Abstract
Traditional Case-Based Reasoning (CBR) methods face significant methodological challenges, including limited information resources in case databases, methodologically inadequate similarity calculation approaches, and a lack of standardized case revision mechanisms. These limitations lead to suboptimal case matching and insufficient solution adaptation, highlighting critical gaps in the development of CBR methodologies. This paper proposes a novel CBR framework enhanced by generative AI, aiming to improve and innovate existing methods in three key stages of traditional CBR, thereby enhancing the accuracy of retrieval and the scientific nature of corrections. First, we develop an ontology model for comprehensive case representation, systematically capturing scenario characteristics, risk typologies, and strategy frameworks through structured knowledge representation. Second, we introduce an advanced similarity calculation method grounded in triangle theory, incorporating three computational dimensions: attribute similarity measurement, requirement similarity assessment, and capability similarity evaluation. This multi-dimensional approach provides more accurate and robust similarity quantification compared to existing methods. Third, we design a generative AI-based case revision mechanism that systematically adjusts solution strategies based on case differences, considering interdependence relationships and mutual influence patterns among risk factors to generate optimized solutions. The methodological framework addresses fundamental limitations in existing CBR approaches through systematic improvements in case representation, similarity computation, and solution adaptation processes. Experimental validation using actual case data demonstrates the effectiveness and scientific validity of the proposed methodological framework, with applications in risk assessment and emergency response scenarios. The results show significant improvements in case-matching accuracy and solution quality compared to traditional CBR approaches. This method provides a robust methodological foundation for CBR-based decision-making systems and offers practical value for risk management applications.
Keywords:
similarity calculation framework; case-based reasoning; generative artificial intelligence; risk assessment MSC:
68T20; 90B50
1. Introduction
Case-based reasoning (CBR) is a problem-solving method that primarily addresses new problems by retrieving, matching, and adapting historical cases, giving it a unique advantage in complex, dynamic, or knowledge-incomplete domains []. Unlike traditional rule-based or model-based reasoning methods, CBR emphasizes extracting knowledge from historical cases and using analogical reasoning to address new situations, offering greater adaptability and interpretability []. Given its reasoning characteristics, it is clear that the accuracy of the three stages—case retrieval, case matching, and historical case adaptation—directly impacts the effectiveness of solving new problems. With the rapid development of artificial intelligence and big data technologies, combined with its inherent reasoning advantages, CBR demonstrates significant application potential across various fields [,]. However, in practical applications, it still encounters numerous challenges, including the efficiency of case representation and retrieval, the dynamic updating of case repositories, the accuracy of similarity measurements, and the feasibility of cross-domain case transferability. Therefore, determining how to further enhance the intelligence level of CBR, efficiently retrieve massive cases, improve cross-domain transfer capabilities, and enhance adaptability in dynamic environments remain key challenges in current research.
Currently, in order to improve the reasoning performance of CBR, scholars in various countries have made relevant improvements to address the limitations of traditional CBR based on the 4R model proposed by Aamodt and Plaza, which includes case retrieval, reuse, revision, and retention []. In the case representation stage, in order to solve the problems of inconsistent data types and some missing data, scholars in various countries have proposed relevant methods. The case representation method based on knowledge graph can greatly improve the flexibility of case knowledge extraction, management and retrieval []. In the field of cascading disaster risk, a cascading disaster risk ontology system constructed by concepts and relationships has been proposed for application []. In the case retrieval matching stage, researchers have proposed different levels of similarity calculation between historical and target cases. The introduction of the combined method of Random Forest algorithm and Bayesian optimization can realize the adaptive retrieval of similarity cases []. Moreover, the quotient space granularity is introduced into the attribute-based similarity computation, and the case retrieval algorithm based on the theory of granularity synthesis is proposed []. In the final stage of case reuse revision, a new differential evolutionary algorithm is used to revise and improve the adaptability of historical cases []. In addition to this, a new approach to case adaptation can be proposed by combining multi-objective genetic algorithms with grey relational analysis called the Grey Relational Analysis-Multi-Objective Genetic Algorithms Approach (GRAMOGA) [].
Although all of the above studies have optimized and improved the traditional CBR method to a certain extent, there is still room for improvement. For example, in the case representation phase, existing methods (such as knowledge graphs and ontology systems) have improved the flexibility of case representation, but they still face challenges in the integrated representation of multi-source heterogeneous data. Additionally, current case representation methods are mostly based on static data and struggle to adapt to dynamic environments. In the case retrieval and matching phase, existing methods (such as Bayesian optimization random forests and commercial space granularity calculations) may still lack precision in similarity measurement for complex high-dimensional data, especially in non-linear relationship data. In the case reuse and revision phase, methods such as differential evolution algorithms and GRAMOGA have improved case adaptability, but the adjustment process still relies on manual rules or fixed strategies, lacking autonomous optimization capabilities. Finally, in terms of case repository maintenance and updates, there is limited research on maintenance mechanisms such as incremental learning, noise filtering, and redundant case deletion for case repositories. Future improvements in these areas are expected to further enhance CBR’s reasoning capabilities.
Based on related research, the purpose of this paper is to propose a case reasoning framework enhanced by generative AI. Overall, there are three innovative aspects of this framework. The first aspect concerns case representation. According to relevant studies [], an ontology model is chosen to represent various types of risk, and the model is easy to share and integrate []. In addition, in the process of data representation, this paper combines the Dempter–Shafer (D-S) evidence theory with the framing theory to obtain a more accurate description of the case in order to minimize the interference of incomplete information []. The second aspect is related to case retrieval. Following [], this paper proposes to use the DEMATEL method to determine the interdependent influence relationship among risks (or multiple risks). Their interdependence will make the risk response program more scientific and effective. The third aspect is case reuse and correction. In this paper, a case reuse method based on generative AI is proposed to generate practical response strategy plans using historical cases as references. In addition, a case study is conducted at the end to test the feasibility and effectiveness of the proposed method.
The stability of urban critical infrastructure is of vital importance to urban development []. With the continuous advancement of Internet technology, human daily life and the normal operation of society are becoming increasingly reliant on a continuous and stable power network []. However, in the face of sudden natural disasters, if risk management is poor or responses are not timely [,], it may cause more severe damage to the power network system. Through the improvement of the research method in this study, to a certain extent, it can provide important references for relevant departments to formulate emergency decisions for the power network under the background of typhoon disasters.
The rest of the paper is organized as follows. In Section 2, firstly, the CBR methods and generative AI currently used in the field of risk assessment are introduced. Then, the relevant theories and models involved in this paper are explained. In Section 3, firstly, the identification of key power risk factors based on D-S evidence theory is expounded, and then the ontology model is used to represent the risk cases. Secondly, a three-dimensional case retrieval method based on the public safety triangle theory is proposed. Finally, a case correction and reuse method based on generative AI is presented. In order to better illustrate the practicality of the method, Section 4 shows a case study of typhoon Capricorn. Section 5 concludes by summarizing the main contributions of the paper and suggestions for future work.
2. Literature Review and Theoretical Foundation
2.1. Literature Review
2.1.1. Risk Assessment Based on CBR
CBR is a method of solving a current problem by examining previous solutions to similar problems []. It is also an important problem-solving and learning method in the field of artificial intelligence because of the cognitive assumption that similar problems have similar solutions []. In addition, CBR is able to mimic the way humans think about problems and continuously accumulate past successes through self-learning, so its coverage gradually expands as the system is used [,]. Currently, CBR methods are widely used to support emergency decision-makers in making their decisions []. In the field of electric power safety, a study combines CBR with ontology to construct an emergency decision-making method for electric power personnel accidents. The method utilizes ontology to enhance the structured representation of case knowledge, which improves the matching efficiency and decision reliability of historical accident cases. Similarly, in renewable energy projects, the fusion of CBR and fuzzy logic is used in a wind farm risk identification framework, which improves the adaptability of risk prediction by handling uncertain risk factors through fuzzy reasoning []. In addition, in the field of hydropower operation and maintenance, the integration of CBR and knowledge graph is applied to assist decision-making for hydropower plant faults. The knowledge graph enhances the semantic association of fault cases, enabling the system to recommend solutions more intelligently []. In the field of grid operation accident handling, a CBR-based case analysis system has been developed to optimize the accident handling process and improve the emergency response speed through historical case matching and adaptive learning [].
Although the CBR method is widely used in the field of electric power network, it is not difficult to find that the existing risk assessment has limitations through the above examples, which are still dominated by the traditional CBR process, whether the construction of the case base is perfect, whether the similarity calculation between the target case and the historical case is reasonable, and whether the case correction link is scientific. In this paper, we improve this research deficiency by proposing a new CBR method, which combines CBR with generative AI, to conduct research on the risk assessment of urban infrastructure-electricity networks and emergency response strategies in the context of typhoon disasters.
2.1.2. Risk Assessment Based on Generative AI
Artificial intelligence (AI) is widely recognized as a key driver of technological change in the Fourth Industrial Revolution []. In recent years, generative AI, as an emerging branch of AI, has received widespread attention due to its great potential for content creation []. Unlike traditional AI, generative AI models, such as ChatGPT, are machine learning models that utilize complex algorithms, models, and rules to generate new data that is similar to, but not identical to, the original data by learning a large amount of data [].
Currently, this technology is widely used and has revolutionized various fields [,,]. Generative AI has also been applied in the field of risk assessment studied in this paper. In biosafety risk assessment, a study has explored the application of AI in synthetic biology to help risk management professionals systematically assess the potential biosafety impacts of synthetic biotechnology through machine learning and big data analytics, so as to develop more scientific prevention and control strategies []. In the field of occupational health and safety, AI-driven risk assessment systems have been developed to monitor the working postures of practitioners in high-risk industries. For example, an intelligent system based on the Rapid Entire Body Assessment standard is able to analyze the working postures of welders in real time, identify potential risks of musculoskeletal injuries, and issue timely warnings to reduce the incidence of occupational injuries []. In chemical risk assessment, AI technology has been introduced to optimize traditional assessment methods, improve the accuracy of predictions of toxicity and the environmental impacts of chemical substances through data modeling and pattern recognition, and provide support for chemical safety management and policy formulation []. In addition, a systematic review of three mainstream risk assessment methods integrating AI between 2010 and 2022 has been conducted in the literature, analyzing the advantages of these methods in terms of accuracy, efficiency, and adaptability, while also pointing out their limitations in terms of data dependency, model interpretability, and generalization ability [].
Based on the above research, it is found that the application of generative AI in risk assessment is mostly limited to the fields of biology, chemistry, medicine, etc., and has not been involved in the field of natural risk disaster. In addition, generative AI is mostly combined with emerging technologies, such as big data, cloud modeling and other methods, and less with traditional CBR methods, so this paper proposes to introduce generative AI into the CBR link to solve the natural disaster risk problem, which largely makes up for the shortcomings in this field.
2.2. Theoretical Foundation
2.2.1. D-S Evidence Theory
There is a large amount of multi-source and incomplete information in the real world, and the diversity of information as well as the lack of information can have an impact on the decision-maker’s decision []. To effectively alleviate the impact of uncertain information on the decision-making process of decision-makers, many scholars have proposed various solutions. The pairwise comparisons methods can quantify the relative importance, preferences, or attribute differences of objects by comparing them in pairs. The core aim is to break down the complex multi-object comparison into a series of simple binary comparisons. It can be applied to the determination of weights in multi-criteria decision-making, the ranking and optimization of schemes or objects, as well as the quantitative expression of subjective preferences []. The proposal of fuzzy sets breaks through the binary logic of “either-or” in traditional sets, allowing elements to belong to a certain set with partial membership degrees (values between 0 and 1), and enabling the quantitative expression of fuzzy concepts []. The D-S evidence theory, first proposed by Dempster in 1967 [], and further developed by Shafer into an imprecise reasoning theory [], can be used to handle uncertain information without the need to determine the prior probability and conditional probability of the factors influencing decisions in advance []. By comparing various methods and in combination with the research questions, we ultimately chose to use D-S evidence theory to handle the problem of information uncertainty. The following are the basic concepts of D-S evidence theory and the associated algorithms.
Definition 1
(Frame of Discernment). In D-S evidence theory, a discernment frame ( }) is an exhaustive set of all possible values of a variable, and the elements in the discernment frame are mutually exclusive. Let the number of elements in the discernment frame be N, then its power set contains elements, with each element of the set corresponding to a subset of the cases about which the variable takes values. The set of all propositions constituted by the power set is
Definition 2
(Basic Probability Assignment (BPA)). For any subset A belonging to , the function m is a mapping → [0, 1] and satisfies
The function m is said to be the basic probability assignment function BPA on , also known as mass function or evidence, and is said to be the basic probability assignment of proposition A, which characterizes the degree of support of the evidence for proposition A. If > 0, then proposition A is said to be a focal element of evidence m, and all the focal elements in evidence m constitute the core of the evidence.
Definition 3
(Fusion Rule of Dempster). Suppose , , …, are the n evidences on the discernment frame θ. According to Dempster’s definition, the fusion result of n evidences ⊕⊕…⊕ is denoted as
where K can be used to denote the conflict between n pieces of evidence satisfying K < 1, defined as follows:
2.2.2. The Public Safety Triangle Theory
The public safety triangle theory was first proposed in 1986, and is a consensus-based theory in the discipline of public safety. The theory covers the three aspects of accident risk, triggering and prevention [], corresponding to the three sides of the triangle, contingency, acceptor, and emergency management, which constitute a closed-loop framework of the triangle, and an analytical model linking the three sides of the nodes with the elements of material, energy, and messages as disaster elements [], as shown in Figure 1, which reveals the basic elements of the science of public safety, and provides a holistic consideration of the decision-making of public safety [].
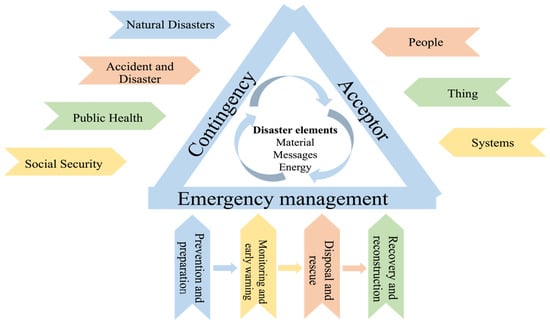
Figure 1.
The model of public safety triangle theory.
According to the public safety triangle theory, contingencies are events triggered by the elements of disasters, and when the elements of disasters break through the critical value, the destructive effect will be exerted on the acceptors, resulting in negative effects []. Contingencies mainly include natural disasters, accidents and disasters, public health and social security, and their impacts are mainly reflected in the damage of urban infrastructure, ecological environment damage, resource shortage, etc., thus posing impacts and threats to economic construction, public interests and normal life.
Among them, the actions that lead to the occurrence and generation of contingencies are called “disaster elements”, which specifically include material, energy and messages []. Acceptor refers to the time of occurrence of contingencies, people, things or systems and other objects subject to the role of contingencies, with ontological damage and functional damage, respectively, manifested in the vulnerability and robustness of acceptors []. Emergency management refers to the process of taking countermeasures [], divided into four main aspects: prevention and preparation, monitoring and early warning, disposal and rescue, recovery and reconstruction, corresponding to the crisis life cycle theory first proposed by Fink in the book Crisis Management: Planning for the Inevitable in 1986. The entire emergency management process plays a role in effectively preventing emergencies and their catastrophic consequences from harming the public [].
To sum up, there is a close relationship within the public safety triangle theory, and the three sides connected at the beginning and end show that the three elements are constrained by each other, and when one of the elements changes, the other two elements will automatically adjust to maintain a constant equilibrium relationship among the three elements, so as to realize the security of the whole system.
3. Methodology
Based on traditional CBR, this section applies D-S evidence theory, the public safety triangle theory, and new generative AI technologies to each key link of CBR to enhance the accuracy of CBR. The following Figure 2 is the method flowchart of this article.
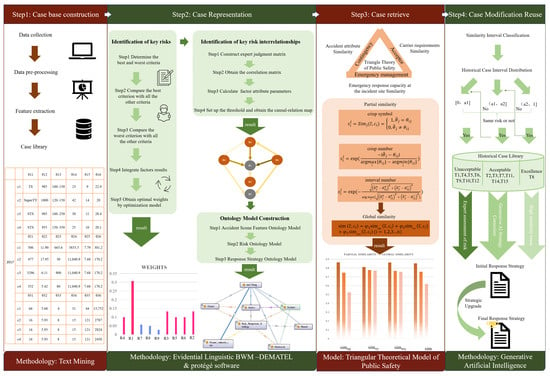
Figure 2.
Research framework of network risk response based on generative AI-enhanced CBR.
3.1. Case Representation Supported by D-S Evidence Theory
Before the case representation, identifying key risk factors and determining their direct relationships is essential to ensuring the accuracy, relevance, and effectiveness of subsequent case representation. This step serves as the foundation of the entire CBR framework. Its core objective is to extract key information from complex risk scenarios, providing clear information for subsequent ontology modeling and case correction, and ultimately enhancing the scientificity and effectiveness of the entire risk response framework. To achieve this, we first collect relevant risk records from official channels. Secondly, the expert group is invited to identify the main risks using evidence-based BWM methods based on the data collected. After that, the secondary risks are screened out and then the expert panelists determine the direct impact relationship among the primary risks based on the DEMATEL evidence method. Finally, based on the results of the above analysis, an ontology model is utilized to represent the power network risk case.
3.1.1. Evidence-Based BWM Primary Risk Determination
In this study, several types of power network risks that often occur in the context of typhoon disasters are summarized by reviewing a large amount of literature. Subsequently, the above risks are ranked in order of importance through expert assessment, and finally the major power network risks that have the greatest impact on various sectors are identified, as follows.
- Step 1:
- Determine the best and worst risk
First, m experts from the field of risk management were invited to rate this questionnaire. Each expert’s choice of maximum risk and minimum risk is collected through the evidence BWM expert questionnaire. Let all risks be {,, , , , …}, respectively, the experts are scored using the evidential linguistic term set proposed by Fei et al. []. In this scoring approach, the identification framework is first defined as S = {, …, }, whose specific linguistic terms and meanings are shown in Table 1. The expert indicates the impact importance of each factor by a value between 0 and 1, and assigns corresponding confidence levels to these values, and the sum of all the confidence levels is 1. This scoring approach is different from the traditional 1–5 scoring system, and can deal with the problem of uncertainty and the cognitive ambiguity of the expert’s information more effectively. By comparing two by two, the maximum and minimum risks among all risks are determined, which are denoted as maximum risk and minimum risk , respectively.

Table 1.
Linguistic terms and meanings.
- Step 2:
- Compare the highest risk with all the other risks
On the basis of the determined maximum risk in Step 1, the experts score the comparison of the determined maximum risk with the other risks, again ensuring that all the confidence sums are 1. Where denotes the result of the comparison of the maximum risk with the other risks , it is clear that the result of the comparison of the maximum risk with the maximal risk is () = 1.
- Step 3:
- Compare the worst risk with all the other risks
Similar to Step 2, the comparison of other risks to minimal risk is still represented using the evidence linguistic term set, where represents the result of comparing other factors to minimal risk. Similarly, the result of the comparison of minimum risk to minimum risk is () = 1.
- Step 4:
- Integrate factors results
Since the results obtained in Steps 1 to 3 are the individual opinions of the experts, the experts’ opinions need to be integrated to obtain the final results regarding the importance of each factor. This integration process was realized through code written to ensure accuracy and consistency in data processing.
- Step 5:
- Obtain optimal weights by optimization model
After integrating all the results, they are transformed into numerical form based on the probabilities and the transformed data are entered into the weight calculation software in order to obtain the weights and consistency coefficients for each risk. Risks with weight values less than 0.05 are eliminated to ensure the simplicity and accuracy of the model.
3.1.2. Evidence-Based DEMATEL Determination of Direct Impact Relationships for Key Risks
Since there will be relevant influences between each risk and their internal relationships will directly affect the effectiveness of the risk response strategy, this paper needs to consider the direct interactions between risks when developing each risk response strategy. This paper mainly uses the DEMATEL method to determine the interaction between factors. It is a methodology of systems science, mainly employing graph theory and matrix tools. By establishing a correlation matrix among the various elements in the system, the causal relationships among the elements and the position of each element in the system are ultimately determined [].
The filtered major risks are obtained through the evidence BWM method, and m experts from different fields are invited to provide their opinions to determine the influence relationships of N factors. Each expert is asked to indicate the extent to which he believes the factor influences the factor (expressed as →). The specific steps of DEMATEL based on the evidential linguistic term set are as follows []:
- Step 1:
- Construct expert judgment matrix
Replace the 0–4 graded scoring method with the evidential linguistic term set. Assuming that the expert gives the degree of interaction between all factors, construct it to form an non-negative judgment matrix , m = 1, 2, 3, …, m, where denotes the degree to which the expert’s judgment of influences . Note that the diagonal of each answer matrix is set to “-”, meaning that the factor does not affect the factor itself.
- Step 2:
- Obtain the initial direct relationship IDR matrix
Based on the scoring method of the evidential linguistic term set used by the experts in Step 1, we first integrated the results, and then transformed the integration results into numerical form according to the corresponding probabilities, which in turn gave us the initial direct relationship IDR matrix as G.
- Step 3:
- Obtain the normalized IDR matrix
The maximum row and column sum of the matrix G is
the normalized IDR matrix can be calculated by equating.
- Step 4:
- Obtain the total relationship matrix
- Step 5:
- Calculate factor attribute parameters and analyze the results
- Step 6:
- Set up the threshold and obtain the causal-relation map
Using the center degree as the horizontal coordinate and the cause degree as the vertical coordinate, draw the scatter plot of the cause degree and center degree among the main risks. The sum of the mean value and the standard deviation of the total relationship matrix of each group is also calculated as the threshold value, and the raw values exceeding the threshold value are considered to demonstrate the existence of influence, which is indicated by arrows on the graph.
3.1.3. Ontology Modeling Primitives
The concept of ontology originally originated in the field of philosophy, where it was defined as “a systematic description of objective things in the world”, i.e., “existentialism”. Later, Gruber defined ontology as “a clear specification of conceptualization” that facilitates the integration and sharing of knowledge []. It enables us to construct disaster cases with domain knowledge and to reuse this knowledge as a whole []. Typically, ontologies are categorized into four types []: top-level ontologies, domain ontologies, task ontologies, and application ontologies. Among them, the top-level ontology mainly studies the relationship between concepts. Domain ontology studies the connection between concepts within a specific domain. Task ontology is used to express the connection between concepts within a specific task. The application ontology is used to describe some specific applications, which can refer to concepts in the domain ontology as well as concepts appearing in the task ontology. Within an ontology, there are five main elements: classes, relations, functions, axioms, and instances. This study uses Protégé software [], a scenario-based ontology case representation, where all historical cases and target cases are represented as ternary groups (i.e., incident attribute descriptions, risk network descriptions, and response strategy descriptions).
3.2. Three-Dimensional Case Retrieval Based on the Public Safety Triangle Theory
Case retrieval is one of the key steps in CBR. It involves searching for historical cases from the case base that are similar to the new case (i.e., the new problem). Once the most similar cases are identified, their solutions can be reused and adapted to the current problem []. Among other things, the quality of the case search determines the effectiveness of the system []. Based on this, this part proposes a three-dimensional case retrieval method based on the public safety triangle theory, which involves three main similarity measures (i.e., accident attribute similarity, carrier requirements similarity, and emergency response capability at the incident site similarity). Firstly, the accident attribute similarity is used to measure the similarity between the two cases themselves, which is calculated through a series of hazard attribute indicators. Secondly, the carrier requirements similarity is used to measure the similarity in terms of the immediate recovery needs of the incident site after the disaster, which is assessed in terms of people, thing and systems. After that, the emergency response capability at the incident site similarity is used to measure the similarity of the local response capacity to the disaster, and this part is based on the crisis life cycle theory. The local similarity is first calculated for each segment, and finally the results of these three similarity measures are aggregated into a composite similarity between the historical cases and the target cases to determine the final set of similar cases.
3.2.1. Local Similarity Calculation
In this step, three data types (crisp symbol, crisp number, and interval number) are used to represent the incident attributes. Let , and denote the data types as crisp symbol, crisp number, and interval number. The attribute feature set is = {, , , …, }, where denotes a certain attribute feature. The accident attribute similarity between each historical case and the target case is denoted as (, ), the carrier requirements similarity is denoted as (, ), and the emergency response capability at the incident site similarity is denoted as (, ). Calculations were performed using the following Equations (10)–(12) depending on the data type.
- (1)
- If ∈, the local similarity between cases is computed as []:where is the value of the attribute , which is the jth in case , and is the value of the attribute, which describes the j-th in the i-th case.
- (2)
- If ∈, the local similarity between cases is computed as []:where max and min denote the maximum and minimum operations, respectively.
- (3)
- If ∈, the local similarity between cases is computed as []:where and denote the number of intervals, respectively.
3.2.2. Global Similarity Calculation
In this step, firstly, the local similarity within the three similarity measures is averaged according to the same weights, and the thresholds of the three similarity measures (, , ) are set by the experts. The cases whose results of the three similarity measures satisfy the thresholds ( ≥ , ≥ , ≥ ) are classified into the initial set of cases = {, , , …, }. After that, the global similarity is calculated for all cases in the initial case set, and the corresponding weights (, , ) are set for each similarity metric to operate according to Equation (13), and the final result of the weighting operation is obtained.
3.3. Case Correction and Reuse Based on Generative AI
The CBR method is based on the strategy of using the most similar historical cases to solve the target case []. However, in general, due to the fact that events may differ from each other to a different extent, the retrieval results of some historical cases cannot be directly applied to solve the current risks [], and it is necessary to formulate reasonable and scientific modification rules to reprocess the response strategies of historical cases. Based on numerous scholarly studies [,,], this paper introduces generative AI into the case revision process to improve the rationality and applicability of response strategies. The specific operation steps are shown in Figure 3.
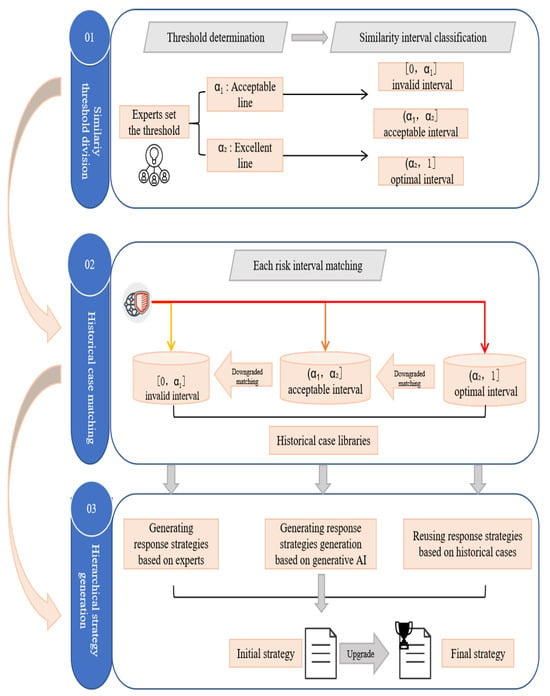
Figure 3.
Flowchart of risk response strategy generation for power network based on historical case similarity.
- Step 1:
- Threshold determination.
This step consists of the expert determining two thresholds, and , from the similarity interval of [0, 1]. where denotes the acceptable bottom line and denotes the similarity merit line.
- Step 2:
- Similarity interval classification.
After the threshold is determined in the first step, the original [0, 1] similarity interval can be divided into three segments as [0, ), [, ), and [, 1], which are named invalid, acceptable, and optimal intervals, correspondingly.
- Step 3:
- All historical cases’ interval distributions.
Match the global similarity results calculated for each historical case in Section 3.2.2 of this paper into each interval defined in Step 2 and organize the historical cases within each interval.
- Step 4:
- Strategy reuse based on high-similarity historical cases.
If the power network risk experienced by the target case can find a response scheme in the historical case within the optimal interval (, 1], the risk response strategy of the target case can directly reuse the response strategy in the historical case. If the corresponding response scheme cannot be found, then go to Step 5.
- Step 5:
- Strategy correction based on generative AI.
If the power network risk experienced by the target case can be found in the response scenarios of the historical cases within the acceptable interval (, ], the current response scenarios of the historical cases need to be optimized and improved with the help of generative AI in order to generate a response strategy that is more applicable to the target case. If the corresponding response scheme cannot be found, then go to Step 6.
- Step 6:
- Strategy revision based on risk experts.
If the power network risk experienced by the target case can only be found in the historical cases within the invalid interval [0, ] for the response scenario, the response strategy is not informative due to the minimal similarity between the historical cases falling within the interval and the target case, so the expert power is needed to make the response decision for this part of the risk.
- Step 7:
- Strategy upgrade
Since direct interactions between risks are discussed in Section 3.1.2, if the direct impact risk and the directly affected risk occur simultaneously in the target case, the decision-maker should decide whether to escalate the existing strategy and increase the treatment of the direct impact risk [], which will also mitigate the occurrence of the directly affected risk to some extent.
- Step 8:
- Risk strategy integration.
Finally, the risk response strategies obtained in different intervals are integrated to obtain a complete risk response strategy for the target case. The above eight steps can result in modified response strategies that are more adapted to the target case to ensure that all risks involved in the target case are effectively addressed []. In addition, the proposed strategy modification process takes into account the direct interdependencies between risks, which can improve the effectiveness of generating risk response strategies. Finally, the target case and its risk response strategies are retained in the case base to enrich the case base and provide more effective strategy references for the next risk.
4. Case Study
In this section, a concrete case is presented to illustrate in detail how the proposed new method can be used to cope with the major risks faced by urban infrastructures under natural disasters.
We collect typhoon information, including the China Meteorological Data Network (http://data.cma.cn/en (accessed on 19 August 2025)), Typhoon Path Network (http://typhoon.zjwater.gov.cn (accessed on 19 August 2025)), and other channels for collecting typhoon information from across China between 2017 and 2024, and the typhoon risk database with 42 source cases is constructed. A case base of electric power network risk under disasters is constructed, and the Capricorn typhoon that occurred in September 2024 is selected as the target case of this study. According to the public safety triangle theory presented in Table 2, 22 attribute characteristics, numbers, weights and their references with regard to the three dimensions are described. The ontology modeling of the partial attribute characteristics of the accident part in Figure 4 is carried out using protégé software. Table 3 shows the values of some of the attribute features for some of the source cases and the selected target case.
Table 2.
Details of disaster scenario features.
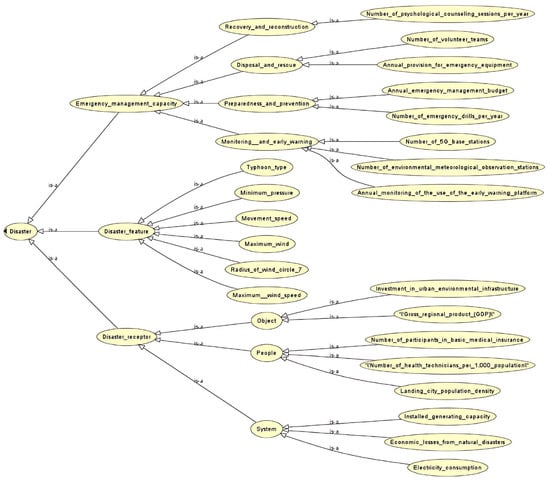
Figure 4.
Accident scene feature ontology model.
Table 3.
Characteristic values of some attributes of some historical cases and target cases.
Based on the evidential BWM questionnaire, the results were validated with a consistency coefficient below 0.5 (as shown in Table 4). Risks with weights below 0.05 were filtered out to identify the key power network risks for this study, and the risk ontology model (shown in Figure 5) was constructed accordingly.
Table 4.
Evidence-based BWM key risk screening results.
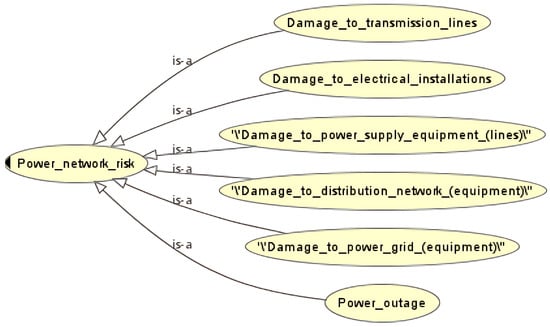
Figure 5.
Risk ontology model.
Then, based on the results of the evidence DEMATEL questionnaire, as shown in Table 5, the direct interrelationships between each of the main power network risks are identified, as shown in Figure 6. From Figure 6, we can clearly observe that (Damage to power grid (equipment)), (damage to power supply equipment (lines)), (damage to electrical installations) and (damage to transmission lines) all affect (power outage) to varying degrees. Meanwhile, and also influence and . We take one group of mutual influence relationships as an example for a detailed analysis. Since (damage to power grid (equipment)) will have a certain impact on (power outage), it can be understood according to the following three aspects: (1) When both and risks occur simultaneously, by strengthening the control of , the consequences of can also be mitigated to a certain extent. (2) When the risk control strategy of is difficult to effectively improve , can be improved, thereby indirectly influencing . (3) When has occurred but has not, since there is a certain connection between the two, the response strategy for can be adjusted in advance to prevent the occurrence of . We have incorporated this reference into our revised manuscript.
Table 5.
Evidence-based DEMATEL results for key risk interactions.
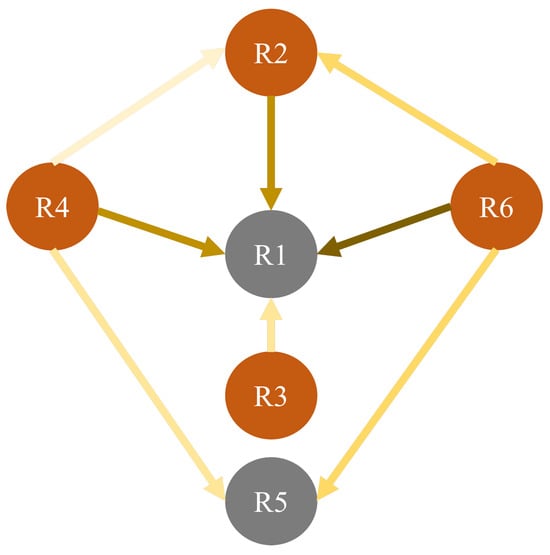
Figure 6.
Direct impact relationships between major risks.
According to Equations (10)–(12), the local similarity between the target case and each historical case is calculated separately, and the results are shown in Table 6, Table 7 and Table 8.
Table 6.
Local similarity of accident attributes between the target case and some of the historical cases.
Table 7.
Local similarity of acceptor attributes between some historical examples of the target cases.
Table 8.
Local similarity of emergency response capability attributes between target cases and selected historical cases.
After that, according to the thresholds set by the experts of each dimension ( = 0.5, = 0.7, = 0.7), the historical cases with the combined similarity of the three dimensions exceeding the thresholds are filtered out and retained in the initial case base. Thus, an initial case base = {, , , …, }, which contains 15 source cases, is established. Finally, according to the weights of each dimension set by the experts ( = 0.6, = 0.2, = 0.2), the global similarity of the three dimensions is calculated according to Equation (13) for the cases in the initial case base, and the results are shown in Table 9.
Table 9.
Global similarity between cases in the initial case base.
The global similarity of the above cases is divided into specified intervals according to the interval thresholds ( = 0.7, = 0.85) given by the experts to briefly illustrate the process of case modification and reuse by taking the power network risk of typhoon Capricorn as an example.
Through the global similarity interval division, one historical case falls in the optimal interval [0.85, 1]; seven historical cases fall in the acceptable interval [0.7, 0.85); and seven historical cases fall in the invalid interval [0, 0.7). After removing all the historical cases in the invalid interval, the risk strategies in the optimal interval are used directly, and the risk strategies in the acceptable interval are used after training and learning based on generative AI, and then the cause factor strategies are upgraded based on the interactions between the major risks, which in turn results in the final risk coping strategy being created to support emergency decision-making. The specific strategies are shown in Table 10. The corresponding response strategy ontology model is shown in Figure 7.
Table 10.
Generation and optimization of emergency strategies for target cases.
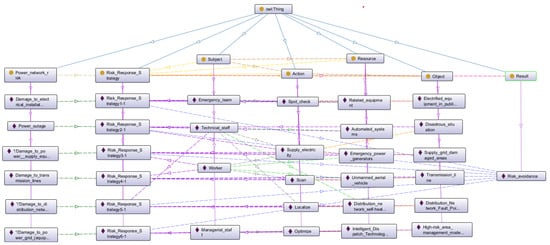
Figure 7.
Response strategy ontology model.
5. Contributions and Future Directions
Solving new events by learning from previous events is an effective and preferred method after all types of emergencies. Therefore, the optimization of CBR methods is an ongoing academic concern. Traditional CBR methods face significant methodological challenges, including limited information resources in case databases, unscientific similarity computation methods, and the lack of a unified case correction mechanism. These limitations lead to suboptimal case matching and insufficient solution adaptation, and although the above problems have been optimized by some scholars, there is still room to improve the effectiveness of the method. Based on this, this paper proposes a CBR framework enhanced by generative AI. The methodological framework addresses fundamental limitations in existing CBR approaches through systematic improvements in case representation, similarity computation, and solution adaptation processes. The specific novelty contributions are the following three.
(1) In the case representation session, the proposed ontology model provides a structured basis for case knowledge organization. The ontology explicitly defines the core concepts, attributes, relationships, and constraint rules in each case, providing a rigorous semantic framework for subsequent retrieval and reasoning. In addition, it ensures the structured storage of case data and solves the problem of loose knowledge representation and semantic ambiguity in traditional approaches.
(2) In the case-matching session, the enhanced similarity computation method provides a more accurate case matching capability. The method not only considers the similarity of the surface features of the cases, but also deeply integrates the analysis of the differences between different scenarios and the interdependence between key factors. This comprehensive consideration significantly improves the accuracy, relevance, and contextualization of case matching and ensures that the retrieved historical cases are more practical references for solving new problems.
(3) In the case revision session, the generative AI enhanced revision mechanism dynamically optimizes the solution. This mechanism leverages the powerful pattern recognition, content generation, and adaptation capabilities of generative models. Based on this, the generative AI model intelligently revises, adjusts, and optimizes the original solution to better fit the needs and constraints of the new problem. This revision process is dynamic and interactive, absorbing feedback and continuously improving the quality and applicability of the solution.
There are still some limitations of this study, in terms of the optimization of the CBR process, the comprehensiveness of the similarity calculations between the historical cases and the target case, and the development of coping strategies for the target case in the face of uncertain natural disaster scenarios, which may lead to unprecedented risk patterns, i.e., “inexperience” cases, which are are issues that still need to be further investigated in this paper. In addition, in terms of the application of the methodology, the methodology proposed in this paper needs to be explored in depth in order to extend its application to other domains, such as risk response in water supply networks, transportation networks, and so on.
Author Contributions
Methodology, Software, Visualization, Writing—original draft, J.S.; Conceptualization, Supervision, Funding acquisition, Writing—review and editing, L.F. All authors have read and agreed to the published version of the manuscript.
Funding
This work is partially supported by National Natural Science Foundation of China (Grant No. 72404172), the Humanities and Social Science Fund of the Ministry of Education of China (Grant No. 24YJC630042), the Natural Science Foundation of Shandong Province of China (Grant No. ZR2023QG099), and the National Key Research and Development Program of China (Grant No. 2024YFE0106600), the Pei Xin Graduate Research Fund of the School of Political Science and Public Administration, Shandong University(Grant No. SDZG2024010208).
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Acknowledgments
The authors would like to express their sincere gratitude to the journal Mathematics for its support and consideration, the editorial team for their professional guidance, and anonymous reviewers for insightful comments, all of which were instrumental in refining this work. The authors are also grateful to the publishing house for upholding academic standards.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Aamodt, A.; Plaza, E. Case-based reasoning: Foundational issues, methodological variations, and system approaches. AI Commun. 1994, 7, 39–59. [Google Scholar] [CrossRef]
- Ketler, K. Case-based reasoning: An introduction. Expert Syst. Appl. 1993, 6, 3–8. [Google Scholar] [CrossRef]
- Bannour, W.; Maalel, A.; Ben Ghezala, H.H. Emergency management case-based reasoning systems: A survey of recent developments. J. Exp. Theor. Artif. Intell. 2023, 35, 35–58. [Google Scholar] [CrossRef]
- Amailef, K.; Lu, J. Ontology-supported case-based reasoning approach for intelligent m-Government emergency response services. Decis. Support Syst. 2013, 55, 79–97. [Google Scholar] [CrossRef]
- Li, P.; Zhou, M.; Lin, X.; Zhou, L.; Cai, P. An Ancillary Decision-Making Method for Hydropower Station Failure Handling Based on Case-Based Reasoning and Knowledge Graph. Processes 2024, 12, 2731. [Google Scholar] [CrossRef]
- Yu, F.; Fan, B.; Li, X. Improving emergency preparedness to cascading disasters: A case-driven risk ontology modelling. J. Contingencies Crisis Manag. 2020, 28, 194–214. [Google Scholar] [CrossRef]
- Li, J.; Guo, Y.; Dou, Y.; Wang, J.; Qiu, B.; Liu, X. An approach to bearing fault diagnosis based on ensemble learning and case-based reasoning. J. Phys. Conf. Ser. 2024, 2787, 012042. [Google Scholar] [CrossRef]
- Lu, J.; Jiang, Q.; Huang, H.; Zhang, Z.; Wang, R. Classification algorithm of case retrieval based on granularity calculation of quotient space. Int. J. Pattern Recognit. Artif. Intell. 2021, 35, 2150003. [Google Scholar] [CrossRef]
- Yu, X.; Li, C.; Zhao, W.X.; Chen, H. A novel case adaptation method based on differential evolution algorithm for disaster emergency. Appl. Soft Comput. 2020, 92, 106306. [Google Scholar] [CrossRef]
- Zhang, B.; Li, X.; Wang, S. A novel case adaptation method based on an improved integrated genetic algorithm for power grid wind disaster emergencies. Expert Syst. Appl. 2015, 42, 7812–7824. [Google Scholar] [CrossRef]
- Hu, J.; Fang, J.; Du, Y.; Liu, Z.; Ji, P. A security risk plan search assistant decision algorithm using deep neural network combined with two-stage similarity calculation. Pers. Ubiquitous Comput. 2019, 23, 541–552. [Google Scholar] [CrossRef]
- Yu, F.; Li, X.Y.; Han, X.S. Risk response for urban water supply network using case-based reasoning during a natural disaster. Saf. Sci. 2018, 106, 121–139. [Google Scholar] [CrossRef]
- Shen, L.; Li, J.; Suo, W. Risk response for critical infrastructures with multiple interdependent risks: A scenario-based extended CBR approach. Comput. Ind. Eng. 2022, 174, 108766. [Google Scholar] [CrossRef]
- Shao, J.; Liang, C.; Liu, Y.; Xu, J.; Zhao, S. Relief demand forecasting based on intuitionistic fuzzy case-based reasoning. Socio-Econ. Plan. Sci. 2021, 74, 100932. [Google Scholar] [CrossRef]
- Fei, L.; Li, T.; Ding, W. Dempster–Shafer theory-based information fusion for natural disaster emergency management: A systematic literature review. Inf. Fusion 2024, 112, 102585. [Google Scholar] [CrossRef]
- Fei, L.; Li, T.; Ding, W. Adaptive multi-source information fusion for intelligent decision-making in emergencies: Integrating personal, event, and environmental factors. Inf. Fusion 2025, 125, 103512. [Google Scholar] [CrossRef]
- Yan, A.; Cheng, Z. A review of the development and future challenges of case-based reasoning. Appl. Sci. 2024, 14, 7130. [Google Scholar] [CrossRef]
- Okudan, O.; Budayan, C.; Dikmen, I. A knowledge-based risk management tool for construction projects using case-based reasoning. Expert Syst. Appl. 2021, 173, 114776. [Google Scholar] [CrossRef]
- Somi, S.; Gerami Seresht, N.; Fayek, A.R. Framework for risk identification of renewable energy projects using fuzzy case-based reasoning. Sustainability 2020, 12, 5231. [Google Scholar] [CrossRef]
- Yu, X.; Xu, C.; Lu, D.; Zhu, Z.; Zhou, Z.; Ye, N.; Mi, C. Design and application of a case analysis system for handling power grid operational accidents based on case-based reasoning. Information 2020, 11, 91. [Google Scholar] [CrossRef]
- Mannuru, N.R.; Shahriar, S.; Teel, Z.A.; Wang, T.; Lund, B.D.; Tijani, S.; Pohboon, C.O.; Agbaji, D.; Alhassan, J.; Galley, J.; et al. Artificial intelligence in developing countries: The impact of generative artificial intelligence (AI) technologies for development. Inf. Dev. 2023, 41, 02666669231200628. [Google Scholar] [CrossRef]
- Shan, S.; Li, Y. Research on the application framework of generative AI in emergency response decision support systems for emergencies. Int. J.-Hum. -Comput. Interact. 2024, 41, 9191–9208. [Google Scholar] [CrossRef]
- Boscardin, C.K.; Gin, B.; Golde, P.B.; Hauer, K.E. ChatGPT and generative artificial intelligence for medical education: Potential impact and opportunity. Acad. Med. 2024, 99, 22–27. [Google Scholar] [CrossRef]
- Hermann, E.; Puntoni, S. Artificial intelligence and consumer behavior: From predictive to generative AI. J. Bus. Res. 2024, 180, 114720. [Google Scholar] [CrossRef]
- Dwivedi, Y.K.; Pandey, N.; Currie, W.; Micu, A. Leveraging ChatGPT and other generative artificial intelligence (AI)-based applications in the hospitality and tourism industry: Practices, challenges and research agenda. Int. J. Contemp. Hosp. Manag. 2024, 36, 1–12. [Google Scholar] [CrossRef]
- Jackson, I.; Ivanov, D.; Dolgui, A.; Namdar, J. Generative artificial intelligence in supply chain and operations management: A capability-based framework for analysis and implementation. Int. J. Prod. Res. 2024, 62, 6120–6145. [Google Scholar] [CrossRef]
- De Haro, L.P. Biosecurity risk assessment for the use of artificial intelligence in synthetic biology. Appl. Biosaf. 2024, 29, 96–107. [Google Scholar] [CrossRef] [PubMed]
- Ruengdech, C.; Howimanporn, S.; Intarakumthornchai, T.; Chookaew, S. Implementing a Risk Assessment System of Electric Welders’ Muscle Injuries for Working Posture Detection with AI Technology. Int. J. Online Biomed. Eng. 2024, 20, 84–95. [Google Scholar] [CrossRef]
- Hartung, T. Artificial intelligence as the new frontier in chemical risk assessment. Front. Artif. Intell. 2023, 6, 1269932. [Google Scholar] [CrossRef]
- Alenjareghi, M.J.; Keivanpour, S.; Chinniah, Y.A.; Jocelyn, S.; Oulmane, A. Safe human-robot collaboration: A systematic review of risk assessment methods with AI integration and standardization considerations. Int. J. Adv. Manuf. Technol. 2024, 133, 4077–4110. [Google Scholar] [CrossRef]
- Li, T.; Sun, J.; Fei, L. Dempster-Shafer theory in emergency management: A review. Nat. Hazards 2025, 121, 6413–6440. [Google Scholar] [CrossRef]
- Koczkodaj, W.W.; Szybowski, J. The limit of inconsistency reduction in pairwise comparisons. Int. J. Appl. Math. Comput. Sci. 2016, 26, 721–729. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Dempster, A. Upper and Lower Probabilities Induced by a Multivalued Mapping. Ann. Math. Stat. 1967, 38, 325–339. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976; Volume 42. [Google Scholar]
- Aliev, R.; Pedrycz, W.; Fazlollahi, B.; Huseynov, O.H.; Alizadeh, A.V.; Guirimov, B.G. Fuzzy logic-based generalized decision theory with imperfect information. Inf. Sci. 2012, 189, 18–42. [Google Scholar] [CrossRef]
- Jia, G.; Zhe, M.; Xingfei, Z.; Shouxiang, L. Safety Analysis of a Building Gray Space Case Based on Public Safety Triangle Theory. Fire Sci. Technol. 2020, 39, 1397. [Google Scholar]
- Hong, H.; Weicheng, F. Building “Safe and Resilient Cities”: Concepts, Theories and Implementation Paths. J. Beijing Adm. Coll. 2024, 2, 1–9. [Google Scholar]
- Wu, L.; Li, J.; Ruan, Y.; Sun, L.; Huang, Q.; Yang, X. Study on risk assessment of typhoon storm surge based on public safety triangle theory. Iop Conf. Ser. Earth Environ. Sci. 2020, 526, 012055. [Google Scholar] [CrossRef]
- Li, H. Stampede risk analysis in historical and cultural districts based on public safety triangle and system dynamics. In Proceedings of the 5th International Conference on Artificial Intelligence and Computer Engineering, Wuhu, China, 8–10 November 2024; pp. 158–162. [Google Scholar]
- Chen, X.; Chen, L. Research on the Construction Method of Public Security Map based on Emergency Space Big Data. E3S Web Conf. 2021, 235, 03023. [Google Scholar] [CrossRef]
- Fei, L.; Liu, X.; Zhang, C. An evidential linguistic ELECTRE method for selection of emergency shelter sites. Artif. Intell. Rev. 2024, 57, 81. [Google Scholar] [CrossRef]
- Li, T.; Fei, L. Exploring obstacles to the use of unmanned aerial vehicles in emergency rescue: A BWM-DEMATEL approach. Technol. Soc. 2025, 81, 102863. [Google Scholar] [CrossRef]
- Fei, L.; Li, T. Investigating determinants of public participation in community emergency preparedness in China using DEMATEL methodology. Int. J. Disaster Risk Reduct. 2024, 112, 104803. [Google Scholar] [CrossRef]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Mizoguchi, R.; Tijerino, Y.; Ikeda, M. Task analysis interview based on task ontology. Expert Syst. Appl. 1995, 9, 15–25. [Google Scholar] [CrossRef]
- Gennari, J.H.; Musen, M.A.; Fergerson, R.W.; Grosso, W.E.; Crubézy, M.; Eriksson, H.; Noy, N.F.; Tu, S.W. The evolution of Protégé: An environment for knowledge-based systems development. Int. J. Hum.-Comput. Stud. 2003, 58, 89–123. [Google Scholar] [CrossRef]
- Fei, L.; Wang, Y. Demand prediction of emergency materials using case-based reasoning extended by the Dempster-Shafer theory. Socio-Econ. Plan. Sci. 2022, 84, 101386. [Google Scholar] [CrossRef]
- Yu, F.; Fan, B.; Qin, C.; Yao, C. A scenario-driven fault-control decision support model for disaster preparedness using case-based reasoning. Nat. Hazards Rev. 2023, 24, 04023040. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, F. A spatial awareness case-based reasoning approach for typhoon disaster management. In Proceedings of the 2014 IEEE 5th International Conference on Software Engineering and Service Science, Beijing, China, 27–29 June 2014; pp. 893–896. [Google Scholar]
- Wang, K.; Yang, Y.; Reniers, G.; Li, J.; Huang, Q. Predicting the spatial distribution of direct economic losses from typhoon storm surge disasters using case-based reasoning. Int. J. Disaster Risk Reduct. 2022, 68, 102704. [Google Scholar] [CrossRef]
- Junhui, Y.; Zhecong, X. Forecast of Typhoon Disaster Emergency Supplies Demand Based on Improved CBR. In Proceedings of the 2024 12th International Conference on Traffic and Logistic Engineering (ICTLE), Macau, China, 23–25 August 2024; pp. 88–92. [Google Scholar]
- Huang, H.; Li, R.; Wang, W.; Qin, T.; Zhou, R.; Fan, W. Concepts, models, and indicator systems for urban safety resilience: A literature review and an exploration in China. J. Saf. Sci. Resil. 2023, 4, 30–42. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, L.; Peng, T. Evaluation of a safe resilient City: A comparison of Hangzhou and Shaoxing, China. Sustain. Cities Soc. 2023, 98, 104798. [Google Scholar] [CrossRef]
- Liu, L.; Pei, J.; Wang, H.; Luo, Y. The evaluation and obstacle analysis of urban safety resilience based on multi-factor perspective in Beijing. Land 2023, 12, 1918. [Google Scholar] [CrossRef]
- Sun, X.; Chen, T.; Huang, Q.; Yang, X.; Lv, Y. Study on Comprehensive Risk Assessment of Marine Environment Safety Based on Public Safety Triangle Theory. E3S Web Conf. 2018, 53, 03028. [Google Scholar] [CrossRef]
- Li, X.; Zhu, Y.; Abbassi, R.; Chen, G. A probabilistic framework for risk management and emergency decision-making of marine oil spill accidents. Process Saf. Environ. Prot. 2022, 162, 932–943. [Google Scholar] [CrossRef]
- Hou, H.; Zhang, Z.; Wei, R.; Huang, Y.; Liang, Y.; Li, X. Review of failure risk and outage prediction in power system under wind hazards. Electr. Power Syst. Res. 2022, 210, 108098. [Google Scholar] [CrossRef]
- Hou, H.; Zhu, S.; Geng, H.; Li, M.; Xie, Y.; Zhu, L.; Huang, Y. Spatial distribution assessment of power outage under typhoon disasters. Int. J. Electr. Power Energy Syst. 2021, 132, 107169. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, S.; Cheng, H.; Li, Z.; Gu, Q.; Tian, X. Boosting the power grid resilience under typhoon disasters by coordinated scheduling of wind energy and conventional generators. Renew. Energy 2022, 200, 303–319. [Google Scholar] [CrossRef]
- Guo, J.; Feng, T.; Cai, Z.; Lian, X.; Tang, W. Vulnerability Assessment for power transmission lines under typhoon weather based on a cascading failure state transition diagram. Energies 2020, 13, 3681. [Google Scholar] [CrossRef]
- Qian, M.; Chen, N.; Chen, Y.; Chen, C.; Qiu, W.; Zhao, D.; Lin, Z. Optimal coordinated dispatching strategy of multi-sources power system with wind, hydro and thermal power based on cvar in typhoon environment. Energies 2021, 14, 3735. [Google Scholar] [CrossRef]
- Ti, B.; Li, G.; Zhou, M.; Wang, J. Resilience assessment and improvement for cyber-physical power systems under typhoon disasters. IEEE Trans. Smart Grid 2021, 13, 783–794. [Google Scholar] [CrossRef]
- Xiang, Y.; Wang, T.; Wang, Z. Risk prediction based preventive islanding scheme for power system under typhoon involved with rainstorm events. IEEE Trans. Power Syst. 2022, 38, 4177–4190. [Google Scholar] [CrossRef]
- Cao, S.; Wei, F.; Lin, X.; Yuan, X.; Huang, Q.; Xiang, H. Risk prediction based preventive typhoon defending for semi-independent power system. Appl. Energy 2025, 377, 124389. [Google Scholar] [CrossRef]
- Mu, Y.; Li, L.; Hou, K.; Meng, X.; Jia, H.; Yu, X.; Lin, W. A risk management framework for power distribution networks undergoing a typhoon disaster. IET Gener. Transm. Distrib. 2022, 16, 293–304. [Google Scholar] [CrossRef]
- Wang, Q.; Li, Y.; Ao, J.; Liu, J.; Zhou, B.; Cheng, L.; Xuan, P. Operation Simulation and Risk Evaluation of New Energy Integrated Distribution Network Under Typhoon. In Proceedings of the 2024 3rd International Conference on Energy and Electrical Power Systems (ICEEPS), Guangzhou, China, 14–16 July 2024; pp. 253–258. [Google Scholar]
- Hou, H.; Yu, S.; Wang, H.; Xu, Y.; Xiao, X.; Huang, Y.; Wu, X. A hybrid prediction model for damage warning of power transmission line under typhoon disaster. IEEE Access 2020, 8, 85038–85050. [Google Scholar] [CrossRef]
- Yu, J.; Hou, H.; Xiao, X.; Huang, Y.; Wu, X.; Tang, A. Risk Assessment of Trip Caused by Air Gap Discharge between Transmission Line and Tower under Typhoon. In Proceedings of the 2020 Asia Energy and Electrical Engineering Symposium (AEEES), Chengdu, China, 29–31 May 2020; pp. 38–42. [Google Scholar]
- Tang, Y.; Xu, X.; Chen, B.; Yi, T. Early warning method of transmission tower considering plastic fatigue damage under typhoon weather. IEEE Access 2019, 7, 63983–63991. [Google Scholar] [CrossRef]
- Hou, H.; Yu, S.; Wang, H.; Huang, Y.; Wu, H.; Xu, Y.; Li, X.; Geng, H. Risk assessment and its visualization of power tower under typhoon disaster based on machine learning algorithms. Energies 2019, 12, 205. [Google Scholar] [CrossRef]
- Hong, L.; Möller, B. An economic assessment of tropical cyclone risk on offshore wind farms. Renew. Energy 2012, 44, 180–192. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).