Abstract
This paper considers online optimization for a sequence of tasks. Each task can be processed in one of multiple processing modes that affect the duration of the task, the reward earned, and an additional vector of penalties (such as energy or cost). Let be a random matrix that specifies the parameters of task k. The goal is to observe at the start of task k and then choose a processing mode for the task so that, over time, time average reward is maximized subject to time average penalty constraints. This is a renewal optimization problem. It is challenging because the probability distribution for the sequence is unknown. Efficient decisions must be learned in a timely manner. Prior work shows that any algorithm that comes within of optimality must have convergence time. The only known algorithm that can meet this bound operates without time average penalty constraints and uses a diminishing stepsize that cannot adapt when probabilities change. This paper develops a new algorithm that is adaptive and comes within of optimality for any interval of tasks over which probabilities are held fixed.
MSC:
65K10; 60K05; 93E35
1. Introduction
This paper considers online optimization for a system that performs a sequence of tasks. At the start of task , a matrix of parameters about the task is revealed. The controller observes and then makes a decision about how the task should be processed. The decision, together with , determines the duration of the task, the reward earned by processing that task, and a vector of additional penalties. Specifically, define
where n is a fixed positive integer. The goal is to make decisions over time that maximize the time average reward subject to a collection of time average penalty constraints. This problem has a number of applications, including image classification, video processing, wireless multiple access, and transportation scheduling.
For example, consider a computational device that performs back-to-back image classification tasks with the goal of maximizing time average profit subject to a time average power constraint of and an average per-task quality constraint of . For each task, the device chooses from a collection of classification algorithms, each having a different duration of time and yielding certain profit, energy, and quality characteristics. The number of options for task k is equal to the number of rows of matrix . Numerical values for each option are specified in the corresponding row. Suppose the controller observes the following matrix for task 1:
Choosing a classification algorithm for task 1 reduces to choosing one of the three rows of . Suppose we choose row 2 (algorithm 2). Then, task 1 will have a duration of units of time, as illustrated by the width in the timeline of Figure 1. Also, the task will have profit, energy, and quality of , , and . If we had instead chosen row 1, then the task duration would be lower and profit would be higher, but the energy consumption would be higher and the task would have lower quality. It is not obvious what decision helps to maximize the time average profit subject to the power and quality constraints. Moreover, the matrices for future tasks can have different row sizes, each matrix is only revealed at the start of task k, and the probability distribution for is unknown.
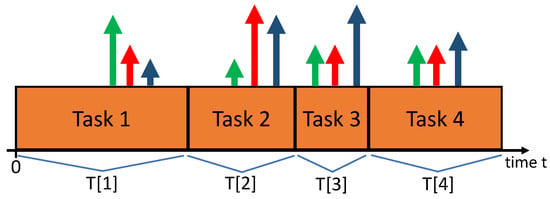
Figure 1.
Four sequential tasks in the timeline. Vertical arrows for each task k represent values for reward and penalty vector . In this example, green is reward (profit), red is energy, blue is quality. Vector depends on choices made at the start of task k.
The specific constrained optimization problem for this example is
where objective (2) represents the time average profit; (3) imposes the time average power constraint; (4) imposes the per-task average quality constraint. For simplicity of this example, we assume the limits exist. This problem is more concisely posed as maximizing subject to and , where , , , are per-task averages.
Problem (2)–(4) involves ratios of averages. This paper converts such problems into a canonical form of maximizing a ratio subject to penalty constraints for , where n is the number of constraints ( in example problem (2)–(4)). The constraint is converted to by defining a penalty process for . However, adaptive minimization of the ratio is nontrivial, and new techniques are required.
Optimality for problem (2)–(4) depends on the joint probability distribution for the size and entries of matrix . We first assume are independent and identically distributed (i.i.d.) as matrices over tasks . This yields a well-defined ergodic optimality for problem (2)–(4). However, the multi-dimensional distribution for the entries of is unknown, and the parameter space is enormous. Instead of attempting to learn the distribution, this paper uses techniques similar to the drift-plus-penalty method of [1] that acts on weighted functions of the observed random . Specifically, this paper develops a new optimization strategy that acts on a single timescale for real-time optimization of ratios of averages.
Given , how long does it take to come within of the infinite horizon optimality for problem (2)–(4)? This question is partially addressed in the prior work [2] for problems without time average penalty constraints. That prior work uses a Robbins–Monro algorithm with a vanishing stepsize. It cannot adapt if probability distributions change over time. The current paper develops a new algorithm that is adaptive. While infinite horizon optimality is defined by imagining as an infinite i.i.d. sequence, our algorithm can be analyzed over any finite block of m tasks for which i.i.d. behavior is assumed. Indeed, fix any algorithm parameter and consider any integer . Over any block of m tasks during which is i.i.d., the time average expected performance of our algorithm is within of infinite horizon optimality (as defined by the distribution for this block), regardless of the distribution or sample path behavior of before the block. When the algorithm is implemented over all time, it tracks the new optimality that results if probability distributions change multiple times in the timeline, without knowing when changes occur, provided that each new distribution lasts for a duration of at least tasks. This new achievability result matches a converse bound proven for unconstrained problems in [2].
1.1. Model
Fix n as a positive integer. At the start of each task the controller observes matrix with size , where is the random number of processing options for task k. Each row has the form
It is assumed that all rows have , where is some minimum task duration. Let be the vector of values for the row selected on task k, where . For each positive integer m, define by
Define and similarly. The infinite horizon problem is
where denotes the set of rows of matrix . Note that always, so there is no divide-by-zero issue.
Problem (5)–(7) is assumed to be feasible, meaning it is possible to satisfy the constraints (6) and (7). Let denote the optimal objective in (5). The formulation (5)–(7) has two differences in comparison with the introductory example (2)–(4): (i) all time average constraints are expressed as a single average (rather than a ratio); (ii) sample path limits are replaced by limits that use expectations. This is similar to the treatment in [2]. This preserves the infinite horizon value of and facilitates analysis of adaptation time.A decision policy is said to be an -approximation with convergence time d if
A decision policy is said to be an -approximation (with convergence time d) if all appearances of in the above definition are replaced by some constant multiple of .
1.2. Prior Work
The fractional structure of the objective (5) is similar in spirit to a linear fractional program. Linear fractional programs can be converted to linear programs using a nonlinear change in variables (see [3,4]). This conversion is used in [3] for offline design of policies for embedded Markov decision problems. Such methods cannot be directly used for our online problem because time averages are not preserved under nonlinear transformations. Related nonlinear transformations are used in [5] for offline control for opportunistic Markov decision problems where states include an process similar to the current paper. The work in [5] discusses how offline strategies can be leveraged for online use (such as with a two-timescale approach), although overall convergence time is unclear.
The problem (5)–(7) is posed in [6], where it is called a renewal optimization problem (see also Chapter 7 of [1]). The solution in [6] constructs virtual queues for each time average inequality constraint (6) and makes a decision for each task k to minimize a drift-plus-penalty ratio:
where is the change in a Lyapunov function on the virtual queues; v is a parameter that affects accuracy; is system history before task k. Exact minimization of (10) is impossible unless the distribution for is known. A method for approximately minimizing (10) by sampling over a window of previous tasks is developed in [6], although only a partial convergence analysis is given there. This prior work is based on the Lyapunov drift and max-weight scheduling methods developed for fixed timeslot queuing systems in [7,8]. Data center applications of renewal optimization are in [9]. Asynchronous renewal systems are treated in [10].
A different approach in [2] is used for a problem that seeks only to maximize time average reward (with no penalties ). For each task k, that method chooses to maximize , where is an estimate of that is updated according to a Robbins–Monro iteration:
where is a stepsize. See [11] for the original Robbins–Monro algorithm and [12,13,14,15,16,17] for extensions in other contexts. The approach (11) is desirable because it does not require sampling from a window of past values. Further, under a vanishing stepsize rule, the optimality gap decreases like , which is asymptotically optimal [2]. However, it is unclear how to extend this method to handle time average penalties . Further, while the vanishing stepsize enables fast convergence, it makes increasing investments in the probability model and cannot adapt if probabilities change. The work in [2] shows a fixed stepsize rule is better for adaptation but has a slower convergence time of .
Fixed stepsizes are known to enable adaptation in other contexts. For online convex optimization, it is shown in [18] that a fixed stepsize enables the time-averaged cost to be within of optimality (as compared with the best fixed decision in hindsight) over any sequence of steps. For adaptive estimation, work in [19] considers the problem of removing bias from Markov-based samples. The work in [19] develops an adaptive Robbins–Monro technique that averages between two fixed stepsizes. Adaptive algorithms are also of interest in convex bandit problems, see [20,21].
A different type of problem is nonlinear robust optimization that seeks to solve a deterministic nonlinear program involving a decision vector x and a vector of (unchosen) uncertain values u (see [22]). The robust design treats worst-case behavior with constraints such as for all , where is a (possibly infinite) set of possible values of u given the decision vector x. Iterative methods, such as those in [23], use gradients and linear approximations to sequentially calculate updates that get closer to minimizing a cost function subject to the robust constraint specifications.
Our problem is an opportunistic scheduling problem because is revealed at the start of each task k (before a scheduling decision is made). While can be viewed as helpful side information, it is challenging to make optimal use of this side information. The policy space huge: Optimality depends on the full (and unknown) joint distribution of entries in matrix . A different class of problems, called vector-based bandit problems, has a simpler policy space where there is no information. There, the controller pulls an arm from a fixed set of m arms, each arm giving a vector-based reward with an unknown distribution that is the same each time it is pulled. In that context, optimality depends only on the mean rewards. Estimation of the means can be performed efficiently by exploring each arm according to various bandit techniques such as the resource-constrained techniques in [24,25,26]. Such problems have a different learning structure that does not relate to the current paper.
1.3. Our Contributions
We develop an algorithm for renewal optimization that does not require probability information or sampling from the past. The algorithm has explicit convergence guarantees and meets the optimal asymptotic convergence time bound of [2]. Unlike the Robbins–Monro method in [2], our new algorithm allows for penalty constraints. Furthermore, our algorithm is adaptive and achieves performance within of optimality over any sequence of tasks. This fast adaptation is enabled by a new hierarchical decision structure.
2. Preliminaries
2.1. Notation
For we use and . In this paper, we use the following vectors and constants:
- matrix for task k (for row selection)
- duration of task k
- reward of task k
- vector of penalties for task k
- vector of virtual queues for penalty constraints
- virtual queue used to optimize reward
- weight emphasis on reward
- size upper bound parameter for virtual queue
- optimal time average reward
- upper bound on
- upper bound on
- bounds on ()
- bounds on
- ,
- Slater condition parameter
- constants in theorems (based on ).
2.2. Boundedness Assumptions
Assume the following bounds hold for all , all , and all choices of :
where , , , c, , are nonnegative constants (with ). Constraint (13) assumes all rewards are nonnegative. This is without loss of generality: If the system can have negative rewards in some bounded interval , where , we define a new nonnegative reward . The objective of maximizing is the same as the objective of maximizing .
2.3. The Sets and
Assume is a sequence of i.i.d. random matrices with an unknown distribution. (When appropriate, this is relaxed to assume i.i.d. behavior occurs only over a finite block of consecutive tasks.) For , define a decision vector as a random vector that satisfies
Let be the set of all expectations for a given task k, considering all possible decision vectors. The set depends on the (unknown) distribution of and considers all conditional probabilities for choosing a row given the observed . The matrices are i.i.d. and so is the same for all . It can be shown that is nonempty, bounded, and convex (see Section 4.11 in [1]). Its closure is compact and convex. Define the history up to task m as
where is defined to be the constant 0.
Lemma 1.
Proof.
By definition of , given any , there is a conditional distribution for choosing a row of (given the observed ) under which the (unconditional) expected value of the chosen row is . Let be a random variable that is independent of . Use to implement the randomized row selection (according to the desired conditional distribution) after is observed. Formally, the random row can be viewed as a Borel measurable function of . (See Proposition 5.13 in [27], where there plays the role of our which takes values in the Borel space ; plays the role of our ; plays the role of our ; plays the role of our ). Since is independent of history , the resulting random row is independent of (so with probability 1, its conditional expectation given is the same as its unconditional expectation). □
2.4. The Deterministic Problem
For analysis of our stochastic problem, it is useful to consider the closely related deterministic problem
where is the closure of . All points have , so there are no divide-by-zero issues. Using arguments similar to those in Section 4.11 in [1], it can be shown that (i) the stochastic problem (5)–(7) is feasible if and only if the deterministic problem (16)–(18) is feasible; (ii) if feasible, the optimal objective values are the same. Specifically, if solves (16)–(18), then
where is the optimal objective for both the deterministic problem (16)–(18) and the stochastic problem (5)–(7). The deterministic problem (16)–(18) seeks to maximize a continuous function over the compact set defined by constraints (17) and (18), so it has an optimal solution whenever it is feasible.
When (so there is at least one time average penalty constraint of the form (17)), we assume a Slater condition that is more stringent than mere feasibility: There is a value and a vector such that
3. Algorithm Development
3.1. Parameters and Constants
3.2. Intuition
For intuition, temporarily assume the following limits exist:
The idea is to make decisions for row selection (and selection) for each task k so that, over time, the following time-averaged problem is solved:
This is an informal description because the constraint “ varies slowly” is not precise. Intuitively, if does not change much from one task to the next, the above objective is close to , which (by the second constraint) is less than or equal to the desired objective . This is useful because, as we show, the above problem can be treated using a novel hierarchical optimization method.
3.3. Virtual Queues
To enforce the constraints , for each define a process with initial condition and update equation
where and are given nonnegative parameters (to be sized later); where denotes the projection of a real number z onto the interval :
To enforce the constraint , define a process by
with . The processes and shall be called virtual queues because their update resembles a queuing system with arrivals and service for each k. Such virtual queues can be viewed as time-varying Lagrange multipliers and are standard for enforcing time average inequality constraints (see [1]).
For each task k and each , define as
Lemma 2.
3.4. Lyapunov Drift
Define . Define
where . The value can be viewed as a Lyapunov function on the queue state for task k. Define
Proof.
The above lemma implies that
For each task , our hierarchical algorithm performs the following:
- Step 1: Choose to greedily minimize the right-hand side of (37) (ignoring the term that depends on ).
- Step 2: Treating as known constants, choose to minimize
3.5. Algorithm
Fix parameters with for (to be sized later). Initialize , , . For each task , perform the following:
- Row selection: Observe and treat these as given constants. Choose to minimizebreaking ties arbitrarily (such as by using the smallest indexed row).
- selection: Observe , and the decisions just made by the row selection, and treat these as given constants. Choose to minimize the following quadratic function of :The explicit solution iswhere denotes the projection of onto the interval .
3.6. Example Decision Procedure
Consider a step where is given by the example matrix with three rows in (1). In that context, each row represents an image classification algorithm option, and and are desired constraints on time average power and task-average quality. The matrix is repeated here with , :
The row selection decision for step k uses the current virtual queue values to compute the following row values:
- Row 1:
- Row 2:
- Row 3:
The smallest row value is then chosen (breaking ties arbitrarily). Assuming this selection leads to row 2, the value is updated as
Finally, the virtual queues are updated via
Row selection is the most complicated part of the algorithm at each step k: Suppose there are at most m rows in the matrix . For each row, we must perform multiply-adds to compute the row value. Then, we must select the minimizing row value. The worst-case complexity of the row selection is roughly . In this example, we have and , so implementation is simple. In cases when the number of rows is large, say, , row selection can be parallelized via multiple processors.
3.7. Key Analysis
Fix . The row selection decision of our algorithm implies
where is any other vector in (including any decision vector for task k that is chosen according to some optimized probability distribution).
The selection decision of our algorithm chooses to minimize a function of that is -strongly convex for parameter . A standard strongly convex pushback result (see, for example, Lemma 2.1 in [16]) ensures that if , , and is a convex function over some interval , and if minimizes over all , then for all . Since our minimizes a -strongly convex function we obtain
where the first inequality highlights the pushback term that arises from strong convexity; the second inequality holds by (39) and the fact .
Dividing the above inequality by gives
Lemma 4.
For any sample path of , for each , our algorithm yields
where are the actual values that arise in our algorithm; is any real number in ; and is any vector in .
Proof.
Adding to both sides of (40) gives
where is defined as the left-hand side of (42). Rearranging terms in gives
where the first inequality holds by (34); the final inequality holds since all satisfy
which holds by completing the square (we use ). Now, observe
where the final inequality uses Cauchy-Schwarz, assumption (14), and the fact . Substituting these bounds into the right-hand side of (43) gives
Substituting this into (42) proves the result. □
Lemma 5.
Proof.
Fix . Fix . Observe that and so . By Lemma 1, there is a decision vector that is independent of such that
Substituting this , along with , into (41) gives
Taking conditional expectations and using (45) gives
This holds for all . Since , there is a sequence in that converges to . Taking a limit over such points in (47) gives
Recall the optimal solution has with for all i. The result is obtained by substituting and . □
4. Reward Guarantee
We first provide a deterministic bound on .
Lemma 6.
Under any sequence, our algorithm yields
where and are nonnegative constants defined
where denotes the smallest integer greater than or equal to the real number z.
Proof.
The update (28) shows is always nonnegative. Define
We first make two claims:
- Claim 1: If for some task , thenTo prove Claim 1, observe that for each task k, we haveThus, the update (28) implies can increase by at most over one task. Thus, can increase by at most over any sequence of m or fewer tasks. By construction, . It follows that if , then for all .
- Claim 2: If for some task , then , and in particular,To prove Claim 2, suppose . Observe thatwhere (a) holds because , , and for all (recall ; equality (b) holds by definition of . Claim 2 follows in view of the iteration (38).
Since , Claim 1 implies for all . Now use induction: Suppose for all for some integer . We show this is also true for . If for some , then Claim 1 implies , and we are done.
Now, suppose for all . Claim 2 implies (52) holds for all and
Therefore, if for some then and the update (28) gives
where the final inequality is the induction assumption, and we are done. We now show the remaining case for all is impossible. Suppose for all (we reach a contradiction). Then, (52) implies
Summing over gives
and so
where inequality (a) holds by definition of m in (51). This contradicts . □
4.1. Reward over Any m Consecutive Tasks
For postive integers , define and as
Assume is i.i.d. over this block of tasks. Define and the corresponding deterministic problem (16)–(18) with respect to the (unknown) distribution for .
Theorem 1.
Suppose the problem (16)–(18) is feasible with optimal solution and optimal objective value . Then, for any parameters , and all positive integers , our algorithm yields
where are defined
where are defined in (49), (50). In particular, fixing and and choosing , , gives for all :
Similar behavior holds when replacing with , where are fine-tuned constants (defined later) in (61), (62).
Proof.
Fix . Using iterated expectations and substituting (from Lemma 6) into (44) gives
Manipulating the second term on the right-hand side above gives
where the final inequality holds by (33). Substituting this into the right-hand side of (57) gives
Summing the above over and dividing by gives
where the final inequality substitutes the definition of and uses
Rearranging terms in (59) gives
Terms on the right-hand side have the following bounds:
where the final inequality uses
and the facts (since from (27)) and (from (48)). This proves the result upon usage of the constants . □
4.2. No Penalty Constraints
A special and nontrivial case of Theorem 1 is when the only goal is to maximize time average reward , with no additional processes (case , in Theorem 1). For this, let and be averages over tasks . Fix . The work in [2] showed that, in the absence of a priori knowledge of the probability distribution of the matrices, any algorithm that runs over tasks and achieves
must have . That is, convergence time is necessarily . The work in [2] developed a Robbins–Monro iterative algorithm with a vanishing stepsize to achieve this optimal convergence time. Specifically, it deviates from by an optimality gap as the algorithm runs over tasks . However, the vanishing stepsize means that the algorithm cannot adapt to changes. The algorithm of the current paper achieves the optimal convergence time using a different technique. The parameter v can be interpreted as an inverse stepsize parameter, so the stepsize is a constant . With this constant stepsize, the algorithm is adaptive and achieves reward per unit time within of optimality over any consecutive block of tasks for which the matrices have i.i.d. behavior, regardless of the distribution before the start of the block.
The value in Theorem 1 can be fine tuned. Using , in (53) gives
where
where
which uses , , and definitions of in (49), (50). The above expression for ignores the pesky ceiling operation in (50) as we are merely trying to right-size the constant (formally, one can assume is chosen to make the quantity inside the ceiling operation an integer). The term in (60) does not vanish as . Choosing to minimize amounts to minimizing
That is, choose to minimize where
This yields . To avoid a very large value of (which affects the constant) in the special case , one might adjust this to using .
5. Constraints
This section considers the process (for ). Fix . By choosing and , inequality (30) already shows for all that the time average of starting at any time satisfies
The next result uses the Slater condition (19) to show events are rare over any block of tasks (regardless of history before the block).
Theorem 2.
Proof of Theorem 2
To prove Theorem 2, define for . For each k, is determined by history , meaning is -measurable. We first prove a lemma.
Lemma 7.
Proof.
Fix . To prove (65), we have
where inequality (a) holds by the queue update (27) and the nonexpansion property of projections; the final inequality uses from (14). Similarly,
where (a) holds by substituting the definition of from (27) and the fact ; (b) holds by the nonexpansion property of projections; (c) holds because from (14). Inequalities (68) and (69) together prove (65).
We now prove (66). The case follows immediately from (65). It suffices to consider . The queue update (27) ensures
We know . For simplicity, assume (else we use a limiting argument over points in that approach ). Lemma 1 ensures the existence of that satisfies (with prob 1):
By (39), we have
Multiplying the above inequality by 2 and rearranging terms gives
where the final inequality uses (from Lemma 6). Substituting this into the right-hand side of (70) gives
where is defined in (64). Taking conditional expectations of both sides and using (71) gives (with prob 1)
where inequality (a) holds by (19); inequality (b) holds by the triangle inequality
Jensen’s inequality and the definition gives
Substituting this into the previous inequality gives
where (a) holds because we assume ; (b) holds because by definition of in (67). The definition of also implies . Since , we can take square roots to obtain . □
Lemma 7 is in the exact form required of Lemma 4 in [28], so we immediately obtain the following corollary:
Corollary 1.
Proof.
This follows by applying Lemma 4 in [28] to the result of Lemma 7. □
We now use Corollary 1 to prove Theorem 2.
Proof.
(Theorem 2) Fix , . Define
Fix . By (63), it suffices to show
To this end, we have, by definition of in (29),
Define . Taking conditional expectations and using (72) gives, for all ,
Summing over the (fewer than m) terms and dividing by m gives
Recall that for all i. To show (77), it suffices to show
We find these are much smaller than . By assumption, and so from (67)
By definition of d in (75):
where (a) holds because (recall Corollary 1); (b) holds by (80); (c) holds because ; (d) holds because ; (e) holds because are all constants that do not scale with . The term goes to zero exponentially fast as , much faster than . This proves (78).
6. Simulation
All simulations are conducted with Matlab R2023b Update 6 (23.2.0.2485118).
6.1. System 1
This subsection considers the sequential project selection problem from Section 2.3 in [2]. The matrices have a random number of rows. Each row represents a project option and has two columns: The duration of time for the project and its corresponding reward . The goal is to simply maximize the time average reward per unit time (so , and there are no additional penalty constraints). As explained in [2], the greedy policy of always choosing the row that maximizes the instantaneous reward/time ratio is not necessarily optimal. The optimal row decision is not obvious and it depends on the (unknown) distribution of . Two different distributions for are considered in the simulations (specified at the end of this subsection). Both distributions have .
Figure 2 illustrates results for a simulation over tasks using i.i.d. with Distribution 1. The vertical axis in Figure 2 represents the accumulated reward per task starting with task 1 and running up to the current task k:
where the expectations and are approximated by averaging over 40 independent simulation runs. Figure 2 compares the greedy algorithm of always choosing the task k that maximizes ; the (nonadaptive) Robbins–Monro algorithm from [2] that uses a stepsize ; the proposed adaptive algorithm for the cases (and using ). The dashed horizontal line in Figure 2 is the optimal value corresponding to Distribution 1. The value is difficult to calculate analytically, so we use an empirical value obtained by the final point on the Robbins–Monro curve.
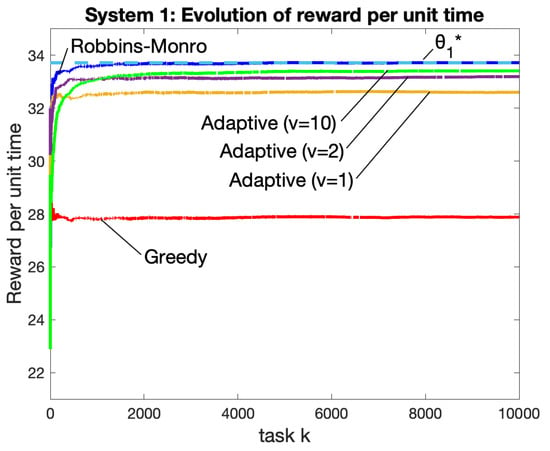
Figure 2.
System 1 and Distribution 1: Accumulated reward per unit time for the proposed adaptive algorithm (with ), the vanishing-stepsize Robbins–Monro algorithm, and the greedy algorithm. All data points are averaged over 40 independent simulations. The dashed horizontal line is the optimal for Distribution 1.
It can be seen that the greedy algorithm has significantly worse performance compared with the others. The Robbins–Monro algorithm, which uses a vanishing stepsize, has the fastest convergence and the highest achieved reward per unit time. As predicted by our theorems, the proposed adaptive algorithm has a convergence time that gets slower as v is increased, with a corresponding tradeoff in accuracy, where accuracy relates to the proximity of the converged value to the optimal . The case converges quickly but has less accuracy. The cases and have accuracy that is competitive with Robbins–Monro.
Figure 3 illustrates the adaptation advantages of the proposed algorithm. Figure 3 considers simulations over tasks. The first half of the simulation refers to tasks , the second half refers to tasks . The matrices in the first half are i.i.d. with Distribution 1; in the second half, they are i.i.d. with Distribution 2. Nobody tells the algorithms that a change occurs at the halfway mark; rather, the algorithms must adapt. The two dashed horizontal lines represent optimal values for Distribution 1 and Distribution 2. Data in Figure 3 is plotted as a moving average with a window of the past 200 tasks (and averaged over 40 independent simulations). As seen in the figure, the adaptive algorithm (with ) produces near-optimal performance that quickly adapts to the change. In stark contrast, the Robbins–Monro algorithm adapts very slowly to the change and takes roughly tasks to move close to optimality. The adaptation time of Robbins–Monro is much slower than its convergence time starting at task 1. This is due to the vanishing stepsize and the fact that, at the time of the distribution change, the stepsize is very small. Theoretically, the Robbins–Monro algorithm has an arbitrarily large adaptation time, as can be seen by imagining a simulation that uses a fixed distribution for a number of tasks x before changing to another distribution: The stepsize at the time of change is , hence an arbitrarily large value of x yields an arbitrarily large adaptation time.
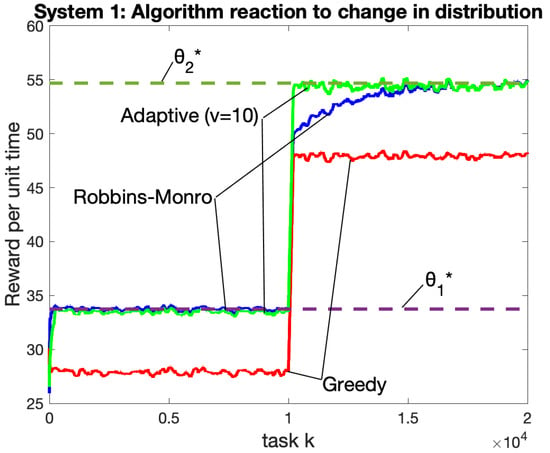
Figure 3.
System 1: Testing adaptation over a simulation of tasks with a distributional change introduced at the halfway point (task ). The two horizontal dashed lines represent optimal values for the two distributions. Each point for task k is the result of a moving window average , where expectations are obtained by averaging over 40 independent simulations. The adaptive algorithm (with ) quickly adapts to the change. The Robbins–Monro algorithm takes a long time to adapt.
Figure 3 shows the greedy algorithm adapts very quickly. This is because the greedy algorithm maximizes for each task k without regard to history. Of course, the greedy algorithm is the least accurate and produces results that are significantly less than optimal for both distributions. To avoid clutter, the adaptive algorithm for cases are not plotted in Figure 3. Only the case is shown because this case has the slowest adaptation but the most accuracy (as compared with cases). While not shown in Figure 3, it was observed that the accuracy of the case was only marginally worse than that of the case (similar to Figure 2).
For the simulation of the proposed algorithm for the scenario of Figure 3, the virtual queue was observed to have a maximum value over the entire timeline, with a noticeable jump in average value of after the midway point in the simulation, as shown in Figure 4.
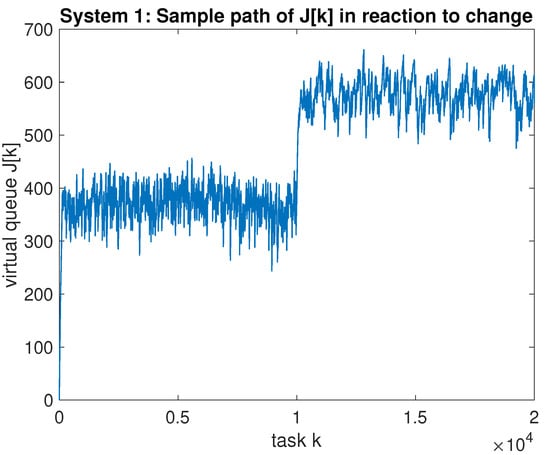
Figure 4.
System 1: A sample path of virtual queue for the proposed algorithm for the same scenario as Figure 3. A change in distribution occurs at the halfway point in the simulation.
- Distribution 1: With being the random number of rows, we use , , , . The first row is always and represents a “vacation” option that lasts for one unit of time and has zero reward (as explained in [2], it can be optimal to take vacations a certain fraction of time, even if there are other row options). The remaining rows r, if any, have parameters generated independently with and , where and is independent of .
- Distribution 2: We use , , , . The first row is always . The other rows r are independently chosen as a random vector with , with independent and , .
6.2. System 2
This subsection considers a device that processes computational tasks with the goal of maximizing time average profit subject to a time average power constraint of energy/time. There is a penalty process and so the Robbins–Monro algorithm of [2] cannot be used. For simplicity, we use (as discussed in Section 7). was observed to be stable with a maximum size of less than 350 over all time. We compare the adaptive algorithm of the current paper to the drift-plus-penalty ratio method of [6]. The ratio of expectations from the main method in [6] requires knowledge of the probability distribution on . A heuristic is proposed in Section VI.B in [6] that uses a drift-plus-penalty minimization of , which has a simple decision complexity for each task that is the same as the decision complexity of the adaptive algorithm proposed in the current paper, and where is defined as a running average:
It is argued in Section VI.B in [6] that, if the heuristic converges, it converges to a point that is within of optimality, where the parameter v is chosen as . We call this heuristic “DPP with ratio averaging” in the simulations. (Another method described in [6] approximates the ratio of expectations using a window of w past samples. The per-task decision complexity grows with w and hence is larger than the complexity of the algorithm proposed in the current paper. For ease of implementation, we have not considered this method.) We also compare to a greedy method that removes any row r of that does not satisfy , and chooses from the remaining rows to maximize .
The i.i.d. matrices have three columns and three rows of the form:
where for . The first row corresponds ignoring task k and remaining idle for 1 unit of time, earning no reward but using no energy, so . The second row corresponds to processing task k at the home device. The third row corresponds to outsourcing task k to a cloud device. Two distributions are considered (specified at the end of this subsection). Under Distribution A, the reward is the same for both rows 2 and 3, but the energy and durations of time are different. Under Distribution B, the reward is higher for processing at the home device. Both distributions have , , . We use for the adaptive algorithm. Under the distributions used, the greedy algorithm is never able to use row 2, can always use either row 1 or 3, and always selects row 3.
Figure 5 and Figure 6 consider reward and power for simulations over 5000 tasks with i.i.d. under Distribution A. Figure 5 plots the running average of where expectations are attained by averaging over 40 independent simulations. The horizontal asymptote illustrates the optimal as obtained by simulation. The simulation uses for the DPP with ratio averaging because this was sufficient for an accurate approximation of , as seen in Figure 5. The proposed adaptive algorithm is considered for . As predicted by our theorems, it can be seen that the converged reward is closer to as v is increased (the case is competitive with DPP with ratio averaging). Figure 6 plots the corresponding running average of . The disadvantage of choosing a large value of v is seen by the longer time required for time-averaged power to converge to the horizontal asymptote . Figure 5 and Figure 6 show the greedy algorithm has the worst reward per unit time and has average power significantly under the required constraint. This shows that, unlike the other algorithms, the greedy algorithm does not make intelligent decisions for using more power to improve its reward. Considering only the performance shown in Figure 5 and Figure 6, the DPP with ratio averaging heuristic demonstrates the best convergence times, which is likely due to the fact that it uses only one virtual queue while our adaptive algorithm uses and . It is interesting to note that the adaptive algorithms and the DPP with ratio averaging heuristic both choose row 1 (idle) a significant fraction of the time. This is because, when a task has a small reward but a large duration of time, it is better to throw the task away and wait idly for a short amount of time in order to see a new task with a hopefully larger reward.
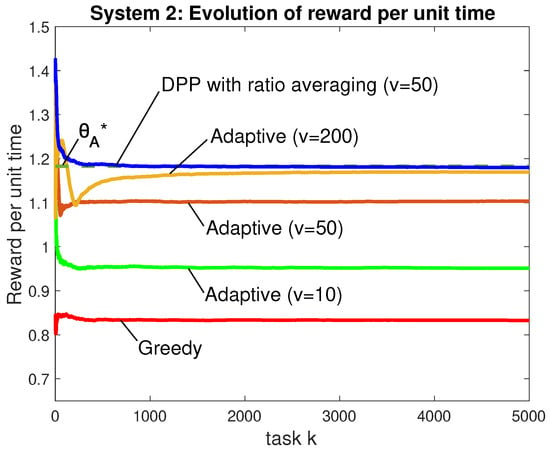
Figure 5.
Time average reward up to task k for the proposed adaptive algorithm (); the DPP algorithm with ratio averaging; the greedy algorithm. The dashed horizontal line is the value .
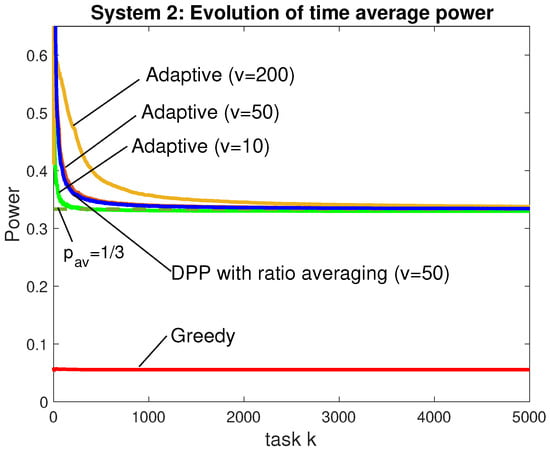
Figure 6.
Corresponding time-averaged power for the simulations of Figure 5. The horizontal asymptote is . The greedy algorithm falls too far under the constraint: it does not know how to use more power to increase its time average reward.
Significant adaptation advantages of our proposed algorithm are illustrated in Figure 7. Performance is plotted over a moving average with window size , and averaged over 100 independent simulations. The first half of the simulation uses i.i.d. with Distribution A, the second half uses Distribution B. The two horizontal asymptotes in Figure 7 are optimal and values for Distributions A and B. As seen in the figure, both the adaptive algorithm and the DPP with ratio averaging heuristic quickly converge to the optimal value associated with Distribution A (the rewards under the adaptive algorithm are slightly less than those of the heuristic). At the time of change, the adaptive algorithm has a spike that lasts for roughly 2000 tasks until it settles down to . This can be viewed as the adaptation time and can be decreased by decreasing the value of v (at a corresponding accuracy cost). It converges from above to because, as seen in Figure 7, the spike marks a period of using more power than the required amount. In contrast, the DPP with ratio averaging algorithm cannot adapt and never increases to the optimal value of .
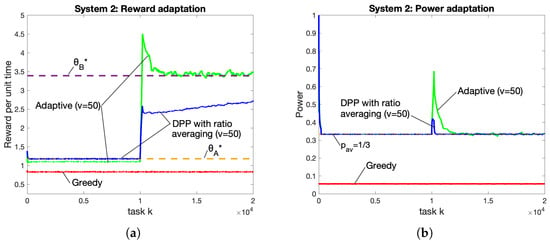
Figure 7.
Adaptation for (a) reward and (b) power when the distribution is changed halfway through the simulation. Horizontal asymptotes are and for Distributions A and B. The adaptive algorithm settles into the new optimality point , while DPP with ratio averaging cannot adapt.
The distributions used are as follows: For each task k, there are two independent random variables generated. Then,
- Distribution A: Note that and always.
- Distribution B: The value is increased in comparison to Distribution A.
6.3. Weight Adjustment
While the adaptation times achieved by the proposed algorithm are asymptotically optimal, an important question is whether the coefficient can be improved by some constant factor. Specifically, this subsection attempts to reduce the 2000-task adaptation time seen in the spikes of Figure 7 and Figure 8 without degrading accuracy. We observe that the and queues are weighted equally in the Lyapunov function . More weight can be placed on to emphasize the average power constraint and thereby reduce the spike in Figure 8b. This can be performed with no change in the mathematical analysis by redefining the penalty as for some constant . The constraint is the same as . We use and also double the v parameter from 50 to 100, which maintains the same relative weight between reward and but deemphasizes the virtual queue by a factor of 2.
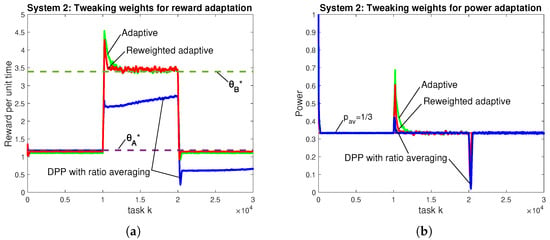
Figure 8.
Comparing (a) reward and (b) power of the reweighted adaptive scheme when the distribution changes twice. Parameters for the adaptive and DPP with ratio averaging algorithms are the same as Figure 7.
Figure 8 plots performance over tasks with Distribution A in the first third, Distribution B in the second third, and Distribution A in the final third. The adaptive algorithm and the DPP with ratio averaging algorithm use the same parameters as in Figure 7. The reweighted adaptive algorithm uses and . It can be seen that the reweighting decreases adaptation time with no noticeable change in accuracy. This illustrates the benefits of weighting the power penalty more heavily than the virtual queue .
The simulations in Figure 8 further show that the proposed adaptive algorithms can effectively handle multiple distributional changes. Indeed, the reward settles close to the new optimality point after each change in distribution. In contrast, the DPP with ratio averaging algorithm, which was not designed to be adaptive, appears completely lost after the first distribution change and never recovers. This emphasizes the importance of adaptive algorithms.
The value of the virtual queue for the proposed algorithm and its reweighted variant are shown in Figure 9. This illustrates that using , which puts no deterministic upper bound on , does not adversely affect performance, as discussed in Section 7. The virtual queue is not shown, but its behavior is similar, and its maximum value over all time was observed to be less than 400.
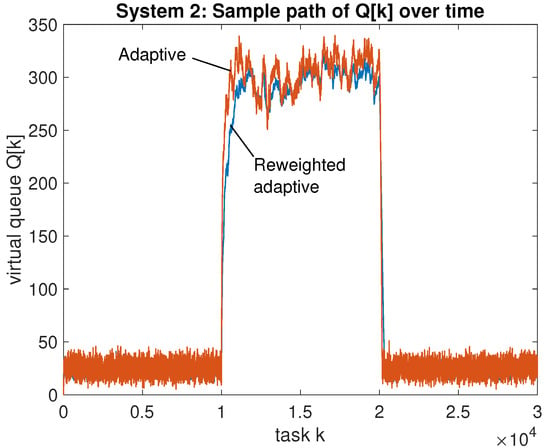
Figure 9.
System 2: A sample path of for the proposed adaptive algorithm and its reweighted variant for the same scenario as Figure 8.
7. Discussion
The proposed algorithm can be run indefinitely over an infinite sequence of tasks. The analysis holds for any block of m tasks over which is i.i.d. over that block. This holds regardless of sample path history before the block. A useful mathematical model that fits our analysis is when evolves over disjoint and variable-length blocks of time during which behavior is i.i.d. with a fixed but unknown distribution, and where the start and end times of each block are unknown. In this scenario, the algorithm adapts and comes within of optimality for every block that lasts for at least tasks.
What happens if is not i.i.d. over a block of interest? The good news is that our analysis provides worst-case bounds on the virtual queues that hold for all time and for any sample path. This means the algorithm maintains reasonable operational states. Of course, our optimality analysis uses the i.i.d. assumption. We conjecture that the algorithm also makes efficient decisions in more general situations where arises from an ergodic Markov chain. The analysis in that situation would be more complicated, and the adaptation times would depend on the mixing time of the Markov process. We leave such open questions for future work.
There are situations where evolves according to an ergodic Markov chain with very slow mixing times, slower than any reasonable timescale over which we want our algorithm to adapt. For example, one can imagine a 2-state Markov chain where is i.i.d. with one distribution in state 1, and i.i.d. with another distribution in state 2. If transition probabilities between states 1 and 2 are very small, then state transitions may occur on a timescale of hours (and ergodic mixing times may be on the order of days or weeks), while thousands of tasks are performed before each state transition. Each state transition starts a new block of tasks. Our algorithm adapts to each new distribution, without knowing the transition times, provided that transition times are separated by at least tasks. In other words, our convergence analysis holds on the shorter timescale of the block, rather than the longer (and possibly irrelevant) mixing time of the underlying Markov chain.
When , the algorithm has a parameter , where . Theorem 2 suggests . This requires knowledge of . In practice, there is little danger in choosing to be too large. Even choosing works well in practice (see simulation section). Intuitively, this is because the virtual queue update (27) for reduces to
which means for all k and the inequality (30) can be modified to
for all positive integers . Intuitively, the Slater condition still ensures concentrates quickly and is still rarely much larger than the parameter in Lemma 7, where . Intuitively, while the virtual queue would no longer be deterministically bounded, it would stay within its existing bounds with high probability. Taking expectations of (82) would then produce a right-hand side proportional to , which is whenever and .
8. Conclusions
This paper gives an adaptive algorithm for renewal optimization, where decisions for each task k determine the duration of the task, the reward for the task, and a vector of penalties. The algorithm has a low per-task decision complexity, operates without knowledge of system probabilities, and is robust to changes in the probability distribution that occur at unknown times. A new hierarchical decision rule enables the algorithm to achieve within of optimality over any sequence of tasks over which the probability distribution is fixed, regardless of system history. This adaptation time matches a prior converse result that shows any algorithm that guarantees -optimality during tasks must have , even if there are no additional penalty processes.
Funding
This work was supported in part by NSF SpecEES 1824418.
Data Availability Statement
The MATLAB simulations and figures in this study are openly available in the provided link: https://ee.usc.edu/stochastic-nets/docs/Adapt-Renewals-Neely2025-simulations.zip, accessed on 20 November 2025.
Conflicts of Interest
The author declares no conflicts of interest.
References
- Neely, M.J. Stochastic Network Optimization with Application to Communication and Queueing Systems; Morgan & Claypool: San Rafael, CA, USA, 2010. [Google Scholar]
- Neely, M.J. Fast Learning for Renewal Optimization in Online Task Scheduling. J. Mach. Learn. Res. 2021, 22, 1–44. [Google Scholar]
- Fox, B. Markov Renewal Programming by Linear Fractional Programming. SIAM J. Appl. Math. 1966, 14, 1418–1432. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Neely, M.J. Online Fractional Programming for Markov Decision Systems. In Proceedings of the 2011 49th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 28–30 September 2011. [Google Scholar]
- Neely, M.J. Dynamic Optimization and Learning for Renewal Systems. IEEE Trans. Autom. Control 2013, 58, 32–46. [Google Scholar] [CrossRef]
- Tassiulas, L.; Ephremides, A. Dynamic Server Allocation to Parallel Queues with Randomly Varying Connectivity. IEEE Trans. Inf. Theory 1993, 39, 466–478. [Google Scholar] [CrossRef]
- Tassiulas, L.; Ephremides, A. Stability Properties of Constrained Queueing Systems and Scheduling Policies for Maximum Throughput in Multihop Radio Networks. IEEE Trans. Autom. Control 1992, 37, 1936–1948. [Google Scholar] [CrossRef]
- Wei, X.; Neely, M.J. Data Center Server Provision: Distributed Asynchronous Control for Coupled Renewal Systems. IEEE/ACM Trans. Netw. 2017, 25, 2180–2194. [Google Scholar] [CrossRef]
- Wei, X.; Neely, M.J. Asynchronous Optimization over Weakly Coupled Renewal Systems. Stoch. Syst. 2018, 8, 167–191. [Google Scholar] [CrossRef]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Borkar, V.S. Stochastic Approximation: A Dynamical Systems Viewpoint; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Nemirovski, A.; Yudin, D. Problem Complexity and Method Efficiency in Optimization; Wiley-Interscience Series in Discrete Mathematics; John Wiley: Hoboken, NJ, USA, 1983. [Google Scholar]
- Kushner, H.J.; Yin, G. Stochastic Approximation and Recursive Algorithms and Applications; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Toulis, P.; Horel, T.; Airoldi, E.M. The Proximal Robbins–Monro Method. J. R. Stat. Soc. Ser. B Stat. Methodol. 2021, 83, 188–212. [Google Scholar] [CrossRef]
- Nemirovski, A.; Juditsky, A.; Lan, G.; Shapiro, A. Robust Stochastic Approximation Approach to Stochastic Programming. SIAM J. Optim. 2009, 19, 1574–1609. [Google Scholar] [CrossRef]
- Joseph, V.R. Efficient Robbins-Monro Procedure for Binary Data. Biometrika 2004, 91, 461–470. [Google Scholar] [CrossRef]
- Zinkevich, M. Online convex programming and generalized infinitesimal gradient ascent. In Proceedings of the 20th International Conference on Machine Learning (ICML), Washington, DC, USA, 21–24 August 2003. [Google Scholar]
- Huo, D.L.; Chen, Y.; Xie, Q. Bias and Extrapolation in Markovian Linear Stochastic Approximation with Constant Stepsizes. In Proceedings of the Abstract Proceedings of the 2023 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems (SIGMETRICS ’23), New York, NY, USA, 19–23 June 2023; pp. 81–82. [Google Scholar] [CrossRef]
- Luo, H.; Zhang, M.; Zhao, P. Adaptive Bandit Convex Optimization with Heterogeneous Curvature. Proc. Mach. Learn. Res. 2022, 178, 1–37. [Google Scholar]
- Van der Hoeven, D.; Cutkosky, A.; Luo, H. Comparator-Adaptive Convex Bandits. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS’20), Red Hook, NY, USA, 6–12 December 2020. [Google Scholar]
- Leyffer, S.; Menickelly, M.; Munson, T.; Vanaret, C.W.; Wild, S. A Survey of Nonlinear Robust Optimization. INFOR Inf. Syst. Oper. Res. 2020, 58, 342–373. [Google Scholar] [CrossRef]
- Tang, J.; Fu, C.; Mi, C.; Liu, H. An interval sequential linear programming for nonlinear robust optimization problems. Appl. Math. Model. 2022, 107, 256–274. [Google Scholar] [CrossRef]
- Badanidiyuru, A.; Kleinberg, R.; Slivkins, A. Bandits with Knapsacks. J. ACM 2018, 65, 1–55. [Google Scholar] [CrossRef]
- Agrawal, S.; Devanur, N.R. Bandits with Concave Rewards and Convex Knapsacks. In Proceedings of the Fifteenth ACM Conference on Economics and Computation (EC ’14), New York, NY, USA, 8–12 June 2014; pp. 989–1006. [Google Scholar] [CrossRef]
- Xia, Y.; Ding, W.; Zhang, X.; Yu, N.; Qin, T. Budgeted Bandit Problems with Continuous Random Costs. In Proceedings of the ACML, Hong Kong, 20–22 November 2015. [Google Scholar]
- Kallenberg, O. Foundations of Modern Probability, 2nd ed.; Probability and Its Applications; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Neely, M.J. Energy-Aware Wireless Scheduling with Near Optimal Backlog and Convergence Time Tradeoffs. IEEE/ACM Trans. Netw. 2016, 24, 2223–2236. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).