

Self-Supervised Autoencoders for Visual Anomaly Detection

Abstract
1. Introduction
2. Related Works
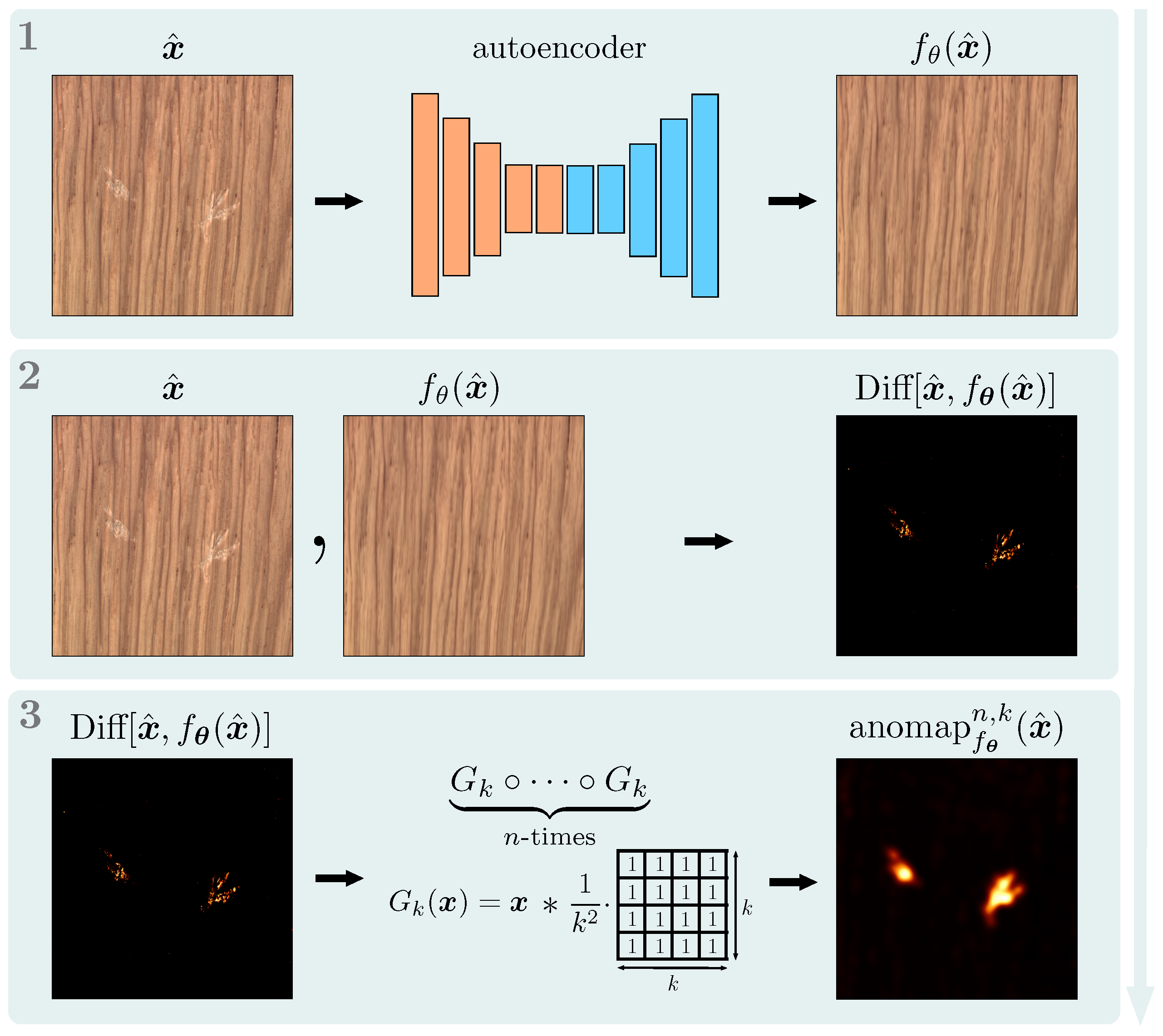
3. Methodology
3.1. Training Objective
3.2. Generating Artificial Anomalies for Training
3.3. Model Architecture
4. Theoretical Analysis
4.1. Connections to Regularized Autoencoders
4.2. Conservation Effect of Orthogonal Projections
4.3. Convergence Guarantees for Input Corruptions
4.3.1. Partial Modification
4.3.2. Additive Noise
5. Experiments
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AD | Anomaly Detection |
| AE | Autoencoder |
| CAE | Contractive Autoencoder |
| DAE | Denoising Autoencoder |
| CCM | Convex Combination Module |
| DNN | Deep Neural Network |
| PAE | Projecting Autoencoder |
| RCAE | Reconstruction Contractive Autoencoder |
| SDC | Stacked Dilated Convolutions |
Appendix A. Auxiliary Statements
Appendix B. Weak Law of Large Numbers for MRFs
Appendix C. Corollary of Theorem A1
Appendix D. Proof of Theorem 1
Appendix E. Proof of Theorem 2
Appendix F. Proof of Proposition 1
Appendix G. Proof of Proposition 2

Appendix H. Proof of Proposition 3

Appendix I. Ablation Study on the Impact of Architectural Components

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | U-Net | U-Net-Small | SDC-AE | SDC-AE (+Skip) | SDC-CCM |
|---|---|---|---|---|---|
| carpet | 65.7 ± 0.81 | 99.4 ± 0.02 | 99.6 ± 0.02 | 99.4 ± 0.03 | 99.4 ± 0.09 |
| grid | 70.3 ± 1.94 | 99.6 ± 0.00 | 99.6 ± 0.00 | 99.6 ± 0.00 | 99.6 ± 0.00 |
| leather | 80.3 ± 0.80 | 99.6 ± 0.03 | 99.4 ± 0.08 | 99.1 ± 0.36 | 99.4 ± 0.07 |
| tile | 58.6 ± 1.16 | 98.4 ± 0.10 | 97.9 ± 0.00 | 98.5 ± 0.08 | 98.4 ± 0.25 |
| cable | 89.4 ± 0.10 | 96.8 ± 0.09 | 94.5 ± 0.05 | 97.7 ± 0.26 | 98.1 ± 0.16 |
| transistor | 87.1 ± 0.49 | 88.5 ± 0.20 | 89.2 ± 0.17 | 91.0 ± 0.27 | 91.3 ± 0.84 |
| avg. all | 75.2 ± 11.25 | 97.05 ± 0.07 | 96.7 ± 3.79 | 97.6 ± 2.99 | 97.7 ± 2.98 |
| Category | U-Net | U-Net-Small | SDC-AE | SDC-AE (+Skip) | SDC-CCM |
|---|---|---|---|---|---|
| carpet | 39.5 ± 0.58 | 99.2 ± 0.24 | 99.3 ± 0.04 | 99.4 ± 0.00 | 99.6 ± 0.25 |
| grid | 84.2 ± 0.13 | 100 ± 0.00 | 100 ± 0.00 | 100 ± 0.00 | 100 ± 0.00 |
| leather | 77.4 ± 3.45 | 98.0 ± 1.24 | 99.0 ± 0.19 | 97.9 ± 0.82 | 99.4 ± 0.15 |
| tile | 81.6 ± 0.78 | 98.9 ± 0.18 | 98.5 ± 0.05 | 99.6 ± 0.41 | 99.6 ± 0.25 |
| cable | 57.0 ± 0.66 | 93.6 ± 0.23 | 67.4 ± 1.64 | 94.2 ± 0.03 | 96.2 ± 0.16 |
| transistor | 64.5 ± 1.94 | 97.6 ± 0.02 | 81.2 ± 1.54 | 97.2 ± 0.19 | 96.6 ± 0.38 |
| avg. all | 67.4 ± 15.70 | 97.9 ± 0.32 | 90.9 ± 12.4 | 98.1 ± 1.98 | 98.6 ± 1.55 |

Appendix J. Illustration of Qualitative Improvement in Reconstruction When Using SDC-CCM over SDC-AE


References
- Haselmann, M.; Gruber, D.P.; Tabatabai, P. Anomaly Detection Using Deep Learning Based Image Completion. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications, ICMLA 2018, Orlando, FL, USA, 17–20 December 2018; Wani, M.A., Kantardzic, M.M., Mouchaweh, M.S., Gama, J., Lughofer, E., Eds.; IEEE: Piscataway, NJ, USA, 2018; pp. 1237–1242. [Google Scholar]
- Bergmann, P.; Löwe, S.; Fauser, M.; Sattlegger, D.; Steger, C. Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders. In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, VISIGRAPP 2019, Volume 5: VISAPP, Prague, Czech Republic, 25–27 February 2019; Trémeau, A., Farinella, G.M., Braz, J., Eds.; SciTePress: Setúbal Municipality, Portugal, 2019; pp. 372–380. [Google Scholar]
- Wang, L.; Zhang, D.; Guo, J.; Han, Y. Image Anomaly Detection Using Normal Data only by Latent Space Resampling. Appl. Sci. 2020, 10, 8660. [Google Scholar] [CrossRef]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. Uninformed Students: Student-Teacher Anomaly Detection with Discriminative Latent Embeddings. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 4182–4191. [Google Scholar]
- Venkataramanan, S.; Peng, K.; Singh, R.V.; Mahalanobis, A. Attention Guided Anomaly Localization in Images. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVII; Lecture Notes in Computer Science. Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12362, pp. 485–503. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery. In Proceedings of the Information Processing in Medical Imaging—25th International Conference, IPMI 2017, Boone, NC, USA, 25–30 June 2017; Proceedings; Lecture Notes in Computer Science. Niethammer, M., Styner, M., Aylward, S.R., Zhu, H., Oguz, I., Yap, P., Shen, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10265, pp. 146–157. [Google Scholar]
- Napoletano, P.; Piccoli, F.; Schettini, R. Anomaly Detection in Nanofibrous Materials by CNN-Based Self-Similarity. Sensors 2018, 18, 209. [Google Scholar] [CrossRef]
- Böttger, T.; Ulrich, M. Real-time texture error detection on textured surfaces with compressed sensing. Pattern Recognit. Image Anal. 2016, 26, 88–94. [Google Scholar] [CrossRef]
- Liu, W.; Li, R.; Zheng, M.; Karanam, S.; Wu, Z.; Bhanu, B.; Radke, R.J.; Camps, O.I. Towards Visually Explaining Variational Autoencoders. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 8639–8648. [Google Scholar]
- Roth, K.; Pemula, L.; Zepeda, J.; Schölkopf, B.; Brox, T.; Gehler, P.V. Towards Total Recall in Industrial Anomaly Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 14298–14308. [Google Scholar]
- Wan, Q.; Gao, L.; Li, X.; Wen, L. Industrial Image Anomaly Localization Based on Gaussian Clustering of Pretrained Feature. IEEE Trans. Ind. Electron. 2022, 69, 6182–6192. [Google Scholar] [CrossRef]
- Chen, X.; Konukoglu, E. Unsupervised Detection of Lesions in Brain MRI using constrained adversarial auto-encoders. arXiv 2018, arXiv:1806.04972. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Langs, G.; Schmidt-Erfurth, U. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef]
- Tan, J.; Hou, B.; Day, T.; Simpson, J.M.; Rueckert, D.; Kainz, B. Detecting Outliers with Poisson Image Interpolation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2021—24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part V; Lecture Notes in Computer Science. de Bruijne, M., Cattin, P.C., Cotin, S., Padoy, N., Speidel, S., Zheng, Y., Essert, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12905, pp. 581–591. [Google Scholar]
- Zimmerer, D.; Isensee, F.; Petersen, J.; Kohl, S.; Maier-Hein, K.H. Unsupervised Anomaly Localization Using Variational Auto-Encoders. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019—22nd International Conference, Shenzhen, China, 13–17 October 2019; Proceedings, Part IV; Lecture Notes in Computer Science. Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P., Khan, A.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11767, pp. 289–297. [Google Scholar]
- Abati, D.; Porrello, A.; Calderara, S.; Cucchiara, R. Latent Space Autoregression for Novelty Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 481–490. [Google Scholar]
- Defard, T.; Setkov, A.; Loesch, A.; Audigier, R. PaDiM: A Patch Distribution Modeling Framework for Anomaly Detection and Localization. In Proceedings of the Pattern Recognition. ICPR International Workshops and Challenges, Virtual Event, 10–15 January 2021; Proceedings, Part IV; Lecture Notes in Computer Science. Bimbo, A.D., Cucchiara, R., Sclaroff, S., Farinella, G.M., Mei, T., Bertini, M., Escalante, H.J., Vezzani, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12664, pp. 475–489. [Google Scholar]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J.; Müller, K. Nonlinear Component Analysis as a Kernel Eigenvalue Problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef]
- Hoffmann, H. Kernel PCA for novelty detection. Pattern Recognit. 2007, 40, 863–874. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the Support of a High-Dimensional Distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Tax, D.M.J.; Duin, R.P.W. Support Vector Data Description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Knorr, E.M.; Ng, R.T.; Tucakov, V. Distance-Based Outliers: Algorithms and Applications. VLDB J. 2000, 8, 237–253. [Google Scholar] [CrossRef]
- Ramaswamy, S.; Rastogi, R.; Shim, K. Efficient Algorithms for Mining Outliers from Large Data Sets. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; Chen, W., Naughton, J.F., Bernstein, P.A., Eds.; ACM: New York, NY, USA, 2000; pp. 427–438. [Google Scholar]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Statist 1962, 33, 106–1076. [Google Scholar] [CrossRef]
- Principi, E.; Vesperini, F.; Squartini, S.; Piazza, F. Acoustic novelty detection with adversarial autoencoders. In Proceedings of the 2017 International Joint Conference on Neural Networks, IJCNN 2017, Anchorage, AK, USA, 14–19 May 2017; pp. 3324–3330. [Google Scholar]
- Chalapathy, R.; Menon, A.K.; Chawla, S. Robust, Deep and Inductive Anomaly Detection. In Proceedings of the Machine Learning and Knowledge Discovery in Databases—European Conference, ECML PKDD 2017, Skopje, Macedonia, 18–22 September 2017; Proceedings, Part I; Lecture Notes in Computer Science. Ceci, M., Hollmén, J., Todorovski, L., Vens, C., Dzeroski, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10534, pp. 36–51. [Google Scholar]
- Kieu, T.; Yang, B.; Guo, C.; Jensen, C.S. Outlier Detection for Time Series with Recurrent Autoencoder Ensembles. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, 10–16 August 2019; Kraus, S., Ed.; 2019; pp. 2725–2732. [Google Scholar]
- Zhou, C.; Paffenroth, R.C. Anomaly Detection with Robust Deep Autoencoders. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; ACM: New York, NY, USA, 2017; pp. 665–674. [Google Scholar]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kim, K.H.; Shim, S.; Lim, Y.; Jeon, J.; Choi, J.; Kim, B.; Yoon, A.S. RaPP: Novelty Detection with Reconstruction along Projection Pathway. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Deng, J.; Zhang, Z.; Marchi, E.; Schuller, B.W. Sparse Autoencoder-Based Feature Transfer Learning for Speech Emotion Recognition. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, ACII 2013, Geneva, Switzerland, 2–5 September 2013; pp. 511–516. [Google Scholar]
- Erfani, S.M.; Rajasegarar, S.; Karunasekera, S.; Leckie, C. High-dimensional and large-scale anomaly detection using a linear one-class SVM with deep learning. Pattern Recognit. 2016, 58, 121–134. [Google Scholar] [CrossRef]
- Kim, M.; Kim, J.; Yu, J.; Choi, J.K. Active anomaly detection based on deep one-class classification. Pattern Recognit. Lett. 2023, 167, 18–24. [Google Scholar] [CrossRef]
- Ruff, L.; Görnitz, N.; Deecke, L.; Siddiqui, S.A.; Vandermeulen, R.A.; Binder, A.; Müller, E.; Kloft, M. Deep One-Class Classification. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Proceedings of Machine Learning Research. Dy, J.G., Krause, A., Eds.; 2018; Volume 80, pp. 4390–4399. [Google Scholar]
- Golan, I.; El-Yaniv, R. Deep Anomaly Detection Using Geometric Transformations. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; pp. 9781–9791. [Google Scholar]
- Tack, J.; Mo, S.; Jeong, J.; Shin, J. CSI: Novelty Detection via Contrastive Learning on Distributionally Shifted Instances. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; [Google Scholar]
- Zavrtanik, V.; Kristan, M.; Skocaj, D. DRÆM—A discriminatively trained reconstruction embedding for surface anomaly detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 8310–8319. [Google Scholar]
- Zavrtanik, V.; Kristan, M.; Skocaj, D. Reconstruction by inpainting for visual anomaly detection. Pattern Recognit. 2021, 112, 107706. [Google Scholar] [CrossRef]
- Li, C.; Sohn, K.; Yoon, J.; Pfister, T. CutPaste: Self-Supervised Learning for Anomaly Detection and Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; pp. 9664–9674. [Google Scholar]
- Pirnay, J.; Chai, K. Inpainting Transformer for Anomaly Detection. In Proceedings of the Image Analysis and Processing—ICIAP 2022—21st International Conference, Lecce, Italy, 23–27 May 2022; Proceedings, Part II; Lecture Notes in Computer Science. Sclaroff, S., Distante, C., Leo, M., Farinella, G.M., Tombari, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2022; Volume 13232, pp. 394–406. [Google Scholar]
- Lee, S.; Lee, S.; Song, B.C. CFA: Coupled-Hypersphere-Based Feature Adaptation for Target-Oriented Anomaly Localization. IEEE Access 2022, 10, 78446–78454. [Google Scholar] [CrossRef]
- Kim, D.; Park, C.; Cho, S.; Lee, S. FAPM: Fast Adaptive Patch Memory for Real-time Industrial Anomaly Detection. arXiv 2022, arXiv:2211.07381. [Google Scholar]
- Bae, J.; Lee, J.; Kim, S. Image Anomaly Detection and Localization with Position and Neighborhood Information. arXiv 2022, arXiv:2211.12634. [Google Scholar]
- Tsai, C.; Wu, T.; Lai, S. Multi-Scale Patch-Based Representation Learning for Image Anomaly Detection and Segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2022, Waikoloa, HI, USA, 3–8 January 2022; pp. 3065–3073. [Google Scholar]
- Zou, Y.; Jeong, J.; Pemula, L.; Zhang, D.; Dabeer, O. SPot-the-Difference Self-supervised Pre-training for Anomaly Detection and Segmentation. In Proceedings of the Computer Vision—ECCV 2022—17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXX; Lecture Notes in Computer Science. Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2022; Volume 13690, pp. 392–408. [Google Scholar]
- Li, N.; Jiang, K.; Ma, Z.; Wei, X.; Hong, X.; Gong, Y. Anomaly Detection Via Self-Organizing Map. In Proceedings of the 2021 IEEE International Conference on Image Processing, ICIP 2021, Anchorage, AK, USA, 19–22 September 2021; pp. 974–978. [Google Scholar]
- Salehi, M.; Sadjadi, N.; Baselizadeh, S.; Rohban, M.H.; Rabiee, H.R. Multiresolution Knowledge Distillation for Anomaly Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; pp. 14902–14912. [Google Scholar]
- Deng, H.; Li, X. Anomaly Detection via Reverse Distillation from One-Class Embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 9727–9736. [Google Scholar]
- Rudolph, M.; Wehrbein, T.; Rosenhahn, B.; Wandt, B. Asymmetric Student-Teacher Networks for Industrial Anomaly Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2023, Waikoloa, HI, USA, 2–7 January 2023; pp. 2591–2601. [Google Scholar]
- Cao, Y.; Wan, Q.; Shen, W.; Gao, L. Informative knowledge distillation for image anomaly segmentation. Knowl. Based Syst. 2022, 248, 108846. [Google Scholar] [CrossRef]
- Zhang, K.; Wang, B.; Kuo, C.J. PEDENet: Image anomaly localization via patch embedding and density estimation. Pattern Recognit. Lett. 2022, 153, 144–150. [Google Scholar] [CrossRef]
- Wan, Q.; Gao, L.; Li, X.; Wen, L. Unsupervised Image Anomaly Detection and Segmentation Based on Pretrained Feature Mapping. IEEE Trans. Ind. Inform. 2023, 19, 2330–2339. [Google Scholar] [CrossRef]
- Wan, Q.; Cao, Y.; Gao, L.; Shen, W.; Li, X. Position Encoding Enhanced Feature Mapping for Image Anomaly Detection. In Proceedings of the 18th IEEE International Conference on Automation Science and Engineering, CASE 2022, Mexico City, Mexico, 20–24 August 2022; pp. 876–881. [Google Scholar]
- Zheng, Y.; Wang, X.; Deng, R.; Bao, T.; Zhao, R.; Wu, L. Focus Your Distribution: Coarse-to-Fine Non-Contrastive Learning for Anomaly Detection and Localization. In Proceedings of the IEEE International Conference on Multimedia and Expo, ICME 2022, Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Gudovskiy, D.A.; Ishizaka, S.; Kozuka, K. CFLOW-AD: Real-Time Unsupervised Anomaly Detection with Localization via Conditional Normalizing Flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2022, Waikoloa, HI, USA, 3–8 January 2022; pp. 1819–1828. [Google Scholar]
- Kim, Y.; Jang, H.; Lee, D.; Choi, H. AltUB: Alternating Training Method to Update Base Distribution of Normalizing Flow for Anomaly Detection. arXiv 2022, arXiv:2210.14913. [Google Scholar]
- Yi, J.; Yoon, S. Patch SVDD: Patch-Level SVDD for Anomaly Detection and Segmentation. In Proceedings of the Computer Vision—ACCV 2020—15th Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020; Revised Selected Papers, Part VI; Lecture Notes in Computer Science. Ishikawa, H., Liu, C., Pajdla, T., Shi, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12627, pp. 375–390. [Google Scholar]
- Hu, C.; Chen, K.; Shao, H. A Semantic-Enhanced Method Based On Deep SVDD for Pixel-Wise Anomaly Detection. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo, ICME 2021, Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Yang, M.; Wu, P.; Feng, H. MemSeg: A semi-supervised method for image surface defect detection using differences and commonalities. Eng. Appl. Artif. Intell. 2023, 119, 105835. [Google Scholar] [CrossRef]
- Yan, Y.; Wang, D.; Zhou, G.; Chen, Q. Unsupervised Anomaly Segmentation Via Multilevel Image Reconstruction and Adaptive Attention-Level Transition. IEEE Trans. Instrum. Meas. 2021, 70, 5015712. [Google Scholar] [CrossRef]
- Collin, A.; Vleeschouwer, C.D. Improved anomaly detection by training an autoencoder with skip connections on images corrupted with Stain-shaped noise. In Proceedings of the 25th International Conference on Pattern Recognition, ICPR 2020, Virtual Event/Milan, Italy, 10–15 January 2021; pp. 7915–7922. [Google Scholar]
- Tao, X.; Zhang, D.; Ma, W.; Hou, Z.; Lu, Z.; Adak, C. Unsupervised Anomaly Detection for Surface Defects with Dual-Siamese Network. IEEE Trans. Ind. Inform. 2022, 18, 7707–7717. [Google Scholar] [CrossRef]
- Liu, T.; Li, B.; Zhao, Z.; Du, X.; Jiang, B.; Geng, L. Reconstruction from edge image combined with color and gradient difference for industrial surface anomaly detection. arXiv 2022, arXiv:2210.14485. [Google Scholar]
- Kim, D.; Jeong, D.; Kim, H.; Chong, K.; Kim, S.; Cho, H. Spatial Contrastive Learning for Anomaly Detection and Localization. IEEE Access 2022, 10, 17366–17376. [Google Scholar] [CrossRef]
- Huang, C.; Xu, Q.; Wang, Y.; Wang, Y.; Zhang, Y. Self-Supervised Masking for Unsupervised Anomaly Detection and Localization. arXiv 2022, arXiv:2205.06568. [Google Scholar] [CrossRef]
- Liznerski, P.; Ruff, L.; Vandermeulen, R.A.; Franks, B.J.; Kloft, M.; Müller, K.R. Explainable Deep One-Class Classification. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, 3–7 May 2021. [Google Scholar]
- Bae, J.; Lee, J.; Kim, S. PNI: Industrial Anomaly Detection using Position and Neighborhood Information. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, 1–6 October 2023; pp. 6350–6360. [Google Scholar]
- Schlüter, H.M.; Tan, J.; Hou, B.; Kainz, B. Natural Synthetic Anomalies for Self-supervised Anomaly Detection and Localization. In Proceedings of the Computer Vision—ECCV 2022—17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXXI; Lecture Notes in Computer Science. Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2022; Volume 13691, pp. 474–489. [Google Scholar]
- Dehaene, D.; Frigo, O.; Combrexelle, S.; Eline, P. Iterative energy-based projection on a normal data manifold for anomaly localization. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Höner, J.; Nakajima, S.; Bauer, A.; Müller, K.R.; Görnitz, N. Minimizing Trust Leaks for Robust Sybil Detection. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; Proceedings of Machine Learning Research. Precup, D., Teh, Y.W., Eds.; 2017; Volume 70, pp. 1520–1528. [Google Scholar]
- Song, J.W.; Kong, K.; Park, Y.I.; Kim, S.G.; Kang, S. AnoSeg: Anomaly Segmentation Network Using Self-Supervised Learning. arXiv 2021, arXiv:2110.03396. [Google Scholar]
- Kohlbrenner, M.; Bauer, A.; Nakajima, S.; Binder, A.; Samek, W.; Lapuschkin, S. Towards Best Practice in Explaining Neural Network Decisions with LRP. In Proceedings of the 2020 International Joint Conference on Neural Networks, IJCNN 2020, Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Lee, Y.; Kang, P. AnoViT: Unsupervised Anomaly Detection and Localization with Vision Transformer-Based Encoder-Decoder. IEEE Access 2022, 10, 46717–46724. [Google Scholar] [CrossRef]
- Jiang, J.; Zhu, J.; Bilal, M.; Cui, Y.; Kumar, N.; Dou, R.; Su, F.; Xu, X. Masked Swin Transformer Unet for Industrial Anomaly Detection. IEEE Trans. Ind. Inform. 2023, 19, 2200–2209. [Google Scholar] [CrossRef]
- Wu, J.; Chen, D.; Fuh, C.; Liu, T. Learning Unsupervised Metaformer for Anomaly Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 4349–4358. [Google Scholar]
- Jiang, X.; Liu, J.; Wang, J.; Nie, Q.; Wu, K.; Liu, Y.; Wang, C.; Zheng, F. SoftPatch: Unsupervised Anomaly Detection with Noisy Data. In Proceedings of the NeurIPS, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Ruff, L.; Kauffmann, J.R.; Vandermeulen, R.A.; Samek, W.; Kloft, M.; Dietterich, T.G.; Müller, K.R. A Unifying Review of Deep and Shallow Anomaly Detection. Proc. IEEE 2021, 109, 756–795. [Google Scholar] [CrossRef]
- Kauffmann, J.; Müller, K.R.; Montavon, G. Towards explaining anomalies: A deep Taylor decomposition of one-class models. Pattern Recognit. 2020, 101, 107198. [Google Scholar] [CrossRef]
- Chong, P.; Ruff, L.; Kloft, M.; Binder, A. Simple and Effective Prevention of Mode Collapse in Deep One-Class Classification. In Proceedings of the 2020 International Joint Conference on Neural Networks, IJCNN 2020, Glasgow, UK, 19–24 July 2020; pp. 1–9. [Google Scholar]
- Hu, C.; Feng, Y.; Kamigaito, H.; Takamura, H.; Okumura, M. One-class Text Classification with Multi-modal Deep Support Vector Data Description. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, EACL 2021, Online, 19–23 April 2021; Merlo, P., Tiedemann, J., Tsarfaty, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 3378–3390. [Google Scholar]
- Ranzato, M.A.; Boureau, Y.l.; Cun, Y. Sparse Feature Learning for Deep Belief Networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, Canada, 3–6 December 2007; Platt, J., Koller, D., Singer, Y., Roweis, S., Eds.; Curran Associates, Inc.: New York, NY, USA, 2007; Volume 20. [Google Scholar]
- Le, Q.V.; Ngiam, J.; Coates, A.; Lahiri, A.; Prochnow, B.; Ng, A.Y. On optimization methods for deep learning. In Proceedings of the 28th International Conference on Machine Learning ICML 2011, Bellevue, WA, USA, 28 June–2 July 2011; Getoor, L., Scheffer, T., Eds.; pp. 265–272. [Google Scholar]
- Rifai, S.; Vincent, P.; Muller, X.; Glorot, X.; Bengio, Y. Contractive Auto-Encoders: Explicit Invariance During Feature Extraction. In Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, WI, USA, 28 June–2 July 2011; Omnipress: Madison, WI, USA, 2011; pp. 833–840. [Google Scholar]
- Alain, G.; Bengio, Y. What regularized auto-encoders learn from the data-generating distribution. J. Mach. Learn. Res. 2014, 15, 3563–3593. [Google Scholar]
- Pathak, D.; Krähenbühl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. 2017, 36, 107:1–107:14. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative Image Inpainting with Contextual Attention. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5505–5514. [Google Scholar]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.; Tao, A.; Catanzaro, B. Image Inpainting for Irregular Holes Using Partial Convolutions. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part XI; Lecture Notes in Computer Science. Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11215, pp. 89–105. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-Form Image Inpainting with Gated Convolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4470–4479. [Google Scholar]
- Bhattad, A.; Rock, J.; Forsyth, D.A. Detecting Anomalous Faces with ‘No Peeking’ Autoencoders. arXiv 2018, arXiv:1802.05798. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P. Extracting and composing robust features with denoising autoencoders. In Proceedings of the Machine Learning, Proceedings of the Twenty-Fifth International Conference (ICML 2008), Helsinki, Finland, 5–9 June 2008; ACM International Conference Proceeding, Series. Cohen, W.W., McCallum, A., Roweis, S.T., Eds.; ACM: New York, NY, USA, 2008; Volume 307, pp. 1096–1103. [Google Scholar]
- Kascenas, A.; Pugeault, N.; O’Neil, A.Q. Denoising Autoencoders for Unsupervised Anomaly Detection in Brain MRI. In Proceedings of the 5th International Conference on Medical Imaging with Deep Learning, PMLR, Zurich, Switzerland, 6–8 July 2022; Volume 172, pp. 653–664. [Google Scholar]
- Liu, Z.; Zhou, Y.; Xu, Y.; Wang, Z. SimpleNet: A Simple Network for Image Anomaly Detection and Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 20402–20411. [Google Scholar]
- Bergmann, P.; Batzner, K.; Fauser, M.; Sattlegger, D.; Steger, C. The MVTec Anomaly Detection Dataset: A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. Int. J. Comput. Vis. 2021, 129, 1038–1059. [Google Scholar] [CrossRef]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing Textures in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015—18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III; Lecture Notes in Computer Science. Navab, N., Hornegger, J., III, Wells, W.M., Frangi, A.F., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Schuster, R.; Wasenmüller, O.; Unger, C.; Stricker, D. SDC—Stacked Dilated Convolution: A Unified Descriptor Network for Dense Matching Tasks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 2556–2565. [Google Scholar]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques—Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Wainwright, M.J.; Jordan, M.I. Graphical Models, Exponential Families, and Variational Inference. Found. Trends Mach. Learn. 2008, 1, 1–305. [Google Scholar] [CrossRef]
- Lafferty, J. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the ICML, Williamstown, MA, USA, 28 June–1 July 2001; Morgan Kaufmann: Burlington, MA, USA, 2001; pp. 282–289. [Google Scholar]
- Bauer, A.; Görnitz, N.; Biegler, F.; Müller, K.R.; Kloft, M. Efficient Algorithms for Exact Inference in Sequence Labeling SVMs. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 870–881. [Google Scholar] [CrossRef] [PubMed]
- Bauer, A.; Braun, M.L.; Müller, K.R. Accurate Maximum-Margin Training for Parsing with Context-Free Grammars. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 44–56. [Google Scholar] [CrossRef]
- Bauer, A.; Nakajima, S.; Müller, K.R. Efficient Exact Inference with Loss Augmented Objective in Structured Learning. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2566–2579. [Google Scholar] [CrossRef]
- Bauer, A.; Nakajima, S.; Görnitz, N.; Müller, K.R. Optimizing for Measure of Performance in Max-Margin Parsing. IEEE Trans. Neural Netw. Learn. Syst. 2019, 21, 2680–2684. [Google Scholar] [CrossRef] [PubMed]
- Bauer, A.; Nakajima, S.; Görnitz, N.; Müller, K.R. Partial Optimality of Dual Decomposition for MAP Inference in Pairwise MRFs. In Proceedings of the Machine Learning Research, Naha, Japan, 16–18 April 2019; Proceedings of Machine Learning Research. Chaudhuri, K., Sugiyama, M., Eds.; Volume 89, pp. 1696–1703. [Google Scholar]
- Bauer, A.; Nakajima, S.; Müller, K.R. Polynomial-Time Constrained Message Passing for Exact MAP Inference on Discrete Models with Global Dependencies. Mathematics 2023, 11, 2628. [Google Scholar] [CrossRef]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD—A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 9592–9600. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Bengio, Y., LeCun, Y., Eds.; Conference Track Proceedings. [Google Scholar]
- Zhou, Y.; Xu, X.; Song, J.; Shen, F.; Shen, H.T. MSFlow: Multi-Scale Flow-based Framework for Unsupervised Anomaly Detection. arXiv 2023, arXiv:2308.15300. [Google Scholar]



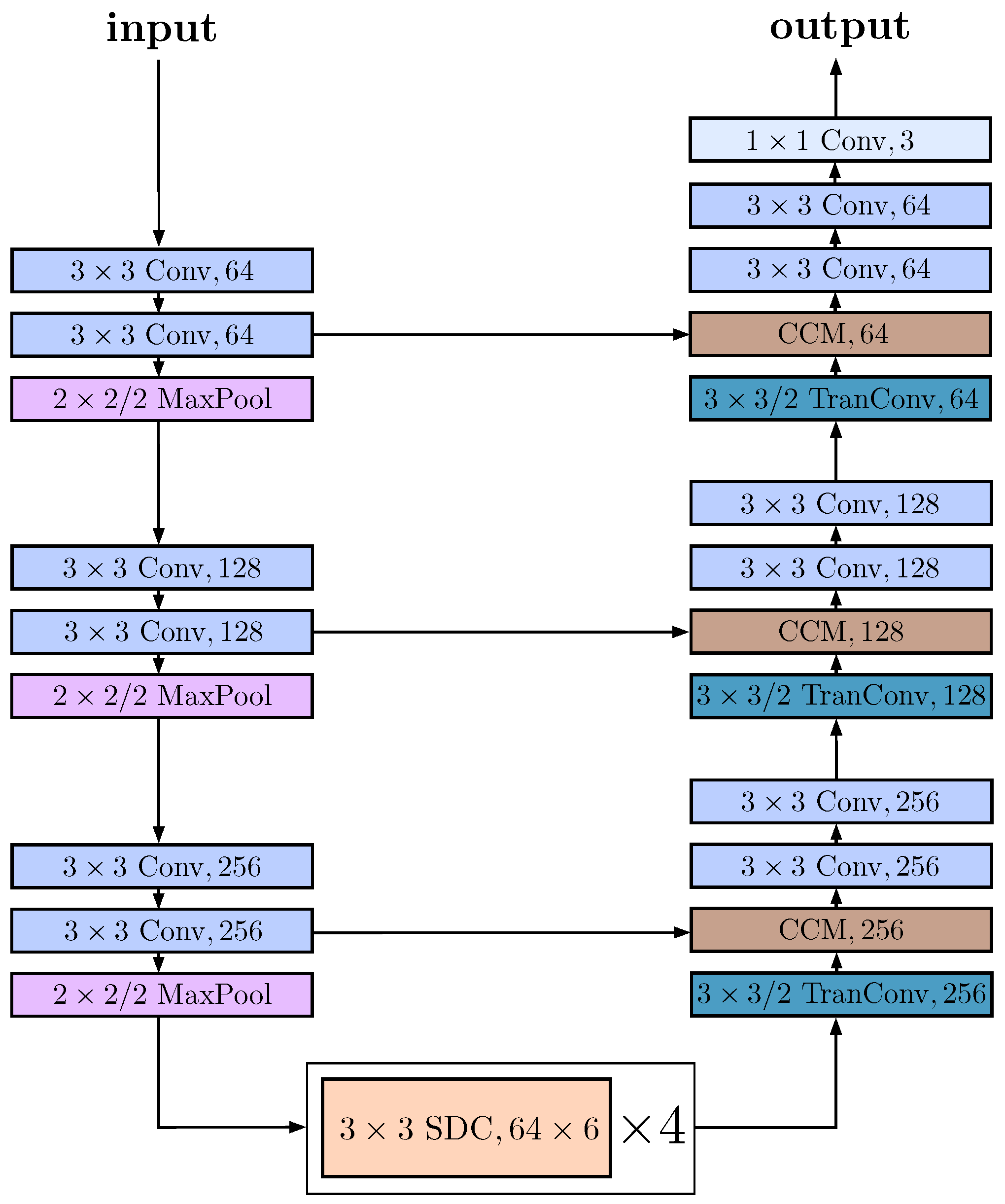






| Layer Type | Number of Filters | Filter Size | Output Size |
|---|---|---|---|
| Conv | 64 | ||
| Conv | 64 | ||
| MaxPool | /2 | ||
| Conv | 128 | ||
| Conv | 128 | ||
| MaxPool | /2 | ||
| Conv | 256 | ||
| Conv | 256 | ||
| MaxPool | /2 | ||
| TranConv | 256 | /2 | |
| Conv | 256 | ||
| Conv | 256 | ||
| TranConv | 128 | /2 | |
| Conv | 128 | ||
| Conv | 128 | ||
| TranConv | 64 | /2 | |
| Conv | 64 | ||
| Conv | 64 | ||
| Conv | 3 |
| Category | AnoGAN | VAE | LSR | RIAD | CutPaste | InTra | DRAEM | SimpleNet | PatchCore | MSFlow | PNI | SDC-AE | SDC-CCM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| carpet | 54 | 78 | 94 | 96.3 | 98.3 | 99.2 | 95.5 | 98.2 | 98.7 | 99.4 | 99.4 | 99.7 | 99.8 |
| grid | 58 | 73 | 99 | 98.8 | 97.5 | 98.8 | 99.7 | 98.8 | 98.8 | 99.4 | 99.2 | 99.7 | 99.8 |
| leather | 64 | 95 | 99 | 99.4 | 99.5 | 99.5 | 98.6 | 99.2 | 99.3 | 99.7 | 99.6 | 99.7 | 99.7 |
| tile | 50 | 80 | 88 | 89.1 | 90.5 | 94.4 | 99.2 | 97.0 | 96.3 | 98.2 | 98.4 | 99.2 | 99.2 |
| wood | 62 | 77 | 87 | 85.8 | 95.5 | 88.7 | 96.4 | 94.5 | 95.2 | 97.1 | 97.0 | 98.4 | 98.4 |
| avg. tex. | 57.6 | 80.6 | 93.4 | 93.9 | 96.3 | 96.1 | 97.9 | 97.5 | 97.7 | 98.8 | 98.7 | 99.3 | 99.4 |
| bottle | 86 | 87 | 95 | 98.4 | 97.6 | 97.1 | 99.1 | 98.0 | 98.6 | 99.0 | 98.9 | 98.6 | 98.9 |
| cable | 86 | 87 | 95 | 94.2 | 90.0 | 91.0 | 94.7 | 97.6 | 98.7 | 98.5 | 99.1 | 98.2 | 98.5 |
| capsule | 84 | 74 | 93 | 92.8 | 97.4 | 97.7 | 94.3 | 98.9 | 99.1 | 99.1 | 99.3 | 99.1 | 99.1 |
| hazelnut | 87 | 98 | 95 | 96.1 | 97.3 | 98.3 | 99.7 | 97.9 | 98.8 | 98.7 | 99.4 | 98.9 | 99.1 |
| metal nut | 76 | 94 | 91 | 92.5 | 93.1 | 93.3 | 99.5 | 98.8 | 99.0 | 99.3 | 99.3 | 98.5 | 98.5 |
| pill | 87 | 83 | 91 | 95.7 | 95.7 | 98.3 | 97.6 | 98.6 | 98.6 | 98.8 | 99.0 | 99.3 | 99.3 |
| screw | 80 | 97 | 96 | 98.8 | 96.7 | 99.5 | 97.6 | 99.3 | 99.5 | 99.1 | 99.6 | 99.7 | 99.7 |
| toothbrush | 90 | 94 | 97 | 98.9 | 98.1 | 98.9 | 98.1 | 98.5 | 98.9 | 98.5 | 99.1 | 99.1 | 99.4 |
| transistor | 80 | 93 | 91 | 87.7 | 93.0 | 96.1 | 90.9 | 97.6 | 97.1 | 98.3 | 98.0 | 98.6 | 98.9 |
| zipper | 78 | 78 | 98 | 97.8 | 99.3 | 99.2 | 98.8 | 98.9 | 99.0 | 99.2 | 99.4 | 99.5 | 99.6 |
| avg. obj. | 83.4 | 88.5 | 94.6 | 95.3 | 95.8 | 96.9 | 97.0 | 98.4 | 98.7 | 98.8 | 99.1 | 99.0 | 99.1 |
| avg. all | 74.8 | 85.9 | 94.2 | 94.8 | 96.0 | 96.7 | 97.3 | 98.1 | 98.4 | 98.8 | 99.0 | 99.1 | 99.2 |
| Category | AnoGAN | VAE | LSR | RIAD | CutPaste | InTra | DRAEM | SimpleNet | PatchCore | MSFlow | PNI | SDC-AE | SDC-CCM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| carpet | 49 | 78 | 71 | 84.2 | 93.1 | 98.8 | 97.0 | 99.7 | 98.2 | 100 | 100 | 100 | 100 |
| grid | 51 | 73 | 91 | 99.6 | 99.9 | 100 | 99.9 | 99.7 | 98.3 | 99.8 | 98.4 | 100 | 100 |
| leather | 52 | 95 | 96 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| tile | 51 | 80 | 95 | 93.4 | 93.4 | 98.2 | 99.6 | 99.8 | 98.9 | 100 | 100 | 100 | 100 |
| wood | 68 | 77 | 96 | 93.0 | 98.6 | 97.5 | 99.1 | 100 | 99.9 | 100 | 99.6 | 100 | 100 |
| avg. textures | 54.2 | 80.6 | 89.8 | 94.0 | 97.0 | 98.9 | 99.1 | 99.8 | 99.0 | 99.9 | 99.6 | 100 | 100 |
| bottle | 69 | 87 | 99 | 99.9 | 98.3 | 100 | 99.2 | 100 | 100 | 100 | 100 | 100 | 100 |
| cable | 53 | 90 | 72 | 81.9 | 80.6 | 70.3 | 91.8 | 99.9 | 99.7 | 99.5 | 99.8 | 98.0 | 99.9 |
| capsule | 58 | 74 | 68 | 88.4 | 96.2 | 86.5 | 98.5 | 97.7 | 98.1 | 99.2 | 99.7 | 98.2 | 98.8 |
| hazelnut | 50 | 98 | 94 | 83.3 | 97.3 | 95.7 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| metal nut | 50 | 94 | 83 | 88.5 | 99.3 | 96.9 | 98.7 | 100 | 100 | 100 | 100 | 100 | 100 |
| pill | 62 | 83 | 68 | 83.8 | 92.4 | 90.2 | 98.9 | 99.0 | 97.1 | 99.6 | 96.9 | 99.5 | 99.6 |
| screw | 35 | 97 | 80 | 84.5 | 86.3 | 95.7 | 93.9 | 98.2 | 99.0 | 97.8 | 99.5 | 98.9 | 98.9 |
| toothbrush | 57 | 94 | 92 | 100 | 98.3 | 100 | 100 | 99.7 | 98.9 | 100 | 99.7 | 100 | 100 |
| transistor | 67 | 93 | 73 | 90.9 | 95.5 | 95.8 | 93.1 | 100 | 99.7 | 100 | 100 | 98.8 | 100 |
| zipper | 59 | 78 | 97 | 98.1 | 99.4 | 99.4 | 100 | 99.9 | 99.7 | 100 | 99.9 | 100 | 100 |
| avg. objects | 56.0 | 88.8 | 82.6 | 89.9 | 94.4 | 93.1 | 97.4 | 99.5 | 99.2 | 99.6 | 99.5 | 99.3 | 99.7 |
| avg. all | 55.4 | 86.1 | 85.0 | 91.3 | 95.2 | 95.0 | 98.0 | 99.6 | 99.2 | 99.7 | 99.6 | 99.6 | 99.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bauer, A.; Nakajima, S.; Müller, K.-R. Self-Supervised Autoencoders for Visual Anomaly Detection. Mathematics 2024, 12, 3988. https://doi.org/10.3390/math12243988
Bauer A, Nakajima S, Müller K-R. Self-Supervised Autoencoders for Visual Anomaly Detection. Mathematics. 2024; 12(24):3988. https://doi.org/10.3390/math12243988
Chicago/Turabian StyleBauer, Alexander, Shinichi Nakajima, and Klaus-Robert Müller. 2024. "Self-Supervised Autoencoders for Visual Anomaly Detection" Mathematics 12, no. 24: 3988. https://doi.org/10.3390/math12243988
APA StyleBauer, A., Nakajima, S., & Müller, K.-R. (2024). Self-Supervised Autoencoders for Visual Anomaly Detection. Mathematics, 12(24), 3988. https://doi.org/10.3390/math12243988