Workload Modeling of Communication Systems. In Proceedings of the International Conference on Modeling Techniques and Tools for Computer Performance Evaluation, Torino, Italy, 13–15 February 1991; pp. 17–31. [Google Scholar]
- Starkie, B. Programming Spoken Dialogs Using Grammatical Inference. In AI 2001: Advances in Artificial Intelligence; Stumptner, M., Corbett, D., Brooks, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 449–460. [Google Scholar]
- Starkie, B. Inferring Attribute Grammars with Structured Data for Natural Language Processing. In Grammatical Inference: Algorithms and Applications; Adriaans, P., Fernau, H., van Zaanen, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 237–248. [Google Scholar]
- Imada, K.; Nakamura, K. Towards Machine Learning of Grammars and Compilers of Programming Languages. In Machine Learning and Knowledge Discovery in Databases; Daelemans, W., Goethals, B., Morik, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 98–112. [Google Scholar]
- Law, M.; Russo, A.; Bertino, E.; Broda, K.; Lobo, J. Representing and Learning Grammars in Answer Set Programming. In Proceedings of the 33th AAAI Conference on Artificial Intelligence (AAAi-19), Honolulu, HI, USA, 27 January–1 February 2019; pp. 229–240. [Google Scholar]
- Knuth, D.E. Semantics of context-free languages. Math. Syst. Theory 1968, 2, 127–145. [Google Scholar] [CrossRef]
- Muggleton, S.; de Raedt, L. Inductive Logic Programming: Theory and methods. J. Log. Program. 1994, 19–20, 629–679. [Google Scholar] [CrossRef]
- Besel, C.; Schlötterer, J.; Granitzer, M. Inferring Semantic Interest Profiles from Twitter Followees: Does Twitter Know Better than Your Friends? In Proceedings of the 31st Annual ACM Symposium on Applied Computing, SAC ’16, Pisa, Italy, 4–8 April 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1152–1157. [Google Scholar]
- Hosseini, M.B. Semantic Inference from Natural Language Privacy Policies and Android Code. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2018, Lake Buena Vista, FL, USA, 4–9 November 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 940–943. [Google Scholar]
- Wang, X.; Tang, X.; Qu, W.; Gu, M. Word sense disambiguation by semantic inference. In Proceedings of the 2017 International Conference on Behavioral, Economic, Socio-cultural Computing (BESC), Krakow, Poland, 16–18 October 2017; pp. 1–6. [Google Scholar]
- Yang, H.; Zhou, Y.; Zong, C. Bilingual Semantic Role Labeling Inference via Dual Decomposition. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2016, 15, 15. [Google Scholar] [CrossRef]
- Bebeshina-Clairet, N.; Lafourcade, M. Multilingual Knowledge Base Completion by Cross-lingual Semantic Relation Inference. In Proceedings of the 2019 Federated Conference on Computer Science and Information Systems (FedCSIS), Leipzig, Germany, 1–4 September 2019; pp. 249–253. [Google Scholar]
- Tejaswi, T.; Murali, G. Semantic inference method using ontologies. In Proceedings of the 2016 International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 21–22 October 2016; pp. 1–6. [Google Scholar]
- Qi, Y.; Zhu, T.; Ning, H. A Semantic-based Inference Control Algorithm for RDF Stores Privacy Protection. In Proceedings of the 2018 IEEE International Conference on Intelligence and Safety for Robotics (ISR), Shenyang, China, 24–27 August 2018; pp. 178–183. [Google Scholar]
- Zhang, L.; Zhang, S.; Shen, P.; Zhu, G.; Afaq Ali Shah, S.; Bennamoun, M. Relationship Detection Based on Object Semantic Inference and Attention Mechanisms. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, ICMR ’19, Ottawa, ON, Canada, 10–13 June 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 68–72. [Google Scholar]
- Zhang, W.; Zhou, S.; Yang, L.; Ou, L.; Xiao, Z. WiFiMap+: High-Level Indoor Semantic Inference With WiFi Human Activity and Environment. IEEE Trans. Veh. Technol. 2019, 68, 7890–7903. [Google Scholar] [CrossRef]
- Deransart, P.; Jourdan, M. (Eds.) Proceedings of the International Conference WAGA on Attribute Grammars and Their Applications; Springer: Berlin/Heidelberg, Germany, 1990. [Google Scholar]
- Alblas, H.; Melichar, B. (Eds.) Attribute Grammars, Applications and Systems. In Lecture Notes in Computer Science, Proceedings of the International Summer School SAGA, Prague, Czechoslovakia, 4–13 June 1991; Springer: Berlin/Heidelberg, Germany, 1991; Volume 545. [Google Scholar]
- Parigot, D.; Mernik, M. (Eds.) Second Workshop on Attribute Grammars and Their Applications WAGA’99; INRIA Rocquencourt: Amsterdam, The Netherlands, 1999. [Google Scholar]
- Mernik, M.; Žumer, V.; Lenič, M.; Avdičaušević, E. Implementation of Multiple Attribute Grammar Inheritance in the Tool LISA. SIGPLAN Not. 1999, 34, 68–75. [Google Scholar] [CrossRef]
- Mernik, M.; Lenič, M.; Avdičaušević, E.; Žumer, V. Multiple attribute grammar inheritance. Informatica 2000, 24, 319–328. [Google Scholar]
- Mernik, M.; Lenič, M.; Avdičaušević, E.; Žumer, V. Compiler/interpreter generator system LISA. In Proceedings of the 33rd Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2000; 10p. [Google Scholar]
- Ross, B.J. Logic-based genetic programming with definite clause translation grammars. New Gener. Comput. 2001, 19, 313–337. [Google Scholar] [CrossRef]
- Črepinšek, M.; Mernik, M.; Javed, F.; Bryant, B.R.; Sprague, A. Extracting Grammar from Programs: Evolutionary Approach. SIGPLAN Not. 2005, 40, 39–46. [Google Scholar] [CrossRef]
- Javed, F.; Bryant, B.R.; Črepinšek, M.; Mernik, M.; Sprague, A. Context-Free Grammar Induction Using Genetic Programming. In Proceedings of the 42nd Annual Southeast Regional Conference, ACM-SE 42, Huntsville, AL, USA, 2–3 April 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 404–405. [Google Scholar]
- Črepinšek, M.; Liu, S.H.; Mernik, M.; Ravber, M. Long Term Memory Assistance for Evolutionary Algorithms. Mathematics 2019, 7, 1129. [Google Scholar] [CrossRef]
- Karafotias, G.; Hoogendoorn, M.; Eiben, A.E. Parameter Control in Evolutionary Algorithms: Trends and Challenges. IEEE Trans. Evol. Comput. 2015, 19, 167–187. [Google Scholar] [CrossRef]
- Veček, N.; Mernik, M.; Filipič, B.; Črepinšek, M. Parameter tuning with Chess Rating System (CRS-Tuning) for meta-heuristic algorithms. Inf. Sci. 2016, 372, 446–469. [Google Scholar] [CrossRef]
- Mernik, M. An object-oriented approach to language compositions for software language engineering. J. Syst. Softw. 2013, 86, 2451–2464. [Google Scholar] [CrossRef]
- Aho, A.; Lam, M.; Sethi, R.; Ullman, J. Compilers: Principles, Techniques, and Tools; Pearson Education: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Dada, E.G.; Bassi, J.S.; Chiroma, H.; Abdulhamid, S.M.; Adetunmbi, A.O.; Ajibuwa, O.E. Machine learning for email spam filtering: Review, approaches and open research problems. Heliyon 2019, 5, e01802. [Google Scholar] [CrossRef]
- Alnabulsi, H.; Islam, M.R.; Mamun, Q. Detecting SQL injection attacks using SNORT IDS. In Proceedings of the Asia-Pacific World Congress on Computer Science and Engineering, Nadi, Fiji, 4–5 November 2014; pp. 1–7. [Google Scholar]
- Lampesberger, H. An Incremental Learner for Language-Based Anomaly Detection in XML. In Proceedings of the 2016 IEEE Security and Privacy Workshops (SPW), San Jose, CA, USA, 23–25 May 2016; pp. 156–170. [Google Scholar]
- Martínez-Santiago, F.; Díaz-Galiano, M.; Ureña-López, L.; Mitkov, R. A semantic grammar for beginning communicators. Knowl.-Based Syst. 2015, 86, 158–172. [Google Scholar] [CrossRef]








| Attribute | Operands | Operators | P(0) | P(1) | P(2) | SumP |
|---|---|---|---|---|---|---|
| P1:S.ok | 4 | 3 | 4 | 48 | 8064 | 8116 |
| P2:A.val | 2 | 1 | 2 | 4 | 32 | 38 |
| P3:A.val | 1 | 1 | 1 | 1 | 3 | 5 |
| P4:B.val | 2 | 1 | 2 | 4 | 32 | 38 |
| P5:B.val | 1 | 1 | 1 | 1 | 3 | 5 |
| P6:C.val | 2 | 1 | 2 | 4 | 32 | 38 |
| P7:C.val | 1 | 1 | 1 | 1 | 3 | 5 |
| SearchSpace | 55.667.644.000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kovačević, Ž.; Mernik, M.; Ravber, M.; Črepinšek, M. From Grammar Inference to Semantic Inference—An Evolutionary Approach. Mathematics 2020, 8, 816. https://doi.org/10.3390/math8050816
Kovačević Ž, Mernik M, Ravber M, Črepinšek M. From Grammar Inference to Semantic Inference—An Evolutionary Approach. Mathematics. 2020; 8(5):816. https://doi.org/10.3390/math8050816
Chicago/Turabian StyleKovačević, Željko, Marjan Mernik, Miha Ravber, and Matej Črepinšek. 2020. "From Grammar Inference to Semantic Inference—An Evolutionary Approach" Mathematics 8, no. 5: 816. https://doi.org/10.3390/math8050816
APA StyleKovačević, Ž., Mernik, M., Ravber, M., & Črepinšek, M. (2020). From Grammar Inference to Semantic Inference—An Evolutionary Approach. Mathematics, 8(5), 816. https://doi.org/10.3390/math8050816