1. Introduction
Modern Optical Character Recognition (OCR) systems operate through a sophisticated pipeline comprising the following three interconnected components: text detection, text recognition, and post-processing optimization. Text detection algorithms identify and localize text regions within images, with recent advances including edge-based approaches such as Edge Approximation Text Detector [
1] and growth-based methods like Text Growing on Leaf [
2], which demonstrate superior performance in complex scene text scenarios. Text recognition modules then convert detected text regions into machine-readable characters, with transformer-based architectures such as Text Spotting Transformers [
3] and SwinTextSpotter [
4] achieving state-of-the-art performance through improved synergy between detection and recognition components [
5]. Recent advances in post-OCR processing have also explored competition-based evaluation frameworks [
6] and multi-lingual optimization approaches [
7].
Chinese OCR technology has emerged as a fundamental enabler of digital transformation across Chinese regions, serving as the technological backbone for automated document processing in diverse domains including legal contract analysis, financial record management, and administrative workflow automation [
8,
9]. The widespread adoption of Chinese OCR systems has revolutionized how organizations handle document digitization, data extraction, and information retrieval, directly impacting business efficiency and legal compliance in sectors where accurate Chinese character recognition is mission-critical [
5].
However, Chinese OCR systems face unprecedented challenges that significantly exceed those encountered in alphabetic writing systems [
10,
11]. The fundamental complexity of Chinese characters presents systematic recognition difficulties through thousands of logographic characters, where visually similar characters frequently share common radicals, stroke patterns, and structural components while differing only in subtle positioning, stroke count, or component arrangements [
11,
12]. These inherent characteristics of Chinese writing systems create persistent recognition ambiguities that conventional OCR approaches struggle to resolve effectively, with radical-based similarities being a primary source of recognition errors [
10,
12].
Current approaches to addressing Chinese OCR limitations encompass traditional image preprocessing and algorithm optimization, sophisticated deep learning architectures, and large language model integration [
13,
14]. While these advances have yielded substantial improvements in overall recognition performance, they consistently fall short when confronted with the nuanced challenges of distinguishing visually similar Chinese characters [
10,
15]. Moreover, existing solutions suffer from critical limitations including dependency on external Chinese linguistic resources, limited adaptability to domain-specific Chinese terminology, substantial computational overhead, and inability to maintain consistent performance across different Chinese OCR systems and deployment environments [
16,
17].
Traditional Chinese OCR post-processing methods, primarily relying on Chinese dictionary-based corrections and rule-based systems, struggle with specialized terminology in legal contracts, technical documents, and domain-specific applications [
18]. Statistical and machine learning approaches, while more sophisticated, often require extensive Chinese training corpora and computational resources that limit their practical applicability in real-time Chinese document processing scenarios [
19]. Natural language processing-based post-processing approaches have demonstrated effectiveness in improving OCR accuracy through linguistic analysis and correction [
20,
21], though these methods typically require language-specific knowledge bases and may not generalize effectively across different domains or writing systems. Language-specific OCR post-processing solutions, such as those developed for Myanmar [
22], have shown the importance of tailored approaches for complex scripts, yet they highlight the challenge of developing universally applicable correction mechanisms that can adapt to diverse linguistic requirements without extensive language-specific customization.
Recent developments have explored large language model integration for post-OCR correction [
14,
23], natural language processing pipelines [
24], and reinforcement learning optimization [
25], yet these approaches face deployment challenges due to computational requirements and external dependencies.
To address these fundamental challenges, this study introduces FLIP (Feedback Learning-based Intelligent Plugin), a novel lightweight and adaptive post-processing plugin specifically designed to improve Chinese OCR accuracy across different systems without requiring external dependencies. FLIP represents a paradigm shift in Chinese OCR post-processing by operating entirely through mathematical calculations at the character encoding level, ensuring universal compatibility with existing Chinese OCR systems while effectively addressing complex character similarities inherent in Chinese writing systems. The plugin’s innovative approach eliminates dependencies on external linguistic resources while providing mathematically grounded similarity analysis that is particularly effective for Chinese character relationships and adaptive learning capabilities.
2. Methodology
The FLIP implementation is fundamentally a classification problem that determines whether two characters are visually similar (a binary classification of similar/dissimilar). The core challenge lies in effectively quantifying uncertainty and establishing reliable decision boundaries. Information entropy has been extensively proven as one of the optimal measures for handling classification problems. The tremendous success of ID3 and C4.5 algorithms validates the effectiveness of information entropy in classification tasks by identifying the most discriminative attributes in complex feature spaces. Based on this well-established theoretical foundation, we selected information entropy as the core algorithmic basis for character similarity computation.
2.1. ID3 and C4.5 Algorithms
ID3 Algorithm Foundation: The ID3 (Iterative Dichotomiser 3) algorithm employs information entropy as the fundamental criterion for attribute selection and tree construction. The algorithm’s effectiveness stems from its ability to systematically reduce uncertainty through optimal attribute partitioning, making it particularly well-suited for classification problems involving high-dimensional feature spaces with subtle inter-class differences.
For a given dataset
S with
c distinct classes, the information entropy quantifies the impurity or uncertainty as follows:
where
represents the proportion of examples belonging to class
i in dataset
S.
ID3’s attribute selection mechanism employs information gain to measure the effectiveness of each attribute in reducing entropy as follows:
where attribute
A partitions dataset
S into subsets
.
Threshold-Based Decision Making in ID3: The algorithm employs threshold comparison for decision node creation. At each internal node, ID3 selects the attribute with maximum information gain as follows:
where
represents the set of available attributes. The algorithm terminates when information gain falls below a predefined threshold
, expressed as follows:
C4.5 Algorithm Enhancement: Building upon ID3’s foundation, the C4.5 algorithm introduces significant improvements that address key limitations while maintaining the core entropy-based approach. C4.5 enhances the original framework through gain ratio normalization, continuous attribute handling, and improved pruning mechanisms, establishing it as one of the most successful entropy-based classification algorithms.
Gain Ratio Normalization: C4.5 addresses ID3’s bias toward attributes with many values by introducing the following gain ratio measure:
where
represents the intrinsic value of attribute
A, expressed as follows:
This normalization ensures that the algorithm selects attributes based on their true discriminative power rather than simply the number of possible values.
2.2. Inspiration for FLIP Design
ID3 and C4.5 inspire FLIP’s design through their entropy-based discrimination capabilities that use information entropy to identify the most discriminative attributes, informing FLIP’s employment of entropy measures to quantify the discriminative power of character differences. Their threshold-based decision making mechanisms provide reference for our similarity threshold approach. Additionally, C4.5’s gain ratio mechanism, which normalizes information gain by intrinsic information to prevent bias toward multi-valued attributes, provides valuable insights for our similarity measurement computation.
The broader applicability of entropy-based approaches has been validated across diverse domains in text processing and OCR optimization. Information-theoretic principles have proven effective in post-OCR statistical analysis [
15], cross-language text processing [
26], and concept extraction for structured text [
27], consistently demonstrating the universal applicability of entropy measures in handling similarity-based classification problems. Building upon these foundations, recent advances have explored more sophisticated applications, including large language model integration for post-OCR correction [
23], natural language processing pipelines for enhanced text recognition [
24], and reinforcement learning optimization for complex OCR scenes [
25]. These reinforcement learning approaches provide similar research backgrounds by demonstrating how adaptive learning mechanisms can be effectively integrated with entropy-based similarity analysis to improve OCR performance, establishing important precedents for FLIP’s feedback learning component that continuously optimizes similarity computation through user interactions.
3. FLIP
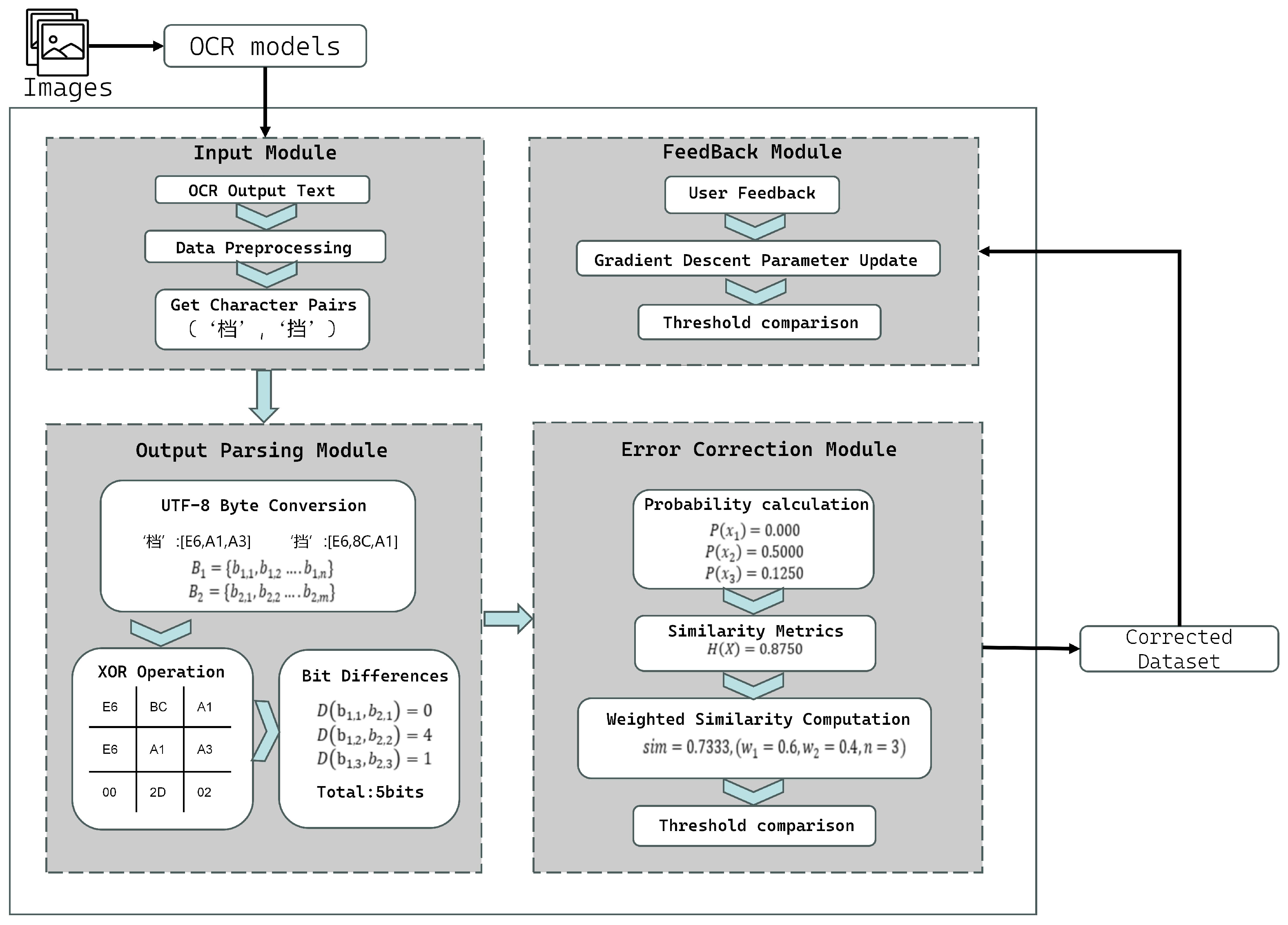
FLIP implements the theoretical framework described above through the following three algorithmic components: Output Parsing, Error Correction, and Feedback Learning. Each component operates through mathematical calculations at the character encoding level, enabling efficient error recognition and correction without external dependencies (
Figure 1).
3.1. Output Parsing
The Output Parsing module converts OCR text output into mathematical representations for similarity computation. It processes character sequences through UTF-8 encoding analysis. This enables universal compatibility across different OCR architectures.
The module automatically captures OCR recognition output and performs character-level decomposition. Each character is individually extracted and prepared for encoding analysis. Complete traceability of character positions is maintained for precise error localization.
- 1
Given OCR output text, we first convert each character into its UTF-8 byte representation to enable mathematical analysis of character similarities. For any OCR-recognized character pair
, the encoding process is as follows:
where
represents the
j th byte of the
i th character.
- 2
To quantify the encoding-level differences between characters, we perform XOR operations on corresponding bytes, enabling the precise measurement of character similarity at the binary level.
where the function
is to calculate the number of binary 1s in the XOR result,
means that the binary in each byte is XORed.
3.2. Error Correction
The Error Correction module implements the core similarity computation algorithms. It combines information-theoretic measures with encoding-level analysis to identify and correct character recognition errors.
The module computes encoding-level similarities using byte-level differences from the output parsing component. Information-theoretic analysis enhances these computations by capturing the statistical properties of character relationships.
The algorithmic implementation encompasses several key computational steps, as follows:
- 1
We employ information entropy to quantify the uncertainty and similarity between character pairs, providing a principled approach to measuring character relationships. The entropy calculation captures the distribution of bit differences across byte positions, offering insights into the structural similarities between characters, as follows:
where
n represents the number of bytes in the UTF-8 encoding (typically
n = 3 for Chinese characters), and
represents the probability of the i-th byte position, calculated as follows:
- 2
For any given character pair requiring similarity analysis, let
denote the target character (the character output by the OCR system) and
denote the source character (a candidate correct character from a reference set or user correction). To balance different aspects of character similarity between these two characters, we implement the following weighted combination approach:
where
and
are weighting coefficients, and
and
represent two different similarity measure components, expressed as follows:
where
represents the total number of differing bits between character pairs, calculated as follows:
where
n represents the number of bytes in the UTF-8 encoding determined by max(len(
B1), len(
B2)) denotes the total count of differing bits between the two characters,
is the information entropy calculated from Equation (
9), and scale is a normalization parameter for entropy-based similarity. The factor 8 in Equation (
12) represents the number of bits per byte, ensuring the proper normalization of the bit-level similarity measure.
- 3
Character pairs are classified as visually similar based on the following threshold:
when
, the character pair is flagged for potential correction. The threshold
is configured according to the characteristics of different OCR models and specific application requirements.
3.3. Feedback
The Feedback Learning module implements gradient-based parameter optimization algorithms that adapt similarity computation based on user corrections. It maintains statistical records of user interactions and employs mean squared error minimization to optimize similarity function parameters.
Unlike static post-processing approaches, this mechanism enables FLIP to continuously refine its capabilities through user interaction, creating a personalized post-processing system.
The algorithmic foundation encompasses several critical computational components, as follows:
- 1
The system maintains comprehensive statistics for each character pair encountered, as follows:
these counters track correct identifications, incorrect identifications, and total feedback instances for each character pair.
- 2
The system employs a mean squared error loss function to measure the discrepancy between predicted similarity scores and actual user feedback as follows:
where
represents the ground truth similarity label (1 for similar pairs, 0 for dissimilar pairs) based on user feedback.
- 3
The similarity function parameters are updated using gradient descent optimization to minimize the loss function as follows:
where
is the learning rate (0 <
), and the gradient is computed as follows:
- 4
Updated parameters undergo validation against a feedback-specific threshold to ensure robust performance, expressed as follows:
where
to maintain conservative correction behavior.
4. Experiment
To evaluate the effectiveness of the proposed FLIP plugin, we conduct comprehensive experiments on multiple OCR models. Our experimental setup aims to demonstrate the significant improvement in OCR accuracy through the triple architecture of output parsing, error correction, and feedback learning.
4.1. Datasets and Metric
Dataset: Our experiments are conducted on the Chinese-OCR-10K dataset, which consists of 10,000 Chinese document images systematically selected from the publicly available Chinese OCR dataset by YCG09 (available at
https://github.com/YCG09/chinese_ocr, accessed on 15 June 2025). The source dataset contains approximately 3.64 million synthetic Chinese text images with uniform 280 × 32 pixel resolution, covering 5990 characters including Chinese characters, English letters, digits, and punctuation marks. Each image contains exactly 10 characters with realistic distortions such as font variations, blur effects, and perspective transformations to simulate real-world document conditions. Our Chinese-OCR-10K subset was systematically sampled from the validation set to ensure comprehensive coverage of character combinations and distortion types while maintaining computational feasibility for extensive comparative analysis across multiple OCR models.
We utilize this dataset to establish baseline performance for each OCR model, followed by the systematic evaluation of our FLIP plugin’s improvement capabilities. The dataset provides a robust foundation for assessing the effectiveness of our post-processing optimization approach across diverse Chinese text recognition scenarios.
Evaluation Metrics: We employ the following metrics to evaluate performance improvements:
Precision: The ratio of correctly recognized characters to all characters output by the system, expressed as follows:
Chinese Precision: Precision is specifically calculated for Chinese characters, focusing on the core OCR challenge, as follows:
Recall: The ratio of correctly recognized characters to all ground truth characters, expressed as follows:
F1 Score: The harmonic mean of precision and recall, providing a balanced evaluation metric, expressed as follows:
where
represents true positives (correctly recognized characters),
represents false positives (incorrectly recognized characters), and
represents false negatives (missed characters in ground truth).
4.2. Experimental Setup and Process
Our experimental evaluation follows a systematic multi-stage approach, aiming to assess the effectiveness of each component and the overall performance of the plugin. We also designed experiments to compare with traditional OCR post-processing methods. The structure of the experimental process is as follows:
4.2.1. Baseline Establishment
Initially, we apply different OCR models to recognize our selected public Chinese dataset and compare the results with ground truth labels to establish baseline performance for each model. This baseline evaluation provides the foundational performance metrics against which our plugin improvements are measured.
4.2.2. Output Parsing Stage
The recognition results from each OCR model are input into our output parsing module to generate preprocessed data suitable for the error correction module. This preprocessing transforms the raw OCR output into UTF-8 encoded character representations and identifies potential character pairs requiring correction analysis. We refer to this processed data as the “character pairs to be corrected dataset”.
It is important to note that practical Chinese documents frequently contain mixed character types including Chinese characters, English letters, Arabic numerals, and punctuation marks within the same image. To address this mixed-character environment, FLIP implements a selective processing strategy that focuses optimization efforts specifically on Chinese characters while preserving the accuracy of non-Chinese characters.
The plugin employs Unicode range-based character classification, where characters are classified as Chinese if they fall within the Unicode range from U+4E00 to U+9FFF. Only characters identified as Chinese undergo the complete FLIP processing pipeline, including similarity analysis, error correction, and feedback learning. Characters outside this range, including English letters, Arabic numerals, and punctuation marks, are automatically excluded from the correction process and retain their original OCR recognition results. This selective approach ensures that computational resources are concentrated on the most challenging character category where improvement is most needed, while maintaining the integrity of typically more accurate non-Chinese character recognition.
4.2.3. Initial Error Correction Stage
The character pairs dataset is input into the error correction module, which applies our mathematical similarity analysis algorithms to identify and correct recognition errors. This first optimization stage primarily targets character pairs that are close in UTF-8 code point positions and exhibit structural similarities detectable through our encoding-level analysis. Characters with calculated similarity scores exceeding the initial threshold () are flagged for correction, resulting in the “first optimization dataset”.
4.2.4. Feedback Learning Stage
We apply the feedback learning module to the first optimization results through both simulated and real-user evaluation approaches to comprehensively validate the adaptive learning capabilities.
Simulated Feedback Evaluation: For systematic experimental comparison, we simulate realistic user feedback scenarios by providing ten consecutive positive feedback instances for character pairs requiring correction. This controlled simulation represents typical user correction patterns in practical OCR post-processing applications. Through the feedback algorithm, the similarity scores of character pairs undergo adaptive adjustment based on these user corrections. When the updated similarities reach our second threshold (), which is more stringent than the initial threshold, these character pairs are incorporated into the final optimization dataset.
Real-User Evaluation: To evaluate effectiveness and enterprise deployment feasibility, we conducted a comprehensive user study using a contract comparison software system integrated with the FLIP plugin. The evaluation examined four key performance metrics: recognition accuracy improvements, computational complexity, time efficiency, and noise-robustness under actual usage conditions.
4.2.5. Traditional Method Comparison
To evaluate the effectiveness of our FLIP algorithm against traditional post-processing approaches, we implement a dictionary-based correction method as a comparative baseline. This approach constructs correction mappings by analyzing character replacement pairs from the OCR output, filtering pairs with occurrence frequencies of at least 2 to ensure reliability, and creating a static lookup table that directly maps frequently misrecognized characters to their correct counterparts. During correction, the system queries this dictionary for each misrecognized character and applies the corresponding correction if a mapping exists, otherwise retaining the original character unchanged. We evaluate both methods using identical datasets and metrics, including correction accuracy, coverage rate, and character-level improvement counts, enabling the direct comparison of the adaptive learning capabilities of our feedback-enhanced approach against this traditional rule-based method.
4.2.6. Final Performance Evaluation
The final performance evaluation systematically validates FLIP’s effectiveness through multiple comparative analyses. We compare the final optimization results with baseline performance across all tested OCR models to quantify overall improvement effects. Ablation studies are conducted by evaluating plugin performance without the feedback learning component to isolate the contribution of adaptive learning mechanisms. Additionally, we perform comparative evaluation against the traditional dictionary-based correction method using identical datasets and metrics. Finally, we analyze the feasibility of the plugin based on the evaluation results of real users.
4.3. Baseline
We evaluate our FLIP plugin on the following four state-of-the-art OCR models representing different technical approaches:
PaddleOCR V3: An open-source OCR toolkit developed by Baidu employing CRNN (Convolutional Recurrent Neural Network) architecture with MobileNetV3 backbone, Bi-directional LSTM for sequence processing, and CTC loss for alignment. We utilize the mobile version, which supports lightweight local client development and provides practical solutions for real-world text recognition applications.
PaddleOCR V4: An enhanced version of Baidu’s OCR toolkit with improved CRNN architecture featuring advanced knowledge distillation strategies and enhanced multilingual recognition capabilities. We utilize the mobile version, which offers better text recognition capabilities for lightweight local client development.
Qwen-VL-OCR: A vision-language model developed by Alibaba utilizing Vision Transformer (ViT) architecture with pre-trained weights from OpenClip’s ViT-bigG as visual encoder and Qwen language model foundation. It supports processing complex documents, including handwritten text, tables, charts, and multilingual content.
Doubao-1.5-v-pro: A multimodal AI model developed by ByteDance employing sparse Mixture of Experts (MoE) architecture that activates only a subset of parameters during inference for enhanced computational efficiency. It excels in OCR, document parsing, visual reasoning, and interactive applications.
The baseline results are presented in
Table 1, showing the original performance of each OCR model before applying our optimization plugin.
4.4. Parameter Settings
The key parameters for FLIP are configured as follows:
Similarity weight coefficients: ,
Similarity parameter:
Similarity threshold:
Learning rate:
Feedback threshold:
The similarity threshold
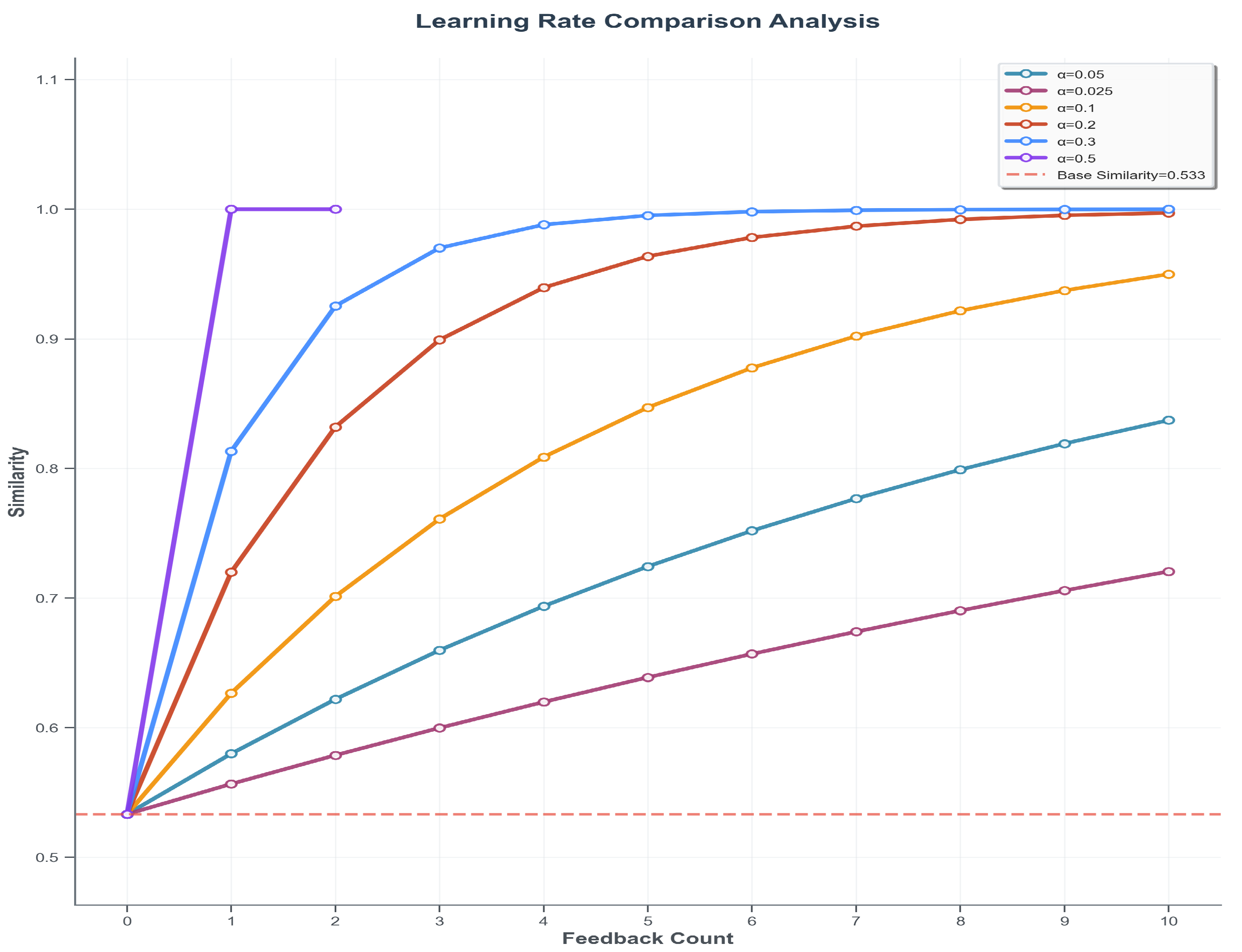
is selected based on experimental analysis revealing that most visually similar Chinese character pairs fall within this range during initial optimization dataset creation, ensuring comprehensive capture of potentially confusable characters while maintaining correction precision. The learning rate
provides robust convergence behavior that balances adaptation speed with stability—sufficiently responsive to user feedback without immediately reaching the secondary threshold
, while avoiding overly slow adaptation that would impair practical deployment effectiveness. As demonstrated in
Figure 2, this learning rate achieves optimal convergence characteristics compared to both higher rates that may cause instability and lower rates that result in insufficient adaptation speed.
4.5. Experimental Results and Analysis
We present our experimental results and analysis to demonstrate the effectiveness of the FLIP plugin. Based on the aforementioned experimental steps, the results show consistent improvements across all tested OCR models under the complete plugin, along with ablation experiments after removing the feedback module, demonstrating notable gains in Chinese character recognition accuracy. These findings validate the universal applicability and effectiveness of our approach.
4.5.1. Overall Performance Improvements
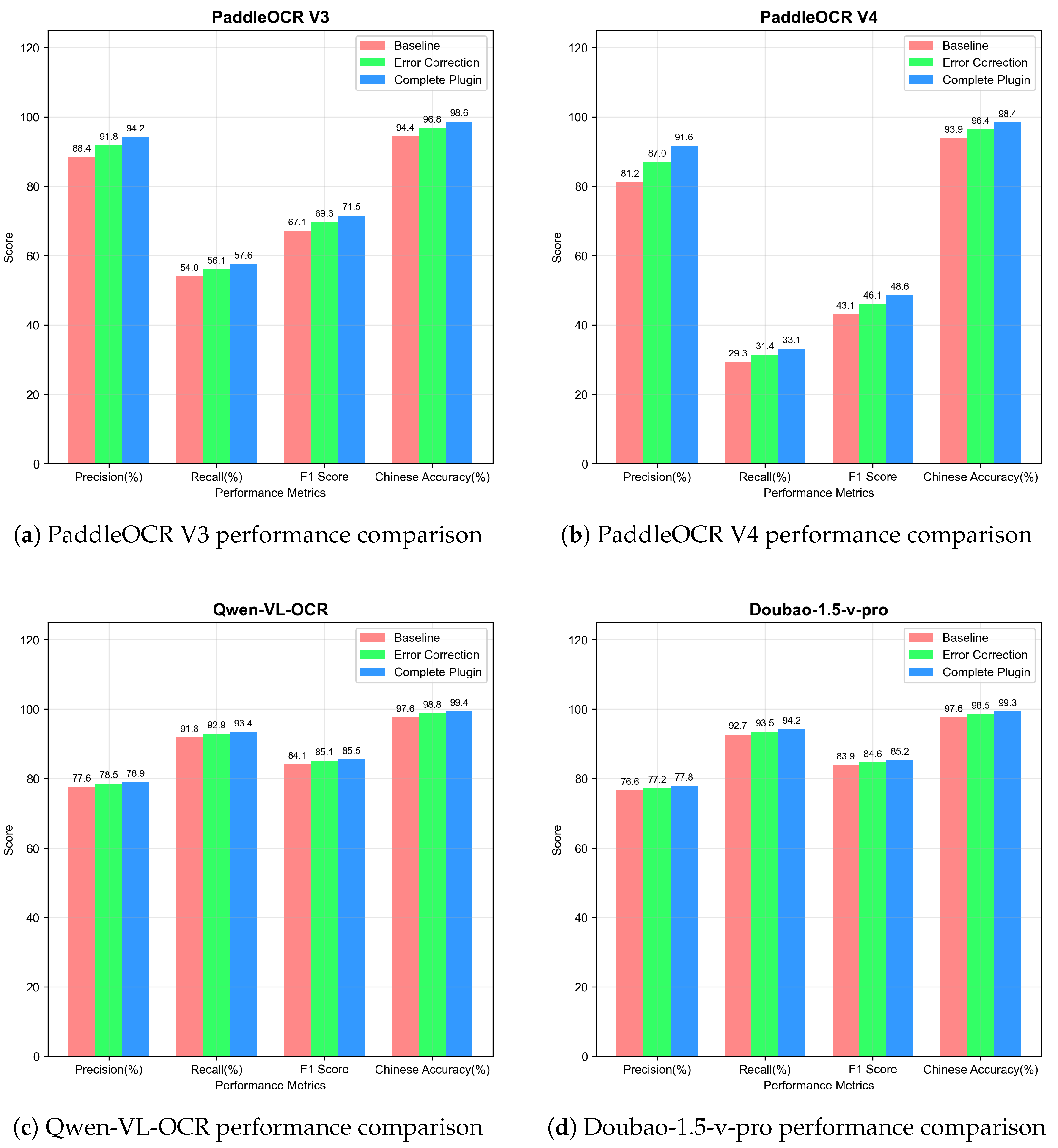
Table 2 presents the performance after applying the complete FLIP plugin.
The results demonstrate significant improvements across all tested OCR models. PaddleOCR V4 shows the most substantial enhancement with 10.37% precision improvement, indicating that the plugin effectively addresses character recognition errors in lower-performing models. High-performance models like Qwen-VL-OCR and Doubao-1.5-v-pro achieve remarkable Chinese character precision rates of 99.42% and 99.33% respectively, demonstrating the plugin’s capability to fine-tune already accurate systems. The consistent improvements in F1 Scores across all models confirm the balanced enhancement of both precision and recall metrics.
4.5.2. Ablation Study Results
We evaluate the feedback learning component by testing the plugin with only the core error correction module. The results are shown in
Table 3.
This validates that the adaptive learning mechanism successfully captures domain-specific character similarities through user interactions, with greater impact on systems requiring more substantial correction.
The ablation study results, combined with the visual evidence in
Figure 3, reveal the nuanced effectiveness of feedback learning across different OCR system types. The numerical comparison between
Table 2 and
Table 3 shows that PaddleOCR V3 gains 2.46% additional precision through feedback learning (from 91.75% to 94.21%), while PaddleOCR V4 achieves a substantial 4.66% improvement (from 86.95% to 91.61%). These improvements are clearly visualized in
Figure 3, where the progressive enhancement from baseline through core correction to complete plugin demonstrates the additive value of each component.
For high-performance models, feedback learning provides more modest but consistent improvements of 0.45% for Qwen-VL-OCR and 0.55% for Doubao-1.5-v-pro. While these gains appear small in absolute terms, they represent significant achievements when optimizing systems already operating near performance limits. The visual comparison effectively illustrates this pattern, showing minimal overall precision changes but remarkable Chinese character precision, reaching 99.42% and 99.33%, respectively, and demonstrating the plugin’s particular effectiveness for logographic character recognition.
Figure 3 reveals distinct improvement trajectories that reflect each model’s architectural characteristics. PaddleOCR models show dramatic visual improvements across all metrics, with clear step-wise enhancements particularly striking for PaddleOCR V4, where feedback learning elevates the system from moderate to high-performance category. In contrast, Qwen-VL-OCR and Doubao-1.5-v-pro demonstrate a different optimization pattern where Chinese character accuracy metrics show the most significant enhancement, confirming that the plugin successfully addresses its primary design objective even for highly optimized systems.
The comprehensive metric display consistently shows that precision improvements are accompanied by balanced recall and F1 Score enhancements, with the ablation study confirming recall improvements ranging from 0.53% to 1.68% across models. This balanced improvement pattern indicates that feedback learning enhances overall recognition quality rather than optimizing individual metrics at the expense of others. The consistency of improvements across architecturally diverse OCR systems validates the universal applicability of the adaptive learning mechanism and confirms FLIP’s effectiveness for practical deployment in Chinese document processing applications.
4.5.3. Traditional Method Comparison Results
The comparative evaluation against traditional dictionary-based correction methods demonstrates the fundamental advantages of FLIP’s adaptive feedback learning approach.
Table 4 shows that FLIP consistently outperforms dictionary-based methods across all tested OCR models.
The results reveal the critical limitations of static dictionary approaches. Traditional methods can only correct pre-defined error patterns that have been manually observed and catalogued, severely constraining their effectiveness when confronted with novel recognition errors. Dictionary-based systems remain fundamentally static after deployment, unable to adapt to new character confusion patterns or domain-specific terminology without manual intervention and system updates.
In contrast, FLIP’s feedback learning mechanism achieves dynamic adaptation by learning from user interactions rather than relying on fixed mappings. This adaptive capability allows the system to continuously refine its correction behavior based on real-world usage patterns and user feedback, enabling it to handle new error types and domain-specific character relationships that were not present in any pre-defined correction dictionary.
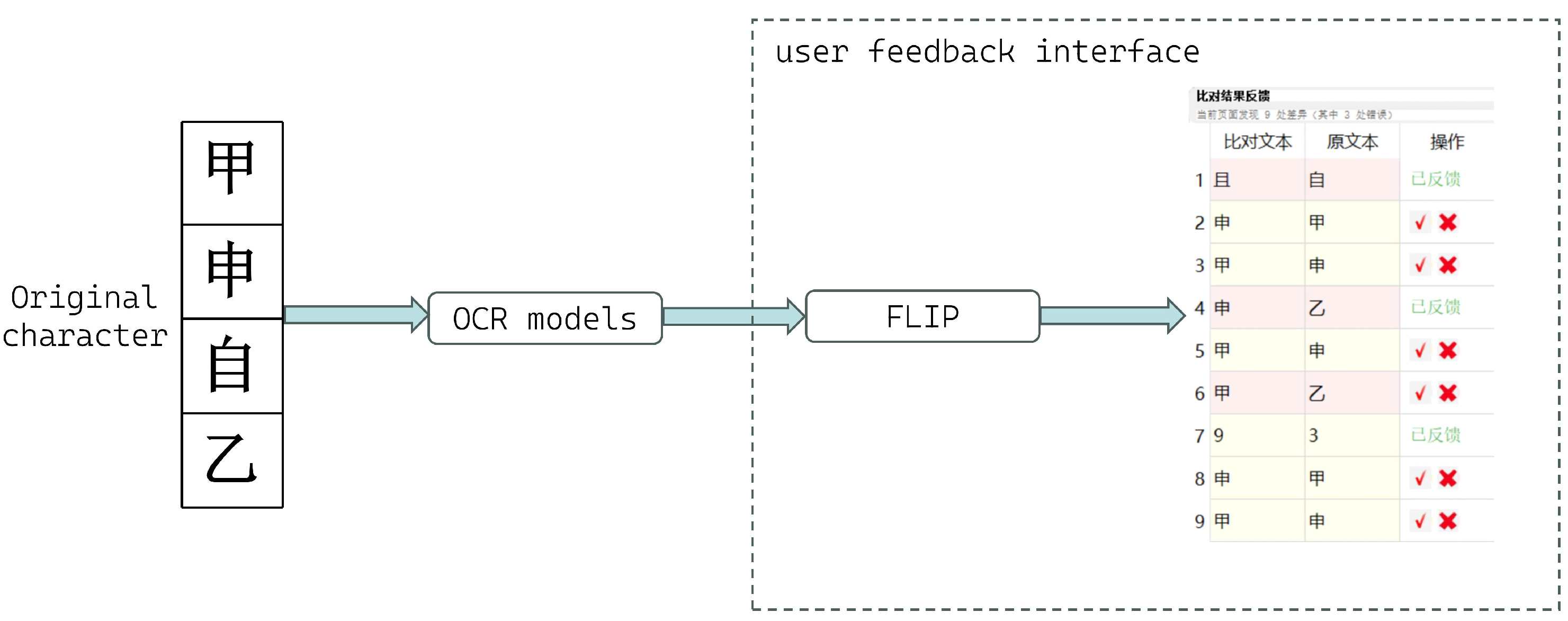
4.5.4. Real-User Evaluation
Figure 4 illustrates the most frequently misrecognized Chinese characters encountered by the OCR system during evaluation. The feedback interaction interface allows users to review the FLIP plugin’s correction results and submit their feedback. we evaluate the FLIP plugin across several key dimensions in actual user scenarios.
Recognition accuracy improvements: Under the sustained effect of user feedback, FLIP’s accuracy continuously improves. The system learns from user corrections and adapts to domain-specific terminology over time. As demonstrated in the examples shown in the figure, these frequently misrecognized characters evolve in the direction desired by users during the usage process.
Computational complexity: FLIP is designed to be lightweight and can run efficiently on standard personal computers without requiring high-end hardware or internet connectivity. The plugin has minimal memory and storage requirements, making it suitable for deployment on individual client devices. This design ensures low operational costs while maintaining data privacy and providing real-time post-processing capabilities.
Noise-robustness: When high-resolution images are input to OCR models, the recognition results are typically more accurate. However, when images are blurry, low-resolution, or contain noise interference, OCR models are prone to misrecognition, particularly for visually similar Chinese characters. These low-quality image conditions are precisely the scenarios where the FLIP plugin can play an important role. Since FLIP is based on character encoding-level similarity analysis, it can effectively identify and correct character confusion errors caused by image quality issues. When OCR systems produce misidentifications of similar characters while processing blurry or low-resolution images, FLIP’s mathematical similarity algorithms can detect these potential errors and provide accurate correction suggestions, thereby significantly improving overall recognition accuracy under various image quality conditions.
Time efficiency: During the period when three users tested our algorithm, it demonstrates exceptional computational efficiency. Error detection and correction are completed at second-level or even millisecond-level speeds for entire documents. The FLIP plugin’s character-level similarity analysis operates at remarkable speeds. This enables instantaneous error identification without perceptible delay in user workflow. Traditional manual verification methods are significantly slower. FLIP-assisted processing provides real-time correction suggestions that appear instantly as users review documents.
5. Limitations
While FLIP demonstrates significant improvements in Chinese OCR accuracy across multiple systems, several inherent limitations must be acknowledged to provide a comprehensive understanding of the plugin’s applicability and potential constraints.
5.1. Homograph Error Challenges
One fundamental limitation of FLIP lies in its handling of homograph errors, where visually identical characters possess different semantic meanings depending on contextual usage. Our current approach relies primarily on character-level similarity analysis through UTF-8 encoding, which cannot distinguish between semantically different uses of the same character. For instance, certain Chinese logographs can represent completely different concepts despite identical visual appearance, such as characters that may function as both verbs and nouns with distinct pronunciations and meanings in different contexts. FLIP’s encoding-based similarity computation treats these as identical characters, potentially missing context-dependent correction opportunities where OCR systems correctly recognize the character form but users require semantic validation.
This limitation becomes particularly pronounced in legal and technical documents where precise semantic interpretation is critical. While our feedback learning mechanism can partially address domain-specific usage patterns through user corrections, it cannot fundamentally resolve the ambiguity inherent in homographic characters without incorporating sophisticated natural language understanding capabilities, which would contradict our design philosophy of maintaining independence from external linguistic resources.
5.2. Scalability to Non-Chinese Languages
Although FLIP’s UTF-8 encoding-based approach theoretically supports universal character analysis, practical scalability to non-Chinese languages presents several challenges that limit its broader applicability. The plugin’s design assumptions and parameter configurations are specifically optimized for Chinese character characteristics, including stroke-based structural similarities and the logographic nature of Chinese writing systems.
Alphabetic writing systems such as Latin, Cyrillic, or Arabic scripts exhibit fundamentally different error patterns and character relationships compared to Chinese logographs. The similarity measures and threshold parameters that prove effective for distinguishing Chinese character pairs may not transfer directly to alphabetic systems where character confusions often involve letter substitutions rather than structural component variations.
Furthermore, our experimental validation exclusively employed Chinese text datasets and OCR systems optimized for Chinese character recognition. The plugin’s performance on non-Chinese languages remains empirically unvalidated, and the feedback learning mechanisms may require substantial recalibration to accommodate different linguistic structures and error patterns characteristic of non-logographic writing systems.
5.3. User-Specific Optimization Variability
A significant practical limitation emerges from the inherent variability in user-specific optimization effects as application contexts and usage patterns evolve over time. While our experimental evaluation demonstrates consistent improvements across different OCR models using standardized datasets, real-world deployment scenarios introduce dynamic factors that can substantially influence optimization effectiveness.
Individual users’ correction patterns, domain-specific terminology preferences, and evolving application requirements create personalized optimization trajectories that may diverge significantly from our standardized experimental results. As users interact with different document types, modify their correction criteria, or adapt their workflow practices, the plugin’s learned parameters may become misaligned with current requirements, potentially reducing optimization effectiveness below experimentally observed levels.
Moreover, the feedback learning mechanism’s dependency on user interaction quality introduces variability that cannot be statistically guaranteed. Inconsistent user corrections, temporary shifts in application focus, or changes in organizational requirements can influence the adaptive optimization process in ways that may not reflect the controlled experimental conditions under which FLIP’s performance was validated.
This limitation suggests that while FLIP provides substantial improvements under controlled conditions, practical deployment may require ongoing monitoring and potential parameter readjustment to maintain optimal performance as user requirements and application contexts evolve. The plugin’s effectiveness should therefore be understood as context-dependent rather than universally guaranteed across all possible deployment scenarios.
6. Conclusions
This study presents FLIP (Feedback Learning-based Intelligent Plugin), contributing significant mathematical innovations to optical character recognition post-processing. The work establishes a rigorous mathematical framework for character similarity quantification. It combines information-theoretic principles with encoding-level analysis.
The primary mathematical advancement applies information entropy theory to character similarity computation. We build upon the established success of ID3 and C4.5 algorithms. Character similarity is formalized as a binary classification problem with entropy-based uncertainty quantification. UTF-8 character encodings are transformed into measurable bit-level differences through XOR operations. This enables the precise quantification of structural relationships between logographic characters.
We introduce a mathematically rigorous weighted similarity measure. It combines bit-level differences with entropy-based structural analysis. The framework employs exponential decay functions and normalized similarity coefficients. This captures both local encoding variations and global structural patterns. The dual-scale approach provides complete mathematical characterization of character relationships.
The feedback learning mechanism implements gradient-based parameter optimization. Mean squared error minimization enables real-time adaptation of similarity functions. The convergence properties demonstrate robust mathematical foundations for continuous learning. We establish a mathematical framework for threshold-based classification. It incorporates both initial similarity thresholds and adaptive feedback thresholds.
Comprehensive experiments across four OCR architectures validate the mathematical framework’s effectiveness. Results demonstrate consistent improvements with precision gains ranging from 1.17% to 10.37%. Ablation studies mathematically isolate the contribution of feedback learning. Additional improvements from 0.45% to 4.66% are shown across different systems. The mathematical relationship between thresholds ensures conservative correction behavior.
The information-theoretic foundation provides mathematical generalizability beyond Chinese characters. Entropy-based similarity computation offers a universal mathematical approach for any UTF-8 encoded character system. This establishes theoretical foundations for broader character recognition applications. The mathematical algorithms achieve computational efficiency through encoding-level operations. They eliminate dependency on external linguistic resources.
Future mathematical research includes extending the entropy-based framework to multi-dimensional character spaces. Advanced similarity learning mathematics for complex character relationships will be developed. Mathematical convergence guarantees for adaptive learning systems need to be established. The mathematical contributions establish FLIP as a theoretically grounded solution. It advances information-theoretic approaches to character recognition and provides significant innovations for computational character analysis.





{kind=link}
{kind=link}
{kind=link}
{kind=link}