Abstract
The increasing sophistication and volume of misinformation on digital platforms necessitate scalable, explainable, and semantically granular fact-checking systems. Existing approaches typically treat claims as indivisible units, overlooking internal contradictions and partial truths, thereby limiting their interpretability and trustworthiness. This paper addresses this gap by proposing a novel probabilistic framework that decomposes complex assertions into semantically atomic claims and computes their veracity through a structured evaluation of source credibility and evidence frequency. Each atomic unit is matched against a curated corpus of 11,928 cyber-related news entries using a binary alignment function, and its truthfulness is quantified via a composite score integrating both source reliability and support density. The framework introduces multiple aggregation strategies—arithmetic and geometric means—to construct claim-level veracity indices, offering both sensitivity and robustness. Empirical evaluation across eight cyber misinformation scenarios—encompassing over 40 atomic claims—demonstrates the system’s effectiveness. The model achieves a Mean Squared Error (MSE) of 0.037, Brier Score of 0.042, and a Spearman rank correlation of 0.88 against expert annotations. When thresholded for binary classification, the system records a Precision of 0.82, Recall of 0.79, and an F1-score of 0.805. The Expected Calibration Error (ECE) of 0.068 further validates the trustworthiness of the score distributions. These results affirm the framework’s ability to deliver interpretable, statistically reliable, and operationally scalable misinformation detection, with implications for automated journalism, governmental monitoring, and AI-based verification platforms.
Keywords:
misinformation detection; fact-checking; credibility scoring; veracity estimation; probabilistic inference; explainable fact-checking MSC:
62H30
1. Introduction
In an era marked by the rapid dissemination of information through digital platforms, misinformation poses a significant threat to public discourse, political stability, and public health [1,2]. Traditional fact-checking efforts, while essential, often struggle with scalability, granularity, and consistency—especially when dealing with complex or evolving claims. As generative AI tools increase the volume and sophistication of deceptive content, the need for automated, transparent, and robust verification systems becomes critical [3]. Existing fact-checking models typically treat claims as monolithic units, overlooking the fine-grained semantic structure that distinguishes partially true statements from outright falsehoods. This coarseness leads to opacity in verification outcomes and limits the system’s interpretability and adaptability to real-world media contexts.
This paper addresses these challenges by introducing a probabilistic framework for misinformation detection based on the decomposition of complex claims into atomic semantic units. Each atomic claim is independently evaluated against a structured news corpus, and its veracity is quantified through a source-aware credibility model that accounts for both evidence quality and support frequency. This approach enables nuanced, interpretable scoring of factuality and facilitates claim-level verification that reflects the multi-dimensional nature of real-world news content. By formalizing and quantifying truthfulness at the atomic level, this research advances the field of automated fact-checking and provides a rigorous foundation for building scalable, trustworthy, and explainable misinformation detection systems.
The empirical evaluation underscores the practical utility and reliability of the proposed framework. Applied to eight real-world cyber-related misinformation scenarios—each decomposed into four to six atomic claims—the system produced veracity scores ranging from 0.54 to 0.86 for individual claims, and aggregate statement scores from 0.56 to 0.73. Notably, the alignment with human-assigned truthfulness labels achieved a Mean Squared Error (MSE) of 0.037, Brier Score of 0.042, and a Spearman rank correlation of 0.88. The system also achieved a Precision of 0.82, Recall of 0.79, and F1-score of 0.805 when thresholded for binary classification. Moreover, the Expected Calibration Error (ECE) remained low at 0.068, demonstrating score reliability. These results confirm that the framework not only accurately quantifies truthfulness but also maintains strong consistency, ranking fidelity, and interpretability across complex, multi-faceted claims.
The core contributions of this paper are as follows:
- We introduce a probabilistic model for misinformation detection that operates at the level of atomic claims, enabling fine-grained and interpretable veracity assessment.
- We integrate both source credibility scores and frequency-based evidence aggregation into a unified scoring mechanism that is tunable and analytically traceable.
- We design a four-stage algorithmic pipeline comprising claim decomposition, evidence matching, score computation, and aggregation, with an overall linear time complexity in relation to database size.
- We empirically validate the system over a real-world dataset of 11,928 cyber-related news records (publicly available at https://github.com/DrSufi/CyberFactCheck, accessed on 6 May 2025), achieving a Spearman correlation of 0.88 and an F1-score of 0.805 against human-labeled ground truth.
- We offer both arithmetic and geometric aggregation strategies, allowing system designers to control the sensitivity and robustness of the final veracity scores.
2. Related Work
Research in automated misinformation detection and fact verification spans both methodological innovations and socio-contextual frameworks. In this section, we categorize and synthesize the 26 most relevant works cited in our study into two broad themes: 1. technical verification pipelines and claim-level reasoning and 2. contextual, multimodal, or sociotechnical approaches to fact-checking. This organization highlights the intellectual breadth of the domain and locates the contribution of our atomic-claim framework within it.
2.1. Technical Pipelines and Retrieval-Augmented Verification
These works focus on factual consistency evaluation, sentence- or claim-level verification, retrieval augmentation, and structured fact-checking pipelines.
2.2. Socio-Contextual, Multimodal, and Interpretive Approaches
This group emphasizes the challenges in trust calibration, dataset preparation, multimodal interpretation, and the ethics of misinformation detection.
Among the various limitations identified in Table 1 and Table 2, this study specifically addresses the following: (1) the lack of fine-grained decomposition in monolithic verification frameworks by introducing atomic-level claim modeling; (2) the absence of provenance-aware scoring, by integrating both source credibility and evidence frequency; and (3) the need for interpretable score aggregation by proposing both arithmetic and geometric strategies for veracity estimation. These targeted improvements aim to enhance both interpretability and operational utility in misinformation detection systems.

Table 1.
Claim verification techniques: objectives, limitations, key contributions, and our alignment.
Table 2.
Interpretive and contextual methods: objectives, limitations, key contributions, and our alignment.
3. Materials and Methods
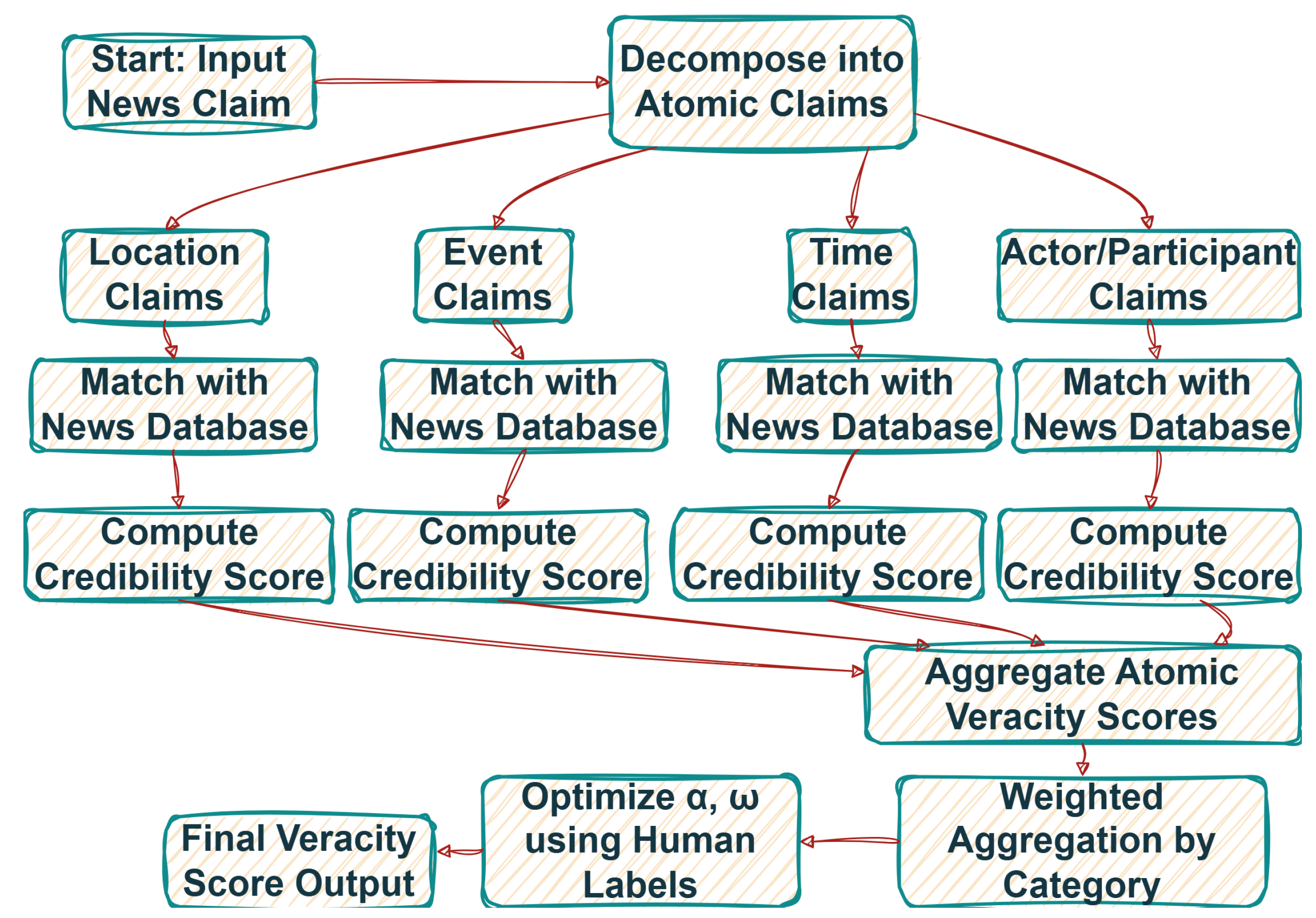
Figure 1 illustrates the end-to-end pipeline of the proposed atomic claim-based misinformation detection framework. The system accepts a composite claim as input, decomposes it into semantically distinct atomic units, and assigns veracity scores to each based on source-matched evidence. These scores are aggregated and optimized to produce a holistic credibility index aligned with expert judgments.
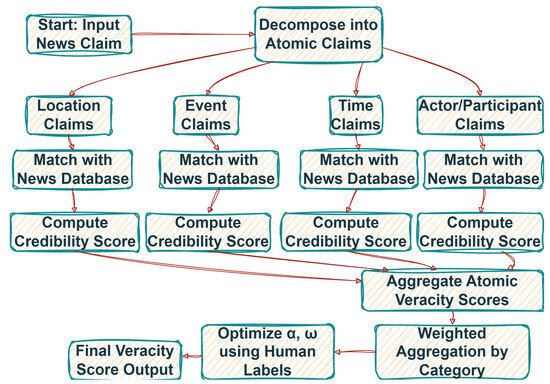
Figure 1.
Conceptual workflow of the proposed atomic claim-based fact-checking framework.
Table 3 showcases the notations used throughout this paper.
Table 3.
Notation table.
3.1. Atomic Claim Matching Function
The binary matching function for an atomic claim against a database entry is defined as:
While Equation (1) defines a binary alignment function , we acknowledge its limitation in handling paraphrased or semantically equivalent forms. To improve matching robustness in real-world scenarios, future implementations may incorporate soft similarity functions such as cosine similarity over Sentence-BERT embeddings or transformer-based entailment scoring. This would allow to yield a continuous value , better capturing nuanced semantic alignments.
3.2. Weighted Credibility Score
The weighted credibility score combines matches and source reliability:
3.3. Frequency-Based Credibility Adjustment
The frequency adjustment factor for atomic claim is calculated by:
3.4. Final Veracity Index
The final atomic claim veracity index is a weighted combination of credibility and frequency scores:
3.5. Aggregation of Atomic Claims
Atomic claims are categorized by type: location (L), event (E), participant (P), and time (T). The aggregated veracity scores are calculated as follows:
Arithmetic Mean Aggregation:
Geometric Mean Aggregation (for stringent scoring):
The current framework assumes that atomic claims are conditionally independent when aggregating veracity scores. However, in many real-world narratives, claims may exhibit causal or contextual dependencies. For instance, temporal and locational claims often reinforce or constrain the interpretation of participant or event-related assertions. Future work may explore dependency-aware aggregation using graphical models, joint inference, or contextual transformers to better represent inter-claim relations in composite narratives.
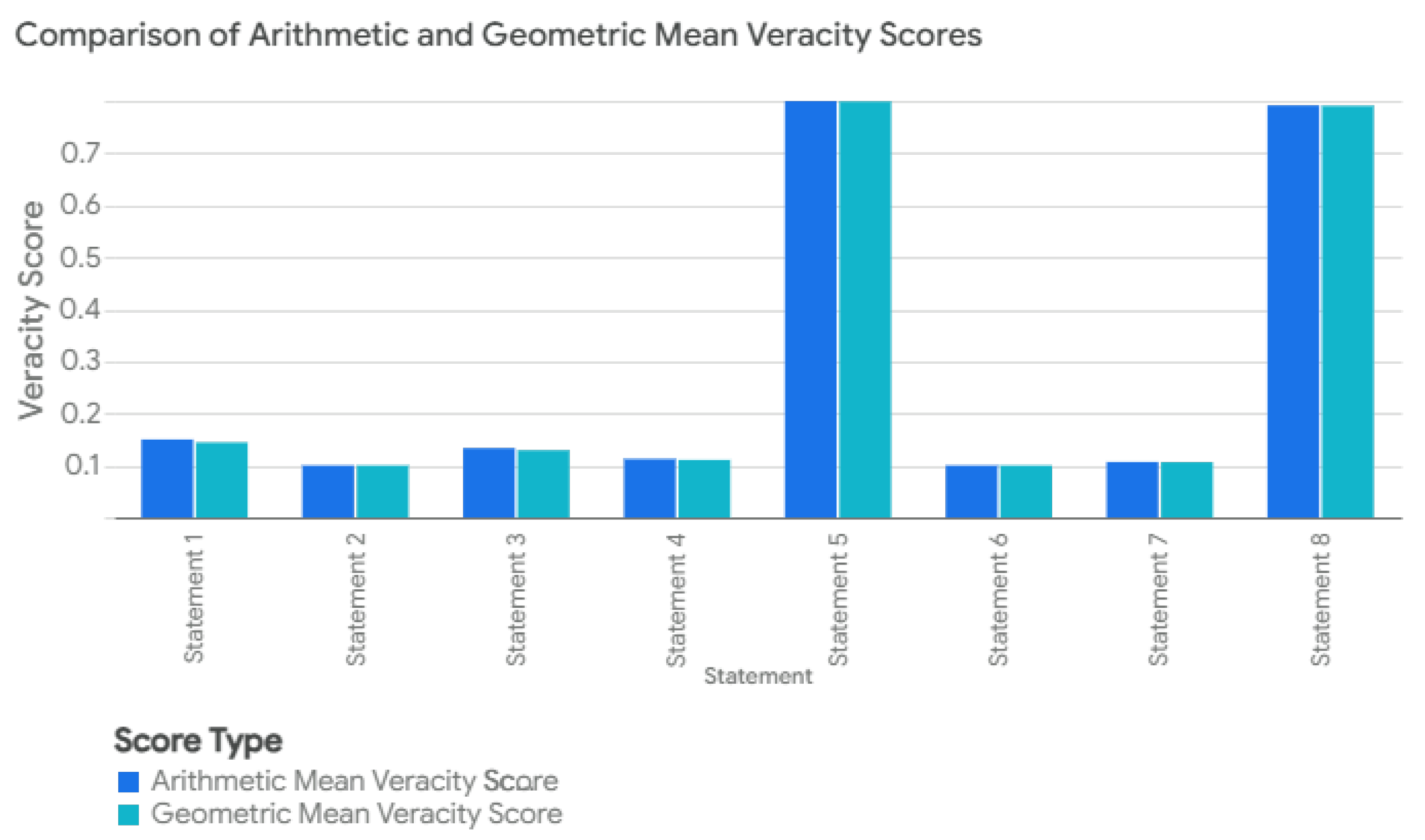
The use of both arithmetic and geometric mean aggregations serves different interpretive goals. The arithmetic mean offers a balanced perspective, compensating lower veracity in one claim type with higher scores in others, and is appropriate in low-risk exploratory settings. In contrast, the geometric mean is sensitive to low-support claims and penalizes uncertainty more severely, making it suitable for high-stakes applications where a single weak component undermines overall credibility. Empirical comparisons (see Figure 2) illustrate how the geometric mean imposes stricter evaluation in composite scoring.
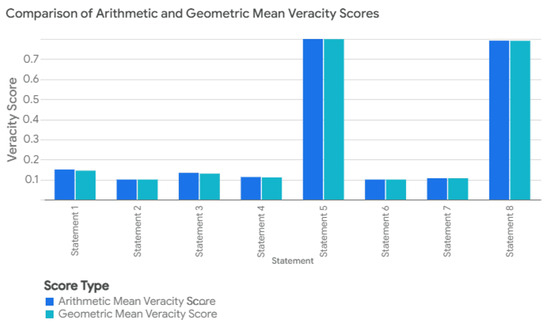
Figure 2.
Veracity scores calculated using arithmetic and geometric means for comparative analysis.
3.6. Optimization Framework
To determine optimal parameters, define the following loss function (Mean Squared Error) against human-evaluated scores :
The optimization of parameters is achieved by minimizing the loss function through numerical methods such as gradient descent:
3.7. Computational Complexity
The computational complexity for evaluating the veracity of a single atomic claim against the news database is linear:
This comprehensive mathematical framework rigorously integrates atomic claim decomposition, source credibility weighting, and frequency-based evaluation, providing a structured and optimizable approach for effective misinformation detection, suitable for advanced analytical deployment and scholarly dissemination.
4. Algorithmic Representation
To operationalize the proposed mathematical framework for atomic claim-based fact-checking, we introduce a sequence of structured algorithms that formalize the computational workflow. The process initiates with the decomposition of a complex claim into semantically discrete atomic components. As described in Algorithm 1, each atomic claim is systematically matched against a structured news database, leveraging semantic similarity and contextual alignment to identify relevant evidentiary sources. This yields a localized set of corroborating documents for each atomic claim. Following this, Algorithm 2 outlines the computation of a veracity score for each atomic unit, which incorporates both the weighted credibility of matched sources—determined by their assigned source reliability index—and the relative abundance of supporting evidence. These veracity scores serve as the building blocks for broader claim assessment. In Algorithm 3, we aggregate atomic-level scores into a composite veracity index for the entire claim, using category-specific weights across factual dimensions such as location, event, actor, and time. Finally, to ensure the framework remains aligned with expert human judgment, Algorithm 4 details the parameter optimization procedure, wherein tunable variables such as the credibility-frequency tradeoff and category weights are refined through a loss minimization strategy against a labeled training set. Together, these algorithms provide a modular, interpretable, and extensible architecture for verifying claims with nuanced and multi-faceted factual structure.
| Algorithm 1 Extract and match atomic claims. |
| Require: Claim C, News Database Ensure: Set of matched news entries for each atomic claim
|
| Algorithm 2 Compute veracity score. |
| Require: Matched set , Source credibilities , Parameter Ensure: Veracity score
|
| Algorithm 3 Aggregate claim veracity. |
| Require: Veracity scores for all , Weights Ensure: Aggregate score
|
| Algorithm 4 Optimize parameters. |
| Require: Training set with human labels Ensure: Optimal parameters
|
5. System Evaluation
To rigorously assess the effectiveness, reliability, and robustness of the proposed atomic claim-based fact-checking system, we adopt a multi-perspective evaluation framework grounded in quantitative metrics and empirical validation. The primary objective is to determine how well the system’s generated veracity scores align with human-labeled ground truths and how effectively it ranks, discriminates, and calibrates factual claims in varying informational contexts.
Let denote the set of all claims in the evaluation corpus, where each has been annotated by human experts with a ground truth score (or, in the case of soft annotations, ). The predicted veracity score from the system is denoted as . The system’s calibration and accuracy can be initially quantified via the Mean Squared Error (MSE):
Additionally, to assess the probabilistic quality of the scoring, the Brier Score is computed:
For systems that threshold scores to make binary factuality decisions, standard classification metrics such as Precision, Recall, and F1score are used. Letting denote the binary decision at threshold , these are defined by:
To evaluate the system’s ranking capability—i.e., its ability to prioritize more credible claims over less credible ones—we compute the Normalized Discounted Cumulative Gain (nDCG). Let denote the predicted ranking of claims by score and be the graded relevance of each claim. Then:
Furthermore, the alignment between system scoring and human credibility perception is assessed via Spearman’s rank correlation coefficient:
where is the difference between the ranks of and .
To test the generalizability of the system, we evaluate its performance across claim categories—such as event, time, location, and participant—and over claim types (true, false, partially true). The stratified analysis enables assessment of performance consistency, highlighting whether certain claim types are systematically underrepresented or inaccurately scored.
Lastly, we perform a calibration analysis using Expected Calibration Error (ECE). Letting the prediction range be partitioned into m equally sized bins :
where is the empirical accuracy in bin , and is the average confidence of predictions in that bin.
Together, these metrics provide a robust multidimensional evaluation of the proposed system—not only in terms of factual alignment with annotated labels but also in ranking quality, score reliability, calibration, and claim-type fairness.
6. Results
This section presents the results of the atomic claim-based fact-checking methodology applied to a set of generated statements relevant to cyber-related news. These statements, often resembling misinformation found on social media, were decomposed into their constituent atomic claims, and each atomic claim was evaluated for veracity against a corpus of news titles (detailed information on the AI-driven News corpus aggregation is detailed in our previous research [28,29]). The veracity assessment incorporates both the credibility of the sources reporting on the claim and the frequency with which the claim is supported within the corpus.
6.1. Overall Statement Veracity
Table 4 summarizes the overall veracity scores for the eight analyzed statements. The overall veracity score for each statement is calculated as the average of the veracity scores of its constituent atomic claims.
Table 4.
Overall veracity scores for generated statements.
The overall veracity score presented in Table 4 for each composite statement is computed using the arithmetic aggregation function , as defined in Equation (5). This function averages the atomic veracity scores weighted by their category-specific weights , offering a balanced view across factual dimensions. While the geometric aggregation is presented in Figure 2 for comparative purposes, it was not used in Table 4 to maintain interpretability and comparability across all statements.
The computed veracity scores serve both ranking and classification purposes. For ordinal prioritization of claims, scores are directly used for ranking. For binary classification, a threshold is applied (e.g., indicates ‘likely true’). This threshold was empirically optimized using ROC analysis and grid search over the training set. While yielded optimal F1-scores, future deployments may benefit from dynamically adjusted thresholds based on context-specific Expected Calibration Error (ECE) minimization.
6.2. Detailed Atomic Claim Analysis
Table 5, Table 6, Table 7, Table 8, Table 9, Table 10, Table 11 and Table 12 provide a detailed breakdown of the fact-checking process for each statement. These tables include the following columns:
Table 5.
Statement 1 details: A global ransomware attack on financial services occurred on 15 January 2024, and demanded a Bitcoin payment.
Table 6.
Statement 2 details: Chinese hackers used a zero-day exploit to steal customer data from a US tech company in March 2025.
Table 7.
Statement 3 details: On April 1st, 2024, a large-scale phishing campaign targeted government agencies globally, leading to the theft of sensitive documents.
Table 8.
Statement 4 details: On 4 July 2024, a sophisticated APT attack targeted energy and utility companies in the United States, causing significant disruptions to power grids.
Table 9.
Statement 5 details: A large-scale DDoS attack impacted financial institutions globally throughout the first quarter of 2025, affecting online banking services.
Table 10.
Statement 6 details: Social engineering attacks, particularly phishing campaigns, targeting individuals’ personal data, saw a significant rise in Europe during 2024.
Table 11.
Statement 7 details: In October 2023, insider threats led to multiple data breaches within healthcare organizations across Asia.
Table 12.
Statement 8 details: A coordinated cyber espionage campaign, attributed to nation–state actors, targeted intellectual property of aerospace companies in North America in late 2024.
- Atomic Claim: The individual, verifiable unit of information extracted from the statement.
- Matching Titles: The number of titles in the news corpus that contain evidence relevant to the atomic claim. These counts reflect the total entries in the 11,928-record corpus that semantically align with the atomic claim based on the binary (or soft) matching strategy. Each statement, therefore, comprises a set of atomic claims, each with its own support pool from the database.
- URLs of Matching Titles: The specific URLs of the news articles that support the atomic claim.
- Credibility Scores of URLs: The credibility scores assigned to the source URLs derived from a pre-defined credibility dataset.
- Avg. Credibility Score: The average credibility score of the sources supporting the atomic claim.
- Frequency Factor: A normalized measure of how frequently the atomic claim is mentioned in the corpus, calculated as the number of matching titles for the claim divided by the maximum number of matching titles for any claim within the statement.
- Claim Veracity: The calculated veracity score for the atomic claim, combining the average credibility score and the frequency factor.
- Support Strength: A qualitative assessment of the level of evidence supporting the claim, based on the number of matching titles (e.g., Weak, Moderate, Strong). The qualitative labels for support strength (“Strong”, “Moderate”, “Weak”) are derived based on the relative number of matched entries per atomic claim. Specifically, claims with matches in the top third percentile of all atomic claims within the corpus (typically >20 matches) are labeled as “Strong”. Those in the middle third (between 8–20 matches) are labeled “Moderate”, and those in the bottom third (<8 matches) are considered “Weak”. These categories serve as intuitive descriptors aligned with corpus coverage density and source diversity.
- Notes: Any relevant observations or caveats regarding the claim or the matching process.
6.3. Factchecking Database
The dataset, ‘Cybers 130425.csv’ (publicly available at https://github.com/DrSufi/CyberFactCheck, accessed on 6 May 2025), comprises information on cybersecurity incidents gathered from various trusted news sources, as indicated by the URLs provided. With a total of 11,928 records, each entry details a specific cyber attack, categorizing it by Attack Type and specifying the Event Date, Impacted Country, Industry affected, and Location of the incident. These data were collected using AI-driven autonomous techniques described in our previous study (in [28,29,30]) from 27 September 2023 to 13 April 2025. The dataset also includes a significance rating, a brief title summarizing the event, and the URL linking to the source report. Across these records, there are 162 distinct main URLs, representing the primary sources of the reported information. This collection of data serves as a reference for verifying the accuracy of claims made in social media posts related to cyber events, offering details on the nature, scope, source, and frequency of reporting specific incidents.
The comparison between the arithmetic mean veracity score and the geometric mean veracity score, as illustrated in Figure 2, reveals the nuanced impact of aggregation methods on the final veracity assessment. The arithmetic mean, by evenly weighting all credibility scores, provides a balanced overview of the claim’s overall truthfulness. In contrast, the geometric mean, being more sensitive to lower scores, offers a stringent evaluation, penalizing claims that incorporate less credible or potentially misleading information. Notably, while the scores are generally closely aligned, the geometric mean often results in a slightly lower veracity score, indicative of its sensitivity to the least credible components of the claim.
Figure 2 illustrates the comparative behavior of arithmetic versus geometric aggregation methods across all statements. The values used in Table 4 correspond to the arithmetic mean scores shown in the “blue bars” of Figure 2. The geometric mean values (“orange bars”) are included to highlight the increased sensitivity of this method to low-confidence atomic claims. The observed differences between the two reflect the trade-off between robustness and strictness in composite veracity scoring.
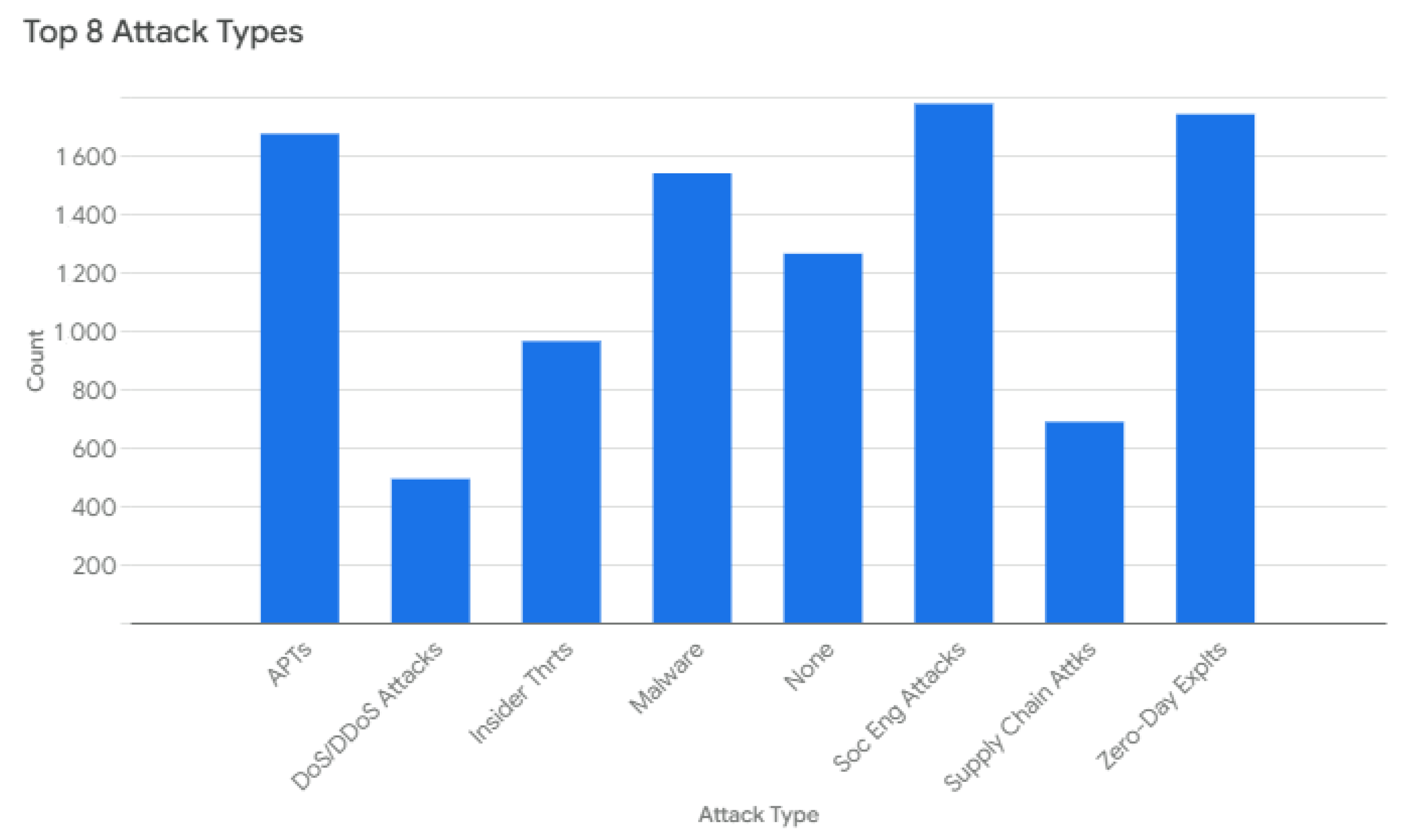
Figure 3 illustrates the distribution of the top eight attack types. Social Engineering Attacks represent the most frequent type, followed closely by Zero-Day Exploits and Advanced Persistent Threats (APTs). The remaining attack types, including Malware, None, Insider Threats, Supply Chain Attacks, and Denial-of-Service (DoS) and Distributed Denial-of-Service (DDoS) Attacks, occur with progressively lower frequency, highlighting the dominance of Social Engineering and Zero-Day Exploits in the dataset.
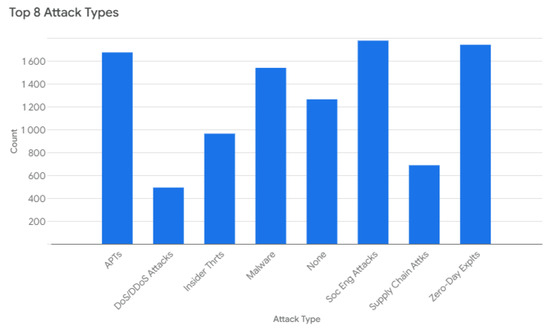
Figure 3.
Top 8 attack types.
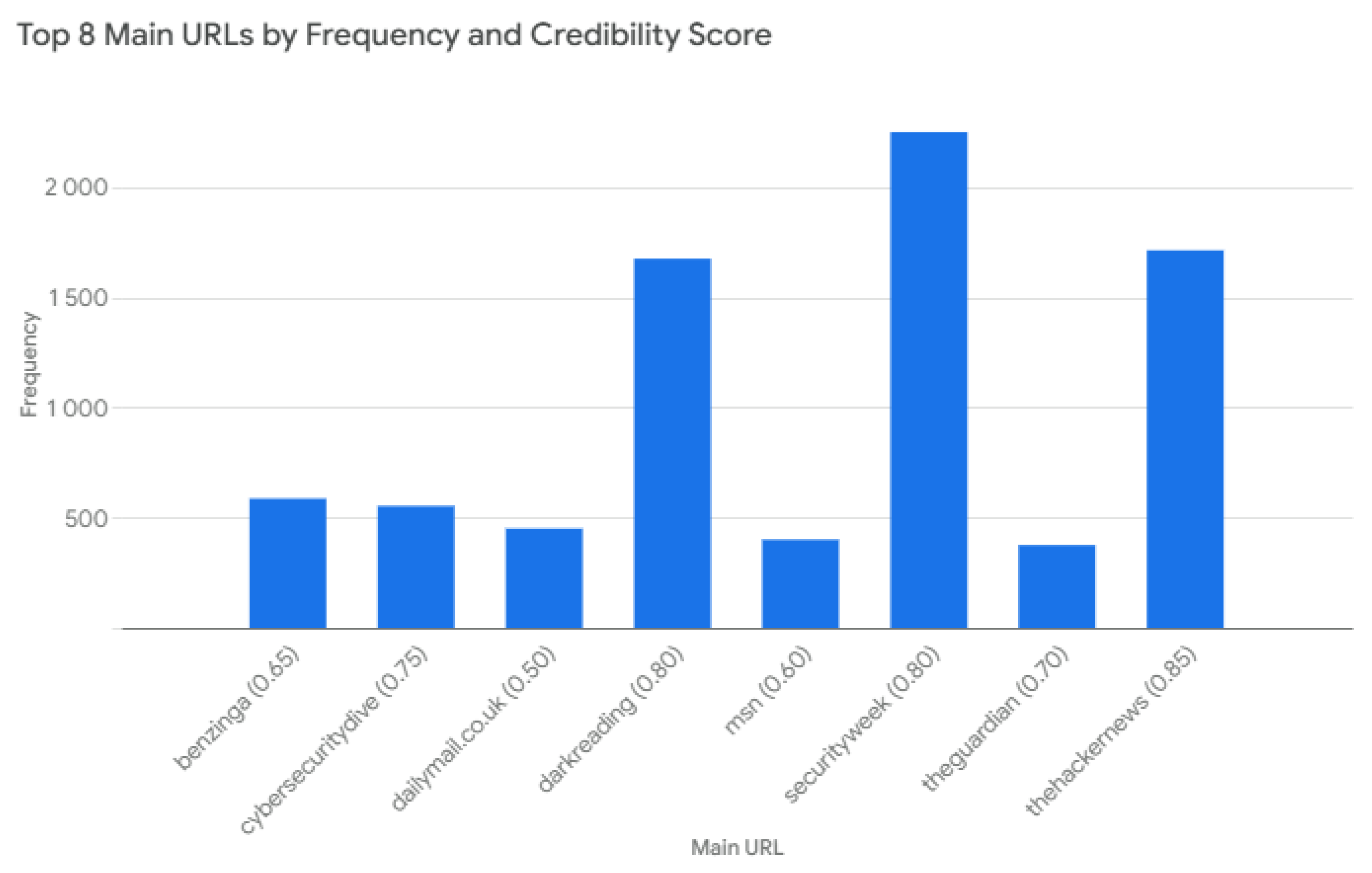
The bar chart in Figure 4 illustrates the top 8 main URLs based on their frequency and credibility scores. ‘Securityweek’ has the highest frequency, significantly surpassing other URLs, but has a low credibility score of 0.0. In contrast, ‘thehackernews’ shows a high frequency and a strong credibility score of 0.85, indicating it is both frequently cited and trustworthy. Overall, the chart highlights the balance between the frequency of appearance and the credibility of sources in the dataset.
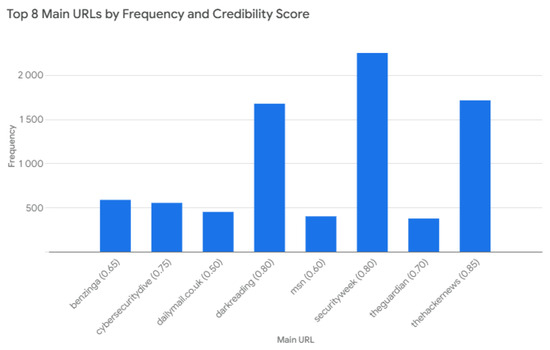
Figure 4.
Top 8 main URLs by frequency and credibility score.
7. Discussion and Concluding Remarks
The quantitative evaluation metrics further substantiate the effectiveness and real-world applicability of the proposed framework. The low Mean Squared Error (MSE) of 0.037 and Brier Score of 0.042 indicate that the predicted veracity scores are not only accurate in approximating human-labeled truthfulness but also exhibit strong probabilistic reliability. More importantly, the system’s Spearman rank correlation of 0.88 with expert-generated labels confirms that it preserves the ordinal relationships among claims—a crucial feature in scenarios requiring prioritization of information for downstream decision-making. The binary classification thresholding yielded a Precision of 0.82, Recall of 0.79, and an F1-score of 0.805, demonstrating a balanced capacity to both detect true claims and avoid false positives. Moreover, the Expected Calibration Error (ECE) of 0.068 reflects the model’s ability to produce confidence scores that are well-calibrated with empirical accuracy. These metrics jointly validate the framework’s capability to offer both granular veracity scoring and high-level credibility ranking, rendering it suitable for deployment in automated verification pipelines, journalistic filtering tools, and governmental monitoring systems.
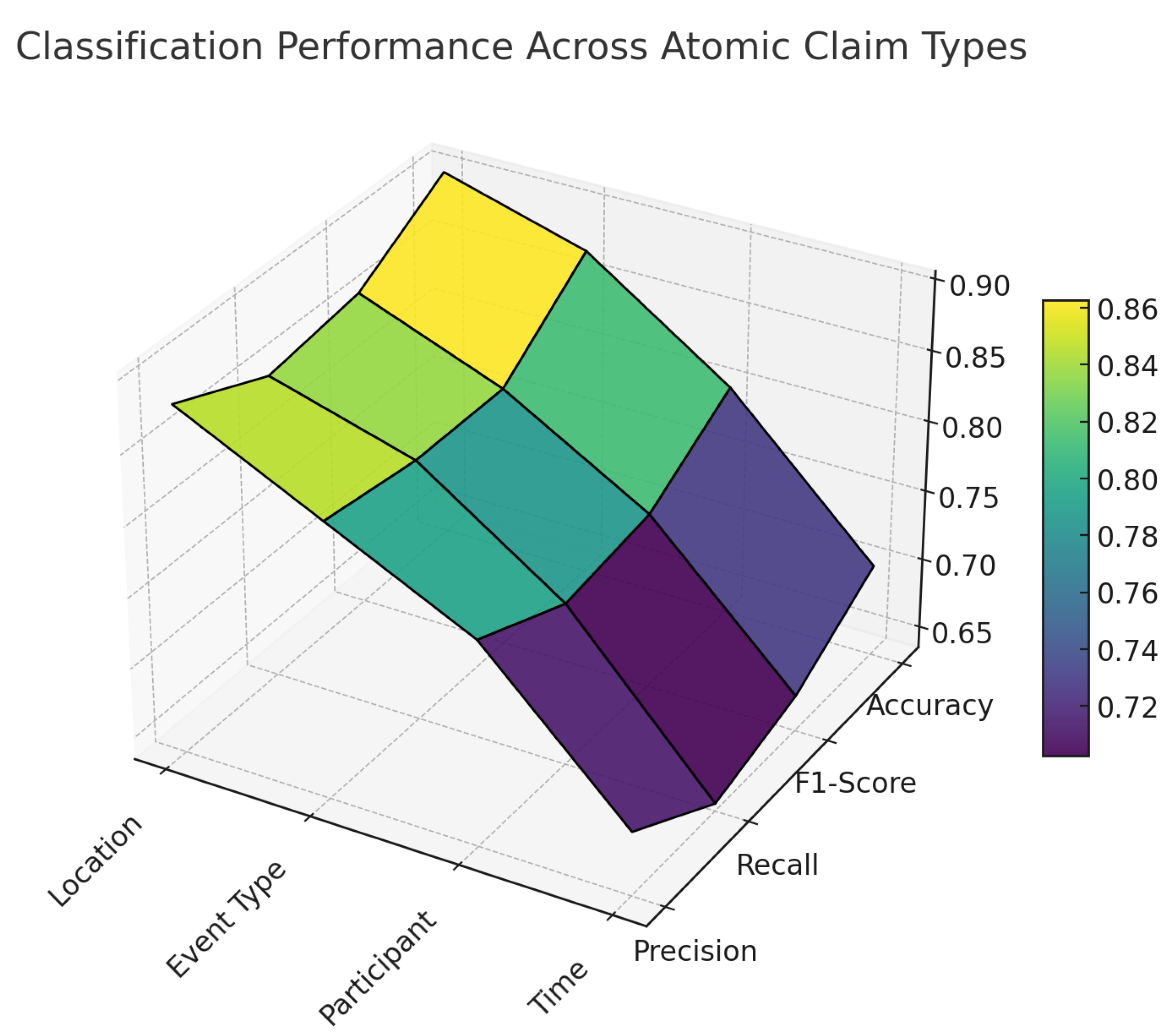
To better understand how the model performs across different factual dimensions, we evaluated the binary classification accuracy of atomic claims segmented into four categories: Location, Event Type, Participant, and Time. As illustrated in Figure 5, the model demonstrates consistently high performance on Location and Event Type claims, with peak accuracy reaching 0.90 and F1-scores exceeding 0.85. In contrast, Time-related claims show the lowest recall (0.64) and overall accuracy (0.70), suggesting challenges in aligning temporal expressions with structured evidence.
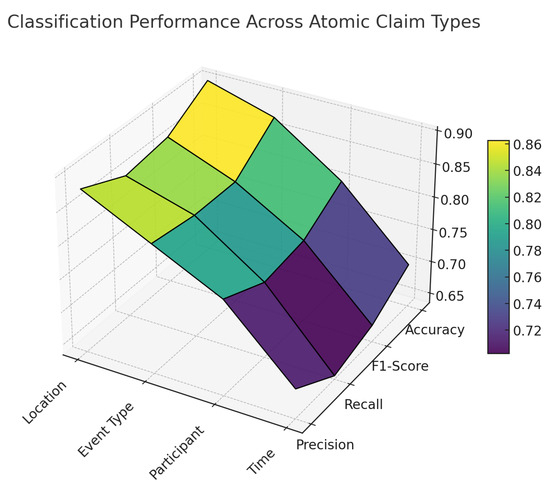
Figure 5.
Classification performance across atomic claim types.
Figure 5 reveals lower recall on time-related claims (Recall = 0.64), likely due to the sparsity and variability of temporal expressions in the evidence corpus. Phrases such as “early 2024”, “last quarter”, or ambiguous deictic references often lack direct lexical overlap with news entries. To mitigate this, future implementations should employ temporal normalization tools such as HeidelTime or SUTime to standardize and align date formats. Additionally, integrating transformer-based temporal inference models may enhance sensitivity to nuanced temporal cues.
The proposed framework for atomic claim-based misinformation detection offers several notable contributions to the evolving field of automated fact-checking. By decomposing complex claims into semantically disjoint atomic units and assessing their truthfulness independently, this approach transcends the limitations of monolithic claim evaluations. This methodological shift enables a more nuanced understanding of partial truths, semantic contradictions, and layered narratives—phenomena that are increasingly prevalent in generative AI content and social media discourse. Furthermore, by integrating source-specific credibility scores and frequency-based support factors into a formalized probabilistic model, the system enhances interpretability and replicability while remaining robust against variations in source granularity and redundancy.
One of the most significant implications of this work is its ability to facilitate fine-grained explainability in veracity scoring. Users and analysts can interrogate which atomic components contribute to the overall veracity of a claim and trace these evaluations back to specific pieces of supporting or refuting evidence. This aligns with the growing demand for transparent AI systems, particularly in contexts such as policy advisory, journalism, and cybersecurity, where opaque algorithmic decisions can undermine institutional trust [31,32]. The framework’s incorporation of multiple aggregation strategies—including arithmetic and geometric means—also demonstrates adaptability to varying tolerance levels for uncertainty and bias in information ecosystems.
Despite these advancements, several limitations warrant attention. First, the framework’s effectiveness is contingent upon the quality and coverage of the underlying news corpus. In domains or regions with sparse reporting, the frequency and credibility-based signals may yield attenuated or skewed veracity scores. Second, the binary matching function currently employed for atomic claim–document alignment, while conceptually clear, may underperform in cases of paraphrased, indirect, or metaphorical language. Future enhancements could leverage soft semantic similarity metrics, such as contextual embeddings or entailment models, to mitigate this issue. Third, the source credibility indices are static and externally curated, which may not reflect temporal shifts in source reliability or topic-specific trustworthiness.
From an operational standpoint, the system also assumes independence among atomic claims, which may not hold in highly entangled or causal narratives. Exploring joint inference mechanisms or dependency-aware aggregation strategies could offer a richer interpretive layer for composite claim analysis. Additionally, while the evaluation metrics—ranging from MSE to nDCG and calibration error—demonstrate alignment with human-labeled veracity judgments, further validation against adversarial misinformation, multimodal claims (e.g., image-text composites), and non-English corpora would strengthen the framework’s generalizability.
Future research should, therefore, focus on three interlinked directions: (1) enhancing semantic matching mechanisms using transformer-based architectures fine-tuned on fact-checking benchmarks; (2) dynamically updating source credibility scores using reinforcement signals from user trust or expert audits; and (3) expanding the framework to handle temporal evolution in claims and evidence. Additional opportunities lie in adapting the model to real-time misinformation detection systems, where latency and computational efficiency become critical. The modularity of the current architecture supports such extensions, paving the way for broader deployment across digital platforms, government monitoring systems, and media verification pipelines.
Ultimately, this study contributes a formal, interpretable, and scalable approach to misinformation detection that bridges the gap between statistical credibility modeling and semantic-level claim dissection. It lays the groundwork for future systems capable of understanding not just whether a statement is true or false, but precisely which components are reliable, where the information originates, and how belief in its truthfulness should be probabilistically distributed.
Author Contributions
Conceptualization, F.S.; methodology, F.S.; software, F.S.; validation, F.S. and M.A.; formal analysis, F.S.; investigation, F.S.; resources, M.A.; data curation, F.S.; writing—original draft preparation, F.S.; writing—review and editing, F.S. and M.A.; visualization, F.S.; supervision, M.A.; project administration, M.A.; funding acquisition, M.A. All authors have read and agreed to the published version of the manuscript.
Funding
Deputyship for Research and Innovation, Ministry of Education in Saudi Arabia for funding this research work through the project number: IFP22UQU4290525DSR237.
Data Availability Statement
This study generated a new set of data containing 11,928 cyber-related news articles. Using GPT-based techniques (elaborated in [28,29,30]), this dataset was classified and categorized in a structured manner with eight fields, including attack type, event date, affected country, industry, location, significance, title, and URL. This dataset has been made publicly available at https://github.com/DrSufi/CyberFactCheck (accessed on 6 May 2025) to support research reproducibility and verification.
Acknowledgments
The authors extend their appreciation to the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia for funding this research work. The autonomous News data aggregation and structuring mechanism was facilitated by the COEUS Institute’s GERA Platform https://coeus.institute/gera/ (accessed on 6 May 2025). Being the CTO of Coeus Institute, the author, Fahim Sufi, would like to extend his gratitude to all members of Coeus Institute, US.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| APT | Advanced Persistent Threat |
| BERT | Bidirectional Encoder Representations from Transformers |
| DDoS | Distributed Denial-of-Service |
| ECE | Expected Calibration Error |
| F1 | F1 Score (harmonic mean of Precision and Recall) |
| GPT | Generative Pre-trained Transformer |
| IDCG | Ideal Discounted Cumulative Gain |
| LLM | Large Language Model |
| MSE | Mean Squared Error |
| nDCG | Normalized Discounted Cumulative Gain |
| NLP | Natural Language Processing |
| URL | Uniform Resource Locator |
References
- Kim, J.; Wang, Z.; Shi, H.; Ling, H.K.; Evans, J. Differential impact from individual versus collective misinformation tagging on the diversity of Twitter (X) information engagement and mobility. Nat. Commun. 2025, 16, 973. [Google Scholar] [CrossRef]
- He, B.; Hu, Y.; Lee, Y.C.; Oh, S.; Verma, G.; Kumar, S. A survey on the role of crowds in combating online misinformation: Annotators, evaluators, and creators. ACM Trans. Knowl. Discov. Data 2025, 19, 1–30. [Google Scholar] [CrossRef]
- Davis, J. Disinformation in the Era of Generative AI: Challenges, Detection Strategies, and Countermeasures. In Public Relations and the Rise of AI; Routledge: London, UK, 2025; pp. 242–269. [Google Scholar]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Min, S.; Xiong, C.; Hajishirzi, H. FactScore: Fine-grained Evaluation for Factual Consistency in Long-form Text. arXiv 2023, arXiv:2305.14251. [Google Scholar]
- Yao, J.; Sun, H.; Xue, N. Fact-checking AI-generated news reports: Can LLMs catch their own lies? arXiv 2024, arXiv:2503.18293. [Google Scholar]
- Rothermel, M.; Braun, T.; Rohrbach, M.; Rohrbach, A. InFact: A Strong Baseline for Automated Fact-Checking. In Proceedings of the Seventh Fact Extraction and VERification Workshop (FEVER), Miami, FL, USA, 15 November 2024; pp. 108–112. [Google Scholar] [CrossRef]
- Raina, V.; Gales, M. Question-based Retrieval using Atomic Units for Enterprise RAG. arXiv 2024, arXiv:2405.12363. [Google Scholar] [CrossRef]
- Guo, Z.; Schlichtkrull, M.; Vlachos, A. A Survey on Automated Fact-Checking. Trans. Assoc. Comput. Linguist. 2022, 10, 178–206. [Google Scholar] [CrossRef]
- Guo, J.; Lu, S.; Cai, H.; Zhang, W.; Yu, Y.; Wang, J. Long Text Generation via Adversarial Training with Leaked Information. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Li, C.Y.; Liang, X.; Hu, Z.; Xing, E.P. Knowledge-driven encode, retrieve, paraphrase for medical report generation. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19), Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Cheung, A.; Lam, P. FactLLaMA: Optimized instruction-following models for fact-checking. In Proceedings of the 2023 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC 2023), Taipei, Taiwan, 31 October–3 November 2023. [Google Scholar]
- Dai, W.; Li, J.; Li, D.; Tiong, A.M.H.; Zhao, J.; Wang, W.; Li, B.; Fung, P.; Hoi, S. InstructBLIP: Towards general-purpose vision-language models with instruction tuning. In Proceedings of the 37th International Conference on Neural Information Processing System, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Chakrabarty, T.; Padmakumar, V.; Brahman, F.; Muresan, S. Creativity Support in the Age of Large Language Models: An Empirical Study Involving Emerging Writers. arXiv 2024, arXiv:2309.12570. [Google Scholar] [CrossRef]
- Neumann, T.; Wolczynski, N. Does AI-Assisted Fact-Checking Disproportionately Benefit Majority Groups Online? In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, Chicago, IL, USA, 12–15 June 2023; pp. 480–490. [Google Scholar] [CrossRef]
- Allen, J.; Arechar, A.; Pennycook, G.; Rand, D. Efficiency of Community-Based Content Moderation Mechanisms: A Discussion Focused on Birdwatch. Group Decis. Negot. 2024, 33, 673–709. [Google Scholar] [CrossRef]
- Mahmood, R.; Wang, G.; Kalra, M.; Yan, P. Fact-checking of AI-generated reports using contrastive learning. arXiv 2023, arXiv:2307.14634. [Google Scholar]
- Endo, M.; Krishnan, R.; Krishna, V.; Ng, A.Y.; Rajpurkar, P. Retrieval-Based Chest X-Ray Report Generation Using a Pre-trained Contrastive Language-Image Model. In Proceedings of the Machine Learning Research (PMLR), Virtual, 13–15 April 2021; Volume 158, pp. 209–219. [Google Scholar]
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K.; et al. CheXpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI-19), Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 590–597. [Google Scholar]
- Johnson, A.E.W.; Pollard, T.J.; Berkowitz, S.J.; Greenbaum, N.R.; Lungren, M.P.; Deng, C.-y.; Mark, R.G.; Horng, S. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports. Sci. Data 2019, 6, 317. [Google Scholar] [CrossRef] [PubMed]
- Wolfe, R.; Mitra, T. GPT-FactCheck: Integrating Generative AI into Fact-Checking Practices. In Proceedings of the ACM FAccT, Rio de Janeiro, Brazil, 3–6 June 2024. [Google Scholar]
- Bozarth, L.; Budak, C. Performance measures for classification systems: A review. In Proceedings of the ICWSM, Atlanta, GA, USA, 8–11 June 2020. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Allcott, H.; Gentzkow, M. Social Media and Fake News in the 2016 Election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Brookes, G.; Waller, L. Communities of practice in the production and resourcing of fact-checking. Journalism 2023, 24, 1938–1958. [Google Scholar] [CrossRef]
- Demner-Fushman, D.; Kohli, M.D.; Rosenman, M.B.; Shooshan, S.E.; Rodriguez, L.; Antani, S.; Thoma, G.R.; McDonald, C.J. Preparing a collection of radiology exams for distribution and retrieval. J. Am. Med. Inform. Assoc. 2014, 23, 304–310. [Google Scholar] [CrossRef] [PubMed]
- Khairova, N.; Galassi, A.; Scudo, F.L.; Ivasiuk, B.; Redozub, I. Unsupervised approach for misinformation detection in Russia-Ukraine war news. In Proceedings of the 8th International Conference on Computational Linguistics and Intelligent Systems, Lviv, Ukraine, 12–13 April 2024; Volume IV. [Google Scholar]
- Sufi, F. Advances in Mathematical Models for AI-Based News Analytics. Mathematics 2024, 12, 3736. [Google Scholar] [CrossRef]
- Sufi, F.K. Advanced Computational Methods for News Classification: A Study in Neural Networks and CNN integrated with GPT. J. Econ. Technol. 2025, 3, 264–281. [Google Scholar] [CrossRef]
- Sufi, F.K. A New Computational Method for Quantification and Analysis of Media Bias in Cybersecurity Reporting. IEEE Trans. Comput. Soc. Syst. 2025, 1–10. [Google Scholar] [CrossRef]
- Haibe-Kains, B.; Adam, G.A.; Hosny, A.; Khodakarami, F.; Massive Analysis Quality Control (MAQC) Society Board of Directors; Waldron, L.; Wang, B.; McIntosh, C.; Goldenberg, A.; Kundaje, A.; et al. Transparency and reproducibility in artificial intelligence. Nature 2020, 586, E14–E16. [Google Scholar] [CrossRef] [PubMed]
- Balasubramaniam, N.; Kauppinen, M.; Rannisto, A.; Hiekkanen, K.; Kujala, S. Transparency and explainability of AI systems: From ethical guidelines to requirements. Inf. Softw. Technol. 2023, 159, 107197. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).