Abstract
We present a nonlinear multigrid implementation for the two-dimensional Cahn–Hilliard (CH) equation and conduct detailed numerical tests to explore the performance of the multigrid method for the CH equation. The CH equation was originally developed by Cahn and Hilliard to model phase separation phenomena. The CH equation has been used to model many interface-related problems, such as the spinodal decomposition of a binary alloy mixture, inpainting of binary images, microphase separation of diblock copolymers, microstructures with elastic inhomogeneity, two-phase binary fluids, in silico tumor growth simulation and structural topology optimization. The CH equation is discretized by using Eyre’s unconditionally gradient stable scheme. The system of discrete equations is solved using an iterative method such as a nonlinear multigrid approach, which is one of the most efficient iterative methods for solving partial differential equations. Characteristic numerical experiments are conducted to demonstrate the efficiency and accuracy of the multigrid method for the CH equation. In the Appendix, we provide C code for implementing the nonlinear multigrid method for the two-dimensional CH equation.
MSC:
65N06; 65N55
1. Introduction
In this paper, we consider a detailed multigrid [1] implementation of the following two-dimensional Cahn–Hilliard (CH) equation [2] and provide its C source code:
where is a conserved scalar field; M is the mobility; is the free energy function (see Figure 1); is the gradient interfacial energy coefficient; and is a bounded domain.
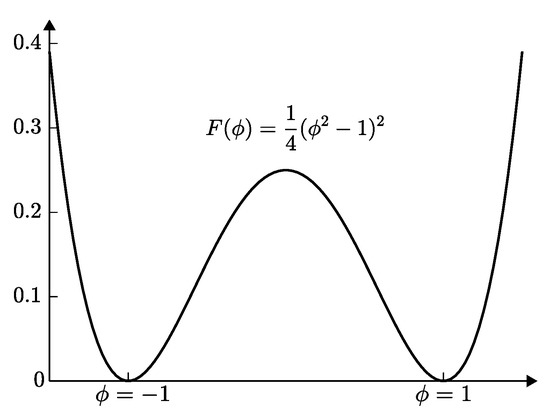
Figure 1.
Double-well potential .
The homogeneous Neumann boundary conditions are used and are given as follows:
Here, is the unit normal vector on the domain boundary . The first boundary condition (1) implies that the interface contacts the domain boundary at a angle. The second boundary condition (2) implies that the total mass is conserved.
We can derive the CH equation from the following total free energy functional
Taking the variational derivative of with respect to , we define the chemical potential:
Conservation of mass implies the following CH equation
where the flux is given by . If we differentiate and with respect to time t, then we have
and
which imply that the total energy is decreasing and that the total mass is conserved in time, respectively. The CH equation was originally developed by Cahn and Hilliard to model spinodal decomposition in a binary alloy. The CH equation has been used to address many major problems such as the spinodal decomposition of a binary alloy mixture [3,4], inpainting of binary images [5,6], microphase separation of diblock copolymers [7,8], microstructures with elastic inhomogeneity [9,10], two-phase binary fluids [11,12], tumor growth models [13,14,15] and structural topology optimization [14,16]. Further details regarding the basic principles and practical applications of the CH equation are available in a recent review [14]. Thus, knowing how to implement a discrete scheme for the CH equation in detail is very useful because this equation is a building-block equation for many applications. The CH equation is discretized by using Eyre’s unconditionally gradient stable scheme [17] and is solved by using a nonlinear multigrid technique [1], which is one of the most efficient iterative methods for solving partial differential equations. Several studies have used the nonlinear multigrid method for the CH-type equations [18,19,20,21,22,23]. However, details regarding the implementation, multigrid performance, and source codes have not been provided.
Therefore, the main purpose of this paper is to describe a detailed multigrid implementation of the two-dimensional CH equation, evaluate its performance and provide its C programming language source code.
The remainder of this paper is organized as follows. In Section 2, we describe the numerical solution in detail. In Section 3, we describe the characteristic numerical experiments that are conducted to demonstrate the accuracy and efficiency of the multigrid method for the CH equation. In Section 4, we provide a conclusion. In the Appendix A, we provide the C code for implementing the nonlinear multigrid technique for the two-dimensional CH equation.
2. Numerical Solution
We consider a finite difference approximation for the CH equation. An unconditionally gradient energy stable scheme, which was proposed by Eyre, is applied to the time discretization. A nonlinear multigrid technique [1] is applied to solve the resulting system at an implicit time level.
2.1. Discretization
We discretize the CH equation in the two-dimensional space . Let and be the numbers of mesh points with integers p and q. Let and be the mesh size. Let be a discrete computational domain. Let and be approximations of and , respectively. Here, and represent the temporal step. We assume a uniform mesh grid and a constant mobility . Using the nonlinear stabilized splitting scheme of Eyre’s unconditionally gradient stable scheme, the CH equation is discretized as
where the discrete Laplace operator is defined by . The homogeneous Neumann boundary conditions (1) and (2) are discretized as
We define the discrete residual as
For each element of size in matrix A, we define the Frobenius norm with a scaling and infinite norm as
respectively. The discretizations (5) and (6) are conservative, that is,
To show this conservation property, we take the summation of Equation (5)
Here, we used the homogenous Neumann boundary conditions (7) and (8). Therefore, Equation (11) holds. We define the discrete energy functional as
where we used the homogenous Neumann boundary conditions (7) and (8). We also define the discrete total mass as
Then, the unconditionally gradient stable scheme satisfies the reduction in the discrete total energy [24]:
which implies the pointwise boundedness of the numerical solution:
The proof of Equation (16) can be found in Reference [25]. We provide the proof herein for the sake of completeness. We show that a constant K exists for all n values that satisfy the following inequality:
Let us assume that there is an integer that is dependent on K such that for any K. Then, exists such that . Let K be the largest solution of , that is, . We then have
where we utilize the fact that the total energy is decreasing and is a strictly increasing function on . Equation (18) leads to a contradiction. Therefore, Equation (17) should be satisfied.
2.2. Multigrid V-Cycle Algorithm
We use the nonlinear full approximation storage (FAS) multigrid method to solve the nonlinear discrete systems (5) and (6). For simplicity, we define the discrete domains, and , which represent a hierarchy of meshes ( and ) created by successively coarsening the original mesh , as shown in Figure 2.
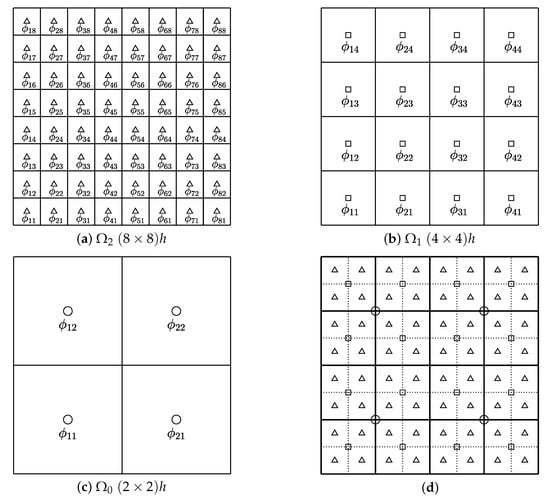
Figure 2.
(a–c) represent a sequence of coarse grids starting with . (d) depicts a composition of grids, and .
We summarize here the nonlinear multigrid method for solving the discrete CH system as follows: First, let us rewrite Equations (5) and (6) as
where the linear operator is defined as
and the source term is denoted by
Next, we describe the multigrid method, which includes the pre-smoothing, coarse grid correction and post-smoothing steps. We denote a mesh grid as the discrete domain for each multigrid level k. Note that a mesh grid contains grid points. Let be the coarsest multigrid level. We now introduce the SMOOTH and V-cycle functions. Given the number of pre-smoothing and of post-smoothing relaxation sweeps, the V-cycle is used as an iteration step in the multigrid method.
FAS multigrid cycle
Now, we define the FAScycle:
In other words, are the approximations of and before and after an FAScycle, respectively. Here, and .
(1) Pre-smoothing
which represents smoothing steps with the initial approximations , source terms and the relaxation operator to obtain the approximations One relaxation operator step consists of solving the systems (22) and (23), given as follows by matrix inversion for each . Here, we derive the smoothing operator in two dimensions. Rewriting Equation (5), we obtain:
Because is nonlinear with respect to , we linearize at , that is,
After substituting of this into (6), we obtain
(2) Compute the defect
(3) Restrict the defect and
The restriction operator maps k-level functions to -level functions.
(4) Compute the right-hand side
(5) Compute an approximate solution of the coarse grid equation on , that is,
If , we explicitly invert the matrix to obtain the solution. If , we solve Equation (24) by performing a FAS k-grid cycle using as the initial approximation:
(6) Compute the coarse grid correction (CGC):
(7) Interpolate the correction:
Here, the coarse values are simply transferred to the four nearby fine grid points, that is, for i and j odd-numbered integers.
(8) Compute the corrected approximation on
(9) Post-smoothing
This completes the description of the nonlinear FAScycle. One FAScycle step stops if the consequent error is less than a given tolerance . The two-grid V-cycle is illustrated in Figure 3.
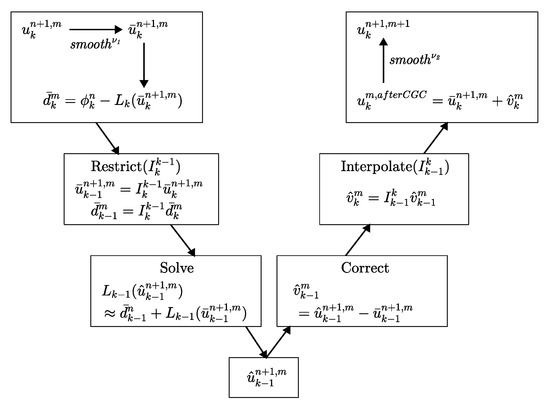
Figure 3.
Multigrid two-grid V-cycle method.
Further Numerical Schemes for the CH Equation
Previous studies have described the numerical solution of the CH equation with a variable mobility [19], the adaptive mesh refinement technique [26,27], the Neumann boundary condition in complex domains [20], the Dirichlet boundary conditions in complex domains [28], contact angle boundary [29], parallel multigrid method [30] and fourth-order compact scheme [31].
3. Numerical Experiments
In numerical experiments, we consider an equilibrium solution for the CH equation on the one-dimensional infinite domain . In other words, satisfies and is an equilibrium solution. Then, across the interfacial regions, varies from to over a distance of approximately (see Figure 4). Therefore, if we want this value to be approximately , the value can be taken as [32].
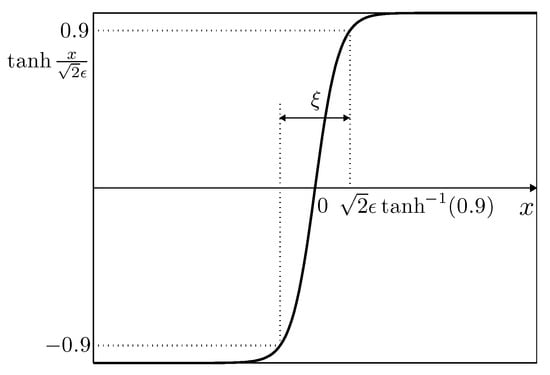
Figure 4.
Concentration field varying from to over a distance of approximately .
All computational simulations described in this section are performed on an Intel Core i5-6400 CPU @ 2.70 GHz with 4 GB of RAM.
3.1. Phase Separation
For the first numerical test, we consider spinodal decomposition in binary alloys. This decomposition is a process by which a mixture of binary materials separates into distinct regions with different material concentrations [2]. Figure 5a–c show snapshots of the phase-field at , and , respectively. The initial condition is on , where is a random value between 0 and 1. The parameters , , and a tolerance of = are used.
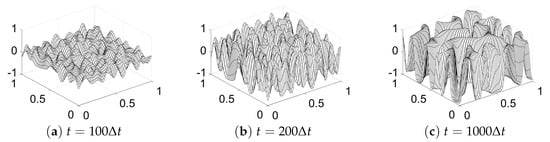
Figure 5.
Snapshots of the phase-field at (a) , (b) and (c) . Here, , and are used.
3.2. Non-Increase in Discrete Energy and Mass Conservation
Figure 6 shows the time evolution of the normalized discrete total energy (solid line) and the average mass (diamond) of the numerical solutions with the initial state (25) on .
where is a random value between 0 and 1.
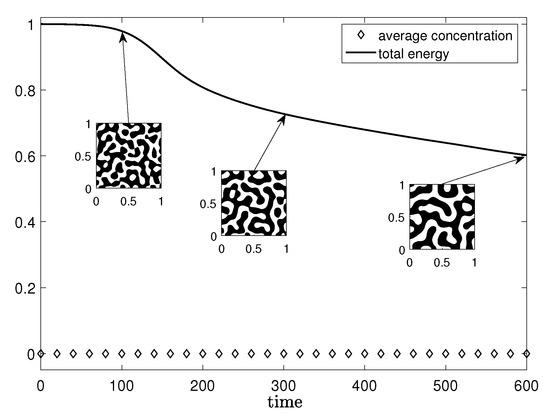
Figure 6.
Normalized discrete total energy (solid line) and average concentration (diamond line) of the numerical solutions with the initial state (25).
We use the simulation parameters, and = . The energy is non-increasing and the average concentration is conserved. These numerical results agree well with the total energy dissipation property (3) and the conservation property (4). The inscribed small figures are the concentration fields at the indicated times.
3.3. Convergence Test
We consider the convergence of the Frobenius norm with a scaling of the residual error with respect to the grid size. The initial condition on the domain is given as
We fix , and = . Here, we use the scheme with a Gauss–Seidel relaxation, where indicates 2 pre- and 2 post-correction relaxation sweeps. We define the residual after m V-cycles as
Table 1 shows the residual norm after each V-cycle. Because no closed-form analytical solution exists for this problem, we define the Frobenius norm with a scaling of the residual error = . The grid sizes are set as , and . The error norms and ratios of residual between successive V-cycle are shown in Table 1. As we have expected, the residual error decreases successively along with the V-cycle. The sharp increase in the residual norm ratio during the last few cycles reflects the fact that the numerical approximation is already accurate to near machine precision.

Table 1.
Error and convergence results for various grid spaces.
3.4. Effect of Tolerance
The effect of multigrid tolerance is related to the average mass convergence. We set the initial condition on with tolerance, = , , , and to investigate the relationship between the mass convergence and . We use the simulation parameters , SMOOTH relaxation = 2, , and mesh size . To compare the theoretical value (solid line) with the computational value = (dotted line), = (dash-dot line), = (dashed line) and = (square), we set the interval of average mass from to . In Figure 7, the average mass gradually converges to a theoretical value with the decrease in tolerance. In addition, comparing the results of = , , and , we observe that the average mass become nearly convergent for = .
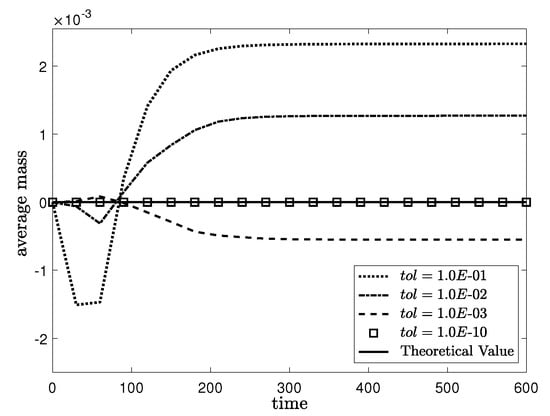
Figure 7.
Average mass of the numerical solutions in various values of tolerance. Here, the theoretical value (solid line), = (dotted line), = (dash-dot line), = (dashed line) and = (square).
3.5. Effects of the Smooth Relaxation Numbers and
We investigate the effects of the SMOOTH relaxation numbers (pre-relaxation) and (post-relaxation) on the CPU time. In this test, we perform a numerical simulation with the initial condition on , , , and = . Table 2 lists the average CPU times and average numbers of V-cycles for various pre- and post-relaxation numbers after 100 time steps. The relaxation numbers are rounded off to the nearest integer. Figure 8 shows the average CPU times for different pre- and post-relaxation numbers. We observe that the average CPU time is the lowest when the numbers of pre- and post-relaxation iterations are and , respectively.
Table 2.
Average CPU times and average numbers of V-cycles (given in parentheses) for various pre- and post-relaxation numbers after 100 time steps.
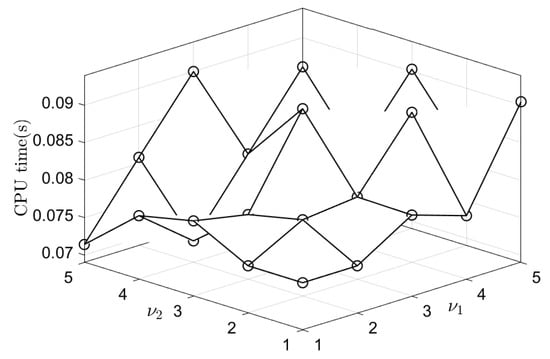
Figure 8.
Average CPU time for different pre- and post-relaxation numbers after 100 time steps.
Next, we investigate the effect of SMOOTH relaxation numbers on the finest multigrid level. We perform a numerical simulation with and = . The SMOOTH relaxation numbers and (on the finest multigrid level) are taken to be 1, 2, 3, 4, 5, 6, 7, 8, 9 and 10. In addition, other multigrid levels are and 3 in the and mesh sizes. The other parameters are the same as those used previously. Table 3 shows the variations in average CPU time for different relaxation numbers with a mesh size. Figure 9 illustrates the results in Table 3.
Table 3.
Average CPU times for various relaxation numbers on finest multigrid level () after 10 time steps. In other grids, relaxation number is fixed at and 3.
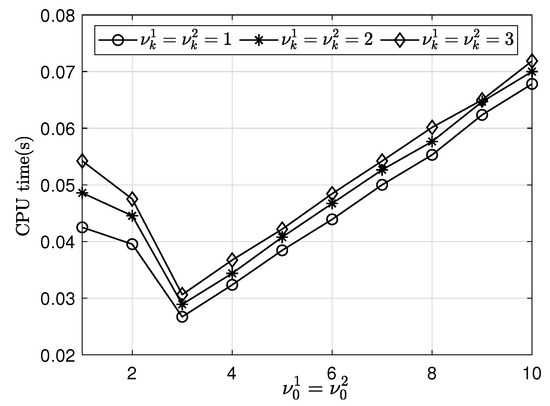
Figure 9.
Average CPU times for various relaxation numbers on finest multigrid level () and fixed relaxation number and 3 on other grids with a mesh size.
Table 4 lists the variations in average CPU time for different relaxation numbers with a mesh size. Figure 10 illustrates the results in Table 4.
Table 4.
Average CPU times for various relaxation numbers on finest multigrid level () after 10 time steps. In other grids, the relaxation number is fixed at and 3.
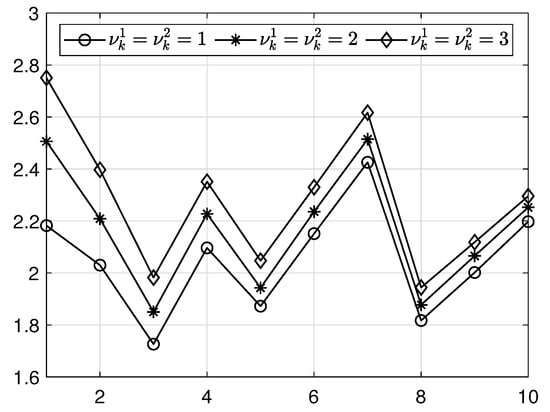
Figure 10.
Average CPU times for various relaxation numbers on finest multigrid level () and fixed relaxation numbers and 3 on other grids with a mesh size.
3.6. Effect Of V-Cycle
Next, we investigate the effect of V-cycle by changing the multigrid levels. In this test, we use the parameters , , SMOOTH relaxation , and on with a initial condition . The highest number of V-cycles is taken to be 10000. We use , , , , and in a single time step as examples to illustrate the effect of the V-cycle. We calculate the CPU time for each level after 100, as listed in Table 5.
Table 5.
Numbers of multigrid levels and CPU times required until tolerance ≤. Here, different levels are used.
The number of the multigrid level and CPU time shown in Figure 11 indicate that a greater number of the multigrid level leads to a obvious decrease in CPU time. It is important to select an appropriate multigrid level for a specific mesh size.
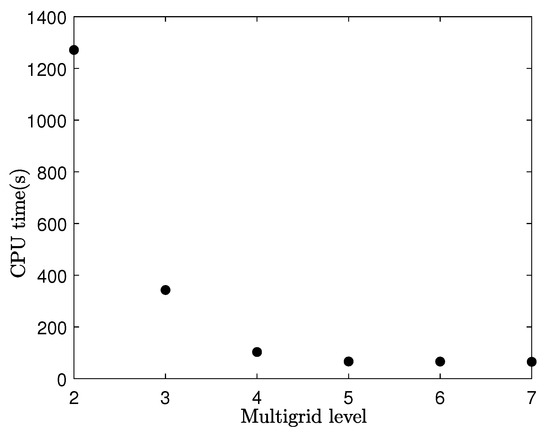
Figure 11.
Required CPU times in various multigrid levels after 100 time steps.
3.7. Comparison between Gauss–Seidel and Multigrid Algorithms
We compare the average CPU times required to perform the Gauss–Seidel algorithm and multigrid algorithm. In this test, the initial condition is taken to be . The following parameters are used—, , the SMOOTH relaxation and . The highest number of V-cycle is taken to be 10000. The mesh sizes are , and . The tolerances are , and . Table 6 shows the average CPU times for these two methods after 10 time steps. We observe that the multigrid method require less CPU time than the Gauss–Seidel method does.
Table 6.
Average CPU times for Gauss–Seidel and multigrid algorithms with different tolerances after 10 time steps.
3.8. Effects of and on the V-Cycle
In this test, we study the effects of and on the V-cycle with the initial condition being , . The highest number of the V-cycle is taken to be 10,000. Table 7 shows the number of V-cycle for various and after a single time step. We can find that lower values of lead to an increase in the V-cycle. For different values of , it is essential to choose an appropriate to reduce the number of V-cycle.
Table 7.
Numbers of V-cycles for various and after a single time step.
3.9. Comparison of the Jacobi, Red–Black and Gauss–Seidel
We compare the performance of three relaxation methods: Jacobi, Red–Black and Gauss–Seidel. The initial condition is on . The parameters are , , , and . The SMOOTH relaxation numbers on the finest multigrid level (i.e., ) are taken to be from 1 to 5 and those on the other multigrid levels are selected as 2 with the mesh size. The relaxation numbers are rounded off to the nearest integer. Table 8 shows the average number of V-cycles for different relaxation numbers with the three methods. The relationship between the average numbers of V-cycles and with the Jacobi, Red–Black and Gauss–Seidel method is plotted in Figure 12. The Gauss–Seidel method is observed to be the fastest. In the parallel multigrid method, the relaxation options are either Jacobi or Red–Black [33]. The Jacobi method requires approximately twice as many V-cycles as the Red–Black method does.
Table 8.
Average numbers of V-cycles for various relaxation numbers. The SMOOTH relaxation numbers on the finest multigrid level (i.e., ) are taken to be from 1 to 5.
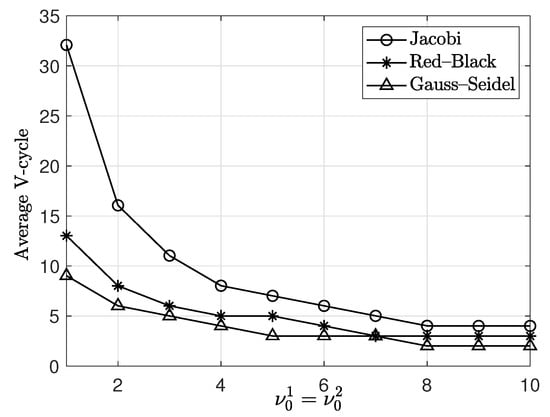
Figure 12.
Plot of the average numbers of V-cycles versus with the Jacobi (○), Red–Black (∗) and Gauss–Seidel (△) method.
3.10. Effect of
Next, we investigate the effect of , which is related to the interface width. In this test, we perform a numerical simulation with the initial condition
on . We use , , SMOOTH relaxation , and . Figure 13 presents the evolution of the CH equation with the three values , and . As we have expected, the lower value of leads to a narrower interface width.
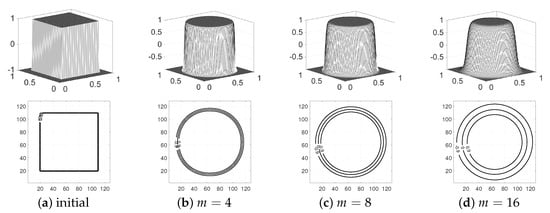
Figure 13.
Evolution of the Cahn–Hilliard (CH) equation with different : (a) initial condition, (b–d) , and at , respectively.
3.11. Effect of mesh size,
In this test, we compare the CPU times with different mesh sizes . The initial condition is on . The parameters are , , , , SMOOTH relaxation and . Table 9 shows the CPU times and their ratios (that is, the ratio of the CPU time with the mesh size to the CPU time with ). We observe that the values converge to 4.
Table 9.
CPU times for different mesh sizes.
4. Conclusions
In this paper, we presented a nonlinear multigrid implementation for the CH equation in a two-dimensional space. Eyre’s unconditionally gradient stable scheme was used to discretize the governing equation. The resulting discretizing equations were solved using the nonlinear multigrid method. We described the implementation of our numerical scheme in detail. We numerically showed the decrease in discrete total energy and the convergence of discrete total mass. We took a convergence test by studying the reductions in residual error on various mesh sizes in a single time step. The results of various numerical experiments were presented to demonstrate the effects of tolerance, SMOOTH relaxation, V-cycle and . The provided multigrid source code will be useful to beginners who needs the numerical implementation of the nonlinear multigrid method for the CH equation.
Author Contributions
All authors, C.L., D.J., J.Y., and J.K., contributed equally to this work and critically reviewed the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
The first author (C. Lee) was supported by Basic Science Research Program through the National Research Foundation of Korea(NRF) funded by the Ministry of Education(NRF-2019R1A6A3A13094308). D. Jeong was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIP) (NRF-2017R1E1A1A03070953). J. Yang is supported by China Scholarship Council (201908260060). The corresponding author (J.S. Kim) expresses thanks for the support from the BK21 PLUS program.
Acknowledgments
The authors thank the editor and the reviewers for their constructive and helpful comments on the revision of this article.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
The C code and MATLAB postprocessing code are given as follows, and the parameters are enumerated in Table A1.
Table A1.
Parameters used for the 2D Cahn–Hilliard equation.
Table A1.
Parameters used for the 2D Cahn–Hilliard equation.
| Parameters | Description |
|---|---|
| nx, ny | maximum number of grid points in the x-, y-direction |
| n_level | number of multigrid level |
| c_relax | number of times being relax |
| dt | |
| xleft, yleft | minimum value on the x-, y-axis |
| xright, yright | maximum value on the x-, y-axis |
| ns | number of print out data |
| max_it | maximum number of iteration |
| max_it_mg | maximum number of multigrid iteration |
| tol_mg | tolerance for multigrid |
| h | space step size |
| h2 | |
| gam | |
| Cahn |
The following C code is available on the following website:
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
#include <malloc.h>
#include <time.h>
#define gnx 32
#define gny 32
#define PI 4.0*atan(1.0)
#define iloop for(i=1;i<=gnx;i++)
#define jloop for(j=1;j<=gny;j++)
#define ijloop iloop jloop
#define iloopt for(i=1;i<=nxt;i++)
#define jloopt for(j=1;j<=nyt;j++)
#define ijloopt iloopt jloopt
int nx,ny,n_level,c_relax;
double **ct,**sc,**smu,**sor,h,h2,dt,xleft,xright,yleft,yright,gam,Cahn,**mu,**mi;
double **dmatrix(long nrl,long nrh,long ncl,long nch){
double **m;
long i,nrow=nrh-nrl+2,ncol=nch-ncl+2;
m=(double **) malloc((nrow)*sizeof(double*)); m+=1;m-=nrl;
m[nrl]=(double *) malloc((nrow*ncol)*sizeof(double)); m[nrl]+=1; m[nrl]-=ncl;
for (i=nrl+1; i<=nrh; i++) m[i]=m[i-1]+ncol;
return m;
}
void free_dmatrix(double **m,long nrl,long nrh,long ncl,long nch){
free(m[nrl]+ncl-1); free(m+nrl-1);
}
void zero_matrix(double **a,int xl,int xr,int yl,int yr){
int i,j;
for (i=xl; i<=xr; i++){ for (j=yl; j<=yr; j++){ a[i][j]=0.0; }}
}
void mat_add2(double **a,double **b,double **c,double **a2,
double **b2,double **c2,int xl,int xr,int yl,int yr){
int i,j;
for (i=xl; i<=xr; i++)
for (j=yl; j<=yr; j++){ a[i][j]=b[i][j]+c[i][j]; a2[i][j]=b2[i][j]+c2[i][j]; }
}
void mat_sub2(double **a,double **b,double **c,double **a2,
double **b2,double **c2,int nrl,int nrh,int ncl,int nch){
int i,j;
for (i=nrl;i<=nrh;i++)
for (j=ncl; j<=nch; j++){ a[i][j]=b[i][j]-c[i][j];a2[i][j]=b2[i][j]-c2[i][j]; }
}
void mat_copy(double **a,double **b,int xl,int xr,int yl,int yr){
int i,j;
for (i=xl; i<=xr; i++){ for (j=yl; j<=yr; j++){ a[i][j]=b[i][j]; }}
}
void mat_copy2(double **a,double **b,double **a2,double **b2,int xl,int xr,int yl,int yr){
int i,j;
for (i=xl; i<=xr; i++)
for (j=yl; j<=yr; j++){a[i][j]=b[i][j]; a2[i][j]=b2[i][j];}
}
void print_mat(FILE *fptr,double **a,int nrl,int nrh,int ncl,int nch){
int i,j;
for(i=nrl; i<=nrh; i++){ for(j=ncl; j<=nch; j++)
fprintf(fptr," %16.15f",a[i][j]); fprintf(fptr,"\n"); }
}
void print_data(double **phi) {
FILE *fphi;
fphi=fopen("phi.m","a"); print_mat(fphi,phi,1,nx,1,ny); fclose(fphi);
}
void laplace(double **a,double **lap_a,int nxt,int nyt){
int i,j;
double ht2,dadx_L,dadx_R,dady_B,dady_T;
ht2=pow((xright-xleft)/(double) nxt,2);
ijloopt {
if (i>1) dadx_L=a[i][j]-a[i-1][j];
else dadx_L=0.0;
if (i<nxt) dadx_R=a[i+1][j]-a[i][j];
else dadx_R=0.0;
if (j>1) dady_B=a[i][j]-a[i][j-1];
else dady_B=0.0;
if (j<nyt) dady_T=a[i][j+1]-a[i][j];
else dady_T=0.0;
lap_a[i][j]=(dadx_R-dadx_L+dady_T-dady_B)/ht2;}
}
void source(double **c_old,double **src_c,double **src_mu){
int i,j;
laplace(c_old,ct,nx,ny);
ijloop{src_c[i][j]=c_old[i][j]/dt-ct[i][j]; src_mu[i][j]=0.0;}
}
double df(double c){return pow(c,3);}
double d2f(double c){return 3.0*c*c;}
void relax(double **c_new,double **mu_new,double **su,double **sw,int ilevel,
int nxt, int nyt){
int i,j,iter;
double ht2,x_fac,y_fac,a[4],f[2],det;
ht2=pow((xright-xleft)/(double) nxt,2);
for (iter=1; iter<=c_relax; iter++){
ijloopt {
if (i>1 && i<nxt) x_fac=2.0;
else x_fac=1.0;
if (j>1 && j<nyt) y_fac=2.0;
else y_fac=1.0;
a[0]=1.0/dt; a[1]=(x_fac+y_fac)/ht2;
a[2]=-(x_fac+y_fac)*Cahn/ht2-d2f(c_new[i][j]); a[3]=1.0;
f[0]=su[i][j]; f[1]=sw[i][j]+df(c_new[i][j])-d2f(c_new[i][j])*c_new[i][j];
if (i>1) { f[0]+=mu_new[i-1][j]/ht2; f[1]-=Cahn*c_new[i-1][j]/ht2; }
if (i<nxt) { f[0]+=mu_new[i+1][j]/ht2; f[1]-=Cahn*c_new[i+1][j]/ht2; }
if (j>1) { f[0]+=mu_new[i][j-1]/ht2; f[1]-=Cahn*c_new[i][j-1]/ht2; }
if (j<nyt) { f[0]+=mu_new[i][j+1]/ht2; f[1]-=Cahn*c_new[i][j+1]/ht2; }
det=a[0]*a[3]-a[1]*a[2];
c_new[i][j]=(a[3]*f[0]-a[1]*f[1])/det;
mu_new[i][j]=(-a[2]*f[0]+a[0]*f[1])/det; }}
}
void restrictCH(double **uf,double **uc,double **vf,double **vc,int nxc,int nyc) {
int i,j;
for (i=1; i<=nxc; i++)
for (j=1; j<=nyc; j++){
uc[i][j]=0.25*(uf[2*i][2*j]+uf[2*i-1][2*j]+uf[2*i][2*j-1]+uf[2*i-1][2*j-1]);
vc[i][j]=0.25*(vf[2*i][2*j]+vf[2*i-1][2*j]+vf[2*i][2*j-1]+vf[2*i-1][2*j-1]);}
}
void nonL(double **ru,double **rw,double **c_new,double **mu_new,int nxt,int nyt) {
int i,j;
double **lap_mu,**lap_c;
lap_mu=dmatrix(1,nxt,1,nyt); lap_c=dmatrix(1,nxt,1,nyt);
laplace(c_new,lap_c,nxt,nyt); laplace(mu_new,lap_mu,nxt,nyt);
ijloopt{ ru[i][j]=c_new[i][j]/dt-lap_mu[i][j];
rw[i][j]=mu_new[i][j]-df(c_new[i][j])+Cahn*lap_c[i][j]; }
free_dmatrix(lap_mu,1,nxt,1,nyt); free_dmatrix(lap_c,1,nxt,1,nyt);
}
void defect(double **duc,double **dwc,double **uf_new,double **wf_new,double **suf,
double **swf,int nxf,int nyf,double **uc_new,double **wc_new,int nxc,int nyc) {
double **ruf,**rwf,**rruf,**rrwf,**ruc,**rwc;
ruc=dmatrix(1,nxc,1,nyc);rwc=dmatrix(1,nxc,1,nyc);ruf=dmatrix(1,nxf,1,nyf);
rwf=dmatrix(1,nxf,1,nyf);rruf=dmatrix(1,nxc,1,nyc);rrwf=dmatrix(1,nxc,1,nyc);
nonL(ruc,rwc,uc_new,wc_new,nxc,nyc);nonL(ruf,rwf,uf_new,wf_new,nxf,nyf);
mat_sub2(ruf,suf,ruf,rwf,swf,rwf,1,nxf,1,nyf);
restrictCH(ruf,rruf,rwf,rrwf,nxc,nyc);
mat_add2(duc,ruc,rruf,dwc,rwc,rrwf,1,nxc,1,nyc);
free_dmatrix(ruc,1,nxc,1,nyc); free_dmatrix(rwc,1,nxc,1,nyc);
free_dmatrix(ruf,1,nxf,1,nyf); free_dmatrix(rwf,1,nxf,1,nyf);
free_dmatrix(rruf,1,nxc,1,nyc); free_dmatrix(rrwf,1,nxc,1,nyc);
}
void prolong_ch(double **uc,double **uf,double **vc,double **vf, int nxc,int nyc){
int i,j;
for (i=1; i<=nxc; i++)
for (j=1; j<=nyc; j++){
uf[2*i][2*j]=uf[2*i-1][2*j]=uf[2*i][2*j-1]=uf[2*i-1][2*j-1]=uc[i][j];
vf[2*i][2*j]=vf[2*i-1][2*j]=vf[2*i][2*j-1]=vf[2*i-1][2*j-1]=vc[i][j];}
}
void vcycle(double **uf_new,double **wf_new,double **su,double **sw,int nxf,int nyf,
int ilevel) {
relax(uf_new,wf_new,su,sw,ilevel,nxf,nyf);
if (ilevel<n_level) {
int nxc,nyc;
double **duc,**dwc,**uc_new,**wc_new,**uc_def,**wc_def,**uf_def,**wf_def;
nxc=nxf/2; nyc=nyf/2;
duc=dmatrix(1,nxc,1,nyc); dwc=dmatrix(1,nxc,1,nyc);
uc_new=dmatrix(1,nxc,1,nyc); wc_new=dmatrix(1,nxc,1,nyc);
uf_def=dmatrix(1,nxf,1,nyf); wf_def=dmatrix(1,nxf,1,nyf);
uc_def=dmatrix(1,nxc,1,nyc); wc_def=dmatrix(1,nxc,1,nyc);
restrictCH(uf_new,uc_new,wf_new,wc_new,nxc,nyc);
defect(duc,dwc,uf_new,wf_new,su,sw,nxf,nyf,uc_new,wc_new,nxc,nyc);
mat_copy2(uc_def,uc_new,wc_def,wc_new,1,nxc,1,nyc);
vcycle(uc_def,wc_def,duc,dwc,nxc,nyc,ilevel+1);
mat_sub2(uc_def,uc_def,uc_new,wc_def,wc_def,wc_new,1,nxc,1,nyc);
prolong_ch(uc_def,uf_def,wc_def,wf_def,nxc,nyc);
mat_add2(uf_new,uf_new,uf_def,wf_new,wf_new,wf_def,1,nxf,1,nyf);
relax(uf_new,wf_new,su,sw,ilevel,nxf,nyf);
free_dmatrix(duc,1,nxc,1,nyc); free_dmatrix(dwc,1,nxc,1,nyc);
free_dmatrix(uc_new,1,nxc,1,nyc); free_dmatrix(wc_new,1,nxc,1,nyc);
free_dmatrix(uf_def,1,nxf,1,nyf); free_dmatrix(wf_def,1,nxf,1,nyf);
free_dmatrix(uc_def,1,nxc,1,nyc); free_dmatrix(wc_def,1,nxc,1,nyc); }
}
double error2(double **c_old,double **c_new,double **mu,int nxt,int nyt){
int i,j;
double **rr,res2,x=0.0;
rr=dmatrix(1,nxt,1,nyt);
ijloopt { rr[i][j]=mu[i][j]-c_old[i][j]; }
laplace(rr,sor,nx,ny);
ijloopt { rr[i][j]=sor[i][j]-(c_new[i][j]-c_old[i][j])/dt; }
ijloopt { x=(rr[i][j])*(rr[i][j])+x; }
res2=sqrt(x/(nx*ny));
free_dmatrix(rr,1,nxt,1,nyt);
return res2;
}
void initialization(double **phi){
int i,j;
double x,y;
ijloop {x=(i-0.5)*h; y=(j-0.5)*h; phi[i][j]=cos(PI*x)*cos(PI*y);}
}
void cahn(double **c_old,double **c_new){
FILE *fphi2;
int i,j,max_it_CH=10000,it_mg2=1;
double tol=1.0e-10, resid2=1.0;
source(c_old,sc,smu);
while (it_mg2<=max_it_CH && resid2>tol) {
it_mg2++; vcycle(c_new,mu,sc,smu,nx,ny,1);
resid2=error2(c_old,c_new,mu,nx,ny);
printf("error2 %16.15f %d \n",resid2,it_mg2-1);
fphi2=fopen("phi2.m","a");
fprintf(fphi2,"%16.15f %d \n",resid2,it_mg2-1); fclose(fphi2);}
}
int main(){
int it=1,max_it,ns,count=1,it_mg=1;
double **oc,**nc,resid2=1.0;
FILE *fphi,*fphi2;
c_relax=2; nx=gnx; ny=gny; n_level=(int)(log(nx)/log(2.0)+0.1);
xleft=0.0; xright=1.0; yleft=0.0; yright=1.0; max_it=100; ns=10; dt=0.01;
h=xright/(double)nx; h2=pow(h,2); gam=0.06; Cahn=pow(gam,2);
printf("nx=%d,ny=%d\n",nx,ny); printf("dt=%f\n",dt);
printf("max_it=%d\n",max_it); printf("ns=%d\n",ns); printf("n_level=%d\n\n",n_level);
oc=dmatrix(0,nx+1,0,ny+1); nc=dmatrix(0,nx+1,0,ny+1); mu=dmatrix(1,nx,1,ny);
sor=dmatrix(1,nx,1,ny); ct=dmatrix(1,nx,1,ny); sc=dmatrix(1,nx,1,ny);
mi=dmatrix(1,nx,1,ny); smu=dmatrix(1,nx,1,ny); zero_matrix(mu,1,nx,1,ny);
initialization(oc); mat_copy(nc,oc,1,nx,1,ny);
fphi=fopen("phi.m","w"); fclose(fphi); print_data(oc);
for (it=1; it<=max_it; it++) {
cahn(oc,nc); mat_copy(oc,nc,1,nx,1,ny);
if (it % ns==0) {count++; print_data(oc); printf("print out counts %d \n",count);}
printf(" %d \n",it);}
return 0;
}
The following MATLAB code produces the results shown in Figure 5. The code can also be downloaded from
clear; clc; close all;
ss=sprintf(’./phi.m’); phi=load(ss); nx=32; ny=32; n=size(phi,1)/nx;
x=linspace(0,1,nx); y=linspace(0,1,ny); [xx,yy]=meshgrid(x,y);
for i=1:n
pp=phi((i-1)*nx+1:i*nx,:);
figure(i); mesh(xx,yy,pp’); axis([0 1 0 1 -1 1]); view(-38,42);
end
References
- Trottenberg, U.; Schüller, A.; Oosterlee, C.W. Multigrid Methods; Academic Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Cahn, J.W.; Hilliard, J.E. Free energy of a nonuniform system. I. Interfacial free energy. J. Chem. Phys. 1958, 28, 258–267. [Google Scholar]
- Copetti, M.I.M.; Elliott, C.M. Kinetics of phase decomposition processes: Numerical solutions to Cahn–Hilliard equation. Mater. Sci. Technol. 1990, 6, 273–284. [Google Scholar]
- Honjo, M.; Saito, Y. Numerical simulation of phase separation in Fe-Cr binary and Fe-Cr-Mo ternary alloys with use of the Cahn–Hilliard equation. ISIJ Int. 2000, 40, 914–919. [Google Scholar]
- Bertozzi, A.L.; Esedoglu, S.; Gillette, A. Inpainting of binary images using the Cahn–Hilliard equation. IEEE Trans. Image Process. 2007, 16, 285–291. [Google Scholar]
- Bosch, J.; Kay, D.; Stoll, M.; Wathen, A.J. Fast solvers for Cahn–Hilliard inpainting. SIAM J. Imaging Sci. 2014, 7, 67–97. [Google Scholar]
- Choksi, R.; Peletier, M.A.; Williams, J.F. On the phase diagram for microphase separation of diblock copolymers: An approach via a nonlocal Cahn–Hilliard functional. SIAM J. Appl. Math. 2009, 69, 1712–1738. [Google Scholar]
- Tang, P.; Qiu, F.; Zhang, H.; Yang, Y. Phase separation patterns for diblock copolymers on spherical surfaces: A finite volume method. Phys. Rev. E 2005, 72, 016710. [Google Scholar]
- Hu, S.Y.; Chen, L.Q. A phase-field model for evolving microstructures with strong elastic inhomogeneity. Acta Mater. 2001, 49, 1879–1890. [Google Scholar]
- Yu, P.; Hu, S.Y.; Chen, L.Q.; Du, Q. An iterative-perturbation scheme for treating inhomogeneous elasticity in phase-field models. J. Comput. Phys. 2005, 208, 34–50. [Google Scholar]
- Gurtin, M.E.; Polignone, D.; Vinals, J. Two-phase binary fluids and immiscible fluids described by an order parameter. Math. Models Methods Appl. Sci. 1996, 6, 815–831. [Google Scholar]
- Lee, T. Effects of incompressibility on the elimination of parasitic currents in the lattice Boltzmann equation method for binary fluids. Comput. Math. Appl. 2009, 58, 987–994. [Google Scholar]
- Jeong, D.; Kim, J. Phase-field model and its splitting numerical scheme for tissue growth. Appl. Numer. Math. 2017, 117, 22–35. [Google Scholar]
- Kim, J.; Lee, S.; Choi, Y.; Lee, S.M.; Jeong, D. Basic Principles and Practical Applications of the Cahn–Hilliard Equation. Math. Probl. Eng. 2016, 2016, 9532608. [Google Scholar]
- Colli, P.; Gilardi, G.; Sprekels, J. A distributed control problem for a fractional tumor growth model. Mathematics 2019, 7, 792. [Google Scholar]
- Myśliński, A.; Wroblewski, M. Structural optimization of contact problems using Cahn–Hilliard model. Comput. Struct. 2017, 180, 52–59. [Google Scholar]
- Eyre, D.J. Unconditionally gradient stable time marching the Cahn–Hilliard equation. MRS Proc. 1998, 529, 39. [Google Scholar]
- Yang, S.; Lee, H.; Kim, J. A phase-field approach for minimizing the area of triply periodic surfaces with volume constraint. Comput. Phys. Commun. 2010, 181, 1037–1046. [Google Scholar]
- Kim, J. A numerical method for the Cahn–Hilliard equation with a variable mobility. Commun. Nonlinear Sci. Numer. Simul. 2007, 12, 1560–1571. [Google Scholar]
- Shin, J.; Jeong, D.; Kim, J. A conservative numerical method for the Cahn–Hilliard equation in complex domains. J. Comput. Phys. 2011, 230, 7441–7455. [Google Scholar]
- Jeong, D.; Kim, J. A practical numerical scheme for the ternary Cahn–Hilliard system with a logarithmic free energy. Phys. A 2016, 442, 510–522. [Google Scholar]
- Lee, H.; Kim, J. A second-order accurate non-linear difference scheme for the N-component Cahn–Hilliard system. Phys. A 2008, 387, 4787–4799. [Google Scholar]
- Lee, H.G.; Shin, J.; Lee, J.Y. A High-Order Convex Splitting Method for a Non-Additive Cahn–Hilliard Energy Functional. Mathematics 2019, 7, 1242. [Google Scholar]
- Shin, J.; Choi, Y.; Kim, J. An unconditionally stable numerical method for the viscous Cahn–Hilliard equation. Discret. Contin. Dyn. Syst. Ser. B 2014, 19, 1737–1747. [Google Scholar]
- Kim, J. Phase-field models for multi-component fluid flows. Commun. Comput. Phys. 2012, 12, 613–661. [Google Scholar]
- Kim, J.; Bae, H.O. An unconditionally gradient stable adaptive mesh refinement for the Cahn–Hilliard equation. J. Korean Phys. Soc. 2008, 53, 672–679. [Google Scholar]
- Wise, S.; Kim, J.; Lowengrub, J. Solving the regularized, strongly anisotropic Cahn–Hilliard equation by an adaptive nonlinear multigrid method. J. Comput. Phys. 2007, 226, 414–446. [Google Scholar]
- Li, Y.; Jeong, D.; Shin, J.; Kim, J. A conservative numerical method for the Cahn–Hilliard equation with Dirichlet boundary conditions in complex domains. Comput. Math. Appl. 2013, 65, 102–115. [Google Scholar]
- Lee, H.G.; Kim, J. Accurate contact angle boundary conditions for the Cahn–Hilliard equations. Comput. Fluids 2011, 44, 178–186. [Google Scholar]
- Shin, J.; Kim, S.; Lee, D.; Kim, J. A parallel multigrid method of the Cahn–Hilliard equation. Comput. Mater. Sci. 2013, 71, 89–96. [Google Scholar]
- Lee, C.; Jeong, D.; Shin, J.; Li, Y.; Kim, J. A fourth-order spatial accurate and practically stable compact scheme for the Cahn–Hilliard equation. Phys. A 2014, 409, 17–28. [Google Scholar]
- Choi, J.W.; Lee, H.G.; Jeong, D.; Kim, J. An unconditionally gradient stable numerical method for solving the Allen–Cahn equation. Phys. A 2009, 388, 1791–1803. [Google Scholar]
- Baker, A.H.; Falgout, R.D.; Kolev, T.V.; Yang, U.M. Scaling hypre’s multigrid solvers to 100,000 cores. In High-Performance Scientific Computing; Springer: London, UK, 2012; pp. 261–279. [Google Scholar]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).