Abstract
This paper proposes a novel multiscale random forest model for stock index trend prediction, incorporating statistical inference principles to improve classification confidence. Traditional random forest classifiers rely on majority voting, which can yield biased estimates of class probabilities, especially under small sample sizes. To address this, we introduce a multiscale bootstrap correction mechanism into the ensemble framework, enabling the estimation of third-order accurate approximately unbiased p-values. This modification replaces naive voting with statistically grounded decision thresholds, improving the robustness of the model. Additionally, stepwise regression is employed for feature selection to enhance generalization. Experimental results on CSI 300 index data demonstrate that the proposed method consistently outperforms standard classifiers, including standard random forest, support vector machine, and weighted k-nearest neighbors model, across multiple performance metrics. The contribution of this work lies in the integration of hypothesis testing techniques into ensemble learning and the pioneering application of multiscale bootstrap inference to financial time series forecasting.
MSC:
62F40; 62P05; 62H20
1. Introduction
The prediction of stock index trends constitutes a central problem in financial engineering and quantitative investment. Against the backdrop of the continuous development of global financial technology, machine learning algorithms have been extensively employed in forecasting stock prices and index movements [1,2,3,4]. These algorithms not only provide powerful tools for addressing complex financial challenges but also foster the advancement of machine learning theory itself.
Among various machine learning approaches, models such as Support Vector Machines (SVMs), Artificial Neural Networks (ANNs), and Random Forests (RFs) have demonstrated greater robustness and adaptability than traditional time-series models in addressing the nonlinear, non-stationary, noisy, and high-dimensional characteristics of financial data [5,6,7,8,9]. Notably, RF has been widely adopted due to its superior classification performance and generalization ability compared with conventional decision trees. A substantial body of research further indicates that, in the classification and prediction of stock price indices, RF exhibits more pronounced advantages over SVMs and ANNs [10,11,12].
Beyond predictive performance, attention has increasingly turned to the development of a rigorous inferential framework for random forests. Wager et al. [13] introduced the Jackknife and Infinitesimal Jackknife methods for variance estimation in bagging and random forests, providing a theoretical foundation for uncertainty quantification. Building on this work, Mentch and Hooker [14] formalized subsample-based predictions as U-statistics, established asymptotic normality under mild conditions, and proposed consistent variance estimators. These developments enable the construction of confidence intervals and hypothesis testing, particularly advancing inference on feature importance. Collectively, this body of research extends the role of random forests beyond predictive performance, integrating them into the broader domain of statistical inference.
Despite these contributions, important limitations remain. The framework proposed by Wager et al. is primarily focused on variance estimation and does not readily extend to hypothesis testing of ensemble predictions. In addition, the approach of Mentch and Hooker relies on asymptotic normality, which may pose challenges in finite samples or in settings with high-dimensional and correlated data, where convergence can be slow and the robustness of statistical inference may be difficult to guarantee.
Building on these developments, it is also important to note that studies aiming to provide a statistical interpretation of the random forest voting mechanism are still limited. The majority vote proportion is often regarded as a posterior probability estimate, interpretable as the “bootstrap probability” (BP). The bootstrap method, introduced by Efron in 1979 [15], represents a milestone in the development of modern statistical inference. In 1985, Felsenstein [16] reframed the reliability assessment of molecular phylogenetic tree selection as a hypothesis testing problem, treating BP derived from the bootstrap as a p-value and thereby providing confidence measures for phylogenetic trees. This work represents one of the earliest applications of BP as a tool for statistical inference. However, theoretical studies have shown that in multivariate testing, BP only provides a biased, first-order approximation to the true p-value [17,18,19,20,21,22]. Consequently, the problem of inflated false positives for BP is pervasive in multivariate testing contexts.
Building on the above discussion, improving the accuracy of BP estimation emerges as a key motivation for further enhancing random forest models, representing a relatively novel research problem. To address this issue, this study introduces the Multiscale Bootstrap (MSB) method to refine the voting mechanism of random forests. Originally proposed by Shimodaira in the context of hypothesis testing [18], MSB calculates bootstrap probabilities across different sample scales and employs regression and extrapolation techniques to obtain unbiased p-value estimates with third-order asymptotic accuracy [18,19,20,21]. Although this method has been applied in bioinformatics [18,23], its systematic exploration in financial time series forecasting remains largely unexplored.
To this end, this study develops a novel Multiscale Random Forest (MRF) model that integrates the multiscale bootstrap inference method into the conventional RF framework. Unlike the traditional approach that directly relies on raw voting proportions, the MRF model determines classification outcomes through statistical hypothesis testing based on bias-corrected p-values, thereby enhancing the statistical reliability of predictive decisions. This approach not only strengthens the interpretability and rigor of RF outputs but also offers a new perspective on uncertainty quantification in machine learning models.
Furthermore, to reduce model complexity and enhance interpretability, this study employs the stepwise regression method for feature selection [24,25]. Using historical data from the CSI 300 Index, we conduct an empirical evaluation of the proposed MRF model and systematically compare its performance with that of conventional RF, SVM, and weighted k-nearest neighbor (WKNN) models across multiple evaluation metrics, including accuracy, precision, recall, and F1 score. The experimental results demonstrate the effectiveness and superiority of the MRF model in financial index classification and prediction.
2. Materials and Methods
2.1. Multiscale Random Forest: Mathematical Definition and Implementation
The traditional RF algorithm [26] combines the bagging algorithm with the random subspace method. Let , be the training dataset, where is a -dimensional feature vector and is a three class label. It constitutes an ensemble prediction model composed of a set of decision trees, where is the input feature vector, is the -th decision tree prediction model, is an independent and identically distributed random vector, and represents the number of decision trees in the RF. Taking a three class classification problem as an example, the specific steps for constructing the RF model are as follows:
Step 1: Given the training data , conduct resampling with replacement on to obtain , and thus obtain the bootstrap dataset . Repeat times to obtain bootstrap datasets .
Step 2: For each bootstrap dataset , apply the random subspace method and the classification tree algorithms for learning. Specifically, when splitting each node of the decision tree, randomly select a feature subset from the entire set of features according to a uniform distribution, and then choose an optimal splitting feature and feature value from this subset to construct the decision tree. In this way, decision trees are obtained.
Step 3: For a new data vector , classification is performed by each decision tree from Step 2, resulting in the output label vector for . The bootstrap probability is the proportion of in the label vector , the formula is:
where I[⋅] is the indicator function.
Step 4: The predicted label is determined by:
It is noteworthy that, for a new data vector , we formulate the following hypothesis regarding the outcome variable predicted by the random forest:
Let the true probability of be denoted by and con sequently the probabilities of and are , where . Since implies that , the hypothesis in (3) can be equivalently expressed as , and the null hypothesis is a polyhedral cone. The BP defined in Equation (1) can then be interpreted as the p-value for testing hypothesis (3). However, as discussed in the introduction, this BP-based p-value is biased and only achieves first-order accuracy. To address this limitation, we introduce the MRF method in what follows.
The proposed MRF model improves on the traditional RF algorithm in both the training and prediction phases using the concept of the multiscale bootstrap method. In the training phase, the training samples are resampled multiple times to generate multiple RF models, which are then integrated to form the MRF model. This enhances the learning ability of the prediction model on existing data. In the prediction phase, the MRF model improves the prediction accuracy by using unbiased p-value testing. Specifically, the multiscale and the relationship between the multiscale and the sample scale are obtained. The unbiased p-value of third-order accuracy is calculated using regression analysis and extrapolation methods, thereby improving the prediction accuracy of the prediction model. To further illustrate the method, we continue with the three-class classification problem as an example. Let denote a bootstrap sample generated from original training data with resampling scale factor , i.e., sample size for the b-th resampling is:
where is the number of scales, [·] denotes the floor function, which returns the greatest integer less than or equal to the input, represents the number of samples in the original training set . The specific steps for the MRF model during the training and prediction phases are as follows:
Step 1: Using the new samples , generate B RF models , according to the standard RF algorithm. Integrate these RF models to obtain the MRF model .
Step 2: During the prediction phase for new data, for a given new input variable , classification is performed by each RF model in the MRF model using its multiple decision trees, and the multiscale at scale is:
where is resampling with replacement on , is the number of decision trees per forest, I[⋅] is the indicator function.
For a new data vector , to estimate the third-order accuracy unbiased p-value , construct , where is the sample scale and is the inverse function of the standard normal distribution. We fit the logistic regression model following Shimodaira [19]:
Step 3: By taking as the dependent variable and as the independent variable, regression analysis yields . Extrapolating gives , then the third-order accuracy unbiased p-value for the new sample having label is given by:
Step 4: The predicted label is determined by:
This process yields a prediction model with higher-order p-value correction, reducing the bias inherent in conventional bootstrap aggregation voting and improving classification reliability. As noted by Shimodaira [19] the improved performance of multiscale bootstrap in noisy datasets arises from the curvature effect in the null hypothesis . By accounting for this curvature, the method corrects the bias in conventional bootstrap probabilities, yielding more accurate p-values and more reliable inference.
In classical hypothesis testing, for a new data , if the hypothesis testing p-value is greater than 0.05, i.e., , we accept the null hypothesis . However, in the rules of the multiscale random forests, an additional condition is attached, namely that the null hypothesis is accepted only when . This threshold of 0.5 follows the rule of ordinary random forests, where the threshold is also 0.5, and it does not contradict the 0.05 threshold used in classical hypothesis testing.
From a statistical inference perspective, comparing the error orders of bootstrap and multiscale reveals critical differences in their asymptotic properties. Specifically, standard exhibits a first-order bias under regularity conditions, with the asymptotic behavior characterized as [19]:
where is the number of original training samples and denotes the true unbiased p-value of the null hypothesis . In contrast, the p-value achieves third-order accuracy, with a substantially reduced asymptotic bias:
By substituting the conventional hard decision rule:
with a statistically justified p-value thresholding:
the MRF model provides a statistically grounded decision boundary that is less sensitive to sampling variability and better aligned with formal hypothesis testing. This modification directly improves prediction reliability in high-variance environments, such as stock market trend classification.
2.2. Stepwise Regression Method
Stepwise regression analysis is based on the linear regression model. This method overcomes the shortcomings of the forward selection method and the backward elimination method while incorporating the advantages of both. The main computational steps of the stepwise regression analysis are as follows:
Step 1: Establish an variable regression equation using all variables . Each of these variables is removed one at a time. Assume the AIC values of the regression equations for variable are . Among these, the minimum value is denoted as . Thus, the variable is first removed from the regression equation. For the sake of explanation, assume that = .
Step 2: Another variable from the remaining independent variables is eliminated, and the previously eliminated variable is added back in. Consequently, the dependent variable is used to establish regression equations for variable and a regression equation of variables.
From these regression equations, the one that has the smallest AIC value is selected, and this corresponds to the obtained regression equation. Repeat Step 2 until the AIC value can no longer be reduced.
2.3. Modeling Steps for Stock Index Prediction Based on Stepwise Regression and MRF Model
The modeling steps for stock index prediction using stepwise regression and the MRF model are as follows:
Step 1: Use the variables obtained through stepwise regression analys is as input variables for the prediction model. Define a three label as the output variable for the prediction model:
where represents the closing price on the t-th trading day. If the current day’s closing price is lower than tomorrow’s closing price, sample is labeled 1, indicating an upward trend in the stock index. If the current day’s closing price is higher than or equal to tomorrow’s closing price, sample is labeled 0 or −1, indicating a downward trend in the stock index. This process results in a labeled dataset.
Step 2: Divide the dataset into training, validation, and test sets. Use the MRF algorithm to build a prediction model on the training set and optimize the hyperparameters of the MRF model using a grid search on the validation set, resulting in a trained prediction model.
Step 3: Input the test set samples into the trained prediction model. The MRF model outputs the prediction results corresponding to each test sample.
Steps 1–3 can be applied to other prediction models after stepwise regression analysis has been implemented.
2.4. Data Source, Preprocessing, and Feature Selection
The CSI 300 stock index includes 300 representative stocks from the Shenzhen and Shanghai stock exchanges, reflecting the comprehensive performance of China’s stock market. For this study, we selected relevant indicators of the CSI 300 stock index and attempted to predict the daily closing price trends. The experimental samples were sourced from the website Choice Financial Terminal [27], with 3019 samples collected from 1 January 2012, to 11 June 2024, excluding holidays and trading halts. The basic indicators include the opening price, highest price, lowest price, closing price, trading volume, and trading amount for the day. The 15 technical indicators include the simple moving average, weighted moving average, momentum, stochastic K, stochastic D, relative strength index, exponential moving average, moving average convergence divergence, Larry Williams’%R, accumulation/distribution oscillator, commodity channel index, price rate of change, bias ratio, different of moving average, and change rate. Among them, the simple moving average, relative strength index, Larry Williams’%R, price rate of change, bias ratio, and exponential moving average were selected for different periods, giving another five technical indicators. The calculation formulas for the 20 technical indicators are provided in Table 1, while the data collections and the calculation procedures of the technical indicators are detailed in the Supplementary Materials (Supplementary Folder S1).

Table 1.
Calculation formulas for the 20 technical indicators.
In Table 1, represents the closing price on day and represents the closing price on the day − 1. and represent the lowest and highest prices, respectively, within the days preceding day . and represent the average increase and average decrease, respectively, of the closing prices within the days preceding day . denotes the exponential moving average up to day − 1. indicates the trading volume on day . and refer to the highest and lowest prices, respectively, on day . is the moving average with parameter for , and is the mean absolute deviation between and .
Combining the basic and technical indicators of various cycles resulted in 26 indicators as high-dimensional input data . The sample matrix of the dataset composed of input and output variables is:
This dataset consists of the input variable and the output variable , with being the number of samples.
We took 80% of the dataset as the training set, 10% as the validation set, and 10% as the test set. The training set ranged from 1 January 2012 to 9 December 2021 (2415 days); the validation set ranged from 10 December 2021 to 10 March 2023 (302 days); and the test set ranged from 11 March 2023 to 11 June 2024 (302 days). The MRF, RF, SVM, and WKNN algorithms were used to build prediction models on the training set. The hyperparameters of the different models were optimized to obtain trained prediction models.
To identify the most influential predictors among the 26 candidate features, a five-fold cross-validated stepwise regression was performed on the combined training and validation dataset. In each fold, four subsets were used for model fitting and evaluated using the Akaike Information Criterion (AIC). The model with the minimum AIC was selected, and its retained variables were adopted as the final input features. Consequently, 16 significant predictors were identified: SMA(10), WMA(10), WR(6), RSI(6), RSI(12), AD, MTM(10), Stochastic D, ROC(12), BIAS(10), BIAS(15), MACD(9), CCI, MA(5), Closing Price, and ROC(1).
To compare the performance improvement of the prediction models produced by stepwise regression analysis, two datasets were used: the original dataset with 26 indicators and the dataset with 16 indicators selected by stepwise regression. The test samples from both datasets were input into the trained prediction models, and the prediction results for each test sample were output. The general process of constructing the prediction models in this study is shown in Figure 1. In Figure 1, the original dataset containing all 26 indicators is denoted as Dataset I, while the dataset comprising the 16 selected indicators is referred to as Dataset II.
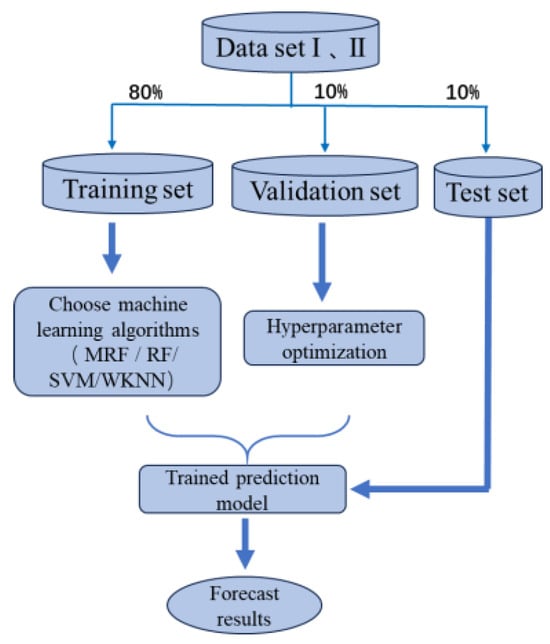
Figure 1.
Construction flowchart of predictive models.
2.5. Model Evaluation Metrics
To intuitively measure the ability of different prediction models to recognize the trend of the CSI 300 stock index, we establish the confusion matrix and introduce the four metrics of accuracy, precision, recall, and F1 score to evaluate the model’s predictive capability. The calculation methods for these metrics are:
where TP represents the number of correctly predicted upward samples, TN represents the number of correctly predicted downward samples, FP represents the number of downward samples incorrectly predicted as upward, and FN represents the number of upward samples incorrectly predicted as downward.
3. Results
3.1. Experimental Environment and Hyperparameter Settings
The experiments were conducted using the R 4.3.0 [28] language on a personal computer with the following specifications: Nvidia 3060 Laptop GPU (6 GB), manufactured by NVIDIA Corporation, Santa Clara, CA, USA, and an Intel Core i9-12900H @ 2.50 GHz CPU, manufactured by Intel Corporation, Santa Clara, CA, USA. The RF and MRF prediction models were established using the “randomForest.default” function from the R package “randomForest”. The full configuration details, resampling scheme, and implementation scripts are provided in the Supplementary Materials (Supplementary Folders S2 and S3).
The RF model has two important hyperparameters: the number of classifiers (ntree), i.e., the number of decision trees, and the maximum number of features (mtry). The maximum number of features controls the number of variables selected when splitting nodes, and thus determines the growth pattern of the decision trees. The MRF model includes these hyperparameters as well as the number of scales , which is the number of sample sizes during the resampling. According to the research experience of the literature [23], this value is typically around 10. For this study, we set = 10.
For the SVM, the Gaussian kernel function was chosen. This has a parameter that affects the data distribution in the new feature space. The penalty coefficient C also requires tuning.
For the WKNN, the hyperparameters are the distance function (distance), weight (weight), and number of neighbors . The Euclidean distance was used for the distance function and we set distance = 2, with rectangular, triangular, and Gaussian kernels used for the weights. The number of neighbors was tuned during model optimization. The parameter ranges considered for the four models considered in this study are presented in Table 2.
Table 2.
Selection range of hyperparameters for different prediction models.
A grid search was used for hyperparameter tuning in these complex parameter spaces. This method divides the parameter space into a grid and searches all points to find the optimal parameters. For this study, the hyperparameters were optimized in two steps: (i) training the model with the training set and (ii) improving the generalization ability of the model with the validation set to detect and adjust for overfitting.
Using the hyperparameter selection method described above, the optimal hyperparameter combinations for the four models on the different datasets were obtained using the R 4.3.0 software for statistical analysis. The results are presented in Table 3.
Table 3.
Hyperparameter selection for different machine learning models.
3.2. Empirical Results Analysis
3.2.1. Comparison of Prediction Performance Based on Test Set I
According to the dataset division rules given in Section 2.5, prediction models were constructed on the training and validation sets, and the confusion matrix obtained on the test set was used to evaluate the prediction results of the different models. The results in Table 4 indicate that, using test set I with all 26 indicators directly as input variables, the machine learning models exhibit different abilities to recognize “upward” and “downward” samples. The MRF and RF models have stronger recognition capabilities for downward samples, the SVM has more balanced recognition capabilities for both types of samples, and the WKNN model has stronger recognition capabilities for upward samples. Based on the confusion matrices of the different prediction models, the accuracy, precision, recall, and F1 score were calculated. The results are given in Table 5.
Table 4.
Confusion matrix of different prediction models (test set I).
Table 5.
Evaluation metrics for different prediction models (test set I).
First, the MRF model demonstrates the best overall performance, with an accuracy of 0.7980 and an F1 score of 0.7766, indicating the highest recognition ability for different types of samples. The proposed model also has the highest precision at 0.7737, meaning that 77.37% of the samples predicted as upward are actually upward. The recall is 0.7794, indicating that the model correctly predicted 77.94% of the actual upward samples. In contrast, the SVM achieves the highest recall of 0.8309, indicating that it is the least likely to misclassify upward samples as downward. The RF model performs similarly to the SVM, with an accuracy of 0.7815, but with a lower recall of 0.7868, suggesting it is less effective than the SVM in correctly identifying all upward samples. The WKNN model gives the worst results across all metrics, reflecting its inadequacy in adapting to the current dataset.
By plotting the ROC curves and calculating the AUC values, the predictive capabilities of the models can also be intuitively compared, as shown in Figure 2. On Test Set I, the MRF model achieves an AUC value of 0.8747, which is higher than that of the RF and WKNN models but slightly lower than that of the SVM model. This indicates that both the MRF and SVM models yield relatively strong predictive performance in the context of stock index movement forecasting.
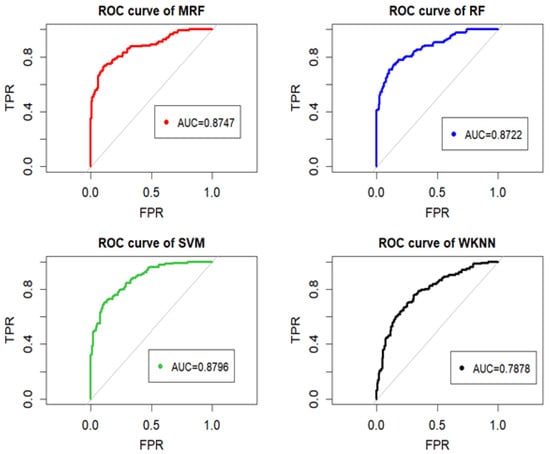
Figure 2.
ROC curves and AUC values of different prediction models (test set I).
3.2.2. Comparison of Prediction Performance Based on Test Set II
Table 6 suggests that using the 16 indicators selected through stepwise regression analysis as input variables improves the prediction performance. At this stage, each prediction model exhibits stronger recognition capabilities for upward samples.
Table 6.
Confusion matrix of different prediction models (test set II).
The evaluation metrics for the different prediction models on test set II are presented in Table 7. Table 7 compares the performance of different prediction models on Test Set II. Among all models, the MRF model achieves the best overall performance, with the highest accuracy (0.8146), recall (0.8162), and F1 score (0.7986). The RF model ranks second across most metrics, while SVM shows relatively high precision but lower recall. The WKNN model performs the weakest, with the lowest scores in all evaluation metrics. Overall, the MRF model per- forms better on test set II than on test set I, demonstrating strong overall performance and accurate recognition of downward samples.
Table 7.
Evaluation metrics for different prediction models (test set II).
Comprehensive analysis of the evaluation metrics achieved on both test sets demonstrates that, while it may not always be the best in terms of individual metrics, the MRF model exhibits superior performance when considering all evaluation metrics together, achieving a good balance. This balance is reflected in its high accuracy in judging upward samples and relatively accurate identification of downward samples, ensuring the stability and accuracy of the prediction model. These characteristics are crucial for many practical applications.
As shown in Figure 3, the ROC curves of different prediction models on Test Set II are presented. The MRF model achieves an AUC value of 0.8727, which is higher than that of the SVM and WKNN models but slightly lower than that of the RF model. This suggests that incorporating stepwise regression analysis can effectively enhance the performance of the MRF model in forecasting the CSI 300 stock index.
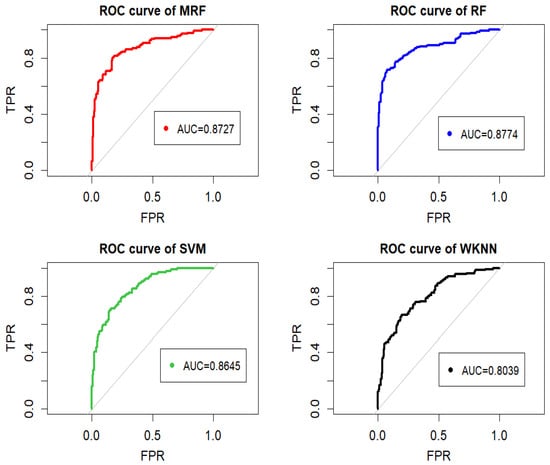
Figure 3.
ROC curves and AUC values of different prediction models (test set II).
3.3. Comparison of Model Computational Efficiency
This section compares the runtimes of the different algorithms to demonstrate the practicality of the MRF algorithm from the perspective of actual operability. Table 8 lists the runtimes on the training and test sets. The MRF model has a shorter runtime on the different training sets than SVM, but requires longer for training than RF and WKNN. Additionally, the proposed MRF model has the longest runtime on the different test sets. However, the overall runtime difference is less than 1 s. This difference is caused by the multiple resampling processes during MRF model training, which require the model to handle more data. During the prediction stage, the MRF model adjusts the using a relatively complex calculation process, leading to increased runtime on the test set. In practical applications, the choice of algorithm should consider runtime, accuracy, and stability. When computational resources are sufficient, algorithms with slightly longer runtimes but higher accuracy are preferable. Therefore, the MRF model developed in this study has practical application value.
Table 8.
Runtimes of different models on training and test sets.
4. Discussion and Conclusions
Comparing this study with related research demonstrates the effectiveness of the MRF model based on stepwise regression analysis for predicting the trend of the CSI 300 stock index.
For instance, Wang and Zhu [29] developed a hybrid deep learning model that integrates financial sentiment scores and news flow features to predict stock index movements. Their model achieved an accuracy, precision, recall rate and F1 score of 80.07%, 80.07%, 80.07% and 80.06%, respectively, on a test set covering the period from October 26, 2020 to December 31, 2021 (291 days). In comparison, on Test Set II covering March 11, 2023 to June 11, 2024 (302 days), the proposed MRF model achieved an accuracy of 81.46%, precision of 78.17%, recall of 81.62%, and F1 score of 79.86%, accuracy and recall of which exceed the metrics reported by Wang and Zhu. This suggests that the MRF model not only captures temporal and structural patterns in financial time series more effectively, but also provides more statistically reliable prediction confidence through the integration of multiscale bootstrap-based p-value correction, even without relying on external text-based sentiment indicators.
Two test sets based on the CSI 300 stock index are used to evaluate the predictive performance of the proposed MRF model. In Test Set I, the accuracy, precision, recall and F1 score reached 79.80%, 77.37%, 77.94% and 77.66%, respectively, while in Test Set II, the accuracy and precision improved to 81.46% and 78.17%, with recall and F1 score reaching 81.62% and 79.86%, respectively. Compared with existing models such as RF, SVM and WKNN, the proposed MRF model achieves superior performance across multiple evaluation metrics, particularly in terms of accuracy and precision. These improvements stem from two key innovations: (i) the introduction of multiscale bootstrap resampling, which increases the diversity and robustness of the ensemble learning framework; and (ii) the incorporation of an unbiased p-value with third-order accuracy during prediction, enhancing classification reliability beyond traditional majority voting schemes. Additionally, stepwise regression contributes further by eliminating redundant variables and enhancing the relevance of input features, thereby improving model interpretability and reducing overfitting. Overall, the combination of statistical feature selection with an advanced ensemble learning framework offers a practical and effective approach for forecasting complex financial time series. From a theoretical standpoint, this work extends the conventional random forest framework by integrating the multiscale bootstrap method proposed by Shimodaira [18,19,20,21] into ensemble learning. The resulting MRF model formally incorporates resampling-scale-dependent bootstrap probabilities and corrects classification bias via third-order p-value extrapolation. This represents a novel application of statistical hypothesis testing techniques in supervised machine learning, offering a mathematically grounded approach to improve voting-based classifiers. The model bridges statistical inference and ensemble learning, providing a new direction for future research in robust and interpretable machine learning algorithms. It should be noted that the MRF model proposed in this paper is limited to predicting classification problems, such as determining whether future stock prices will rise or fall. At present, it cannot be applied to continuous variables. However, the conventional random forest does not have this limitation and can be used for regression problems.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/math13223601/s1. Folder S1: Technical indicators description; Folder S2: R codes of 26 indicators; Folder S3: R codes of 16 indicators.
Author Contributions
A.R.: writing—review and editing, supervision; Y.D.: validation; J.L.: data curation. All authors have read and agreed to the published version of the manuscript.
Funding
This work was sponsored by the National Natural Science Foundation of China (Grant No. 32160258) and the APC was funded by the National Natural Science Foundation of China (Grant No. 32160258).
Data Availability Statement
The original contributions presented in this study are included in the Supplementary Material. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MRF | Multiscale Random Forest |
| RF | Random Forest |
| SVM | Support Vector Machine |
| ANN | Artificial Neural Network |
| WKNN | Weighted k-Nearest Neighbor |
| AIC | Akaike’s Information Criterion |
References
- Mintarya, L.N.; Halim, J.N.; Angie, C.; Achmad, S.; Kurniawan, A. Machine learning approaches in stock market prediction: A systematic literature review. Procedia Comput. Sci. 2023, 216, 96–102. [Google Scholar] [CrossRef]
- Yin, L.; Li, B.; Li, P.; Zhang, R. Research on stock trend prediction method based on optimized random forest. CAAI Trans. Intell. Technol. 2023, 8, 274–284. [Google Scholar] [CrossRef]
- Deng, S.; Zhu, Y.; Yu, Y.; Huang, X. An integrated approach of ensemble learning methods for stock index prediction using investor sentiments. Expert Syst. Appl. 2024, 238, 121710. [Google Scholar] [CrossRef]
- Kara, Y.; Boyacioglu, M.A.; Baykan, Ö.K. Predicting Direction of Stock Price Index Movement Using Artificial Neural Networks and Support Vector Machines: The Sample of the Istanbul Stock Exchange. Expert Syst. Appl. 2011, 38, 5311–5319. [Google Scholar] [CrossRef]
- Adebiyi, A.A.; Adewumi, A.O.; Ayo, C.K. Comparison of ARIMA and artificial neural networks models for stock price prediction. J. Appl. Math. 2014, 1, 614342. [Google Scholar] [CrossRef]
- Rady, E.H.A.; Fawzy, H.; Fattah, A.M.A. Time Series Forecasting Using Tree Based Methods. J. Stat. Appl. Probab. 2021, 10, 229–244. [Google Scholar] [CrossRef]
- Wijesinghe, G.W.R.I.; Rathnayaka, R.M.K.T. Stock Market Price Forecasting using ARIMA vs. ANN; A Case study from CSE. In Proceedings of the International Conference on Advances in Computing and Technology (ICACT-2020) Proceedings, Malabe, Sri Lanka, 10–11 December 2020; pp. 91–93. [Google Scholar] [CrossRef]
- Nti, I.K.; Adekoya, A.F.; Weyori, B.A. Random Forest Based Feature Selection of Macroeconomic Variables for Stock Market Prediction. Am. J. Appl. Sci. 2019, 16, 200–212. [Google Scholar] [CrossRef]
- Oukhouya, H.; El Himdi, K. A comparative study of ARIMA, SVMs, and LSTM models in forecasting the moroccan stock market. Int. J. Simul. Process Model. 2023, 20, 125–143. [Google Scholar] [CrossRef]
- Patel, J.; Shah, S.; Thakkar, P.; Kotecha, K. Predicting stock and stock price index movement using trend deterministic data preparation and machine learning techniques. Expert Syst. Appl. 2014, 42, 259–268. [Google Scholar] [CrossRef]
- Wei, X.; Tian, Y.; Li, N.; Peng, H. Evaluating ensemble learning techniques for stock index trend prediction: A case of China. Port. Econ. J. 2024, 23, 505–530. [Google Scholar] [CrossRef]
- Ji, S. Predict stock market price by applying ANN, SVM and RandomForest. SHS Web Conf. 2024, 196, 02005. [Google Scholar] [CrossRef]
- Wager, S.; Hastie, T.; Efron, B. Confidence intervals for random forests: The jackknife and the infinitesimal jackknife. J. Mach. Learn. Res. 2014, 15, 1625–1651. [Google Scholar]
- Mentch, L.; Hooker, G. Quantifying Uncertainty in Random Forests via Confidence Intervals and Hypothesis Tests. J. Mach. Learn. Res. 2016, 17, 1–41. [Google Scholar]
- Efron, B. Bootstrap methods: Another look at the jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Felsenstein, J. Confidence limits on phylogenies: An approach using the bootstrap. Evolution 1985, 39, 783–791. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R. The problem of regions. Ann. Stat. 1998, 26, 1687–1718. [Google Scholar] [CrossRef]
- Shimodaira, H. An approximately unbiased test of phylogenetic tree selection. Syst. Biol. 2002, 51, 492–508. [Google Scholar] [CrossRef]
- Shimodaira, H. Testing regions with nonsmooth boundaries via multiscale bootstrap. J. Stat. Plan. Inference 2008, 138, 1227–1241. [Google Scholar] [CrossRef]
- Shimodaira, H. Higher-order accuracy of multiscale bootstrap for testing regions. J. Multivar. Anal. 2014, 125, 184–197. [Google Scholar] [CrossRef]
- Terada, Y.; Shimodaira, H. Selective inference for the problem of regions via multiscale bootstrap. arXiv 2018, arXiv:1711.00949. [Google Scholar] [CrossRef]
- Ren, A.; Ishida, T.; Akiyama, Y. Mathematical proof of the third order accuracy of the speedy double.bootstrap method. Commun. Stat. Theory Methods 2020, 49, 3950–3964. [Google Scholar] [CrossRef]
- Suzuki, R.; Shimodaira, H. Pvclust: An R package for assessing the uncertainty in hierarchical clustering. Bioinformatics 2006, 22, 1540–1542. [Google Scholar] [CrossRef] [PubMed]
- Genell, A.; Nemes, S.; Steineck, G.; Dickman, P.W. Model selection in medical research: A simulation study comparing Bayesian model averaging and stepwise regression. BMC Med. Res. Methodol. 2010, 10, 108. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Wright, J.; Brownlee, A.; Buswell, R. A comparison of approaches to stepwise regression on variables sensitivities in building simulation and analysis. Energy Build. 2016, 127, 313–326. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Choice Financial Terminal. Available online: https://choice.eastmoney.com/ (accessed on 5 November 2024).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2012; Available online: https://www.R-project.org/ (accessed on 13 March 2025).
- Wang, J.; Zhu, S. A Novel Stock Index Direction Prediction Based on Dual Classifier Coupling and Investor Sentiment Analysis. Cogn. Comput. 2023, 15, 1023–1041. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).