Abstract
Modern healthcare and engineering both rely on robust reliability models, where handling censored data effectively translates into longer-lasting devices, improved therapies, and safer environments for society. To address this, we develop a novel inferential framework for the ZLindley (ZL) distribution under the improved adaptive progressive Type-II censoring strategy. The proposed approach unifies the flexibility of the ZL model—capable of representing monotonically increasing hazards—with the efficiency of an adaptive censoring strategy that guarantees experiment termination within pre-specified limits. Both classical and Bayesian methodologies are investigated: Maximum likelihood and log-transformed likelihood estimators are derived alongside their asymptotic confidence intervals, while Bayesian estimation is conducted via gamma priors and Markov chain Monte Carlo methods, yielding Bayes point estimates, credible intervals, and highest posterior density regions. Extensive Monte Carlo simulations are employed to evaluate estimator performance in terms of bias, efficiency, coverage probability, and interval length across diverse censoring designs. Results demonstrate the superiority of Bayesian inference, particularly under informative priors, and highlight the robustness of HPD intervals over traditional asymptotic approaches. To emphasize practical utility, the methodology is applied to real-world reliability datasets from clinical trials on leukemia patients and hydrological measurements from River Styx floods, demonstrating the model’s ability to capture heterogeneity, over-dispersion, and increasing risk profiles. The empirical investigations reveal that the ZLindley distribution consistently provides a better fit than well-known competitors—including Lindley, Weibull, and Gamma models—when applied to real-world case studies from clinical leukemia trials and hydrological systems, highlighting its unmatched flexibility, robustness, and predictive utility for practical reliability modeling.
Keywords:
ZLindley; improved censoring; likelihood and Bayes estimations; MCMC; asymptotic and credible intervals; reliability; Markov iterative; leukemia patients; River Styx floods MSC:
62F10; 62F15; 62N01; 62N02; 62N05
1. Introduction
Recently, Saaidia et al. [1] introduced the ZLindley (ZL) distribution, a new one-parameter model designed to enhance the flexibility of Lindley-type families. The proposed distribution extends the modeling capacity of existing alternatives, demonstrating superior performance in terms of goodness-of-fit when compared with several well-established models, including the Zeghdoudi, XLindley, New XLindley, Xgamma, and the classical Lindley distributions. In their study, the authors derived key statistical properties of the ZL distribution, such as its probability density and cumulative distribution functions, measures of central tendency and dispersion, and reliability characteristics. Furthermore, estimation procedures for the model parameters were explored, with particular emphasis on classical inference approaches. The distribution was also evaluated empirically through real data applications, illustrating its potential as a flexible and competitive alternative for modeling lifetime and reliability data.
Unlike the Weibull and Gamma lifetime models, which are restricted to monotone hazard rate shapes (increasing or decreasing) and hence fail to accommodate data exhibiting non-monotonic or bathtub-shaped hazard structures, the classical Lindley-type families also show limitations in modeling high-variance or heavy-tailed reliability data, often leading to biased tail-area estimates and underestimation of extreme lifetimes. In contrast, the proposed ZLindley distribution exhibits enhanced flexibility through its parameter-induced shape control. It allows for both increasing and near-constant hazard rate patterns and improved representation of over-dispersed datasets. This flexibility leads to more efficient and accurate estimation of the reliability and hazard rate functions, particularly in heterogeneous systems such as biomedical survival studies and environmental lifetime processes. Empirically, the superiority of the proposed ZLindley model was confirmed through the two real data analyses: One for the leukemia survival dataset and the other for the River Styx flood. Both applications demonstrate a significantly better fit than the classical Lindley, Weibull, and Gamma models. Collectively, these results confirm that the ZLindley framework not only enhances shape adaptability and inferential efficiency but also offers superior empirical performance across diverse reliability environments.
Let Y denote a non–negative continuous random variable representing a lifetime. If , with as the scale parameter, then its probability density function (PDF) and cumulative distribution function (CDF) are defined as
and
respectively, where .
Estimating the reliability and hazard rate functions offers essential insights into a system’s survival characteristics, where the reliability function measures the probability of operating beyond a certain time, and the hazard rate function indicates the immediate risk of failure. These estimates are crucial in engineering, medical, and industrial fields, among others. However, the respective reliability function (RF) and hazard rate function (HRF) at time , of the ZL lifespan model, are given by
and
It is worth mentioning that the ZL distribution’s PDF is unimodal, starting at a positive value, rising to a peak, and then decaying exponentially with the rate of decay increasing as grows, whereas its HRF is monotonically increasing with respect to y.
In reliability analysis and survival studies, a variety of censoring mechanisms have been suggested, which are typically organized into two major groups: Single-stage and multi-stage procedures. A single-stage censoring plan is characterized by the absence of withdrawals during the course of the test; the experiment proceeds uninterrupted until it concludes, either upon reaching a predetermined study duration or once a specified number of failures has been recorded. The traditional Type-I and Type-II censoring schemes fall within this category. On the other hand, multi-stage censoring frameworks introduce greater flexibility by permitting the removal of units at scheduled stages prior to the completion of the experiment. Well-established examples include progressive Type-I censoring and its Type-II counterpart (T2-PC), which have been studied extensively in the literature (see Balakrishnan and Cramer [2]). On the other hand, to save more time and testing cost, the hybrid progressive Type-I censoring (T1-HPC) has been introduced by Kundu and Joarder [3]. To enhance their flexibility, Ng et al. [4] introduced the adaptive progressive Type-II censoring (T2-APC) scheme, from which the T2-PC plan can be obtained as a special case. This approach allows the experimenter to terminate the test earlier if the study time exceeds a pre-specified limit. According to Ng et al. [4], the T2-APC performs well in statistical inference provided that the overall duration of the test is not a primary concern.
Nevertheless, when the test units are highly reliable, the procedure may lead to excessively long experiments, making it unsuitable in contexts where test duration is an important factor. To overcome this drawback, Yan et al. [5] introduced the improved adaptive progressive Type-II censoring (T2IAPC) scheme. This design offers two notable advantages: It guarantees termination of the experiment within a specified time window, and it generalizes several multi-stage censoring strategies, including T2-PC and T2-APC plans. Formally, consider n items placed on test with a pre-specified number of failures r, a T2-PC , and two thresholds . When the ith failure occurs at time , of the remaining items are randomly withdrawn from the test. Within this censoring framework, one of the following three distinct situations may occur:
- Case 1: When , the test terminates at , yielding the standard T2-PC;
- Case 2: When , the test ends at after modifying the T2-PC at by assigning , where denotes the number of failures observed before . Following the rth failure, all remaining units are removed. This corresponds to the T2-APC;
- Case 3: When , the test stops at . The T2-PC is then adapted by setting , where is the number of failures observed before . At time , all remaining units are withdrawn, with their total given by .
Let denote T2I-APC order statistics with size collected from a continuous population characterized by PDF and CDF , then the corresponding joint likelihood function (JLF) for this sample can be defined as
where for simplicity. All math notations presented in Equation (5) are defined in Table 1.

Table 1.
Options of , and .
Several well-known censoring plans can be regarded as particular cases of the T2I-APC strategy, from Equation (5), such as:
- The T1-HPC (by Kundu and Joarder [3]) when ;
- The T2-APC (by Ng et al. [4]) when ;
- The T2-PC (by Balakrishnan and Cramer [2]) when ;
- The T2-C (by Bain and Engelhardt [6]) when , for , and .
Within this setting, the lower threshold plays the role of a warning point that signals the progress of the experiment, while the upper threshold specifies the maximum admissible testing time. If is reached before observing the required number of failures m, the test must be stopped at . This feature overcomes the drawback of the T2-APC plan of Ng et al. [4], in which the total test length could become unreasonably long. The inclusion of the upper bound guarantees that the test duration is always confined to a predetermined finite interval. Although the T2I-APC plan has proven to be effective in statistical inference, it has attracted relatively limited attention; see, for example, Nassar and Elshahhat [7], Elshahhat and Nassar [8], and Dutta and Kayal [9], among others.
Reliability analysis is very important in medicine, engineering, and applied sciences because it helps us understand how long systems will last when we don’t know for sure. The newly proposed ZL distribution has demonstrated greater flexibility compared to classical Lindley-type families for modeling lifetime data; however, its implementation in practical situations frequently encounters the issue of censoring. Taking into account the T2I-APC scheme, which fixes these problems by making sure that experiments end in a set amount of time while still being able to draw conclusions quickly. Nonetheless, its utilization in contemporary flexible lifetime models, such as the ZL distribution, remains insufficiently investigated. This study addresses the gap by incorporating the ZL model through T2I-APC to create a more robust and applicable framework for survival analysis. The main objectives in this study are summarized in sixfold:
- A comprehensive reliability analysis of the ZL model under the proposed censoring is introduced, enhancing both flexibility and practical relevance.
- Both maximum likelihood (with asymptotic and log-transformed confidence intervals) and Bayesian methods (with credible and highest posterior density (HPD) intervals) are developed for the estimation of the model parameters, reliability function, and hazard function.
- Efficient iterative schemes, including Newton–Raphson for likelihood estimation and a Metropolis–Hastings iterative algorithm for Bayesian inference, are tailored.
- Extensive Monte Carlo simulations are conducted to compare the performance of different estimation approaches across varying censoring designs, thresholds, and sample sizes, identifying optimal conditions for practitioners.
- The study demonstrates how different censoring strategies (left-, middle-, and right-censoring) influence the accuracy of estimating the scale parameter, hazard rate, and reliability function, offering practical guidelines for experimenters.
- The methodology is validated using clinical data on leukemia patients and physical data from engineering contexts, confirming the versatility of the proposed model for heterogeneous reliability scenarios.
The structure of the paper is as follows: Section 2 and Section 3 develop the frequentist estimations, respectively. Section 4 reports the Monte Carlo results and their interpretations, while Section 5 demonstrates the applicability of the proposed approaches and techniques through two real data analyses. Concluding remarks and final observations are provided in Section 6.
2. Classical Inference
This part considers the estimation of maximum likelihood to carry out both point and interval estimators of , , and . To achieve this goal, we assume that is a T2I-APC sample collected from the proposed ZL population.
2.1. Maximum Likelihood Estimators
This subsection is devoted to deriving the MLEs of the ZL parameters , , and , denoted by , , and , respectively. Using (1), (2) and (5), we can re-express the JLF (5) as follows:
where and .
The corresponding log-JLF of (6) becomes
Thus, the MLE of can be formulated as follows:
where
and
It is clear that the MLE is obtained by solving the nonlinear likelihood equation given in (8). For this purpose, we employ the Newton–Raphson (NR) iterative scheme. Let denote the score function based on (8), and its derivative with respect to . Starting from an initial guess , the iteration proceeds as
until convergence is achieved. The process is terminated when either the relative change in successive estimates falls below a prescribed tolerance (e.g., ) or the absolute value of the score function becomes sufficiently small. This iterative approach guarantees a stable and efficient estimation of .
It is also important to investigate the existence and uniqueness of the MLE . Owing to the complicated structure of the score equation in (8), establishing these properties analytically is not straightforward. To overcome this difficulty, we examine them numerically by generating a T2I-APC sample from the ZL distribution with two different choices of , namely , under the setup , , , and . The resulting MLEs of are 0.7458 and 1.2721 for the two cases, respectively. Figure 1 illustrates the log-JLF together with its first and second derivatives. The plot indicates that the vertical line at the MLE intersects the log-JLF at its maximum and the score function at zero. These graphical observations confirm that the MLE of exists and is unique.
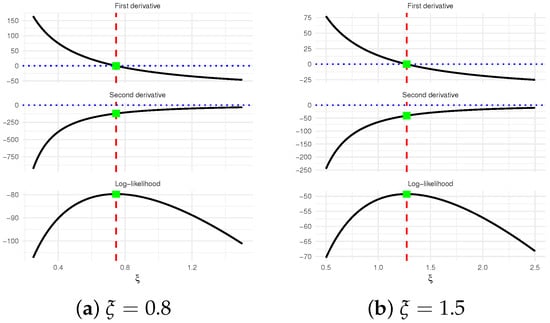
Figure 1.
The existence and uniqueness diagram of .
Once the estimate is obtained, making use the invariance feature of , the MLEs of the reliability and hazard rate functions, denoted by and , can be directly derived (for ) as follows:
respectively.
2.2. Asymptotic Interval Estimators
Besides obtaining point estimates, it is crucial to construct the ACIs for the parameters , , and . These intervals are derived from the large-sample properties of the MLE , which is asymptotically normal with mean and variance–covariance (VC) matrix . While the theoretical VC matrix is defined through the Fisher information (FI) (say, ), its analytical form is often intractable for the present model. To overcome this difficulty, the VC matrix is approximated by the inverse of the observed FI (OFI) matrix evaluated at the MLE, that is, . Hence, the estimated VC matrix can be expressed as:
where
and
For deriving the ACIs of the RF and HRF , one must first obtain suitable approximations for the variances of their estimators, and . An effective approach is the delta method, which provides variance estimates denoted by and . As outlined in Greene [10], the delta method ensures that can be treated as approximately normal with mean and variance , and likewise, is approximately normal with mean and variance . Subsequently, the quantities of and are given by:
respectively, where
and
Consequently, the ACI based on the normal approximation (say, ACI[NA]) of (at a significance level ) is given by
where is the upper th standard Gaussian percentile point. Similarly, the ACI[NA] estimator of or can be easily acquired.
A major drawback of the conventional ACI[NA] method is that it can produce lower confidence bounds that fall below zero, even when the parameter of interest is strictly positive. In practice, negative bounds are typically truncated to zero; however, this correction is ad hoc and does not constitute a formal statistical solution. To overcome this drawback and enhance the robustness of interval estimation, Meeker and Escobar [11] proposed the log-transform normal approximation, referred to as ACI[NL]. Accordingly, the ACI[NL] for the scale parameter can be expressed as
is equivalent to
Similarly, the ACI[NL] estimator of or can be easily derived. To obtain the fitted values of the ML estimates as well as the ACI[NA] and ACI[NL] estimators for , , and , we recommend employing the Newton–Raphson (NR) algorithm, which can be efficiently implemented using the maxLik package in the R environment.
3. Bayesian Inference
In this section, we derive Bayesian point and credible estimates for the ZL parameters , , and . The Bayesian approach requires explicit specification of prior information and a loss function, both of which strongly influence the resulting inference. Choosing an appropriate prior distribution for an unknown parameter, however, is often a challenging task. As highlighted by Gelman et al. [12], there is no universally accepted rule for selecting priors in Bayesian analysis. Given that the parameter of the ZL model is strictly positive, a gamma prior offers a convenient and widely adopted option. Accordingly, we assume
with prior density
It should be emphasized that the squared-error loss (SEL) function is adopted here, as it represents the most commonly employed symmetric loss criterion in Bayesian inference. Nevertheless, the proposed framework can be readily generalized to accommodate alternative loss functions without altering the overall estimation procedure. Given the posterior PDF (12) and the JLF (6), the Bayes estimator of , denoted by , against the SEL is given by
It noted, from (13), that obtaining (closed-form) Bayes estimator of , , or under the SEL function is not feasible. To address the analytical intractability of the Bayes estimates, we rely on the Markov chain Monte Carlo (MCMC) procedure to simulate samples from the posterior distribution in (12). These simulated draws enable the computation of Bayesian point estimates together with Bayes credible interval (BCI) and HPD interval estimates for the parameters of interest. Since the posterior density of does not follow any known continuous law, yet resembles a normal distribution as illustrated in Figure 2, the Metropolis–Hastings (M-H) algorithm is adopted to update the posterior draws of (see Algorithm 1). The resulting samples are then employed to evaluate Bayes estimates of , , and as well as their corresponding uncertainty measures.
| Algorithm 1 The MCMC Steps for Sampling , , and |
|
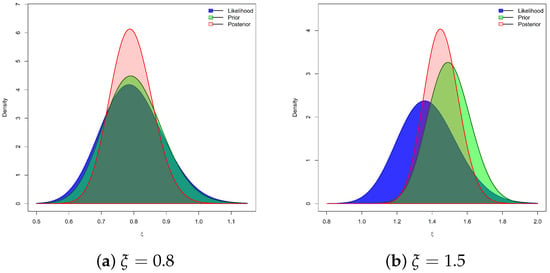
Figure 2.
The likelihood, prior, and posterior density shapes of .
4. Monte Carlo Evaluations
To evaluate the accuracy and practical performance of the estimators of , , and derived earlier, a series of Monte Carlo simulations were carried out. Using Algorithm 2, the T2I-APC procedure was replicated 1000 times for each of the parameter settings and , yielding estimates of all quantities of interest. At the fixed time point , the corresponding reliability measures are obtained as for and for . Additional simulations were performed under varying conditions defined by the threshold parameters , the total sample size n, the effective sample size r, and the censoring pattern . In particular, we considered , , and . Table 2 summarizes, for each choice of n, the corresponding values of r along with their associated T2-PC schemes . For ease of presentation, a notation such as indicates that five units are withdrawn at each of the first two censoring stages.
| Algorithm 2 Simulation of T2I-APC Sample. |
|
Table 2.
Different plans of in Monte Carlo simulations.
Once 1000 T2I-APC datasets are generated, the frequentist estimates along with their corresponding 95% asymptotic confidence intervals (ACI-NA and ACI-NL) for , , and are obtained using the maxLik package (Henningsen and Toomet [13]) in the R environment (version 4.2.2).
For the Bayesian analysis, we generate MCMC samples, discarding the first iterations as burn-in. The Bayesian posterior estimates, together with their 95% BCI/HPD intervals for , , and , are computed using the coda package (Plummer et al. [14]) in the same R environment.
To further assess the sensitivity of the proposed Bayesian estimation procedures, two distinct sets of hyperparameters were examined. Following the prior elicitation strategy of Kundu [15], the hyperparameters of the gamma prior distribution were specified as follows: Prior-A = and Prior-B = for , and Prior-A = and Prior-B = for . The hyperparameter values of and for the ZL parameter were selected such that the resulting prior means corresponded to plausible values of . Notably, Prior-A represents a diffuse prior with larger variance, reflecting minimal prior information, whereas Prior-B corresponds to a more concentrated prior informed by empirical knowledge of the ZLindley model’s scale range. Simulation evidence revealed that, although both priors produced consistent posterior means, Prior-B yielded smaller posterior variances, narrower HPD intervals, and improved coverage probabilities, highlighting the stabilizing influence of informative priors without introducing substantial bias.
To evaluate the performance of the ZL parameter estimators of , , and , we compute the following summary metrics:
- Mean Point Estimate:
- Root Mean Squared Error:
- Average Relative Absolute Bias:
- Average Interval Length:
- Coverage Probability: where denotes the ith point estimate of and is the indicator function. The same precision metrics are also applied to the estimates of and .
From Table 3, Table 4, Table 5, Table 6, Table 7 and Table 8, the following key findings can be drawn, emphasizing configurations with the lowest RMSEs, ARABs, and AILs, and the highest CPs:
Table 3.
Point estimation results of .
Table 4.
Point estimation results of .
Table 5.
Point estimation results of .
Table 6.
Interval estimation results of .
Table 7.
Interval estimation results of .
Table 8.
Interval estimation results of .
- Across all simulation scenarios, the estimation of , , and performs satisfactorily.
- Estimation accuracy improves as either n (or r) increases, with similar gains achieved when the total number of removals decreases.
- Higher threshold values () yield more precise parameter estimates. Specifically, the RMSEs, ARABs, and AILs decrease, while CPs increase.
- As increases:
- -
- RMSEs of , , and rise;
- -
- ARABs of and decreased, whereas that of increased;
- -
- AILs grow for all parameters, with corresponding CPs narrowed down.
- Bayesian estimates obtained via MCMC, together with their credible intervals, exhibit greater robustness than frequentist counterparts due to the incorporation of informative priors.
- For all tested values of , the Bayesian estimator under Prior-B consistently outperforms alternative approaches, benefiting from the smaller prior variance relative to Prior-A. A parallel advantage is observed when comparing Bayesian intervals (BCI and HPD) to asymptotic ones (ACI-NA and ACI-NL).
- A comparative assessment of the proposed designs of in Table 2, for each set of n and r, reveals that:
- -
- Estimates of achieve superior accuracy based on Ci (for ), i.e., right censored sampling;
- -
- Estimates of achieve superior accuracy based on Bi (for ), i.e., middle censored sampling;
- -
- Estimates of achieve superior accuracy based on Ai (for ), i.e., left censored sampling.
- Regarding interval estimation strategies:
- -
- ACI-NA outperforms ACI-NL for and , whereas ACI-NL is more suitable for ;
- -
- HPD intervals are uniformly superior to BCIs;
- -
- Overall, Bayesian interval estimators (BCI and HPD) dominate their asymptotic counterparts (ACI-NA and ACI-NL).
- As a conclusion, for reliability practitioners, the ZL lifetime model is most effectively analyzed within a Bayesian framework, leveraging MCMC methods—particularly the Metropolis–Hastings algorithm.
5. Data Analysis
This section is devoted to demonstrating the practical utility of the proposed estimators and validating the effectiveness of the suggested estimation procedures. To this end, we analyze two real-world data sets originating from the fields of medical and physics.
5.1. Clinical Application
Remission time is a critical endpoint in evaluating the effectiveness of treatments for leukemia, as it reflects both the biological response and potential durability of therapeutic interventions. In this study, we focus on remission times, measured in weeks, among leukemia patients who were randomly assigned to receive a specific treatment. Such randomized allocation ensures unbiased comparison and provides a robust framework for assessing treatment efficacy in clinical research. In this application, we shall examine the remission times (measured in weeks) for twenty leukemia patients randomly assigned to a treatment protocol. The corresponding times in ascending order are 1, 3, 3, 6, 7, 7, 10, 12, 14, 15, 18, 19, 22, 26, 28, 29, 34, 40, 48, and 49. The dataset was reported and analyzed by Bakouch et al. [16]. Using the complete leukemia dataset, we assess the adequacy and superiority of the ZL model by comparing its fit with seven alternative models from the literature:
- Xgamma (XG) distribution by Sen et al. [17];
- Chris-Jerry (CJ) distribution by Onyekwere and Obulezi [18];
- Lindley (L) distribution by Johnson et al. [19];
- Exponential (E) distribution by Johnson et al. [20];
- Weibull (W) distribution by Rinne [21];
- Gamma distribution by Johnson et al. [20];
- Nadarajah–Haghighi (NH) distribution by Nadarajah and Haghighi [22].
In addition to the Kolmogorov–Smirnov () statistic and its associated p-value, we compute several model selection criteria, namely the negative log–likelihood (), Akaike information (), consistent AI (), Bayesian information (), and Hannan–Quinn information (); see Table 9. The MLE and its standard error (SE) are used for fitting all criteria.
Table 9.
Fitting outputs of the ZL and others from leukemia data.
To evaluate the suitability of competitive distributions for modeling given lifetime data, the AdequacyModel package (by Marinho et al. [23]) in the R environment is employed. This package provides a comprehensive framework for assessing the goodness-of-fit of parametric models through numerical and graphical techniques. As shown in Table 9, the ZL lifespan distribution consistently provides the most favorable values across all considered criteria compared to its competitors. Thus, based on the leukemia data, the ZL lifetime model demonstrates superior performance relative to the alternative distributions.
To complement the numerical results, Figure 3 presents several graphical diagnostics, including: (i) estimated and fitted RF curves, (ii) probability–probability (PP) plots, (iii) quantile–quantile (QQ) plots, (iv) scaled total time on test (TTT) transform curves, (v) the log-likelihood curve relative to the fitted normal equation, and (vi) a boxplot-overlaid violin plot. From the complete leukemia dataset, Figure 3a–c clearly demonstrate that the ZL model offers an adequate fit, consistent with the goodness-of-fit measures. The TTT plot in Figure 3d suggests an increasing HRF, while Figure 3e confirms both the existence and uniqueness of the MLE , making it a reasonable starting value for further estimation. Finally, the distributional features depicted in Figure 3f indicates that the leukemia data distribution is approximately symmetric, with reduced variability and concentration around the median, although a slight right-skewness remains evident.
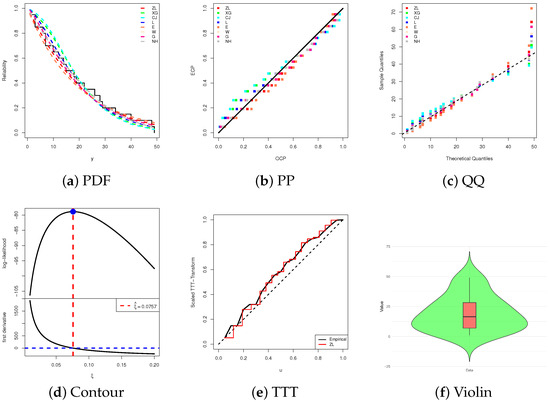
Figure 3.
Fitting diagrams of the ZL and others from leukemia data.
From the complete leukemia dataset, three synthetic T2I-APC samples are constructed with fixed and different specifications of and threshold values , as summarized in Table 10. Since the ZL() model is not directly supported by prior information from the leukemia data, an improper gamma prior with hyperparameters is adopted for updating . The proposed MCMC sampler is initialized using the frequentist point estimates of . After discarding the first 10,000 iterations from a total of 50,000, Bayesian point estimates along with credible intervals are obtained for , , and . For each design , , Table 11 presents the point estimates (with SEs) and corresponding 95% interval estimates (with interval lengths (ILs)) of , , and at . The findings suggest that the likelihood-based and Bayesian procedures yield comparable estimates for , , and . Nevertheless, the Bayesian approach generally provides smaller SEs, and its 95% BCI/HPD intervals are narrower than the corresponding 95% ACI-NA/ACI-NL intervals, reflecting improved precision.
Table 10.
Different T2I-APC samples from leukemia dataset.
Table 11.
Estimates of , , and from leukemia data.
To assess the existence and uniqueness of the MLE of , Figure 4 displays the log-likelihood profiles along with the associated score functions for all sample settings , , over a range of values. Each plot exhibits a single, well-defined maximum, thereby confirming that both exists and is unique. These graphical observations are consistent with the numerical results in Table 11, providing additional support for treating the estimated values as dependable initial points for the subsequent Bayesian analysis.
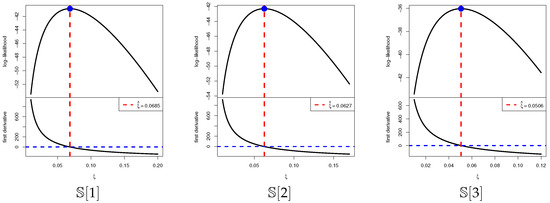
Figure 4.
Plots of log-likelihood/score functions of from leukemia data.
Convergence of the MCMC samples for , , and is assessed through trace plots and posterior density plots shown in Figure 5. The posterior mean and the 95% BCI estimates are highlighted by red solid and dashed lines, respectively. As illustrated in Figure 5, the Markov chains exhibit satisfactory mixing and stabilization for all parameters. The posterior of appears nearly symmetric, whereas and display negative and positive skewness, respectively. Using the 40,000 post–burn-in samples, several posterior summaries were calculated for , , and , including the mean, mode, quartiles , standard deviation (Std.D), and skewness (Sk.); see Table 12. These summaries align well with the results reported in Table 11 and the graphical evidence in Figure 5. To further evaluate the convergence behavior of the MCMC chains, ergodic average plots (i.e., cumulative means) were generated for the posterior samples of the parameters , , and based on [1] (as an example); see Figure 6. The trajectories of these running averages flatten after the initial 30,000 burn-in iterations, confirming that the chains have reached stationarity. This visual stabilization, together with the absence of strong autocorrelation patterns, supports the ergodicity of the generated Markov chains and validates the reliability of the Bayesian estimates fitted from the leukemia dataset.
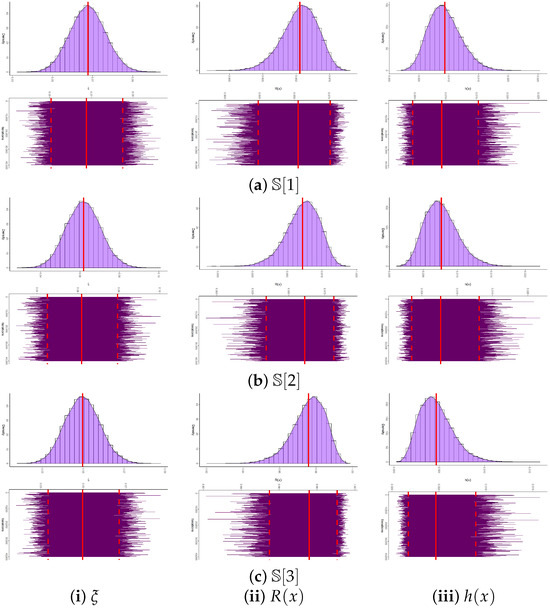
Figure 5.
Convergence diagnostics of , , and from the leukemia dataset.
Table 12.
Statistics of , , and from leukemia data.
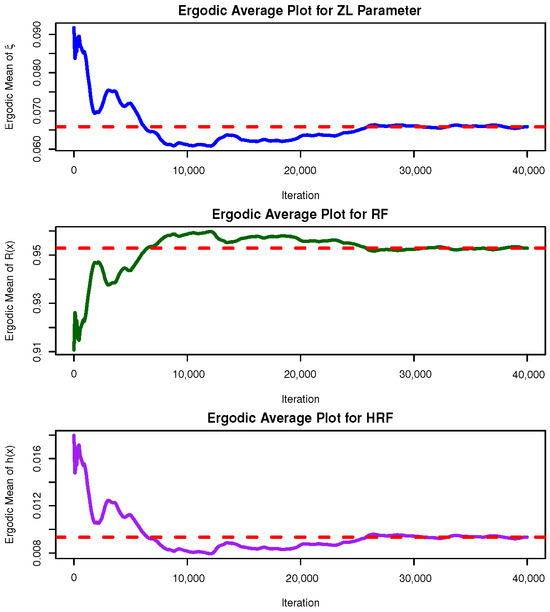
Figure 6.
Ergodic plot of , , and from the leukemia dataset.
In addition, Figure 7 compares the 95% ACI[NA]/ACI[NL] with the BCI/HPD intervals for and under the sample from the leukemia data. The BCI/HPD intervals are consistently narrower than their ACI counterparts, reinforcing the superior precision observed in Table 11.
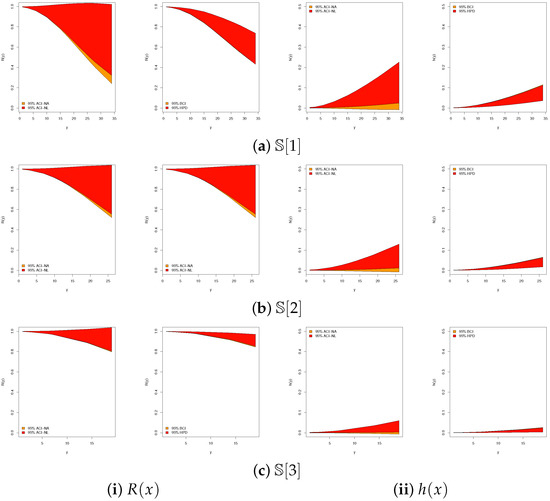
Figure 7.
Plots for 95% interval limits of and from leukemia data.
5.2. Physical Application
The River Styx at Jeogla provides a long-term record of annual maximum flood peaks, representing the most extreme discharge events each year. Analysis of these data enables the application of probability models and frequency methods to estimate design floods and recurrence intervals. Consequently, this record serves as a valuable resource for flood risk assessment, hydraulic design, and water resource management in flood-prone regions. In this study, the annual maximum flood peak series for 47 consecutive years from the River Styx (Jeogla) is examined. For computational convenience, the flood peak values in Table 13 are scaled by dividing by one hundred, and the transformed dataset is presented. This dataset was previously analyzed by Kuczera and Frank [24] and later reported by Bhatti and Ahmad [25].
Table 13.
Flooding in the River Styx for 47 years.
Following the same fitting framework described in Section 5.1, we evaluate the adequacy and relative superiority of the ZL model by comparing its performance with seven competing models from the literature, using the complete River Styx dataset. The results in Table 14 show that the ZL model achieves a satisfactory fit, as evidenced by relatively narrow confidence intervals and a high p-value. As illustrated in Figure 8a–c, the ZL model provides an excellent fit to the River Styx data, consistent with the numerical goodness-of-fit measures. Also, Figure 8d confirms the existence and uniqueness of the MLE , making it a suitable initial value for subsequent computations. Figure 8e suggests an increasing HRF. Finally, Figure 8f reveals that the data are right-skewed with a concentration around lower values, a moderate spread, and one high outlier.
Table 14.
Fitting outputs of the ZL and others from River Styx data.
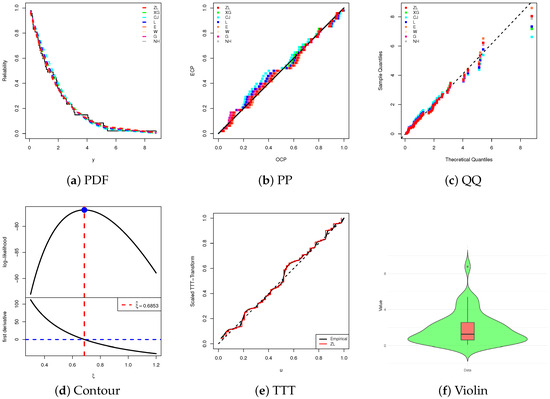
Figure 8.
Fitting diagrams of the ZL and others from River Styx data.
Using the complete River Styx dataset, we generated three artificial T2I-APC samples with a fixed censoring size and different settings of and threshold values ; see Table 15. In the absence of prior knowledge about the ZL() model, an improper gamma prior with hyperparameters is adopted for updating . The MCMC algorithm is initialized with the frequentist point estimates of , and a total of iterations are run, discarding the first as burn-in. Posterior summaries, including Bayesian point estimates and 95% credible intervals for , , and , are then obtained. Table 16 reports the point estimates (with SEs) and interval estimates (with ILs) for each configuration , evaluated at . The findings reveal close agreement between the likelihood-based and Bayesian methods, though the Bayesian approach achieves smaller standard errors and narrower 95% BCI/HPD intervals compared to the 95% ACI-NA/ACI-NL intervals, highlighting its higher precision.
Table 15.
Different T2I-APC samples from River Styx dataset.
Table 16.
Estimates of , , and from River Styx data.
The existence and uniqueness of the MLE are illustrated in Figure 9, which depicts the log-likelihood functions together with their score counterparts across the three sample configurations . In each case, the curves exhibit a single maximum, confirming both the identifiability of the model and the robustness of the estimation procedure. These visual findings corroborate the numerical results summarized in Table 16, further supporting the choice of as an appropriate initial value in Bayesian computations.
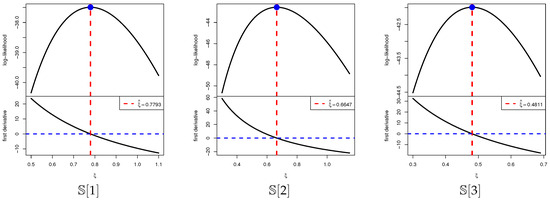
Figure 9.
Plots of log-likelihood/score functions of from River Styx data.
Convergence diagnostics of the MCMC chains for , , and are presented in Figure 10, where trace and posterior density plots are supplemented with the posterior mean (red solid line) and the 95% BCI bounds (red dashed lines). The plots confirm stable convergence across all parameters, with an approximately symmetric posterior for , and negatively and positively skewed posteriors for and , respectively. Using 40,000 post–burn-in iterations, we computed summary statistics including the posterior mean, mode, quartiles, standard deviation, and skewness (see Table 17), which are fully consistent with the estimates in Table 16. As shown in Figure 11, all ergodic convergence diagnostics based on (as a representative case) indicate that the running averages of , , and stabilize rapidly after the burn-in period, confirming the ergodicity and satisfactory convergence of the M-H sampler when the sample information are drawn from the River Styx dataset. In addition,Figure 12 compares the 95% ACI[NA]/ACI[NL] and BCI/HPD intervals for and based on the River Styx sample, showing that Bayesian intervals are consistently narrower, thereby reinforcing their higher efficiency.
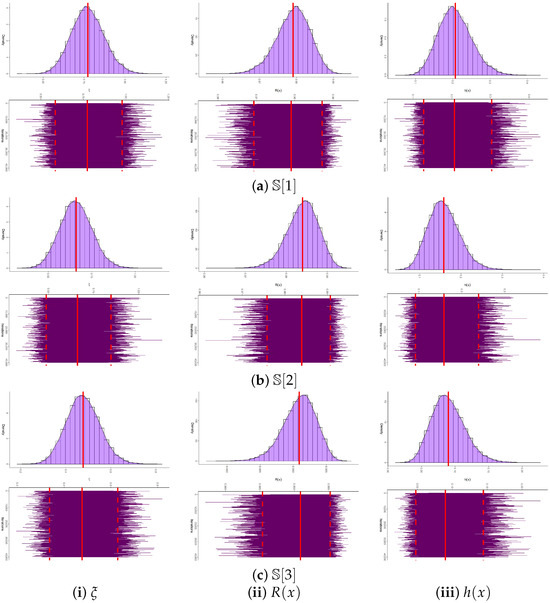
Figure 10.
Convergence diagnostics of , , and from the River Styx dataset.
Table 17.
Statistics for 40,000 MCMC iterations of , , and from River Styx data.
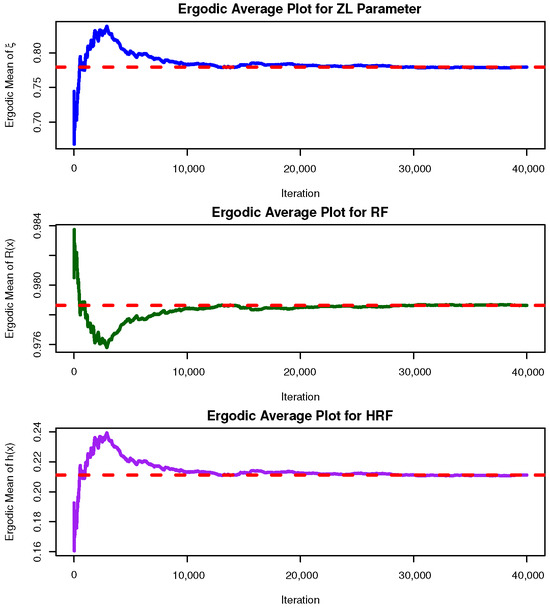
Figure 11.
Ergodic plot of , , and from the River Styx dataset.
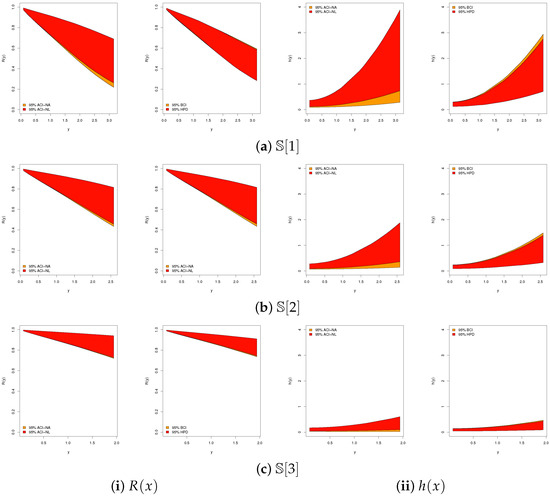
Figure 12.
Plots for 95% interval limits of and from River Styx data.
In conclusion, the analyses conducted using samples obtained under the proposed censored dataset, applied to both the leukemia and River Styx datasets, offer a comprehensive evaluation of the ZLindley lifetime model. The findings are consistent with the simulation results and further emphasize the practical utility of the proposed approach in reliability investigations within engineering and physical sciences.
6. Concluding Remarks
This study has advanced the reliability analysis of the ZLindley distribution by embedding it within the improved adaptive progressive Type-II censoring framework. Methodologically, both classical and Bayesian estimation procedures were developed for the model parameters, reliability, and hazard functions. Asymptotic and log-transformed confidence intervals, along with Bayesian credible and highest posterior density intervals, were derived to provide robust inferential tools. The incorporation of MCMC techniques, particularly the Metropolis–Hastings algorithm, ensured accurate Bayesian inference and highlighted the practical benefits of prior information. Through extensive Monte Carlo simulations, the proposed inferential methods were systematically evaluated. The findings confirmed that estimation accuracy improves with larger sample sizes, fewer removals, and higher censoring thresholds. Moreover, Bayesian estimators under informative priors consistently outperformed their frequentist counterparts, and HPD intervals dominated alternative interval estimators in terms of coverage and precision. Importantly, the comparative assessment of censoring schemes demonstrated that left, middle, and right censoring each provide superior accuracy depending on the parameter of interest, offering guidance for practitioners in reliability testing. The practical utility of the proposed methodology was demonstrated through two diverse real-life applications: Leukemia remission times and River Styx flood peaks. In both datasets, the ZLindley distribution outperformed a range of established lifetime models, as confirmed by goodness-of-fit measures, model selection criteria, and graphical diagnostics. These applications validate the model’s flexibility in accommodating both biomedical and environmental reliability data, thereby broadening its applicability in clinical and physical domains. The ZLindley model inherently exhibits a monotonically increasing hazard rate, a behavior commonly associated with ageing or wear-out mechanisms in reliability analysis. This property makes the model suitable for processes where the risk of failure intensifies over time, such as medical survival data under cumulative treatment exposure or environmental stress models like flood levels. However, in systems characterized by early-life failures or mixed failure mechanisms, more flexible distributions such as the exponentiated Weibull, generalized Lindley, or Kumaraswamy–Lindley may provide improved adaptability. Future work could extend the ZLindley framework by introducing an additional shape parameter to capture non-monotonic hazard patterns, thereby broadening its range of applicability. In summary, the contributions of this work are threefold: (i) the integration of the ZLindley distribution with an improved censoring design that ensures efficient and cost-effective testing, (ii) the development of a comprehensive inferential framework combining likelihood-based and Bayesian approaches, and (iii) the demonstration of practical superiority through simulation studies and real data analysis. Collectively, these findings underscore the potential of the ZLindley distribution, under improved adaptive censoring, as a powerful model for modern reliability and survival analysis. Future research may explore its extension to competing risks, accelerated life testing, and regression-based reliability modeling.
Author Contributions
Methodology, R.A. and A.E.; Funding acquisition, R.A.; Software, A.E.; Supervision, R.A.; Writing—original draft, R.A. and A.E.; Writing—review & editing, R.A. All authors have read and agreed to the published version of the manuscript.
Funding
The authors extend their appreciation to the Deanship of Scientific Research and Libraries in Princess Nourah bint Abdulrahman University for funding this research work through the Program for Supporting Publication in Top-Impact Journals, Grant No. (SPTIF-2025-8).
Data Availability Statement
The authors confirm that the data supporting the findings of this study are available within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Saaidia, N.; Belhamra, T.; Zeghdoudi, H. On ZLindley distribution: Statistical properties and applications. Stud. Eng. Exact Sci. 2024, 5, 3078–3097. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Cramer, E. The Art of Progressive Censoring; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Kundu, D.; Joarder, A. Analysis of Type-II progressively hybrid censored data. Comput. Stat. Data Anal. 2006, 50, 2509–2528. [Google Scholar] [CrossRef]
- Ng, H.K.T.; Kundu, D.; Chan, P.S. Statistical analysis of exponential lifetimes under an adaptive Type-II progressive censoring scheme. Nav. Res. Logist. 2009, 56, 687–698. [Google Scholar] [CrossRef]
- Yan, W.; Li, P.; Yu, Y. Statistical inference for the reliability of Burr-XII distribution under improved adaptive Type-II progressive censoring. Appl. Math. Model. 2021, 95, 38–52. [Google Scholar] [CrossRef]
- Bain, L.J.; Engelhardt, M. Statistical Analysis of Reliability and Life-Testing Models, 2nd ed.; Marcel Dekker: New York, NY, USA, 1991. [Google Scholar]
- Nassar, M.; Elshahhat, A. Estimation procedures and optimal censoring schemes for an improved adaptive progressively type-II censored Weibull distribution. J. Appl. Stat. 2024, 51, 1664–1688. [Google Scholar] [CrossRef] [PubMed]
- Elshahhat, A.; Nassar, M. Inference of improved adaptive progressively censored competing risks data for Weibull lifetime models. Stat. Pap. 2024, 65, 1163–1196. [Google Scholar] [CrossRef]
- Dutta, S.; Kayal, S. Inference of a competing risks model with partially observed failure causes under improved adaptive type-II progressive censoring. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2023, 237, 765–780. [Google Scholar] [CrossRef]
- Greene, W.H. Econometric Analysis, 4th ed.; Prentice-Hall: New York, NY, USA, 2000. [Google Scholar]
- Meeker, W.Q.; Escobar, L.A. Statistical Methods for Reliability Data; John Wiley and Sons: New York, NY, USA, 2014. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis, 2nd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2004. [Google Scholar]
- Henningsen, A.; Toomet, O. maxLik: A package for maximum likelihood estimation in R. Comput. Stat. 2011, 26, 443–458. [Google Scholar] [CrossRef]
- Plummer, M.; Best, N.; Cowles, K.; Vines, K. CODA: Convergence diagnosis and output analysis for MCMC. R News 2006, 6, 7–11. [Google Scholar]
- Kundu, D. Bayesian inference and life testing plan for the Weibull distribution in presence of progressive censoring. Technometrics 2008, 50, 144–154. [Google Scholar] [CrossRef]
- Bakouch, H.S.; Jazi, M.A.; Nadarajah, S. A new discrete distribution. Statistics 2014, 48, 200–240. [Google Scholar] [CrossRef]
- Sen, S.; Maiti, S.S.; Chandra, N. The xgamma distribution: Statistical properties and application. J. Mod. Appl. Stat. Methods 2016, 15, 774–788. [Google Scholar] [CrossRef]
- Onyekwere, C.K.; Obulezi, O.J. Chris-Jerry distribution and its applications. Asian J. Probab. Stat. 2022, 20, 16–30. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Atieh, B.; Nadarajah, S. Lindley distribution and its application. Math. Comput. Simul. 2008, 78, 493–506. [Google Scholar] [CrossRef]
- Johnson, N.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions, 2nd ed.; John Wiley and Sons: New York, NY, USA, 1994. [Google Scholar]
- Rinne, H. The Weibull Distribution: A Handbook; Chapman and Hall/CRC: Boca Raton, FL, USA, 2008. [Google Scholar]
- Nadarajah, S.; Haghighi, F. An extension of the exponential distribution. Statistics 2011, 45, 543–558. [Google Scholar] [CrossRef]
- Marinho, P.R.D.; Silva, R.B.; Bourguignon, M.; Cordeiro, G.M.; Nadarajah, S. AdequacyModel: An R package for probability distributions and general purpose optimization. PLoS ONE 2019, 14, e0221487. [Google Scholar] [CrossRef] [PubMed]
- Kuczera, G.; Frank, S. Australian Rainfall Bruno Book 3, Chapter 2: At-Site Flood Frequency Analysis-Draft; Engineers Australia: Barton, Australia, 2015. [Google Scholar]
- Bhatti, F.A.; Ahmad, M. On the modified Burr IV model for hydrological events: Development, properties, characterizations and applications. J. Appl. Stat. 2022, 49, 2167–2188. [Google Scholar] [CrossRef]












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).