Abstract
Industrial-Internet security faces a core challenge: improving detection accuracy for critical minority-class network attacks. The existing intrusion detection methods based on Conditional Generative Adversarial Nets (CGANs) aim to achieve data balance by reconstructing minority-class attack samples. However, they encounter problems such as generating deceptive samples, poor sample quality, vanishing gradients and difficulties in training. This paper proposes an intrusion detection method based on the Multi-Discriminator Conditional Classification Generative Adversarial Network (MDCCGAN), an improved variant of CGAN, which integrates multiple discriminators and an independent classifier into the traditional CGAN framework. The multiple discriminators reduce the probability of generating deceptive samples, the independent classifier decouples the classification loss to clarify the direction of gradient updates, and the introduction of the Wasserstein distance fundamentally addresses the gradient-vanishing problem. Experiments conducted on the NSL-KDD and UNSW-NB15 datasets demonstrate that the proposed method significantly improves the recall, F1-score and accuracy for minority-class attacks. Specifically, on the NSL-KDD dataset, the overall accuracy increases from 74% to 94%, and the F1-score for the extremely rare U2R attack surges from 0% to 77%. Similarly, on the UNSW-NB15 dataset, the accuracy reaches 88%, a 10% improvement over the baseline DNN, and the F1-scores for extreme minority attacks such as Analysis, Backdoor, and Worms improved to 97%, 62%, and 84%, respectively. These results confirm that our method effectively outperforms traditional generation models and common class-balancing methods. It provides reliable technical support for industrial-Internet security.
Keywords:
minority-class attack; conditional generative adversarial networks; multiple discriminators; Wasserstein distance; class balance MSC:
68-06
1. Introduction
Intrusion Detection Systems (IDSs) play a critical role in enhancing the cybersecurity of the industrial Internet. As a key technical component of the industrial-Internet security protection system, an IDS can ensure information integrity and the privacy and security of transmitted data [1]. Its working principle is to retrieve known attack signatures or identify abnormal features that deviate from preset normal activities [2]. Leveraging an active defense mode, the system is capable of detecting and reporting any abnormal traffic with network security risks automatically, which covers risk scenarios ranging from internal attacks and external intrusions to operational errors [3]. When network attacks or malicious behaviors occur, the system can automatically trigger alarm mechanisms or implement corresponding protective actions. Therefore, an IDS is pivotal to safeguarding the cybersecurity of the industrial Internet, protecting information integrity and the privacy and security of transmitted data, ensuring data integrity and reliability, and maintaining the normal operation of industrial production.
Currently, deep learning models are widely applied to construct intrusion detection systems, thanks to their capacity for processing massive high-dimensional feature data and their adaptive learning characteristics. Although existing studies have significantly improved the overall accuracy of intrusion detection by optimizing model architectures, these schemes share a critical flaw: detection accuracy of minority-class attack samples is often masked by overall metrics, which weakens the ability of models to identify low-frequency attacks in practical industrial scenarios. Moreover, the imbalance between normal traffic samples and attack traffic samples is particularly pronounced in practical application environments of the industrial Internet [4]. Dimensional completeness and sample diversity of dataset are key prior conditions determining performance of deep learning-based intrusion detection models [5]. This is because deep learning-based intrusion detection methods rely heavily on large-scale labeled samples for model training, which readily leads to the issue of “majority-class-dominated training process” in imbalanced data scenarios. Such a problem impairs the model detection performance on critical minority-class samples in multi-classification tasks, resulting in low detection rates and high false positive rates for minority-class attacks and thus severely limiting practical applicability of the models [6]. Notably, attack behaviors in industrial-Internet scenarios typically exhibit characteristics of concealment, diversity and suddenness. The missed detection of minority-class attack samples is highly likely to trigger serious security incidents such as equipment failures, production interruptions and even industrial control system paralysis. To clarify the problem formulation across different datasets, in this study, we formally define “minority classes” as those attack categories that constitute an extremely small fraction of the overall network traffic, typically accounting for less than 1.5% of the total dataset. For instance, this corresponds to the R2L and U2R aggregated classes in the NSL-KDD dataset, and the Analysis, Backdoors, Shellcode, and Worms categories in the UNSW-NB15 multi-class dataset. Furthermore, these minority attacks are designated as “critical” because, despite their low occurrence frequency, their mechanisms, such as gaining unauthorized root privileges or stealthily bypassing security protocols, pose severe threats. The successful execution of these attacks can lead to devastating system-level compromises, making their accurate detection disproportionately important relative to their minimal sample size. Therefore, addressing the data imbalance problem and improving detection accuracy of minority-class attacks have become core bottlenecks urgently requiring breakthroughs in the field of industrial-Internet intrusion detection, which are directly related to the practical application value of deep learning models in industrial security protection.
In the early stage of research, oversampling technology is one of the classic core methods to address class imbalance problems [7]. Due to its significant advantages of simple principles and convenient implementation, it is widely applied in many classification tasks such as intrusion detection. The core idea of such technologies lies in actively adjusting the distribution ratio of samples of various classes in the dataset. Specifically, the data imbalance can be alleviated through two key approaches: first, directly performing repeated sampling to increase the number of minority-class attack samples, such as Random Over Sampling (ROS); second, generating virtual minority-class samples through interpolation in the feature space, such as Synthetic Minority Oversampling Technique (SMOTE) [8] and Adaptive Synthetic Sampling Approach (ADASYN) [9]. Through the aforementioned approaches, although oversampling technology can assist classification models in learning feature representations of samples from various classes in a more balanced way and thereby improve the ability of models to identify minority-class attacks to a certain extent, the improvement effect is not significant. The root cause of this phenomenon lies in the inherent limitations of oversampling technology, which directly restrict the performance improvement of deep learning-based intrusion detection models. This is specifically manifested in two aspects: first, random oversampling achieves data balance by simply repeating minority-class samples. This mechanical sample augmentation easily leads to data redundancy, causing deep learning models to overfit local features of minority-class samples during training. This significantly impairs model generalization ability and hinders effective adaptation to the practical demand of diverse attack types in industrial scenarios. Second, for interpolation-based oversampling methods such as SMOTE and its improved algorithms, the generated virtual samples often fail to accurately match the distribution of real data and tend to distort the feature space structure of original data. This prevents models from accurately learning essential data features, thereby reducing the detection accuracy of minority-class attacks. These limitations indicate that traditional oversampling technologies cannot fundamentally solve the data imbalance problem in industrial-Internet intrusion detection, nor can they provide high-quality balanced training data for deep learning models. Against this backdrop, the current Conditional Generative Adversarial Nets (CGANs) [10] have stood out due to their powerful capability of generating specified real samples. This type of model introduces a conditional discrimination mechanism on the basis of the generative adversarial network. Through the adversarial training mechanism of the generator and the discriminator, it overcomes the drawback that the generative adversarial networks (GANs) [11] cannot generate labeled samples. A CGAN can learn the distribution characteristics of real data and generate high-fidelity attack samples as specified, precisely making up for the deficiencies of oversampling techniques in terms of sample generation quality and data distribution fitting. Although the traditional CGAN has demonstrated significant advantages in generating targeted samples, when directly applied to the industrial-Internet intrusion detection scenario, it still has inherent drawbacks that cannot be ignored, mainly reflected in the following three aspects:
- Insufficient stability during training. During the adversarial training of a traditional CGAN generator and discriminator, problems are prone to occur. These include difficulty in convergence and training oscillation. Such issues make it hard to achieve dynamic balance between the two components. This further affects the stability and consistency of generated samples. Meanwhile, traditional CGAN with a single discriminator has poor discrimination ability. The generator tends to produce deceptive samples. This leads to imbalance in the generative discrimination cycle game. Consequently, the gradient signal received by the generator approaches zero, resulting in model collapse.
- The quality of generated samples needs improvement. In industrial-Internet scenarios where attack samples have complex features and diverse patterns, the single discriminator of traditional CGANs must undertake two core tasks simultaneously. One is to evaluate the authenticity of generated samples, which is quality discrimination. The other is to verify the matching between generated samples and labels, which is category discrimination. This dual task load makes it difficult for the discriminator to accurately distinguish and optimize discrimination loss and classification loss. It further transmits vague gradient guidance signals to the generator. Eventually, this results in the poor quality of generated samples. These samples can hardly accurately fit the distribution characteristics of real attack samples.
- The category discrimination ability is limited. Traditional CGANs can generate labeled samples. However, in multi-class generation scenarios, the single discriminator’s performance is limited in multi-class scenarios, preventing it from providing the generator with accurate gradients regarding category matching. As a result, the generator generates samples that do not match the target labels. This directly undermines the effectiveness of the data augmentation process.
To address the problem of missed detection of key minority attacks caused by data imbalance in industrial-Internet intrusion detection, as well as the inherent defects of conditional generative adversarial networks, this paper proposes to introduce a multi-discriminator collaborative mechanism and an independent classifier module into the traditional CGAN architecture to construct a Multi-discriminator Conditional Classification Generative Adversarial Network (MDCCGAN) model, and cascades it with a Deep Neural Network (DNN) to form an MDCCGAN-DNN hybrid detection framework. Specifically, the core collaborative mechanism of this framework is divided into two modules. First, the MDCCGAN module is responsible for high-quality sample generation and data balancing. Multiple discriminators jointly judge the authenticity and category consistency of generated samples. An independent classifier is introduced to specifically undertake the task of accurate category determination for generated samples. The gradient loss output by the two components collaboratively guide the generator to generate high-quality and category-accurate minority-class attack samples. By using multiple discriminators and independent classifiers, the discrimination loss and classification loss of the traditional CGAN discriminator can be effectively decoupled. This not only avoids the problem of unclear gradient direction transmission but also significantly reduces the probability of the generator generating deceptive samples, ultimately achieving the expansion and balance of the original imbalanced dataset. Ultimately, the expansion and balancing of the original imbalanced dataset are achieved. Second, the DNN classifier module enables accurate identification of attack patterns. Leveraging the balanced dataset enhanced by MDCCGAN, the DNN deeply mines the high-level semantic features of attack behaviors through stacked layers of nonlinear transformation units, thereby constructing a precise attack pattern recognition model. The collaborative design of this hybrid framework not only effectively mitigates the interference of class imbalance on model training but also significantly improves the detection accuracy and generalization ability of the detection model for critical minority-class attacks by effectively expanding the feature space with generated samples.
This paper is divided into six sections: Section 1 introduces the development of intrusion detection technology and the challenges encountered, followed by the solutions proposed based on these issues; Section 2 systematically elaborates on the applications and advancements of class balancing techniques and generative adversarial networks in the field of intrusion detection; Section 3 provides a detailed elaboration and theoretical explanation of the MDCCGAN-DNN intrusion detection model proposed in this paper; Section 4 presents the experimental results and discussions; Section 5 presents the conclusive opinions; Section 6 addresses the challenges and future prospects.
2. Related Works
Intrusion detection technology has gradually evolved from traditional machine learning models to deep learning models. Early studies mostly relied on shallow learning models, with typical representatives including Logistic Regression (LR) [12], Support Vector Machine (SVM) [13], Random Forest (RF) [14], and Gradient Boosting Decision Tree (GBDT) [15]. The core limitation of such models lies in the fact that their detection performance is highly dependent on manual feature engineering. And they require professional knowledge in the field of industrial-Internet security to extract effective features from the raw data in order to achieve the identification and distinction of attack categories. With the development of deep learning technology, intrusion detection technology has been deeply integrated with various deep learning models. By virtue of the hierarchical feature extraction mechanism of multi-layer neural networks, deep learning can automatically learn and fuse high-level abstract features from low-level raw data such as network traffic packets and host logs. This effectively overcomes the excessive dependence of traditional methods on expert experience [16]. Vigneswaran et al. [17] investigated the application of DNNs in intrusion detection, with a focus on the impact mechanism of network layer depth on detection performance. The experiments conducted on the KDDCup-99 benchmark dataset showed that the DNN model with a three-layer network achieved optimal performance, with a detection accuracy of 93%. Li et al. [18] proposed a heterogeneous ensemble model that integrated Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and SVM. This model extracted and compressed spatial features from network traffic through a CNN and simultaneously utilized the time-recursive structure of an RNN to capture the temporal dependencies in the traffic sequence. After deep pre-training, the joint spatio-temporal feature vectors were input into the SVM classifier for final decision-making. The binary classification experiments on the CIC-IDS2017, UNSW-NB15, and WSN-DS benchmark datasets showed that the model achieved detection accuracies of 99.59%, 93.68%, and 99.61% respectively, which validated the effectiveness of the joint spatio-temporal feature modeling and classifier cascading mechanism. Bamber et al. [19] proposed an intelligent network intrusion detection system based on a hybrid model of CNN and Long Short-Term Memory (LSTM). The system aimed to improve detection accuracy and robustness by combining the spatial feature extraction capability of a CNN and the time series modeling advantage of LSTM. The study adopted the NSL-KDD dataset as the benchmark, and the experimental results showed that the CNN-LSTM model achieved the optimal performance across multiple evaluation metrics. Without using recursive feature elimination, the model achieved an accuracy of 95%, a recall of 89%, and an F1-score of 94%. Even with recursive feature elimination applied, its accuracy still reached 93%, which was significantly higher than that of other comparative models. In addition, the study further verified the model’s effectiveness in class distinction and false-alarm reduction through ROC curves and confusion matrices, with an AUC value of 0.948, indicating strong classification and discrimination capabilities.
Although the aforementioned studies have fully verified the application value of deep learning technology in the field of intrusion detection, most of these research outcomes have not designed effective detection mechanisms for minority-class attacks. In industrial-Internet environments, minority-class attacks usually exhibit stronger concealment and destructiveness; their successful intrusion may trigger severe industrial production accidents. Therefore, improving the detection rate of critical minority-class attacks has become a research focus in recent years. Against this backdrop, the research hot topic in the intrusion detection field is gradually shifting toward addressing the class imbalance problem of training datasets, which is also the core bottleneck currently restricting the improvement in the detection efficiency of minority-class attacks. With the technological breakthroughs of two mainstream generative models, Variational Auto-encoder (VAE) [20] and GAN, the research paradigm for addressing class imbalance has gradually shifted to minority-class sample augmentation methods based on generative models. Compared with traditional oversampling techniques that are prone to overfitting due to sample redundancy or distribution distortion, generative models can generate high-quality minority-class samples by virtue of their ability to accurately model and learn the latent distribution of data. This characteristic not only effectively addresses the class imbalance problem of datasets but also avoids the degradation of the generalization performance of detection models caused by overfitting. Liu et al. [21] employed a Conditional Variational Autoencoder (CVAE) data augmentation scheme to balance the class distribution of the CSE-CICIDS2018 dataset, resulting in increased sample diversity in the balanced dataset. Experiments showed that training different intrusion detection models with the class-balanced dataset improved their F1-score. Chuang and Huang [22] addressed the issue of insufficient decoder performance in VAEs, thereby improving the classification accuracy of intrusion detection. Xu et al. [23] addressed the challenge of CVAEs in fitting the distribution of minority-class samples by proposing an optimization method based on the log-cosh loss function. By replacing the traditional reconstruction loss function with the log-cosh function, the model’s ability to estimate the density of sparse samples in the discrete feature space was enhanced, improving the quality of generated samples and achieving excellent performance on the NSL-KDD dataset. Javaid et al. [24] and Yan and Han [25] integrated sparse auto-encoders into intrusion detection models and achieve good experimental results, demonstrating that sparse auto-encoders can serve as effective intrusion detection models. Ding et al. [26] conducted a systematic comparative study on traditional oversampling techniques and GAN-based models to address the class imbalance problem in intrusion detection. The experiments selected classic oversampling methods such as Random Over-Sampling (ROS), SMOTE, and ADASYN, and compared their performance with a CGAN, a Wasserstein Generative Adversarial Network (WGAN) [27], and the proposed TACGAN model in that study. Results on three benchmark datasets, KDDCup-99, NSL-KDD and UNSW-NB15, showed that generative models significantly outperformed oversampling techniques in improving detection accuracy. The TACGAN model achieved a 4.5% accuracy improvement on the KDDCup-99 dataset, verifying the technical advantages of generative adversarial networks in solving class imbalance problems. Zhu et al. [28] proposed a deep fusion model of a VAE and a CGAN, constructing a three-stage feature optimization mechanism of “encoding–adversarial enhancement–decoding” by embedding a CGAN module in the latent space between the encoder and decoder. Specifically, the CGAN dynamically adjusted the manifold distribution of minority-class samples in the latent space through adversarial training, making the feature vectors output by the encoder more discriminative in the low-dimensional space and thus improving the decoder’s reconstruction accuracy for sparse samples. That model provided a new paradigm for solving the representation challenge of sparse attack samples in industrial scenarios, while similar VAE-GAN fusion ideas were also explored in Tian et al. [29], Li et al. [30] and Yang et al. [31], further validating the effectiveness of generative model joint modeling in class imbalance problems. Yang et al. [32] addressed the problems of insufficient conditional constraints and difficulty in balancing the quality and diversity of generated samples in traditional GAN for intrusion detection data augmentation. They proposed a conditional aggregated encoding–decoding generative adversarial network (CE-GAN) and constructed an ensemble classifier by integrating the game theory-based Nash equilibrium principle, providing an integrated solution for solving the data imbalance problem in multiple categories intrusion detection. That study conducted experiments on two classic imbalanced datasets, namely, NSL-KDD and UNSW-NB15. The results demonstrated that the CE-GAN could effectively augment minority-class attack samples and significantly improve the recognition performance of the classifier on minority classes. After data augmentation, the ensemble classifier achieved significant improvements in multiple evaluation metrics, especially exhibiting stronger recognition capability for previously hard-to-detect minority-class attacks.
To systematically identify the current research gaps, Table 1 presents a comparison matrix of the aforementioned data augmentation and balancing approaches regarding three critical dimensions: generated sample quality, training stability, and label-consistency. As illustrated in the matrix, while existing methods address certain aspects of the class imbalance problem, none provide a comprehensive solution. Specifically, traditional oversampling techniques offer process stability but severely compromise sample quality by distorting the original feature space. Traditional CGANs introduce conditional generation but suffer from severe training instability (e.g., gradient vanishing) and poor label consistency. This stems from a fundamental structural flaw: a single discriminator is overloaded with dual, often conflicting tasks (verifying sample authenticity and matching categorical labels). Recent hybrid variants (such as VAE-GANs) and WGANs improve stability and feature representation, yet the fundamental issue of coupled optimization objectives in multi-class scenarios remains unresolved. Without a decoupled architecture, the generator struggles to simultaneously produce high-fidelity samples and strictly align them with specific minority class labels. This specific unresolved gap motivates the proposed MDCCGAN. By introducing an independent classifier, our model completely decouples the label consistency task from the discriminator, providing precise category gradients. Concurrently, the multi-discriminator architecture prevents the generator from exploiting structural vulnerabilities, thereby guaranteeing the quality and diversity of the generated samples.

Table 1.
Comparison matrix of existing class-balancing approaches in intrusion detection (Note: The symbol “✓” denotes an advantage in the respective dimension, with a higher number of “✓”s indicating a stronger advantage).
This specific unresolved gap motivates the proposed MDCCGAN. The objective is to construct an efficient detection scheme tailored to industrial-Internet scenarios for critical minority-class attacks. By introducing an independent classifier, our model completely decouples the label consistency task from the discriminator, providing precise category gradients. Concurrently, the multi-discriminator architecture prevents the generator from exploiting structural vulnerabilities, thereby guaranteeing the quality and diversity of the generated samples. This method specifically overcomes the performance bottlenecks of traditional CGAN in terms of generated sample quality, mode diversity, and training stability, as detailed below:
- Design of Multi-Discriminator Collaborative Architecture: by introducing multiple discriminators, a multi-dimensional adversarial learning constraint mechanism is constructed. Compared with the adversarial mode of a single discriminator in traditional CGAN, the multi-discriminator architecture significantly reduces the probability of the generator producing deceptive samples. Meanwhile, it increases the difficulty for the generator to generate samples that conform to the real distribution, forcing the generator to fully learn the multi-dimensional feature distribution of minority-class samples. This effectively alleviates the model-collapse problem that is prone to occur in traditional CGAN and improves the diversity and representativeness of generated samples.
- Decoupling Optimization Mechanism of Independent Classifier: the classification task and the adversarial discrimination task are decoupled, and an independent classifier module is embedded into the generative adversarial network framework. This design clarifies the optimization objective of “class consistency” for the generator in the sample generation process, ensuring that the generated minority-class samples not only are close to real samples in distribution but also can accurately match the core features of the target attack classes.
- Loss Function Improvement Driven by Wasserstein Distance: the Wasserstein distance is adopted to replace the Jensen–Shannon (JS) divergence commonly used in traditional CGANs for constructing the loss function. From the perspective of mathematical principles, the Wasserstein distance can effectively measure the distance between any two distributions. Even in scenarios where data distributions are non-overlapping or have extremely low overlap, it can still provide continuous and smooth gradient information. This fundamentally solves the gradient-vanishing problem caused by the saturation of the JS divergence in traditional CGANs, significantly improving the stability and convergence efficiency of the model training process.
3. Proposed Methodology
In this chapter, we elaborate in detail on the MDCCGAN-DNN industrial-Internet intrusion detection method proposed in this paper. The core design objective of this method is to address the problem of low detection rate caused by the scarcity of minority-class attack samples in the industrial-Internet intrusion detection scenario. Among them, the MDCCGAN model undertakes the core data augmentation task, leveraging its strong generative capability to generate high-quality minority-class samples for balancing the dataset distribution; the DNN model serves as the back-end intrusion detection classifier, responsible for the accurate classification and recognition of the balanced data. The workflow of the MDCCGAN-DNN industrial-Internet intrusion detection model based on the aforementioned architecture is illustrated in Figure 1. Through a three-stage processing workflow consisting of (1) Data Preprocessing, (2) Generation of Minority Class Data, and (3) Classification Decision, the model constructs a closed-loop system for minority-class attack detection in the industrial internet.
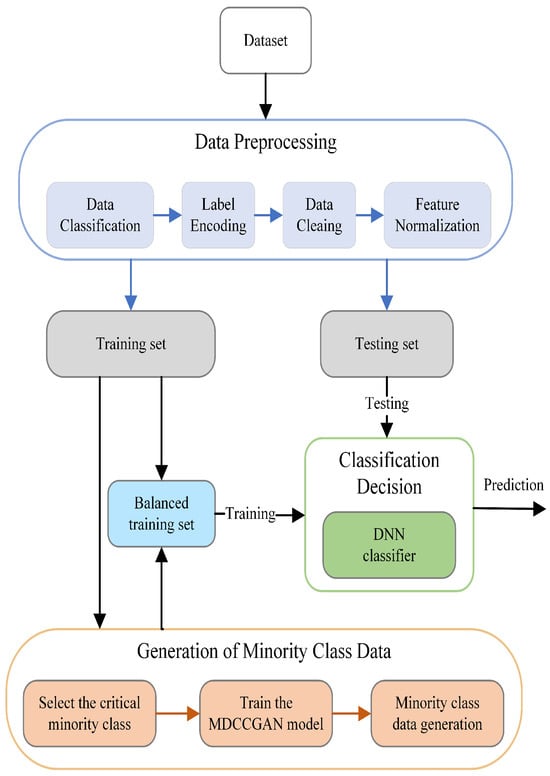
Figure 1.
Intrusion detection architecture based on MDCCGAN-DNN.
3.1. Data Preprocessing
Data preprocessing, as a fundamental step in deep learning model training, aims to transform raw intrusion detection data into standardized feature representations suitable for model learning. The data preprocessing module designed in this study includes the following four-stage processing flow: (1) Data classification; (2) Data cleaning; (3) Label encoding; (4) Feature normalization.
Existing intrusion detection datasets contain numerous attack types and a large number of redundant values, which hinder the learning of attack patterns by intrusion detection models. In this paper, according to the different characteristics of each dataset, attack types are scientifically categorized and reclassified based on the characteristics of each dataset (details of specific data classification and data cleaning are shown in Section 4.1). Meanwhile, the dataset is cleaned by removing redundant samples, samples with missing values, and noisy samples (i.e., samples with identical feature values but different attack labels). Excessive noisy data significantly affect model training, and deleting redundant values, missing values, and noisy samples can improve model performance and reduce the learning cost.
After data cleaning, numerical encoding of non-numerical features is required. Label encoding converts non-numerical features in the dataset into numerical values without increasing dimensionality, where original non-numerical features are sequentially encoded as [0, 1, 2, …, ]. For example, the Protocol Type attribute in the NSL-KDD dataset is encoded as [0, 1, 2] corresponding to the original values [icmp, tcp, udp]. Feature normalization scales feature values to reduce the impact of extreme values on the model. Min-max normalization is a widely recognized and utilized standardization method, which compresses feature values into the range [0, 1] [33]. The formula is as follows:
Here, represents the minimum value of feature , and represents the maximum value of feature . After preprocessing, the dataset can be divided into a training set and a test set.
3.2. Generation of Minority Class Data Based on MDCCGAN
The MDCCGAN-based minority-class data generation module is the core unit of the intrusion detection method proposed in this paper for addressing the class imbalance problem. Its design objective is as follows: utilizing the trained MDCCGAN model to generate high-quality synthetic samples that are highly consistent with the feature distribution of real minority-class attack samples; subsequently fusing these synthetic samples with the original training set to construct an augmented dataset with a balanced class distribution. This provides sufficient and balanced data support for the subsequent training of the DNN decision classification model, ultimately enhancing the model’s detection accuracy and generalization ability for minority-class attacks. This section focuses on elaborating the design logic of MDCCGAN from a theoretical perspective, centering on the inherent drawbacks of traditional CGANs in minority-class data generation tasks, clarifying the targeted improvement directions and technical measures of MDCCGAN, and detailing its network architecture design and model training mechanism.
Generative adversarial networks enable the generator and discriminator to learn real data distributions through adversarial training. However, due to the lack of explicit conditional constraint mechanisms, their generation process is uncontrollable, failing to produce generated samples of specified categories. To address this limitation, a CGAN introduce a class-label-conditioned generation mechanism, embedding the class label vector synchronously into the input layers of both the generator and discriminator to construct the conditional constraint architecture shown in Figure 2.
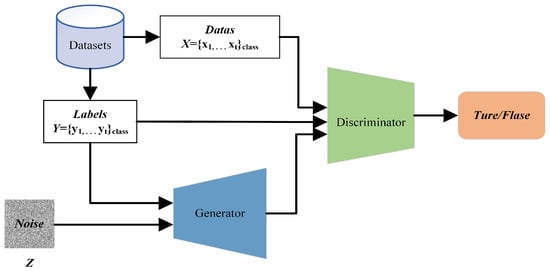
Figure 2.
Basic architecture of a traditional CGAN.
In the traditional CGAN, both the generator and discriminator adopt deep neural network architectures. They achieve controllable sample generation through a minimax adversarial game mechanism under conditional constraints, with the formula as follows:
where denotes the real sample vector, and represents a random noise vector (typically following a Gaussian distribution or uniform distribution). represents the expectation. represents the output of the discriminator, and represents the output of the generator.
In the traditional CGAN, the generator learns the distribution of real samples, fuses input random noise with label vectors, and generates synthetic samples corresponding to the label information. The discriminator undertakes dual tasks: first, determining whether input samples originate from the real data distribution or the synthetic sample distribution; second, verifying the consistency between samples and class label information. Only when the input sample is real data and matches the label will the discriminator give a score close to 1; otherwise, the score approaches 0. Through adversarial training, the generator and discriminator iteratively optimize until can sufficiently fit real samples, making it impossible for to distinguish the sample source. At this point, outputs 0.5, indicating a 50% probability that the input sample is either real or synthetic, and there is no room for improvement for either side, meaning that a Nash equilibrium state has been reached.
By introducing class label information into both the generator and discriminator, a traditional CGAN effectively overcome the limitation of GANs that makes it difficult to generate samples of specified classes, thereby providing a feasible approach for the targeted generation of minority-class attack samples. However, the direct application of traditional CGAN still has unavoidable inherent drawbacks, which restrict their application effectiveness in addressing class imbalance problems. Specifically, these drawbacks are as follows:
(1) In the traditional CGAN, the discriminator’s loss function can be transformed into minimizing the Jensen–Shannon (JS) divergence between the real data distribution and the generated distribution . The JS divergence is introduced to measure the difference between the distributions of real and synthetic samples; the closer the two distributions, the smaller the JS divergence. Derived from the Kullback–Leibler (KL) divergence, the JS divergence is mathematically defined as:
where denotes the Kullback–Leibler divergence. represents the distribution of real samples, and denotes the distribution of generated samples.
During the initial training phase, the distribution of samples generated by the generator may deviate significantly from the real sample distribution. In this case, the discriminator is likely to assign a probability near 0 to the event that generated samples belonging to the real distribution, while assigning a non-zero probability to those belonging to the generated distribution. That is, when and , where denotes the probability that the discriminator assigns to the sample being from the real space, and from the synthetic space, the JS divergence converges to a constant value, expressed as:
This situation leads to the vanishing of the update gradient for the generator .
(2) Due to the architectural characteristics of a traditional CGAN, in the initial training phase, the classification capability of the discriminator is not yet mature. This enables the generator to exploit a certain weakness, namely, learning to generate deceptive samples that meet specific conditions, leading the discriminator to incorrectly classify them as high-scoring samples despite significant deviations between these deceptive samples and the actual data distribution. Once the generator masters this strategy of making fake samples fool the discriminator, it will continuously generate samples of the same type to deceive the discriminator during adversarial training, ultimately causing the model to fall into model collapse.
(3) In the traditional CGAN, the discriminator must perform two critical tasks simultaneously: verifying sample authenticity and ensuring category consistency. This means its gradient update direction is determined by both sample quality (authenticity) and category alignment (label accuracy). The generator’s gradient, however, relies entirely on the discriminator’s feedback. When the discriminator assigns low scores to generated samples, a key challenge emerges: the generator struggles to distinguish whether the low scores result from poor sample quality or misaligned category labels, making it difficult to optimize gradient directions for both objectives simultaneously.
In view of the aforementioned problems, this paper proposes a MDCCGAN model, whose network architecture is shown in Figure 3 and consists of a generator , an independent classifier , and two heterogeneous discriminators and . Figure 3 illustrates the intuitive workflow of the proposed MDCCGAN. The process begins with the generator receiving a joint input of a random noise vector (z) and a specific target label (y). The intuition is that the generator acts as a high-dimensional mapping function, translating this noise into a synthetic feature vector. This synthetic vector is then simultaneously evaluated by three independent modules. and check if the overall structure resembles real traffic, and classifier C strictly verifies if the generated vector truly possesses the label characteristics. This collaborative architecture forces the synthetic sample to be both realistic and categorically accurate. Consistent with the traditional CGAN, the generator, classifier and discriminators of the MDCCGAN are all built based on deep neural networks, and the two discriminators are designed with differentiated network architectures: discriminator adopts a fully connected layer neural network architecture, while discriminator is constructed based on a one-dimensional convolutional neural network. This heterogeneous design requires the generator to simultaneously learn the optimization strategies to fool the two discriminators with distinct feature extraction mechanisms and network architectures during the adversarial training process. Moreover, the probability that the generator can fool the two heterogeneous discriminators at the same time is much lower than that of fooling the single discriminator in the traditional CGAN, and this design artificially increases the difficulty for the generator to generate samples that conform to the real data distribution. This constraint compels the generator to abandon the optimization “shortcut” of exploiting vulnerabilities in a specific network structure but instead to fully and deeply learn the real distribution laws of minority-class samples in the high dimensional feature space. Relying on the above-mentioned multi-module collaborative constraint mechanism, this architecture can effectively alleviate the model-collapse problem in the traditional CGAN caused by the generator exploiting vulnerabilities in the discriminator architecture, which not only improves the stability of model training but also significantly enhances the diversity and feature representativeness of the finally generated samples.
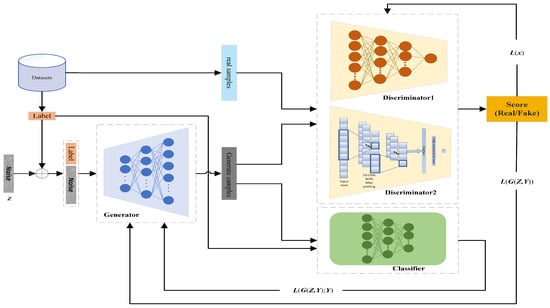
Figure 3.
Architecture of MDCCGAN.
To ensure the reproducibility of the proposed model, the precise network specifications of the four core components within the MDCCGAN (generator, discriminator , discriminator , and classifier) are detailed in Table 2. In this architecture, a leaky ReLU is predominantly used in the discriminators to prevent the “dying ReLU” problem and ensure stable gradient flow. Dropout layers are incorporated to mitigate overfitting. For discriminator , the 1D-CNN extracts local spatial patterns from the sequence of feature inputs through stacked 1D convolutional layers and max-pooling operations. Batch normalization is applied in the generator to stabilize the adversarial training process.
Table 2.
Detailed network specifications of the MDCCGAN components.
The generator of our MDCCGAN follows the “noise + label” conditional input mode of a traditional CGAN. The generator precisely learns the feature distribution of real minority-class samples, and based on the input label vector and random noise, generates synthetic samples corresponding to the target label, ensuring the category orientation of the generated samples. The core differences from a traditional CGAN lie in the design of the multi-discriminator architecture and the decoupling mechanism of classification tasks. The discriminator of a traditional CGAN must undertake the dual tasks of “sample authenticity judgment” and “class consistency verification” simultaneously, which is prone to cause mutual interference between the two tasks and reduce the quality of generated samples and the accuracy of class matching. The MDCCGAN achieves this by employing a multi-discriminator design, enabling the generator to simultaneously acquire the optimization strategies for probabilities that can deceive the discriminators of two different network architectures. This probability is much lower than that of deceiving a single discriminator, thereby effectively alleviating the model-collapse problem caused by the generator exploiting the vulnerabilities of the discriminators. In contrast, the MDCCGAN adopts a multi-discriminator design, enabling the generator to simultaneously acquire the probability of optimizing strategies that can deceive the discriminators of two different network architectures. This probability is much lower than that of deceiving a single discriminator, thereby effectively alleviating the model-collapse problem caused by the generator capturing the vulnerabilities of the discriminators. And the embedded independent classifier is responsible for determining the class consistency between the generated samples and the input labels. By decoupling the classification loss from the discriminator, it clarifies the gradient update direction of the generator, thereby improving the generation quality of samples of the specified class. This scheme not only solves the problem that the generator in the traditional CGAN may generate deceptive samples but also enables the generator to learn the sample distribution features more accurately. This architectural design and function decoupling strategy not only simplifies the learning objective of a single module and improves the stability of adversarial training, but also strengthens the feature consistency between the generated samples and the target class through the exclusive optimization of the classifier, providing a guarantee for the subsequent generation of high-quality minority-class samples.
Compared with the two-player zero-sum game framework of the traditional CGAN, the multi-player game adopted by the MDCCGAN in this paper, consisting of a generator , two discriminators , and an independent classifier , reconstructs the model’s convergence mechanism and Nash equilibrium characteristics from the perspective of game theory. The two-player zero-sum game of the traditional CGAN relies on the antagonistic optimization between the generator and the discriminator, which is prone to gradient vanishing or model collapse due to a single gradient signal, and its theoretical Nash equilibrium point is extremely difficult to converge to in the high-dimensional and sparse traffic data of the industrial Internet. Through a hybrid structure of collaborative confrontation by the dual discriminators and constraint guidance by the classifier, the multi-player game of the MDCCGAN decouples the authenticity discrimination task of a single discriminator into multi-dimensional feature fitting by the dual discriminators: is responsible for capturing global features and for capturing temporal local features, while an independent classifier is introduced to provide categorical consistency constraints. This design enables the generator to obtain richer gradient signals, and its convergence direction is confined to a feasible region of high fidelity and accurate categorization, leading to a significant improvement in training stability. Theoretically, its Nash equilibrium point needs to satisfy distribution equilibrium, categorical equilibrium and collaborative equilibrium simultaneously, forming a robust optimal solution under multiple constraints, rather than the zero-sum antagonistic equilibrium of the traditional CGAN.
To address the gradient-vanishing issue in the traditional CGAN caused by the discriminator’s use of the JS divergence, the MDCCGAN model adopts the Wasserstein distance as the core metric to replace the Jensen–Shannon (JS) divergence of the traditional CGAN. Instead of directly performing a formal rewriting of the Wasserstein distance formula, its discriminator loss function transforms the calculation of the Wasserstein distance into the optimization objective of the discriminator by virtue of the duality theory. The original Wasserstein distance formula is as follows:
In the formula: inf denotes the infimum (the minimum cost of transforming the real distribution into the generated distribution ), represents the set of all possible joint distributions between the real distribution and the generated distribution , and signifies the distance between the real sample x and the generated sample .
In the original definition, refers to an infinite dimensional set of joint distributions, which cannot be directly calculated or optimized and thus cannot be directly used as a loss function to guide model training. This constitutes the core reason for the introduction of the duality theory of the Wasserstein distance in this paper. According to the Kantorovich–Rubinstein duality theorem, when and are probability distributions defined on a compact metric space—in this paper, the normalized network traffic feature space where feature values are compressed into the range [0, 1]—satisfying compactness, and is the 1-norm, the Wasserstein-1 distance can be transformed into its dual form, with the formula given as follows:
where sup denotes the supremum, to find a function f that satisfies the constraints to maximize the difference in the parentheses; f represents a continuous real-valued function mapping from the sample feature space to the real number field, which is embodied by the discriminator in this paper, = , and the discriminator is a neural network that fits this function; means that f satisfies the Lipschitz continuity constraint (with the Lipschitz constant = 1), which is a necessary condition for dual transformation and aims to prevent the divergence of the difference caused by the unboundedness of the function . In this paper, the network traffic features are high-dimensional continuous features, and the 2-norm is adopted to measure the sample distance. Thus, the Lipschitz constant is generalized to , and the constraint is implemented through weight clipping or gradient penalty. The dual form can be extended to an engineering optimizable form as follows:
In this paper, the MDCCGAN is designed with two heterogeneous discriminators and , which share the same loss function form derived directly from the dual form of the Wasserstein distance. The core logic is to define the optimization objective of the discriminators as maximizing the dual form of the Wasserstein distance, and then derive the loss function for minimization. It can be inferred from the dual form of the Wasserstein distance that is positively correlated with . The core task of the discriminators is to accurately distinguish real samples from generated samples, i.e., to maximize the expected difference between the outputs of the discriminator for real and generated samples. Thus, the optimization objective of the discriminator D is given by:
The core of model training in deep learning is to minimize the loss function. Therefore, the maximization objective of the discriminator is transformed into a minimization loss function, that is, let the discriminator loss ; then:
To make the physical meaning of the loss function more intuitive and facilitate its implementation in engineering applications, this paper reverses the sign of the loss function and ultimately obtains the discriminator’s loss function:
The dual transformation of the Wasserstein distance relies on the Lipschitz continuity constraint, which is implemented via the weight clipping method in this paper. The specific operation is as follows: after each round of parameter update for the discriminators and , all their network parameters are clipped to a fixed interval [−, ], where = 0.01 was adopted in this study. This value is the standard recommended in the original WGAN paper, which performs stably in most generation tasks and ensures that the output function of the discriminators satisfies the Lipschitz continuity condition. This operation is an essential step connecting the theoretical Wasserstein distance with the engineered loss function. If this step is omitted, the dual transformation no longer holds, the discriminator loss fails to truly reflect the distance between distributions, and the gradient-vanishing problem existing in the traditional CGAN still arises.
denotes the cross-entropy classification loss of the independent classifier C, with its calculation form given as follows:
where represents the probability predicted by the classifier that the generated sample belongs to the target real class . Based on the classifier’s category judgment results for generated samples, the feature consistency between generated samples and the target attack categories is constrained. This ensures that the generated samples do not fit real samples indiscriminately but accurately generate samples of the specified minority-class attacks, thus solving the problem of category matching deviation caused by the single discriminator undertaking multiple tasks in traditional CGANs.
In this paper, the construction of the generator loss function for the MDCCGAN involves the weighted fusion of the adversarial loss of the discriminators and the categorical classification loss of the classifier, ultimately forming a loss function form adapted to the generation of minority-class attack samples on the industrial Internet. The core training objectives of the generator consist of two dimensions: first, to make the generated samples approximate the real minority-class attack samples in terms of feature distribution (adversarial fitting); second, to make the generated samples accurately match the label of the target attack category (categorical consistency). Based on this, the generator loss function was defined as:
Incorporating the classifier loss as a positive term into the generator loss function, instead of a negative term or a weighted penalty term, is a design based on dual considerations of the training optimization direction of the generator and the task positioning of the independent classifier. From the perspective of the optimization direction, the minimization objective of the classifier loss is fully consistent with the category constraint objective of the generator. The core task of the independent classifier C is to accurately determine whether a generated sample matches the target class , and the value of its cross-entropy loss is negatively correlated with the category matching degree of the generated sample. The category constraint objective of the generator is to maximize the category matching degree of the generated samples, which corresponds to minimizing the classifier loss , while the overall training objective of the generator is to minimize the total loss . Therefore, after incorporating as a positive term into the total loss, the generator naturally minimizes synchronously in the process of minimizing , thereby achieving the objective of category consistency constraint indirectly through the optimization of the total loss. This design eliminates the need for the additional setting of penalty coefficients or designing reverse optimization logic, and ensures the uniqueness and simplicity of the model’s optimization direction. From the perspective of task decoupling, incorporating into the generator loss as a positive term enables the collaborative optimization of the two objectives (adversarial fitting and category constraint) and effectively avoids gradient conflict. A core innovation of the MDCCGAN proposed in this paper is the decoupling of the dual tasks of “authenticity discrimination + category judgment” undertaken by a single discriminator in the traditional CGAN, where independent discriminators are designed to be solely responsible for adversarial fitting and an independent classifier for category judgment. The key essence of this decoupling design is to realize the independent transmission and collaborative optimization of the gradient signals of the two tasks, and incorporating into the generator loss as a positive term is the core means to achieve this design objective. After fusing the adversarial loss and the classification loss in the form of an additive positive term, the total gradient of the generator is the direct sum of the gradients of the two subtasks. This approach neither causes gradient cancellation or conflict due to the superposition of negative terms, nor leads to the dominance of the gradient of a single objective due to the introduction of weighted terms, thus truly achieving the balanced optimization of the two training objectives. It fundamentally solves the problems of low quality of generated samples and poor category matching in the traditional CGAN caused by ambiguous gradient signals. From the perspective of model training stability, incorporating into the generator loss as a positive term imposes a hard constraint on the generator for categorical consistency, which can effectively avoid model collapse and the generation of deceptive samples. In the traditional CGAN, a single discriminator undertakes dual tasks simultaneously, so the generator can easily fool the discriminator by learning deceptive features, which in turn leads to model collapse or a severe deviation of generated samples from the target class. In this paper, incorporating into the generator loss function as a positive term sets a hard constraint for the generator on categorical consistency: if the generator attempts to generate deceptive samples to evade the discriminator’s detection, the categorical features of the generated samples will deviate from the target class . In this case, will surge sharply, directly causing a rise in the generator’s total loss , and such opportunistic optimization directions of the generator will be suppressed directly. This design of positive term incorporation directly avoids the opportunistic optimization behaviors of the generator from the perspective of loss optimization, which not only ensures the stability of model training but also improves the quality and categorical accuracy of generated samples simultaneously.
The training process of the proposed MDCCGAN model for generating critical minority-class samples is illustrated in Figure 4, and its training procedure is specified in Algorithm 1 as follows. The specific training process of the model is as follows:
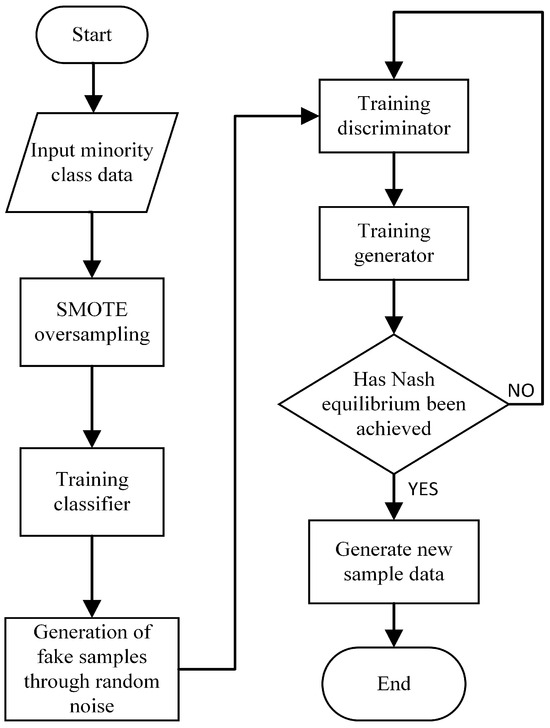
Figure 4.
Training process of MDCCGAN.
- Step 1:
- During the training phase of the MDCCGAN, key minority-class attack samples are first filtered from the preprocessed dataset. Due to the severe imbalance in the distribution of the key minority-class samples that are selected, the original sample size is insufficient to enable the independent classifier to learn stable category features, and it is even unable to provide the generator with an accurate direction for updating the category gradient. Therefore, the SMOTE oversampling method is first employed to augment these samples, and the augmented minority-class samples are then fed into the independent classifier for training, enabling the classifier to fully learn the class distribution characteristics of the key minority-class samples. It is important to note that the core task of this classifier is to determine the class consistency between generated samples and input labels, and its performance relies on the precise fitting of the conditional distribution of real minority-class samples. Unlike conventional classification tasks that aim to pursue generalization and avoid overfitting, the tighter the classifier fits the real minority-class samples within a reasonable range, the more fully it learns the features of minority-class samples, thereby enhancing its ability to judge the class consistency of generated samples. Thus, the classifier in this model does not suffer from the traditional “overfitting flaw”. Augmenting samples via SMOTE oversampling can, to a certain extent, ensure that the classifier comprehensively learns the distribution characteristics of various types of samples in the key minority class, laying a foundation for improving the accuracy of class consistency judgment.
- Step 2:
- During the training phase of the discriminators, the generator parameters are first fixed, and the synthetic samples generated by the generator and the real minority-class samples are input into discriminator and , respectively. It should be emphasized that the loss function of the discriminators in this model is constructed based on the Wasserstein distance, whose core function is to accurately measure the difference between the real sample distribution and the synthetic sample distribution. At this stage, the training objective of the discriminators is to maximize this distribution distance, namely, to enhance their ability to distinguish between real samples and synthetic samples. During the training process, the loss functions and corresponding to discriminators and are minimized through the gradient descent algorithm and Back Propagation algorithm, thereby completing the iterative update of the network parameters of the dual discriminators.
| Algorithm 1 Training algorithm of MDCCGAN |
| Input: training dataset; Output: expanded dataset; |
|
- Step 3:
- During the training phase of the generator, the parameters of the trained discriminators are first fixed; meanwhile, the parameters of the independent classifier have been optimized and fixed in the previous Step 1. The loss function of the generator consists of two components: one is the Wasserstein distance loss fed back by the discriminators, and the other is the class constraint loss provided by the classifier. The specific training process is as follows: the random noise vector is concatenated with the target class label vector and input into the generator G to generate synthetic samples of the target class; subsequently, the synthetic samples are input into discriminators and respectively to calculate the Wasserstein distance loss, and the cross-entropy loss between the generated samples and the input labels is calculated through the independent classifier C; the core training objective of the generator is to minimize the total generation loss , where is defined as the weighted sum of the negative value of the discriminator loss and the classification loss, and the iterative update of the generator network parameters is completed through the gradient descent algorithm.
- Step 4:
- Alternately execute the discriminator training Step 2 for n times and the generator training Step 3 for m times. Typically, is set to ensure that the discriminators are fully optimized first. After multiple rounds of iterative training, the discriminator loss and generator loss gradually stabilizes and converges, and the classifier loss also gradually decreases to a convergent state. At this point, the entire model reaches the Nash equilibrium state, and the generator can be stably used to synthesize critical minority-class samples, achieving effective augmentation of the imbalanced dataset.
Unlike the traditional CGAN, which uses the JS divergence and inherently suffers from gradient vanishing when distributions do not overlap, the MDCCGAN model fundamentally addresses this issue by introducing the Wasserstein distance and restructuring the training process. During training, the discriminators are preferentially subjected to n iterative training rounds () to enable them to fully learn the discrepancy between real and generated distributions. Since the Wasserstein distance can still provide meaningful gradient signals in non-overlapping distribution regions, the discriminators can effectively transfer this distribution discrepancy information to the generator to guide its parameter updates. This design allows the generator to more accurately capture the distribution characteristics of real samples, thereby significantly improving the generation quality of minority-class samples.
3.3. Classification Decision Module
This paper selected a DNN model as the classification decision model, whose structure is shown in Figure 5. The DNN is composed of three fully connected layers, arranged sequentially as input layer → hidden layer 1 (125 neurons) → hidden layer 2 (64 neurons) → output layer. Notably, the dimensions of the input and output layers are determined by the feature dimensions of the dataset and the number of classification categories, respectively. The hidden layers employ the leaky-ReLU activation function, chosen to mitigate the “dying neuron” issue inherent to the standard ReLU, while the output layer uses the Softmax activation function to produce class probability distributions. To ensure the reproducibility of experiments, the specific training and optimization hyperparameters of the DNN classifier were set as follows. In the training phase, the training dataset balanced by the MDCCGAN was used for model training to improve the detection performance of the model on minority-class critical attacks. Training was stopped when the loss function converged to an extreme value. To prevent overfitting, regularization (weight decay = ) was incorporated into the Adam optimizer (lr = 0.001), and a Dropout layer (rate = 0.2) was added after each hidden layer. Furthermore, since the MDCCGAN module had achieved strict balance among all classes before DNN training, it was unnecessary to set additional class weights, and the standard categorical cross-entropy loss function was directly adopted.
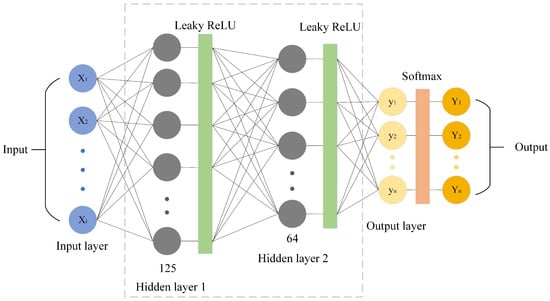
Figure 5.
Architecture of DNN.
The newly balanced training set input was fed to the DNN detection model for training, requiring presetting a reasonable number of training iterations. When the number of model training iterations reached the preset threshold, the training process of the DNN detection model was completed. The test set was used to verify the detection capability of the trained model: by inputting test data, the model outputted detection results, enabling performance evaluation and analysis based on these results and preset evaluation metrics, such as accuracy, recall, F1-score, etc.
4. Experiments and Evaluation
The experiments were conducted on a computing platform with an Intel Core i7-12700 @ 2.10 GHz processor and used the deep learning framework Pytorch 1.12.0 and Sklearn 1.3.2 as the training environment. The hyperparameters of the intrusion detection model and data generation model, including learning rates, input batch sizes, and iteration counts, were determined through combined training. The final values are shown in Table 3.
Table 3.
MDCCGAN model parameters.
4.1. Introduction to the Dataset
This study used NSL-KDD and UNSW-NB15 as benchmark datasets.
4.1.1. NSL-KDD Dataset
The NSL-KDD dataset [34], serving as a standard dataset in the field of intrusion detection, is a reduced version of the KDD-Cup99 dataset [35] which removes missing samples and prunes duplicate and redundant records. Compared with the original KDD-Cup99, NSL-KDD avoids interference from redundant samples, making it more suitable for intrusion detection performance evaluation. The NSL-KDD dataset comprises a designated training set (KDDTrain+) and a test set (KDDTest+), providing standardized dataset partitioning for model training and evaluation. The training set KDDTrain+ contains 125,973 samples, while the test set KDDTest+ includes 22,544 samples. Each sample in NSL-KDD consists of 41 features and one label. The dataset labels consist of one “Normal” class and 39 distinct attack types. These attack types are categorized into four major classes based on the DARPA/CIDF model: DoS (Denial of Service), Probe (Surveillance and Reconnaissance), U2R (User to Root), and R2L (Remote to Local). This classification provides a standardized framework for multiple-category performance evaluation of intrusion detection models. The training set, KDDTrain+, only contains 22 out of the 39 types of attack data, while the remaining 17 types are all in the test set, KDDTest+. These 17 types of attack data that are missing in the training set cover the above four major categories. This partitioning scheme introduces the challenge of detecting unseen attack types during testing, providing a rigorous assessment of the model’s generalization capability of the classification model for various attacks. Table 4 details the distribution of the four major attack categories and the normal category in the NSL-KDD dataset.
Table 4.
Data distribution in NSL-KDD.
Table 4 reveals a severe class imbalance within the NSL-KDD training set: the U2R class contains only 52 samples and the R2L class contains only 995 samples, exhibiting differences exceeding three and one order of magnitude, respectively, compared to the Normal class (67,343 samples). Probe attack samples (11,656) also show a significant deficit. This extreme imbalance induces a gradient update bias in intrusion detection models during training as optimization objectives tend to minimize the classification loss of majority-class samples, thereby suppressing or ignoring the feature learning of minority-class samples. Consequently, intrusion detection models exhibit extremely low detection rates for critical minority-class samples, compromising model performance and posing hidden risks to networks security protection.
4.1.2. UNSW-NB15 Dataset
To verify the model’s generalization ability, this paper conducted supplementary experiments using the UNSW-NB15 [36] intrusion detection dataset. Developed by the Cyber Security Research Centre at the University of New South Wales (Canberra), Australia, this dataset used the IXIA PerfectStom tool to construct a mixed dataset containing modern normal traffic and abnormal traffic. UNSW-NB15 covers one “Normal” class and nine attack categories: Generic, Exploits, Fuzzers, DoS, Reconnaissance, Analysis, Backdoors, Shellcode, and Worms. Their descriptions are as follows:
- Normal: natural transaction data;
- Generic: A technique that works against all block ciphers (with a given block and key size), without consideration about the structure of the block cipher;
- Exploits: The attacker knows of a security problem within an operating system or a piece of software and leverages that knowledge by exploiting the vulnerability;
- Fuzzers: Attempting to cause a program or networks to suspend by feeding it randomly generated data;
- DoS: A malicious attempt to make a server or a networks resource unavailable to users, usually by temporarily interrupting or suspending the services of a host connected to the Internet;
- Reconnaissance: contains all strikes that can simulate attacks that gather information;
- Analysis: It contains different attacks of port scan, spam and html files penetrations;
- Backdoors: A technique in which a system security mechanism is bypassed stealthily to access a computer or its data;
- Shellcode: A small piece of code used as the payload in the exploitation of software vulnerability.
- Worms: A worm replicates itself in order to spread to other computers. Often, it uses a computer networks to spread itself, relying on security failures on the target computer to access it.
The UNSW-NB15 dataset contains 175,341 records in the training set (UNSW-NB15_training) and 82,332 records in the test set (UNSW-NB15_testing), with the specific quantities of each attack type referenced in Table 5. Each record comprises 43 features and two labels (totaling 45 attributes). The “ID” feature serves as a unique identifier and was excluded as non-predictive. The two labels consist of a binary label (“label”) and a multiple categories label (“attack_cat”). As our focus was on multiple categories detection, particularly for minority-attack categories, we retained only the “attack_cat” label. After processing, the dataset contained 42 feature attributes and one multiple-category label attribute. Furthermore, we identified and removed numerous redundant records exhibiting identical feature values but differing attack categories, as such noise can significantly interfere with model training. The training set in the cleaned data contained 101,040 samples, and the test set had 53,946 samples. The overall distribution is shown in Table 6. It should be noted that the removal of redundant records was performed on the original UNSW-NB15_training and UNSW-NB15_test training sets without redividing the dataset. It is evident that the UNSW-NB15, similar to the NSL-KDD, exhibits an extreme class imbalance problem.
Table 5.
Data distribution in UNSW-NB15.
Table 6.
Cleaned data distribution in UNSW-NB15.
4.2. Evaluation Metrics
This paper used four core metrics in multiple categories model evaluation to quantitatively analyze model performance: accuracy, precision, recall, and F1-score. Accuracy, a quantitative indicator of the model’s overall classification performance, is calculated as the ratio of correctly predicted samples to the total number of predicted samples. Precision measures the reliability of predicted positive instances. Recall (also known as sensitivity) evaluates the model’s ability to capture actual positive instances. The F1-score, as the harmonic mean of precision and recall, more comprehensively reflects model performance in class-imbalanced scenarios. It avoids evaluation bias caused by majority-class dominance in single metrics (e.g., accuracy). The calculation formulas for each indicator are as follows:
In Equations (15)–(18), TP (True Positive) denotes the number of samples that are actually positive and correctly predicted as positive. TN (True Negative) denotes the number of samples that are actually negative and correctly predicted as negative. FP (False Positive) denotes the number of samples that are actually negative but mistakenly predicted as positive. FN (False Negative) denotes the number of samples that are actually positive but mistakenly predicted as negative.
4.3. Experiments and Results
This paper used two typical datasets, NSL-KDD and UNSW-NB15, to conduct model evaluation. Cross-dataset validation effectively verified the proposed model’s generalization ability in industrial-Internet scenarios; the differences in traffic features, attack type distributions, and degrees of class imbalance across datasets comprehensively tested the model’s adaptability to diverse industrial network environments, providing more convincing performance references for practical engineering applications.
4.3.1. Results Based on the NSL-KDD Dataset Experiment
To verify the model’s effectiveness, we compared the MDCCGAN against classic oversampling techniques (ROS, SMOTE, ADASYN) for class balancing the NSL-KDD training set. An identical DNN classifier (same architecture and hyperparameters) was then trained on each balanced dataset. Performance was evaluated on the standard test set (KDDTest+). The sample distributions in NSL-KDD after processing by each balancing method (ROS, ROS, SMOTE, ADASYN and MDCCGAN) are shown in Table 7.
Table 7.
Data distributions in NSL-KDD after class balancing.
In the proposed MDCCGAN model, adopting the SMOTE technique to balance the training data of the independent classifier is a critical design choice. To verify the necessity of this method and address the potential concern that SMOTE may introduce artificial noise into the adversarial generation process, we conducted targeted ablation experiments on the NSL-KDD dataset. Specifically, the SMOTE-based pre-training strategy proposed in this paper was compared with three baseline methods: pre-training directly on the original imbalanced data, pre-training using ROS, and pre-training using ADASYN. In terms of the experimental process, we integrated the classifier pre-trained with the aforementioned different sampling strategies into the MDCCGAN model to participate in the subsequent joint training and minority-class sample generation. Subsequently, using the datasets expanded and balanced by each MDCCGAN variant, we trained the downstream DNN intrusion detection classifiers separately and evaluated their performance on an independent test set. The final test performance of the downstream DNN classifiers objectively and intuitively reflects the real sample generation quality of each MDCCGAN variant, and the detailed experimental comparison results are shown in Table 8.
Table 8.
Classifier ablation experiment comparison on NSL-KDD.
As shown in Table 8, when the independent classifier is directly trained on the original imbalanced data, its decision boundary is severely inclined toward the majority class. This bias prevents the classifier from providing accurate category conditional gradients for minority classes (e.g., U2R) to the generator, making it difficult for the generator to learn minority-class label information during adversarial training, resulting in an F1-score of only 12% for U2R. On the other hand, compared with directly using the original dataset, the use of ROS can increase the F1-score of U2R by 15%. However, since ROS merely performs simple physical replication of minority-class samples, it is highly prone to causing the classifier to overfit to duplicate samples. This overfitting transmits rigid gradient guidance signals to the generator, which severely limits the diversity and generalization ability of generated samples, thereby leading to a bottleneck in the overall accuracy of the model that is difficult to further break through. More importantly, when comparing the two advanced synthetic methods, ADASYN performs worse than SMOTE. Because ADASYN adaptively generates more synthetic data for minority samples that are more difficult to learn, usually outliers near dense majority-class regions, this causes the classifier to form an overly aggressive and distorted decision boundary. Therefore, the gradients provided to the generator excessively push the synthetic minority samples into the majority-class regions, thereby increasing the misjudgment rate. In contrast, SMOTE can provide more uniform and stable interpolation, enabling to output smooth and accurate classification guidance. The experimental results also indicate that SMOTE is overall superior to ADASYN in terms of data quality.
Furthermore, it is particularly emphasized that any inherent noise or feature distortion associated with SMOTE is not transmitted to the finally generated samples. In our decoupled architecture, the classifier (C) only provides directional gradients to ensure label consistency. The high-fidelity feature distribution and structural authenticity of the generated samples are completely determined by the dual discriminators ( and ), which are specifically trained using original real network traffic data. Therefore, the dual discriminators act as strict filters to ensure that the generated data are authentic and reliable and completely avoid artifacts caused by SMOTE.
Table 9 demonstrates the detection performance of the DNN model integrated with class balancing techniques for different attack categories. The data indicate that in experiments with the original unbalanced dataset, the DNN intrusion detection model exhibited significant defects in detecting minority-class attacks: the recall rate for R2L attacks was only 6%, while the precision, recall, and F1-score for U2R attacks were all zero. This extreme result demonstrates that when the U2R attack sample size is only 52 (accounting for 0.04% of total samples), the model completely fails to capture the feature patterns of that class, falling into a state of feature learning failure.
Table 9.
Class balancing technique comparison on NSL-KDD.
After oversampling processing by ROS, SMOTE, and ADASYN, the DNN model’s detection capability for minority-class attacks improved marginally, which is directly attributed to the technical limitations of each method: ROS balances classes by simply replicating minority-class samples, which is prone to causing the model to learn redundant feature patterns and inducing overfitting. When training sets contain duplicate samples, the model’s generalization ability to new samples significantly declines during testing. SMOTE generates synthetic samples via feature space interpolation based on the K-nearest neighbor algorithm. If adjacent samples belong to different classes or contain noise, it leads to feature space distortion, causing generated pseudo-samples to deviate from the real distribution and inducing excessive generalization in the model. ADASYN dynamically adjusts minority-class sample weights and generates new samples through kernel density estimation. Its performance highly depends on distribution assumptions of the original data; when minority-class samples have sparse features or uneven distribution, sample overlap or invalid generation easily occurs. Moreover, the weight adaptation mechanism may amplify noisy features in the original data, also triggering overfitting issues.
Compared to the DNN trained on the original imbalanced data, MDCCGAN-DNN improved accuracy by 20%. Compared to the oversampling techniques (ROS-DNN/SMOTE-DNN/ADASYN-DNN), MDCCGAN-DNN demonstrated significant advantages, verifying that generated samples enhance the model’s generalization ability. Specifically, compared to the original DNN, the F1-score for Probe, R2L, and U2R attacks increased by 22%, 76%, and 77% respectively, among which the F1-score for U2R attacks surges from 0% to 77%. The average recall rate across all attack classes for the MDCCGAN-DNN model showed a 51.75% improvement compared to the DNN trained on the original imbalanced data.
The model effectively alleviates the feature space distortion caused by simple sample replication or interpolation in traditional methods without compromising accuracy, verifying the superiority of generative sample augmentation based on the MDCCGAN model in complex traffic scenarios of the industrial Internet. This provides a fruitful solution to the “detection blind spot” problem of traditional models.
To verify the technical superiority of the MDCCGAN model, comparative experiments were conducted with a CGAN and a CWGAN (Conditional Wasserstein GAN) from two dimensions: the stability of generated samples and the performance of the generation model. The stability of generated samples was quantitatively evaluated through the convergence characteristics of the loss functions of the generator and discriminator, specifically including: (1) convergence speed, the number of iterations for the loss function to stabilize; (2) convergence accuracy, the fluctuation range of the loss value and the final convergence state; (3) training stability, whether abnormal phenomena such as gradient vanishing and mode collapse occurred during training. The relevant results are shown in Figure 6. The quality of the generated samples was evaluated indirectly by training the final DNN classifier on the dataset augmented by each GAN variant and measuring its performance on the test set; the higher the detection rate of the discriminator optimized by generated samples for minority-class attacks (such as R2L, U2R), the stronger the fitting ability of the generation model for real attack features. Table 10 presents the detection performance of the DNN model combined with generative techniques for each attack category.
Figure 6.
Loss optimization process comparison.
Table 10.
Generative model performance comparison in NSL-KDD.
Furthermore, it is worth noting that the performance comparison between the MDCCGAN and the traditional CGAN and CWGAN in Table 10 essentially serves as a macro-level ablation study for our core architectural innovations. From a structural perspective, if the multi-discriminator mechanism and the independent classifier were removed, the MDCCGAN would directly degrade into a traditional CGAN or CWGAN with coupled tasks. Therefore, the substantial performance improvements achieved by the MDCCGAN over the CGAN/CWGAN, particularly the significant surge in minority-class F1-scores shown in Table 10, explicitly quantify and highlight the isolated contributions and the absolute necessity of our proposed “architectural decoupling and multi-constraint” design.
As clearly shown in Figure 6a, the traditional CGAN exhibits significant oscillations in discriminator and generator losses when processing minority-class attack data, with poor training stability. It fails to stably converge to the theoretical equilibrium point of 0.693 (i.e., the discriminator gives a score of 0.5 to input data, corresponding to ). The generator loss tends to 0.2, indicating that the discriminator prefers to assign high scores to generated samples. This may be caused by the generator producing deceptive samples or the discriminator’s inability to effectively distinguish real samples from generated ones (related to the discriminator’s “multi-tasking”—simultaneously discriminating sample authenticity and matching input samples with labels). The discriminator loss tends to 0.45 because the discriminator assigns high scores to generated samples, leading to a smaller overall loss. This phenomenon aligns with and demonstrates the core limitation of traditional CGANs. Figure 6b shows that introducing the Wasserstein distance into a traditional CGAN enables the generator and discriminator losses to rapidly converge to zero within 200 iterations, significantly improving model stability compared to the traditional CGAN. Figure 6c depicts the training losses of the proposed model. By introducing multiple discriminators and an independent classifier, the losses of the two discriminators with distinct architectures, the generator, and the classifier all converge to zero after 600 training iterations. While the convergence speed is slower than that of CWGAN, this is due to the generator’s weak performance in the early training phase, which leads to high classification loss. Even if the discriminator losses converge rapidly, the generator loss is jointly constrained by both discriminator losses and classification loss, resulting in slower convergence and longer overall training time. However, this slower convergence is accompanied by a substantial improvement in final performance, demonstrating that the multi-discriminator and independent classifier architecture not only enhances training stability but also delivers a tangible boost in generated sample quality.
Comparisons in Figure 6a–c show that introducing the Wasserstein distance significantly improves the training stability of both CWGAN and MDCCGAN compared to the traditional CGAN. By measuring the “earth-mover distance” between distributions, the Wasserstein distance solves the gradient-vanishing problem caused by the JS divergence, enabling more balanced adversarial training between the generator and discriminator. Compared with CWGAN’s single-discriminator design, the proposed model avoids model collapse by learning special cases through multi-discriminator and independent classifier mechanisms, thereby improving the quality of generated samples.
Table 10 shows that DNN models trained on datasets processed by adversarial generative networks (CGAN, CWGAN, MDCCGAN) outperform the original imbalanced data in both overall classification performance and minority-class detection capability. Except for the recall of U2R (where CWGAN-DNN achieved the highest value), the proposed MDCCGAN-DNN model achieved the best performance across all other metrics, indicating that the samples generated by the proposed model had higher quality than those of CGAN-DNN and CWGAN-DNN. Compared with CGAN-DNN and CWGAN-DNN, the proposed model improved accuracy by 9% and 5%, F1-score for R2L attacks by 11% and 14%, and F1-score for U2R attacks by 12% and 4%. Except for the recall of U2R being inferior to that of the CWGAN, all other performance metrics of the proposed model were equivalent to or superior to those of the CGAN and CWGAN.
To fully verify the effectiveness of the proposed MDCCGAN model, we conducted performance comparison experiments with recent generative models. Notably, although various generative methods have been proposed recently, such as CVAE [21], TACGAN [26], CE-GAN [32], and the VAE-GAN hybrid model [29] (which have been discussed in Section 2), they are not directly included as empirical baselines in Table 11. The main reason lies in the inconsistency of dataset selection and benchmarking strategies.
Table 11.
Performance comparison of different state-of-the-art generative models on the NSL-KDD dataset.
Table 11 presents a fair performance comparison between the MDCCGAN-DNN proposed in this paper and the current mainstream advanced generative intrusion detection models under the exact same dataset selection and the official strict division standards. The comparison models include not only VAE-WGAN, AE-WGAN, and WGAN-GP-based models, but also BEGAN as an important baseline. When facing the strict challenge of unseen attacks in the official test set, MDCCGAN-DNN still achieves the best comprehensive detection performance. It can be observed from the experimental results that MDCCGAN-DNN obtains the best overall classification performance, with an accuracy of 94% on the NSL-KDD dataset, and establishes a significant advantage in terms of F1-score for critical minority-class attacks such as R2L and U2R. These recent generative models have their own innovations in generation mechanisms. VAE-WGAN and AE-WGAN combine autoencoders to optimize high-dimensional feature reconstruction; WGAN-GP effectively stabilizes the training process via gradient penalty; while BEGAN innovatively adopts an autoencoder as the discriminator and introduces an equilibrium hyperparameter () to balance the loss distribution between the generator and the discriminator, thereby greatly improving the overall fidelity of generated samples.
However, when dealing with multi-class detection tasks characterized by an extreme scarcity of minority-class samples on the industrial Internet, all the aforementioned models expose an inherent limitation in their underlying architecture: relying on a single discriminator to simultaneously handle the dual tasks of “sample authenticity identification” and “multi-class label matching”. Taking BEGAN as an example, although its global balance mechanism can ensure the stability of the overall distribution, this “task coupling” design makes it difficult for the single autoencoder discriminator to capture the local fine-grained features of samples from an extremely minority class. During the adversarial game, the gradient guidance signals corresponding to labels from the extremely minority class received by the generator often become ambiguous or even overwhelmed by the reconstruction errors of the majority-class samples, eventually leading to the overlap of the generated samples from the extremely minority class at the category boundaries. Experimental results also further confirm that the recall rate and F1-score of the U2R attack category are both poor.
Table 12 presents the comparison results between the proposed MDCCGAN-DNN intrusion detection approach and traditional machine learning methods. The data indicate that traditional intrusion detection models suffer from low accuracy due to their inability to effectively learn from minority-class attack data, with the recall rates and F1-scores of minority-class attacks (R2L, U2R) almost approaching zero. This verifies the fundamental constraint of class imbalance on traditional methods. The MDCCGAN-DNN model demonstrates significant advantages on the NSL-KDD dataset: it achieves the best recall rates and F1-score for all attack types. Notably, for minority-class attacks R2L and U2R, the F1-score are on average 84% and 73% higher, respectively, than those achieved by the four traditional models (RF, SVM, CNN, KNN). Compared to the best performing traditional model (KNN at 76%), MDCCGAN-DNN improves accuracy by 18% (94% vs. 76%), fully verifying its breakthrough in detecting minority-class attacks under class imbalance scenarios.
Table 12.
Comparison of intrusion detection performance on NSL-KDD.
A critical challenge of the NSL-KDD dataset is the presence of 17 unseen attack types in the test set that are entirely absent from the training set. The substantial improvement in test metrics, e.g., the U2R F1-score surging from 0% to 77%, provides compelling evidence of the model’s generalization capability. The MDCCGAN does not merely memorize known attack signatures; rather, by learning the underlying high-dimensional feature distribution of the minority classes, the generated synthetic samples populate sparse regions of the feature space. Consequently, the DNN classifier learns a broader and more robust decision boundary. When an unseen attack (which often shares latent characteristics with known attacks in the same major category) is encountered during testing, this robust decision boundary correctly identifies it, proving that the generative augmentation fundamentally enhances generalization rather than merely fitting known types.
4.3.2. Results Based on the UNSW-NB15 Dataset Experiment
To verify the cross-dataset generalization ability of the MDCCGAN-DNN model, supplementary experiments were conducted using the UNSW-NB15 dataset, with the experimental environment and evaluation metrics (accuracy, recall, F1-score) kept consistent with the NSL-KDD experiment. As described in Section 4.1.2, we used the cleaned UNSW-NB15 dataset. Table 6 shows the quantities of each class in the cleaned dataset, where attack categories such as Reconnaissance, Analysis, Backdoors, Shellcode, and Worms account for less than or equal to 1% of total samples, with Shellcode accounting for only 0.12%, exhibiting extremely strong class imbalance. Unlike the NSL-KDD dataset, which uses the DARPA/CIDF model for class division, the UNSW-NB15 dataset adopts multiple-category division, significantly increasing model training difficulty. The dual challenge of “multiple categories + extremely rare samples” can more strictly verify the model’s adaptability in the following scenarios, while better testing the model’s extreme performance, providing a more convincing validation for intrusion detection in complex traffic environments of Industrial Internet.
The experimental design for comparing the classification performance of different machine learning models on the UNSW-NB15 dataset was as follows: All comparative models except the proposed one were trained directly on the cleaned but imbalanced UNSW-NB15 training dataset. In contrast, the proposed model leveraged the MDCCGAN for class balancing, expanding the sample size of each attack category to 50,000. This value was chosen to establish a class-balanced training environment, enabling a fair evaluation of each model’s ability to learn from all categories and avoiding bias toward majority-class samples. After augmentation, the total number of training samples reached 501,815, with the sample size of each category being approximately equivalent to that of normal samples. As shown in Table 13. All models were evaluated using the same cleaned UNSW-NB15 testing dataset, ensuring the fairness and rigor of the comparative experiments. The classification performance comparisons are presented in Table 14.
Table 13.
Data distributions in UNSW-NB15 after class balancing.
Table 14.
Comparison of intrusion detection performance on UNSW-NB15.
Expanding extreme minority classes to 50,000 samples represents a significant intervention in the data distribution. To ensure that the high classification performance was not artificially inflated by the classifier learning generative “artifacts” (anomalous patterns unique to synthetic data), our evaluation inherently relied on the rigorous Train on Synthetic/Augmented, Test on Real (TSTR) paradigm. It is crucial to emphasize that the testing set (UNSW-NB15_testing) consisted entirely of pristine, real-world network traffic and was strictly isolated from the MDCCGAN augmentation process. If the generator had introduced artifacts to bypass the discriminators, the DNN would have overfitted to these specific artifacts and subsequently failed catastrophically when evaluated on the real testing set. The fact that the proposed MDCCGAN-DNN model achieved an 88% accuracy and remarkable minority-class F1-scores on the real test set serves as definitive proof of synthetic-data quality. It confirms that the generated samples possessed high feature-wise fidelity and accurately aligned with the true distribution of real minority attacks, effectively avoiding artificial classification shortcuts.
Table 14 shows that traditional intrusion detection models also exhibit learning blind spots for minority-class samples on the UNSW-NB15 dataset. For example, the recall rate and F1-score of Analysis-type attacks are both close to zero. Notably, decision trees perform relatively well in Worm attacks (F1-score = 49%), and random forests excel in Shellcode attacks (recall = 71%), but both still have significant defects on the Analysis class (F1-score < 1%). The superior performance of decision trees and random forests in “multiple categories + extremely rare samples” scenarios is attributed to their rule-based feature-splitting mechanism, which adapts well to sparse data. Other traditional models show poor learning ability for minority-class attacks, among which the SVM model has the weakest performance recall rates and F1-scores for Analysis, Backdoor, Shellcode, and Worm attacks (all are zero), verifying the kernel function mapping limitations of SVM in small-sample scenarios. In contrast, the proposed model demonstrates excellent performance in detecting minority-class attacks: compared with the single DNN detection model, the F1-score for Analysis, Backdoor, and Worm attacks with extremely few samples are improved by 97%, 62%, and 84% respectively.
Table 15 presents the experimental results of oversampling techniques and generative methods on the UNSW-NB15 dataset, while Figure 7 illustrates the accuracy of each intrusion detection model tested on the UNSW-NB15 dataset. Results show that the DNN intrusion detection model integrating oversampling techniques (ROS, SMOTE, ADASYN) demonstrates insignificant improvement in detecting minority-class attacks, with the recall rate of Analysis attacks increasing by less than 5%. The reason lies in the fact that the sample replication mechanism of traditional oversampling techniques fails to effectively expand feature diversity but instead triggers severe overfitting issues. Figure 7 further reveals that the overall accuracy of models using oversampling techniques averagely decreases by 14%, among which ADASYN causes a 16% accuracy drop due to its weight adaptation mechanism amplifying noisy features. This not only verifies the above conclusion but also indicates that the UNSW-NB15 dataset imposes extremely high requirements on model generalization ability. CGAN and CWGAN models show unsatisfactory performance on the UNSW-NB15 dataset. Although their recall rates and F1-score for Analysis, Backdoor, and Worm attacks are improved compared with oversampling techniques, those for Reconnaissance, DoS, and Shellcode attacks decrease. Figure 7 shows that the overall accuracy of CGAN-DNN and CWGAN-DNN models decreases by 9% and 7% respectively compared with the single DNN model. This is because the UNSW-NB15 dataset contains numerous attack categories, which overburdens the multi-task discriminator, which is unable to provide correct gradient information to the generator. As a result, the generator produces low-quality samples with significant noise, degrading the detection model’s performance. This verifies the defects of traditional CGANs in multiple categories scenarios. The proposed MDCCGAN model still demonstrates excellent performance on the UNSW-NB15 dataset. Due to the structural advantage of its independent classifier, it can better address the data imbalance problem in multiple-category datasets. By decoupling adversarial tasks from classification tasks, the model achieves dual optimization in multiple-category scenarios. As shown in Figure 7, the model’s accuracy reaches 88%, representing a 10% improvement over the single DNN model and a 17% improvement over the CGAN-DNN model.
Table 15.
Comparison of class balance techniques on UNSW-NB15.
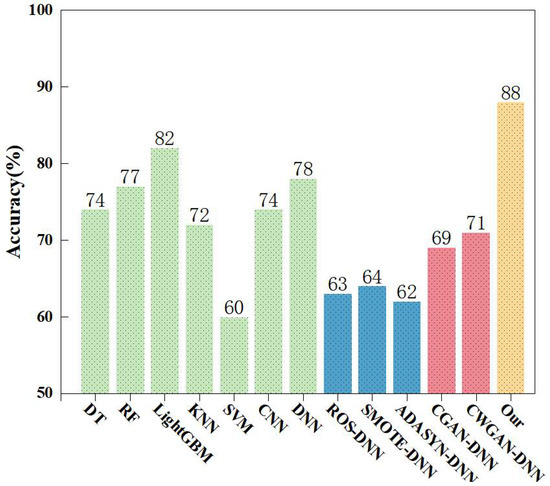
Figure 7.
MDCCGAN model accuracy on UNSW-NB15.
4.4. Evaluations
Comprehensive cross-dataset experiments demonstrated that the proposed MDCCGAN-DNN model exhibits excellent generalization ability. The experimental results verify that the model’s intrusion detection performance outperforms other deep learning models. Notably, on the UNSW-NB15 dataset, which better simulates real industrial networks traffic, the model does not suffer from performance degradation, confirming its outstanding performance in multiple-category scenarios. This provides a reliable solution for intrusion detection in complex traffic environments of the industrial Internet.
Finally, a brief discussion regarding the computational cost and training time is warranted. Due to the architectural expansion, specifically the incorporation of a heterogeneous multi-discriminator and an independent classifier, the proposed MDCCGAN inherently demands higher computational resources and a longer training time compared to the standard CGAN baseline. However, it is crucial to emphasize the specific task positioning of the MDCCGAN within our proposed framework. The MDCCGAN functions strictly as an offline data augmentation module aimed at generating high-fidelity minority-class samples. It is not deployed directly into the network environment for real-time intrusion detection. The actual real-time detection task is executed entirely by the downstream DNN classifier. Therefore, the additional computational cost and training time are incurred entirely offline and do not compromise the real-time inference efficiency or latency of the network security system. Given the substantial improvements in generated sample quality and the resulting surge in downstream detection accuracy for critical minority attacks, this offline computational trade-off is highly acceptable and worthwhile.
5. Conclusions
In recent years, the field of industrial-Internet intrusion detection has made remarkable achievements thanks to the vigorous development of deep learning. However, the high dependency of deep learning models on dataset quality poses severe challenges in handling minority-class intrusion attacks; the “feature learning blind spot” caused by class imbalance in traditional deep networks has become the core bottleneck restricting the cybersecurity protection of critical infrastructure. To address the aforementioned issues, this paper proposed a MDCCGAN model, which systematically addresses dataset class imbalance through minority-class data reconstruction and generation. This approach enables intrusion detection models to learn key minority-class attack features, avoids model entrapment in learning blind spots, and improves detection accuracy for critical minority-class attacks. The model proposed in this study innovatively incorporates multiple discriminators and independent classifiers on the basis of the traditional CGAN model. Multiple discriminators with different network architectures effectively reduce the probability of the generator producing deceptive samples. Moreover, the independent classifier provides clearer gradient update directions for the generative model through a conditional classification constraint mechanism, enabling the generation of higher-quality samples. This creates an optimized training dataset for the detection model, leading to enhanced classification performance, particularly for minority-attack classes. This study conducted experiments using two intrusion detection datasets with distinct characteristics. Experimental results comprehensively demonstrated the significant effectiveness of the MDCCGAN model in addressing the limitations of traditional class-balancing techniques and the inherent drawbacks of the traditional CGAN. The findings fully validate the model’s adaptability and effectiveness in industrial-Internet intrusion detection scenarios, thereby providing an innovative technical solution to ensure the secure and stable operation of industrial-Internet systems.
6. Challenges and Future Scope
Although the MDCCGAN-DNN model proposed in this paper achieved remarkable results in the task of minority-class attack detection for the industrial Internet, combined with the complex application scenarios and technological development trends of the industrial Internet, industrial-Internet attack methods display the characteristics of dynamic evolution and polymorphic fusion, and new unknown attacks emerge one after another. Existing sample generation methods based on generative adversarial networks mainly rely on the distribution learning of historical attack category data. They have high generalization ability for learned attack categories, but their generalization ability is limited when facing unseen attack patterns or variations in attack features. In addition, the network traffic characteristics of different industries on the industrial Internet are significantly different, and the manifestations of attack behaviors also have industry specificity. How to realize the rapid adaptation of the model in cross-industry scenarios and avoid overfitting to a single industry dataset remains an urgent problem to be solved.
Combined with the development needs of industrial-Internet security and the cutting-edge trends of artificial intelligence technology, in-depth research can be carried out in the future on constructing a dynamically adaptive generator model, enabling the MDCCGAN model to quickly learn the feature distribution laws of different industries and different attack scenarios, and realize rapid adaptation across scenarios. By constructing a dynamic generation strategy, the parameter update direction of the generator is adjusted according to the distribution changes of real-time traffic data, thereby improving the adaptive ability to new unknown attacks. With the deep integration of artificial intelligence technology and the security needs of the industrial Internet, building a more intelligent, efficient and secure generative detection model will provide a more solid technical guarantee for the safe and stable operation of the industrial Internet.
Author Contributions
Conceptualization, X.L.; validation, X.L. and X.H.; resources, X.H.; data curation, X.L.; writing—original draft preparation, X.L.; writing—review and editing, X.H.; supervision, X.H.; funding acquisition, X.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Chongqing Municipal Talent Program Project (No. cstc2024ycjh-bgzxm0088).
Data Availability Statement
The data that support the findings of this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- He, J.; Wang, X.; Song, Y.; Xiang, Q.; Chen, C. Network intrusion detection based on conditional wasserstein variational autoencoder with generative adversarial network and one-dimensional convolutional neural networks. Appl. Intell. 2023, 53, 12416–12436. [Google Scholar] [CrossRef]
- Abdulganiyu, O.H.; Ait Tchakoucht, T.; Saheed, Y.K. A systematic literature review for network intrusion detection system (IDS). Int. J. Inf. Secur. 2023, 22, 1125–1162. [Google Scholar] [CrossRef]
- Al-Fuhaidi, B.; Farae, Z.; Al-Fahaidy, F.; Nagi, G.; Ghallab, A.; Alameri, A. Anomaly-Based Intrusion Detection System in Wireless Sensor Networks Using Machine Learning Algorithms. Appl. Comput. Intell. Soft Comput. 2024, 2024, 2625922. [Google Scholar] [CrossRef]
- Bedi, P.; Gupta, N.; Jindal, V. I-SiamIDS: An improved Siam-IDS for handling class imbalance in network-based intrusion detection systems. Appl. Intell. 2021, 51, 1133–1151. [Google Scholar] [CrossRef]
- Turukmane, A.V.; Devendiran, R. M-MultiSVM: An efficient feature selection assisted network intrusion detection system using machine learning. Comput. Secur. 2024, 137, 103587. [Google Scholar] [CrossRef]
- Khanam, S.; Ahmedy, I.; Idris, M.Y.I.; Jaward, M.H. Towards an effective intrusion detection model using focal loss variational autoencoder for internet of things (IoT). Sensors 2022, 22, 5822. [Google Scholar] [CrossRef]
- Bagui, S.; Li, K. Resampling imbalanced data for network intrusion detection datasets. J. Big Data 2021, 8, 6. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence); IEEE: New York, NY, USA, 2008; pp. 1322–1328. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- LaValley, M.P. Logistic regression. Circulation 2008, 117, 2395–2399. [Google Scholar] [CrossRef]
- Suthaharan, S. Support vector machine. In Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning; Springer: Berlin/Heidelberg, Germany, 2016; pp. 207–235. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Wongsuphasawat, K.; Smilkov, D.; Wexler, J.; Wilson, J.; Mane, D.; Fritz, D.; Krishnan, D.; Viégas, F.B.; Wattenberg, M. Visualizing dataflow graphs of deep learning models in tensorflow. IEEE Trans. Vis. Comput. Graph. 2017, 24, 1–12. [Google Scholar] [CrossRef]
- Vigneswaran, R.K.; Vinayakumar, R.; Soman, K.; Poornachandran, P. Evaluating shallow and deep neural networks for network intrusion detection systems in cyber security. In Proceedings of the 2018 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT); IEEE: New York, NY, USA, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Li, S.; Chai, G.; Wang, Y.; Zhou, G.; Li, Z.; Yu, D.; Gao, R. Crsf: An intrusion detection framework for industrial internet of things based on pretrained cnn2d-rnn and svm. IEEE Access 2023, 11, 92041–92054. [Google Scholar] [CrossRef]
- Bamber, S.S.; Katkuri, A.V.R.; Sharma, S.; Angurala, M. A hybrid CNN-LSTM approach for intelligent cyber intrusion detection system. Comput. Secur. 2025, 148, 104146. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar] [CrossRef]
- Liu, C.; Antypenko, R.; Sushko, I.; Zakharchenko, O. Intrusion detection system after data augmentation schemes based on the VAE and CVAE. IEEE Trans. Reliab. 2022, 71, 1000–1010. [Google Scholar] [CrossRef]
- Chuang, P.J.; Huang, P.Y. B-VAE: A new dataset balancing approach using batched Variational AutoEncoders to enhance network intrusion detection. J. Supercomput. 2023, 79, 13262–13286. [Google Scholar] [CrossRef]
- Xu, X.; Li, J.; Yang, Y.; Shen, F. Toward effective intrusion detection using log-cosh conditional variational autoencoder. IEEE Internet Things J. 2020, 8, 6187–6196. [Google Scholar] [CrossRef]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A deep learning approach for network intrusion detection system. In Proceedings of the 9th EAI International Conference on Bio-Inspired Information and Communications Technologies (Formerly BIONETICS); EAI: Bratislava, Slovakia, 2016; pp. 21–26. [Google Scholar] [CrossRef]
- Yan, B.; Han, G. Effective feature extraction via stacked sparse autoencoder to improve intrusion detection system. IEEE Access 2018, 6, 41238–41248. [Google Scholar] [CrossRef]
- Ding, H.; Chen, L.; Dong, L.; Fu, Z.; Cui, X. Imbalanced data classification: A KNN and generative adversarial networks-based hybrid approach for intrusion detection. Future Gener. Comput. Syst. 2022, 131, 240–254. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. Available online: https://proceedings.mlr.press/v70/arjovsky17a.html (accessed on 8 March 2026).
- Zhu, N.; Zhao, G.; Yang, Y.; Yang, H.; Liu, Z. Aec_gan: Unbalanced data processing decision-making in network attacks based on ACGAN and machine learning. IEEE Access 2023, 11, 52452–52465. [Google Scholar] [CrossRef]
- Tian, W.; Shen, Y.; Guo, N.; Yuan, J.; Yang, Y. VAE-WACGAN: An Improved Data Augmentation Method Based on VAEGAN for Intrusion Detection. Sensors 2024, 24, 6035. [Google Scholar] [CrossRef]
- Li, Z.; Huang, C.; Qiu, W. An intrusion detection method combining variational auto-encoder and generative adversarial networks. Comput. Netw. 2024, 253, 110724. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, K.; Wu, B.; Yang, Y.; Wang, X. Network intrusion detection based on supervised adversarial variational auto-encoder with regularization. IEEE Access 2020, 8, 42169–42184. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, X.; Wang, D.; Sui, Q.; Yang, C.; Li, H.; Li, Y.; Luan, T. A CE-GAN based approach to address data imbalance in network intrusion detection systems. Sci. Rep. 2025, 15, 7916. [Google Scholar] [CrossRef]
- Raju, V.G.; Lakshmi, K.P.; Jain, V.M.; Kalidindi, A.; Padma, V. Study the influence of normalization/transformation process on the accuracy of supervised classification. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT); IEEE: New York, NY, USA, 2020; pp. 729–735. [Google Scholar] [CrossRef]
- Revathi, S.; Malathi, A. A detailed analysis on NSL-KDD dataset using various machine learning techniques for intrusion detection. Int. J. Eng. Res. Technol. (IJERT) 2013, 2, 1848–1853. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications; IEEE: New York, NY, USA, 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A Comprehensive Data Set for Network Intrusion Detection Systems (UNSW-NB15 Network Data Set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS); IEEE: New York, NY, USA, 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Arafah, M.; Phillips, I.; Adnane, A.; Hadi, W.; Alauthman, M.; Al-Banna, A.K. Anomaly-based network intrusion detection using denoising autoencoder and Wasserstein GAN synthetic attacks. Appl. Soft Comput. 2025, 168, 112455. [Google Scholar] [CrossRef]
- Yao, Q.; Zhao, X. An intrusion detection imbalanced data classification algorithm based on CWGAN-GP oversampling. Peer-Netw. Appl. 2025, 18, 121. [Google Scholar] [CrossRef]
- Park, C.; Lee, J.; Kim, Y.; Park, J.G.; Kim, H.; Hong, D. An enhanced AI-based network intrusion detection system using generative adversarial networks. IEEE Internet Things J. 2022, 10, 2330–2345. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.