Abstract
Better understanding mathematical and numerical models often requires investigating the impacts of inputs on the model outputs, as well as interactions. Quantifying such effects for models with non-independent input variables (NIVs) relies on conditional distributions of the outputs given every subset of inputs. In this paper, by firstly providing additional dependency models of NIVs, functional outputs are composed by dependency models (yielding equivalent representations of outputs) to derive distributions of outputs conditional on inputs. We then provide an algorithm for selecting the necessary and sufficient equivalent representations that allow for obtaining all the conditional distributions of outputs given every subset of inputs, and for assessing the main, total, and interaction effects (i.e., indices) of every subset of NIVs. Unbiased estimators of covariances of sensitivity functionals and consistent estimators of such indices are derived by distinguishing the case of the multivariate and/or functional outputs, including dynamic models. Finally, analytical results and numerical results are provided, including an illustration based on a dynamic model.
Keywords:
computer models; copulas; dependency models; multivariate sensitivity analysis; non-independent and discrete variables MSC:
49Q12; 60E05; 62F12
1. Introduction
Mathematical and numerical models and/or simulators are being increasingly developed and used for supporting decision-making in different scientific fields, such as engineering, environment, agronomy, and biology. To better understand such complex models or to design emulators, it is worth investigating the impacts of inputs on the model outputs, including the interactions among inputs. Uncertainty quantification and global sensitivity analysis are dedicated to addressing such issues. While variance-based methods (see, e.g., Sobol’ indices [1] for real-valued functions and generalized sensitivity indices [2,3,4,5,6,7] for dynamic and multivariate outputs) are well established for independent inputs, three are cases where the input variables are correlated or dependent.
Non-independent variables (NIVs) arise when two or more variables do not vary freely and are widely encountered in different scientific fields, such as in data analysis, quantitative risk analysis, and inverse problems. Performing uncertainty quantification and variance-based sensitivity analysis of computer and/or mathematical models in the presence of dependent and/or correlated input variables (i.e., NIVs) still remains a challenge when one is interested in assessing the contributions of any subset of input variables and their interactions over all the outputs. Indeed, the dependency structures inferred by the constraints imposed on model outputs and/or inputs, and the dependency structures of the initial distributions of inputs may have significant impacts on the results of Sobol’ indices and generalized sensitivity indices. A number of papers report inconsistent ranking of inputs using the above indices in the presence of NIVs (e.g., [8,9,10,11]).
In the presence of NIVs, most existing variance-based methodologies provide the same first-order index of one input or one group of dependent inputs (e.g., [8,9,10,11,12,13]). Some of them provide the total indices of inputs, and there can be cases in which the first-order index is greater than the total index. To be able to rank input variables, the works in [14,15] introduced a methodology that ensures that the first-order index is always less than the total index for every single input and for real-valued functions. In the same sense, the recent works in [16,17,18] provided in-depth approaches for quantifying the effects of each single input and some subsets of inputs (but not all the subsets) by making use of dependency models of NIVs. Note that dependency models provide functions that model the dependency structures of NIVs ([16,19,20]), and such recent approaches rely on different DMs of the same NIVs for defining and computing dependent generalized sensitivity indices (dGSIs) of some subsets of inputs.
In this paper, we propose a new methodology for (i) deriving all the conditional distributions of outputs given every subset of NIVs and (ii) assessing the impacts of every subset of uncertain NIVs and their interactions on the model outputs by making use of the necessary and sufficient equivalent representations of the model of interest. Equivalent representations are obtained by composing the model outputs by the necessary and sufficient DMs, leading to reducing the number of model runs for computing such quantities of interest.
This paper is organized as follows: in Section 2, we provide additional and generic DMs of NIVs so as to cover more distribution functions, and we investigate the DM transforms, which avoids searching dependency functions for some distributions by making use of known DMs already derived in [16,19,20]. We also provide computational DMs when analytical distributions of the input variables are not available, such as the resultant distribution of inputs associated with complex mathematical models under constraints. Section 3 provides the famous algorithm for selecting the necessary and sufficient DMs. It also deals with different representations of the model outputs associated with subsets of NIVs that are equivalent in distributions using the necessary and sufficient DMs. Such representations are useful for assessing the main, total, and interaction effects of any subset of NIVs in Section 4 by providing dGSIs of every subset of inputs and for the multivariate and/or functional outputs, including spatiotemporal models and dynamic models. Section 5 aims at constructing unbiased estimators of the cross-covariances of sensitivity functionals and the consistent estimators of dGSIs. We also provide the asymptotic distributions of dGSIs. Analytical results and numerical results are provided, including an illustration based on a dynamic model (see Section 6), and we conclude this work in Section 7.
General Notation
For an integer , we use : = for a random vector of NIVs. Given , we use : =, : = and for its cardinality, leading to the partition . We also use to say that and have the same cumulative distribution function (CDF). For , we use for the Euclidean norm. For a matrix , we use for the trace of , and for the Frobenius norm of . We use for the expectation operator and for the variance–covariance operator.
2. Dependency Functions of Non-Independent Random Variables
This section provides generic DMs of NIVs and some transformations of such DMs. Formally, the inputs have F as the CDF and C as the copula, that is, with or the marginal CDF of , and a sample value of . We use for the generalized inverse of , and for the distribution of conditional on for all and . For a given discrete variable , let us consider the distribution transform of given by with . Such a distribution transform ensures that for all [21,22,23,24]
For continuous distributions, the former term of Equation (1) comes down to the Rosenblatt transform [25], and the latter term is equivalent to the inverse of the Rosenblatt transform. Denote with an arbitrary permutation of , and . A generic DM of is given by [16,20]
where is a random vector of independent variables, and it is independent of as well. It is worth noting that the dependency function is not unique. Indeed, one may replace, in Equation, (2) with for any continuous variable or with for any discrete variable , provided that such variables are independent of . But, DMs are uniquely defined once the marginal CDFs of are prescribed.
Proposition 1
([18]). Let be a dependency function; ; be a vector and . Then,
Moreover, there exists such that
2.1. Distribution-Based and Copula-Based Expressions of Dependency Models
The distribution-based dependency model of is given by [16,19]
Likewise, the copula-based dependency function is of interest to master all joint distributions having the same copula C, regardless of their marginal CDFs ([23,26]). It allows one to use the same DMs for the class of distributions sharing the same copula. For independent variables , , and , the copula-based DM is given by
by making use of the conditional sampling algorithm based on copulas [26,27]. Note that for Gaussian copulas and continuous marginal CDFs of inputs, DMs in (6) have a particular form provided in [16]. Lemma 1 extends such DMs to cope with discrete CDFs as well. To that end, denote with the Gauss copula having as the correlation matrix; the Cholesky factor of (i.e., ); the CDF of the standard Gaussian variable; and the identity matrix.
Lemma 1.
Let , and be independent variables.
If has the copula , then
with
Proof.
See Appendix A. □
Likewise, to provide DMs for the Student copulas (Lemma 2), we use for the standard t-distribution with degrees of freedom and for its CDF.
Lemma 2.
Let , and be independent variables.
If has the Student copula , then
with
Proof.
See Appendix B. □
Note that for every continuous variable , we have to replace with in Lemmas 1 and 2. For discrete variables, we have to include additional and independent uniformly distributed variables in copula-based DMs (see Equation (6)).
2.2. Empirical and Computational Dependency Models
This section deals with the derivation of DMs for unknown distributions of inputs, such as distributions obtained by imposing constraints on the initial inputs or outputs. Formally, given a function and a domain of interest D, we are interested in deriving a dependency function of a random vector defined by
While we are able to derive the analytical distribution of and its dependency function for some distributions and constraints (see [16,20]), we have to estimate such dependency functions in general. Using Equation (9), we can generate a sample of , that is, and a pseudo-sample from the copula C of , that is, with for continuous variables, where is an estimator of . In general, we use .
With such samples, we consider two main ways to derive the empirical dependency functions. Firstly, we fit a distribution to such observations and then derive dependency functions using results from Section 2. To that end, there are numerous papers about fitting a distribution to data. For instance, direct methods for estimating densities and distributions can be found in [28,29,30,31], and the copula-based methods for modeling distributions are provided in [23,27,32,33,34,35].
Secondly, we derive empirical dependency functions using the estimators of the conditional quantile functions [36,37,38,39,40,41,42,43]. Formally, consider the loss function of Koenker and Bassett [36] given by with and the indicator function. A dependency function can be written as follows:
where is a class of smooth functions, and is independent of . Using the sample of , the M-estimator of a dependency function is given by ([43], Lemma 3)
where is a bandwidth, is a given norm, and .
3. Equivalent Representations of Functional Outputs
This section formalizes different representations of complex models with NIVs . Formally, given , , consider a function with random evaluations, that is, with . It may represent any multivariate and functional outputs. When with , we obtain a class of vector-valued functions. In what follows, is organized as follows:
(O): consists of K independent random vector(s), that is, where are the sets that form a partition of ; : = is independent of : = for all and . Without loss of generality, we use for a random vector of independent variable(s); with for a random vector of NIVs. Note that .
Denote with : = an arbitrary permutation of and : = . Thus, . If we use : = , then : = contains independent variables and : = with : = , .
Using the DMs of Section 2, we can write
where : = is a vector of independent variables, is independent of . By using : = , we can see that contains only independent variables. Compiling the DMs given by (11) in one function, that is, yields
and we have the following partition:
Composing by (12) yields
and Lemma 3 provides useful properties of g linked to f. For a given integer , consider the vectors : = and : = with . By definition, when , we have , and when , and .
Lemma 3.
Let , , . Then,
Proof.
See Appendix C. □
It comes out from Lemma 3 that the distribution of given the inputs : = is equal (in distribution) to the distribution of conditional on . Thus, we are able to assess the effect of on using and , leading to the following definition.
Definition 1.
Consider , and f and g are given by Equation (13).
A function g is said to be an equivalent representation of f regarding the input(s) if the distribution of can be determined using g and some of its inputs.
Different equivalent representations (ERs) of f (i.e., g) are necessary for assessing the effects of for all . For instance, a representation in Lemma 3 for a given set can be used to assess the effects of some subsets of inputs given by
Modifying and leads to another representation of f, which allows for assessing other inputs’ effects, such as the effects of s with . Permutations of s give such modifications. Obviously, we have ERs of f that allow for deriving the effects of all the subsets of inputs with the possibility to have some replications.
Definition 2.
Let and be two ERs of f.
The representations are said to be replicated representations of f regarding if allow for determining the distribution of .
To avoid unnecessary replicated representations and to be able to recover all the subsets of using permutations, we use Algorithm 1 for selecting the necessary and sufficient permutations (see Lemma 4). Formally, consider integers
and the super-sets given by
The set consists of all the subsets of that contain exactly elements, and its cardinality is . Basically, the algorithm takes as the input and provides the super-sets , which are initially empty. The first step of Algorithm 1, corresponding to , focuses on selecting permutations, and on bringing different sets of the form in one hand and in the other hand. We repeat that process by increasing and bringing the sets of the forms:
until we are able to derive all the subsets of , that is, until . The formal algorithm is given as follows:
| Algorithm 1: Construction of the sets and for all . |
 |
Algorithm 1 provides the permutations selected (i.e., ) that are used for deriving different DMs. For instance, if , the permutations and lead to the following DMs:
and the associated ERs, that is,
The set from Algorithm 1 contains permutations. The set is built using , and it consists of sets containing the first ı elements of for any and . Lemma 4 shows the properties of such sets.
Lemma 4.
Proof.
See Appendix D. □
Based on Lemma 4, we quantify the necessary and sufficient number of ERs of f given for all in Theorem 1. For , recall that : = and with .
Theorem 1.
Consider integers . Then, the minimum number of ERs of f given for all is
Such necessary and sufficient ERs are given by
where for all and .
Proof.
See Appendix E. □
It is worth noting that each ER of Equation (18) shares the same distribution of , and two different ERs should be considered independent to avoid misleading dependencies. When a function includes only independent variables, we see that . Reducing will depend on the analysis of interest one is going to perform. For instance, one ER is sufficient to determine the distribution of conditional on for all
Likewise, ERs are used for assessing the main and total effects of s for any in [16]. It is also worth noting that the above ERs can lead to assessing the effects of other inputs or groups of inputs.
Discussions About High-Dimensional Cases
Implementation of Algorithm 1 can be made fast for moderate values of each , that is with . Since Algorithm 1 must be run separately for each with and , implementation of Algorithm 1 remains fast in high-dimensional settings, provided that each with . When there is such that , Algorithm 1 can still be used with a substantial requirement of time to obtain all the necessary and sufficient permutations of . But, as the selected permutations are not going to change for a given with , a table of selected permutations for different values of will avoid tuning this algorithm all the time.
Regarding the ERs, we can check that because with the largest integer that is less than . Thus, computing all the effects of inputs will require at least ERs and at most ERs, which grow exponentially with respect to with . If the effects of are not significant, then . Based on the values of , different conclusions can be drawn.
4. Dependent Multivariate Sensitivity Analysis
This section extends dependent generalized sensitivity indices (dGSIs) for models with NIVVs introduced in [16] by defining the dGSIs for every subset of inputs and for functional outputs. Since the ER given by Equation (18) includes only independent variables, we define dGSIs by relying on the multivariate sensitivity analysis ([2,3,4,44,45]). To ensure that the proposed dGSIs in this section are well defined, assume that
(A1): .
Definitions of GSIs and dGSIs are based on sensitivity functionals (SFs), which contain information about the single and overall contributions of input variables over the whole functional outputs [2,6,16,46]. To define SFs, recall that , and with , and define . According to Lemmas 3 and 4, for all , there exists , a vector and with such that and
where , . Thus, the effects of inputs are equal to the effects of using . For concise notations, we use
Note that is a partition of .
The first-order SF of with is given by
and the total SF, which contains the overall information about , is given by
where means that the expectation is taken with respect to . The SFs given by (19) and (20) are random processes, and their components may be correlated and/or dependent. Using the variance–covariance as an importance measure, the definitions of dGSIs rely on the cross-covariances of SFs. For , the first-order cross-covariance or the cross-covariance of is given by
Furthermore, the cross-covariances of and f are given as follows:
To account for the different properties of the aforementioned SFs, we distinguish three different types of dGSIs.
Definition 3.
Consider the cross-covariances of SFs, and assume that (A1) holds.
- (i)
- For the first-type dGSIs, the first-order and total indices are given by
- (ii)
- The second-type dGSIs are defined as follows:
- (iii)
- The third-type dGSIs are given as follows:
The first-type and the second-type dGSIs treat independently the outputs and when , but the second-type dGSIs account for the correlations among the components of SFs from the same output . Furthermore, the third-type dGSIs account for the correlations among the cross-components of SFs.
4.1. Properties of Dependent Generalized Sensitivity Indices
The two types of dGSIs share the same properties as those proposed in [16] for , only. Proposition 2 extends such properties for all .
Proposition 2.
Under (A1), consider the dGSIs of Definition 3. Then,
Moreover, if the cross-covariances are positive semi-definite, then we have
Proof.
See Appendix F. □
When the total dGSI of is zero or almost zero (i.e., ), we have to fix using the DM associated with each , . Indeed, for the DM , fixing comes down to fix to its nominal values. Since we can compute the total of each block of NIVs, that is, using any ER of f, it becomes possible to quickly identify the non-influential block of NIVs, and then put our computational efforts on the most important groups of NIVs.
Remark 1.
Given , the same rankings of the inputs and using either or with are obtained under the assumptions or . Note that means that is a positive semi-definite matrix, a.k.a. the Loewner partial ordering between matrices (see also Section 6.3 in [16]).
Remark 2.
Case of the multivariate dynamic function
Consider a model that is evaluated at and provides n dynamic(s), such as a spatiotemporal model. Such a model is a particular case of multivariate and functional outputs. Indeed, the multivariate dynamic model given by and with is mathematically identical to using and .
4.2. Case of the Multivariate Response Models
When , the multivariate and functional outputs come down to with h: . Thus, the dGSIs of Definition 3 can be adapted for quantifying the effect of inputs. It is worth noting that the third-type dGSIs are equal to the second-type dGSIs, and both types of dGSIs boil down to the second-type dGSIs provided in Definition 4. Moreover, the cross-covariances become the covariances, and we use : = , : = and : = .
Definition 4.
Consider the above covariances of SFs and assume (A1) holds.
- (i)
- The first-type dGSIs for a given multivariate response function are
- (ii)
- The second-type dGSIs are defined as follows:
Also, in the case where , the two types of dGSIs of Definition 4 are equal and boil down to dependent sensitivity indices (dSIs) for single-response models (see Definition 5).
Definition 5.
For a function (), the dSIs of are given by
5. Estimators of Dependent Generalized Sensitivity Indices
In this section, we provide unbiased estimators of the cross-covariances and covariances of SFs, consistent estimators of dGSIs, and their asymptotic distributions. For the sake of simplicity, we provide estimators of covariances and dGSIs using the functions that include only independent variables, that is, Note that the Supplementary Materials provides such estimators using f directly thanks to the relation
To derive the estimators of cross-covariances that are useful for computing dGSIs, we are given two i.i.d. samples from , that is, and , and we use , , . Since is a partition of , we can deduce the following two i.i.d. samples: and .
Theorem 2.
Assume (A1) holds. Then, unbiased and consistent estimators of , and are, respectively, given by
Proof.
See Appendix G. □
Note that when , the estimators provided in Theorem 2 are minimum-variance unbiased estimators (MVUEs). Using Theorem 2, we deduce the estimators of the variance–covariances of SFs for the multivariate response models and single-response models. To provide such results for the vector-valued function in Corollary 1, let us consider the following symmetric kernels:
Corollary 1.
Assume that f has finite fourth moments (i.e., (A2)) and (A1) hold. Then, the MVUEs and consistent estimators of the covariance matrices , , and Σ are, respectively, given by
Proof.
See Appendix H. □
For single-response models (i.e., ), the MVUEs of the covariances of SFs in Corollary 1 have simple expressions, given below.
Corollary 2.
Under the assumptions (A1)-(A2) and , the MVUEs , , and become, respectively,
If we are only interested in the total effects, we should use the expressions of and given, respectively, by
Using the results from Theorem 2, Corollary 1, and Corollary 2, we derive the estimators of dGSIs and dSIs in Corollary 3, Theorem 3, and Corollary 4, respectively.
Corollary 3.
Assume that (A1) and (A2) hold. If we observe the model outputs at with , then
- (i)
- the consistent estimators of the first-type dGSIs are given as follows:when , where denotes the convergence in probability.
- (ii)
- The estimators of the second-type dGSIs are given as follows:
- (iii)
- The estimators of the third-type dGSIs are given as follows:
Proof.
Using Theorem 2, the results hold by applying the Slutsky theorem. □
For computing the first-order and total-effect covariances of each , model runs are needed. Some of such runs can be combined for computing the model outputs’ covariance. From now on, M model runs are used for computing the model outputs’ covariance. The operator transforms a matrix into a vector, that is, and denotes the null matrix.
Theorem 3.
Assume that (A1) and (A2) hold, , and .
(i) The estimators of the first-type dGSIs are given as follows:
with the following asymptotic distributions:
(ii) For the second-type dGSIs, we have
provided that and .
Proof.
See Appendix I. □
Using Theorem 3, we give the estimators of dSIs (see Definition 5) for real-valued functions in Corollary 4.
Corollary 4.
Let and . Assume that (A1)-(A2) hold, , and . The estimators of dSIs are given as follows:
The computation of the dGSIs or dSIs of for all using the above estimators will require ERs of f. When we are only interested in with , , the ERs of f are necessary and sufficient, and we need model evaluations to estimate the first-order and total dGSIs or dSIs of for all . Note that with the same ERs and additional model runs, we are able to compute the effects of other subsets of inputs and interactions.
6. Analytical and Numerical Results
In this section, we illustrate our approach by means of analytical test cases, including a dynamic model so as to highlight some theoretical properties of the new indices.
6.1. Linear Function Without Explicit Interaction (, )
We consider with . A dependency function of is given by , where
, and an ER of f is given by
Using such ERs of f, we have the following dSIs of and :
respectively. Using the same reasoning and knowing that , the two extra ERs of f lead to the remaining results. When using , we have
Likewise, using , we obtain
6.2. Functional Outputs: Dynamic Model (, )
The following dynamic model includes two inputs :
where , and . When , there is no explicit interaction between and . To illustrate the difference between both types of dGSIs, we suppose that we have observed the model outputs at with and . Using the dependency functions and with and , Figure 1 shows the two types of dGSIs.
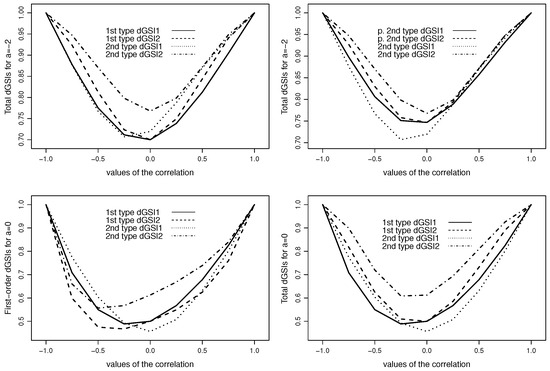
Figure 1.
First-type, prime second-type, and second-type dGSIs for different values of the correlation between the two inputs and for .
The first figure (top-left panel) depicts the first-type and second-type dGSIs, and we see that both types of dGSIs give the same ranking of inputs for negative values of the correlation. In the absence of correlation (i.e., ), and have the same effect according to the first-type dGSIs, while the second-type dGSIs identify as the most influential input. When , the first-type dGSIs show that is the most important input, while the second-type dGSIs suggest that both inputs have the same total effects. The second figure (top-right panel) compares the prime second-type and the second-type total dGSIs, and the results are similar to those of the first figure. The third figure (bottom-left panel) compares the first-order dGSIs of the first and second types, and it comes out that such dGSIs give different main effects of inputs for positive correlations. In the last figure, the first-type and second-type dGSIs give the same ranking of inputs except for . As different rankings of inputs can happen using both types of dGSIs, and knowing that the second-type dGSIs account for the correlations among SFs, we should prefer such indices.
6.3. Sobol’s g-Function (, )
Here, we consider with . The inputs are organized into blocks as follows:
- are independent variables, that is, ;
- and have a Gaussian copula with as the correlation values, and ;
- , where with .
The dependency functions of are given by and where , ; and are independent of , [20].
Based on the ERs of (see Appendix J), we computed the dSIs using Sobol’s sequences and the sample size m = 10,000 (see Table 1). We can see that are the most influential inputs. For fixing , we need the copula-based dependency model of , that is, . Since the block of inputs is not important, we have also computed the dSIs of the pairs of variables selected out of (see Table 1). As expected, the total indices are always greater than the first-order indices.

Table 1.
Estimates of dSIs for Sobol’s g-function with NIVs.
7. Conclusions
In this paper, we have proposed a new way of deriving the distributions of the model outputs conditional on every subset of inputs using dependency models of random vectors of NIVs. We have provided additional generic dependency models, including empirical or computational dependency functions, of d-dimensional random vectors following many distributions, such as copula-based distributions with discrete variables, as well as distributions of inputs of complex mathematical models subjected to constraints. It came out that different equivalent representations of the model output of interest are necessary and sufficient for recovering all the conditional distributions and for assessing the effects of every subset of NIVs, including their interactions. An algorithm is then provided for selecting such representations or equivalently such dependency models.
Based on such conditional distributions and using variance–covariance as an important measure, we have extended i) dGSIs for the multivariate and/or functional outputs (including spatiotemporal models and dynamic models), and ii) dependent sensitivity indices for single-response models so as to cope with every subset of NIVs. Such indices are also well suited for models with both discrete and continuous variables. Consistent estimators of such indices and their asymptotic distributions are provided. It is worth noting that such conditional distributions are also relevant for commuting the variance-based Shapley effects [47].
Analytical test cases confirmed that the first-order index of any subset of inputs is less than its total index, as expected. In the case of the dynamic model considered, it came out that the second-type dGSIs, which account for the correlations among the components of sensitivity functionals, and the first-type dGSIs can give different rankings of input variables. Therefore, we should prefer the second-type dGSIs in practice. Moreover, it came out that the sum of the main and interaction indices can be greater than one. In the next works, it will be interesting to investigate a new approach for which the main and interactions indices sum up to one. Also, the derivation of MSEs of the estimators of covariances of sensitivity functionals is quite interesting.
Since the computations of the effects of all the subsets of inputs rely on ERs, which grow exponentially with respect to , it becomes difficult to deploy such efficient approaches in higher dimensions under the following conditions: and all the K groups of NIVs are important, which is not often the case.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/math13050766/s1, Derivation of estimators of covariances and dGSIs.
Funding
This research received no external funding.
Data Availability Statement
No data sets are used in this paper. This paper provides theoretical results with analytical test cases. Simulated data are in the paper.
Acknowledgments
We would like to thank the two referees and the associate editor for their comments and suggestions that have helped improving this paper.
Conflicts of Interest
The author has no conflicts of interest to declare regarding the content of this paper.
Appendix A. Proof of Lemma 1
Consider the variable if is continuous and otherwise. It is well known that follows the standard normal distribution with , and has the same copula as [26], as (resp. ) is a strictly increasing transformation on the range of . Therefore, . Knowing that the dependency function of is given by (see [16]), the result follows using the inverse transformation of the form .
Appendix B. Proof of Lemma 2
Using the same reasoning as in Appendix A, we can see that with for continuous variable and otherwise. We then have to derive the dependency function of to obtain the result, and it is performed below. As , with being the Cholesky factor of , the result holds knowing that [20]
Appendix C. Proof of Lemma 3
Consider any measurable and integrable function . It is known from Proposition 1 that
Using and the fact that the components of are independent, we can write
Appendix D. Proof of Lemma 4
For Equation (15), at the end of the first step (i.e., ), contains super-sets of for all of the form with . Indeed, for two super-sets and of , we must have
leading to .
Secondly, when (from iteration to ), we add the super-sets of of the form , which were not in at the end of the first step . As for the two new super-sets, that is, , , we must have , , and ; the first two steps allow for obtaining .
Thirdly, we repeat that procedure up to to obtain the super-sets of and . These operations are possible because for all , and we avoid permutations () that bring replicated sets in both and .
Fourthly, the iterations (when possible) aim to add the remaining subsets of elements.
Fifthly, we have because for any with , there exists such that . Indeed, was added in when constructing all the subsets with thanks to and the fact that . Thus, . Finally, we use the same reasoning to obtain the results.
Equation (16) is obvious by construction (see Algorithm 1).
Appendix E. Proof of Theorem 1
First, for with , there exists such that according to Lemma 4. Lemma 3 ensures the determination of the distribution of f given using g associated with .
Second, for , where , and with , there exists only one permutation such that . As only one representation of f associated with allows for determining the distribution of f given , and , then different representations of f are needed to obtain the distribution of f given for all . The result follows because is the highest number of possibilities of , and other possibilities are in the representations (Lemma 4).
Appendix F. Proof of Proposition 2
The proofs are straightforward. The results rely on the Hoeffding decomposition of an equivalent representation of f and the fact that for two positive semi-definite matrices , , the Loewner partial ordering, that is, , implies and . See [16] for more details.
Appendix G. Proof of Theorem 2
Since are not random quantities, the proofs of Points (i)–(iii) are straightforward. Indeed, by expanding the above expressions of the estimators, we obtain unbiased estimators, and by applying the law of large numbers, we obtain consistent estimators. Detailed similar proofs can be found in [6,16,44].
Appendix H. Proof of Corollary 1
Firstly, the proposed estimators are unbiased and consistent by applying Theorem 2 where is a constant. Secondly, the MVU properties are due to the symmetric properties of the kernels used [48]. Indeed, each kernel remains unchanged when one permutes its arguments. More details can be found in [44] (Theorems 2 and 3).
Appendix I. Proof of Theorem 3
The results for the consistency are deduced from Corollary 3, as .
For the asymptotic distribution of Points (i)–(ii), the derivation of the results is similar to the one provided in [45] (Theorem 6), under the condition .
Appendix J. Equivalent Representations of the Function Used in Section 6.3
The equivalent representations of are given as follows:
where are particular cases of DMs provided in Lemma 1.
References
- Sobol, I.M. Sensitivity analysis for non-linear mathematical models. Math. Model. Comput. Exp. 1993, 1, 407–414. [Google Scholar]
- Lamboni, M. Multivariate sensitivity analysis: Minimum variance unbiased estimators of the first-order and total-effect covariance matrices. Reliab. Eng. Syst. Saf. 2019, 187, 67–92. [Google Scholar] [CrossRef]
- Lamboni, M.; Monod, H.; Makowski, D. Multivariate sensitivity analysis to measure global contribution of input factors in dynamic models. Reliab. Eng. Syst. Saf. 2011, 96, 450–459. [Google Scholar] [CrossRef]
- Gamboa, F.; Janon, A.; Klein, T.; Lagnoux, A. Sensitivity indices for multivariate outputs. Comptes Rendus Math. 2013, 351, 307–310. [Google Scholar] [CrossRef]
- Xiao, S.; Lu, Z.; Xu, L. Multivariate sensitivity analysis based on the direction of eigen space through principal component analysis. Reliab. Eng. Syst. Saf. 2017, 165, 1–10. [Google Scholar] [CrossRef]
- Lamboni, M. Derivative-based generalized sensitivity indices and Sobol’ indices. Math. Comput. Simul. 2020, 170, 236–256. [Google Scholar] [CrossRef]
- Perrin, T.; Roustant, O.; Rohmer, J.; Alata, O.; Naulin, J.; Idier, D.; Pedreros, R.; Moncoulon, D.; Tinard, P. Functional principal component analysis for global sensitivity analysis of model with spatial output. Reliab. Eng. Syst. Saf. 2021, 211, 107522. [Google Scholar] [CrossRef]
- Veiga, S.D.; Wahl, F.; Gamboa, F. Local Polynomial Estimation for Sensitivity Analysis on Models With Correlated Inputs. Technometrics 2009, 51, 452–463. [Google Scholar] [CrossRef]
- Mara, T.A.; Tarantola, S. Variance-based sensitivity indices for models with dependent inputs. Reliab. Eng. Syst. Saf. 2012, 107, 115–121. [Google Scholar] [CrossRef]
- Kucherenko, S.; Tarantola, S.; Annoni, P. Estimation of global sensitivity indices for models with dependent variables. Comput. Phys. Commun. 2012, 183, 937–946. [Google Scholar] [CrossRef]
- Hao, W.; Zhenzhou, L.; Wei, P. Uncertainty importance measure for models with correlated normal variables. Reliab. Eng. Syst. Saf. 2013, 112, 48–58. [Google Scholar] [CrossRef]
- Chastaing, G.; Gamboa, F.; Prieur, C. Generalized Hoeffding-Sobol’ decomposition for dependent variables—Applications to sensitivity analysis. Electron. J. Stat. 2012, 6, 2420–2448. [Google Scholar] [CrossRef]
- Kucherenko, S.; Klymenko, O.; Shah, N. Sobol’ indices for problems defined in non-rectangular domains. Reliab. Eng. Syst. Saf. 2017, 167, 218–231. [Google Scholar] [CrossRef]
- Mara, T.A.; Tarantola, S.; Annoni, P. Non-parametric methods for global sensitivity analysis of model output with dependent inputs. Environ. Model. Softw. 2015, 72, 173–183. [Google Scholar] [CrossRef]
- Tarantola, S.; Mara, T.A. Variance-based sensitivity indices of computer models with dependent inputs: The fourier amplitude sensitivity test. Int. J. Uncertain. Quantif. 2017, 7, 511–523. [Google Scholar] [CrossRef]
- Lamboni, M.; Kucherenko, S. Multivariate sensitivity analysis and derivative-based global sensitivity measures with dependent variables. Reliab. Eng. Syst. Saf. 2021, 212, 107519. [Google Scholar] [CrossRef]
- Lamboni, M. On exact distribution for multivariate weighted distributions and classification. Methodol. Comput. Appl. Probab. 2023, 25, 1–41. [Google Scholar] [CrossRef]
- Lamboni, M. Kernel-based Measures of Association Between Inputs and Outputs Using ANOVA. Sankhya A 2024, 86, 790–826. [Google Scholar] [CrossRef]
- Skorohod, A.V. On a representation of random variables. Theory Probab. Appl. 1976, 21, 645–648. [Google Scholar]
- Lamboni, M. Efficient dependency models: Simulating dependent random variables. Math. Comput. Simul. 2021, 200, 199–217. [Google Scholar] [CrossRef]
- Ferguson, T. Mathematical Statistics: A Decision Theoretic Approach; Academic Press: New York, NY, USA, 1967. [Google Scholar]
- Rschendorf, L. Stochastically ordered distributions and monotonicity of the oc-function of sequential probability ratio tests. Ser. Stat. 1981, 12, 327–338. [Google Scholar] [CrossRef]
- Rschendorf, L. Stochastic ordering of risks, influence of dependence and a.s. constructions. In Advances on Models, Characterizations and Applications; Balakrishnan, N., Bairamov, I.G., Gebizlioglu, O.L., Eds.; CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar]
- Rschendorf, L. On the distributional transform, Sklar’s theorem, and the empirical copula process. J. Stat. Plan. Inference 2009, 139, 3921–3927. [Google Scholar] [CrossRef]
- Rosenblatt, M. Remarks on a Multivariate Transformation. Ann. Math. Statist. 1952, 23, 470–472. [Google Scholar] [CrossRef]
- Nelsen, R. An Introduction to Copulas; Springer: New York, NY, USA, 2006. [Google Scholar]
- McNeil, A.J.; Frey, R.; Embrechts, P. Quantitative Risk Management; Princeton University Press: Princeton, NJ, USA; Oxford, UK, 2015. [Google Scholar]
- Rosenblatt, M. Remarks on some nonparametric estimates of a density function. Ann. Math. Stat. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Epanechnikov, V. Nonparametric estimation of a multidimensional probability density. Theory Probab. Appl. 1969, 14, 153–158. [Google Scholar] [CrossRef]
- Silverman, B. Density Estimation for Statistics and Data Analysis; Chapman & Hall: New York, NY, USA, 1986. [Google Scholar]
- Clayton, D.G. A Model for Association in Bivariate Life Tables and Its Application in Epidemiological Studies of Familial Tendency in Chronic Disease Incidence. Biometrika 1978, 65, 141–151. [Google Scholar] [CrossRef]
- Joe, H. Multivariate Models and Dependence Concepts; Chapman & Hall/CRC: Boca Raton, FL, USA; London, UK; New York, NY, USA, 1997. [Google Scholar]
- Smith, M.; Min, A.; Almeida, C.; Czado, C. Modeling Longitudinal Data Using a Pair-Copula Decomposition of Serial Dependence. J. Am. Stat. Assoc. 2010, 105, 1467–1479. [Google Scholar] [CrossRef]
- Durante, F.; Sempi, C. Principles of Copula Theory; CRC/Chapman & Hall: London, UK, 2015. [Google Scholar]
- Koenker, R.; Bassett, G. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Truong, Y.K. Asymptotic Properties of Kernel Estimators Based on Local Medians. Ann. Stat. 1989, 17, 606–617. [Google Scholar] [CrossRef]
- Hendricks, W.; Koenker, R. Hierarchical Spline Models for Conditional Quantiles and the Demand for Electricity. J. Am. Stat. Assoc. 1992, 87, 58–68. [Google Scholar] [CrossRef]
- Koenker, R.; Ng, P.; Portnoy, S. Quantile smoothing splines. Biometrika 1994, 81, 673–680. [Google Scholar] [CrossRef]
- Koenker, R.; Hallock, K.F. Quantile Regression. J. Econ. Perspect. 2001, 15, 143–156. [Google Scholar] [CrossRef]
- Bassett, R., Jr.; Koenker, R. An Empirical Quantile Function for Linear Models with iid Errors. J. Am. Stat. Assoc. 1982, 77, 407–415. [Google Scholar]
- Koenker, R. Quantile Regression; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Takeuchi, I.; Le, Q.V.; Sears, T.D.; Smola, A.J. Nonparametric Quantile Estimation. J. Mach. Learn. Res. 2006, 7, 1231–1264. [Google Scholar]
- Lamboni, M. Uncertainty quantification: A minimum variance unbiased (joint) estimator of the non-normalized Sobol’ indices. Stat. Pap. 2018, 61, 1939–1970. [Google Scholar] [CrossRef]
- Lamboni, M. Weak derivative-based expansion of functions: ANOVA and some inequalities. Math. Comput. Simul. 2022, 194, 691–718. [Google Scholar] [CrossRef]
- Lamboni, M. Global sensitivity analysis: An efficient numerical method for approximating the total sensitivity index. Int. J. Uncertain. Quantif. 2016, 6, 1–17. [Google Scholar] [CrossRef]
- Owen, A.B. Sobol’ Indices and Shapley Value. Siam/Asa J. Uncertain. Quantif. 2014, 2, 245–251. [Google Scholar] [CrossRef]
- Sugiura, N. Multisample and multivariate nonparametric tests based on U-statistics and their asymptotic efficiencies. Osaka J. Math. 1965, 2, 385–426. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).