
Rank-Based Family of Probability Laws for Testing Homogeneity of Variable Grouping

 , , , and
, , , and
Abstract
1. Introduction
- In Section 2, we define the family of grouping distributions—which, in our opinion, should be denominated Mexia distributions, honoring the statistician extraordinaire João Tiago Mexia who proposed them for the first time—we detail some properties of the family and present tables of quantiles of the grouping distributions for moderate values of parameters computed from the full discrete distribution, and we state some remarks that highlight the motivation for the problems studied in the following.
- In Section 3, we present some results on moment generating functions that may have an independent interest, namely, Theorem 3, showing, under some general hypothesis, that the Kolmogorov distance between probability distributions is bounded by the distance between the correspondent moment generating functions. We prove a negative asymptotic result based on observed properties of some fully computable grouping distributions and we propose two methodologies to build approximate laws for grouping distributions with large parameter values; these methodologies may be considered implementation open problems due to technical difficulties.
- In Section 4, we present an application of a grouping distribution to assess the within-group homogeneity of clusters of observations from a cocoa breeding experiment.The clusters are obtained by the well-known KMeans clustering technique applied to the whole set of values of the variables. We show that the use of the grouping distribution allows to recover some important features of the observations, namely, the homogeneity of production variables in one type of soil that other statistical methods—such as ANOVA—do not bring to light.
2. The Definition of the Grouping Probability Law
- 1.
- The set of integers ;
- 2.
- The set of all partitions of in p subsets such that
- 3.
- The values of the following function , defined on :from which we can obtain the corresponding frequencies of those values.
2.1. Statistical Relevance of Grouping Distributions
2.2. Computational Issues for the Groupings Statistic Family
3. On an Asymptotic Result for Some Grouping Distributions
3.1. Some Auxiliary Results on Moment Generating Functions
- The densities and have exponential decay that isThis is equivalent to the fact that the interior of the sets and —that is, respectively, and —are non-empty sets (see Proposition 5.1 in [9]). The sets and are, in fact, intervals.
- Also as a consequence, we have that and are holomorphic (analytic) in a strip of the complex plane defined by (see Proposition 5.3 in [9]).
- For every in the complex plane strip defined by , we have that
- There exists an integrable function G in the variable such that, for every in the complex plane strip defined by , we have
- In order to address the inversion formula, we recall that, by the definition in Formula (4), we can extend the MGF to a strip in the complex plane, with defined, for , bysince in the right-hand side we always have an integrable function. Formula (6) shows that the extension of the MGF to the strip defined by can be considered a family of Fourier transforms, namely, the Fourier transforms of the family . Now by the standard results on the inversion of the Fourier transform—or the characteristic function—we have, for instance, that if for all the function is integrable, then by the inversion theorem (see [10], p. 185 or [11], p. 126), we obtain that almost surely in x,that is,with , where the right-hand expression is the usual one for the inversion of the Laplace transform (see [12], pp. 60–66), with the integral being taken in the principal value sense. We have similar expressions for all . The inversion of the MGF in Formula (7) may hold with a more general hypothesis. It must be noticed that by reason of the Cauchy theorem on contour integrals, the integral in the right-hand side of Formula (7) does not depend on (see [13], p. 226).
3.2. A Negative Asymptotic Result on the Limit Law of Grouping Distributions
- A.
- .
- B.
- For all , there exists a sequence such that, with , for we have
- C.
- For , there exists such that
- D.
- We finally suppose that for all m and ,
- These hypothesis are verified in the cases analyzed and referred to in Example 1.
- I
- If , we have thatthis case encompasses the extreme case , where the number of groups converges to the number of elements to group, and so asymptotically, all the groups have only one element.
- II
- As a consequence, if , we have thata case which encompasses the case where the number of groups stays fixed while the number of elements to group goes to infinity and so asymptotically at least one of the subgroups has an unbounded number of elements.
- We observe that in both cases, the generalized function presented—such that its MGF is given by Formula (17)—is unique. If , we want to recover Formula (17) by the rules of calculus of the generalized functions. We notice that , given by Formula (21), is a generalized function with compact support and so, its definition domain is the test space of indefinitely differentiable functions over . Recall that if the generalized function with compact support K is given by a locally integrable function f with support K, we have that for every indefinitely differentiable function ,
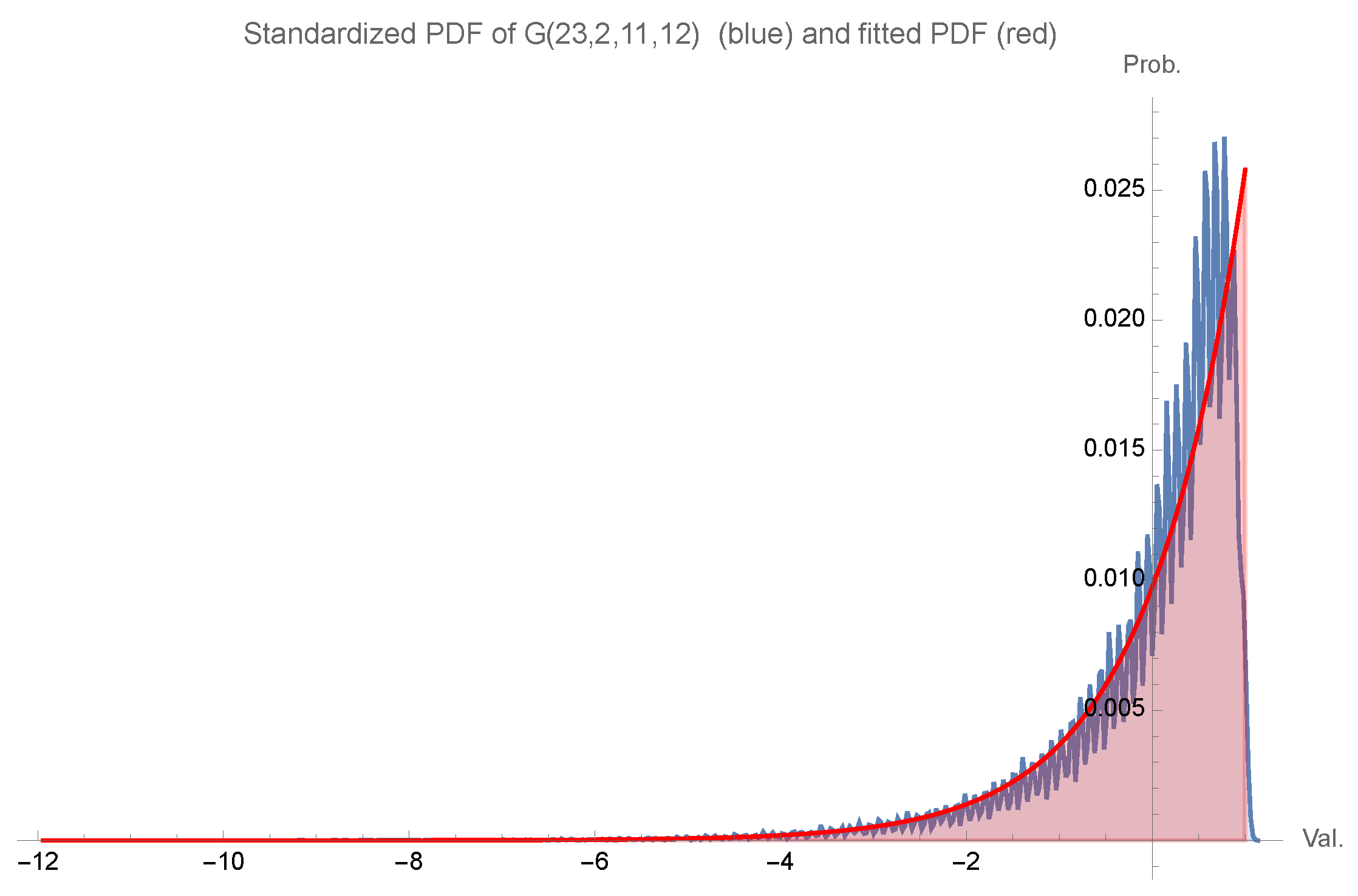
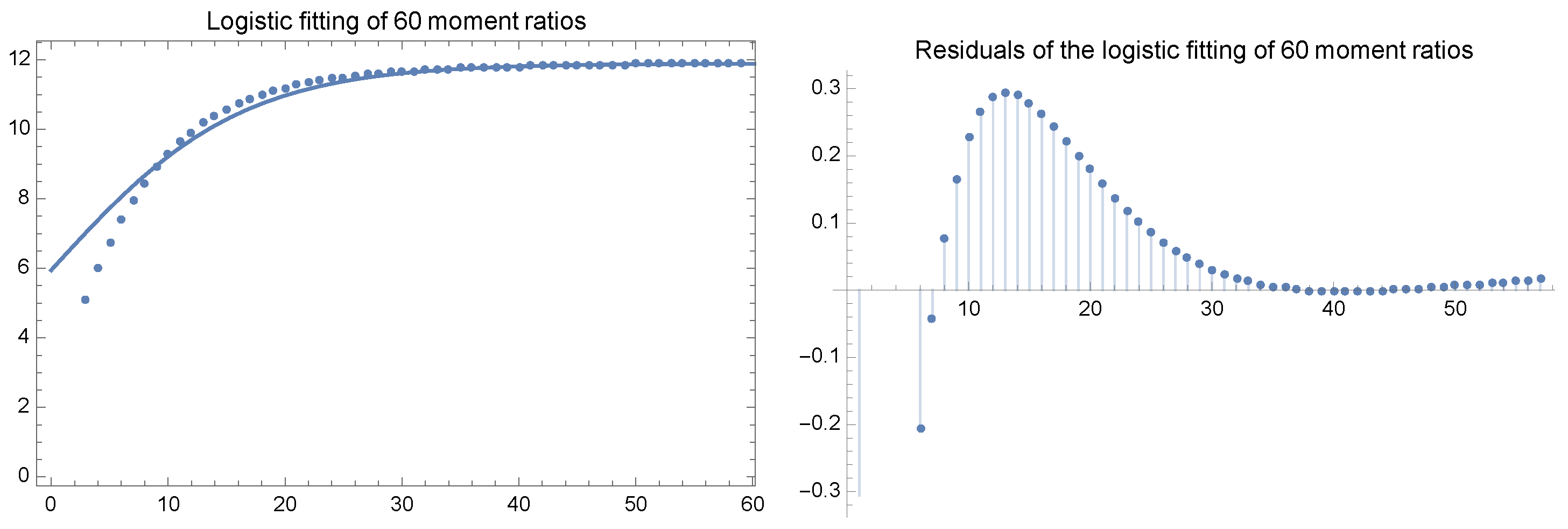
3.3. Determining Approximate Laws for Grouping Distributions with Large Parameter Values
- I
- The sequence is a moment sequence represented by a measure supported on n points.
- II
- We have that
4. An Application of the Grouping Statistic to a Clustering Analysis
- 1.
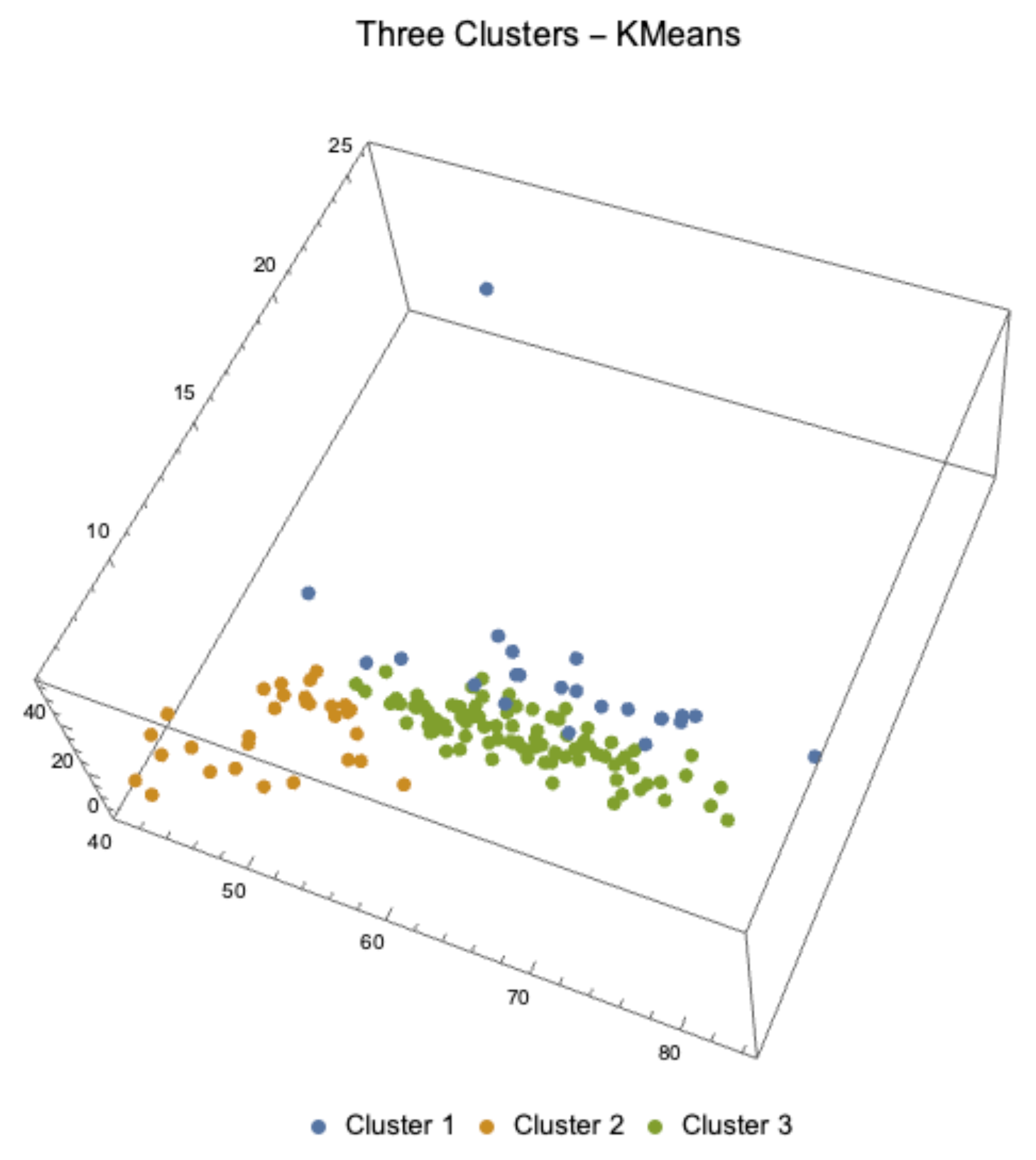
- We first determine the data grouping in three clusters using the KMeans clustering classification method. A good introduction to classification techniques can be read in [21]. The results of the classification are presented in Table 6, and a graphical representation of the 3-dimensional clusters of observations is presented in Figure 4.
- 2.
- As a consequence of the classification, we then use the grouping statistics and to assess for each one of the four soils the quality of the grouping. The values obtained are given in Table 7.
- 3.
- We then present some conclusions reached by the use of the statistics and to the results of the KMeans grouping.
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MGF | Moment Generating Function |
| ANOVA | Analysis of Variance |
| Probability Density Function | |
| KMeans | Clustering classification methodology |
Appendix A. Data Characteristics
Appendix A.1. On the Varieties of Plants of Cocoa in the Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | Variety | Code | Variety | Code | Variety |
|---|---|---|---|---|---|
| Standard Variety | |||||
Appendix A.2. On the Soils of the Data
| Name | Region of Provenance in Ghana |
|---|---|
| Soil 1 | Forest Ochrosols-Oxysols intergrades (Saamang) |
| Soil 2 | Forest Oxysol (Samreboi) |
| Soil 3 | Forest Ochrosol (Boako) |
| Soil 4 | Forest Rubrisols-Ochrosol intergrade (Tafo) |
| Soil Name | pH (a) | OC (b) (%) | TN (c) (%) | AP (d) (mg/kg) | K (e) (cmolc/kg) | Mg (f) (cmolc/kg) | Ca (g) (cmolc/kg) |
|---|---|---|---|---|---|---|---|
| Soil 1 | 4.991 | 3.36 | 0.327 | 17.593 | 0.263 | 0.55 | 7.98 |
| Soil 2 | 4.208 | 0.5 | 0.095 | 20.715 | 0.569 | 3.142 | 1.729 |
| Soil 3 | 5.072 | 2.34 | 0.309 | 19.849 | 0.329 | 2.861 | 6.309 |
| Soil 4 | 5.635 | 0.76 | 0.123 | 23.845 | 0.57 | 3.009 | 6.473 |
| Critical min | 5.6 | 3.5 | 0.09 | 20 | 0.25 | 1.33 | 7.5 |
Appendix A.3. ANOVA of the Data
| Factors | Plant Height | Stem Diameter | Dry Matter |
|---|---|---|---|
| Variety | |||
| Soil | |||
| Variety–Soil |
| Variety | A (PH) (a) | Plant Height (b) | A (SD) (c) | Stem Diameter (d) | A (DM) (e) | Dry Matter (f) |
|---|---|---|---|---|---|---|
| 67.2778 | 10.4125 | 34.1715 | ||||
| 59.7215 | 11.297 | 32.4229 | ||||
| 64.3505 | 10.2296 | 31.4934 |
Appendix A.4. A Proof of a Referred Result
References
- Opoku-Ameyaw, K.; Nunes, C.; Esquível, M.L.; Mexia, J.T. CMMSE: A nonparametric test for grouping factor levels: An application to cocoa breeding experiments in acidic soils. J. Math. Chem. 2023, 61, 652–672. [Google Scholar] [CrossRef]
- Yitzhaki, S. Gini’s mean difference: A superior measure of variability for non-normal distributions. Metron 2003, 61, 285–316. [Google Scholar]
- Zenga, M.; Polisicchio, M.; Greselin, F. The variance of Gini’s mean difference and its estimators. Statistica 2004, 64, 455–475. [Google Scholar]
- Haye, R.L.; Zizler, P. The Gini mean difference and variance. Metron 2019, 77, 43–52. [Google Scholar] [CrossRef]
- Baz, J.; Pellerey, F.; Díaz, I.; Montes, S. Stochastic ordering of variability measure estimators. Statistics 2024, 58, 26–43. [Google Scholar] [CrossRef]
- Conover, W.J. Practical Nonparametric Statistics, 3rd ed.; John Wiley & Sons, Inc.: New York, NY, USA, 1999; pp. viii+584. [Google Scholar]
- Butucea, C.; Tribouley, K. Nonparametric homogeneity tests. J. Stat. Plan. Inference 2006, 136, 597–639. [Google Scholar] [CrossRef]
- Graham, R.L.; Knuth, D.E.; Patashnik, O. Concrete Mathematics: A Foundation for Computer Science, 2nd ed.; Addison-Wesley Publishing Company: Reading, MA, USA, 1994; pp. xiv+657. [Google Scholar]
- Esquível, M.L. Probability generating functions for discrete real-valued random variables. Teor. Veroyatn. Primen. 2007, 52, 129–149. [Google Scholar] [CrossRef]
- Rudin, W. Real and Complex Analysis, 3rd ed.; McGraw-Hill Book Co.: New York, NY, USA, 1987; pp. xiv+416. [Google Scholar]
- Katznelson, Y. An Introduction to Harmonic Analysis; Dover Publications, Inc.: New York, NY, USA, 1976; corrected edition; pp. xiv+264. [Google Scholar]
- Widder, D.V. The Laplace Transform; Princeton Mathematical Series; Princeton University Press: Princeton, NJ, USA, 1941; Volume 6, pp. x+406. [Google Scholar]
- Schwartz, L. Mathematics for the Physical Sciences; Dover Publications, Inc.: Mineola, NY, USA, 1966; p. 358. [Google Scholar]
- Kallenberg, O. Foundations of Modern Probability, 3rd ed.; Probability Theory and Stochastic Modelling; Springer: Cham, Switzerland, 2021; Volume 99, pp. xii+946. [Google Scholar] [CrossRef]
- Schmüdgen, K. The Moment Problem; Graduate Texts in Mathematics; Springer: Cham, Switzerland, 2017; Volume 277, pp. xii+535. [Google Scholar]
- Durrett, R. Probability—Theory and Examples, 5th ed.; Cambridge Series in Statistical and Probabilistic Mathematics; Cambridge University Press: Cambridge, UK, 2019; Volume 49, pp. xii+419. [Google Scholar] [CrossRef]
- Beffa, F. Weakly Nonlinear Systems—With Applications in Communications Systems; Understanding Complex Systems; Springer: Cham, Switzerland, 2024; pp. xiv+371. [Google Scholar] [CrossRef]
- Lindner, M. An introduction to the limit operator method. In Infinite Matrices and Their Finite Sections; Frontiers in Mathematics; Birkhäuser Verlag: Basel, Switzerland, 2006; pp. xv+191. [Google Scholar]
- Ran, A.C.M.; Serény, A. The finite section method for infinite Vandermonde matrices. Indag. Math. 2012, 23, 884–899. [Google Scholar] [CrossRef]
- Hernández-Pastora, J.L. On the solutions of infinite systems of linear equations. Gen. Relativ. Gravit. 2014, 46, 1622. [Google Scholar] [CrossRef]
- Scitovski, R.; Sabo, K.; Martínez-Álvarez, F.; Ungar, Š. Cluster Analysis and Applications; Springer: Cham, Switzerland, 2021. [Google Scholar] [CrossRef]

| 14 | 15 | 16 | 17 | 18 | 19 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (2,12) | 598 | (2,13) | 778 | (2,14) | 964 | (2,15) | 1178 | (2,16) | 1422 | (2,17) | 1698 |
| 618 | 778 | 984 | 1200 | 1450 | 1728 | ||||||
| (3,11) | 512 | (3,12) | 670 | (3,13) | 832 | (3,14) | 1022 | (3,15) | 1260 | (3,16) | 1512 |
| 528 | 678 | 852 | 1046 | 1284 | 1540 | ||||||
| (4,10) | 446 | (4,11) | 580 | (4,12) | 724 | (4,13) | 910 | (4,14) | 1110 | (4,15) | 1350 |
| 466 | 598 | 752 | 934 | 1146 | 1380 | ||||||
| (5,10) | 400 | (5,10) | 514 | (5,11) | 652 | (5,12) | 814 | (5,13) | 1004 | (5,14) | 1220 |
| 416 | 536 | 676 | 842 | 1036 | 1256 | ||||||
| (6,8) | 374 | (6,9) | 476 | (6,10) | 600 | (6,11) | 750 | (6,12) | 922 | (6,13) | 1118 |
| 394 | 502 | 628 | 780 | 954 | 1156 | ||||||
| (7,7) | 364 | (7,8) | 456 | (7,9) | 568 | (7,10) | 706 | (7,11) | 864 | (7,12) | 1044 |
| 384 | 482 | 596 | 734 | 896 | 1084 | ||||||
| – | – | – | – | (8,8) | 560 | (8,9) | 684 | (8,10) | 830 | (8,11) | 998 |
| – | – | – | – | 588 | 714 | 862 | 1036 | ||||
| – | – | – | – | – | – | – | – | (9,9) | 816 | (9,10) | 974 |
| – | – | – | – | – | – | – | – | 852 | 1012 |
| 8 | 9 | 10 | 11 | 12 | 13 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (2,6) | 72 | (2,7) | 114 | (2,8) | 186 | (2,9) | 260 | (2,10) | 352 | (2,11) | 464 |
| 84 | 128 | 186 | 274 | 368 | 482 | ||||||
| (3,5) | 60 | (3,6) | 102 | (3,7) | 148 | (3,8) | 208 | (3,9) | 296 | (3,10) | 392 |
| 68 | 102 | 156 | 222 | 304 | 410 | ||||||
| (4,4) | 52 | (4,5) | 84 | (4,6) | 126 | (4,7) | 180 | (4,8) | 248 | (4,9) | 332 |
| 60 | 90 | 130 | 188 | 264 | 356 | ||||||
| – | – | – | – | (5,5) | 120 | (5,6) | 160 | (5,7) | 228 | (5,8) | 304 |
| – | – | – | – | 128 | 182 | 240 | 320 | ||||
| – | – | – | – | – | – | – | – | (6,6) | 216 | (6,7) | 286 |
| – | – | – | – | – | – | – | – | 236 | 302 |
| 1780 | 1808.76 (1.59%) | 1838 | 1836.86 (0.062%) | |
| 1338 | 1360.82 (1.68%) | 1386 | 1384.2 (0.13%) | |
| 974 | 993.586 (1.97%) | 1012 | 1012.67 (0.066%) | |
| 684 | 699.057 (2.15%) | 714 | 714.285 (0.04%) | |
| 456 | 469.233 (2.82%) | 482 | 481.035 (0.2%) | |
| 286 | 296.114 (1.59%) | 302 | 304.924 (0.062%) |
| Types of Soil | Plant Height | Stem Diameter | Dry Matter |
|---|---|---|---|
| Soil 1: cluster varieties (a) | |||
| Soil 2: cluster varieties | (b) | (b) | (b) |
| Soil 3: cluster varieties | |||
| Soil 4: cluster varieties | |||
| Types of Soil | Plant Height | Stem Diameter | Dry Matter |
|---|---|---|---|
| Soil 1 | 360 | 324 | 344 |
| Soil 2 | 332 | 344 | 332 |
| Soil 3 | 248 (a) | 284 (a) | 268 (a) |
| Soil 4 | 320 | 312 | 352 |
| Types of Soil | Plant Height | Stem Diameter | Dry Matter |
|---|---|---|---|
| Soil 1: cluster ranks (a) | |||
| Soil 2: cluster ranks (b) | (c) | (c) | (c) |
| Soil 3: cluster ranks (a) | |||
| 3 : {10, 11, 12} | 3 : {1, 11, 12} | 3 : {9, 11, 12} | |
| Soil 4: cluster ranks (a) | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Esquível, M.L.; Krasii, N.P.; Nunes, C.; Opoku-Ameyaw, K.; Mota, P.P. Rank-Based Family of Probability Laws for Testing Homogeneity of Variable Grouping. Mathematics 2025, 13, 1805. https://doi.org/10.3390/math13111805
Esquível ML, Krasii NP, Nunes C, Opoku-Ameyaw K, Mota PP. Rank-Based Family of Probability Laws for Testing Homogeneity of Variable Grouping. Mathematics. 2025; 13(11):1805. https://doi.org/10.3390/math13111805
Chicago/Turabian StyleEsquível, Manuel L., Nadezhda P. Krasii, Célia Nunes, Kwaku Opoku-Ameyaw, and Pedro P. Mota. 2025. "Rank-Based Family of Probability Laws for Testing Homogeneity of Variable Grouping" Mathematics 13, no. 11: 1805. https://doi.org/10.3390/math13111805
APA StyleEsquível, M. L., Krasii, N. P., Nunes, C., Opoku-Ameyaw, K., & Mota, P. P. (2025). Rank-Based Family of Probability Laws for Testing Homogeneity of Variable Grouping. Mathematics, 13(11), 1805. https://doi.org/10.3390/math13111805