Abstract
Numerical inverse Z-transformation (NIZT) methods have been efficiently used in engineering practice for a long time. In this paper, we compare the abilities of the most widely used NIZT methods, and propose a new variant of a classic NIZT method based on contour integral approximation, which is efficient when the point of interest (at which the value of the function is needed) is smaller than the order of the NIZT method. We also introduce a vastly different NIZT method based on concentrated matrix geometric (CMG) distributions that tackles the limitations of many of the classic methods when the point of interest is larger than the order of the NIZT method.
1. Introduction
Z-transformation is one of the most frequently used non-linear transformations for describing discrete time series [1]. In several engineering and applied mathematical fields, non-linear transformations provide a compact description of the system behavior. Many practically important operations, e.g., discrete convolution, are much easier to handle in Z-transform domain, which makes the use of Z-transform domain system description widespread in many fields. While a lot of important characteristics (e.g., poles, frequency response, initial/final values, etc.) can be obtained directly from Z-transform domain description, there are plenty of practically important cases where explicit time domain values are needed. In this case, inverse Z-transformation (IZT) must be performed.
In some special cases, symbolic IZT is feasible, but in a wide range of practically important cases numerical IZT (NIZT) is required to compute the time domain values based on the Z-transform domain description. This paper focuses on the problem of NIZT.
Since NIZT has been widely applied in practice for a long time, its literature is rather rich. In this paper, we consider only the most efficient methods of the recent literature [2]. These methods are introduced in the subsequent discussions and are used also for numerical comparison.
Section 2 is devoted to the general setup of Z-transformation. Section 3 gives a brief review of general methods in the literature. From among the few NIZT methods available in the literature, one stands out, described by several authors independently [2,3,4]. We will refer to this method as the CIR method, and it is described in Section 4 along with an interpretation based on Contour Integral approximation starting from the positive Real axis. Section 5 provides a variant of this method with the starting point of the Contour Integral Shifted, referred to as the CIS method. Section 6 provides an entirely new method, referred to as the CMG method, based on Concentrated Matrix Geometric (CMG) functions with the necessary background. Section 7 contains numerical comparison of the various NIZT methods. Section 8 concludes the paper.
2. The Z-Transform and Its Inverse
Let be a series with countably many elements. The (unilateral) Z-transform of is defined as
where is the Z-transform of .
The inverse transform problem is to find the T-th element of , i.e., based on . This paper focuses on the case when symbolic inverse Z-transformation is available and NIZT is required to find an approximate value of based on .
The region of convergence (ROC) for the summation in (1) is always of the form , possibly including some points of the boundary . (1) is absolute convergent on , divergent on , and on the boundary can be either absolute convergent, convergent or divergent. The region may also be empty (), or the entire complex plane (). The real constant c is known as the limit of absolute convergence. In case c is finite, the function may extend analytically to a domain larger than the region of convergence (e.g., for , (1) is convergent for , but extends analytically to ).
The inverse at point T can be obtained from the contour integral [1]
where C is a counterclockwise closed path encircling the origin and entirely in the region of convergence, and i is the complex unit.
The Z-transform has a natural scaling property:
which allows any NIZT method to be applied to instead of to approximate (and then by multiplying by ). In some cases, the scaling with a has special analytical interpretation; we provide such interpretation for contour integral methods. In the numerical section we study the effect of a for all the methods included in the present paper.
In this work, we assume that is real for any non-negative integer t. This assumption is well-suited for most practical applications and implies (where denotes the complex conjugate of z). Consequently, it is sufficient to evaluate only at one of each complex conjugate pair.
3. General Inverse Z-Transformation Methods
In this section, we provide a short overview of various NIZT methods proposed in the literature that do not use the contour integral in (2) for the inverse Z-transformation. The contour integral-based NIZT approach of [2,3,4] will be discussed separately in Section 4.
3.1. Inverse Transformation Based on Moments
In [5], Tagliani proposes a method for NIZT that requires the availability of a finite number of the transform’s derivatives. The derivatives are used to calculate the moments of , and based on these moments an approximating “analytical form” is calculated. Consequently, while the author presents it as an inverse Z-transform method, it is more of a moment fitting algorithm. The benefit of Tagliani’s approach is that it can be used as long as the moments of are obtainable even if only a functional equation is available for the Z-transform. However, the performance of the method is significantly worse than numerical integration-based methods both in terms of precision and in computation time.
3.2. Inverse Transformation Based on Orthogonal Decomposition
Rajković et al. propose an inversion method in [6] that approximates with
where
Parameter q can be chosen freely, but should be slightly smaller than 1 (in the numerical experiments of [6] and are used). The coefficients are calculated as
where
The coefficients are calculated as
The above parameters will minimize for the given set of series. The idea behind the method is that the parameters are chosen such that is a set of orthogonal series, i.e., , where is the Kronecker-delta ( if and otherwise) and is a function of q. It is the consequence of this orthogonality that the values calculated as above are optimal (in 2-norm).
3.3. Inverse Transformation Based on a Linear System of Equations
The series can also be approximated based on a simple truncation of the Z-transform presented by Merrikh–Bayat in [4]. From the definition of the Z-transform we have
By using this approximation in the set of points chosen from the ROC we obtain
If , the above equation has a unique solution (assuming that the matrix is non-singular, which is true if ). The issue with the case is that it leads to an ill-conditioned problem, thus Merrikh–Bayat proposes to choose then minimize , where , , and
Minimization of is a least squares problem, which is done using QR decomposition or singular value decomposition in [4]. These have a computational cost of ( when ) for an matrix, thus this method is computationally expensive compared to numerical integration-based methods.
The error in (4) is small when is rapidly decaying and N is large enough so that captures most of the significant values in the sequence. Accordingly, numerical experiments show that the method gives best results for rapidly decaying sequences when N is sufficiently large; however, increasing N further does not seem to improve the error. Overall, the non-vanishing error renders the applicability of this method limited. This is addressed further in Section 7.
4. Contour Integral-Based Inverse Z-Transformation Methods
Equation (2) can be rewritten as
where ℑ is the complex unit. Equation (6) corresponds to the case when C is the circle of radius a in (2). a is actually equivalent to the scaling parameter in (3), as shown in Remark 4.
Contour integral-based methods, in general, approximate integral (5) with the finite sum
where define a properly chosen partition of and N is the order of the approximation.
This method is described in [3,4,7] in a slightly different manner independently from each other. In theory any partition could be chosen, but the above papers use
exclusively. Since the ’s are equidistant with , (6) can be further simplified as
where
The parameters are referred to as nodes in the rest of the paper. Choosing the nodes according to (9) has several consequences:
- Since the s consist of complex conjugate pairs (along with real numbers 1 (and also for even N)), approximation (8) is guaranteed to be real.
- In case one of the values coincides with a pole of , (8) cannot be evaluated (even if they are close, there is numerical instability). A typical example is when has a pole at 1 and .
- Selecting a to be larger than the limit of absolute convergence c guarantees that (8) avoids all poles of . That said, selecting a too large may also cause issues: depending on the function g (and ) evaluating with sufficient precision might be difficult; also, the large factor may cause numerical instability if there are cancellations in the sum in (8). The choice of a that provides the most accurate estimate for is highly dependent on g (and ) and can be difficult to determine in general.
- Due to complex conjugate pairs, the actual number of evaluations of to compute (8) is . However, we stick with N in the notation as N is in general a better indicator for the properties of the approximation.
4.1. FFT-Based Implementation
Calculating for with a naive approach has computational cost. This can be reduced, however, by realizing that (8) has the form of an inverse discrete Fourier transform (IDFT). The IDFT of the sequence is with
thus is the IDFT of .
The IDFT of the sequence can be calculated using fast Fourier transform (FFT) algorithms, which have computational cost. The first FFT algorithm was presented by Cooley and Tukey in [8]. Its most commonly used radix-2 version requires that . Efficient implementations of the radix-2 Cooley-Tukey algorithm are available in most major programming languages (see, e.g., [9]). There are multiple other FFT methods (e.g., Rader’s method, the prime-factor algorithm [10], Bluestein’s algorithm [11], etc.). Some of these can calculate the IDFT in time even for prime N; however, in general, choosing is the most efficient.
4.2. Interpretation Using Approximate Dirac function
This section provides a different interpretation of the approximating function . Substituting (1) into (8) gives
where
(10) tells us that is a convolution of the original with the function ; will approximate g well if is close to the function (which is defined to be 1 at 0 and 0 at every other integer).
At integer points simplifies to
thus , and the closest non-zero values are at . As , converges to at integer points.
(10) and (12) also ensure that is N-periodic except for the exponential factor introduced by a, i.e.,
This periodic behavior indicates that for non-periodic functions the approximation might be poor.
The error of the approximation is
Remarks about (14):
- As long as , the first sum vanishes, since for .
- (15) can be intuitively understood as cutting the sequence into sections of length N, shifting them over the same interval and summing them, see Figure 1. The first section () corresponds to values of the original function over the interval , while the rest corresponds to the error. One consequence of (15) is that for non-decaying or slowly decaying sequences, selecting is necessary to ensure fast decay of the error.
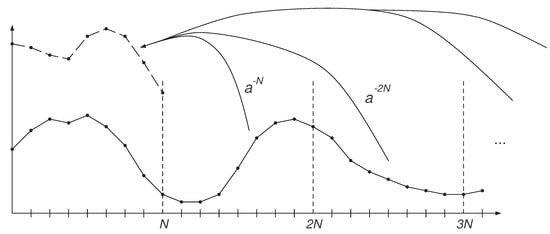 Figure 1. Sections shifted and summed according to (15) when .
Figure 1. Sections shifted and summed according to (15) when . - If , then the first sum in (15) is magnified and the second sum is diminished. This is particularly useful when , since in that case the first sum vanishes and the second sum can be diminished arbitrarily (at the cost of loss of precision, more on this later).
- If , the first sum is diminished, and the second sum is magnified.
- If , the first sum in (15) does not vanish, and is magnified when choosing . However, choosing magnifies the second sum in (15) instead; altogether, this results in a non-vanishing error regardless of the choice of a. Consequently, the classic method (or any contour integral-based method) has significant approximation error when , as shown by the numerical results in Section 7.
- When , according to (12) the second sum has positive terms only, so there are no cancellations. On the other hand, the approximation preserves nonnegativity, which might be a relevant property in certain applications.
- If has positive and negative values alternating, then there can be cancellations according to (15) which reduce the corresponding error.
5. Shifting the Nodes of the CIR Method
In this section, we present a variant of the CIR method, referred to as CIS method, where the nodes are shifted by a half period compared to (7), i.e., we propose to use
in (6) instead of (7). Figure 2 and Figure 3 display the positioning of the nodes for the CIR and the nodes for the CIS methods for even and odd values of N.
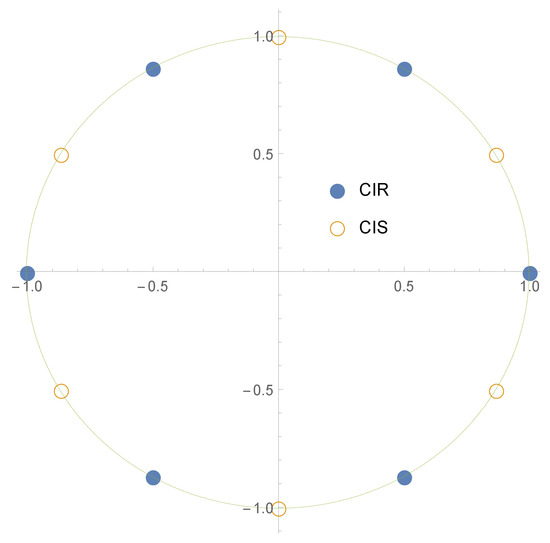
Figure 2.
Nodes of the CIR and CIS NIZT methods for in the complex plane.
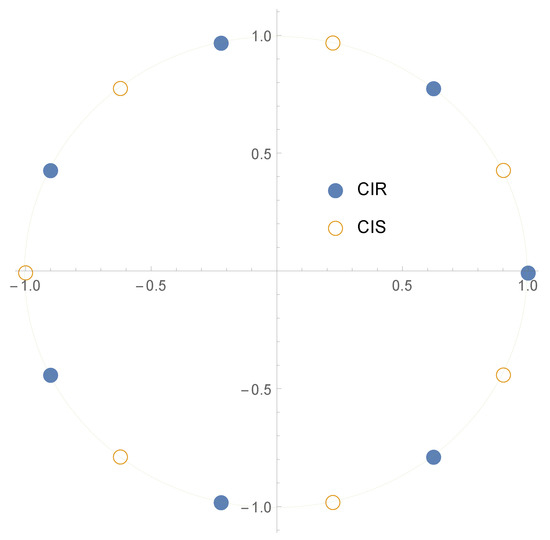
Figure 3.
Nodes of the CIR and CIS NIZT methods for in the complex plane.
Theorem 1.
Applying the nodes partition in the contour integral-based NIZT according to (8), results in the NIZT procedure
whose error is
where
As , converges to at integer points.
Proof.
Remarks about (18):
- , and the closest non-zero values are at , which are negative.
- As long as , the first sum vanishes, since for .
- If , then the first sum is magnified, and the second sum is diminished. This is particularly useful when , since in that case the first sum vanishes, and the second sum can be diminished arbitrarily.
- If , the first sum is diminished, and the second sum is magnified.
- When , (22) has alternating terms, so there are cancellations in the second sum, reducing the corresponding error. This is particularly useful when has a pole at c, since the values do not include a after the node shift, so (17) can still be evaluated with , and the error from the second sum will be smaller due to cancellations. On the other hand, unlike for CIR, the approximation does not necessarily preserve nonnegativity.
- If is alternating, then there are no cancellations in (22).
- Due to complex conjugate pairs, the actual number of evaluations of necessary to compute (17) is . However, just like for CIR, we stick with N as the notation.
6. Concentrated Matrix Geometric Distribution-Based Inverse Transformation
As we have seen in Remark 5 of (14), contour integral-based approximation methods are generally ill-suited to approximate when the node number is smaller than T, i.e., . If increasing N further is not feasible (e.g., because the computational cost of evaluating N times gets too large, or due to the precision loss of the procedure with the given floating point number representation), then a different NIZT procedure is needed.
In this section, we propose an approach for NIZT based on concentrated matrix geometric distributions, which we thus call CMG method and is the application of the CME (concentrated matrix exponential) method [12] for discrete time. The CME method is a numerical inverse Laplace transformation (NILT) procedure that uses the Abate–Whitt framework [13]. In the following, we first introduce the Abate–Whitt framework, then we present the CME method, finally we show how it can be applied to discrete time to obtain the proposed CMG method.
6.1. Abate–Whitt Framework for Numerical Inverse Laplace Transformation
The Laplace-transform of a function is defined as
The inverse transform problem is to find an approximate value of function h at point T (i.e., ) based on . The Abate–Whitt framework uses the following form for this approximation:
This approximation has a simple interpretation based on the reformulation
where
If was the Dirac impulse function at point T, then the Laplace inversion would be perfect, but depending on the weights and nodes , the function only approximates the Dirac impulse function with a given accuracy. There are multiple different types of functions that can be used for the approximation [12].
6.2. CME Method
In the CME method the probability density function (pdf) of a matrix exponential distribution is chosen as the function. The class of matrix exponential (ME) distributions of order N contains positive random variables with pdf of the form
where is a real row vector of length N, A is a real matrix of size , and is a column vector of ones of size N [14]. To ensure , and A are such that and the eigenvalues of A have negative real part.
Nonnegativity of does not follow from (25), but some ) pairs result in functions that are non-negative for [15]. When A is diagonalizable with spectral decomposition where are the eigenvalues, are the right eigenvectors and are the left eigenvectors of A for , then can be written as
with and . Comparing (26) and (24) shows that ME distributions with diagonalizable matrix A can be used in the place of to obtain an ILT method of the Abate–Whitt framework.
As mentioned before, the primary task when using the Abate–Whitt framework is to approximate the Dirac impulse with the function as closely as possible. The squared coefficient of variation (SCV) measures how concentrated a non-negative normalized function on is, and it is a good indicator of the quality of the approximation. The SCV of f can be calculated as
Function f with is the Dirac function and the smaller is, the better f approximates the Dirac function. The parameters of CME distributions with low SCV have been calculated for up to order 1000 [15] and can be accessed at [16].
The CME method has several advantages compared to other NILT methods [12]. It is more stable numerically, provides smooth, over- and under-shooting free approximation even for discontinuous functions and, contrary to other methods of the family, its precision gradually improves when increasing its order (N). The application of the CME method for NIZT is discussed in the next section.
6.3. CMG Method
A discrete counterpart of the CME method is formulated in the following theorem.
Theorem 2.
For a discrete function , defining the continuous function
and applying the CME inverse Laplace transformation method at point T with weights and nodes , results in the NIZT procedure
where
Proof.
In general, the interpretation of the CMG method is similar to the one of the CME method for NILT in that the approximation is essentially based on a discrete approximation of the Dirac function. The main advantage of this method compared to many other NIZT methods discussed above is that the error of CMG method remains small also when .
The parameter a affects the “shape” of the discrete approximation of the Dirac function, such that for , the contribution of the terms to the error of is magnified for and diminished for , while for , it is the other way around. The effect of a on the accuracy of is examined in Section 7.
7. Numerical Examples
To evaluate the numerical properties of the above listed NIZT methods we use a collection of test functions according to Table 1. This set of functions exhibits a wide range of behaviors. For each function, Table 1 lists the name, the t domain form, , the z domain form, , and the limit of absolute convergence, c.

Table 1.
Set of test functions.
We check the behavior of the NIZT methods by evaluating the difference of the values computed from with the ones computed from () with different choices of the order, the largest evaluated point and the scaling factor (, and a). Apart from the error in the approximation, we also keep track of the precision loss (number of digits lost due to round-off error) during the calculation of . The computations were carried out using Wolfram Mathematica. The precision of the applied arithmetic was high enough (200 digits) to dominate the precision loss.
7.1. Numerical Properties When
When we are interested in the cases with , we use the following error measure based on infinity norm over an interval :
is the largest point we are interested in, i.e., we assume in this subsection.
7.1.1. General Comparison of the NIZT Methods
For this comparison, we included the NIZT methods from the previous sections which provide the best results. Ort1 and Ort2 refer to the method presented in Section 3.2 and [6] (using the suggested and parameters), based on orthogonal functions. MB refers to the method in Section 3.3, based on matrix pseudoinverse calculation.
Table 2 compares the error of all methods for the list of functions in Table 1 for and . In the table,“∼0” means practical zero, a value smaller than , “p.inf.” stands for practical infinity, denoting errors larger than , while “n/a” means not applicable due to a pole of which is evaluated by the given NIZT method (e.g., the CIR method with fails for functions with a pole at 1). All calculations related to Table 2 were carried out using high precision (200 digits) floating point arithmetic.
Table 2.
Errors for various test functions ().
According to Remark 4 at the end of Section 4 (and Remark 5 at the end of Section 5), as long as , the accuracy of the contour integral-based methods CIR and CIS improves as a is increased, and this also helps avoiding the pole at 1 for the CIR method. Table 3 displays this effect by setting instead of .
Table 3.
Errors for various test functions ().
Based on Table 2 and Table 3, we conclude that the Ort1 method gives the most precise results, the CIR, CIS give precise results when a is sufficiently large, the Ort2 and MB methods are unreliable, and CMG is relatively reliable for (although the error is not as small as for CIR, CIS and Ort1), but unreliable for . Altogether, one might have the impression that Ort1 is the best method; however, we have not yet examined other important questions like precision loss or running time. In the next subsection, precision loss is examined along with a more detailed analysis of the role of a.
7.1.2. Precision Loss and the Effect of a
For a more detailed view on the performance of the methods CIR, CIS, Ort1, and CMG, we investigate their accuracy as a function of parameter a.
Table 4 contains the error and precision loss (p.l., in digits, calculated using Wolfram Mathematica) for the Polynomial() function with , and a taking the values .
Table 4.
The error and precision loss for Polynomial() function, .
For contour integral methods CIR and CIS, as long as , setting a to a larger value will diminish the error in the second term of (14) and (18), while the first term cancels out entirely.
For , the approximations in Table 4 are poor. This is because for , the error in the tail is magnified. If is rapidly decaying, then the error introduced by is small, but or are still better choices.
For , the “n/a” values for the CIR method are due to the pole of the function at 1. This is where the CIS method has an advantage: the shifted nodes avoid the pole when , so it gives a meaningful result.
For , the error decreases rapidly for the contour integral methods CIR and CIS as the error in the tail is diminished, at the cost of increased precision loss. Interestingly, the precision loss is of similar order as the error. (This is not necessarily the case in general, but the precision loss does seem to increase rapidly with a in general.)
The error for the CIS method is slightly smaller than for the CIR due to cancellations (see Remark 6 after (18)), but the difference is practically negligible.
The Ort1 method, while gives the lowest error, suffers from huge precision losses. Notably, for any calculations with precision smaller than 142 digits, Ort1 would give meaningless results due to precision loss. The precision loss is inherent to the Ort1 method due to the highly fluctuating orthogonal functions involved. Overall, we recommend avoiding the use of the Ort1 method due to its unpredictable high precision loss, and instead we recommend using either CIR or CIS when , with a set to as large as possible, depending on the precision loss tolerated.
Interestingly, with the Polynomial() function the CMG method works best when setting . An intuitive explanation of this property is as follows. For the CMG method, enlarges the errors that are caused by the non-zero values for and diminishes errors that are caused by the non-zero values for , and has the opposite effect. Since Polynomial() is a rather flat function the effect of enlarging the error is more dominant for both and . This property might slightly change for steeper functions, but, in general, we recommend using for the CMG method. We also note that the CMG method involves practically no loss of precision, so it can be used efficiently even with standard precision floating point arithmetic.
Table 5 investigates the error and the precision loss for various Z-transform functions using the CIR, CIS and Ort1 methods with parameters . We note that the CMG method fails due to .
Table 5.
Error and precision loss for various test functions ().
From Table 5, we conclude that the precision loss heavily depends on the function. As a result, high precision calculations with precision loss check is recommended for NIZT with the CIR, CIS and Ort1 methods. However, with high precision calculations, the precision loss remains tolerable for CIR and CIS.
7.2. Numerical Properties of NIZT Methods When
Finally, we examine the case when . This case is relevant when sampling of the Z-transform is costly, but we still need to approximate for large values of T.
7.2.1. Failure of Contour Integral Methods
To start off, we display the remarks at the end of Section 4.2 in practice. Table 6 shows the result of applying the CIR approximation method to the z-transform of the Poisson(1) distribution with order and various choices of a, compared with the actual values of the Poisson distribution.
Table 6.
Order 4 CIR method approximation of the Poisson(1) distribution.
For , the approximation is relatively accurate up to , but there is a sharp change in the behavior at : the approximation is periodic with a period of N, rendering the approximation values for useless (see also Figure 1). For , the approximation is even more accurate up to , but the error is magnified for (due to the scaling by in accordance with (13), e.g., in this case). For , the error for the terms is diminished, but the approximation up to is much less accurate. Altogether, the CIR method cannot be used to obtain an approximation suitable for both and . The CIS method suffers from the same issues.
7.2.2. Comparing The Error of NIZT Methods When
Since the error of the cases when has been considered in Section 7.1, in this section we define the error as
Table 7 contains the error of each method for various functions. The parameters are and a either 1 or . In this table, “p.inf.” marks elements larger than . We note that the MB method is not applicable with these parameters, since the pseudoinverse calculation is only applicable when .
Table 7.
Errors for various test functions ().
Based on Table 7, we conclude that as long as , the error of the CIR and CIS methods ((14) and (18)) is large either in first or the second term depending on whether or , and the Ort1 and Ort2 methods are also unreliable. Only the CMG method gives meaningful results for the case when . As for the value of a, we recommend using 1 as generally that seems to give a reliably low error.
Table 8 contains the errors with parameters and . At this parameter setting, all other methods except CMG fail, while CMG gives a reasonably good approximation.
Table 8.
Errors for various test functions ().
8. Conclusions
In this paper, we collected many of the NIZT methods from the literature and presented two new methods. One of them, the CIS method, is a variant of the contour integral-based CIR method and the other one, the CMG method, is inherited from numerical inverse Laplace transformation.
A wide numerical investigation on these NIZT methods indicated that different methods are accurate when the order of the method is higher than the required parameter () and when it is lower (). In the first case, the CIR and the CIS methods are the most reliable (moderate error and tolerable precision loss) and they perform rather similarly. Their behavior differs only when one of the methods must evaluate the transform function near one of its poles. In the second case, when , the CMG method outperforms all other methods in both accuracy and precision loss. The rest of the methods perform poorly, in general, except the Ort1 method, which gives more accurate results than the CIR and the CIS methods if appropriately high precision is used, but its numerical instability often results in larger precision loss than the applied high precision arithmetic.
While the optimal method to choose may depend on multiple factors (e.g., tolerated precision loss, computational time, tolerated error, etc.) as a rule of thumb for we recommend to use the CIR and CIS methods, and for the CMG method. The Mathematica implementation of the considered NIZT methods and some results of the numerical evaluation are available at http://webspn.hit.bme.hu/~telek/tools/nizt.zip.
Author Contributions
The contribution is equally shared by the authors. All authors have read and agreed to the published version of the manuscript.
Funding
This work is partially supported by the OTKA K-123914 and the TUDFO/51757/2019-ITM projects.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Oppenheim, A.V.; Schafer, R.W. Discrete-Time Signal Processing, 3rd ed.; Pearson: London, UK, 2009. [Google Scholar]
- Abate, J.; Choudhury, G.L.; Whitt, W. An Introduction to Numerical Transform Inversion and Its Application to Probability Models. In Computational Probability; Grassmann, W.K., Ed.; Springer US: Boston, MA, USA, 2000; pp. 257–323. [Google Scholar] [CrossRef]
- Mills, P.L. Numerical inversion of z-transforms with application to polymerization kinetics. Comput. Chem. 1987, 11, 137–151. [Google Scholar] [CrossRef]
- Merrikh-Bayat, F. Two Methods for Numerical Inversion of the Z-Transform. arXiv 2014, arXiv:1409.1727. [Google Scholar]
- Tagliani, A. Inverse Z transform and moment problem. Probab. Eng. Inf. Sci. 2000, 14, 393–404. [Google Scholar] [CrossRef]
- Rajković, P.M.; Stanković, M.S.; Marinković, S.D. A method for numerical evaluating of inverse Z-transform. Facta Univ.-Ser. Mech. Autom. Control. Robot. 2004, 4, 133–139. [Google Scholar]
- Abate, J.; Whitt, W. Numerical inversion of probability generating functions. Oper. Res. Lett. 1992, 12, 245–251. [Google Scholar] [CrossRef]
- Cooley, J.W.; Tukey, J.W. An algorithm for the machine calculation of complex Fourier series. Math. Comput. 1965, 19, 297–301. [Google Scholar] [CrossRef]
- Rosetta Code. Fast Fourier Transform. 2019. Available online: https://rosettacode.org/wiki/Fast_Fourier_transform (accessed on 1 August 2019).
- Duhamel, P.; Vetterli, M. Fast Fourier transforms: A tutorial review and a state of the art. Signal Process. 1990, 19, 259–299. [Google Scholar] [CrossRef]
- Bluestein, L. A linear filtering approach to the computation of discrete Fourier transform. IEEE Trans. Audio Electroacoust. 1970, 18, 451–455. [Google Scholar] [CrossRef]
- Horváth, G.; Horváth, I.; Almousa, S.A.D.; Telek, M. Numerical Inverse Laplace Transformation by concentrated matrix exponential distributions. Perform. Eval. 2020, 137, 102067. [Google Scholar] [CrossRef]
- Abate, J.; Whitt, W. A Unified Framework for Numerically Inverting Laplace Transforms. INFORMS J. Comput. 2006, 18, 408–421. [Google Scholar] [CrossRef]
- Asmussen, S.; Bladt, M. Renewal Theory and Queueing Algorithms for Matrix-Exponential Distributions. In Lecture Notes in Pure and Applied Mathematics; Alfa, A.S., Chakravarthy, S.R., Eds.; Marcel Dekker: New York, NY, USA, 1997; pp. 313–341. [Google Scholar]
- Horváth, G.; Horváth, I.; Telek, M. High order concentrated matrix-exponential distributions. Stoch. Model. 2019. [Google Scholar] [CrossRef]
- inverselaplace.org. Available online: http://inverselaplace.org/ (accessed on 13 February 2020).



© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).