Abstract
The increasing demand for low-latency, computationally intensive vehicular applications, such as autonomous navigation and real-time perception, has led to the adoption of cloud–edge–vehicle infrastructures. These applications are often modeled as Directed Acyclic Graphs (DAGs) with interdependent subtasks, where precedence constraints enforce causal ordering while allowing concurrency. We propose a task offloading framework that decomposes applications into precedence-constrained subtasks and formulates the joint scheduling and offloading problem as a Markov Decision Process (MDP) to capture the latency–energy trade-off. The system state incorporates vehicle positions, wireless link quality, server load, and task-buffer status. To address the high dimensionality and sequential nature of scheduling, we introduce DepSchedPPO, a dependency-aware sequence-to-sequence policy that processes subtasks in topological order and generates placement decisions using action masking to ensure partial-order feasibility. This policy is trained using Proximal Policy Optimization (PPO) with clipped surrogates, ensuring stable and sample-efficient learning under dynamic task dependencies. Extensive simulations show that our approach consistently reduces task latency, energy consumption and QOS compared to conventional heuristic and DRL-based methods. The proposed solution demonstrates strong applicability to real-time vehicular scenarios such as autonomous navigation, cooperative sensing, and edge-based perception.
Keywords:
Internet of Vehicles; computational methods; deep reinforcement learning; QoS optimization MSC:
68T07
1. Introduction
With the rapid advancement of mobile communication technologies, cloud computing, and distributed artificial intelligence, modern network systems are experiencing a paradigm shift towards decentralized, latency-sensitive computing [1]. Within this shift, Mobile Edge Computing (MEC) has become a key paradigm, relocating compute, storage, and networking capabilities from distant data centers to access points near users [2]. Executing analytics and decisions at the edge shortens round-trip times and yields faster system response. MEC now supports applications across smart manufacturing, industrial IoT, telemedicine, and intelligent transportation systems (ITS) [3,4,5].
Among these applications, Intelligent Transportation Systems (ITS) have gained particular attention due to the increasing demand for real-time services and the proliferation of connected and autonomous vehicles [6,7]. Vehicular Edge Computing (VEC), a specialized form of MEC tailored for vehicular networks, plays a central role in supporting the computational requirements of in-vehicle services such as autonomous navigation, augmented reality dashboards, cooperative perception, and traffic-aware route planning [8]. These vehicular applications typically involve data-intensive and latency-sensitive workloads, which must be processed under strict Quality of Service (QoS) constraints [9,10,11].
While traditional task offloading techniques in VEC assume that computational workloads are independent and can be flexibly partitioned or distributed, real-world vehicular applications often consist of a series of interdependent subtasks with intricate data and control dependencies [12]. Such applications are best modeled using Directed Acyclic Graphs (DAGs) [13], where each node represents an atomic subtask and directed edges represent precedence constraints and data flows, for example, DAG-based task structures are commonly seen in autonomous driving pipelines (e.g., perception → localization → planning → control), video analytics (e.g., decoding → object detection → event reasoning), and traffic management systems (e.g., data collection → fusion → prediction → decision) [5].
In a typical VEC architecture, vehicles interact with nearby Roadside Units (RSUs) equipped with MEC servers and may also access remote cloud servers through Base Stations (BSs) [14]. However, the dynamic topology of vehicular networks—characterized by high mobility, intermittent connectivity, and fluctuating bandwidth—introduces substantial uncertainty into the task offloading process [15,16]. Additionally, the coverage range of RSUs is geographically limited, and MEC servers deployed at the edge possess only limited computational and communication resources [17]. As a result, efficient task offloading in such environments must not only respect the structural dependencies among subtasks but also adapt to link variations, resource constraints, and deadline requirements.
Despite extensive research efforts in this field, most existing works fall short in two aspects. (1) They oversimplify task models by assuming subtask independence, which limits their applicability to real-world vehicular services [18,19,20]; (2) they lack robust mechanisms to adapt to environmental dynamics, such as vehicle movement and RSU availability, resulting in degraded system performance and reliability [17,21,22].
To address these limitations, this paper investigates a dependency-aware task offloading framework, a hierarchical VEC system composed of three layers: the cloud layer, the edge layer, and the vehicle layer. In this framework, vehicular tasks are modeled as DAGs, where nodes represent atomic subtasks and edges denote data dependencies. Each subtask executes either onboard the vehicle, at a nearby MEC node, or in the remote cloud. The framework jointly optimizes the execution order and offloading decisions of subtasks, considering vehicle mobility, link availability, computation capacity, and task deadlines.
We formulate the joint scheduling and offloading problem as a Markov Decision Process (MDP), which captures the evolution of system states including vehicle positions, network connectivity, task queue status, and resource availability. To tackle the high-dimensional, complex action space and non-convex optimization landscape, we propose DepSchedPPO (Dependency-Aware Task Scheduling using Proximal Policy Optimization), an actor–critic paradigm deep reinforcement learning algorithm. DepSchedPPO integrates a sequence-to-sequence (Seq2Seq) graph encoder to extract DAG inside structural features, enabling the policy network to make informed decisions on subtask scheduling and placement. The critic network estimates long-term rewards and guides policy updates, ensuring convergence and robustness in a dynamic environment.
The main contributions of this paper are summarized as follows:
- Hierarchical VEC Architecture with DAG Task Modeling: We propose a cloud–edge–vehicle architecture that uses DAGs to represent subtasks, incorporating both sequential and parallel execution for vehicular applications.
- Seq2Seq-Based Policy Network for Dependency-Aware Scheduling: Unlike conventional DRL methods that use feedforward DNNs, we design a novel Seq2Seq policy network to capture task dependencies and historical scheduling decisions, improving offloading accuracy and system performance.
- PPO-Based Optimization for QoS Maximization: We adopt Proximal Policy Optimization (PPO) to ensure stable learning and maximize the quality of service (QoS) in dynamic vehicular environments.
- Comprehensive Performance Evaluation: Extensive simulations demonstrate that DepSchedPPO outperforms existing methods in reducing task latency and energy consumption under diverse network conditions.
2. Related Work
In vehicular edge computing (VEC) environments, efficient task offloading has become a prominent research topic in recent years. Existing studies have proposed a variety of offloading decision-making strategies based on different optimization objectives, including minimizing delay [23,24,25], energy consumption [26,27], system cost [28], and maximizing quality of service (QoS) [29,30] in single-objective optimization scenarios, as well as multi-objective joint optimization problems [31,32]. These studies provide a wealth of solutions in the task offloading domain; however, for applications with data or execution dependencies between tasks and for achieving resource-awareness and policy learning in dynamic vehicular networks, systematic approaches are still lacking. Therefore, this paper reviews the related work from the perspectives of VEC architectures and task offloading.
2.1. Vehicular Edge Computing Architectures
VEC systems generally adopt a multi-layer distributed architecture, consisting of the cloud layer, vehicle layer and edge layer. The traditional VEC architecture primarily relies on roadside units (RSUs) equipped with edge servers to respond to computation demands, combined with cloud servers for support [33,34,35]. For example, Xun et al. [33] constructed a three-tier vehicle–edge–cloud collaborative architecture that uses cloud-trained models to evaluate driving behavior at the edge. Liu et al. [36] investigated cooperative task computing and on-demand resource allocation in VEC, proposing a multi-resource cooperative framework involving central cloud, RSUs, and mobile vehicles. Dai et al. [34] studied the heterogeneous computing collaboration problem between MEC servers and the cloud, optimizing task allocation to minimize overall task delay. They considered service migration in multi-server scenarios and used asynchronous deep reinforcement learning to optimize the task offloading problem, minimizing the weighted sum of user utility.
Another model is the vehicle-assisted edge computing (VAEC) architecture [18,19,20], which leverages idle computational resources from nearby vehicles to perform task execution, thereby reducing communication overhead and improving system responsiveness [37,38]. For instance, Han et al. [39] proposed a VAEC framework to distribute delay-sensitive tasks to neighboring vehicles and edge servers for joint processing. Feng et al. [40] introduced an innovative partial reverse offloading (PRO) strategy to utilize vehicle resources, reducing the load on VEC and minimizing system delay through optimized reverse offloading decisions and resource allocation. Ma et al. [41] presented a three-tier VEC framework that utilizes the vast underused resources of parked and moving vehicles in urban areas to build a collaborative distributed computing architecture, effectively addressing resource constraints and expanding VEC service coverage. Qin et al. [42] addressed the issue of limited computational resources in vehicles by leveraging idle resources from other vehicles and applying Lyapunov optimization to decompose the task offloading problem into vehicle-side offloading and cooperative vehicle-side resource allocation, achieving optimization of short-term decisions and long-term queue delays.
Although the above architectures have made progress in service migration, task scheduling and heterogeneous resource management, there are still challenges in practical deployment, such as communication instability caused by high mobility, channel interference, and limited service coverage. Furthermore, some VAEC systems face risks of privacy leakage and insufficient device security authentication. Considering system robustness and privacy protection requirements, current research tends to favor using fixed infrastructure (RSUs and MEC servers) for task offloading scheduling.
2.2. Task Offloading
With the rapid development of VEC, vehicular computational tasks increasingly become complex, often comprising multiple interdependent subtasks. These subtasks exhibit strong coupling in data flows, execution order, and timing constraints, as seen in typical applications such as image recognition, path planning, and decision making in autonomous driving, frame processing and behavior detection in video analytics, and multi-sensor data fusion [43]. Such dependencies are often modeled as directed acyclic graphs (DAGs), where nodes represent atomic subtasks and edges represent data or control dependencies.
Compared with independent task offloading, dependency-aware task offloading is more complex. On the one hand, the execution order of subtasks must strictly follow the DAG’s topology to preserve logical consistency; on the other hand, offloading involves multiple computational nodes (vehicles, edge servers, and cloud servers) and must consider node computation capacity, network bandwidth, transmission delay, and vehicle mobility to formulate optimal offloading and scheduling strategies. Since task scheduling for DAG structures has been proven to be NP-hard [44], traditional heuristic algorithms (e.g., HEFT [45], ITAGS [46]) or metaheuristic algorithms (e.g., GSA [47], QPSO [48]) may perform well for small-scale tasks but suffer from rapidly increasing scheduling time as the number of tasks grows, limiting their application in large-scale and computation-intensive scenarios. Moreover, most existing dependency-aware task offloading algorithms focus on single DAG scheduling or static scheduling, whereas the complexity of dynamic vehicular applications in VEC makes handling multi-vehicle, multi-task dependency scenarios a key research challenge.
As deep reinforcement learning (DRL) has been widely applied to dynamic optimization problems, more research has introduced DRL into dependency-aware task offloading to overcome the limitations of traditional methods in responsiveness and generalization under dynamic, complex environments. DRL learns policies through environment interaction, enabling end-to-end modeling and adaptive optimization of task scheduling and resource allocation. Lin et al. [49] proposed the SA-DQN algorithm, modeling the task offloading problem as a Markov decision process (MDP) and introducing task queue depth to measure subtask priority, combined with simulated annealing to optimize task selection strategies. Liu et al. [50] targeted a vehicle–edge–cloud collaborative architecture and adopted an improved DDPG algorithm with a task execution delay-based reward function to achieve minimum-delay strategies in heterogeneous computing environments. Liu et al. [51] aimed to minimize the deadline violation ratio and proposed the DVRMO-MM scheme, which incorporates task migration and merging by decomposing the dependency-aware task offloading problem into two subproblems. Zhao et al. [52] presented a Stackelberg game-based dependency-aware task offloading and resource pricing framework (SDOP) that models the interaction between SDN controllers and vehicles, considering task dependencies and using backward induction with gradient ascent plus a genetic algorithm (GAPG) to solve for Nash and Stackelberg equilibria, significantly improving both controller and vehicle utility while achieving better delay and energy performance in various scenarios. Luo et al. [53] proposed a joint task offloading and resource allocation strategy in an MEC environment with vehicle–roadside infrastructure sensor (RIS) collaboration, incorporating delay, energy consumption, and tolerance for interruptions of incremental information (T3I) into a unified decision-making framework via Lyapunov optimization, effectively improving offloading accuracy and system stability in asymmetric resource scenarios. Considering the structural characteristics of DAG tasks, some studies have further integrated graph neural networks (GNNs) into DRL architectures. Sun et al. [54] proposed the GRLO framework, which uses GNNs to encode task graph structures, extracting task dependencies via message passing, and combines this with an Actor–Critic strategy to output scheduling actions and evaluate performance. Yan et al. [55] employed an Actor–Critic structure, analyzing graph paths to construct a Critic evaluation function and introducing a graph neural structure to optimize the Actor’s offloading policy, significantly improving task completion rate and system stability. Zhang et al. [56] proposed the DSO algorithm for dependency-aware task offloading and service placement optimization, combining improved multi-agent Q-learning (IMAQL) with a greedy scheduling algorithm to maximize application hit ratio and improve QoS in multi-application scenarios. Additionally, for continuous action space scenarios (e.g., fine-grained task offloading, dynamic resource allocation), a number of studies based on DDPG, PPO, and other policy gradient methods [57,58] have emerged. These methods can handle complex state–action spaces while adapting to dynamic VEC environments, gradually becoming mainstream in this research direction.
2.3. Summary
In summary, Vehicular Edge Computing (VEC) systems have made significant strides in architecture design, resource collaboration, and task scheduling. A variety of methods have been proposed to optimize key objectives such as latency, energy consumption, and system cost. Additionally, there is a growing trend to integrate Deep Reinforcement Learning (DRL) into task offloading processes, aiming to enhance decision-making efficiency and adaptability in dynamic, unpredictable environments.
However, when dealing with large-scale, complex dependency-aware tasks, existing DRL-based methods still suffer from several limitations. First, these methods often struggle with insufficient state modeling, which prevents the accurate representation of dynamic vehicular systems and their interactions. Furthermore, the task dependency features, which are critical for efficient offloading and scheduling, are often underutilized. This leads to suboptimal convergence efficiency and robustness, particularly in continuous action spaces. Another significant gap is the lack of a unified and scalable framework for collaborative optimization of heterogeneous resources, which are essential for achieving optimal performance in real-world, multi-vehicle VEC scenarios. Additionally, task topology features, which can further optimize offloading decisions, remain inadequately exploited.
The studies reviewed in this section highlight these challenges. Table 1 provides a comparative analysis of the key literature in VEC task offloading, showcasing how each approach addresses these challenges and identifying their respective limitations. Notably, existing work either overlooks or fails to fully address the integration of task dependencies, real-time QoS optimization, and dynamic resource allocation, which are crucial for achieving optimal system performance in heterogeneous environments.

Table 1.
Comparison of key literature in vehicular edge computing (VEC) and task offloading.
Our work contributes to filling these gaps by proposing a dependency-aware task offloading optimization framework using Proximal Policy Optimization (PPO). This framework not only incorporates a dynamic, task dependency model but also leverages task topology features, improving convergence efficiency and robustness while providing a scalable solution for collaborative resource optimization across heterogeneous vehicles.
3. System Model
The vehicular edge computing (VEC) architecture employed in this study is illustrated in Figure 1, which models a road scenario. The system is organized into three hierarchical layers: cloud, edge and vehicle layers. The vehicle layer consists of vehicles equipped with limited onboard computational capabilities. These vehicles are able to communicate with base stations (BSs) and roadside units (RSUs) via 5G/LTE networks and dedicated wireless interfaces. The edge layer includes multiple roadside nodes deployed at various locations along the road. Each node integrates an RSU with limited wireless coverage and an associated Mobile Edge Computing (MEC) server that provides moderate computing and storage resources. Notably, the coverage areas of RSUs are non-overlapping to prevent signal interference. The cloud layer forms the top tier, pooling large-scale compute resources accessed from BSs via cabled backhaul. These cloud servers offer centralized computing support for vehicle applications when edge resources are insufficient or unavailable. When a task is generated onboard the vehicle, it can either be executed locally or offloaded to the MEC server or the cloud server, depending on resource availability, task urgency, and network conditions.
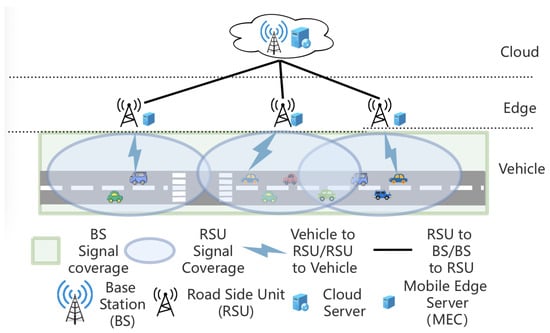
Figure 1.
VEC system architecture.
The VEC architecture considered in this study, as shown in Figure 1, models a road scenario with three layers:
- Vehicle layer—on-road vehicles with limited computing capacity, communicating with BS and RSU.
- Edge layer—roadside nodes each combining an RSU (non-overlapping coverage to avoid interference) and an MEC server with moderate computing and storage capabilities.
- Cloud layer—large-scale compute resources accessed from BSs via cabled backhaul, providing centralized resources when edge capacity is insufficient.
When a task is generated, it may run locally or be offloaded to MEC or cloud servers. according to resource availability, task urgency, and network conditions.
Referring to [59], the vehicular edge computing (VEC) system in this paper operates in discrete time slots with uniform duration. At each time slot, a MEC server is capable of communicating with vehicles located within its current coverage region. The base station (BS) provides full-area wireless coverage and enables all vehicles to access cloud computing services when necessary. For vehicles outside the RSU service range, computation tasks must be offloaded to the cloud.
Let denote the RSU set, and denote the vehicle set in the system. As illustrated in Figure 2, the navigation application is modeled as a task graph, and nodes represent subtasks and directed edges describe dependency relationships. The label inside each node indicates the subtask’s local execution time.
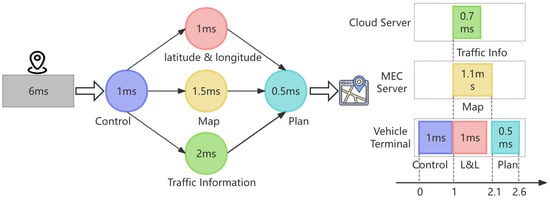
Figure 2.
Topology of vehicle navigation task.
The execution process proceeds as follows. A user inputs a destination into the navigation interface, prompting the controller module to retrieve the vehicle’s current GPS coordinates. Subsequently, three parallel subtasks are initiated to acquire location data, route options, and traffic conditions along the planned route. These subtasks are designed for concurrent execution, and their dependencies are represented by a Directed Acyclic Graph (DAG). A subtask must be executed when all of its predecessor subtasks have completed, as their outputs act as its inputs.
Based on this dependency representation, task offloading must respect both sequential constraints and parallelism among subtasks. Each vehicular task generated within a time slot is formulated as a DAG, denoted by , where L is the set of subtasks and E is the set of directed edges. For vehicle i’s m-th task, the e-th subtask is represented as . Each subtask is described by the tuple , where denotes the input data size, indicates the computational workload (in CPU cycles), and represents the maximum allowable execution latency. Table 2 summarizes the definitions of the key symbols used in this paper.
Table 2.
Key notations used in this paper.
3.1. Problem Assumptions
In VEC environment, task offloading decisions are influenced by dynamic factors, like vehicle speed, network bandwidth, geographic location, and signal strength. However, considering all these factors simultaneously is highly complex in real-world scenarios. Building upon the foundations established previously, the following assumptions are made in this paper to facilitate tractable analysis of the proposed problem:
- The considered tasks are dependency-aware, representing intelligent vehicular applications composed of multiple interdependent subtasks. Each subtask is atomic, meaning it cannot be further divided and must be executed in a single stage without interruption.
- The vehicular edge computing system operates in a time-division manner, providing services to all vehicles in discrete time slots. It is assumed that tasks generated by vehicles can be completed within a single time slot.
- Due to data dependencies among subtasks, the output of a predecessor subtask may serve as input for its successor. Consequently, the return of intermediate results must be considered during task offloading to ensure correct execution of downstream subtasks.
- The dependency structure among subtasks may permit partial parallelism, meaning some subtasks can be executed concurrently. This increases the number of subtasks potentially offloaded to remote servers. However, due to the limited bandwidth capacity of MEC server communication channels, offloaded subtasks may experience queuing delays when the channel is occupied.
3.2. Problem Modeling
(1) Task Model
Unlike independent tasks, dependent tasks consist of multiple subtasks that can be executed locally or offloaded to edge or cloud servers. These subtasks are interdependent, where the output of one may serve as the input to another. We map each task to a DAG ; L enumerates the subtasks and E contains directed edges capturing execution dependencies. For vehicle i, the m-th task is denoted by , and its e-th subtask is denoted by . A directed edge indicates that subtask can only start after the completion of subtask .
Figure 3 illustrates an example where the main task is subdivided into nine subtasks: . In this task partitioning, acts as the start node, and serves as the end node, which only begins execution after all its predecessor subtasks are completed. is the predecessor for both and . Conversely, and are successors of , meaning and can only start after finishes. Additionally, subtasks like , , or , , can execute in parallel. Each subtask is represented by a triple , where denotes the e-th subtask’s input data size, represents the amount of computational resources required to complete subtask , and denotes the maximum allowable delay for subtask .
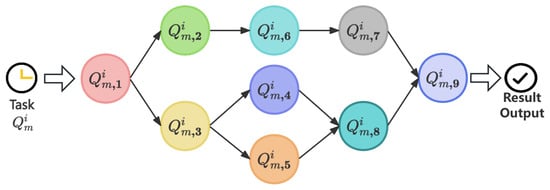
Figure 3.
Example of DAG.
Based on the DAG, this paper introduces the Ready Time (RT) and Finish Time () to describe subtask dependencies. For subtask , the Ready Time is the earliest moment it can start, determined by the completion of all its immediate predecessors. denotes the moment the subtask completes execution. According to these definitions, the Ready Time of subtask is:
Equation (1) indicates that when a subtask has no direct predecessors (i.e., ), its Ready Time is the start time of the entire in-vehicle application, . Otherwise, when subtask is not the start task, its Ready Time depends on its direct predecessor nodes , equaling the maximum Finish Time among all its direct predecessor tasks.
(2) Computation Model
Local Computation Model:
Within time slot t, is the subtask’s local execution on vehicle i, and then we can write
where is the computational complexity, and represents the local processing capability of the vehicle.
Due to limitations in the vehicle’s onboard computational resources, this study assumes that only one subtask can be executed locally within a time slot. The subtask’s Earliest Start Time () denotes the earliest time it can begin local execution as
where is the Available Time of subtask for local computation on the vehicle terminal, signifying the earliest time the vehicle has idle computational resources for execution:
where is the queue of tasks waiting to be executed locally. As shown, the Available Time of subtask is the maximum Finish Time among all remaining subtasks in the queue.
The Finish Time of subtask executed locally on the vehicle terminal is
The local energy consumption for computing subtask on the vehicle terminal is
where denotes the power consumption.
MEC Computation Model:
The time required to offload a computation task to MEC for execution mainly consists of three phases:
- Transmission Phase: The period to send the computation task to MEC. Due to limited channel bandwidth, tasks might experience waiting time before accessing an idle channel. Thus, the delay here consists of both the waiting time for channel availability and the wireless transmission duration.
- Execution Phase: The duration taken by MEC to process the assigned task.
- Download Phase: The time needed to deliver the computation results back to the vehicle terminal. As the returned data size is much smaller than the uploaded input, channel bandwidth is typically negligible here.
For subtask , the time spent in the transmission, execution, and download phases can be expressed by Equations (7), (8), and (9), respectively, as
where represents the upload delay for sending subtask to MEC server j, represents the execution time of subtask on MEC server j, and represents the time required from MEC server to vehicle terminal to return the computation results. and denote the upload and download speeds of the V2M link, respectively.
When subtask is offloaded to an MEC server, its Earliest Eligible Transmission time () is
where is the Ready Time of subtask , and represents the Available Time of the V2M upload channel. It is defined as
where represents the set of subtasks queued for transmission from vehicle i to MEC server j at time . The Earliest Reception Time () at the edge server j is then
When subtask is offloaded to an MEC server for execution, its Finish Time on the MEC server is
The energy consumption for offloading subtask to the MEC server can be expressed as
where and are the power consumption rates for the MEC server’s upload and download channels, respectively, and is the power consumption rate for computation on the MEC server.
Cloud Computation Model:
The time required to offload a computation task to the cloud server for execution also consists of three phases:
- Transmission Phase: The period required to transmit the computation task to the cloud server. Due to abundant communication resources at the cloud server, tasks do not need to wait for an idle channel; transmission starts immediately upon readiness.
- Execution Phase: The duration taken by the cloud server to execute the task. Sufficient computational resources are available on the cloud server; subtasks can be executed directly upon arrival.
- Download Phase: The time taken for the computation results to the vehicle terminal device. As with the MEC model, the returned data size is assumed to be small, so channel bandwidth limitations are ignored.
Let represent the computational capability of the cloud server. The transmission time for subtask to the cloud server (V2C) is denoted , the time for results to return is denoted , and the computation time on the cloud server is denoted . Specifically, the transmission and execution delays are calculated as follows:
When subtask is offloaded to the cloud, the Earliest Reception Time () at the cloud server and the Finish Time () on the cloud server can be expressed as
Due to cloud server’s abundant computational resources, the energy consumption associated with computation execution on the cloud is not considered by the system. Therefore, the energy consumption when offloading subtask to the cloud server is
Considering the Finish Time () and energy consumption (E) of subtask when executed locally, on MEC, or in the cloud, we define as the offloading decision variable, where denotes local processing, represents execution on MEC, and corresponds to cloud execution. For a given task , the overall completion time is determined by the largest among its subtasks, while the total energy consumption equals the sum of E for all subtasks.
where denotes the indicator function, which returns 1 when the specified condition holds true and 0 otherwise.
3.3. Problem Formulation
We quantify system-level QoS as a weighted combination of latency and energy consumption. The aggregate latency and energy over all tasks are given by:
A higher QoS represents a better quality of service provided by the system to the vehicle users. Therefore, lower overall system delay and energy consumption correspond to higher user QoS. The QoS is defined as
Based on the above models, the optimization goal of this paper is to maximize the system’s QoS. The optimization problem can be formulated as
where C1 and C2 are constraints on the energy consumption weighting coefficients, reflecting the balance between latency and energy consumption within the optimization goal, with C2 specifying the valid range for the weights. C3 is the offloading decision constraint; the value of indicates the offloading decision for subtask . When , the subtask is executed locally on the vehicle terminal; when , the subtask is offloaded to an MEC server; when , the subtask is offloaded to the cloud server.
4. Algorithm Design
The optimization objective of this paper is to maximize the QOS during system operation. From a system perspective, this is achieved by minimizing task delay and energy consumption as much as possible. This paper introduces a dependency-aware vehicular task offloading method based on PPO to solve the target optimization problem (26). Building upon the DRL framework for VEC proposed in the previous paper, this section first describes the MDP model for the problem, then introduces the neural network architecture used in this reinforcement learning framework, and finally details the DepSchedPPO algorithm based on the PPO framework along with its training process.
4.1. Markov Decision Process Elements
According to the definition of the dependency task model, for the offloading decision of vehicle subtask , it depends on the network environment, vehicle state, edge server state, task-specific information, and previous task scheduling results.
State Space: When scheduling subtask , the system’s state space is defined as
where represents the coordinate positions of mobile edge computing servers, is the coordinate position matrix of vehicles, is the task model represented as a Directed Acyclic Graph (DAG) after modeling, containing task dependencies along with task-specific data size and computational complexity information. is the partial offloading decision matrix, including the scheduling decision set for subtasks from to .
While a DAG can model dependencies between subtasks, it is difficult to directly input into a neural network. Therefore, the DAG corresponding to task dependencies needs to be embedded and converted into vector representation. To ensure that the embedded DAG sequence still satisfies the task characteristics of dependency tasks, it is necessary to determine the order of subtasks for different DAG sequences. Based on this, a priority queue model for subtasks is first established to determine the operational order for different applications. We rank subtasks using their latest completion time and latest execution time. Specifically, the Latest Completion Time (LCT) for is
where represents the delay of subtask when offloaded to local, edge server, or cloud server without considering queuing time. The is obtained through iterative calculation starting from the end node. Based on the , the Latest Execution Time () of the subtask is
where represents the execution time of the subtask at offloading destination loc, and indicates the urgency of the subtask. A higher value indicates lower urgency. Therefore, for all subtasks, they are sorted in ascending order of to determine the operational order, i.e., the subtask priority queue.
After converting the task’s DAG into a prioritized task sequence, embedding operations are performed to facilitate neural network training. The embedding vector contains three elements: subtask-related information including estimated runtime delay, an index vector of predecessor subtasks, and an index vector of successor subtasks. The initial vector is padded with −1 and then fed into the neural network to train for offloading decisions.
Action Space: Subtask may be executed locally, on MEC, or in the cloud. The agent’s action determines the subtask’s offloading destination, with the action space defined as
where represents the task decision matrix of vehicle i at step t, composed of elements . The numbers 0, 1, and 2 indicate whether the offloading location is local, edge server, or cloud server, respectively.
Reward: The optimization objective defined in this paper is to maximize system quality of service. To optimize QoS, we take the cumulative return in (26) as the agent’s reward
4.2. Seq2Seq Neural Network Architecture
After modeling the abstracted MDP elements of the optimization problem, this section elaborates on the construction of the Seq2Seq neural network for the DepSchedPPO algorithm. Considering the characteristics of dependency tasks, a DAG is used to model the dependencies between subtasks. As mentioned in the previous subsection, to facilitate neural network training, the prioritized DAG task sequence is embedded. The embedded DAG sequence is , where E is the number of subtasks. According to the MDP definition, for a DAG task graph, the policy represents the probability of selecting action for subtask in state . Let be the probability of choosing an offloading plan for a task graph G, given the environment state . By applying the chain rule of probability, we can express this as a product of sequential decisions as
To approximate the policy of the MDP defined in Equation (32) and evaluate the value function of the current state, unlike traditional DNN neural networks used in conventional reinforcement learning structures, this paper employs a Seq2Seq network architecture as the neural network for the DepSchedPPO algorithm. This is because traditional DNNs are feedforward networks without feedback loops, where data passes sequentially through input, hidden, and output layers, with each layer containing multiple neurons transformed using nonlinear activation functions. This makes DNNs more suitable for data without dependency relationships in input information. However, according to Equation (32), for task graph G, its offloading plan depends on the previous offloading plan .
The Seq2Seq neural network architecture defined in this paper is shown in Figure 4. This architecture consists of two recurrent neural networks: an Encoder network and a Decoder network. The embedded DAG sequence is input into the Encoder network. Through forward propagation, all input sequences are encoded into a unified feature vector, denoted as . Subsequently, combined with an attention mechanism, the Decoder network decodes the feature vector output by the Encoder to produce the output sequence. The detailed processing of the Seq2Seq neural network is as follows.
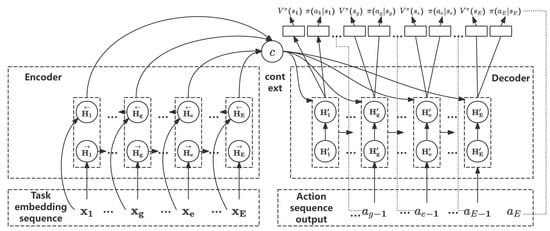
Figure 4.
Seq2Seq neural network architecture.
(1) Encoder Network Processing: For the defined DAG sequence , the Encoder processes the sequence. At each time step, the Encoder receives a vector and outputs a hidden state .
Using the attention mechanism, define as the relevance between the hidden state at stage g of the Encoder and the hidden state at stage e of the Decoder . Therefore, the feature vector is represented as the weighted sum of all over :
The attention distribution is calculated as follows, where is the hidden layer state of the Decoder at stage e, and is the attention scoring function, computed using the dot product model:
(2) Decoder Network Processing: After the Encoder outputs the feature vector , the Decoder decodes it. At each stage, the Decoder produces a scheduling decision output until the complete output queue is generated. The hidden layer node state of the Decoder is computed as follows:
Specifically, the Decoder operates as follows. At each time step e, based on the previous scheduling decision output , the current hidden state , and the context vector provided by the Encoder, it computes a logits vector. Then, a fully connected layer applies the softmax function to convert these logits into a probability distribution.
Here, is the logit value corresponding to output , and the denominator is the sum of the exponentials of all possible output logits, ensuring that the sum of all output probabilities is 1. Additionally, to approximate the value network of the MDP process, the value of the state is output through another fully connected layer. Finally, the Decoder selects the output with the highest probability as the output for this stage.
4.3. DepSchedPPO Algorithm Architecture
This section proposes the Dependency-Aware Task Scheduling Algorithm based on Proximal Policy Optimization (DepSchedPPO) tailored for dependency task offloading characteristics. The architecture of DepSchedPPO is shown in Figure 5.
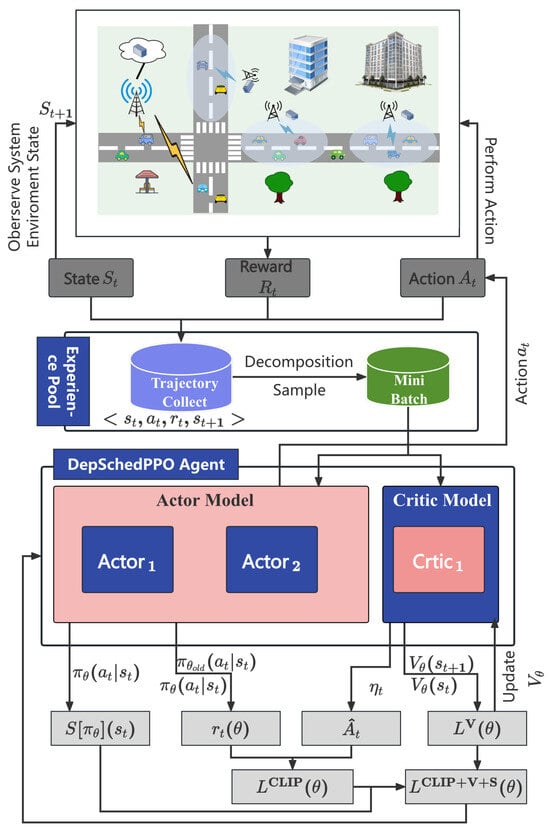
Figure 5.
DepSchedPPO algorithm architecture.
Actor–Critic reinforcement learning algorithms contain two core components: an Actor network responsible for behavioral decisions and a Critic network for value assessment. The learning process starts with the Actor network, which selects an action a in a given state s based on a determined probability p. After executing action a, the Actor receives a reward r and a new state . This transition information is then passed to the Critic network. The Critic calculates a label value called Temporal Difference Error (), representing the deviation between the Critic’s prediction and the actual outcome. This is used to adjust the Critic network and is also fed back to the Actor network to assist in updating its parameters.
As shown in Figure 5, the proposed DepSchedPPO framework employs an Actor–Critic structure. The Actor component consists of two separate neural networks, and , which generate the current policy and the previous policy , respectively. To regulate policy updates, the Actor computes the probability ratio between the current and previous policies, ensuring that policy changes remain within a controlled range to preserve training stability. The computation of is expressed as:
After computing the ratio , the objective function clips the value of to avoid instability caused by excessive updates, enabling smooth policy optimization. The network’s objective function is computed as:
Here, denotes the expectation, computed by averaging over samples at time step t. The term denotes the probability ratio between the updated policy and the previous policy, while refers to the estimated advantage, acting as a learning signal that measures the benefit to the mean performance. The clipping operation constrains within , thereby preventing excessive changes to the policy; here, specifies the clipping threshold.
To lower the variance in gradient estimation, the algorithm adopts the Generalized Advantage Estimator (GAE) [60] as the advantage function, defined as:
where is the discount factor reducing the current value of future rewards, and is the GAE parameter acting as a smoothing factor weighting bias and variance. is the Temporal Difference (TD) error at time step t, representing the difference between the predicted state value function and the observed return. Minimizing TD error improves the accuracy of the value function prediction, enhancing learning performance. The TD error is calculated as:
Due to parameter sharing, the loss function combines the policy gradient error term and value function. Therefore, the loss function of DepSchedPPO combines the clipped policy gradient part , the entropy bonus [61], and the value function loss part . As defined in Equation (39), prevents instability from large policy changes. The value function loss improves prediction accuracy of future rewards. The entropy bonus encourages the policy to explore more possible actions, promoting better long-term decisions and avoiding local optima. Combining these balances exploration and exploitation during learning, optimizing long-term policy performance. The loss function is expressed as:
Here, and are hyperparameters that balance the contribution of the value loss and the entropy term in the overall loss function.
The value loss component is evaluated via the Mean Squared Error (MSE) [62], with the objective of reducing the discrepancy between predicted outputs and target values
where represents the value network’s prediction for state , and is the target value prediction for the next state.
The entropy bonus is added to the total loss function to encourage exploration. Entropy measures uncertainty; in reinforcement learning, high entropy indicates a more uniform probability distribution over possible actions in a given state, encouraging exploration of more action combinations and avoiding premature convergence to local optima. The entropy bonus term is defined as:
4.4. DepSchedPPO Training and Testing Algorithms
Based on the DepSchedPPO architecture above, this section further presents the DepSchedPPO training and testing algorithms.
Algorithm 1 outlines the DepSchedPPO training process. It trains the Seq2Seq neural network to output scheduling decisions for the DAG task sequence corresponding to each dependency task. The process first constructs the Seq2Seq neural network structure for the agent’s actor and critic networks and initializes a trajectory set D to record system state–action transition pairs and trajectories. Lines 3–20 describe the training loop. During each episode iteration, priority embedding operations are performed on all vehicle DAG tasks according to Equations (28) and (29). The embedded DAG sequence is then fed into the agent. Lines 6–10 depict the sampling process of the Actor network, where it samples actions for the DAG sequence, executes them in the system environment, and stores the resulting trajectory data in set . Lines 11–20 update the Actor and Critic networks. Specifically, a random subset of trajectory segments is selected from . Using the Critic network, the advantage estimate is computed via Equations (40) and (41), and the target state value estimate is output and stored in . The Actor network then calculates the ratio between new and old policies using Equation (38), computes the Actor’s optimization objective via Equation (39), and updates the Actor. Finally, the combined objective is optimized using Equations (42), (43) and (44), and the Critic network is updated. The synchronized policy network parameters are returned.
Algorithm 2 describes the DepSchedPPO testing algorithm, simulating the operation of the vehicular edge system and testing the effectiveness of DepSchedPPO. The training algorithm processes vehicle driving states and outputs policy network parameters .
The testing algorithm then uses these trained parameters to make scheduling decisions for each vehicle’s DAG tasks during system operation in each time slot, computing delay, energy consumption, and system quality of service.
| Algorithm 1: DepSchedPPO training algorithm |
 |
| Algorithm 2: DepSchedPPO validating algorithm |
 |
5. Simulation and Result Analysis
5.1. Experimental Setup
The simulation process is crucial to demonstrate the effectiveness of our proposed dependency-aware task offloading framework. We employ a vehicular edge computing (VEC) environment to simulate the task offloading process under varying network conditions and vehicular mobility. The simulation involves multiple steps to ensure comprehensive evaluation of the algorithm’s performance.
The experimental setup utilizes Python 3.9 with TensorFlow on an Ubuntu 22.04.1 system, equipped with an Intel Xeon Gold 6148 CPU (2.40 GHz) and an NVIDIA GeForce RTX 3090 GPU. The VEC network follows a three-tier cloud–edge–vehicle framework, comprising centralized cloud servers, distributed mobile edge servers, and multiple vehicular nodes. The simulation is conducted on a straight segment of a bidirectional highway. In this setup, the cloud server’s base station covers the entire 2D rectangular map, while mobile edge servers are positioned randomly along the roadside, each providing circular wireless coverage. Vehicles travel at constant speeds within the base station’s coverage area.
In vehicular edge computing systems, intelligent vehicle applications can be modeled as Directed Acyclic Graphs (DAGs) with various topological structures. For example, navigation applications consist of tasks with multiple linear dependencies, while autonomous driving systems involve more complex interdependencies. To train a general and effective task offloading strategy, diverse task profiles and dependencies of different intelligent vehicle applications must be considered. Since existing application datasets contain limited application information [63], this experiment uses the DAG Generator [64] to generate DAGs for heterogeneous vehicular applications. The DAG Generator constructs DAG properties through parameters such as , , and , where: controls the width and height of the DAG, measures the connectivity level of nodes in the DAG, represents the ratio of communication cost to computation cost.
Following references [65,66], the DAG generation parameters are configured as follows: values: ; values: ; values: (since most intelligent vehicle applications are computation-intensive). For task information in DAGs: number of subtasks per DAG: , subtask data size: KB, computational complexity: Gcycles. For reinforcement learning hyperparameters, both Actor and Critic networks use the Seq2Seq architecture, which includes encoder neural network and decoder neural network, and both networks are 2-layer LSTMs with 256 hidden layer nodes.
To ensure optimal performance, the proposed algorithm relies on the fine-tuning of several key hyperparameters that directly influence its efficiency and stability. Specifically, the clipping range () is chosen to prevent large policy updates, which could otherwise lead to instability during training. The learning rate ( = ) is carefully set to control the speed of convergence. Additionally, the Generalized Advantage Estimator (GAE) factor () and the discount factor ( = 0.99) are selected to strike an effective balance between bias and variance in reward estimation, which is crucial for maintaining the algorithm’s robustness across dynamic task dependencies and varying network conditions in vehicular edge computing (VEC) environments. Furthermore, the value loss coefficient () and the entropy coefficient () play a critical role in balancing exploration and exploitation, enhancing the long-term decision-making capabilities of the algorithm. The architecture of the neural network is also optimized, with the number of layers and hidden units adjusted to align with the computational capabilities of the VEC system.
Table 3 and Table 4 detail the experimental environment parameters and deep learning configurations.
Table 3.
Experimental parameter settings.
Table 4.
Deep learning hyperparameter settings.
The simulation reflects dynamic vehicular mobility, fluctuating network bandwidth, and varying link quality. Vehicles travel at constant speeds within a defined area, with edge servers along the road and the base station ensuring full-area coverage for cloud connectivity, allowing vehicles outside the edge server’s range to offload tasks to the cloud.
- Task Offloading Simulation: Task graphs for each vehicle simulate offloading under three execution environments: local vehicle processing, MEC servers, and cloud servers. The DepSchedPPO algorithm makes offloading decisions based on real-time data, including network state, vehicular position, and available resources.
- Dynamic Mobility and Network Conditions: The simulation incorporates changing vehicle mobility and network conditions, which affect task offloading decisions due to bandwidth fluctuations and edge server status.
- Evaluation Metrics: We evaluate the algorithm using the following. Task Latency: Time from task initiation to result return. Energy Consumption: Total energy used by the vehicle, MEC, and cloud. Quality of Service (QoS): A composite metric balancing latency and energy consumption.
Results are compared with baseline methods, including heuristic and reinforcement learning-based offloading strategies, highlighting the effectiveness of our approach in reducing latency and energy consumption while maintaining high QoS under dynamic conditions.
This detailed simulation process demonstrates the practicality and robustness of our method, addressing challenges in dynamic task dependencies and real-time resource management in VEC systems.
5.2. Result and Analysis
Based on the above experimental setup, this subsection first verifies the effectiveness of the DepSchedPPO algorithm, then compares its algorithmic efficiency with baseline algorithms through controlled variable experiments. The impact of the number of DAG subtasks, V2M transmission rates, energy–delay trade-off weights, and vehicle computational capabilities on system delay, energy consumption, and quality of service (QoS) is evaluated.
5.2.1. Effectiveness of DepSchedPPO
As mentioned in Section 4.3, DepSchedPPO adopts an Actor–Critic framework. The Actor network adjusts policy update magnitudes using Equations (38) and (39) to compute the ratio between new and old policies and the clipped policy objective , thereby avoiding training instability from excessive updates and enabling smooth policy optimization. Additionally, according to Equation (42), the overall loss function consists of three components: : Stabilizes policy updates; : Policy entropy bonus encourages exploration of under-evaluated actions, preventing premature convergence to local optima; : Value function loss minimizes prediction errors in the Critic network, providing accurate feedback for Actor decisions.
The combined loss function optimizes long-term returns while ensuring stability and enhancing overall policy efficacy through exploration. Beyond the conventional average reward metric, this section uses policy loss, entropy bonus, and value loss to validate DepSchedPPO’s effectiveness.
Figure 6a shows the Value Loss during the training process. The decreasing trend indicates that the Critic network is improving its ability to estimate the value function over time. Initially, the sharp drop reflects rapid learning from random initialization, while the stabilization after 600 epochs suggests that the model has converged to a stable and reliable value estimate, which is essential for guiding the offloading decisions effectively. Figure 6b illustrates the Policy Loss over time. The high initial volatility reflects the exploration–exploitation trade-off as the policy network tries to learn optimal offloading decisions. As the training progresses, the policy loss decreases, indicating that the algorithm is stabilizing its decision-making process. After 600 epochs, the policy loss stabilizes, suggesting that the algorithm has achieved a balance between exploration of new strategies and exploiting learned behaviors. Figure 6c shows entropy bonus, which serves to encourage exploration. A higher entropy value indicates a more uniform action distribution, meaning that the policy is exploring a wider range of possible decisions. As the training progresses, the entropy stabilizes, which shows that the policy network has converged to a more refined decision-making strategy, balancing exploration with exploitation. Figure 6d confirms performance improvement through rising average rewards, with convergence after 600 epochs indicating mastery of effective offloading decisions.
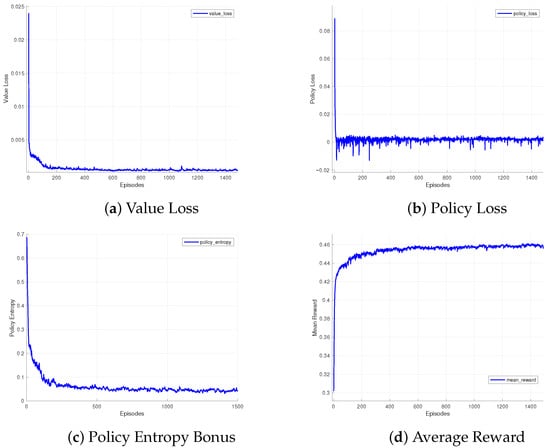
Figure 6.
Value loss, policy loss, policy entropy bonus, and average reward during DepSchedPPO training.
5.2.2. Efficiency of DepSchedPPO
To evaluate DepSchedPPO’s efficiency, we compare it against seven baselines under varying experimental parameters. Metrics include average delay, energy consumption, and QoS:
- ASTOTL [67]: All subtasks execute locally on vehicles (baseline for potential offloading benefits).
- ASTOTM [67]: All subtasks offloaded to MEC servers.
- ASTOTC [60]: All subtasks offloaded to cloud servers (high compute but long transmission).
- RANDOS [60]: Random offloading strategy (lower-bound reference).
- RRSA [68]: Round-Robin scheduling algorithm is suitable for fairness scenarios, and the subtasks are alternately offloaded to the vehicle terminal, MEC server and cloud.
- HBSA [69]: HEFT-Based scheduling algorithm considers both computation and communication costs of tasks. Beginning from the exit node of the DAG task graph, it recursively determines the uplink ranking for each task by computing its average execution and communication times. Based on this ranking, the algorithm assigns each task to the resource that yields the earliest possible completion time. The start time of a task is then set according to the availability of its allocated resource and the completion times of all its predecessors.
- SchedDDQN [27]: SchedDDQN is an improved version of DQN algorithm, which aims to improve the stability and accuracy of learning by separating action selection and action evaluation. Specifically, the SchedDDQN combines the duel depth Q network and dual dqn technology, without considering the long-term dependence between tasks. The algorithm uses the behavior network to select the next action, and uses the target network to evaluate the Q value of the action.
Figure 7 benchmarks several algorithms for different numbers of subtasks. As illustrated in Figure 7a, there are significant differences in the average latency performance of different algorithms when processing varying numbers of subtasks. The observations indicate that latency generally increases for all algorithms as the number of subtasks grows. Specifically, the ASTOTL algorithm and the ASTOTC algorithm exhibit relatively high latency. This is primarily due to the limited local computing resources of the vehicle terminals and the long transmission distance to the cloud, resulting in low transmission rates for V2C communication. The RANDOS algorithm and the RRSA algorithm demonstrate similar performance. The SchedDDQN algorithm incurs high latency costs, while the DepSchedPPO algorithm and the HBSA algorithm show superior performance. The results highlight the critical importance of offloading computation to external servers as task complexity rises, ensuring that the system can maintain low latency under high workloads.
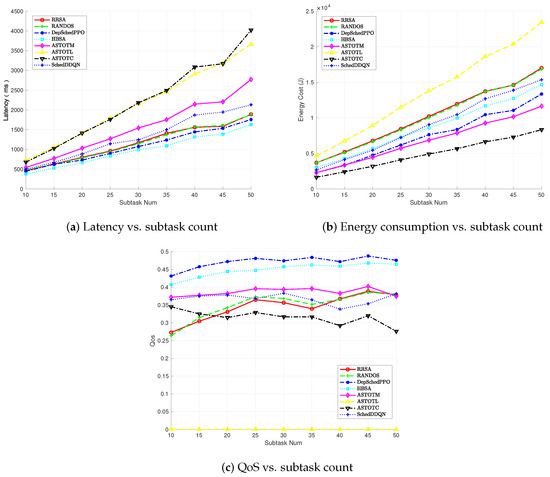
Figure 7.
Performance comparison under varying subtask counts.
Figure 7b compares the energy consumption of the algorithms as the number of subtasks increases. As expected, the ASTOTC and ASTOTM algorithms show lower energy consumption due to their reliance on edge and cloud servers, which distribute the computational load. In contrast, ASTOTL exhibits an increase in energy consumption as the number of subtasks rises. The vehicle terminal must process more tasks locally, consuming more energy with the increased workload. This result underscores the significant energy advantage of offloading computations to remote servers, especially as the number of tasks grows; collectively considering Figure 7a,b, the DepSchedPPO algorithm achieves a favorable balance across both critical metrics—closely approaching the latency-optimal algorithm in delay performance while nearing the energy-optimal offloading execution algorithm in energy efficiency, highlighting its scheduling efficacy; conversely, the SchedDDQN algorithm, by neglecting long-term task dependencies, incurs prohibitively high latency costs despite reasonable energy performance, indicating its inability to effectively balance these competing objectives during learning. In Figure 7c, we observe how the Quality of Service (QoS) changes with an increasing number of subtasks. The DepSchedPPO algorithm consistently delivers superior QoS, outperforming other algorithms. It effectively balances both latency and energy consumption, ensuring high performance across varying task sizes. The ASTOTL algorithm, while effective at lower subtask counts, sees its QoS performance decline as the task load increases, highlighting the limitations of relying on local computation for larger task sets. This demonstrates the importance of considering both latency and energy in QoS optimization, as seen with the DepSchedPPO algorithm’s superior performance.
Figure 8 presents a performance comparison of the algorithms under different V2M transmission rates, where Figure 8a shows the impact of varying V2M transmission rates on latency. As transmission rates increase, latency decreases for all algorithms, but with differing patterns. The ASTOTL and ASTOTC algorithms show stable latency across different transmission rates, reflecting their reliance on external computational resources that are unaffected by transmission speed. The other algorithms, however, show more improvement with increasing V2M rates, as faster transmission allows quicker offloading to edge servers, reducing the time spent waiting for computation. In Figure 8b, the energy consumption trends are similar. The ASTOTC algorithm consistently consumes the least energy, thanks to its reliance on powerful edge and cloud servers. The ASTOTL algorithm, which depends on local computation, shows higher energy consumption, particularly at lower transmission rates, as the vehicle terminal is required to handle more tasks locally. As transmission speeds increase, the benefits of faster offloading become evident, with edge-based algorithms (especially DepSchedPPO) showing the greatest improvement in energy efficiency. Collectively analyzing Figure 8a,b, although the latency-priority algorithm excels in average latency, it exhibits relatively high energy consumption, and notably, the edge-based execution algorithm shows the most significant performance enhancement with increasing V2M rates as these rates directly impact subtask offloading speed to edge servers; crucially, the DepSchedPPO algorithm demonstrates robust performance across both latency and energy metrics under all tested V2M transmission rates.
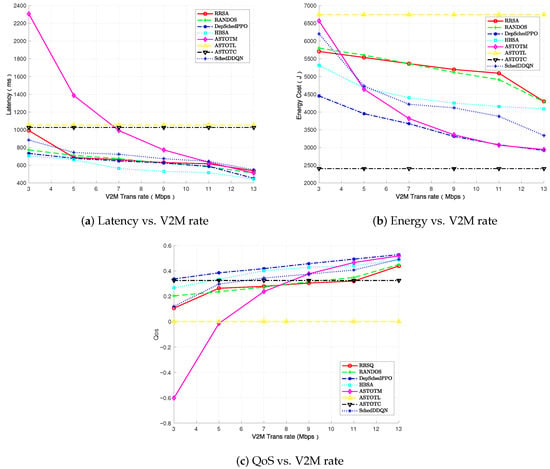
Figure 8.
Performance comparison under varying V2M transmission rates.
Figure 8c presents the performance of the algorithms on the average Quality of Service (QoS) metric under varying V2M transmission rates, showing that, except for the ASTOTL and ASTOTC algorithm, all other algorithms’ performance improves with increasing V2M rates; moreover, when the V2M rate exceeds 11 Mbps, the edge-based execution algorithm’s QoS approaches the optimal value, indicating that higher V2M rates increase the algorithm’s tendency to offload subtasks to edge servers for processing. Significantly, the DepSchedPPO algorithm consistently outperforms all others across all V2M rate levels, demonstrating its capability to effectively maximize QoS under diverse V2M conditions.
Figure 9 compares algorithm performance across different vehicle terminal computational capabilities. In Figure 9a, we observe the latency performance as the computational capabilities of the vehicle increase. The ASTOTM and ASTOTC algorithms show stable latency across all computational levels, as they rely on remote servers, whose performance is not affected by the vehicle’s computational power. The ASTOTL algorithm, however, demonstrates a noticeable reduction in latency as vehicle computational power increases. This suggests that, as the vehicle’s processing capacity grows, local execution becomes more efficient, reducing the need for offloading tasks and decreasing latency. Figure 9b compares energy consumption under varying vehicle computational capabilities. The ASTOTC algorithm continues to show the lowest energy consumption, due to its reliance on remote servers for task execution. The ASTOTL algorithm’s energy consumption decreases as the vehicle’s computational power increases, indicating that local computation becomes more energy-efficient with greater computational resources. At 3 GHz, the energy consumption of ASTOTL even becomes lower than ASTOTC, highlighting the advantages of local execution when computational resources are sufficient. Figure 9c evaluates average QoS performance across computational capabilities, where, using the local execution algorithm as the QoS reference baseline, results indicate the performance advantage of other algorithms relative to local execution diminishes—and even reverses—as terminal computational power increases, with ASTOTM and ASTOTC algorithms exhibiting negative QoS values between 2 GHz and 3 GHz, further confirming the superiority of local offloading strategies under high computational capability. Crucially, the DepSchedPPO algorithm proposed in this paper demonstrates superior performance across all tested computational capabilities. Additionally, at 3 GHz, its QoS approaches zero, indicating its increasing preference for local subtask processing on the terminal as computational capability strengthens.
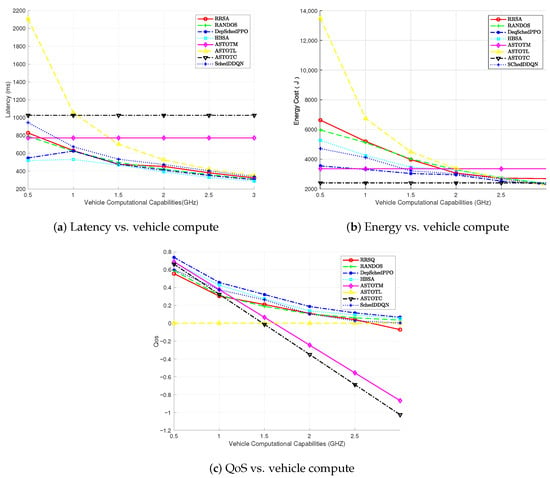
Figure 9.
Performance comparison under varying vehicle computational capabilities.
6. Conclusions and Future Work
In this paper, we investigate the dependency-aware computation offloading problem in vehicular edge computing environments, addressing a critical gap in existing research which predominantly assumes computationally independent tasks. To overcome this limitation, we propose a vehicle–edge–cloud-based vehicular edge computing system architecture. Our objective is to maximize system Quality of Service (QoS) for dependent tasks. To tackle the challenges posed by task dependencies, a Deep Reinforcement Learning (DRL) algorithm named DepSchedPPO (Dependency-Aware Task Scheduling based on Proximal Policy Optimization) was proposed. Specifically, the algorithm models task dependencies via Directed Acyclic Graphs (DAGs) and formulates the offloading problem as a Markov Decision Process (MDP). It employs Seq2Seq networks to approximate policy and value functions, effectively capturing long-term dependencies among DAG-structured tasks during training. A detailed explanation of the training and evaluation stages is provided, with both the Actor and Critic networks built upon Seq2Seq architectures. Subsequently, we conduct extensive simulations to validate the algorithm’s efficacy across four key metrics: value loss, policy loss, policy entropy reward, and mean reward. Experiments evaluate DepSchedPPO’s performance under varying subtask quantities, V2M transmission rates, and vehicle computational capabilities, with comparisons against baseline algorithms. Results demonstrate that DepSchedPPO efficiently makes offloading decisions in vehicular edge environments and effectively maximizes QoS.
The main contributions of this work include:
- Dependency-Aware Task Scheduling and Offloading: We introduce a novel approach that models vehicular tasks as Directed Acyclic Graphs (DAGs), ensuring that the task offloading respects both sequential constraints and parallelism, thereby improving system performance under realistic conditions.
- Deep Reinforcement Learning with PPO: We leverage the PPO algorithm to stabilize learning and enhance the offloading decision-making process, allowing for optimal scheduling in high-dimensional, dynamic environments.
- Integration of Task Dependencies and QoS Optimization: Unlike previous work, which often oversimplifies task dependencies, our approach models inter-subtask relationships and integrates Quality of Service (QoS) metrics to minimize latency and energy consumption, providing a more accurate representation of real-world vehicular applications.
- Comprehensive Evaluation: We conduct detailed evaluations under varying vehicular mobility and network conditions, showing that our method outperforms existing benchmarks, ensuring better adaptability and system robustness.
These contributions push the boundary of task offloading in VEC systems by addressing the dual challenges of dynamic task dependencies and network variability. Our method sets the stage for more efficient and reliable vehicular applications, especially those requiring real-time processing, such as autonomous driving, traffic management, and connected vehicle systems.
In the future, the proposed framework can be extended in several ways to improve its real-world applicability. First, we plan to relax the assumption that tasks are completed within a single time slot, allowing for multi-slot task execution and preemption, which would better suit real-world vehicular applications. Second, integrating advanced graph representation learning techniques, such as Graph Attention Networks (GATs) or Temporal Graph Neural Networks (TGNNs), could enhance the policy network’s ability to capture complex temporal–spatial dependencies in large-scale DAGs. Third, extending the framework to Multi-Agent Reinforcement Learning (MARL) would enable decentralized decision making across vehicles, improving scalability and robustness in ultra-dense networks. Additionally, while our current validation is based on synthetic simulations, we plan to validate the framework using real vehicular datasets and large-scale testbeds. Specifically, we will integrate the DepSchedPPO framework with Veins, SUMO, and OMNeT++ for high-fidelity simulations, capturing realistic vehicular mobility and network conditions. In the longer term, we aim to deploy the framework on a small-scale vehicular testbed to assess its feasibility under real operational conditions. Moreover, we will conduct a detailed comparison with other DRL algorithms such as A3C, SAC, and GNN-based RL. Finally, to address scalability challenges, we will explore hierarchical scheduling, task clustering, and policy distillation techniques to ensure the framework remains effective in large-scale, real-world vehicular networks.
Author Contributions
Conceptualization, W.S.; Methodology, W.S.; Software, W.S.; Validation, B.C.; Formal analysis, B.C.; Investigation, B.C.; Resources, W.S.; Data curation, B.C.; Writing—original draft, W.S.; Writing—review and editing, B.C.; Visualization, W.S.; Supervision, B.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ma, Y.; Wang, Z.; Yang, H.; Yang, L. Artificial intelligence applications in the development of autonomous vehicles: A survey. IEEE/CAA J. Autom. Sin. 2020, 7, 315–329. [Google Scholar] [CrossRef]
- Wang, Z.; Zhong, Z.; Zhao, D.; Ni, M. Vehicle-Based Cloudlet Relaying for Mobile Computation Offloading. IEEE Trans. Veh. Technol. 2018, 67, 11181–11191. [Google Scholar] [CrossRef]
- Tran, T.X.; Hajisami, A.; Pandey, P.; Pompili, D. Collaborative Mobile Edge Computing in 5G Networks: New Paradigms, Scenarios, and Challenges. IEEE Commun. Mag. 2017, 55, 54–61. [Google Scholar] [CrossRef]
- Zhao, J.; Li, W.; Zhu, B.; Zhang, P.; Tang, R. A Tachograph-Based Approach to Restoring Accident Scenarios From the Vehicle Perspective for Autonomous Vehicle Testing. IEEE Trans. Intell. Transp. Syst. 2025, 26, 13909–13926. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, F.; Chen, X.; Wu, Y. Efficient Multi-Vehicle Task Offloading for Mobile Edge Computing in 6G Networks. IEEE Trans. Veh. Technol. 2022, 71, 4584–4595. [Google Scholar] [CrossRef]
- Yin, L.; Luo, J.; Qiu, C.; Wang, C.; Qiao, Y. Joint Task Offloading and Resources Allocation for Hybrid Vehicle Edge Computing Systems. IEEE Trans. Intell. Transp. Syst. 2024, 25, 10355–10368. [Google Scholar] [CrossRef]
- Liang, J.; Tan, C.; Yan, L.; Zhou, J.; Yin, G.; Yang, K. Interaction-Aware Trajectory Prediction for Safe Motion Planning in Autonomous Driving: A Transformer-Transfer Learning Approach. IEEE Trans. Intell. Transp. Syst. 2025; early access. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, B.; Wang, B.; Sun, Q.; Dai, Y. Computation Offloading Strategy Based on Improved Polar Lights Optimization Algorithm and Blockchain in Internet of Vehicles. Appl. Sci. 2025, 15, 7341. [Google Scholar] [CrossRef]
- Zhang, K.; Zhu, Y.; Leng, S.; He, Y.; Maharjan, S.; Zhang, Y. Deep Learning Empowered Task Offloading for Mobile Edge Computing in Urban Informatics. IEEE Internet Things J. 2019, 6, 7635–7647. [Google Scholar] [CrossRef]
- Ma, G.; Wang, X.; Hu, M.; Ouyang, W.; Chen, X.; Li, Y. DRL-Based Computation Offloading With Queue Stability for Vehicular-Cloud-Assisted Mobile Edge Computing Systems. IEEE Trans. Intell. Veh. 2023, 8, 2797–2809. [Google Scholar] [CrossRef]
- Zhang, J.; Guo, H.; Liu, J.; Zhang, Y. Task Offloading in Vehicular Edge Computing Networks: A Load-Balancing Solution. IEEE Trans. Veh. Technol. 2020, 69, 2092–2104. [Google Scholar] [CrossRef]
- Song, T.J.; Jeong, J.; Kim, J.H. End-to-End Real-Time Obstacle Detection Network for Safe Self-Driving via Multi-Task Learning. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16318–16329. [Google Scholar] [CrossRef]
- Wu, J.; Zou, Y.; Zhang, X.; Liu, J.; Sun, W.; Du, G. Dependency-Aware Task Offloading Strategy via Heterogeneous Graph Neural Network and Deep Reinforcement Learning. IEEE Internet Things J. 2025, 12, 22915–22933. [Google Scholar] [CrossRef]
- Shang, Y.; Li, Z.; Li, S.; Shao, Z.; Jian, L. An Information Security Solution for Vehicle-to-Grid Scheduling by Distributed Edge Computing and Federated Deep Learning. IEEE Trans. Ind. Appl. 2024, 60, 4381–4395. [Google Scholar] [CrossRef]
- Li, Y.; Yang, C.; Chen, X.; Liu, Y. Mobility and dependency-aware task offloading for intelligent assisted driving in vehicular edge computing networks. Veh. Commun. 2024, 45, 100720. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, X.; He, X.; Sun, Y. Bandwidth Allocation and Trajectory Control in UAV-Assisted IoV Edge Computing Using Multiagent Reinforcement Learning. IEEE Trans. Reliab. 2023, 72, 599–608. [Google Scholar] [CrossRef]
- Li, C.; Wu, J.; Zhang, Y.; Wan, S. Energy-Latency Tradeoff for Joint Optimization of Vehicle Selection and Resource Allocation in UAV-Assisted Vehicular Edge Computing. IEEE Trans. Green Commun. Netw. 2025, 9, 445–458. [Google Scholar] [CrossRef]
- Cui, Y.; Du, L.; He, P.; Wu, D.; Wang, R. Cooperative vehicles-assisted task offloading in vehicular networks. Trans. Emerg. Telecommun. Technol. 2022, 33, 4472–4488. [Google Scholar] [CrossRef]
- Li, M.; Gao, J.; Zhao, L.; Shen, X. Adaptive Computing Scheduling for Edge-Assisted Autonomous Driving. IEEE Trans. Veh. Technol. 2021, 70, 5318–5331. [Google Scholar] [CrossRef]
- Fan, W.; Liu, J.; Hua, M.; Wu, F.; Liu, Y. Joint Task Offloading and Resource Allocation for Multi-Access Edge Computing Assisted by Parked and Moving Vehicles. IEEE Trans. Veh. Technol. 2022, 71, 5314–5330. [Google Scholar] [CrossRef]
- Wang, H.; Lv, T.; Lin, Z.; Zeng, J. Energy-Delay Minimization of Task Migration Based on Game Theory in MEC-Assisted Vehicular Networks. IEEE Trans. Veh. Technol. 2022, 71, 8175–8188. [Google Scholar] [CrossRef]
- Zhou, W.; Fan, L.; Zhou, F.; Li, F.; Lei, X.; Xu, W.; Nallanathan, A. Priority-Aware Resource Scheduling for UAV-Mounted Mobile Edge Computing Networks. IEEE Trans. Veh. Technol. 2023, 72, 9682–9687. [Google Scholar] [CrossRef]
- Tran-Dang, H.; Kim, D.S. FRATO: Fog Resource Based Adaptive Task Offloading for Delay-Minimizing IoT Service Provisioning. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 2491–2508. [Google Scholar] [CrossRef]
- Ning, Z.; Zhang, K.; Wang, X.; Guo, L.; Hu, X.; Huang, J.; Hu, B.; Kwok, R.Y.K. Intelligent Edge Computing in Internet of Vehicles: A Joint Computation Offloading and Caching Solution. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2212–2225. [Google Scholar] [CrossRef]
- Gu, B.; Zhou, Z. Task Offloading in Vehicular Mobile Edge Computing: A Matching-Theoretic Framework. IEEE Veh. Technol. Mag. 2019, 14, 100–106. [Google Scholar] [CrossRef]
- Ning, Z.; Huang, J.; Wang, X.; Rodrigues, J.J.P.C.; Guo, L. Mobile Edge Computing-Enabled Internet of Vehicles: Toward Energy-Efficient Scheduling. IEEE Netw. 2019, 33, 198–205. [Google Scholar] [CrossRef]
- Tang, H.; Wu, H.; Qu, G.; Li, R. Double Deep Q-Network Based Dynamic Framing Offloading in Vehicular Edge Computing. IEEE Trans. Netw. Sci. Eng. 2023, 10, 1297–1310. [Google Scholar] [CrossRef]
- Hui, Y.; Su, Z.; Luan, T.H.; Li, C. Reservation Service: Trusted Relay Selection for Edge Computing Services in Vehicular Networks. IEEE J. Sel. Areas Commun. 2020, 38, 2734–2746. [Google Scholar] [CrossRef]
- Li, J.; Liang, W.; Xu, W.; Xu, Z.; Jia, X.; Zhou, W.; Zhao, J. Maximizing User Service Satisfaction for Delay-Sensitive IoT Applications in Edge Computing. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 1199–1212. [Google Scholar] [CrossRef]
- He, X.; Lu, H.; Du, M.; Mao, Y.; Wang, K. QoE-Based Task Offloading With Deep Reinforcement Learning in Edge-Enabled Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2252–2261. [Google Scholar] [CrossRef]
- Wan, S.; Li, X.; Xue, Y.; Lin, W.; Xu, X. Efficient computation offloading for Internet of Vehicles in edge computing-assisted 5G networks. J. Supercomput. 2019, 76, 2518–2547. [Google Scholar] [CrossRef]
- Xu, X.; Gu, R.; Dai, F.; Qi, L.; Wan, S. Multi-objective computation offloading for Internet of Vehicles in cloud-edge computing. Wirel. Netw. 2020, 26, 1611–1629. [Google Scholar] [CrossRef]
- Xun, Y.; Qin, J.; Liu, J. Deep Learning Enhanced Driving Behavior Evaluation Based on Vehicle-Edge-Cloud Architecture. IEEE Trans. Veh. Technol. 2021, 70, 6172–6177. [Google Scholar] [CrossRef]
- Dai, P.; Hu, K.; Wu, X.; Xing, H.; Teng, F.; Yu, Z. A Probabilistic Approach for Cooperative Computation Offloading in MEC-Assisted Vehicular Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 899–911. [Google Scholar] [CrossRef]
- Zhou, J.; Tian, D.; Wang, Y.; Sheng, Z.; Duan, X.; Leung, V.C. Reliability-Optimal Cooperative Communication and Computing in Connected Vehicle Systems. IEEE Trans. Mob. Comput. 2020, 19, 1216–1232. [Google Scholar] [CrossRef]
- Liu, L.; Feng, J.; Mu, X.; Pei, Q.; Lan, D.; Xiao, M. Asynchronous Deep Reinforcement Learning for Collaborative Task Computing and On-Demand Resource Allocation in Vehicular Edge Computing. IEEE Trans. Intell. Transp. Syst. 2023, 24, 15513–15526. [Google Scholar] [CrossRef]
- Fu, J.; Zhu, P.; Hua, J.; Li, J.; Wen, J. Optimization of the energy efficiency in Smart Internet of Vehicles assisted by MEC. EURASIP J. Adv. Signal Process. 2022, 2022, 1–17. [Google Scholar] [CrossRef]
- Jia, Y.; Zhang, C.; Huang, Y.; Zhang, W. Lyapunov Optimization Based Mobile Edge Computing for Internet of Vehicles Systems. IEEE Trans. Commun. 2022, 70, 7418–7433. [Google Scholar] [CrossRef]
- Han, D.; Chen, W.; Fang, Y. A Dynamic Pricing Strategy for Vehicle Assisted Mobile Edge Computing Systems. IEEE Wirel. Commun. Lett. 2019, 8, 420–423. [Google Scholar] [CrossRef]
- Feng, W.; Zhang, N.; Li, S.; Lin, S.; Ning, R.; Yang, S.; Gao, Y. Latency Minimization of Reverse Offloading in Vehicular Edge Computing. IEEE Trans. Veh. Technol. 2022, 71, 5343–5357. [Google Scholar] [CrossRef]
- Ma, C.; Zhu, J.; Liu, M.; Zhao, H.; Liu, N.; Zou, X. Parking Edge Computing: Parked-Vehicle-Assisted Task Offloading for Urban VANETs. IEEE Internet Things J. 2021, 8, 9344–9358. [Google Scholar] [CrossRef]
- Qin, P.; Fu, Y.; Tang, G.; Zhao, X.; Geng, S. Learning Based Energy Efficient Task Offloading for Vehicular Collaborative Edge Computing. IEEE Trans. Veh. Technol. 2022, 71, 8398–8413. [Google Scholar] [CrossRef]
- Xiao, Z.; Shu, J.; Jiang, H.; Min, G.; Chen, H.; Han, Z. Overcoming Occlusions: Perception Task-Oriented Information Sharing in Connected and Autonomous Vehicles. IEEE Netw. 2023, 37, 224–229. [Google Scholar] [CrossRef]
- Rajak, R.; Kumar, S.; Prakash, S.; Rajak, N.; Dixit, P. A novel technique to optimize quality of service for directed acyclic graph (DAG) scheduling in cloud computing environment using heuristic approach. J. Supercomput. 2023, 79, 1956–1979. [Google Scholar] [CrossRef]
- Topcuoglu, H.; Hariri, S.; Wu, M.Y. Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans. Parallel Distrib. Syst. 2002, 13, 260–274. [Google Scholar] [CrossRef]
- Sundar, S.; Liang, B. Offloading Dependent Tasks with Communication Delay and Deadline Constraint. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 37–45. [Google Scholar] [CrossRef]
- Choudhary, A.; Gupta, I.; Singh, V.; Jana, P.K. A GSA based hybrid algorithm for bi-objective workflow scheduling in cloud computing. Future Gener. Comput. Syst. 2018, 83, 14–26. [Google Scholar] [CrossRef]
- Dong, S.; Xia, Y.; Kamruzzaman, J. Quantum Particle Swarm Optimization for Task Offloading in Mobile Edge Computing. IEEE Trans. Ind. Inform. 2023, 19, 9113–9122. [Google Scholar] [CrossRef]
- Lin, B.; Lin, K.; Lin, C.; Lu, Y.; Huang, Z.; Chen, X. Computation offloading strategy based on deep reinforcement learning for connected and autonomous vehicle in vehicular edge computing. J. Cloud Comput. 2021, 10, 33. [Google Scholar] [CrossRef]
- Liu, G.; Dai, F.; Huang, B.; Qiang, Z.; Wang, S.; Li, L. A collaborative computation and dependency-aware task offloading method for vehicular edge computing: A reinforcement learning approach. J. Cloud Comput. 2022, 11, 68. [Google Scholar] [CrossRef]
- Liu, S.; Yu, Y.; Lian, X.; Feng, Y.; She, C.; Yeoh, P.L.; Guo, L.; Vucetic, B.; Li, Y. Dependent Task Scheduling and Offloading for Minimizing Deadline Violation Ratio in Mobile Edge Computing Networks. IEEE J. Sel. Areas Commun. 2023, 41, 538–554. [Google Scholar] [CrossRef]
- Zhao, L.; Huang, S.; Meng, D.; Liu, B.; Zuo, Q.; Leung, V.C.M. Stackelberg-Game-Based Dependency-Aware Task Offloading and Resource Pricing in Vehicular Edge Networks. IEEE Internet Things J. 2024, 11, 32337–32349. [Google Scholar] [CrossRef]
- Luo, K.; Wang, Y.; Liu, Y.; Zhu, K. Collaborative Integration of Vehicle and Roadside Infrastructure Sensor for Temporal Dependency-Aware Task Offloading in the Internet of Vehicles. Int. J. Intell. Syst. 2025. [Google Scholar] [CrossRef]
- Sun, Z.; Mo, Y.; Yu, C. Graph-Reinforcement-Learning-Based Task Offloading for Multiaccess Edge Computing. IEEE Internet Things J. 2023, 10, 3138–3150. [Google Scholar] [CrossRef]
- Yan, J.; Bi, S.; Zhang, Y.J.A. Offloading and Resource Allocation With General Task Graph in Mobile Edge Computing: A Deep Reinforcement Learning Approach. IEEE Trans. Wirel. Commun. 2020, 19, 5404–5419. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, X.; Yuan, P.; Dong, H.; Zhang, P.; Tari, Z. Dependency-Aware Task Offloading Based on Application Hit Ratio. IEEE Trans. Serv. Comput. 2024, 17, 3373–3386. [Google Scholar] [CrossRef]
- Chen, M.; Wang, T.; Zhang, S.; Liu, A. Deep reinforcement learning for computation offloading in mobile edge computing environment. Comput. Commun. 2021, 175, 1–12. [Google Scholar] [CrossRef]
- Lu, H.; He, X.; Du, M.; Ruan, X.; Sun, Y.; Wang, K. Edge QoE: Computation Offloading With Deep Reinforcement Learning for Internet of Things. IEEE Internet Things J. 2020, 7, 9255–9265. [Google Scholar] [CrossRef]
- Sun, H.; Zhang, X.; Zhang, B.; Sha, K.; Shi, W. Optimal Task Offloading and Trajectory Planning Algorithms for Collaborative Video Analytics With UAV-Assisted Edge in Disaster Rescue. IEEE Trans. Veh. Technol. 2024, 73, 6811–6828. [Google Scholar] [CrossRef]
- Chen, J.; Yang, Y.; Wang, C.; Zhang, H.; Qiu, C.; Wang, X. Multitask Offloading Strategy Optimization Based on Directed Acyclic Graphs for Edge Computing. IEEE Internet Things J. 2022, 9, 9367–9378. [Google Scholar] [CrossRef]
- Zhan, W.; Luo, C.; Wang, J.; Wang, C.; Min, G.; Duan, H.; Zhu, Q. Deep-Reinforcement-Learning-Based Offloading Scheduling for Vehicular Edge Computing. IEEE Internet Things J. 2020, 7, 5449–5465. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar] [CrossRef]
- Sharma, N.; Ghosh, A.; Misra, R.; Das, S.K. Deep Meta Q-Learning Based Multi-Task Offloading in Edge-Cloud Systems. IEEE Trans. Mob. Comput. 2024, 23, 2583–2598. [Google Scholar] [CrossRef]
- Arabnejad, H.; Barbosa, J.G. List Scheduling Algorithm for Heterogeneous Systems by an Optimistic Cost Table. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 682–694. [Google Scholar] [CrossRef]
- Chai, F.; Zhang, Q.; Yao, H.; Xin, X.; Gao, R.; Guizani, M. Joint Multi-Task Offloading and Resource Allocation for Mobile Edge Computing Systems in Satellite IoT. IEEE Trans. Veh. Technol. 2023, 72, 7783–7795. [Google Scholar] [CrossRef]
- Guo, Z.; Bhuiyan, A.; Liu, D.; Khan, A.; Saifullah, A.; Guan, N. Energy-Efficient Real-Time Scheduling of DAGs on Clustered Multi-Core Platforms. In Proceedings of the 2019 IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Montreal, QC, Canada, 16–18 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 156–168. [Google Scholar] [CrossRef]
- Sahni, Y.; Cao, J.; Yang, L.; Ji, Y. Multihop Offloading of Multiple DAG Tasks in Collaborative Edge Computing. IEEE Internet Things J. 2021, 8, 4893–4905. [Google Scholar] [CrossRef]
- Zhang, X.; Li, R.; Zhao, H. A Parallel Consensus Mechanism Using PBFT Based on DAG-Lattice Structure in the Internet of Vehicles. IEEE Internet Things J. 2023, 10, 5418–5433. [Google Scholar] [CrossRef]
- Xiao, Q.z.; Zhong, J.; Feng, L.; Luo, L.; Lv, J. A Cooperative Coevolution Hyper-Heuristic Framework for Workflow Scheduling Problem. IEEE Trans. Serv. Comput. 2022, 15, 150–163. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).