Abstract
Automated negotiation in multi-agent electronic commerce environments relies heavily on efficient and reliable matching mechanisms to connect negotiation participants. However, existing matching protocols often fail to ensure transaction security and user data privacy, while also lacking adaptability to dynamic negotiation contexts. To address these challenges, this study proposes a privacy-enhanced multi-agent matching optimization framework that integrates trust evaluation, privacy protection, and adaptive decision-making. First, a trust-based negotiation relationship network is constructed through complex network analysis to establish a secure and trustworthy negotiation environment. Second, a privacy-enhanced automated negotiation protocol is developed, employing the cumulative distribution function to transform sensitive data into probabilistic representations, thereby safeguarding user privacy without compromising data availability. Finally, a reinforcement learning algorithm is incorporated to optimize the matching process dynamically, using satisfaction as the reward function to achieve efficient and Pareto-optimal results. A series of experiments verify the framework’s effectiveness, demonstrating significant improvements in system robustness, adaptability, and matching accuracy. This study aims to provide a comprehensive solution that integrates trust network modeling, privacy protection, and adaptive matching optimization, serving as a valuable reference for the development of secure and intelligent automated negotiation platforms.
Keywords:
intelligent agent; automated negotiation; complex network analysis; trust networks; adaptive matching strategy MSC:
68T42; 91A25
1. Introduction
With the rapid expansion of digital transactions, Multi-Agent Systems (MAS) have become increasingly prevalent in electronic commerce environments. Among their various applications, adaptive matching in multi-agent transactions serves as a crucial bridge between user demand and service supply, playing a vital role in automated negotiation systems [1,2]. This process enables intelligent decision support in complex negotiation settings by helping manufacturers and consumers identify compatible trading partners, thereby improving transaction efficiency and user satisfaction [3,4]. For example, Pactum’s automated negotiation platform automates counterpart matching and price negotiation, substantially reducing labor and time costs. However, as multi-agent negotiation systems continue to evolve, ensuring their security, reliability, and privacy protection has emerged as a critical challenge.
The matching process, as a fundamental prerequisite for automated negotiation, significantly influences negotiation performance. The success rate of automated negotiation depends heavily on the reliability of participating agents. Engaging with untrustworthy agents can compromise negotiation outcomes, undermine system stability, and increase transaction risks. Existing research on transaction matching in automated negotiation primarily employs rule-based or heuristic matching algorithms [5], often leveraging historical data [6], user preferences [7], and transaction intentions [4]. While these approaches improve efficiency, they typically overlook the complex trust and social relationships among users, leading to mismatches and limited robustness in scenarios with sparse or uncertain data. Moreover, without explicit consideration of trust and reliability assessments among network nodes, such methods are susceptible to manipulation and may diverge from real-world negotiation dynamics.
To address these shortcomings, this study proposes a multi-dimensional trust evaluation framework that integrates complex network analysis to construct a trust-based negotiation relationship network. By quantifying and screening trust relationships across local and global dimensions, the framework identifies and excludes untrustworthy nodes, effectively refining the negotiation counterpart search space. This approach aims to enhance the security, transparency, and stability of automated negotiation environments.
Meanwhile, the increasing focus on trust also highlights renewed concerns regarding data security and privacy protection in automated negotiation systems [8]. Negotiation processes often involve sensitive information—such as pricing strategies, trading terms, and private user data—that must be protected against leakage and misuse. Traditional methods like data masking [9], data segmentation [10], and strict access control [11] provide partial protection but often compromise processing efficiency and adaptability to dynamic negotiation data streams. To overcome these limitations, this study introduces a privacy-enhanced automated negotiation protocol that transforms deterministic data into statistical cumulative distribution functions. This transformation enables effective decision-making in matching while minimizing direct data exposure, thereby balancing privacy preservation and computational efficiency in real-time negotiation contexts.
In addition to improving data security, this study aims to further enhance the matching process through intelligent optimization. Traditional matching algorithms typically rely on static rules or historical data [12], making them inflexible to changing user requirements and prone to unstable recommendation quality. To overcome this, we incorporate a Q-learning algorithm based on reinforcement learning to dynamically optimize the matching process. By defining inter-item satisfaction as a reward function, the algorithm continuously learns from negotiation feedback and adjusts strategies in real time, thereby improving adaptability, efficiency, and the likelihood of achieving Pareto-optimal outcomes.
In summary, while existing studies have made exploratory progress in trust modeling and privacy protection within automated negotiation systems, these two aspects are typically examined in isolation. To address this limitation, this paper presents an integrated framework for multi-agent automated negotiation, combining trust network modeling, privacy-enhancing data processing, and reinforcement learning. Compared with existing research, this paper contributes in three major aspects:
- (1)
- From a mechanism design perspective, we propose a trust-aware negotiation framework in which multi-dimensional trust evaluation is integrated into the negotiation matching process, rather than functioning as a loosely coupled auxiliary module.
- (2)
- We develop a privacy-enhanced negotiation protocol that transforms sensitive negotiation attributes into probabilistic representations, allowing privacy protection to be endogenously incorporated into the protocol design and decision-making process, instead of relying on exogenous privacy safeguards.
- (3)
- Building upon the integrated trust and privacy framework, we design a reinforcement learning-based adaptive matching strategy that dynamically optimizes negotiation outcomes under privacy and trust constraints.
The remainder of this paper is organized as follows: Section 2 provides a survey of related works. Section 3 elaborates on the proposed model. A case study with a series of experiments is conducted, and the experimental analysis is presented and discussed in Section 4. Section 5 concludes this paper, and Section 6 discusses the theoretical implications, practical implications, and limitations.
2. Literature Review
2.1. Adaptive Matching in Automated Negotiation
Automated negotiation employs intelligent agents to represent human participants in the negotiation process, aiming to enhance negotiation efficiency and decision quality through automation technologies [13,14]. Within this field, the design of adaptive matching strategies plays a pivotal role, as the quality of matching directly affects negotiation efficiency, success rate, and overall system performance [15].
Recent studies have increasingly focused on modeling both explicit and implicit relationships among potential negotiation counterparts in the pre-negotiation phase. Such modeling enables a deeper understanding of how interpersonal and inter-agent relationships influence counterpart selection and subsequent strategic alignment, using either qualitative or quantitative methods [1,16]. The objective of these approaches is to assist negotiation platforms in identifying optimal counterparts by analyzing attributes such as cooperation potential, cost, and resource complementarity [4,5,17]. For instance, Beauprez et al. [18] proposed a heuristic agent strategy that dynamically reorders negotiation counterparts to accelerate bilateral negotiations and reduce time costs. However, this approach relies on local search mechanisms, which may lead to suboptimal global outcomes. Similarly, Munroe et al. [19] emphasized balancing conflict reduction and cost minimization when selecting negotiation partners under resource-constrained environments. While these studies focus on the structural elements of matching, they frequently neglect participant satisfaction and the alignment of attributes in traded commodities within e-commerce negotiation settings. To bridge this gap, recent work—including the present study—aims to explore the integration of reinforcement learning algorithms to enhance satisfaction-based adaptive matching and promote the intelligent evolution of automated negotiation systems.
Furthermore, the open and dynamic nature of e-commerce environments introduces security risks [20], such as malicious participation, unauthorized access, and service fraud. Ensuring the trustworthiness of negotiation participants is therefore critical to maintaining reliable transactions. Previous research has generally assessed trust from a single-dimensional perspective. For example, Shao et al. [21] developed a dynamic recommendation trust model based on normal distribution to filter unreliable information using indirect trust factors and hierarchical pruning. Zhu et al. [22] proposed a trust evaluation method grounded in social cognition theory, constructing a trust ontology for service agents to support computational trust inference. Although these studies have advanced the field, most remain exploratory and lack multi-dimensional perspectives on trust. In response, this paper tries to propose a multi-dimensional trust evaluation framework and constructs a multi-level negotiation relationship network to narrow the search space for negotiation counterparties. By filtering untrustworthy nodes and strengthening reliable connections, the proposed approach enhances both the security and efficiency of transaction matching in automated negotiation systems.
Based on the above discussion, existing studies have investigated adaptive matching strategies from different perspectives, including heuristic opponent selection, trust-based filtering, and learning-assisted decision-making. To provide a systematic comparison of these approaches, Table 1 presents a summary of representative adaptive matching methods in automated negotiation.

Table 1.
Comparison of adaptive matching methods in automated negotiation.
In summary, existing adaptive matching methods either rely on static heuristics or incorporate trust in a limited or auxiliary manner, lacking learning-driven dynamic adaptation. By contrast, this work integrates reinforcement learning with multi-dimensional trust modeling to enable continuous and adaptive optimization of negotiation matching decisions.
2.2. Protocols in Automated Negotiation
In automated negotiation systems, protocols define the fundamental rules that govern communication, offer exchange, decision-making, and consensus formation among agents. These protocols play a critical role in ensuring negotiation efficiency, fairness, and reliability, while also reducing the need for human intervention. Over the years, research on negotiation protocols has primarily focused on the design of stopping rules and aggregation rules, which determine when to accept, reject, or modify offers and how to manage time constraints to accelerate decision-making [22,23,24].
Beyond rule definition, recent studies have explored various enhancements to negotiation protocols to improve adaptability, personalization, and decision optimization. For instance, Zhou et al. [25] developed a mediator-based multilateral protocol that employs relational networks to generate personalized offers and improve cooperation among agents. Shinohara and Fujita [26] designed a protocol incorporating opponent modeling, enabling agents to estimate counterpart utility functions while maintaining fairness in information disclosure. Similarly, Kolomvatsos et al. [23] introduced a token-based bilateral negotiation protocol that balances privacy preservation with negotiation effectiveness. These advances have contributed to more flexible and human-like automated negotiation systems.
However, despite these achievements, data security and privacy protection remain insufficiently addressed in most existing protocols. Automated negotiation often involves highly sensitive information—such as pricing strategies, trading conditions, and proprietary business data—that, if improperly handled, may lead to privacy breaches or exploitation risks. While some studies touch upon confidentiality or partial encryption, few have proposed systematic approaches that explicitly integrate privacy protection into the core negotiation protocol. To bridge this gap, this study aims to develop a privacy-enhanced automated negotiation protocol that transforms sensitive transactional data into secure probabilistic forms. The proposed framework aims to mitigate privacy and security risks while maintaining negotiation efficiency and transparency, thereby supporting the practical deployment of automated negotiation systems in complex and data-sensitive business environments.
Based on the above discussion on privacy protection in automated negotiation, existing studies have proposed various negotiation protocols with different privacy-preserving mechanisms. To facilitate a systematic comparison, Table 2 presents a comparison of representative negotiation protocols with privacy-preserving mechanisms.
Table 2.
Comparison of negotiation protocols with privacy-preserving mechanisms.
In summary, most existing negotiation protocols introduce privacy protection as an external or auxiliary mechanism, rather than embedding it into the protocol design itself. Although certain approaches partially integrate privacy-preserving elements, they often provide limited protection and incur efficiency trade-offs.
3. The Proposed Model
3.1. Model Framework
This study aims to establish a secure and reliable automated negotiation transaction matching system to foster stable negotiation relationships and facilitate high-quality negotiation outcomes. The model framework comprises three modules, illustrated in Figure 1. The first module involves establishing a trust network to ensure the inclusion of secure and trustworthy negotiation participants, which also lays the foundation for network analysis. The second module focuses on constructing a privacy-enhanced automated negotiation protocol. Building upon Module 1, this protocol encrypts the sensitive information of negotiation participants to safeguard data security and privacy. The third module introduces the reinforcement learning algorithm into the negotiation counterpart matching process, integrating satisfaction functions into the Q-learning algorithm to dynamically match optimal adversaries for each negotiation participant. The integration of these three modules not only improves negotiation efficiency but also ensures the protection of user privacy and information security. Additionally, it establishes a unified, computable input framework for automated negotiations, thereby enhancing the system’s transparency and interpretability.
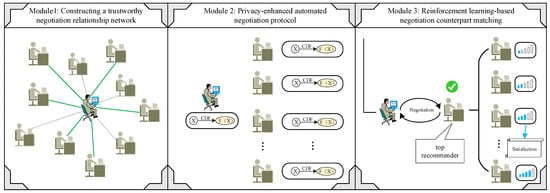
Figure 1.
The framework of the proposed model.
Specifically, our research commences with defining key concepts such as imperfectly competitive negotiation, negotiation relationship network, negotiation subject, and negotiation counterpart. In the initial phase, we construct a negotiation relationship network centered around the negotiation subject, utilizing the theory of six degrees of separation. This network serves as the basis for narrowing the negotiation space by evaluating local and global trust attributes. Subsequently, we classify commodity attribute data into interval number type, fuzzy number type, and semantic number type, detailing transformation steps for each data type into cumulative distribution function form. Finally, we use the Q-learning reinforcement algorithm oriented to the user’s satisfaction with goods, enabling precise matching between user needs and negotiation counterparts.
3.2. Definitions and Construction Method of Negotiation Network
This section aims to establish a negotiation relationship network using the six degrees of separation theory. It details the construction of this network through the breadth-first search method, highlighting the hierarchy of relationships formed by direct and indirect connections between nodes.
3.2.1. Key Concepts and Definitions
To facilitate understanding, this subsection begins with clear definitions of concepts related to imperfectly competitive negotiations and negotiation relationship networks:
Definition 1.
An imperfectly competitive negotiation assumes a blend of competitiveness and cooperation among participants [28]. In this type of negotiation, participants leverage their strengths to secure more favorable conditions while also considering the reactions and interests of the other party to achieve a mutually acceptable agreement.
Definition 2.
Negotiation Relationship Network assumes that the relationship network formed by each participant in the negotiation within an organizational environment can be represented by a graph model, denoted as . Here,
represents the set of nodes, which are the negotiation participants, and represents the set of edges, which indicate the social relationships between these negotiation participants.
Definition 3.
The negotiation subject refers to the party or parties involved in the negotiation [8], specifically the decision-making entities responsible for selecting other parties to engage in the negotiation. The negotiating subject can be an individual, a company, or another type of organization. The negotiating subject is capable of identifying and selecting the negotiating counterpart that best suits its needs using the proposed methods.
Definition 4.
Negotiation counterpart refers to the other party or parties selected for negotiation [2], i.e., the counterparty or partner chosen by the negotiating subject. This selection is based on an analysis of negotiation costs, security levels, and other factors within the negotiation relationship network.
3.2.2. The Negotiation Network Construction Based on Breadth-First Search
In the context of imperfectly competitive negotiations, constructing negotiation relationship networks is crucial for clarifying participant relationships and enhancing negotiation security. Typically, negotiation participants may lack direct communication channels, resulting in sparse negotiation networks. To address this, the Six Degrees of Separation Theory [29] is applied in this study to construct a hierarchical and relatively complete network of negotiation relationships by systematically searching for direct or indirect connections.
The basic principle of the Six Degrees of Separation Theory is that there exists an implicit connection path between the nodes of a social network. Through forwarding information or establishing direct connections from one level to another, the entire network can achieve a high degree of connectivity. In this theory, “degree” refers to the length of the path connecting two individuals. According to the Six Degrees of Separation Theory, the negotiation counterpart with direct contact with the negotiation subject is categorized as the first level of relationship. Based on the first level, the negotiation counterpart connected to the first level forms the second level of the relationship. This process is repeated until the predetermined requirements are met. In practice, the search scope is generally controlled within four levels of relationships [30]. This is because, in real-world scenarios, a shallower search range can usually identify the target node or target relationship more accurately. Additionally, limiting the search range can prevent a drastic increase in the load of the relationship network and improve the accuracy of search results.
Accordingly, based on the Six Degrees of Separation Theory, this study uses the negotiation subject as the starting node for a breadth-first search [31]. The search depth is controlled to no more than four degrees to construct the negotiation agent relationship network. The steps are as follows:
Step 1: Initialize the relationship network graph , which stores relationships between negotiation participants.
Step 2: Add negotiation subject: Include the negotiation subject agent as a node in the relationship network.
Step 3: Extend the relational network using breadth-first search, limiting the search depth to 4: Firstly, create an empty queue for storing pending nodes and their depth information. Secondly, create an empty collection for recording nodes that have been accessed to avoid repeated access. Then, add the negotiation subject agent to the queue and mark it as accessed. Finally, continuously remove nodes from the queue and iterate through their neighboring nodes.
Step 4: Generate the relationship network graph.
To facilitate understanding, this study provides a schematic diagram of the negotiation relationship network constructed based on breadth-first search, as shown in Figure 2.
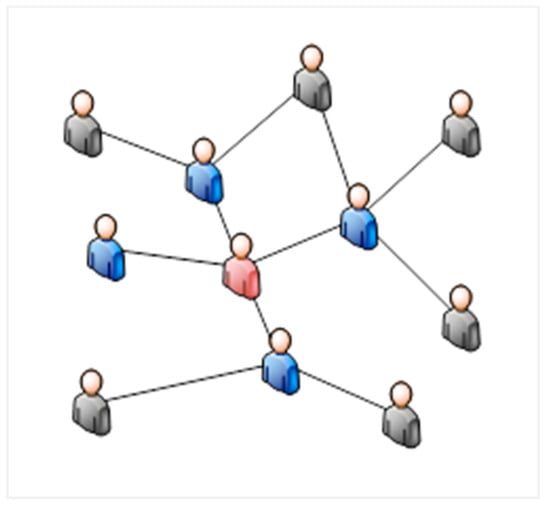
Figure 2.
Schematic diagram of the negotiation relationship network.
In this network relationship schematic, the red node represents the negotiation subject agent; the blue nodes indicate negotiation agents with a direct connection to the negotiation subject, classified as first-level relationship nodes; and the grey nodes represent negotiation agents with an indirect connection to the negotiation subject, classified as second-level relationship nodes. Overall, the combination of red, blue, and grey nodes constitutes a hierarchical negotiation relationship network.
3.3. Trust-Based Negotiation Space Reduction Method
In this subsection, we employ logistic regression to fuse trust-related features among nodes within the negotiation relationship network. This approach evaluates the trustworthiness levels between nodes. Subsequently, nodes identified as untrustworthy are removed from the negotiation network. This refinement reduces the search scope for potential negotiation partners, thereby enhancing the efficiency and security of subsequent negotiation processes.
3.3.1. Local Trust Evaluation
The local trust focuses on the trust relationship between individuals they interact with, either directly or indirectly. It infers the level of trust by analyzing transaction history data, such as transaction frequency, success rate, and behavioral patterns. Additionally, the model considers indirect trust information, including social network recommendations and friend evaluations, which provide supplementary trust support and serve as an important basis for individuals to form trust preferences during transactions.
In this study, local trust is divided into two components: direct trust and recommendation trust. Direct trust is measured by interaction frequency; more frequent transactions indicate a higher level of trust. Accordingly, the following local direct trust metric formula is proposed:
where denotes the local direct trust between user i and user j, represents the number of transactions between user i and user j within a specific date range , is the maximum number of transactions between user i and any other users within the same date range , and is a regulating parameter, a positive real number arbitrarily less than 1, to avoid division by zero errors.
In service transaction environments, constructing recommendation trust features often relies on the evaluations and feedback of other users to assist in decision-making. These evaluations reflect the degree of user approval and satisfaction with the transaction object. Therefore, evaluation similarity is considered an effective recommendation trust feature for measuring the trust relationship between users, especially when there is no direct interaction between them, but they have evaluated the same object. This approach quantifies the level of trust by comparing the consistency of user evaluations. The cosine similarity is calculated as follows:
where denotes the local indirect trust between user and user , and represent each element in the evaluation vectors of nodes and , respectively, and denotes the dimension of the evaluation vector.
3.3.2. Global Trust Evaluation
Global trust is built on a broad foundation, encompassing the relationships between all individuals in a trust network and a specific individual. It reflects the degree of trust formed through long-term experience and shared values. Typically, the calculation of local trust fully considers the information from direct or indirect interactions between individuals, providing a critical basis for constructing global trust. Building on this, the global trust degree is defined using the structure feature of the in-degree inspired by the trust network. Generally, an individual’s direct interaction with more individuals indicates higher centrality in the network, which usually implies greater global trust. The global trust feature is defined as follows:
where denotes the global trust of user , represents the incidence of user i within a specific date range , and presents the maximum number of interactions of nodes in the network. is also a tuning parameter, a positive real number arbitrarily less than 1.
3.3.3. Relationship Prediction Based on Logistic Regression
Logistic regression is employed to construct predictive models that generate output probability values for classification. This is achieved by combining the trust-related features of known entities with a probability function. The aforementioned trust-related features can be used as input variables in a logistic regression model to predict the trustworthiness between individuals within the negotiation counterpart search space.
Consider nodes i and j as examples, assuming that there are two possible types of relationships between these nodes: (1) the relationship between nodes i and j is mutually trustworthy, and (2) the relationship between nodes i and j is not mutually trustworthy. This study uses a logistic regression model to predict the probability that the relationship between a node i and a node j is trustworthy, utilizing local trust features and global trust features as follows:
where denotes the probability that the relationship between nodes i and j is trustworthy; denotes the feature vector, which consists of local trust features and global trust features; and denotes the vector of feature weights estimated by the maximum likelihood method.
3.3.4. Negotiation Space Reduction
To ensure negotiation security, it is essential to focus on trusted negotiation objects, i.e., nodes that have a high degree of trust with the negotiation subject agent. Based on the relationship modeling results in Section 3.2, the trustworthiness of transaction nodes within the negotiation object search space can be predicted. This helps to eliminate untrustworthy nodes, thereby reducing the negotiation object search space and enhancing transaction security. Specifically, nodes predicted to be untrustworthy are removed from the original list of negotiators, retaining only those deemed trustworthy. This process narrows and refines the original search space into a new secure search space , comprising only trusted negotiation objects.
Assume that node i is the negotiation subject agent, and node j represents any other negotiation participant. For each pair of nodes i and j, the probability score of their belonging to a trust relationship is calculated based on a logistic regression model. We then set a threshold θ and use the following expression to decide whether to include node j in node i’s new search space :
where denotes the new search space for node i, and is the probability that a trusted relationship exists between nodes i and j. If this probability exceeds the threshold , node j is considered suitable for inclusion in the new search space of node i.
3.4. Privacy-Enhanced Data Processing Protocol
The screening of trust relationships offers negotiation participants a relatively secure selection pool, which is essential for achieving an optimal match between negotiation counterparts. This mechanism not only significantly improves the likelihood of successful negotiations but also establishes a foundation for maximizing potential gains. However, in automated negotiation environments, participants often need to handle data containing sensitive information—such as bid ranges, preference parameters, and product attributes—during the sharing and computation processes. To address the growing concerns regarding user privacy protection, this paper proposes a privacy-enhanced data processing protocol.
In designing this protocol, we adopt a semi-honest (honest-but-curious) threat model, a widely used assumption in privacy-preserving computation and automated negotiation research. Under this threat model, negotiation participants and the platform are expected to execute the protocol correctly while potentially attempting to infer sensitive information from exchanged data. The proposed protocol aims to prevent the direct exposure of exact attribute values and preference boundaries by transforming sensitive information into probabilistic representations.
Specifically, the proposed protocol utilizes the Cumulative Distribution Function (CDF) to process sensitive data, converting deterministic numerical values into distributional forms, thereby minimizing the risks associated with direct data exposure. Specifically, in online platforms, product attributes are often represented as interval numbers, fuzzy numbers, or linguistic variables—representations that may implicitly contain crucial transactional details. By transforming these data representations into CDF-based distributions, the protocol effectively achieves data anonymization and enhances privacy protection. This approach not only ensures the security of sensitive information but also fosters negotiation transparency and improves computational efficiency, thereby establishing a secure, reliable, and efficient privacy protection framework for automated negotiation systems.
3.4.1. Interval-Type Data Under the Privacy-Enhanced Protocol
In automated negotiation, data such as commodity prices is often represented as intervals rather than precise values. These intervals reflect the participants’ reservation values and the proposal value with the maximum potential returns. Consequently, interval number types are well-suited to reflect these characteristics. Here, the buyer agent’s demand interval is defined as , and the seller agent’s supply interval is defined as . The interval number type typically represents the upper and lower bounds of the attributes for the participants, meaning the intervals and are relatively fixed.
In this context, denotes a specific proposal value within either the buyer’s demand interval or the seller’s supply interval. The actual value of x is usually drawn from a uniformly or normally distributed interval. Thus, represents the probability density of within the buyer’s demand interval, while denotes the probability density of within the seller’s supply interval. The cumulative distribution function can be expressed as follows:
where is the set of attributes for the buyer’s commodity and is the set of attributes for the seller’s commodity.
3.4.2. Fuzzy-Type Data Under the Privacy-Enhanced Protocol
Users’ perceptions of commodity satisfaction, service quality, and other attributes are often not explicit values but are subjective and fuzzy. The fuzzy number type effectively describes this characteristic. Taking a buyer as an example, a certain buyer attribute is generally expressed using triangular fuzzy numbers , where represents the minimum possible value, represents the most likely value, and represents the maximum possible value. Similarly, a seller’s attribute can be represented using triangular fuzzy numbers .
Through introducing constants and into the membership functions of the buyer and the seller, these fuzzy numbers can be transformed into corresponding probability density functions [32]. Consequently, the cumulative distribution function for the buyer, , can be expressed as follows:
Similarly, the cumulative distribution function for the seller, , can be expressed as follows:
3.4.3. Linguistic-Type Data Under the Privacy-Enhanced Protocol
For general products, information such as reviews is often expressed in natural language. Linguistic number types can effectively capture and clarify the semantics of such data. The set of linguistic variables is defined as follows:
where denotes the linguistic variable in the set.
According to the literature [33], these linguistic variables are transformed into corresponding triangular fuzzy numbers in the form of:
Based on the method of transforming triangular fuzzy numbers into random variables, the corresponding cumulative distribution functions and can be determined in a similar manner.
3.5. Adaptive Matching Strategy
After the implementation of the privacy-enhanced data processing protocol, the attribute data of negotiation participants is transformed into random variables represented by cumulative distribution functions. This probabilistic representation not only conceals sensitive information but also enables the system to process diverse data types in a unified manner. Building upon this privacy-preserving data structure, this study introduces a reinforcement learning-based matching strategy that incorporates the Q-learning algorithm into the negotiation matching system. Through iterative learning, the system dynamically adjusts its matching decisions in response to evolving market conditions and user preference patterns. In this framework, the satisfaction measure between buyers and sellers is redefined and employed as the reward function within the Q-learning algorithm, providing an objective evaluation of matching outcomes and improving user satisfaction. The update function of the Q-learning algorithm is formulated as follows:
where α represents the learning rate, denotes the matching state, indicates the selection of a matching strategy based on the current state, is the immediate reward, and signifies the discount factor.
To improve the reproducibility of the proposed approach, we further clarify the implementation details of the Q-learning algorithm. In this study, the reinforcement learning agent corresponds to the platform-level matching decision module, while the learning environment is defined by the current pool of feasible negotiation agents, the associated trust relationships, and the privacy-preserving attribute representations derived from cumulative distribution functions (CDFs).
State space (). The state space is designed to characterize the current matching context. Specifically, each state is represented by a feature vector that integrates the trust levels between candidate buyer–seller pairs, the satisfaction information computed from the privacy-protected attribute representations, and the current matching status (e.g., whether an agent has already been matched). This state representation provides sufficient decision-relevant information for learning while avoiding the exposure of raw sensitive data.
Action space (). The action space consists of the set of feasible matching decisions available in the current state. Each action corresponds to selecting a buyer–seller pair for matching under one-to-one matching constraints or choosing to defer matching at the current decision step. This design allows the system to flexibly adjust its decisions across different negotiation stages.
Exploration strategy. To balance exploration and exploitation during training, an ε-greedy exploration strategy is adopted. Specifically, with probability ε, the agent randomly selects a matching action to explore the strategy space, while with probability 1 − ε, it selects the action with the highest Q-value. Through iterative updates, the learning process gradually converges to a stable and effective matching policy.
Generally, commodity attributes are categorized into benefit and cost types, and the satisfaction formulas of buyers and sellers are also different under different attributes. Thus, we adopt the revenue evaluation function proposed in the literature [34] to establish our satisfaction function. For a benefit-type attribute, let denote buyer ’s requirement for attribute , and denote the requirement for attribute to achieve a satisfaction level of 1. In this context, , and the minimum value provided by the seller for this attribute is . Conversely, for a cost-type attribute, , the maximum value provided by the seller for this attribute is . Figure 3 illustrates the satisfaction levels for both benefit-type and cost-type attributes. Buyer ’s satisfaction with attribute , denoted by , is calculated as follows:
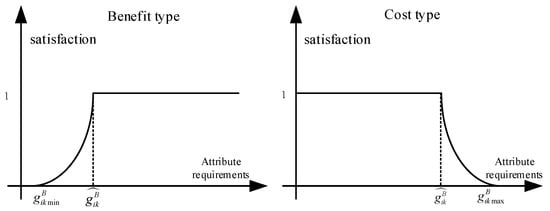
Figure 3.
Satisfaction Levels for Benefit-Type and Cost-Type Attributes.
4. Experiments and Results
This section presents a comprehensive case study, supported by numerical experiments, to demonstrate the effectiveness and reliability of the proposed model. The case study examines the matching process of multi-attribute goods in an online social commerce environment, where the demand side specifies detailed requirements for particular commodities. Based on these requirements, the platform employs the proposed matching mechanism to identify suitable suppliers and facilitate subsequent automated negotiations and transactions. Throughout this process, multiple factors are jointly considered, while privacy protection and transaction security are strictly maintained.
4.1. Screening of Trusted Negotiation Relationship Networks
All experiments were conducted using Python (version 3.9), with the negotiation relationship network constructed and analyzed through the NetworkX library (version 2.8). The proposed models were developed and executed within the PyCharm (version 2022.2) integrated development environment (IDE). NetworkX was utilized for graph representation, topological analysis, and the extraction of trust-related features, thereby providing a stable and reproducible platform for the experiments.
4.1.1. Dataset Description
For the validation of the trusted negotiation relationship network, we selected the Sina Weibo dataset, which exemplifies the complex interpersonal interactions and trust relationships inherent in social business networks. Sina Weibo, one of China’s largest social media platforms, offers extensive user interaction data and a rich social network structure, making it ideal for studying automated negotiation and transaction matching systems. The dataset includes 63,641 users, encompassing basic user information and interactions. It conforms to the power-law and long-tail distribution characteristics of social networks, and its basic in-degree and out-degree information is shown in Table 3.
Table 3.
Network structure characteristics.
4.1.2. Evaluation Metrics
To evaluate the validity of the trusted negotiation relationship network model proposed in this paper, we utilize the following metrics: accuracy, precision, recall, and F1 score. These metrics are defined as follows:
Accuracy: the ratio of correctly predicted samples to the total number of samples.
Precision: the proportion of correctly predicted positive samples to all samples predicted as positive.
Recall: The proportion of correctly predicted positive samples to all actual positive samples.
F1 Score: The harmonic mean of precision and recall.
Here, TP (true positive), TN (true negative), FP (false positive), and FN (false negative) refer to correctly identified positive samples, correctly identified negative samples, incorrectly labeled positive samples, and missed positive samples, respectively, in the context of relationship prediction.
4.1.3. Experimental Results and Analysis
This section evaluates the effectiveness of the trusted negotiation network established for the negotiation subject. Figure 4 illustrates the construction process for the trusted negotiation network of the node number “1,006,718,042”: the red node represents the negotiation subject node, the yellow nodes are unreliable nodes that were eliminated, and the green nodes constitute the final credible relationship network.
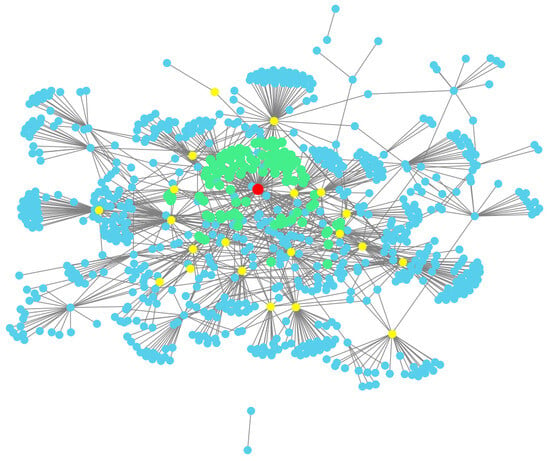
Figure 4.
The trusted negotiation network visualization of the selected node.
We conducted 50 independent numerical experiments, each selecting a random set of 50 negotiation agents as target nodes to evaluate the classification performance of the trust prediction model across different negotiation relationship subnetworks. For each experiment, we first constructed the corresponding negotiation subnetwork centered on the selected node and performed model evaluation using 10-fold cross-validation. Specifically, the samples within the subnetwork were randomly divided into 10 mutually exclusive subsets of approximately equal size. In each iteration, one subset was designated as the test set, while the remaining 9 subsets were used to train the logistic regression model. This process was repeated 10 times, ensuring that each subset served as the test set exactly once.
During training, the model’s input features included direct trust, recommended trust, and global trust, all derived from the negotiation relationship network. Model parameters were estimated through maximum likelihood estimation. After training, the model was applied to the corresponding test subset to predict the reliability of the negotiation relationships between agents.
Performance metrics, including accuracy, precision, recall, and F1 score, were averaged across the 10-fold validation for each node group experiment. The final experimental results represent the average of the evaluation outcomes across 50 distinct target nodes, effectively minimizing sampling bias induced by network structural heterogeneity. Subsequently, we compared our method with the approach presented in the literature [35], which analyzes network topology using structural equilibrium theory. The comparison results are displayed in Figure 5.
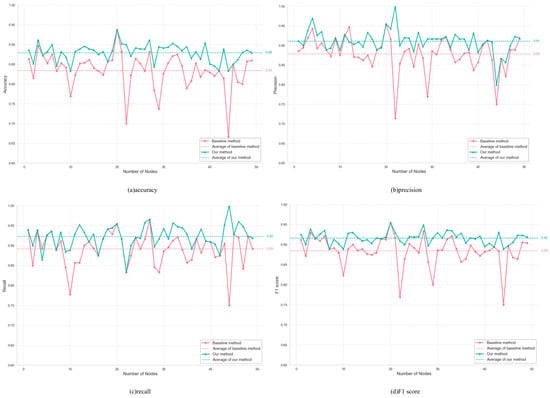
Figure 5.
Comparison of classification performance between our method and the baseline method.
The classification effect of node relationships in constructing trusted negotiation networks was presented in Figure 5 Figure 5a–d show the visualization of our model’s performance compared to the baseline method in terms of accuracy, precision, recall, and F1 score, respectively. The horizontal axis represents the 50 different sets of numerical experiment results, while the vertical axis indicates the percentage. The green line represents our method, the red line represents the baseline method, and the corresponding dashed line represents the average value for each method. The results indicate that our method achieved average scores of 0.8798 in accuracy, 0.9114 in precision, 0.9230 in recall, and 0.9171 in F1 score. These scores represent improvements of 4.52%, 3.27%, 3.15%, and 3.21%, respectively, over the baseline method. This demonstrates that our model provides better performance in establishing an effective network and constructing a credible negotiation relationship network.
Additionally, the green dashed line of our method shows greater stability, whereas the baseline method exhibits significant fluctuations for individual numerical experiments. To further verify the reliability of the results, we calculated the variance of the above experimental results of the two methods, as shown in Table 4.
Table 4.
Variance comparison of model performances.
According to Table 4, the variance for our method is lower than that of the baseline method across all four indicators of model effectiveness. We further analyzed the cause of this difference and found that the baseline method overly depends on the current node’s network structure, resulting in weaker judgment of inter-node relationships when data is sparse. In contrast, our method incorporates both global and local trust, enhancing the accuracy of inter-node trust assessments. Through integrating local trust with global trust, our model demonstrates greater robustness.
In summary, our model not only surpasses the comparative method in classification effectiveness but also exhibits higher stability and robustness. By comprehensively assessing both global and local trust, our method demonstrates strong adaptability and accuracy in constructing a trusted negotiation relationship network, which can better improve the reliability and effectiveness of negotiation counterpart matching.
4.2. Application of the Privacy-Enhanced Protocol
In this scenario, we assume there are five negotiating parties () seeking to purchase a chair and thirty suppliers () available within the constructed trusted negotiation relationship network. The platform provides optimal matching options for each demand party, facilitating subsequent negotiation and transaction conclusion. The details of the demanders and suppliers are listed in Table 5 and Table 6, which present the requirements and supply attributes for the commodity as specified by buyers and sellers. Specifically, denotes the price, including the lowest price, current price, and highest acceptable price proposed by the participant, represented as an interval number type; denotes quality, characterized by a fuzzy number type with its fuzzy set denoted as ; and denotes delivery time, a soft constraint where shorter times are preferable. For delivery time, Table 5 and Table 6 list the fastest delivery time, the average delivery time, and the longest delivery time, represented as linguistic number types with the unit in days. The data in Table 5 and Table 6 are obtained from the website of Alibaba (1688.com). The specific process of applying the privacy-enhanced automated negotiation protocol is detailed below.
Table 5.
Buyer’s requirements for different attributes of the commodity.
Table 6.
Seller’s supplies for different attributes of the commodity.
Based on the assumption that the attributes of buyers and sellers follow a uniform distribution, the buyer and seller information in Table 5 and Table 6 are converted into cumulative distribution functions and , respectively, using the formulas outlined in Section 3.4, where and . Due to space constraints, we only present the results of the transformation for the demand side B1 and the supply side S1 as follows:
4.3. Case Study
In this subsection, we process all the data of buyers and sellers using cumulative distribution functions to obtain the corresponding distribution functions. Subsequently, we apply the Q-learning reinforcement learning algorithm, as proposed in Section 3.5, for matching. The learning rate α is set to 0.5, and the discount factor γ is set to 0.9. Meanwhile, we compared our method with the improved Kuhn-Munkres algorithm [36], which is utilized to solve the multiple assignment problem and effectively addresses resource allocation tasks. The comparison of matching outcomes is presented in Table 7.
Table 7.
Comparison of matching outcomes and performance.
In addition, we calculated the satisfaction measures for each group of buyers and sellers sequentially. Due to space constraints, we present only the calculation process for buyers B1–B5 and sellers S1–S5, as illustrated in Figure 6.
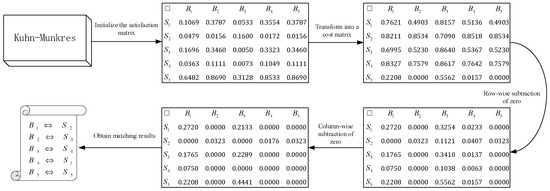
Figure 6.
The satisfaction measure calculation process for buyers and sellers.
The optimal matching results, calculated across all combinations, are also summarized in Table 7. The joint satisfaction achieved by the method proposed in this study is 13.7927, surpassing the 13.3675 obtained by the baseline method described in the literature [36]. Although the baseline method achieves higher satisfaction in terms of attribute 1, its overall joint satisfaction is not optimal and reflects a local optimum. This limitation arises from the Kuhn-Munkres algorithm’s constraints: it has a limited search space, lacks global search capabilities, and tends to converge on local optima when handling multi-attribute data streams. In contrast, the method proposed in this paper integrates various types of data into distribution functions using privacy-preserving data processing protocols. This approach not only standardizes the data format but also broadens the algorithm’s search scope. Meanwhile, by leveraging the global search capabilities of the reinforcement learning algorithm, this method enhances joint satisfaction and ensures that the matching results achieve Pareto optimality. Furthermore, the computation time for the method proposed in this study is 1.2 s, compared to 1.0 s for the baseline method [36]. This slight difference indicates that while the proposed method improves result optimization, it maintains comparable efficiency.
4.4. Comparative Experiments and Analysis
To further verify the effectiveness of the proposed method, we designed two sets of comparative experiments following the framework of the case study. Specifically, 150 items of “chair” products were collected from the Alibaba platform using a web crawler, and their attributes were cleaned and organized to obtain the following attribute ranges: price , quality level , and delivery time . To simulate diverse buyer preferences, buyer attribute intervals were generated using a simple random distribution within the above ranges. The experimental setting consisted of 5 buyers and 30 sellers, and a total of 100 independent configurations of buyer–seller attribute profiles were randomly generated. In each experimental run, both the baseline methods and the proposed method were applied to perform matching, and the satisfaction achieved from the finalized transactions was recorded. Subsequently, the mean satisfaction and its variation across the 100 experiments were computed to evaluate the stability and superiority of the proposed method under different random environments.
Baseline method 1 [37] is an experience-based multi-dimensional trust allocation model, which updates trust levels based on historical matching records, with trust values gradually converging as experience accumulates. It should be noted that the method in [37] introduces a strata-based trust discretization mechanism at the trust comparison stage to mitigate the potential over-influence of minor numerical differences between continuous trust values on the decision-making process. For the sake of simplifying the experimental procedure, this strata mechanism was not explicitly incorporated in our implementation of the baseline method; instead, matching and decision-making were performed directly based on continuous trust values. Baseline method 2 [36] is the Kuhn-Munkres algorithm. The experimental results are shown in Figure 7.
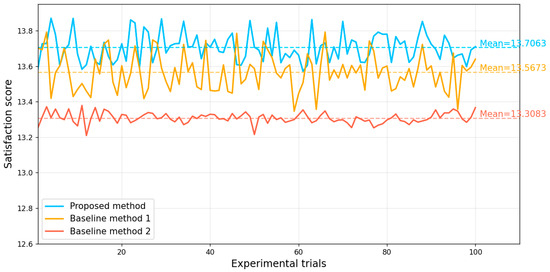
Figure 7.
Line chart of satisfaction comparison experiments.
Figure 7 illustrates the performance of the proposed method and the baseline methods in terms of matching satisfaction over 100 mutually independent repeated experiments. The horizontal axis represents the experiment index, while the vertical axis denotes the corresponding satisfaction value. The dashed lines indicate the average satisfaction levels of each method across all experiments. As shown in Figure 7, the proposed method consistently maintains a higher and relatively stable level of satisfaction across all experimental runs, with a mean satisfaction of 13.7063, which is noticeably higher than that of baseline method 1 (mean 13.5673) and baseline method 2 (mean 13.3083). These results indicate that the proposed method is able to consistently achieve superior matching performance under different random experimental configurations, and that the observed performance improvement is not dependent on any single experimental setting or specific parameter combination.
Although in a few experimental runs the satisfaction achieved by baseline method 1 exceeds that of the proposed method, the overall trend and statistical results indicate that the proposed method achieves higher satisfaction in the vast majority of experiments, with its overall mean level consistently outperforming both baseline methods. This demonstrates that the proposed method exhibits superior overall performance under long-term and repeated execution conditions. In contrast, baseline method 2 shows relatively smaller fluctuations in its satisfaction curve, indicating higher stability; however, its mean satisfaction is noticeably lower. This is mainly because baseline method 2 has limited capability to explore the matching space and cannot effectively adapt to changes in buyer and seller attributes, making it difficult to achieve high-quality matching results in complex and diverse matching environments.
The other set of comparative experiments primarily evaluates the computational performance of the proposed method. We measured the processing time required for matching as the number of sellers increased from 30 to 500, and the experimental results are shown in Figure 8.
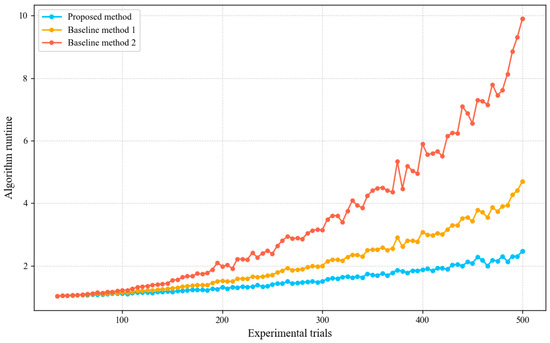
Figure 8.
Line chart of runtime comparison experiments.
As shown in Figure 8, as the data scale continuously increases, the proposed method consistently maintains a low and relatively stable processing time. In contrast, the processing times of the two baseline methods increase more noticeably as the problem scale grows. In particular, baseline method 2 exhibits the steepest growth trend in processing time under large-scale scenarios, while baseline method 1 shows a more moderate increase, but its overall runtime remains higher than that of the proposed method.
The above differences mainly arise from the distinct computational mechanisms adopted by the compared methods. Baseline method 2 has a time complexity of , which performs well in small-scale and static matching problems; however, as the problem scale and state space expand rapidly, its computational burden increases significantly, leading to reduced processing efficiency. Baseline method 1 only considers experience-based trust and does not model trust from the perspective of network structure, resulting in insufficient control over computational complexity in large-scale application scenarios.
It should be noted that baseline method 1 implicitly adopts an incremental trust update and caching strategy in its original formulation, which helps reduce the computational overhead caused by repeated calculations when the network structure remains relatively stable. In contrast, the experimental setting in this study focuses on evaluating the overall matching efficiency when new users join the system, during which the network structure may undergo dynamic changes, thereby increasing the need for recomputing trust relationships. Under this experimental scenario, an explicit trust memoization mechanism was not incorporated in our implementation of the baseline method.
In contrast, the proposed method has a time complexity of and employs a Q-learning-based decision mechanism, which can effectively cope with the expanding state space through incremental exploration and policy learning. By avoiding exhaustive enumeration of the matching space, the proposed method is able to maintain high computational efficiency even as the problem scale increases.
In summary, the two sets of experiments demonstrate that in social commerce platform environments characterized by large-scale data and dynamic features, the model proposed in this paper exhibits significant advantages in terms of scalability and computational efficiency. The results indicate that while improving matching quality, the proposed method is still able to maintain favorable runtime performance, showing strong potential for practical application in continuously changing environments.
5. Conclusions
This study establishes a trusted and secure automated negotiation transaction matching system to address the challenge of selecting reliable negotiation counterparts for platform users in social commerce networks. The proposed system achieves accurate and personalized matching under multi-attribute constraints, providing a solid foundation for subsequent automated negotiations. From the platform perspective, the model emphasizes the dual objectives of trust assurance and privacy protection. By implementing a privacy-enhanced automated negotiation protocol, sensitive data are transformed into probabilistic representations, effectively safeguarding user information while maintaining computational efficiency. Moreover, the integration of reinforcement learning algorithms enables the system to dynamically adjust its matching strategies, achieving Pareto-optimal outcomes, avoiding local optima, and improving overall negotiation performance.
The findings further demonstrate that trust-based relationship modeling enhances the reliability and stability of the negotiation environment. By combining local and global trust indicators through logistic regression, the model accurately identifies trustworthy relationships and effectively narrows the search space for negotiation counterparts. This process strengthens network stability and improves the credibility of matching decisions. Meanwhile, the privacy-enhanced protocol significantly reduces the risk of exposing sensitive information by employing the cumulative distribution function to convert deterministic data into distributional forms. It also ensures that interval-type, fuzzy-type, and linguistic-type data can be securely processed, enhancing transparency and efficiency within the negotiation process. Additionally, the incorporation of Q-learning further refines the matching mechanism, enabling the system to adapt to dynamic market conditions and evolving user preferences. By redefining satisfaction as the reward function, the model promotes fairness, efficiency, and user satisfaction across negotiation outcomes.
Finally, a series of experimental results and case studies confirm the robustness, scalability, and adaptability of the proposed system. The results demonstrate that it consistently achieves efficient and accurate Pareto-optimal solutions, outperforming traditional approaches in handling large-scale and dynamic negotiation scenarios. Overall, this study verifies the effectiveness of integrating trust modeling, privacy-enhanced mechanisms, and reinforcement learning to realize secure, intelligent, and adaptive automated negotiation systems within social commerce environments.
6. Discussion
6.1. Theoretical Implications
In this study, we developed a transaction matching model that integrates complex network analysis with reinforcement learning-driven adaptive matching. The proposed model incorporates trust relationships and multi-attribute satisfaction into an automated negotiation framework, enhancing both the security and intelligence of the transaction process. By mining trust relationships and applying a privacy-enhanced automated negotiation protocol, sensitive user data are transformed into protected probabilistic forms, thereby strengthening privacy preservation and ensuring a secure data-sharing environment.
Furthermore, this study provides an in-depth examination of security risks and trust dynamics within automated negotiation systems. The proposed identification of multi-dimensional trust relationships improves the structural accuracy of the negotiation network and enhances the model’s adaptability to complex transaction environments. Experimental analyses demonstrate that, compared with traditional complex network-based matching methods in the literature [36], the proposed model achieves higher effectiveness and robustness, resulting in a more secure and reliable negotiation ecosystem and offering a novel perspective for studying trust-driven matching in social commerce platforms.
Additionally, by integrating the Q-learning algorithm into the decision-making process, the model dynamically optimizes the satisfaction of multi-attribute commodities to derive Pareto-optimal matching strategies. The experimental results confirm that the proposed approach avoids local optima and ensures fast convergence in large-scale data scenarios. This highlights the scalability, efficiency, and adaptability of the model in handling dynamic data streams and complex negotiation behaviors.
6.2. Practical Implications
The proposed model offers substantial practical value for the design and management of automated negotiation platforms in social commerce environments. By integrating a privacy-enhanced automated negotiation protocol, the system ensures secure information exchange throughout the transaction matching process. Sensitive data such as reservation prices and user preferences are effectively protected from leakage, enabling trusted interactions among participants. From an operational perspective, the framework provides a transparent and controllable management mechanism, allowing platform administrators to oversee the overall negotiation process, enhance regulatory efficiency, and support informed decision-making at the system level.
In practical electronic transaction environments, commodity data typically exhibit multi-attribute and heterogeneous characteristics, requiring robust handling of diverse data types. This study addresses this challenge by formalizing the processing of interval-type, fuzzy-type, and linguistic-type data through cumulative distribution function-based transformation. This approach enhances the flexibility of the matching mechanism, allowing dynamic adjustment of commodity attributes in response to market fluctuations. In practice, platform operators can selectively activate, modify, or remove specific attributes to reflect changing participant preferences, demonstrating the model’s high adaptability and generalizability.
Furthermore, in addition to its applications in social commerce, the proposed system can be extended to multi-party matching and allocation problems such as supply chain coordination, multi-agent resource distribution, and collaborative procurement. By combining trust evaluation, privacy protection, and adaptive matching, the model serves as a scalable decision-support tool for real-world negotiation and coordination across various industries.
6.3. Limitations and Future Research
This study proposes an automated negotiation transaction matching model that integrates security and intelligent decision-making to enhance the reliability and efficiency of social commerce platforms. Despite its promising results, several limitations remain, suggesting avenues for further research.
The current analysis of trust relationships focuses primarily on local and global perspectives, whereas real-world social interactions on online platforms are often more dynamic and multi-dimensional. Future research will incorporate additional behavioral and contextual attributes to enrich trust evaluation and improve the accuracy of relationship network construction. Moreover, the present model distinguishes only between trust and distrust states without accounting for varying degrees of trust intensity. Further exploration of fine-grained trust segmentation is planned to better understand how different trust levels influence negotiation outcomes and matching performance. In addition, the proposed approach does not aim to provide cryptographic-level privacy guarantees and may be vulnerable to inference attacks when adversaries possess strong prior knowledge or engage in long-term observation across multiple negotiation rounds. Future research will explore the incorporation of stronger privacy-preserving mechanisms, including cryptography-inspired or hybrid solutions, to mitigate inference risks under stronger adversarial assumptions while preserving the efficiency of the negotiation process.
In the comparative experiments, some baseline methods were not implemented with all mechanisms described in their original studies. For example, the trust stratification mechanism and the trust memoization update strategy proposed in [37] were not explicitly implemented in our experiments. These implementation differences may, to some extent, affect the decision stability and computational efficiency of the comparative methods. Future work will incorporate these mechanisms to conduct more rigorous replication experiments and more comprehensive performance evaluations.
Addressing these directions in future work will further enhance the adaptability, scalability, and practical applicability of automated negotiation transaction matching systems in complex and dynamic trading environments.
Author Contributions
Y.Z.: Conceptualization, Methodology, Writing—Original Draft Preparation, Writing—Editing. R.C.: Conceptualization, Validation, Writing—Reviewing and Editing. J.W.: Investigation, Software, Visualization, Project Administration. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China (grant number 71972177).
Data Availability Statement
The data that support the fundings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Liu, C.J.; Cong, J.M.; Zhao, T.H.; Zhu, E. Improving Agent Decision Payoffs via a New Framework of Opponent Modeling. Mathematics 2023, 11, 3062. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, J.H.; Cao, R.Y. Optimizing Automated Negotiation: Integrating Opponent Modeling with Reinforcement Learning for Strategy Enhancement. Mathematics 2025, 13, 679. [Google Scholar] [CrossRef]
- Li, W.S.; Zhong, H.; Zhou, J.M.; Chang, C.; Lin, R.H.; Tang, Y. An attention mechanism and residual network based knowledge graph-enhanced recommender system. Knowl.-Based Syst. 2024, 299, 112042. [Google Scholar] [CrossRef]
- Baarslag, T.; Hendrikx, M.J.C.; Hindriks, K.V.; Jonker, C.M. Learning about the opponent in automated bilateral negotiation: A comprehensive survey of opponent modeling techniques. Auton. Agents Multi-Agent Syst. 2016, 30, 849–898. [Google Scholar] [CrossRef]
- Hou, Y.Q.; Sun, M.Y.; Zhu, W.X.; Zeng, Y.F.; Piao, H.Y.; Chen, X.F.; Zhang, Q. Behavior Reasoning for Opponent Agents in Multi-Agent Learning Systems. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 6, 1125–1136. [Google Scholar] [CrossRef]
- Bagga, P.; Paoletti, N.; Alrayes, B.; Stathis, K. ANEGMA: An automated negotiation model for e-markets. Auton. Agents Multi-Agent Syst. 2021, 35, 28. [Google Scholar] [CrossRef]
- Gao, T.G.; Huang, M.; Wang, Q.; Yin, M.Q.; Ching, W.K.; Lee, L.H.; Wang, X.W. A systematic model of stable multilateral automated negotiation in e-market environment. Eng. Appl. Artif. Intell. 2018, 74, 134–145. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, Y.; Cao, R.; Li, Y. An agent-based emotional persuasion model driven by integrated trust assessment. Eng. Appl. Artif. Intell. 2025, 149, 110567. [Google Scholar] [CrossRef]
- Sweeney, L. k-Anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- Archana, R.A.; Hegadi, R.S.; Manjunath, T.N. A Study on Big Data Privacy Protection Models using Data Masking Methods. Int. J. Electr. Comput. Eng. 2018, 8, 3976–3983. [Google Scholar]
- Cho, H.; Kirch, C.; Kontoghiorghes, E.J.; Dijk, H.V.; Colubi, A.M. Data segmentation algorithms: Univariate mean change and beyond. Econom. Stat. 2021, 30, 76–95. [Google Scholar] [CrossRef]
- He, X.J.; Meng, X.; Wu, Y.Y.; Chan, C.S.; Pang, T. Semantic Matching Efficiency of Supply and Demand Texts on Online Technology Trading Platforms: Taking the Electronic Information of Three Platforms as an Example. Inf. Process. Manag. 2020, 57, 102258. [Google Scholar] [CrossRef]
- Le, D.T.; Zhang, M.J.; Ren, F.H. An Economic Model-Based Matching Approach Between Buyers and Sellers Through a Broker in an Open E-Marketplace. J. Syst. Sci. Syst. Eng. 2018, 27, 156–179. [Google Scholar] [CrossRef]
- Albrecht, S.V.; Stone, P.; Wellman, M.P. Special issue on autonomous agents modelling other agents: Guest editorial. Artif. Intell. 2020, 285, 103292. [Google Scholar] [CrossRef]
- Liang, C.-C.; Liang, W.-Y.; Tseng, T.-L. Evaluation of intelligent agents in consumer-to-business e-Commerce. Comput. Stand. Interfaces 2019, 65, 122–131. [Google Scholar] [CrossRef]
- Yesevi, G.; Keskin, M.O.; Dogru, A.; Aydogan, R. (Eds.) Time Series Predictive Models for Opponent Behavior Modeling in Bilateral Negotiations. In Proceedings of the 24th International Conference on Principles and Practice of Multi-Agent Systems (PRIMA), Electr Network, Kyoto, Japan, 16–18 November 2024; pp. 381–398. [Google Scholar]
- Keskin, M.O.; Buzcu, B.; Aydogan, R. Conflict-based negotiation strategy for human-agent negotiation. Appl. Intell. 2023, 53, 29741–29757. [Google Scholar] [CrossRef]
- Beauprez, E.; Caron, A.C.; Morge, M.; Routier, J.C. (Eds.) A Multi-Agent Negotiation Strategy for Reducing the Flowtime. In Proceedings of the 13th International Conference on Agents and Artificial Intelligence (ICAART), Electr Network, Virtual, 4–6 February 2021; pp. 58–68. [Google Scholar]
- Munroe, S.; Luck, M. Motivation-based selection of negotiation opponents. In Engineering Societies in the Agents World V; Gleizes, M.P., Omicini, A., Zambonelli, F., Eds.; Lecture Notes in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3451, pp. 119–138. [Google Scholar]
- Joe, M.M.; Ramakrishnan, B. Novel authentication procedures for preventing unauthorized access in social networks. Peer-to-Peer Netw. Appl. 2016, 10, 833–843. [Google Scholar] [CrossRef]
- Shao, K.; Luo, F.; Mei, N.-X.; Liu, Z.-T. Normal distribution based dynamical recommendation trust model. Ruanjian Xuebao/J. Softw. 2012, 23, 3130–3148. [Google Scholar] [CrossRef]
- Zhu, M.-L.; Jin, Z. Approach for evaluating the trustworthiness of service agent. Ruanjian Xuebao/J. Softw. 2011, 22, 2593–2609. [Google Scholar] [CrossRef]
- Kolomvatsos, K.; Trivizakis, D.; Hadjiefthymiades, S. An adaptive fuzzy logic system for automated negotiations. Fuzzy Sets Syst. 2015, 269, 135–152. [Google Scholar] [CrossRef]
- Imran, K.; Zhang, J.; Pal, A.; Khattak, A.; Ullah, K.; Baig, S.M. Bilateral negotiations for electricity market by adaptive agent-tracking strategy. Electr. Power Syst. Res. 2020, 186, 106390. [Google Scholar] [CrossRef]
- Zhou, H.Z.; Zhan, J.Y.; Ma, W.J. A negotiation protocol with recommendation for multilateral negotiation in trust networks. Expert Syst. Appl. 2024, 246, 123185. [Google Scholar] [CrossRef]
- Shinohara, H.; Fujita, K. (Eds.) Alternating Offers Protocol Considering Fair Privacy for Multilateral Closed Negotiation. In Proceedings of the 20th International Conference on Principles and Practice of Multi-Agent Systems (PRIMA), Nice, France, 30 October–3 November 2017; pp. 533–541. [Google Scholar]
- Chen, L.; Dong, H.; Zhou, Y. A reinforcement learning optimized negotiation method based on mediator agent. Expert Syst. Appl. 2014, 41, 7630–7640. [Google Scholar] [CrossRef]
- Zhu, J.L.; Cao, Y.; Guo, M.X.; Zhou, X.Y.; Zhang, C.H.; Li, J.; Yu, X.S.; Zhao, Y.L.; Zhang, J.; Wang, Q. Multi-protocol updating for seamless key negotiation in quantum metropolitan networks. J. Opt. Commun. Netw. 2024, 16, 735–749. [Google Scholar] [CrossRef]
- Crump, L. Competitively-linked and non-competitively-linked negotiations: Bilateral trade policy negotiations in Australia, Singapore and the United States. Int. Negot. 2006, 11, 431–466. [Google Scholar] [CrossRef]
- Newman, M.E.J. Models of the small world. J. Stat. Phys. 2000, 101, 819–841. [Google Scholar] [CrossRef]
- Daraghmi, E.Y.; Yuan, S.M. We are so close, less than 4 degrees separating you and me! Comput. Hum. Behav. 2014, 30, 273–285. [Google Scholar] [CrossRef]
- Chen, X.Y.; Xu, Z.F.; Wu, Y.S.; Wu, Q.Y. Heuristic algorithms for reliability estimation based on breadth-first search of a grid tree. Reliab. Eng. Syst. Saf. 2023, 232, 109083. [Google Scholar] [CrossRef]
- Zaras, K. Rough approximation of a preference relation by a multi-attribute dominance for deterministic, stochastic and fuzzy decision problems. Eur. J. Oper. Res. 2004, 159, 196–206. [Google Scholar] [CrossRef]
- Jiang, Y.-P.; Fan, Z.-P.; Ma, J. A method for group decision making with multi-granularity linguistic assessment information. Inf. Sci. 2008, 178, 1098–1109. [Google Scholar] [CrossRef]
- Zhang, B.; Liu, W.Q.; Zhang, Y.; Yang, R.; Li, M.Z. Implicit Negative Link Prediction with a Network Topology Perspective. IEEE Trans. Comput. Soc. Syst. 2023, 10, 3132–3142. [Google Scholar] [CrossRef]
- Zhu, H.; Liu, D.; Zhang, S.; Zhu, Y.; Teng, L.; Teng, S. Solving the many to many assignment problem by improving the Kuhn–Munkres algorithm with backtracking. Theor. Comput. Sci. 2016, 618, 30–41. [Google Scholar] [CrossRef]
- Griffiths, N. (Ed.) Task delegation using experience-based multi-dimensional trust. In Proceedings of the Fourth International Joint Conference on Autonomous Agents and Multiagent Systems, Utrecht, The Netherlands, 25–29 July 2005; pp. 489–496. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.