Abstract
The Maxwell–Boltzmann (MB) distribution is fundamental in statistical physics, providing an exact description of particle speed or energy distributions. In this study, a discrete formulation derived via the survival function discretization technique extends the MB model’s theoretical strengths to realistically handle lifetime and reliability data recorded in integer form, enabling accurate modeling under inherently discrete or censored observation schemes. The proposed discrete MB (DMB) model preserves the continuous MB’s flexibility in capturing diverse hazard rate shapes, while directly addressing the discrete and often censored nature of real-world lifetime and reliability data. Its formulation accommodates right-skewed, left-skewed, and symmetric probability mass functions with an inherently increasing hazard rate, enabling robust modeling of negatively skewed and monotonic-failure processes where competing discrete models underperform. We establish a comprehensive suite of distributional properties, including closed-form expressions for the probability mass, cumulative distribution, hazard functions, quantiles, raw moments, dispersion indices, and order statistics. For parameter estimation under Type-II censoring, we develop maximum likelihood, Bayesian, and bootstrap-based approaches and propose six distinct interval estimation methods encompassing frequentist, resampling, and Bayesian paradigms. Extensive Monte Carlo simulations systematically compare estimator performance across varying sample sizes, censoring levels, and prior structures, revealing the superiority of Bayesian–MCMC estimators with highest posterior density intervals in small- to moderate-sample regimes. Two genuine datasets—spanning engineering reliability and clinical survival contexts—demonstrate the DMB model’s superior goodness-of-fit and predictive accuracy over eleven competing discrete lifetime models.
Keywords:
discrete Maxwell–Boltzmann; survival discretization; type-II censoring; Bayesian with Markov iterative; failure rate; moments; bootstrapping; genuine data modeling MSC:
60E05; 62E10; 62N01; 62N05; 62P10
1. Introduction
In recent decades, discrete distributions have been suggested as a preferable alternative to continuous distributions for complex count datasets. Classical models including binomial, Poisson, geometric, and negative binomial distributions are commonly used to model count data; however, they may not always yield the greatest fit. This highlights the need for more adaptable distribution methods. According to Alizadeh et al. [1], modeling using continuous lifespan distributions is a popular topic in a variety of sectors, including engineering science, medicine, economics, and others. Geometric and negative binomial distributions are used as discrete substitutes for the gamma and exponential distributions. However, these distributions do not always correspond to the facts as viewed. Several continuous lifespan distributions have recently been discretized in the literature due to the demand for more reliable discrete distributions capable of replicating discrete data in a range of real-world scenarios. In decision analysis, discretization refers to the process of reducing probability distributions of uncertainty to a small number of point masses that occur frequently. More information is available in Keefer and Bodily [2].
Determining the values of numerous points in the distribution, much less the actual distribution, can be difficult or costly when a decision analysis model is ambiguous. To speed up the computation and reduce the expense of computing some parallels, discretization substitutes difficult and computationally expensive integrations with the evaluation of a small number of utilities. Miller and Rice [3] discovered that discretization improves a decision analyst’s ability to communicate with clients. Even with increased processing power, discretization allows for the examination and assessment of conclusions that humans cannot understand. One way to think about the discretization process is as two separate processes. The first step is to select the points that will be used for discretization. These points typically correspond to the percentiles of the original distribution.
In the second phase of the discretization process, each location is assigned a probability mass. Days can reflect the length of life for people with brain tumors, or the period required for remission to return to survival studies. Every second of the day, reliability engineers check to see whether a system is operational. The observed data display the number of units that were completed successfully before breaking down. The count phenomenon can be observed in a variety of real-world circumstances, including accident frequency, ecological species types, insurance claims, and longevity data. Discrete distributions are effective for simulating lifespan data in certain cases. Because of their usefulness, discretization techniques are extensively used. Discrete probability distributions can be obtained by dividing them into intervals based on values or cumulative distributions. Each time, a percentile is assigned to the mean or median. Finally, each interval is allocated a probability proportional to its size. Means and percentiles are another option for discretization. Nakagawa and Osaki [4] provide information on the odds corresponding to the seconds in the original distribution.
Discrete models have recently been developed for use in domains such as medical, engineering, reliability studies, and survival analysis. For a more in-depth understanding and practical uses of discrete distributions, see references such as Alotaibi et al. [5] and Chesneau et al. [6]. While these studies expand discrete reliability theory and other application areas, they generally rely on continuous formulations or generic discretization techniques, which do not address the intricacies of the Maxwell–Boltzmann (MB) distribution. As a result, several scholars have made significant contributions to the growth of discrete dependability theory by introducing novel perspectives and approaches. Several discretization techniques are used to convert continuous models into discrete equivalents, and these techniques have been extensively studied and documented in scientific publications. The purpose of these strategies is to create discrete distributions that closely match their continuous sources. The literature has investigated several discretization strategies; Lai [7], Chakraborty [8], Afify et al. [9], and Augusto Taconeli and Rodrigues de Lara [10] are some examples.
A prominent method in the creation of discrete distributions is the use of the survival function as a discretization technique. Notable contributions in this field include the derivation of discrete analogs for the normal and Rayleigh distributions, which were presented by Roy ([11] and [12]), respectively, both of which used the survival function methodology. Building on this framework, Bebbington et al. [13] conducted a thorough investigation of the discrete additive counterpart of the Weibull distribution. Later, Haj Ahmad and Elshahhat [14], among others, provide further developments and examples of discrete transformations across different distributions.
In this study, we use the survival discretization approach to convert the continuous MB distribution into its discrete counterpart. Despite the MB distribution’s excellent adaptability in replicating various shapes of hazard rate function (HRF) in a continuous framework, real-world applications typically require data that have been censored or recorded at discrete intervals. In addition to preserving crucial statistical properties like percentiles and quantiles, discretizing the MB distribution using the survival function approach makes it easier to evaluate data that are subject to restrictions like Type-II censoring. This discrete formulation directly addresses the practical difficulties in survival and reliability analysis, which require discretely recording the exact time of failure occurrences for precise modeling and inference. Compared to traditional discretization procedures, this approach provides a framework that is more resilient to data inconsistencies while retaining the essential properties of the continuous model.
We address the limitations of the discrete MB (DMB) model, such as its computational complexity and reliance on numerical approaches, by extensive simulation tests and methodological modifications. Although our comparative study found that the DMB model performed better, it may be susceptible to certain types of data distributions, particularly if the failure rate deviates from the monotonic hazard rate structure that the model is designed to support. We assume that only the first r failure times, denoted as , are reported when n items undergo a life-testing experiment. This set is known as a type-II censored (T2C) sample; . The remaining elements are constrained and only have failure times larger than . The DMB model distinguishes itself from other one-, two-, and three-parameter discrete distributions by providing an increasing HRF form. The proposed model’s hazard rates make it suitable for modeling various datasets, including negatively skewed data. Other competitive models may not adequately model these probability mass shapes. The article introduces many statistical and reliability features, such as moments, probability functions, reliability, failure (or hazard) rates, and order statistics. The DMB distribution performed well in two real-world applications, outperforming eleven other discrete distribution models in the literature. The proposed parameters are estimated using maximum likelihood, Bayesian, and bootstrapping methods with T2C data. Monte Carlo simulations are used to evaluate the performance of the acquired estimators based on accuracy metrics such as the squared error, absolute bias, interval length, and coverage probability.
The remainder of the paper is organized as follows. Section 2 and Section 3 introduce the DMB distribution and present its main properties, respectively. Six interval estimation methods for the DMB parameter are examined in Section 4. Section 5 describes two approaches to parameter estimation. Section 6 reports and discusses the results of a Monte Carlo simulation study, while Section 7 analyzes two real-world datasets from engineering and clinical applications. Finally, Section 8 concludes the paper with the main findings and closing remarks.
2. New DMB Distribution
The Maxwell–Boltzmann (MB) distribution is a fundamental probability distribution in statistical physics that describes the distribution of speeds (or energies) of particles in an ideal gas at thermal equilibrium. Its mathematical formulation allows for precise modeling of the molecular speed, which is critical in deriving key physical laws such as the ideal gas law, diffusion rates, and reaction kinetics. The MB distribution’s importance extends beyond physics into areas like chemistry, atmospheric science, and even computational modeling, where it serves as a foundational tool for simulating particle-based systems and understanding statistical mechanics at a molecular level. For more discussions on the MB model, one may refer to Peckham and McNaught [15] and Rowlinson [16]. Now, we define the probability density function (say, ) and the distribution function (say, ) of a random variable X that follows a one-parameter MB() model, where is a scale parameter, respectively, as
and
where is the regularized lower incomplete gamma function, and is the complete gamma function. The equivalent form of the function (5) takes the following expression
where is the error term, and .
The classical MB distribution is widely used to model continuous particle speeds; however, many real-world systems generate or require discrete data, such as counts or binned measurements. In various practical scenarios, the assumption of continuity may not align with the way data are observed or recorded. Introducing a discrete MB (DMB) distribution helps bridge this gap, enabling more accurate and computationally efficient modeling of discrete thermal systems and kinetic processes. Several discretization approaches exist, the most notable of which is survival function-based discretization. The surviving discretization approach is utilized to construct its counterpart, the DMB model. The probability mass function (PMF), cumulative distribution function (CDF), and other properties of the DMB model are now derived. Following Roy ([17,18]), the DMB’s PMF using survival discretization is defined as
where
Consequently, from (4), the CDF and HRF of the newly DMB() model are
and
respectively. Upon several levels of DMB(), Figure 1 displays various shapes of the PMF and HRF for the DMB distribution.
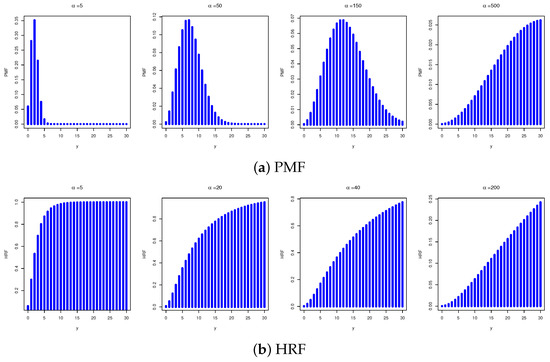
Figure 1.
The PMF and HRF shapes of the new DMB distribution.
Figure 1a highlights the flexibility of the DMB’s PMF, including increasing (right-skewed), decreasing (left-skewed), or symmetrical (bell-shaped), while Figure 1b states that the DMB’s HRF is always increasing. As changes, this flexibility makes the newly developed DMB highly valuable in statistical distribution theory for accurately describing a wide range of real-world discrete phenomena. In the next section, several additional statistical properties and characteristics of the DMB model, such as quantiles, moments, and ordered statistics, are derived.
Remark 1.
Krishna and Pundir [19] also proposed a discrete Maxwell distribution (dMax) obtained via SF-discretization. However, their formulation differs from ours in two important respects. First, in (4), the kernel of our distribution contains a scale factor proportional to , whereas in Krishna and Pundir [19] the corresponding factor is proportional to . For the two PMFs to coincide, both the exponential and prefactor terms would need to match. The prefactors reduce to which cannot be reconciled for a free scale parameter except under a degenerate constraint. Second, this reparameterization leads to different distributional behaviors. The DMB PMF can exhibit three probability mass forms depending on the value of α (see Figure 1). By contrast, the dMax PMF in Krishna and Pundir [19] is restricted to a positively skewed shape only. This additional shape flexibility broadens the applicability of the DMB distribution, enabling it to accommodate a wider variety of empirical patterns.
3. Statistical Functions
The quantile function, moments, and order statistics are among the statistical functions for the DMB distribution that are covered in this section.
3.1. Quantiles and Moments
For a discrete distribution, the quantile function is the inverse of the CDF. It is mostly used to produce random samples for simulation purposes. To find the symbolic expression for the quantile function of the distribution, we begin with the CDF in Equation (5) and proceed algebraically as follows:
hence,
where .
Substituting in Equation (7), we have
After some simplifications, the symbolic quantile function (8) is
This problem should be addressed numerically because it is based on a truncated sum of exponentially weighted quadratic terms with the denominator containing the entire infinite sum.
To calculate the moments of the DMB model, we use the non-negative random variable . The following r-th is the final formula for the moment, such as :
With in Equation (10), the mean of the DMB distribution () is
To compute the variance of the DMB distribution (), we use the formula , where
Using for , the skewness, denoted by , and the kurtosis, denoted by , of the DMB distribution can be obtained, respectively, as follows:
When comparing the variability of two independent samples, the coefficient of variation () is often employed, as it provides a relative measure of dispersion. The is defined as the ratio of the standard deviation to the mean and is a widely used measure of relative variability. Mathematically, it is expressed as
where and denote the standard deviation and mean, respectively. One of the key properties of the is that it is both dimensionless and scale-invariant, making it particularly useful for comparing variability across datasets with different units or scales.
In contrast, the index of dispersion (), also known as the variance-to-mean ratio, is defined as
While the is dimensionless when applied to count data or other dimensionless quantities, it is not scale-invariant. The is primarily used for non-negative discrete variables—especially count data—and plays a central role in identifying dispersion characteristics of a dataset.
The interpretation of the is as follows:
- : indicates over-dispersion (greater variability than expected under a Poisson distribution),
- : indicates equi-dispersion (variance equals the mean, as in the Poisson case),
- : indicates under-dispersion (less variability than expected).
This diagnostic tool is especially useful in model assessment and goodness-of-fit analysis for count data models. In the context of the DMB model, its statistic is derived as follows:
Specifically, taking several options of , Table 1 shows the statistical summary for the DMB model, including the mean (), variance (), index of dispersion (), coefficient of variation (), skewness (), and kurtosis (). As a result, when grows, we have noted that the results of and decreased, while those of and increased. It also reveals that the exhibits positive skewness, and exhibits that the DMB distributions are approximately mesokurtic to mildly platykurtic. Figure 2 displays shows some metrics of , , and for the proposed DMB model, and confirms the same details mentioned in Table 1.

Table 1.
Useful statistics of the DMB model using several choices of .
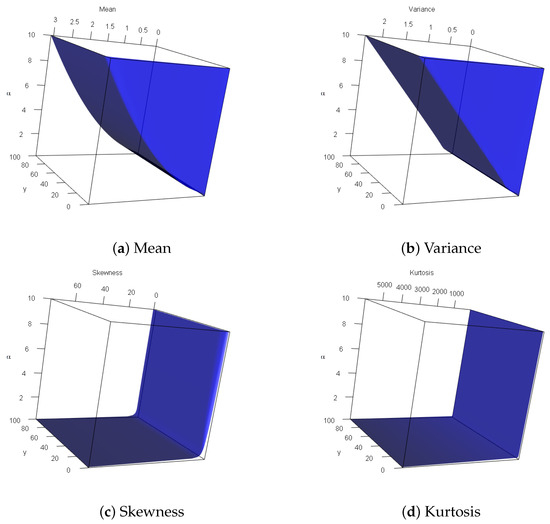
Figure 2.
Three-dimensional plots for the DMB characteristics.
3.2. Order Statistics
Taking as a random sample from the DGM model and assuming that represent their related order statistics, the order statistics have a CDF at y, whereby
The CDF can be represented as a series using the negative binomial theorem, which can be expressed as
Consequently,
The PMF for the i-th order statistic in the DMB model is as follows:
4. DMB Parameter Estimation
In this section, we estimate the DMB parameter by applying the maximum likelihood and Bayesian estimation methodologies.
4.1. Maximum Likelihood Estimator
This part develops the MLE of under a T2C strategy. Let denote a T2C sample from the DMB distribution. Using (4) and (5), the likelihood function (symbolized by ) and the corresponding log-likelihood function (symbolized by ) are given, by setting , respectively, by
and
where , and .
Differentiating (20), the normal equation of (which must be equated to zero to get its corresponding MLE ) can be written as follows:
where , and
Remark 2.
The closed-form expressions for the integrals and for cannot be obtained analytically in terms of incomplete gamma functions. Therefore, it is often preferable to compute the MLE using the Newton–Raphson () iterative method. For this purpose, the method is implemented via the maxNR command, which is available in the maxLik package (by Henningsen and Toomet [20]).
We now investigate the existence and uniqueness of the MLE . Owing to the complicated structure of the gradient equation in (21), it is analytically intractable to establish these properties in closed form. Consequently, a numerical assessment is conducted by simulating a T2C sample from the DMB distribution for with . The resulting MLEs of are and , respectively. Figure 3 displays the log-likelihood function in (20) and the corresponding score function in (21) as functions of over a specified range. In each case, the vertical line denoting the MLE intersects the log-likelihood curve at its maximum (red line) and the score function (blue line) at zero. These numerical findings verify that the MLE of exists and is unique for the considered scenarios.
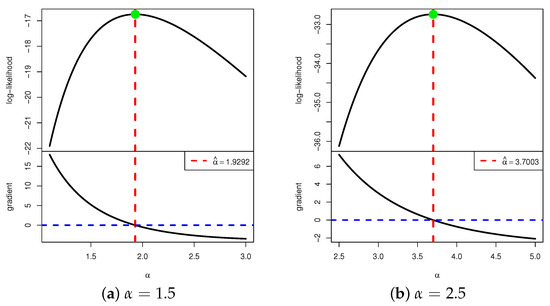
Figure 3.
The log-likelihood curve versus its gradient function curve for DMB .
4.2. Bayesian Estimator
This section discusses Bayesian estimation, which is used to estimate the unknown parameters of the DMB model. This method interprets the parameters as random variables that follow a specific model, known as the prior distribution. Because prior knowledge is frequently unavailable, it becomes vital to select an appropriate prior. A joint conjugate prior distribution is chosen for parameters , with each parameter assumed to have a gamma distribution. Hence, represent non-negative hyper-parameters of the given distributions. The prior distribution for , say , is defined as follows:
where () represents non-negative hyper-parameters of the DMB distribution parameter.
Given the objective T2C data , the posterior PDF of , say , can be represented as
where is the normalized term that does not depend on .
The squared-error loss (SEL) function has been used to examine the DMB model’s parameter estimate. Afterward, to assess the effectiveness of the estimation approaches and investigate how the parameter values affect them, a simulated analysis is conducted to evaluate the estimators’ effectiveness using several measure.
The Bayesian estimate of a parameter , say , is defined under the SEL as the expected value for the posterior distribution, such as
It is important to use numerical methods to compute the integration described in Equation (25). The Metropolis–Hastings (M-H) sampler, a fundamental concept in the MCMC family of Bayesian computation algorithms, was developed to solve this problem. A suitable R code was produced based on Algorithm 1 to implement this method. In doing so, we used the MCMC iterative approach beyond just providing the conditional posterior PDF of as
| Algorithm 1 The M-H Algorithm for Sampling |
|
5. Interval Estimation
This section presents six different interval estimation methods for the DMB() parameter, including two bootstrapping methods, two asymptotic confidence interval methods, and two credible interval methods. These estimators are derived under different inferential paradigms, frequentist, bootstrap-based, and Bayesian, each offering distinct theoretical foundations and practical characteristics. The subsequent subsections describe the formulation, computational procedures, and interpretation of each method in detail.
5.1. Asymptotic Intervals
To construct the asymptotic confidence interval (ACI) for the DMB parameter , the variance of is obtained from the Fisher information matrix (FIM), denoted by , which is derived as follows:
where the expectation operator is taken under the existing distribution of . However, for censored (or complex) data models, the observed information is often preferred due to its computational tractability. Thus, the expectation operator is dropped in practice; see Lawless [21].
The inverse of the FIM yields the variance, which is then used to construct the ACI for the DMB parameter . In practice, one may employ the observed FIM—the negative of the Hessian matrix of evaluated at the MLE —to approximate its variance, i.e., . As a result, to get the quantity of , where , we use
where , and .
Now, from (28), we can utilize the asymptotic normality approximation (NA) of the MLE , which is normally distributed with mean and variance . As a consequence, at a significance level , the ACI using NA-based (ACI[NA]) of is given by
where is the upper percentile of the standard normal distribution.
A well-recognized limitation of the ACI[NA] is its potential to produce negative lower bound of that is, by definition, restricted to positive values. In practice, such negative bounds are often replaced with zero; however, this constitutes a heuristic adjustment rather than a principled statistical remedy. To overcome this limitation and enhance the reliability of interval estimation, Meeker and Escobar [22] proposed the use of the ACI based on the log-transformed-NL (ACI[NL]), which is given by
5.2. Bootstrap Intervals
For small complete sample sizes (n), the performance of ACI[NA] (or ACI[NL]) approach is often unsatisfactory, as their validity relies on large-sample properties implied by the law of large numbers. To improve interval estimation under such conditions, two resampling-based procedures are employed: the bootstrap-p and bootstrap-t algorithms. These methods are applied to estimate the interval bounds of the DMB() parameter. The computation of the bootstrap-p (or bootstrap-t) intervals for these quantities begins by generating a bootstrap sample, as described in Algorithm 2. For additional details on creating bootstrap estimates in the R environment, see Chernick and LaBudde [23].
5.3. Credible Intervals
In the Bayesian framework, a BCI specifies a range of parameter values that, given the observed data and prior information, contain the true parameter with a stated posterior probability. Unlike the frequentist confidence interval, which is defined through the long-run behavior of repeated sampling, the BCI has a direct probabilistic interpretation. The BCI bounds are commonly reported either as HPD interval bounds, which include the most probable parameter values, or as equal-tailed intervals, which assign identical posterior probabilities to each tail of the distribution. In this part, via the MCMC sampling procedure described in Algorithm 1, both BCI and HPD methods are constructed; see Algorithm 3.
| Algorithm 2 Bootstrapping Confidence Intervals for |
| 1: Compute the MLE from the original sample. 2: for to do 3: Generate a bootstrap sample from . 4: Compute (MLE from the bootstrap sample). 5: end for 6: Sort the bootstrap estimates in ascending order: . 7: Bootstrap-p (Percentile) Interval (BP): 8: 9: 10: Boot-p 11: Bootstrap-t Interval (BT): 12: for to do 13: 14: end for 15: Sort T-statistics: 16: 17: 18: Boot-t |
| Algorithm 3 The BCI and HPD Interval Estimates for |
|
6. Simulation Comparisons
In this part, we conduct an extensive Monte Carlo simulation analysis to evaluate the associated behavior of the proposed estimators for the parameters of DMB() distribution. From this investigation, we conclude a discussion that provides a comprehensive examination of the experimental results obtained.
6.1. Simulation Setups
To generate T2C samples from the DMB() distribution and to establish the simulation setup for evaluating the proposed estimation procedures, we performed the following structured steps:
- Step 1:
- Specify the true parameter configurations of the DMB () distribution:
- Pop-1: DMB (0.8);
- Pop-2: DMB (1.5).
- Step 2:
- Select the sample sizes: .
- Step 3:
- Generate n independent pseudo-random values from the uniform distribution, say for .
- Step 4:
- Generate complete samples (with size n) from the DMB() distribution as
- Step 5:
- Sort for in ascending order.
- Step 6:
- Specify the failure percentage (FP%) as
- Step 7:
- Replicate Steps 2–6 5000 times.
- Step 8:
- Specify the hyperparameters :
- For Prior 1: and (6, 5) for Pop-, respectively;
- For Prior 2: and (12, 9) for Pop-, respectively.
- Step 9:
- Set and = 2000 for Bayes’ computations.
- Step 10:
- Set for bootstrapping computations.
- Step 11:
- For point estimates (including likelihood and Bayes), compute the following evaluation metrics:
- Average Point Estimate (APE):
- Root Mean Squared Error (RMSE):
- Mean Relative Absolute Bias (MRAB):where denotes the ith point estimate of .
- Step 12:
- For point estimates (including BP, BT, ACI[NA], ACI[NL], BCI, and HPD), compute the following evaluation metrics:
- Average Interval Length (AIL):
- Coverage Probability (CP) at 95% level:where and denote the lower and upper interval bounds, respectively.
6.2. Simulation Outcomes and Discussion
Table 2, Table 3, Table 4 and Table 5 summarize the simulation findings for each group of model parameters. Specifically, in Table 2, Table 3, Table 4 and Table 5, the APEs, RMSEs, and MRABs are reported in the first, second, and third columns, respectively. In Table 4 and Table 5, the AILs and CPs are reported in the first and second columns, respectively. Several assessments and recommendations are drawn from Table 2, Table 3, Table 4 and Table 5 based on the lowest RMSE, MRAB, and AIL values, as well as the highest CP values, as follows:
Table 2.
The point estimation results of from Pop-1.
Table 3.
The point estimation results of from Pop-2.
Table 4.
The interval estimation results of from Pop-1.
Table 5.
The interval estimation results of from Pop-2.
- The estimator accuracy improves with larger levels of n, reflecting the estimators’ consistency and robustness. In addition, a higher FP% contributes efficiency to the precision of all the acquired estimates.
- The Bayesian approaches using MCMC consistently outperform traditional likelihood-based estimation, especially with smaller values of n (or m), emphasizing the benefits of including prior information.
- The credible intervals (including BCI and HPD) exhibit superior performance compared to the proposed frequentist intervals (including BP, BT, ACI[NA], and ACI[NL]), benefiting from the efficiency gains introduced by informative IG prior information.
- Across all simulation scenarios, informative priors provide improved estimation accuracy in both point and interval Bayes calculations compared to those developed from the frequentist calculation.
- The point estimates perform better for Pop-1 than its competitor, indicating that moderate parameter values are more favorable for estimation accuracy.
- A comparative analysis of the estimation techniques yields the following insights:
- –
- For point estimation approaches, the Bayes proves superior to its competitor ML approach;
- –
- For interval estimation approaches:
- *
- The credible intervals (including BCI and HPD) exhibit satisfactorily compared to all others;
- *
- The BT method outperformed the BP method;
- *
- The ACI[NA] outperformed the ACI[NL] method;
- *
- The HPD outperformed the BCI method.
- As increases, the following behaviors are observed:
- –
- The RMSE and MRAB values decreased;
- –
- The AIL values increased, while the CP values decreased.
- Overall, Bayesian estimation alongside the HPD (or BCI) interval approach proves highly effective for parameter inference in both complete and incomplete (censoring) frameworks, delivering reliable and accurate results even in the presence of incomplete data.
Figure 4, Figure 5 and Figure 6 provide graphical representations of the simulation results, specifically illustrating the behavior of the RMSE, MRAB, AIL, and CP metrics across varying parameter configurations. These visual summaries corroborate and reinforce the patterns and conclusions presented in Table 2, Table 3, Table 4 and Table 5, offering further empirical validation of the estimator performance.
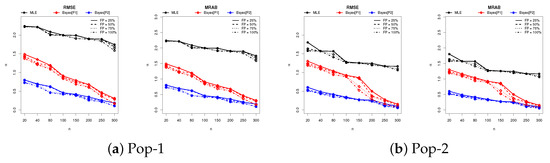
Figure 4.
Plot of the RMSE and MRAB results of .
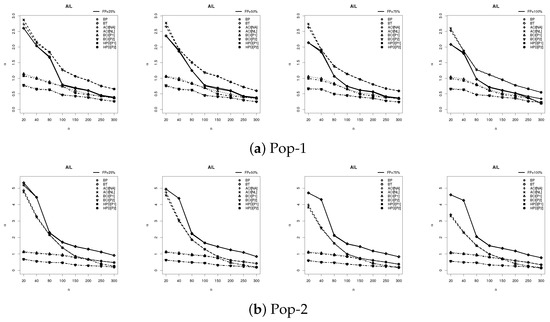
Figure 5.
Plot of the AIL results of .
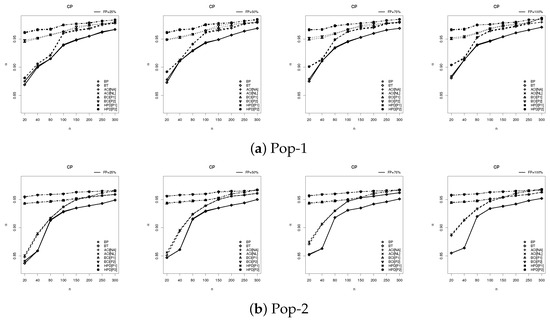
Figure 6.
Plot of the CP results of .
7. Real Data Applications
This section examines two different real-world datasets, gathered from engineering and clinical domains, to achieve the following objectives: (a) to evaluate the flexibility, effectiveness, and applicability of the proposed DMB model in the real world; (ii) to highlight how the model’s inferential outputs can inform decisions in practical settings; and (iii) to show how its performance compares to eleven well-established existing discrete models. Table 6 provides the datasets used, which are as follows:
Table 6.
Failure time points of liver cancer (Data-1) and shocks (Data-2).
- Liver Cancer in Female Mice:
- This application examines the temporal patterns of mortality in female mice treated with continuously fed dietary concentrations of 2-acetylaminofluorene (2-AAF), a fluorene-derived compound known for its mutagenic and carcinogenic properties. Throughout the 18-month experimental period, mice were either systematically sacrificed at scheduled intervals, found dead, or euthanized upon reaching a moribund condition. Necropsies were conducted to determine the presence of hepatic neoplasms. The resulting data consist of time-to-death information and liver tumor incidence rates, offering a longitudinal perspective on chemically induced carcinogenesis in a controlled murine model. See, for more details, Zhang and Zelterman [24]. We henceforward refer to this dataset as Data-1.
- Shocks Before Failure:
- This application investigates a dataset comprising twenty independent measurements, each reflecting the count of mechanical shocks sustained by a component before its functional breakdown. We henceforward refer to this dataset as Data-2. This dataset was first reported by Murthy et al. [25] and rediscussed later by Cordeiro et al. [26].
It is important to remember that the two datasets selected for this study, Data-1 from the medical domain and Data-2 from engineering, provide a diverse empirical basis, highlighting the proposed model’s ability to operate effectively across different application areas. Both datasets display complex real-world features, including discreteness and deviations from normality, which pose significant challenges for model validation. Table 7 presents the summary statistics for each dataset (Data-i, ), capturing key distributional characteristics such as the range (minimum and maximum), quartiles (), measures of central tendency (mean, mode), variability (standard deviation (SD)), and shape patterns (skewness and kurtosis). It indicates that Data-1 exhibits greater dispersion (SD = 8.229) and a right-skewed distribution (skewness = 0.474), whereas Data-2 shows lower variability (SD = 4.283) and mild left skewness (skewness = -0.359). Both datasets display mesokurtic tendencies (kurtosis < 3), indicating moderate tail behavior relative to the normal distribution.
Table 7.
Statistical summary for datasets 1 and 2.
To provide a comprehensive visualization of the data distribution, Figure 7 presents violin plots (in yellow color) for Data-i, . These plots integrate boxplots (in red color) with kernel density estimates, thereby conveying both key summary statistics and the underlying distributional characteristics. Figure 7(left) shows greater variability and a positive skew, with at least one clear outlier, indicating more extreme values in the liver neoplasms dataset. Figure 7(right) shows a symmetric, unimodal distribution with moderate spread and no clear outliers.
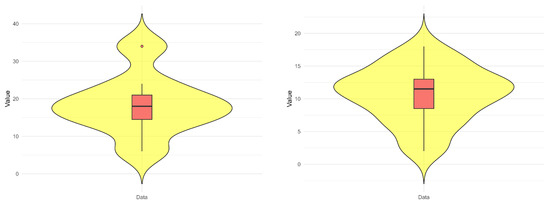
Figure 7.
Violin diagrams of Data-1 (left) and Data-2 (right).
To infer the form of the hazard rate and to provide a graphical diagnostic for assessing the fit of lifetime distribution models in survival and reliability analysis, the scaled TTT-transform plots for Data-i, are shown in Figure 8. It reveals that both datasets 1 and 2 show an increasing failure rate, which is one of the DMB failure rates depicted in Figure 1.
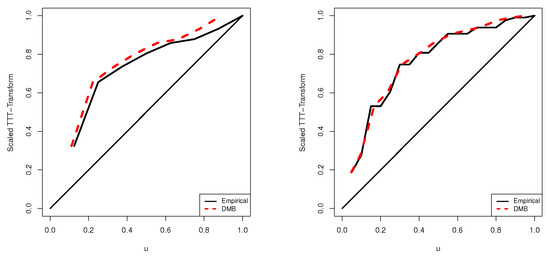
Figure 8.
Scaled TTT curves of Data-1 (left) and Data-2 (right).
Now, to demonstrate the adaptability, flexibility, and effectiveness of the proposed DMB distribution, a comprehensive comparative analysis is conducted. Using each dataset summarized in Table 6, the goodness-of-fit performance of the DMB is evaluated against 11 popular discrete models from the literature; see Table 8.
Table 8.
Eleven competing models of the DMB distribution.
To specify the most suitable model among the DMB and its competitors, a comprehensive analysis of model selection and goodness-of-fit criteria is employed, including the negative log-likelihood (NLL), Akaike information (AI), consistent AI (CAI), Bayesian information (BI), Hannan–Quinn information (HQI), and Kolmogorov–Smirnov (KS) statistics alongside its corresponding p-value. Table 9 reports the MLE (with its standard error (SE)) for each model parameter across all datasets under investigation. It also presents the estimated values of all metrics of model selection for each distribution listed in Table 8. Notably, the fitting outcomes provided in Table 9 show that the new DMB distribution demonstrates superior performance across all criteria, yielding the lowest values for each information-based metric. Table 9 also exhibits that the DMB model has the highest p-value with the lowest statistic compared to others. These findings stated that the proposed DMB model outperforms the competing alternatives; hence, it is the best choice when the entire Data-1 (or Data-2) is analyzed.
Table 9.
Fitting summary for the DMB and its competitors from Data-.
Goodness-of-fit visualization techniques serve as valuable diagnostic tools for evaluating the concordance between empirical data and a proposed theoretical distribution. For this purpose, in Figure 9, we demonstrate the superior performance of the DMB model through the application of three key graphical evaluation methods: (i) lines representing fitted probability mass lines with data histograms, (ii) fitted reliability function lines, and (iii) probability–probability (PP) lines.
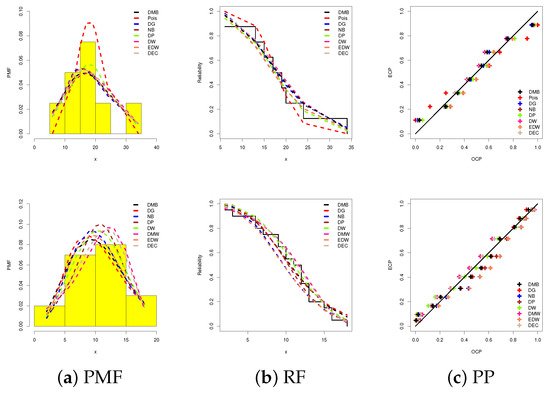
Figure 9.
Data visualizations of the DMB and its competitors Data-1 (top) and Data-2 (bottom).
Figure 9 confirms the numerical outcomes presented in Table 9, collectively supporting the conclusion that the proposed DMB model demonstrates superior fitting performance compared to several existing statistical models, both classical and newly developed.
To assess the performance of the estimators for the DMB () parameter—derived via MLE, bootstrap methods (with 10,000 replications), and Bayesian inference—different type-II right-censored samples, corresponding to different FP% levels, are generated from each dataset provided in Table 6. For each sample (where ), both point estimates (along with their SEs) and 95% interval estimates (along with their interval widths (IWs)) of are computed and presented in Table 10. A comparative analysis of Table 10 reveals that the Bayesian point estimators consistently exhibit smaller SEs than those obtained through frequentist (likelihood-based) methods, indicating greater estimation precision within the Bayesian framework. Furthermore, Table 10 shows that the Bayesian interval estimates, based on BCI (or HPD) interval method, consistently yield narrower IWs compared to those developed from frequentist intervals (including BP/BT and ACI[NA]/ACI[NL]). It is also observed that as the FP% increases, both the SEs and IWs associated with the estimation of tend to decrease, reflecting improved estimator efficiency. The utility of the proposed methodology is further demonstrated through its application to two widely used real-world datasets collected from distinct scientific domains, thereby affirming its practical relevance.
Table 10.
The point and 95% interval estimates of from Data-.
A main issue in utilizing the MCMC methodology is verifying that the simulation has achieved satisfactory convergence. To this end, Figure 10 displays both the trace plots and posterior density estimates for the parameter . Each panel includes the posterior mean (represented by a solid red line) and the 95% BCI bounds (shown as dashed red lines), providing a visual assessment of convergence and the underlying distributional characteristics. The plotted outcomes suggest that the proposed M-H approach attains reliable convergence, with the resulting DMB posterior distributions exhibiting approximate symmetry across samples from Data-. Additionally, Table 11 presents a comprehensive summary of key statistics for , derived from 30,000 iterations of the MCMC algorithm. Notably, the results in Table 11 support the numerical findings reported in Table 10 and behave similarly to the facts shown in Figure 10.
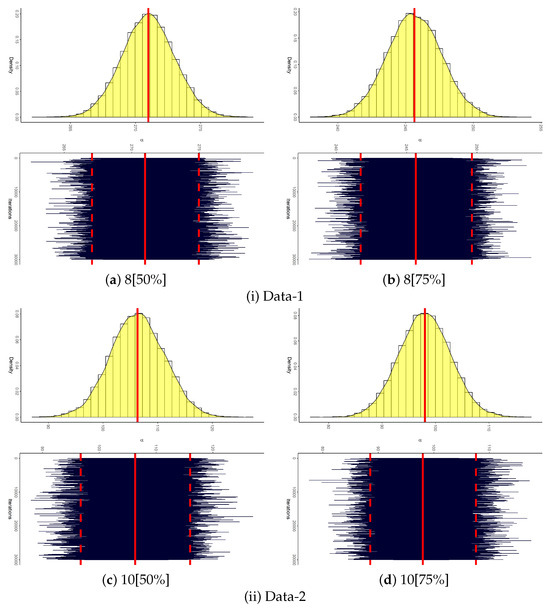
Figure 10.
Convergence MCMC diagrams of from Data-.
Table 11.
Statistics for 30,000 MCMC iterations of from Data-.
In summary, from the data analysis of Data-, it is clear that the proposed one-parameter DMB distribution exhibits excellent statistical properties, providing robust performance, high flexibility, and superior empirical fit compared to classical and modern discrete models. Its adaptability to diverse domains and reliable inference capabilities (especially within a Bayesian framework) underscore its value as a practical and theoretically sound tool for modeling real-world discrete data.
8. Conclusions
A novel one-parameter discrete probability called the discrete Maxwell–Boltzmann distribution was proposed in this article. It is a viable substitute for a few well-known discrete distributions. The DMB distribution’s mathematical characteristics are shown. Bayesian and maximum likelihood techniques are used to estimate the parameter. To compare these approaches, thorough simulation results are performed. Based on our discussion, the Bayes method outperforms its rival, the maximum likelihood approach, for point estimating techniques. Overall, the HPD (or BCI) interval approach combined with Bayesian estimation works very well for parameter inference in both complete and incomplete (censoring) frameworks, producing accurate and dependable results even when the data are incomplete. Beyond its theoretical development, the discrete MB model was shown to be highly adaptable to real-world count data exhibiting specific dispersion structures. Two distinct datasets were analyzed, one based on liver cancer in female mice and the other based on the count of mechanical shocks sustained, to demonstrate its superior goodness-of-fit over existing competing models, thereby confirming its flexibility and making it the optimal option. The work also highlighted potential applications in reliability analysis, actuarial science, and information theory, opening avenues for further interdisciplinary research.
Author Contributions
Methodology, A.E., H.R. and R.A.; Funding acquisition, R.A.; Software, A.E.; Supervision H.R.; Writing—original draft, A.E., H.R. and R.A.; Writing—review and editing, A.E. and R.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R50), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Data Availability Statement
The authors confirm that the data supporting the findings of this study are available within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Alizadeh, M.; Khan, M.N.; Rasekhi, M.; Hamedani, G.G. A new generalized modified Weibull distribution. Stat. Optim. Inf. Comput. 2021, 9, 17–34. [Google Scholar] [CrossRef]
- Keefer, D.L.; Bodily, S.E. Three–point approximations for continuous random variables. Manag. Sci. 1983, 29, 595–609. [Google Scholar] [CrossRef]
- Miller, A.C., III; Rice, T.R. Discrete approximations of probability distributions. Manag. Sci. 1983, 29, 352–362. [Google Scholar] [CrossRef]
- Nakagawa, T.; Osaki, S. The discrete Weibull distribution. IEEE Trans. Reliab. 2009, 24, 300–301. [Google Scholar] [CrossRef]
- Alotaibi, R.; Rezk, H.; Park, C.; Elshahhat, A. The discrete exponentiated–Chen model and its applications. Symmetry 2023, 15, 1278. [Google Scholar] [CrossRef]
- Chesneau, C.; Gillariose, J.; Joseph, J.; Tyagi, A. New discrete trigonometric distributions: Estimation with application to count data. Int. J. Model. Simul. 2024, 1–16. [Google Scholar] [CrossRef]
- Lai, C.D. Issues concerning constructions of discrete lifetime models. Qual. Technol. Quant. Manag. 2013, 10, 251–262. [Google Scholar] [CrossRef]
- Chakraborty, S. Generating discrete analogues of continuous probability distributions–A survey of methods and constructions. J. Stat. Distrib. Appl. 2015, 2, 6. [Google Scholar] [CrossRef]
- Afify, A.Z.; Ahsan-ul-Haq, M.; Aljohani, H.M.; Alghamdi, A.S.; Babar, A.; Gómez, H.W. A new one—Parameter discrete exponential distribution: Properties, inference, and applications to COVID-19 data. J. King Saud-Univ. -Sci. 2022, 34, 102199. [Google Scholar] [CrossRef]
- Augusto Taconeli, C.; Rodrigues de Lara, I.A. Discrete Weibull distribution: Different estimation methods under ranked set sampling and simple random sampling. J. Stat. Comput. Simul. 2022, 92, 1740–1762. [Google Scholar] [CrossRef]
- Roy, D.; Gupta, R.P. Characterizations and model selections through reliability measures in the discrete case. Stat. Probab. Lett. 1999, 43, 197–206. [Google Scholar] [CrossRef]
- Roy, D.; Ghosh, T. A new discretization approach with application in reliability estimation. IEEE Trans. Reliab. 2009, 58, 456–461. [Google Scholar] [CrossRef]
- Bebbington, M.; Lai, C.D.; Wellington, M.; Zitikis, R. The discrete additive Weibull distribution: A bathtub-shaped hazard for discontinuous failure data. Reliab. Eng. Syst. Saf. 2012, 106, 37–44. [Google Scholar] [CrossRef]
- Haj Ahmad, H.; Elshahhat, A. A new Hjorth distribution in its discrete version. Mathematics 2025, 13, 875. [Google Scholar] [CrossRef]
- Peckham, G.D.; McNaught, I.J. Applications of Maxwell–Boltzmann distribution diagrams. J. Chem. Educ. 1992, 69, 554. [Google Scholar] [CrossRef]
- Rowlinson, J.S. The Maxwell—Boltzmann distribution. Mol. Phys. 2005, 103, 2821–2828. [Google Scholar] [CrossRef]
- Roy, D. The discrete normal distribution. Commun. Stat. Methods 2003, 32, 1871–1883. [Google Scholar] [CrossRef]
- Roy, D. Discrete Rayleigh distribution. IEEE Trans. Reliab. 2004, 53, 255–260. [Google Scholar] [CrossRef]
- Krishna, H.; Pundir, P. Discrete Maxwell distribution. InterStat 2007, 1–15. Available online: http://interstat.statjournals.net/YEAR/2007/articles/0711003.pdf (accessed on 1 August 2025).
- Henningsen, A.; Toomet, O. maxLik: A package for maximum likelihood estimation in R. Comput. Stat. 2011, 26, 443–458. [Google Scholar] [CrossRef]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data; John Wiley and Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Meeker, W.Q.; Escobar, L.A. Statistical Methods for Reliability Data; John Wiley and Sons: New York, NY, USA, 2014. [Google Scholar]
- Chernick, M.R.; LaBudde, R.A. An Introduction to Bootstrap Methods with Applications to R; John Wiley and Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Zhang, H.; Zelterman, D. Binary Regression for Risks in Excess of Subject-Specific Thresholds. Biometrics 1999, 55, 1247–1251. [Google Scholar] [CrossRef]
- Murthy, D.N.P.; Xie, M.; Jiang, R. Weibull Models; John Wiley: Hoboken, NJ, USA, 2004. [Google Scholar]
- Cordeiro, G.M.; Lima, M.D.C.S.; Cysneiros, A.H.; Pascoa, M.A.; Pescim, R.R.; Ortega, E.M. An extended Birnbaum–Saunders distribution: Theory, estimation, and applications. Commun. Stat. Theory Methods 2016, 45, 2268–2297. [Google Scholar] [CrossRef]
- Gómez–Déniz, E.; Calderín–Ojeda, E. The discrete Lindley distribution: Properties and applications. J. Stat. Comput. Simul. 2011, 81, 1405–1416. [Google Scholar] [CrossRef]
- Poisson, S.D. Recherches sur la Probabilité des Jugements en Matière Criminelle et en Matière Civile: Précédées des Règles Générales du Calcul des Probabilités; Bachelier: Paris, France, 1837. [Google Scholar]
- Johnson, N.L.; Kemp, A.W.; Kotz, S. Univariate Discrete Distributions; John Wiley and Sons: New York, NY, USA, 2005. [Google Scholar]
- Chakraborty, S.; Chakravarty, D. Discrete gamma distributions: Properties and parameter estimations. Commun. Stat. Theory Methods 2012, 41, 3301–3324. [Google Scholar] [CrossRef]
- Tyagi, A.; Choudhary, N.; Singh, B. A new discrete distribution: Theory and applications to discrete failure lifetime and count data. J. Appl. Probab. Statist. 2020, 15, 117–143. [Google Scholar]
- Shafqat, M.; Ali, S.; Shah, I.; Dey, S. Univariate discrete Nadarajah and Haghighi distribution: Properties and different methods of estimation. Statistica 2020, 80, 301–330. [Google Scholar]
- Almalki, S.J.; Nadarajah, S. A new discrete modified Weibull distribution. IEEE Trans. Reliab. 2014, 63, 68–80. [Google Scholar] [CrossRef]
- Nekoukhou, V.; Bidram, H. The exponentiated discrete Weibull distribution. Sort 2015, 39, 127–146. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).