Abstract
This paper proposes a new approach based on the regression framework employing a pivotal quantity to estimate unknown parameters of a Weibull distribution under the progressive Type-II censoring scheme, which provides a closed form solution for the shape parameter, unlike its maximum likelihood estimator counterpart. To resolve serious rounding errors for the exact mean and variance of the pivotal quantity, two different types of Taylor series expansion are applied, and the resulting performance is enhanced in terms of the mean square error and bias obtained through the Monte Carlo simulation. Finally, an actual application example, including a simple goodness-of-fit analysis of the actual test data based on the pivotal quantity, proves the feasibility and applicability of the proposed approach.
1. Introduction
The progressive Type-II censoring scheme is one of the useful censoring schemes capable of saving experimental cost and time. Under the progressive Type-II censoring scheme, is the pre-fixed failure number and denotes the number of removed units when the ith failure arises. When the 1st failure arises, units are randomly removed from surviving units. After some time, units are randomly removed from surviving units when the 2nd failure arises and so on. The experiment is terminated when the mth failure arises, removing all remaining units. Many studies in various fields have discussed the progressive Type-II censoring scheme and used a Weibull distribution as the lifetime distribution because of the flexibility afforded by its wide variety of shapes. This paper proposes a new estimation method based on the regression framework employing a pivotal quantity when a progressive Type-II censored sample is available from a Weibull distribution with the cumulative distribution function and the probability density function (pdf), as given by
and
respectively, where is the scale parameter and is the shape parameter. As mentioned earlier, the versatility of the Weibull distribution enables it model the characteristics of other types of distribution, due to the shape parameter. For this reason, this distribution has been studied by many researchers under various censoring schemes, especially the progressive Type-II censoring scheme. Pareek etal. [1] provided the maximum likelihood estimators (MLEs), approximate MLEs (AMLEs) and the Fisher information matrix based on the competing risks data from a Weibull distribution under the progressive Type-II censoring scheme. Wang etal. [2] proposed an inverse estimation and exact confidence intervals based on a pivotal quantity for the proportional hazard distributions such as the Weibull, Gompertz, and Lomax distributions under the progressive Type-II censoring scheme. Abdel-Hamid and Al-Hussaini [3] provided a progressive stress-accelerated life test model based on a progressive Type-II sample from a Weibull distribution through graphical and maximum likelihood methods of estimations. Valiollahi etal. [4] studied the estimation of the stress strength reliability that represents the system stress less than its strength when the system stress and its strength are independent Weibull random variables under the progressive Type-II censoring scheme.
However, these approaches suffer a disadvantage in that the shape parameter must be numerically estimated, despite its importance. Instead of these approaches, the present article develops a closed form for the parameter of interest, i.e., the shape parameter, by proposing a weighted linear regression framework based on a pivotal quantity under the progressive Type-II censoring scheme. In our approach, the concept proposed by Lu and Tao [5] is extended to the progressive Type-II censoring scheme and the rounding error which was revealed by Balakrishnan and Aggarwala [6] in the exact determination of the single and product moments for large samples is resolved by utilizing two different Taylor series expansions. The superiority of the approach relative to the maximum likelihood estimation is proved in terms of the mean square error (MSE) and bias through the Monte Carlo simulation.
The rest of this paper is organized. Section 2 proposes a new estimation method using the weighted least squares method based on the linear regression framework, which provides a closed form for the shape parameter that may be of interest and also enhances the performance in terms of the MSE and bias, compared to the MLEs. Section 3 proves the superiority of the proposed method through the Monte Carlo simulations and the real data analysis. Section 4 concludes the paper.
2. Weighted Least Squares Estimation
Let be a progressive Type-II censored sample from the Weibull distribution with the pdf (1). Then the corresponding likelihood function is given by
and the MLEs and can be found by maximizing its logarithm. Although estimation based on the likelihood function is most commonly used, it does not provide a closed form for the shape parameter that can be of interest. To resolve this shortcoming, estimation methods based on a linear regression-type framework are proposed in this section. First, a pivotal quantity is provided.
Let
Then, are progressive Type-II censored order statistics that have a standard exponential distribution with a mean , where . To obtain a simple linear model, is considered, which is a progressive Type-II censored sample from a standard extreme value distribution with
and
respectively, where = and is the Euler’s constant.
From the quantity and its mean (3), a simple linear regression model can be obtained as
where is the error term with . Now, an approach based on the weighted least squares method is proposed since the weight of each data point is not identical constant, as mentioned in Lu and Tao [5].
Theorem 1.
The weighted least squares estimators (WLSEs) of θ and λ are
and
respectively, where
Proof.
The weighted least squares equation corresponding to the progressive Type-II censoring scheme is
Then, by letting and minimizing the quantity (6) for each parameter, it completes the proof. ☐
Note that Balakrishnan and Aggarwala [6] pointed out the serious rounding errors arising in the exact determination of the single and product moments for a large sample size n. To resolve that, two types of Taylor series expansion for are provided.
First, can be approximated in a Taylor series around due to , where is the ith order statistic from a standard uniform distribution under the progressive Type-II censoring scheme. For notation simplicity, is denoted as . Then, we have
By (7), the mean (3) and variance (4) are approximated as
and
respectively, where . The approximate WLSEs are provided by substituting the mean (3) and variance (4) in Theorem 1 with their approximations (8) and (9), which are denoted as and , respectively.
Second, by approximating in a Taylor series around because be a progressive Type-II sample from a standard exponential distribution, we have
3. Application
This section assesses the proposed estimators in terms of the MSE and bias through the Monte Carlo simulations, and analyzes a real dataset to illustrate the validity and application of the proposed approach.
3.1. Simulation Result
To assess the proposed estimators, the progressive censored samples are generated from the Weibull distribution with = 0.5(1.0)2.5 and = 1.0 under the following progressive Type-II censoring schemes (Lee etal. [7])
by using the algorithm in Balakrishnan and Sandhu [8]. The sample size n and the pre-fixed failure number m are considered as follows.
Then, for each scheme, the MSEs and biases are obtained over 10,000 replications after computing all the estimators considered in Section 2. The results are reported in Figure 1 and Figure 2.
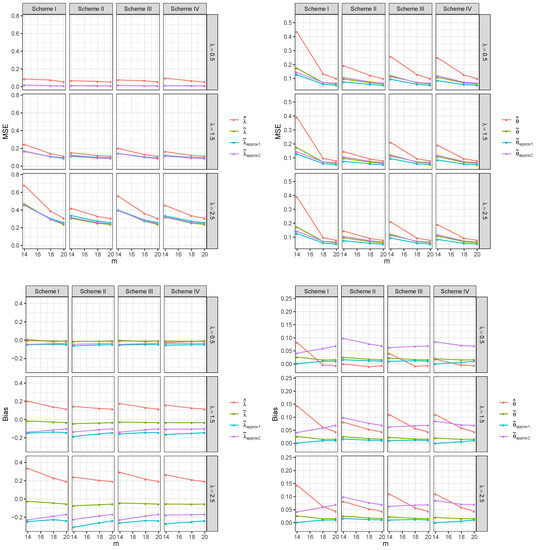
Figure 1.
The MSEs and biases of the estimators for the sample size n = 20.
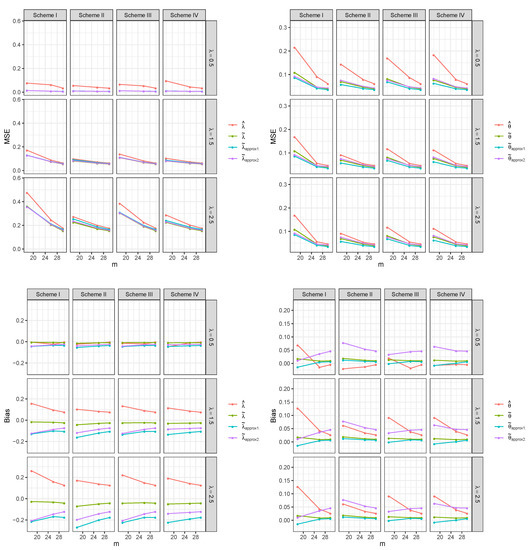
Figure 2.
The MSEs and biases of the estimators for the sample size n = 30.
Figure 1 and Figure 2 show that the proposed WLSEs are more efficient than the MLEs in terms of the MSE. Among the WLSEs, for , has larger values than other WLSEs in some cases but the differences are small. In addition, shows the best result in that the bias values are close to zero. In the case of , generally has better performance than that of other WLSEs in terms of the MSE. As expected, the MSEs decrease as the sample size n increases. In addition, for the fixed sample size n, the same pattern is observed as the pre-fixed failure number m increases. One interesting thing is that the MSEs generally decrease as decreases for the estimators of .
3.2. Real Data
Wind is increasingly used worldwide as an alternative clean energy source. The most important parameter of wind energy is the wind speed, which is a random parameter that can be estimated by using the proposed approach. This subsection considers 30 monthly average wind speed values (Table 1) presented in Abd-Elfattah [9], which was computed from the daily wind speed values of the index Swedish Meteorological and Hydrological Institute records for 2006 to 2008. In addition, the progressive Type-II censored sample (Table 2) generated by Zhang and Gui [10] from Table 1 is analyzed and Table 3 reports the results.

Table 1.
30 monthly observed average wind speed data from 2006 to 2008.
Table 2.
Progressive Type-II censored sample generated by Zhang and Gui [10] from the real data.
Table 3.
Estimates of and for the observed progressive Type-II censored sample.
To examine the goodness-of-fit of a Weibull distribution to the observed progressive Type-II censored sample, two approaches are considered: One is to use the replicated data that are generated from the following steps
- (a)
- Compute the estimates of and .
- (b)
- Generate from the marginal density function with the estimates obtained in (a), where
- (c)
- Repeat 10,000), (b).
Other is to compare with its mean as follows:
- (a)
- Compute the estimates of and .
- (b)
- Compute = with the estimates obtained in (a).
Figure 3 plots the predictive regions for and the scatter plot between the observed progressive Type-II censored sample and . The result shows that the Weibull distribution fits the observed progressive Type-II censored sample very well for all estimates, while the MLE has better performance than the WLSEs in terms of the uncertainty because of its smaller predictive regions. Figure 4 illustrates the relationship and the sample correlation coefficient r between and . The strong correlation coefficients in Figure 4 indicate that the Weibull distribution fits the observed progressive Type-II censored sample very well for all estimates, as in the case of Figure 3.
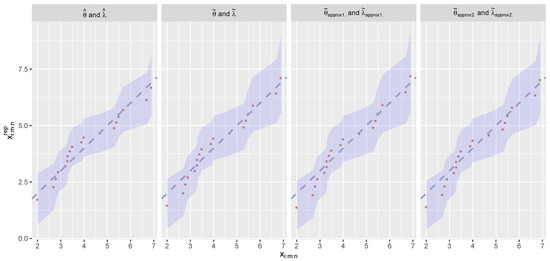
Figure 3.
95% predictive regions for and the scatter plot between the observed progressive Type-II censored sample and .
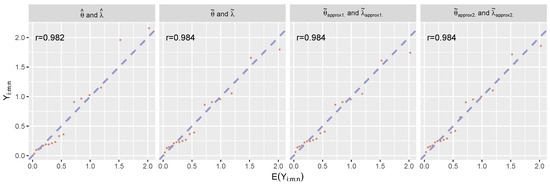
Figure 4.
The scatter plots between and .
4. Conclusions
This study proposes a new estimation method based on the weighted least squares method under the progressive Type-II censoring scheme, which provides a closed form solution of the shape parameter that can be of interest, unlike the MLE. Whereas many studies have generally used a pivotal quantity , this article employed , which leads to a simple linear regression model. To obtain the WLSEs based on the regression model, the exact mean and variance of are employed, but they suffer serious rounding errors for large samples. For this reason, two different types of Taylor series expansion are provided to approximate the mean and variance of . To prove the superiority of the proposed estimation method, the Monte Carlo simulation is conducted, and the results demonstrate the superiority of all the proposed WLSEs to the MLE in terms of the MSE. Our approach offers three benefits: it can be expressed in a closed form of a shape parameter that can be a parameter of interest, the resulting performance is enhanced in terms of MSE, and it can be applied to other censoring schemes.
Author Contributions
Conceptualization, S.-B.K.; Formal analysis, J.-I.S. and Y.E.J.; Funding acquisition, J.-I.S.; Methodology, J.-I.S., Y.E.J. and S.-B.K.; Software, J.-I.S. and Y.E.J.; Supervision, S.-B.K.; Validation, S.-B.K.; Writing—original draft, Y.E.J.; Writing—review & editing, J.-I.S. and S.-B.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (Ministry of Education) (No. NRF-2019R1I1A3A01062838).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Pareek, B.; Kundu, D.; Kumar, S. On progressively censored competing risks data for Weibull distributions. Comput. Stat. Data Anal. 2009, 53, 4083–4094. [Google Scholar] [CrossRef]
- Wang, B.X.; Yu, K.; Jones, M.C. Inference under progressively Type-II right-censored sampling for certain lifetime distributions. Technometrics 2010, 52, 453–460. [Google Scholar] [CrossRef]
- Abdel-Hamid, A.H.; Al-Hussaini, E.K. Inference for a progressive stress model from Weibull distribution under progressive Type-II censoring. J. Comput. Appl. Math. 2011, 235, 5259–5271. [Google Scholar] [CrossRef]
- Valiollahi, R.; Asgharzadeh, A.; Raqab, M.Z. Estimation of P(Y<X) for Weibull distribution under progressive Type-II censoring. Commun. Stat.-Theory Methods 2013, 42, 4476–4498. [Google Scholar]
- Lu, H.L.; Tao, S.H. The estimation of Pareto distribution by a weighted least square method. Qual. Quant. 2007, 41, 913–926. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Aggarwala, R. Progressive Censoring: Theory, Methods, and Applications; Birkhauser: Boston, MA, USA, 2000. [Google Scholar]
- Lee, K.; Sun, H.; Cho, Y. Exact likelihood inference of the exponential parameter under generalized Type-II progressive hybrid censoring. J. Korean Stat. Soc. 2016, 45, 123–136. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Sandhu, R.A. A simple simulational algorithm for generating progressive Type-II censored samples. Am. Stat. 1995, 49, 229–230. [Google Scholar]
- Abd-Elfattah, A.M. Goodness of fit test for the generalized Rayleigh distribution with unknown parameters. J. Stat. Comput. Simul. 2011, 81, 357–366. [Google Scholar] [CrossRef]
- Zhang, Z.; Gui, W. Statistical inference of reliability of Generalized Rayleigh distribution under progressively Type-II censoring. J. Comput. Appl. Math. 2019, 361, 295–312. [Google Scholar] [CrossRef]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).