
Developing a Model to Predict the Effectiveness of Vaccination on Mortality Caused by COVID-19



Abstract
1. Introduction
2. Methodology
2.1. Dataset
- Country: The name of the country.
- ISO code: Standardized country identifiers.
- Date: The specific day of record.
- Total vaccinations: Cumulative count of all vaccine doses administered up to that date.
- People vaccinated: The number of individuals who have received at least one dose (partial vaccination).
- People fully vaccinated: The number of individuals who completed the full vaccination course.
- New death: The cumulative number of COVID-19-related deaths reported on that day.
- Population: The total population of the country, used for normalization.
- Vaccination ratio: A derived feature calculated the proportion of the population vaccinated.
- Consistency checks: All date entries were converted into a uniform date–time format. Data were validated against other trusted sources where possible to verify accuracy.
- Anomaly detection: Exploratory data analysis identified anomalies, such as days with zero reported deaths and sudden spikes in vaccination counts. These anomalies were reviewed to determine their plausibility; where appropriate, smoothing techniques or data flagging were employed to prevent distortion in modeling.
- Handling missing data: Missing values in key variables were addressed through forward filling or interpolation.
- Normalization and scaling: Numeric features, such as total vaccinations, total deaths, and vaccination ratios were scaled to standardize the feature ranges. This step aids in model convergence and comparability across features.
- Feature engineering: New features, such as the vaccination coverage ratio and daily increments in vaccinations and deaths, were created to capture dynamic trends and facilitate deeper insights. Furthermore, a binary classification was adapted based on differential assessment in vaccination and mortality rates. This approach compares the full vaccination rate with the rate of new deaths per population. This approach integrates mean-based threshold and median-based threshold for a more comprehensive evaluation. It is particularly well suited for realistic, context-aware assessments of vaccine effectiveness.
- Correlation analysis: A correlation analysis was conducted to assess feature importance, revealing several notable insights. The strongest association was observed between higher levels of full vaccination and a reduction in the mortality rate. If the ratio of people vaccinated/people fully vaccinated is high, mortality may not drop significantly. Indeed, a high ratio suggests many are only partially vaccinated, which may be less protective. Overall, mortality tends to decrease as vaccination efforts progress over time. Clearly, small countries achieve high vaccination rates quickly, while large populations face slower declines in mortality.
2.2. Modeling
3. Proposed Work
3.1. Machine Learning Algorithms
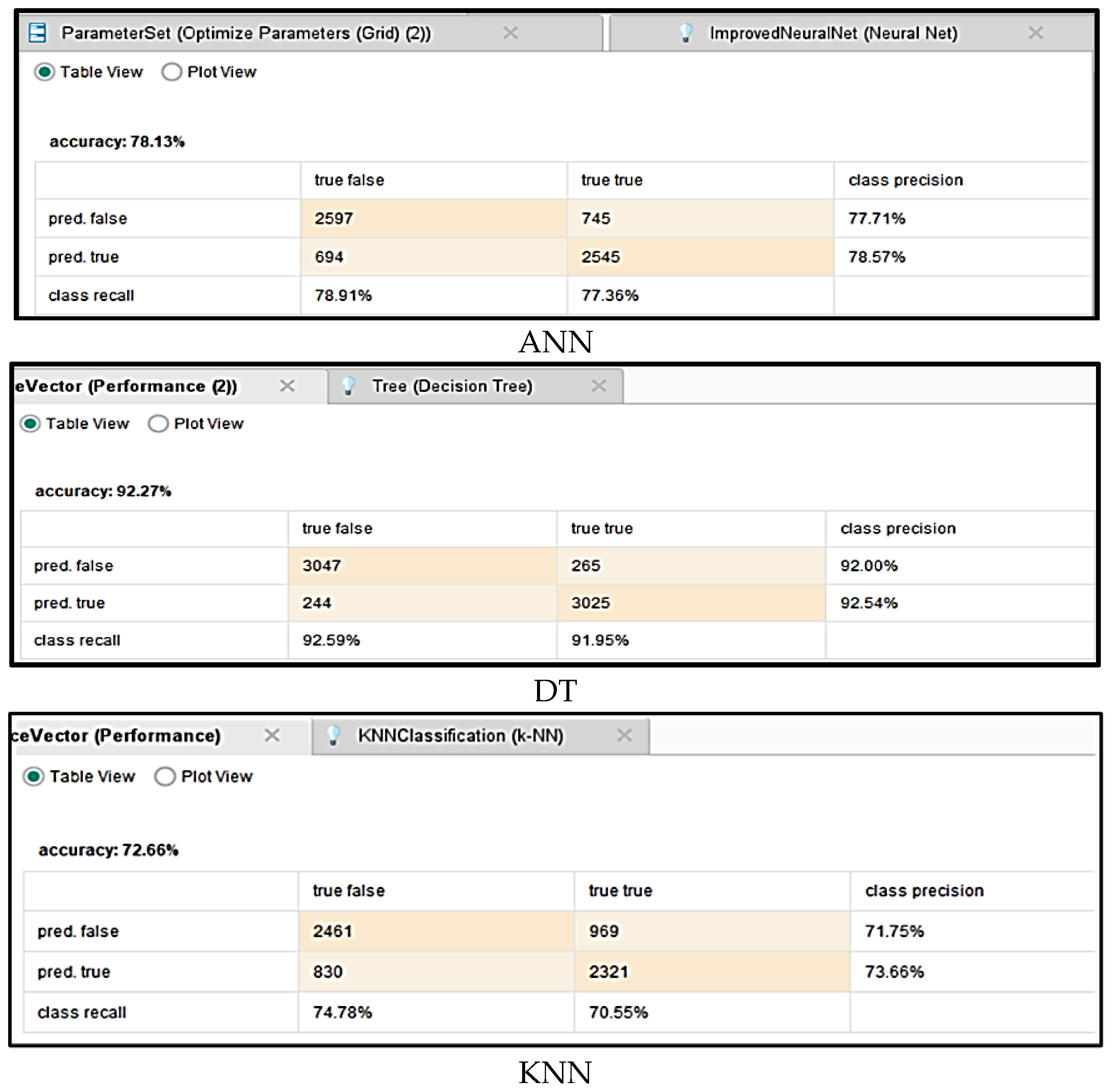
3.1.1. Artificial Neural Network
3.1.2. Decision Tree
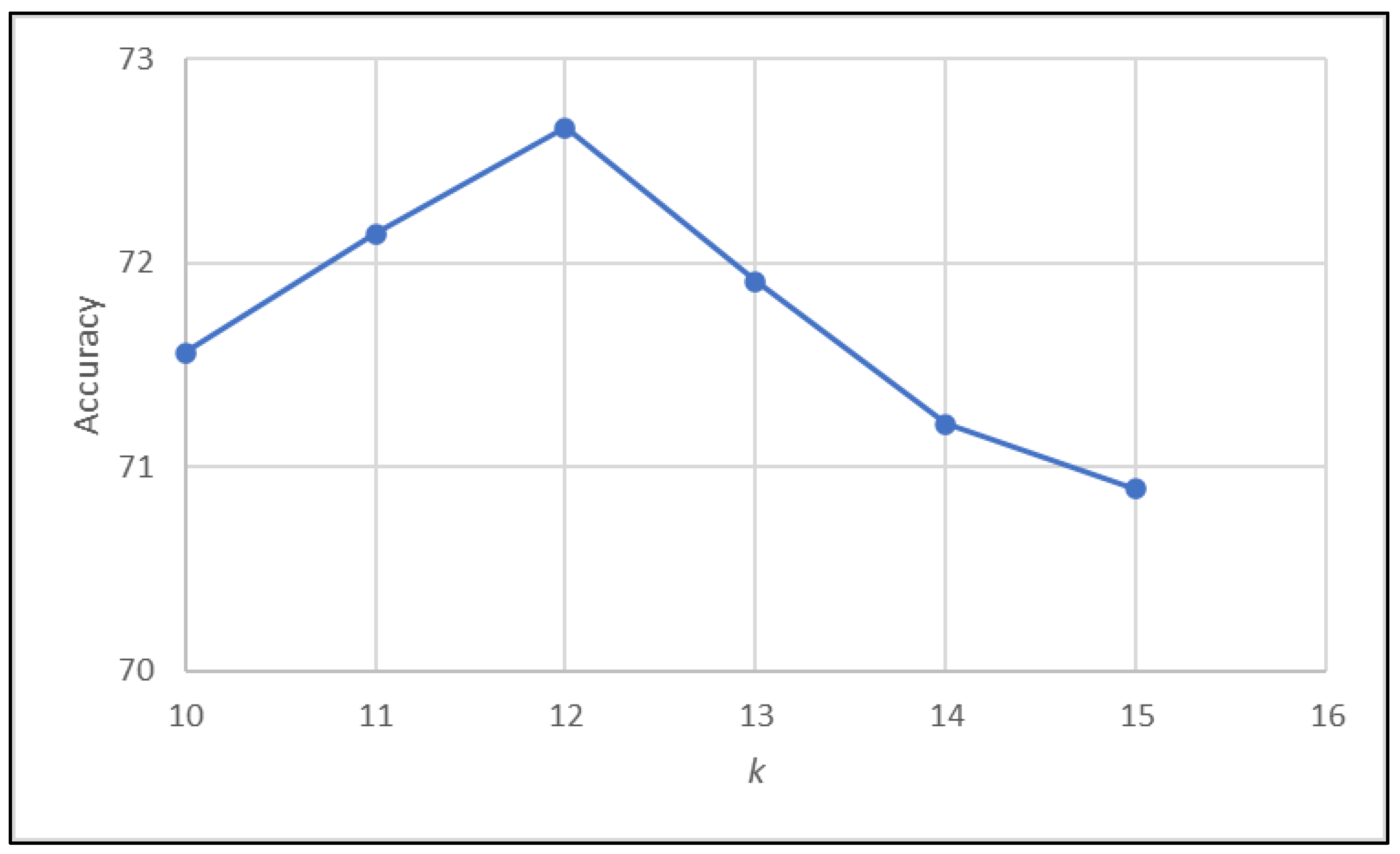
3.1.3. k -Nearest Neighbor
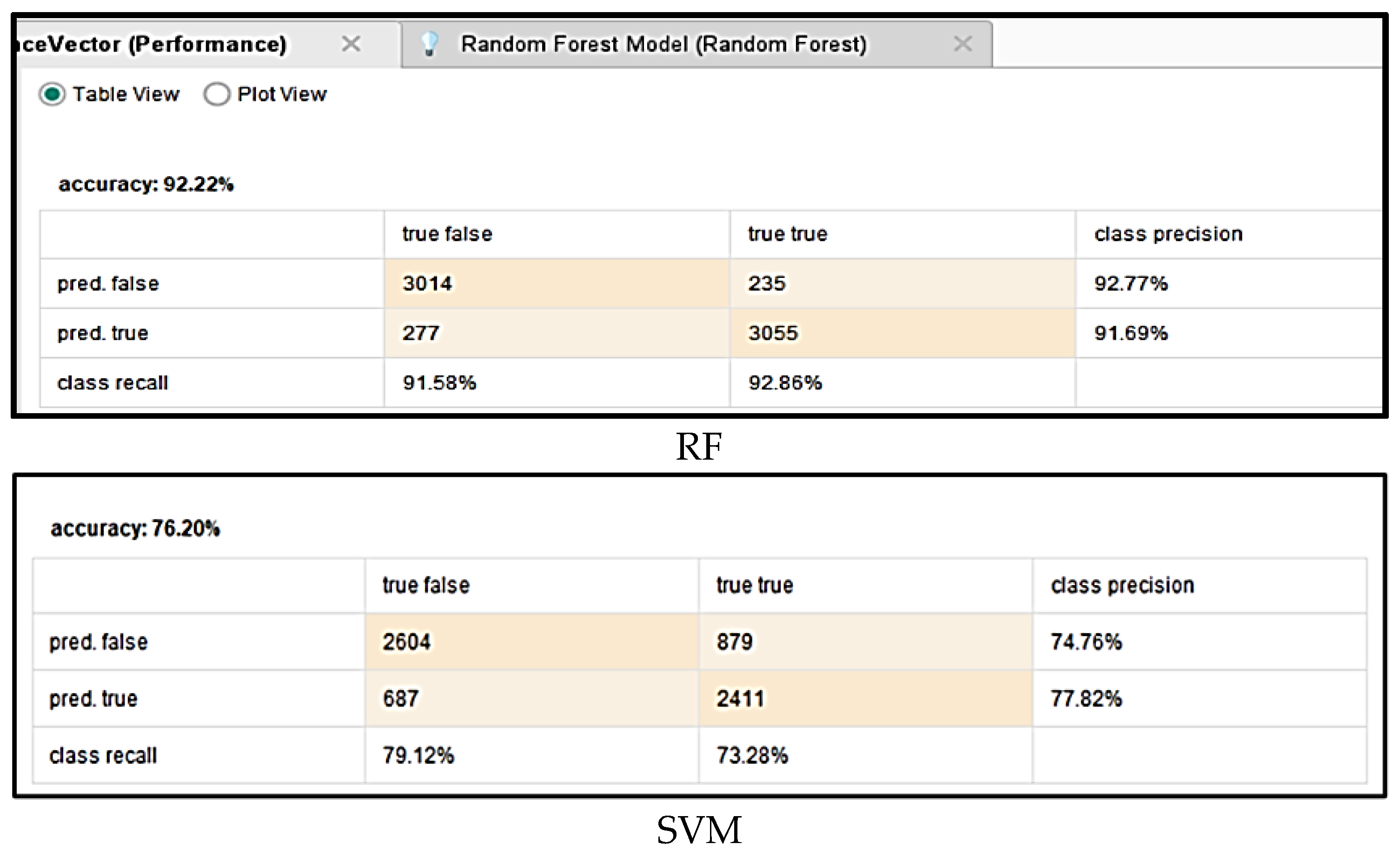
3.1.4. Random Forest
3.1.5. Support Vector Machine
3.2. Evaluation Metrics
- (True Positives): The model correctly predicts positive cases (the actual class is positive, and the prediction is positive).
- (True Negatives): The model correctly predicts negative cases (the actual class is negative, and the prediction is negative).
- (False Positives): The model incorrectly predicts positive when the actual class is negative.
- (False Negatives): The model incorrectly predicts negative when the actual class is positive.
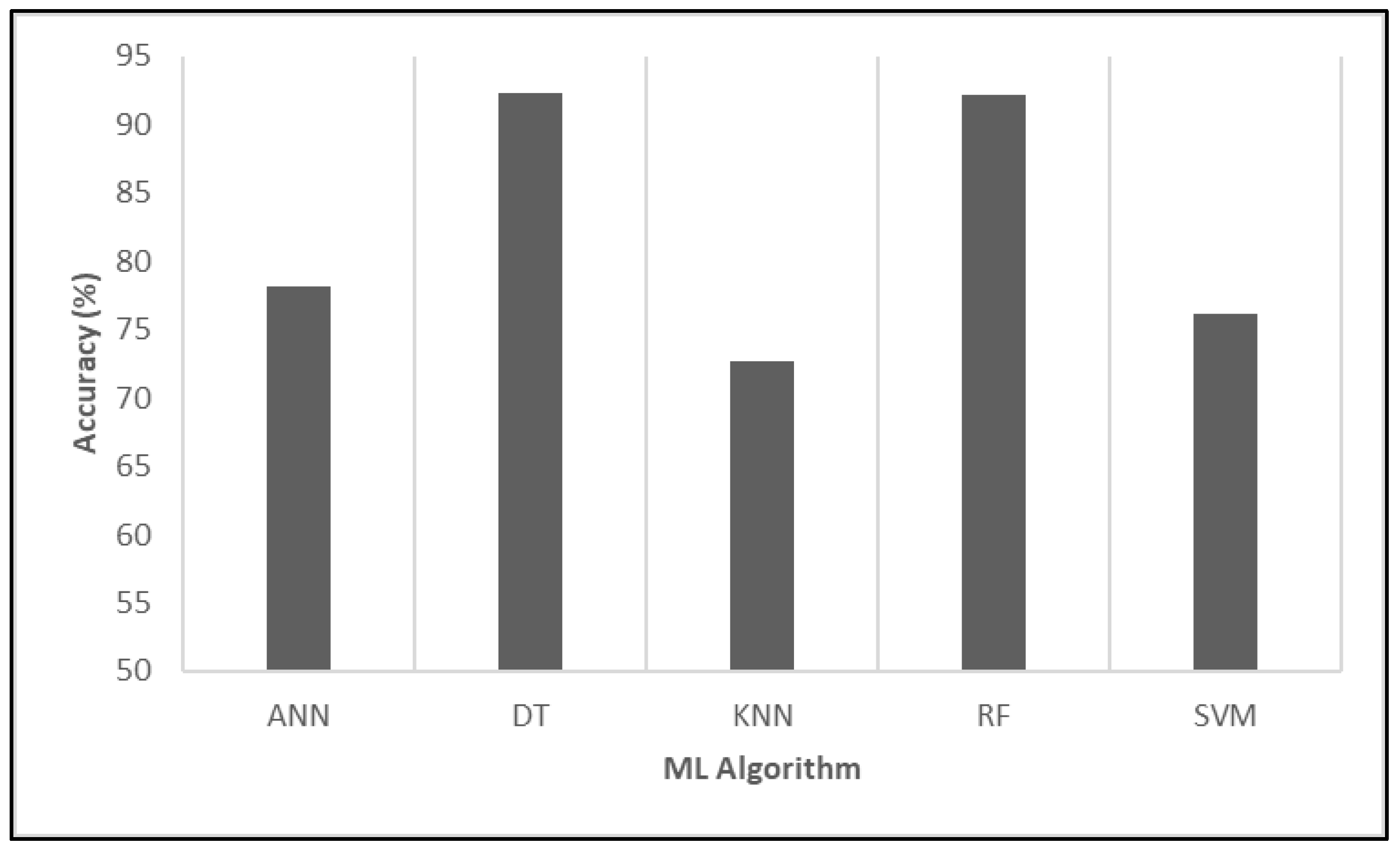
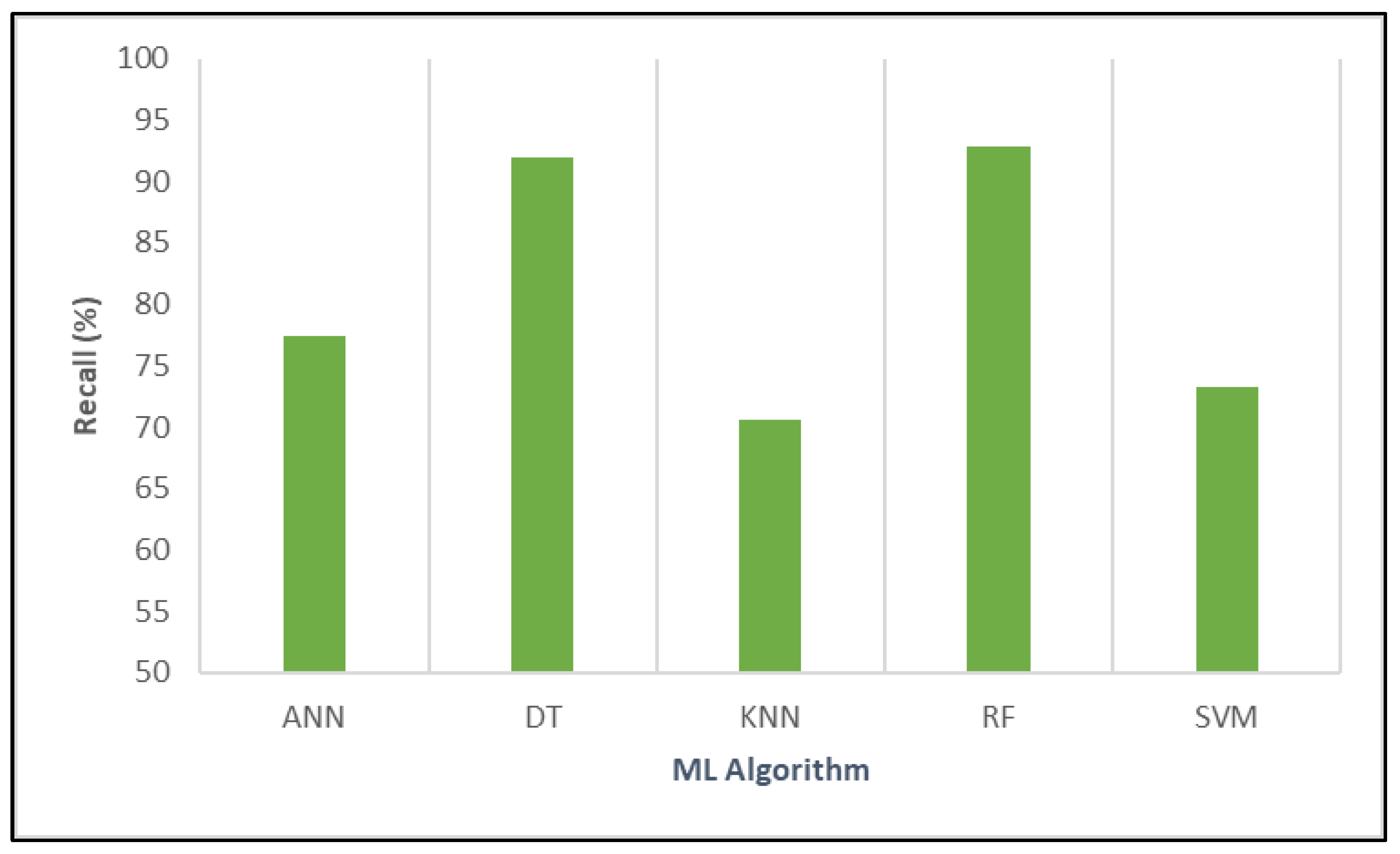
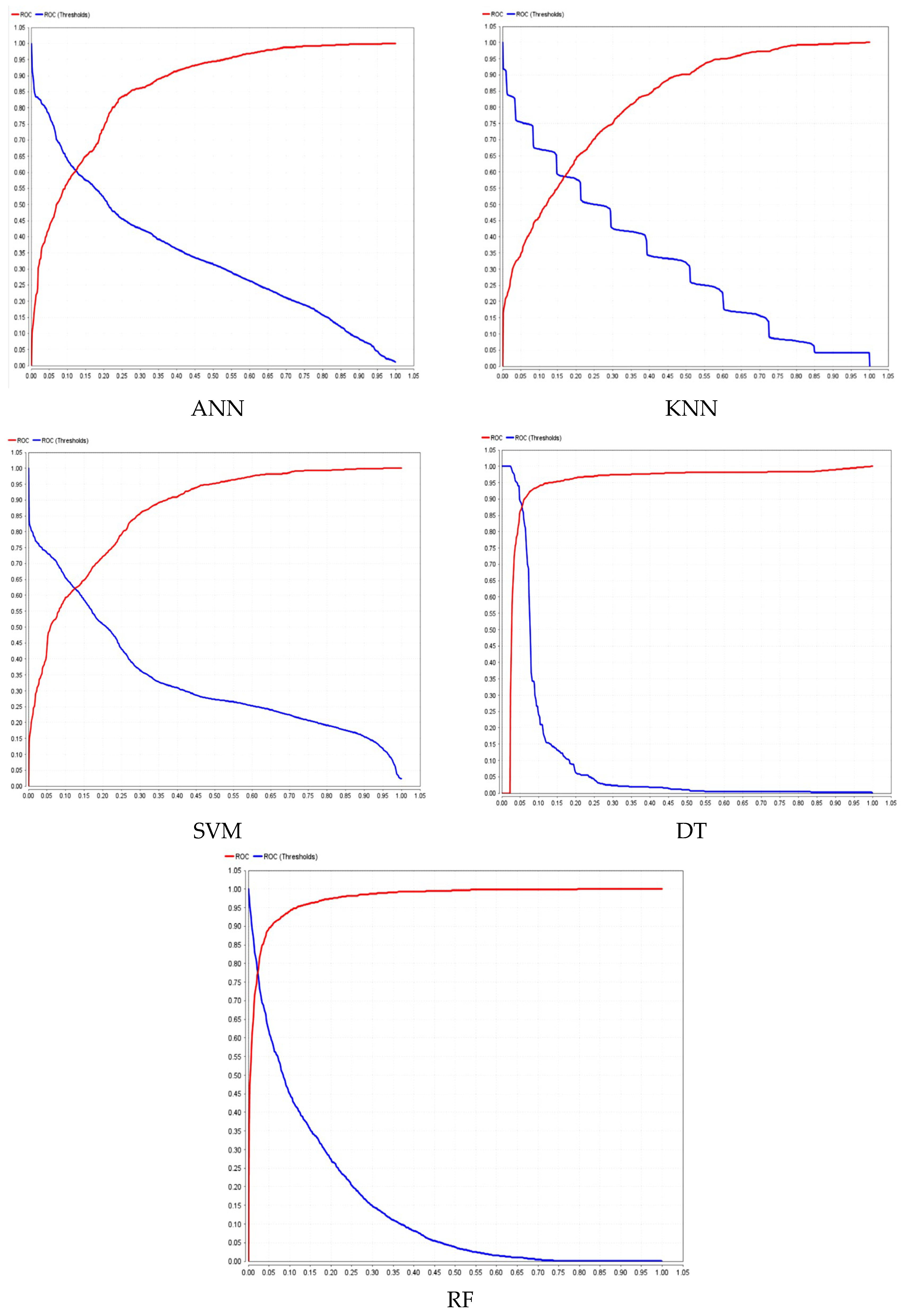
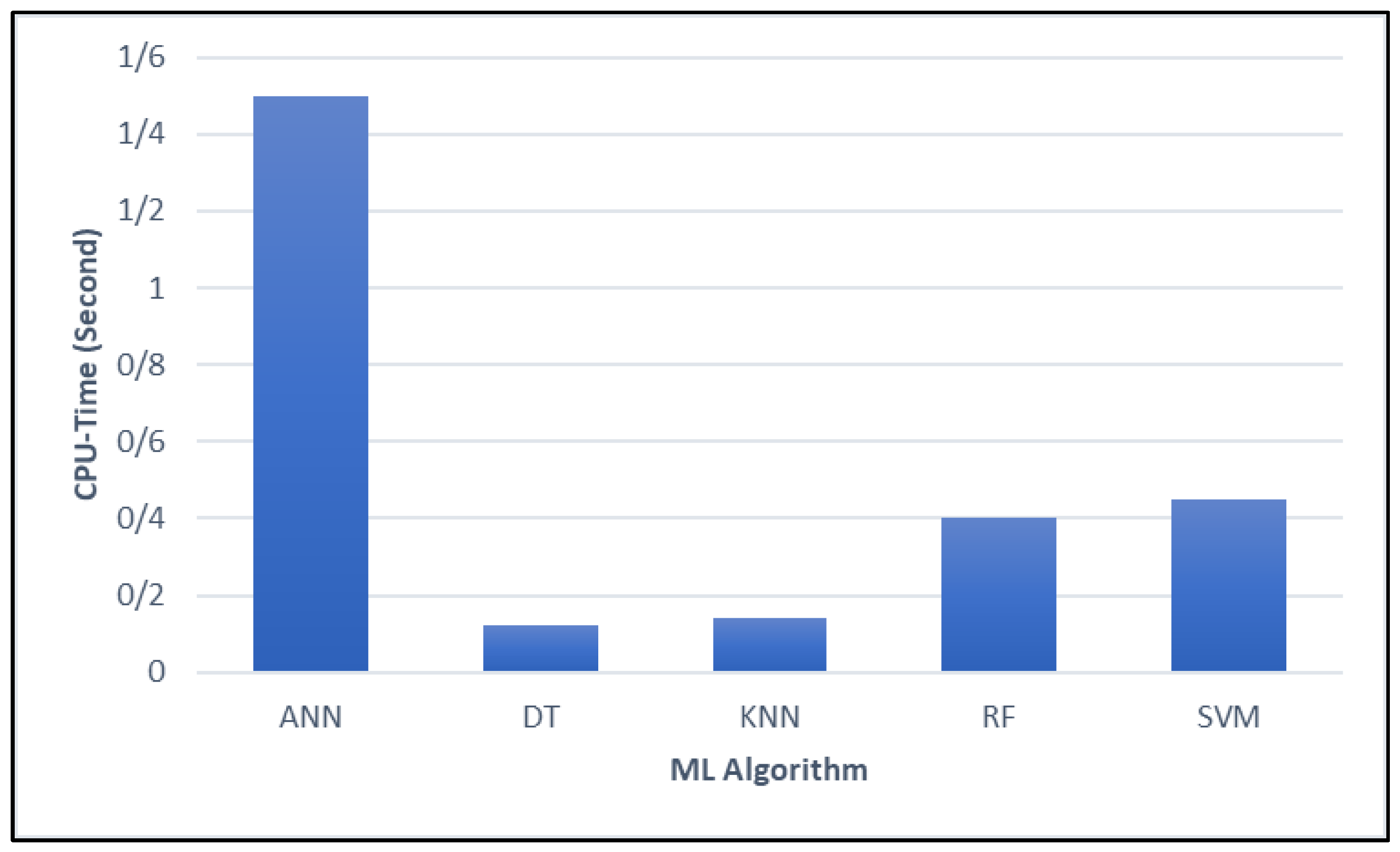
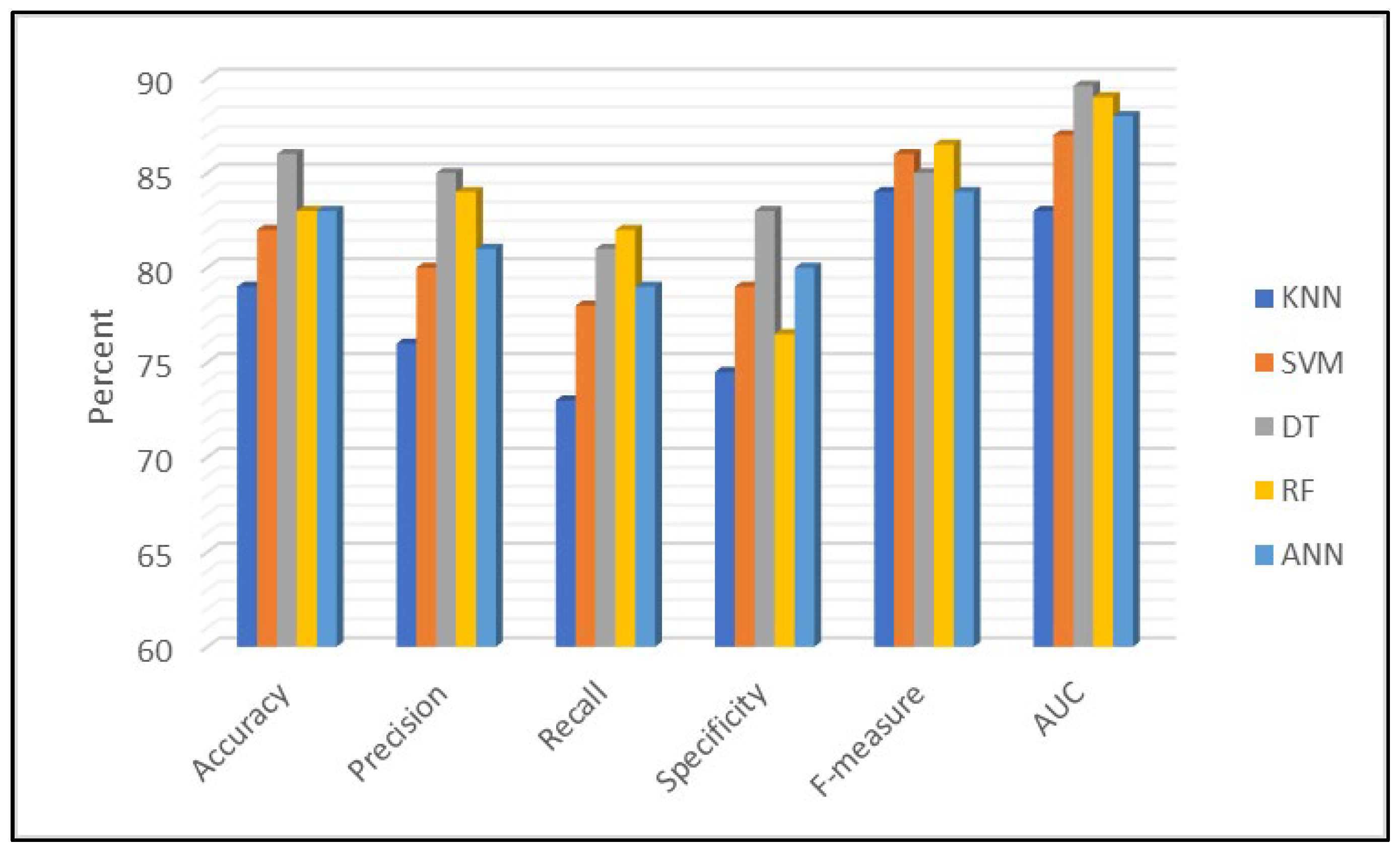
4. Results Analysis
- Variables such as population size, total vaccinations, fully vaccinated individuals, and vaccination ratio played a significant role in determining outcomes.
- The presence of a date-related node indicated that the model incorporated temporal information, potentially linking vaccination timelines to other predictive features.
- Pathways where high numbers of fully vaccinated individuals aligned with specific population sizes appeared strongly correlated with certain predictions.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nishiura, H.; Jung, S.M.; Linton, N.M.; Kinoshita, R.; Yang, Y.; Hayashi, K.; Kobayashi, T.; Yuan, B.; Akhmetzhanov, A.R. The extent of transmission of novel coronavirus in Wuhan, China, 2020. J. Clin. Med. 2020, 9, 330. [Google Scholar] [CrossRef] [PubMed]
- Dashtbali, M.; Mirzaie, M. The impact of vaccination and social distancing on COVID-19: A compartmental model and an evolutionary game theory approach. J. Frankl. Inst. 2024, 361, 106994. [Google Scholar] [CrossRef]
- Chakraborty, C.; Lo, Y.H.; Bhattacharya, M.; Das, A.; Wen, Z.H. Looking beyond the origin of SARS-CoV-2: Significant strategic aspects during the five-year journey of COVID-19 vaccine development. Mol. Ther. Nucleic Acids 2025, 36, 102527. [Google Scholar] [CrossRef]
- Tiwari, S.; Chanak, P.; Singh, S.K. A review of the machine learning algorithms for COVID-19 case analysis. IEEE Trans. Artif. Intell. 2022, 4, 44–59. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Zheng, N.; Liu, M.; Yao, D.; Wang, Y.; Wang, J.; Xin, J. Multi-weight susceptible-infected model for predicting COVID-19 in China. Neurocomputing 2023, 534, 161–170. [Google Scholar] [CrossRef]
- Ambalarajan, V.; Mallela, A.R.; Dhandapani, P.B.; Sivakumar, V.; Leiva, V.; Castro, C. Multi-strain COVID-19 dynamics with vaccination strategies: Mathematical modeling and case study. Alex. Eng. J. 2025, 119, 665–684. [Google Scholar] [CrossRef]
- Kalachev, L.; Graham, J.; Landguth, E.L. A simple modification to the classical SIR model to estimate the proportion of under-reported infections using case studies in flu and COVID-19. Infect. Dis. Model. 2024, 9, 1147–1162. [Google Scholar] [CrossRef] [PubMed]
- Etli, D. Evaluating Vaccine Effectiveness During the COVID-19 Pandemic: Insights from Statistical and Machine Learning Methods. In World Congress in Computer Science, Computer Engineering & Applied Computing; Springer: Cham, Switzerland, 2025; pp. 445–453. [Google Scholar]
- Dodoo, C.C.; Hanson-Yamoah, E.; Adedia, D.; Erzuah, I.; Yamoah, P.; Brobbey, F.; Cobbold, C.; Mensah, J. Using machine learning algorithms to predict COVID-19 vaccine uptake: A year after the introduction of COVID-19 vaccines in Ghana. Vaccine X 2024, 18, 100466. [Google Scholar] [CrossRef]
- Girma, S.; Paton, D. Using double-debiased machine learning to estimate the impact of Covid-19 vaccination on mortality and staff absences in elderly care homes. Eur. Econ. Rev. 2024, 170, 104882. [Google Scholar] [CrossRef]
- Jdid, T.; Benbrahim, M.; Kabbaj, M.N.; Naji, M. A vaccination-based COVID-19 model: Analysis and prediction using Hamiltonian Monte Carlo. Heliyon 2024, 10, e38204. [Google Scholar] [CrossRef]
- Rayguru, C.; Husnayain, A.; Chiu, H.S.; Sumazin, P.; Su, E.C.Y. Predictive analysis of COVID-19 occurrence and vaccination impacts across the 50 US states. Comput. Biol. Med. 2025, 185, 109493. [Google Scholar] [CrossRef] [PubMed]
- Zaidi, S.A.J.; Tariq, S.; Belhaouari, S.B. Future prediction of COVID-19 vaccine trends using a voting classifier. Data 2021, 6, 112. [Google Scholar] [CrossRef]
- Chhabra, A.; Singh, S.K.; Sharma, A.; Kumar, S.; Gupta, B.B.; Arya, V.; Chui, K.T. Sustainable and intelligent time-series models for epidemic disease forecasting and analysis. Sustain. Technol. Entrep. 2024, 3, 100064. [Google Scholar] [CrossRef]
- Omar, O.A.; Elbarkouky, R.A.; Ahmed, H.M. Fractional stochastic modelling of COVID-19 under wide spread of vaccinations: Egyptian case study. Alex. Eng. J. 2022, 61, 8595–8609. [Google Scholar] [CrossRef]
- Webb, G. A COVID-19 epidemic model predicting the effectiveness of vaccination in the US. Infect. Dis. Rep. 2021, 13, 654–667. [Google Scholar] [CrossRef]
- Garcia-Carretero, R.; Ordoñez-Garcia, M.; Vazquez-Gomez, O.; Rodriguez-Maya, B.; Gil-Prieto, R.; Gil-de-Miguel, A. Impact and Effectiveness of COVID-19 Vaccines Based on Machine Learning Analysis of a Time Series: A Population-Based Study. J. Clin. Med. 2024, 13, 5890. [Google Scholar] [CrossRef] [PubMed]
- Nirmalarajah, K.; Aftanas, P.; Barati, S.; Chien, E.; Crowl, G.; Faheem, A.; Farooqi, L.; Jamal, A.J.; Khan, S.; Mubareka, S.; et al. Identification of patient demographic, clinical, and SARS-CoV-2 genomic factors associated with severe COVID-19 using supervised machine learning: A retrospective multicenter study. BMC Infect. Dis. 2025, 25, 132. [Google Scholar] [CrossRef]
- Mengüç, K.; Aydin, N.; Ulu, M. Optimization of COVID-19 vaccination process using GIS, machine learning, and the multi-layered transportation model. Int. J. Prod. Res. 2025, 63, 404–417. [Google Scholar] [CrossRef]
- Dhanaraj, R.K. A Comprehensive Exploration of Artificial Intelligence Methods for COVID-19 Diagnosis. EAI Endorsed Trans. Pervasive Health Technol. 2024, 10. [Google Scholar]
- Lv, C.; Guo, W.; Yin, X.; Liu, L.; Huang, X.; Li, S.; Zhang, L. Innovative applications of artificial intelligence during the COVID-19 pandemic. Infect. Med. 2024, 3, 100095. [Google Scholar] [CrossRef]
- COVID Vaccination vs. Mortality. 2022. Available online: https://www.kaggle.com/datasets/sinakaraji/covid-vaccination-vs-death (accessed on 1 January 2022).
- Azeem, M.; Javaid, S.; Khalil, R.A.; Fahim, H.; Althobaiti, T.; Alsharif, N.; Saeed, N. Neural networks for the detection of COVID-19 and other diseases: Prospects and challenges. Bioengineering 2023, 10, 850. [Google Scholar] [CrossRef]
- Bagriacik, M.; Otero, F.E. Multiple fairness criteria in decision tree learning. Appl. Soft Comput. 2024, 167, 112313. [Google Scholar] [CrossRef]
- Samet, H. K-nearest neighbor finding using MaxNearestDist. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 243–252. [Google Scholar] [CrossRef] [PubMed]
- Sandhu, G.; Singh, A.; Lamba, P.S.; Virmani, D.; Chaudhary, G. Modified Euclidean-Canberra blend distance metric for KNN classifier. Intell. Decis. Technol. 2023, 17, 527–541. [Google Scholar]
- Tomat, A. Interval pattern structures for interpreting K-nearest neighbor approach in lazy classification. In Proceedings of the 11th FCA4AI Workshop Co-Located with the IJCAI 2023 Conference, Macao, China, 20 August 2023; pp. 17, 24. [Google Scholar]
- Deng, S.; Wang, L.; Guan, S.; Li, M.; Wang, L. Non-parametric Nearest Neighbor Classification Based on Global Variance Difference. Int. J. Comput. Intell. Syst. 2023, 16, 26. [Google Scholar] [CrossRef]
- Hamar, Á.; Mohammed, D.; Váradi, A.; Herczeg, R.; Balázsfalvi, N.; Fülesdi, B.; László, I.; Gömöri, L.; Gergely, P.A.; Gombos, K.; et al. COVID-19 mortality prediction in Hungarian ICU settings implementing random forest algorithm. Sci. Rep. 2024, 14, 11941. [Google Scholar] [CrossRef]
- Azzeh, M.; Elsheikh, Y.; Nassif, A.B.; Angelis, L. Examining the performance of kernel methods for software defect prediction based on support vector machine. Sci. Comput. Program. 2023, 226, 102916. [Google Scholar] [CrossRef]
- Guido, R.; Ferrisi, S.; Lofaro, D.; Conforti, D. An overview on the advancements of support vector machine models in healthcare applications: A review. Information 2024, 15, 235. [Google Scholar] [CrossRef]
- Naidu, G.; Zuva, T.; Sibanda, E.M. A review of evaluation metrics in machine learning algorithms. In Proceedings of the Computer Science On-Line Conference, Online, 3–5 April 2023; Springer International Publishing: Cham, Switzerland, 2023; pp. 15–25. [Google Scholar]
- Levashenko, V.; Rabcan, J.; Zaitseva, E. Reliability evaluation of the factors that influenced COVID-19 patients’ condition. Appl. Sci. 2021, 11, 2589. [Google Scholar] [CrossRef]
- Feroze, Z. Cancer Cases Report in All the World in Last 10 Years. 2024. Available online: https://www.kaggle.com/datasets/zahidmughal2343/global-cancer-patients-2015-2024/code (accessed on 10 May 2025).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
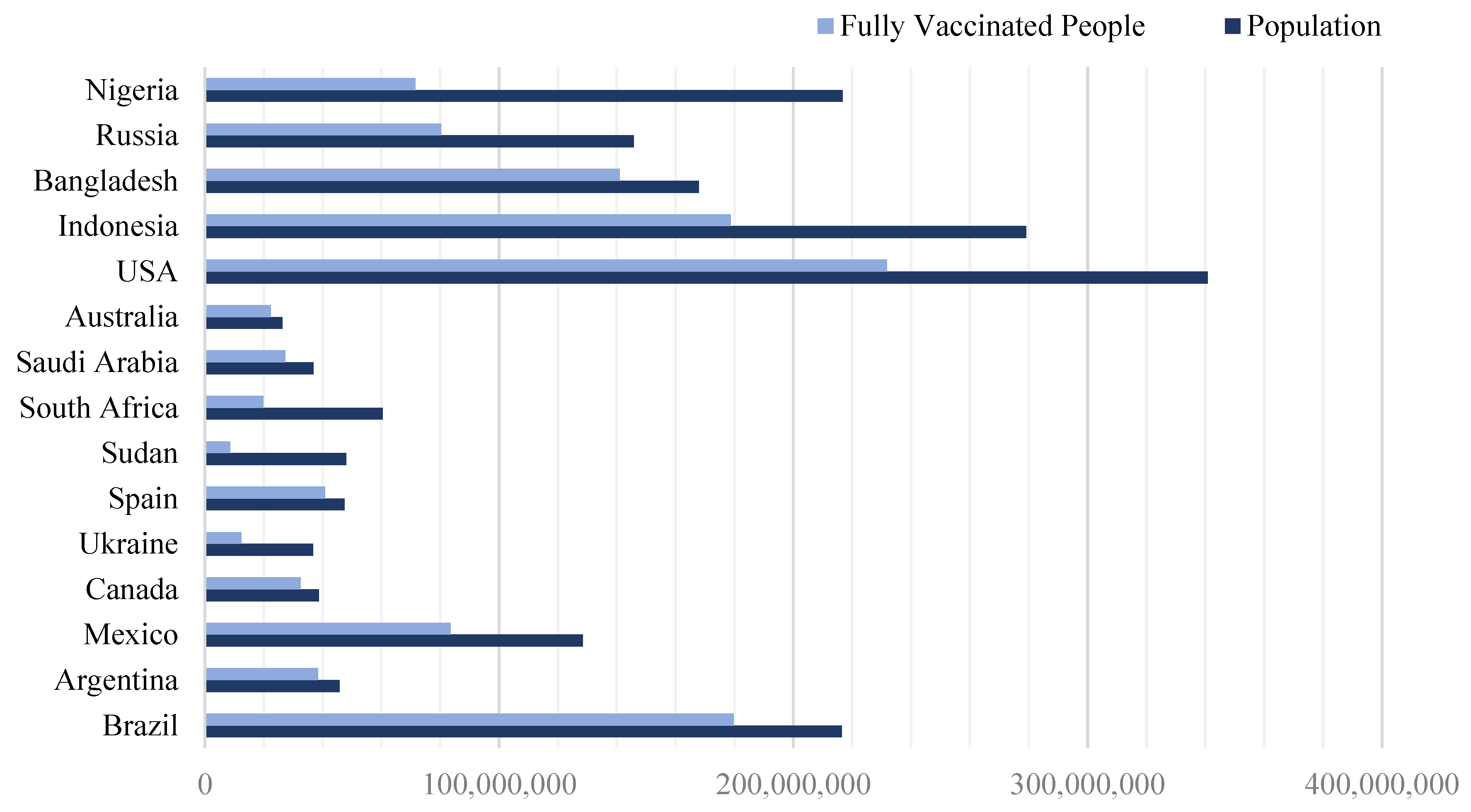
| Country | Population | People Fully Vaccinated | Ratio |
|---|---|---|---|
| Brazil | 216,422,446 | 179,630,630 | 0.83 |
| Argentina | 45,773,884 | 38,450,063 | 0.84 |
| Mexico | 128,455,567 | 83,496,119 | 0.65 |
| Canada | 38,781,291 | 32,576,284 | 0.84 |
| Ukraine | 36,744,634 | 12,493,176 | 0.34 |
| Spain | 47,519,628 | 40,866,880 | 0.86 |
| Sudan | 48,109,006 | 8,659,621 | 0.18 |
| South Africa | 60,414,495 | 19,936,783 | 0.33 |
| Saudi Arabia | 36,947,025 | 27,340,799 | 0.74 |
| Australia | 26,439,111 | 22,473,244 | 0.85 |
| USA | 340,779,371 | 231,729,972 | 0.68 |
| Indonesia | 279,134,505 | 178,646,083 | 0.64 |
| Bangladesh | 167,885,689 | 141,023,978 | 0.84 |
| Russia | 145,805,947 | 80,193,270 | 0.55 |
| Nigeria | 216,746,934 | 71,526,488 | 0.33 |
| Parameters | Testing Bound | Optimal Value |
|---|---|---|
| Learning rate | [0, 1] | 0.01 |
| Momentum | [0, 2] | 0.9 |
| Parameters | Testing Bound | Optimal Value |
|---|---|---|
| Maximum depth | [12, 23] | 20 |
| Confidence | [0.01, 0.2] | 0.1 |
| Minimum leaf size | [1, 4] | 2 |
| Minimum gain | [0.001, 1] | 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niksirat, M.; Tayyebi, J.; Javadi, S.F.; Deaconu, A.M. Developing a Model to Predict the Effectiveness of Vaccination on Mortality Caused by COVID-19. Mathematics 2025, 13, 1816. https://doi.org/10.3390/math13111816
Niksirat M, Tayyebi J, Javadi SF, Deaconu AM. Developing a Model to Predict the Effectiveness of Vaccination on Mortality Caused by COVID-19. Mathematics. 2025; 13(11):1816. https://doi.org/10.3390/math13111816
Chicago/Turabian StyleNiksirat, Malihe, Javad Tayyebi, Seyedeh Fatemeh Javadi, and Adrian Marius Deaconu. 2025. "Developing a Model to Predict the Effectiveness of Vaccination on Mortality Caused by COVID-19" Mathematics 13, no. 11: 1816. https://doi.org/10.3390/math13111816
APA StyleNiksirat, M., Tayyebi, J., Javadi, S. F., & Deaconu, A. M. (2025). Developing a Model to Predict the Effectiveness of Vaccination on Mortality Caused by COVID-19. Mathematics, 13(11), 1816. https://doi.org/10.3390/math13111816