
TANS: A Tolerance-Aware Neighborhood Search Method for Workflow Scheduling with Uncertainties in Cloud Manufacturing


Abstract
1. Introduction
- (i)
- To handle the fuzzy uncertainty in task execution and logistics times, we propose a fuzzy quantization model based on triangular fuzzy numbers. This model effectively quantifies and controls the propagation of fuzziness through workflow tasks, mitigating the impact of uncertainty on scheduling performance.
- (ii)
- To deal with complex partial-order task constraints and soft deadlines, we develop fuzzy sub-deadline partitioning strategies and a maximum sub-workflow time consumption priority strategy. These strategies systematically prioritize tasks, ensuring feasible task scheduling sequences that effectively minimize total delays.
- (iii)
- Addressing the trade-off between execution efficiency and logistics overhead, we propose a comprehensive tolerance-aware neighborhood search optimization framework, including novel neighborhood structure construction operators and adaptive search strategies. This approach efficiently explores the solution space, balancing task allocation and logistics optimization.
2. Related Work
2.1. Workflow Scheduling in Cloud Manufacturing
2.2. Workflow Scheduling Under Uncertainty
2.3. Workflow Scheduling with Soft Deadline Constraints
3. System Model
3.1. System Architecture
- At the workflow level, users submit workflow applications with soft deadline constraints to the cloud manufacturing platform. Both the soft deadlines and the topological structure of the workflows are predefined and known in advance, and they do not change during the scheduling process. All workflows are final upon submission and cannot be modified or resubmitted.
- At the task level, the total number of tasks contained within a workflow application, as well as the workload of each task, is predefined and known in advance, and it remains unchanged during the scheduling process.
- At the service resource level, the execution speed of each service and the logistic time between different services are fuzzy and uncertain values. The quantity of services, execution speeds, and logistics times between different services are predefined and known in advance and do not change during the scheduling process. There is no logistic time for the same service.
- During the scheduling process, only the execution time and logistics time of the tasks are considered, while the setup time of the tasks is ignored. A task can only be executed by one service resource, and it cannot be interrupted for preemption or migration during its execution; a service resource can only handle one task at a time.
3.2. Representation Methods for Fuzzy Factors
3.3. Problem Formulation
4. Proposed Algorithm
4.1. Fuzzy Time Parameter Estimation
4.2. Task Fuzzy Sub-Deadline Partitioning
4.3. Task Scheduling Sequence Generation
4.4. Service Search and Matching
4.5. Neighborhood Search
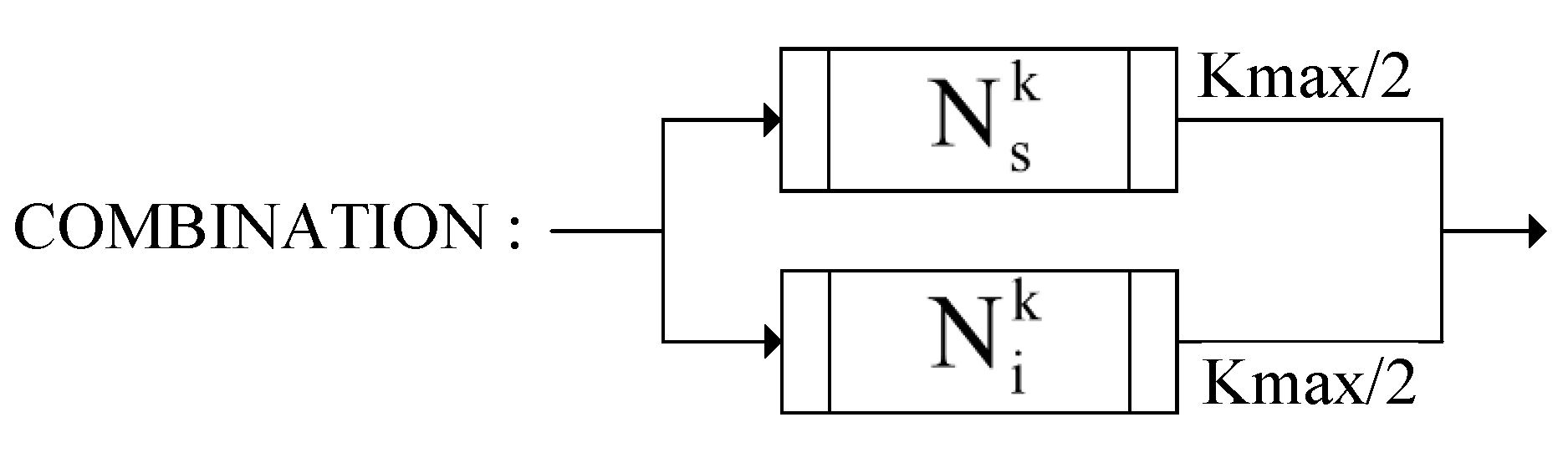
4.5.1. Neighborhood Structure Construction Operator
| Algorithm 1: Allocating Algorithm—EFT |
 |
| Algorithm 2: Allocating Algorithm—SET |
 |
| Algorithm 3: Allocating Algorithm—LRU |
 |
4.5.2. Neighborhood Search Method
| Algorithm 4: Fixed Neighborhood Search (FNS) |
 |
- 1.
- From Equation (35), we know the RPD (Relative Percentage Deviation) is monotonically decreasing, since each iteration only accepts improved solutions:
- 2.
- Let , where this positive minimum is guaranteed by the discrete nature of fuzzy numbers.
- 3.
- When the counter temp accumulates consecutive iterations without improvement, we must have:which triggers loop termination by the algorithm’s stopping condition.
| Algorithm 5: Variable Neighborhood Search (VNS) |
 |
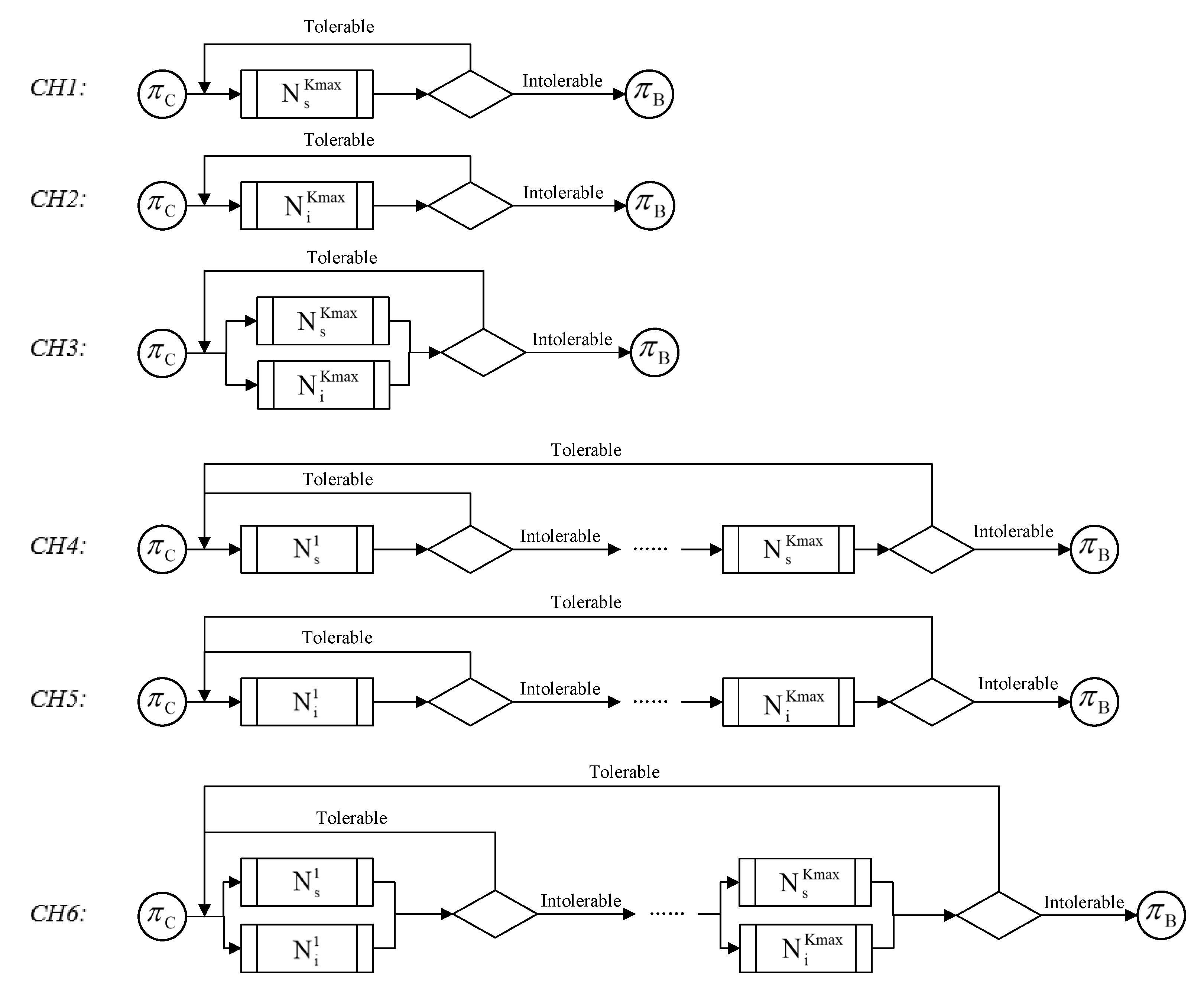
4.5.3. Neighborhood Structure and Composite Heuristic Neighborhood Search Algorithm
5. Experimental Results
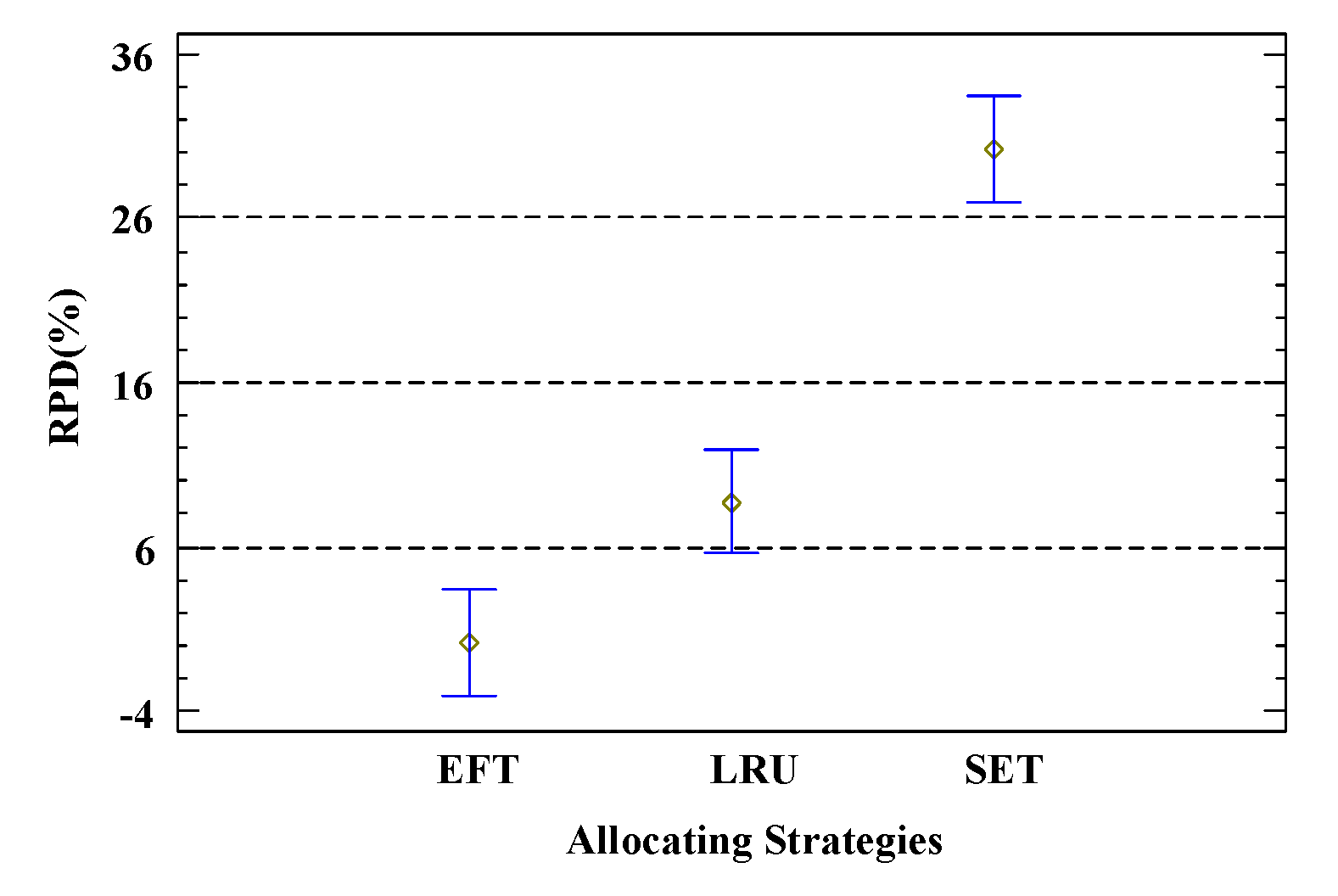
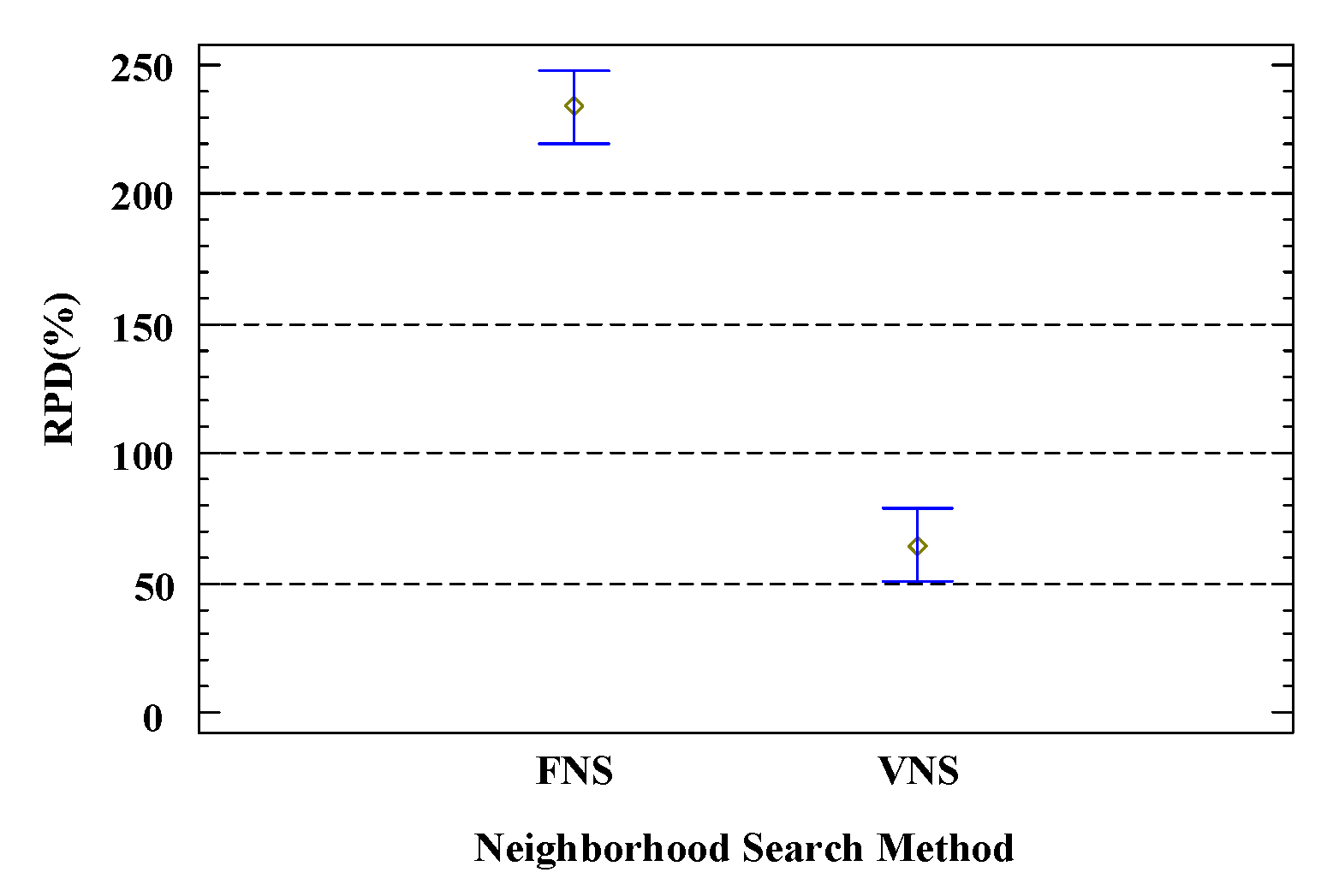
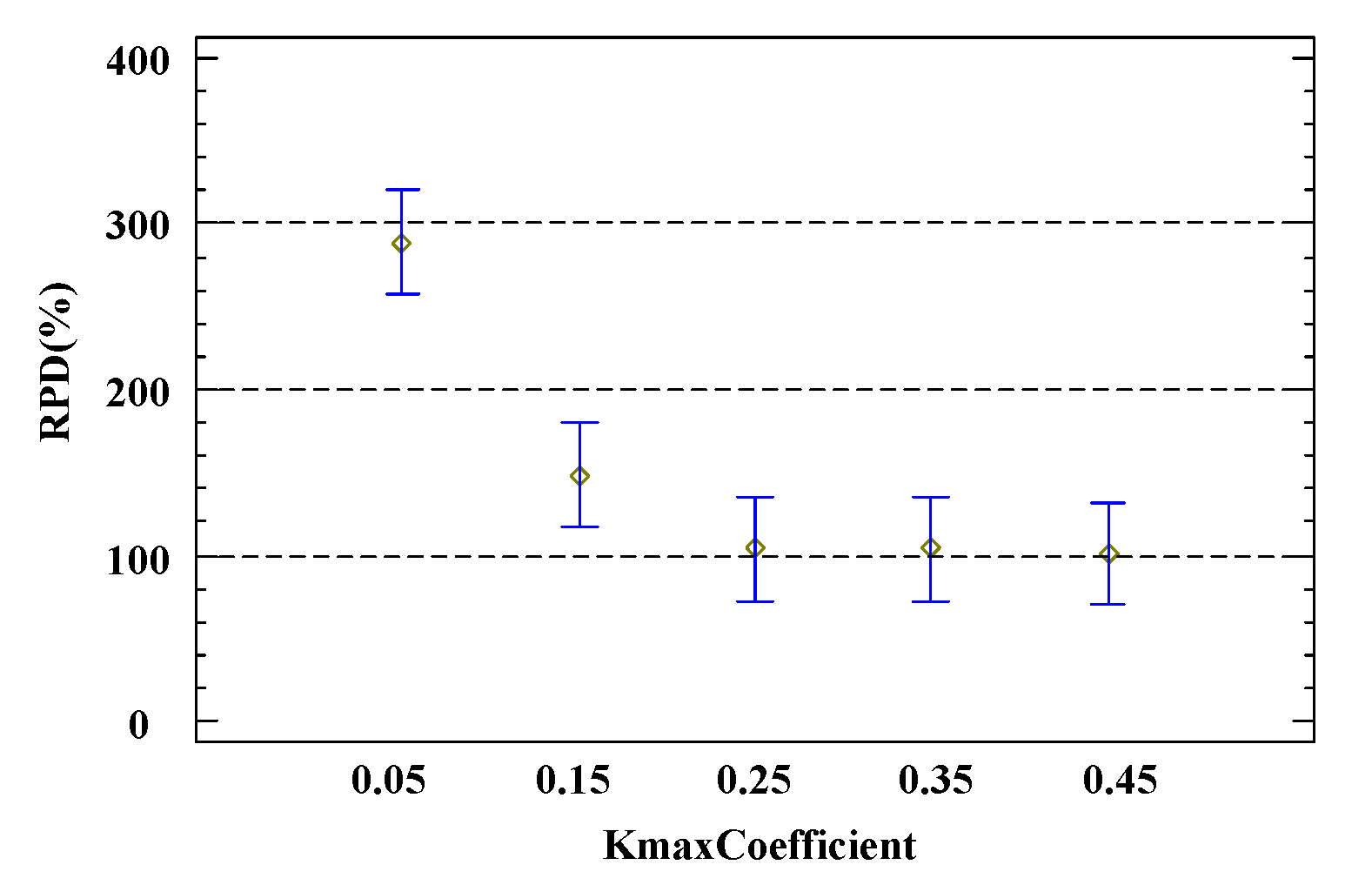
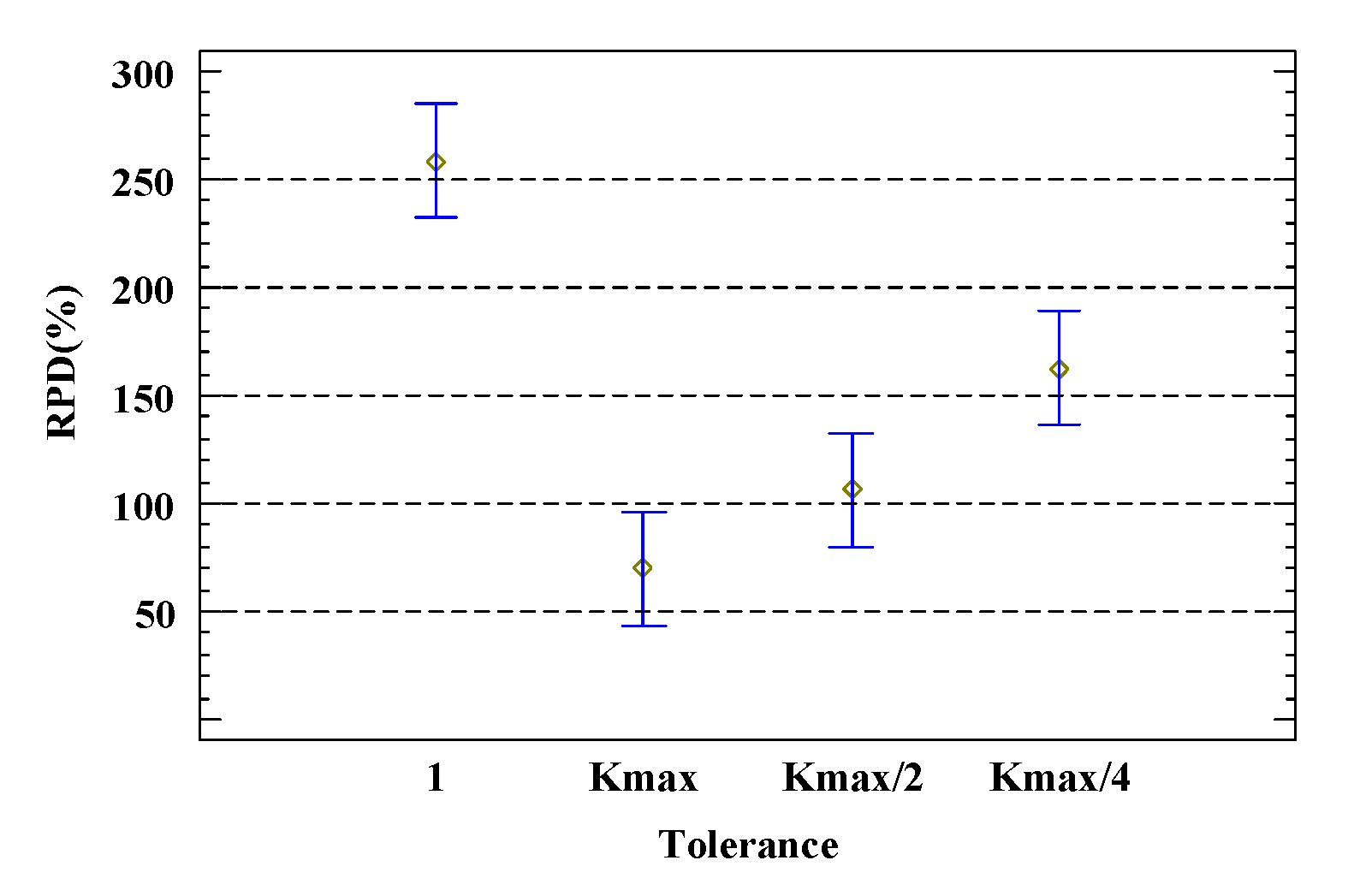
5.1. Parameter and Component Calibration
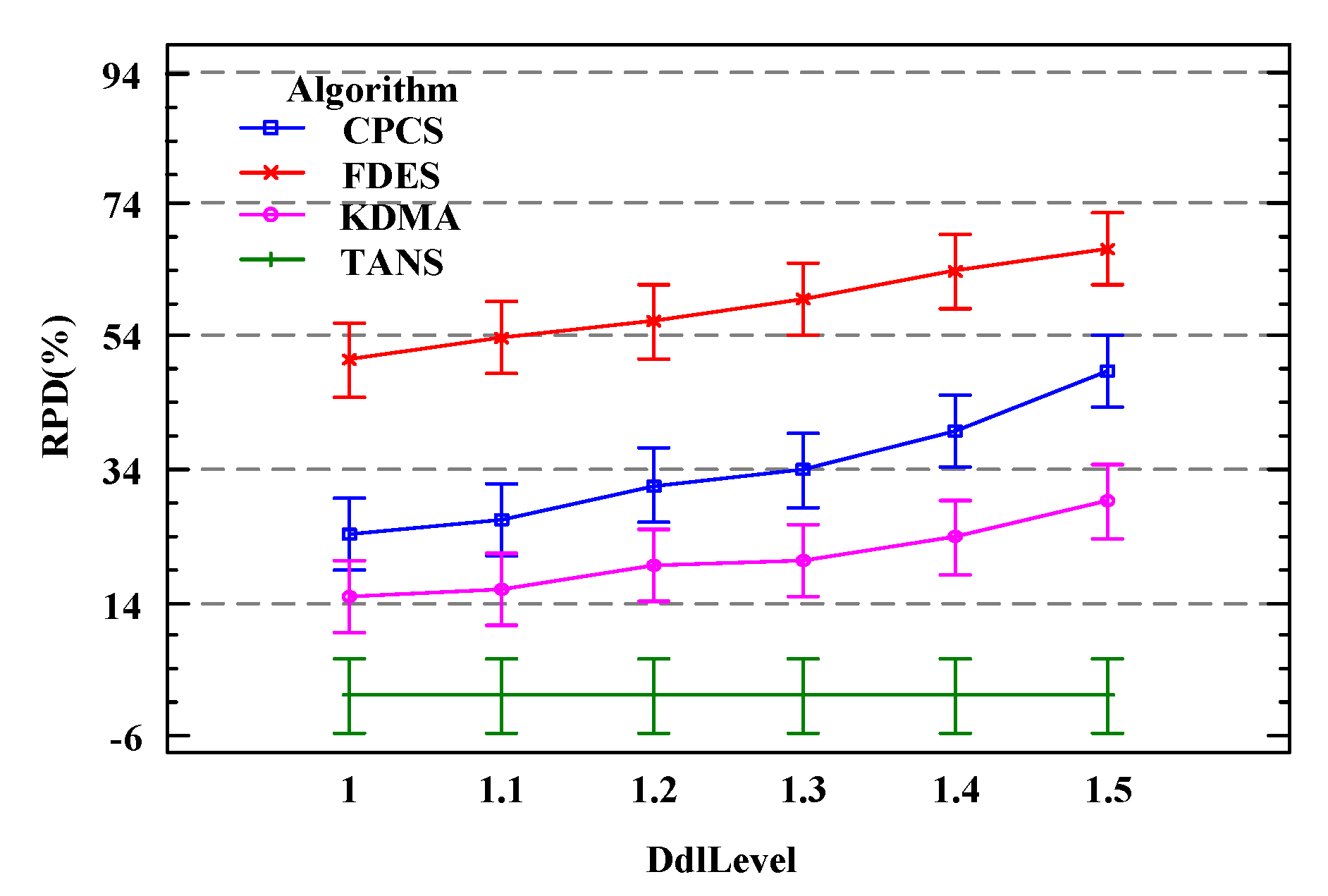
5.2. Algorithm Evaluation
- Baseline 1 (KDMA): KDMA is a memetic workflow scheduling algorithm that embeds a heuristic local search operator into the metaheuristic algorithm to combine their strengths and complement each other’s shortcomings.
- Baseline 2 (CPCS): CPCS is a scheduling algorithm that clusters tasks using a recursive critical path. Since list scheduling and clustering scheduling represent two categories within heuristic scheduling, comparing CPCS with the list scheduling algorithm proposed in this paper is of significant importance.
- Baseline 3 (FDES): FDES is a fuzzy dynamic event scheduling algorithm based on heap sorting. Comparing it with the static scheduling scheme generated by the algorithm proposed in this paper can provide a more comprehensive validation of the performance of our algorithm.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, F.; Liao, W.; Cai, W.; Zhang, L. Multitask Scheduling in Consideration of Fuzzy Uncertainty of Multiple Criteria in Service-Oriented Manufacturing. IEEE Trans. Fuzzy Syst. 2020, 28, 2759–2771. [Google Scholar] [CrossRef]
- Zhu, G.; Shao, X. A Scheduling Optimization Algorithm Based on Non-Cooperative Game in the Cloud Manufacturing. In Proceedings of the 2022 8th International Conference on Information Management (ICIM), Cambridge, UK, 25–27 March 2022; pp. 155–159. [Google Scholar] [CrossRef]
- Ma, Y.; Xu, W.; Tian, S.; Liu, J.; Zhou, Z.; Hu, Y.; Feng, H. Digital Twin Enhanced Optimization of Manufacturing Service Scheduling for Industrial Cloud Robotics. In Proceedings of the 2020 IEEE 18th International Conference on Industrial Informatics (INDIN), Warwick, UK, 20–23 July 2020; Volume 1, pp. 469–476. [Google Scholar] [CrossRef]
- Li, X.; Wang, X.; Zhao, Y.; Dong, Y.; Wang, P. Improved Grey Wolf Optimization Algorithm for Solving Cloud Manufacturing Scheduling Problem with Limit Logistics Resource. In Proceedings of the 2021 4th International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 28–31 May 2021; pp. 174–178. [Google Scholar] [CrossRef]
- Bi, X.; Yu, D.; Liu, J.; Hu, Y. Multi-Agent Scheduling System in Cloud Manufacturing Environment. In Proceedings of the 2020 10th Institute of Electrical and Electronics Engineers International Conference on Cyber Technology in Automation, Control, and Intelligent Systems (CYBER), Xi’an, China, 10–14 October 2020; pp. 385–389. [Google Scholar]
- Zhang, Y.; Yu, J. Research on High-Efficiency Resource Allocation of Multi-edge Devices Based on Cloud Manufacturing Mode. In Proceedings of the 2021 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 29–31 July 2021; pp. 682–687. [Google Scholar] [CrossRef]
- Liu, S.; Li, L.; Zhang, L.; Shen, W. Game Theory Based Dynamic Event-Driven Service Scheduling in Cloud Manufacturing. IEEE Trans. Autom. Sci. Eng. 2022, 21, 618–629. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, C.; Yan, Y.; Hu, Y. Distributed Real-Time Scheduling in Cloud Manufacturing by Deep Reinforcement Learning. IEEE Trans. Ind. Inform. 2022, 18, 8999–9007. [Google Scholar] [CrossRef]
- Yang, F.; Feng, T.; Xu, F.; Jiang, H.; Zhao, C. Collaborative clustering parallel reinforcement learning for edge-cloud digital twins manufacturing system. China Commun. 2022, 19, 138–148. [Google Scholar] [CrossRef]
- Lin, B.; Lin, C.; Chen, X.; Lin, M.; Huang, G.; Xu, Z. Cost-Driven Scheduling for Workflow Decision Making Systems in Fuzzy Edge-Cloud Environments. IEEE Trans. Autom. Sci. Eng. 2025, 22, 3756–3771. [Google Scholar] [CrossRef]
- Yang, Y.; Shen, H.; Tian, H. Scheduling Workflow Tasks With Unknown Task Execution Time by Combining Machine-Learning and Greedy-Optimization. IEEE Trans. Serv. Comput. 2024, 17, 1181–1195. [Google Scholar] [CrossRef]
- Rajput, K.Y.; Li, X.; Zhang, J.; Lakhan, A. A Novel Scheduling Approach for Spark Workflow Tasks With Deadline and Uncertain Performance in Multi-Cloud Networks. IEEE Trans. Cloud Comput. 2024, 12, 1145–1157. [Google Scholar] [CrossRef]
- Wang, Y.J.; Wang, G.G.; Tian, F.M.; Gong, D.W.; Pedrycz, W. Solving energy-efficient fuzzy hybrid flow-shop scheduling problem at a variable machine speed using an extended NSGA-II. Eng. Appl. Artif. Intell. 2023, 121, 105977. [Google Scholar] [CrossRef]
- Sun, M.; Cai, Z.; Zhang, H. A teaching-learning-based optimization with feedback for L-R fuzzy flexible assembly job shop scheduling problem with batch splitting. Expert Syst. Appl. 2023, 224, 120043. [Google Scholar] [CrossRef]
- Zhou, W.; Chen, F.; Ji, X.; Li, H.; Zhou, J. A Pareto-based discrete particle swarm optimization for parallel casting workshop scheduling problem with fuzzy processing time. Knowl.-Based Syst. 2022, 256, 109872. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, J. Emergency Logistics Scheduling Under Uncertain Transportation Time Using Online Optimization Methods. IEEE Access 2021, 9, 36995–37010. [Google Scholar] [CrossRef]
- Congcong, C.; Yueyu, L.; Jiaojiao, W. A Dynamic Optimization Method of Intelligent Material Distribution Based on Hybrid Heuristic Algorithm. In Proceedings of the 2020 9th International Conference on Industrial Technology and Management (ICITM), Oxford, UK, 11 February 2020; pp. 210–214. [Google Scholar]
- Fizza, K.; Auluck, N.; Azim, A. Improving the Schedulability of Real-Time Tasks Using Fog Computing. IEEE Trans. Serv. Comput. 2022, 15, 372–385. [Google Scholar] [CrossRef]
- Mukherjee, M.; Kumar, V.; Zhang, Q.; Mavromoustakis, C.X.; Matam, R. Optimal Pricing for Offloaded Hard- and Soft-Deadline Tasks in Edge Computing. IEEE Trans. Intell. Transp. Syst. 2022, 23, 9829–9839. [Google Scholar] [CrossRef]
- He, X.; Dou, W. Offloading Deadline-aware Task in Edge Computing. In Proceedings of the 2020 IEEE 13th International Conference on Cloud Computing (CLOUD), Beijing, China, 18–24 October 2020; pp. 28–30. [Google Scholar] [CrossRef]
- He, X.; Zheng, J.; He, Q.; Dai, H.; Liu, B.; Dou, W.; Chen, G. CONFECT: Computation Offloading for Tasks with Hard/Soft Deadlines in Edge Computing. In Proceedings of the 2021 IEEE International Conference on Web Services (ICWS), Chicago, IL, USA, 5–10 September 2021; pp. 262–271. [Google Scholar] [CrossRef]
- Yao, F.; Chen, H.; Liu, X.; Gong, M.; Xing, L.; Zhao, W.; Zheng, L. A Multi-Objective Memetic Algorithm for Workflow Scheduling in Clouds. IEEE Trans. Emerg. Top. Comput. Intell. 2024. [Google Scholar] [CrossRef]
- Cai, K.; Wu, Q.; Zhou, M.; Chen, C.; Wen, J.; Wang, S. Dynamically Scheduling Deadline-Constrained Interleaved Workflows on Heterogeneous Computing Systems. IEEE Trans. Serv. Comput. 2025, 18, 758–769. [Google Scholar] [CrossRef]
- Nakahira, Y.; Ferragut, A.; Wierman, A. Generalized Exact Scheduling: A Minimal-Variance Distributed Deadline Scheduler. Oper. Res. 2020, 71, 397–790. [Google Scholar] [CrossRef]
- ISO 22400:2014; Automation Systems and Integration—Key Performance Indicators (KPIs) for Manufacturing Operations Management. International Organization for Standardization: Geneva, Switzerland, 2014.
- IEEE Std 1855-2016; IEEE Standard for Fuzzy Markup Language. IEEE: New York, NY, USA, 2016.
- Ebaid, A.; Ammar, R.; Rajasekaran, S.; Fergany, T. Task clustering & scheduling with duplication using recursive critical path approach (RCPA). In Proceedings of the 10th IEEE International Symposium on Signal Processing and Information Technology, Luxor, Egypt, 15–18 December 2010; pp. 34–41. [Google Scholar] [CrossRef]
- Zhu, J.; Li, X.; Ruiz, R.; Li, W.; Huang, H.; Zomaya, A.Y. Scheduling Periodical Multi-Stage Jobs With Fuzziness to Elastic Cloud Resources. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 2819–2833. [Google Scholar] [CrossRef]


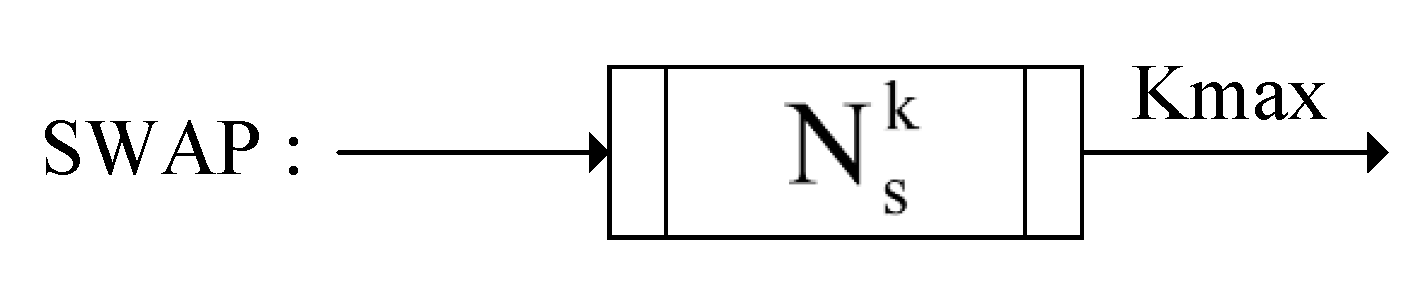






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Application Environment | Uncertainty Model | Deadline Type | Advantages | Disadvantages |
|---|---|---|---|---|---|
| Zhu et al. (2022) [2] | Cloud Manufacturing | Deterministic | Hard | Clear cost optimization | Ignores time/logistics uncertainty |
| Ma et al. (2020) [3] | Industrial Cloud Robots | Deterministic | Hard | Digital Twin integration; real-time feedback | Limited scalability; no fuzzy handling |
| Li et al. (2021) [4] | Cloud Manufacturing and Logistics | Deterministic/ Stochastic | Hard | Effective logistics optimization | Moderate scalability; lacks fuzzy uncertainty |
| Lin et al. (2025) [10] | Edge-Cloud Environments | Fuzzy (TFNs) | Soft | Robust fuzzy logistics handling | Moderate scalability; limited resource optimization |
| Yang et al. (2024) [11] | Cloud Workflow Scheduling | Stochastic (ML predictions) | Soft | Effective prediction-based scheduling | Computationally intensive; requires training data |
| Rajput et al. (2024) [12] | Multicloud Networks | Stochastic | Mixed | Significant cost-performance improvement | Ignores fuzzy uncertainties |
| Wang et al. (2023) [13] | Hybrid Flow Shop Scheduling | Fuzzy | Hard | Minimizes fuzzy energy consumption | High computational complexity |
| Sun et al. (2023) [14] | Flexible Assembly Scheduling | Fuzzy (L-R fuzzy numbers) | Hard | Effective fuzzy assembly handling | Limited flexibility; computationally demanding |
| Zhou et al. (2022) [15] | Parallel Casting Workshop | Fuzzy (UPMS model) | Hard | Effective fuzzy optimization | Not cloud-oriented; computationally complex |
| Yao et al. (2024) [22] | Workflow Scheduling | Deterministic/ Stochastic | Soft | Effective heuristic–metaheuristic combination | Limited fuzzy uncertainty handling |
| Proposed TANS | Cloud Manufacturing | Fuzzy (TFNs) | Soft | Robust uncertainty handling; adaptive heuristic; good scalability | / |
| Notation | Definition |
|---|---|
| n | Number of Tasks Contained in Workflow |
| m | Number of Service Resources |
| Workflow Application, | |
| The ith Task of Workflow , | |
| V | Set of Tasks Contained in , |
| E | Set of Partial-Order Constraints Among Tasks in Workflow , |
| Set of Service Resources, | |
| The jth Service Resource, | |
| Set of Direct Predecessor Tasks of Task | |
| Set of Direct Successor Tasks of Task | |
| Set of All Successor Tasks of Task | |
| Workload of Task | |
| Soft Deadline of Workflow | |
| Fuzzy Completion Time of Workflow | |
| Fuzzy Total Delay of Workflow | |
| Fuzzy Sub-Deadline of Task | |
| Fuzzy Execution Time of Task | |
| Fuzzy Estimated Execution Time of Task | |
| Fuzzy Logistics Time between Task and | |
| Fuzzy Start Time of Task | |
| Fuzzy Completion Time of Task | |
| Fuzzy Earliest Possible Start Time of Task | |
| Fuzzy Earliest Possible Completion Time of Task | |
| Fuzzy Execution Speed of Service Resource | |
| Fuzzy Logistics Time between Service Resource and | |
| Set of Fuzzy Logistics Times between Service Resources, , where | |
| Fuzzy Estimated Logistics Time | |
| Task Fuzzy Sub-Deadline Partition Operator | |
| Task Resource Matching Status Decision Variable |
| Variable | Value |
|---|---|
| n | |
| U(1,30000) | |
| m | |
| U(500,1000) | |
| U(0,10) | |
| 0 | |
| 0.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Ma, F.; Chen, L. TANS: A Tolerance-Aware Neighborhood Search Method for Workflow Scheduling with Uncertainties in Cloud Manufacturing. Mathematics 2025, 13, 1806. https://doi.org/10.3390/math13111806
Xu H, Ma F, Chen L. TANS: A Tolerance-Aware Neighborhood Search Method for Workflow Scheduling with Uncertainties in Cloud Manufacturing. Mathematics. 2025; 13(11):1806. https://doi.org/10.3390/math13111806
Chicago/Turabian StyleXu, Haiyan, Fanhao Ma, and Long Chen. 2025. "TANS: A Tolerance-Aware Neighborhood Search Method for Workflow Scheduling with Uncertainties in Cloud Manufacturing" Mathematics 13, no. 11: 1806. https://doi.org/10.3390/math13111806
APA StyleXu, H., Ma, F., & Chen, L. (2025). TANS: A Tolerance-Aware Neighborhood Search Method for Workflow Scheduling with Uncertainties in Cloud Manufacturing. Mathematics, 13(11), 1806. https://doi.org/10.3390/math13111806