Abstract
Automatic algorithm selection is a critical challenge in data-driven decision-making due to the proliferation of available algorithms and the diversity of application scenarios, with no universally optimal solution. Traditional methods, including rule-based systems, grid search, and single-modal meta-learning, often struggle with high computational cost, limited generalization, and insufficient modeling of complex dataset-algorithm interactions, particularly under data sparsity or cold-start conditions. To address these issues, we propose a Dual-Channel Heterogeneous Graph Neural Network (DCHGNN) for automatic algorithm recommendation. Datasets and algorithms are represented as nodes in a heterogeneous bipartite graph, with edge weights defined by observed performance. The framework employs two channels, one for encoding the textual descriptions and the other for capturing the meta-features of the dataset. Cross-channel contrastive learning aligns embeddings to improve consistency, and a random forest regressor predicts algorithm performance on unseen datasets. Experiments on 121 datasets and 179 algorithms show that DCHGNN achieves an average relative maximum value of 94.8%, outperforming baselines, with 85% of predictions in the high-confidence range . Ablation studies and visualization analyses confirm the contributions of both channels and the contrastive mechanism. Overall, DCHGNN effectively integrates multimodal information, mitigates sparsity and cold-start issues, and provides robust and accurate algorithm recommendations.
Keywords:
algorithm recommendation; meta-learning; heterogeneous graph neural network; dual-channel; contrastive learning MSC:
68T05
1. Introduction
With the proliferation of machine learning applications in managerial tasks such as demand forecasting and risk assessment, automated algorithm selection has become critical to overcome algorithm overload and scenario heterogeneity []. While traditional methods like rule-based systems and grid search suffer from poor generalization and high computational cost [,], meta-learning and graph-based approaches have emerged as promising alternatives by leveraging historical performance meta-data [] or modeling dataset-algorithm interactions as graphs []. Nevertheless, four core challenges remain: (1) limited representational capacity of meta-features for complex multimodal data; (2) inability of single-model frameworks to balance automation and precision at scale; (3) neglect of high-order structured interactions between datasets and algorithms; and (4) performance degradation under data sparsity or cold-start scenarios due to insufficient meta-knowledge or incomplete graph structures.
To address these limitations, several recent works have explored graph-based and meta-learning based approaches for algorithm selection. Graph-based fine-grained model selection for multi-source domain (GFMS) constructs a library of source models, exploits graph neural networks (GNNs) to learn feature-model associations and dataset similarities, and blends over multiple source models rather than selecting just one, showing strong performance in cross-domain image classification tasks []. Cohen et al. [] proposed MARCO-GE, which also MARCO-GE similarly represents datasets as graphs and applies a Graph Convolutional Networks to learn embeddings; it then trains a ranking meta-model to recommend clustering algorithms across a large suite of datasets, algorithms, and clustering evaluation measures, outperforming previous meta-learning baselines. To enhance the sparsity performance and improve the accuracy of recommendations, Cohen-Shapira et al. [] used graph convolutional networks to aggregate structural information from dataset-algorithm performance graphs, and proposed a meta-learning method for algorithm recommendation. Together, these efforts suggest that integrating graph structure, embedding representations, and meta-models can significantly improve algorithm and model recommendation under challenges such as dataset variability, sparsity, and domain migration. These methods effectively model the interaction between the dataset and the algorithm, but mainly operate on isomorphic graphs or rely on single-modal features, thus lacking a framework to integrate multimodal data and handle complex scene tasks.
Inspired by this, this paper proposes a novel dual-channel heterogeneous graph neural network framework for algorithm recommendation. The framework embeds datasets and algorithms as nodes in a heterogeneous bipartite graph, with edge weights determined by algorithm performance. A dual-channel heterogeneous graph attention mechanism learns fine-grained representations of dataset-algorithm relationships, reinforced through cross-channel contrastive learning to ensure consistency. Finally, a random forest regressor is used to predict the performance on unseen datasets, enabling accurate algorithm recommendation.
The main contributions of this work are summarized as follows:
- Dual-channel heterogeneous graph framework: We model datasets and algorithms as nodes in a heterogeneous bipartite graph and design Semantic and Meta HGNN Channels to fuse textual descriptions and numerical meta-features, capturing rich dataset-algorithm interaction patterns beyond single-modal approaches.
- Cross-channel contrastive learning: We introduce a contrastive learning mechanism to align embeddings from the two channels, improving consistency and robustness of node representations and alleviating the negative impact of data sparsity.
- Extensive experimental validation: Through experiments on 121 datasets and 179 algorithms—including baseline comparisons, ablation studies, visualization analyses, and case studies—we demonstrate that DCHGNN outperforms state-of-the-art methods in both accuracy and stability, and effectively addresses challenges such as data sparsity and cold-start scenarios.
2. Related Work
2.1. Automated Algorithm Recommendation
Meta-learning has long served as a key technical framework for automatic algorithm recommendation, and its core idea lies in learning the mapping rules between dataset characteristics and algorithm performance from historical task data, thereby predicting the optimal algorithm for new tasks. This type of method mainly relies on numerical meta-features to construct meta-models and has achieved mature applications in early algorithm recommendation scenarios. The meta-models in existing studies mainly include rule-based, distance-based, regression-based, and ensemble learning-based meta-models.
The rule-based meta-model generates selection rules for each candidate algorithm. When the meta-features meet the selection rules, it indicates that the corresponding candidate algorithm is the appropriate one for the task. Ali et al. [] used the rule-based learning algorithm C5.0 to describe which types of algorithms are suited to solving which types of classification problems. Azadeh et al. [] extracted 18 types of dataset meta-features and used Classification and Regression Trees (CART) to select the optimal algorithm from six candidate algorithms. Distance-based meta-models measure the distance between tasks using meta-features. Their basic idea is that algorithms exhibit similar performance on similar tasks, and the similarity between tasks can be quantified and calculated through meta-feature distance. For a new task, the appropriate algorithm for it is predicted by using the applicable algorithms of other tasks that are closest to it in distance. Common distance metrics include Euclidean distance, Manhattan distance, cosine distance, and Jaccard index [,,,]. In addition, some studies map the algorithm selection problem to a regression problem. They train meta-models using task meta-features and the performance metric values of candidate algorithms, input the meta-features of a new task into each meta-model to obtain predicted performance metric values, and output the appropriate algorithm by comparing the predicted performance of each algorithm. Lorena et al. [] used the Support Vector Regression (SVR) algorithm as the meta-model and constructed 28 meta-models respectively for 14 candidate regression algorithms and two types of regression problem meta-features. Diego et al. [] trained meta-models on each meta-dataset using the Linear Regression (LR) algorithm. They predicted the performance metric values of candidate algorithms on new datasets through these meta-models, thereby forming a ranking of the predicted algorithms. Garcia et al. [] employed three regression meta-algorithms including SVR to predict the performance metric values of five candidate classification algorithms. They compared the application effects of different types of meta-features based on the prediction biases. Some scholars have constructed meta-models with strong generalization performance and algorithm selection performance by introducing the idea of ensemble learning. Random forest (RF) is one of the widely used meta-models in meta-learning-based algorithm selection research. Owing to its ability to evaluate feature importance, random forest can clearly identify the impact of dataset meta-features on model selection. It also balances accuracy and interpretability in small-to-medium-sized tasks, thus becoming a benchmark method in numerous studies []. Auto-sklearn, as a representative automated machine learning framework, further optimizes the meta-learning process by integrating Bayesian optimization technology. It constructs a search space covering multiple algorithms and their hyperparameters, and dynamically adjusts the search direction based on historical performance feedback to efficiently screen out the optimal algorithm configuration for a specific dataset. Feurer et al. [] verified through a large number of experiments that Auto-sklearn outperforms manual parameter tuning in standard classification and regression tasks, and its highly encapsulated framework reduces the application threshold for automatic algorithm recommendation.
However, traditional meta-learning-based methods have obvious limitations. Firstly, they have a single dependence on feature modalities. These methods can only process structured numerical meta-features and completely ignore unstructured information such as dataset text descriptions (e.g., domain semantics, task objective explanations) and algorithm principle texts. This leads to a significant decline in recommendation accuracy in cross-domain scenarios. For example, when recommending algorithms for a medical text classification dataset, traditional methods cannot capture the semantic association between medical domain and text processing algorithms, resulting in the possible recommendation of algorithms more suitable for image data. Secondly, they ignore the interaction structure between datasets and algorithms. These methods treat datasets and algorithms as independent entities and do not model the implicit association relationships between them, such as the high-frequency adaptation between a certain type of dataset and a certain type of algorithm. Finally, in data-sparse or cold-start scenarios (e.g., a new dataset with no historical interaction records), the meta-model lacks sufficient information support for prediction, and its generalization ability is severely limited.
2.2. Graph Representation Learning for Recommendation
Graph representation learning (GRL) has become a fundamental paradigm for modeling relational and structured data in recommender systems. By capturing high-order dependencies and complex interaction patterns, GRL provides a powerful mechanism to go beyond shallow feature engineering and leverage the relational nature of user-item data. Early works primarily focused on general principles of GNNs and representation learning [,,,], while more recent surveys have systematically summarized their applications in recommendation [,], social recommendation [], and dynamic graphs []. Collectively, these studies highlight the capability of graph-based methods to address long-standing challenges such as data sparsity, scalability, and the cold-start problem, thereby motivating a growing body of research on graph-based recommendation frameworks.
A large number of concrete models have been proposed to demonstrate the effectiveness of GRL in diverse recommendation scenarios. For instance, Liu et al. [] introduced a multi-perspective social recommendation model built upon GCNs, emphasizing the role of social ties. Ge et al. [] exploited cross-modal graph representations to enhance news recommendation, showing how heterogeneous modalities can be aligned within a graph structure. Wang et al. [] applied network representation learning to point-of-interest (POI) recommendation, effectively capturing geographical and social relations, while Amara et al. [] recently proposed a multi-view GNN framework to integrate heterogeneous signals for more robust predictions. These works collectively underline the flexibility of GRL in adapting to different domains, data modalities, and recommendation settings.
Building on these foundations, heterogeneous graph neural networks (HGNNs) have emerged as a particularly powerful extension for recommendation tasks, as they explicitly model multiple types of nodes, relations, and semantic contexts. Fan et al. [] pioneered a metapath-guided HGNN for intent recommendation, demonstrating the benefit of semantic path-based message passing. Shi et al. [] further proposed a general HGNN framework, showing that heterogeneous semantics can yield significant performance gains compared to homogeneous graphs. Notably, Yang et al. [] developed Heterogeneous Graph Attention Networks (HGAT) with a dual-level attention mechanism, significantly enhancing node representation learning in sparse short-text scenarios. Similarly, Fan et al. [] proposed the framework GraphRec, which extended social recommendation by jointly modeling user-item interactions and social relations through attentive graph aggregation. More specialized designs have also been developed: Cai et al. [] introduced an inductive HGNN to mitigate the user cold-start problem; Pang et al. [] applied a heterogeneous global graph neural network to session-based recommendation; Sang et al. [] explored adversarial training to improve robustness; Wei et al. [] studied privacy-preserving HGNNs; and Yan et al. [] developed a federated HGNN framework for secure and distributed recommendation. These lines of research collectively demonstrate the versatility and adaptability of HGNNs to address both algorithmic and practical challenges.
Taken together, the above advances clearly indicate that GRL, in particular HGNNs, provides a principled way to capture multi-type interactions and complex semantic structures in recommendation tasks. Motivated by these developments, our work introduces a dual-channel heterogeneous GNN framework tailored for algorithm recommendation. Specifically, the framework integrates dataset descriptions, meta-features, and algorithm properties into a unified graph-based representation, enabling the model to learn richer structural semantics and ultimately deliver more accurate and generalizable algorithm recommendation outcomes.
3. Materials and Methods
3.1. Overview
Motivated by recent advances in graph neural networks and meta-recommendation, this paper proposes a dual-channel heterogeneous graph meta-learning framework (DCHGNN) for algorithm recommendation, as shown in Figure 1. The framework comprises four core components as the following: (1) heterogeneous graph construction, (2) dual-channel representation learning, (3) cross-channel contrastive learning, and (4) performance prediction. We provide the details of each component and their interrelationships below.
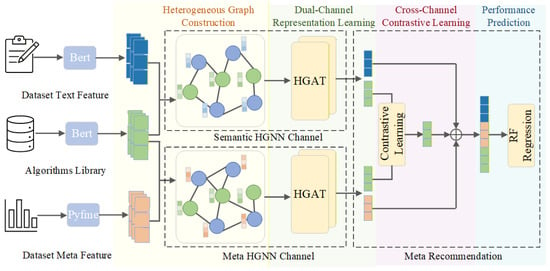
Figure 1.
Overview of the proposed DCHGNN framework for algorithm recommendation. The framework employs a dual-channel heterogeneous graph attention mechanism, maintaining semantic (textual) and meta-feature channels in parallel to model dataset-algorithm relationships, leverages contrastive learning to refine representations, and relies on RF regression for meta-recommendation.
The framework adopts a sequential yet deeply integrated pipeline design where modules are interconnected through well-defined input-output relationships. The process initiates with the heterogeneous graph construction module, which formulates the recommendation problem as a bipartite graph structure, providing the fundamental computational topology and initial features for the entire system. This graph structure is then fed into the dual-channel representation learning module, where two parallel graph neural networks extract complementary feature representations from semantic and numerical perspectives respectively. The outputs from both channels are then processed by the cross-channel contrastive learning module, which serves as the critical bridge between representation learning and final prediction. This module employs a contrastive learning mechanism that aligns the dual-channel representations in a shared latent space, explicitly enhancing representational consistency and robustness against channel-specific noise. The resulting fused dataset-algorithm pair representations are subsequently delivered to the performance prediction module. Finally, the fused high-quality embeddings serve as the input for the performance prediction module. In this module, a random forest regressor accomplishes accurate prediction of algorithm performance on unseen datasets, enabling automated recommendation.
Throughout this pipeline, graph construction serves as the foundation, dual-channel learning acts as the feature engine, fusion and contrastive mechanisms are key to enhancing generalization capability, and the prediction module represents the ultimate value realization of all preceding processing. Particularly noteworthy is that contrastive learning functions as a supervisory signal that directly influences and optimizes the representation learning process through backpropagation, forming a cross-module closed-loop optimization that ensures all components work synergistically rather than in isolation.
3.2. Problem Definition
Algorithm recommendation aims to identify suitable algorithms for a new dataset by considering dataset characteristics, task type, and evaluation criteria. Let the dataset set be denoted as , the algorithm set as , and the performance matrix as , where each entry represents the performance (e.g., classification accuracy) of algorithm when applied to dataset .
The goal of algorithm recommendation is to learn a mapping function as the following:
such that for a new dataset , the predicted performance of algorithm can be obtained as the following:
where denotes the estimated accuracy of algorithm on dataset . Based on these predictions, the system recommends the algorithm(s) expected to achieve the best performance for the unseen dataset.
3.3. Data Preparation
To effectively learn the mapping function f, it is crucial to represent datasets and algorithms in a way that captures their characteristics and interactions. This requires collecting comprehensive descriptive and performance data for both datasets and algorithms, as well as any domain-specific semantic information that can enrich these representations. Accordingly, this study collected experimental results of 179 algorithms across 121 datasets from the UCI repository (http://archive.ics.uci.edu, accessed on 1 September 2024), Kaggle (https://www.kaggle.com/, accessed on 1 September 2024) and openML []. These datasets are widely used in the classification field and are representative of practical classification problems. We further integrated domain-specific semantic information from Wikipedia to construct a heterogeneous knowledge network. Based on these sources, we organized the data into four complementary components to support heterogeneous graph representation learning as the following:
Dataset Text Description: Dataset text description contains the basic characteristics of datasets (e.g., name, number of instances, number of attributes, maximum number of classes), domain-specific semantic descriptions, and annotator notes. Its core value lies in establishing explicit associations between datasets and domain knowledge. We extracted the text descriptions of dataset from the UCI repository, detailed in Table 1.

Table 1.
Dataset text description.
Dataset Meta-Feature: Dataset meta-features were extracted using the open-source library PyFME [], as it provides a standardized, reproducible, and comprehensive toolkit widely used in meta-learning research to characterize dataset complexity and statistical properties. In total, 111 meta-features were extracted across five categories, encompassing general, statistical, information-theoretic, model-based, and landmarking features, as shown in Table 2.
Table 2.
Extracted 111 meta-features grouped into five categories.
Algorithm Descriptive Data: This module includes algorithm names, hyperparameter configurations (e.g., kernel function for SVM, tree depth range for random forest), performance statistics (e.g., average accuracy across datasets), and textual descriptions of algorithm principles. Standardized algorithm descriptions enable a multidimensional representation of algorithm characteristics.
To construct the algorithm description data, this study employed an automated pipeline based on the DeepSeek Chat API. Specifically, algorithm names were first parsed from a prepared text file and sequentially processed by a script that generated standardized prompts. The key details are provided in the Appendix A. Each prompt was strictly formatted to query the official documentation of R, Matlab, Caret, and Weka libraries, requiring the model to return results exclusively in JSON format with six predefined fields: algorithm name, category, input data type and format, number of variables, output data type and format, and theoretical foundation. The model responses were subsequently post-processed by removing code block delimiters and extraneous characters, followed by JSON parsing. Finally, the extracted information was aggregated to form the structured algorithm description dataset.
Dataset-Algorithm Interaction Data: This module records the performance of each dataset across multiple algorithms []. The accuracy metric was chosen as the edge weight between datasets and algorithms, serving as a measure of their compatibility. Although accuracy has certain limitations, such as sensitivity to class imbalance, its interpretability and broad applicability make it a widely accepted benchmark for cross-domain comparisons.
3.4. Dual-Channel Heterogeneous Graph Construction
In the graph construction stage, datasets and algorithms are regarded as two types of nodes, and the performance evaluation results between them are used as edge weights to form a bipartite graph. To fully leverage the heterogeneous information available, we introduce a dual-channel design combined with a contrastive learning mechanism, enabling the model to jointly exploit both textual descriptions and numerical meta-features of datasets. This approach allows the framework to capture complementary aspects of dataset characteristics, leading to more comprehensive and informative feature representations.
The heterogeneous interaction graph is denoted as , where is the set of nodes, consisting of dataset nodes D and algorithm nodes A; is the set of edges, representing the interactions between datasets and algorithms, with edge weight . The dual-channel design consists of the following:
Semantic HGNN Channel: The semantic HGNN channel encodes the semantic information of datasets and algorithms into a heterogeneous graph. Specifically, textual descriptions of datasets and algorithms are first transformed into high-dimensional embeddings using BERT, due to its strong capability in capturing contextual semantics from dataset descriptions. These embeddings serve as the initial node features for datasets and algorithms in the graph. Edges between dataset and algorithm nodes are weighted by algorithm performance metrics (e.g., accuracy), enabling the model to learn fine-grained semantic relationships between datasets and algorithms. By leveraging this channel, the framework can reason about which algorithms are likely to perform well on a given dataset based on textual semantic similarity and historical performance.
Meta HGNN Channel: In the meta HGNN channel, dataset meta-features are explicitly extracted and used as the node features for dataset nodes. These meta-features capture intrinsic statistical, information-theoretic, model-based, and landmarking characteristics of the datasets, providing complementary structural information beyond textual descriptions. Algorithm nodes, on the other hand, inherit their features from the BERT embeddings computed in the semantic HGNN channel, ensuring consistency across channels. The edges between dataset and algorithm nodes continue to represent performance metrics (e.g., accuracy), allowing the graph to encode both the intrinsic properties of datasets and their historical algorithm performance. By combining meta-features with semantic embeddings, the meta HGNN channel enhances the model’s ability to reason about dataset-algorithm suitability, particularly when textual descriptions alone are insufficient.
3.5. Heterogeneous Graph Attention Network Representation Learning
To model the above heterogeneous graphs, we proposed a novel heterogeneous graph attention mechanism, maintaining two parallel channels on the graph: the semantic (textual description) channel and the meta (numerical meta-feature) channel. Node features from different sources were first projected into a shared message space using dedicated linear transformations. The attention mechanism then performs importance-weighted aggregation over each central node’s neighbors.
Specifically, at each layer, the neighbor representations are weighted by attention coefficients , summed, and passed through a nonlinear transformation to produce the node’s layer-wise representation. By stacking multiple layers, the receptive field of each node is gradually expanded, and complementary semantic information across the two channels is captured. This hierarchical, dual-channel aggregation ultimately yields heterogeneous graph representations suitable for downstream tasks such as algorithm recommendation. The update functions of semantic HGNN channel and meta HGNN channel at the l-th layer are defined as the following:
where and are the outputs of the semantic and meta channels respectively; is a nonlinear activation function; and are channel-specific transformation matrices; is the representation of neighbor node j at layer ; and is the attention coefficient computed as the following:
where is a learnable attention vector, and applying the LeakyReLU nonlinearity.
3.6. Cross-Channel Contrastive Learning
Since the two channels capture information from different modalities, their embeddings may diverge if left unconstrained, potentially degrading recommendation performance. To address this, we introduced a contrastive learning mechanism to enforce consistency between the two channels, thereby enhancing robustness, reducing sparsity, and promoting information sharing.
For a dataset , let denote its neighboring algorithm nodes. For each algorithm , its normalized representations in the two channels are as the following:
For a dataset , the contrastive loss for algorithm is defined as the following:
where the positive pair is formed by the same algorithm node across two channels, i.e., , and the negative pairs are cross-channel embeddings of different algorithms in the same neighborhood. is a temperature parameter.
Finally, the overall contrastive loss is averaged across all datasets and their neighboring algorithms as follows:
3.7. Random Forest Regression for Performance Prediction
The task of algorithm recommendation can be formulated as a regression problem where the goal is to predict the dataset-algorithm edge weight (i.e., accuracy). After the heterogeneous graph attention network learning phase, we obtain node embeddings from both channels. The embeddings of algorithm nodes from the two channels are averaged to form a unified representation. The embeddings of dataset nodes from the two channels are concatenated to preserve complementary information. The resulting dataset-algorithm pair representation is then used as input to a random forest regressor with the observed accuracy serving as the target label. Model training is performed using a leave-one-out strategy where one dataset is held out as the test set while the model is trained on the remaining datasets, as shown in Figure 2.
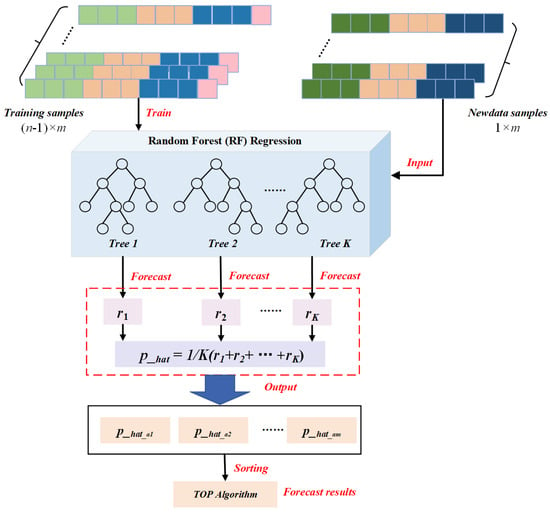
Figure 2.
Random forest regressor for algorithm recommendation. The message aggregation features of algorithms and datasets obtained by the heterogeneous graph attention network, are combined with the accuracy rate to form training samples, and trains a random forest regressor consisting of K decision trees. For the new dataset, its aggregated information features of the attention mechanism are combined with the dual-channel features of m algorithms respectively to form m testing samples, and then input into the regressor to obtain the recommendation algorithm with largest prediction value.
Through this process, the regressor predicts the performance of all algorithms on the unknown dataset, selecting the algorithm with the highest predicted value as the recommended algorithm for this dataset.
4. Experimental Results and Analysis
4.1. Baseline Methods
To validate the effectiveness of the proposed framework, we compared it against four representative baselines:
- Random Forest (RF) []: An ensemble learning method based on decision trees. RF builds multiple decision trees and aggregates their predictions to improve accuracy and reduce overfitting. It is widely used and has demonstrated competitive performance across various datasets.
- Auto-Sklearn []: An automated machine learning (AutoML) framework built on scikit-learn. It leverages Bayesian optimization for algorithm selection and hyperparameter tuning, enabling efficient model search and strong performance on diverse tasks.
- LightGCN []: A lightweight graph neural network designed for recommendation tasks. It simplifies traditional GCN by removing feature transformation and nonlinear activation, retaining only neighborhood aggregation. This design makes it highly efficient for large-scale user-item graphs while maintaining strong recommendation performance.
- HGAT []: Heterogeneous Graph Attention Network designed for semi-supervised classification. HGAT extends the standard graph attention mechanism to heterogeneous graphs, effectively capturing node- and edge-type-specific interactions to learn expressive node representations, and has demonstrated strong performance on classification tasks.
4.2. Evaluation Metric
We adopted the Relative Maximum Value (RMV) [] to evaluate the performance of algorithm recommendation. RMV measures the ratio between the performance of the algorithm selected by the predictive model and that of the true best-performing algorithm on the dataset, and it is defined as the following:
where denotes the accuracy of the algorithm recommended by the model, obtained by selecting the algorithm with the highest predicted performance score and then retrieving its actual accuracy on the corresponding dataset. represents the accuracy of the true top-performing algorithm, which serves as the performance upper bound. We records the accuracy performance of each dataset across multiple algorithms [].
Accuracy is defined as the following:
where TP, FP, TN, and FN denote the numbers of true positives, false positives, true negatives, and false negatives, respectively.
To evaluate the consistency between the predicted accuracy and the true accuracy , this study introduces the Expected Calibration Error (ECE), which measures the degree to which the predicted confidence aligns with the actual performance. A lower ECE indicates better calibration and higher reliability of the prediction model.
First, the predicted accuracies are divided into M equally spaced intervals:
For each interval , the average predicted accuracy and the average true accuracy are computed as the following:
Finally, the Expected Calibration Error (ECE) is calculated as the following:
where N denotes the total number of samples.
In this study, ECE serves as an evaluation metric to verify whether the predicted performance scores of algorithms are well-calibrated with their actual observed results. A smaller ECE value reflects that the model’s predicted confidence is more consistent with true accuracy, thus indicating stronger reliability and trustworthiness of the meta-recommendation framework.
4.3. Overall Results
Table 3 and Table 4 summarize the Average RMV and RMV distribution across all methods. The results indicate that our proposed DCHGNN framework achieves the highest overall performance, with an Average RMV of 94.8%, outperforming traditional ensemble methods (RF), AutoML approaches (Auto-Sklearn), and state-of-the-art graph-based models (LightGCN, HGAT). Notably, 85% of the predictions fall within the confidence interval, while predictions in the low-performance range are completely eliminated ( 0%), highlighting the model’s ability to generate highly reliable recommendations. Beyond accuracy, we further evaluated the calibration quality of predicted performance using the Expected Calibration Error (ECE). As shown in Table 3, DCHGNN achieves an ECE of 0.042, which is lower than all graph-based and AutoML baselines, and only slightly higher than the random forest method. This suggests that while RF exhibits naturally strong calibration due to its ensemble averaging mechanism, DCHGNN achieves a comparable level of reliability while maintaining a significantly higher predictive accuracy. Therefore, DCHGNN provides not only precise but also well-calibrated recommendations, effectively balancing performance and confidence consistency.
Table 3.
Average RMV and calibration comparison.
Table 4.
RMV distribution comparison.
Compared to other graph-based methods, DCHGNN substantially reduces the proportion of low-confidence predictions, indicating that the dual-channel architecture and contrastive learning strategy stabilize node embeddings and enhance model robustness. By jointly leveraging semantic textual features and numerical meta-features, DCHGNN captures complementary information that single-channel approaches (e.g., HGAT or LightGCN) fail to exploit, leading to more accurate and reliable recommendations. The superior performance across multiple RMV intervals demonstrates that DCHGNN generalizes well to diverse datasets, maintaining strong confidence even in challenging cases.
Overall, the experimental analysis confirms that DCHGNN not only improves average predictive performance but also enhances calibration and reliability, validating the effectiveness of the dual-channel heterogeneous graph approach in achieving both accuracy and trustworthiness.
4.4. Robustness Evaluation
To address the concern that our reported improvements might be contingent on the specific choice of RF as the final performance predictor, we conducted additional experiments employing a diverse set of regression models. These include linear regression, gradient boosted trees (GBT), and multi-layer perceptron (MLP). As shown in Table 5 and Table 6, clearly demonstrate that the superiority of our DCHGNN framework is consistent across different predictive models.
Table 5.
Average RMV under different prediction methods.
Table 6.
RMV distribution comparison under different prediction methods.
The results show that RF achieves the highest average RMV (94.80%), indicating strong predictive performance. In contrast, while GBT yield comparable average RMV values (93.72%), it exhibits a larger proportion of lower RMV scores, particularly in the [0, 0.8] range. This suggests that random forest is not only more accurate but also more robust across diverse datasets. The superior performance of random forest can be attributed to its ability to capture complex interactions among features with minimal risk of overfitting, confirming its effectiveness as the meta-classifier for algorithm selection.
To further validate the proposed method’s predictive stability and resilience in real-world scenarios where data imperfections are common, we conducted a comprehensive robustness evaluation. As shown in Table 7 and Table 8, This experiment simulates increasingly noisy and incomplete graph structures by simultaneously removing true edges and introducing non-existent edges at varying interference ratios: 0.1, 0.15, 0.2, 0.25, and 0.3. This dual-perturbation strategy effectively corrupts the original data topology, testing the proposed method’s dependency on reliable connectivity and its ability to maintain performance under structural degradation.
Table 7.
Average RMV under different interference ratios.
Table 8.
RMV distribution comparison under different interference ratios.
The results confirm that our method maintains strong predictive performance even under significant data corruption. The key finding is that performance degrades gracefully rather than collapsing. The distribution across RMV intervals reveals crucial insights into the method’s stability. Most notably, the proportion of high-confidence predictions (RMV ) remains consistently strong across all perturbation levels. Even at 0.3 perturbation ratio, 76% of samples maintain this high-confidence status compared to 85% in the no interference scenario. This suggests that the method’s core predictive capability remains largely intact for the majority of instances, with confidence scores accurately reflecting the reduced but still substantial reliability.
The observed robustness can be attributed to the inherent design of the DCHGNN framework. The dual-channel architecture provides complementary views of the data, potentially mitigating the impact of corrupted connections in one channel. Furthermore, the rich heterogeneous information integrated into the node representations may allow the model to rely on feature-based evidence when topological information becomes unreliable. This resilience to structural noise strongly supports the practical deployment of DCHGNN in real-world environments where data quality and completeness are frequently compromised.
4.5. Statistical Significance Test
Although the proposed model achieves numerically superior performance compared to baseline methods, it is important to verify whether the observed improvements are statistically significant rather than arising from random fluctuations. Since the RMV score distributions do not satisfy the normality assumption, we adopt the non-parametric Wilcoxon signed-rank test for paired comparisons across datasets.
The hypotheses are formulated as follows:
For each dataset , let and . The paired difference is computed as the following:
and samples with are removed. The absolute differences are ranked in ascending order, assigning ranks . The test statistic is then obtained as the sum of ranks corresponding to positive differences:
For a one-sided test evaluating whether the proposed method is significantly better, the statistic follows an approximately normal distribution under with the following:
The standardized test statistic is computed as the following:
where is the continuity correction term. The corresponding p-value is calculated by the following:
where denotes the cumulative distribution function of the standard normal distribution.
The Wilcoxon signed-rank test was conducted between DCHGNN and each baseline method across multiple datasets. The results indicate that the performance difference between DCHGNN and Auto-Sklearn is statistically significant (), confirming that the observed improvement is unlikely due to random variation. Compared with RF (), the result is close to the significance threshold, showing a potential upward trend in performance. In contrast, the differences with LightGCN () and HGAT () are not statistically significant, suggesting comparable performance levels.
Overall, the statistical results demonstrate that DCHGNN achieves a significant performance advantage over traditional AutoML-based models while maintaining competitive results with advanced graph-based architectures, highlighting both the effectiveness and stability of the proposed dual-channel heterogeneous graph framework.
4.6. Ablation Study
To investigate the contribution of key components, we conducted ablation experiments under four settings as the following:
- w/o Con: Employing the dual-channel framework without the contrastive learning mechanism
- w/o Meta: Employing a single channel without incorporating meta-features
- w/o Sema: Employing a single channel without incorporating dataset textual description features
- w/o Dual: Employing a single channel without removing any features. The meta-features were first normalized to zero mean and unit variance. The dataset node features were then obtained by directly column-wise concatenating the textual embeddings and the normalized meta-features without any further post-processing.
The ablation results in Table 9 and Table 10 reveal several important insights. First, removing contrastive learning leads to the most significant performance degradation, with the Average RMV dropping to 90.6%. This highlights the crucial role of contrastive learning in aligning the two channels and improving the consistency of learned representations. Second, excluding meta-features reduces performance to 91.6%, suggesting that dataset meta-information provides complementary structural cues that are not captured by textual descriptions alone. Third, removing description features yields the lowest score (88.2%), indicating that semantic information extracted from textual descriptions is indispensable for accurate algorithm recommendation. Finally, using a single concatenated channel achieves 92.0%, which outperforms some individual feature settings but still falls short of the dual-channel architecture, confirming the advantage of explicitly modeling and fusing heterogeneous information through separate channels.
Table 9.
Average RMV scores for ablation studies.
Table 10.
Distribution of RMV scores across ablation settings.
Overall, the proposed framework consistently surpasses all ablation variants, achieving the highest average RMV (94.8%) and the most stable RMV distribution. These findings validate the necessity of jointly incorporating contrastive learning, meta-features, and the dual-channel design, each of which plays a pivotal role in enhancing robustness and ensuring reliable recommendation quality.
4.7. Parameter Sensitivity Analysis
To further investigate the robustness and reproducibility of our method, we analyzed the sensitivity of three key hyperparameters: the contrastive loss temperature (), the embedding dimension, and the learning rate, the results are shown in Table 11, Table 12 and Table 13 and Figure 3.
Table 11.
Sensitivity analysis for embedding dimension hyperparameter.
Table 12.
Sensitivity analysis for contrastive loss temperature hyperparameter.
Table 13.
Sensitivity analysis for learning rate hyperparameter.
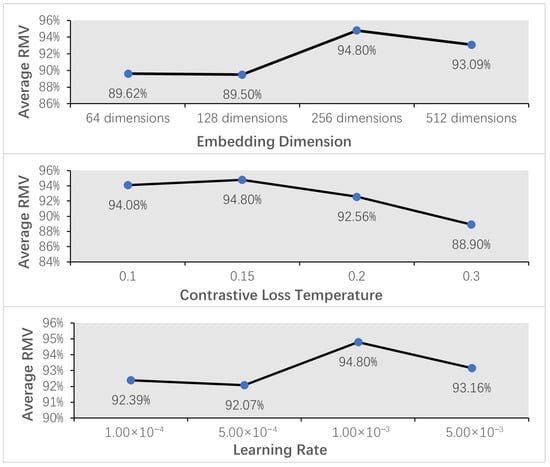
Figure 3.
Sensitivity analysis regarding the embedding dimensions, temperature parameters and learning rates.
The embedding dimension is a key determinant of the model’s representational capacity. Our experiments tested dimensions of 64, 128, 256, and 512. As shown in Figure 3 and Table 11, the results indicate that performance does not increase monotonically with dimensionality. The optimal average RMV was achieved with a dimension of 256. While a higher dimension of 512 yielded a competitive result, the performance slightly decreased, suggesting potential redundancy. Conversely, lower dimensions of 64 and 128 resulted in notably inferior performance, indicative of insufficient representational power. Therefore, an embedding dimension of 256 is identified as the ideal trade-off between model expressiveness and generalization.
The temperature parameter governs the penalty on hard negative samples in the contrastive loss, critically influencing the structure of the embedding space. We evaluated the model performance with ranging from 0.1 to 0.3. As shown in Figure 3 and Table 12, the model achieves its peak performance at , attaining an average RMV of 94.80% and the highest proportion of samples with an RMV score ≥ 0.9. A deviation from this optimal value leads to a performance degradation. Specifically, a lower may cause the model to over-penalize hard negatives, while a higher excessively softens the loss, resulting in a significant drop in the average RMV to 88.90%. This analysis validates that optimally facilitates inter-channel embedding consistency, thereby maximizing the matching performance.
The learning rate is pivotal for the optimization dynamics. We compared rates from to . As shown in Figure 3 and Table 13, the analysis reveals that a learning rate of provides the best convergence efficiency and final performance, yielding the highest average RMV. Lower learning rates of and likely lead to insufficient or slower convergence, resulting in lower average RMVs of 92.39% and 92.07%, respectively. This confirms that a learning rate of enables the model to converge stably and efficiently to a superior optimum.
This extensive sensitivity analysis strongly reinforces the robustness and reproducibility of our proposed method, as it demonstrates consistent high performance under the chosen hyperparameter settings while clearly quantifying the impact of their variation.
4.8. Visualization of Algorithm Representations
To further assess the effectiveness of the proposed DCHGNN model, we conducted a t-SNE visualization of algorithm representations after training and compared them with the BERT-initialized algorithm node features. The study includes 179 algorithms grouped into nine major categories. As shown in Figure 4, a clear difference can be observed between the two visualizations. In the right figure (BERT-initialized features, before training), nodes of different colors—representing different algorithm categories—are largely mixed, with blurred class boundaries and dispersed intra-class distributions. In contrast, the left figure (features after DCHGNN training) exhibits compact clusters within each category and clear separations between categories. This result demonstrates that the proposed model effectively captures intra-class similarities and inter-class differences among algorithms, thereby enhancing the discriminative ability of the learned representations.
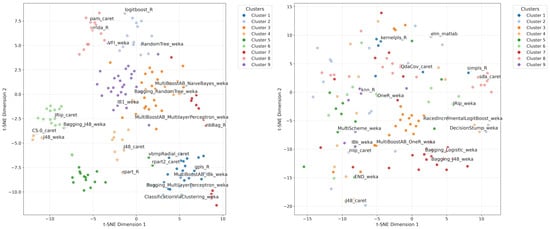
Figure 4.
Visualization of algorithm representations after DCHGNN training (left, silhouette score: 0.27) and before training (right, silhouette score: 0.41).
To provide a clearer understanding of the algorithm representations learned by the DCHGNN model, we summarized the results of clustering into nine major categories in Table 14. Most algorithms within each cluster belong to the same family, while a few exceptions from different types are also present. For example, Cluster 1, labeled as partial least squares and principal component regression, also includes the algorithm bagging_DecisionStump_weka. This phenomenon arises because our model learns algorithm representations based on the scale of algorithm-data interactions, rather than strictly following the conventional taxonomy of algorithms. As a result, the DCHGNN framework captures both the dominant family structures and cross-family relationships in the embedding space.
Table 14.
Clustering results of 179 algorithms into nine major categories.
4.9. Case Study
To validate the effectiveness of the proposed framework, we conducted empirical analyses on two benchmark datasets: Yeast and Zoo. The Yeast dataset, created by Kenta Nakai’s team at the Institute of Molecular and Cellular Biosciences, Osaka University (1996) and included in the UCI machine learning repository, is suitable for heterogeneous feature recommendation tasks. It consists of 1484 protein instances, encompassing 10 biochemical feature attributes and non-numeric localization labels. The Zoo dataset, also available in the UCI repository, exhibits biological classification features that align well with algorithm recommendation scenarios. It contains 101 animal instances with seven class labels and 16 mixed-type features, including both categorical and integer attributes. These datasets allow for a comprehensive evaluation of the framework’s ability to handle multi-dimensional, heterogeneous data.
Based on these datasets, the framework generates algorithm recommendation sequences using graph-based representation learning. For the Yeast dataset, the top five recommended algorithms are: RRFglobal_caret, elm_kernel_matlab, rbfDDA_caret, rforest_R, and IBK_weka. For the Zoo dataset, the top five algorithms are: parRF_caret, dkp_C, knn_R, rforest_R, and rf_caret. Table 15 summarizes the performance comparison between local validation and interaction-based evaluation.
Table 15.
Top five algorithm recommendation performance (sorted by recommendation rank).
The Yeast dataset poses a challenging scenario due to larger instance numbers, blurred inter-class boundaries, and potential noise or redundant features. Consequently, overall accuracies are lower and performance varies more across algorithms. The best algorithm accuracy on the interaction data for Yeast is 0.64, closely matching the top five recommended algorithms. This demonstrates that the framework is robust to noise and distributional shifts. In contrast, the Zoo dataset presents a relatively regular classification task with predominantly discrete or integer features and well-defined class boundaries. All top five recommended algorithms perform consistently well, with local and interaction-based accuracy exceeding 0.94. This indicates that the proposed model successfully captures the discrete and structured characteristics of the Zoo data, prioritizing tree- and nearest-neighbor-based algorithms. Across both datasets, the model consistently recommends algorithm sets that align well with the intrinsic data structure, further validating its effectiveness and generalization capability in algorithm recommendation tasks.
4.10. Time Complexity Analysis
To evaluate computational efficiency, this paper compared the proposed framework with a representative baseline, Auto-sklearn, which performs algorithm selection by executing candidate models on the given dataset. During its search process, Auto-sklearn trains and validates multiple algorithms using cross-validation to estimate performance, resulting in substantial computational overhead. In contrast, our framework generates algorithm recommendations directly through graph-based inference, without training or re-evaluating candidate algorithms on the target dataset.
Theoretical Complexity. Let N denote the number of dataset instances, F the number of extracted meta-features, M the number of candidate algorithms, and E the number of edges in the constructed algorithm–feature graph.
For Auto-sklearn, the time complexity can be approximated as the following:
where is the average training time per model and K is the number of cross-validation folds. This cost scales linearly with both the number of candidate algorithms and their respective training/validation iterations, leading to high computational demand.
In contrast, the proposed DCHGNN framework performs a single-pass inference on the heterogeneous graph, where node embeddings are computed and propagated via message passing. Its computational cost can be approximated as the following:
which depends mainly on the graph size (nodes and edges) and feature dimensionality. Since no model retraining or iterative search is required, the total cost remains nearly constant across datasets, ensuring scalability to large-scale tasks.
Empirical Comparison. We further conducted inference-time comparisons using the same Yeast and Zoo datasets. Two evaluation schemes were considered: (1) comparing accuracy within equal inference time, and (2) comparing inference time when achieving the same target accuracy threshold. Since Auto-sklearn requires at least 30 s of search time while our model completes inference in approximately 15 s, we report results following the second scheme. The maximum search time for Auto-sklearn was set to 20 min. Table 16 summarizes the detailed inference time comparison.
Table 16.
Inference time comparison between the proposed DCHGNN and Auto-sklearn.
As shown in Table 16, the proposed model exhibits a significant advantage in computational efficiency. For the Yeast dataset, our model completed inference in 15.6 s while evaluating 179 candidate algorithms and providing the optimal recommendation. In contrast, Auto-sklearn required 117.4 s to reach a comparable accuracy (0.5897), during which it explored 35 algorithm configurations. For the Zoo dataset, our model achieved 0.96 accuracy in 15.7 s, whereas Auto-sklearn required 116.1 s and 54 trials to reach 0.9677 accuracy.
Overall, the proposed framework achieves approximately a 7.5 times speed advantage while maintaining comparable recommendation accuracy. Theoretically, its single-pass inference complexity of further supports its superior scalability compared to the iterative search in Auto-sklearn. These results collectively verify that the proposed model serves as an efficient and deployable solution for real-world algorithm recommendation systems.
5. Conclusions
In this work, we proposed DCHGNN, a dual-channel heterogeneous graph neural network framework for automatic algorithm recommendation. By modeling datasets and algorithms as nodes in a bipartite graph and integrating semantic textual features with numerical meta-features through two complementary channels, the framework captures complex dataset-algorithm interaction patterns that single-modal approaches cannot fully exploit. A cross-channel contrastive learning mechanism aligns the embeddings of both channels, enhancing representation consistency and robustness, while a random forest regressor predicts algorithm performance on unseen datasets. Unlike existing graph-based recommendation models such as LightGCN and HGAT, which rely primarily on single-modal features and homogeneous message passing, DCHGNN integrates semantic textual information and numerical meta-features within a dual-channel design. This enables the model to capture richer dataset-algorithm interaction patterns and maintain representation consistency, even under sparse or cold-start conditions.
Extensive experiments on 121 datasets and 179 algorithms demonstrate that DCHGNN consistently outperforms state-of-the-art baselines in recommendation accuracy and stability. Ablation studies and visualization analyses confirm the importance of dual-channel design, meta-features, and contrastive learning. The proposed framework effectively addresses challenges such as data sparsity and cold-start scenarios, providing a scalable, reliable, and adaptive solution for real-world data-driven tasks. While the current evaluation primarily focuses on tabular classification tasks, a common and challenging benchmark in automated machine learning, the general architecture of DCHGNN is designed to be modality-agnostic. Future work will systematically extend and validate the framework’s effectiveness across diverse data modalities, including image, text, and time-series domains, to further demonstrate its broader applicability and generalization capabilities. Additionally, we will explore dynamic graph modeling, support for a broader range of task types, and enhanced interpretability, further extending the applicability and impact of this approach in data-driven decision-making.
Author Contributions
Writing—original draft preparation, X.Z. (Xiaoyu Zhang) and Y.S.; conceptualization, X.Z. (Xianzhong Zhou); methodology, X.Z. (Xiaoyu Zhang); software, X.Z. (Xiaoyu Zhang); formal analysis, X.Z. (Xiaoyu Zhang); investigation, X.Z. (Xiaoyu Zhang), Y.S. and X.Z. (Xianzhong Zhou); validation, X.Z. (Xianzhong Zhou) and Y.S.; resources, Y.S.; data curation, X.Z. (Xiaoyu Zhang); visualization, X.Z. (Xiaoyu Zhang); supervision, Y.S.; funding acquisition, Y.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Intelligent Command and Control Technology Complex Target System Software Procurement Project (No. JZXTP20250329).
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Prompt for Algorithm Description Extraction
The following standardized prompt was used to query the official documentation on the official websites of algorithms from R, Matlab, Caret, and Weka via the DeepSeek Chat API. The model was instructed to return strictly formatted JSON objects.
- You are a professional assistant for algorithm information retrieval.
- I need you to consult the official manuals of algorithms implemented in
- R, Matlab, Caret, and~Java Weka, and~accurately return the following
- information in JSON format only:
- {
- ``Algorithm Name’’: ``{algorithm_name}’’,
- ``Category’’: ``The category of the algorithm, e.g.,~classification, clustering, etc.’’,
- ``Input Data Type and Format’’: ``Explicitly describe the type of input data and its required format’’,
- ``Number of Variables’’: ``Specify the number of variables required’’,
- ``Output Data Type and Format’’: ``Describe the type and format of the output data’’,
- ``Theoretical Foundation’’: ``Provide a detailed description of the theoretical basis of the algorithm’’
- }
- Please strictly rely on the following official documentation sources:
- - R: CRAN official package manuals
- - Matlab: https://ww2.mathworks.cn/help/stats/classification.html
- - Caret: official documentation of the caret package
- - Weka: https://weka.sourceforge.io/packageMetaData/
- Only return JSON format, without~any additional explanation or~commentary.
References
- David, H.; William, G. No Free Lunch Theorems for Search. Work. Pap. 1995, 122, 431–434. [Google Scholar]
- Kononenko, I. Estimating attributes: Analysis and extensions of RELIEF. In Proceedings of the Machine Learning: ECML-94, Catania, Italy, 6–8 April 1994. [Google Scholar]
- Franceschi, L.; Donini, M.; Perrone, V.; Klein, A.; Archambeau, C.; Seeger, M.; Pontil, M.; Frasconi, P. Hyperparameter Optimization in Machine Learning. arXiv 2025, arXiv:2410.22854. [Google Scholar] [CrossRef]
- Li, G.; Liu, Y.; Qin, W.; Li, H.; Zheng, Q.; Song, M.; Ren, X. Survey on Meta-Learning Research of Algorithm Selection. J. Front. Comput. Sci. Technol. 2023, 17, 88–107. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2019, 32, 4–24. [Google Scholar] [CrossRef]
- Hu, Z.; Huang, Y.; Zheng, H.; Zheng, M.; Liu, J. Graph-based fine-grained model selection for multi-source domain. Pattern Anal. Appl. 2023, 26, 1481–1492. [Google Scholar] [CrossRef]
- Cohen-Shapira, N.; Rokach, L. Automatic selection of clustering algorithms using supervised graph embedding. Inf. Sci. 2021, 577, 824–851. [Google Scholar] [CrossRef]
- Cohen-Shapira, N.; Rokach, L.; Shapira, B.; Katz, G.; Vainshtein, R. AutoGRD: Model Recommendation Through Graphical Dataset Representation. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 821–830. [Google Scholar] [CrossRef]
- Ali, S.; Smith, K.A. On learning algorithm selection for classification. Appl. Soft Comput. 2006, 6, 119–138. [Google Scholar] [CrossRef]
- Arjmand, A.; Samizadeh, R.; Dehghani, S.M. Meta-learning in multivariate load demand forecasting with exogenous meta-features. Energy Effic. 2020, 13, 871–887. [Google Scholar] [CrossRef]
- Li, L.; Wang, Y.; Xu, Y.; Lin, K.-Y. Meta-learning based industrial intelligence of feature nearest algorithm selection framework for classification problems. J. Manuf. Syst. 2022, 62, 767–776. [Google Scholar] [CrossRef]
- Chen, H.; Liu, Y.; Ahuja, J.K.; Ler, D. A distance-weighted class-homogeneous neighbourhood ratio for algorithm selection. In Proceedings of the Asian Conference on Machine Learning, Bangkok, Thailand, 18–20 November 2020. [Google Scholar]
- Zhang, X.; Li, R.; Zhang, B.; Yang, Y.; Guo, J.; Ji, X. An instance-based learning recommendation algorithm of imbalance handling methods. Appl. Math. Comput. 2019, 351, 204–218. [Google Scholar] [CrossRef]
- Olier, I.; Sadawi, N.; Bickerton, G.; Vanschoren, J.; Grosan, C.; Soldatova, L.; King, R. Meta-QSAR: A large-scale application of meta-learning to drug design and discovery. Mach. Learn. 2018, 107, 285–311. [Google Scholar] [CrossRef]
- Lorena, A.C.; Maciel, A.I.; Miranda, P.B.; Costa, I.G.; Prudêncio, R.B. Data complexity meta-features for regression problems. Mach. Learn. 2018, 107, 209–246. [Google Scholar] [CrossRef]
- García-Saiz, D.; Zorrilla, M.; Nguyen, N.-T.; Núñez, M.; Trawiński, B. A meta-learning based framework for building algorithm recommenders: An application for educational arena. J. Intell. Fuzzy Syst. 2017, 32, 1449–1459. [Google Scholar] [CrossRef]
- Garcia, L.P.F.; Rivolli, A.; Alcobaça, E.; Lorena, A.C.; Carvalho, A.C.P.L.F. Boosting meta-learning with simulated data complexity measures. Intell. Data Anal. 2020, 24, 1011–1028. [Google Scholar] [CrossRef]
- Talagala, T.S.; Hyndman, R.J.; Athanasopoulos, G. Meta-learning how to forecast time series. J. Forecast. 2023, 42, 1476–1501. [Google Scholar] [CrossRef]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.T.; Blum, M.; Hutter, F. Efficient and robust automated machine learning. Adv. Neural Inf. Process. Syst. (NeurIPS) 2015, 29, 2755–2763. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Representation learning on graphs: Methods and applications. arXiv 2017, arXiv:1709.05584. [Google Scholar]
- Khoshraftar, S.; An, A. A survey on graph representation learning methods. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–55. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, J.; Liu, S.; Han, S. A pre-trained multi-representation fusion network for molecular property prediction. Inf. Fusion 2024, 103, 102092. [Google Scholar] [CrossRef]
- Kang, L.; Zhou, S.; Fang, S.; Liu, S. Adapting differential molecular representation with hierarchical prompts for multi-label property prediction. Briefings Bioinform. 2024, 25, bbae438. [Google Scholar] [CrossRef]
- Wu, S.; Sun, F.; Zhang, W.; Xie, X.; Cui, B. Graph neural networks in recommender systems: A survey. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Gao, C.; Zheng, Y.; Li, N.; Li, Y.; Qin, Y.; Piao, J. A survey of graph neural networks for recommender systems: Challenges, methods, and directions. ACM Trans. Recomm. Syst. 2023, 1, 1–51. [Google Scholar] [CrossRef]
- Sharma, K.; Lee, Y.C.; Nambi, S.; Salian, A.; Shah, S. A survey of graph neural networks for social recommender systems. ACM Comput. Surv. 2024, 56, 1–34. [Google Scholar] [CrossRef]
- Yang, L.; Chatelain, C.; Adam, S. Dynamic graph representation learning with neural networks: A survey. IEEE Access 2024, 12, 43460–43484. [Google Scholar] [CrossRef]
- Liu, H.; Zheng, C.; Li, D.; Zhang, Z.; Lin, K.; Shen, X.; Xiong, N.N. Multi-perspective social recommendation method with graph representation learning. Neurocomputing 2022, 468, 469–481. [Google Scholar] [CrossRef]
- Ge, S.; Wu, C.; Wu, F.; Qi, T.; Huang, Y. Graph enhanced representation learning for news recommendation. In Proceedings of the WWW’20: The Web Conference, Taipei, Taiwan, 20–24 April 2020. [Google Scholar]
- Wang, Q.; Yu, Y.; Gao, H.; Zhang, L.; Cao, Y.; Mao, L. Network representation learning enhanced recommendation algorithm. IEEE Access 2019, 7, 61388–61399. [Google Scholar] [CrossRef]
- Amara, A.; Taieb, M.A.H.; Aouicha, M.B. A multi-view GNN-based network representation learning framework for recommendation systems. Neurocomputing 2025, 619, 129001. [Google Scholar] [CrossRef]
- Fan, S.; Zhu, J.; Han, X.; Shi, C.; Hu, L.; Ma, B. Metapath-guided heterogeneous graph neural network for intent recommendation. In Proceedings of the SIGKDD, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Shi, J.; Ji, H.; Shi, C.; Wang, X.; Zhang, Z.; Zhou, J. Heterogeneous graph neural network for recommendation. arXiv 2020, arXiv:2009.00799. [Google Scholar] [CrossRef]
- Yang, T.; Hu, L.; Shi, C.; Ji, H.; Li, X.; Nie, L. HGAT: Heterogeneous graph attention networks for semi-supervised short text classification. ACM Trans. Inf. Syst. (TOIS) 2021, 39, 1–29. [Google Scholar] [CrossRef]
- Fan, W.; Ma, Y.; Li, Q.; He, Y.; Zhao, Y.E.; Tang, J.; Yin, D. Graph Neural Networks for Social Recommendation. In Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Cai, D.; Qian, S.; Fang, Q.; Hu, J.; Xu, C. User cold-start recommendation via inductive heterogeneous graph neural network. ACM Trans. Inf. Syst. 2023, 41, 1–27. [Google Scholar] [CrossRef]
- Pang, Y.; Wu, L.; Shen, Q.; Zhang, Y.; Wei, Z.; Xu, F. Heterogeneous global graph neural networks for personalized session-based recommendation. In Proceedings of the WSDM, Virtual Event, 21–25 February 2022. [Google Scholar]
- Sang, L.; Xu, M.; Qian, S.; Wu, X. Adversarial heterogeneous graph neural network for robust recommendation. IEEE Trans. Comput. Soc. Syst. 2023, 10, 2660–2671. [Google Scholar] [CrossRef]
- Wei, Y.; Fu, X.; Sun, Q.; Peng, H.; Wu, J. Heterogeneous graph neural network for privacy-preserving recommendation. In Proceedings of the 2022 IEEE International Conference on Data Mining (ICDM), Orlando, FL, USA, 28 November–1 December 2022. [Google Scholar]
- Yan, B.; Cao, Y.; Wang, H.; Yang, W.; Du, J. Federated heterogeneous graph neural network for privacy-preserving recommendation. In Proceedings of the WWW’24, Singapore, 13–17 May 2024. [Google Scholar]
- Casalicchio, G.; Bossek, J.; Lang, M.; Kirchhoff, D.; Kerschke, P.; Hofner, B.; Seibold, H.; Vanschoren, J.; Bischl, B. OpenML: An R package to connect to the machine learning platform OpenML. Comput. Stat. 2019, 34, 977–991. [Google Scholar] [CrossRef]
- Alcobaça, E.; Siqueira, F.; Rivolli, A.; Garcia, L.P.; Oliva, J.T.; De Carvalho, A.C. MFE: Towards reproducible meta-feature extraction. J. Mach. Learn. Res. 2020, 21, 1–5. [Google Scholar]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Feurer, M.; Eggensperger, K.; Falkner, S.; Lindauer, M.; Hutter, F. Auto-sklearn 2.0: Hands-free AutoML via meta-learning. J. Mach. Learn. Res. 2022, 23, 1–61. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. LightGCN: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Dagan, I.; Vainshtein, R.; Katz, G.; Rokach, L. Automated algorithm selection using meta-learning and pre-trained deep convolution neural networks. Inf. Fusion 2024, 105, 102210. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).