A Distributed Quantum-Behaved Particle Swarm Optimization Using Opposition-Based Learning on Spark for Large-Scale Optimization Problem


Abstract
1. Introduction
2. Literature Review
2.1. Real-World Optimization Applications
2.2. Large-Scale Optimization
2.3. Distributed Optimization Using MapReduce
2.4. Distributed Optimization Using Spark
3. A Distributed Cooperative Evolutionary Algorithm Framework Using Spark (SDCEA)
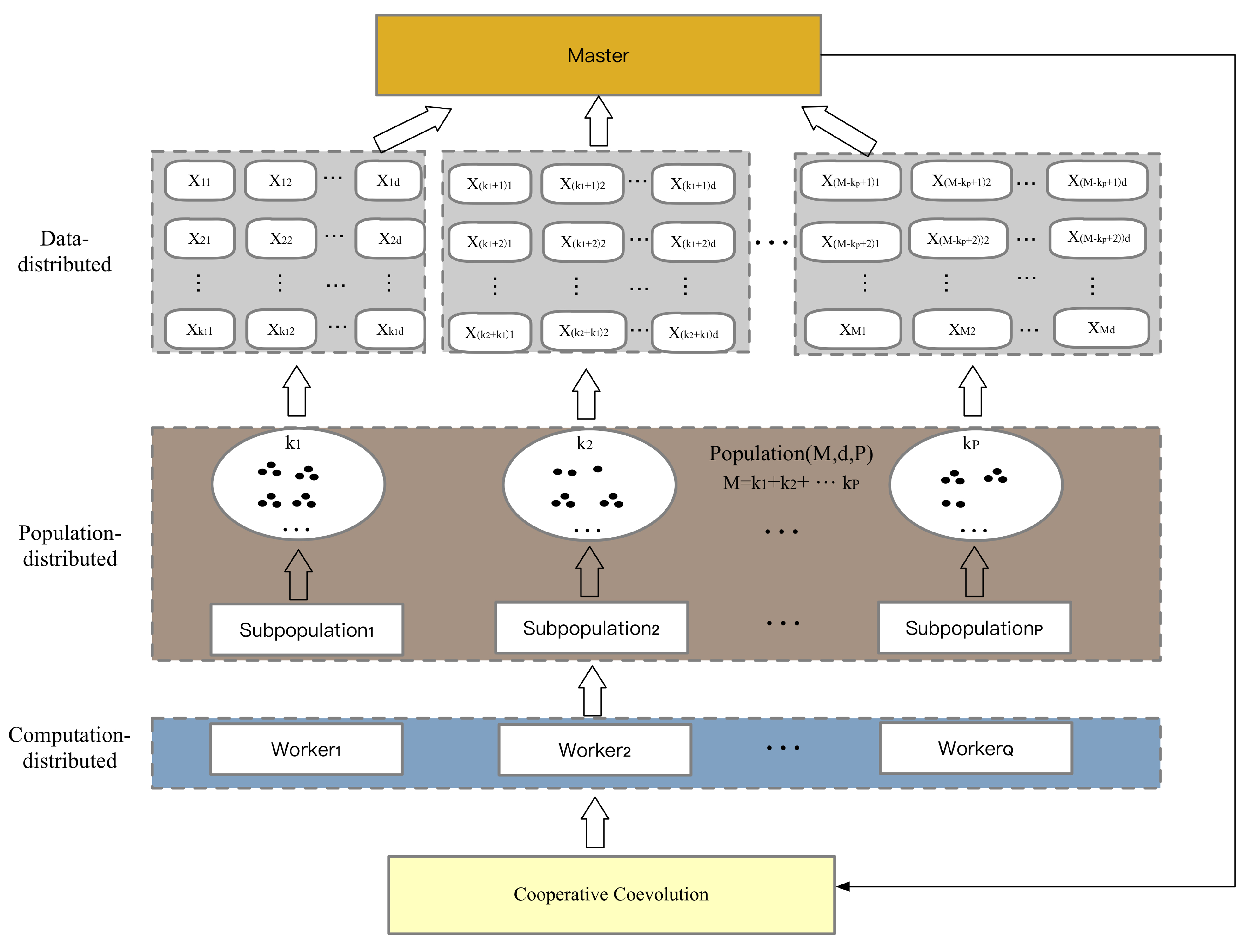
3.1. Background of the Distributed Framework
3.2. The Main Steps of the Proposed SDCEA Framework
- Configure a distributed computing cluster using Spark. Given Q workers and one master, where Q workers are independent of each other. Based on the task mechanism, the distributed evolution is divided into population distribution and data distribution. Furthermore, the master–slave model is adopted for the proposed SDCEA framework.
- Group the whole population into many sub-populations based on the parallelization, where each sub-population consists of different individuals, and then each sub-population evolves independently in parallel. Specifically, divide the whole population into P sub-populations denoted by sub-population 1, sub-population 2, …, and sub-population P, respectively.
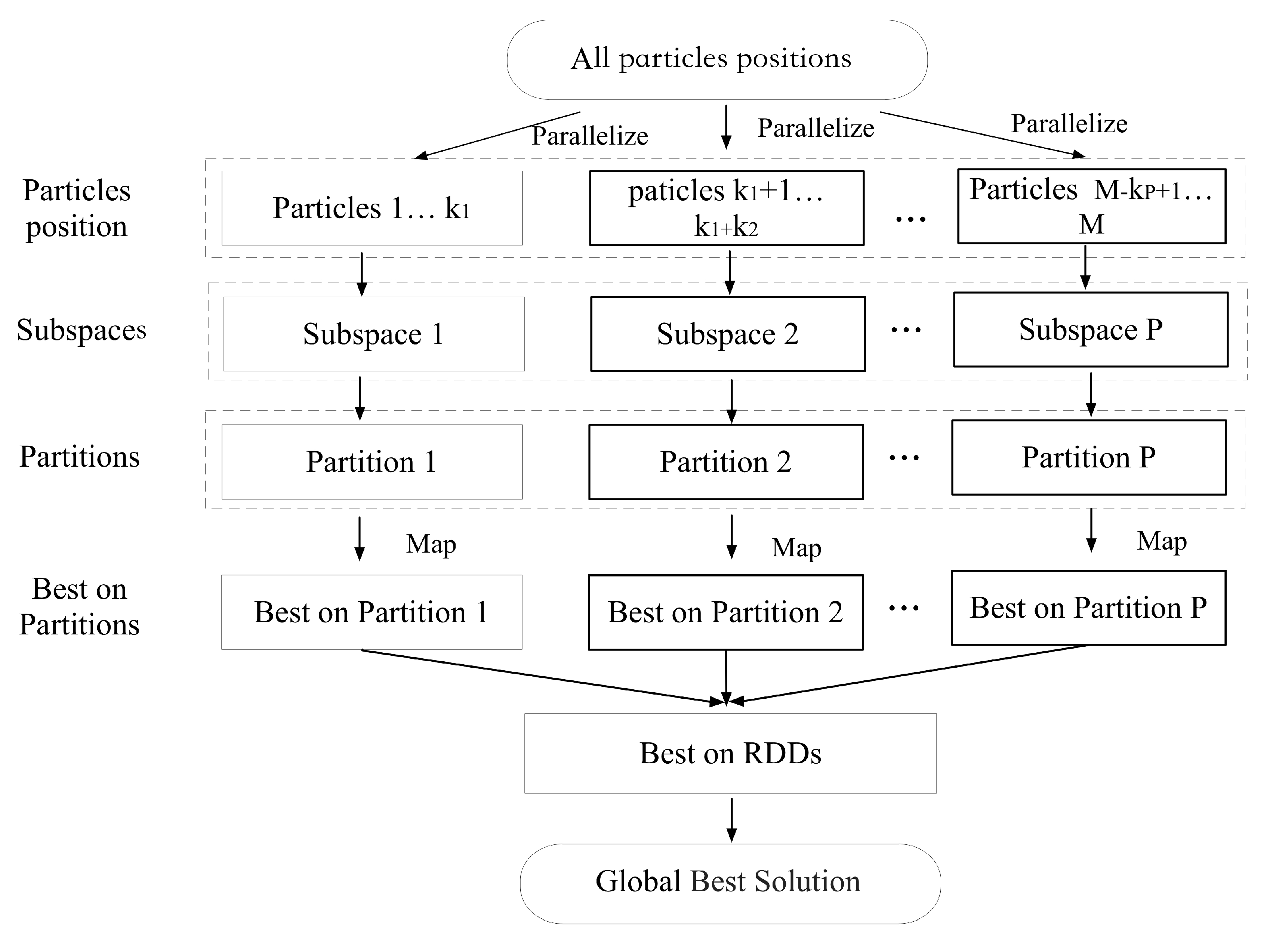
- The search space is partitioned into multiple subspaces for the whole population, and the individual of each sub-population searches on the sub-spaces in parallel.
- After each sub-population evolves separately for one iteration, the result is further collected through the master. Specifically, the optimum on each search space found by the distributed cooperation is collected by the master. Therefore, the global best optimum of the whole population is achieved, and then the global best optimum is distributed to each worker. Finally, when each worker receives it, the particle position and fitness evaluation of the population are updated.
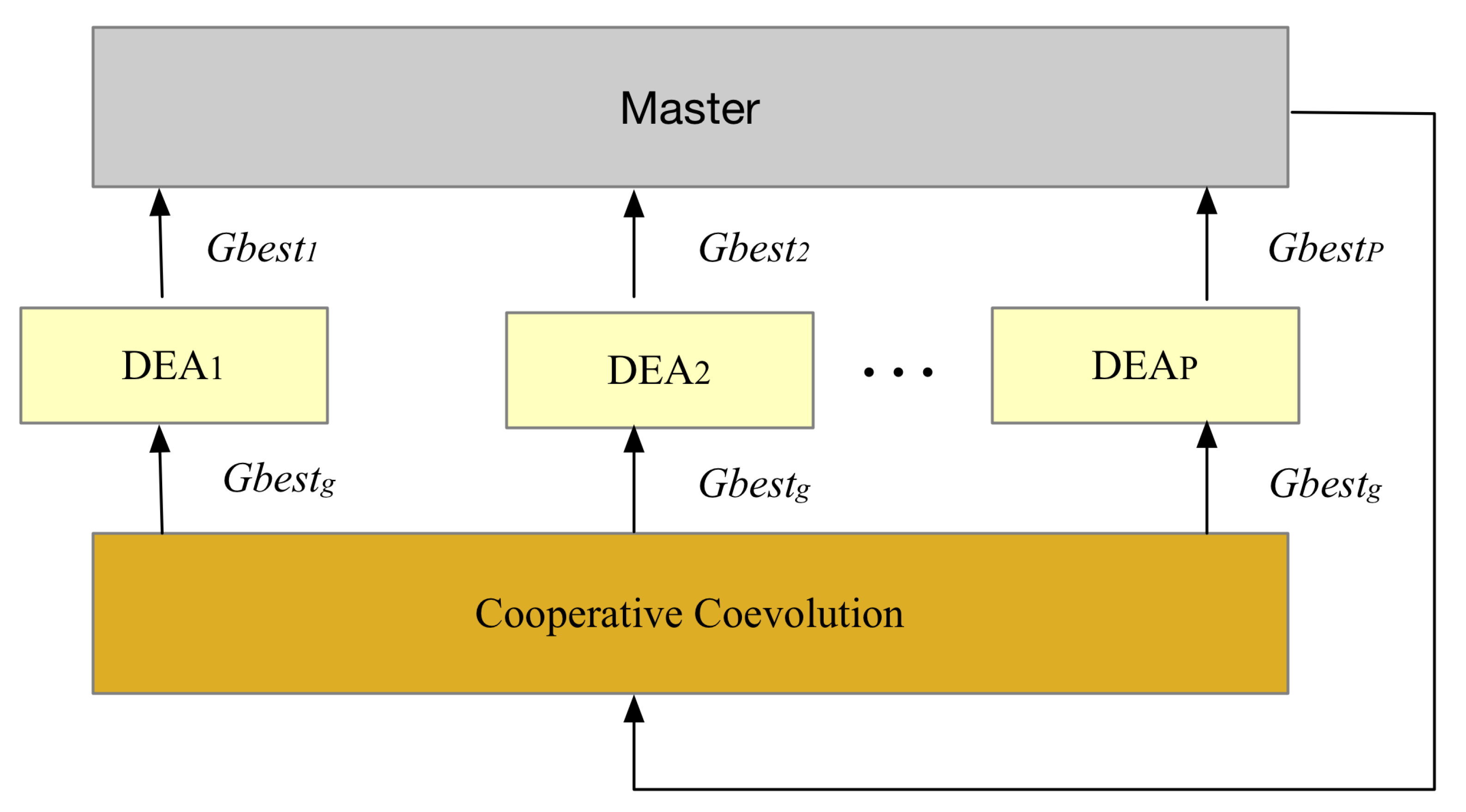
3.3. Distributed and Cooperative Co-evolution Based on SDCEA
3.3.1. Population Distribution
3.3.2. Data Distribution
3.3.3. Distributed Cooperative Co-evolution
4. Methodology
4.1. SDQPSO Using Opposition-Based Learning
4.1.1. Population Initialization Using Opposition-Based Learning
4.1.2. Evolving through Generations
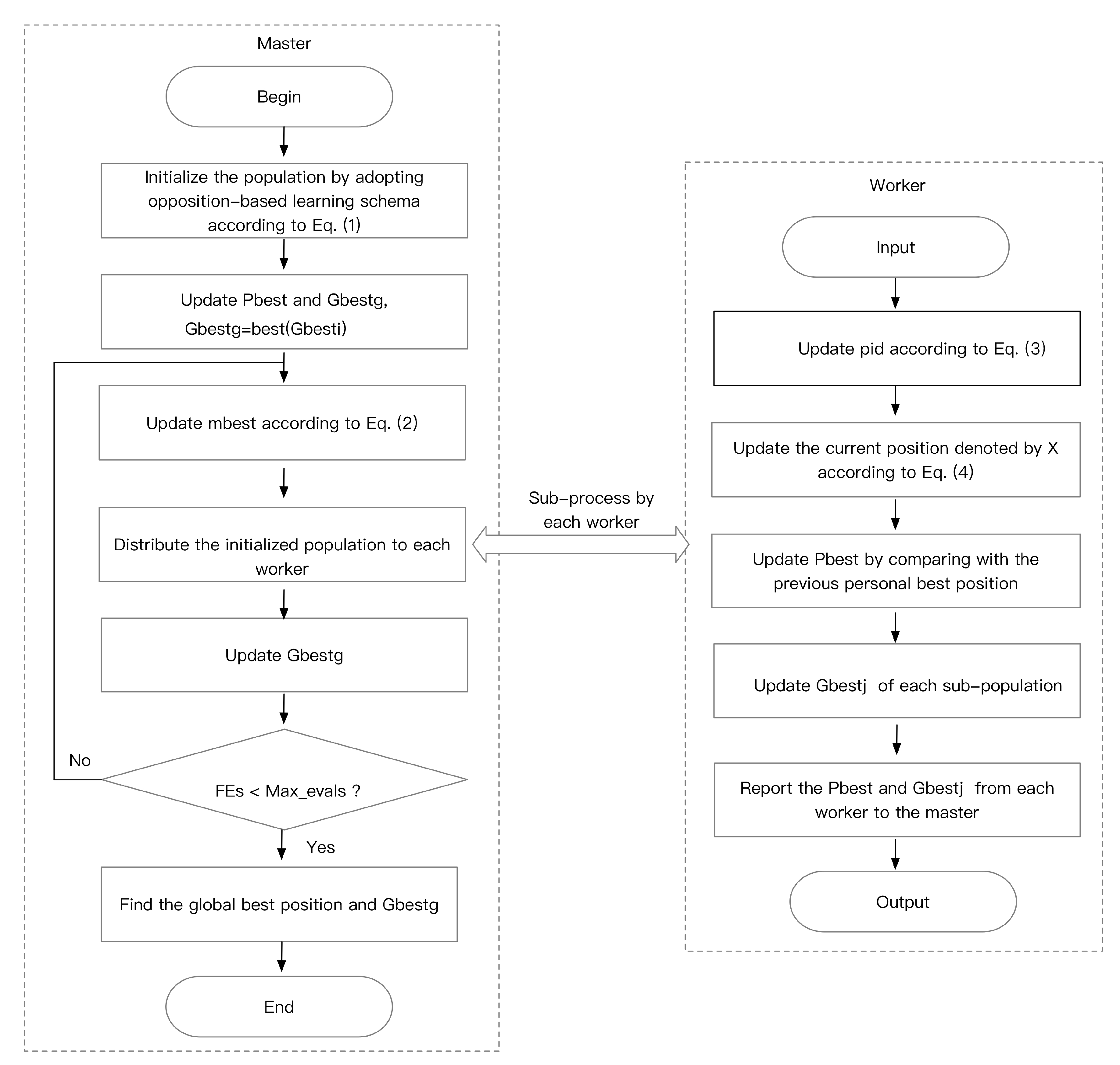
4.2. Evolution Process of the Proposed SDQPSO
- The population is initialized by adopting opposition-based learning scheme on the master, where the population size is M, the current position is , the personal best position is , and the global best position is . Furthermore, the positions of the population are within the range of .
- According to Equation (2), the mean best position denoted by is updated by averaging the personal best position on the master.
- The population is divided into P sub-populations on the master, then the sub-population and are distributed to each worker. Moreover, the computing resource is distributed to each subpopulation, and the search space is partitioned into several search subspaces.
- According to Equation (3), the local attractor of the particle denoted by is updated on the worker, where .
- Each subpopulation on the worker evolves independently generation by generation, and the position of each particle is updated according to the Equation (4).
- The fitness value of each particle is evaluated on the worker. When compared with , if the current fitness value is better than the previous personal best position, then is updated, otherwise not.
- For each worker, the particle with the best fitness value of each subpopulation is set as .
- The updated of each subpopulation and the current position are sent to the master.
- The of all the sub-populations on the worker is sent to the master, where . Furthermore, each is compared with , if it is less than , the global best position is updated, otherwise not. Then the updated is distributed to each worker.
5. Results and Discussion
5.1. Experimental Environment and Parameter Settings
5.1.1. Experimental Environment
5.1.2. Test Problems and Parameter Settings
5.2. Comparison with SDQPSO, SPSO, SCLPSO, and SALCPSO
5.2.1. Optimization Performance on Four Low-Cost Test Functions
5.2.2. Optimization Performance under Different Function Dimensions
5.2.3. Optimization Performance under Different Function Evaluations
5.3. Performance on the Running Time and Function Evaluation Proportion
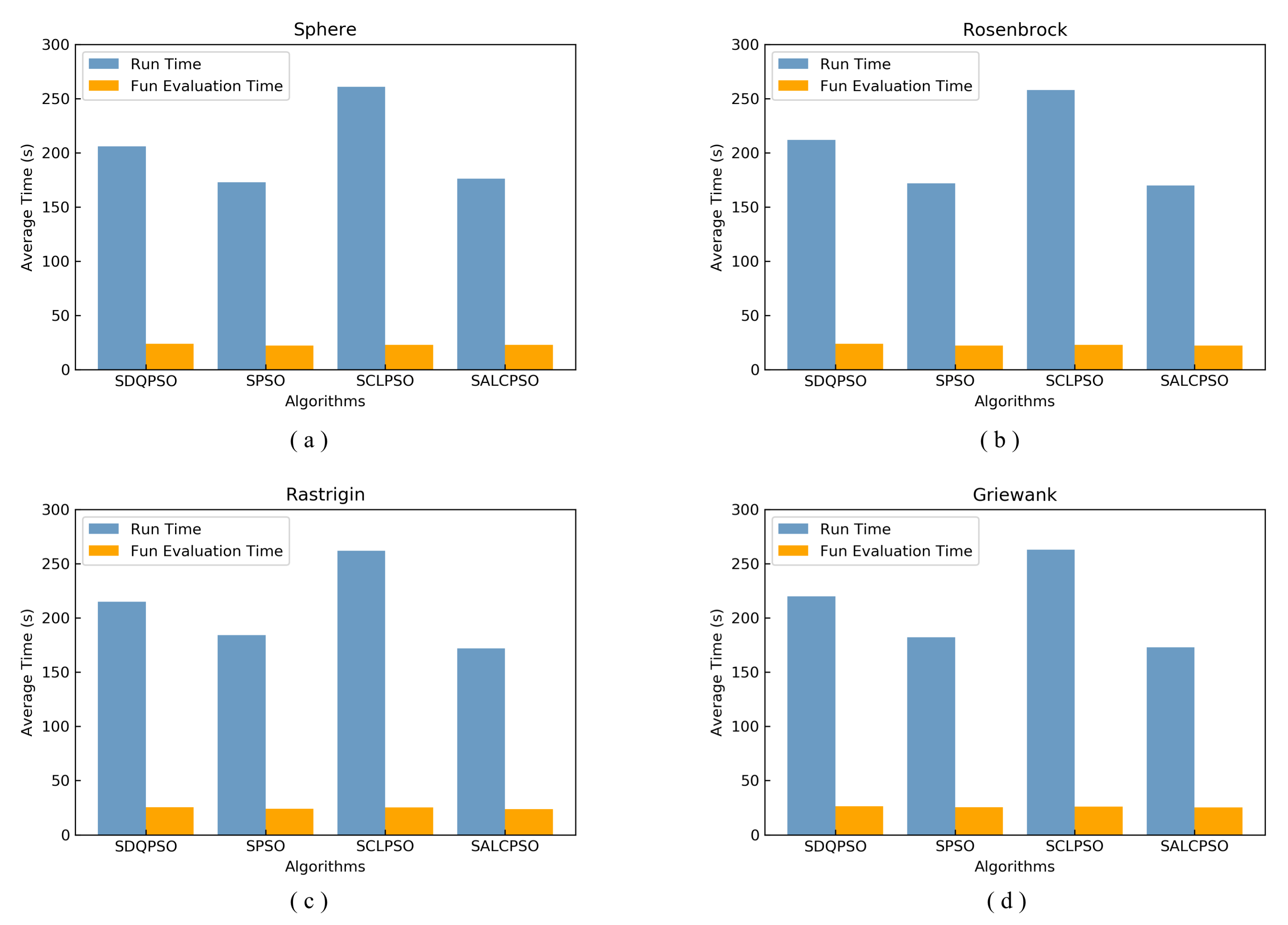
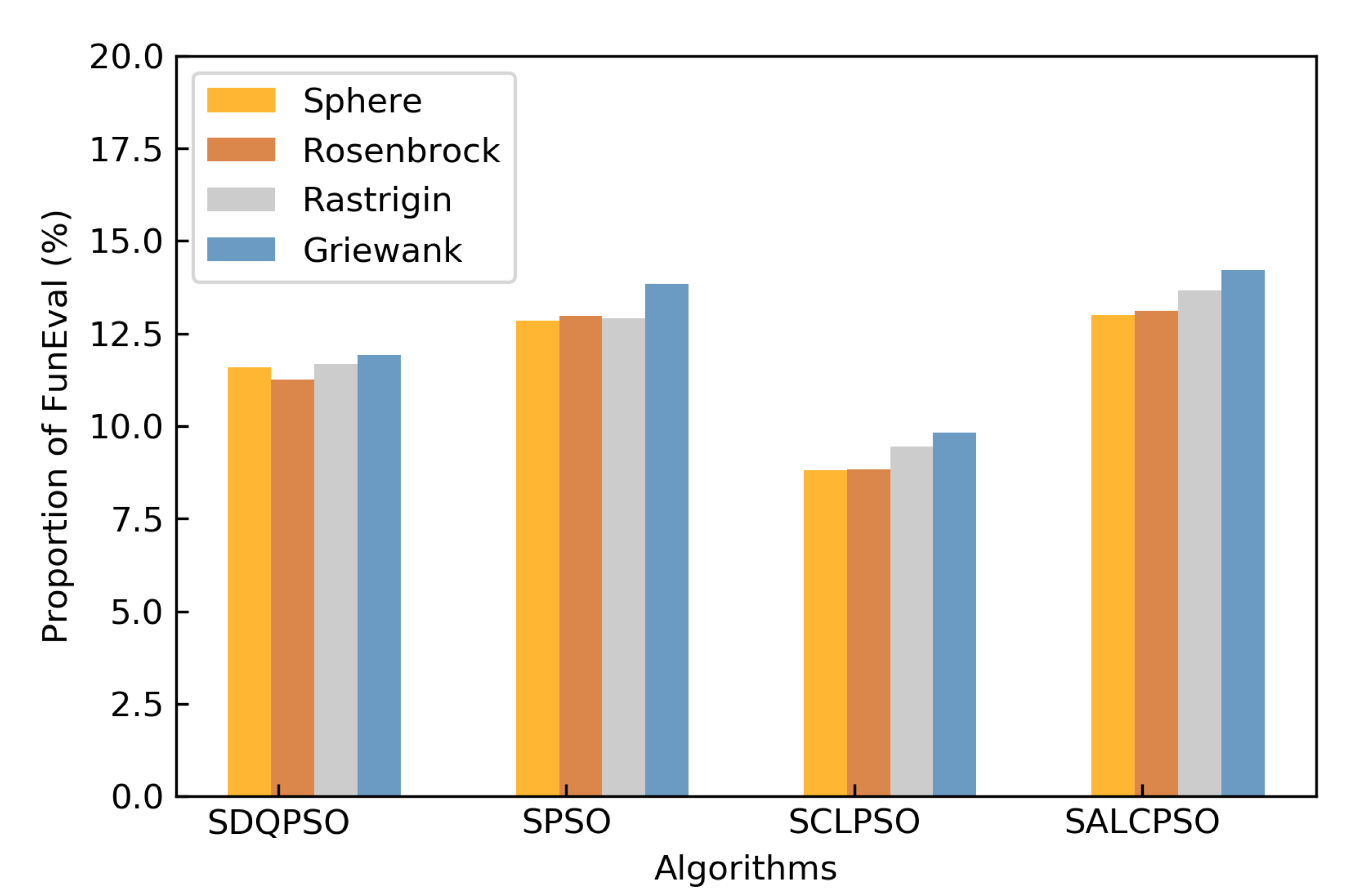
5.3.1. Running Time and Function Evaluation Proportion on Four Low-Cost Test Functions
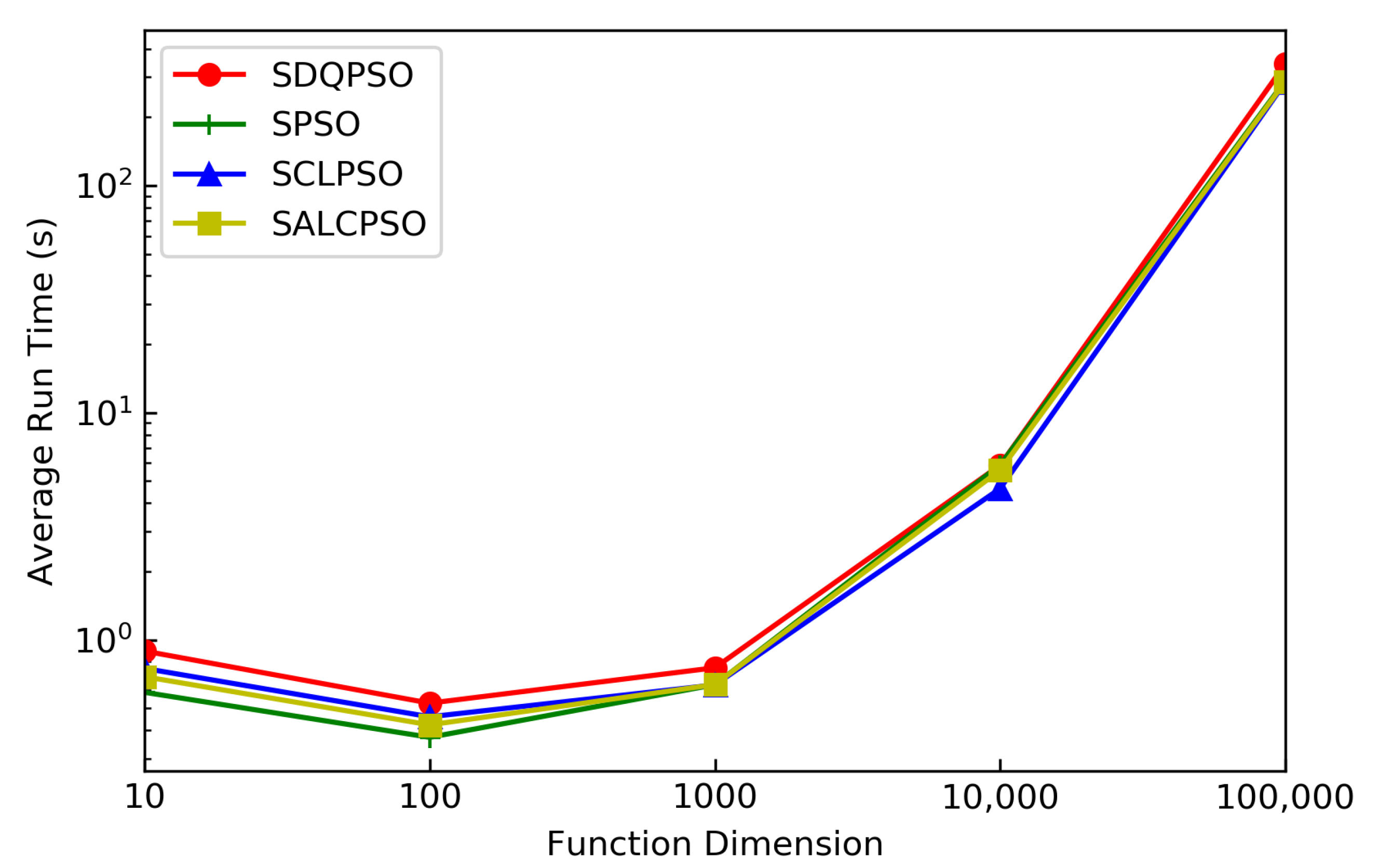
5.3.2. Running Time and Function Evaluation Proportion under Different Dimensions
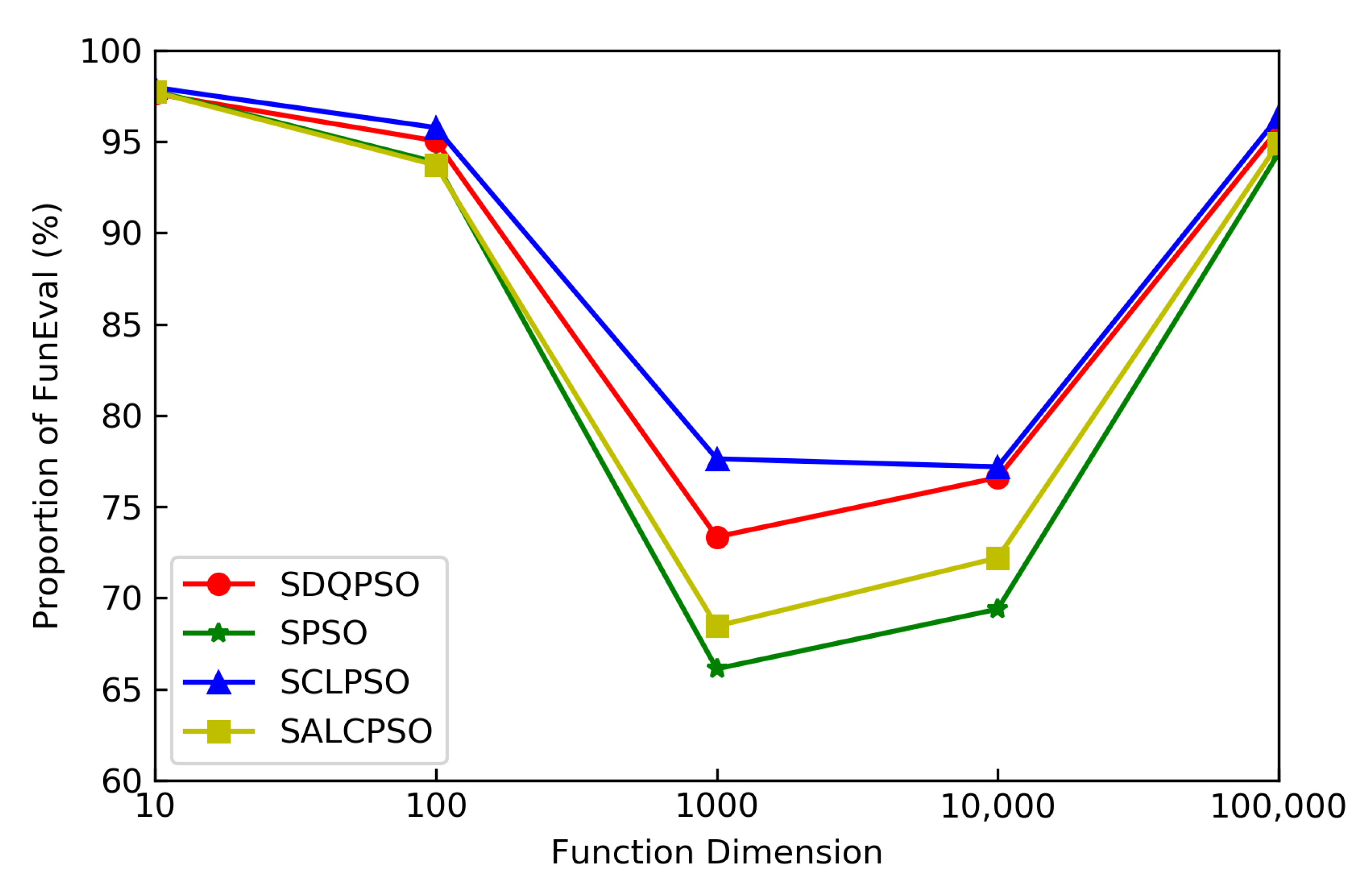
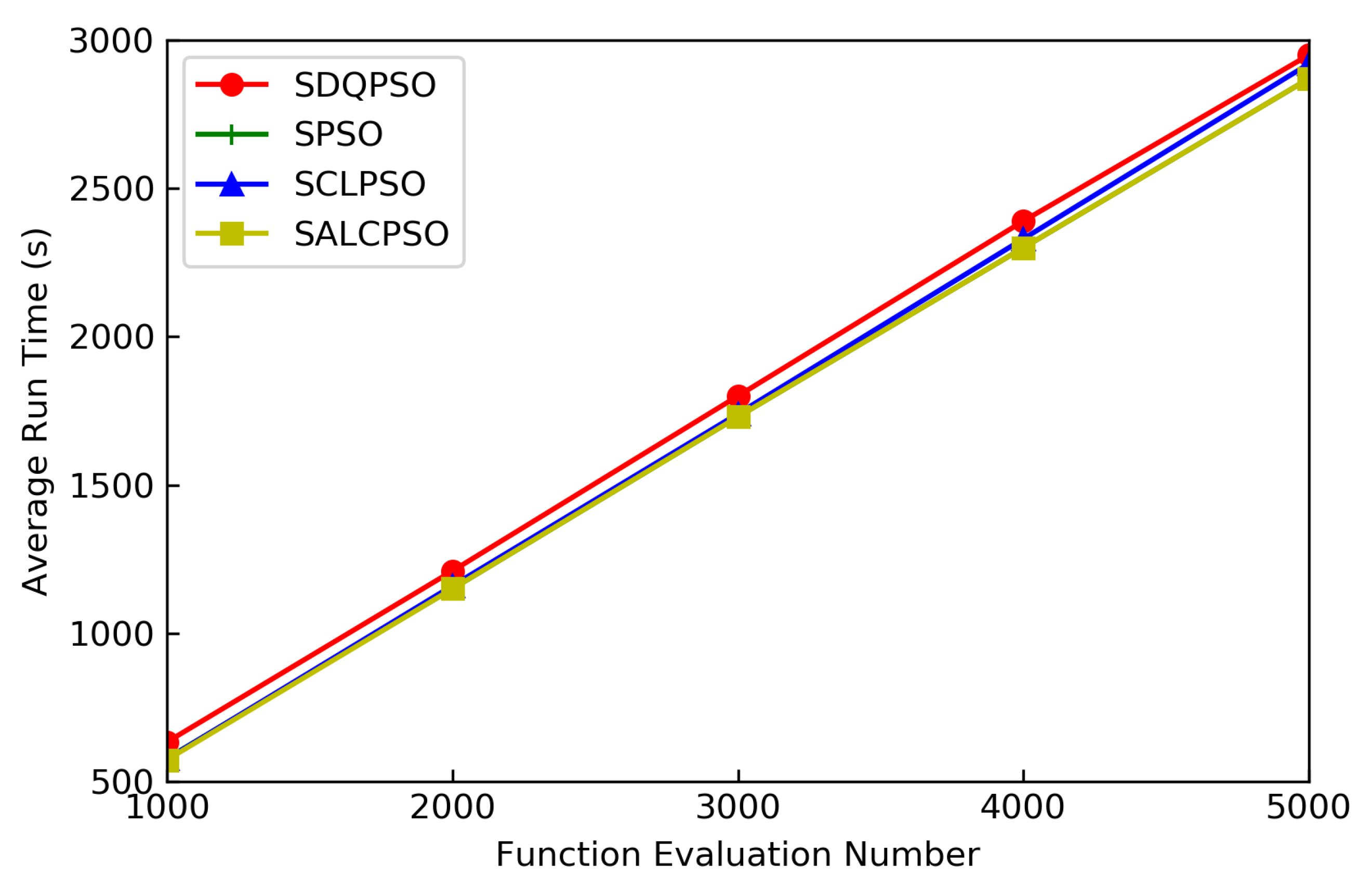
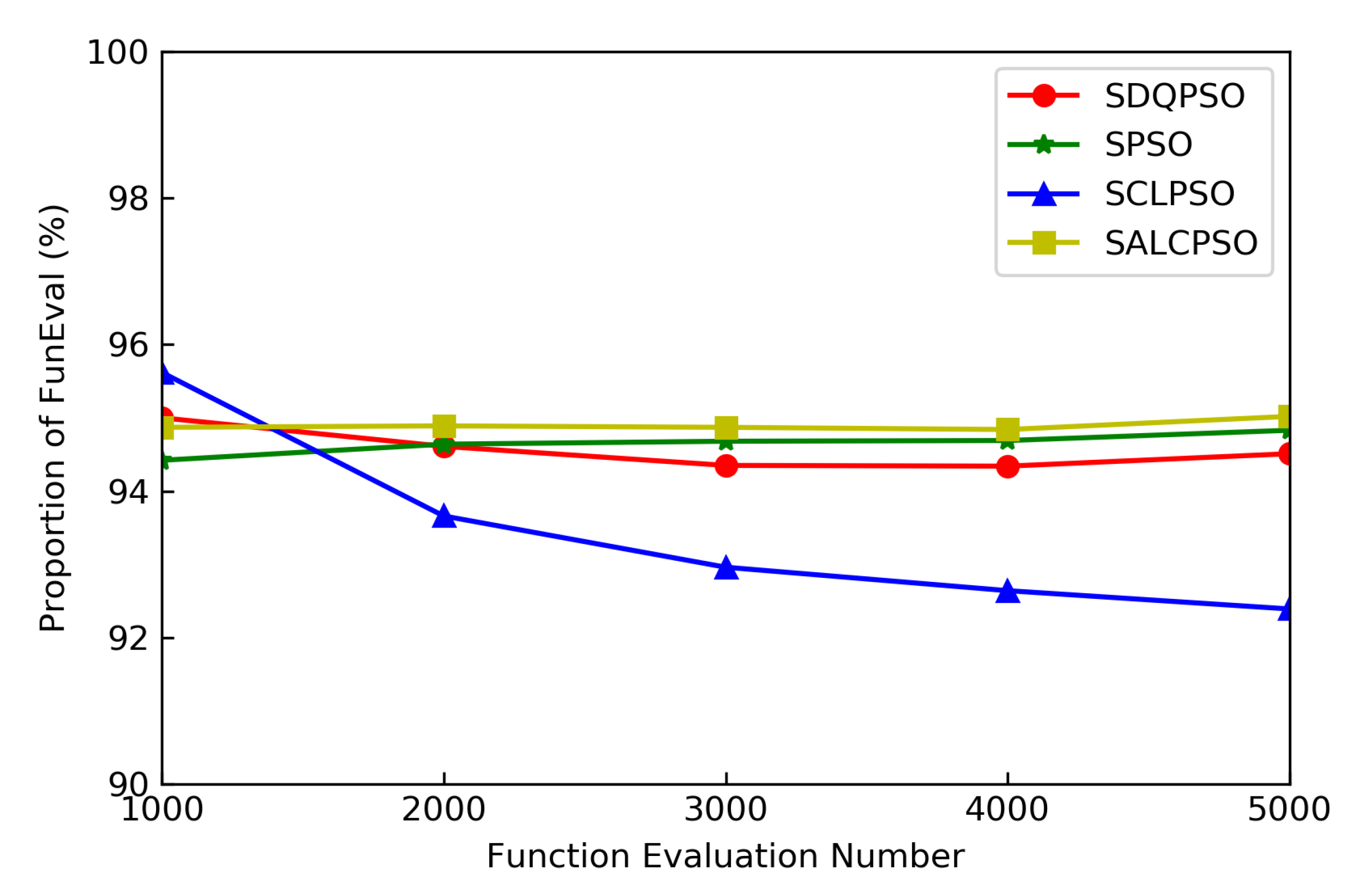
5.3.3. Running Time and Function Evaluation Proportion under Different Function Evaluations
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gong, Y.J.; Chen, W.N.; Zhan, Z.H.; Zhang, J.; Li, Y.; Zhang, Q.; Li, J.J. Distributed evolutionary algorithms and their models: A survey of the state-of-the-art. Appl. Soft Comput. 2015, 34, 286–300. [Google Scholar] [CrossRef]
- Wang, W.L. Artificial Intelligence: Principles and Applications; Higher Education Press: BeiJing, China, 2020. [Google Scholar]
- Wang, W.L.; Zhang, Z.J.; Gao, N.; Zhao, Y.W. Research progress of big data analytics methods based on artificial intelligence technology. Comput. Integr. Manuf. Syst. 2019, 25, 529–547. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified Data Processing on Large Clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar]
- McNabb, A.W.; Monson, C.K.; Seppi, K.D. Parallel pso using mapreduce. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; pp. 7–14. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 95. [Google Scholar]
- Ghasemi, P.; Khalili-Damghani, K.; Hafezalkotob, A.; Raissi, S. Uncertain multi-objective multi-commodity multi-period multi-vehicle location-allocation model for earthquake evacuation planning. Appl. Math. Comput. 2019, 350, 105–132. [Google Scholar] [CrossRef]
- Ghasemi, P.; Khalili-Damghani, K. A robust simulation-optimization approach for pre-disaster multi-period location–allocation–inventory planning. Math. Comput. Simul. 2020, 179, 69–95. [Google Scholar] [CrossRef]
- Fakhrzad, M.B.; Goodarzian, F. A fuzzy multi-objective programming approach to develop a green closed-loop supply chain network design problem under uncertainty: Modifications of imperialist competitive algorithm. RAIRO-Oper. Res. 2019, 53, 963–990. [Google Scholar] [CrossRef]
- Goodarzian, F.; Hosseini-Nasab, H.; Muñuzuri, J.; Fakhrzad, M.B. A multi-objective pharmaceutical supply chain network based on a robust fuzzy model: A comparison of meta-heuristics. Appl. Soft Comput. 2020, 92, 106331. [Google Scholar] [CrossRef]
- Verdejo, H.; Pino, V.; Kliemann, W.; Becker, C.; Delpiano, J. Implementation of Particle Swarm Optimization (PSO) Algorithm for Tuning of Power System Stabilizers in Multimachine Electric Power Systems. Energies 2020, 13, 2093. [Google Scholar] [CrossRef]
- Zhang, X.; Zou, D.; Shen, X. A novel simple particle swarm optimization algorithm for global optimization. Mathematics 2018, 6, 287. [Google Scholar] [CrossRef]
- Yildizdan, G.; Baykan, O.K. A new hybrid BA-ABC algorithm for global optimization problems. Mathematics 2020, 8, 1749. [Google Scholar] [CrossRef]
- Wei, C.L.; Wang, G.G. Hybrid Annealing Krill Herd and Quantum-Behaved Particle Swarm Optimization. Mathematics 2020, 8, 1403. [Google Scholar] [CrossRef]
- Jin, C.; Vecchiola, C.; Buyya, R. MRPGA: An extension of MapReduce for parallelizing genetic algorithms. In Proceedings of the 2008 IEEE Fourth International Conference on eScience, Indianapolis, IN, USA, 7–12 December 2008; pp. 214–221. [Google Scholar]
- Wu, H.; Ni, Z.W.; Wang, H.Y. MapReduce-based ant colony optimization. Comput. Integr. Manuf. Syst. 2012, 18, 1503–1509. [Google Scholar]
- Cheng, X.; Xiao, N. Parallel implementation of dynamic positive and negative feedback ACO with iterative MapReduce model. J. Inf. Comput. Sci. 2013, 10, 2359–2370. [Google Scholar] [CrossRef]
- Xu, X.; Ji, Z.; Yuan, F.; Liu, X. A novel parallel approach of cuckoo search using MapReduce. In Proceedings of the 2014 International Conference on Computer, Communications and Information Technology (CCIT 2014), Beijing, China, 16–17 January 2014. [Google Scholar]
- Al-Madi, N.; Aljarah, I.; Ludwig, S.A. Parallel glowworm swarm optimization clustering algorithm based on MapReduce. In Proceedings of the 2014 IEEE Symposium on Swarm Intelligence, Orlando, FL, USA, 9–12 December 2014; pp. 1–8. [Google Scholar]
- Ding, W.P.; Lin, C.T.; Prasad, M.; Chen, S.B.; Guan, Z.J. Attribute equilibrium dominance reduction accelerator (DCCAEDR) based on distributed coevolutionary cloud and its application in medical records. IEEE Trans. Syst. Man Cybern. Syst. 2015, 46, 384–400. [Google Scholar] [CrossRef]
- Hossain, M.S.; Moniruzzaman, M.; Muhammad, G.; Ghoneim, A.; Alamri, A. Big data-driven service composition using parallel clustered particle swarm optimization in mobile environment. IEEE Trans. Serv. Comput. 2016, 9, 806–817. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.; Chen, Z.; Xue, Y. Cooperative particle swarm optimization using MapReduce. Soft Comput. 2017, 21, 6593–6603. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Z.; Wang, Y.; Jiao, L.; Xue, Y. A novel distributed quantum-behaved particle swarm optimization. J. Optim. 2017, 2017. [Google Scholar] [CrossRef]
- Ding, W.; Lin, C.T.; Chen, S.; Zhang, X.; Hu, B. Multiagent-consensus-MapReduce-based attribute reduction using co-evolutionary quantum PSO for big data applications. Neurocomputing 2018, 272, 136–153. [Google Scholar] [CrossRef]
- Khalil, Y.; Alshayeji, M.; Ahmad, I. Distributed whale optimization algorithm based on MapReduce. Concurr. Comput. Pract. Exp. 2019, 31, e4872. [Google Scholar] [CrossRef]
- Cao, B.; Li, W.; Zhao, J.; Yang, S.; Kang, X.; Ling, Y.; Lv, Z. Spark-based parallel cooperative co-evolution particle swarm optimization algorithm. In Proceedings of the 2016 IEEE International Conference on Web Services (ICWS), San Francisco, CA, USA, 27 June–2 July 2016; pp. 570–577. [Google Scholar]
- Qi, R.Z.; Wang, Z.J.; Li, S.Y. A parallel genetic algorithm based on spark for pairwise test suite generation. J. Comput. Sci. Technol. 2016, 31, 417–427. [Google Scholar] [CrossRef]
- Liu, P.; Ye, S.; Wang, C.; Zhu, Z. Spark-Based Parallel Genetic Algorithm for Simulating a Solution of Optimal Deployment of an Underwater Sensor Network. Sensors 2019, 19, 2717. [Google Scholar] [CrossRef] [PubMed]
- Yuan, J. An Anomaly Data Mining Method for Mass Sensor Networks Using Improved PSO Algorithm Based on Spark Parallel Framework. J. Grid Comput. 2020, 18, 251–261. [Google Scholar] [CrossRef]
- Peng, H.; Tan, X.; Deng, C.; Peng, S. SparkCUDE: A spark-based differential evolution for large-scale global optimisation. Int. J. High Perform. Syst. Archit. 2017, 7, 211–222. [Google Scholar] [CrossRef]
- Teijeiro, D.; Pardo, X.C.; González, P.; Banga, J.R.; Doallo, R. Implementing parallel differential evolution on Spark. In Proceedings of the European Conference on the Applications of Evolutionary Computation, Porto, Portugal, 30 March–1 April 2016; pp. 75–90. [Google Scholar]
- Sun, L.; Lin, L.; Li, H.; Gen, M. Large scale flexible scheduling optimization by a distributed evolutionary algorithm. Comput. Ind. Eng. 2019, 128, 894–904. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Ma, J.; McCauly, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Proceedings of the 9th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 12), San Jose, CA, USA, 25–27 April 2012; pp. 15–28. [Google Scholar]
- Barba-González, C.; García-Nieto, J.; Nebro, A.J.; Cordero, J.A.; Durillo, J.J.; Navas-Delgado, I.; Aldana-Montes, J.F. jMetalSP: A framework for dynamic multi-objective big data optimization. Appl. Soft Comput. 2018, 69, 737–748. [Google Scholar] [CrossRef]
- Duan, Q.; Sun, L.; Shi, Y. Spark clustering computing platform based parallel particle swarm optimizers for computationally expensive global optimization. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Coimbra, Portugal, 8–12 September 2018; pp. 424–435. [Google Scholar]
- Tizhoosh, H.R. Opposition-based learning: A new scheme for machine intelligence. In Proceedings of the International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC’06), Vienna, Austria, 28–30 November 2005; Volume 1, pp. 695–701. [Google Scholar]
- Shi, Y.; Eberhart, R. A modified particle swarm optimizer. In Proceedings of the 1998 IEEE International Conference on Evolutionary Computation Proceedings. IEEE World Congress on Computational Intelligence (Cat. No. 98TH8360), Anchorage, AK, USA, 4–9 May 1998; pp. 69–73. [Google Scholar]
- Liang, J.J.; Qin, A.K.; Suganthan, P.N.; Baskar, S. Comprehensive learning particle swarm optimizer for global optimization of multimodal functions. IEEE Trans. Evol. Comput. 2006, 10, 281–295. [Google Scholar] [CrossRef]
- Chen, W.N.; Zhang, J.; Lin, Y.; Chen, N.; Zhan, Z.H.; Chung, H.S.H.; Li, Y.; Shi, Y.H. Particle swarm optimization with an aging leader and challengers. IEEE Trans. Evol. Comput. 2012, 17, 241–258. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spark Cluster | Platform Configuration |
|---|---|
| Distributed computing nodes | 1 Master and 3 Workers |
| System | VMware ESXi 6.5.0, Ubuntu 16.04 |
| Framework version | Hadoop 3.2.1, Spark 2.4.5 |
| Software version | Scala 2.11.12, java 1.8.0, Sbt 1.1.6 |
| Test Function | Name |
|---|---|
| Sphere | |
| Rosenbrock | |
| Rastrigin | |
| Griewank | |
| Schwefel 1.2 |
| Function | SDQPSO | SPSO | SCLPSO | SALCPSO | |
|---|---|---|---|---|---|
| F1 | Min | 2.74 × 10 | 1.59 × 10 | 1.75 × 10 | 2.69 × 10 |
| Mean | 2.86 × 10 | 1.61 × 10 (-) | 1.75 × 10 (-) | 2.70 × 10 (-) | |
| Max | 2.97 × 10 | 1.62 × 10 | 1.76 × 10 | 2.70 × 10 | |
| Std | 7.41 × 10 | 9.97 × 10 | 6.63 × 10 | 4.33 × 10 | |
| F2 | Min | 1.31 × 10 | 7.28 × 10 | 7.35 × 10 | 1.69 × 10 |
| Mean | 1.32 × 10 | 7.38 × 10 (-) | 7.44 × 10 (-) | 1.69 × 10 (-) | |
| Max | 1.32 × 10 | 7.49 × 10 | 7.53 × 10 | 1.70 × 10 | |
| Std | 3.44 × 10 | 6.74 × 10 | 5.30 × 10 | 3.26 × 10 | |
| F3 | Min | 1.27 × 10 | 2.55 × 10 | 2.73 × 10 | 3.61 × 10 |
| Mean | 1.28 × 10 | 2.59 × 10 (-) | 2.74 × 10 (-) | 3.61 × 10 (-) | |
| Max | 1.29 × 10 | 2.60 × 10 | 2.76 × 10 | 3.62 × 10 | |
| Std | 7.03 × 10 | 1.55 × 10 | 7.81 × 10 | 3.37 × 10 | |
| F4 | Min | 6.73 × 10 | 3.97 × 10 | 4.36 × 10 | 6.73 × 10 |
| Mean | 7.16 × 10 | 4.03 × 10 (-) | 4.37 × 10 (-) | 6.75 × 10 (-) | |
| Max | 7.34 × 10 | 4.10 × 10 | 4.40 × 10 | 6.76 × 10 | |
| Std | 1.93 × 10 | 3.43 × 10 | 1.38 × 10 | 8.46 × 10 | |
| +/=/- | 0/0/4 | 0/0/4 | 0/0/4 |
| Dimension | SDQPSO | SPSO | SCLPSO | SALCPSO | |
|---|---|---|---|---|---|
| 10 | Min | 1.22 × 10 | 7.19 × 10 | 3.29 × 10 | 2.19 × 10 |
| Mean | 6.94 × 10 | 1.81 × 10 (-) | 9.93 × 10 (-) | 4.43 × 10 (-) | |
| Max | 1.99 × 10 | 2.69 × 10 | 1.60 × 10 | 9.17 × 10 | |
| Std | 4.97 × 10 | 5.58 × 10 | 2.98 × 10 | 1.56 × 10 | |
| 100 | Min | 1.21 × 10 | 1.79 × 10 | 6.41 × 10 | 3.47 × 10 |
| Mean | 2.00 × 10 | 2.96 × 10 (-) | 9.00 × 10 (-) | 5.64 × 10 (-) | |
| Max | 2.60 × 10 | 4.20 × 10 | 1.21 × 10 | 1.01 × 10 | |
| Std | 4.35 × 10 | 5.63 × 10 | 1.46 × 10 | 1.32 × 10 | |
| 1000 | Min | 1.47 × 10 | 1.51 × 10 | 5.23 × 10 | 2.79 × 10 |
| Mean | 2.34 × 10 | 2.85 × 10 (-) | 8.73 × 10 (-) | 5.24 × 10 (-) | |
| Max | 2.94 × 10 | 3.94 × 10 | 1.25 × 10 | 8.39 × 10 | |
| Std | 4.15 × 10 | 5.28 × 10 | 1.95 × 10 | 1.17 × 10 | |
| 10,000 | Min | 1.50 × 10 | 1.89 × 10 | 5.44 × 10 | 3.85 × 10 |
| Mean | 2.53 × 10 | 2.98 × 10 (-) | 8.98 × 10 (-) | 5.44 × 10 (-) | |
| Max | 3.56 × 10 | 4.68 × 10 | 1.53 × 10 | 7.93 × 10 | |
| Std | 5.68 × 10 | 6.23 × 10 | 1.95 × 10 | 1.01 × 10 | |
| 100,000 | Min | 1.75 × 10 | 2.26 × 10 | 4.44 × 10 | 3.25 × 10 |
| Mean | 2.59 × 10 | 3.16 × 10 (-) | 8.89 × 10 (-) | 5.47 × 10 (-) | |
| Max | 3.42 × 10 | 4.18 × 10 | 1.35 × 10 | 9.05 × 10 | |
| Std | 7.16 × 10 | 5.26 × 10 | 2.11 × 10 | 1.32 × 10 | |
| +/=/- | 0/0/5 | 0/0/5 | 0/0/5 |
| Evaluation | SDQPSO | SPSO | SCLPSO | SALCPSO | |
|---|---|---|---|---|---|
| 1000 | Min | 1.43 × 10 | 1.49 × 10 | 4.20 × 10 | 2.61 × 10 |
| Mean | 2.54 × 10 | 2.21 × 10 (=) | 7.96 × 10 (-) | 4.20 × 10 (-) | |
| Max | 2.99 × 10 | 3.06 × 10 | 1.08 × 10 | 5.76 × 10 | |
| Std | 4.10 × 10 | 4.48 × 10 | 1.59 × 10 | 6.80 × 10 | |
| 2000 | Min | 1.42 × 10 | 1.07 × 10 | 3.67 × 10 | 2.21 × 10 |
| Mean | 2.31 × 10 | 1.78 × 10 (+) | 6.82 × 10 (-) | 3.33 × 10 (-) | |
| Max | 2.87 × 10 | 2.50 × 10 | 9.90 × 10 | 4.52 × 10 | |
| Std | 3.21 × 10 | 3.40 × 10 | 1.50 × 10 | 6.74 × 10 | |
| 3000 | Min | 1.61 × 10 | 1.13 × 10 | 3.76 × 10 | 2.17 × 10 |
| Mean | 2.32 × 10 | 1.64 × 10 (+) | 5.59 × 10 (-) | 3.20 × 10 (-) | |
| Max | 2.75 × 10 | 2.54 × 10 | 8.09 × 10 | 3.92 × 10 | |
| Std | 4.12 × 10 | 3.01 × 10 | 1.05 × 10 | 4.58 × 10 | |
| 4000 | Min | 1.88 × 10 | 1.10 × 10 | 3.57 × 10 | 2.20 × 10 |
| Mean | 2.16 × 10 | 1.51 × 10 (+) | 5.67 × 10 (-) | 2.89 × 10 (-) | |
| Max | 2.44 × 10 | 2.02 × 10 | 7.52 × 10 | 4.08 × 10 | |
| Std | 1.85 × 10 | 2.04 × 10 | 9.85 × 10 | 4.50 × 10 | |
| 5000 | Min | 1.63 × 10 | 1.16 × 10 | 4.11 × 10 | 2.02 × 10 |
| Mean | 2.11 × 10 | 1.53 × 10 (+) | 5.52 × 10 (-) | 2.68 × 10 (-) | |
| Max | 2.85 × 10 | 1.96 × 10 | 7.50 × 10 | 4.01 × 10 | |
| Std | 3.80 × 10 | 1.93 × 10 | 8.23 × 10 | 4.14 × 10 | |
| +/=/- | 4/1/0 | 0/0/5 | 0/0/5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Wang, W.; Pan, G. A Distributed Quantum-Behaved Particle Swarm Optimization Using Opposition-Based Learning on Spark for Large-Scale Optimization Problem. Mathematics 2020, 8, 1860. https://doi.org/10.3390/math8111860
Zhang Z, Wang W, Pan G. A Distributed Quantum-Behaved Particle Swarm Optimization Using Opposition-Based Learning on Spark for Large-Scale Optimization Problem. Mathematics. 2020; 8(11):1860. https://doi.org/10.3390/math8111860
Chicago/Turabian StyleZhang, Zhaojuan, Wanliang Wang, and Gaofeng Pan. 2020. "A Distributed Quantum-Behaved Particle Swarm Optimization Using Opposition-Based Learning on Spark for Large-Scale Optimization Problem" Mathematics 8, no. 11: 1860. https://doi.org/10.3390/math8111860
APA StyleZhang, Z., Wang, W., & Pan, G. (2020). A Distributed Quantum-Behaved Particle Swarm Optimization Using Opposition-Based Learning on Spark for Large-Scale Optimization Problem. Mathematics, 8(11), 1860. https://doi.org/10.3390/math8111860